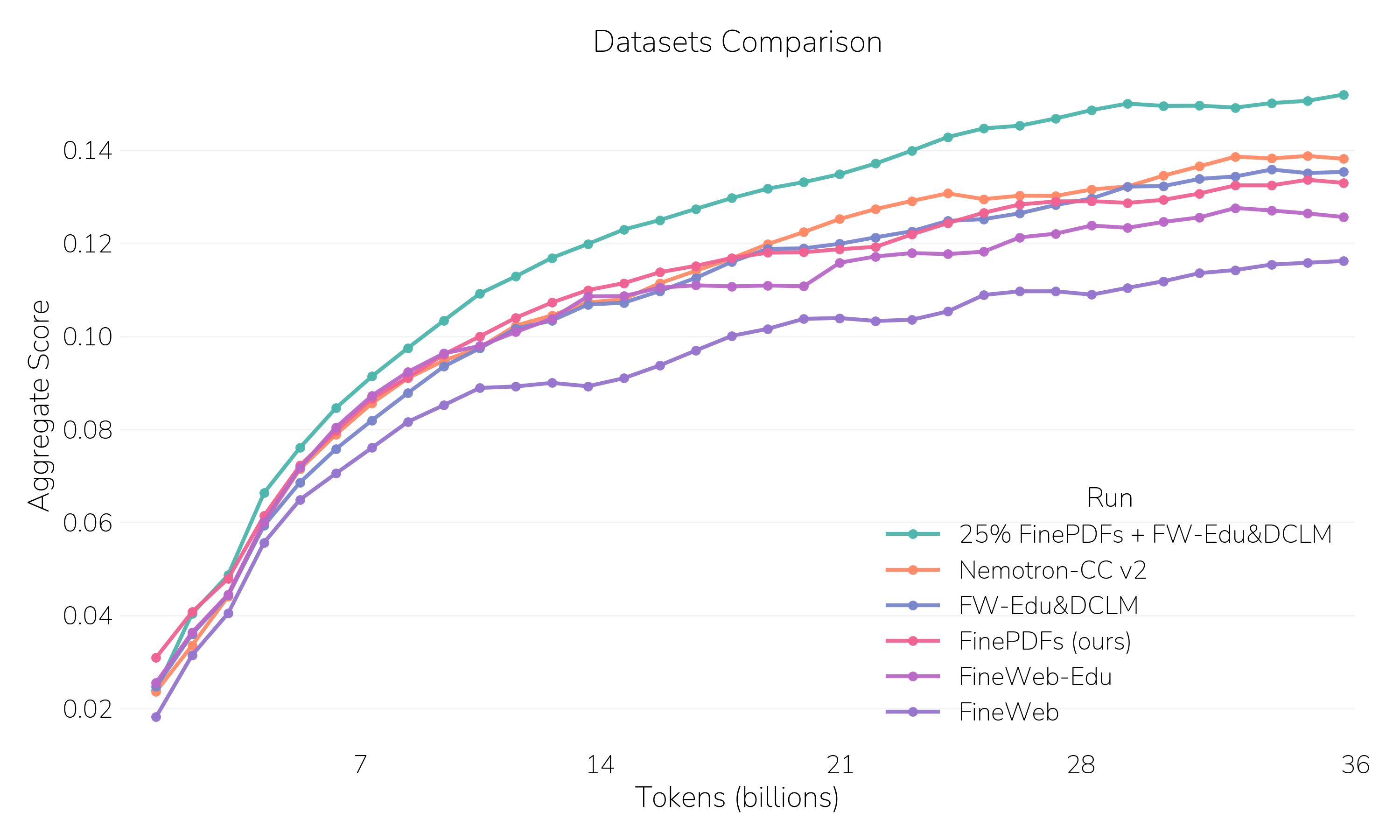
In the FinePDF card they have a graph with general benchmark scores marked every billion tokens. Interestingly, at 1B tokens just training on the PDFs gave similar scores to just the web data (FineWeb) trained for twice the amount of tokens. The gap narrows immediately after that, then turns again to about a factor of 2 later on.
https://huggingface.co/datasets/HuggingFaceFW/finepdfs
Even with a small amount of training tokens for a model pretrained from scratch the data makes a ton of difference. It wouldn't be surprising if with very specialized data you'd get a better model with considerably less tokens than normal---in your field of interest.