Binary Quantization For LLMs Through Dynamic Grouping
https://arxiv.org/abs/2509.03054
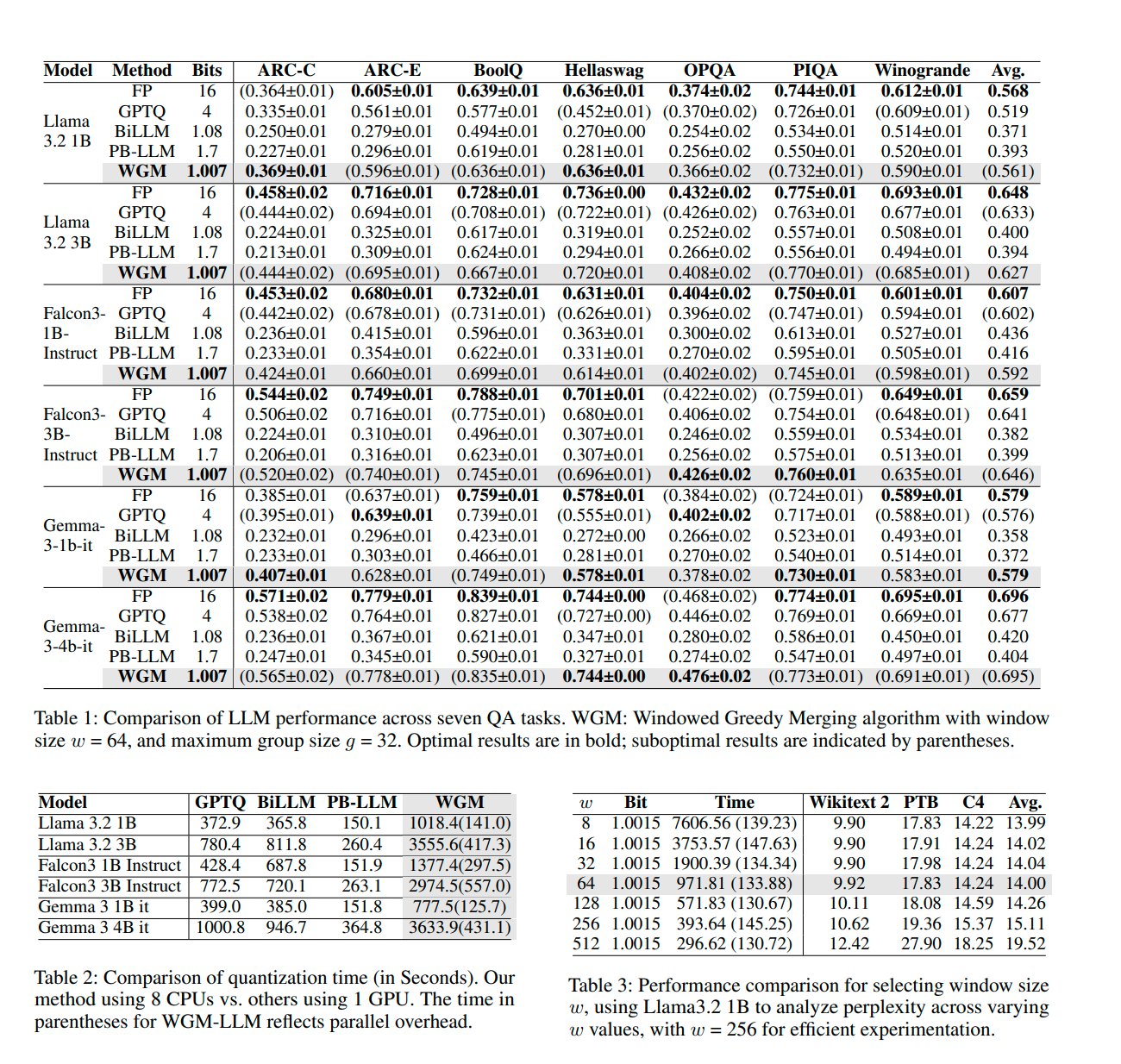
>Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of Natural Language Processing (NLP) tasks, but require substantial memory and computational resources. Binary quantization, which compresses model weights from 16-bit Brain Float to 1-bit representations in {-1, 1}, offers significant reductions in storage and inference costs. However, such aggressive quantization often leads to notable performance degradation compared to more conservative 4-bit quantization methods. In this research, we propose a novel optimization objective tailored for binary quantization, along with three algorithms designed to realize it effectively. Our method enhances blocked quantization by dynamically identifying optimal unstructured sub-matrices through adaptive grouping strategies. Experimental results demonstrate that our approach achieves an average bit length of just 1.007 bits, while maintaining high model quality. Specifically, our quantized LLaMA 3.2 3B model attains a perplexity of 8.23, remarkably close to the original 7.81, and surpasses previous SOTA BiLLM with a perplexity of only 123.90. Furthermore, our method is competitive with SOTA 4-bit approaches such as GPTQ in both performance and efficiency. The compression process is highly efficient, requiring only 14 seconds to quantize the full LLaMA 3.2 3B weights on a single CPU core, with the entire process completing in under 100 minutes and exhibiting embarrassingly parallel properties.
https://github.com/johnnyzheng0636/WGM_bi_quan
I don't really believe them but new day new quant so posting.