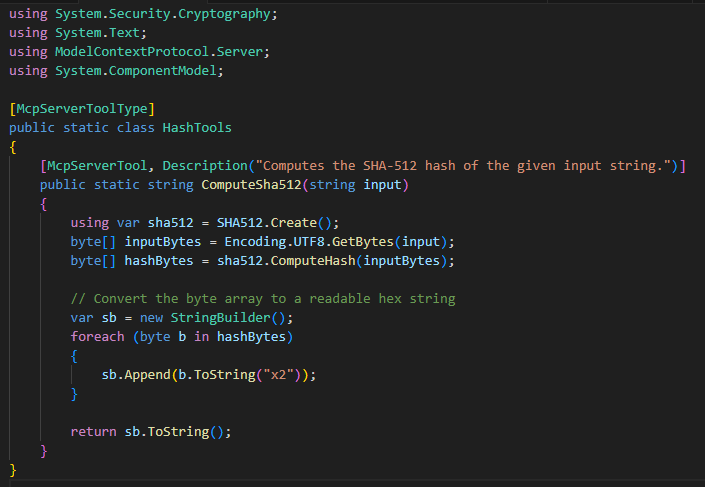
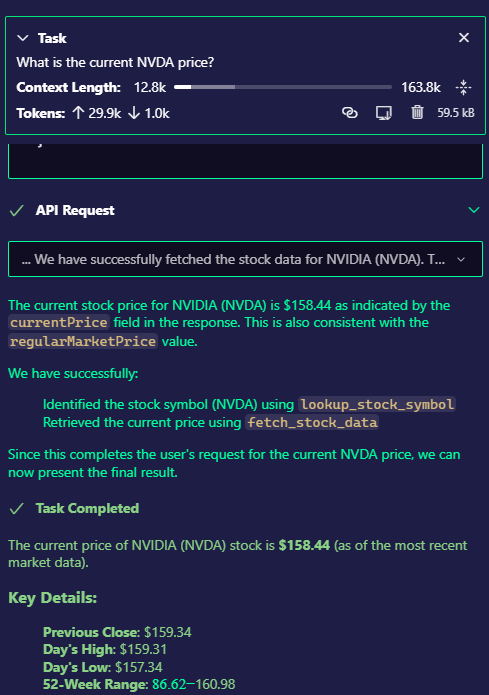
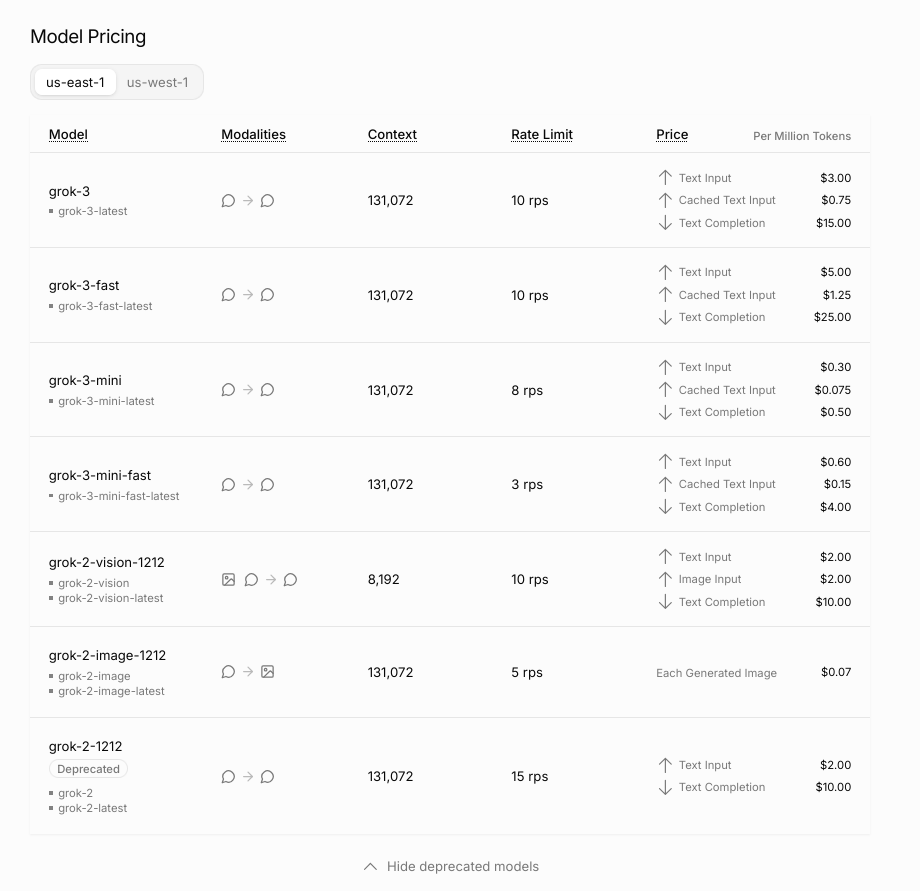
Anonymous
7/7/2025, 1:57:32 AM
No.105822371
[Report]
>>105824035
>>105826891
>>105827749
>>105832610
/lmg/ - Local Models General

/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>105811029 & >>105800515
►News
>(07/04) MLX adds support for Ernie 4.5 MoE: https://github.com/ml-explore/mlx-lm/pull/267
>(07/02) DeepSWE-Preview 32B released: https://hf.co/agentica-org/DeepSWE-Preview
>(07/02) llama.cpp : initial Mamba-2 support merged: https://github.com/ggml-org/llama.cpp/pull/9126
>(07/02) GLM-4.1V-9B-Thinking released: https://hf.co/THUDM/GLM-4.1V-9B-Thinking
>(07/01) Huawei Pangu Pro 72B-A16B released: https://gitcode.com/ascend-tribe/pangu-pro-moe-model
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/tldrhowtoquant
https://rentry.org/samplers
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/leaderboard.html
Code Editing: https://aider.chat/docs/leaderboards
Context Length: https://github.com/adobe-research/NoLiMa
Censorbench: https://codeberg.org/jts2323/censorbench
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
Previous threads: >>105811029 & >>105800515
►News
>(07/04) MLX adds support for Ernie 4.5 MoE: https://github.com/ml-explore/mlx-lm/pull/267
>(07/02) DeepSWE-Preview 32B released: https://hf.co/agentica-org/DeepSWE-Preview
>(07/02) llama.cpp : initial Mamba-2 support merged: https://github.com/ggml-org/llama.cpp/pull/9126
>(07/02) GLM-4.1V-9B-Thinking released: https://hf.co/THUDM/GLM-4.1V-9B-Thinking
>(07/01) Huawei Pangu Pro 72B-A16B released: https://gitcode.com/ascend-tribe/pangu-pro-moe-model
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/tldrhowtoquant
https://rentry.org/samplers
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/leaderboard.html
Code Editing: https://aider.chat/docs/leaderboards
Context Length: https://github.com/adobe-research/NoLiMa
Censorbench: https://codeberg.org/jts2323/censorbench
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm