Search Results
7/17/2025, 10:34:11 PM
>>937237029
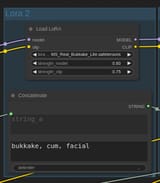
The second lora group (and 3rd and 4th) has a Concatenate node instead of the basic string node. This adds the string a and string b together and outputs them as a single string. So if you feed the output of the last groups string into the input of this groups concatenate node string a, then put the lora trigger into string b, it will output a single string containing the trigger words for each lora you've connected. You'll also need something to separate these so it doesn't just mash them into a single word, that's the delimiter. In that field you'll want to type a comma. Each group after the first is set up the same way with only the last one being connected slightly differently. In essence you want to take the output of Model and Clip from the Load Checkpoint node, feed it into the first group's Lora inputs, and then take those Model and Clip outputs and feed them into the next lora's inputs, until you get to the last which feeds the last clip into the clip text encode (positive and negative) and the last model into the ksampler. For the strings you take the first string, into the second, combine them, and so on until you eventually send the final output string into the Positive Text encode (don't send it to the negative or it will cancel itself out). I usually color code my text encoders so I don't mix up which is connected where.
I understand that's a lot of setup, but that's essentially it. There's the resizer group that we went over back in the inpaint and the save image extended, but again, every other node is something we've already gone through. I actually built this one by saving a copy of my inpainting workflow and removing a few nodes before adding in some extra lora groups. So we've got all this facial stuff set up, how well does it work. Let's load up that test image and give it a try.
The second lora group (and 3rd and 4th) has a Concatenate node instead of the basic string node. This adds the string a and string b together and outputs them as a single string. So if you feed the output of the last groups string into the input of this groups concatenate node string a, then put the lora trigger into string b, it will output a single string containing the trigger words for each lora you've connected. You'll also need something to separate these so it doesn't just mash them into a single word, that's the delimiter. In that field you'll want to type a comma. Each group after the first is set up the same way with only the last one being connected slightly differently. In essence you want to take the output of Model and Clip from the Load Checkpoint node, feed it into the first group's Lora inputs, and then take those Model and Clip outputs and feed them into the next lora's inputs, until you get to the last which feeds the last clip into the clip text encode (positive and negative) and the last model into the ksampler. For the strings you take the first string, into the second, combine them, and so on until you eventually send the final output string into the Positive Text encode (don't send it to the negative or it will cancel itself out). I usually color code my text encoders so I don't mix up which is connected where.
I understand that's a lot of setup, but that's essentially it. There's the resizer group that we went over back in the inpaint and the save image extended, but again, every other node is something we've already gone through. I actually built this one by saving a copy of my inpainting workflow and removing a few nodes before adding in some extra lora groups. So we've got all this facial stuff set up, how well does it work. Let's load up that test image and give it a try.
7/12/2025, 2:30:24 AM
>>936978327
The second lora group (and 3rd and 4th) has a Concatenate node instead of the basic string node. This adds the string a and string b together and outputs them as a single string. So if you feed the output of the last groups string into the input of this groups concatenate node string a, then put the lora trigger into string b, it will output a single string containing the trigger words for each lora you've connected. You'll also need something to separate these so it doesn't just mash them into a single word, that's the delimiter. In that field you'll want to type a comma. Each group after the first is set up the same way with only the last one being connected slightly differently. In essence you want to take the output of Model and Clip from the Load Checkpoint node, feed it into the first group's Lora inputs, and then take those Model and Clip outputs and feed them into the next lora's inputs, until you get to the last which feeds the last clip into the clip text encode (positive and negative) and the last model into the ksampler. For the strings you take the first string, into the second, combine them, and so on until you eventually send the final output string into the Positive Text encode (don't send it to the negative or it will cancel itself out). I usually color code my text encoders so I don't mix up which is connected where.
I understand that's a lot of setup, but that's essentially it. There's the resizer group that we went over back in the inpaint and the save image extended, but again, every other node is something we've already gone through. I actually built this one by saving a copy of my inpainting workflow and removing a few nodes before adding in some extra lora groups. So we've got all this facial stuff set up, how well does it work. Let's load up that test image and give it a try.
The second lora group (and 3rd and 4th) has a Concatenate node instead of the basic string node. This adds the string a and string b together and outputs them as a single string. So if you feed the output of the last groups string into the input of this groups concatenate node string a, then put the lora trigger into string b, it will output a single string containing the trigger words for each lora you've connected. You'll also need something to separate these so it doesn't just mash them into a single word, that's the delimiter. In that field you'll want to type a comma. Each group after the first is set up the same way with only the last one being connected slightly differently. In essence you want to take the output of Model and Clip from the Load Checkpoint node, feed it into the first group's Lora inputs, and then take those Model and Clip outputs and feed them into the next lora's inputs, until you get to the last which feeds the last clip into the clip text encode (positive and negative) and the last model into the ksampler. For the strings you take the first string, into the second, combine them, and so on until you eventually send the final output string into the Positive Text encode (don't send it to the negative or it will cancel itself out). I usually color code my text encoders so I don't mix up which is connected where.
I understand that's a lot of setup, but that's essentially it. There's the resizer group that we went over back in the inpaint and the save image extended, but again, every other node is something we've already gone through. I actually built this one by saving a copy of my inpainting workflow and removing a few nodes before adding in some extra lora groups. So we've got all this facial stuff set up, how well does it work. Let's load up that test image and give it a try.
Page 1