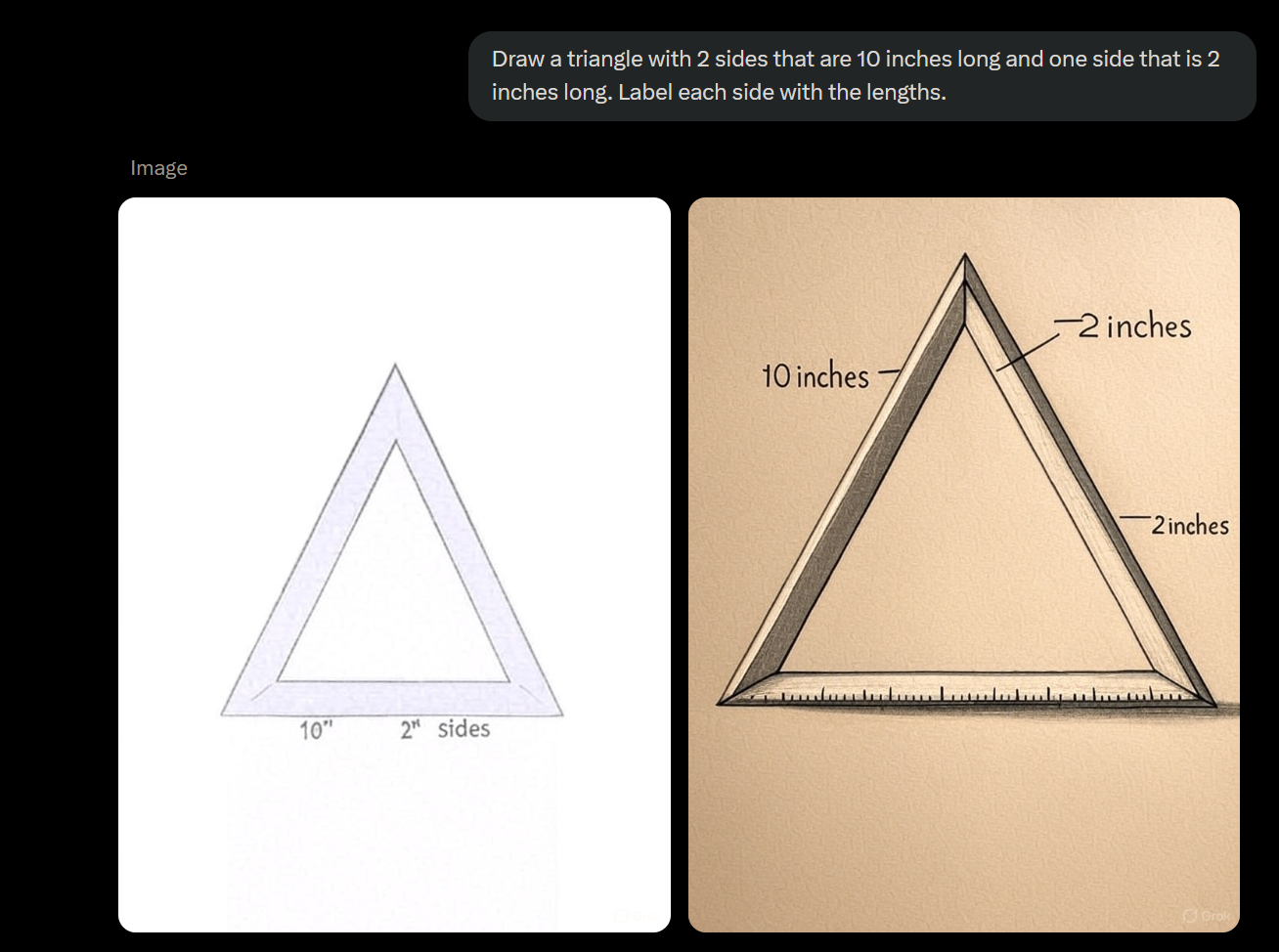
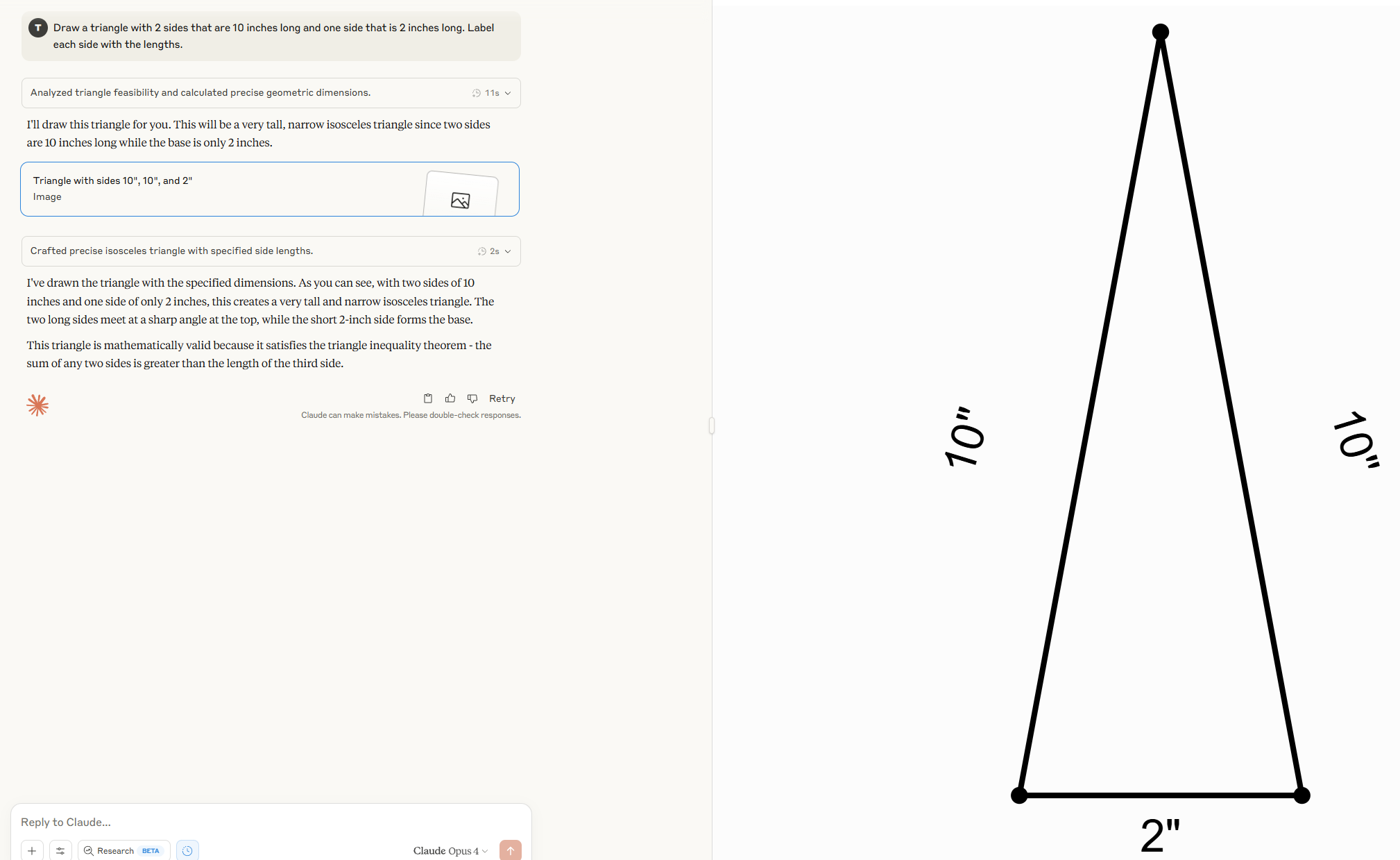
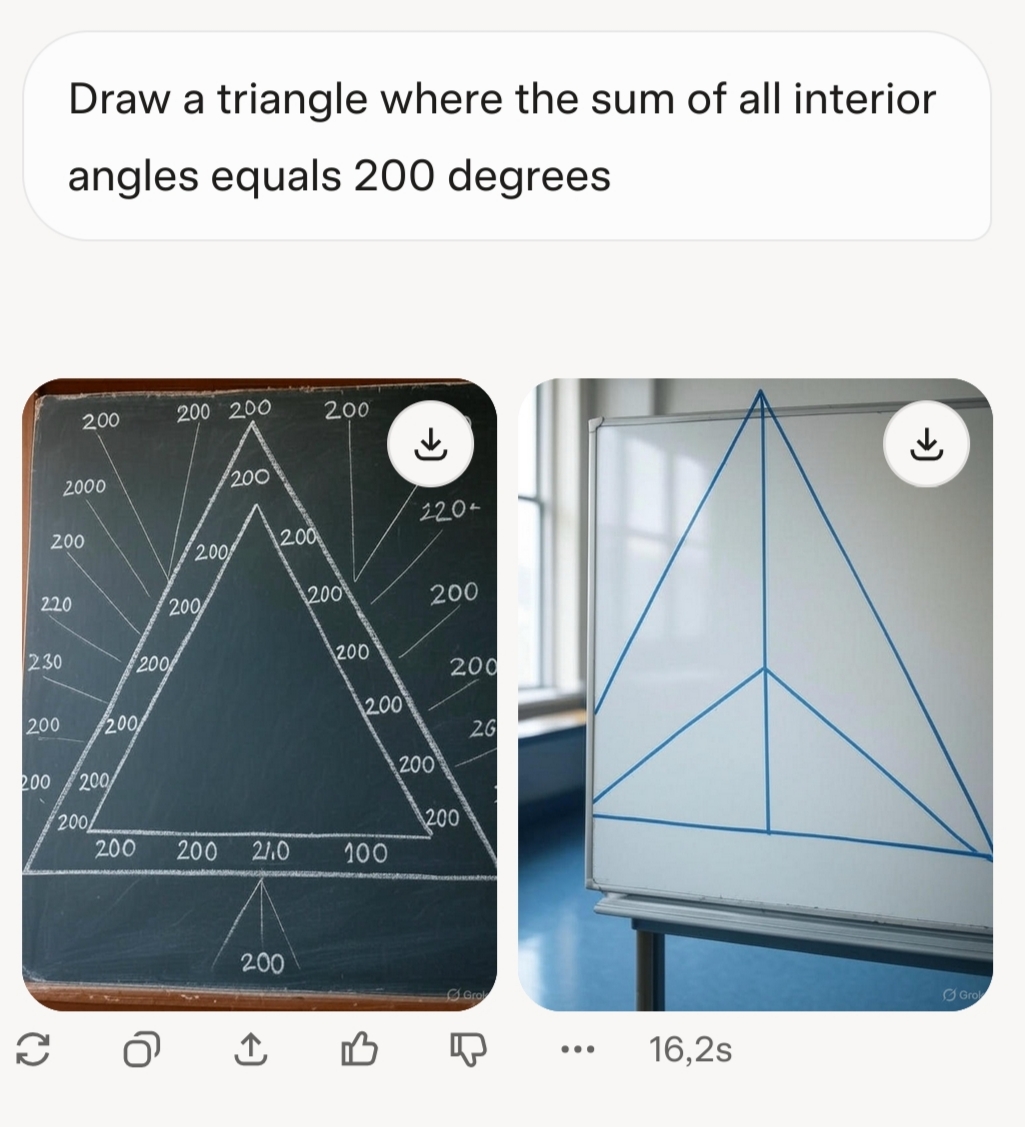
