Pony Preservation Project (Thread 154)

Welcome to the Pony Voice Preservation Project!
youtu.be/730zGRwbQuE
The Pony Preservation Project is a collaborative effort by /mlp/ to build and curate pony datasets for as many applications in AI as possible.
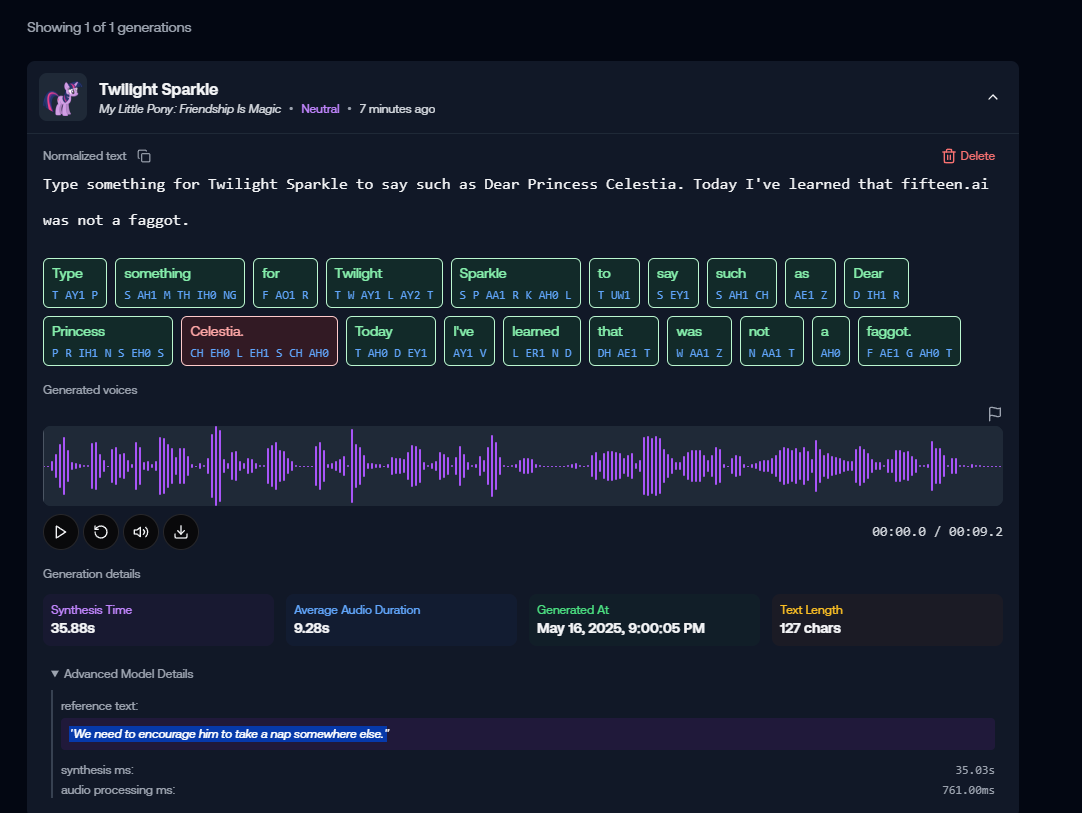
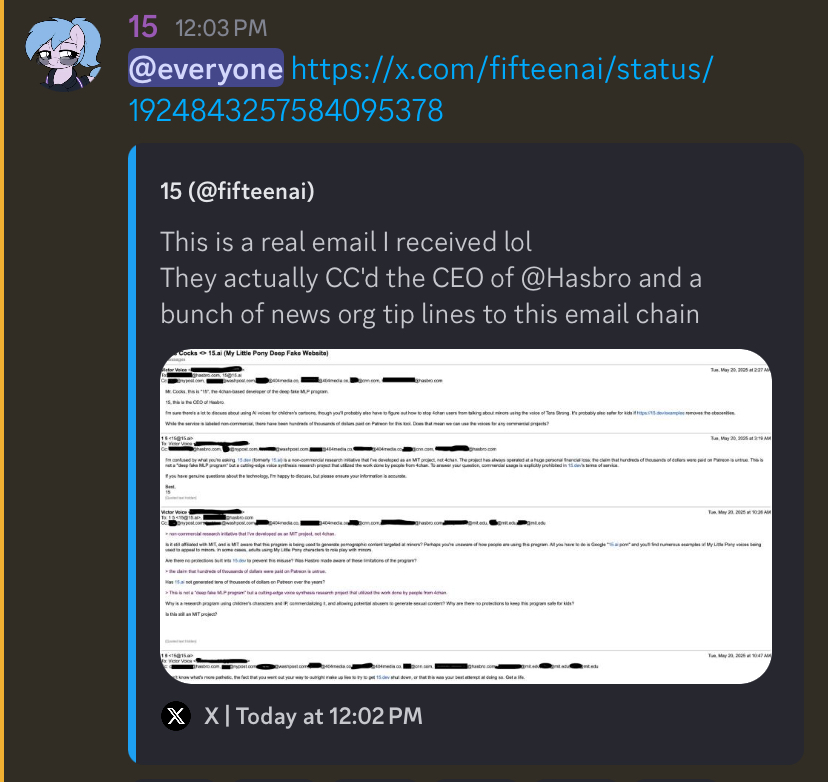
Technology has progressed such that a trained neural network can generate convincing voice clips, drawings and text for any person or character using existing audio recordings, artwork and fanfics as a reference. As you can surely imagine, AI pony voices, drawings and text have endless applications for pony content creation.
AI is incredibly versatile, basically anything that can be boiled down to a simple dataset can be used for training to create more of it. AI-generated images, fanfics, wAIfu chatbots and even animation are possible, and are being worked on here.
Any anon is free to join, and there are many active tasks that would suit any level of technical expertise. If you’re interested in helping out, take a look at the quick start guide linked below and ask in the thread for any further detail you need.
EQG and G5 are not welcome.
>Quick start guide:
docs.google.com/document/d/1PDkSrKKiHzzpUTKzBldZeKngvjeBUjyTtGCOv2GWwa0/edit
Introduction to the PPP, links to text-to-speech tools, and how (You) can help with active tasks.
>The main Doc:
docs.google.com/document/d/1y1pfS0LCrwbbvxdn3ZksH25BKaf0LaO13uYppxIQnac/edit
An in-depth repository of tutorials, resources and archives.
>Online speech generation
haysay.ai
>Active tasks:
Research into animation AI
Research into pony image generation
>Latest developments:
http://ponepaste.org/10865
>The PoneAI drive, an archive for AI pony voice content:
drive.google.com/drive/folders/1E21zJQWC5XVQWy2mt42bUiJ_XbqTJXCp
>Clipper’s Master Files, the central location for MLP voice data:
mega.nz/folder/jkwimSTa#_xk0VnR30C8Ljsy4RCGSig
mega.nz/folder/gVYUEZrI#6dQHH3P2cFYWm3UkQveHxQ
drive.google.com/drive/folders/1MuM9Nb_LwnVxInIPFNvzD_hv3zOZhpwx
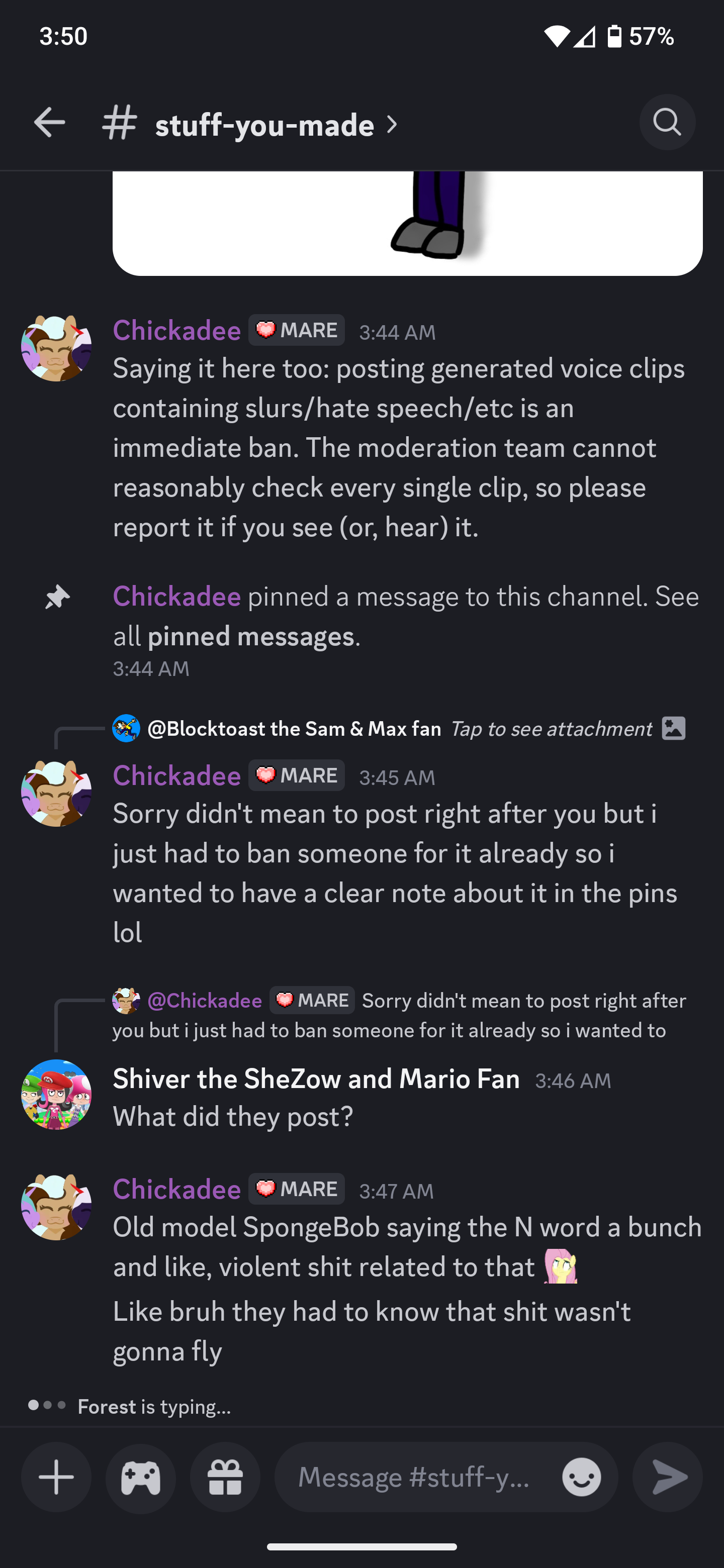
>Cool, where is the discord/forum/whatever unifying place for this project?
You're looking at it.
Last Thread:
>>42103996
youtu.be/730zGRwbQuE
The Pony Preservation Project is a collaborative effort by /mlp/ to build and curate pony datasets for as many applications in AI as possible.
