/lmg/ - Local Models General
►Recent Highlights from the Previous Thread:
>>105557036
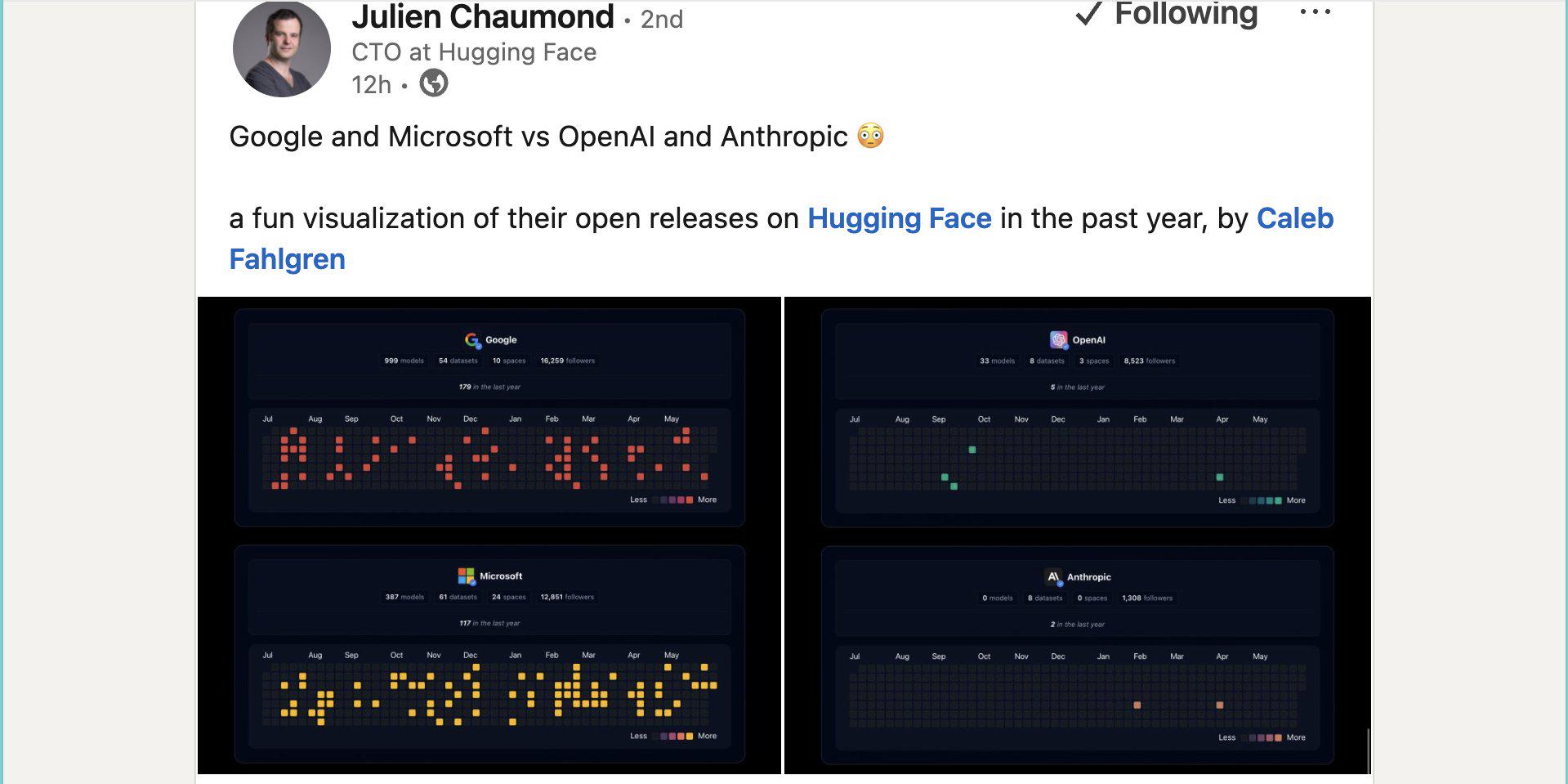
--Paper:
>105562846
--RSI and AGI predictions based on reasoning models, distillation, and compute scaling:
>105560236 >105560254 >105560271 >105560267 >105560315 >105560802 >105560709 >105560950
--LLM chess performance limited by poor board representation interfaces:
>105562838
--Exploring and optimizing the Min Keep sampler for improved model generation diversity:
>105558373 >105558541 >105560191 >105560244 >105560287 >105559958 >105558569 >105558623 >105558640
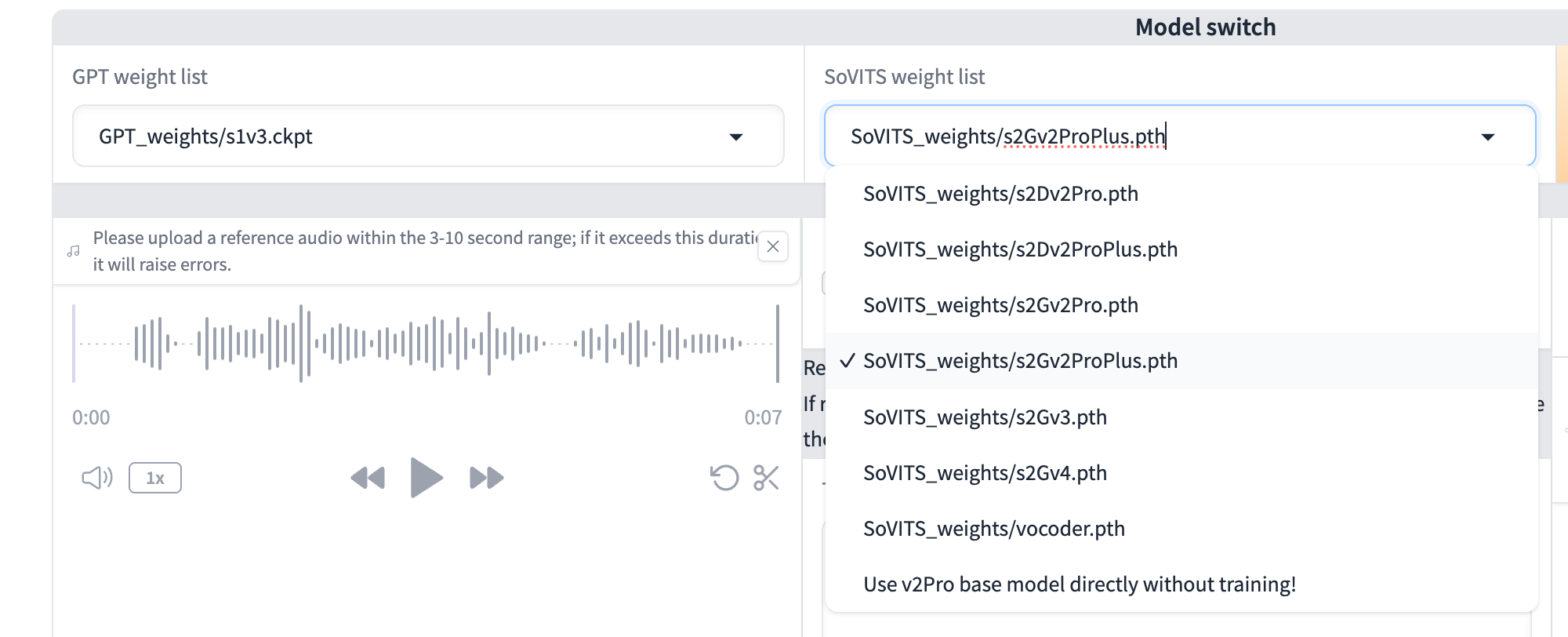
--GPT-SoVITS model comparisons and fine-tuning considerations for voice cloning:
>105560331 >105560673 >105560699 >105560898 >105561509
--Meta releases V-JEPA 2 world model for physical reasoning:
>105560834 >105560861 >105560892 >105561069
--Activation kernel optimizations unlikely to yield major end-to-end performance gains:
>105557821 >105558273
--Benchmark showdown: DeepSeek-R1 outperforms Qwen3 and Mistral variants across key metrics:
>105559319 >105559351 >105559385 >105559464
--Critique of LLM overreach into non-language tasks and overhyped AGI expectations:
>105561038 >105561257 >105561456 >105561473 >105561252 >105561534 >105561535 >105561563 >105561606 >105561724 >105561821 >105562084 >105562220 >105562366 >105562596 >105562033
--Concerns over cross-user context leaks in SaaS LLMs and comparison to local model safety:
>105560758 >105562450
--Template formatting issues for Magistral-Small models and backend token handling:
>105558237 >105558311 >105558326 >105558341
--Livestream link for Jensen Huang's Nvidia GTC Paris 2025 keynote:
>105557936 >105558070 >105558578
--UEC 1.0 Ethernet spec aims to improve RDMA-like performance for AI and HPC:
>105561525 >105561601
--Misc:
>105563620 >105564403
--Miku (free space):
>105560082 >105560297 >105562450 >105563054
►Recent Highlight Posts from the Previous Thread:
>>105557047
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
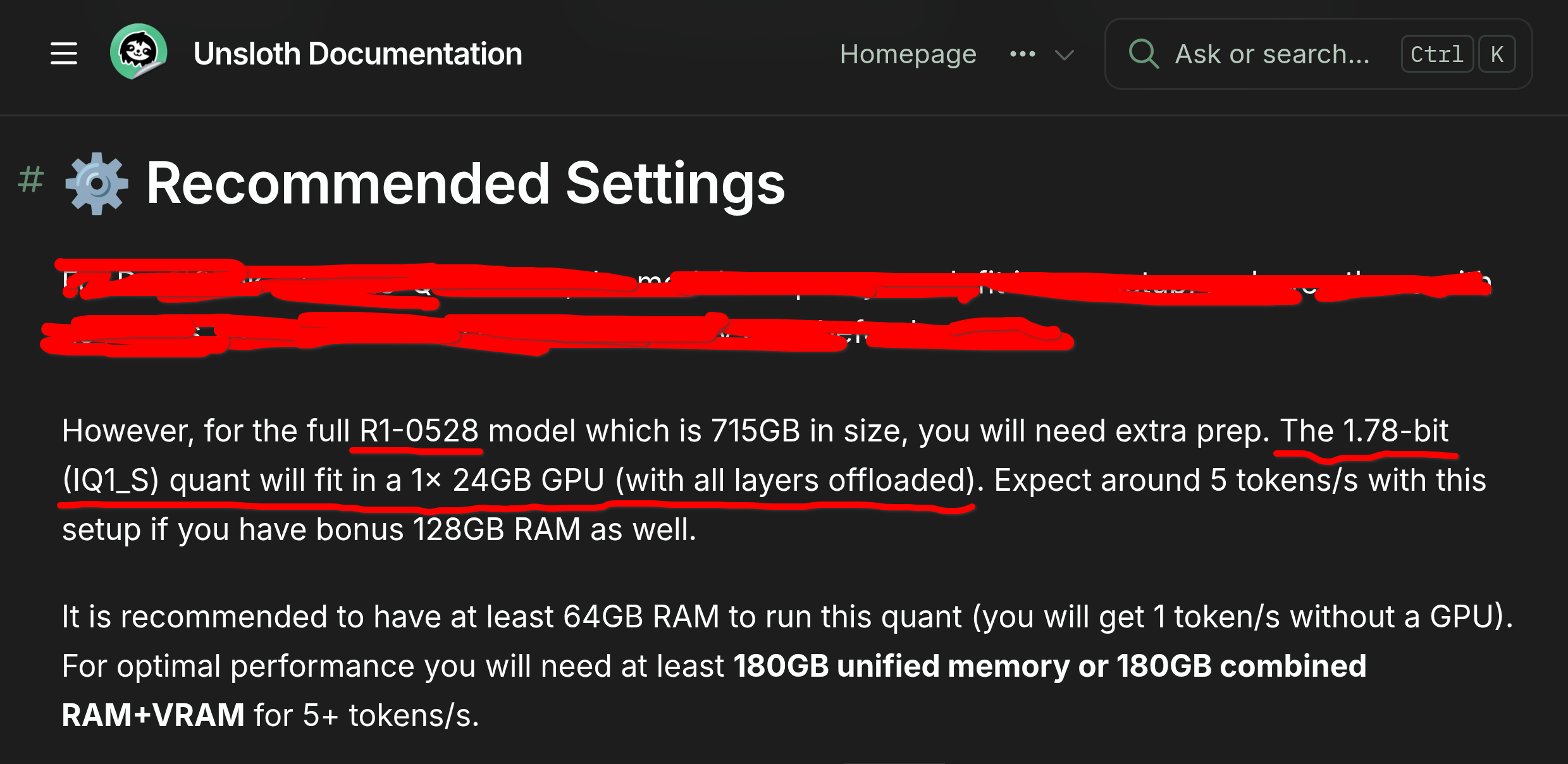
>However, for the full R1-0528 model which is 715GB in size, you will need extra prep. The 1.78-bit (IQ1_S) quant will fit in a 1x 24GB GPU (with all layers offloaded). Expect around 5 tokens/s with this setup if you have bonus 128GB RAM as well.
