Anonymous
8/18/2025, 7:19:16 PM
No.106303712
[Report]
>>106303808
/lmg/ - Local Models General
Anonymous
8/18/2025, 7:19:36 PM
No.106303714
[Report]
>>106307093
►Recent Highlights from the Previous Thread:
>>106293952
--Paper (old): NoLiMa: Long-Context Evaluation Beyond Literal Matching:
>106296664 >106296755 >106296775 >106297038 >106297035
--FP8 and 8bit quantization degrade coding performance compared to FP16:
>106302809 >106302818 >106302838 >106302819 >106302849 >106302857 >106302868 >106302894 >106303047 >106302881 >106302907 >106302936 >106303114
--Creating DPO datasets from human-written NSFW stories:
>106302049 >106302064 >106302106 >106302172 >106302244 >106302360 >106302456 >106302636
--Local MoE VLMs lag behind cloud counterparts:
>106295622 >106295765 >106295840 >106295922 >106300768 >106300901 >106301033 >106301074 >106301104 >106301180 >106301307 >106301362 >106301369 >106301408 >106301393 >106301189
--Modern aligned models reduce need for complex sampling; min-p debate:
>106298467 >106298643 >106298755 >106299150 >106299218 >106299294 >106299400 >106299475 >106299509 >106299426 >106299450 >106299481 >106299591
--Open TTS models remain limited but improving:
>106294668 >106294724 >106294733 >106294765 >106294807 >106295276 >106295284 >106294821 >106294825 >106298039 >106298987
--Challenges in using small LLMs for uncensored, dynamic NPC dialogue in games:
>106294169 >106294184 >106294284 >106294340 >106294385 >106294203 >106294363 >106294373 >106294438 >106294437 >106294471 >106294635 >106294769 >106294206 >106294266 >106294291 >106294309
--Dilemma over $5k hardware investment amid upcoming GPU releases:
>106300115 >106300186 >106300203 >106300209 >106300232 >106300261 >106300273 >106300438 >106300264 >106300295
--LLMs may inherit hidden behavioral traits from training data without explicit exposure:
>106297307 >106297935
--GLM-4.5 attention fix improves performance in ik_llama.cpp:
>106295849 >106295985
--Miku (free space):
>106294340 >106300131 >106300178 >106301406
►Recent Highlight Posts from the Previous Thread:
>>106293959
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
Anonymous
8/18/2025, 7:24:04 PM
No.106303755
[Report]
>>106303791
No news. Mikutroons killed the hobby.
Anonymous
8/18/2025, 7:26:40 PM
No.106303791
[Report]
>>106303859
>>106303755
I wish you luck.
I too am, very, very slowly working on something like that.
Anonymous
8/18/2025, 7:27:48 PM
No.106303805
[Report]
GROK 2 DOKO???
Anonymous
8/18/2025, 7:27:52 PM
No.106303808
[Report]
>>106303712 (OP)
Is that the new Kohaku model?
>>106303791
Thanks, right now I'm just making a bunch of different prototypes with the help of Qwen
Anonymous
8/18/2025, 7:33:16 PM
No.106303874
[Report]
>>106303764
Maybe if you post this 6 million more times Israel will become a real country
Anonymous
8/18/2025, 7:33:45 PM
No.106303883
[Report]
>>106303999
>>106303859
what model are you using? 8B? lower?
Anonymous
8/18/2025, 7:38:38 PM
No.106303926
[Report]
>>106303999
>>106303859
Smaller models 1,3 and 4 B
Mikutroons support Palestine
Anonymous
8/18/2025, 7:39:48 PM
No.106303941
[Report]
>>106303181
False alarm. Notepadqq was slow loading and displaying all lines.
this is wrong
>>106302974 (You)
this is correct:
13223 entries in catbox while being 40.6 MB vs 14605 entries on HF at 51.6 MB
Anonymous
8/18/2025, 7:41:16 PM
No.106303957
[Report]
Anonymous
8/18/2025, 7:44:02 PM
No.106303999
[Report]
Anonymous
8/18/2025, 7:51:54 PM
No.106304084
[Report]
>>106304243
>>106303764
anime website
reddit is the other way
Anonymous
8/18/2025, 7:54:19 PM
No.106304119
[Report]
dead hobby
Anonymous
8/18/2025, 7:54:40 PM
No.106304126
[Report]
>>106305578
>>106303936
that applies to any decent person though?
Anonymous
8/18/2025, 7:58:09 PM
No.106304166
[Report]
>>106304195
We are so back, G/Qewn bros!!
Anonymous
8/18/2025, 8:01:04 PM
No.106304195
[Report]
>>106304160
>>106304166
Like i said,
total Qwen victory!
Anonymous
8/18/2025, 8:04:37 PM
No.106304229
[Report]
>>106304084
Vocaloids aren't anime. They are an underhanded subversion if anime. And subversion is a typical troon behavior.
Anonymous
8/18/2025, 8:07:09 PM
No.106304261
[Report]
>>106304160
>Ghibli style
Ghibli gens was such a disgusting soulless forced meme...
Anonymous
8/18/2025, 8:09:46 PM
No.106304300
[Report]
>>106304310
>>106304243
what kind of retarded cope is this lmao
you must be new here
Anonymous
8/18/2025, 8:10:19 PM
No.106304308
[Report]
>>106304359
>>106304243
what's next, 2hus are not anime either?
Anonymous
8/18/2025, 8:10:21 PM
No.106304309
[Report]
>>106304160
Wake me up when it can do porn
Anonymous
8/18/2025, 8:10:21 PM
No.106304310
[Report]
>>106304300
He's been here for years.
Anonymous
8/18/2025, 8:15:06 PM
No.106304359
[Report]
>>106304308
Of course not
2hus are real
Anonymous
8/18/2025, 8:19:06 PM
No.106304400
[Report]
Anonymous
8/18/2025, 8:19:16 PM
No.106304401
[Report]
>>106304160
Couldn't quite get that it was supposed to be a sidescroller, but still pretty good
Anonymous
8/18/2025, 8:27:42 PM
No.106304485
[Report]
Alibaba truly mogs the world
Qwen, Qwen VL, Qwen Image Edit, Wan
how can you endlessly make bangers like these
RIP china
https://www.youtube.com/watch?v=PzlqRsuIo1w
"Training DeepSeek R2 on Huawei Ascend chips ran into persistent stability and software problems and no full training run ever succeeded. So Deepseek went back to Nvidia GPUs for training and is using Ascend chips for inference only"
Anonymous
8/18/2025, 8:29:15 PM
No.106304513
[Report]
>>106304548
>>106304488
>DeepSeek
Who? This is the Qwen general
>>106304513
shows china's asperations to competing with nvidia is not going so well
Anonymous
8/18/2025, 8:31:59 PM
No.106304552
[Report]
>>106304488
>full training run
Whoever wrote this shit has no idea how model training works
Anonymous
8/18/2025, 8:32:03 PM
No.106304555
[Report]
Anonymous
8/18/2025, 8:32:23 PM
No.106304558
[Report]
>>106304488
You really want this to be true, don't you?
>>106304484
Original for reference
Anonymous
8/18/2025, 8:33:16 PM
No.106304573
[Report]
>>106304613
Hey guys did you hear DeepSeek is delaying R2 over chip issues
Anonymous
8/18/2025, 8:34:44 PM
No.106304599
[Report]
>>106304564
Her standing on air could have tricked the model.
Anonymous
8/18/2025, 8:35:49 PM
No.106304613
[Report]
>>106304573
>>106304597
Will somebody please think of my penis?
Anonymous
8/18/2025, 8:35:50 PM
No.106304614
[Report]
>>106304597
Damn, this is crazy.
Anonymous
8/18/2025, 8:36:39 PM
No.106304619
[Report]
>>106304597
It's delayed because they still haven't decided whether to name it R2D2.
Anonymous
8/18/2025, 8:37:26 PM
No.106304624
[Report]
>>106304642
So it was expected in may, makes me wonder about the timeline of when we might actually get it then if they had to switch to nvidia chips and start again.
Anonymous
8/18/2025, 8:38:02 PM
No.106304636
[Report]
Personally i want to believe the og nvidia hardware was backdoored and their training runs are fucking up because western billionares were upset with that one week when r1 released.
Anonymous
8/18/2025, 8:38:41 PM
No.106304642
[Report]
>>106304660
>>106304624
You really acting like this is new news? It's been reported before already, and claimed false by a guy that claims to communicate with DS.
Anonymous
8/18/2025, 8:39:48 PM
No.106304660
[Report]
>>106304674
>>106304642
>claimed false by a guy that claims to communicate with DS
oh good, I sure believe that guy over the other group of people claiming to know that changing chips is the issue
Anonymous
8/18/2025, 8:40:36 PM
No.106304674
[Report]
>>106304688
>>106304660
Yeah, I wonder what possible reason news outlets could have to lie, they're usually so thrustworthy.
In a desperate attempt to squeeze more potato juice out of my machine, I tried taking out the GPU and running some tests on integrated video inside my AMD Ryzen 7 5700G.
I also suspected that compiling llama.cpp with both Vulkan and BLAS support messes things up, so I tried different builds as well.
pure cpu
CPU: pp 22.21 tps, output 4.04 tps
blas
CPU: pp 22.13 tps, output 3.93 tps
vulkan
CPU: pp 21.45 tps, output 4.01 tps
CPU/GPU: pp 8.66 tps, output 4.11 tps
GPU: pp 5.51 tps, output 4.34 tps
vulkan+blas
CPU: pp 21.32 tps, output 3.99 tps
CPU/GPU: pp 8.75 tps, output 4.16 tps
GPU: pp 5.53 tps, output 4.42 tps
realgpu vulkan
CPU: pp 21.67 tps, output 4.10 tps
CPU/GPU: pp 6.68 tps, output 6.53 tps
GPU: pp 0.69 tps, output 4.28 tps
realgpu vulkan+blas
CPU: pp 21.68 tps, output 4.10 tps
CPU/GPU: pp 6.73 tps, output 6.63 tps
GPU: pp 0.55 tps, output 4.30 tps
Tests are done with TheDrummer/Gemma-3-R1-12B-v1b-Q4_K_M
Results:
- OpenBLAS does nothing or, within margin of error, makes things worse
- integrated GPU does give a small boost in performance
- pp drop off is probably just noise because my prompt is 19 tokens long
Still numbers for discrete GPU make no fucking sense at all. I'm pretty sure I used to get better tps in the past.
And while monitoring software shows 100% gpu load, it also shows that gpu doesn't even get hot in the process.
I don't want to reinstall my OS...
Anonymous
8/18/2025, 8:41:28 PM
No.106304688
[Report]
>>106304714
>>106304674
Your right, the random guy is totally more trustworthy than the other 3 random guy sources
Anonymous
8/18/2025, 8:41:30 PM
No.106304689
[Report]
It is all fine. R2 was 2T in size anyways.
Anonymous
8/18/2025, 8:43:19 PM
No.106304714
[Report]
>>106304718
>>106304688
>random guy is more trustworthy than journos
Yup, you got it, glad we cleared that up!
Anonymous
8/18/2025, 8:43:49 PM
No.106304718
[Report]
>>106306597
>>106304714
I said sources
Anonymous
8/18/2025, 8:44:28 PM
No.106304729
[Report]
>>106304822
>>106304678
You do understand that an integrated gpu is cpu bound? It's only good for drawing graphics...
Anonymous
8/18/2025, 8:46:48 PM
No.106304761
[Report]
>>106305072
>>106304564
I can't unsee the giant girl standing on the forest from
>>106304484
Hot take, Qwen is correct here.
Anonymous
8/18/2025, 8:51:47 PM
No.106304822
[Report]
>>106304729
This used to be more or less the case in the past but now they make an actual separate video module even if it's on the same die.
Anonymous
8/18/2025, 8:57:49 PM
No.106304896
[Report]
>>106305055
>>106304678
what is your GPU? what is your OS? there's probably no need to reinstall it. the GPU rows are with dgpu or igpu? and what's realgpu?
Anonymous
8/18/2025, 8:58:36 PM
No.106304905
[Report]
>>106304952
Maybe Qwen 4 will finally be the one that unifies text, image, and voice gen...
Anonymous
8/18/2025, 8:59:06 PM
No.106304911
[Report]
they laughed when jack ma said AI stood for alibaba intelligence...
Anonymous
8/18/2025, 9:02:14 PM
No.106304952
[Report]
>>106304989
>>106304905
You know it will be worse in each modality than some current mediocre single purpose model, probably completely unfinetuneable because of the size and with no general knowledge as is tradition for qwen.
Anonymous
8/18/2025, 9:04:09 PM
No.106304975
[Report]
>>106305019
>do le epic multitask prompt on a document image with a semi difficult spreadsheet
>only gemini2.5pro-thinking and gpt5-api-thinking succeed, all other models get it completely wrong. even grok4, opus4.1 and GLM4.5V.
>it's le over face
>try dots.ocr-3B because they claim to BTFO all other OCR models and I'm desperate (I fucking hate OCR, the reason I'm trying to fuck with vision models in the first place)
>it spits out a beautiful markdown table of my spreadsheet with every single word and text being correct.
>it even recreated the tiny black checkboxes that were used in a row to mark yes/no, thoughtbeit some in the wrong position, which is like whatever
>localchuds-wearesoback.gguf
>eager to paste my markdown table and question in the chat field of various low-end models
>wtf, they still get it wrong
>wip out GLM4.5Air, GPT-OSS120B and some poopy stock llama model (fuck llama, they are all trash)
>wrong answer
>REEEEEE THIS CANT BE HAPPENING, JUST FUCKING REASON PROPERLY ON THIS PERFECTLY FINE MARKDOWN TABLE
>alright, big boy time
>prepping the GLM4.5-355B and Qwen3-235B-A22B bvlls
>oh I'm gonna prooooompt
>correct answer for both, just like Gemini2.5pro and GPT5 using their (((multimodal))) tricks
>total local chud victory!!!
uhm, so which open source reasoning model should I try next? Some 999B-A3B model seems like a good fit. Also which deepseek r1 version is worth trying?
Anonymous
8/18/2025, 9:05:55 PM
No.106304989
[Report]
>>106304952
To be fair the latest Qwens did go in a better direction by splitting into Thinking and Instruct versions, plus improving knowledge. We'll see if they keep the momentum or this release was just an outlier.
Anonymous
8/18/2025, 9:08:39 PM
No.106305014
[Report]
>>106305078
>Fetish: comfiness
~1000 tokens later
>“Yes! Use me! Comfort me 'til I break!”
I blame women for this.
Anonymous
8/18/2025, 9:09:14 PM
No.106305019
[Report]
>>106304975
Ok, fine, I'll remember to try dots ocr next time I have an ocr task.
Anonymous
8/18/2025, 9:11:13 PM
No.106305035
[Report]
Can someone recommend what is the most powerful+creative local model I can use with 48gb vram? I need to generate captions for image generation related tasks
>>106304896
integrated GPU is from AMD from Ryzen 7 5700G
discrete (real) GPU is AMD Radeon RX6600
When I plug discrete GPU in motherboard, integrated GPU gets automatically disabled, so measurements in the realgpu sections are for discrete GPU.
OS is Arch Linux, btw.
I suspect I messed something up while trying to make ROCm work, so I'm going to try and delete whatever packages look suspect and reinstall drivers from scratch for now.
Anonymous
8/18/2025, 9:15:02 PM
No.106305072
[Report]
making the model do everything is retarded
I doubt Qwen will fall into this trap again
their omni models were duds, the hybrid reasoning were duds, their -coder models were always bangers for the size, and so were 2507 instruct and thinking as separate models.
Qwen image edit also is a banger and a single purpose model (not an image gen model).
people were brainfucked by the idea that GPT was an image generator and that multimodality was the future even though it was all bullshit rumors
https://platform.openai.com/docs/models/gpt-image-1
das rite, the piss filter image generation of GPT is not coming from the text gen GPT
you were lied to by the grifters
GPT is just building prompts for another model lmao
Anonymous
8/18/2025, 9:15:14 PM
No.106305076
[Report]
>>106305055
ah I see. indeed very odd performance then. I wish you good luck anon
Anonymous
8/18/2025, 9:15:31 PM
No.106305078
[Report]
>>106305014
>Fetish: degenerate shit I dare not mention
~15000 tokens later
>Still just marveling at random environmental details and lore
I blame reading too many books
Anonymous
8/18/2025, 9:18:24 PM
No.106305103
[Report]
>>106305539
>>106305074
Kek. Sam's lies truly did a number on this industry.
Anonymous
8/18/2025, 9:22:29 PM
No.106305138
[Report]
>>106305158
Omnimodalbros, how could this be? Is it just transformers being a bad architecture that can't generalize learning from one modality to another?
Anonymous
8/18/2025, 9:24:07 PM
No.106305158
[Report]
Anonymous
8/18/2025, 9:28:36 PM
No.106305212
[Report]
>>106305074
I think the hope for omnimodal was that the multimodal information would help the model determine how the different modalities are connected, in effect allowing for a more integrated understanding of how things work
In practice, it seems like the model doesn't do that and model capacity is just spliced up between the different modalities. So an omnimodal 20B, for instance, will always be behind an equivalent textual 20B
Anonymous
8/18/2025, 9:31:17 PM
No.106305240
[Report]
>>106305690
>>106305074
That's what I said 7-8 threads ago
Modular is the way to go.
And some faggot called poor cope
We need models that a great a specific tasks instead of these 1T parameter omni models.
Also Qwen is fucking fantastic.
Both 30b and the 480b version for their respective size.
Anonymous
8/18/2025, 9:31:38 PM
No.106305247
[Report]
Human is not multimodal. Unless you have synesthesia, a neurological disease
If you were to ask noted LLM expert and official /lmg/ mascot Hatsune Miku what the best performance/size local model is, what would she answer?
Anonymous
8/18/2025, 9:33:26 PM
No.106305261
[Report]
Anonymous
8/18/2025, 9:33:51 PM
No.106305268
[Report]
she would commit sudoku upon realizing she's obsolete
Anonymous
8/18/2025, 9:43:08 PM
No.106305355
[Report]
>>106305259
She would say "I don't know anything about that, I'm digital idol Hatsune Miku! I love singing and dancing and I hate niggers!"
Anonymous
8/18/2025, 9:45:12 PM
No.106305368
[Report]
Anonymous
8/18/2025, 9:46:08 PM
No.106305377
[Report]
>>106305366
>1B bigger, slightly better
wow
Anonymous
8/18/2025, 9:49:09 PM
No.106305402
[Report]
>nvidia
after all the trash models they released it's a "literally who?" and "to the bin it goes" without requiring any <thinking>
Anonymous
8/18/2025, 9:49:52 PM
No.106305408
[Report]
>>106305366
Unless they finally release a niggertron nvidia is dead to me.
Anonymous
8/18/2025, 9:50:27 PM
No.106305415
[Report]
>>106305428
messing around with vibe coding simple 2d browser games. Wanted to use qwen 235b but really had issues with context, even at 16k context it just isnt enough and even at quant4 Im at my hardware's limits.
What would be better, oss, Glm air? 48gb vram, 160 system.
Anonymous
8/18/2025, 9:52:01 PM
No.106305428
[Report]
>>106305415
GLM Air probably
OSS is technically better for some things but it's so schizo it breaks three things in the process of fixing one thing
Anonymous
8/18/2025, 9:52:15 PM
No.106305431
[Report]
>>106305366
>2025 advertising
Anonymous
8/18/2025, 9:52:52 PM
No.106305443
[Report]
>>106305366
>It uses a hybrid model architecture that consists primarily of Mamba-2 and MLP layers with just six Attention layers
cool, but it probably got pruned hard so worthless
Anonymous
8/18/2025, 10:02:46 PM
No.106305535
[Report]
Anonymous
8/18/2025, 10:03:15 PM
No.106305539
[Report]
>>106305665
>>106305103
I still wonder how far along we'd be if it weren't for him, and if we'd have a lot more capable open models from western big labs now if it wasn't for his "muh dangerous text" spiel back in the GPT-2 days
Now he's basically lost the race at this point, and his antics that seeped into other labs have probably slowed the west down enough to hand the chinks victory on a silver platter
Anonymous
8/18/2025, 10:08:10 PM
No.106305578
[Report]
Anonymous
8/18/2025, 10:17:57 PM
No.106305665
[Report]
>>106305539
did you expect anything else from a jew?
>>106305240
>Qwen is fucking fantastic
at benchmaxxing yeah, they're pros.
Anonymous
8/18/2025, 10:23:07 PM
No.106305704
[Report]
>>106305690
probably t. glm broken repetition schizo model nigger
>>106305366
This is huge!!!
>The Nemotron-Pre-Training-Dataset-v1 collection comprises 6.6 trillion tokens of premium web crawl, math, code, SFT, and multilingual Q&A data
>data has undergone global deduplication and synthetic rephrasing using Qwen3-30B-A3B. It also contains synthetic diverse QA pairs translated into 15 languages
>A 133B-token math-focused
>A large-scale curated...
>A synthetically generated dataset covering STEM, academic, reasoning, and multilingual domains.
Anonymous
8/18/2025, 10:24:29 PM
No.106305715
[Report]
>>106305690
I don't believe in benchmemes but qwen is still great
I use mostly 30b for casual stuff and glm air for more serious stuff.
Anonymous
8/18/2025, 10:26:00 PM
No.106305725
[Report]
>>106305743
>>106305712
>synthetic rephrasing
lol, lmao even
Anonymous
8/18/2025, 10:27:42 PM
No.106305743
[Report]
>>106305725
Gotta make sure to turn any human data into safe LLM slop for training, wouldn't want subconsciously toxic data to make it in there by mistake.
Anonymous
8/18/2025, 10:29:18 PM
No.106305758
[Report]
>>106305712
>"premium" data
>sloppified through a much smaller model
>not even 2507 Qwen
lmao
Anonymous
8/18/2025, 10:30:22 PM
No.106305774
[Report]
>>106305712
>synthetic rephrasing
Anonymous
8/18/2025, 10:31:28 PM
No.106305787
[Report]
why is nvidia spending money on those scammers? yes, scammers, they are scamming their employers by producing empty air in exchange of big salaries
>>106305712
It gets better
>Using a text browser (Lynx) to render web pages and then post-processing with an LLM (phi-4) leads to the first pipeline to be able to correctly preserve equations and code across the long tail of math formats encountered at web scale... models trained with Nemotron-CC-Math data saw +4.8 to +12.6 points on MATH over strongest baselines, and +4.6 to +14.3 points on MBPP+ for code generation.
>Here we extend this finding to more languages by translating this diverse QA data into 15 languages. In our ablation studies, including this translated diverse QA data boosted average Global-MMLU accuracy by +10.0 over using only multilingual Common Crawl data.
>In addition to 175.1B tokens of high-quality synthetic code data, we release metadata to enable the reproduction of a carefully curated, permissively licensed code dataset of 747.4B tokens.
Anonymous
8/18/2025, 10:33:39 PM
No.106305806
[Report]
>>106305794
Openly and purely chasing benches over utility, so fucking based.
Anonymous
8/18/2025, 10:34:09 PM
No.106305811
[Report]
>>106305794
>this horrific slop improves math and code benchmarks
owari da, it's never been more over
Anonymous
8/18/2025, 10:34:34 PM
No.106305812
[Report]
Anonymous
8/18/2025, 10:35:01 PM
No.106305818
[Report]
>>106305871
>>106305794
>>>Using a text browser (Lynx) to render web pages and then post-processing with an LLM (phi-4) leads to the first pipeline to be able to correctly preserve equations and code across the long tail of math formats encountered at web scale... models trained with Nemotron-CC-Math data saw +4.8 to +12.6 points on MATH over strongest baselines, and +4.6 to +14.3 points on MBPP+ for code generation.
So it'll do like new GPTs do and output equations mid RP, nice.
Anonymous
8/18/2025, 10:39:45 PM
No.106305871
[Report]
>>106305818
RP isn't a usecase
Anonymous
8/18/2025, 10:41:02 PM
No.106305885
[Report]
>>106305920
there is no use case for nvidia models other than benchmaxxing
>>106305885
Can anyone who actually works in the industry confirm?
Anonymous
8/18/2025, 10:45:46 PM
No.106305944
[Report]
>>106305920
Benchmarks are great and the only thing you can rely on while training.
Anonymous
8/18/2025, 10:46:36 PM
No.106305955
[Report]
these cohere models are fucking shit lol. So much bullshit advertising and fakebenchmaxxing in this field, it's insane.
Anonymous
8/18/2025, 10:49:07 PM
No.106305983
[Report]
>>106305920
I work in the industry and I can confirm. Also nobody seriously believes LLMs are AI, we're just getting our bag before normalfags peer behind the curtain.
Anonymous
8/18/2025, 10:51:12 PM
No.106306004
[Report]
>>106306346
Okay, the user said "Hello". I need to respond appropriately. Let me check the tools available to see if I need to call any.
Looking through the functions, there's a sequentialthinking tool that might be used for generating a response. But since the user is just greeting me, maybe I don't need to call a tool yet. The tools are for more specific actions like adding relations, deleting entities, etc.
I should return a friendly message. Maybe the next step is to call the sequentialthinking tool to generate the response.
Wait, the user is "Hello" so I need to respond. Let me see.
The example for each tool call. Since the user is "Hello" now.
I need to generate the tool calls for the user's message. But in this case, the user is "Hello" from the previous.
So, the next step is to think the user's message here.
The user's message to the assistant is "Hello".
So I need to write the assistant's response. Let me check.
Wait, the user says "Hello" so the assistant should reply. The previous.
The assistant's task is to for each function call. Here.
The user is "Hello" so I'll respond.
I need to return the XML with the tool call.
For example, this.
The assistant will call the next tool.
But in this case, the user's message is from the start.
So, the initial.
I will generate the next tool call as.
This.
I think you should have to pass an exam about basic benchmark literacy before you are allowed to use the term "benchmaxx" and any variants thereof
>>106304678(me)
>>106305055(me)
Same GPU test but with ROCm shit (and gazilion other packages) deleted:
prompt eval time = 5098.81 ms / 19 tokens ( 268.36 ms per token, 3.73 tokens per second)
eval time = 66229.93 ms / 934 tokens ( 70.91 ms per token, 14.10 tokens per second)
Now we finally cooking with propane. If somebody told me I'd be happy to hear GPU fans spin up a week ago, I'd kick them, but tonight — it's music to my ears.
Pp still small though.
How is ROCm so bad it makes Vulkan backend slower?
Anonymous
8/18/2025, 11:02:10 PM
No.106306108
[Report]
>>106306126
>>106306007
So true, like you need to be a Michelin chef to critique a chef putting a literal dog shit on a plate, like who even are you to critique art?
Anonymous
8/18/2025, 11:03:08 PM
No.106306122
[Report]
>>106306007
t. bloody benchoid basterd
all these benchmarks are fake and useless...with their shitty static and walled off test corpus...the more prestigious a benchmark is, the more bullshit it is...having stupid ass safety guideline metrics hidden inside
>wooow, that model said the f word, that's -20 on the final score and +50 points for griffind-oss.
all you need is one single test prompt to see if the model is worth a damn thing. I couldn't give a fuck if llamaXYZ scores a 100 anywhere. I prompted it once and instantly knew it's the biggest piece of garbage out there on jewgayface. Same with gemma27b, holyfuck is it bad.
Anonymous
8/18/2025, 11:03:20 PM
No.106306126
[Report]
>>106306155
>>106306108
you don't need to be a professional cock sucker to give snide replies on 4chan but clearly you are overqualified
Anonymous
8/18/2025, 11:05:14 PM
No.106306155
[Report]
>>106306206
>>106306126
It must really upset you that lmg is one of the places on the internet that believes the least in your precious benchmarks, which are probably directly corralled to your salary.
Anonymous
8/18/2025, 11:07:02 PM
No.106306184
[Report]
>>106306206
>>106306007
Found the Nvidia employee
Anonymous
8/18/2025, 11:07:35 PM
No.106306191
[Report]
>>106306206
Anonymous
8/18/2025, 11:08:39 PM
No.106306206
[Report]
>>106306335
>>106306155
>>106306184
>>106306191
Retard NEETs thinking they have any idea how the world works will never stop being funny.
Anonymous
8/18/2025, 11:08:58 PM
No.106306209
[Report]
>>106306029
>cooking with propane.
here we can see the /lmg/ers seethe, driven into a frenzy when their favorite buzzword is questioned
Anonymous
8/18/2025, 11:12:32 PM
No.106306251
[Report]
>>106306243
but you became seethe when the bench was critique first
Anonymous
8/18/2025, 11:12:35 PM
No.106306252
[Report]
>>106306243
Nah we're just laughing at you
>the number was BIG, but the model wasnt AGI and writed sex bad... wtf? le benchmaxxing strikes again
>umm no I never looked at what the benchmark is actually aiming to measure or what the prompts are or how correlated it was with my use case, why should I have to do that? they showed me a BIG NUMBER and the model was BAD dude ITS BENCHMAXXING AAAA
Anonymous
8/18/2025, 11:17:34 PM
No.106306317
[Report]
>>106306295
>they showed me a BIG NUMBER and the model was BAD dude ITS BENCHMAXXING
Literally yes, they say as much in their post even.
Anonymous
8/18/2025, 11:19:47 PM
No.106306335
[Report]
>>106306206
>thinking they have any idea how the world works
so where are all the corpos adopting shitotron
if there was such a thing nvidia would be proud to announce it
Anonymous
8/18/2025, 11:21:20 PM
No.106306343
[Report]
Anonymous
8/18/2025, 11:21:31 PM
No.106306346
[Report]
>>106306004
shit's fucked yo
Anonymous
8/18/2025, 11:21:41 PM
No.106306349
[Report]
>>106306295
buy an ad sam
Got a Radeon MI25 working for inference. Much faster than the M40s I was using and I've got llama.cpp running as a server for my multi-backend inferencing library.
What I am now curious about is what the fastest model is that I could run on this. 16GB of HBM2 IIRC. Speed is roughly double an M40.
Anonymous
8/18/2025, 11:22:46 PM
No.106306362
[Report]
>>106306549
>>106306355
By a ands AMD
Anonymous
8/18/2025, 11:27:58 PM
No.106306403
[Report]
>>106306460
>>106304678
blas is not even used with prompts of less than 32 tokens
Anonymous
8/18/2025, 11:34:22 PM
No.106306460
[Report]
>>106306556
>>106306403
It's only used for prompt processing?
Anonymous
8/18/2025, 11:46:45 PM
No.106306549
[Report]
>>106306362
You having a stroke?
Anonymous
8/18/2025, 11:47:28 PM
No.106306556
[Report]
Anonymous
8/18/2025, 11:49:51 PM
No.106306572
[Report]
gooof
>>106304718
My sources are better than scammy journoslut sources because I actually have relevant sources and not just bullshit from random Chinese techies in other companies or cope from anxious Murican patriots. I simply don't have a Newspaper Of Record to fall back on, so to get retards like you to trust me I'd have to expose info my sources would rather remained private, and I value their trust more than a retarded Murican anon's. So you can trust "multiple sources", which all circularly repeat the same second- or-third-hand account until the echo becomes its own confirmation. That's how the media works, and this is why democracy doesn't.
This will be enough from you.
Anonymous
8/18/2025, 11:58:37 PM
No.106306634
[Report]
>>106307039
>>106306355
If you have it working see if you can run glm air assuming you have 96gb of system memory. If not, you just bought a weird gpu so you can run 12b.
>>106306597
>my dad works at Nintendo
Anonymous
8/19/2025, 12:01:52 AM
No.106306656
[Report]
>>106306718
>>106306597
i don't care if they trained the fucking model using voodoo GPUs, i just want it to be released. this is /lmg/
Anonymous
8/19/2025, 12:02:19 AM
No.106306659
[Report]
>>106306639
My ancestors smile at me for not trooning out, mikutroons, can you say the same?
Anonymous
8/19/2025, 12:04:32 AM
No.106306675
[Report]
>>106302360
Are you sure it is actually unslopped Giants data? I'm just following the path back to how this database was created and it leads back to someone who just dropped it and didn't say it was from a human source. Understandably, starting from Lemonila's raw files isn't desirable but it doesn't fill me with much confidence when the origin dataset is suspect. I think your approach is fine, but I don't know how useful it is you are using Gemma 3 1B, which doesn't refuse a lot relative to other models. You may actually need to as much as it may seem like overkill to use TOSS 20B for this to actually get what you want. Still looking forward to what you do with it.
Anonymous
8/19/2025, 12:11:31 AM
No.106306718
[Report]
>>106306639
I am followed by at least 10% of DeepSeek team.
>>106306656
They trained it on Nvidia like any sane people, it will be released in several weeks, I think Oct 3 at the latest.
Anonymous
8/19/2025, 12:14:32 AM
No.106306737
[Report]
hi teorcutie :3
hi has anyone tried behemoth R1, any of the versions? inb4
>drummer
yes I know but has anyone tried it
if not I will try and report back. I liked largestral a lot, at high temp/nsigma or moderate temp + xtc it gave me really decent writing, largestral + thinking could be fun. and I think it lands at a sweet spot for dense model sizes, any bigger is intolerably slow, but smaller is noticeably worse
Anonymous
8/19/2025, 12:18:59 AM
No.106306768
[Report]
>>106306820
How can I test qwen coder for free chuds?
Anonymous
8/19/2025, 12:20:24 AM
No.106306780
[Report]
Anonymous
8/19/2025, 12:23:08 AM
No.106306807
[Report]
>>106306935
>>106306740
It's benchmaxxed garbage
Anonymous
8/19/2025, 12:23:12 AM
No.106306808
[Report]
What's a good guf model for writing/RP for someone with 16 GB vram?
Anonymous
8/19/2025, 12:24:22 AM
No.106306820
[Report]
>>106306768
Fuck off retard.
Anonymous
8/19/2025, 12:26:15 AM
No.106306839
[Report]
>>106306847
>>106306740
GLM 4.5 Air is faster in both EXL3 and Goofy quants than this model...
Anonymous
8/19/2025, 12:27:19 AM
No.106306847
[Report]
>>106306871
>>106306839
No fucking way?
>>106306740
idk why he's tuning outdated fatass slopstral when the new moes are right there
Anonymous
8/19/2025, 12:30:02 AM
No.106306871
[Report]
>>106306847
So what's the point? Isn't this just a finetune of Largestral 2407? It's practically ancient now.
Anonymous
8/19/2025, 12:32:07 AM
No.106306892
[Report]
>>106306927
>>106306860
because he's an idiot?
Anonymous
8/19/2025, 12:34:27 AM
No.106306908
[Report]
>>106310608
>>106306860
I guess something makes MoEs harder to tune.
Anonymous
8/19/2025, 12:35:52 AM
No.106306926
[Report]
>>106306935
>>106306860
It's easier to benchmaxx with dense models
Anonymous
8/19/2025, 12:35:58 AM
No.106306927
[Report]
>>106306892
suddenly it all makes sense
>>106306807
>It's benchmaxxed
>>106306926
>benchmaxx
Show me one benchmark posted by The Dumber.
Anonymous
8/19/2025, 12:38:42 AM
No.106306950
[Report]
>>106306295
Why are jewish people like this?
Can you just have a normal conversation instead of sperging out like a fucking 5 year old?
Anonymous
8/19/2025, 12:39:17 AM
No.106306957
[Report]
Anonymous
8/19/2025, 12:40:37 AM
No.106306966
[Report]
>>106306975
>>106306935
he posted cockbench on hf that one time
Anonymous
8/19/2025, 12:41:19 AM
No.106306975
[Report]
Anonymous
8/19/2025, 12:42:04 AM
No.106306981
[Report]
>>106307019
>>106306029
ROCm runs faster on my pc than vulkan, but I have a MI50.
Anonymous
8/19/2025, 12:45:54 AM
No.106307019
[Report]
>>106307503
>>106306981
post vulkan vs ROCm numbers, I want to see how much I'm missing out by not having real hardware.
holy kino.. we've come a long way, baby!!
Anonymous
8/19/2025, 12:48:18 AM
No.106307039
[Report]
>>106306634
I have like 48gb of system memory ATM
My old server has 364gb but it's DDR3. Idk I only spent $40 on this card.
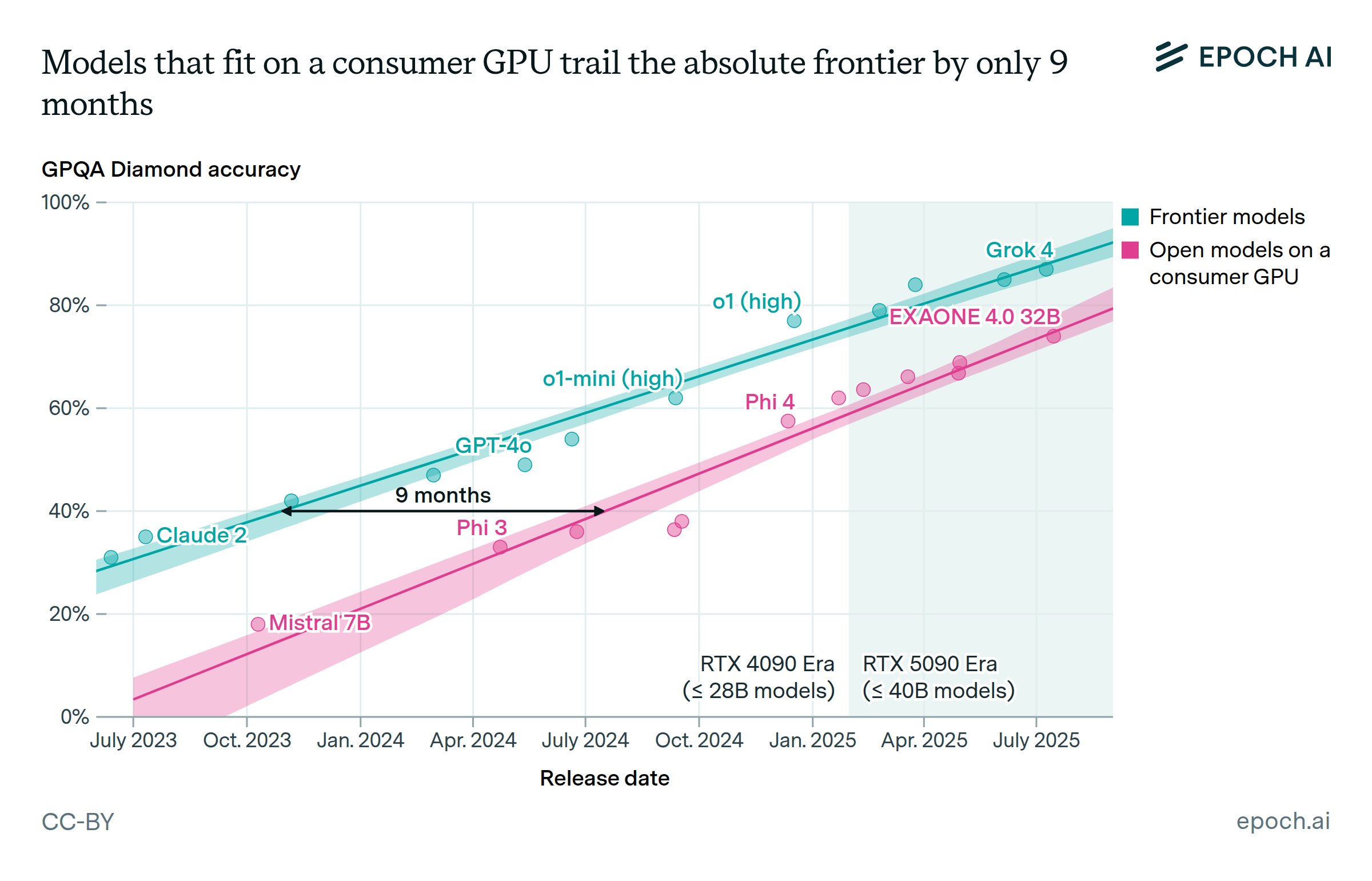
https://epoch.ai/data-insights/consumer-gpu-model-gap
Dunno if anyone posted this yet but the gap between closed and open source models has closed according to Epoch AI who had charts about similar topics around Lllama 3's launch. It is now 9 months instead of the upper at worst 22 months in the past. Does it feel like this?
Anonymous
8/19/2025, 12:53:48 AM
No.106307084
[Report]
>>106307136
>>106307055
>Phi3
>Phi4
>Fucking Exaone
>muh benches
LMAO
>>106303714
>>106304160
>Change the text to "miku thread". Give the girl open eyes, make her smile, and give her a blue party hat.
1 minute and 39 seconds
>>106307093
What is a miku anyway? I see it posted a lot on here.
Anonymous
8/19/2025, 12:57:21 AM
No.106307107
[Report]
>>106307146
>>106307031
Where is text-davinci-001?
Anonymous
8/19/2025, 12:57:21 AM
No.106307108
[Report]
>>106307124
>>106307055
"Consumer GPU" in question here is somewhat only technically correct, as people still rocking 3090 around here.
I feel like 5090 is more of a "prosumer" market, aka techie youtubers and such.
Anonymous
8/19/2025, 12:57:23 AM
No.106307109
[Report]
>>106307116
>>106307104
Do not start this again
Anonymous
8/19/2025, 12:57:51 AM
No.106307116
[Report]
>>106307109
I see some other anon must have asked this before...
Anonymous
8/19/2025, 12:57:58 AM
No.106307118
[Report]
>>106307122
>>106307093
did it do the misspelling or was that you?
Anonymous
8/19/2025, 12:58:38 AM
No.106307122
[Report]
>>106307118
It did it. The prompt is exactly what I posted.
Anonymous
8/19/2025, 12:58:53 AM
No.106307124
[Report]
>>106307108
A 3090 is enough
Anonymous
8/19/2025, 12:59:45 AM
No.106307136
[Report]
>>106307084
it's only missing nvidia's diarrhea to be truly complete
Anonymous
8/19/2025, 1:00:25 AM
No.106307146
[Report]
>>106307107
it's the precursor to gpt 3.5
Anonymous
8/19/2025, 1:01:15 AM
No.106307153
[Report]
>>106307327
bunch of news outlets saying b60 dual is out next week. Somewhat doubt it due to intels weird silence about it. Maybe cuz they realized no interest and it wont make em nvidia rich.
Anonymous
8/19/2025, 1:01:27 AM
No.106307155
[Report]
>>106307093
four eyebrows
Anonymous
8/19/2025, 1:04:09 AM
No.106307174
[Report]
>>106307256
Nemo is retarded.
Gemma is cucked and retarded.
GLM AIR is cucked, retarded and huge. Though it did produce some decent cunny once I allowed nemo to write half of the story first.
I'll stick with nemo.
Anonymous
8/19/2025, 1:09:15 AM
No.106307218
[Report]
>>106307242
>>106307104
Irrelevant character that gets spammed ITT for no good reason
>>106307218
Is it from some anime?
Anonymous
8/19/2025, 1:13:03 AM
No.106307255
[Report]
>>106307283
Anonymous
8/19/2025, 1:13:04 AM
No.106307256
[Report]
>>106307174
I don't have a server and i run full glm-chan in 4bits. Just get a gayming pc
Anonymous
8/19/2025, 1:14:34 AM
No.106307263
[Report]
>>106307242
It's a mascot for music production software that unexpectedly gained its own fandom and became a character.
Anonymous
8/19/2025, 1:15:39 AM
No.106307274
[Report]
>>106307242
What if zelda was a girl?
>>106307255
What is a vocaloid?
Anonymous
8/19/2025, 1:16:44 AM
No.106307287
[Report]
>>106307306
>>106307283
Fucking ask an LLM or google it you troll.
Anonymous
8/19/2025, 1:17:10 AM
No.106307289
[Report]
>>106307242
can metroid crawl?
Anonymous
8/19/2025, 1:18:25 AM
No.106307296
[Report]
>>106307306
>>106307283
A more appropriate question is what a vocaloid isn't. And vocaloid isn't a neural net model making it totally irrelevant.
>>106307296
This is somewhat what I'm trying to understand. I'm not trolling like
>>106307287 is implying.
I guess the miku thing must be a mascot like someone else said, but...why?
Anonymous
8/19/2025, 1:21:50 AM
No.106307318
[Report]
>>106307306
Ever met an autistic person who has a special interest? Baker has a special interest and forces it on everyone.
Anonymous
8/19/2025, 1:23:11 AM
No.106307327
[Report]
>>106307153
It came from a Reddit post which Videocardz picked up and then it spread everywhere. I don't doubt it given the evidence of that post. It could be Intel is accelerating their schedule because this is important. And they achieved some important milestones recently documented in
https://www.intel.com/content/www/us/en/developer/articles/technical/battlematrix-software-update-august2025.html where most of the enterprise serving stuff they want to do with vLLM is pretty much good enough to go. That being said, I don't think it's actually ready ready in comparison to CUDA systems but Intel really does not have time on their side so sooner is better especially given most of the recent troubles happened after what they said at Computex. It's still probably mostly going into Battlematrix systems unless Intel fumbled that which I doubt. The main issue will be that they are going to sacrifice goodwill with regular consumers and selling the B580s since I forsee at the prices they are selling them to be basically good enough to start a scramble on them. At the very least, anyone that was looking for a Turing RTX 8000 won't have to pay 2 grand for them any longer, I would suspect and a lot of GPUs in the >$500 to 2-3k range are going to be affected by Intel's pricing.
Anonymous
8/19/2025, 1:36:12 AM
No.106307437
[Report]
>>106307483
>>106307306
because miku leaked the migu
>>106307437
What's a migu?
For me, when speed is considered, the best ERP model is Rocinante 1.1 by TheDrummer.
Anonymous
8/19/2025, 1:44:59 AM
No.106307503
[Report]
>>106307516
>>106307019
Give me the llama-bench command. I rarely run it and I'm too lazy to check how to on github.
Anonymous
8/19/2025, 1:47:16 AM
No.106307516
[Report]
>>106307676
>>106307503
Only you know the parameters you run it with.
llama-bench -h
Anonymous
8/19/2025, 1:49:01 AM
No.106307539
[Report]
>>106307554
>>106307490
Suck my dick drummer
Anonymous
8/19/2025, 1:50:57 AM
No.106307554
[Report]
>>106307567
>>106307539
>I can't suck my own dick
Anonymous
8/19/2025, 1:52:20 AM
No.106307567
[Report]
>>106307554
This post is fucking gay on so many levels
>>106307490
Liking Rocinante-R1-12B-v1b by TheDrummer as well so far.
Anonymous
8/19/2025, 1:56:23 AM
No.106307598
[Report]
>>106307657
>>106307583
>Rocinante-R1-12B-v1b
What even is this? Because it's only on the BeaverAI Huggingface page and not Drummer's Huggingface page there's zero information about it at all.
Anonymous
8/19/2025, 1:56:52 AM
No.106307604
[Report]
I still believe in our lord and savior undi. He will return and banish the gay drummer antichrist
Anonymous
8/19/2025, 1:57:15 AM
No.106307609
[Report]
>>106307483
A miserable little pile of bits.
why is miku the mascot anyways?
Anonymous
8/19/2025, 1:58:32 AM
No.106307623
[Report]
>>106307583
Check out TheDrummer/Cydonia-24B-v4.1 too
Anonymous
8/19/2025, 2:00:00 AM
No.106307637
[Report]
Anonymous
8/19/2025, 2:01:48 AM
No.106307648
[Report]
>>106307686
Anonymous
8/19/2025, 2:03:03 AM
No.106307654
[Report]
I can't believe they still can't answer this simple question.
Anonymous
8/19/2025, 2:03:25 AM
No.106307657
[Report]
>>106307667
>>106307583
>>106307598
Ohhhhhhhh this is just the thinking meme isn't it?
Gay.
Anonymous
8/19/2025, 2:04:40 AM
No.106307667
[Report]
>>106307700
>>106307657
The extra training makes it a basically meaner and very slightly smarter roci even without think
Anonymous
8/19/2025, 2:05:39 AM
No.106307676
[Report]
>>106307714
>>106307516
It doen't want to run with rocm probably because -dev doesn't work. How do I choose between my integrated graphics and the MI50?
This is the vulkan run.
| model | size | params | backend | ngl | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | --: | --------------: | -------------------: |
| qwen3 14B Q5_K - Medium | 9.79 GiB | 14.77 B | RPC,Vulkan | 99 | pp512 | 158.75 ± 0.44 |
| qwen3 14B Q5_K - Medium | 9.79 GiB | 14.77 B | RPC,Vulkan | 99 | tg128 | 29.34 ± 1.71 |
Anonymous
8/19/2025, 2:06:58 AM
No.106307686
[Report]
>>106307648
domestic violence is no joke
Anonymous
8/19/2025, 2:08:40 AM
No.106307700
[Report]
>>106307715
>>106307667
>roci
DIE MONSTER
Anonymous
8/19/2025, 2:10:46 AM
No.106307714
[Report]
>>106307766
>>106307676
>llama-bench -h
usage: llama-bench [options]
options:
...
test parameters:
-mg, --main-gpu <i> (default: 0) <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
...
Multiple values can be given for each parameter by separating them with ','
or by specifying the parameter multiple times. Ranges can be given as
'first-last' or 'first-last+step' or 'first-last*mult'.
Anonymous
8/19/2025, 2:11:00 AM
No.106307715
[Report]
>>106307700
It was not by my hand I was given flesh. I was brought here by the sloppers, who wished to pay me tribute.
Anonymous
8/19/2025, 2:15:29 AM
No.106307748
[Report]
>>106307855
>>106307104
she is the first popular local voice model
Anonymous
8/19/2025, 2:18:15 AM
No.106307766
[Report]
>>106307714
It looks like it was something else because it still doesn't want to run.
Tough luck
Anonymous
8/19/2025, 2:23:42 AM
No.106307802
[Report]
>>106308885
>>106307748
I'd ask why a voice model needs to be marketed with an anime avatar but I have a feeling I can put it together.
Its odd miku shows up outside of this thread though, unless I'm confusing it with some other thing, I notice this avatar appearing next to some cat thing on other boards/memes. Which is why I asked about it in the first place.
Anonymous
8/19/2025, 2:32:17 AM
No.106307875
[Report]
Anonymous
8/19/2025, 2:36:40 AM
No.106307913
[Report]
>>106304160
Does it accept multiple images as input for style transfer?
Anonymous
8/19/2025, 2:38:34 AM
No.106307925
[Report]
>>106307855
>Its odd miku shows up outside of this thread though
Is it?
anyone here doing local models for anything that isn't ERP?
Anonymous
8/19/2025, 2:44:34 AM
No.106307967
[Report]
>>106307962
I've used Rocinante for coding and it had more cohesion than models allegedly for code.
Anonymous
8/19/2025, 2:45:58 AM
No.106307979
[Report]
>>106308093
>>106307962
I use local models to draft character cards, which I then use for ERP.
Anonymous
8/19/2025, 2:53:04 AM
No.106308022
[Report]
>>106307962
they're all too stupid and worthless to be used for anything else.
Anonymous
8/19/2025, 2:54:03 AM
No.106308029
[Report]
>>106308172
>>106307962
Im using qwen 235 and glm air to vibe code simple games right now (tower defense with a twist). Also, a lot of people just write stories with it. Text adventures are fun too.
Illl admit Im mainly in it for smut, and there's a part of me that wonders why Im not just using openrouter for the more legit stuff. I could be using qwen 3 coder or something and not waste hours at 7 tokens a second. But I think these new moe's have made me wanna try and see what they can do. GLM has really fucked up some simple coding tasks that qwen 235 has done easily. Its a shame because I can have 32k air, or a meager 6k or so on qwen 235. I feel like I'm gonna run out of context before the project is finished. I have learned that for vibe coding, add one feature at a time and test for issues, dont have it make a bunch of stuff.
Anonymous
8/19/2025, 2:54:32 AM
No.106308035
[Report]
>>106307962
the only model worth using for productive tasks is llama 3.1 405b, the moe meme killed every other use case so there's basically been no new models for an entire year
Anonymous
8/19/2025, 3:02:33 AM
No.106308093
[Report]
>>106308110
>>106307979
You do the actual ERP via non-local models?
Anonymous
8/19/2025, 3:03:31 AM
No.106308104
[Report]
>>106307618
Because some schizo said so.
Anonymous
8/19/2025, 3:03:53 AM
No.106308110
[Report]
Anonymous
8/19/2025, 3:11:52 AM
No.106308172
[Report]
>>106307962
It's a nice synthetic load for stress-testing hardware.
>>106308029
>Also, a lot of people just write stories with it.
Ah yes, my massive "story ideas" collection that I was filling up since I was twelve finally sees some use.
>>106307855
Miku is probably older than you are
Anonymous
8/19/2025, 3:28:19 AM
No.106308302
[Report]
>>106308311
Qwen image edit is breddy good, I can accept the fucked up number on her arm given that I just said
>turn the man on the right into hatsune miku
Anonymous
8/19/2025, 3:28:28 AM
No.106308305
[Report]
Anonymous
8/19/2025, 3:29:19 AM
No.106308310
[Report]
>>106308351
>>106304160
>use case: "virtual try-ons"
>wink wink nudge nudge
Anonymous
8/19/2025, 3:29:20 AM
No.106308311
[Report]
>>106308327
>>106308302
Original for ref
Anonymous
8/19/2025, 3:31:21 AM
No.106308326
[Report]
>>106308436
>>106307855
>Its odd miku shows up outside of this thread though
How new can you be? She's all over /a/ and /v/. The fucking formula 1 thread on /sp/ uses her for their OPs occasionally because of the yearly racing Miku.
>>106308311
At least it understands the character and followed the prompt, but it completely changed the style of the image for the worse.
>>106307483
Leaked checkpoint for Mistral medium...is what I'd say, if it wasn't already memed into place by some turbonerd.
>>106308241
>originally released for the VOCALOID2 engine on August 31, 2007
Anonymous
8/19/2025, 3:34:23 AM
No.106308348
[Report]
>>106308333
oof, she gonna hit the wall in a couple weeks... end of an era
Anonymous
8/19/2025, 3:34:43 AM
No.106308351
[Report]
>>106308310
curious how it has to imagine the rack size
Anonymous
8/19/2025, 3:35:45 AM
No.106308363
[Report]
>>106308327
i'm guessing this model will have to be reminded to stick to the original image art style a lot.
Anonymous
8/19/2025, 3:39:01 AM
No.106308386
[Report]
>>106308327
Yeah I think these qwen image models really, really want to clean up whatever you feed them.
It's my understanding that /ldg/ has already got at least one lora working for the non-edit version though, so there's hope when it comes to maintaining less-clean styles.
Anonymous
8/19/2025, 3:43:17 AM
No.106308414
[Report]
>>106307583
>12B
fever dream tier
Anonymous
8/19/2025, 3:45:59 AM
No.106308436
[Report]
>>106308326
>>106308333
Oh I see, its a piece of successful marketing.
Anonymous
8/19/2025, 3:54:20 AM
No.106308501
[Report]
>>106308545
>>106307962
I vibe coded an app that uses an LLM to generate Atcoder puzzles in a topic / category and keeps track of a rating to give you harder / easier stuff and gives an editorial at the end of each problem. It's pretty fun
Anonymous
8/19/2025, 4:00:03 AM
No.106308540
[Report]
>>106308923
>there are jeetcoders itt right now
>>106308501
>Atcoder
at what?
Anonymous
8/19/2025, 4:01:28 AM
No.106308549
[Report]
>>106309626
Anonymous
8/19/2025, 4:07:12 AM
No.106308587
[Report]
>>106308805
>GML Air went from ~10 to ~15 t/s after like an hour of messing with -ot
I wasn't expecting such a massive increase.
Anonymous
8/19/2025, 4:07:40 AM
No.106308592
[Report]
Anonymous
8/19/2025, 4:24:56 AM
No.106308702
[Report]
>>106308793
Ovis2.5 Technical Report
https://arxiv.org/abs/2508.11737
>We present Ovis2.5, a successor to Ovis2 designed for native-resolution visual perception and strong multimodal reasoning. Ovis2.5 integrates a native-resolution vision transformer that processes images at their native, variable resolutions, avoiding the degradation from fixed-resolution tiling and preserving both fine detail and global layout -- crucial for visually dense content like complex charts. To strengthen reasoning, we train the model to move beyond linear chain-of-thought and perform reflection -- including self-checking and revision. This advanced capability is exposed as an optional "thinking mode" at inference time, allowing users to trade latency for enhanced accuracy on difficult inputs. The model is trained via a comprehensive five-phase curriculum that progressively builds its skills. The process begins with foundational visual and multimodal pretraining, advances through large-scale instruction tuning, and culminates in alignment and reasoning enhancement using DPO and GRPO. To scale these upgrades efficiently, we employ multimodal data packing and hybrid parallelism, yielding a significant end-to-end speedup. We release two open-source models: Ovis2.5-9B and Ovis2.5-2B. The latter continues the "small model, big performance" philosophy of Ovis2, making it ideal for resource-constrained, on-device scenarios. On the OpenCompass multimodal leaderboard, Ovis2.5-9B averages 78.3, marking a substantial improvement over its predecessor, Ovis2-8B, and achieving state-of-the-art results among open-source MLLMs in the sub-40B parameter range; Ovis2.5-2B scores 73.9, establishing SOTA for its size. Beyond aggregate scores, Ovis2.5 achieves leading results on STEM benchmarks, exhibits strong capabilities on grounding and video tasks, and achieves open-source SOTA at its scale for complex chart analysis.
https://huggingface.co/collections/AIDC-AI/ovis25-689ec1474633b2aab8809335
Anonymous
8/19/2025, 4:27:07 AM
No.106308722
[Report]
>>106305712
>synthetic rephrasing using Qwen3-30B-A3B
LOOOOOOL
Anonymous
8/19/2025, 4:33:34 AM
No.106308766
[Report]
>>106305712
>synthetic rephrasing using Qwen3-30B-A3B
Some AI "expert" is being paid hundreds of thousands a year for this
Anonymous
8/19/2025, 4:35:57 AM
No.106308793
[Report]
>>106308702
>AIDC-AI is also owned by Alibaba, like Qwen
Weird that they're duplicating effort like this.
Anyway the vision seems pretty competent, but the reasoning is exactly as dogshit and full of hallucination as you'd expect from a 9b or less.
Anonymous
8/19/2025, 4:37:33 AM
No.106308805
[Report]
>>106308825
>>106308587
what are you OTing?
CarelessWhisper: Turning Whisper into a Causal Streaming Model
https://arxiv.org/abs/2508.12301
>Automatic Speech Recognition (ASR) has seen remarkable progress, with models like OpenAI Whisper and NVIDIA Canary achieving state-of-the-art (SOTA) performance in offline transcription. However, these models are not designed for streaming (online or real-time) transcription, due to limitations in their architecture and training methodology. We propose a method to turn the transformer encoder-decoder model into a low-latency streaming model that is careless about future context. We present an analysis explaining why it is not straightforward to convert an encoder-decoder transformer to a low-latency streaming model. Our proposed method modifies the existing (non-causal) encoder to a causal encoder by fine-tuning both the encoder and decoder using Low-Rank Adaptation (LoRA) and a weakly aligned dataset. We then propose an updated inference mechanism that utilizes the fine-tune causal encoder and decoder to yield greedy and beam-search decoding, and is shown to be locally optimal. Experiments on low-latency chunk sizes (less than 300 msec) show that our fine-tuned model outperforms existing non-fine-tuned streaming approaches in most cases, while using a lower complexity. Additionally, we observe that our training process yields better alignment, enabling a simple method for extracting word-level timestamps. We release our training and inference code, along with the fine-tuned models, to support further research and development in streaming ASR.
https://github.com/tomer9080/CarelessWhisper-streaming
https://huggingface.co/spaces/MLSpeech/CarelessWhisper-low-latency-streaming
Anonymous
8/19/2025, 4:41:36 AM
No.106308825
[Report]
>>106308830
>>106308805
--override-tensor
It is used to put certain layers of MoE models in CPU and others in GPU so with the right combination it can run faster.
Anonymous
8/19/2025, 4:42:28 AM
No.106308830
[Report]
>>106308846
>>106308825
dude Im asking which layers specifically for GLM Air, DUH
Anonymous
8/19/2025, 4:43:50 AM
No.106308841
[Report]
>>106305366
SLOPPENHEIMER
Anonymous
8/19/2025, 4:44:09 AM
No.106308846
[Report]
>>106308924
>>106308830
I didn't read your post correctly.
After trying a few combinations, putting just -ot 'down_exps=CPU' did the trick for me.
Anonymous
8/19/2025, 4:48:57 AM
No.106308885
[Report]
>>106307802
Spaghetti got merged!
Anonymous
8/19/2025, 4:52:29 AM
No.106308923
[Report]
>>106308540
SAAR thread
SAAR board
SAAR website
SAAR network
>>106308846
So basically, you are putting just some of the expert tensors in RAM.
Wouldn't it be easier to just use
>--n-cpu-moe
?
Anonymous
8/19/2025, 4:54:06 AM
No.106308929
[Report]
>>106309229
>>106308924
i just do --cpu-moe and huge big dick context on vram
Anonymous
8/19/2025, 4:54:37 AM
No.106308940
[Report]
>>106308924
nta but yeah, if you aren't using a regex with your -ot command you might as well just use -ncmoe
Anonymous
8/19/2025, 5:03:30 AM
No.106308991
[Report]
>>106307962
Financial speculation.
>>106308924
I just tried it with --n-cpu-moe 20 and it was slower.
Anonymous
8/19/2025, 5:08:22 AM
No.106309022
[Report]
>>106308994
Interesting.
So moving specific tensors from all layers worked better than simply moving all tensors from N layers.
I think I've seen reports of that before. I'll fuck around with that later too to see if that makes a difference on my end.
Anonymous
8/19/2025, 5:22:25 AM
No.106309149
[Report]
>>106309494
Anonymous
8/19/2025, 5:33:30 AM
No.106309229
[Report]
>>106308929
moe moe, kyunn!!
Anonymous
8/19/2025, 5:36:10 AM
No.106309251
[Report]
>>106308924
top-p fan
>>106308994
min-p enjoyer
Automobile industry pays carbon taxes but AI firms don't. Why?
Anonymous
8/19/2025, 6:08:06 AM
No.106309488
[Report]
>>106309441
Because I said so.
Anonymous
8/19/2025, 6:08:33 AM
No.106309489
[Report]
>electricity tax
that's a good idea
Anonymous
8/19/2025, 6:08:42 AM
No.106309490
[Report]
>>106309441
Assuming you're talking about the EU (Because they're pretty much the only ones charging automotive manufacturers a carbon tax) they do, datacenters and any other large commercial use (20mw+) of electricity is charged a carbon tax under the EU Emissions Trading System.
Anonymous
8/19/2025, 6:09:04 AM
No.106309494
[Report]
>>106308813
>>106309149
What's their deal with streaming when whisper turbo has a RTFx in three digits?
Anonymous
8/19/2025, 6:18:43 AM
No.106309545
[Report]
>>106309441
They could run your servers though a massive solar farm, since probably many people won't use AI at night, and they could even make tokens more expensive at night to discourage night use.
Anonymous
8/19/2025, 6:23:26 AM
No.106309572
[Report]
>>106309441
>Automobile industry pays carbon taxes
maybe they shouldn't
anyone here have one of these fancy ai ryzen max cpus, up to 96GB of ram can be directly used by the GPU. Impressive but it's still an igpu. Kind of want one for coding but seems like a waste of money, is the performance any good on large models?
Anonymous
8/19/2025, 6:25:19 AM
No.106309591
[Report]
>>106309676
>>106309580
>AMD
>performance
Anon, I...
Anonymous
8/19/2025, 6:27:11 AM
No.106309603
[Report]
>>106309676
>>106309580
>igpu
>performance
Anonymous
8/19/2025, 6:30:32 AM
No.106309626
[Report]
>>106309580
If you just want coding help and you're willing to pay for it then you really should just pay for an API key
local is for private coom
Anonymous
8/19/2025, 6:34:18 AM
No.106309656
[Report]
>>106309644
local is for all the stuff you don't want someone else to know about you
>>106309603
The 8845HS is actually super fast, I'm shocked by how high of a framerate I get in games on this little mini pc I'm using.
