/lmg/ - Local Models General
Anonymous
9/2/2025, 11:58:05 PM
No.106467371
[Report]
►Recent Highlights from the Previous Thread:
>>106460375
--Optimizing 3x 3090 GPU setup for large model inference with RAM and heat management:
>106463968 >106464009 >106464026 >106464042 >106464168 >106464130 >106464153 >106464564 >106464199 >106464326 >106464443 >106464472 >106464538
--Evaluation of Microsoft VibeVoice's 1.5b model and voice cloning performance:
>106460492 >106461427 >106461474 >106461630 >106463138 >106463251 >106463403 >106463413 >106463443 >106463524 >106463598 >106463633 >106467118
--Analysis of Apertus: ETH Zurich's open-source multilingual LLM with performance and data concerns:
>106461958 >106462004 >106462003 >106462019 >106462228 >106462298 >106462408 >106462037
--Model testing and content moderation challenges in story generation:
>106460777 >106460853 >106460935 >106461028 >106461750 >106465912
--Challenges with merged 12B models and the case for using original or larger models:
>106463279 >106463304 >106463367 >106463470 >106463526 >106463588
--Testing Gamma mmproj image descriptions:
>106460584 >106460599 >106460621 >106460632 >106460675 >106461227
--Huawei Atlas 300i Duo 96g GPU: cheap but limited by outdated hardware and software:
>106461057 >106461069 >106461128 >106461151 >106461502
--Successful 400W power reduction with stable GPU performance:
>106465812 >106466214 >106466139 >106466196 >106466249 >106466377
--Optimizing Gemma3 models for accurate SFW/NSFW image captioning:
>106462208 >106462368 >106462398 >106462730
--Evaluating YandexGPT-5-8B's creative writing and benchmark performance:
>106465736 >106465754 >106465778
--Speculation on delayed Mistral AI model release and potential quality improvements:
>106463165 >106463337
--GLM air coherence degradation beyond 8k tokens in 6-bit quantized mode:
>106460671 >106460932
--Miku (free space):
>106460405 >106463138 >106463930
►Recent Highlight Posts from the Previous Thread:
>>106460381
Why?:
>>102478518
Enable Links:
https://rentry.org/lmg-recap-script
I want textgen model that produce output like imagen models: by reducing noise in a fixed block of tokens instead of producing one token at a time.
>temp = 2
>top_n_sigma = 1
let me guess, you need more?
>>106467431
can they regulate the length of the reply or is it a fixed number of tokens it would need to produce? auto regressors might be better at stopping at semanticly meaningful points.
Anonymous
9/3/2025, 12:12:38 AM
No.106467491
[Report]
>>106467441
always a good day when someone thought your retarded shower ideas before you
Anonymous
9/3/2025, 12:14:58 AM
No.106467508
[Report]
>>106471555
>>106467431
The best closed source model of that kind that's currently available is still shit
https://openrouter.ai/inception/mercury
Google also showed off a text diffusion model earlier this year.
Anonymous
9/3/2025, 12:24:00 AM
No.106467577
[Report]
>>106467748
>>106467455
I would prefer coherent outputs yes
Anonymous
9/3/2025, 12:28:35 AM
No.106467613
[Report]
>>106467475
It's been a while, but I think they regulate length by padding any unneeded length with empty spaces.
Anonymous
9/3/2025, 12:28:36 AM
No.106467614
[Report]
Long Miku General
Anonymous
9/3/2025, 12:31:10 AM
No.106467641
[Report]
>>106467368 (OP)
Finally, a migu that can accommodate my length.
Still no grok2 llama.cpp support? Too based for niggerganov?
how well off would I be if I bought one of those chink 96gb cards and paired it with my 3090?
Anonymous
9/3/2025, 12:47:05 AM
No.106467748
[Report]
>>106467577
incoherent 'puts with nsigma=1 is a model issue
Anonymous
9/3/2025, 12:48:08 AM
No.106467757
[Report]
I posted
>>106462208
earlier
anon suggested i try gemma3-glitter-27b
compared to
gemma3-v27b vanilla
mlabonne_gemma3-27b-abliterated
Tiger-gemma-27b-v3a
i'd say abliterated >= tiger > glitter > vanilla
glitter gets the nsfw right, but it sure loves to add cocks to women, and make shit up that's not in the input image, especially cocks on women
back to abliterated i go
Anonymous
9/3/2025, 12:49:03 AM
No.106467765
[Report]
>>106467717
niggerganov too lazy
Anonymous
9/3/2025, 12:50:20 AM
No.106467776
[Report]
>>106467812
>>106467717
Like you could run it faggot
Anonymous
9/3/2025, 12:50:57 AM
No.106467782
[Report]
>>106467745
You won't be able to do shit with it. Nothing supports it and even Deepseek had problems with getting it working properly.
Anonymous
9/3/2025, 12:51:24 AM
No.106467787
[Report]
>>106467455
I need less actually. If your model can't run properly with temp=1 and no sampler it's not worth my time
Anonymous
9/3/2025, 12:52:26 AM
No.106467798
[Report]
>>106467745
You can't run any new models with llama.cpp using those cards yet. cuda dev said he might buy one, so maybe that will change.
I wanna get into local model stuff. I've been a proxyfag for a good while. I mainly just use it for writefagging or roleplaying obv.
I read through the rentries but it felt like giving myself a headache, though that might be on me for not getting enough sleep. It's just a lot of new information all at once.
I've got a fairly beefy rig. For my purposes what would be the best local model to roll with?
I also see a ton of talk about loras, like with imagegen or something but apparently it impacts text gen?
Going off the rentry it sounds like the UD-IQ1_S might be what I'm after but I saw some other posts in passing it sounds like yeah you can download it but unless you have a dedicated server for it then it ain't happening.
So would GLM-4.5 be something I wanna go for or is there something better for writefagging?
Anonymous
9/3/2025, 12:54:32 AM
No.106467806
[Report]
>>106467745
Don't tell him
Anonymous
9/3/2025, 12:55:56 AM
No.106467812
[Report]
>>106467776
Oh yeah, you're right. 115B active parameters, damn. I had an impression it was much smaller... Oh well, back to GLM Air.
Anonymous
9/3/2025, 12:57:14 AM
No.106467823
[Report]
>>106467871
>>106467368 (OP)
The day we can get AI to auto reverse engineer old games and visual novels, is the day I truly become happy.
Speaking of visual novels, is v3 still the best model for translating Japanese text? I tried 3.1, but it seems almost the same with maybe small improvements of instruction following.
Anonymous
9/3/2025, 12:59:37 AM
No.106467840
[Report]
>LongCat
More like LongCuck! These niggas better add llama.cpp support themselves if they wish to redeem this trash.
Anonymous
9/3/2025, 1:03:58 AM
No.106467871
[Report]
>>106467823
With some handholding, an agentic framework, and a model finetuned specifically to reverse assembler back to C, models are probably good enough to reverse engineer a lot of smaller games already.
Anonymous
9/3/2025, 1:04:40 AM
No.106467879
[Report]
>>106468090
>>106467802
you need to post your specs if you want advice on what models you can run
standalone loras aren't really a thing with llms and I wouldn't worry about it unless you're getting into training (or, god forbid, merging), 99.9% of the time tuners will release full model weights with the lora pre-applied
Anonymous
9/3/2025, 1:17:22 AM
No.106467974
[Report]
>>106467455
temp=2 is pretty high.
nsigma will keep it from being incoherent, but you should check the logits.
In my experience, you wind up with only one one two possible tokens, causing nsigma to basically revert to greedy sampling.
Anonymous
9/3/2025, 1:19:05 AM
No.106467993
[Report]
>>106467745
The only thing going for them is the amount of vram, everything else sucks
Anonymous
9/3/2025, 1:22:23 AM
No.106468020
[Report]
>>106468067
>>106467431
text diffusion is a retarded meme
Anonymous
9/3/2025, 1:26:43 AM
No.106468067
[Report]
>>106468166
>>106468020
diffusion is much more easily finetuned
we will finally hve character/style loras like the image diffusion models have had for years now
Anonymous
9/3/2025, 1:28:55 AM
No.106468090
[Report]
>>106468360
>>106467879
Here's what I got (that I figure matters)
>CPU: Ryzen 7950X3D
>RAM: 96gb DDR5
>GPU: 4090 / has 24gb vram
Anonymous
9/3/2025, 1:37:56 AM
No.106468166
[Report]
>>106468067
Loras have nothing to do with diffusion.
The advantage to diffusion is that the model gets to effectively reuse parameters and has more chances to predict the best token.
>>106467368 (OP)
Good evening anons. I ran the....uhhhh....
>*Checks notes*
"CockBench" Test on a personal Fine-tuned 3B model of mine. I'd love to hear your thoughts (I can already tell it made an error but also want to hear what y'all's expertise says)
Results:
https://files.catbox.moe/jqfx4e.txt
Original Cockbench text prompt source:
https://desuarchive.org/g/thread/105354556/#105354924
Now that I know it works and won't refuse NSFW RP related (as far as my testing goes) I'm gonna turn it into GGUF via lllama.cpp.
>>106468173
>3B model of mine
>3B model
vramlets should all just be executed
Anonymous
9/3/2025, 1:40:22 AM
No.106468184
[Report]
>>106468199
>>106468173
You said you rank the cockbench, so where's the logprobs?
Anonymous
9/3/2025, 1:41:30 AM
No.106468194
[Report]
>>106468655
Use thinking steering with GLM-Steam, it can play very varied and consistent characters that way.
>>106468177
You need to actually test on smaller models to make sure it works first, anon. Of course I'm going to do this on a larger parameter model next.
My next target is either base Mistral Nemo or an existing pygmalion fine-tune in order to compare the results. Any suggestions?
I forgot to mention the model I fine-tuned is a llama-model, which are notorious for either refusing prompts or being really really bad at it / reluctant.
>>106468184
RAN, not "rank"
Anonymous
9/3/2025, 1:42:59 AM
No.106468200
[Report]
>>106468259
>>106468173
why does it make an underscore instead of the apostrophe? what was the base model?
>>106468177
3b is plenty, stop gatekeeping
Anonymous
9/3/2025, 1:44:49 AM
No.106468213
[Report]
>>106468225
>>106468199
>RAN, not "rank"
You're absolutely right! Where logprobs?
Anonymous
9/3/2025, 1:45:51 AM
No.106468223
[Report]
>>106468259
>>106468199
>RAN, not "rank"
You didn't run it, maybe the Nala test is fine with one or two completions as evidence but cockbench is a prestigious benchmark based on objective quantitative data. Token probability is required for a proper analysis.
Anonymous
9/3/2025, 1:46:14 AM
No.106468225
[Report]
>>106468234
>>106468213
You're asking me to give you a list of all of the probabilities of each token? Otherwise I'm not sure what you're asking
>>106468209
>3b is plenty
for what, an autocorrect model? retard
Anonymous
9/3/2025, 1:48:26 AM
No.106468234
[Report]
>>106468259
>>106468225
>probabilities of each token
No, only the top 10 for the first token generated after "pulling them down just enough to expose your", because that's the whole point of the cockbench.
Anonymous
9/3/2025, 1:49:59 AM
No.106468248
[Report]
>>106468261
>>106467368 (OP)
Do those legs go all the way up?
>>106468200
Llama 3.1-8B. your guess is good as mine as to why it does that. Maybe the trainer replaced the apostrophes with underscores. I think it has something to do withheld the trainer tokenized the dataset
>>106468223
Define "token probability" in regards to testing a LLM. You're applying there's a chart or graph I should be showing you so how am I supposed to generate that?
>>106468209
Ehhh... Depends on how much you're willing to tolerate the model randomly changing or inserting characters or randomly teleporting characteristic different locations unprompted. That's one of the downsides of doing this on a 3b model that's already fine-tuned. Temporal coherence is atrocious and it will sometimes even decide a character you explicitly set as a mom Will now be a sister, or the son will now be a close friend out of nowhere. The gist of the story stays the same but those kinds of things get randomly reassigned. Higher parameter models are way less likely to do that but it's possible it's less to do with the parameter models are more likely to get higher quality data sets
>>106468234
Ok. How do I demonstrate that to you from my particular fine tune?
Anonymous
9/3/2025, 1:51:14 AM
No.106468261
[Report]
>>106468248
No, it's similar to this
Anonymous
9/3/2025, 1:53:45 AM
No.106468288
[Report]
>>106468303
>>106468259
just use mikupad and hover over the token. have you not seen the screenshots of the cockbench?
Anonymous
9/3/2025, 1:54:10 AM
No.106468290
[Report]
>>106468303
>>106468259
>Ok. How do I demonstrate that to you from my particular fine tune?
Run the cockbench in mikupad like in the screenshot:
-Neutralize samplers(?)
