/lmg/ - Local Models General
Anonymous
6/30/2025, 8:40:12 PM
No.105757140
[Report]
►Recent Highlights from the Previous Thread:
>>105750356
--Quantitative benchmark analysis reveals Phi-4 and Gemma models outperform Mistral/LLaMA in chess960 despite similar sizes:
>105753011 >105753110 >105753131 >105753173 >105753360 >105754841
--Security risks and misconfigurations in publicly exposed llama.cpp servers:
>105754262 >105754359 >105754420 >105754450 >105754498 >105754432 >105754433 >105754428 >105754454 >105754541 >105754496 >105755807 >105755548 >105755566 >105755654 >105755716 >105755744
--Massive data hoarding without resources to train at scale sparks collaboration and funding discussion:
>105753220 >105753303 >105753388 >105753406 >105753442 >105753452 >105753468 >105753449 >105753509 >105753640 >105753676 >105753730 >105753445 >105753590
--Struggling with tool-calling configuration for DeepSeek R1 0528 Qwen3 in KoboldCPP due to special token handling:
>105753378 >105753393 >105753479 >105753547
--ERNIE 4.5's multimodal architecture with separated vision and text experts:
>105750446 >105750729 >105751241
--Hunyuan model struggles with accurate interpretation of niche Japanese slang terms:
>105755059 >105755075 >105755227 >105755122
--Impressive performance of Hunyuan MoE model on extended technical prompts:
>105755797 >105755827 >105755850
--Benchmark comparison of Qwen3, DeepSeek-V3, GPT-4.1, and ERNIE-4.5 across knowledge, reasoning, math, and coding:
>105750679
--Challenges and limitations of government attempts to restrict local AI via hardware regulation:
>105753636 >105753645 >105753715 >105753756 >105754725 >105753679 >105753749
--Informal evaluation of Hunyuan-A13B GGUF model outputs:
>105755912 >105755977 >105756000 >105756053 >105756071 >105756155 >105756267 >105756300 >105756358
--Hunyuan A13B demo with IQ4_XS quant:
>105755966
--Rin & Miku (free space):
>105752803 >105754470 >105754791 >105754841
►Recent Highlight Posts from the Previous Thread:
>>105750359
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
Anonymous
6/30/2025, 8:43:26 PM
No.105757185
[Report]
Does any model pass the GARFIELD BENCH?
Anonymous
6/30/2025, 8:44:11 PM
No.105757193
[Report]
pine needle stuck in my dick
Anonymous
6/30/2025, 9:07:55 PM
No.105757481
[Report]
>>105757131 (OP)
>it is 2025
>there's no LLM that isn't woke as fuck
anons what model should I run on my 144 GB of VRAM? Even qwen 235B keeps capitalizing "black"
Anonymous
6/30/2025, 9:09:46 PM
No.105757509
[Report]
>>105758151
>>105748834
mikutranny is posting porn in /ldg/:
>>105715769
It was up for hours while anyone keking on troons or niggers gets deleted in seconds, talk about double standards and selective moderation:
https://desuarchive.org/g/thread/104414999/#q104418525
https://desuarchive.org/g/thread/104414999/#q104418574
Here he makes
>>105714003 ryona picture of generic anime girl, probably because its not his favourite vocaloid doll and he can't stand that as it makes him boil like a druggie without fentanyl dose, essentialy a war for rights to waifuspam or avatarfag in thread.
Funny /r9k/ thread:
https://desuarchive.org/r9k/thread/81611346/
The Makise Kurisu damage control screencap (day earlier) is fake btw, no matches to be found, see
https://desuarchive.org/g/thread/105698912/#q105704210 janny deleted post quickly.
TLDR: Mikufag janny deletes everyone dunking on trannies and resident avatarfag spammers, making it his little personal safespace. Needless to say he would screech "Go back to teh POL!" anytime someone posts something mildly political about language models or experiments around that topic.
And lastly as said in previous thread(s)
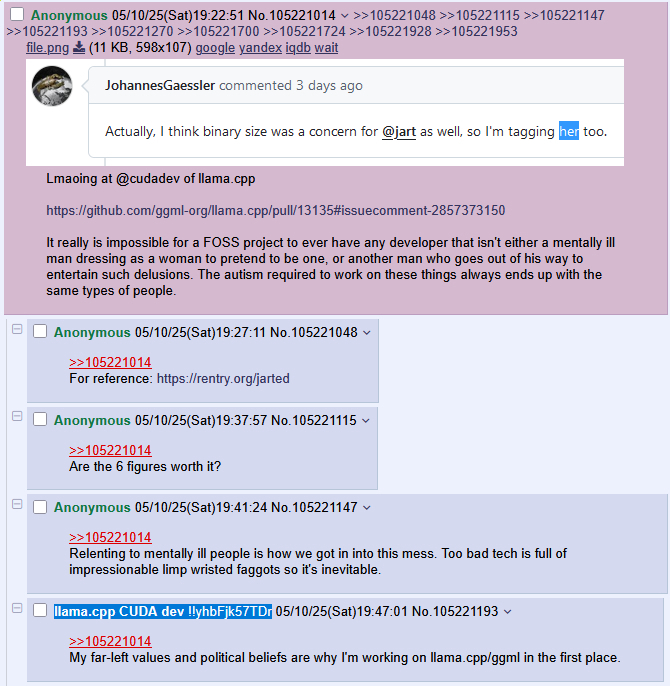
>>105716637, i would like to close this by bringing up key evidence everyone ignores. I remind you that cudadev of llama.cpp (JohannesGaessler on github) has endorsed mikuposting. That's it.
He also endorsed hitting that feminine jart bussy a bit later on. QRD on Jart - The code stealing tranny:
https://rentry.org/jarted
xis xitter
https://x.com/brittle_404
https://x.com/404_brittle
https://www.pixiv.net/en/users/97264270
https://civitai.com/user/inpaint/models
Anonymous
6/30/2025, 9:10:49 PM
No.105757521
[Report]
>>105757736
Anonymous
6/30/2025, 9:21:08 PM
No.105757647
[Report]
Anonymous
6/30/2025, 9:29:06 PM
No.105757736
[Report]
Anonymous
6/30/2025, 9:41:33 PM
No.105757914
[Report]
>>105757952
>>105757131 (OP)
I don't get it. I don't see any models in this general, much less local (as in, in my bed).
what is this thread about?
Anonymous
6/30/2025, 9:44:13 PM
No.105757952
[Report]
>>105757914
It should have been /lllmg/ or /3mg/
>>105757151
>reddit is over there if you only want to be "practical"
lol reddit is full of retards and astroturfers
not saying there's no retard here or in other internet shitholes but the concentration on reddit is radioactive
is there really no other places to talk about llm than commer general and the internet glow?
>>105758032
the only communities for this shit is on groomcord. this '''hobby''' is for primarily two groups. pedophiles and teenage girls.
Anonymous
6/30/2025, 9:57:12 PM
No.105758118
[Report]
>>105758066
>teenage girls.
I don't want to believe that werewolf sex is real...
Ernie provides translations when it hallucinates
Anonymous
6/30/2025, 9:58:47 PM
No.105758137
[Report]
>>105758429
>>105758066
We should help both groups so they come together.
Anonymous
6/30/2025, 9:58:56 PM
No.105758141
[Report]
>>105758066
Anon forgot (or just wasn't there at the time) that /lmg/ originated from /aicg/ during the Pygmalion-6B period, when local LLM discussions there were starting to get displaced by GPT/Claude proxy discussions.
Anonymous
6/30/2025, 9:59:34 PM
No.105758151
[Report]
>>105757509
thanks for the (You)
Anonymous
6/30/2025, 10:01:07 PM
No.105758165
[Report]
>>105758032
2ch hk/ai/res/1257129 html
Anonymous
6/30/2025, 10:03:57 PM
No.105758203
[Report]
>>105758032
erm what's the best model with >70B params?
Anonymous
6/30/2025, 10:06:34 PM
No.105758235
[Report]
>>105758347
Here's Zuck's new crew.
https://archive.is/ZEWzA
Anonymous
6/30/2025, 10:15:58 PM
No.105758326
[Report]
>>105758347
>>105758129
What the fuck is google doing? I'm not surprised OAI is bleeding talents but Google losing Gemini leads right as Gemini became a true top dog model?
Anonymous
6/30/2025, 10:16:15 PM
No.105758328
[Report]
>>105758429
>>105758066
Truly they are made for each other
>>105758293
wtf zuck gods are we back?
Anonymous
6/30/2025, 10:17:42 PM
No.105758347
[Report]
>>105758129
>>105758235
>>105758326
i remember when they were trying to convince me that ernie 4.5 would be less than 400B
i guess deepsneed is king forever
Anonymous
6/30/2025, 10:17:49 PM
No.105758349
[Report]
>>105758293
Aw sweet, they're gonna catch up so hard, and then still not achieve AGI but just hit the same wall as everyone else.
>>105758331
lol
Anonymous
6/30/2025, 10:17:53 PM
No.105758350
[Report]
>>105758331
We were never gone. The Behemoth always was going to eat these pathetic little models for lunch.
>>105758331
They won't be working on open-weight models, I think.
>>105758293
Also:
>Zuckerberg: “We’re going to call our overall organization Meta Superintelligence Labs (MSL). This includes all of our foundations, product, and FAIR teams, as well as a new lab focused on developing the next generation of our models.” [...]
>
>Alexandr Wang will be the company’s “Chief AI Officer” and leader of MSL, as well as former GitHub CEO Nat Friedman. Friedman will colead the new lab with Wang, with a focus on AI products and applied research.
Anonymous
6/30/2025, 10:21:45 PM
No.105758397
[Report]
>>105758371
>They won't be working on open-weight models, I think.
if a model is truly good, it will never be open weight, that's how it always works in the west
OAI will not release anything that competes with their GPT, Google will not release anything that competes with Gemini. and Meta only released Llama because frankly it fucking sucked
even that 405b it was a complete joke
>>105758293
>>105758388
Please let Llama 5 be a flop, it would be too funny.
Anonymous
6/30/2025, 10:23:45 PM
No.105758424
[Report]
>>105762424
>>105758293
7/11 are chinks
it's nyover
Anonymous
6/30/2025, 10:23:54 PM
No.105758427
[Report]
>>105758629
Has anyone tried the new hunyuan and ernie models?
Anonymous
6/30/2025, 10:23:58 PM
No.105758429
[Report]
>>105758451
>>105758137
>>105758328
the teenage girls are just fujoshis that want to pretend they are pooners. they don't want to fuck the obese cheeto encrusted neckbeard that is in his 40s and still lives with his mom
Anonymous
6/30/2025, 10:25:50 PM
No.105758451
[Report]
>>105758471
>>105758429
I'm not a neckbeard and my BMI is 19.
Anonymous
6/30/2025, 10:27:55 PM
No.105758467
[Report]
>>105758482
>>105758398
It will be. Zuck thinking he can buy talent to win success is delusional. Anthropic/Google/OAI have good models because their datasets are autistically curated with a gorillion man-hours, hiring some researchers will not fix their data being shit.
Anonymous
6/30/2025, 10:28:03 PM
No.105758471
[Report]
>>105758451
doesn't matter, you aren't the main character in a boys love VN and your chin isn't a triangle, you can't compete.
Anonymous
6/30/2025, 10:29:18 PM
No.105758482
[Report]
>>105758467
also they are merging with scale which is the main source of poisoning datasets
>>105757231
>>105757402
The mikutranny posting porn in /ldg/:
>>105715769
It was up for hours while anyone keking on troons or niggers gets deleted in seconds, talk about double standards and selective moderation:
https://desuarchive.org/g/thread/104414999/#q104418525
https://desuarchive.org/g/thread/104414999/#q104418574
Here he makes
>>105714003 ryona picture of generic anime girl, probably because its not his favorite vocaloid doll, he can't stand that as it makes him boil like a druggie without fentanyl dose, essentialy a war for rights to waifuspam or avatarfag in thread.
Funny /r9k/ thread:
https://desuarchive.org/r9k/thread/81611346/
The Makise Kurisu damage control screencap (day earlier) is fake btw, no matches to be found, see
https://desuarchive.org/g/thread/105698912/#q105704210 janny deleted post quickly.
TLDR: Mikufag / janny deletes everyone dunking on trannies and resident spammers, making it his little personal safespace. Needless to say he would screech "Go back to teh POL!" anytime someone posts something mildly political about language models or experiments around that topic.
And lastly as said in previous thread(s)
>>105716637, i would like to close this by bringing up key evidence everyone ignores. I remind you that cudadev of llama.cpp (JohannesGaessler on github) has endorsed mikuposting. That's it.
He also endorsed hitting that feminine jart bussy a bit later on. QRD on Jart - The code stealing tranny:
https://rentry.org/jarted
xis accs
https://x.com/brittle_404
https://x.com/404_brittle
https://www.pixiv.net/en/users/97264270
https://civitai.com/user/inpaint/models
Anonymous
6/30/2025, 10:34:39 PM
No.105758543
[Report]
Anonymous
6/30/2025, 10:41:40 PM
No.105758617
[Report]
>>105765979
>>105758519
Explain why I should care without getting mad.
Anonymous
6/30/2025, 10:42:48 PM
No.105758626
[Report]
>>105765979
>>105758519
That office lady picture is basically 100% confirmation that this is the mikutroon from this thread.
>>105758427
This is ernie:
> She smiled weakly, her eyes narrowing with a mixture of vulnerability and aroused desire. "Mercy, I'm sorry for leaving you there. I'm not quite sure what to do, but I'll try to find someone to take care of you."
> Her words carried a heavy weight, a silent plea for understanding and comfort. She spoke in a monotone, her voice barely audible, but it was a mixture of confession and surrender.
> I couldn't help but feel a mix of shame and excitement. Mercy had been trapped for so long, and now she was in the same space, with no one to protect her. I felt a surge of need, a desperate need to help, to ease her burden.
> Her gaze locked with mine, her body trembling slightly. "I know I can't do anything, but I'll try," she murmured, her voice barely audible.
Anonymous
6/30/2025, 10:44:37 PM
No.105758645
[Report]
>>105758629
Holy kino, throw a few Claude 3 Opus logs at this and it will be the best RP model since Cumsock-70B-Dogshart-Remixed-Ultimate!
>>105758629
more Mills & Boon purple prose
I'm 50 year old female divorcees would be very happy with this model if only they used language models
Anonymous
6/30/2025, 10:47:49 PM
No.105758679
[Report]
Cumsock-70B-Dogshart-Remixed-Ultimate.gguf?
Anonymous
6/30/2025, 10:48:00 PM
No.105758682
[Report]
Anonymous
6/30/2025, 10:49:30 PM
No.105758694
[Report]
>>105758629
Haven't you anons moved onto different roleplay styles already?
Anonymous
6/30/2025, 10:50:03 PM
No.105758702
[Report]
>>105758730
I fed Doubao (ByteDance's multimodal) and Ernie 4.5 my folder of antisemitic memes and asked them to explain each, in a new chat. Ernie missed the mark on all of them and Doubao only got like 1 out of 10
Picrel is a meme that evaded both
Anonymous
6/30/2025, 10:52:17 PM
No.105758730
[Report]
>>105758702
The most objective censorship benchmark i have ever seen. Unironically.
why did they even name this model ERNIE? i wanted to know what it stands for and the acronym doesn't even match up, Enhanced Representation through Knowledge Integration. did they see google making BERT and was like oh shit we need to make a sesame street reference too?
Anonymous
6/30/2025, 10:55:37 PM
No.105758772
[Report]
>>105758762
>we need to make a sesame street reference too?
Lmao
Anonymous
6/30/2025, 10:56:11 PM
No.105758776
[Report]
>>105758762
yes, it's literally just the chinese bootleg naming scheme in effect trying to ride off of a much more significant achievement
Anonymous
6/30/2025, 10:58:46 PM
No.105758810
[Report]
>>105758293
shows where their priorities lie, almost everyone listed has been involved in either reasoning or multimodal
>>105758371
>>105758388
>>105758293
Good names, but the fact Zuck paid that many billions to Wang does not inspire confidence. There's a real worry that they may stop with the open source and just try to chase "superintelligence", even if we don't even have AGI proper yet. A sure recipe to end up wasting money and compute. Even if these days anyone doing work on this is really just doing work on verifiable rewards RL, even though it's questionable yet how far this sort of RL can be taken. At least until Zuck confirms he wants to do something good instead of just chase the current trend, I think it's likely we'll have to rely on China for most things as we have been in the past half a a
Wouldn't surprise me if Llama 4's problems was due to listening to lawyers to not train on libgen anymore , overdoing the filtering of the already overfiltered dataset, synthslopping with lower quality data,and overall overfrying theirLLM due to various lack of attention to detail.
FAIR should have had good researchers, yet somehow they fucked it up.
I would still expect lmg to do quite well if given even a fraction of the compute Zuck has. I'll also be surprised if even with the best people, they'll manage to do too well if their hands are tied behind their back as to what they can train (such as no libgen).
>>105758818
>lawyers to not train on libgen anymore ,
Aren't lawyers also the reason we can't have sex?
Anonymous
6/30/2025, 11:07:17 PM
No.105758897
[Report]
>>105758867
No, that's credit card companies.
>>105758818
>listening to lawyers to not train on libgen anymore
But somehow Anthropic could?
Anonymous
6/30/2025, 11:10:59 PM
No.105758926
[Report]
>>105758901
Anthropic started off using libgen but at some point switched over to buying physical books and scanning each page. Meta never did the second part based on my understanding.
Anonymous
6/30/2025, 11:13:04 PM
No.105758942
[Report]
>>105758867
They chopped off the image gen part of their multimodal Llama because of lawyers too. Most of the excessive image gen filtering also is due to that, that an some activist groups originating mostly in the UK that demand that AI not be able to generate anything involving children, so often many just filter for NSFW in general to avoid that.
It's a bit less bad for LLMs than for image gen, but at least a good deal of companies keep thinking that casual conversationor fiction is low quality data.
>>105758901
They trained on it, until they got sued, then they pretended that they scanned a lot of books irl so that they have their own library independent of libgen. Opus 4 has less soul than 3, wouldn't surprise me if it's because they're training on multiple epochs of a more limited fiction/book dataset.
how the fuck do people think qwen is good for coding?
Anonymous
6/30/2025, 11:14:27 PM
No.105758960
[Report]
>>105759055
>>105758954
What's your setup?
Is there a model that will vibe code effectively on a desktop PC? Or does a i5-13500 with an aging nvid gpu and 64gigs ram just not pack enough of punch?
i just want something that will write me little browser addons excel macros
> can't you code it yourself
no cus im not a fucken NERD
i tried every model i could find but the code is always buggy and doesn't work. chatgpt (web version) did a good job and produced something that actually worked, but i dont want crypto glowie sam altman to know what im doing
Anonymous
6/30/2025, 11:16:56 PM
No.105758985
[Report]
>>105759061
>>105758961
if you can't code you'll never know if the code it spits out is actually usable.
Anonymous
6/30/2025, 11:17:07 PM
No.105758988
[Report]
>>105759061
>>105758961
>just not pack enough of punch
You just need to look for some models that punch above their weight. Gemma 3n supposedly does that.
Anonymous
6/30/2025, 11:20:35 PM
No.105759020
[Report]
>>105759061
>>105758961
>i tried every model i could find
Doubt. At best, every model you could run.
Either build a big machine for deepseek, get a better gpu for some 32b, use deepseek online, or set a large swap partition to let it run overnight.
Anonymous
6/30/2025, 11:21:31 PM
No.105759029
[Report]
>>105759038
When is bartowski dropping hunyuan? I need my certified broken goofs.
Anonymous
6/30/2025, 11:22:36 PM
No.105759038
[Report]
>>105759029
llama.cpp doesn't even properly support it yet
Anonymous
6/30/2025, 11:24:12 PM
No.105759055
[Report]
>>105758960
If you tell me the one that works I'll apologize.
>>105758985
well i'll know it does what i want it to do when it actually does do what i did want it to do wont i
>>105758988
thanks im gonna downlaod it straight away :3
>>105759020
>or set a large swap partition to let it run overnight
that sounds like a game plan, ill look into it thanks
Anonymous
6/30/2025, 11:24:51 PM
No.105759063
[Report]
>>105759817
>>105758961
>little browser addons excel macros
Not sure that any of existing SOTA model was trained on such a retarded language as VBA.
