>>106471064
>>106471100
>>106471187
Why exactly do "we" expect a supervised learning next token predictor to be factual anyway? There's no real understanding, just predicting the nearest or most likely outcome. Considering this, I'm surprised that small sub 8B basemodels are even capable of outputting anything, really.
ENTER:
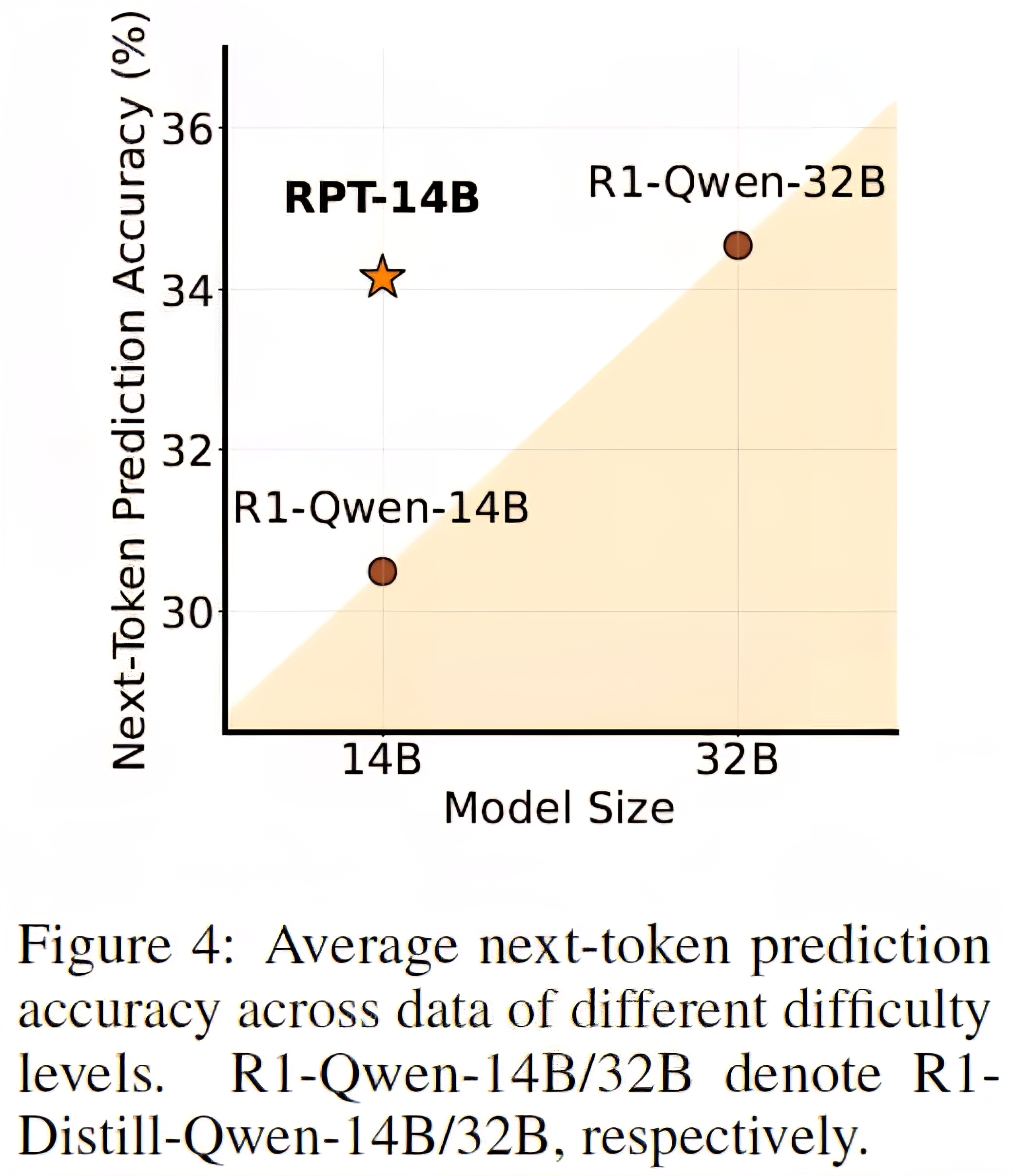
reinforcement pre-training
I don't think there's a open source model yet which uses something like this, but it could be key for AI advancement. Even if it's just a small part of a MoE model or a reasoning/thinking orchestrator guiding the LLM.
The theory of teaching a model how to think instead of what to think first sounds more logical to me than the current approach, which seems to be to first teach the what (pre training) and then the how (fine tuning). I guess in theory a LLM trained solely in logic with RL and connected to websearch/knowledge would produce remarkable results. But then again surely there would be downsides as well, like reasoning/thinking time needed to come to the correct conclusion
4chan Search
1 results for "e0253610ef18bf4e0bc576a8f90a23f4"