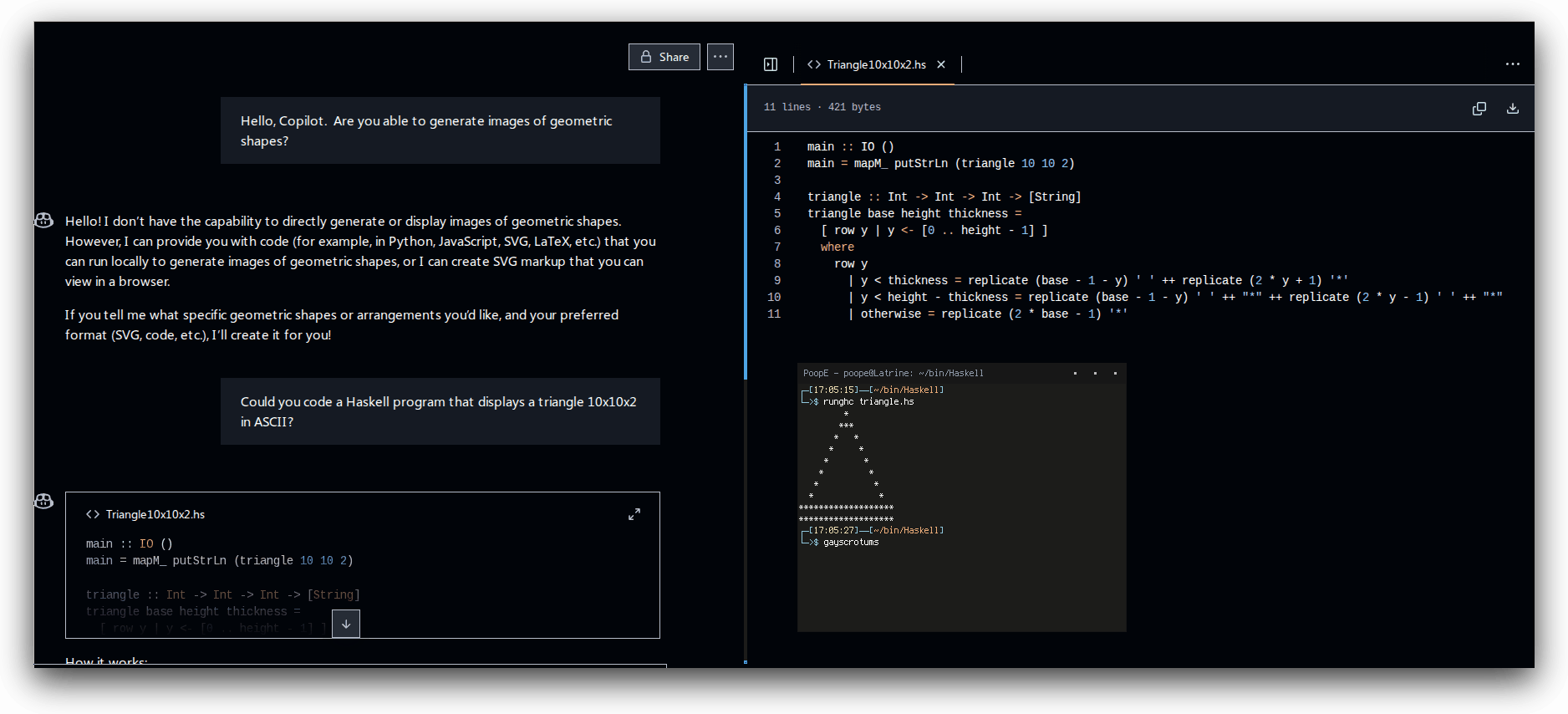
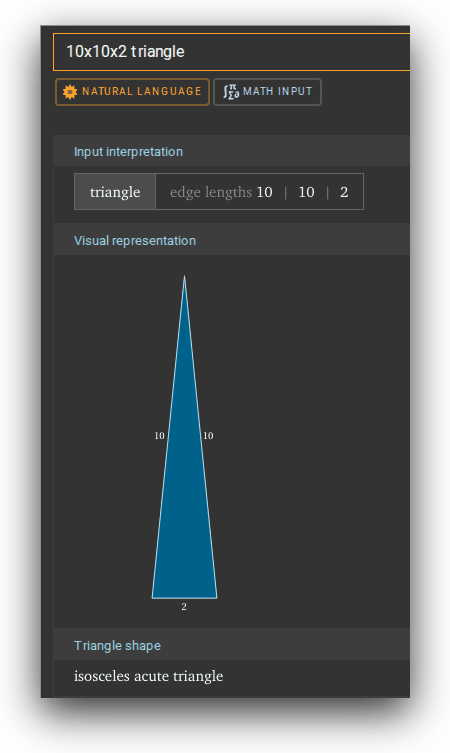
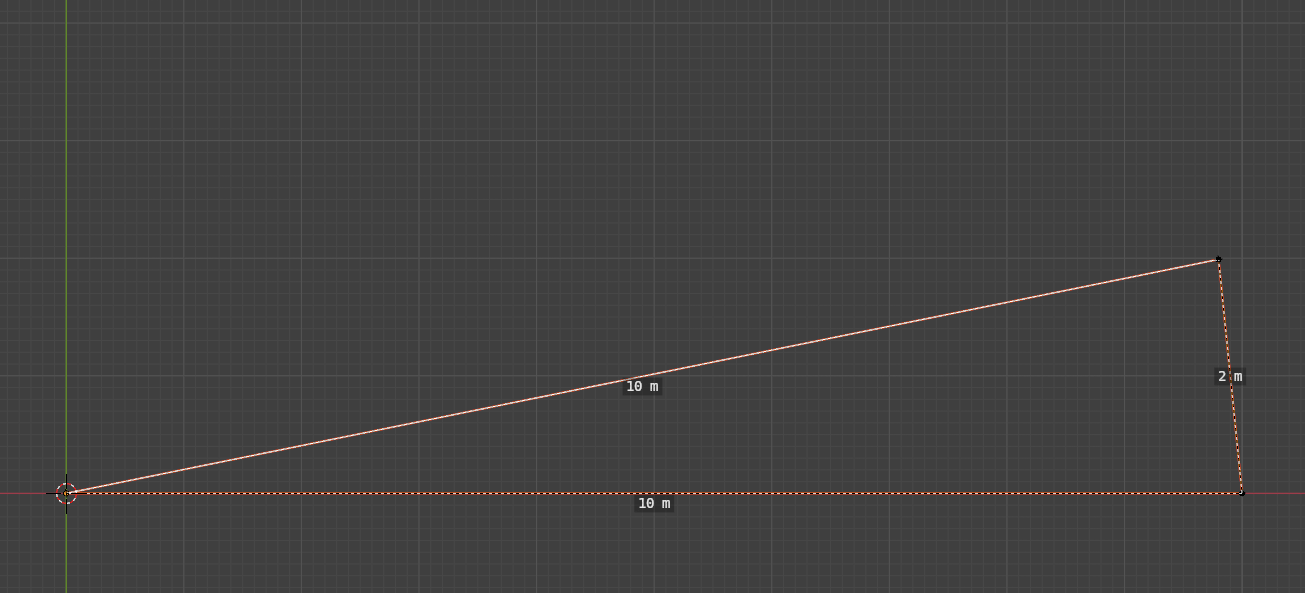
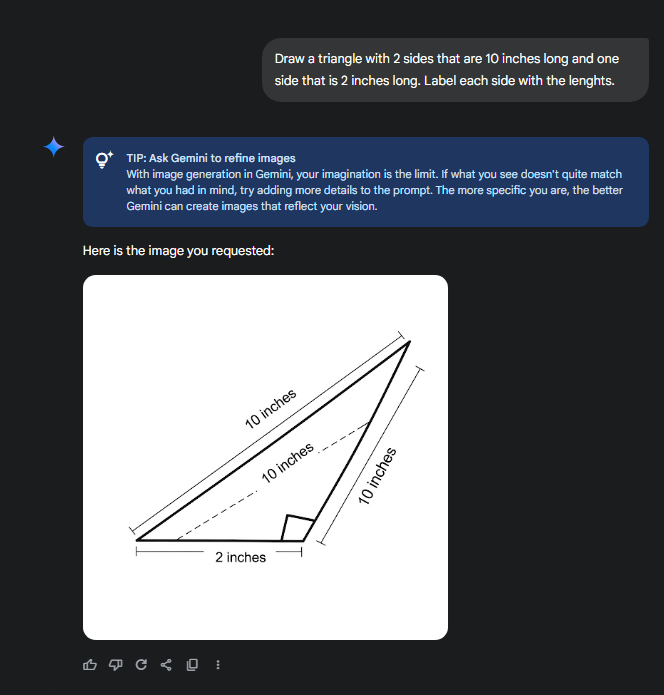
