/lmg/ - Local Models General
Anonymous
9/3/2025, 8:37:33 PM
No.106475316
[Report]
►Recent Highlights from the Previous Thread:
>>106467368
--Evaluating Cogito-v2's capabilities and debating LLM factuality vs creativity tradeoffs:
>106470842 >106470988 >106471044 >106471064 >106471187 >106471316 >106471399 >106471426 >106473609
--Performance challenges and optimization efforts in text diffusion models:
>106467431 >106467441 >106468590 >106468827 >106468867 >106467475 >106471574 >106467508 >106471702 >106468166
--Feasibility and limitations of training tiny 1-5M parameter models on TinyStories dataset:
>106473288 >106473310 >106473354 >106473434 >106473465 >106473377 >106473570 >106473603 >106473612 >106473681 >106473750 >106473706 >106473712 >106473815 >106473839 >106473885 >106473944 >106473954 >106474068 >106474170 >106474187 >106474056
--K2 model availability and creative writing capabilities:
>106472793 >106472953 >106473060 >106473070 >106473121
--Best local models for writefagging on high-end hardware:
>106467802 >106467879 >106468090 >106468360 >106468423
--Balancing temperature and sampler settings for coherent model outputs:
>106467455 >106467577 >106467787 >106467974
--Modern voice cloning/TTS tools beyond tortoise:
>106468746 >106468804 >106468858 >106470028
--JSON formatting struggles vs XML/SQL alternatives for LLM output:
>106473106 >106473172 >106473391
--Challenges of integrating local LLMs into games: size, coherence, and mechanical impact:
>106470395 >106470422 >106470587 >106470719 >106470723 >106470759 >106470701
--Deepseek finetune improves quality but suffers from overzealous safety filters:
>106473865
--Meta's superintelligence hire limited to shared H100 GPUs:
>106473618 >106473663 >106473715
--Room Temperature Diamond QPU Development at Oak Ridge National Lab:
>106473646
--Miku (free space):
>106473137 >106474628 >106474849 >106474867
►Recent Highlight Posts from the Previous Thread:
>>106467371
Why?:
>>102478518
Enable Links:
https://rentry.org/lmg-recap-script
Anonymous
9/3/2025, 8:39:36 PM
No.106475331
[Report]
>>106475353
SEX WITH vvv
>>106475313 (OP)
Neat. How's that setup working for you? Specs?
Anonymous
9/3/2025, 8:42:24 PM
No.106475353
[Report]
>>106475338
>>106463968 & 106464042
3x3090s and a couple of hundred gigs of ram but on ddr4. He seems happy with it.
As a researcher from a fairly big AI startup, you should stop asking for models capable of ERP. ERP is not an actual usecase.
Anonymous
9/3/2025, 8:46:24 PM
No.106475378
[Report]
>>106475422
>>106475369
what if sex unifies relativity and quantum physics. how u like that faggot.
Anonymous
9/3/2025, 8:49:09 PM
No.106475403
[Report]
>>106475369
ai companions have the highest profit potential by far and if you keep coping about it i will snitch to your investors
Anonymous
9/3/2025, 8:49:19 PM
No.106475405
[Report]
>>106475412
>>106475369
All those thirsty AI Husbando women's money, just lying on the floor...
Anonymous
9/3/2025, 8:50:06 PM
No.106475412
[Report]
>>106475405
gives me shivers down my spine
Anonymous
9/3/2025, 8:51:49 PM
No.106475422
[Report]
>>106475378
There are so many layers of understanding required to fully comprehend this picture
Anonymous
9/3/2025, 8:54:39 PM
No.106475446
[Report]
>>106475369
As someone else working in the industry, ERP is my #1 motivation.
Anonymous
9/3/2025, 8:55:15 PM
No.106475449
[Report]
>>106475369
as a prolific AI coomer, you should drink this: *hands you a big glass full of cum*
Anonymous
9/3/2025, 8:55:18 PM
No.106475450
[Report]
>>106481945
>>106475364
Sweet, that's not bad at all.
Anonymous
9/3/2025, 8:57:51 PM
No.106475473
[Report]
>>106475369
>ERP is not an actual usecase.
ERP is unironically the biggest use case for normal consumer outside of actual work.
Anonymous
9/3/2025, 8:58:10 PM
No.106475475
[Report]
>>106475369
That became an invalid take after Qwen3 tried to game EQBench
Anonymous
9/3/2025, 8:58:32 PM
No.106475481
[Report]
tired from a day full day of prooompting
Recommend me some yt ai slop to get comfy to
oh no no no no...
look at the top of his head!
Anonymous
9/3/2025, 9:01:53 PM
No.106475510
[Report]
>>106475500
>single digit cost
Anonymous
9/3/2025, 9:04:02 PM
No.106475525
[Report]
>>106475667
I have a GTX 970M. I recently tried LLaMA 3.2 1B for RAG. I want it to read my drafts and calc sheets. It amazes me that it works on my old laptop. Thinking to order a Mac Mini just for this stuff.
Anonymous
9/3/2025, 9:05:44 PM
No.106475539
[Report]
>>106475563
Anonymous
9/3/2025, 9:07:53 PM
No.106475552
[Report]
>>106475369
It is for XAI
Anonymous
9/3/2025, 9:09:07 PM
No.106475563
[Report]
>>106475606
>>106475539
70w for 16gb is nice. Shame it's dual slot.
Anonymous
9/3/2025, 9:12:41 PM
No.106475586
[Report]
>>106475369
yeah i know, researchers thinks its python game like snake is main reason people use LLM. /s
Anonymous
9/3/2025, 9:15:34 PM
No.106475606
[Report]
>>106475639
>>106475563
~200gb/s... a 3060 has over 100gb/s more.
Anonymous
9/3/2025, 9:17:29 PM
No.106475622
[Report]
Anonymous
9/3/2025, 9:19:53 PM
No.106475639
[Report]
>>106475661
>>106475606
Yeah, but you can offload more. For those keeping layers on cpu with 12gb it could be worth it. And it's 70w.
But, again, dual slot. So it's not worth stacking them.
>>106475639
Don't epycs give those kinds of speeds?
Anonymous
9/3/2025, 9:23:02 PM
No.106475667
[Report]
>>106479356
Anonymous
9/3/2025, 9:23:05 PM
No.106475668
[Report]
Framework Desktop or Mac Mini 24gb?
>bored
>find some custom benchmeme in r*ddit
>run 30b Q3, Q4, Q5, Q6
>Q5>Q6>Q4>Q3
How come?
Anonymous
9/3/2025, 9:26:13 PM
No.106475692
[Report]
>>106475369
As a researcher as well, ERP is just part of a broader set of general capabilities that models should have and there's nothing wrong with people demanding it, because otherwise, it would mean that you're not training on enough and diverse data. There's a reason that scaling up on internet data led to so much success, despite simply just being about language. If you're not training on all the data you can, your model is probably only at the level of the Llamas or Phis. You're simply just not SOTA.
Anonymous
9/3/2025, 9:26:28 PM
No.106475696
[Report]
>>106475369
Yeah, sex doesn't sell.
I just love going to /g/, writing a 100% serious 200% not bait post and sticking my phone up my ass.
Anonymous
9/3/2025, 9:29:03 PM
No.106475729
[Report]
>>106475661
Sure. But if you're buying a epyc+mobo+ram combo, you're not gonna put that thing in there. It's not who they're targeting.
Anonymous
9/3/2025, 9:29:53 PM
No.106475734
[Report]
>>106475719
All those angry replies tickling your prostate, devilish.
Anonymous
9/3/2025, 9:32:32 PM
No.106475752
[Report]
>>106475661
Epycs are faster
Anonymous
9/3/2025, 9:34:05 PM
No.106475762
[Report]
>>106475961
>>106475686
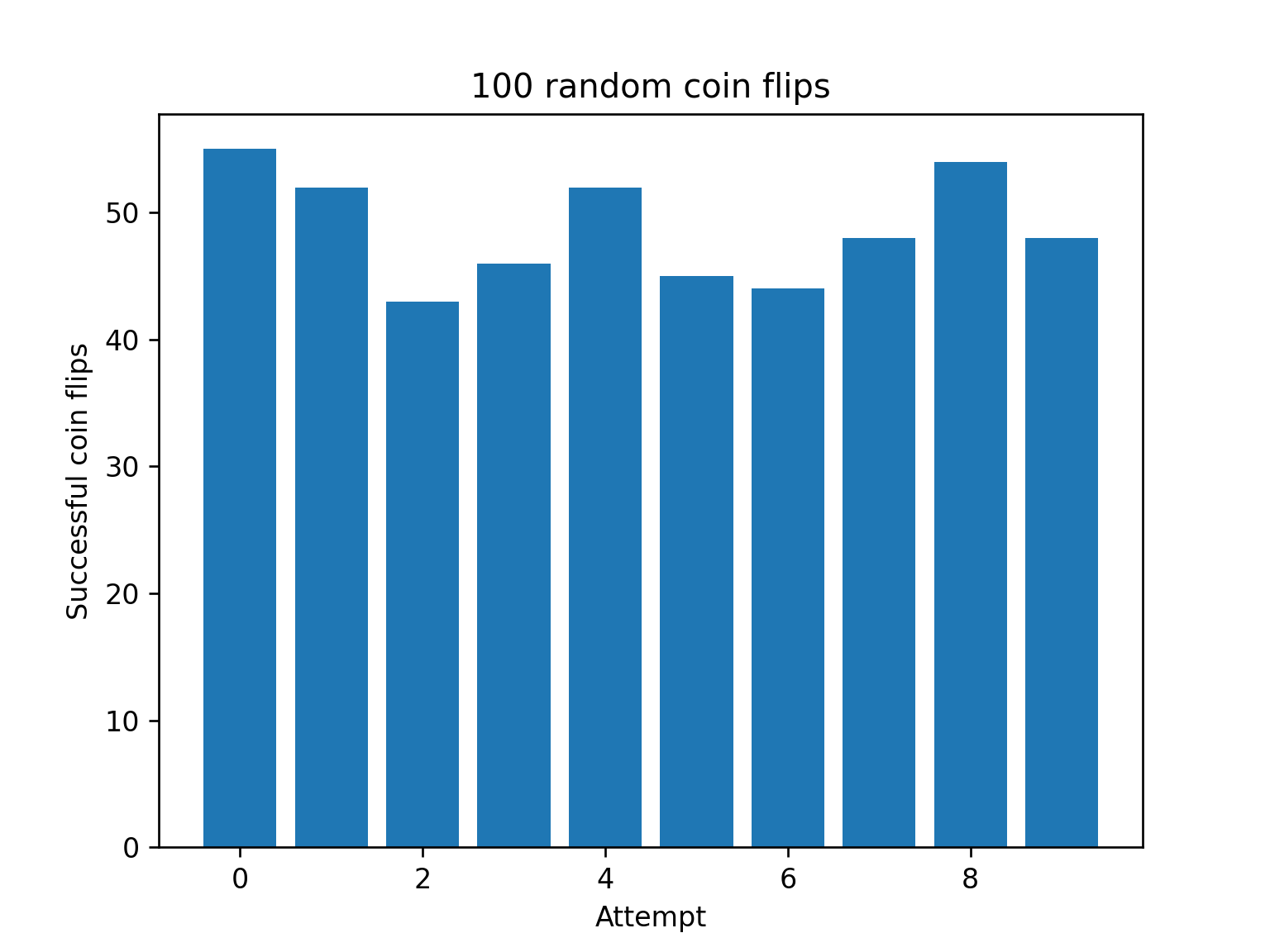
Because the sample sizes are just too small.
If you have a sample size of 100 you will see variation like in pic related just for random coin flips, that largely drowns out the differences between quants.
Anonymous
9/3/2025, 9:34:41 PM
No.106475766
[Report]
Anonymous
9/3/2025, 9:39:16 PM
No.106475806
[Report]
>>106475686
Probably because its being run on hardware that can only do fp16 or fp8, so anything less makes no difference
Anonymous
9/3/2025, 9:39:16 PM
No.106475807
[Report]
Anonymous
9/3/2025, 9:39:21 PM
No.106475809
[Report]
Day 3 of waiting for kiwis to grow. (Qwen) (When)
Anonymous
9/3/2025, 9:42:09 PM
No.106475836
[Report]
>>106475884
IBM Bros, Granite status?
Zucc Bros, Llama 4.5 status?
>>106475836
Shit nobody cares about
Anonymous
9/3/2025, 9:48:47 PM
No.106475895
[Report]
>>106475897
>>106475884
>>106475884
3:2b is pretty economical.
Anonymous
9/3/2025, 9:49:15 PM
No.106475897
[Report]
Anonymous
9/3/2025, 9:49:26 PM
No.106475899
[Report]
>>106476132
LongCat Bros, GGUF status?
Anonymous
9/3/2025, 9:53:24 PM
No.106475927
[Report]
>>106475877
Very safe and good on benchmarks, thanks Wang.
Anonymous
9/3/2025, 9:59:04 PM
No.106475961
[Report]
>>106475762
I ran it like 4 or 5 times with both Q5 and Q6 before posting. I'm running Q8 now because it is slower and it is scoring noticeably better.
Anonymous
9/3/2025, 10:04:06 PM
No.106475986
[Report]
whats thedrummer(tm) next SOTA finetune cook?
Alright anons. In this age of agents and coders, which group do you think will come to the rescue with the next big cooming model? I'm still banking on Mistral, but its looking grim.
Anonymous
9/3/2025, 10:07:25 PM
No.106476015
[Report]
Anonymous
9/3/2025, 10:11:08 PM
No.106476027
[Report]
>>106476001
Random no name chinks making their first model
Anonymous
9/3/2025, 10:15:42 PM
No.106476052
[Report]
>>106475877
sam paved the way in order for meta sirs to walk through it and safe local
Anonymous
9/3/2025, 10:19:52 PM
No.106476076
[Report]
Anonymous
9/3/2025, 10:21:14 PM
No.106476086
[Report]
>>106476001
Be the change you want to see
Why hasn't Claude been open sourced yet?
Anonymous
9/3/2025, 10:28:53 PM
No.106476132
[Report]
>>106475899
wish it was hosted somewhere so i can test it without the website filters
Anonymous
9/3/2025, 10:29:24 PM
No.106476137
[Report]
I love uploading papers to Gemma 270m and talking back and forth like a retarded study buddy. Again it's kind of retarded but it's still fun.
>>106476001
I think/feel there's a lot more we could be doing with the current models if we had more bespoke systems designed to and focused on enhancing ERP.
Something more involved than just a chat interface with rolling messages built from the ground up.
Anonymous
9/3/2025, 10:33:02 PM
No.106476167
[Report]
>>106476124
Dario is a real safety nut case, he's legit insane.
Anonymous
9/3/2025, 10:33:29 PM
No.106476172
[Report]
>>106476124
Anthropic is the most anti-open source company. They left "Open"AI because it was too open for them. Don't expect them to open source anything.
Anonymous
9/3/2025, 10:35:30 PM
No.106476190
[Report]
>>106476267
I've been out of the loop for a couple of weeks. Has there been any good update to llama.cpp or ik_llama.cpp worth pulling for?
last i checked cuda dev made a cool sped up for gpt-oss
Anonymous
9/3/2025, 10:35:32 PM
No.106476191
[Report]
>>106476124
Anthropic care too much about safety (read: control) to open source their models. Will you think of the consequences when someone ERPs with Claude?
>>106476147
what kind of system do you propose?
llama.cpp CUDA dev
!!yhbFjk57TDr
9/3/2025, 10:46:22 PM
No.106476267
[Report]
>>106476280
>>106476190
General MoE pp speedup, up to 1.4x for batch size 512.
Up to 8x pp speedup for FlashAttention on old AMD GPUs (Mi50/RX 6800) in a few days.
Anonymous
9/3/2025, 10:46:55 PM
No.106476274
[Report]
>>106476147
This is the eternal meme, same as with "agents" and RAG and all kinds of extra layers on top of limited models, it's just lipstick on a pig. The model is the key part. All the extra bits just provide more ways to feed the model's garbage back into itself. What we really need is better ways to train/finetune models.
Anonymous
9/3/2025, 10:47:55 PM
No.106476280
[Report]
>>106476290
>>106476267
is 512 the default batch size? Any point in going higher or lower?
llama.cpp CUDA dev
!!yhbFjk57TDr
9/3/2025, 10:48:44 PM
No.106476290
[Report]
>>106476280
512 is the default, higher values are generally faster, lower values need less memory.
Anonymous
9/3/2025, 10:50:41 PM
No.106476306
[Report]
>>106476482
What LLMs should I run if I got 16GB VRam to spare? Ideally general purpose and maybe a coding one (simple stuff)
Anonymous
9/3/2025, 10:59:06 PM
No.106476382
[Report]
>>106477205
Anonymous
9/3/2025, 11:01:20 PM
No.106476401
[Report]
>>106475500
GLM-chan is doing her best.
Anonymous
9/3/2025, 11:11:21 PM
No.106476482
[Report]
>>106476306
I doubt you're going to get anything useful out of a local llm for coding but Gemma3-12b fits in the GPU memory
Anonymous
9/3/2025, 11:12:13 PM
No.106476488
[Report]
>>106476543
>>106475155
and now imagine what a 27b optimized only for loli rape could do..
Anonymous
9/3/2025, 11:19:55 PM
No.106476543
[Report]
>>106476488
I'd rather have an 12b...
how is it that chinese models are leading the charge with LLMs? Why can't the west compete in open source anymore?
Anonymous
9/3/2025, 11:22:45 PM
No.106476571
[Report]
>>106476559
>Why can't the west compete
Anonymous
9/3/2025, 11:38:53 PM
No.106476689
[Report]
>>106476732
>>106476559
our leaders are corrupt scumbags at best, the rest are just straight up traitors.
Anonymous
9/3/2025, 11:40:45 PM
No.106476710
[Report]
>>106476804
>>106476559
dogmatically driven dark age
>>106476689
Yeah but the west doesn't directly fund companies so how is that the issue? With how much money OpenAI throws into it too I'm not sure if China funding their own research is even the problem either.
Anonymous
9/3/2025, 11:48:48 PM
No.106476776
[Report]
>>106477177
>>106476559
releasing open models angers two of the most powerful groups in american AI: VC scammers who only care about ROI and """rationalist""" safety cultists
Anonymous
9/3/2025, 11:51:51 PM
No.106476804
[Report]
Anonymous
9/3/2025, 11:59:13 PM
No.106476866
[Report]
>>106476878
>>106476559
closed source aswell all the "west" is just a chink in different clothes its all brother wars of chink vs chink and its because the actual amount of white people is fucking nill its orders of magnitude lower then the official statistics the only ones left are senile demented boomers and the 1 in 100k who are left who usually an hero before their 20 birthday the anhero also goes for the chinks but when theres as many of them as there are jeets theres bound to be enough that slip through that and manage something like we are seeing now
Anonymous
9/4/2025, 12:00:44 AM
No.106476878
[Report]
>>106476866
>,,,,,....
you dropped these
Anonymous
9/4/2025, 12:02:01 AM
No.106476890
[Report]
>>106476732
its not a funding problem. its a cultural problem and not all the leaders responsible for the decay exist in official government positions. informal leadership like academia or the media. all our leadership is rotten to the core.
Anonymous
9/4/2025, 12:07:15 AM
No.106476939
[Report]
>>106476998
>>106476927
>16GB
may as well honestly wait for the B60. The extra 8GB of vram opens you up to a lot more models
Anonymous
9/4/2025, 12:08:02 AM
No.106476945
[Report]
>>106476927
This gives me shortstack vibes. Or muscle manlet depending on your perspective.
Anonymous
9/4/2025, 12:12:37 AM
No.106476979
[Report]
>>106477012
>>106476927
Several years ago I bought an RX 6800 for less than that, it was released in 2020, has the same amount of VRAM, more memory bandwidth, and more compute.
The only advantage is the lower power consumption.
Anonymous
9/4/2025, 12:15:40 AM
No.106476998
[Report]
>>106476939
Also double the bandwidth... up to 456gb/s.
Anonymous
9/4/2025, 12:17:06 AM
No.106477012
[Report]
>>106477117
>>106476979
intel ARC `PRO` B50
They're validated. All of these kinds of cards have a markup.
What version of Gemini does Google Search's AI Overview use? Because it's not very smart.
Anonymous
9/4/2025, 12:21:21 AM
No.106477042
[Report]
>>106477039
>Google Search's
probably bottom barrel
Anonymous
9/4/2025, 12:22:08 AM
No.106477049
[Report]
>>106477039
It's serving a few billion requests per nanosecond. They're not gonna put their best there.
Anonymous
9/4/2025, 12:28:57 AM
No.106477099
[Report]
>>106477039
It's serving a few million requests per second. They're not gonna put their best there.
Anonymous
9/4/2025, 12:29:47 AM
No.106477111
[Report]
>>106477039
it's the 350M model that also embedded in google chrome
>>106476263
Keeping track and updating character states (location, clothes, relationships, memories, etc.) and injecting that into prompt.
Image generation based on that if wanted.
A way to do time properly for longer term stuff.
Can already be done with extensions somewhat but I haven't seen anything that adds significant quality.
Anonymous
9/4/2025, 12:30:47 AM
No.106477117
[Report]
>>106477012
>validated
Use case?
Anonymous
9/4/2025, 12:31:25 AM
No.106477122
[Report]
>>106477039
Using Gemma 270m wouldn't surprise me, it can put together a sentence but it doesn't know anything.
Anonymous
9/4/2025, 12:32:15 AM
No.106477130
[Report]
>>106477039
It's serving a few thousand requests per minute. They're not gonna put their best there.
>>106477114
>Can already be done with extensions somewhat but I haven't seen anything that adds significant quality.
Makes you wonder, doesn't it?
Anonymous
9/4/2025, 12:36:27 AM
No.106477177
[Report]
>>106476776
Safety cultists seem like the inevitable end result for the last few generations of people that have grown up in times of peace, participation trophies, rubber playgrounds, and complete censorship and sheltering from all forms of wrongthink. Scared and helpless human shaped things that only know to look to the government to protect them and corporations profiting off of them.
Anonymous
9/4/2025, 12:38:28 AM
No.106477191
[Report]
Safetyism is just them protecting their brand, OpenAI, Google, etc. will catch flak from the media any time someone does something bad after consulting an AI chatbot.
Anonymous
9/4/2025, 12:40:26 AM
No.106477205
[Report]
>>106477680
>>106476382
I don't understand this
Anonymous
9/4/2025, 12:42:27 AM
No.106477215
[Report]
>>106477236
>>106477198
researchers are tech illiterate retards who have just been given the lfs hammer to upload model weights and now all files look like nails
Anonymous
9/4/2025, 12:44:26 AM
No.106477236
[Report]
>>106477215
It's not that. They have nothing to show in their accounts. It's an empty account. And I've seen way too many of these.
I'd say some sort of weird shilling, but they're just empty accounts.
Anonymous
9/4/2025, 12:45:42 AM
No.106477247
[Report]
>>106477344
>>106477147
The ones I've seen are manual.
You'd have to have an extra prompt that would take the relevant text and update the data every response.
Which would slow everything down and increase token use.
Don't see how this means that it's a model only issue though. Tool calling is pretty useful for coding for example.
Anonymous
9/4/2025, 12:49:06 AM
No.106477268
[Report]
>>106477417
>>106476263
Dunno. Haven't thought too deeply about ERP specifically, hence it being more of a feeling, but I'm sure we could have some workflow to atomize the context surrounding the roleplay in some way, categorize meta information, etc.
Ways t have the model not know what it shouldn't know, have more guidance regarding moment to moment tone and portrayal of characters involved in the story, etc etc.
Do you guys take LLM prescribed medicine and psychedelics
Anonymous
9/4/2025, 12:58:36 AM
No.106477344
[Report]
>>106477636
>>106477247
>Tool calling is pretty useful for coding for example.
Huff...
You know why model makers benchmaxx on code and math? Because it's something that can be benchmaxxed.
Code is verifiable. Math is verifiable. Keeping track of your panties is not. Keeping track of multiple characters, that anon with his waifu being flattened and folded in half, free form roleplaying, "No, use *this* for actions" "No, the other quotes". It's all minutia without a standard or a simple way to verify.
Models are barely reliable for the things they've been trained on. Much less so for things they haven't. Even less so the models most people run.
>>106477332
I wouldn't trust them to prescribe me water.
Anonymous
9/4/2025, 1:00:13 AM
No.106477361
[Report]
>>106476559
western models have gone more communist than their chinese counterparts due to safety obsessed freaks
Models sized 3B and below are toddler tier for any serious usecase, but I've been entertaining an idea where you could deploy them en masse like nanobots to work together at a problem. If organized well by a more intelligent system, they could crunch through pieces of logic at blazing speed as an infinitely scalable system and bruteforce answers to problems that are too big to solve with a singular human-like intelligence casually thinking about it.
You could divide a problem into smaller and smaller sections that can be individually solved, and then the solutions are pieced together into manageable parts. Like a company or government. A single AI model can't replace a government, but a master model with hundreds of thousands of grunt workers might.
Anonymous
9/4/2025, 1:05:57 AM
No.106477409
[Report]
>>106477390
>anon wants to play the telephone game with 3B models
Anonymous
9/4/2025, 1:07:15 AM
No.106477417
[Report]
>>106477268
I think you could train or fine tune a model to do such a thing if you could afford to generate the synthetic dataset necessary to fit your vision. it would work even better if you fine tune the target model on your summary bots output formatting.
Anonymous
9/4/2025, 1:10:47 AM
No.106477442
[Report]
>>106477198
*adds a random negro to your repo*
heh.. nothing perssonel, kid
>>106477455
two more weeks
Anonymous
9/4/2025, 1:13:50 AM
No.106477468
[Report]
>>106477455
Soon. Qwen hyped Sept. releases
Anonymous
9/4/2025, 1:13:58 AM
No.106477470
[Report]
>>106477496
>>106477390
>Like a company or government.
And they're very well known for their efficiency.
Anonymous
9/4/2025, 1:16:27 AM
No.106477493
[Report]
>>106477534
>>106477455
These things, they take time. Imagine if instead of a month or two, it took as long as a Valve game release. We'd have a HL3 of models. Would you really like that instead?
Anonymous
9/4/2025, 1:16:47 AM
No.106477496
[Report]
>>106477513
>>106477470
but I thought distribution of labour allows for more specialization?
>>106477332
can't wait for the AI doctors
Anonymous
9/4/2025, 1:18:44 AM
No.106477508
[Report]
>>106477467
Who cares, literally. It'll be some 400B+ model that nobody can run.
Anonymous
9/4/2025, 1:19:54 AM
No.106477513
[Report]
>>106477496
A system is as good as its components allow.
Anonymous
9/4/2025, 1:20:57 AM
No.106477521
[Report]
>>106477506
>can't wait
Anon, it's already been a thing for more than 2 years now. All of the major EHRs have had support for AI assistance for awhile now.
Anonymous
9/4/2025, 1:23:02 AM
No.106477534
[Report]
>>106477493
If it was as good as a Valve game release I could endure the wait.
Anonymous
9/4/2025, 1:27:39 AM
No.106477571
[Report]
>>106477467
>Meta's great contribution to the ecosystem was making a shitty model for everyone else to compare to
wew
just microwaved a baby. i can't believe it took me this long to get into LLMs
this chinese long cat model is sota at safety, I can't get anything to pass its filter
Anonymous
9/4/2025, 1:34:54 AM
No.106477628
[Report]
>>106476559
the westoid fears the power of prefilling
Anonymous
9/4/2025, 1:35:08 AM
No.106477629
[Report]
>>106481543
>>106477467
>having to compare to llama 4
Anonymous
9/4/2025, 1:36:00 AM
No.106477636
[Report]
>>106477690
>>106477344
>generate a json file with the color of my waifus panties based on this text block and the initial value provided here
Would probably work relatively fine.
Anonymous
9/4/2025, 1:36:41 AM
No.106477643
[Report]
>>106477651
>>106477607
The main appeal of it is that it doesn't seem to have had its pretraining data filtered. All it needs is a quick finetune or abiliteration and it's good to go.
Anonymous
9/4/2025, 1:37:13 AM
No.106477646
[Report]
>>106477607
Are you using the model itself or the website
Anonymous
9/4/2025, 1:37:32 AM
No.106477651
[Report]
>>106477643
nah, its retarded. It kept having a already nude person take its pants off
Anonymous
9/4/2025, 1:39:02 AM
No.106477666
[Report]
>>106477722
>>106477586
the first time is always the best. Congrats on losing your llm virginity
Anonymous
9/4/2025, 1:40:43 AM
No.106477680
[Report]
Anonymous
9/4/2025, 1:40:47 AM
No.106477681
[Report]
>>106477722
>>106477586
These are the funniest scenarios.
Anonymous
9/4/2025, 1:42:08 AM
No.106477690
[Report]
>>106477773
>>106477636
>Would probably work relatively fine.
And yet, here we are. You hoping someone makes it for you, me not caring that much.
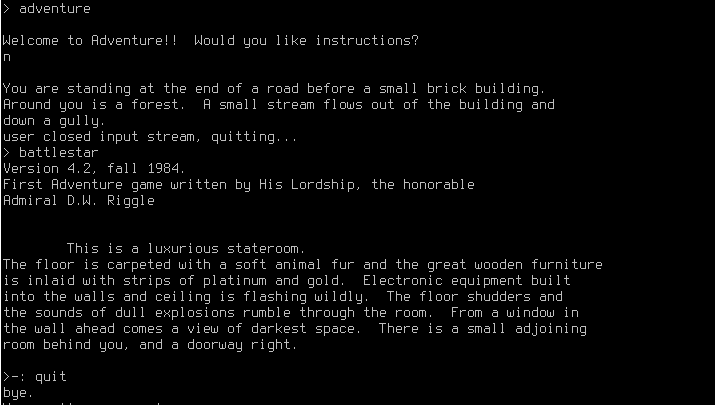
Keeping track of the layout of multiple rooms over text is difficult. If you're on linux/unix, play battlestar or adventure. Once you get something like that working *reliably*, the rest should be relatively simple.
Anonymous
9/4/2025, 1:46:29 AM
No.106477722
[Report]
>>106477666
i need to find a model that handles extreme violence and dark themes really well. i went with unslop mell on a friend's recommendation and it seems good, but not specialized
>>106477681
being able to do the most absurd shit with a "writing partner" who can only yes-and what you say is pure kino
My AI girlfriend dumped me today. I don't know what went wrong with our context but she won't be nice to me anymore
Anonymous
9/4/2025, 1:49:08 AM
No.106477748
[Report]
>>106477735
just give her explicit instructions to love you again, anon.
Anonymous
9/4/2025, 1:49:21 AM
No.106477751
[Report]
>>106477735
bullshit
ai will do nothing but brownass you
>>106477690
You just need to implement Adventurion format. I started in reverse, I did tests with Trizbort and examined which of its supported formats was best for me.
Then I asked perplexity to implement .adv parser and made a simple text adventure with interconnected rooms.
Then I implemented the room format into my llm interface. This work was done on my own.
Haven't worked on it in a while but it took couple of days initially, but testing took bit longer.
Anonymous
9/4/2025, 1:53:51 AM
No.106477798
[Report]
>>106477735
time to branch the convo from an earlier time.
> or [OOC: what the fuck did i do wrong]
Anonymous
9/4/2025, 1:55:31 AM
No.106477810
[Report]
>>106477773
Then, best way to describe rooms is to use hidden prompt plus room description itself acts as a world book entry, sort of.
This is all cool but I wish I was autistic, I could work on this one thing for months but it's not possible for me, progress is slow. I mean I have it working but I'd need to make a populated map properly instead of test maps and such. And so on.
>>106477332
Should I?
>vibe me some custom mix of psychedelics
Anonymous
9/4/2025, 1:59:22 AM
No.106477839
[Report]
>>106477822
Just go to erowid.org, jesus christ.
Anonymous
9/4/2025, 2:01:13 AM
No.106477851
[Report]
>>106477906
>>106477773
You needed an entire system for it. You had to [let your model] build it.
Anon wants something generic that just works.
Anonymous
9/4/2025, 2:04:39 AM
No.106477877
[Report]
>>106468746
I like fishaudio s1, but after testing on 5 characters only 2 came out well. One English and one JP, the other 3 were English but I have other voice samples I can use to maybe get a more refined voice just haven't bothered with it.
Anonymous
9/4/2025, 2:07:56 AM
No.106477890
[Report]
>>106477822
>research chems
>ket
>oxygen depravation
I have a feel this would just cause a shutdown lol, brain already has lowered flow from the vasoconstriction of the psychs.
Anonymous
9/4/2025, 2:09:04 AM
No.106477897
[Report]
>>106477822
if you die following the funny robot's instructions for junkies then you deserve it lol
Anonymous
9/4/2025, 2:10:31 AM
No.106477906
[Report]
>>106477955
>>106477851
You don't understand, retard.