Technology has progressed such that a trained neural network can generate convincing voice clips, drawings and text for any person or character using existing audio recordings, artwork and fanfics as a reference. As you can surely imagine, AI pony voices, drawings and text have endless applications for pony content creation.
AI is incredibly versatile, basically anything that can be boiled down to a simple dataset can be used for training to create more of it. AI-generated images, fanfics, wAIfu chatbots and even animation are possible, and are being worked on here.
Any anon is free to join, and there are many active tasks that would suit any level of technical expertise. If you’re interested in helping out, take a look at the quick start guide linked below and ask in the thread for any further detail you need.
EQG and G5 are not welcome.
>Quick start guide:
docs.google.com/document/d/1PDkSrKKiHzzpUTKzBldZeKngvjeBUjyTtGCOv2GWwa0/edit
Introduction to the PPP, links to text-to-speech tools, and how (You) can help with active tasks.
>The main Doc:
docs.google.com/document/d/1y1pfS0LCrwbbvxdn3ZksH25BKaf0LaO13uYppxIQnac/edit
An in-depth repository of tutorials, resources and archives.
>Online speech generation
haysay.ai
>Active tasks:
Research into animation AI
Research into pony image generation
>Latest developments:
http://ponepaste.org/10865
>The PoneAI drive, an archive for AI pony voice content:
drive.google.com/drive/folders/1E21zJQWC5XVQWy2mt42bUiJ_XbqTJXCp
>Clipper’s Master Files, the central location for MLP voice data:
mega.nz/folder/jkwimSTa#_xk0VnR30C8Ljsy4RCGSig
mega.nz/folder/gVYUEZrI#6dQHH3P2cFYWm3UkQveHxQ
drive.google.com/drive/folders/1MuM9Nb_LwnVxInIPFNvzD_hv3zOZhpwx
>Cool, where is the discord/forum/whatever unifying place for this project?
You're looking at it.
Last Thread:
>>42103996