ProMode: A Speech Prosody Model Conditioned on Acoustic and Textual Inputs
https://arxiv.org/abs/2508.09389
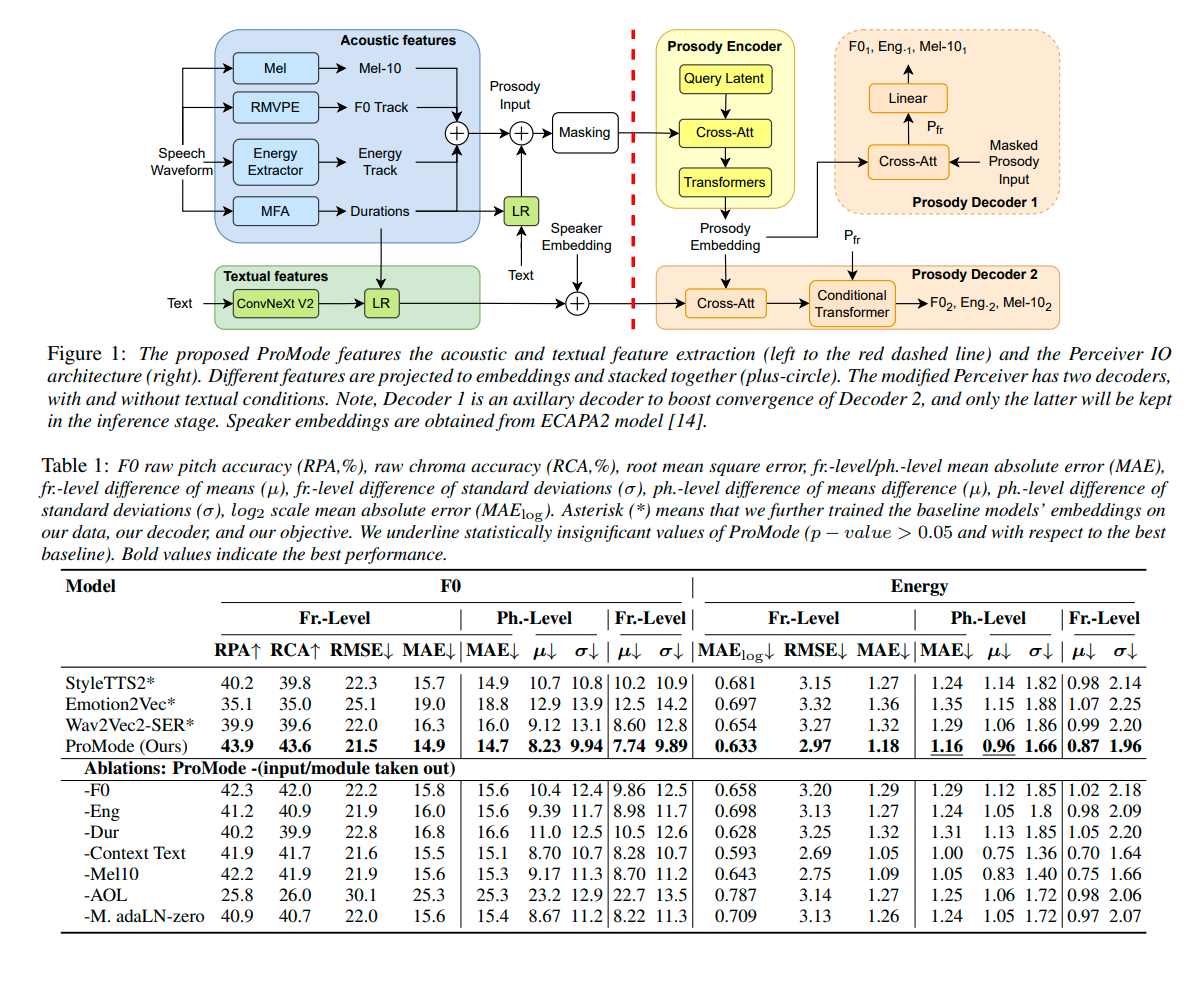
>Prosody conveys rich emotional and semantic information of the speech signal as well as individual idiosyncrasies. We propose a stand-alone model that maps text-to-prosodic features such as F0 and energy and can be used in downstream tasks such as TTS. The ProMode encoder takes as input acoustic features and time-aligned textual content, both are partially masked, and obtains a fixed-length latent prosodic embedding. The decoder predicts acoustics in the masked region using both the encoded prosody input and unmasked textual content. Trained on the GigaSpeech dataset, we compare our method with state-of-the-art style encoders. For F0 and energy predictions, we show consistent improvements for our model at different levels of granularity. We also integrate these predicted prosodic features into a TTS system and conduct perceptual tests, which show higher prosody preference compared to the baselines, demonstrating the model's potential in tasks where prosody modeling is important.
https://promode8272.github.io/promode/index.html
>Code (Coming Soon)
I don't think they'll post the model since they seem to be selling products to film productions (https://flawlessai.com/). but kind of neat. Went back to listen to indextts2 examples (still no model posted) and I think index sounds better
https://index-tts.github.io/index-tts2.github.io/
https://huggingface.co/IndexTeam
but maybe not a surprise since promode only trained on the GigaSpeech dataset
https://huggingface.co/datasets/speechcolab/gigaspeech