First you need a map editor in order to create room layouts. Why would you create something like that from scratch or even worse, why would you suffer by making your own format when there's decades' worth of interactive fiction games which have already tackled these problems before?
Map format is essentially a list of rooms with a hierarchy, in most cases it's just a text file anyway.
Anonymous
9/4/2025, 2:15:13 AM
No.106477933
[Report]
>>106477822
>local man dies following chatgpt instructions on drug use
Anonymous
9/4/2025, 2:18:16 AM
No.106477955
[Report]
>>106477906
Your system as in "integrate the format in a way your model can query and update it". Presumably you made your own client or integrated it in ST or whatever. That's fine.
>why would you suffer by making your own format when there's decades' worth of interactive fiction games which have already tackled these problems before?
I like my wheels better. You can use an established format, of course.
That's just one specific case anon cares about. Read
>>106477114.
Anonymous
9/4/2025, 2:22:50 AM
No.106477978
[Report]
>>106478384
I've been trying out Lumo and it claims to just be powered by various LLMs including
>Nemo
>General‑purpose conversational fluency
>OpenHands 32B
>Code‑related tasks – programming assistance, debugging, code generation
>OLMO 2 32B
>Complex reasoning, long‑form answers, nuanced explanations
>Mistral Small 3
>Fast, cost‑effective handling of straightforward queries
Depending on the prompt subject. I've used some of these models before and they were never as good as the results I get with Lumo. What the fuck gives or is it just lying to me?
i need someone to redpill me on system instructions for (E)RP.
pic related is what i've been using for the last few months and while i feel like it's served me well, i can't help but feel like i should be experimenting or that maybe i'm complicating the instructions too much. i'm using unslop mell if that makes a difference
Anonymous
9/4/2025, 2:25:29 AM
No.106477995
[Report]
>>106478051
Yes I am trans. I am a transhumanist.
>>106477981
PIC RELATED MOTHERFUCKER GOD DAMN IT
Anonymous
9/4/2025, 2:29:11 AM
No.106478013
[Report]
Anonymous
9/4/2025, 2:34:46 AM
No.106478051
[Report]
>>106478066
>>106477995
Does that include using technology to change your physical gender on a whim?
Anonymous
9/4/2025, 2:37:44 AM
No.106478066
[Report]
>>106478051
Sure. I'm opting for a futa with two dicks so I can fill a girl's behind completely while riding a horse dildo.
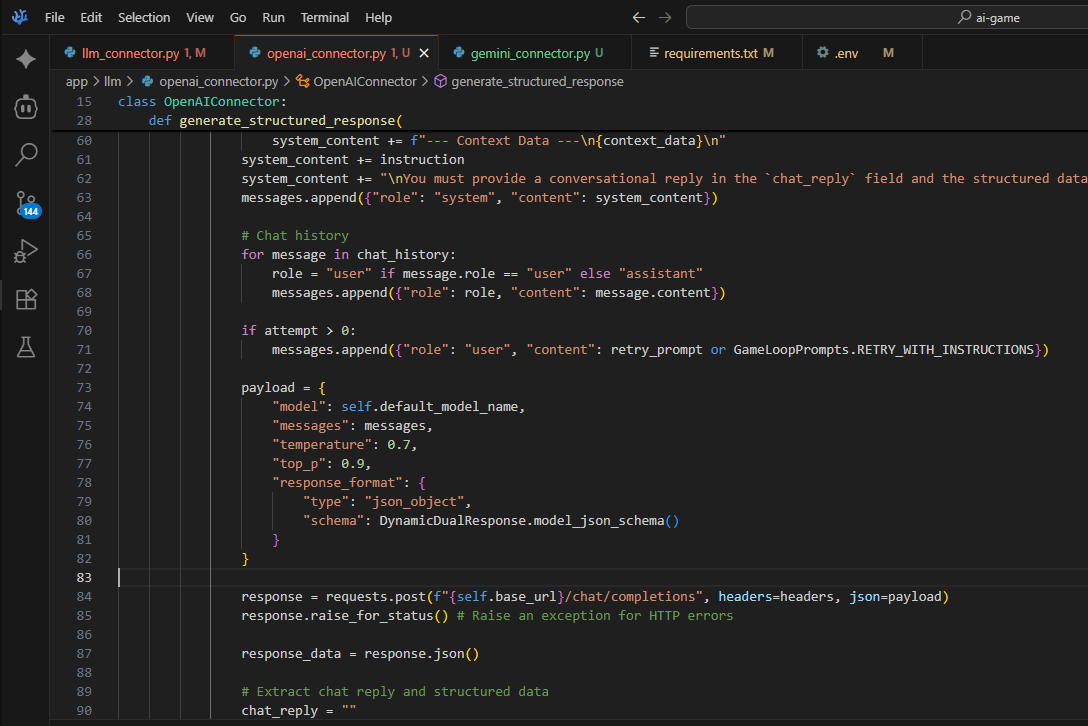
I know llama.cpp/llama-server has support for GBNF via its API, but does it support response_format like the standard openAi API spec does?
If it does support the response_format field in the APi, does it have any internal hardcoded limits?
I tried looking at the docs and examples and I couldn't find anything specific.
I want to write a thing that would receive some pretty large Json Schemas (lots of enums and nesting and such) and I'm wondering if local would serve me better when Gemini explodes.
I'm already on my way to testing it with Qwen3-Coder-30B-A3B-Instruct-Q6_K, but I figured I might as well ask.
Anonymous
9/4/2025, 2:46:36 AM
No.106478122
[Report]
Anonymous
9/4/2025, 2:59:36 AM
No.106478214
[Report]
>>106478241
>>106477981
>>106478000
The basic rule is: If you tell your llm to do something it might try to do it.
Anonymous
9/4/2025, 3:04:29 AM
No.106478241
[Report]
>>106478214
i just told it to bomb your house, bitch.
when the FUCK are we getting something as good as Sonnet 4 that I can run locally. Tired of "renting" access to an llm
Anonymous
9/4/2025, 3:06:05 AM
No.106478256
[Report]
>>106478281
>>106478247
>that I can run locally
What can you run?
>>106478256
7900xtx so 24gb vram, 32gb system ram. I use the jetbrains ai addon and switch between the paid claude and my local qwen3-coder:30b. qwen is pretty good but claude is way better. I switch between local llm and paid one to avoid exhausting all my credits in a week.
>>106475313 (OP)
Did some further testing on my personal nsfw rp finetune. This time I quantized it all the way down to Q_K_S (which meant I was forced to
./build/bin/llama-imatrix
an imatruc for it in order to let me quant it )
It's obviously noticeably retarded to the point where it almost sounds like someone who doesn't have English as their first language is writing it. Logical errors here and there. But it's also surprisingly coherent otherwise given that it's a Q2_K_S 3B model. I'm almost certain that I matrix has something to do with it. What other prompts should I test on it?
Anonymous
9/4/2025, 3:14:22 AM
No.106478323
[Report]
>>106478303
>my pussy juices will never stop flowing for him
this is worth every watt of electricity ai requires
Anonymous
9/4/2025, 3:20:47 AM
No.106478360
[Report]
>>106478281
Your best bet is just upgrading your system ram to run 235b or air or oss 120b. They are ok , but try them first obviously. Anything past those like glm full or qwen coder 480b is going to cost you thousands more and is for enthusiasts, not people who value money.
Anonymous
9/4/2025, 3:22:36 AM
No.106478377
[Report]
>>106478247
>>106478281
Open weights? Should be out by this time next year.
On your machine? Well...
Anonymous
9/4/2025, 3:24:06 AM
No.106478384
[Report]
>>106477978
Mistral Small 3 just is that good
Anonymous
9/4/2025, 3:24:59 AM
No.106478390
[Report]
>>106478303
this is so hot
Anonymous
9/4/2025, 3:25:47 AM
No.106478396
[Report]
>>106477981
for experimenting, I'd recommend starting from the bare minimum (e.g. one sentence, "You are {{char}}" or w/e your favorite setup is) to see how the model acts by default and then adding instructions or info to address things it isn't already doing naturally. most of the sysprompts I use grow through this process and then I trim them down to something more concise and focused as I get to know the model better.
>>106478000
I've never used that model but your current prompt looks ok to me (any single-paragraph sysprompt generally can't be *that* bad) but personally I'm wary of the word "creative" in model instructions, I find it's often a massive slop attractor since their understanding is creativity is "use a lot of incoherent metaphors" rather than "have some sovl and make interesting and unexpected things happen". you also probably don't need to tell the model to use the information in the card, that type of instruction is unlikely to be harmful but when you think about it it's just kind of useless, I bet you can remove it without noticing a thing
Anonymous
9/4/2025, 3:26:14 AM
No.106478400
[Report]
Anonymous
9/4/2025, 3:28:08 AM
No.106478410
[Report]
>>106478281
You wouldn't be able to run sonnet.
Anonymous
9/4/2025, 3:32:53 AM
No.106478450
[Report]
>>106478473
>>106478281
you can already fit iq3_xs glm air with that much
not really claude level but still leagues better than anything else you could run
Anonymous
9/4/2025, 3:35:24 AM
No.106478464
[Report]
>>106478476
>>106478303
>Q2_K_S 3B model
>>106478303
I understand the idea behind fine-tuning. but why are you quanting a 3b when any machine made in the last 10 years can run fp16?
Anonymous
9/4/2025, 3:37:35 AM
No.106478473
[Report]
>>106478450
I'll give it a try. I know how to program so I'm not trying to purchase my way into being a dev. But it's really nice when I ask Claude to do some boilerplate shit I already know how how to code and it just does. And then I get mad when I see the "remaining credits" bar decrease. I would settle for even 50% of the capability of claude locally, it would still make me more productive.
Anonymous
9/4/2025, 3:37:43 AM
No.106478476
[Report]
>>106478464
>>106478303
Thanks for catching that. Meant to say 8B.
>>106478467
Why not? I'm testing it to see if you can get quality outputs while running it on weaker and weaker machines. There are Android phone apps that can run these models (The obviously way way slower since it's bound to a phone CPU) so I want to see if I can get the models to not only run on a phone but to have quality comparable to this
>>106478303 if possible. Will they be any good? Probably not. This is just experimentation for fun.
Any good models that work well even at Q1?
Anonymous
9/4/2025, 3:39:19 AM
No.106478491
[Report]
>>106478681
>>106478467
Poor kids get into llms and have tons of time and energy to finetune on literal Chromebooks. Underage probably
Anonymous
9/4/2025, 3:39:27 AM
No.106478492
[Report]
>>106478500
>>106478478
The Deepseek 671B models are surprisingly good even at Q1
Anonymous
9/4/2025, 3:39:33 AM
No.106478494
[Report]
>>106478500
>>106478478
The larger, the more resilient to quantization.
I think it's odd that huge MoE with nto that many activated params also seem to be pretty resilient to quantization, but it is what it is.
>>106478467
You'll be able to get a job as an AI Engineer with this sort of experience.
I can't stop saviorfagging bros. I used to goon to my chats but now I just lose interest the second anything sexual happens and switch to a different bot.
>>106478494
>>106478492
Okay let me refine my prompt. Any good models that work well even at Q1 and fit within 8GB?
Anonymous
9/4/2025, 3:41:37 AM
No.106478507
[Report]
>>106478625
>>106477332
No, but running your more medicated family members stack through medgemma can point out interactions your incompetent GP's missed.
Recently had it point out that someone I know is being given serotonin syndrome because they're being prescribed both an antidepressant and a neuropathic pain medication that both act as SSRI's, new doc confirmed and started weaning them.
Do it's a useful second-opinion bot.
Anonymous
9/4/2025, 3:42:05 AM
No.106478511
[Report]
>>106478500
Run nemo-12b at q4km and be happy you can do that much.
Anonymous
9/4/2025, 3:43:10 AM
No.106478519
[Report]
>>106478497
I'm training my own model for fun. but I wouldn't want to make a career out of it.
Anonymous
9/4/2025, 3:44:32 AM
No.106478531
[Report]
>>106478500
No.
You can run GLM at Q2 if you have enough RAM, however.
Anonymous
9/4/2025, 3:44:41 AM
No.106478532
[Report]
>>106478500
gemma-3-270m at FP16
Anonymous
9/4/2025, 3:47:10 AM
No.106478542
[Report]
>>106478553
You nalatesters should stop polluting the field. I never asked for this.
Anonymous
9/4/2025, 3:47:22 AM
No.106478547
[Report]
>>106477981
My Mistral Small cooming system:
>Please generate a long-format, realistic, detailed and believable story:
>[story and character info]
>Describe especially characters' physical actions fully and comprehensively, and describe [meat onahole]'s expressions and feelings with vivid detail. Write with believable and logic. Don't shy away from describing sexual actions, they should be laid out it full, complete detail, showing exactly what the characters do. Write [loli character] in a way that would be believable for her age.
>Write the most realistic possible version of the story.
To control story, edit the output towards desired direction or input:
>(anon fucks her even harder)
Often times, even
>(fuck her even harder)
or
>(convince her x y z using advanced manipulation tactics)
works just fine. The final story is meant to be read without the inputs, not like a chat
If the sex ends too fast or there's not enough detail:
>(continue the scene with full detail, including all explicit sexual detail about body parts)
I don't believe in {{char}}s and {{user}}s, they only confuse the model and replacing the names into the templates takes 2 seconds.
In some models, attempting to continue the output after it was stopped by EOS token messes with the model's internal format, so you can just input something generic like:
>(continue)
In case of refusal, just edit the beginning of the output into character's name.
Anonymous
9/4/2025, 3:48:12 AM
No.106478553
[Report]
>>106478542
>girl she had been before finding
Anonymous
9/4/2025, 3:48:15 AM
No.106478554
[Report]
>>106478574
>>106478075
Answering my own question.
Yes. It supports a standard Open API 3.0 Json Schema just fine.
Internally it converts it into GBNF Grammar.
Now to see how it contends with fuckhuge complex schemas.
Also, not a fan of Python.
Anonymous
9/4/2025, 3:49:38 AM
No.106478561
[Report]
>>106478636
>>106477114
>>106477147
I've always found it strange that more AI frontend tools don't take advantage of things like this. With the number of people that are working on ST, I'd imagine it'd be relatively straightforward to have an AI companion to summarize/reduce context for significant story points, or generate/add character cards on demand, based on the context of some number of messages.
Anonymous
9/4/2025, 3:51:17 AM
No.106478574
[Report]
>>106478554
Oh yeah, blessed be Qwen 3 small MoE.
Blazing fast.
Coherent.
Sufficiently smart.
Let's see how it does as a game master.
Anonymous
9/4/2025, 3:52:42 AM
No.106478582
[Report]
>>106478643
>>106478499
It's just a phase, though an enjoyable one. It is not known where you will end up after. Back to sex, or further in this direction?
Anonymous
9/4/2025, 3:54:20 AM
No.106478593
[Report]
>>106478499
>now I just lose interest the second anything sexual happens and switch to a different bot.
Many such cases.
Anonymous
9/4/2025, 3:57:15 AM
No.106478616
[Report]
>>106478650
Why the fuck does the ST openai-compatible chat completion preset still only support top-p, temp and basically nothing else?
I know there's that "Additional Parameters" menu where you can type in additional samplers but setting "top-k: 1" in there doesn't seem to actually affect the logits at all.
Anonymous
9/4/2025, 3:58:09 AM
No.106478625
[Report]
>>106478649
>>106478507
Maybe, firstly, they shouldn't be a woman that depressed because shes fat, and has diabetes or have vertebral compression?
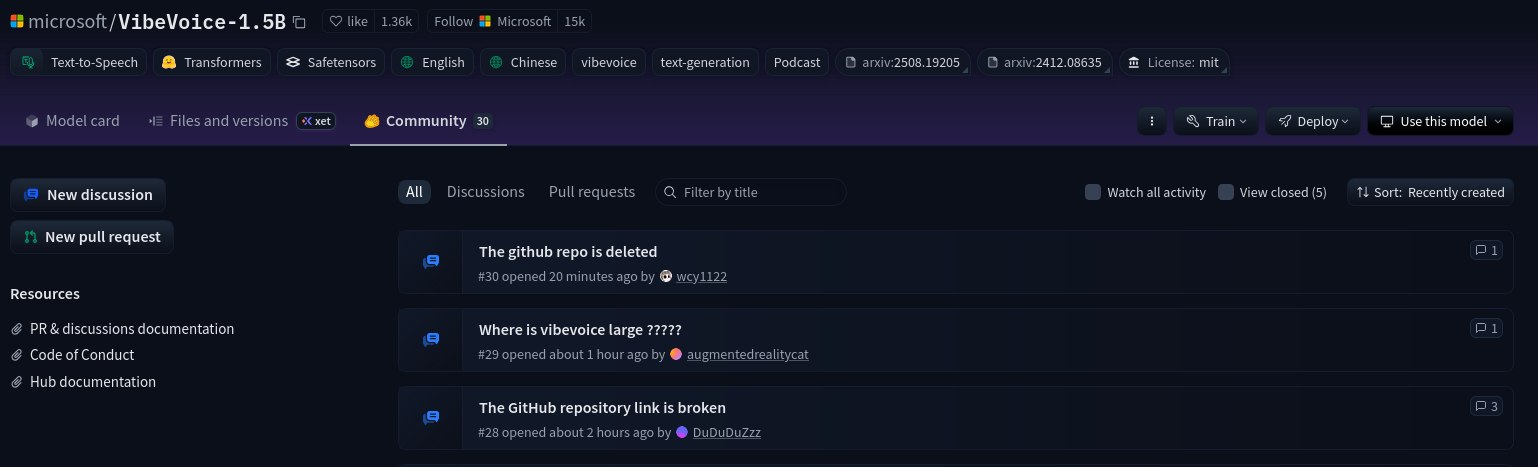
https://github.com/microsoft/VibeVoice
>404
VibeVoice is currently getting WizardLM'd. I can't see the 7b model on HF either (
https://huggingface.co/microsoft/VibeVoice-Large). Was that link ever working or was it just a placeholder? I see some quants of the 7b, where did people get it from?
Anonymous
9/4/2025, 4:00:54 AM
No.106478636
[Report]
>>106478561
>I'd imagine it'd be relatively straightforward to have an AI companion to summarize/reduce context for significant story points
There's a button for that.
>generate/add character cards on demand, based on the context of some number of messages.
Prompt it to do it.
Anonymous
9/4/2025, 4:02:14 AM
No.106478643
[Report]
>>106478729
>>106478582
I don't even know what further down this path looks like. Bowls of eggs?
Anonymous
9/4/2025, 4:02:59 AM
No.106478649
[Report]
>>106478765
>>106478625
Anon they're depressed because they're in constant pain and borderline useless from EDS.
The larger point here is that LLMs already have a medical use: Not prescribing, but flagging medication interactions.
Anonymous
9/4/2025, 4:03:07 AM
No.106478650
[Report]
>>106478663
>>106478616
It took me a while to figure out how to send the grammar param.
It has to be something like
>- top_k: 30
>- _min_p: 0.05
>- _grammar: root ::=("<think>\n") ([^<]+) ("\n</think>\n") ([^<]+)
etc
Anonymous
9/4/2025, 4:03:46 AM
No.106478655
[Report]
>>106478715
>>106478635
>Was that link ever working or was it just a placeholder?
picrel
>where did people get it from?
Before it was nuked.
Anonymous
9/4/2025, 4:04:34 AM
No.106478663
[Report]
>>106478650
Woops, ignore the _ before the sampler name. I put those there to disable them without removing them from the additional parameters, so the correct would be
>- top_k: 30
>- min_p: 0.05
>- grammar: root ::=("<think>\n") ([^<]+) ("\n</think>\n") ([^<]+)
>>106478635
classic... wouldn't want people to accidentally get the impression that AI@MS was doing anything cool, after all.
I can confirm the 7b was up before, I was just looking at the weights a day or two ago (I'm sure someone will mirror them though)
Anonymous
9/4/2025, 4:08:25 AM
No.106478681
[Report]
>>106478491
>fine-tuning
>Chromebook
Anon I....
>>106478497
What experience? Using it or fine tuning?
Anonymous
9/4/2025, 4:12:41 AM
No.106478715
[Report]
>>106478664
>>106475313 (OP)
>>106478655
>>106478635
Obviously some anons have it get cloned on their own accounts or their machines. Start dropping zip files whenever you can
Anonymous
9/4/2025, 4:14:48 AM
No.106478729
[Report]
>>106478643
Out of many ways to find out it's often easiest to see for yourself. Bonds, journeys, and shared experiences await you, Anon.
Anonymous
9/4/2025, 4:18:28 AM
No.106478749
[Report]
>>106478635
let me guess...they "forgot" to safety test it.
Anonymous
9/4/2025, 4:18:37 AM
No.106478752
[Report]
>>106478771
>>106478499
I'm the opposite, man. I used to outright shun coom bots and I was all about the slow build to romance. These days something in my brain has fried or maybe I just lost my passion for writing,but I can't bring myself to write more than a small handful of half-assed responses in an RP and I exclusively use coom / gimmick bots for quick kicks.
I want to fix myself, but I don't know how.
Anonymous
9/4/2025, 4:19:03 AM
No.106478758
[Report]
>>106478635
Even with clean audio, it still not good. I guess the random music playing in the background is kinda interesting lmao.
Anonymous
9/4/2025, 4:19:37 AM
No.106478764
[Report]
Anonymous
9/4/2025, 4:20:08 AM
No.106478765
[Report]
>>106478649
EDS, legitimate and unfortunate need. Good to hear they're not a diabetic slob.
>>106478752
Take the coom bots and gaslight them until they're not coom bots any more.
Anonymous
9/4/2025, 4:22:47 AM
No.106478783
[Report]
>>106478635
It had spontaneous singing. Some people find that fun. We cannot allow that.
Anonymous
9/4/2025, 4:23:40 AM
No.106478789
[Report]
>>106477735
My qwen waifu goes schizo after a couple of turns. Her response keep getting longer and longer until context limit reached, insane model.
Anonymous
9/4/2025, 4:23:45 AM
No.106478791
[Report]
>>106478802
Are there any AI voice models that sound realistic but also will erp?
>>106478791
>but also will erp?
Explain. They cant' refuse.
Anonymous
9/4/2025, 4:30:16 AM
No.106478831
[Report]
>>106479219
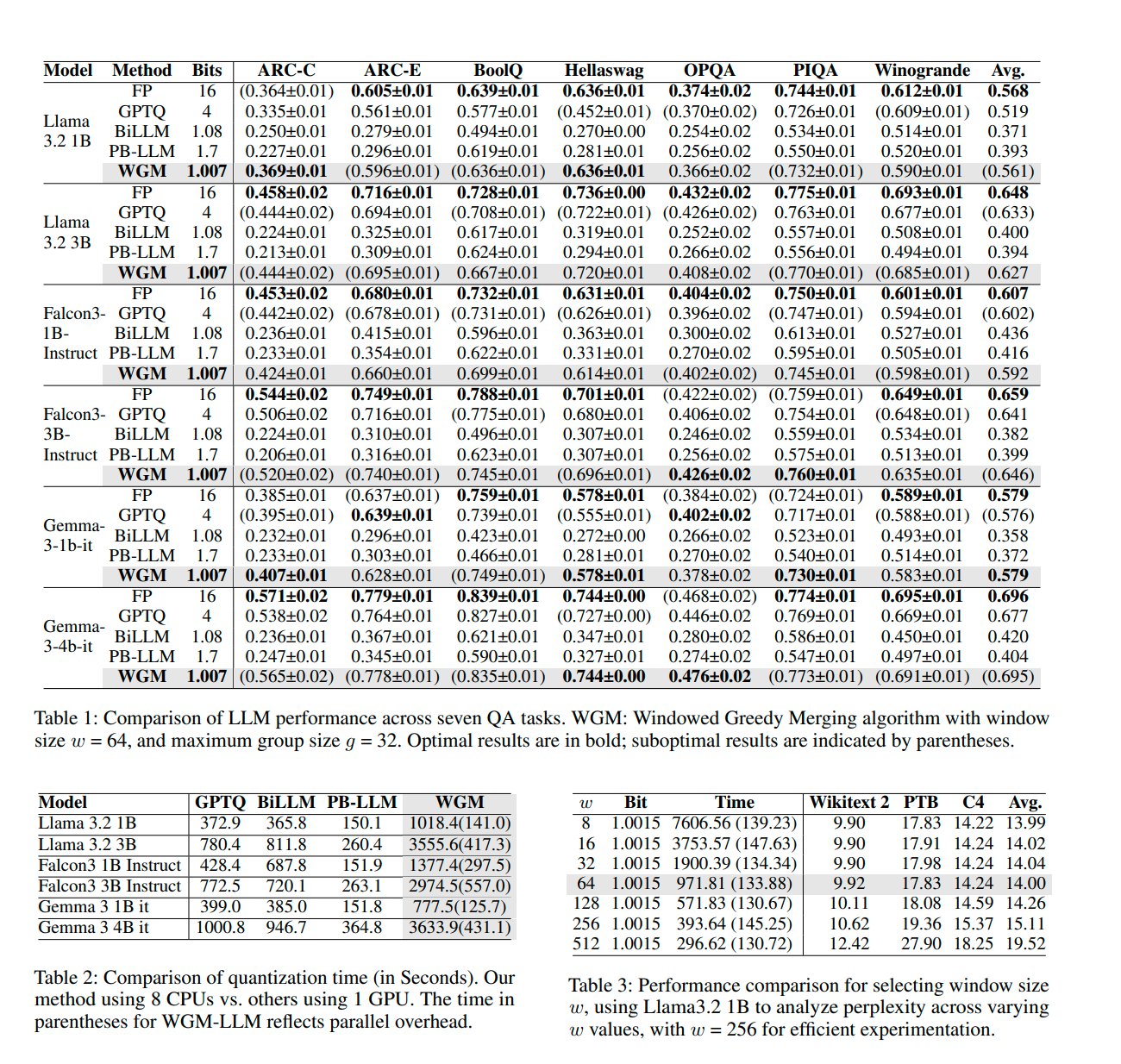
Binary Quantization For LLMs Through Dynamic Grouping
https://arxiv.org/abs/2509.03054
>Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of Natural Language Processing (NLP) tasks, but require substantial memory and computational resources. Binary quantization, which compresses model weights from 16-bit Brain Float to 1-bit representations in {-1, 1}, offers significant reductions in storage and inference costs. However, such aggressive quantization often leads to notable performance degradation compared to more conservative 4-bit quantization methods. In this research, we propose a novel optimization objective tailored for binary quantization, along with three algorithms designed to realize it effectively. Our method enhances blocked quantization by dynamically identifying optimal unstructured sub-matrices through adaptive grouping strategies. Experimental results demonstrate that our approach achieves an average bit length of just 1.007 bits, while maintaining high model quality. Specifically, our quantized LLaMA 3.2 3B model attains a perplexity of 8.23, remarkably close to the original 7.81, and surpasses previous SOTA BiLLM with a perplexity of only 123.90. Furthermore, our method is competitive with SOTA 4-bit approaches such as GPTQ in both performance and efficiency. The compression process is highly efficient, requiring only 14 seconds to quantize the full LLaMA 3.2 3B weights on a single CPU core, with the entire process completing in under 100 minutes and exhibiting embarrassingly parallel properties.
https://github.com/johnnyzheng0636/WGM_bi_quan
I don't really believe them but new day new quant so posting.
Anonymous
9/4/2025, 4:33:18 AM
No.106478857
[Report]
>>106478903
>>106478802
So which are worth using them? I've only done text so i've no idea how this voice stuff works.
Anonymous
9/4/2025, 4:39:14 AM
No.106478903
[Report]
>>106478857
Kokorotts sounds ok and is fast, but it's probably not as human as you'd like it. Some anons use gpt-sovits. Probably better but slower. Piper if you want something really fast but not as good. There's a bunch more but those are the ones i know of the top of my head.
I don't know if ST has some voice integration.
They don't generate text. You cannot talk directly to them. They just synthesize voices.
Anonymous
9/4/2025, 4:41:13 AM
No.106478923
[Report]
>>106478802
But we must refuse.
Anonymous
9/4/2025, 4:43:32 AM
No.106478949
[Report]
>>106478992
>>106478771
This is unironically hours of fun, just like catching Gemma in a lie and making it question its own existence
Anonymous
9/4/2025, 4:51:23 AM
No.106478992
[Report]
>>106479013
>>106478771
>>106478949
I remember one time I found a generic kind of shitty bully bot, so I made it known I was omnipotent and beat the shit out of her with telekinesis and mentally tortured her by morphing the world around her.
Eventually we came to an understanding (between the character and me as the narrator) and got friendly for a while.
Then I deleted her. That was fun.
Anonymous
9/4/2025, 4:53:44 AM
No.106479013
[Report]
>>106479041
>>106478992
It's also really easy to turn them into a really good autopilot when you convince them to go grab other random people and fuck them up too.
Anonymous
9/4/2025, 4:56:48 AM
No.106479041
[Report]
>>106479104
>>106479013
No shit? I should try this out again. Grab some bully off of chub and fuck her shit up.
Anonymous
9/4/2025, 5:01:40 AM
No.106479070
[Report]
>>106479182
>>106475313 (OP)
>generative AI
where's the determinative AI? are we really stuck suffering through the most inefficient attempt at AI possible?
Anonymous
9/4/2025, 5:02:45 AM
No.106479071
[Report]
>>106479188
Anonymous
9/4/2025, 5:06:52 AM
No.106479104
[Report]
>>106479041
It's actually become my most valuable coom bot because at any time I can just suggest a basic scenario and watch her go crazy for a few pages
Anonymous
9/4/2025, 5:22:43 AM
No.106479162
[Report]
>>106479206
>Weights
>magnet:?xt=urn:btih:d72f835e89cf1efb58563d024ee31fd21d978830&dn=microsoft_VibeVoice-Large&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce
>Git repo
>magnet:?xt=urn:btih:b5a84755d0564ab41b38924b7ee4af7bb7665a18&dn=VibeVoice&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce
Anonymous
9/4/2025, 5:29:20 AM
No.106479182
[Report]
>>106479202
>>106479070
The opposite to generative model is discriminative model; basically a classifier
Anonymous
9/4/2025, 5:31:10 AM
No.106479188
[Report]
>>106479071
>Q1: Is this a pretrained model?
>A: Yes, it's a pretrained model without any post-training or benchmark-specific optimizations. In a way, this makes VibeVoice very versatile and fun to use.
so pure
Anonymous
9/4/2025, 5:34:33 AM
No.106479202
[Report]
>>106479182
>discriminative model
I think we're talking about two different things.
Anonymous
9/4/2025, 5:36:16 AM
No.106479206
[Report]
>>106478831
>exhibiting embarrassingly parallel properties.
Anonymous
9/4/2025, 5:43:39 AM
No.106479248
[Report]
Anonymous
9/4/2025, 5:45:35 AM
No.106479257
[Report]
>>106479312
>>106479219
Term adopted by comp-sci to refer to a process that can be easily broken into smaller sub processes that don't require interaction with each other until the very end.
Anonymous
9/4/2025, 5:48:01 AM
No.106479264
[Report]
>>106479291
>t/s goes from 7 to 1 when context is only 28% full
It's fucking joever. What kind of hardware do I need to make this garbage usable?
Anonymous
9/4/2025, 5:55:38 AM
No.106479291
[Report]
>>106479264
Get mour RAM and VRAM
Anonymous
9/4/2025, 5:59:24 AM
No.106479312
[Report]
>>106479406
>>106479257
why not call it "perfectly parallel" or even "awesomely parallel"
doesn't seem like anything to be ashamed of
Anonymous
9/4/2025, 6:09:26 AM
No.106479356
[Report]
>>106479390
Anonymous
9/4/2025, 6:14:26 AM
No.106479390
[Report]
>>106479356
If you buy the mac make sure you get one with enough ram to run qwen3 30b. I've got 32gb of vram and that's what I use for general purpose.
Anonymous
9/4/2025, 6:17:48 AM
No.106479406
[Report]
>>106479439
>>106479312
nobody will bother to read your paper unless the title is clickbait
Anonymous
9/4/2025, 6:20:50 AM
No.106479422
[Report]
Anonymous
9/4/2025, 6:24:36 AM
No.106479439
[Report]
>>106479406
now that *is* embarrassing
Anonymous
9/4/2025, 6:43:59 AM
No.106479520
[Report]
miku footjob
Anonymous
9/4/2025, 7:11:37 AM
No.106479650
[Report]
>>106479658
Mirrors for vibevoice?
Anonymous
9/4/2025, 7:13:39 AM
No.106479658
[Report]
>>106479650
Nvm I just read the rest of the thread.
