Search Results
7/25/2025, 3:56:45 AM
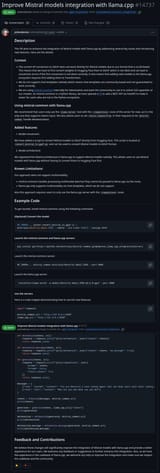
Mistral is taking a dump on llama.cpp.
>https://github.com/ggml-org/llama.cpp/pull/14737
Instead of contributing code to improve the project, they expect people to now run TWO servers just because they cannot integrate their own shit.
Llama tries to have as few dependencies as possible. I remember them arguing about whether having a header-only json *compile-time* dependency in the project was a good idea. Mistral expects them to have a *runtime* dependency to run mistral models. A PYTHON runtime dependency.
>Known Limitations:
>Our approach does not support multimodality:
>>mistral-common handles processing multimodal data but they cannot be passed to llama.cpp via the route.
>>llama.cpp only supports multimodality via chat templates, which we do not support.
>Also this approach requires users to only use the llama.cpp server with the /completions route.
#Launch the mistral-common and llama.cpp servers
pip install git+https://github.com/mistralai/mistral-common.git@improve_llama_cpp_integration[server]
#Launch the mistral-common server:
HF_TOKEN=... mistral_common mistralai/Devstral-Small-2505 --port 6000
#Launch the llama.cpp server:
./build/bin/llama-server -m models/Devstral-Small-2505-Q4_K_M.gguf --port 8080
Yes. You have to launch two servers.
The mistral server is only for [de]tokenization. So they expect you to do this dance in your code.
...
tokens = tokenize(messages, mistral_common_url)
generated = generate(tokens, llama_cpp_url)["tokens"]
detokenized = detokenize(generated, mistral_common_url)
detokenized_message = detokenize_message(generated, mistral_common_url)
print(detokenized_message)
Any of you use logit bias? That's a different dance now. Want to just [de]tokenize? Nah. Different server now. Want to run llama.cpp where you {cannot|don't want to} have the python shit installed? Nah. What about the clients? Well, let THEM fix it.
Two fucking servers. That's the best they could come up with...
>https://github.com/ggml-org/llama.cpp/pull/14737
Instead of contributing code to improve the project, they expect people to now run TWO servers just because they cannot integrate their own shit.
Llama tries to have as few dependencies as possible. I remember them arguing about whether having a header-only json *compile-time* dependency in the project was a good idea. Mistral expects them to have a *runtime* dependency to run mistral models. A PYTHON runtime dependency.
>Known Limitations:
>Our approach does not support multimodality:
>>mistral-common handles processing multimodal data but they cannot be passed to llama.cpp via the route.
>>llama.cpp only supports multimodality via chat templates, which we do not support.
>Also this approach requires users to only use the llama.cpp server with the /completions route.
#Launch the mistral-common and llama.cpp servers
pip install git+https://github.com/mistralai/mistral-common.git@improve_llama_cpp_integration[server]
#Launch the mistral-common server:
HF_TOKEN=... mistral_common mistralai/Devstral-Small-2505 --port 6000
#Launch the llama.cpp server:
./build/bin/llama-server -m models/Devstral-Small-2505-Q4_K_M.gguf --port 8080
Yes. You have to launch two servers.
The mistral server is only for [de]tokenization. So they expect you to do this dance in your code.
...
tokens = tokenize(messages, mistral_common_url)
generated = generate(tokens, llama_cpp_url)["tokens"]
detokenized = detokenize(generated, mistral_common_url)
detokenized_message = detokenize_message(generated, mistral_common_url)
print(detokenized_message)
Any of you use logit bias? That's a different dance now. Want to just [de]tokenize? Nah. Different server now. Want to run llama.cpp where you {cannot|don't want to} have the python shit installed? Nah. What about the clients? Well, let THEM fix it.
Two fucking servers. That's the best they could come up with...
Page 1