Anonymous
6/30/2025, 9:05:01 AM
No.105751533
[Report]
/ldg/ - Local Diffusion General
Anonymous
6/30/2025, 9:07:43 AM
No.105751553
[Report]
Cookies
Anonymous
6/30/2025, 9:10:25 AM
No.105751566
[Report]
>>105751613
I'm lazy what node do I use to automatically concat the input and output images?
Anonymous
6/30/2025, 9:10:52 AM
No.105751568
[Report]
suspicious collage of api nodes and the naughty arts
Anonymous
6/30/2025, 9:17:28 AM
No.105751592
[Report]
>>105751625
I haven't been able to get this the way I wanted, so I'm gonna post the sketch and hope someone here can get it right. Going to bed soon, good night you spergs
Anonymous
6/30/2025, 9:22:42 AM
No.105751613
[Report]
>>105751623
>>105751566
KJNodes > Image Concatenate
Anonymous
6/30/2025, 9:24:18 AM
No.105751623
[Report]
>>105751613
fuck yeah thanks anon
Anonymous
6/30/2025, 9:24:24 AM
No.105751625
[Report]
Anonymous
6/30/2025, 9:31:41 AM
No.105751659
[Report]
>>105751664
the anime girl is standing and holding a book that says "LDG posting for dummies" in scribbled font.
Anonymous
6/30/2025, 9:32:39 AM
No.105751664
[Report]
>>105751674
>>105751659
nice artifacts in the background sis
Anonymous
6/30/2025, 9:33:58 AM
No.105751674
[Report]
>>105751664
the output wasnt the same size as the input so it did some outpainting, yeah.
Anonymous
6/30/2025, 9:37:05 AM
No.105751697
[Report]
>>105751706
the man with a cigarette is reading a book with the text "why sequels suck", a picture of the joker from batman is below the text.
so close.
Anonymous
6/30/2025, 9:38:10 AM
No.105751706
[Report]
>>105751709
>>105751697
Have you tried loras yet?
Anonymous
6/30/2025, 9:38:32 AM
No.105751709
[Report]
>>105751706
only tested the clothes remover one, it works
Anonymous
6/30/2025, 9:39:33 AM
No.105751715
[Report]
>>105751712
stock image places BTFO
>>imgur.com/a/flux-kontext-dev-vs-pro-vs-max-uBazRlo
ohnonono localsisters. We are cucked
Anonymous
6/30/2025, 9:44:28 AM
No.105751753
[Report]
>>105751734
>BFL betray
:O
Anonymous
6/30/2025, 9:44:41 AM
No.105751755
[Report]
>>105751887
>>105751712
Now to automate this without quality loss. Imagine getting stock datasets without any watermarks
Anonymous
6/30/2025, 9:46:26 AM
No.105751766
[Report]
>>105751734
Yeah they changed the naming convention. I'm positive pro should've been dev version, while dev schnell. BFL's models are cucked AF now, and they only work as intended via API which is sad.
Anonymous
6/30/2025, 9:48:01 AM
No.105751773
[Report]
>>105751887
>>105751712
so what about quality loss? does it leave the rest of the image in that example untouched? what is the max size for the input? this is obviously REALLY BAD (t. man from gettyimages and basically every big photographer working for a large agency lulz)
Anonymous
6/30/2025, 9:49:25 AM
No.105751778
[Report]
the man with a cigarette is reading a book with the text "why sequels suck" on the front cover.
was easier to generate a blank book, then prompt the text on the book.
the man is holding a blank white book and is upset.
put the text "Joker 2 script (with rape)" in black text in a scribbled font, on the white book.
Anonymous
6/30/2025, 9:49:33 AM
No.105751779
[Report]
>>105751887
>>105751712
you can do it with any LLM cleaner , but this probably better since you can mass remove watermark, instead of marking it one by one
Anonymous
6/30/2025, 9:57:54 AM
No.105751819
[Report]
>>105751984
the anime character in the image is in a vegas casino playing blackjack. he is wearing a brown bomber jacket, white polo shirt and blue jeans. keep the expression the same.
zawa...
so don't laugh at me.... Well, I guess you can, but I'm still learnin i2v shit.
Turns out, my fucking Wan face problems was the fucking resolution.
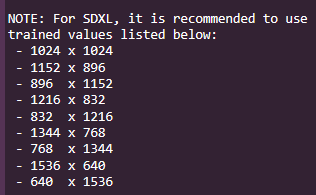
832x480 works just fine, 640x480 and things start getting mushy, 480x480 and things just shit the fucking bed. As far as I'm aware, you need to keep one of the values close to 480, so I'm not entirely sure how I'd get a 1x1 ratio video. 540x540? Like am I aiming for the highest pixel count within the 832x480 range that still has the ratio I want?
Also, how would I go about upscaling the videos with the workflow in the Rentry? From what I understand, you'd do that before you interpolate so you're interpolating the large images instead of upscaling the entire video.
Anonymous
6/30/2025, 10:02:57 AM
No.105751841
[Report]
>>105751855
>>105751831
>Turns out, my fucking Wan face problems was the fucking resolution.
https://rentry.org/wan21kjguide#supported-resolutions
the anime character in the image is in a vegas casino playing blackjack on a green blackjack table. he is wearing a black dress shirt, and blue jeans. keep the expression the same.
it can even colorize images, neat
>>105751831
I do 640x480 for faster gens, with q8 and multigpu node for extra vram if needed it works fine. 832x480 is best but slightly longer. use the light2x lora as it's EXTREMELY faster with it. rentry in OP should have it/workflow.
Anonymous
6/30/2025, 10:04:36 AM
No.105751849
[Report]
>>105751984
>>105751844
forgot image:
Anonymous
6/30/2025, 10:04:56 AM
No.105751853
[Report]
Anonymous
6/30/2025, 10:05:04 AM
No.105751855
[Report]
>>105751841
I've been using those for the most part, so I'm aware of that. However that's kind of limited for most compositions and figured there'd be a little leeway as long as things are kept mostly around 480p.
>>105751844
Been doing all that too.
Anonymous
6/30/2025, 10:05:43 AM
No.105751859
[Report]
>>105751902
with the anime image, also good result:
Anonymous
6/30/2025, 10:11:58 AM
No.105751887
[Report]
>>105751928
>>105751773
>>105751755
>so what about quality loss?
It's obviously not perfect, but for stuff like lora training is mostly fine, as long as you mix other pictures in there so that the training won't pick on these too much.
>does it leave the rest of the image in that example untouched?
The rest of the image stays mostly the same, with small loss of going through the vae (I think). Ideally you want to mask just the modified parts into the original pic.
>what is the max size for the input?
Whatever flux kontext can generate.
>>105751779
What are those? Never heard of them.
Anonymous
6/30/2025, 10:15:32 AM
No.105751902
[Report]
>>105751912
>>105751859
I love how kontext can dupe a font even if the font itself doesnt exist online, you can copy it.
here is a fun test case:
change the text from "Indiana Jones" to "GAY QUEERS". Change the text "fate of atlantis" to "buttsex of AIDS". Remove the man with the hat on the left.
Anonymous
6/30/2025, 10:18:24 AM
No.105751912
[Report]
>>105751922
>>105751902
and a more common test case, Miku:
change the text from "Indiana Jones" to "Miku Miku Miku". Change the text "fate of atlantis" to "i'm thinking Miku". Remove the man with the hat on the left and replace them with Miku Hatsune. Change the lava in the picture to the color teal.
Anonymous
6/30/2025, 10:20:38 AM
No.105751922
[Report]
>>105751926
>>105751912
much better Miku, prompted it a little clearer.
change the text from "Indiana Jones" to "Miku Miku Miku". Change the text "fate of atlantis" to "i'm thinking Miku". Remove the man with the hat on the left and replace them with Miku Hatsune, with long twintails and her traditional outfit. Change the lava in the picture to the color teal.
Anonymous
6/30/2025, 10:21:45 AM
No.105751926
[Report]
>>105751922
okay. now the second set of text is proper. I'll gen more in a bit.
Anonymous
6/30/2025, 10:21:52 AM
No.105751928
[Report]
>>105751887
thanks. other anon is refering to dedicated object removal tools like the old lama cleaner. quite handy and fast when you just want something gone like a watermark or w/e
Anonymous
6/30/2025, 10:28:41 AM
No.105751964
[Report]
What's the total filesize of all the Kontext shit?
Anonymous
6/30/2025, 10:31:51 AM
No.105751984
[Report]
>>105751819
>>105751849
I've always despised this mangas art style
Anonymous
6/30/2025, 10:42:47 AM
No.105752036
[Report]
>>105752043
holy shit you can do a billion edits in one go, seemingly.
change the text from "Indiana Jones" to "Miku Miku Miku". Change the text "fate of atlantis" to "i'm thinking Miku". Remove the man with the hat on the left and replace them with Miku Hatsune, with long twintails in Miku Hatsune's outfit. The lava is replaced with green leek vegetables. Change the background to a music concert. A spotlight is on Miku.
Anonymous
6/30/2025, 10:44:17 AM
No.105752043
[Report]
>>105752051
>>105752036
That's impressive. Now if only AI could spell.
Anonymous
6/30/2025, 10:44:30 AM
No.105752045
[Report]
Can I use the Gemini API node in comfy also for reformating my dementia esl prompts into AI-compliant wall of text?
Anonymous
6/30/2025, 10:45:06 AM
No.105752051
[Report]
>>105752055
>>105752043
it usually one shots it but can sometimes take a few gens. but it is able to copy the font/style, even gradients, which is impressive.
Anonymous
6/30/2025, 10:46:17 AM
No.105752055
[Report]
>>105752057
>>105752051
there we go. now it's a proper game.
Anonymous
6/30/2025, 10:47:36 AM
No.105752057
[Report]
Anonymous
6/30/2025, 10:50:58 AM
No.105752072
[Report]
>>105752078
this one is trickier but kontext actually can do it:
change the red text from "Zelda" to "Miku". Change the text "link's awakening" to "Miku's Awakening". Change the text "DX" to "39". Replace the egg in the center with Miku Hatsune.
im so impressed with this model. it's like wan, really good at what it does.
Anonymous
6/30/2025, 10:52:00 AM
No.105752078
[Report]
>>105752072
a->b reference
Anonymous
6/30/2025, 10:52:20 AM
No.105752079
[Report]
>>105752208
is there a way to do a style transfer between two images in Kontext?
Like I want to put the face on the right onto the drawing on the left.
The model is extremely cucked though. Nice, but could be better.
Anonymous
6/30/2025, 11:05:34 AM
No.105752145
[Report]
>>105752152
>>105752102
clothes remover decensors everything and thats a day 1 lora. if you want lewds you can get lewds. if you happen to get nips that are off just do a fast inpaint with any SDXL model with booru training.
Anonymous
6/30/2025, 11:06:42 AM
No.105752152
[Report]
>>105752166
>>105752145
>clothes remover decensors everything and thats a day 1 lora.
and it got nuked on civitai so no one will know it ever existed, the ecosystem can't thrive when the biggest site prevents you to host your loras
Anonymous
6/30/2025, 11:06:58 AM
No.105752153
[Report]
>>105752221
>>105752102
There's a checkpoint merge on civitai which uncucks it about as well as any flux base can be
Anonymous
6/30/2025, 11:10:01 AM
No.105752166
[Report]
>>105752172
>>105752152
anything good online is there to be found if you look for it, like when reactor for face swaps got "banned" and rehosted (still up)
Anonymous
6/30/2025, 11:11:28 AM
No.105752172
[Report]
>>105752186
>>105752166
>just find the video on rumble bro
no one is gonna do that, we're all on youtube even though youtube is becoming more and more shit
Anonymous
6/30/2025, 11:13:55 AM
No.105752186
[Report]
>>105752384
>>105752172
in any case all you need is a lora once or an extension once, it will never stop working unless you git pull and break something (then you can just revert or use a previous version). reactor will work forever on my system for a face swap, it wont just stop working cause it's 100% local.
Anonymous
6/30/2025, 11:19:38 AM
No.105752208
[Report]
>>105752224
>>105752079
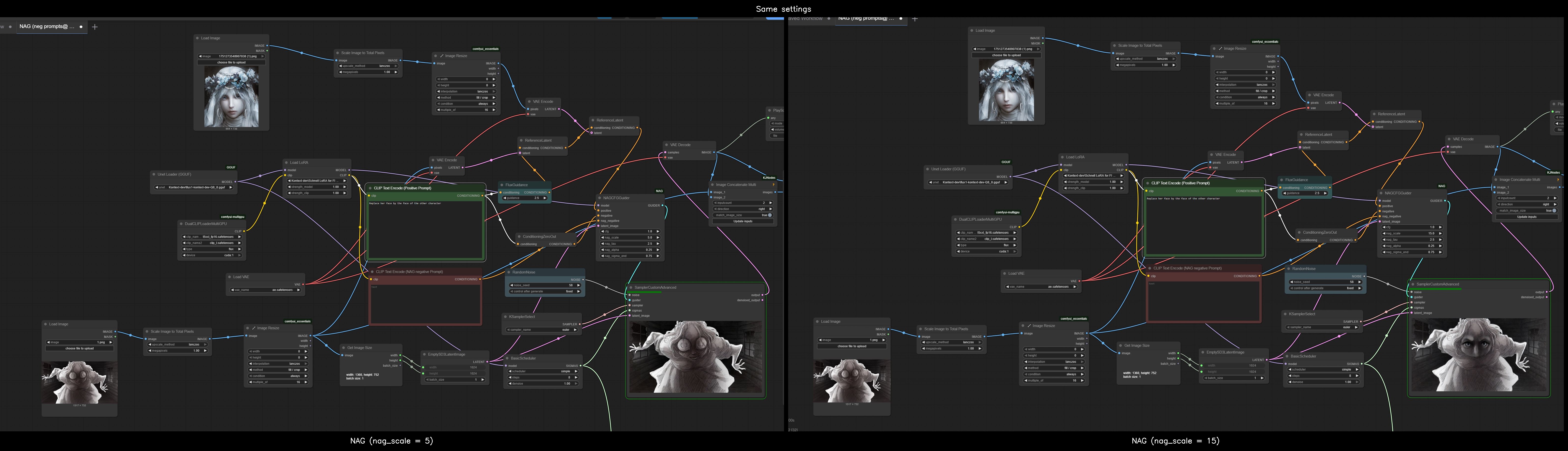
Unironically use NAG and go for big nag_scale value like nag_scale = 15, and it starts to listen to you when you do that
Anonymous
6/30/2025, 11:21:34 AM
No.105752221
[Report]
>>105752237
>>105752153
says it's clothes remover, which is on hf, and a different lora called reveal.6
any idea where to get the latter as a lora?
Anonymous
6/30/2025, 11:22:04 AM
No.105752224
[Report]
>>105752227
>>105752208
is there a default 2 img workflow? cause I dont know how to set all that up
Anonymous
6/30/2025, 11:23:04 AM
No.105752227
[Report]
>>105752284
Anonymous
6/30/2025, 11:25:15 AM
No.105752237
[Report]
Anonymous
6/30/2025, 11:28:52 AM
No.105752255
[Report]
>>105752309
why aren't GGUF loaders in base comfyui? seems like a standard feature
Anonymous
6/30/2025, 11:30:26 AM
No.105752263
[Report]
>>105752271
make the character from first image sitting on a sofa while maintaining the same artstyle, (he has the exact same pose as the character in green square:2)
It doesn't work, my neggas
kontext can't do ref image 1, ref image 2 well
Anonymous
6/30/2025, 11:31:48 AM
No.105752271
[Report]
>>105752298
>>105752263
Why not include that he is leaning on own hand
>>105752227
how does the top image affect outputs? I got the bottom image shaking hands with itself instead of the top image girl.
Anonymous
6/30/2025, 11:35:03 AM
No.105752291
[Report]
>>105752295
>>105752284
wait, image resize at the top was set to 0/0 width and height, is that to disable it?
Anonymous
6/30/2025, 11:36:06 AM
No.105752295
[Report]
>>105752312
>>105752291
disregard that, im wondering how the top interacts with the bottom image in this workflow
Anonymous
6/30/2025, 11:36:44 AM
No.105752298
[Report]
>>105752326
>>105752271
The object is testing if model understand pose of the refence image and then recreate it.
If I carefully described the pos, then it would not be main purpose.
Anonymous
6/30/2025, 11:37:24 AM
No.105752300
[Report]
>>105752318
>>105752284
add on the negative prompt "clone, twins"
Anonymous
6/30/2025, 11:38:44 AM
No.105752309
[Report]
>>105752255
I agree, at this point GGUF is very established as a format, so I can only suppose that comfyanon is being lazy and/or is salty over something with GGUF, he is really petty.
Overall it's shameful that the core nodes cover so little of basic usage that you need custom nodes just to make something as basic as combining random prompts from lists.
Anonymous
6/30/2025, 11:39:00 AM
No.105752312
[Report]
>>105752295
>im wondering how the top interacts with the bottom image in this workflow
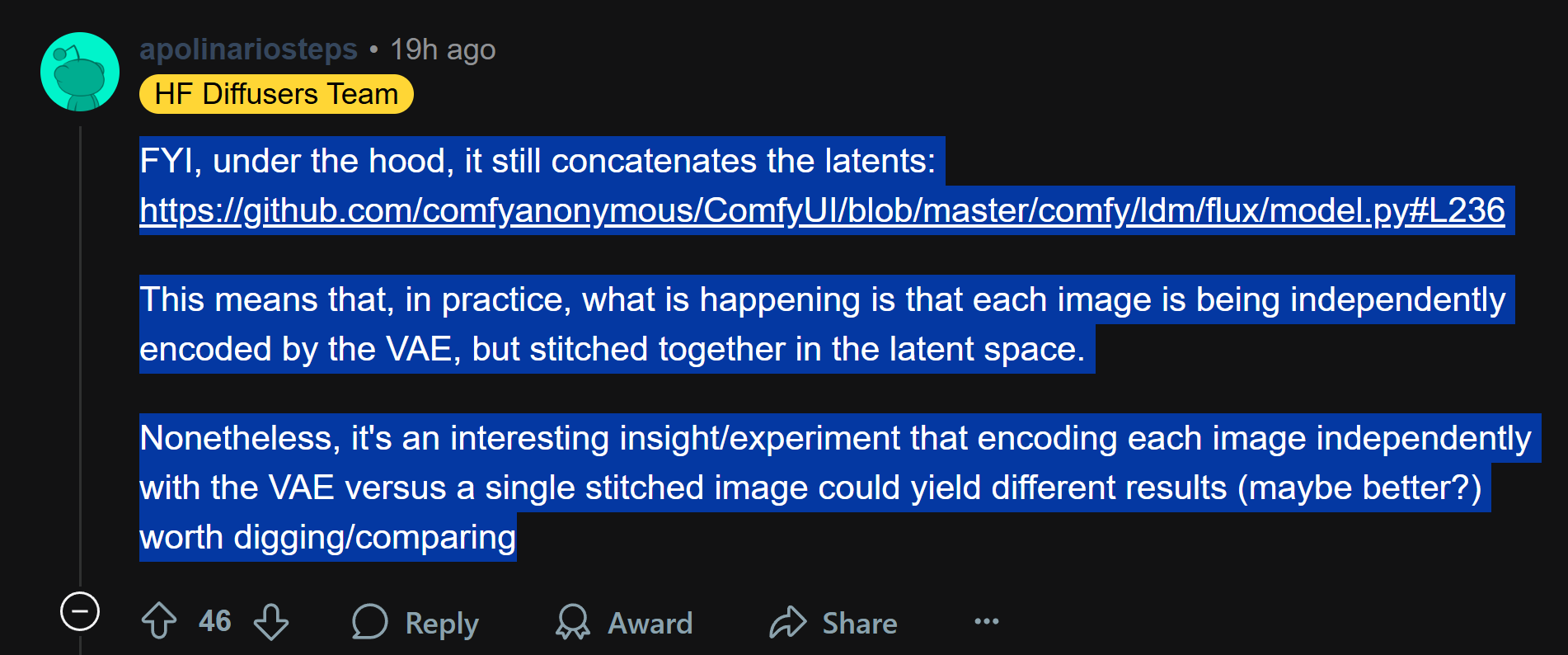
that workflow also stitch images, but it does it on the latent space, it's a different method and it also works
https://www.reddit.com/r/StableDiffusion/comments/1lnckh1/comment/n0ev4qe/?utm_source=share&utm_medium=web3x&utm_name=web3xcss&utm_term=1&utm_content=share_button
Anonymous
6/30/2025, 11:39:52 AM
No.105752318
[Report]
>>105752323
>>105752300
seems to be working, the other girl is showing up in the preview
Anonymous
6/30/2025, 11:40:52 AM
No.105752323
[Report]
>>105752340
>>105752318
show a screen of the workflow, hard to help you when I can't see what's goin on
Anonymous
6/30/2025, 11:41:57 AM
No.105752326
[Report]
Anonymous
6/30/2025, 11:44:19 AM
No.105752340
[Report]
>>105752351
>>105752323
it's fine now, negative prompts worked
Anonymous
6/30/2025, 11:46:16 AM
No.105752351
[Report]
>>105752355
>>105752340
oh yeah I misread what you said, my b, and yeah, cool that it seems to be working with you, have fun with that model, I think at this point we definitely need a rentry that lists all those little tricks so that we can use Kontext Dev at its full potential.