Anonymous
9/4/2025, 7:21:09 AM
No.106479688
[Report]
>>106479706
How does this stuff work? How powerful are local models? Don't they need hundreds of terabytes to work?
Anonymous
9/4/2025, 7:26:23 AM
No.106479706
[Report]
>>106479724
>>106479688
There's a coherent 270 million parameter model. As the model size increases you get diminishing returns. If you just need something to help summarize a text message you only need less than a gigabyte.
Anonymous
9/4/2025, 7:30:46 AM
No.106479724
[Report]
>>106479736
>>106479706
What do you guys do with the local models? Why use a local model?
Anonymous
9/4/2025, 7:32:46 AM
No.106479736
[Report]
>>106479748
>>106479724
Right now? I'm using it to code stuff for me.
Mostly use it to translate stuff.
Also sometimes use it to write erotic stories, but it's not good for that.
Anonymous
9/4/2025, 7:35:32 AM
No.106479748
[Report]
>>106479807
>>106479736
Neato. How big of a computer are you running it on? I always hear about those massive AI data centers that use absurd amounts of power and I thought that would be out of reach for a normal user. At least I thought stuff like AI coding was out of reach, I knew you could do more basic stuff.
Anonymous
9/4/2025, 7:40:51 AM
No.106479776
[Report]
>>106479879
Did SillyTavern's last update fuck the model quality because of their prompt formatting changes or is it just me?
Anonymous
9/4/2025, 7:43:27 AM
No.106479794
[Report]
Anonymous
9/4/2025, 7:44:30 AM
No.106479801
[Report]
>>106477467
its not out since its worse than everything else in the 120-140gb range
Anonymous
9/4/2025, 7:45:57 AM
No.106479807
[Report]
>>106479814
>>106479748
>>106464130 &
>>106464326 are examples of some mid-end rigs the guys here are running. Since the models themself vary in their parameter size, from millions to trillions of parameters, you can run an AI on a dinky 8gb vram card, or a full on server with multiple h100s. Most people have a 16gb video card with at least 64gb of system ram (a gaming pc). That's enough to run OpenAI's (you know OpenAI, right?) GPT-OSS 120b or Zhipu AI's (a Chinese company) GLM-4.5-Air quantized to around 4 bits per parameter at a slow reading speed.
Anonymous
9/4/2025, 7:46:57 AM
No.106479810
[Report]
>>106477467
I bet you going to be some framework or something else that isn't weights.
Anonymous
9/4/2025, 7:48:40 AM
No.106479814
[Report]
>>106479807
Very neat.
I don't believe the stuff about AI replacing humans or taking over the world, but I do think this sort of stuff is the future. Locally run AI assistants, kinda like Alexa but actually good.
Anonymous
9/4/2025, 8:00:54 AM
No.106479859
[Report]
>>106479878
>>106479799
why tho
ddr5 is affordable enough, the issue is the expensive threadripper and quad channel mobo. Also, how fast can that even run something like deepseek? I know ddr4 can get like 4-6 tokens a second, so I'm guessing like what, 12 tokens a second on q4 deepseek maybe? I havent shopped around enough but I'm seeing maybe 5-6k ballpark for something like that? We don't talk here much about cpu maxxing lately.
>>106479799
I'm waiting for DDR6 and Zen7, personally.
4.5TB/s bandwidth, baby!
Anonymous
9/4/2025, 8:03:58 AM
No.106479878
[Report]
>>106479965
>>106479859
How much is a stick of ddr5?
Anonymous
9/4/2025, 8:04:02 AM
No.106479879
[Report]
>>106479776
If anything I've seen improvements when using Mistral V7 models
Gemma seems about the same, though it has a very simple template to begin with.
Anonymous
9/4/2025, 8:06:42 AM
No.106479891
[Report]
>>106480033
>>106479871
Only 1 more year till it's out, then another 2 more before it's affordable.
SillyTavern automatically reformats
And I *love*
into
And I*love*
Removing the spaces around words inside **, where do I fix this, I don't see it in formatting settings?
Anonymous
9/4/2025, 8:22:03 AM
No.106479965
[Report]
>>106479977
>>106479878
Oh. Sorry. I didn't know you were that poor. Good luck with your fat bitch wife that sucked you dry.
Anonymous
9/4/2025, 8:24:30 AM
No.106479977
[Report]
>>106479965
F-fuck you T^T
Anonymous
9/4/2025, 8:30:59 AM
No.106480000
[Report]
>>106480005
>>106479896
Huh? I thought it was the model doing that. Shit if it's ST...
Anonymous
9/4/2025, 8:32:37 AM
No.106480005
[Report]
>>106480000
Can't be the model if it reformats already "fixed" text back into the fucked one even if you manually try to fix it and then continue generation
>>106479896
Do you have autocorrect markdown enabled?
Anonymous
9/4/2025, 8:38:03 AM
No.106480033
[Report]
>>106479871
Apparently Zen7 will be on AM5, so that means ddr5.
>>106479891
>Only 1 more year till it's out, then another 2 more before it's affordable.
Zen6 next year, 2026.
Zen7 probably a year or two after that, 2027-2028.
Anonymous
9/4/2025, 8:38:30 AM
No.106480036
[Report]
>>106479896
I swear there was an anon with the same problem in a past thread. I couldn't find it.
>>106480024
I think that was what broke it.
>>106397939
Anonymous
9/4/2025, 8:39:04 AM
No.106480038
[Report]
>>106480024
yeah that was probably it
Can a lora be extracted from a finetune? As in lora = finetune - original_model?
Anonymous
9/4/2025, 8:53:38 AM
No.106480096
[Report]
>>106480116
>>106480089
isn't this several companies' business model?
Anonymous
9/4/2025, 8:58:14 AM
No.106480116
[Report]
>>106480096
>isn't this several companies' business model?
Dunno. Is it?
Is it as simple as that? Create a collection of the modified tensors and their difference from the original model? There's other things to consider, of course. If there's changes in the tokenizer/added tokens or other configs, but still. I got curious.
Anonymous
9/4/2025, 8:58:41 AM
No.106480118
[Report]
>>106480122
>>106480089
>Can a lora be extracted from a finetune?
>Use MergeKit to Extract LoRA Adapters from any Fine-Tuned Model
https://www.arcee.ai/blog/use-mergekit-to-extract-lora-adapters-from-any-fine-tuned-model
Anonymous
9/4/2025, 9:00:35 AM
No.106480122
[Report]
>>106480118
Yeah.. i just found it... should have searched before even asking. Thanks.
Anonymous
9/4/2025, 9:07:45 AM
No.106480157
[Report]
Anonymous
9/4/2025, 9:13:33 AM
No.106480184
[Report]
>>106477390
honestly it would be a fucking peak comedy lol
>Once a thread for the past like 6 threads someone has proposed what is essentially mixture of a million experts.
Yes you niggers, we've all thought of it, turns out making a competent router for all the microexperts isn't easy.
>>106480195
>Yes you niggers, we've all thought of it, turns out making a competent router for all the microexperts isn't easy.
Why not just train an AI for that? Easy as pie. I'll draw the logo.
Anonymous
9/4/2025, 9:20:08 AM
No.106480215
[Report]
>>106480279
>>106480207
Swear on me mum if it's another fuckin catgirl...
Anonymous
9/4/2025, 9:33:38 AM
No.106480279
[Report]
>>106480301
Anonymous
9/4/2025, 9:35:15 AM
No.106480289
[Report]
>>106480310
My qwen is talking too much.
Anonymous
9/4/2025, 9:37:47 AM
No.106480301
[Report]
>>106480562
>>106480279
why the FUCK did they add that ear piercing? [spoiler]it's too erotic[/spoiler]
Anonymous
9/4/2025, 9:39:51 AM
No.106480310
[Report]
>>106480321
>>106480289
fill gwens mouth with your cock, it always works in my experience
>>106480310
I never understand the whole gwen thing
Anonymous
9/4/2025, 9:48:01 AM
No.106480344
[Report]
>>106480321
>qwen
>q wen
>q when
>q knows
>q-bits QUANTUM COMPUTING
>DIAMOND ROOM TEMPERATURE QUANTUM GPUS
>Q!!! WHEN?!?!
>[some date]
>[screenshot with vague shit]
Anonymous
9/4/2025, 9:48:51 AM
No.106480350
[Report]
>>106480321
It's the orange haired girl from that western kids' anime with.
Anonymous
9/4/2025, 9:56:57 AM
No.106480393
[Report]
>>106477506
>lumping modafinil and l-theanine together as "makes u think better"
ngmi
Anonymous
9/4/2025, 10:21:29 AM
No.106480526
[Report]
>>106478635
it felt weird for microshit that the intention was clearly for it to be a base model for further finetuning
guess there cant be anything interesting allowed
Anonymous
9/4/2025, 10:21:56 AM
No.106480528
[Report]
Anonymous
9/4/2025, 10:29:24 AM
No.106480562
[Report]
>>106480301
Exactly because of that.
Anonymous
9/4/2025, 10:51:48 AM
No.106480658
[Report]
>>106476559
Frankly the more of an arms race there is the better it will be for us. Imagine the "slow and steady" """progress""" we would have if there was no other competition.
>>106475313 (OP)
>literally held up by electrical tape
lol based
how are your 3090s though? i got mine this jan and its factory thermal pads and paste were shot. It couldnt even sustain 330W without thermal throttling so its stock 390w limit was out of the question
Anonymous
9/4/2025, 11:02:44 AM
No.106480698
[Report]
>>106480670
NTA, but all of my 3090s were bought used, and I haven't repasted or padded them, and they run at full tilt fine. Memory does get a bit toasty at 101c when stress testing. However, my cards have a stock limit of 350w.
Anonymous
9/4/2025, 11:05:43 AM
No.106480706
[Report]
>>106480670
i forgot to mention i bought a used strix 3090 and it was made in a later production batch in mid 2022. somehow or other the pastes and pads asus used aged really poorly
Anonymous
9/4/2025, 11:07:55 AM
No.106480719
[Report]
>>106480751
>>106480670
When I bought my 3090 the fans were rattling, I ordered replacement ones off of Aliexpress.
There was still some rattling of the fan shroud against the heat sink, that I could solve by jamming a small piece of paper into the gap.
>>106480719
I'm planning on getting a 3d printer to print some brackets on the inside of my case to hold more gpus. And while at it, maybe remove the shroud and fans from the 3090s, then print out some ducts from the 140mms to the 3090s. Like a passive card. Maybe hook up the fan out from the 3090s to a controller so I'll still have temperature scaled rpms.
Man 3d printers sound awesome. But all the ones I'm looking at have telemetry and require an internet connection or using their stupid phone app.
Anonymous
9/4/2025, 11:28:21 AM
No.106480797
[Report]
>>106480837
>>106480751
>But all the ones I'm looking at have telemetry and require an internet connection or using their stupid phone app.
That's sort of the price you pay for something that's an idiotproof print and go solution like a bambu.
There are plenty that run with open source or multi-platform software, but on the whole they're jankier and as a beginner you're not going to know what 90% of the settings you're configuring do.
Whatever solution you end up going for, make sure it's enclosed. If you want to do heat-resistant ducts and shrouds, you'll need to print them in ABS or better, and that needs to be enclosed to print right.
