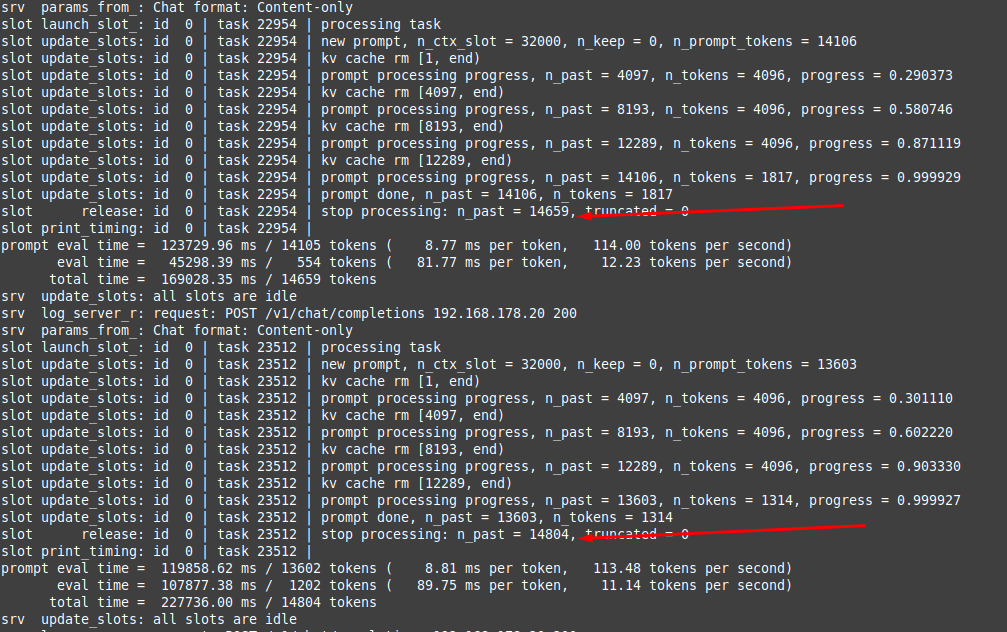
Why the fuck are my token generation speeds consistently much faster using the horrible RisuAI client than when I use ST?
The second request here was done with ST with just around 14k tokens in ctx. Gen speed was just over 11t/s. The first request was done over my local RisuAI client to the exact same llama.cpp instance, with just about the same ctx and it's more than 1t/s faster than when I do it over tavern.
Both use a very simple sampler setup with only temp and min-p. Both requests were done with chat completion to the same model so the same template was used. Neither has anything like token bias or top-k enabled.
I don't see how using another frontend can affect the token generation speeds to this degree if they're set up pretty much the same.