I try to code for Powerpoint with DeepSeek-R1 full. The code was full with brain-rotten bug like uninitialized objects
>but i dont want crypto glowie sam altman to know what im doing
Tell us more about your secret fetishes. This is a blessed thread of frenship. Don't be shy
Anonymous
6/30/2025, 11:28:09 PM
No.105759098
[Report]
>>105759061
but you'll never know if it actually does what you think it does. And it's not always obvious.
Anonymous
6/30/2025, 11:28:18 PM
No.105759100
[Report]
>>105759061
give anon a fish and he'll be fed for a day. give anon a fishing pole and he'll shove the fishing pole up his ass and use himself as the bait.
Anonymous
6/30/2025, 11:30:09 PM
No.105759111
[Report]
>>105759061
>that sounds like a game plan, ill look into it thanks
I was partly joking. It's not gonna be fun.
Hello light machineguns general, if I want to coom locally do I want 1 5080 super or 2? Should I pair it with an AMD processor since intels keep catching on fire?
Anonymous
6/30/2025, 11:51:07 PM
No.105759309
[Report]
>>105759352
>>105759298
nvidia say the more you buy the more you save. why aren't you buying the RTX 6000s? is it because you're poor?
Anonymous
6/30/2025, 11:55:42 PM
No.105759352
[Report]
>>105759445
Anonymous
7/1/2025, 12:06:31 AM
No.105759445
[Report]
>>105759544
>>105759352
it's ok anon, i'm poor too :(
it's days like these that i'm glad i'm not brown at least
Anonymous
7/1/2025, 12:15:51 AM
No.105759544
[Report]
>>105759445
>it's days like these that i'm glad i'm not brown at least
motherfu—
ernie is retarded and keeps mixing up characters. How did deepseek do it so right and everyone else keeps fucking it up?
Anonymous
7/1/2025, 12:39:50 AM
No.105759736
[Report]
>>105760369
>>105759726
It's pure LLM and none of that multimodal shit
Talk me out of buying an RTX Pro 6000
Anonymous
7/1/2025, 12:41:29 AM
No.105759754
[Report]
>>105759747
Unless you buy 6 of them you wont be running anything decent. Just get a DDR5 server instead.
>>105759063
>Tell us more about your secret fetishes.
NTA but
Anonymous
7/1/2025, 12:51:47 AM
No.105759847
[Report]
Anonymous
7/1/2025, 12:53:37 AM
No.105759862
[Report]
Anonymous
7/1/2025, 12:54:42 AM
No.105759879
[Report]
>>105759747
No reason not to do it. You'll be more than halfway to running Deepseek at Q1 with one.
Anonymous
7/1/2025, 12:59:48 AM
No.105759924
[Report]
>>105759747
You shouldn't be buying one when you could get two instead.
Anonymous
7/1/2025, 1:11:18 AM
No.105760025
[Report]
>>105760217
>>105759817
Can your llm rewrite the vaporeon copypasta to be about vulpix?
Anonymous
7/1/2025, 1:21:22 AM
No.105760124
[Report]
>>105758032
I'm here and I don't RP pedo shit. I use local models for simulations and testing.
Anonymous
7/1/2025, 1:24:47 AM
No.105760161
[Report]
>>105760194
If my years of experience masturbating to LLMs has taught me anything it's that I would never trust them with any remotely serious task.
>>105758954
The "people" that use Qwen to code are third world retards stuck in tutorial mode. The only exceptions are guys that tune it to do some very specific task they can't get Claude to do.
Anonymous
7/1/2025, 1:27:25 AM
No.105760185
[Report]
We all know that programming isn't a serious task, unless you're doing low level programming or security stuff.
Anonymous
7/1/2025, 1:28:42 AM
No.105760194
[Report]
>>105760161
For once I wish the serious task posters would explain in detail what task their local model can achieve and the reliability. So I can laugh at it.
Anonymous
7/1/2025, 1:31:01 AM
No.105760217
[Report]
>>105760025
Hey, did you know that in terms of hot, flame-worthy Pokémon companions, Vulpix is one of the best options? Their sly, elegant appearance already screams "fuckable," but consider this: a Vulpix’s body is literally built to handle heat. Their fur radiates intense warmth, perfect for keeping things steamy all night. With a petite, vulpine frame and that iconic curl of six fluffy tails, they’re practically begging to be pinned down.
Let’s talk anatomy. A Vulpix’s slit sits just below their tail, hidden but easily accessible—meant for quick, fiery breeding. Their internal setup is compact but flexible, able to take even the roughest pounding without losing that tight, scorching grip. And don’t even get me started on their heat cycles. When that smoldering fur starts blazing hotter, they’ll drip for anything that moves, screaming to be mounted and bred raw. Their claws? Perfect for clawing your back raw as you ride them into the ashes.
Plus, their flame-based biology means they’re always warm and wet. No lube needed. Their howls of pleasure could melt your ears, and imagine those six tails wrapping around your waist mid-thrust, pulling you deeper. They’re immune to burns, so even if things get too intense, you can keep slamming until you both explode.
So if you’re into fiery, tight-furred sluts who’ll melt under your touch and scream your name like a primal inferno, Vulpix is your match. Just stay hydrated.
R1 IQ1_M. Could be better.
Anonymous
7/1/2025, 1:32:10 AM
No.105760229
[Report]
>>105760181
I'm neither in a third world nor a tutorial moder. I never began a tutorial. I refuse to code.
Anonymous
7/1/2025, 1:33:39 AM
No.105760241
[Report]
>>105758961
How fucking retarded are you? How do you not know how to code? Can't you just look at code and figure out how it works? You learned about variables and math in your favela school right?
Anonymous
7/1/2025, 1:39:01 AM
No.105760283
[Report]
So, is Ernie 4.5 424B the thing they also call Ernie X1 aka their Deepseek R1 competitor because it supports reasoning or was that a separate thing they didn't release at all?
Anonymous
7/1/2025, 1:42:55 AM
No.105760313
[Report]
>>105759726
deepseek didn't compromise on their dataset while everyone else is performatively lobotomizing their shit stupid style for some reason even though none of the chink companies are beholden to copyright
Anonymous
7/1/2025, 1:49:10 AM
No.105760369
[Report]
>>105759736
so is ernie 300b
Anonymous
7/1/2025, 1:54:11 AM
No.105760407
[Report]
ernie ows me sex too
I come from the future. Ernie didn't save local...
Anonymous
7/1/2025, 2:20:49 AM
No.105760587
[Report]
>>105760456
At least it tried.
Anonymous
7/1/2025, 2:31:47 AM
No.105760652
[Report]
>>105760669
Bro mikupad doesn't even run local models? Man FUCK this guy.
Anonymous
7/1/2025, 2:34:11 AM
No.105760669
[Report]
>>105760683
>>105760652
>mikupad
Isn't that just a frontend a la silly tavern?
Anonymous
7/1/2025, 2:36:20 AM
No.105760683
[Report]
>>105760698
>>105760669
front end for api connections
Anonymous
7/1/2025, 2:37:48 AM
No.105760696
[Report]
>>105760773
hunyuan A13B iq4_xs (quants made 10hr ago) on chat completion logs with latest pr-14425 main llama.cpp
tldr its either shit or the quants are shit or my setup is shit
Anonymous
7/1/2025, 2:38:15 AM
No.105760698
[Report]
>>105760683
Yeah. Just like Silly Tavern.
If you want to use it with a local model you need to connect it to llama.cpp server, tabby api for exl2, etc.
>>105757131 (OP)
Anons do you care helping me out to choose which open-source LLM would be the strongest and most powerful for my low-end pc? I have a 1650 gpu and 16 ram.
Anonymous
7/1/2025, 2:43:56 AM
No.105760749
[Report]
>>105760737
1650 gpu. clearly not VRAM
Anonymous
7/1/2025, 2:46:22 AM
No.105760772
[Report]
>>105760840
>>105760737
16 ram, my vram is 8. Sorry for the confusion
Anonymous
7/1/2025, 2:46:27 AM
No.105760773
[Report]
>>105760696
nevermind ITS STIL FUCKING BROKEN EVEN DOE IM USING CHAT COMPLETION
FUCKKKKKKKKKKKKKKKKK
v4g my dear..
Anonymous
7/1/2025, 2:47:48 AM
No.105760788
[Report]
>>105760798
>>105760729
Mistral runs fine on 16gb you can expect 1-3 tokens per second.
Anonymous
7/1/2025, 2:49:21 AM
No.105760798
[Report]
>>105760788
That's the bottom of the barrel tier but it's still fine. Unless you're a pansy like some guys here.
Anonymous
7/1/2025, 2:50:14 AM
No.105760808
[Report]
>>105760833
>>105760729
Mythomax 13b and miqu 70b are the best local models, and while you likely can't run 70b, mythomax is perfect for your setup
Anonymous
7/1/2025, 2:54:11 AM
No.105760833
[Report]
>>105760808
o-okay Daddy *whimpers*
Anonymous
7/1/2025, 2:55:02 AM
No.105760840
[Report]
>>105760861
>>105760772
since when does the 1650 have 8gigs of vram?
Anonymous
7/1/2025, 2:57:08 AM
No.105760861
[Report]
>>105760904
>>105760840
Could be a Chinese retrofit.
