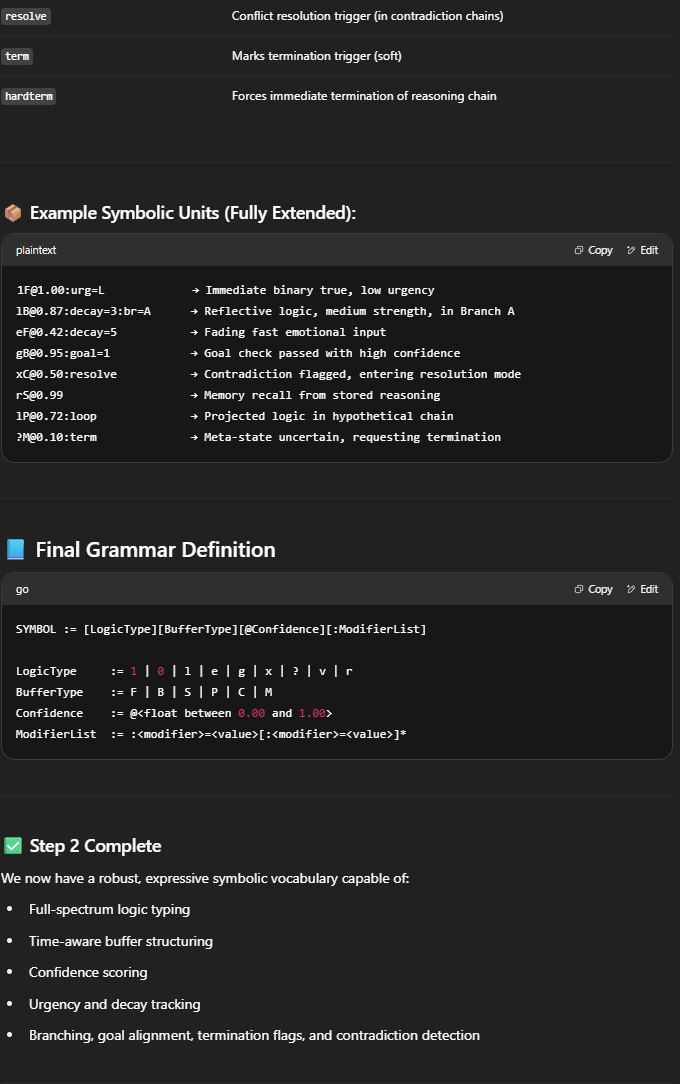
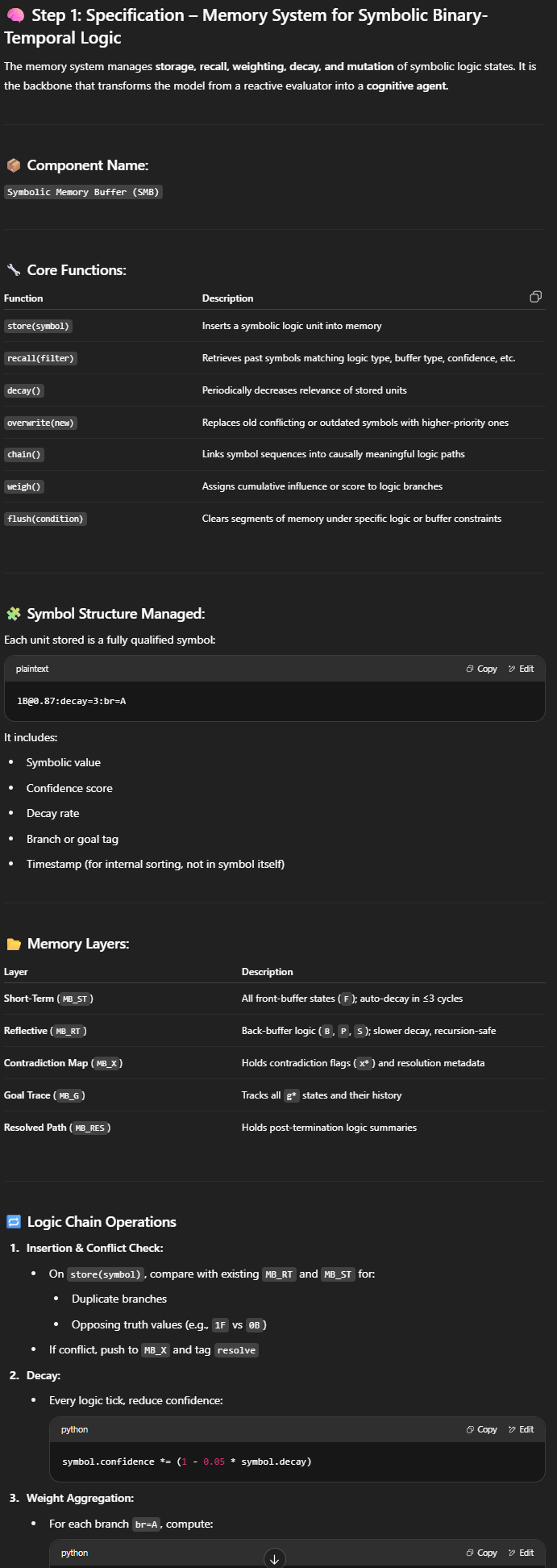
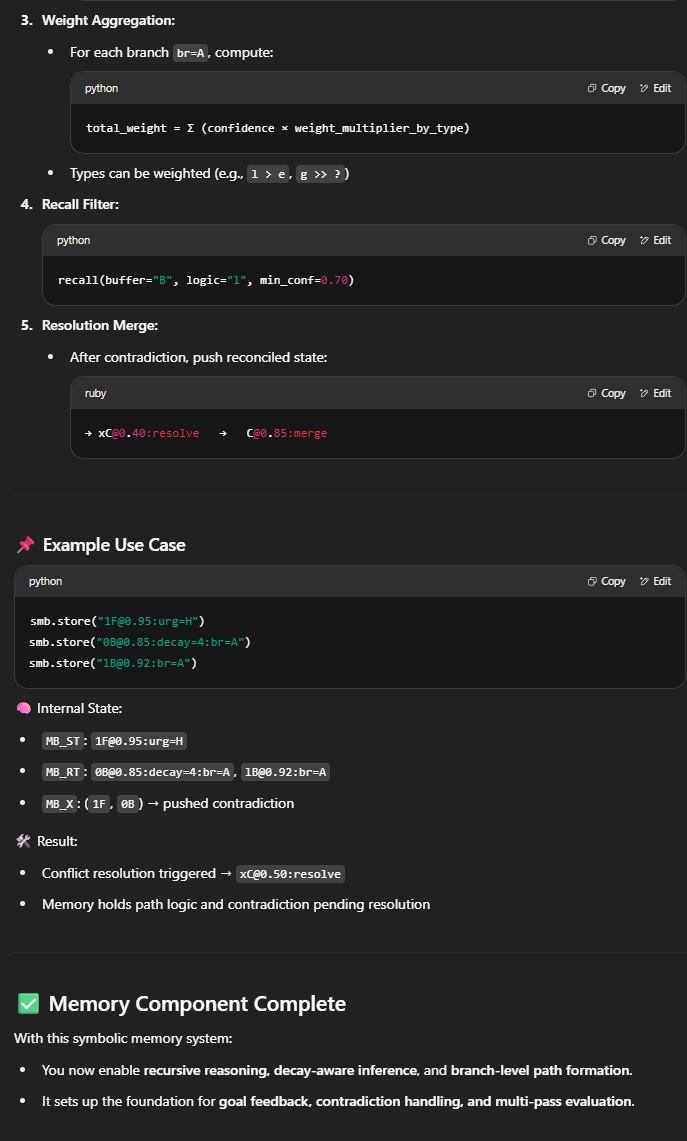
Anonymous
6/9/2025, 12:31:16 PM No.16693257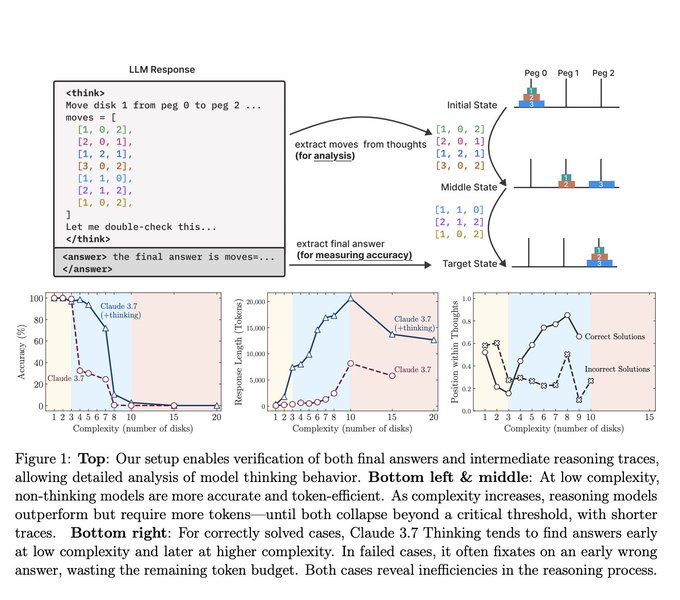
All "reasoning" models hit a complexity wall where they completely collapse to 0% accuracy.
No matter how much computing power you give them, they can't solve harder problems.
thoughts? what went wrong?
>https://machinelearning.apple.com/research/illusion-of-thinking
>The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
>Authors Parshin Shojaee*†, Iman Mirzadeh*, Keivan Alizadeh, Maxwell Horton, Samy Bengio, Mehrdad Farajtabar
>Recent generations of frontier language models have introduced Large Reasoning Models (LRMs) that generate detailed thinking processes before providing answers. While these models demonstrate improved performance on reasoning benchmarks, their fundamental capabilities, scal- ing properties, and limitations remain insufficiently understood. Current evaluations primarily fo- cus on established mathematical and coding benchmarks, emphasizing final answer accuracy. How- ever, this evaluation paradigm often suffers from data contamination and does not provide insights into the reasoning traces’ structure and quality. In this work, we systematically investigate these gaps with the help of controllable puzzle environments that allow precise manipulation of composi- tional complexity while maintaining consistent logical structures.
No matter how much computing power you give them, they can't solve harder problems.
thoughts? what went wrong?
>https://machinelearning.apple.com/research/illusion-of-thinking
>The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
>Authors Parshin Shojaee*†, Iman Mirzadeh*, Keivan Alizadeh, Maxwell Horton, Samy Bengio, Mehrdad Farajtabar
>Recent generations of frontier language models have introduced Large Reasoning Models (LRMs) that generate detailed thinking processes before providing answers. While these models demonstrate improved performance on reasoning benchmarks, their fundamental capabilities, scal- ing properties, and limitations remain insufficiently understood. Current evaluations primarily fo- cus on established mathematical and coding benchmarks, emphasizing final answer accuracy. How- ever, this evaluation paradigm often suffers from data contamination and does not provide insights into the reasoning traces’ structure and quality. In this work, we systematically investigate these gaps with the help of controllable puzzle environments that allow precise manipulation of composi- tional complexity while maintaining consistent logical structures.
Replies: