>>103681431
Nothing wrong with this, the models aren't necessarily what I would choose since MarbleNet for the VAD to detect audio turn and activity and Canary for the TTS are the leaders in the field if you don't need non-English capabilities but non-Nvidia can't use SOTA models from Nvidia themselves easily. Which is whatever, Also PC laptops are now coming out with 32GB at the price M1 is selling at with 16GB at $599. It's not bad though, but certainly, I want something stronger than quantized 12B Gemma 3.
>>103685000
Ouch, yeah, not ready yet then.
>>103685781
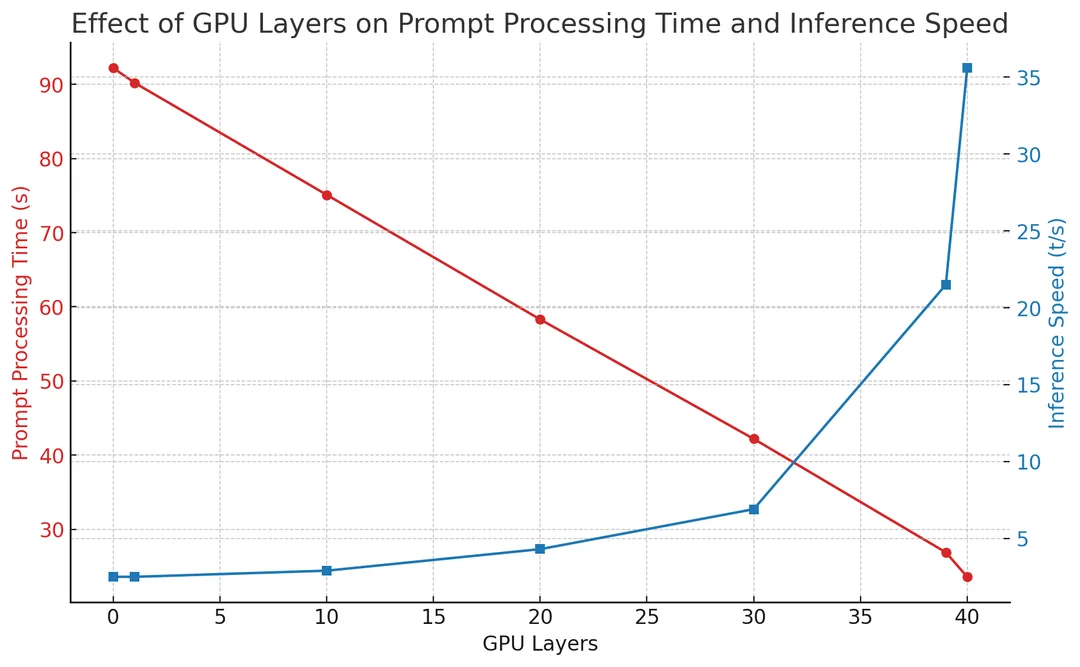
Other than using --batch-size on llama.cpp and the usual tweaks, no. As long as you need to do some CPU offloading, the slowdown is expected and scales linearly pretty much.