
>>103649242
The West, as much as I would like to support them, has nothing to offer really. Lots to write on but not much to really praise.
WIth OpenAI's new open sourced models, they have been safety aligned to the maximum, both the 20B with 3.6B active and 120B with 5B active. If you don't cross those boundaries which I will be honest is really wide and broad ranging, they are actually pretty good at benchmarks but the Chinese models are just straight better in a sense, Qwen 3 30B-3AB and GLM 4.5 Air you don't have to jailbreak and you get comparable performance and no nagging about safety this and that.
From Google, even though Gemini 2.5 is pretty good now, Gemma 3 came out and for a time was okay and may still be the best at multilingual stuff. There are also some interesting things with Gemma 3n. But at 27B at its biggest size, it can't compete with the above models because Google has a policy of not releasing models that are too large to compete with their Flash models which may be changing since GLM 4.5 Air handily beats their proprietary Gemini 2.5 Flash and you can run that on a moderately powerful computer, not to mention again the Chinese models. Will be interesting if they actually do break the mold which is likely with Gemma 4 but yeah, for now, nothing on local from Google worth really looking at because too small.
With Meta, Llama 4 indeed came out, but weirdly enough, after Llamacon and it was underwhelming. They basically lost the plot and it was a laughingstock. Given that, you may have heard about Zuck jettisoning the current AI team he has and paying absurd amounts of money to build a super intelligence group to catch up. They mentioned to throw out the biggest LLama 4 model and starting from scratch but in the process, it was mentioned that models may no longer be open source so the Llama line may die out. Sad but it is what it is.
Grok may open source Grok 2 like they did Grok 1 but they missed the deadline from last week and it isn't going to be noteworthy or SOTA for anything except be interesting to researchers possibly. We'll see if he open sources Grok 3 once Grok 4 is actually running at blast which is where it starts to actually be good, it scores in between the R1 releases which isn't bad but not cutting edge. I haven't seen if anyone has had some great luck with RPing with Grok but given Ani and etc. might be good one day?
And so, as far as recommendations, Qwen 3 30B-3AB and GLM 4.5 Air as I mentioned prior are the two models I would recommend for local RP, depending on RAM size you have and if you even have a GPU but Qwen 3 30B-A3B is for lower RAM sizes and CPU only machines as long as you have 16GB, you can run a quant of the model and it will still run pretty quick even if dumbed down a lot. GLM 4.5 Air for higher end machines with gaming in mind where you can offload a bigger expert. For both, you can use --cpu-moe option in llama.cpp to run them at relatively fast speeds or similar options in front ends that use it. All in all, some good stuff out now. The baseline for all these models are now as good if not better than what we had with OpenAI's O1 models. Now to wait on the finetunes. It is much harder to tune MOE models like Mixtral proved a year ago. Despite that, one tune has poppped up, Mythomax author made https://huggingface.co/Gryphe/Pantheon-Proto-RP-1.8-30B-A3B for the Qwen 30B-A3B and it seems pretty alright. ArliRP has https://huggingface.co/ArliAI/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast also. Hopefully more to follow and of different models other than Qwen.
One trend I would like to point out is the fact that a split in open-weight model development may be happening following what Qwen did. There will be specialized models that are “reasoners” which rely on tool use i.e. browser access and etc. for facts, and base instruct models that are more like “knowledge bases” tuned for retrieval-heavy work. The first is going to be shitty for RP, so it is recommended you stick with the 2nd. Another thing to talk about is the gap in cloud vs local. Things have now narrowed down that overall, local is around 9 months behind cloud in performance on a single GPU. Not good news for LLMs slowing down but good news if you are talking about what you can run. And on that topic, an opinion. It feels like mostly, RP performance is more or less somewhat equal with trying to hammer in general purpose chatbots whether local or cloud. The cloud still has inertia and momentum and is still better but the gap is so small now that I honestly question if people are actually going still with cloud because they like the "personality" or if it is because people are used to it. It's what it is but the day might come soon that everything will just plateau in RP until someone unearths a new way to make better chatbots. But we'll see when that bears out. But anyways, that's it for news on local models. See you next time when I see you.
