i'm training a chroma lora using diffusion-pipe. previously, i've trained using a single resolution on all images. for example, a lora i did recently had 100 images, and i used a micro bath size of 4, meaning i had 25 steps per epochs. it's simple and it made sense.
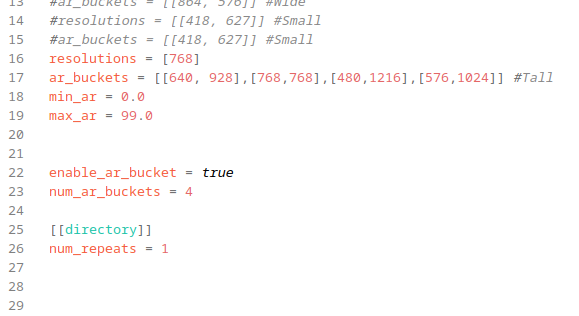
however, i decided to test making a lora with several different resolutions, so i resized my training data into 4 different resolutions, and set those as my bucket sizes. but now when i train my lora, around 70 images total, i am now getting 7 steps per epoch. and at a batch size of 4, that tells me it's only training on 28 images or so.
i've made sure that there are enough images in each bucket so that they dont get skipped. i've watched the output in my terminal and seen that all images have been cached before training started. i've put my output into various chat bots and i dont really trust their response.
is this expected when using multiple buckets, or is something terribly wrong? to me it seems like it's skipping more than half the training images for some reason.
4chan Search
1 results for "b1a8cc5876b4f23e616bf28afc01bbde"