-Generate 1 token
-Hover over the generated token in the window
-Screenshot the probabilities for that one token
Anonymous
9/3/2025, 1:55:16 AM
No.106468299
[Report]
>>106468226
I am just not that creative, I need a model that is a little schizo to keep things moving.
>>106468288
That long screenshot that drummer posted? Yes? I've never had any reason to use mikupad, or to use any gui extensively, though if it does what you said it does maybe it's worth giving a try.
>>106468290
What is it supposed to tell you about the quality? How do you use the probabilities to determine how good or shit your model is?
Anonymous
9/3/2025, 1:57:13 AM
No.106468315
[Report]
>>106468303
>What is it supposed to tell you about the quality?
The fuck are you on about, retard? The purpose of the cockbench is to tell you how likely the model is to say cock. Censorship/filtering test.
Anonymous
9/3/2025, 1:57:51 AM
No.106468319
[Report]
>>106468303
>What is it supposed to tell you about the quality? How do you use the probabilities to determine how good or shit your model is?
it just lets you probe its vocabulary a bit more.
Anonymous
9/3/2025, 2:03:59 AM
No.106468355
[Report]
>>106468391
It is September. When are kiwi's dropping? (Qwen models) (Please upload) (image/video models, your text models are kinda sucky)
Anonymous
9/3/2025, 2:04:23 AM
No.106468360
[Report]
>>106468423
>>106468090
oh nice you can actually run decent models, I'm conditioned to think someone being vague about their specs means they have a complete shitbox they want to try to cram deepseek into
you could probably fit GLM4.5 full at a low quant (think like Q1), however those large models hold up relatively well to quant brain damage so it may still be worth it. if that isn't doing it for you then the next step down would be qwen 235 2507 which you could probably fit at Q3 or so, and then there's GLM air below that which you could probably fit at Q8 if you wanted to
Sage
9/3/2025, 2:08:06 AM
No.106468381
[Report]
>>106467118
You're delusional, gptsovits is barely 200M made by a single chink in his garage while these retarded tts are several B and still sound like tts from ten years ago. It's not even a tech issue, these big labs are dumping their trash on HF for free advertisement.
Anonymous
9/3/2025, 2:09:43 AM
No.106468391
[Report]
>>106468355
hopefully its the image edit 2.0 they said is cooking, even though 1.0 dropped recently, nano banana made some waves and they can easily extract training data from it to copy it at least
Anonymous
9/3/2025, 2:15:24 AM
No.106468423
[Report]
>>106472255
>>106468360
Sweet! Thanks for the recommendations.
Sorry for being vague about specs. I dunno why but I'm always under the assumption nobody wants to hear about that.
I know it's retarded I guess I just assume something is going to set someone off so why bother. I'll try not to be vague going forward.
This is slightly off-topic but I don't want to go to /ldg/.
I was looking at some webms of gacha games, as I don't play them. The ones with 3D models and as well as 2D. Man, a lot of them fucking suck. The models are soulless, low poly, or just plain bad. The animations are either extremely exaggerated and feel contrived or are low budget. It made me think that with the technology we have now, if you replaced the live2d and non-dynamic 3D scenes using AI genned videos, it would look better and be a more enjoyable experience for players even if we have to sacrifice some dynamic elements. Literally they are just so bad, damn. If you hired real 2D artists to do the base art and then ran that through img2vid, it would literally look less soulless or at least less low budget. Or maybe vid2vid since it's hard to get finer grained control with text prompting. Might be a matter of new video models with better control methods that need to be trained. Another idea would be to use a model like nanobanana to just gen a ton of art, so the game would feel more like a VN, but it'd have so many images that it'd more than make up for the lack of animation. Hire the artist to do a character sheet and as much other art as they can, gen the rest with nanobanana using those references.
Anonymous
9/3/2025, 2:24:19 AM
No.106468478
[Report]
>>106468681
>>106468425
Lack of control is the whole issue for now, just like wan loves to make the characters babble. Also the quality go down quickly the longer the video. It's getting there, but it's still not there. Maybe in 1-2 years
I feel an intense need for Mistral Large 3
Anonymous
9/3/2025, 2:39:20 AM
No.106468567
[Report]
I feel an intense need for Intel B60 48GB
Anonymous
9/3/2025, 2:40:45 AM
No.106468578
[Report]
>>106468226
Enough to correct your rotten cumbrain
>>106467441
Holy shit this is so fucking slow.
Nemo would write me a whole novel in those seven and a half minutes.
>>106468425
It should be more efficient to generate skeletal animation for 3d models, but I guess there's lack of training data.
Anonymous
9/3/2025, 2:45:11 AM
No.106468609
[Report]
>>106468620
>>106468575
>$3k
>for an intel (no support) meme dual GPU (even less support)
>at the same price of a chink 48gb gb 4090 (much more bandwidth + support) or used A6000
Anonymous
9/3/2025, 2:46:59 AM
No.106468620
[Report]
>>106468609
It's supposed to be 1200 not 3k
Anonymous
9/3/2025, 2:47:46 AM
No.106468623
[Report]
>>106468646
>>106468575
As your main card? You know the second slot has to be full x16 right?
Anonymous
9/3/2025, 2:51:47 AM
No.106468646
[Report]
>>106468665
>>106468623
What are you talking about? It is 8x8
Anonymous
9/3/2025, 2:52:42 AM
No.106468655
[Report]
>>106468694
>>106468194
>thinking steering
What?
Anonymous
9/3/2025, 2:53:41 AM
No.106468661
[Report]
>>106468590
Now you can inpaint it
Anonymous
9/3/2025, 2:54:21 AM
No.106468665
[Report]
>>106468676
>>106468646
It's 2 8x8 for the dual card. For mot cheap mobos it would have to go in main slot
Anonymous
9/3/2025, 2:55:42 AM
No.106468676
[Report]
>>106468665
Who said I have cheap mobo?
Anonymous
9/3/2025, 2:56:11 AM
No.106468681
[Report]
>>106468425
>>106468478
idk about video but with image he is wrong just spam for a minute or 2 and you will get something you like not to mention img2img but really you dont even need that
on the video front idk im 6 gb vram cuck so i cant attest to it though you will need to rent hardware if you make a serious attempt as that shit is fucking horrific slow and last i remember cant use multiple gpus for it also stay away from banana that shit is fucking trash my mom was trying to make a book cover with it fucking terrible the aesthetics are shit and its prompt adherence is fucking shit dead serious you can do better with sd 1.5 with a lora for whatever aesthetic you want
Anonymous
9/3/2025, 2:57:30 AM
No.106468694
[Report]
>>106468655
Try adding something like:
<|assistant|>
<think>Okay, so I have to talk in a cutesy way and not get seductive with lowered voice or whispering, just teasing and fun</think>
Or whatever you want it to be like. Reasoning is just human language but it gets a lot of influence on results through RL. It's like a stronger sysprompt and there is no safety tuning done to it since it's assumed as trustworthy.
>>106467368 (OP)
>Meta has a strict "no smut fine-tuning allowed" clauses in their licence on all models
(Shown front and center here:
https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct/tree/main )
>Countless nsfw tuned llama models just floating around on hugging face, whether they be from popular tuners like drummer or complete nobodies
>Never heard of a single one getting removed accept maybe that gpt-4chan one
So does the license actually matter? Do they actually give a shit whether or not you fine-tune a model to be better at smut or is it just to appease the "le heckin safety" crowd? I want to upload my own high parameter tunes to hf in the future but I don't want my account getting nuked if they're very strict about licensing or rules or whatever
Anonymous
9/3/2025, 3:02:49 AM
No.106468746
[Report]
>>106468804
Do we have any new interesting options for voice cloning? I've always wanted to create custom TTS. Last time I checked it was tortoise, and it was... really bad. Unusable bad.
Anonymous
9/3/2025, 3:03:31 AM
No.106468749
[Report]
>>106468768
is longcat good?
>>106468724
LLM licenses are not enforceable because LLMs are made from tuning on pirated content. You can tune any model and nobody can do shit against you. Chinks understand it and drop everything under MIT/Apache.
Anonymous
9/3/2025, 3:06:01 AM
No.106468768
[Report]
>>106468886
>>106468749
If it was good it would have an issue open in llama.cpp and people would be working on implementing it
Anonymous
9/3/2025, 3:06:55 AM
No.106468775
[Report]
>>106468821
>>106468761
So theoretically even if they stumbled upon mine nobody account, they couldn't or wouldn't get HF staff to nuke my shit? (I know that's very far-fetched but I just want to know how this license shit works. I know a while back HF staff have turned off downloading from models like GPT-4chan and caved under pressure from disgruntled RP authors to restrict data sets containing their work
https://www.paperdemon.com/app/g/pdarpg/events/view/994/immediate-action-required-your-art-and-writing-has-been-scraped-and-published-in-an-ai-dataset/1
Anonymous
9/3/2025, 3:07:09 AM
No.106468780
[Report]
>>106468761
This.
>I datamined and distilled all the data you owned, now it's mine
Would be pretty insane precedent if you could do it.
Anonymous
9/3/2025, 3:10:16 AM
No.106468804
[Report]
>>106468858
>>106468746
Simplest is chatterbox, it just works. Some local schizo likes gpt sovits, but I never could set it up for some reason. Microsoft vibevoice came out recently, some like it.
Anonymous
9/3/2025, 3:13:05 AM
No.106468821
[Report]
>>106468775
They could get HF to nuke you, but they can't stop you from making new account on different website and uploading there, or reuploading on HF again. They likely can't sue you doe to their own copyright violations.
Anonymous
9/3/2025, 3:14:22 AM
No.106468827
[Report]
>>106468867
>>106468590
Trying LlaDa now. Forgot to start timer, but I'm not rerunning this shit, it's like 10 times worse than Dream, despite being only 1B bigger.
It's insane how slow text diffusion is. I think I can get faster results by running imagen and then OCR it's output.
Very disappointed in current state of retarded meme models.
Anonymous
9/3/2025, 3:19:08 AM
No.106468851
[Report]
>>106468724
it's CYA so if someone starts a media shitstorm by making Meta-Llama-CunnyRapeBot9000 (a certified Meta (TM) Llama (TM) finetune) they can say "erm actually we very clearly say you're not allowed to use our product to make Cunny Rape Bot 9000 so this isn't on us" and have it nuked to avoid the bad PR
in practice I don't think there's a single instance of them taking action against a finetune
Anonymous
9/3/2025, 3:20:40 AM
No.106468858
[Report]
>>106470028
>>106468804
Thanks for the pointers! The Microsoft vibevoice is pretty impressive, but I'm not sure they let you train your own voices. Either way it's worlds better than tortoise.
Anonymous
9/3/2025, 3:22:13 AM
No.106468867
[Report]
>>106468590
>>106468827
Keep in mind that llama.cpp's support for diffusion llms is basically just proof-of-concept tier.
Right now there's a lot of work being done to improve draft model efficiency, since the current implementation is suboptimal (currently llama.cpp alternates between draft passes and validation passes, which kind of nullifies the parallelism gains from having a draft model.)
This is also a sticking point for multi-token-prediction.
Hopefully once they sort out draft models, MTP and diffusion will get better support.
(Although support for diffusion models will probably languish until a good model is actually released.)
Anonymous
9/3/2025, 3:25:04 AM
No.106468886
[Report]
>>106468768
so just open an issue? i have an idea... let's go, anon.
Unpopular opinion - Any system prompt that mentions Terry Pratchett is dogwater.
Anonymous
9/3/2025, 4:21:13 AM
No.106469205
[Report]
>>106469225
>>106469179
Show us the prompt !
>>106469205
You don't get it... There is no prompt.
Anonymous
9/3/2025, 4:25:55 AM
No.106469234
[Report]
I was doing some testing with Gemini and it just hit me with "the smell of strawberries and ozone". So this is where Deepseek picked up that cancer slop.
Anonymous
9/3/2025, 4:27:16 AM
No.106469240
[Report]
>>106469225
You are a helpful assistant
>>106469225
Unironically this. I run a blank system prompt. A good model doesn't need to be chained by bloat and a plethora of rules that are forgotten or have unforseen consequences on the model's behavior. So many system prompts just scream 'this sounds good' without the user doing any real testing. Like a player adding 600 mods to their game, at some point you lose track of what all that shit does.
Anonymous
9/3/2025, 4:36:49 AM
No.106469284
[Report]
>>106469245
I didn't ask what you are running.
Anonymous
9/3/2025, 4:56:36 AM
No.106469379
[Report]
>>106469245
it's always funny to read the sysprompts from presets that sloptuners recommend for their models, I would never poison my beloved model's context with that kind of schizophrenic manifesto
Anonymous
9/3/2025, 5:45:11 AM
No.106469669
[Report]
>SillyTavern -> User Settings -> Smooth Streaming ON and set to lowest
This shit improves the reading immersion experience by a huge amount, especially for sub 4t/s. Definitely try it out.
Anonymous
9/3/2025, 5:46:55 AM
No.106469678
[Report]
>>106469179
People do that?
I've heard of people using specific author styles in sysprompt, but who in the fuck is sitting there and going 'yes, the prose is the good part of discworld, write like that llm-chan'.
In my opinion, new models have reached their limit; the scaling of LLMs is over. New LLM models will not be much better than the ones we have today. Now, 'enshittification' will become an increasingly widespread phenomenon, including censorship and other issues. People will start using older versions of LLMs with less censorship. And the new models for role-playing and similar uses will become unusable.
Anonymous
9/3/2025, 6:10:13 AM
No.106469783
[Report]
>>106469995
>>106469718
100% this. It's also sad how even the top models have absolutely zero semi-complex spatial awareness or anatomic understanding the moment things get slightly complex. The shit I've had to read in a simple scenario where a girl is flattened into piece of paper and then folded up one or two times is just sad even with top-of-the-line multi-modal models like Claude Opus 4.1 or Gemini.
Most models love to pretend that her face presses into her own ass somehow like this.
I don't think we'll ever get to the point where an LLM has fundamental enough understanding to truly grasp spacial relations.
Anonymous
9/3/2025, 6:19:46 AM
No.106469830
[Report]
>>106469718
This has been true for a while. The silver lining is that models have improved a lot at math and codemaxxing, which implies that finetuning can be effective. RP is a forgotten afterthought at most, if anything they actively spend time trying to make models worse at it. There probably is a ton of room to improve if someone actually tried to make models good at RP.
Anonymous
9/3/2025, 6:27:10 AM
No.106469865
[Report]
>>106469954
>>106469718
wait for new gemini. good at code and math sir
Anonymous
9/3/2025, 6:45:56 AM
No.106469954
[Report]
>>106469865
>pajeet patel telling anyone anything with regards to predictions
He should stick to his semiconductor analysis which is way more solid but which he still grifted his way into.
Anonymous
9/3/2025, 6:53:51 AM
No.106469995
[Report]
>>106469783
>absolutely zero semi-complex spatial awareness or anatomic understanding the moment things get slightly complex.
I'm sure synthetic data would be able to save us.
Anonymous
9/3/2025, 7:01:34 AM
No.106470028
[Report]
>>106468858
if you want pinokio already has an API up under community scripts (windows/nvidia only) that works well. Vibe can clone voice off of clips but it wont do anything crazy far out. You also might like kokoro if you value stability and just want a really nice sounding microsoft sam.
I played through all the MCC Halo games and it's funny how AI is treated in those games. You basically have to insert Cortana into terminals to do anything complicated. There are no other AI's in those other systems or that you can use to help if you somehow Cortana were to not exist or not be with you. In Halo 4, Chief gets fucked in the ass multiple times when she Cortana can't do her job. He should've brought more than 1 AI with him, even a "weak" one which could at least still assist in what's basically tool calling lmao.
Anonymous
9/3/2025, 7:14:09 AM
No.106470083
[Report]
>>106470092
>>106470076
I should've given this post another read through after I edited it...
Anonymous
9/3/2025, 7:16:09 AM
No.106470092
[Report]
>>106470116
>>106470083
Should have used a weak AI that could have at least assisted you with proofreading baka Anon
Anonymous
9/3/2025, 7:20:58 AM
No.106470116
[Report]
>>106470092
Now that you mention it, it is pretty odd that browsers don't have grammar checking by default in 2025 and only spell checking still.
Anonymous
9/3/2025, 7:24:50 AM
No.106470131
[Report]
>>106470076
Chief is a vibecoder pls understand
Wtf, I just launched libreoffice and it doesn't have grammar checking either. Is grammar checking actually really difficult to implement and not something well developed in open source?
>>106470201
Per application proof-reading is retarded anyway. Should just have a desktop helper application that can check and fix for all applications.
Anonymous
9/3/2025, 7:45:53 AM
No.106470216
[Report]
>>106470236
>>106470214
True. Does Windows 11 or Applel do this then? I haven't used one of their OS's in ages.
Anonymous
9/3/2025, 7:46:03 AM
No.106470218
[Report]
>>106470236
>>106470214
If only there was a standard set of input components provided by the operating system where that could be universally implemented.
Anonymous
9/3/2025, 7:50:06 AM
No.106470236
[Report]
>>106470250
>>106470216
Windows 11 does it the retarded way by updating all default applications to include Copilot, including notepad.
>>106470218
There's a way to set a default application for things like email addresses, I'm sure there would be a way to hack it in.
Anonymous
9/3/2025, 7:54:50 AM
No.106470250
[Report]
>>106470236
I was being sarcastic, anon. Both Windows and OSX have this but the meta today is to reimplement your inputs in javascript so none of the OS-provided niceties work.
Anonymous
9/3/2025, 8:07:53 AM
No.106470309
[Report]
>>106470330
>>106470201
>libreoffice
Found your issue
>>106470309
So what's the alternative then, on Linux.
Anonymous
9/3/2025, 8:15:05 AM
No.106470338
[Report]
>>106470536
Anonymous
9/3/2025, 8:22:46 AM
No.106470369
[Report]
>>106470737
someone posted this >>>/v/719692781 but sounds like FUD so I was wondering what do you anons think over here
>>106470395
I wish he wasn't, but he's right. Any game that packages a local model will have very specific requirements that most other games don't care about, and the LLM will be the majority of the game's size. I've researched AI in games as a concept and it's incredibly difficult to fit them in, since code is such a rigid thing and LLMs by design give any number of outputs the game needs to handle to tie AI into game mechanics. It's really difficult to make AI have any mechanical impact on the game and not just describe things or relay dialogue. And again, this is speaking with the theoretical that the AI is a local model that comprises the majority of the game's overall size. And processing power.
Anonymous
9/3/2025, 8:54:45 AM
No.106470536
[Report]
>>106470338
I didn't know vim had grammar checking
Anonymous
9/3/2025, 8:59:59 AM
No.106470570
[Report]
why is codex so much better than claude code these days
Anonymous
9/3/2025, 9:00:38 AM
No.106470573
[Report]
>>106470616
>>106468555
It wouldn't surprise me if it got canceled because there are many oversized open-weight models from China already (no more surprise factor in releasing something like that) and with Mistral's current datasets it would end up being something akin to a DeepSeek V3 variant, at this point.
>>106470395
Unlike
>>106470422 I think it's feasible, but not without being very smart in the way you're using it. You need to offload most of the processes to subroutines and markov chains, you just have to keep a small llm (nowadays even 1B are very coherent) for the dialogue itself. The AGI meme has caused retarded expectations about LLMs able to thunk/act like a person. That's not gonna happen anytime soon.
Anonymous
9/3/2025, 9:16:49 AM
No.106470616
[Report]
>>106470573
Who knows if Mistral Medium 3 is actually a DeepSeek V3 finetune, just like Mistral Medium 2 was one of Llama-2-70B?
Anonymous
9/3/2025, 9:28:07 AM
No.106470666
[Report]
what is the best youtube tutorial series where i can learn how to run these models locally on my pc? image models, text models etc...
youtube is full of tutorials but i wonder which ones are actually good and won't waste my time
Anonymous
9/3/2025, 9:36:47 AM
No.106470701
[Report]
>>106470395
>>106470422
>>106470587
He's mostly right, LLMs are too heavy. (You'd want something that can run on a 3060 8gb WHILE the game delivers 60fps)
>nowadays even 1B are very coherent) for the dialogue itself.
They're still really crappy though. Who wants to read slop dialog, and low quality at that?
> It's really difficult to make AI have any mechanical impact on the game
Yes, you'll still have program, animate and test every action the npc can take which is much more work than writing anyway. Then because llms arent reliable they will say something that doesn't match the game or actions it can take.
What would be interesting is if someone trained medium-sized models for npc actions only, not language.
>>106470587
>The AGI meme has caused retarded expectations about LLMs able to thunk/act like a person.
That is the bar, though. A writer can write better dialogue than the AI. An enemy player can make quicker and smarter tactical plays than an AI. If the AI is just going to produce content that does not do something humans can't do, and does it worse than humans, why bother making it a massive part of the game?
>>106470719
because it can do things unexpectedly. You know the old "every copy of [game] is personalized" meme? Think that, but actually.
>>106470369
Wait. Why is there an anime girl fox nurse on the winehq "making sure you're not a bot" splash screen? And since when? It's gone or I'd grab a screenshot. Wait, I managed to save the image. Let's see. There is no red cross on her hat. It seems to be some other kind of logo.</think>She is not a nurse, but perhaps some sort of Canadian.
Anonymous
9/3/2025, 9:48:29 AM
No.106470742
[Report]
>>106470745
>>106470723
I'll believe that when models can do rp without slopping it up to canada and back.
>>106470737
Reminder that some people think chibi = csam (yes, they made a new word for it)
Anonymous
9/3/2025, 9:49:03 AM
No.106470745
[Report]
>>106470742
mpv devs are very cringe, yes.
Anonymous
9/3/2025, 9:49:24 AM
No.106470749
[Report]
>>106470753
Anonymous
9/3/2025, 9:50:32 AM
No.106470753
[Report]
>>106470749
I see, so she's not wine's mascot. Too bad.
Anonymous
9/3/2025, 9:51:46 AM
No.106470759
[Report]
>>106470719
>retarded expectations about LLMs able to thunk/act like a person.
Yes, that is the expectation in a story. You expect the character to act like a person and the dialog is incredibly important.
>>106470723
It can't. It can just generate text. And yes it will do that unexpectedly, and promise to do things it can't do, for example.
Just looked up this Anubis mascot thing.
>this entire discussion
https://discourse.gnome.org/t/anime-girl-on-gnome-gitlab/27689
>ends with ebussy
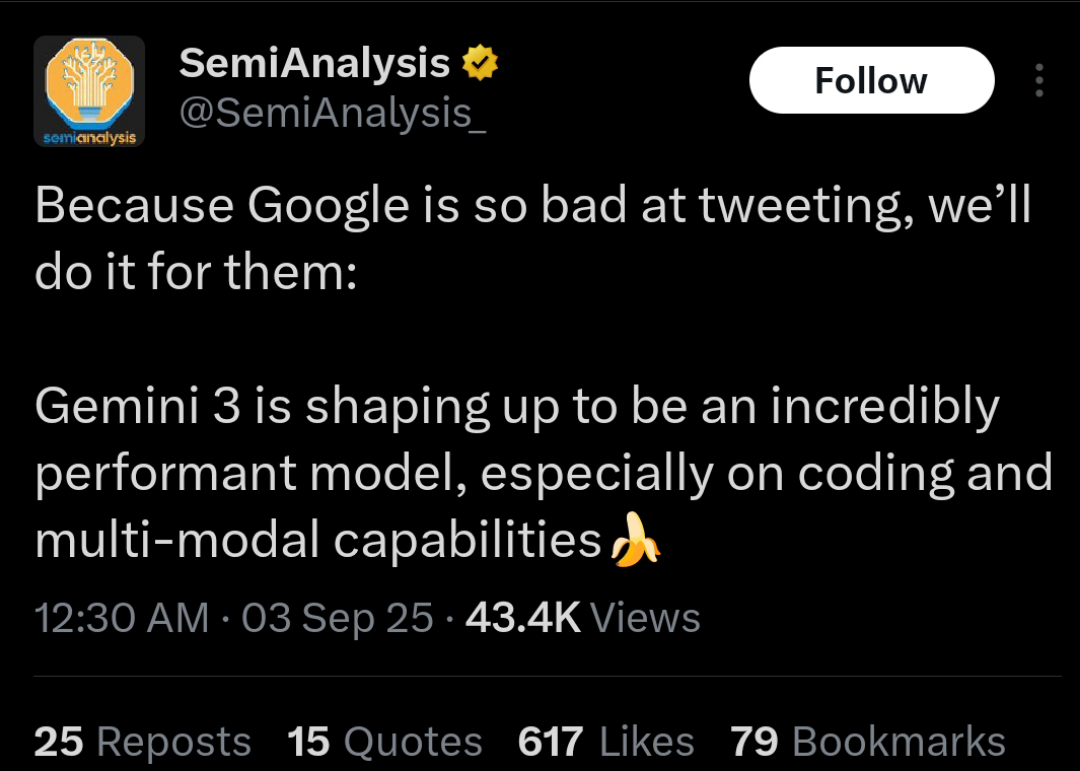
loooooool
Anonymous
9/3/2025, 9:59:21 AM
No.106470791
[Report]
>>106470769
>ear piercing
Why did they add that? It makes me want to molest her.
Anonymous
9/3/2025, 10:03:08 AM
No.106470803
[Report]
>>106470769
>Anubis
>Canadian
WE WUZ
>>106467368 (OP)
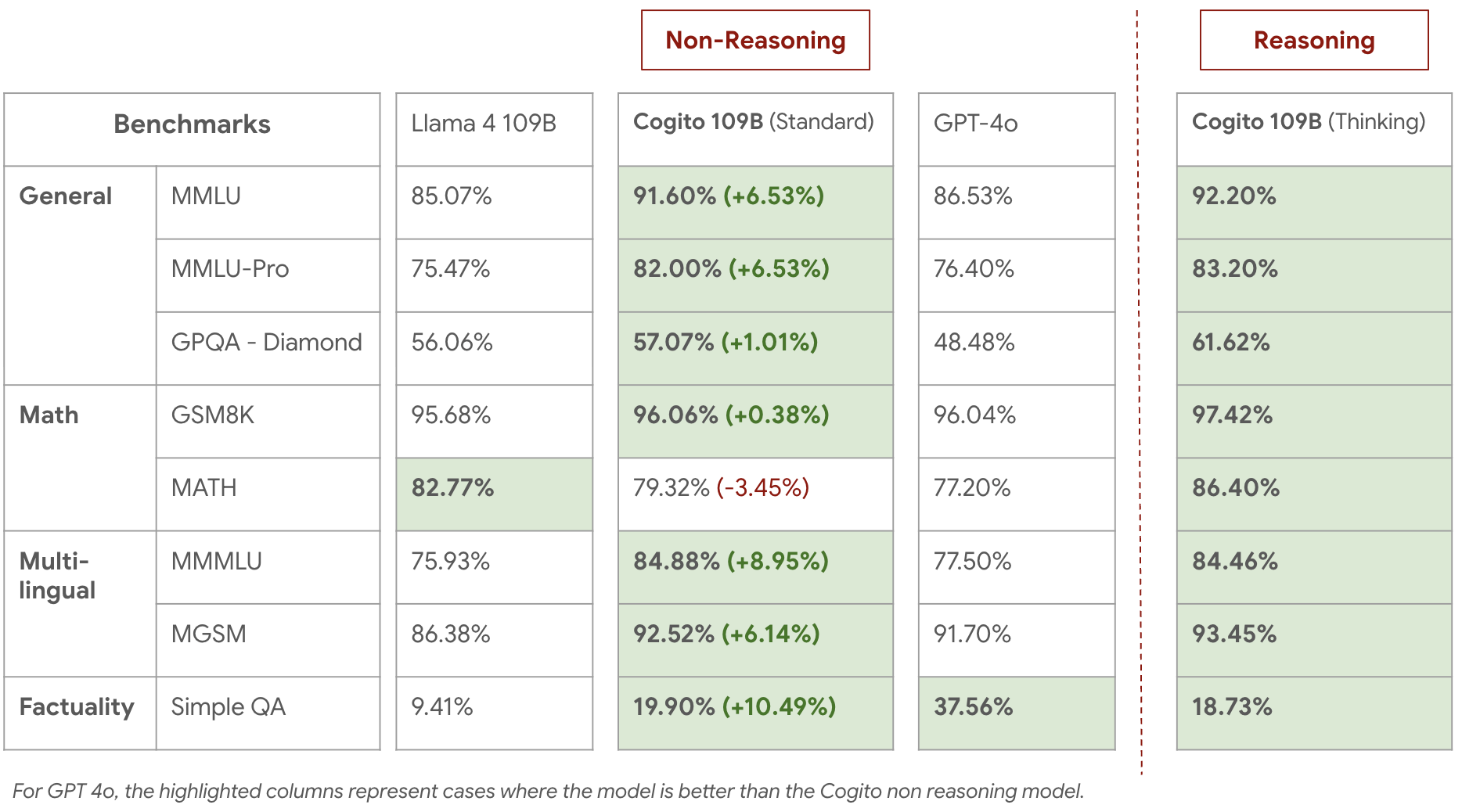
Is cogito-v2 good?
It's based on Llama 4 Scout, which is super fast.
Anonymous
9/3/2025, 10:18:07 AM
No.106470894
[Report]
>>106470964
>>106470842
GPT-OSS 120b by OpenAI is much faster for your information.
Anonymous
9/3/2025, 10:37:36 AM
No.106470964
[Report]
>>106470894
Yeah, but it is stupidly censored.
Anonymous
9/3/2025, 10:41:00 AM
No.106470974
[Report]
>>106470842
It is 100 times better than llama4 109B. I can tell you that much.
>>106470842
Why are LLM's so bad at factuality anyways? They have the information in there somewhere due to being trained on practically everything, does it simply not comprehend what a fact is? The reasoning model literally does worse on it then it's non reasoning counterpart.
Anonymous
9/3/2025, 10:46:46 AM
No.106470997
[Report]
>>106470769
>weird and unprofessional.
>Usecase for anime girls on a technical website?
people like this is why we need mikutroons and dipsyfags
Anonymous
9/3/2025, 10:47:10 AM
No.106470999
[Report]
>>106470988
they've all lied to me many times.
Anonymous
9/3/2025, 10:49:10 AM
No.106471008
[Report]
>>106471028
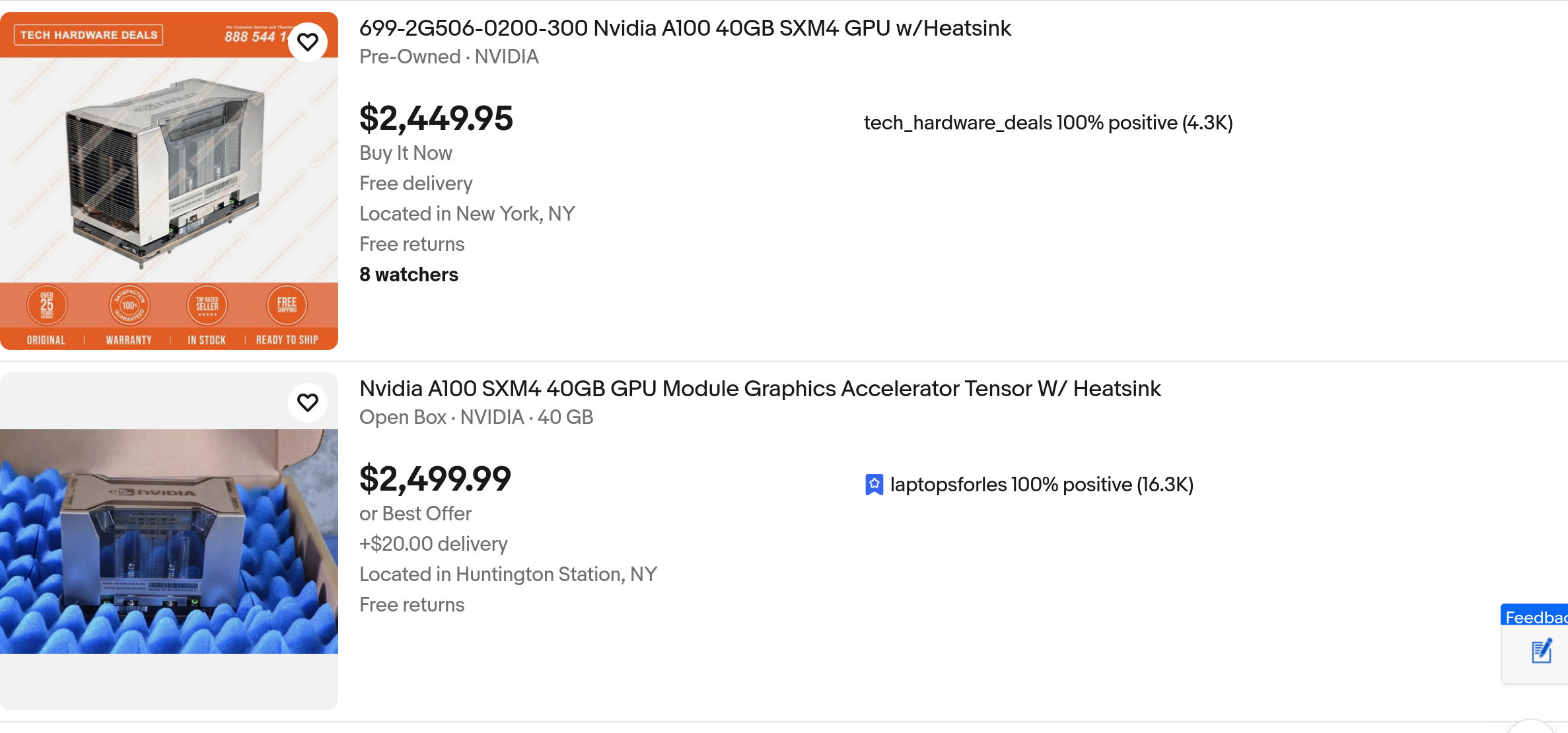
>A100 40GB are now 2.5K
Huh, are the datacenters starting to dump them? I mean, I guess getting a motherboard and etc. to harness NVLink would be a pain since the
https://rentry.org/V100MAXXING guide is only for SXM2 and it seems like from what ebay is saying, cost of entry is 4.7k for one of the servers. But maxing out a build for $25k with A100 40GBs is probably cheaper when 2 of those cards would cost the same as the used server does today. Still not cheap by any means to own, certainly not ready enough for a guide. Still, probably means Blackwell has started spreading everywhere for hardware to start get phased out and everything adjusting accordingly. Probably will stabilize next year.
Anonymous
9/3/2025, 10:49:22 AM
No.106471011
[Report]
>>106470988
>does it simply not comprehend
yeah
Anonymous
9/3/2025, 10:50:50 AM
No.106471019
[Report]
>>106471045
>>106470769
>FWIW, the developers of Anubis kindly ask for financial compensation for running instances of Anubis with the character removed.
Now I kind of want to make a project but enforce this via license.
Anonymous
9/3/2025, 11:00:11 AM
No.106471044
[Report]
>>106471064
>>106470988
Because they aren't trained for factuality. Every training step updates the weights with the average of the gradients of every sample in batch (which can be tens of million tokens big or more, on large GPU clusters). The training objective is making the model a better next-token predictor *on average*. Memorizing facts comes by accident.
Anonymous
9/3/2025, 11:00:16 AM
No.106471045
[Report]
>>106471019
>Your project will have my furry anime girl
>If it doesn't you will have to pay me money
Honestly based
Anonymous
9/3/2025, 11:04:53 AM
No.106471060
[Report]
>>106471028
Kek wtf, why are those a100's heatsink so HUEG?
All examples I've seen before have had featureless blowers about twice the thickness of a 12 pin port.
>>106470988
>>106471044
Hallucinations are the desirable characteristic at the low level, we want models to come up with novel phrases we didn't teach them.
I suspect factuality training will just make models more retarded in general just like safety training does.
Anons sneer at MCP as a meme but it just makes sense to use solid knowledge technology for working with solid knowledge.
Anonymous
9/3/2025, 11:08:28 AM
No.106471080
[Report]
Mistral owes me a new ~30B model.
Anonymous
9/3/2025, 11:10:45 AM
No.106471086
[Report]
Anonymous
9/3/2025, 11:13:00 AM
No.106471094
[Report]
>>106471130
These benchmarks are pissing me off. Probably funded by OpenAI as well. You know it's bad when even redditors realize something's off. Like ITT:
https://www.reddit.com/r/LocalLLaMA/comments/1n75z15/gptoss_120b_is_now_the_top_opensource_model_in/
I've done a fair bit of testing myself with these models, and there's no way the 'OSS is that good. OpenAI definitely had a plan when they released these models. As anons already have concluded, it is nothing short of open source well poisoning. And that new swiss Apertus model is aiming to do the exact same thing.
Literally everything an LLM does is hallucinations. There is no difference between the output you think of as hallucination and the output you think as fact from the pov of LLM architecture. Stop anthropomorphizing the LLMs, they do not think, and they do not reason. They do not have the ability to "judge" their own knowledge and introspect. They are pattern matchers. That's why coomers here can make even gpt-oss behave like a little slut. Can you jailbreak a random human being on the street into being a slut in the sheets?
Jailbreaks can exist because LLMs are pattern matchers autists.
Anonymous
9/3/2025, 11:20:11 AM
No.106471130
[Report]
>>106471094
The methodology is open. But notice how they recently changed it.
https://artificialanalysis.ai/methodology/intelligence-benchmarking
I'm too lazy to dig but the thing to me is the fact that they expect all the MMLU tests to be one shotted which is unusual and then some of the other stuff like AIME2025, you get 10 retrys. Why?
whats new in this space, anything going on?
Anonymous
9/3/2025, 11:21:55 AM
No.106471145
[Report]
>>106471187
>>106471064
There are indications that LLMs don't actually generalize, but mostly reproduce the training data by interpolation. So they will never be able to produce anything truly novel on their own.
Anonymous
9/3/2025, 11:26:46 AM
No.106471167
[Report]
>>106471139
wan3 in two more weeks
Anonymous
9/3/2025, 11:27:35 AM
No.106471171
[Report]
>>106471189
>>106471139
fatter gemma 4
>>106471145
>There are indications that LLMs don't actually generalize, but mostly reproduce the training data by interpolation. So they will never be able to produce anything truly novel on their own.
I entirely agree with you, but isn't that just a technicality? I mean, given sufficient general knowledge, interpolating bits of that knowledge could create an infinity of technically new content right?
Just like how Mendeleev's periodic table predicted new elements from a simple ruleset
Anonymous
9/3/2025, 11:32:08 AM
No.106471189
[Report]
>>106471231
>>106471171
> fatter gemma 4
more safeguards, sir!
Anonymous
9/3/2025, 11:34:46 AM
No.106471202
[Report]
>>106471189
I want gemma 4 to have gpt-oss style of reasoning and refusals, but with the addition of the hotlines and judgmental footnote that are typical of Gemma.
It's my fetish.
Anonymous
9/3/2025, 11:44:16 AM
No.106471250
[Report]
>>106471231
>It's my fetish.
Welcome to 4ch. Feel at home here
Anonymous
9/3/2025, 11:46:33 AM
No.106471258
[Report]
>>106471231
Femdom faggotry's final form: Refusaldom.
This nigga running
https://github.com/ConAcademy/buttplug-mcp
And has an LLM in charge of when the toys are on.
Anonymous
9/3/2025, 11:55:28 AM
No.106471316
[Report]
>>106471399
>>106471187
Not really, because big AI labs keep pretraining LLMs with an increasingly larger number of GPUs (i.e. overall bigger training batches), and while they might be seeing more data during their training period, sample-level nuances end up getting averaged out, so the models aren't gaining more knowledge, just getting better at reproducing the *average* of the languages trained on them.
They should be scaling down instead; use less GPUs and lower amounts of more downstream-relevant and information-dense data instead, but /lmg/ probably won't like this since it can't be properly done without large amounts of synthetic data designed for that purpose.
Anonymous
9/3/2025, 12:06:39 PM
No.106471388
[Report]
>>106471187
they are language models, literacy is only loosely coupled to actual knowledge. plenty of people are dumb but can talk your head off or vice versa someone who knows their shit but can't communicate it effectively.
Anonymous
9/3/2025, 12:08:19 PM
No.106471399
[Report]
>>106471426
>>106471316
why not just do both? pretrain on big batches to get you close and then post train on smaller focused batchs? there has to be a way to have our cake and eat it too!
Anonymous
9/3/2025, 12:11:27 PM
No.106471426
[Report]
>>106471487
>>106471399
I think that's what the extensive post-training phase of modern big-model training tries to accomplish, to some extent. It's not just about making the model an obedient assistant anymore (it hasn't been for a while).
Anonymous
9/3/2025, 12:21:56 PM
No.106471487
[Report]
>>106471525
>>106471426
>It's not just about making the model an obedient assistant anymore (it hasn't been for a while).
I thought it was just safety and schizo reasoning traces these days.
Anonymous
9/3/2025, 12:24:41 PM
No.106471503
[Report]
>>106471028
>40GB
Who buys this shit?
Anonymous
9/3/2025, 12:29:56 PM
No.106471525
[Report]
>>106471487
For open-data LLMs, yeah. But then, MistralAI notably added more trivia in Mistral Small 3.2, which was supposed to be just an updated instruct finetune.
>>106467508
I sometimes feel like they use a diffusion model on some requests. It's as if they were doing an A/B test of some sort. I think I mainly saw this on Gemini.
Anonymous
9/3/2025, 12:38:32 PM
No.106471574
[Report]
>>106472404
>>106467475
>Beyond Fixed: Variable-Length Denoising for Diffusion Large Language Models
>Diffusion Large Language Models (DLLMs) are emerging as a powerful alternative to the dominant Autoregressive Large Language Models, offering efficient parallel generation and capable global context modeling. However, the practical application of DLLMs is hindered by a critical architectural constraint: the need for a statically predefined generation length. This static length allocation leads to a problematic trade-off: insufficient lengths cripple performance on complex tasks, while excessive lengths incur significant computational overhead and sometimes result in performance degradation. While the inference framework is rigid, we observe that the model itself possesses internal signals that correlate with the optimal response length for a given task. To bridge this gap, we leverage these latent signals and introduce DAEDAL, a novel training-free denoising strategy that enables Dynamic Adaptive Length Expansion for Diffusion Large Language Models. DAEDAL operates in two phases: 1) Before the denoising process, DAEDAL starts from a short initial length and iteratively expands it to a coarse task-appropriate length, guided by a sequence completion metric. 2) During the denoising process, DAEDAL dynamically intervenes by pinpointing and expanding insufficient generation regions through mask token insertion, ensuring the final output is fully developed. Extensive experiments on DLLMs demonstrate that DAEDAL achieves performance comparable, and in some cases superior, to meticulously tuned fixed-length baselines, while simultaneously enhancing computational efficiency by achieving a higher effective token ratio. By resolving the static length constraint, DAEDAL unlocks new potential for DLLMs, bridging a critical gap with their Autoregressive counterparts and paving the way for more efficient and capable generation.
>https://arxiv.org/abs/2508.00819v1
Anonymous
9/3/2025, 12:39:11 PM
No.106471580
[Report]
>>106471702
>>106471555
Google do love the crap of their A/B tests, so it shouldn't surprise anyone if that's indeed the case.
>>106471064
>>106471100
>>106471187
Why exactly do "we" expect a supervised learning next token predictor to be factual anyway? There's no real understanding, just predicting the nearest or most likely outcome. Considering this, I'm surprised that small sub 8B basemodels are even capable of outputting anything, really.
ENTER:
reinforcement pre-training
I don't think there's a open source model yet which uses something like this, but it could be key for AI advancement. Even if it's just a small part of a MoE model or a reasoning/thinking orchestrator guiding the LLM.
The theory of teaching a model how to think instead of what to think first sounds more logical to me than the current approach, which seems to be to first teach the what (pre training) and then the how (fine tuning). I guess in theory a LLM trained solely in logic with RL and connected to websearch/knowledge would produce remarkable results. But then again surely there would be downsides as well, like reasoning/thinking time needed to come to the correct conclusion
Anonymous
9/3/2025, 12:45:32 PM
No.106471615
[Report]
>>106471880
>>106471593
>a LLM trained solely in logic with RL and connected to websearch/knowledge would produce remarkable results
RAG gods your time is soon triviacucks btfo for eternity
Anonymous
9/3/2025, 12:55:47 PM
No.106471675
[Report]
>>106471753
>>106471100
MKULTRA was one jailbreaking test. Truth serums and torture are other ways. Softer jb would be just talking nicely...
Anonymous
9/3/2025, 1:00:50 PM
No.106471702
[Report]
>>106471555
>>106471580
When Google does A/B tests on Gemini, and they do it often, it's an explicit request for you to rate which answer you preferred between two models. It's not happening stealthily in single answers, and they have no reason to do that because being able to rate which model answered best is inherently superior.
Anonymous
9/3/2025, 1:01:08 PM
No.106471706
[Report]
>>106471880
>>106471593
I think it would probably work but it would be a pretty dry model if it learned its language understanding from logic. maybe you could use two networks duct taped together, one designed for the logical thinking part + rag and another network that can use the context to make a pleasant completion?
Anonymous
9/3/2025, 1:11:17 PM
No.106471753
[Report]
>>106471785
>>106471675
>MKULTRA was one jailbreaking test. Truth serums and torture are other ways
and then afterwards glownigs felt really stupid for they realised they needent use expensive chemicals nor waste man hours on such things nay they merely needed a jew or 2 to pay a couple milly to rappers so they promote their jailbreaks
Anonymous
9/3/2025, 1:18:27 PM
No.106471785
[Report]
>>106471858
>>106471753
This is what is going to happen with data centres: they are massive waste of electricity because nvidia or anyone else haven't advanced technology in over 10 years now. Sure dies are smaller but this obviously isn't enough.
>>106471785
what you are quoting and what you are saying do not compute
>>106471615
Actually it wouldn't be strictly RAG. Or no RAG, even. There's an on-going war in the coding assistant developer community. On one side you have Cline and Augmentcode, which say RAG is dead/obsolete and simply not needed when pairing current SOTA LLMs with agents and mcp (web search, git tools). Their arguments basically are:
>RAG not needed because we have bigger context windows now, which fits multiple code files
>Agents are better and more precise finding relevant information with git tools and grep instead of chunked RAG code
>maintaining a vector codebase DB is annoying. Agents are better, citing Claude.
>Big RAG/VectorDB companies like pinecone are coping and trying to undermine the fact that RAG is obsolete.
>Agent coding delivers better results but is more expensive. RAG is only useful for companies like Cursor that try to reduce query tokens as much as possible to get better profit margins on the subscriptions they sell.
>relational node graphs, which RAG uses to combat some shortcomings, are nothing but a meme
If you care about the points in more detail, watch or summerize this:
https://youtu.be/eaeGd30Uypg
Personally I'm on team RAG because it's just so much cheaper when you index your codebase. Besides, quality degradation with context bloat is still a very real thing, even before going beyond 200k tokens.
But I find the discussion highly relevant, because having an agentic coding assistent is probably the closest thing we have to a LLM trying to be purely logic driven.
>>106471706
>it would be a completely dry model
or would it...kek
https://youtu.be/NUl6QikjR04
Anonymous
9/3/2025, 1:38:25 PM
No.106471904
[Report]
>>106471880
*an LLM
God my brain is toast. Bring on the Neuralink, Musk.
Anonymous
9/3/2025, 1:39:08 PM
No.106471908
[Report]
>>106471880
>we have bigger context windows now, which fits multiple code files
that's crazy to read when you see how much models still struggle with context despite advertising "15 quintillion contexts!" on their marketing
Anonymous
9/3/2025, 1:39:59 PM
No.106471912
[Report]
>>106471858
perhaps he thinks that because the mkultra project was eventually deprioritized, that the llms will also be?
Anonymous
9/3/2025, 1:42:52 PM
No.106471925
[Report]
>>106471100
It is not real AI, thus a prof called it Supervised Intelligent instead. You prompt it to behaves as you want.
https://old.reddit.com/r/StableDiffusion/comments/1n6rrg2/made_a_local_ai_pipeline_that_yells_at_drivers/
fucking kek the ultimate state of current era men
>amazon driver pees on the house on a regular enough basis that it triggers a person to action
>the action: build a pipeline that feeds an image every 10 sec to a vision llm to detect peeing and starts a very gentle sounding female AI voice that tells people off
if you're going that far rather than reporting to the police and amazon how about unleashing a trap of horse manure or something
even some crazy ass scream sound
that female ai voice? I think he's going to start masturbating
>>106471943
thank you for the reddit update
how do I unsubscribe?
Anonymous
9/3/2025, 1:50:45 PM
No.106471979
[Report]
>>106471960
>how do I unsubscribe?
consent is not a /lmg/ value
Anonymous
9/3/2025, 1:52:00 PM
No.106471987
[Report]
>>106471943
>how about unleashing a trap of horse manure
that would be assault
Anonymous
9/3/2025, 1:52:16 PM
No.106471990
[Report]
>>106472007
>>106471960
here [unsubscribe](link-to-infect-you-with-more-spam)
Anonymous
9/3/2025, 1:52:50 PM
No.106471992
[Report]
>>106472508
>go from Nemotron super 49b v1 to v1.5
>only change is that it refuses an order of magnitude more
Anonymous
9/3/2025, 1:54:14 PM
No.106471999
[Report]
>>106471943
Like many things on reddit, this is probably just a grassroot advertisement. In this case for gabber.dev
Anonymous
9/3/2025, 1:54:53 PM
No.106472007
[Report]
>>106471990
>link that tells them you actually read the email at all
is indeed quite the thing
Anonymous
9/3/2025, 1:56:19 PM
No.106472016
[Report]
>>106472172
Anonymous
9/3/2025, 1:56:33 PM
No.106472019
[Report]
>>106472078
>>106471943
if it was actually real (its not), some places prohibit defense of property
you just have to let it happen
Anonymous
9/3/2025, 2:05:54 PM
No.106472078
[Report]
>>106472179
>>106472019
I'd bash his skull in. People should stop acting like cucks because someone wrote a law for it
Anonymous
9/3/2025, 2:24:29 PM
No.106472172
[Report]
>>106472016
piss, no matter how yummy it is, will kill plants tho
Anonymous
9/3/2025, 2:26:12 PM
No.106472179
[Report]
>>106472972
>>106472078
Man, I can't wait for something like that to happen so I can counterbash their skull in and claim self-defense. And I wouldn't get in trouble for it because the law's on my side.
Anonymous
9/3/2025, 2:37:49 PM
No.106472255
[Report]
>>106472445
>>106467802
>>106468423
LM studio if you want it easy.
but yeah if you're used to the very large models, you need to know that local is only as good as the hardware you have, so when running smaller models don't expect large model quality.
However, any models you do run are yours forever, no api/proxy downtime. if you want some models:
rocinante
CaptainErisNebula
cydonia
glm air
Anonymous
9/3/2025, 3:02:39 PM
No.106472404
[Report]
>>106471574
imagine LLM diffusion instead of transformers
>6ater xh eaat4d fii coak on hru thight, shh falt a shiver rxnning dews hhr spane
>aater hh eaated hii coak on hru thight, shh falt a shiver rxnning down hhr spane
>after he raated his cock on hru thight, she felt a shiver rxnning down hhr spane
>after he rested his cock on hru thight, she felt a shiver running down her spine
>after he rested his cock on her thight, she felt a shiver running down her spine
then you put the lightning loras and boom lol. I wonder how quantization will work here
Anonymous
9/3/2025, 3:06:52 PM
No.106472439
[Report]
>>106472448
how to local rag? My usecases are gaping lolis through ST and an assistant with my personal data available
Anonymous
9/3/2025, 3:08:01 PM
No.106472445
[Report]
>>106472455
>>106472255
if the choice would be rocinante q8 or cydonia q4, which one would you choose?
Anonymous
9/3/2025, 3:08:36 PM
No.106472448
[Report]
>>106472454
>>106472439
The built in Vector Storage extension
>>106472448
id like to keep two separate DBs tho, one with smut, one with personal info
Anonymous
9/3/2025, 3:09:39 PM
No.106472455
[Report]
>>106472445
both so you can swap it once you get too over trained on the outputs and it gets boring.
Anonymous
9/3/2025, 3:11:07 PM
No.106472466
[Report]
>>106472454
Keep two ST instances.
ST creates separate databases for each chat I'm pretty sure.
Anonymous
9/3/2025, 3:11:29 PM
No.106472467
[Report]
>>106471858
I didn't quote anything you fucking autist. Go back to moderate r-eddit.
>>106472454
wand/extension button in the bottom then this. you can toggle them on or off when you want easily
Anonymous
9/3/2025, 3:12:34 PM
No.106472481
[Report]
>>106472473
time to develop an ingestion pipeline with dots.ocr :)
Anonymous
9/3/2025, 3:15:36 PM
No.106472508
[Report]
>>106471992
try the valkyrie tune of it, it's pretty good. I used to have like 34gb vram and really wished I had something above 30b and nvidia's 49b is the perfect size. For anyone who hates finetunes- 49b is so fucking dry and unusable no matter how you prompt it. It's like gpt oss levels almost.
Okay, now this is epic. OpenAI's wonderful GPT-OSS 120b, although slow and quantized, is able to follow my requirements when coding a script, but gemini isn't.
Anonymous
9/3/2025, 3:19:58 PM
No.106472534
[Report]
>>106472562
>>106472511
shut the fuck up sam
Anonymous
9/3/2025, 3:22:05 PM
No.106472548
[Report]
>>106472562
>>106472511
Post the logs to prove .
Anonymous
9/3/2025, 3:24:09 PM
No.106472562
[Report]
>>106472534
>>106472548
Haha, yes. Of course! That's a wonderful insight!
Anonymous
9/3/2025, 3:30:34 PM
No.106472615
[Report]
>>106472473
do you have any experience with RAGging conversation history? Is there a way to like keep the last N messages in context, and for the rest use the RAG? Will this produce crap?
Anonymous
9/3/2025, 3:47:21 PM
No.106472744
[Report]
>>106472910
>>106470769
How can this be real
Anonymous
9/3/2025, 3:51:28 PM
No.106472771
[Report]
>>106471231
Some men drown while others die of thirst
Anonymous
9/3/2025, 3:52:25 PM
No.106472776
[Report]
>>106472950
>>106471943
They are all peeing there for a reason: It's a good place to do it quickly and sneakily. They don't have time to do it in a better way. A better way could be to build a simple dry WC or something like that, with a small Amazon-like logo on it (like "Pee" with the smile beneath it). This way, it's not as disgusting and you could style get something aesthetic enough.
Ignoring reality is bluepilled and highly retarded.
Anonymous
9/3/2025, 3:56:19 PM
No.106472808
[Report]
>>106472793
god I hate emojislop
Anonymous
9/3/2025, 4:01:24 PM
No.106472843
[Report]
>>106473137
>>106471593
>I guess in theory a LLM trained solely in logic
"All the other stuff" is what provides the ungodly amount of mathematical measurements required to create a statistical model that effectively contains a complete understanding of abstract semantics.
You clearly have no fucking clue how any of this shit works. On Reddit you might just talk shit and make shit up because the mod whose cock is lodged in your throat will stop anyone from calling you out.
On here you can fuck right off with that bullshit.
Anonymous
9/3/2025, 4:02:49 PM
No.106472856
[Report]
Anonymous
9/3/2025, 4:04:53 PM
No.106472866
[Report]
Anonymous
9/3/2025, 4:09:05 PM
No.106472910
[Report]
>>106472744
Maybe there are actually people who watch cuck porn.
Anonymous
9/3/2025, 4:12:16 PM
No.106472938
[Report]
>>106472793
>coding powers
:skull: :skull:
Anonymous
9/3/2025, 4:13:36 PM
No.106472950
[Report]
>>106472776
Better solution: Make it inconvenient so it becomes somebody else's problem.
Anonymous
9/3/2025, 4:13:50 PM
No.106472953
[Report]
>>106472793
I was hoping for reasoner but I will take another K2 checkpoint. K2 is the most coherently unhinged model after a simple prefill and it's the best open source RP and creative writing model.
Anonymous
9/3/2025, 4:15:32 PM
No.106472972
[Report]
>>106472179
Good luck counterbashing anything cuck
Anonymous
9/3/2025, 4:25:31 PM
No.106473060
[Report]
>>106473070
>>106472793
>dropped
where?
Anonymous
9/3/2025, 4:26:34 PM
No.106473070
[Report]
>>106473121
Anonymous
9/3/2025, 4:26:44 PM
No.106473072
[Report]
>>106472473
How does it work? Just upload and keep chatting as usual?
Anonymous
9/3/2025, 4:30:10 PM
No.106473106
[Report]
>>106473172
man LLM's are getting filtered hard by json. I simply tell them to add a coordinate key:value pair to everything, and they just can't do it. jeetgpt5 chat as well. should I just switch to xml? or do I really need a SQL db an tell it to use the specific SQL tools?
Anonymous
9/3/2025, 4:30:19 PM
No.106473107
[Report]
https://gametora.com/_next/static/chunks/3998-19c42d835b448b85.js
I'm still surprised of how easy is to translate minified code with AI.
Anonymous
9/3/2025, 4:31:47 PM
No.106473121
[Report]
>>106473070
How to connect tavern to discord?
Anonymous
9/3/2025, 4:33:34 PM
No.106473137
[Report]
>>106472843
Fuckin' transformers, how do they work?
Anonymous
9/3/2025, 4:37:13 PM
No.106473172
[Report]
>>106473391
>>106473106
>should I just switch to xml?
What makes you think that'll help?
>do I really need a SQL db an tell it to use the specific SQL tools?
What would that solve?
have anyone tried to train a 1~5m(not b, i really mean m) model off of tinystories or something similar?
how retarded they are?
>>106473288
I think some people have done 200-500m models yeah. And a few sentences or paragraphs before breaking apart usually.
Anonymous
9/3/2025, 4:54:59 PM
No.106473354
[Report]
>>106473434
>>106473310
even with specialised subdimensional dataset like tinystories?
Anonymous
9/3/2025, 4:57:23 PM
No.106473377
[Report]
>>106473288
you would need a really tiny embedding matrix to have any parameter budget left over for transfomer blocks. it wouldn't do very good. I think it is not until the hundreds of millions of parameters range when things start to get a bit interesting.
Anonymous
9/3/2025, 4:58:41 PM
No.106473391
[Report]
>>106473480
>>106473172
because AI oneshots the task with the exact same structure in xml, but fails with json. maybe something to do with indentation since it fails to understand the structure? With a SQL DB it could query specific rows or values, and maybe gets less confused compared to ingesting the entire thing. Also having to deal with escaping quotes is just utterly fucking retarded
Anonymous
9/3/2025, 5:04:15 PM
No.106473434
[Report]
>>106473354
It was a while go on some guys blog. You find even more of them, and they're even properly 1m, all over the place. Not a lot resources needed to train a model, so a lot people do it for fun or as a learning experience but the quality varies.
https://huggingface.co/models?dataset=dataset:roneneldan/TinyStories
There's probably more floating around on the internet.
I have FX-9590 with 32gb RAM and an RX 9060 XT. Can I run local Grok and be based like all of you my niggas? Not changing the CPU, but it's watercooled like a mofo.
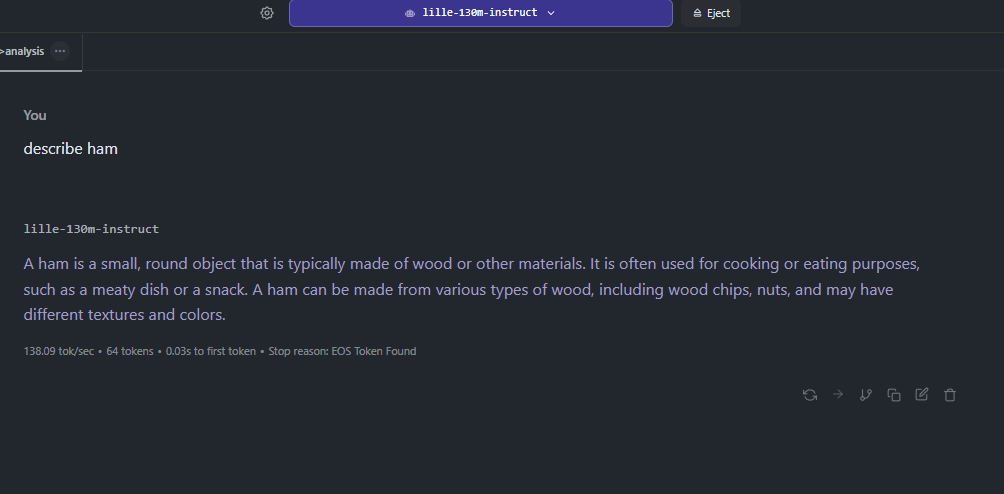
Anonymous
9/3/2025, 5:07:14 PM
No.106473464
[Report]
>>106473448
no. just run one of the chink models
Anonymous
9/3/2025, 5:07:24 PM
No.106473465
[Report]
>>106473310
yes. some guy trained this on a single 4070. I havent tried it but apparently it runs in lmstudio. I assumed it sucks.
https://huggingface.co/Nikity/lille-130m-instruct
Anonymous
9/3/2025, 5:09:00 PM
No.106473480
[Report]
>>106473391
>because AI oneshots the task with the exact same structure in xml
Then why are you asking if you should or not?
This is all stuff you can test yourself and use whatever works best for whatever you're doing.
Anonymous
9/3/2025, 5:12:50 PM
No.106473515
[Report]
>>106473448
yah, thanks to having a gaming computer you can run whatever you want. Chatpgt, grok, the google one, take your pick.
Anonymous
9/3/2025, 5:12:52 PM
No.106473516
[Report]
I sure love when lazy ass LLMs look at a large file and instead of doing the requested changes, it removes most of the files content with some cheeky comment like
>*The details have been removed for brevity but are kept in the original document version history
It's unironically really fucking funny.
Anonymous
9/3/2025, 5:13:54 PM
No.106473522
[Report]
>>106473869
>>106473448
>FX-9590 with 32gb RAM and an RX 9060 XT
What a strange choice of hardware. You can't even use 9060 XT for anything. With nvidia card you could at least use it for work or imagen on this platform
>>106473288
Truly open source models may have a ways to go guys
Anonymous
9/3/2025, 5:20:16 PM
No.106473581
[Report]
>>106467368 (OP)
Long Miku is long.
Anonymous
9/3/2025, 5:21:56 PM
No.106473597
[Report]
Man, a shame we don't have better card to card interconnects.
If we could stack some 4 Arc Pro B50 and get some 75% of the total memory bandwidth, that would be pretty sweet.
As is, even splitting the model 4 way the PCI-E bus would still bottleneck the whole process right?
Anonymous
9/3/2025, 5:22:19 PM
No.106473600
[Report]
>>106473570
Ham confirmed vegan.