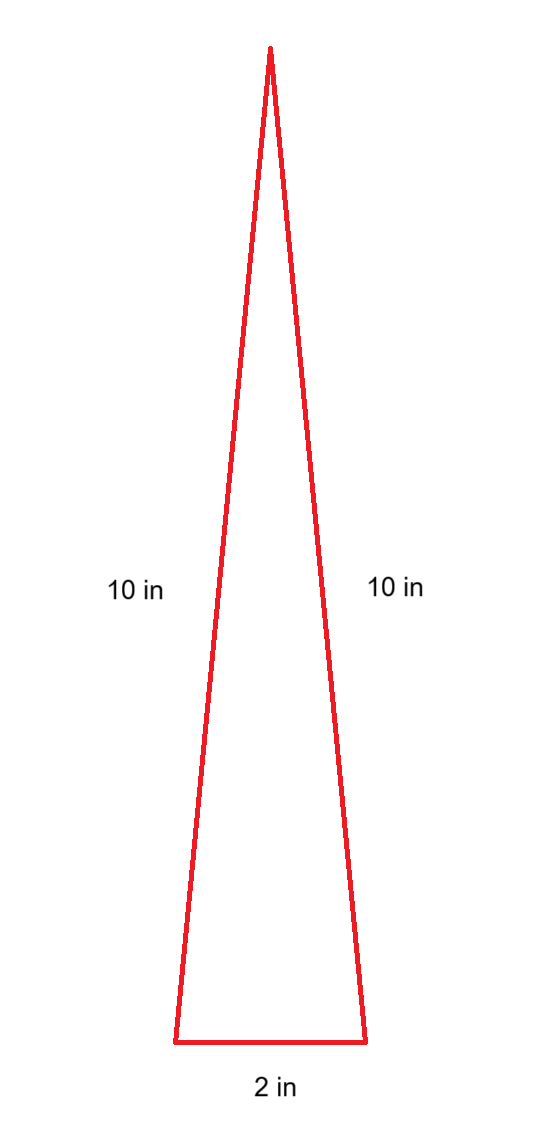
>>105612321LLMs don't see images, at best they tokenize images and then detokenize them, which somewhat works but utterly breaks when precision is required.
This would require VLMs but they are much more compute and memory intensive. Another approach would be a general diffusion model that's trained on text input as images (in addition to images).
tl;dr it's a resource constraint