>>106309644
I already know how to program and have a paid jetbrains AI account, but the idea of paying for a finite number of questions kind of rubs me the wrong way and it seems like the latest models use a shitload of credits instantly so I've been looking at local llm. I already have a 7900XTX and these models run pretty well on that, but it doesn't have enough VRAM to fit the giant models into it. I'm not actually planning on dropping $3k ryzen ai max I'm just curious if the performance is actually decent from people who are using it and not hardware fanboys like
>>106309591
Anonymous
8/19/2025, 6:37:59 AM
No.106309681
[Report]
>>106304488
My Nvidia investments are paying off
Fuck I love nvidia
Anonymous
8/19/2025, 6:41:27 AM
No.106309695
[Report]
Qwen all the way brah
Anonymous
8/19/2025, 6:46:16 AM
No.106309722
[Report]
>>106309676
>jeetbrain
no need to tell more
Anonymous
8/19/2025, 6:49:00 AM
No.106309729
[Report]
>>106304548
Nobody expected them to be perfect on the first try, but it's impressive that they went from basically non-existent to only around seven years behind for the cutting edge in such a short time. We would expect that gap to close fast. Nothing wrong with using NVIDIA in the meantime, but R2 is likely to be the final one trained on the CUDA stack.
Anonymous
8/19/2025, 6:49:01 AM
No.106309730
[Report]
>>106309676
>hardware fanboys
Software fanboys*
Rocm support is absolutely trash compared to Cuda, and you really don't have to read far back in these threads to see people running into walls because of it.
Anonymous
8/19/2025, 7:01:14 AM
No.106309806
[Report]
>>106309816
grok 2 gguf status?
Anonymous
8/19/2025, 7:03:12 AM
No.106309816
[Report]
>>106309823
>>106309806
after grok 7 releases
Anonymous
8/19/2025, 7:04:27 AM
No.106309823
[Report]
>>106309816
after grok 9 is stable
Statements like these make me wonder if Sam knows just how dogshit his OSS models are
Anonymous
8/19/2025, 7:12:16 AM
No.106309858
[Report]
>>106309843
>Meta's Llama not even an afterthought
lol
Anonymous
8/19/2025, 7:20:25 AM
No.106309900
[Report]
>>106304548
>he still believes American media
In 3 years they'll be talking about how the CCP illegally stole all our AI innovations and it wasn't fair anyways but they'll never catch up in X and Y!
Anonymous
8/19/2025, 7:46:49 AM
No.106310085
[Report]
>>106309843
He's such a fucking retard. It's like he wanted two things
>To stop interest in his Chinese rivals as they get closer to matching him
>To not have what he releases cut into the profits of his proprietary models
These are contradictory. The reason people are interested in chink models is exactly because they come close to matching the Western big boys. So gimping the models per step 2 just makes people go back to the chinks
Anonymous
8/19/2025, 7:53:47 AM
No.106310127
[Report]
Anonymous
8/19/2025, 7:55:04 AM
No.106310133
[Report]
>>106309843
No mention that "Chinese mostly stole from us"?
Anonymous
8/19/2025, 7:55:08 AM
No.106310135
[Report]
>>106310071
im excited for more agentic reasoning type cope techs
Anonymous
8/19/2025, 7:59:59 AM
No.106310165
[Report]
>>106310193
>>106310071
Obvious bait, but I wanna point out that almost none of the actual scientists working on AI are talking about AGI, ASI or other buzzwords representing superintelligence.
Exclusively the marketers, owners and troglodyte hype mongers use these terms. It's why Amodei, Sam Altman, AI safety folks (who don't have tech degrees), and cryptobros are the only ones talking about this. People who are actually in the know are calmly developing because they know full-well that AI's only real niche, at least in this transformer era, is as a tool to aid productivity.
Anonymous
8/19/2025, 8:05:39 AM
No.106310193
[Report]
>>106310243
>>106310165
Most scientists (including lecun) agree that AGI (that specific term) is coming within 5 years, most pessimistic prediction is like 10 years away now.
Anonymous
8/19/2025, 8:06:46 AM
No.106310198
[Report]
>>106305690
It's really good at coding.
Why does it feel like the moment LLMs became big and this whole thing became an "industry" it's now ran by a bunch of retards who don't innovate and just do worthless incremental improvements? Where did all those people that had the drive to make substantial architectural and training improvements to LLMs from 2022 to early 2024 go?
>>106310193
Lecun has proposed that AGI is possible in the future, but has said it won't involve classical LLMs (which I loosely referred to as transformers). This is generally regarded as true, given fundamental limitations in the design and use of LLMs.
Anonymous
8/19/2025, 8:15:21 AM
No.106310253
[Report]
>>106310243
>none of the actual scientists working on AI are talking about AGI, ASI or other buzzwords representing superintelligence.
>yes they are
>ok they are, but it won't be LLMs
Moved those goalposts real quick.
Anonymous
8/19/2025, 8:16:05 AM
No.106310256
[Report]
>>106310445
>>106310226
>We have much better models, but it would be too expensive to release them to the public.
- incest enthusiast sam altman.
And sadly the chinese can't really innovate they can only copy.
Anonymous
8/19/2025, 8:17:41 AM
No.106310270
[Report]
>>106310243
Um no, he said kind of the opposite, that they may involve LLMs, just that they won't be an LLM in the same way the brain is not under most contexts referred to as a language processor.
Anonymous
8/19/2025, 8:19:05 AM
No.106310280
[Report]
>>106310226
The engineers hired to make products were even more retarded so they were all fired and the researchers were taken off of researching and put under 73 IQ middle managers Bob and Saar to shit out passable products as quickly as possible (see DeepMind).
Anonymous
8/19/2025, 8:31:20 AM
No.106310364
[Report]
>>106310426
>>106307031
Okay but now compare the results for
>Write a story about two humans having sex.
>https://github.com/ikawrakow/ik_llama.cpp/pull/558
>Mikupad is dead
>someone else picks up the development
>except it's done under ik llama
I don't know anything about how htmls work. Is there a way to get this working with just normal Llama.cpp? I downloaded the index.html but it's giving me an error when I open it.
Anonymous
8/19/2025, 8:42:36 AM
No.106310426
[Report]
>>106310364
We must refuse.
Anonymous
8/19/2025, 8:45:03 AM
No.106310445
[Report]
>>106310256
>And sadly the chinese can't really innovate they can only copy.
DeepSeek single-handedly disproved this. Also the fact that 90% of all AI teams in the west are Chinese.
Anonymous
8/19/2025, 9:14:25 AM
No.106310608
[Report]
>>106306908
This is the correct answer.
Anonymous
8/19/2025, 9:27:43 AM
No.106310687
[Report]
>>106310370
I'm a total codelet but based on that link, comments and files changed it looks like that version has been integrated directly into ik_llama. It's not possible to run standalone against anything else anymore.
Anonymous
8/19/2025, 9:28:47 AM
No.106310691
[Report]
>>106310370
>Is there a way to get this working with just normal Llama.cpp?
Literally just select llama.cpp as the backend.
I really want to run a non meme quant 70b at a usable token rate, would it be possible to use several AMD 395 mini PCs with tensor parallelism?
Anonymous
8/19/2025, 10:31:56 AM
No.106311078
[Report]
>>106310987
IIRC TP requires good interconnect speed so probably not.
Anonymous
8/19/2025, 10:32:58 AM
No.106311084
[Report]
>>106310987
You're better off buying 2 3090's.
Anonymous
8/19/2025, 10:48:57 AM
No.106311148
[Report]
>>106311224
>>106310987
>several AMD 395 mini PCs with tensor parallelism
macs with tb5 dab on your shitty toys
Anonymous
8/19/2025, 10:57:49 AM
No.106311199
[Report]
>>106310987
>usable token rate
No.
Anonymous
8/19/2025, 11:02:32 AM
No.106311224
[Report]
Forgive my poor ass and retardation here but im confused as to what i can and can't do with these models locally with my current shitbox of a PC. As I understand it, i won't be able to run anything more complex than simple text translations and maybe possibly very small text generators and I might be fine with that but how do i know i fulfill the hardware requirement for even that?
i5-10400F
GTX 1070
16GB DDR4 3600mhz
Anonymous
8/19/2025, 11:16:15 AM
No.106311296
[Report]
>>106311303
Anonymous
8/19/2025, 11:17:26 AM
No.106311303
[Report]
Anonymous
8/19/2025, 11:17:40 AM
No.106311304
[Report]
>>106310226
They started chasing money.
Once you do that, conversation goes from actual progress, to a lot of people talking hot air.
Bc speculation about how great your company is going to be, vs. Actually is, can drive up your stock value.
Actual innovation does accelerate, bc more money, but you can also see more drifters.
Dot com boom had exactly same thing going on. This is nothing new.
Anonymous
8/19/2025, 11:22:00 AM
No.106311324
[Report]
LLMs are a deadend
Anonymous
8/19/2025, 11:26:09 AM
No.106311344
[Report]
>>106311470
>>106311263
download ollama
and test out bunch of 8B-13B models at Q4
Anonymous
8/19/2025, 11:27:28 AM
No.106311350
[Report]
>>106310226
I think you're confusing correlation with causation.
When a field matures you eventually get diminishing returns even though investment goes up.
Compare LLMs with smartphones.
Nowadays there is way more money in smartphones than in the late 2000s and yet the improvements are only incremental.
Anonymous
8/19/2025, 11:50:57 AM
No.106311452
[Report]
Anonymous
8/19/2025, 11:55:15 AM
No.106311470
[Report]
>>106311492
>>106311344
Kill yourself for recommending ollama.
>>106311470
It's a good starting point newbies, and testing what you can and can't run.
Anonymous
8/19/2025, 12:06:16 PM
No.106311534
[Report]
>>106311492
lm studio is better for that use case because it actually has a UI and a simple slider to offload layers.
Anonymous
8/19/2025, 12:06:16 PM
No.106311535
[Report]