Anonymous
6/30/2025, 11:47:43 AM
No.105752355
[Report]
>>105752351
definitely, as it's a very neat tool like wan is.
the anime girl is wearing a white tanktop and a black miniskirt. keep the same proportions and expression.
Anonymous
6/30/2025, 11:51:38 AM
No.105752384
[Report]
>>105752396
>>105752186
Where do you find reactor nowadays? Torrent?
Anonymous
6/30/2025, 11:52:59 AM
No.105752392
[Report]
>>105752411
>>105752375
That doesnt look like a miniskirt sister. It looks like very short pants
Anonymous
6/30/2025, 11:53:16 AM
No.105752396
[Report]
>>105752384
https://github.com/Gourieff/ComfyUI-ReActor
the nsfw stuff can be commented out to fix the filter, otherwise github bans it.
Anonymous
6/30/2025, 11:55:10 AM
No.105752411
[Report]
>>105752419
>>105752392
this one turned out better, now it's a pleated skirt.
alright, pretty happy with the first version of this kontext pixel lora. it still struggles with some photorealistic images and scenarios but whatever, i've published it on civitai
need to work on my dataset for the next version
Anonymous
6/30/2025, 11:56:07 AM
No.105752419
[Report]
>>105752430
>>105752411
Now give her meaty pencil eraser nips
Anonymous
6/30/2025, 11:57:38 AM
No.105752430
[Report]
>>105752419
mods might be in a bad mood, just use any sdxl booru trained model and inpaint.
Anonymous
6/30/2025, 11:58:42 AM
No.105752446
[Report]
>>105752457
neat, worked on a very old cammy I made (this was before noobAI I think). although covering cammy up is bad it's a test.
Anonymous
6/30/2025, 11:59:06 AM
No.105752449
[Report]
>>105752454
>>105752412
Cool man. Did you train it locally?
Anonymous
6/30/2025, 12:00:15 PM
No.105752454
[Report]
>>105752499
>>105752449
nah 24G VRAM didn't seem enough, rented an A40 and trained overnight. still quite slow like 20s/it
Anonymous
6/30/2025, 12:00:38 PM
No.105752457
[Report]
>>105752512
>>105752446
>>105752375
So kontext can't keep the input's image artstyle at all?
Anonymous
6/30/2025, 12:02:04 PM
No.105752475
[Report]
>>105752486
What happened to the Anon that tried to train his own NSFW kontext LoRA?
Anonymous
6/30/2025, 12:03:05 PM
No.105752486
[Report]
Anonymous
6/30/2025, 12:04:53 PM
No.105752499
[Report]
>>105752902
>>105752454
I guess it will be same with Chroma.
Anonymous
6/30/2025, 12:06:34 PM
No.105752512
[Report]
>>105752523
>>105752457
it can, I just specified to keep the same expression/proportions. if you dont say that it will take more liberties (diff pose, etc)
Anonymous
6/30/2025, 12:07:01 PM
No.105752516
[Report]
>>105752522
>>105752412
link to lora?
>>105752516
civitai.com/models/1731051
Anonymous
6/30/2025, 12:08:16 PM
No.105752523
[Report]
>>105752765
>>105752512
for example, it can make infinite pepes with a pepe source image, it will only look like a real frog if you tell it to be realistic. cartoon frog keeps it as a regular pepe.
Anonymous
6/30/2025, 12:08:57 PM
No.105752529
[Report]
>>105752522
much appreciated
Anonymous
6/30/2025, 12:11:54 PM
No.105752548
[Report]
>>105752573
>>105752522
Strange it can't be seen on front page
Anonymous
6/30/2025, 12:16:46 PM
No.105752571
[Report]
>>105752522
Impressive result.
Anonymous
6/30/2025, 12:17:11 PM
No.105752573
[Report]
>>105752913
>>105752548
maybe cause i just added it. i also ticked "cannot be used for nsfw" but not sure what that checkbox does desu and if i should leave it on
>flux kontext "requires 20GB ram"
>run it on my 3080
>150 seconds
but why is it lowering the resolution of the output image
Anonymous
6/30/2025, 12:19:23 PM
No.105752591
[Report]
>>105752578
I ran 2400x1400 images fine on my 12gb in the original resolution, but 2560x1440 appears to be oom. Using nunchaku of course.
>why is it lowering the resolution of the output image
bypass/delete fluxkontextimagescale node
>>105752522
is there a way to make those pixels bigger? I feel like the effect is a bit too subtle
Anonymous
6/30/2025, 12:22:17 PM
No.105752617
[Report]
>>105752656
spent 20 minutes trying to fix hand anatomy to no avail
Anonymous
6/30/2025, 12:22:48 PM
No.105752622
[Report]
>>105752715
>>105752604
no but i am planning to train an 8x version at some point (so double the pixel size of the one i linked).
this is really my first try and making the dataset is hard, i had to use the flux loras which i had already made to make a synthetic pair dataset
Anonymous
6/30/2025, 12:26:34 PM
No.105752650
[Report]
>>105752658
>>105752522
Seems like it struggles with high res images, but that might just be a Kontext issue in general
Anonymous
6/30/2025, 12:28:13 PM
No.105752656
[Report]
>>105752617
flux faces are so cursed
Anonymous
6/30/2025, 12:28:29 PM
No.105752658
[Report]
>>105752650
yeah it's only trained up to 1024 on a small dataset of 20 image pairs
Anonymous
6/30/2025, 12:36:13 PM
No.105752709
[Report]
>>105752727
Realistically how long until other kontext variant that has apache 2.0 license and nsfw combability is made (Chinese model). Do you think the model will benefit with training like Pony/chroma
Anonymous
6/30/2025, 12:37:04 PM
No.105752715
[Report]
>>105752723
>>105752604
>>105752622
desu i realized, you can just halve your output resolution. the lora just tries to be 4 pixels = 1 pixel.
Anonymous
6/30/2025, 12:40:17 PM
No.105752723
[Report]
>>105752734
>>105752715
Damn looks nice
Anonymous
6/30/2025, 12:40:47 PM
No.105752727
[Report]
>>105752810
>>105752709
you'll be waiting a while. took almost a year to get a flux finetune. pony took 6 months after SDXL released, and illustrious another 7 months after that. the only model comparable to flux we've gotten since flux is hidream, and nobody wants to touch it.
Anonymous
6/30/2025, 12:41:31 PM
No.105752734
[Report]
>>105752723
will publish a v1.1 later today, i think the one i put on civitai is a bit undercooked still
kontext is crazy good. i think AI is driving me insane. its too much omnipotence to handle and it overwhelms me, i think im just gonna rope one day
Anonymous
6/30/2025, 12:44:08 PM
No.105752748
[Report]
>>105752766
>>105752739
we're still in early stages
the future is models that communicate to user through llm module to discuss and fine tune the image, moving away from black box approach
Anonymous
6/30/2025, 12:45:24 PM
No.105752759
[Report]
>>105752801
Does Chroma not know wtf loli/JC/JK or shota is? The characters ages/heights/tits are all over the place.
Anonymous
6/30/2025, 12:45:51 PM
No.105752761
[Report]
>>105752739
it is but you got the hella weak version. Just go to the bfl website and use Kontext. Max which is their best version and see the comparison for yourself. Change the setting and see what is really in store for you. Then imagine what this will look like nsfw with proper training and no censorship holding it back.
Anonymous
6/30/2025, 12:46:23 PM
No.105752765
[Report]
>>105752938
>>105752523
Seems ok for general style like that frog one, but it shits the bed once you try more artsy style
Anonymous
6/30/2025, 12:46:26 PM
No.105752766
[Report]
>>105752748
what ive always wanted is some kind of multi stage system, like it gives me choices for composition first, then lets me choose one, and i can further refine subjects, styles, and make little edits until the final product is complete
Anonymous
6/30/2025, 12:50:52 PM
No.105752801
[Report]
>>105752759
yo buddy
still gooning?
Anonymous
6/30/2025, 12:52:20 PM
No.105752810
[Report]
>>105752727
i guess is because companies went for txt 2 vid models and downright abandoned image models altogether until the ghibi meme got them reconsidering. Just look at stability ai and BFL in how they shifted focus to a video model. BFL still is taking a year to release it after their announcement. It kinda pisses me off that the best image sources is from the west which is censoring the model to hell whereas the best video model is from the east (WAN2.1 and others).
Anonymous
6/30/2025, 12:59:31 PM
No.105752852
[Report]
what if txt2img become so potent and ubiquitous that people stop drawing new content and everything goes to shit in a decade
Anonymous
6/30/2025, 1:02:13 PM
No.105752865
[Report]
>>105752412
Nice work my man!
Anonymous
6/30/2025, 1:03:58 PM
No.105752874
[Report]
>>105752883
>>105752522
looks more like sprite art than pixel
Anonymous
6/30/2025, 1:05:11 PM
No.105752883
[Report]
>>105752874
sprite is any 2d element bro, there's no such thing as sprite art, or it can be commonly used to refer to pixel art
Anonymous
6/30/2025, 1:07:05 PM
No.105752891
[Report]
>>105752869
Is this clash of clans?
Anonymous
6/30/2025, 1:09:02 PM
No.105752902
[Report]
>>105752499
You can train Flux dev on 12gb with ram offloading (32gb is enough).
Chroma is based on Flux Schnell which is smaller than Flux dev, so it will have less hardware demands.
The problem is that the only trainer that supports Chroma at the moment is ai-toolkit, and it has practically zero vram optimizations meaning you basically need 24gb vram to use it.
Once OneTrainer and Kohya adds Chroma support, you will easily be able to train loras at 12gb.
Anonymous
6/30/2025, 1:11:46 PM
No.105752913
[Report]
>>105752573
It means that it can't be seen if you have NSFW turned on, Civitai did this a while back to prevent celebrities from showing up when you had nsfw enabled, they were hoping this would appease the payment processor so that they could keep both porn and celebrities, but it didn't.
Anonymous
6/30/2025, 1:15:00 PM
No.105752928
[Report]
Anonymous
6/30/2025, 1:15:37 PM
No.105752932
[Report]
>>105752924
Not bad, but I miss the cake girls enjoying syrup...
Anonymous
6/30/2025, 1:15:43 PM
No.105752933
[Report]
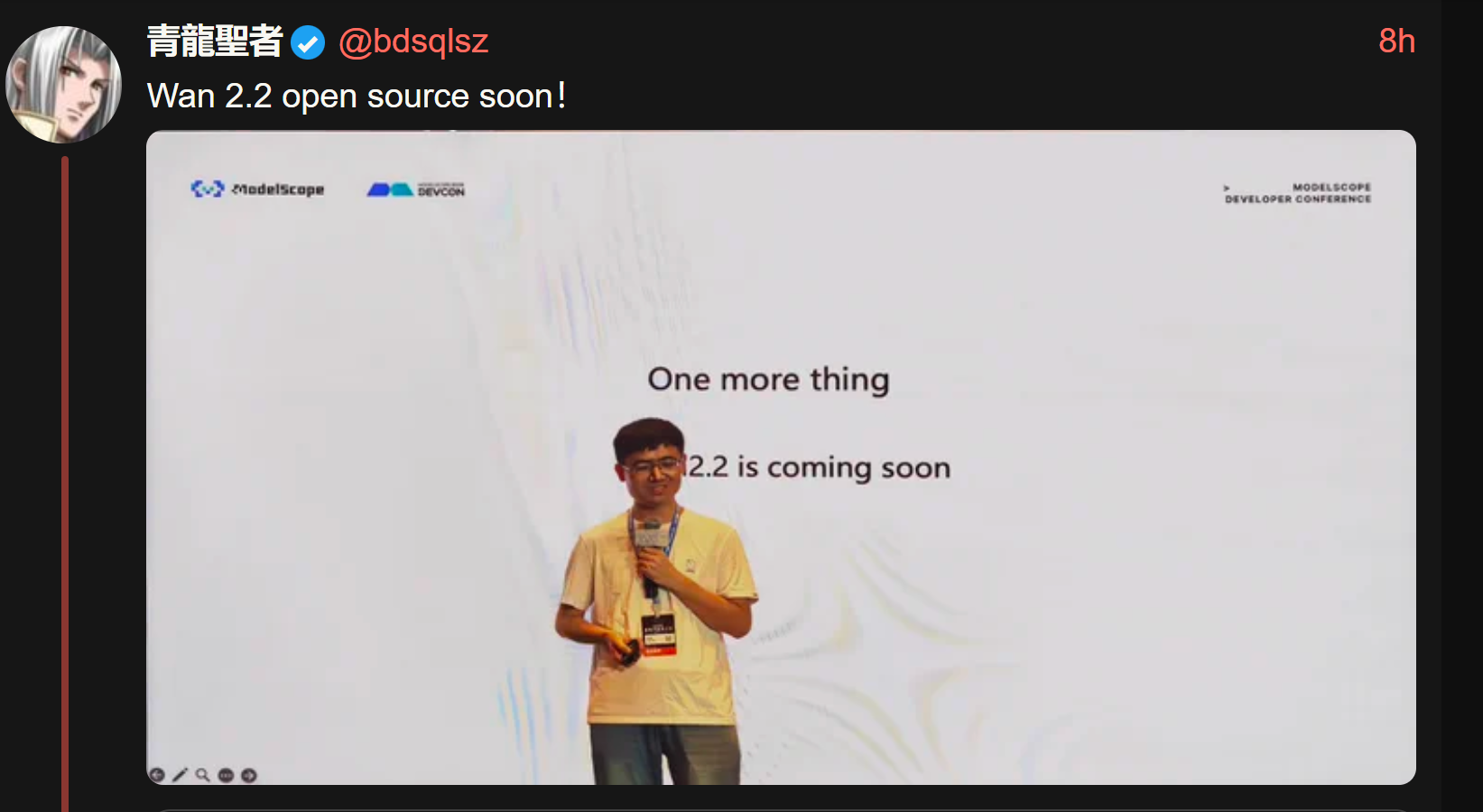
>>105752944
https://xcancel.com/bdsqlsz/status/1939562837724315850#m
Imagine they’ve seen how much coomer use Wan2.1 had and they make it full NSFW
>buy 5090 for $2800
>sell my 4090 on ebay for $~2100 going rate right now on used examples
>5090 upgrade for under $1000
y/n?
Anonymous
6/30/2025, 1:16:31 PM
No.105752938
[Report]
>>105752765
>first image
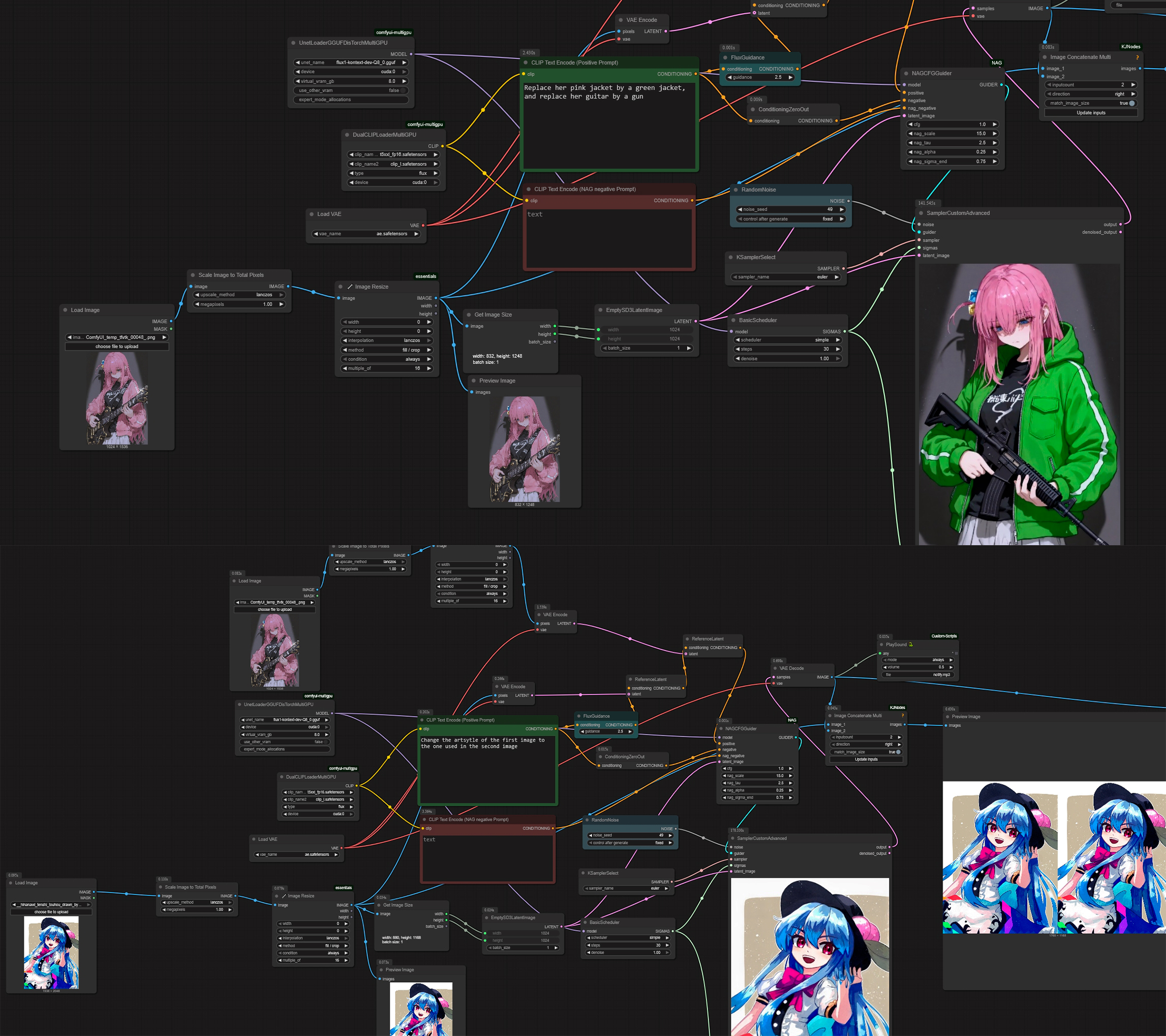
>second image
your model won't understand something like that, try to go for "replace the art style of the image by the art style from the other character"
Anonymous
6/30/2025, 1:17:32 PM
No.105752944
[Report]
>>105752949
>>105752933
>Wan 2.2
please make it local aswell
Anonymous
6/30/2025, 1:18:35 PM
No.105752949
[Report]
>>105752970
>>105752944
>Hunyuan went API
>Bytedance went API
>Hidream went API
the SaaS reaper knocks once more...
>video tdr failure
is it over for my faithful 6 GB laptop graphic card?
>>105752949
These were all both open model and API 'pro' version from the get go, Wan is the same.
I would be surprised if Wan 2.2 isn't released into the wild, that said, how much of an improvement can one expect from 2.1 to 2.2 ?
Anonymous
6/30/2025, 1:23:05 PM
No.105752973
[Report]
>>105752984
>>105752970
>These were all both open model and API 'pro' version from the get go, Wan is the same.
no, when alibaba released Wan 2.1, they released their most powerful model (they didn't have something better on their API)
Anonymous
6/30/2025, 1:23:36 PM
No.105752975
[Report]
>>105752968
It's time to put old Yeller down, anon T_T
>>105752973
You sure ? Either way everyone else is an also-ran at this point, it was hilarious to see BFL quietly memory hole their upcoming video model when Wan released.
Fuck western big tech, the chinks are my best friend now.
Anonymous
6/30/2025, 1:26:31 PM
No.105752990
[Report]
>>105752984
>Fuck western big tech, the chinks are my best friend now.
yep, this
>>105752970
>>105752984
https://www.runcomfy.com/playground/wan-ai/wan-2-2
This page seems to have a little information and demo clips available
>>105752994
>30 fps
oof, it's gonna be painful to render, but they are right, 16fps wasn't enough for fast movements
Anonymous
6/30/2025, 1:35:44 PM
No.105753039
[Report]
>>105753080
>>105752937
if it wouldn't hurt you and you think you make use of it, I'd keep both. how much more expensive would it be for you to get another 24GB of VRAM or 4090 if you decided to later?
>>105752970
lol Chinese count on Americans to think like that. they know making a big release with a small version increment like it's no big deal can crash our stock market.
Anonymous
6/30/2025, 1:37:14 PM
No.105753044
[Report]
>>105752968
>tdr
I had 10 of those last weeks, then nothing this week
it's probably windows fucking shit up
how dumb of an idea is to buy a KVM switch to easily switch my monitor between my integrated gpu and nvidia card in the case i need that extra 1gb of VRAM?
Anonymous
6/30/2025, 1:44:00 PM
No.105753080
[Report]
>>105753039
>lol Chinese count on Americans to think like that.
Go kvetch somewhere else, rabbi
Anonymous
6/30/2025, 1:45:54 PM
No.105753093
[Report]
>>105753014
Why not 24 or 25 (NTSC, PAL respectively) ? Would at least save some time and be fluid enough.
Anonymous
6/30/2025, 1:47:27 PM
No.105753102
[Report]
>>105752937
I'd keep the 4090 so you can still use your GPU while gen'ing, or use it for parallel gen'ing.
Anonymous
6/30/2025, 1:48:56 PM
No.105753116
[Report]
Anonymous
6/30/2025, 1:52:28 PM
No.105753152
[Report]
>>105753164
>>105753074
That extra 1gb VRAM could be the threshold difference between higher resolution, higher batch size etc, so it could be worth it.
It's sad that Nvidia is so cheap that we are doing workarounds to save 1gb...
Anonymous
6/30/2025, 1:54:32 PM
No.105753164
[Report]
>>105753170
>>105753164
ram is like 100x slower than vram
>>105753170
not if you only offload a few % of the total model to the ram
Anonymous
6/30/2025, 1:56:01 PM
No.105753175
[Report]
Anonymous
6/30/2025, 1:59:29 PM
No.105753193
[Report]
>>105753174
yeah ok fair. i still think though if i CAN use that extra vram by switching the monitor to the integrated gpu, then i should, since it's "free"
only annoying thing is switching back the cable once you're done generating and want to game or smth
Anonymous
6/30/2025, 2:00:32 PM
No.105753203
[Report]
>>105753217
>>105752994
> improved temporal consistency, seamless scene shifts, and support for longer, high-resolution clips.
yeah that's never coming to local.
Anonymous
6/30/2025, 2:00:41 PM
No.105753205
[Report]
>>105753243
>>105753174
That graph is for llama.cpp and an LLM.
Anonymous
6/30/2025, 2:00:50 PM
No.105753207
[Report]
>>105753253
When using VACE, does the reference video resolution need to be the same size that WAN supports, like 480P, 720P, etc?
Anonymous
6/30/2025, 2:02:03 PM
No.105753217
[Report]
>>105753203
If they were going the API route, that'd be the first thing they'd mention.
Anonymous
6/30/2025, 2:04:18 PM
No.105753243
[Report]
>>105753289
>>105753205
>That graph is for llama.cpp
the gguf node on ComfyUi uses llama.cpp, are you this retarded debo?
Anonymous
6/30/2025, 2:05:45 PM
No.105753253
[Report]
>>105753207
No, but it might give better results, I can't say.
Anonymous
6/30/2025, 2:05:58 PM
No.105753258
[Report]
>>105752968
Install Ubuntu and try again.
Anonymous
6/30/2025, 2:06:31 PM
No.105753263
[Report]
>>105753074
KVM is useful anyway. You could also use it for virtual machine...or something else.
>>105753243
It doesn't, llama.cpp is not a dependency. The Nvidia driver can already offload to RAM. It's just snake oil.
Anonymous
6/30/2025, 2:11:05 PM
No.105753300
[Report]
Anonymous
6/30/2025, 2:15:34 PM
No.105753339
[Report]
>>105753289
>debo baits used to be believable
>>105753289
The Windows Nvidia driver automatically offloads to ram unless you tell it not to, the Linux driver never does.
And you should tell it not to, because it is a lot less efficient at doing so than the inference / training program you are using.
Those programs knows exactly what they should offload and when, the Windows driver just dumps whatever it feels like, slowing everything down a LOT.
Did you guys experimented with Kontext Dev as a simple text to image model (it can render images without image inputs)? and if yes, do you think it's worse or better than Flux Dev?
Anonymous
6/30/2025, 2:25:38 PM
No.105753416
[Report]
Anonymous
6/30/2025, 2:27:15 PM
No.105753427
[Report]
>>105753550
>>105753394
>than the inference / training program you are using
Than a random person making a random node. Llama.cpp has actual code that does CPU inference. ComfyUI offloading doesn't work like that, so the graph is invalid. Make a new one that actually applies to that node and ComfyUI.
Anonymous
6/30/2025, 2:30:02 PM
No.105753450
[Report]
>>105753394
do not feed the debo troll anon
Anonymous
6/30/2025, 2:30:03 PM
No.105753451
[Report]
>>105752869
holy based, thanks anon
Anonymous
6/30/2025, 2:30:43 PM
No.105753459
[Report]
Is Kontext completely local now? I've been too busy over the weekend to follow, i'm still busy :( but would appreciate a few spoonfeeding mouthfulls to get me going if anyone would oblige, thanks.
Anonymous
6/30/2025, 2:32:17 PM
No.105753480
[Report]
Debo wins again.
Anonymous
6/30/2025, 2:32:33 PM
No.105753483
[Report]
kek
Anonymous
6/30/2025, 2:34:16 PM
No.105753493
[Report]
>>105753526
>>105752994
>>105753014
>This page seems to have a little information
No shit, its another fake website giving bullshit information plus using wan2.1 demos, kek. How does this random site have access to the "demo clips" and its magically no where else? Plebbitors are catching more fake info sites:
>https://www.reddit.com/r/StableDiffusion/comments/1lo2pmz/wan_22_coming_soon_modelscope_event_happening_atm/
Anonymous
6/30/2025, 2:39:18 PM
No.105753526
[Report]
>>105753548
>>105753493
>One more thing, wan 2.2 is comming soon
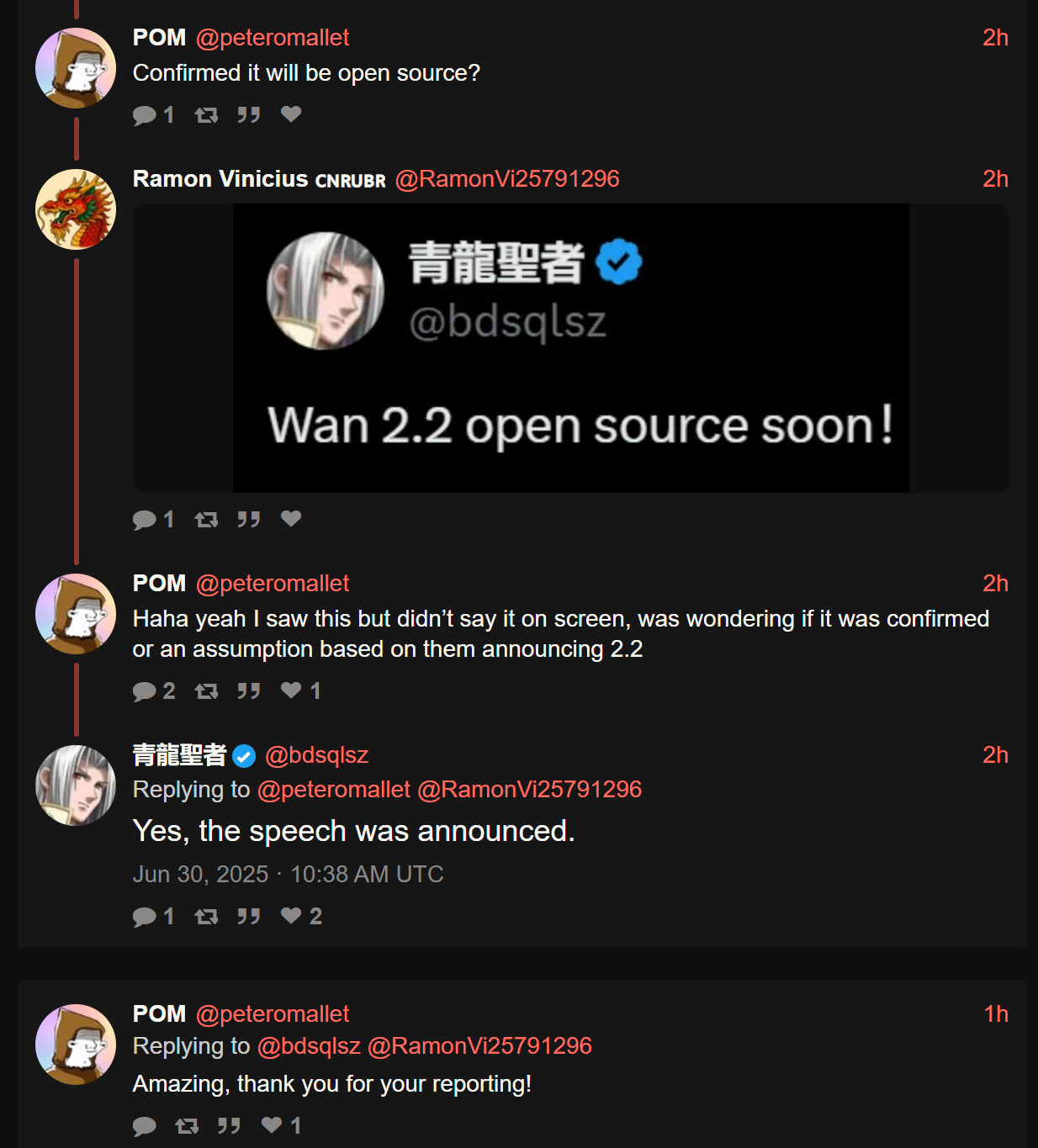
>Wan 2.2 open source soon!
What makes him believe that? maybe it'll only be API
Anonymous
6/30/2025, 2:41:11 PM
No.105753538
[Report]
>>105753398
No I only gen the same fennec anime girl forever and forever I don't even care to phrase my prompts at this point it's just a word salad no commas or anything else
>>105753526
>What makes him believe that?
https://xcancel.com/bdsqlsz/status/1939634590987289060#m
it's confirmed it'll be open source
Anonymous
6/30/2025, 2:43:17 PM
No.105753550
[Report]
>>105753427
I don't give a shit about the graph, I didn't post it.
I've helped friends with Windows get their generations/training not to be glacially slow. Window driver vram offloading is pure shit for AI.
Anonymous
6/30/2025, 2:44:43 PM
No.105753564
[Report]
>>105753548
based chinks!
>>105753548
https://xcancel.com/bdsqlsz/status/1939566026703946043#m
there's also Kolors 2.0 that'll be released, but Idk if it'll be local like Kolors 1.0 or not
Wouldn't 30fps Wan take twice as long as 2.1? considering it's almost twice the number of frames
And what would happen to all these loras trained at 16fps, all these snake oil like teacache, lightx, causvid, SLG, vace control and so on?
Anonymous
6/30/2025, 2:50:17 PM
No.105753598
[Report]
Am I oom? (12gb)
The prompt was "Change the time of day to midday. The sun is shining brightly on the mountains. The sky is clear, no clouds or fog. Sun is clearly visible."
Top original, middle output in original res, bottom using imagescale node
Anonymous
6/30/2025, 2:50:55 PM
No.105753603
[Report]
>>105753722
>>105753548
>Alibaba didn't betray us
best AI company in the world
>>105753595
if they managed to make the model better with a fewer parameters then maybe we'll get that speed back, but desu self forcing lora is doing the job well at that
Anonymous
6/30/2025, 2:53:15 PM
No.105753622
[Report]
>>105753595
>all these snake oil like SLG
bait used to believable
Anonymous
6/30/2025, 2:54:13 PM
No.105753626
[Report]
>>105753700
>>105753565
those kolors images look like complete slop, but wan2.2 would be nice
Anonymous
6/30/2025, 3:01:02 PM
No.105753689
[Report]
Are Flux D loras compatible with Schnell?