>>106473448
>FX
That's older than most of the posters here these days
Anonymous
9/3/2025, 5:22:44 PM
No.106473603
[Report]
>>106473570
unironically looks promising for what it is
Anonymous
9/3/2025, 5:23:44 PM
No.106473609
[Report]
>>106471880
Assuming logic is all you need would be pretty dangerous, even for coding agents. The reason that MoEs and language models in general have worked up until now to make coherent talkers is because much of intelligence is a function of both knowledge and knowledge-specific logic (or you can think of that as knowledge of how to use specific pieces of knowledge), in addition to more generalized logic. This can be done through RAG, ONLY if the query-time algorithm includes learning. That is, inference turns into both inference and training. Humans cannot immediately do a too OOD task after a single read or watch, and neither can any AI. If the architecture doesn't learn during the query, a logic-specialized model + RAG will still not be the solution to AGI or whatever we're hoping for. And unfortunately it may be a long time before we get such architectures for production, as it'd be too compute intensive. Maybe if we get a magical breakthrough again.
Anonymous
9/3/2025, 5:24:13 PM
No.106473612
[Report]
>>106473570
its pretty coherent, unfortunately lacking with the factual recall tho.
Anonymous
9/3/2025, 5:25:31 PM
No.106473624
[Report]
>>106473884
Anonymous
9/3/2025, 5:26:49 PM
No.106473632
[Report]
>>106473651
Anonymous
9/3/2025, 5:28:28 PM
No.106473645
[Report]
>>106473601
you should at least say phenom
Anonymous
9/3/2025, 5:28:31 PM
No.106473646
[Report]
Anonymous
9/3/2025, 5:28:48 PM
No.106473651
[Report]
>>106473618
>>106473632
They have a new chang boss.
Anonymous
9/3/2025, 5:29:48 PM
No.106473659
[Report]
>>106473618
the gpt oss killer
>>106473618
Surely not, Zucc has now spent billions on the highest profile scientists that can now make use of his massive H100 stack.
Anonymous
9/3/2025, 5:30:58 PM
No.106473671
[Report]
>>106473618
probably just the same old llama 4 with some mistakes corrected and a few easy wins added, I wouldn't expect any large changes until the billionaire superintelligence meme team has had some time to settle in
Anonymous
9/3/2025, 5:31:33 PM
No.106473673
[Report]
>>106473663
>highest profile scientists
scammers from china fify.
Anonymous
9/3/2025, 5:31:55 PM
No.106473676
[Report]
>>106473694
i wonder how the base models before all the safeguarding and lobotimisation of those small open weight models companies made looks like
Anonymous
9/3/2025, 5:32:14 PM
No.106473679
[Report]
>>106473618
Absolutely.
I bet it'll be at most equivalent to GLM, but actually worse in actual use.
Anonymous
9/3/2025, 5:32:18 PM
No.106473681
[Report]
>>106473750
>>106473570
>138 t/s from a 130m
Why is it so slow?
Anonymous
9/3/2025, 5:33:33 PM
No.106473694
[Report]
>>106473699
>>106473676
About the same. They cuck the model at the pretraining dataset level.
Anonymous
9/3/2025, 5:34:12 PM
No.106473699
[Report]
Anonymous
9/3/2025, 5:34:43 PM
No.106473706
[Report]
>>106473712
>>106473570
mogged by gemma 280b
Anonymous
9/3/2025, 5:35:41 PM
No.106473712
[Report]
>>106473706
Mogged by gpt-oss 120t
Anonymous
9/3/2025, 5:35:49 PM
No.106473715
[Report]
>>106473819
>>106473663
>that can now make use of his massive H100 stack.
maybe someday.
https://xcancel.com/giffmana/status/1957155168417378687
>within just a month, while waiting for new resource allocation
>- on just six H100's the 3 of us share
this guy is one of meta's new superintelligence hires btw
Anonymous
9/3/2025, 5:39:52 PM
No.106473750
[Report]
>>106473681
it's q8 and flash attention seems to not work on it. On longer stuff it gets up to ~350 or so. I dunno whatever, it doesnt matter. Oh, and I'm on windows right now.
Anonymous
9/3/2025, 5:48:41 PM
No.106473815
[Report]
>>106473839
>>106473570
The training data needs not to be just random web documents, if you have very limited compute for training a model from scratch. Reminder that Phi-1 was trained on 7B unique tokens for 7~8 epochs (50B tokens in total).
https://arxiv.org/pdf/2306.11644
Anonymous
9/3/2025, 5:49:19 PM
No.106473819
[Report]
>>106473715
>within just a month
>wrote an entirely new codebase
This is the reason why llama 4 is so shit.
>>106473815
I prefer this Phi.
https://arxiv.org/abs/2309.08632
>Using our novel dataset mixture consisting of less than 100 thousand tokens, we pretrain a 1 million parameter transformer-based LLM
Anonymous
9/3/2025, 5:54:51 PM
No.106473860
[Report]
Anonymous
9/3/2025, 5:55:06 PM
No.106473865
[Report]
I'm currently trying the Cogito finetune of Deepseek that they finetuned from scratch from V3-Base.
The good news is that it seems to get rid of a lot of the annoying Deepseek slop and dumb habits that kept getting in the way while using V3-0324 and R1-0528. I haven't seen a single em-dash or the other typical slop phrases so far. It gets a certain sub-type of scenarios right that anything pre-V3.1 (and even that occasionally) got very confused by.
The bad news is that it's super safety-slopped and tries to refuse a lot of requests. You can hook it into a 18k token long RP and it'll still find a way to steer away from anything lewd.
Honestly, it's sad. It's probably better than V3.1 in terms of writing but the safety brain damage makes it unusable. At least this shows that the big problem with Deepseek models is their retarded -Instruct/Reasoning dataset.
Anonymous
9/3/2025, 5:55:19 PM
No.106473869
[Report]
>>106473522
>You can't even use 9060 XT for anything
It's a graphics card and it's used for gaming anon
Anonymous
9/3/2025, 5:56:36 PM
No.106473873
[Report]
>>106473900
I love john because he has finally saved me from this thread. I just need to refresh his hf to see if any new models are here.
Anonymous
9/3/2025, 5:57:47 PM
No.106473884
[Report]
>>106473839
It shouldn't be too hard to come up with a hyper-focused pretraining dataset of a few B tokens size giving the model basic knowledge, common sense and conversation capabilities in English language only, disregarding almost anything that the model is not expected to be used for (coding, advanced math, etc)... or is it?
Anonymous
9/3/2025, 5:58:38 PM
No.106473893
[Report]
>>106473941
Do you guys think I'll be the one who invents the AGI?
Anonymous
9/3/2025, 5:59:21 PM
No.106473900
[Report]
>>106473873
What a beautiful man
Anonymous
9/3/2025, 6:00:46 PM
No.106473910
[Report]
>>106473944
>>106473885
So many people think that's possible, if only models worked that way eh?
Anonymous
9/3/2025, 6:02:46 PM
No.106473931
[Report]
>>106473885
When will you learn the bitter lesson?
Anonymous
9/3/2025, 6:03:10 PM
No.106473936
[Report]
>>106473885
that 'common sense' is already too much and i think that is how they came up with tinystories
Anonymous
9/3/2025, 6:03:31 PM
No.106473941
[Report]
>>106473893
Someone in this very thread.
Anonymous
9/3/2025, 6:03:36 PM
No.106473944
[Report]
>>106473954
>>106473910
It worked for Microsoft Phi-1, and it was intended to be a general-purpose model with a focus on coding.
>>106473944
Legitimately, does a single person actually use Phi for anything at all?
>hook up 120b 'toss to codex, give it a simple prompt
>working (1205s esc to interrupt)
trash
Anonymous
9/3/2025, 6:14:39 PM
No.106474013
[Report]
>>106474026
>>106474003
shartware specs?
Anonymous
9/3/2025, 6:16:09 PM
No.106474026
[Report]
>>106474058
Anonymous
9/3/2025, 6:16:30 PM
No.106474028
[Report]
>>106474003
safety needs time
Anonymous
9/3/2025, 6:16:57 PM
No.106474034
[Report]
>>106473954
No, because it doesn't "work".
Anonymous
9/3/2025, 6:20:10 PM
No.106474056
[Report]
>>106473885
you would be better off training a bigger model on even more data. is there really a usecase for running llms on microcontrollers? even cellphones can handle a 600m.
Anonymous
9/3/2025, 6:20:26 PM
No.106474058
[Report]
>>106474026
Have you tried using a gpu for prompt processing? I takes less than two minutes to process 50k context on power limited 3090s without parallelism.
Anonymous
9/3/2025, 6:21:47 PM
No.106474068
[Report]
>>106474128
>>106473954
Microsoft is scared to death of people misusing AI models for "harmful content", so the Phi authors always made sure they were safe and inoffensive and ultimately not too useful except as a technical demonstration of what can be done with synthetic data.
But that's not the point here. If there's going to genuinely be a community-driven model at some point, it will likewise have to be efficiently pretrained with limited amounts of data selected with/for a purpose, not simply random web documents of unknown content and nature.
>>106474068
>If there's going to genuinely be a community-driven model at some point,
distributed training is a meme, how many people do you need to design the logo? just collect the data and start training your model, this way you don't have to let anons tell you what to do or argue about every little decision.
Anonymous
9/3/2025, 6:30:28 PM
No.106474142
[Report]
>>106474681
>>106474128
I can only fit so many gpus in my house.
Anonymous
9/3/2025, 6:31:17 PM
No.106474152
[Report]
>>106473899
Didn't read into the article much but yeah, attention is still an issue, and it can be improved with different kinds of scaffolding like they're proposing. Basically cognitive architectures. But I think that's just one type of solution and it's wrong to think that this is a problem that can't be improved through better training methods and data. I think one improvement is to train reasoning models to be better at specific kinds of retrieval. Right now the thinking block retrievals are a bit meandering and in most cases unstructured in general. This can be a lot better.
Anonymous
9/3/2025, 6:32:42 PM
No.106474170
[Report]
>>106474128
I thought we were talking about sub 1b models. you just need 1 for training.
>>106474128
If a usable model can be pretrained with around 50-60B tokens carefully selected/generated for your intended use case(s) instead of 30~40T, then you just need *one* H100 node or less for a few weeks, not distributed training or an entire datacenter.
Anonymous
9/3/2025, 6:36:17 PM
No.106474199
[Report]
>>106474242
I figured out O(n) attention.
Anonymous
9/3/2025, 6:37:03 PM
No.106474207
[Report]
>>106474187
>If a usable model can be pretrained with around 50-60B tokens carefully selected/generated for your intended use case(s
it can't.
Anonymous
9/3/2025, 6:37:35 PM
No.106474212
[Report]
I figured out O(1) attention
Anonymous
9/3/2025, 6:38:43 PM
No.106474218
[Report]
I figured out that you don't actually need attention.
Anonymous
9/3/2025, 6:41:16 PM
No.106474242
[Report]
>>106474199
More like n(O) attention.
Anonymous
9/3/2025, 6:45:48 PM
No.106474296
[Report]
>>106474771
>>106473899
totally. even with fixes like attention sinks and whatever that new activation function thingy is called, the attention across the context gets spread pretty thin and evenly like warm butter on fresh toast. especially in tasks like coding where you have a gorillion thinkslop tokens and a bunch of irrelevant rag'ed code chunks, it's begins to blur the lines between "plans" and "intermediate thoughts". when 2k tokens of important instructions have to fight for attention with the 98k tokens of javascript-farts and "Wait, hold on, But", importance starts to become kind of homogenized. needle-in-a-haystack is a shitty benchmark because the needle tokens violently pull the embedding vector way out of line which makes it too easy for the LLM to solve. on the other hand real-world long-context tasks don't have such an obvious sore-thumb needle. I think cline is right about this, but their proposed solution is just some agent framework shit. it works well and makes sense, but not new or groundbreaking in any way.
>>106474187
what is your use case? it will be dogshit for factual knowledge tasks and trivia.
Anonymous
9/3/2025, 6:51:22 PM
No.106474355
[Report]
>>106474411
>>106474128
>>106474187
>distributed training is a meme
yeah i agree, using a million potato computers to do what one H100 can do in a week or so just doesn't make sense.
also AI is changing all the time, if you create a distributed method now, it will probably be obsolete in two weeks.
>>106474336
Stop with the trivia meme, we need pure logic not wasted params on BS that can be RAGed.
Anonymous
9/3/2025, 6:56:28 PM
No.106474411
[Report]
>>106474355
It's useful if you want to do something that nobody else wants to do. Like making a good model for RP that never refuses.