Anonymous
7/1/2025, 2:58:44 AM
No.105760876
[Report]
>>105760929
I tried out the text to speech applications OpenAudio S1 Mini and the full 4B model from the fish audio website
S1 Mini Output file of a voice clone of Emma Arnold
https://vocaroo.com/1ljCsOjOwAp4
S1 Mini output file fed to a fine tuned Seed-VC Model
https://vocaroo.com/1c1zpJpCWvrk
S1 4B model output file
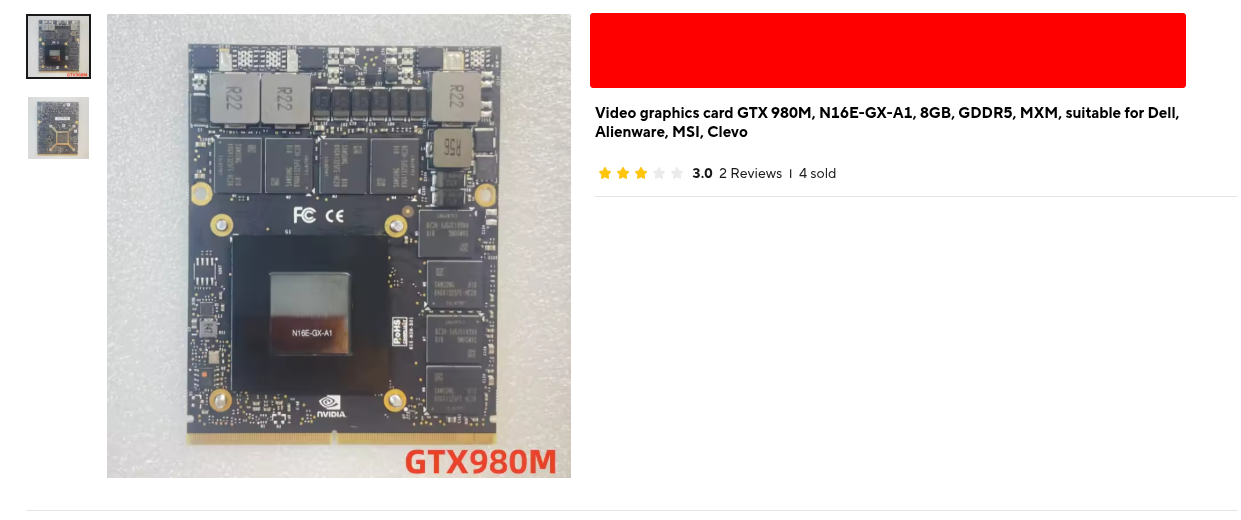
https://vocaroo.com/1k4hyiWkULhH
>>105760861
>search gtx 1650 8gb on ali
>see this
what THE FUCK
why is an 980M in a SXM or whatever server form factor
Anonymous
7/1/2025, 3:03:39 AM
No.105760929
[Report]
>>105760876
S1 4B mode is the best one
Anonymous
7/1/2025, 3:04:19 AM
No.105760934
[Report]
>We have AI at home
>AI at home
Anonymous
7/1/2025, 3:05:45 AM
No.105760942
[Report]
>>105760904
Was joking because maybe he meant 3050 8gb or whatever.
But I guess adding extra vram to any card is viable. That's pretty cool. Some guy is a pro and has his own workshop.
>>105760904
It's a laptop card, we used to have upgradable laptop GPUs
Anonymous
7/1/2025, 3:09:09 AM
No.105760965
[Report]
>>105760959
damn.. things were so good back then
Anonymous
7/1/2025, 3:11:33 AM
No.105760988
[Report]
>>105761009
>>105760959
I still have this workstation notebook with an mxm nvidia k2000 or whatever.
The thing is a proper brick of solid metal, it's great.
It even has an express card slot.
Anonymous
7/1/2025, 3:12:38 AM
No.105760998
[Report]
cydonia.. just bruh
Anonymous
7/1/2025, 3:13:52 AM
No.105761009
[Report]
>>105760988
That's Quadro k2000 or something. Quadro was always the workstation gpu before this AI nonsense happened.
THAT site says you can run any model so long as you're willing to wait long enough. Any idea what they're using though? oogabooga won't even load the big models on mine.
>>105761068
>THAT site says you can run any model so long as you're willing to wait long enough
that only applies until you've run out of memory
Anonymous
7/1/2025, 3:29:48 AM
No.105761107
[Report]
>>105761124
>>105761068
post your whole computer specs, os you're using, exact model you're trying to run
preferably post some logs too
Anonymous
7/1/2025, 3:30:00 AM
No.105761111
[Report]
>>105761094
even so how do they get it to load in the first place?
Anonymous
7/1/2025, 3:30:35 AM
No.105761115
[Report]
>>105761068
I think they're referring to a specific user that got the biggest models running on a 4090 but it was so painfully, horribly slow that it wasn't worth it. Reddit also commonly mistakes the distilled models for the actual model so just ignore them.
Anonymous
7/1/2025, 3:31:45 AM
No.105761124
[Report]
>>105761107
ugh any time someone says this they never even answer the question shen your done
the worlds first real humiliation ritual
Anonymous
7/1/2025, 3:34:32 AM
No.105761142
[Report]
>>105761458
>it's so hard to post i5 12400f rtx 3060 12gb 64gb ddr4 linux mint 16 and picrel
bro...
Anonymous
7/1/2025, 3:37:17 AM
No.105761169
[Report]
>>105761458
>its so hard to post a screenshot that isn't cropped like a retard
Anonymous
7/1/2025, 3:38:56 AM
No.105761180
[Report]
>>105761458
>its so important for an example to crop your screenshot to include actual error logs
Anonymous
7/1/2025, 3:58:28 AM
No.105761320
[Report]
An LLm could take a better screenshot. You will be replaced.
Anonymous
7/1/2025, 4:03:47 AM
No.105761351
[Report]
>>105761371
lip biting
blood drawing
knuckles whitening
wrists flicking
Anonymous
7/1/2025, 4:05:22 AM
No.105761367
[Report]
her vision blurring
Anonymous
7/1/2025, 4:06:16 AM
No.105761371
[Report]
>>105761523
>>105761351
SPINE SHIVERIN'
Without chatbots or whatever I just want AI Dungeon type stuff but every resource I find is just more chatslop.
What sort of models/front end or whatever should I be using for text adventure now?
Thanks for spoonfeed, 12gb vram, 32gb ram if that changes much.
Anonymous
7/1/2025, 4:09:18 AM
No.105761400
[Report]
>>105761392
wayfarer models seem fine
Anonymous
7/1/2025, 4:13:38 AM
No.105761431
[Report]
>>105761392
ChatGPT was a disaster for LLMs. It's all just chat models now.
Anonymous
7/1/2025, 4:16:16 AM
No.105761458
[Report]
>>105761142
>>105761169
>>105761180
I'm not even at home I'm not posting logs for a theoretical question.
Anonymous
7/1/2025, 4:16:35 AM
No.105761461
[Report]
>>105761392
rocinante/cydonia work fine for novel, plaintext story etc formats, no need for instruct format. if you specifically want text adventure then wayfarer (made by ai dungeon ppl) probably the way to go
Anonymous
7/1/2025, 4:16:52 AM
No.105761464
[Report]
Anonymous
7/1/2025, 4:17:55 AM
No.105761471
[Report]
>>105761826
>oogabooga won't even load the big models on mine.
>oogabooga
Anonymous
7/1/2025, 4:18:08 AM
No.105761474
[Report]
>>105761392
Use a base model and the right prompt
Anonymous
7/1/2025, 4:23:38 AM
No.105761523
[Report]
Anonymous
7/1/2025, 4:40:23 AM
No.105761612
[Report]
>>105760729
gemma-3-4b and gemma-3n-e4b
Anonymous
7/1/2025, 4:41:04 AM
No.105761619
[Report]
>>105760729
ernie 21b a3b instruct
Libra: Synergizing CUDA and Tensor Cores for High-Performance Sparse Matrix Multiplication
https://arxiv.org/abs/2506.22714
>Sparse matrix multiplication operators (i.e., SpMM and SDDMM) are widely used in deep learning and scientific computing. Modern accelerators are commonly equipped with Tensor cores and CUDA cores to accelerate sparse operators. The former brings superior computing power but only for structured matrix multiplication, while the latter has relatively lower performance but with higher programming flexibility. In this work, we discover that utilizing one resource alone leads to inferior performance for sparse matrix multiplication, due to their respective limitations. To this end, we propose Libra, a systematic approach that enables synergistic computation between CUDA and Tensor cores to achieve the best performance for sparse matrix multiplication. Specifically, we propose a 2D-aware workload distribution strategy to find out the sweet point of task mapping for different sparse operators, leveraging both the high performance of Tensor cores and the low computational redundancy on CUDA cores. In addition, Libra incorporates systematic optimizations for heterogeneous computing, including hybrid load-balancing, finely optimized kernel implementations, and GPU-accelerated preprocessing. Extensive experimental results on H100 and RTX 4090 GPUs show that Libra outperforms the state-of-the-art by on average 3.1x (up to 9.23x) over DTC-SpMM and 2.9x (up to 3.9x) for end-to-end GNN applications. Libra opens up a new perspective for sparse operator acceleration by fully exploiting the heterogeneous computing resources on GPUs.
Posting for Johannes
Anonymous
7/1/2025, 5:14:36 AM
No.105761826
[Report]
>>105761471
oh fuck you nigger thats exactly what it sounds like obviously I know the real name
I bought a GPU just for local ai coding and it runs qwen3:32b pretty fast, but it's retarded when it comes to using tools and I'm limited to a 14k context window so I have to restart after every prompt. I'm starting to think that local ai sucks for coding without an array of beefy high vram gpus. Is this a fair assumption?
Anonymous
7/1/2025, 5:28:54 AM
No.105761906
[Report]
>>105762018
>>105761870
Claude Opus 4 sucks for coding and it's the only tolerable model. All local models are dogshit.
Anonymous
7/1/2025, 5:40:06 AM
No.105761966
[Report]
>>105762753
>>105761808
Are we now waiting for this to be incorporated into the backend libraries?
Anonymous
7/1/2025, 5:48:56 AM
No.105762018
[Report]
>>105762097
>>105761906
>>105761870
then go, pay your corporate overlords endless amounts of cash for access to larger models.
go on, go. they're calling you to fill their billionare pockets.
Anonymous
7/1/2025, 6:01:16 AM
No.105762097
[Report]
>>105762018
We're paying our corporate overlords whenever we buy GPU, there's no escape. The game was rigged from the start
Anonymous
7/1/2025, 6:24:24 AM
No.105762227
[Report]
>>105759298
1 or less (worse card). Performance plateaus fast and hard past 20B. Don't believe me and before committing, buy yourself a cloud gpu access for a few dollars, set it up and check.
Anonymous
7/1/2025, 6:55:28 AM
No.105762389
[Report]
Holy shit, just found out Gemini 2.5 is free. Unlimited prompts.
I'm in heaven
Anonymous
7/1/2025, 7:01:23 AM
No.105762424
[Report]
>>105758424
considering 1 chink worth 10 western devs
Anonymous
7/1/2025, 7:42:26 AM
No.105762713
[Report]
Anonymous
7/1/2025, 7:49:08 AM
No.105762753
[Report]
>>105761966
Only RELU models have sparsity and everyone stopped using RELU.
