/lmg/ - Local Models General

/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>105757131 & >>105750356
►News
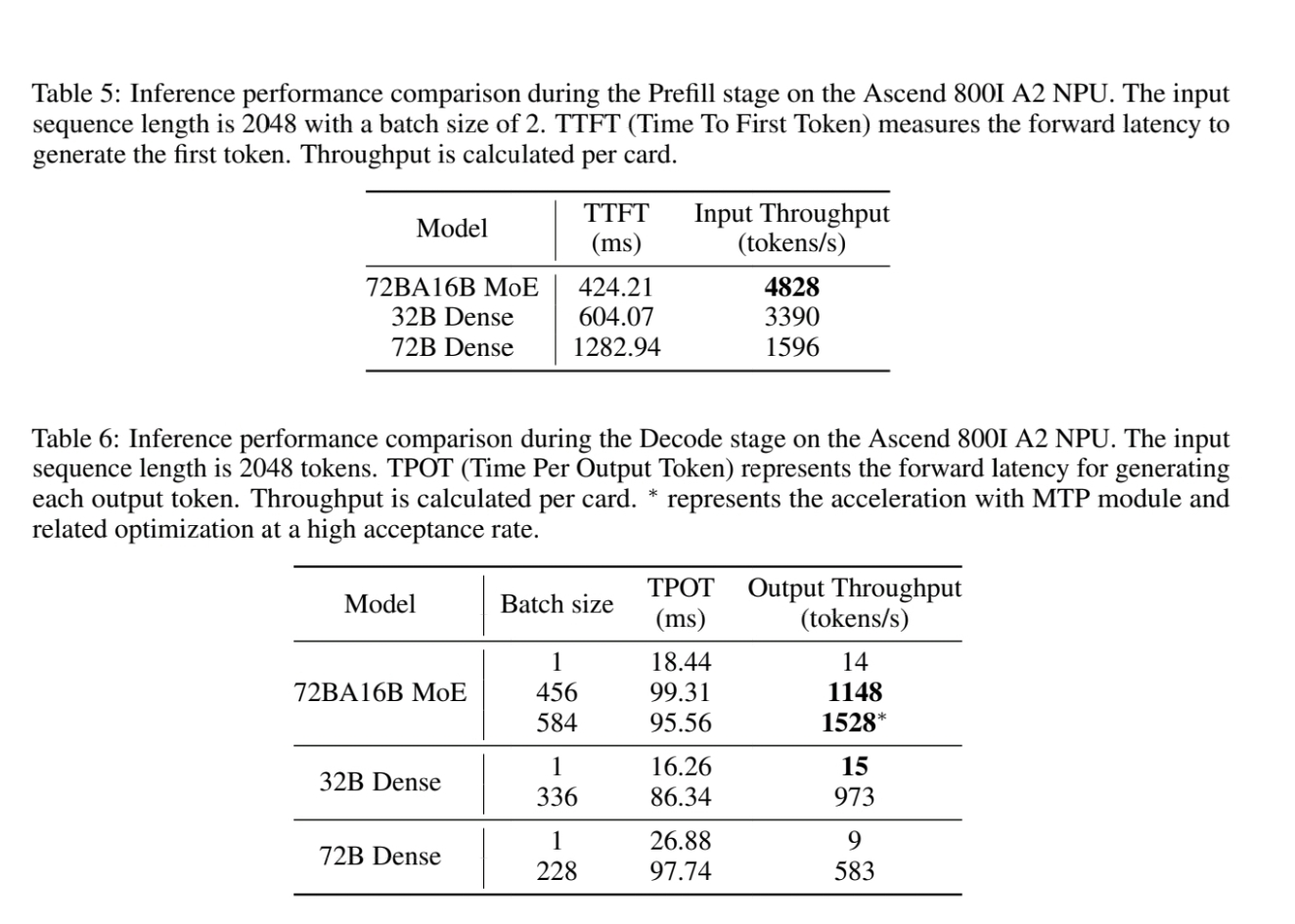
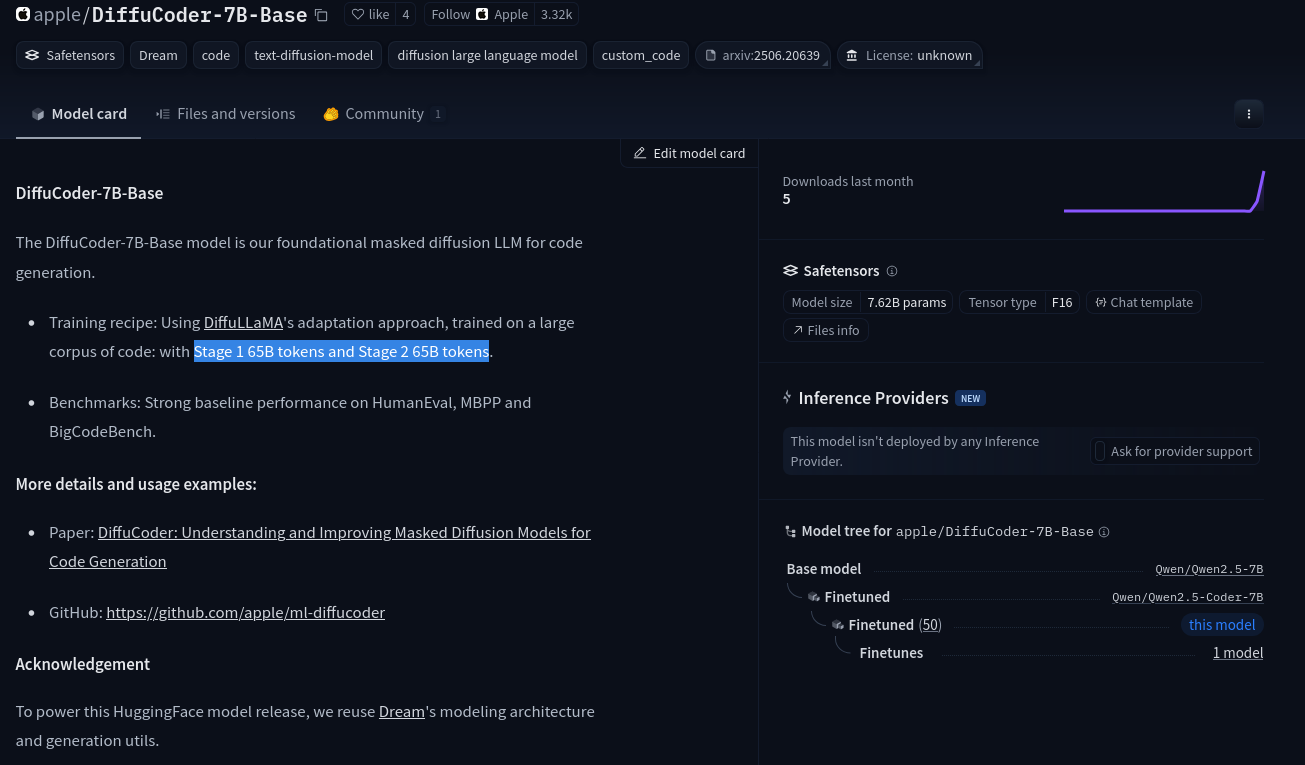
>(07/01) Huawei Pangu Pro 72B-A16B released: https://gitcode.com/ascend-tribe/pangu-pro-moe-model
>(06/29) ERNIE 4.5 released: https://ernie.baidu.com/blog/posts/ernie4.5
>(06/27) VSCode Copilot Chat is now open source: https://github.com/microsoft/vscode-copilot-chat
>(06/27) Hunyuan-A13B released: https://hf.co/tencent/Hunyuan-A13B-Instruct
>(06/26) Gemma 3n released: https://developers.googleblog.com/en/introducing-gemma-3n-developer-guide
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/tldrhowtoquant
https://rentry.org/samplers
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
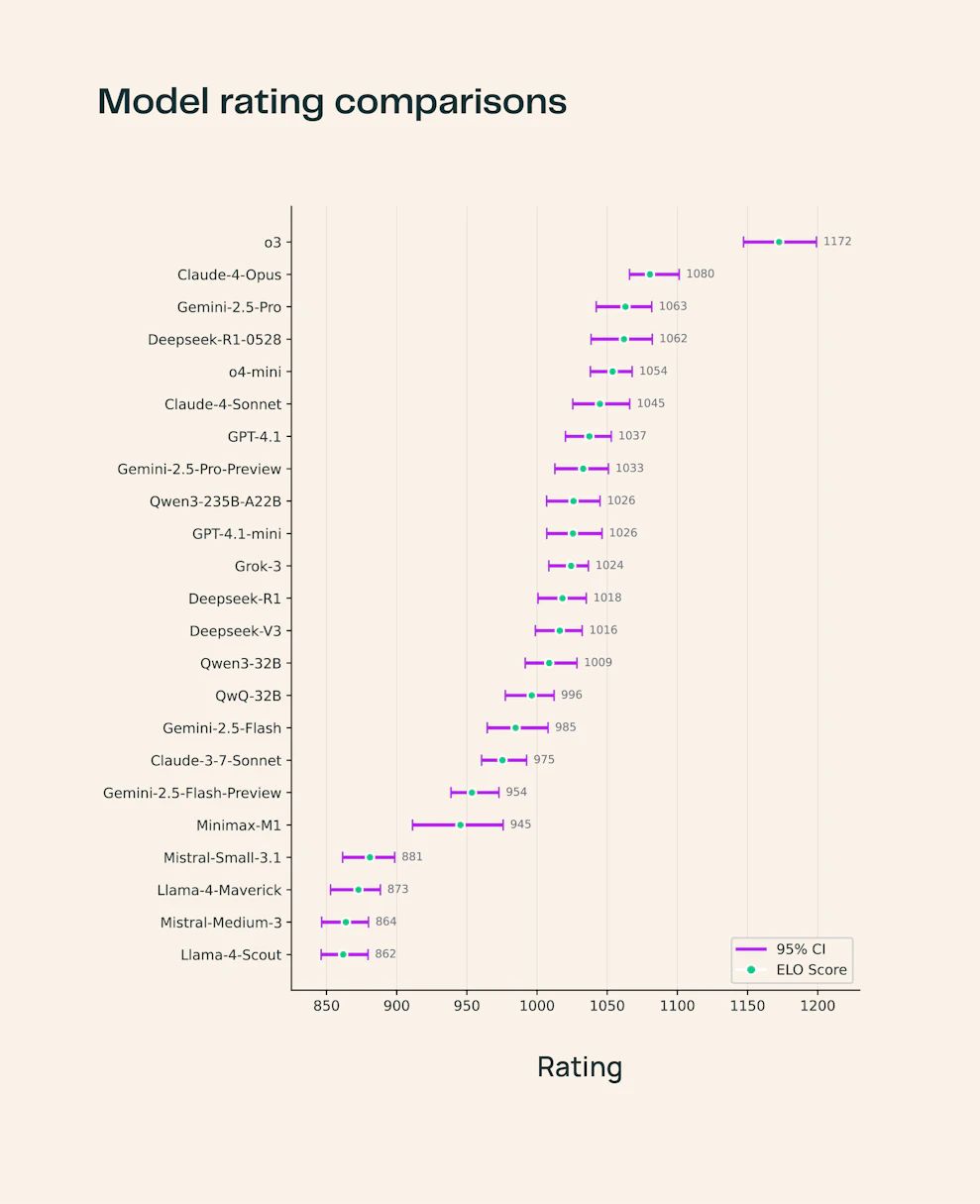
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/leaderboard.html
Code Editing: https://aider.chat/docs/leaderboards
Context Length: https://github.com/adobe-research/NoLiMa
Censorbench: https://codeberg.org/jts2323/censorbench
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
Previous threads: >>105757131 & >>105750356
►News
>(07/01) Huawei Pangu Pro 72B-A16B released: https://gitcode.com/ascend-tribe/pangu-pro-moe-model
>(06/29) ERNIE 4.5 released: https://ernie.baidu.com/blog/posts/ernie4.5
>(06/27) VSCode Copilot Chat is now open source: https://github.com/microsoft/vscode-copilot-chat
>(06/27) Hunyuan-A13B released: https://hf.co/tencent/Hunyuan-A13B-Instruct
>(06/26) Gemma 3n released: https://developers.googleblog.com/en/introducing-gemma-3n-developer-guide
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/tldrhowtoquant
https://rentry.org/samplers
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/leaderboard.html
Code Editing: https://aider.chat/docs/leaderboards
Context Length: https://github.com/adobe-research/NoLiMa
Censorbench: https://codeberg.org/jts2323/censorbench
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm