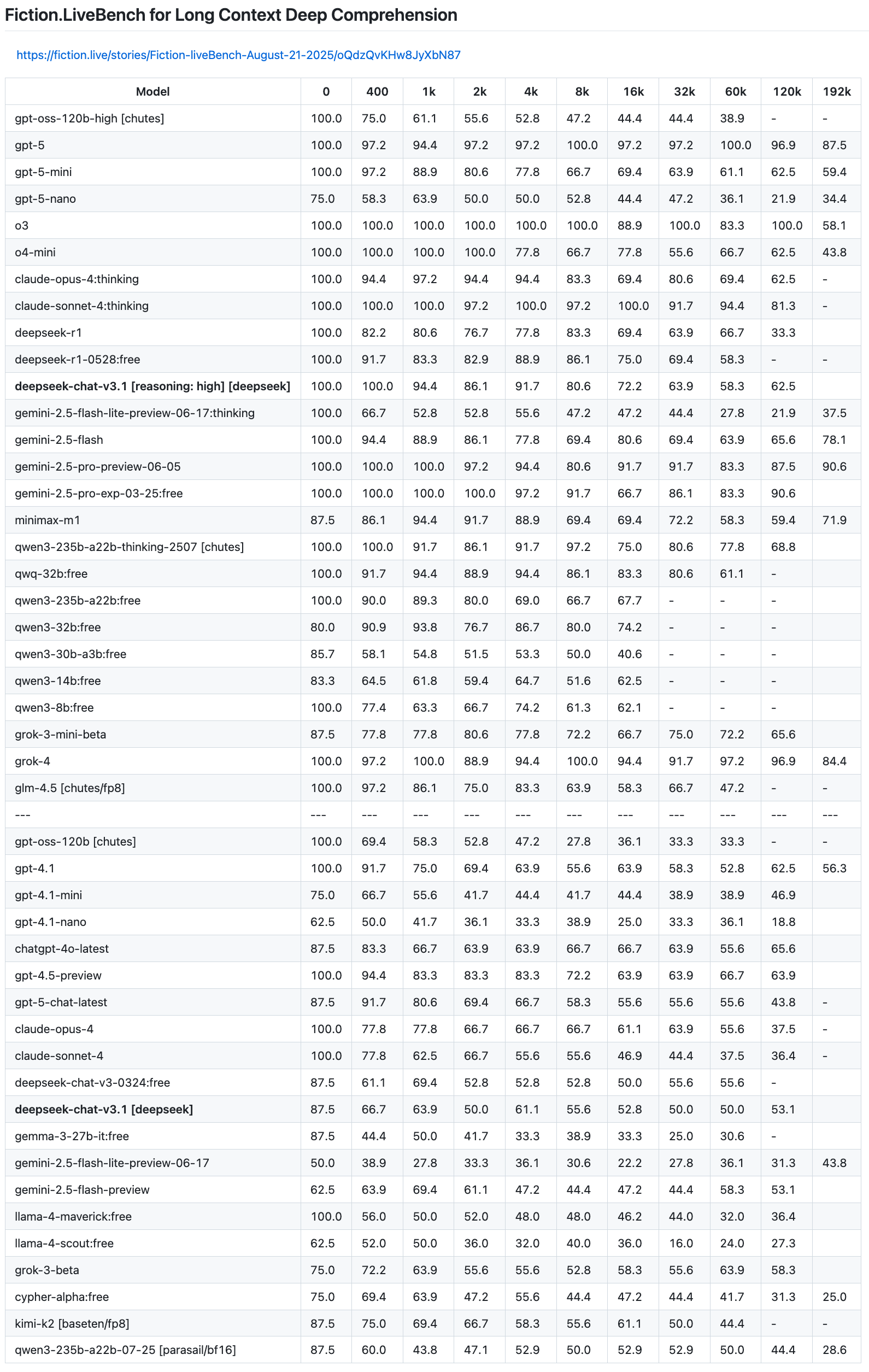
Has this been discussed before? A while ago Fiction LiveBench added deepseek V3.1 to their tests and found it middling. They test how good LLMs can logically comprehend long stories. Companies often brag about how their models can remember 100k+ tokens, but in fact most models severely degrade after just a few thousand.
https://fiction.live/stories/Fiction-liveBench-Feb-21-2025/oQdzQvKHw8JyXbN87