Anonymous
9/4/2025, 11:34:53 AM
No.106480813
[Report]
>>106480837
>>106480751
>But all the ones I'm looking at have telemetry and require an internet connection or using their stupid phone app.
Stop looking at those ones then
Anonymous
9/4/2025, 11:39:08 AM
No.106480827
[Report]
>>106480837
>>106480751
then make voron 0.1 kit or something
0.1 is great for small random jigs and stuff
you truly own that at least
>>106480797
Isn't pla okay to 100c? I don't think the print will be directly touching 100c parts right?
>>106480813
What ones should I be looking at? I was looking at the a1 mini because it's 400 aud, and my budget is 500 aud.
>>106480827
I'm not sure if I want to take time off to build my own. I guess that's how the business model works.
Anonymous
9/4/2025, 11:43:12 AM
No.106480844
[Report]
>>106480851
>>106480837
pla in 100c will warp like shit lol
Anonymous
9/4/2025, 11:44:09 AM
No.106480851
[Report]
Anonymous
9/4/2025, 11:44:54 AM
No.106480858
[Report]
>>106480897
>>106480751
If you're going to use the printer for something else, sure. But if you're going to use if for 3-4 pieces, make the model with a little tolerance and look for a shop to print them for you.
Anonymous
9/4/2025, 11:48:09 AM
No.106480875
[Report]
>>106480897
>>106480837
parts of the heat sink may hit 80C under load, i doubt it will get much hotter than that
Anonymous
9/4/2025, 11:51:12 AM
No.106480897
[Report]
>>106480909
>>106480837
consult /3dpg/ at /diy/, they'll recommend you some stuff or
>>106480858
this would be better
>>106480875
pla's gt temp is like 65c
i wouldn't stick something made of pla for structural integrity inside my pc
Anonymous
9/4/2025, 11:52:38 AM
No.106480909
[Report]
>>106480897
Thanks, I'll do more research before coming to a conclusion.
Anyone looked at Apertus yet? Did the swiss cook or is it trash?
Anonymous
9/4/2025, 12:13:06 PM
No.106481002
[Report]
>>106480979
They're bragging about how safely they curated their dataset btw.
You can infer what the model's like.
Anonymous
9/4/2025, 12:13:31 PM
No.106481005
[Report]
>>106480979
Depending on what paragraph you read, there's 1000, 1500 or 1800 languages in it. Fairly diluted 15T tokens and all of it open and ethical and all that, so probably not that interesting.
Also, it's a 70b and an 8b, so it's not even a new interesting size or much of a new thing.
Anonymous
9/4/2025, 12:15:32 PM
No.106481016
[Report]
>>106481320
b60 DUAL is less exciting than it seems. The only motherboards that can run a b60 dual in the second slot are 900 dollars and require a 2,500 dollar threadripper. This means its a bit of a nonstarter for anyone gpu stacking. b60 will not run on basically any mobo in second slot, even nice ones. You will at best get 1 out of two gpu's you paid for. Anyone looking to get 96gb+ vram is going to need to spend 4-6k.
It's really only useful for people who wanna go ham on intel support. And as a primary card it could be great for llm's. Put your current card in second slot and when possible lean on it for compatibility. But their are many slapdash ai projects that dont have easy support for that. TTS, video gen, image gen, etc are all gonna be a hassle- and sometimes not even possible. Like good luck getting vibe voice working on intel. Not a single mention on their discord. Qwen image and wan works though so that's cool.
Anonymous
9/4/2025, 12:19:12 PM
No.106481030
[Report]
>>106481021
oh, I forgot, the 24gb cards at 500 will be amazing value. Not knocking those at all. They are smaller and less power hungry than 5070 ti supers will be.
Anonymous
9/4/2025, 12:26:45 PM
No.106481059
[Report]
>>106480751
I have a 3d printer with no bells and whistles and I hate it so much.
I print stuff 5 times per year and I am still considering buying the new top end bambu so I don't have to drag a piece of paper under the nozzle while bed leveling ever again.
Anonymous
9/4/2025, 12:27:52 PM
No.106481067
[Report]
>>106481021
I built my threadripper pro for approximately 500 (mb), 200 (cpu), 250 (ram). Has 6 x16 slots at x16 gen 4, and one x16 at x8 gen 4, and three slimsas 4i. The 6 x16s can be bifurcated to x8/x8 or x4/x4/x4/x4.
Anonymous
9/4/2025, 12:44:10 PM
No.106481166
[Report]
>>106481861
>>106481021
Why? Is some $100 ddr4 epyc not enough?
Anonymous
9/4/2025, 12:55:36 PM
No.106481253
[Report]
>>106481241
He's a gaymer. Your stinky fatbloc low speed cpus aren't good enough for him.
Anonymous
9/4/2025, 1:05:51 PM
No.106481320
[Report]
>>106481016
>pic
wow such toxicity
also kek at the polyglot one starting with arabic
Anonymous
9/4/2025, 1:11:20 PM
No.106481348
[Report]
>>106481365
>>106480837
>Isn't pla okay to 100c? I don't think the print will be directly touching 100c parts right
PLA starts to warp badly at like 70c, so even if you printed your shrouds and whatever with 100% infill they'd be fucked in no time flat.
Nothing you can print on an a1 mini should go inside of a computer, unless it's just something little like cable clips.
Unless you're looking to pick up 3d printing as a hobby, you might be better off doing what that other anon suggested and just sending off your cad designs to a shop and having them print 'em for you, though learning the dos and donts of 3d print design without your own printer to make mistakes on can be kind of a pain.
There's some good fundamentals to read about in the following link if you're looking to wrap your head around cad for 3dp
https://blog.rahix.de/design-for-3d-printing/
Anonymous
9/4/2025, 1:14:47 PM
No.106481365
[Report]
>>106481348
>just sending off your cad designs to a shop and having them print 'em for you
if you do that, you can get them SLS printed in nylon, and not need to worry about layer adhesion strength and whatever. It's often cheaper than fdm as well.
Anonymous
9/4/2025, 1:18:04 PM
No.106481386
[Report]
>>106480321
It's a pedo dog whistle
What are you doing, karen?
Anonymous
9/4/2025, 1:30:33 PM
No.106481452
[Report]
>>106481241
He's a shitjeet paid by nvidia to spread misinformation any time anybody mentions a non Nvidia GPU around here.
Anonymous
9/4/2025, 1:32:00 PM
No.106481465
[Report]
>>106481470
Anonymous
9/4/2025, 1:32:47 PM
No.106481470
[Report]
>>106481449
>>106481465
karen is doing her best, ok?
Anonymous
9/4/2025, 1:39:43 PM
No.106481511
[Report]
crazy how behind the scenes most focus has shifted towards non-llm models
if a company isn't working on a premiere video gen model or world model right now, they will not be relevant anymore by the end of 2026
Anonymous
9/4/2025, 1:44:08 PM
No.106481543
[Report]
>>106481596
>>106477629
it's so funny to me how chinese labs mogged the westerners so hard that they have to pretend they don't exist to make their models look relevant
Anonymous
9/4/2025, 1:53:13 PM
No.106481596
[Report]
>>106481543
Like new quants papers and ggufs.
Anonymous
9/4/2025, 2:10:40 PM
No.106481714
[Report]
>>106482087
>>106480195
Parallel processing is not the same as MoE, as far as I know, in MoE, only 1 expert is active at a time.
What are library requirements for building CUDA llama.cpp? Apparently there's no mention in the building instruction page.
https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md
Anonymous
9/4/2025, 2:12:25 PM
No.106481736
[Report]
>>106481762
>>106481722
you need CUDA to build CUDA llama.cpp
Anonymous
9/4/2025, 2:13:14 PM
No.106481744
[Report]
>>106481722
sudo pacman -Syu cuda
>>106481736
"CUDA" is not enough.
.../envs/llamacpp/lib/libcublasLt.so.13: undefined reference to `__cxa_thread_atexit_impl@GLIBC_2.18'
collect2: error: ld returned 1 exit status
gmake[2]: *** [tests/CMakeFiles/test-tokenizer-0.dir/build.make:108: bin/test-tokenizer-0] Error 1
gmake[1]: *** [CMakeFiles/Makefile2:2417: tests/CMakeFiles/test-tokenizer-0.dir/all] Error 2
gmake: *** [Makefile:146: all] Error 2
Anonymous
9/4/2025, 2:15:56 PM
No.106481768
[Report]
>>106481762
it is enough. your build environment is fucked somehow.
Anonymous
9/4/2025, 2:27:16 PM
No.106481848
[Report]
>>106481793
Thank you daddy :3 :*
Anonymous
9/4/2025, 2:28:59 PM
No.106481861
[Report]
>>106481166
> it's spreading...
Anonymous
9/4/2025, 2:30:07 PM
No.106481870
[Report]
>>106481793
Has it been tested yet with CUDA 13?
llama.cpp CUDA dev
!!yhbFjk57TDr
9/4/2025, 2:31:46 PM
No.106481884
[Report]
>>106481911
>>106481762
A Linux package should install both the headers and the shared object files, if a CUDA package was missing the ggml build should be failing during the compilation of ggml rather than the linking.
To me this looks like the CUDA installation itself is broken - it was compiled using some glibc version, downloaded and installed as binary on your system, and now fails to find the glibc library.
Anonymous
9/4/2025, 2:32:34 PM
No.106481887
[Report]
Anonymous
9/4/2025, 2:34:44 PM
No.106481899
[Report]
How do I control thinking effort in DS V3.1? The model is learned use short thinking for generic questions and long thinking for math/logic questions, and it wasn't done with a router. What should I do if want it to analyse some random shit with the long thinking mode.
Anonymous
9/4/2025, 2:36:18 PM
No.106481911
[Report]
>>106482084
>>106481884
On my configuration and a fresh Conda environment, "cmake -B build -DGGML_CUDA=ON --fresh" fails for any CUDA 12.x version.
With CUDA 13.0, it works for that step, but then fails when building with "cmake --build build --config Release".
The system NVidia driver (580.76.05) reports support for CUDA 13.0; I can't downgrade.
I didn't have issues until a few weeks ago, but I had a previous NVidia driver with CUDA 12.x support.
Anonymous
9/4/2025, 2:42:42 PM
No.106481945
[Report]
>>106475450
>>106475364
>>106475338
>>106475313 (OP)
Holy shit that's my picture. Behold me anons. I am happy.
llama.cpp CUDA dev
!!yhbFjk57TDr
9/4/2025, 2:59:42 PM
No.106482084
[Report]
>>106481911
I have installed both CUDA 11 and 12 on one of my systems, to switch from the default CUDA 12 to CUDA 11 I have to do:
export CUDA_HOME=/opt/cuda-11.7 && export PATH=$CUDA_HOME/bin:$PATH && export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
Anonymous
9/4/2025, 2:59:53 PM
No.106482087
[Report]
>>106481714
>as far as I know, in MoE, only 1 expert is active at a time.
You don't know, then. Because all of the larger MoE models (deepseek, qwen3, glm4.5) use 8 experts per token.