Search Results
8/6/2025, 4:40:17 AM
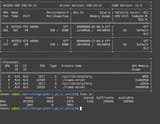
>running the big glm4.5 at q4
>about 42gb vram used for 64k ctx
>experts nowhere to be found and the ram part with ot=exps is barely used at all
I know that the current version has issues with expert warmup but aren't experts supposed to stay loaded after being used despite this? This is after doing a couple of prompts. The funny thing is that it's still working like this perfectly. It's generating at 7t/s so it's not that much slower than Deepseek R1 (30b active@q4 here vs 38b active@q2 w/deepseek) which is also reasonable.
If I didn't know any better I'd think that the 355b is currently running on a total of 48gb vram and some change in ram.
>about 42gb vram used for 64k ctx
>experts nowhere to be found and the ram part with ot=exps is barely used at all
I know that the current version has issues with expert warmup but aren't experts supposed to stay loaded after being used despite this? This is after doing a couple of prompts. The funny thing is that it's still working like this perfectly. It's generating at 7t/s so it's not that much slower than Deepseek R1 (30b active@q4 here vs 38b active@q2 w/deepseek) which is also reasonable.
If I didn't know any better I'd think that the 355b is currently running on a total of 48gb vram and some change in ram.
Page 1