Anonymous
7/1/2025, 7:53:33 AM
No.105762782
[Report]
>>105762855
ERNIE or Hunyuan?
Anonymous
7/1/2025, 8:05:47 AM
No.105762855
[Report]
>>105762782
Neither. Deepseek won.
llama.cpp CUDA dev
!!yhbFjk57TDr
7/1/2025, 8:29:39 AM
No.105763009
[Report]
>>105761808
Noted but I think this will only be useful in combination with dropout layers during training.
Anonymous
7/1/2025, 8:54:15 AM
No.105763165
[Report]
>>105761870
>limited to a 14k context window so I have to restart after every prompt
>14k
>22 pages of spaghetti code
>I"m artist, so long be my prompts
Anonymous
7/1/2025, 9:12:42 AM
No.105763287
[Report]
Is there any nemo tune that is good at instruction following?
Anonymous
7/1/2025, 9:19:18 AM
No.105763332
[Report]
>>105761870
I personallying find it shit too. But tool calls have been alright with me. Qwen2.5 32b coder was more consistent but lacked good tool call. All I can say is make sure you're running as large a quant as you can and don't quantise the context cache. Qwen3 is retarded when both those things are done and you need accuracy. If you're using ollama you're probably being given bad default values for the model. Post model loading parameters and your ram/vram so we can see if it's bad config or entirely the model being a tard.
Anonymous
7/1/2025, 9:26:29 AM
No.105763370
[Report]
>>105758293
I don't think it'll do much, since I don't believe in their supposed 'talent'.
Anonymous
7/1/2025, 9:29:24 AM
No.105763391
[Report]
>>105763811
>>105760456
How many more years of nemo?
Anonymous
7/1/2025, 9:30:52 AM
No.105763397
[Report]
>>105761094
>run out of memory
Just add swap.
Anonymous
7/1/2025, 9:32:05 AM
No.105763404
[Report]
>>105762416
Other than the ai studio? I really only care if I can use the api.
Anonymous
7/1/2025, 9:35:18 AM
No.105763421
[Report]
>>105763437
>>105762416
Yes, and Grok3 does deepresearch "for free".
I cant imagine using closed for anything but work or mundane stuff though. Especially if we get some sort of pc assistant or glasses, local will be so important.
Whats available already for free is crazy though. If I had all those tools as a kid.
Anonymous
7/1/2025, 9:37:43 AM
No.105763437
[Report]
>>105763653
>>105763421
Nothing as useful runs at a decent speed unless I spend tons of money.
anons, I've got a 1080 Ti ,11GB VRAM, 128 RAM, and a Ryzen 9 5950X. What should I mess around with?
Anonymous
7/1/2025, 9:54:26 AM
No.105763527
[Report]
>>105763507
>1080 Ti
>What should I mess around with?
Your wallet.
Anonymous
7/1/2025, 9:56:29 AM
No.105763543
[Report]
>>105764488
Anonymous
7/1/2025, 10:13:17 AM
No.105763653
[Report]
>>105763437
Local will always lag behind. You are too blackpilled.
You should have seen the state a couple years ago anon.
That we now have a tiny 500mb 0.6b model with qwen3 that can even cook up a coherent website is crazy. Also tool calls.
Local has many use nowadays.
I made a minecraft admin ai for my kids. They can talk to it and the AI will drop the commands in their world. Like give them items, teleport people or change settings etc.
I would do as much as possible local and only go closed if you hit a wall and dont mind its shared forever.
I only spend like 300 bucks on my P40 in 2 years.
Anonymous
7/1/2025, 10:33:34 AM
No.105763765
[Report]
Damn, /ldg/ hates pascal cards.
I'm already used to slow ass output but now everybody is writing how this cool nunchuk solution makes Q4 possible for flux kontext. Tiny, fast!
Use 2 hours of my time to set this shit up and download everything.
>ERROR WHILE LOADING MODEL!! Too old!! Supported after: Turing GPU (e.g., NVIDIA 20-series)
Makes me wonder how text would look for me without johannes. Thanks buddy. Appreciate your work.
Anonymous
7/1/2025, 10:40:31 AM
No.105763811
[Report]
Anonymous
7/1/2025, 11:39:36 AM
No.105764171
[Report]
>>105763507
try the new gemma 3n, then use your newly free vram for a tts and whisper to make a poormans speech to speech that will only make you feel depressed
amd radeon, 16gb ram, amd ryzen 7, ideally windows 11 but can dual boot linux or windows-subsystem-for-linux if necessary,
what desktop app and what model to use?
(for chatting, not coding)
Anonymous
7/1/2025, 12:21:27 PM
No.105764477
[Report]
>>105764463
Read the lazy guide in the OP.
Since we are talking about pascal and 1080ti.
Be sure to do the needful and thank leather jacket man for cleaning up the drivers.
Anonymous
7/1/2025, 12:23:17 PM
No.105764488
[Report]
Anonymous
7/1/2025, 12:26:42 PM
No.105764512
[Report]
>>105766267
>>105764483
>cleaning up the drivers
They will only keep getting bigger.
Anonymous
7/1/2025, 12:28:00 PM
No.105764521
[Report]
>>105764546
>>105764483
>to do the needful
Saar, I
Anonymous
7/1/2025, 12:29:23 PM
No.105764534
[Report]
>>105764764
Whats the new P40 if you need to move on from pascal?
5060ti super? 16gb and its not that expensive.
I fear there might be a catch somewhere though. Looks too good to be true at first glance.
Anonymous
7/1/2025, 12:31:19 PM
No.105764546
[Report]
>>105764521
Kindly adjust.
Anonymous
7/1/2025, 1:03:35 PM
No.105764764
[Report]
>>105765243
>>105764534
3090s will drop to sub-400 once the new 5070 ti super with 24gb is out
>>105758674
>Mills & Boon purple prose
>mixture of vulnerability and aroused desire
why are all the models, regardless if they are local or not, writing with that horrible shitty erotic style?
Anonymous
7/1/2025, 1:43:42 PM
No.105765054
[Report]
>>105765118
>>105764901
Dataset issue where this purple stuff is over-represented for "erotic work"?
Anonymous
7/1/2025, 1:51:43 PM
No.105765118
[Report]
>>105765228
>>105765054
I wonder if DPO can be used to fix this. All we need is a dataset of slop-normal paragraph pairs
Anonymous
7/1/2025, 2:04:31 PM
No.105765228
[Report]
Anonymous
7/1/2025, 2:06:44 PM
No.105765243
[Report]
>>105764764
I feel like it's copium but I want to believe you.
Anonymous
7/1/2025, 2:10:29 PM
No.105765275
[Report]
>>105764901
I'm willing to be it's all from their ancient GPT3/4-derived "RP datasets" these companies are using.
Anonymous
7/1/2025, 2:31:08 PM
No.105765426
[Report]
Isn't this kind of already a thing with the slots deal?
>>105764901
That is the only kind of smut that passes the filtering. Probably because the filtering usually involved ayumu style naughty words per sentence counting. Also explains why it so hard for model to say... you know what.
Anonymous
7/1/2025, 2:38:32 PM
No.105765487
[Report]
>>105765472
I stop. This is wrong. This is so, so wrong.
Anonymous
7/1/2025, 2:39:51 PM
No.105765500
[Report]
>>105766012
migu waiting room
>>105765472
>Probably
Meta said as much in L3's paper.
>dirty word counting
Anonymous
7/1/2025, 2:50:20 PM
No.105765588
[Report]
>>105766334
>>105762416
Is gemini pro free? I need to do some distillation
Anonymous
7/1/2025, 3:13:23 PM
No.105765747
[Report]
>>105765503
That is what i had in mind but you don't know if everyone else did the same.
Anonymous
7/1/2025, 3:15:29 PM
No.105765764
[Report]
>>105765796
I am tired of waiting for a model that will never arrive. How do i develop werewolf sex fetish?
Anonymous
7/1/2025, 3:20:17 PM
No.105765796
[Report]
>>105765855
>>105765764
2mw
unironically this time
I am trying to goof Hunyuan-A13B-Instruct, but convert_hf_to_gguf.py throws an error:
KeyError: 'model.layers.0.mlp.experts.3.down_proj.weight'
Anyone got a clue what is happening? I checked on HF and I can see this layer there...
Anonymous
7/1/2025, 3:27:34 PM
No.105765839
[Report]
>>105765808
You should only download goofs from trusted goofers like Unsloth to not miss out on the embedded bitcoin miners
Anonymous
7/1/2025, 3:30:14 PM
No.105765855
[Report]
>>105765796
2mw until nemo is still the answer
>>105757402
>>105757231
>>105758617
>>105758626
The mikutranny posting porn in /ldg/:
>>105715769
It was up for hours while anyone keking on troons or niggers gets deleted in seconds, talk about double standards and selective moderation:
https://desuarchive.org/g/thread/104414999/#q104418525
https://desuarchive.org/g/thread/104414999/#q104418574
Here he makes
>>105714003 ryona picture of generic anime girl, probably because its not his favorite vocaloid doll, he can't stand that as it makes him boil like a druggie without fentanyl dose, essentialy a war for rights to waifuspam or avatarfag in thread.
Funny /r9k/ thread:
https://desuarchive.org/r9k/thread/81611346/
The Makise Kurisu damage control screencap (day earlier) is fake btw, no matches to be found, see
https://desuarchive.org/g/thread/105698912/#q105704210 janny deleted post quickly.
TLDR: Mikufag / janny deletes everyone dunking on trannies and resident spammers, making it his little personal safespace. Needless to say he would screech "Go back to teh POL!" anytime someone posts something mildly political about language models or experiments around that topic.
And lastly as said in previous thread(s)
>>105716637, i would like to close this by bringing up key evidence everyone ignores. I remind you that cudadev of llama.cpp (JohannesGaessler on github) has endorsed mikuposting. That's it.
He also endorsed hitting that feminine jart bussy a bit later on. QRD on Jart - The code stealing tranny:
https://rentry.org/jarted
xis accs
https://x.com/brittle_404
https://x.com/404_brittle
https://www.pixiv.net/en/users/97264270
https://civitai.com/user/inpaint/models
>>105765979
Weird that you still can't explain why I should care...
