>>106402811
Nothing special about Qwen, I just picked a modern LLM of small but not insignificant size that could be pretrained within reasonable amounts of time to a proof-of-concept level on 1 GPU. I don't have to deal with synchronization issues so I can't help there.
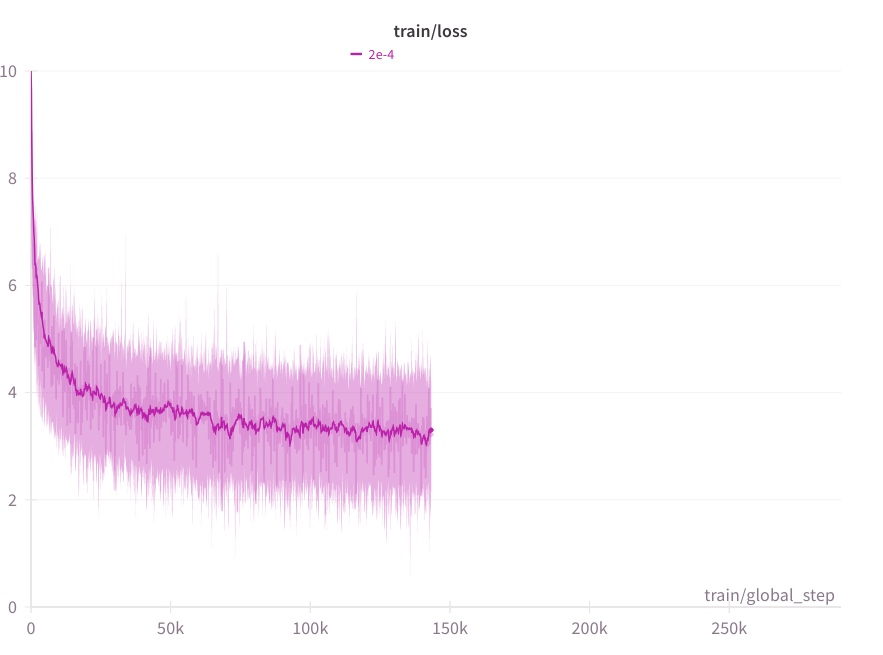
It's noisy but it goes down quicker than I thought. Turns out that large batch sizes don't really allow to increase the learning rate a lot from an optimized BS1 baseline.