>>106409184
>>106410412
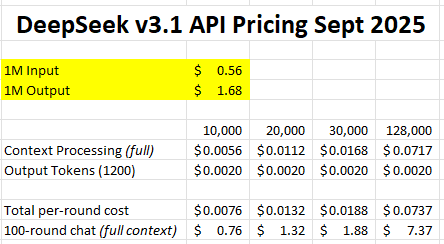
So, here's an example of costs. They're so low, I did the total chat cost of 100 rounds, assuming that context was full the entire time (which it wouldn't be), as well as one where you used the entire 128K context (which I don't think is realistic.)
As you can see... it's nothing. And this is at September pricing; current pricing is about 1/2 of this.
Per-round costs are fractions of a penny, and as context size climbs, that cost dominates the per-round cost.
The bleeding edge of technology vs. the low cost of paid inference is why running local needs either a strong business case or an anon with money to burn.