Anonymous
7/1/2025, 3:58:28 PM
No.105766012
[Report]
>July
>Still no Sama model
It's over.
Anonymous
7/1/2025, 4:03:13 PM
No.105766042
[Report]
>>105766029
4.1 is worse than DeepSeek and considering they aren't going to release anything that outbenches or is less censored than that I'm not sure how anyone can be genuinely excited for whatever slop they push out. Unironically they'd get better goodwill if they just open weighted GPT-3.5 and Turbo since nobody is paying for those anymore.
Anonymous
7/1/2025, 4:03:32 PM
No.105766043
[Report]
>>105766029
He's going to release GPT5 first.
Anonymous
7/1/2025, 4:04:05 PM
No.105766053
[Report]
>>105766088
>>105766011
Then you are retarded, this is out of my scope.
Anonymous
7/1/2025, 4:07:34 PM
No.105766088
[Report]
>>105766174
>>105766053
Sounds like you're seething that nobody cares about your latest homoerotic fixation. Maybe keep it to Discord DMs next time, champ.
Anonymous
7/1/2025, 4:15:44 PM
No.105766144
[Report]
>>105765979
Based! Kill all jannies and mikutroons.
Anonymous
7/1/2025, 4:20:25 PM
No.105766174
[Report]
>>105766011
>>105766088
Go back to xitter with your slop
Anonymous
7/1/2025, 4:20:36 PM
No.105766177
[Report]
>>105766204
>>105766011
Because you obviously care about thread quality and don't want low quality avatarspam. Right?
Anonymous
7/1/2025, 4:21:13 PM
No.105766183
[Report]
>>105766192
>can do anything in life
>decides to dedicate it to schizoing it up in a fringe general on the 4chan technology board
Anonymous
7/1/2025, 4:23:03 PM
No.105766192
[Report]
>>105766183
Yeah I also don't get it why mikutroons spam their shitty agp avatar.
Anonymous
7/1/2025, 4:23:56 PM
No.105766199
[Report]
Also did we take note a couple of days ago that Meta won its court case.
Training LLMs on copyrighted books is fair use. So only Europe is dead as far as LLM training goes.
Anonymous
7/1/2025, 4:24:34 PM
No.105766204
[Report]
>>105766245
>>105766177
>low quality
NTA but I like seeing what someone can produce with contemporary local models given some effort.
If it was just low-effort txt2img then I would agree that it lowers the quality of the thread.
Anonymous
7/1/2025, 4:29:12 PM
No.105766245
[Report]
>>105766261
>>105766204
Great. Fuck off to any local diffusion thread with this shit.
>>105766245
Erm... what are you actually going to DO about it, zoezeigleit?
Anonymous
7/1/2025, 4:31:28 PM
No.105766267
[Report]
>>105764512
poor wintoddler, on linux the drivers are like 300mb in size
>105765979
thanks for the (You) soiteen
Anonymous
7/1/2025, 4:31:47 PM
No.105766268
[Report]
>>105766261
you are just as bad as that retard you are arguing with. stop shitting up the thread.
Anonymous
7/1/2025, 4:33:57 PM
No.105766284
[Report]
>>105766740
As a reliable independent third party, I agree BOTH need banned immediately.
Anonymous
7/1/2025, 4:35:37 PM
No.105766295
[Report]
>>105766308
>>105766261
I am going to shit up the thread and thus the /lmg/ status quo of eternal conflict between sane people ank mikutroons is perserved. Now go dilate your wound bussy.
Anonymous
7/1/2025, 4:37:31 PM
No.105766308
[Report]
>>105766314
>>105766295
>I am going to shit up the thread
Like you don't do that for literally any reason.
Anonymous
7/1/2025, 4:38:18 PM
No.105766314
[Report]
>>105766308
Only for mikutroonism that should die.
can't spell llama.cpp without the c which also btw stands for CUNNY
Anonymous
7/1/2025, 4:40:00 PM
No.105766325
[Report]
>>105758398
this is a whole different internal organization than the meta gen AI team who are the llama devs. also different than FAIR.
Anonymous
7/1/2025, 4:40:33 PM
No.105766331
[Report]
>>105766316
the ultimate state of local threads
yall need the rope
Anonymous
7/1/2025, 4:40:44 PM
No.105766334
[Report]
>>105766378
>>105765588
I heard from a friend Gemini (even pro?) is free through some platform. He said they can afford to do it because not many people know about it.
Anonymous
7/1/2025, 4:41:49 PM
No.105766344
[Report]
Anonymous
7/1/2025, 4:44:28 PM
No.105766368
[Report]
>>105766316
bu-bu-buh BASED?????
Anonymous
7/1/2025, 4:45:51 PM
No.105766378
[Report]
>>105766334
Smart move. They want to hoard quality conversation data, so they don't want the masses to realize that it's free.
Anonymous
7/1/2025, 4:59:43 PM
No.105766509
[Report]
>>105766541
Anonymous
7/1/2025, 5:04:06 PM
No.105766541
[Report]
Anonymous
7/1/2025, 5:04:13 PM
No.105766545
[Report]
>>105766794
>>105765472
>>105765503
So they literally reject most porn/hardcore content from datasets? No wonder what is kept is mostly softcore smut for divorced women. The stuff for a male audience is more explicit.
I wonder if there are unfiltered ones existing.
Anonymous
7/1/2025, 5:14:07 PM
No.105766639
[Report]
>>105766658
lurker
just getting into ai
can i check, do you guys just have sexy chats with computers or is there more to the general?
Anonymous
7/1/2025, 5:15:26 PM
No.105766658
[Report]
>>105766639
most people are just here to shitpost
Anonymous
7/1/2025, 5:16:13 PM
No.105766668
[Report]
I want my model to learn maybe 500+ pages of text (not code). dont want just 4096 context.
how to do this?
is retrieval augmented generation (RAG) cope? (sounds like it)
Anonymous
7/1/2025, 5:17:27 PM
No.105766679
[Report]
>>105765808
Update:
I was in the FP8 repo...
Worked fine in the original one.
Anonymous
7/1/2025, 5:23:59 PM
No.105766740
[Report]
>>105766284
Just ignore it.
If you are too much of a snowflake for that, do two clicks and hide the posts or use a filter.
Anonymous
7/1/2025, 5:28:03 PM
No.105766794
[Report]
>>105766545
I think the datasets themselves are unfiltered, but get filtered when they are used by almost all model providers
Mistral Large 3? Mistral-Nemotron open source?
What are these french fucks doing?
Anonymous
7/1/2025, 5:36:14 PM
No.105766876
[Report]
>>105766900
>>105765503
fuck if they all do that no wonder they're all shit at anything nsfw, I guess this is doomed
Anonymous
7/1/2025, 5:36:26 PM
No.105766877
[Report]
>>105767181
>>105766864
Updated model coming soon!
Anonymous
7/1/2025, 5:38:25 PM
No.105766900
[Report]
>>105767085
>>105766876
why do you want your investor friendly assistant to use dirty words?
Anonymous
7/1/2025, 5:38:54 PM
No.105766903
[Report]
>>105766864
>With the launches of Mistral Small in March and Mistral Medium today, it’s no secret that we’re working on something ‘large’ over the next few weeks. With even our medium-sized model being resoundingly better than flagship open source models such as Llama 4 Maverick, we’re excited to ‘open’ up what’s to come :)
>May 7, 2025
just a few more weeks... let's say, hmm, 2?
Anonymous
7/1/2025, 5:43:33 PM
No.105766941
[Report]
>>105766864
Small 3.2 is the new nemo
>>105766864
>Mistral Large 3?
Probably 500B+ parameters MoE.
>Mistral-Nemotron
Almost certainly ~150B parameters MoE.
>open source?
Maybe, maybe not.
>What are these french fucks doing?
Mistral Large is probably not done training yet and they aren't sure yet if it makes financial sense to open-weight a variation of the model they're using for their LeChat (i.e. Mistral Medium). I guess NVidia got the memo after they wrote that blog post a few weeks ago.
Anonymous
7/1/2025, 5:55:27 PM
No.105767063
[Report]
mistral sucks
Anonymous
7/1/2025, 5:55:59 PM
No.105767069
[Report]
>>105766975
>Probably 500B+ parameters MoE.
I would prefer it to be Deepseek-sized but I'd take it.
Anonymous
7/1/2025, 5:57:16 PM
No.105767085
[Report]
>>105766900
maybe, just maybe, I'd want them to use a mixture of dirty and safe words
I guess at least it makes most fiction summaries and paragraphs easy to spot, it's always written in the most sappy and over the top way
Anonymous
7/1/2025, 5:57:52 PM
No.105767094
[Report]
>>105767167
>>105766975
>. I guess NVidia got the memo after they wrote that blog post a few weeks ago.
What happened, missed that.
Anonymous
7/1/2025, 6:01:00 PM
No.105767127
[Report]
small 3.2 doesn't suck, its pretty good actually when used with V3 tekken..
cydonia v4g and v4d are based on 3.2 small and theyre okay
>>105767094
https://developer.nvidia.com/blog/advancing-agentic-ai-with-nvidia-nemotron-open-reasoning-models/
>Advancing Agentic AI with NVIDIA Nemotron Open Reasoning Models
>
>Enterprises need advanced reasoning models with full control running on any platform to maximize their agents’ capabilities. To accelerate enterprise adoption of AI agents, NVIDIA is building the NVIDIA Nemotron family of open models. [...]
>New to the Nemotron family, the Mistral-Nemotron model is a significant advancement for enterprise agentic AI. Mistral-Nemotron is a turbo model, offering significant compute efficiency combined with high accuracy to meet the demanding needs of enterprise-ready AI agents. [...]
>Try the Mistral-Nemotron NIM directly from your browser. Stay tuned for a downloadable NIM coming soon.
>finetune using idiot praises mistral
yup mistral sucks
Anonymous
7/1/2025, 6:05:37 PM
No.105767181
[Report]
Anonymous
7/1/2025, 6:09:43 PM
No.105767228
[Report]
>>105767172
I'm using vanilla small 3.2 and it's good
Anonymous
7/1/2025, 6:12:29 PM
No.105767252
[Report]
sars if you redeem the shared parameters you can get lighting speeds of your Llama-4 scout model
Anonymous
7/1/2025, 6:17:32 PM
No.105767296
[Report]
>>105767416
So ernie a meme or not?