2/2
4chan Search
2 results for "0363c9b4b77393c5faedf6739494201b"
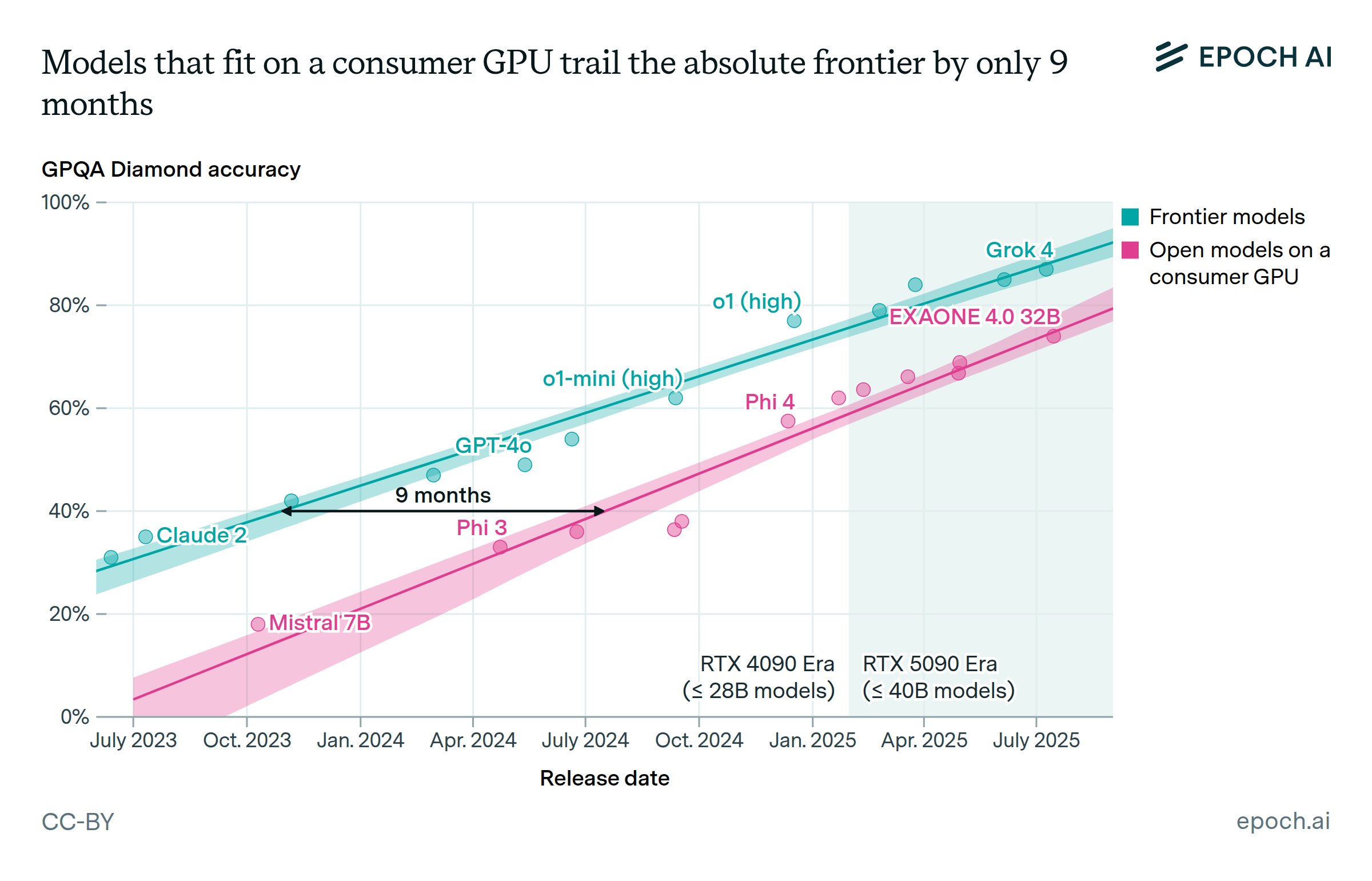
https://epoch.ai/data-insights/consumer-gpu-model-gap
Dunno if anyone posted this yet but the gap between closed and open source models has closed according to Epoch AI who had charts about similar topics around Lllama 3's launch. It is now 9 months instead of the upper at worst 22 months in the past. Does it feel like this?
Dunno if anyone posted this yet but the gap between closed and open source models has closed according to Epoch AI who had charts about similar topics around Lllama 3's launch. It is now 9 months instead of the upper at worst 22 months in the past. Does it feel like this?