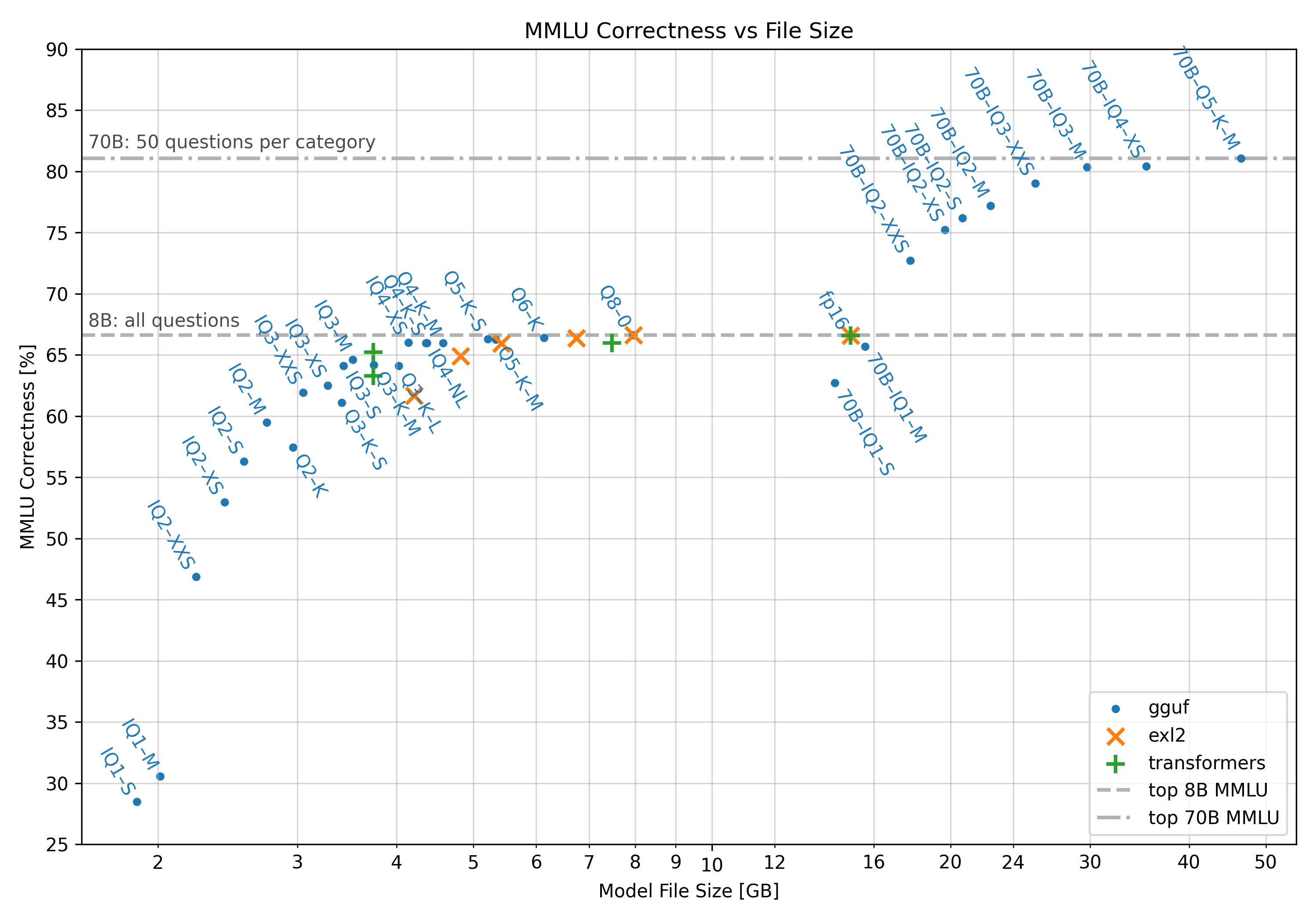
>>106363201
The smaller the more degradation, generally.
Basically, since you are losing numerical precision of the numbers that are being used in the calculations, each "internal nudge" towards the final output is that little bit more different ("inaccurate") compared to full precision.
Something like that.
How much the degradation is noticeable or matter will depend on a lot.
The heuristic is, use the largest bpw (correlated with file size) that you can run at the speeds you are comfortable with the context size you need.