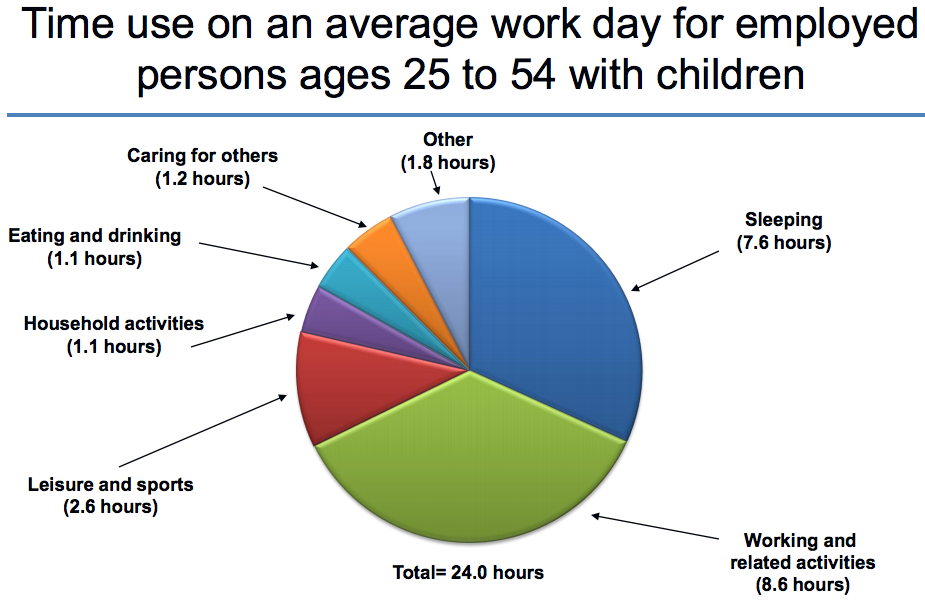
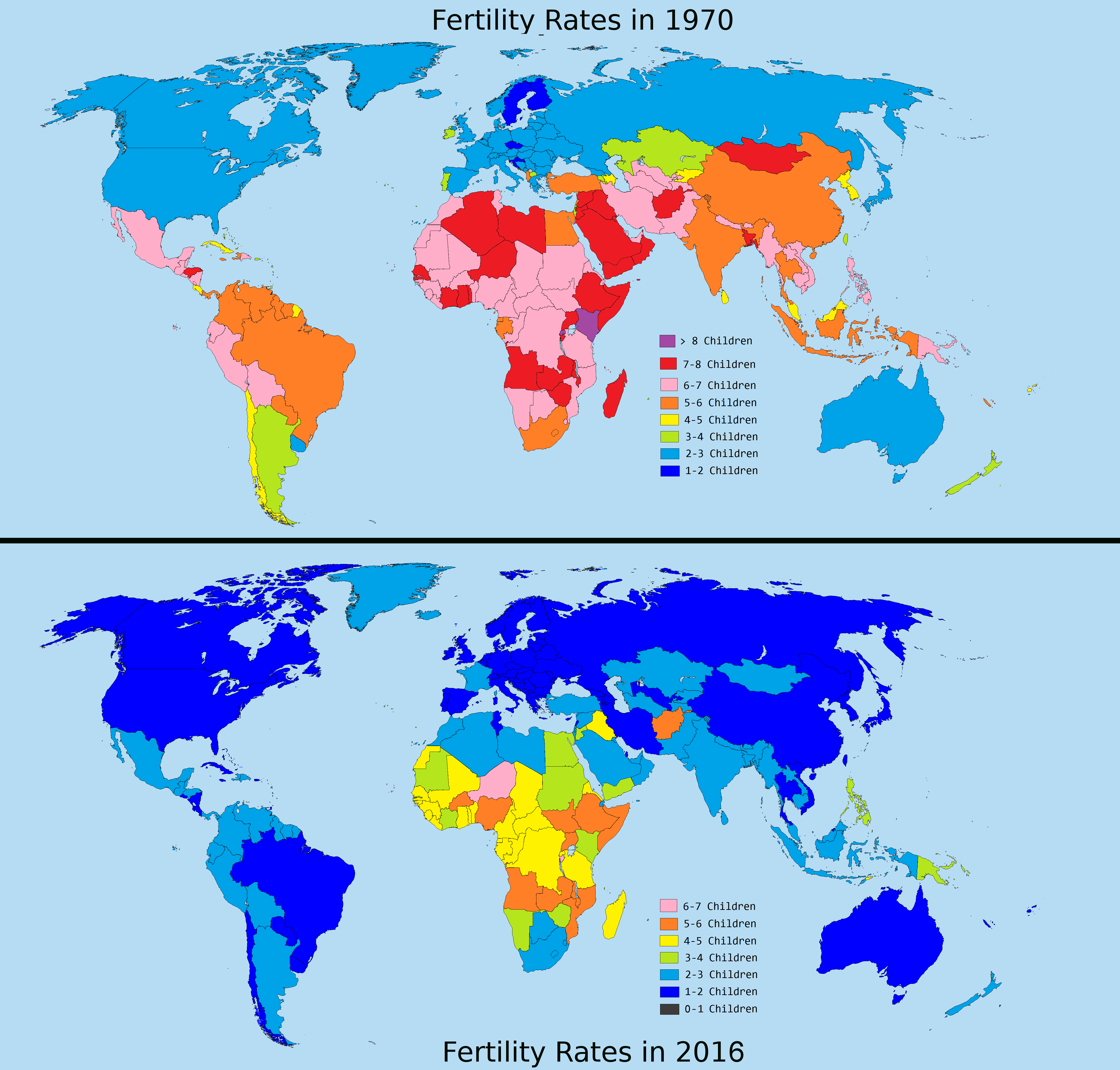
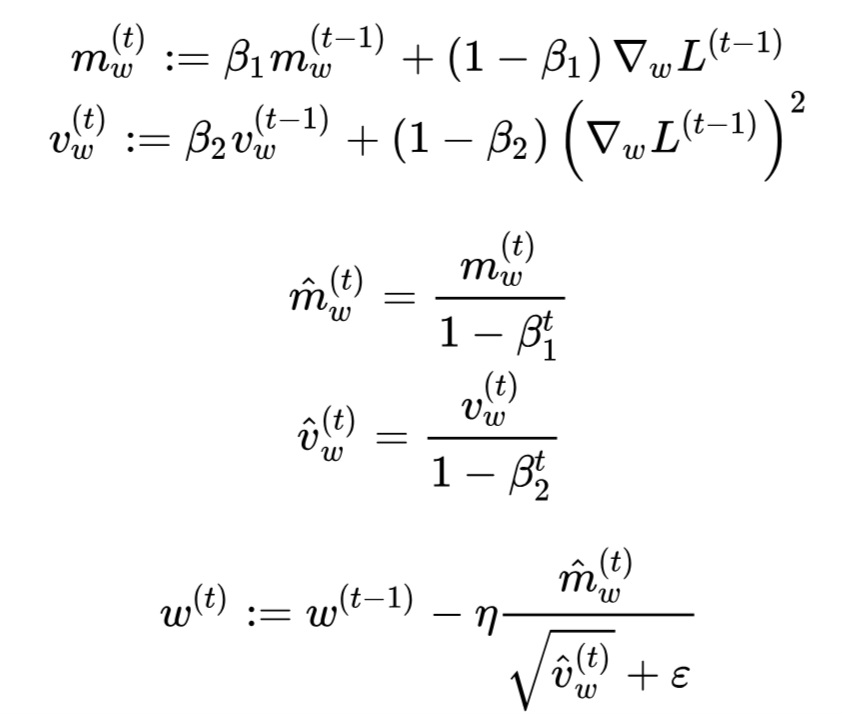>>16693585
>Human brains run much slower then LLMs
This is not the case, and it isn't close.
The rate limiter to human text output is actually typing speed, and anguage production is localized to a pretty specific area of the brain on one side, Broca's area.
The rate limiter to producing visual art is likewise more a physical expression limit. So long as you don't have aphantasia, you should be able to visualize things at a speed and efficiency well exceeding the current generative tech, and odds are what you imagine is continuous and maybe even multisensory. And it's also exactly accurate to what you imagine - you aren't rolling and re-rolling because you imagined a horse when you wanted to imagine a dragon, and you can make changes to details on the fly.
I still wonder how much AI art evangelism is from people with aphantasia. Exercise your imagination, it's good for you.
Regardless, much of your brain is dedicated to sensory processing, and in visual processing especially your brain still blows perceptrons out of the water in terms of speed and efficiency. Even where a perceptron may categorize a given image slightly faster, it can't categorize a continuous stream of visual information without obscene power draw and compute scale. And it can't actively learn while doing so.
We're talking, even with current tech, a 10,000+ watt system the size of a small building approximating a small portion of what your brain does for 20 watts. The inefficiency of converting energy to consumable calories is so far off the magnitude scale we're talking about it's irrelevant to the comparison.
>has been optimized
Well... no. These inefficiencies come from randomness and other fundamental architectural limitations. They never fully go away for LLMs because the systems ARE stochastic no matter how much tech bros kvetch about it, and a monetary cost claim for training efficiency isn't relevant to operation efficiency because training is a one-time event per model version.