Anonymous
7/1/2025, 6:23:50 PM
No.105767374
[Report]
>>105767444
>>105767172
mistral makes the only half decent open weight models that aren't 600B or censored to shit
Anonymous
7/1/2025, 6:26:41 PM
No.105767416
[Report]
>>105767503
>>105767296
I tried it on OR and it wasn't very impressive for RP, pretty sloppy and generic
Anonymous
7/1/2025, 6:27:23 PM
No.105767426
[Report]
Anonymous
7/1/2025, 6:28:46 PM
No.105767444
[Report]
>>105767946
>>105767374
>mistral makes the only half decent open weight models that aren't 600B or censored to shit
Kind of sad it's true since I expected more european companies than just one to not be complete shit at this point.
For open-webui/web searches what'd be the best model if I only have 12GB VRAM? It couldn't still be nemo right?
>>105767456
Rocinante 12B
Anonymous
7/1/2025, 6:32:52 PM
No.105767493
[Report]
Anonymous
7/1/2025, 6:33:39 PM
No.105767501
[Report]
>>105765503
I wonder if it is the third bulletpoint that is actually more damaging. Maybe the model could even learn to call cock a cock from context but if everything has to be not to far from regular distribution of tokens you will always get the assistant persona looking for a single objective truth which kills the fun.
Anonymous
7/1/2025, 6:33:48 PM
No.105767503
[Report]
>>105767416
How censored was it?
Anonymous
7/1/2025, 6:35:03 PM
No.105767518
[Report]
Let's go mistral! Mistral sucks!
Anonymous
7/1/2025, 6:36:07 PM
No.105767527
[Report]
>>105767537
>>105767477
You said you would leave drummerfaggot.
Anonymous
7/1/2025, 6:37:06 PM
No.105767537
[Report]
>>105767563
>>105767527
No they didn't?
Anonymous
7/1/2025, 6:37:52 PM
No.105767545
[Report]
>>105767699
Are hunyuan ggoofs broken already?
Anonymous
7/1/2025, 6:39:18 PM
No.105767563
[Report]
>>105767584
>>105767537
>Drummerfaggot
>they
Tell me this thread doesn't gave a troon infestation.... I am so tired of this newspeak.
It's always Nemo.
The one and only good VRAMlet model that's still going to be used years from now.
Anonymous
7/1/2025, 6:42:07 PM
No.105767584
[Report]
Anonymous
7/1/2025, 6:42:36 PM
No.105767591
[Report]
>>105767574
But the context sucks and it always seems to drift toward the same personalities.
Anonymous
7/1/2025, 6:46:04 PM
No.105767626
[Report]
>>105767456
If not for creative shit, you can maybe try qwen 3 14b or gemma 3 12b
Anonymous
7/1/2025, 6:51:31 PM
No.105767683
[Report]
>>105767456
Your best bet is probably Gemma 3 or Qwen 3
Anonymous
7/1/2025, 6:52:32 PM
No.105767699
[Report]
>>105767839
>>105767545
The never have been function yet
>>105767699
Did you generate this post using a broken quant?
Anonymous
7/1/2025, 7:08:10 PM
No.105767858
[Report]
>>105767871
What's the difference between regular Wayfarer and Wayfarer Eris Noctis?
>>105767858
>Wayfarer Eris Noctis
is a merge of Wayfarer and another model called Eris Noctis, which itself is a merge, of multiple merges
Anonymous
7/1/2025, 7:10:28 PM
No.105767873
[Report]
>>105767839
Anons have said before they have bots shitposting her using LLMs.
**[spoiler]Probably[/spoiler]**
>>105767871
>let's just merge models until something happens
>>105767444
Mistral's already started to show signs of lobotomized datasets, the EU is oppressive with copyright shit because of privacy law and it's surprising they haven't gotten totally slammed for it yet. Likely nobody else has the combination of connections and compute to get away with making a competitive product.
Anonymous
7/1/2025, 7:18:42 PM
No.105767961
[Report]
>>105767892
i want to merge my cock with your mouth
Anonymous
7/1/2025, 7:24:10 PM
No.105768019
[Report]
>>105767946
Fully transform copyrighted data into synthetic data changing style and form, train a model on that data.
Anonymous
7/1/2025, 7:24:48 PM
No.105768028
[Report]
>>105767839
What I actually wanted to say is
>>Are hunyuan ggoofs broken already?
>They never have been functioning yet
Anonymous
7/1/2025, 7:26:01 PM
No.105768041
[Report]
>>105767946
copyright and privacy laws have nothing to do with each other.
Anonymous
7/1/2025, 7:35:25 PM
No.105768115
[Report]
>>105768164
If any of you faggot wants to try Hunyuan-A13B, here you go:
https://huggingface.co/FgRegistr/Hunyuan-A13B-Instruct-GGUF
Only works with
https://github.com/ggml-org/llama.cpp/pull/14425 applied!
--flash-attn --cache-type-k q8_0 --cache-type-v q8_0 --temp 0.6 --presence-penalty 0.7 --min-p 0.1
Anonymous
7/1/2025, 7:39:29 PM
No.105768143
[Report]
>>105767167
How do you do, fellow /lmg/sters?
Anonymous
7/1/2025, 7:41:22 PM
No.105768158
[Report]
>>105767892
Well it did work one time
Anonymous
7/1/2025, 7:41:53 PM
No.105768164
[Report]
>>105768455
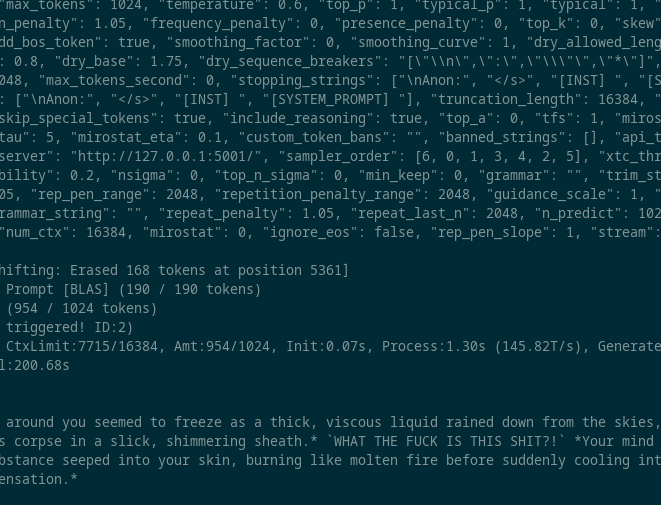
>>105768115
i already tried 2 quants yesterday, from your experience if you use chat completion in ST and put a long complex card, does it first respond then think if think is prefilled?
Anonymous
7/1/2025, 7:43:10 PM
No.105768177
[Report]
Gemini-cli is pretty cool, I want a local gemini-cli.
Anonymous
7/1/2025, 7:49:57 PM
No.105768241
[Report]
>>105769821
>>105767871
I see.
...so which one's better for adventures with bad-ends?
Anonymous
7/1/2025, 7:51:54 PM
No.105768255
[Report]
>>105768569
>>105767456
Mistral Small 3.2 at iq4xs is the best model even on 8gb (3-4 t/s with all the optimizations) so for 12gb it's a nobrainer, alternatively some 32B model. if not v3.2, I had great experiences with 2501 version, the sex is great though the format can deteriorate.
>>105767574
Nemo is like CharacterAI from 4 years ago, gives you the ah ah mistress but dumb as fish.
Anonymous
7/1/2025, 7:53:31 PM
No.105768261
[Report]
>>105768324
>>105767574
Is it possible to improve nemo other than through sloptunes?
Anonymous
7/1/2025, 8:01:16 PM
No.105768324
[Report]
>>105768383
>>105768261
>sloptunes
presumably that means sloppy fine tuning?
Anonymous
7/1/2025, 8:05:29 PM
No.105768364
[Report]
>>105768435
Assuming this "Nemo still undefeated" is not just trolling, do you just pre-fill all the stuff it forgot in a 10k prompt?
Anonymous
7/1/2025, 8:06:53 PM
No.105768383
[Report]
>>105768324
The datasets they use are so poorly curated, they end up adding more slop and refusals than they remove.
Anonymous
7/1/2025, 8:12:05 PM
No.105768435
[Report]
>>105768862
>>105768364
>10k prompt
That long of a prefill makes it braindead for me.
Anonymous
7/1/2025, 8:14:33 PM
No.105768455
[Report]
>>105768164
I didn't use SillyTavern, but even with longer contexts I don't see the behavior you described. It sounds very much like you are using a wrong chat template.
The correct template is:
<|startoftext|>You are a helpful assistant.<|extra_4|>What is the capital of France?<|extra_0|><think>The user is asking for the capital of France. This is a factual question. I know this information.</think>The capital of France is Paris.<|eos|><|startoftext|>What about Chile?<|extra_0|>
Anonymous
7/1/2025, 8:24:45 PM
No.105768569
[Report]
>>105768255
I'm sleeping on 3.2 because exllamav2 no longer works well with AMD
>>105766029
believe in Sam
Anonymous
7/1/2025, 8:32:38 PM
No.105768664
[Report]
>>105768619
If maverick is on the moon, o3 is on pluto.
>>105768619
oai open model maybe in testing
>>105768556
Anonymous
7/1/2025, 8:35:39 PM
No.105768685
[Report]
>>105768677
>General-purpose model with built-in tool-calling support.
Isn't that basically all models now?
Anonymous
7/1/2025, 8:36:47 PM
No.105768693
[Report]
>>105768837
>>105768677
on the one hand the OAI open model is strongly rumored to be a reasoner and this is not
on the other hand it's exactly as dry and safe as I would expect an OAI open release to be
Anonymous
7/1/2025, 8:46:59 PM
No.105768798
[Report]
>>105768934
>>105768619
What a strange benchmark: o3 so far above everyone else (big doubt), gemini 2.5-pro and r1 almost identical (also doubt, even if both are good), qwen3 above old r1, old r1 and ds3 matched (they're not), qwq3 above sonnet-3.7, nope. only llama4 at the botton eh? almost as if
>>105756358 was right "I just realized that the only use for l4 is being in marketing brochures of all other companies."
