Search Results
7/17/2025, 10:16:00 PM
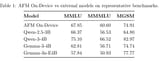
Apple updated their foundation model page and released a technical report on them.
https://machinelearning.apple.com/research/apple-foundation-models-2025-updates
https://machinelearning.apple.com/papers/apple_intelligence_foundation_language_models_tech_report_2025.pdf
Some interesting tidbits.
>On device models are approximately 3B parameters. Server model is approximately the same size in terms of total parameters and activate parameters as LLama 4 Scout but behind Qwen 3 235B.
>Apple did some interesting things here like adopting KV-cache sharing, 2-bit quantization-aware training and using a Parallel-Track Mixture-of-Experts (PT-MoE) transformer for their server model.
>Apple uses 3 things to claw performance back mostly. They use QAT (Quantization aware training), compress the model with ASTC, a texture compression format on mobile GPU to take advantage of hardware already there, and they use something called Quality Recovery Adapters.
>Quality Recovery Adapters are basically LoRAs that take the most important layers of the base unquantized model and then they reapply it back onto the model so it can retain more performance from
They will be late by the time they release, but I'm not sure how hard Apple is gaming the benchmarks given how the prior generation of their models made headlines in a bad way.
https://machinelearning.apple.com/research/apple-foundation-models-2025-updates
https://machinelearning.apple.com/papers/apple_intelligence_foundation_language_models_tech_report_2025.pdf
Some interesting tidbits.
>On device models are approximately 3B parameters. Server model is approximately the same size in terms of total parameters and activate parameters as LLama 4 Scout but behind Qwen 3 235B.
>Apple did some interesting things here like adopting KV-cache sharing, 2-bit quantization-aware training and using a Parallel-Track Mixture-of-Experts (PT-MoE) transformer for their server model.
>Apple uses 3 things to claw performance back mostly. They use QAT (Quantization aware training), compress the model with ASTC, a texture compression format on mobile GPU to take advantage of hardware already there, and they use something called Quality Recovery Adapters.
>Quality Recovery Adapters are basically LoRAs that take the most important layers of the base unquantized model and then they reapply it back onto the model so it can retain more performance from
They will be late by the time they release, but I'm not sure how hard Apple is gaming the benchmarks given how the prior generation of their models made headlines in a bad way.
Page 1