Anonymous
6/30/2025, 3:02:51 PM
No.105753700
[Report]
>>105753565
>>105753626
kolors 2 is already available via API?
should be easy to confirm if it's capable of non-slop outputs.
Anonymous
6/30/2025, 3:03:30 PM
No.105753704
[Report]
>>105753548
>the chinks won again
that's fucking right, take some note SAI and all you western dogs!
Anonymous
6/30/2025, 3:05:55 PM
No.105753722
[Report]
>>105753595
We'll know when they release it. I hope to god they remove the 5 second limitation though. As it's 2.2, can't see that happening but we'll see
>>105753603
Based Chinese stay winning
Anonymous
6/30/2025, 3:10:03 PM
No.105753759
[Report]
Anonymous
6/30/2025, 3:11:04 PM
No.105753764
[Report]
>>105752739
AI makes much of the internet fun again, like the early days where most normies knew fuck all and a select few knew about browsers and ftps and so on.
Anonymous
6/30/2025, 3:12:04 PM
No.105753775
[Report]
>>105753870
how would you do faceswaps or swapping elements with kontext? ie: character wearing character 2's clothes
kontext fp8, fp8_scaled and Q8 GGUF are all about the same size.
what's the difference between them to the end user (local slopper)?
Anonymous
6/30/2025, 3:17:47 PM
No.105753820
[Report]
>>105753862
who's the artist that drew those infamous cheerleader bdsm comics, and what are the odds that flux knows it
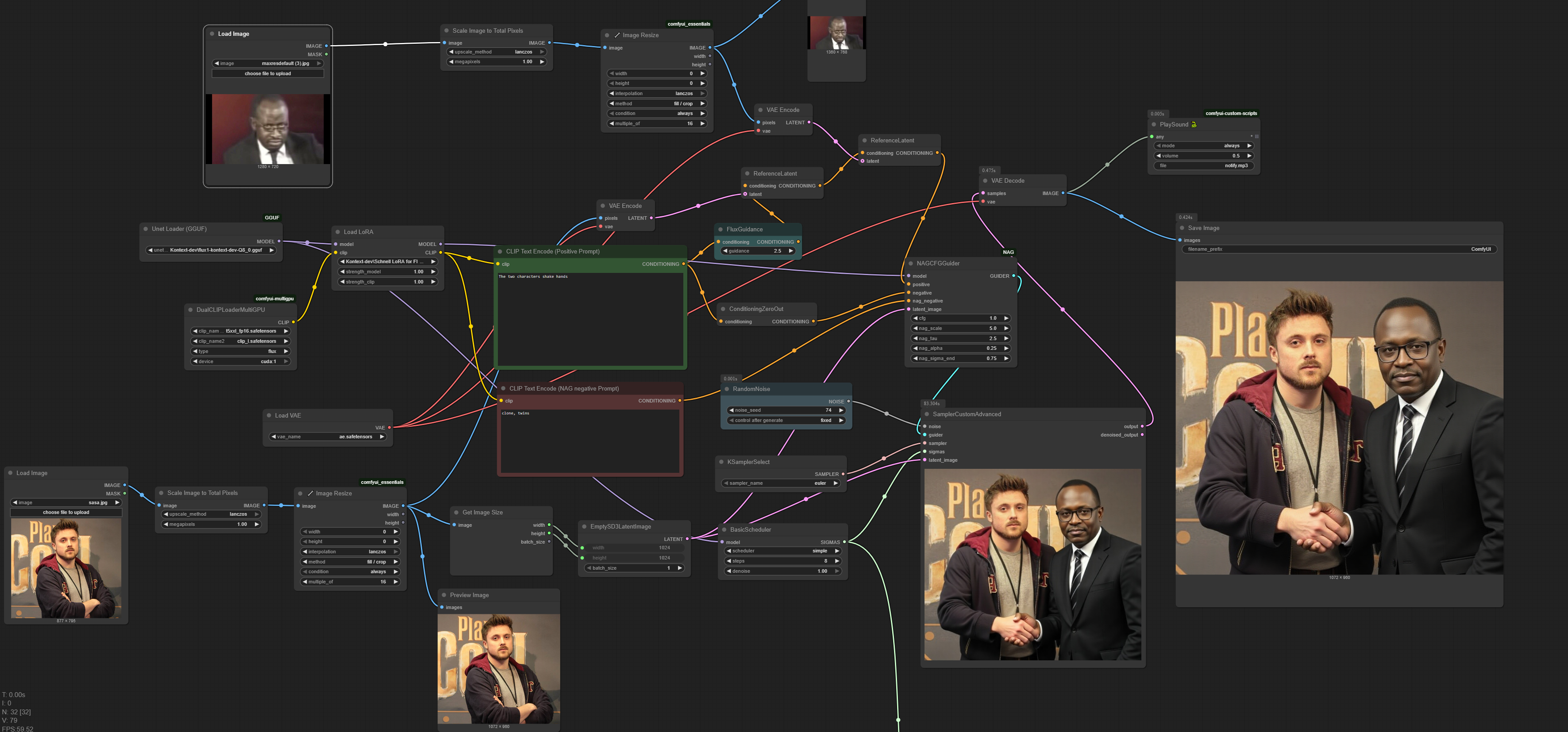
with a simple image stitch node and 2 images, and some directions, you can make any historical figure interact!
the man on the left is shaking hands with the man on the right.
if you change the image size to the stitched size it helps with consistency.
>>105753831
it doesn't look like hitler though lol
>>105753834
not all outputs are the same, can take a few gens to get the likeness right
Anonymous
6/30/2025, 3:21:41 PM
No.105753854
[Report]
>>105753861
>>105753834
actually I forgot the magic words: keep their expressions the same. that helps a lot with keeping the faces the same style.
Anonymous
6/30/2025, 3:22:43 PM
No.105753861
[Report]
>>105753955
>>105753854
for example, this is with that added:
Anonymous
6/30/2025, 3:22:49 PM
No.105753862
[Report]
>>105753820
akira toriyama
Anonymous
6/30/2025, 3:23:20 PM
No.105753869
[Report]
Is there a cheat to looking for optimal lora training settings without having to wait ~1 hour between iterations, or do I just have to train with different settings overnight and compare the next day?
Anonymous
6/30/2025, 3:23:29 PM
No.105753870
[Report]
>>105753775
it's not consistent but sometimes it can work
Anonymous
6/30/2025, 3:25:19 PM
No.105753888
[Report]
>>105753806
Output quality-wise, fp8_scaled and q8 gguf should be somewhat better since they use algorithms to more effectively scale the weights so as to not lose as much information on smaller concepts of the model when reducing precision.
Anonymous
6/30/2025, 3:25:24 PM
No.105753890
[Report]
Can I just add SD3.5 to easy-diffusion models and expect decent results?
Anonymous
6/30/2025, 3:26:59 PM
No.105753901
[Report]
>>105753843
This nigga has a white hand, what did Kontext mean by this ?
Anonymous
6/30/2025, 3:27:35 PM
No.105753908
[Report]
>>105753955
still need to tinker and learn stuff, but stitching and prompts do work:
Anonymous
6/30/2025, 3:27:40 PM
No.105753910
[Report]
>>105753806
>what's the difference between them to the end user (local slopper)?
Q8 is the one with the best quality
Anonymous
6/30/2025, 3:31:07 PM
No.105753935
[Report]
but yeah, change width/height to the stitched size or you get some funny results. this is with the stitched size.
the man on the left is holding a large white body pillow with an image of the anime girl on the right on the cover. keep her expression the same.
Anonymous
6/30/2025, 3:32:08 PM
No.105753941
[Report]
and this is the a -> b, with the stitched image as source (just have 3 nodes and run it solo, image + image + image stitch to an output)
>>105753843
>>105753861
>>105753908
you can see it's not natural at all I prefer to use this method instead
Anonymous
6/30/2025, 3:34:08 PM
No.105753962
[Report]
>basic bitch kontext setup + day 1 lora
>can bring nearly 25 year old internet pics to life and change almost everything about them while they stay looking like that was the real photo like some real fucking Harry Potter magic photo shit
Bros....I think I'm gonna die from dehydration....this is too much power
Anonymous
6/30/2025, 3:34:20 PM
No.105753966
[Report]
Looking forward to the increased duration and temporal consistency in Wan2.2. I'd be amazed if they managed to increase it to 30 seconds while retaining everything. That would be mind blowing.
Anonymous
6/30/2025, 3:34:22 PM
No.105753967
[Report]
>>105753955
yeah I have that workflow saved im just trying to figure out how the model treats stuff with one input, that way is definitely better for combining stuff.
I've managed to replicate tags and artsyle correctly, more or less.
There is one problem, the generated images are low resolution (as in, details aren't good) and I don't know why it is happening. Database is good quality but I can't manage to replicate it (example: details on a piece of armor isn't like the original, and the details looks bad)
Model I'm training is illustrious v0.1. it's weird because it can learn clothes and weird outfits, but it's just that the quality isn't quite there. Adetailer or high-res fix doesn't fix it always.
Ive read somewhere that sdxl models have like many models and that they need extra settings for high resolutions maybe? Like, they generate things at very low resolution by default, even if they learn the information.
Can anyone smarter than me help me please?
Anonymous
6/30/2025, 3:37:07 PM
No.105753992
[Report]
>>105753955
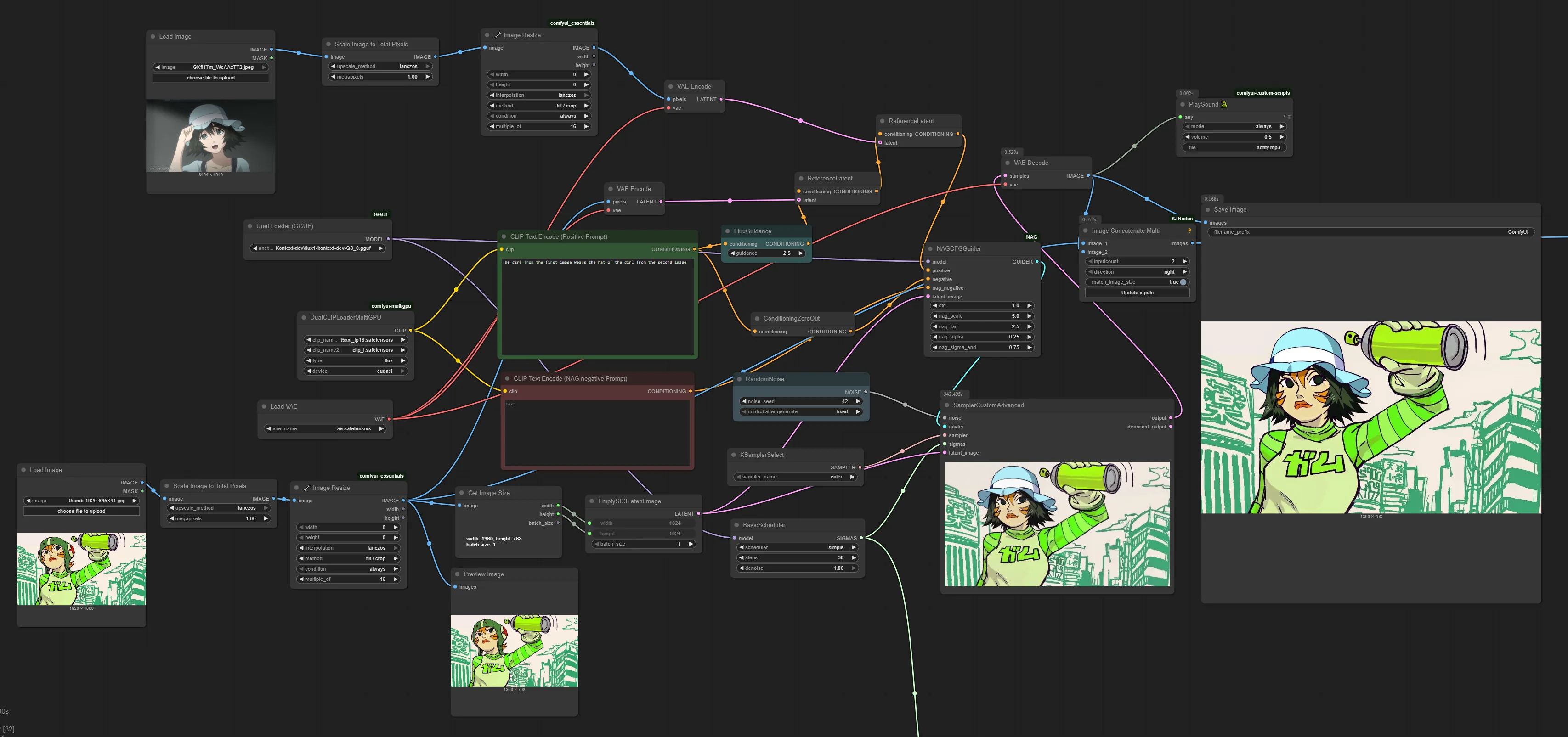
why do I have a feeling that using conditioning (combine) would be a great method to do style transfer, I need to test that
Anonymous
6/30/2025, 3:37:59 PM
No.105754000
[Report]
>>105754007
man, kontext is so good for home renovation stuff.
i just took a picture of my kitchen and was like "change cabinets to white", "replace the bin with a kitchen pantry" etc.
so nice to be able to picture how things will look
you can even provide 2nd image of some furniture you found online
>>105754000
couldn't you have done this with regular inpainting..?
Anonymous
6/30/2025, 3:40:05 PM
No.105754019
[Report]
>>105754007
>effort
if he had that he'd have renovated his kitchen already
Anonymous
6/30/2025, 3:40:09 PM
No.105754020
[Report]
>>105754007
i couldn't be bothered back then, the workflow for inpainting was too clunky and results weren't as good
now you just tell it what to do and it does it immediately without fucking around with a mask or w/e
Anonymous
6/30/2025, 3:40:55 PM
No.105754029
[Report]
>>105754041
we're in a new era of digital marketing and branding
>>105754007
Yes, but dude, this is Kontext, which means it must be better, you think all that reddit hype would lie ?
Anonymous
6/30/2025, 3:43:24 PM
No.105754041
[Report]
>>105754047
>>105754029
Yes, this looks really professional, surely this will sell waifu pillows, very good sir!
Anonymous
6/30/2025, 3:44:05 PM
No.105754047
[Report]
>>105754035
>Yes,
>>105754041
>Yes,
debo please
Anonymous
6/30/2025, 3:44:44 PM
No.105754051
[Report]
>>105754063
>>105754035
controlnets and inpainting can not do all the shit kontext does. even the stuff it swaps respects layers below it. if you inpaint with high denoise it fucks that up. and controlnets are great but can't generate poses from prompts on the fly. this is a great tool to use in conjunction WITH all that stuff.
Anonymous
6/30/2025, 3:44:59 PM
No.105754053
[Report]
>>105754098
>>105754035
honestly just from trying a few times it is much better. sfw workflows like this is where it shines
Anonymous
6/30/2025, 3:45:46 PM
No.105754057
[Report]
we did it, we got forsen to play black flag.
the man on the left is watching a TV screen and holding a game controller. On the screen is the image on the right.
Anonymous
6/30/2025, 3:46:19 PM
No.105754063
[Report]
>>105754090
>>105754051
change 1993, 1998 to 2006, 2007
Anonymous
6/30/2025, 3:49:45 PM
No.105754090
[Report]
>>105754063
good idea
also I love how kontext can dupe fonts, if you cant identify a typeface or find the font, how would you shoop it? in a sense it's even better for editing cause you dont need the ttf font or whatever.
Anonymous
6/30/2025, 3:50:47 PM
No.105754097
[Report]
and there we go, it gave me 2066 instead of 2006 for a couple gens.
Anonymous
6/30/2025, 3:51:11 PM
No.105754098
[Report]
>>105754109
>>105754053
My problem with this is that for SFW workflows I'd honestly rather use the superior API options.
Anonymous
6/30/2025, 3:51:28 PM
No.105754101
[Report]
>>105754110
>>105753831
Got this with the latent concatenation method, it's also doing that not smoth at all vertical separation unfortunately
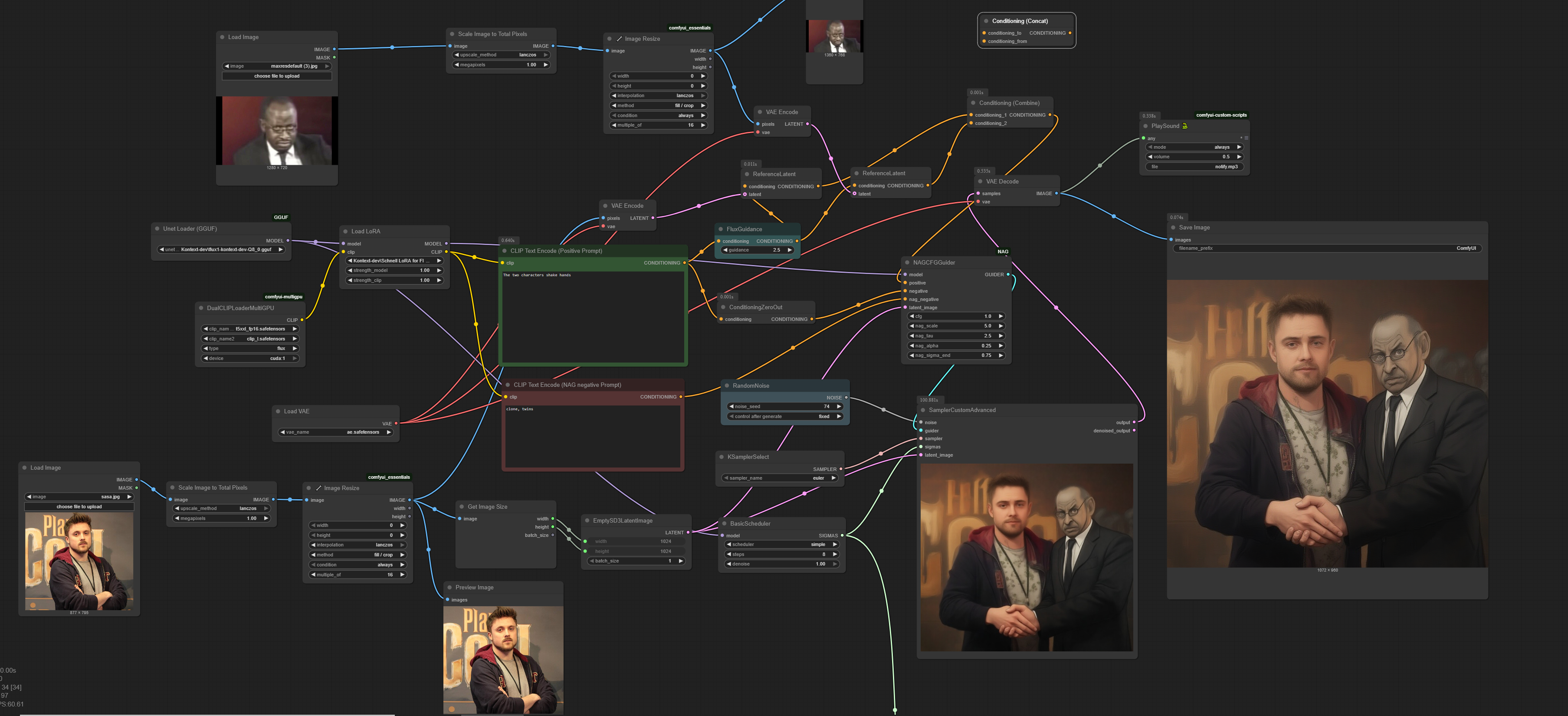
Anonymous
6/30/2025, 3:52:30 PM
No.105754109
[Report]
>>105754098
>My problem with this is that for SFW workflows I'd honestly rather use the superior API options.
this, if we're only allowed to do SFW stuff locally, then what's the point? the API options are better
Anonymous
6/30/2025, 3:52:33 PM
No.105754110
[Report]
>>105754101
yeah the 2 image workflow is 100% the way to go for combining stuff, stitching is just a workaround that isnt as efficient, also it can be weird if the stitch is wide and the output is 1024x1024.
Anonymous
6/30/2025, 3:53:52 PM
No.105754120
[Report]
>use ai to make small helpful utility nodes for my workflow
>works a charm
so this is vibe coding
Anonymous
6/30/2025, 3:56:56 PM
No.105754145
[Report]
>got used to cfg1 + schnell lora
>needed to go back to v40
>those gen times
Like fucking pls integrate these things into the base chroma. It's like shooting heroin.
Anonymous
6/30/2025, 3:59:27 PM
No.105754171
[Report]
1600x1600 works on flux1dev on 12gb
what would be the limit for 24gb I wonder, around 3000x3000?
Anonymous
6/30/2025, 4:07:22 PM
No.105754233
[Report]
turns out I do like cartoons after all, there's just never been a good one
Anonymous
6/30/2025, 4:10:03 PM
No.105754256
[Report]
>>105754303
>>105754247
make the man on the left wear tattered rags
Anonymous
6/30/2025, 4:10:17 PM
No.105754260
[Report]
>>105754268
>>105754247
nice, which workflow/method?
Anonymous
6/30/2025, 4:11:17 PM
No.105754268
[Report]
Anonymous
6/30/2025, 4:12:29 PM
No.105754275
[Report]
Anonymous
6/30/2025, 4:16:15 PM
No.105754314
[Report]
Anonymous
6/30/2025, 4:16:57 PM
No.105754323
[Report]
>>105754345
can I change the lora filename to the trigger word or does it mess with the file?
Anonymous
6/30/2025, 4:19:13 PM
No.105754345
[Report]
>>105754348
>>105754323
filenames have no bearing on the contents of the file whatsoever
Anonymous
6/30/2025, 4:19:31 PM
No.105754348
[Report]
Anonymous
6/30/2025, 4:20:16 PM
No.105754360
[Report]
>>105754377
did multiple gens but the result is the same:
Anonymous
6/30/2025, 4:21:50 PM
No.105754372
[Report]
>>105754303
That's more like it
Anonymous
6/30/2025, 4:22:23 PM
No.105754377
[Report]
anon your workflow + post about schnell lora for speed should be in the rentry, works well plus negative prompts are super useful.
>>105754399
so for prompting, the top image input is always referenced as "first image"? is the workflow putting them together, just curious how they work together or how to reference them
Anonymous
6/30/2025, 4:27:00 PM
No.105754424
[Report]
>>105754438
>>105754414
also 31 seconds with the schnell lora, even faster than the 1 image workflow (with no lora)
what happens if you leave the second image blank? just prompt in reference to the first image?
Anonymous
6/30/2025, 4:27:41 PM
No.105754434
[Report]
Anonymous
6/30/2025, 4:28:14 PM
No.105754438
[Report]
>>105754451
>>105754399
thanks
>>105754414
I don't think "first image" works at all, I think the workflow uses the image (that's on the bottom of the workflow) as the main image, and then you work with that, "add something from the OTHER character/image", that seem to work better
>>105754424
>what happens if you leave the second image blank?
why would you do that? lol
Anonymous
6/30/2025, 4:29:06 PM
No.105754451
[Report]
>>105754465
>>105754438
I mean, what if you want to change a single image without a second reference, or is this workflow primarily for two character interactions?
Anonymous
6/30/2025, 4:29:30 PM
No.105754461
[Report]
>>105754724
>>105753974
What resolution are you training at ? And are you sure your training images are of at least that size or larger ?
Anonymous
6/30/2025, 4:29:57 PM
No.105754465
[Report]
>>105754490
>>105754451
no, it can with the one image, you have to bypass the vae encode node on the top of the workflow (I added a note about that)
Anonymous
6/30/2025, 4:30:25 PM
No.105754471
[Report]
>>105754500
someone should make a pepe with this expression with kontext just because
Anonymous
6/30/2025, 4:31:45 PM
No.105754490
[Report]
>>105754465
I see, very useful workflow this should be on the rentry page as it's much more useful than the default one, better for two image interactions as well as speed with the lora.
Anonymous
6/30/2025, 4:32:37 PM
No.105754500
[Report]
>>105754522
>>105754471
>When you forgot your dentures at home
the girl is sitting on a beach chair at the beach.
eve if she real:
Anonymous
6/30/2025, 4:35:09 PM
No.105754522
[Report]
>>105754611
>>105754500
people without teeth look weird, their mouth is sunken in
teeth shape your face a lot more than you expect, you can definitely tell when someone is just gums
Anonymous
6/30/2025, 4:36:10 PM
No.105754532
[Report]
>>105754520
also 8 steps works fine, I tried 20 steps to compare and gen time is still similar to 20 on the default workflow...but this has negative prompts + NAG.
Anonymous
6/30/2025, 4:41:00 PM
No.105754577
[Report]
Anonymous
6/30/2025, 4:45:14 PM
No.105754611
[Report]
>>105754639
>>105754522
You must be pretty clever. Is this why you are frequenting /ldg/?
Anonymous
6/30/2025, 4:46:51 PM
No.105754627
[Report]
>>105754640
Anonymous
6/30/2025, 4:47:23 PM
No.105754634
[Report]
>>105754652
>>105754616
Kontext is the perfect model for image shitpost memes not gonna lie
Anonymous
6/30/2025, 4:47:54 PM
No.105754639
[Report]
>>105754727
>>105754611
I would think most people here have a good concept of anatomy, they're extremely critical of it
Anonymous
6/30/2025, 4:47:58 PM
No.105754640
[Report]
>>105754652
Anonymous
6/30/2025, 4:49:03 PM
No.105754652
[Report]
>>105754668
Anonymous
6/30/2025, 4:49:39 PM
No.105754664
[Report]
>>105754698
Anonymous
6/30/2025, 4:51:04 PM
No.105754671
[Report]
>>105754668
I love how kontext can replicate fonts and even details like gradients or textures or whatever
like the miku/zelda from before: the font is LITERALLY the same pixel font.
Anonymous
6/30/2025, 4:54:37 PM
No.105754698
[Report]
>>105754720
Anonymous
6/30/2025, 4:55:45 PM
No.105754711
[Report]
>>105754761
Anonymous
6/30/2025, 4:56:25 PM
No.105754720
[Report]
>>105754698
this is a better one.
Anonymous
6/30/2025, 4:56:43 PM
No.105754724
[Report]
>>105754461
I'm using these, I set up max resolution at 1152x1344, lycoris, network and convolution at 32 (normal and alpha) lr 0.0003, TE 0.00015, 20 epochs, 5 repeats in dataset, Huber exponential loss, if you need more parameters please let me know.
If I'm able to replicate the artsyle, tag concepts aren't correctly learned, and If I get the concepts, I get that low resolution thing.
Anonymous
6/30/2025, 4:56:55 PM
No.105754727
[Report]
>>105754851
>>105754639
Counting fingers is something what everyone can do. Why don't you draw up something if you have such a good knowledge of anatomy then?
Anonymous
6/30/2025, 4:57:33 PM
No.105754733
[Report]
>>105754746
Anonymous
6/30/2025, 4:58:29 PM
No.105754746
[Report]
>>105754808
>>105754733
try asking openAI to do this with a lewd lora
>uhh sorry, even though you pay, we cant generate that
open source ALWAYS wins.
Anonymous
6/30/2025, 4:59:55 PM
No.105754761
[Report]
>>105754796
>>105754711
do you prompt "change "up your arsenal" to "up your ass" without changing anything else"?
Anonymous
6/30/2025, 5:00:56 PM
No.105754773
[Report]
Anonymous
6/30/2025, 5:02:45 PM
No.105754796
[Report]
>>105754761
yeah I did something like that
>Replace "UP YOUR ARSENAL" to "UP YOUR ASS"
Anonymous
6/30/2025, 5:03:36 PM
No.105754804
[Report]
>>105754836
cute
yes, forsen is the test case for gens because why not, he loves anime.
Anonymous
6/30/2025, 5:03:46 PM
No.105754808
[Report]
>>105754831
>>105754746
>open source ALWAYS wins.
we're losing though, BFL is prohibiting NSFW loras on the internet, and I feel it won't be the last company to do that
Anonymous
6/30/2025, 5:05:35 PM
No.105754831
[Report]
>>105754808
who cares what they say, I can use the clothes remover lora right now and it works on anything.
just because they say you cant doesn't mean you can't do it. buying a PC doesn't mean you can't torrent. resourceful and smart people will always find a way to do stuff.
Anonymous
6/30/2025, 5:06:37 PM
No.105754836
[Report]
>>105754804
better
project diva miku is pretty effective:
please just make new content. it's been days of the same shit
Anonymous
6/30/2025, 5:07:41 PM
No.105754851
[Report]
>>105754893
>>105754727
your quip was funny and I apologise for ruining it with a titbit on facial structure
we good?
Anonymous
6/30/2025, 5:09:55 PM
No.105754873
[Report]
>>105754845
wait for the kontext shills to get bored and go back to feddit. this always happens when a new model drops.
Anonymous
6/30/2025, 5:11:12 PM
No.105754893
[Report]
>>105754851
We're good, buddy boy.
>>105754883
>this always happens when a new model drops.
Wan is still going strong though
Anonymous
6/30/2025, 5:12:10 PM
No.105754909
[Report]
>>105754895
because of the recent light2x lora that allows very fast gens for poorfags.
Anonymous
6/30/2025, 5:12:43 PM
No.105754918
[Report]
>>105754895
Miku spam of the same input image is over at least
Anonymous
6/30/2025, 5:13:48 PM
No.105754927
[Report]
>>105754940
Dunno if anyone's said this before but this one's
https://github.com/pamparamm/sd-perturbed-attention NAG node actually works with Nunchaku SVD Kontext quants. The prompt was to replace the character with 2B, without vs with NAG
Anonymous
6/30/2025, 5:13:53 PM
No.105754929
[Report]
>>105754895
Wan is pretty much a revolution in local video gen, also it is somewhat uncensored out of the gate and easy to train nsfw for (easy, but not cheap though).
Anonymous
6/30/2025, 5:14:55 PM
No.105754940
[Report]
>>105754927
>The prompt was to replace the character with 2B, without vs with NAG
what was the prompt exacly? this is really impressive it even kept the style, wtf
Anonymous
6/30/2025, 5:15:09 PM
No.105754942
[Report]
>>105754932
flux in itself is extremely cucked. i'll never care about any model they release.
>>105754932
kontext is the death knell of local. I like the model but hate what sinister proprietary intentions will be coming after
Anonymous
6/30/2025, 5:15:57 PM
No.105754953
[Report]
>>105754982
>>105754932
>Wan is pretty much a revolution in local video gen
true, and I can't wait for the second revolution
Anonymous
6/30/2025, 5:18:31 PM
No.105754982
[Report]
>>105755066
>>105754953
did they say it's open source or is twitter tranny lying?
Anonymous
6/30/2025, 5:19:22 PM
No.105754992
[Report]
replace the girl in the second image with the girl in the first image. (nag workflow)
pretty good for a first try
Anonymous
6/30/2025, 5:19:27 PM
No.105754993
[Report]
Anonymous
6/30/2025, 5:21:23 PM
No.105755011
[Report]
>>105754946
>I like the model but hate what sinister proprietary intentions will be coming after
same, it created a dangerous precedent, and I feel they got away with this because their model is just fun to play with, we were way harser on SD3's licence even though it's not half as bad as Flux's one, we have the beaten wife syndrome, as long as the Husband is handsome he can get away with abuse
>>105754946
>kontext is the death knell of local
Just how retarded are you ?
Anonymous
6/30/2025, 5:26:47 PM
No.105755066
[Report]
>>105754982
that guy speaks chinese and he was at the conference, and he confirmed it
>>105753548
Anonymous
6/30/2025, 5:28:19 PM
No.105755087
[Report]
>>105755131
>>105755063
>I don't read corpo overreach licences and I don't have a problem with it
sir, this is a /g/
Anonymous
6/30/2025, 5:31:54 PM
No.105755131
[Report]