Search Results
6/15/2025, 6:38:31 PM
>>105601953
>Have you tried running ikllama to see how it goes?
I did. I tried as they suggest in their wiki an existing unsloth Q2 quant + ik_llama.cpp. I had a bash script written by AI to install it, so it was easy.
It could not beat 4t/s which I get on the original llama.cpp
>you're in a cpumax rig, server based processors im guessing?
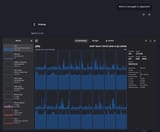
Kinda yes. It is HP Z840 with 2xCPU, that's why I have to micromanage the CPU cores.
>It took me from 1tk/s to 4.5tk/s almost constant through 16k context with pp of about 10tk/s sheet 10k+ context used
I like how stable the pp speed is even for 10k+ context sizes. I figured, it get better (that stable) with -fa
>4090+a6000+128gb ram with a ryzen 3300x
RTX 3090 + 1TB RAM on Intel Xeon from 2017
Thanaks to this big memory, the model, once loaded which takes minutes even with ssd, stays in the memory. It take mere 15 seconds to restart llama-cli
I could find what is different between CLI and SERVER runs. While all 16 cores (hypertheading on 8 physical cores) are running at 100% in case of CLI, they are rather relaxed in case of SERVER
>Have you tried running ikllama to see how it goes?
I did. I tried as they suggest in their wiki an existing unsloth Q2 quant + ik_llama.cpp. I had a bash script written by AI to install it, so it was easy.
It could not beat 4t/s which I get on the original llama.cpp
>you're in a cpumax rig, server based processors im guessing?
Kinda yes. It is HP Z840 with 2xCPU, that's why I have to micromanage the CPU cores.
>It took me from 1tk/s to 4.5tk/s almost constant through 16k context with pp of about 10tk/s sheet 10k+ context used
I like how stable the pp speed is even for 10k+ context sizes. I figured, it get better (that stable) with -fa
>4090+a6000+128gb ram with a ryzen 3300x
RTX 3090 + 1TB RAM on Intel Xeon from 2017
Thanaks to this big memory, the model, once loaded which takes minutes even with ssd, stays in the memory. It take mere 15 seconds to restart llama-cli
I could find what is different between CLI and SERVER runs. While all 16 cores (hypertheading on 8 physical cores) are running at 100% in case of CLI, they are rather relaxed in case of SERVER
Page 1