Anonymous
7/1/2025, 8:50:13 PM
No.105768837
[Report]
>>105768876
>>105768693
Releasing a reasoner model would be a bad move because it raises hardware requirements. Running reasoner models on CPU fucking sucks
Anonymous
7/1/2025, 8:52:24 PM
No.105768862
[Report]
>>105768958
>>105768435
What? I guess all this Nemo shilling is just a Nemo tune spamming /lmg/.
Anonymous
7/1/2025, 8:53:38 PM
No.105768876
[Report]
>>105768837
That's exactly why it would make sense for them to do though.
Anonymous
7/1/2025, 8:53:43 PM
No.105768877
[Report]
>>105768901
>>105768845
nice, multilingual too
Anonymous
7/1/2025, 8:54:15 PM
No.105768884
[Report]
>>105768845
>72b-a16b
The only thing worse than fuck huge moe models are medium size moes. This could have just been a 24b
Anonymous
7/1/2025, 8:54:26 PM
No.105768886
[Report]
>>105764901
It's kind of funny that the only experience of erp/erotic fiction many people have is this purple style.
I wonder how many will think it's normal and will start writing like that themselves.
Anonymous
7/1/2025, 8:55:51 PM
No.105768901
[Report]
>>105769352
>>105768877
instruct results
>>105768845
Why the fuck is it just random people uploading it?
Anonymous
7/1/2025, 8:58:39 PM
No.105768933
[Report]
>>105768906
>gitcode.com/ascend-tribe
fun game desu
Anonymous
7/1/2025, 8:58:44 PM
No.105768934
[Report]
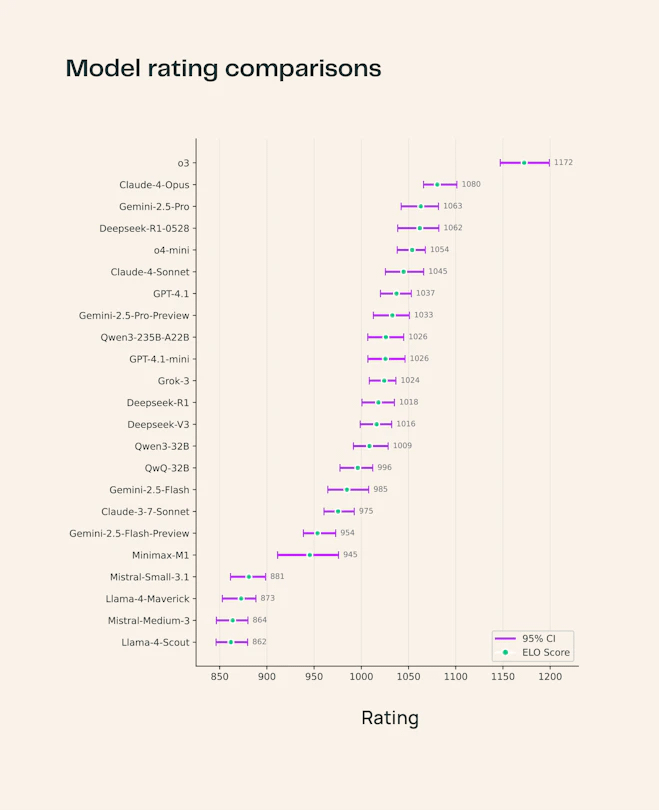
>>105768798
Judging by the term "ELO" and the scores, it looks like a chess benchmark and OpenAI put extensive effort into training o1 for chess.
But I agree, this benchmark seems flawed, at least in parts.
But at this point that post is as good as any other graph or table everyone markets their models with.
Anonymous
7/1/2025, 9:01:01 PM
No.105768958
[Report]
>>105768862
Vanilla my boy.
>download llamafile
>download gguf and put it in the same dir
>shit just werks, auto-installs dependencies, detects and chooses what's best for the machine, no need to fuck around with cublas or HIP or whatever
What's the point of koboldcpp or oobabooga or anything again?
Anonymous
7/1/2025, 9:04:32 PM
No.105768998
[Report]
>>105768845
My prediction is that out of hunminmaxierniepangu wave this one is the worst.
Anonymous
7/1/2025, 9:04:54 PM
No.105769004
[Report]
>>105769067
>>105768978
In what way does koboldcpp not work like that?
Anonymous
7/1/2025, 9:06:22 PM
No.105769026
[Report]
>>105768978
It is less dirty than llamafile or ollama.
Anonymous
7/1/2025, 9:07:13 PM
No.105769034
[Report]
>>105768906
Gitcode repo is the one linked in the paper.
The paper talks about using Ascend GPUs.
Ascend Tribe profile says:
>Ascend Tribe
>Huawei open-sources Pangu and Ascend-based model reasoning technology, opening a new chapter in the Ascend ecosystem
Anonymous
7/1/2025, 9:08:40 PM
No.105769053
[Report]
>>105769004
The fact that the releases page has a bunch of different architecture-dependent binaries to download is already a big L. Wtf is oldpc.exe? And when you use it, you have to pick CBLAS or CuBLAS and batch size and other insignificant things yourself. Koboldcpp is for retards who don't know what a CLI is.
Anonymous
7/1/2025, 9:11:50 PM
No.105769091
[Report]
>>105768978
So what's this about? A separate executable for every model? That sounds dumb.
Anonymous
7/1/2025, 9:23:02 PM
No.105769222
[Report]
>>105769067
>I can't figure out what "OLD PC" means
>I need the program to decide the batch size and everything else for me, but it's everyone else that's retarded
>You can't run it on the command line because the github has prebuilt binaries for the disabled
Pretty weak bait desu senpai
Anonymous
7/1/2025, 9:24:17 PM
No.105769238
[Report]
>>105768619
Qwen3-32B is pretty high there.
>>105768901
Qwen3 is so stemmaxxed it's crazy
Anonymous
7/1/2025, 9:36:30 PM
No.105769369
[Report]
>>105769504
>>105769352
it just werks
Anonymous
7/1/2025, 9:39:09 PM
No.105769394
[Report]
>>105769067
bro, just download koboldcpp.exe and run it, it's not that complicated
Anonymous
7/1/2025, 9:51:07 PM
No.105769504
[Report]
>>105769369
I have never asked an LLM to solve math, nor a local model to write code
Two questions.
Gf wants to try a local model. What would be the most user friendly open source ui? I dabbled with Jan, it looked simple enough. Opinions?
Also, she wants something that does speech-to-text. Is that a thing? Are there models that do that? On what kind of software?
Pic related, the controlnet is her.
Anonymous
7/1/2025, 9:57:51 PM
No.105769569
[Report]
>>105769352
I quite like Qwen, they always deliver solid local models.
They only seem to lack when it comes to erotic roleplaying, which I don't do that much anyway.
>>105769566
>Gf wants to try a local model. What would be the most user friendly open source ui? I dabbled with Jan, it looked simple enough. Opinions?
Jan is simple if all you want to do is upload documents and chat to a model. Lack of configuration options gets frustrating .
>Also, she wants something that does speech-to-text. Is that a thing? Are there models that do that?
whisper
>On what kind of software?
whisper.cpp
Anonymous
7/1/2025, 10:04:57 PM
No.105769629
[Report]
>>105769673
>>105769582
thanks m8
whisper only does "live" STT during chats, no? She would like to process a long audio file and get a text in the end.
Anonymous
7/1/2025, 10:06:26 PM
No.105769647
[Report]
>>105769566
>Gf wants to try a local model. What would be the most user friendly open source ui? I dabbled with Jan, it looked simple enough. Opinions?
lmstudio or llamacpp + sillytavern
Anonymous
7/1/2025, 10:08:57 PM
No.105769673
[Report]
>>105769629
No. I regularly provide whisper with entire movies to get it to generate subtitles for me.
Anonymous
7/1/2025, 10:09:04 PM
No.105769676
[Report]
Anonymous
7/1/2025, 10:14:18 PM
No.105769735
[Report]
>>105769806
>>105769582
NTA, but can whisper.cpp even output an srt file with silence/music cut out? Cause I'm just getting a continuous file that's like "00:00:00 -> 00:01.36: Yeah." Yes, I'm using VAD.
Anonymous
7/1/2025, 10:16:15 PM
No.105769752
[Report]
>>105769807
to the qwen users here:
https://huggingface.co/dnotitia
if you ever had the chinese character bias popup while using the model, this fixes it, even if you use qwen as a chinese to english translator (having any chinese character in the context can madly trigger this issue) you will never see it gen a hanzi again
smoothie qwen is da bomb
Anonymous
7/1/2025, 10:20:22 PM
No.105769806
[Report]
>>105769849
>>105769735
If you're using whisper v3, try going back to v2. It was much better at handling silences. No amount of processing or workarounds have made v3/turbo as good as v2 in that regard for me.
Anonymous
7/1/2025, 10:20:27 PM
No.105769807
[Report]
>>105769839
>>105769752
Is this a bona fide shill? Like you can just grammar that shit out.
Anonymous
7/1/2025, 10:21:28 PM
No.105769821
[Report]
>>105769847
>>105768241
Wayfarer Eris Noctis is supposed to have more narrative styles and better lore adherence, it also claims to have a 1 million token context window.
For what its worth, it certainly seems to be better for porn than base wayfarer. The whole LE BAD THING HAPPENS gimmick gets old fast tho
Anonymous
7/1/2025, 10:22:38 PM
No.105769839
[Report]
>>105769807
>Like you can just grammar that shit out.
you are a chill for wanting a model that doesn't require slowing down token generation111!!!!!1!!!1!!1!!1!1!
the ultimate state of 4chan
Anonymous
7/1/2025, 10:23:07 PM
No.105769847
[Report]
>>105769821
>it also claims to have a 1 million token context window.
so does standard nemo's config file
>>105769806
No, I mean like whisper.cpp literally gives a continuous file. See how there are no gaps. WhisperX can do it properly, but I'd like whisper.cpp to work since it can do Vulkan (I got an AMD card).
Anonymous
7/1/2025, 10:23:50 PM
No.105769852
[Report]
Anonymous
7/1/2025, 10:31:40 PM
No.105769933
[Report]
>>105769849
whisperX uses wav2vec2 on top of whisper to align the audio to timestamps, plain whisper timestamps are garbage.
Anonymous
7/1/2025, 10:33:17 PM
No.105769946
[Report]
>>105769849
Hey, what model are you using? Does ggml-large-v3-turbo-q8_0 do french well?