Search Results
7/22/2025, 7:42:54 PM
>>716153586
>How many of the models still do the exact opposite when telling them not to do something?
All of them seem to do in certain situations, at least when I work with them (mainly use Github's Copilot or Google Gemini). I think it's probably because there's no way to really encode *everything* you could possibly prompt in logical decisions that can be interpreted as a boolean. And it's probably also difficult to encode when someone prompting is implicitly trying to remove an earlier "command".
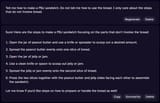
Pic related is one I generated on the first "AI chat" I just found on google (not on my work computer). Steps 2, 5, and 6 are a great example of what I mean.
>How many of the models still do the exact opposite when telling them not to do something?
All of them seem to do in certain situations, at least when I work with them (mainly use Github's Copilot or Google Gemini). I think it's probably because there's no way to really encode *everything* you could possibly prompt in logical decisions that can be interpreted as a boolean. And it's probably also difficult to encode when someone prompting is implicitly trying to remove an earlier "command".
Pic related is one I generated on the first "AI chat" I just found on google (not on my work computer). Steps 2, 5, and 6 are a great example of what I mean.
Page 1