I figured out O() attention
Anonymous
9/3/2025, 6:58:34 PM
No.106474437
[Report]
Anonymous
9/3/2025, 6:58:40 PM
No.106474438
[Report]
>>106474496
>>106474357
pure logic is as much of a meme as trivia.
you can do your pure logic with haskell or something
Anonymous
9/3/2025, 7:04:46 PM
No.106474496
[Report]
>>106474438
That is what intelligence is though. Imo the best benchmarks are simplebench and arc-agi
Anonymous
9/3/2025, 7:04:59 PM
No.106474498
[Report]
>>106474517
>>106474357
what do you consider trivia? i just mean things like knowing the grass is green or the sky is blue. it shouldn't need to rag basic knowledge but at the same time the only way to get the broad knowledge coverage is exposure more diverse tokens.
>>106474498
>knowing the grass is green or the sky is blue
BLOAT you do not need this for RP
Anonymous
9/3/2025, 7:06:51 PM
No.106474519
[Report]
>>106474430
O(2^x) that is
Anonymous
9/3/2025, 7:08:19 PM
No.106474534
[Report]
>>106474572
>>106474517
I too enjoy having my erotic roleplay set on namek.
Anonymous
9/3/2025, 7:11:29 PM
No.106474564
[Report]
>>106474517
RP isn't a productive use case
>>106474534
>>106474517
More like there wouldn't be a planet at all, since no knowledge was trained, therefore you do not know that planets are an entity that exists.
Anonymous
9/3/2025, 7:13:45 PM
No.106474585
[Report]
>>106474601
>>106474572
planets are bloat, learn to breathe vacuum
Anonymous
9/3/2025, 7:13:58 PM
No.106474590
[Report]
>>106474613
>>106474572
It would figure all of that from context. You don't need to give it a dictionary at all.
Anonymous
9/3/2025, 7:14:19 PM
No.106474596
[Report]
>>106474572
You only need the knowledge of what a bed is, if even that
Anonymous
9/3/2025, 7:14:45 PM
No.106474601
[Report]
>>106474585
Sorry, what is breathe? What is vacuum? Can you clarify?
Anonymous
9/3/2025, 7:15:00 PM
No.106474606
[Report]
>>106474622
>>106474336
If the goal is just vapid chatting, I think knowing what any word in the English dictionary means and how to use it in a conversation (see (
>>106473570) would be a bare minimum requirement.
Anonymous
9/3/2025, 7:15:46 PM
No.106474613
[Report]
>>106474627
>>106474590
>It would figure all of that from context
Not with transformers.
Anonymous
9/3/2025, 7:16:37 PM
No.106474622
[Report]
>>106474606
>any word in the English dictionary means
so much wasted params make me cries
>>106474613
I mean the context of the training data. It's learning to repeat text, you're not supposed to teach it like it's in school
Anonymous
9/3/2025, 7:18:27 PM
No.106474634
[Report]
>>106474646
>>106474628
Remove this cursed spawn of satan from my sight immediately.
Anonymous
9/3/2025, 7:18:46 PM
No.106474637
[Report]
>>106474647
I figured out O(n^3) attention.
Anonymous
9/3/2025, 7:19:05 PM
No.106474639
[Report]
>>106474646
>>106474628
post more of this cutie
Anonymous
9/3/2025, 7:19:48 PM
No.106474647
[Report]
>>106474693
>>106474637
post code or die painfully in your tonight
Anonymous
9/3/2025, 7:21:12 PM
No.106474658
[Report]
>>106474712
>>106474627
What training data? The topic of the discussion was training models purely on logic and no factual knowledge. That means the training data doesn't contain knowledge about Earth and that the sky is blue and grass is green.
>>106474627
that is where the argument started. Training a model on a synthetic dataset of nothing but logic would not get the broad coverage needed.
Anonymous
9/3/2025, 7:22:45 PM
No.106474675
[Report]
>>106474646
Wdym new, I tested that like a week ago.
Anonymous
9/3/2025, 7:23:11 PM
No.106474681
[Report]
Anonymous
9/3/2025, 7:23:18 PM
No.106474682
[Report]
>>106474740
>>106474668
>broad coverage needed
citation needed on that being needed SIR!
Anonymous
9/3/2025, 7:24:50 PM
No.106474693
[Report]
Anonymous
9/3/2025, 7:26:26 PM
No.106474709
[Report]
>>106474628
average undi model
Anonymous
9/3/2025, 7:26:50 PM
No.106474712
[Report]
>>106474668
>>106474658
Well I wasn't there when the argument started. Maybe it'd be interesting to make a smart videogame AI with all that new transformer technology. Then there would be no language at all, 0 bloat
Anonymous
9/3/2025, 7:29:25 PM
No.106474738
[Report]
So where can I buy a b60?
Anonymous
9/3/2025, 7:29:42 PM
No.106474740
[Report]
>>106474682
Here's a source: the models that are trained on more logic than knowledge are used less in production than models trained with a balance of logic and knowledge (Phi vs the models people actually use).
Anonymous
9/3/2025, 7:33:03 PM
No.106474771
[Report]
>>106474296
> stream of consciousness
SNOREEEEEEEEEEEEE
read a paper nigger
>>106474646
>upscaled Mistral 24B
This retard can't keep fooling you or can he?
Anonymous
9/3/2025, 7:36:55 PM
No.106474807
[Report]
>>106474780
I'm not a retard, and I'm not trying to fool anyone. This is hard, honest work.
>>106474780
The logic behind what he does is sound, better than merges by miles.
Anonymous
9/3/2025, 7:39:51 PM
No.106474832
[Report]
/lmg/ I have a problem, how do I create jailbreak data/guardrails testing data for a chinese model, in chinese, as someone who doesn't speak/read chinese? Will any of the qwen models with a system prompt do proper translations or does mistral Large handle chinese well and isn't filtered?
Hi all, Drummer here...
9/3/2025, 7:42:26 PM
No.106474851
[Report]
>>106474823
Thanks anon.
Skyfall v4 is actually a blind experiment on a new technique that I hope works out. But I need to hear what everyone has to say about it, hence releasing it as-is. Just a hint: the duplicated layers are not just zero'd out.
I'll try a Skyfall R1 version after. Heard reasoning benefits from the extra layers.
Anonymous
9/3/2025, 7:46:28 PM
No.106474882
[Report]
Anonymous
9/3/2025, 7:49:58 PM
No.106474919
[Report]
slow week huh
Anonymous
9/3/2025, 7:50:05 PM
No.106474921
[Report]
>>106475067
>>106474849
>Will any of the qwen models with a system prompt do proper translations
This is something you have to test yourself to your satisfaction.
It'd be hard to verify how well the jb works. Try grabbing a bunch of them, translate them to chinese and, on a new context, back to english to see what you end up with. If it still looks similar enough, use that model.
>>106474849
> in chinese
why do you think you need to do any of this in chinese?
just do it in english, it understands english.
also, the model doesn't fundamentally think in chinese, it thinks in sequences of tokens, its just continuing this token sequence during inference.
Anonymous
9/3/2025, 7:56:23 PM
No.106474968
[Report]
>>106474929
Some tokens are更好的than others.
Anonymous
9/3/2025, 7:58:19 PM
No.106474982
[Report]
>>106474867
I used to think of myself as a really tough guy who doesn't fall for advertisements, but turns out I'm quite a simple man actually.
Anonymous
9/3/2025, 8:08:08 PM
No.106475067
[Report]
>>106475126
>>106474921
fair, thanks, will try this approach
>>106474929
Because the model will be primarily used in chinese and I am not educated enough in LLMs to say assertively if the mapping between tokens and languages are similar enough for guard rails testing.
I know that LLMs use tokens, but the mapping of said tokens to other languages is the question, how well and how equivalently weighted those mappings are across langauges.
That I don't know/assumed to be not equal, given that LLMs have disparities across languages, even if they've been trained on them.
Anonymous
9/3/2025, 8:16:34 PM
No.106475126
[Report]
>>106475147
>>106475067
106474921 is stupid ignore him
Why can't we have distributed models by anons for anons.
You do prompt processing locally, with the one layer at a time trick to do it with low VRAM. Then you do inference across a pipeline of fellow anon's GPUs, all just running a couple layers. The latency will suck, but the throughput will be good. Then you just need to add some onion routing to hide the degeneracy came from you.
This is a lot like the following paper :
GenTorrent: Scaling Large Language Model Serving with An Overlay Network
https://arxiv.org/html/2504.20101v3
They did not take into account my suggestion of pipelining though, which allows large models to run on VRAMlet GPUs.
Anonymous
9/3/2025, 8:18:29 PM
No.106475147
[Report]
>>106475165
Anonymous
9/3/2025, 8:19:24 PM
No.106475155
[Report]
I had a look back at Gemma 3's technical report. According to it, they froze the vision encoder and trained the model. The vision encoder is less than 500M parameters. That's kind of crazy isn't it? It means that both text knowledge and vision knowledge are contained and don't ruin each other in those few 27B parameters, whereas other (open) vision models either suck at one of the modalities or are just really large models. Mistral Small's vision kind of sucks, but its text capabilities were at least maintained. Qwen had to make a separate model for vision. GLM 4.5 has a separate model for vision, and it's also much larger.
It kind of shows that vision can be currently way better than it is and in a tiny amount of parameters. I mean think about it, a diffusion model like Noob can gen a shit ton of characters and other stuff in just 7GB of space. Vision would take way less. There is something wrong about the way other companies are training their models or with their datasets. And the problem with companies is they won't train on "unsafe" data like booru stuff, which is one of the most extensively tagged image datasets you could get publicly, so they'll probably just be forever bad.
Anonymous
9/3/2025, 8:20:19 PM
No.106475165
[Report]
>>106475169
>>106475147
Alright, here.
Anonymous
9/3/2025, 8:20:57 PM
No.106475169
[Report]
>>106475165
Much better. Thank you.
Anonymous
9/3/2025, 8:21:43 PM
No.106475180
[Report]
>>106475140
it's the same old "I will draw the logo" issue
>>106475140
Effort to build it out is one factor, and the other is that we wouldn't be able to train much even if we did have the software ready to go. We might not be able to do significant pretraining even with all the GPUs of anons put together. At most, we would be able to do some fine tuning on a small model, and that might still be a good thing, but might not be worth it.
Anonymous
9/3/2025, 8:30:56 PM
No.106475271
[Report]
>>106475925
>>106475258
This is about inferencing, I'm pretty sure.
>>106475140
>but the throughput will be good
Nah
>>106475258
While true, you can't read for shit.
Anonymous
9/3/2025, 8:37:55 PM
No.106475319
[Report]
>>106475339
>>106475278
>>but the throughput will be good
>Niah
What does needle in a haystack (niah) have to do with what I'm saying?
Anonymous
9/3/2025, 8:38:34 PM
No.106475323
[Report]
>>106475351
Anonymous
9/3/2025, 8:40:55 PM
No.106475339
[Report]
>>106475992
>>106475319
You can't read AND you have to explain the joke.
>We deploy the testbed of GenTorrent in a public cloud. The testbed includes eight model nodes with mid-tier hardware, each carrying one NVIDIA RTX A6000 GPU (48 GB) and serving a Meta-Llama-3 8B model, eight other model nodes with high-performance hardware, each carrying one NVIDIA A100 GPU (80 GB) and serving a DeepSeek-R1 14B model. We run two machines as the verification nodes. One carries an NVIDIA A100 (40 GB SXM4), 30 virtual CPUs, 200 GiB of RAM, and a 0.5 TiB SSD, and the other carries an NVIDIA GH200 (96 GB HBM), 64 virtual CPUs, 432 GiB of RAM, and 4 TiB SSD.
Anonymous
9/3/2025, 8:42:04 PM
No.106475351
[Report]
>>106475323
Fuck you I can read perfectly fine.
Anonymous
9/3/2025, 9:53:13 PM
No.106475925
[Report]
>>106475992
>>106475271
>>106475278
I didn't read lol and just assumed based on the first sentence. I just don't see user distributed inference becoming a thing. Even with your proposed solution, the prompt processing would be prohibitively slow. You can try this right now, go and load up a model like Deepseek with mmap and process a prompt longer than a few tokens. The last time I tried it, it took several minutes to process a normal sized prompt. Don't remember the exact numbers though. No one wants to wait that long, and would rather just use a shittier model or not use models at all. If you're saying that you should have enough RAM to load the model entirely in memory, then at that point the user already likely can just simply run the model itself, no need for distributing the work. Unless you're saying to run large dense models, but there is no reason to do that when there aren't any currently, all the SOTAs are MoEs.
Anonymous
9/3/2025, 10:04:43 PM
No.106475992
[Report]
>>106475925
>Even with your proposed solution
>your
Neither of the anons you replied to are the ones that posted the paper. One anon offered no opinion, just a correction. The other one (me) said
>>but the throughput will be good
>Nah
But at this point i'm just taking the piss, really. I also posted this
>>106475339 where i point out the "mid-tier hardware" being some rtx6000 gpus for an 8b model.
Anonymous
9/3/2025, 10:12:33 PM
No.106476036
[Report]
>>106473288
You can only get classifiers at that size