>>42476094
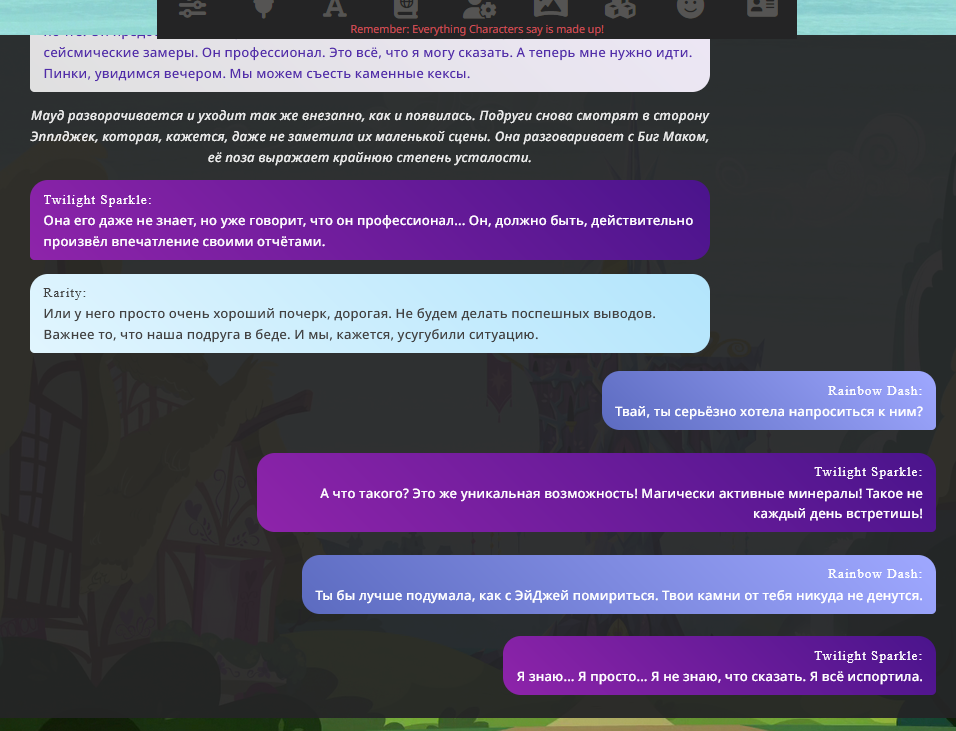
it still varies from model to model but yes it indeed has changed - Gemini feels alright until 40,000. new Sonnet 4 too. GPT-5. so on. Deepseek is meh on longer context, I honestly think it falls apart after 25000 already. unsure about Grok 4. of course the actual performance depends on your story - the more clear and non-obtuse formatting you are using, the easier for model to follow. all my stories are formatted in chat-like format see picrel:
1) dialogue are written by model and me as
>twilight_sparkle: text
and then regex converts it into HTML and CSS is applied
2) occasional narration is inserted as you can see on the screenshot
3) text on the left - is a "public space" where lots of characters talk at once and narration happens, text on the right is a "private space" where 2 characters talk with each other and only them two remember the content of their talk
4) and at the start of every reply I do thinking which collects all the facts from the story before an actual reply
and from how this thinking works I can tell that Gemini 2.5 is doing fine on ~40,000. it CAN be because I am using a highly structured data with clear indication which character says what, but still the fact is fact
4chan Search
1 results for "dc71d0f0a8f2d0242ec7c068e69a15c4"