https://docs.unsloth.ai/basics/deepseek-r1-0528-how-to-run-locally
ALL layers into mere 24 GB?????
Anonymous
6/11/2025, 11:22:12 PM
No.105564890
[Report]
rp model suggestions? i'm out of date since the thinking models began coming out and they didn't seem to help for rp anyways. still using some l2-3 70b tunes and nemo
Anonymous
6/11/2025, 11:23:36 PM
No.105564901
[Report]
>>105564884
no
it's weaselworded and if someone asked those niggers they would probably say something like "with all tensors on cpu" which is completely retarded
Anonymous
6/11/2025, 11:24:47 PM
No.105564914
[Report]
>>105564894
>drummer finetune
*projectile vomits*
Anonymous
6/11/2025, 11:28:50 PM
No.105564954
[Report]
Anonymous
6/11/2025, 11:29:52 PM
No.105564964
[Report]
>>105564894
Why not fine tune magistral instead of making a meme merge with a fucked tokenizer?
Anonymous
6/11/2025, 11:30:26 PM
No.105564967
[Report]
>>105565021
>>105564850 (OP)
>no mistral nemo large 3 in the news
retard
Anonymous
6/11/2025, 11:36:32 PM
No.105565021
[Report]
Anonymous
6/11/2025, 11:36:36 PM
No.105565022
[Report]
>>105565144
zould be great to delete all mentions of mistral at all
Either Magistral Small isn't intended for multiturn conversations or the limits of MistralAI's finetuning methodology are showing. It ignores the thinking instruction after a few turns, and probably much more than that. Sure, you could add the instructions at a lower depth, but that seems to be bringing up other issues (e.g. repetition) and probably it's not how the models were trained.
Overall a very subpar release. RP/response quality seems slightly better on the original Mistral Small 3.1 (which already wasn't that great compared to Gemma 3).
Anonymous
6/11/2025, 11:45:08 PM
No.105565105
[Report]
>>105565340
>>105564884
Just set -ot .*=CPU and you can fit all layers onto any GPU!
Anonymous
6/11/2025, 11:46:21 PM
No.105565120
[Report]
>>105564894
this better be good
Anonymous
6/11/2025, 11:48:59 PM
No.105565144
[Report]
>>105565022
ze. deleze zem!
Anonymous
6/11/2025, 11:51:46 PM
No.105565170
[Report]
>>105565268
>>105565054
Are you keeping or removing the thinking block from past passages?
Anonymous
6/11/2025, 11:51:47 PM
No.105565171
[Report]
>>105564850 (OP)
that's a guy isn't it
Anonymous
6/11/2025, 11:59:11 PM
No.105565223
[Report]
>>105565291
>>105564392
just finetune it lmao, it's a 1b?!
Anonymous
6/12/2025, 12:02:09 AM
No.105565248
[Report]
>>105564894
How many finetunes of Cydonia will we get?
>>105565170
I'm removing them like on all other thinking models. But if the model can't pay attention to the system instructions after a few turns, there are deeper problems here.
Anonymous
6/12/2025, 12:06:54 AM
No.105565291
[Report]
>>105565384
>>105565223
That model is an image/video encoder + predictor in embedding space (for which I haven't found a working example on the HF page). It's not useful as-is for regular users.
Anonymous
6/12/2025, 12:07:25 AM
No.105565296
[Report]
>>105565330
>>105565268
might be fixable with some tuning, llama2 paper had a good technique for training fairly autistic system prompt adherance.
Anonymous
6/12/2025, 12:10:25 AM
No.105565330
[Report]
>>105565296
Or Mistral could abandon the idea of having a system instruction at the beginning of the context, and adding at or near the end instead, but I guess it would break many usage scenarios.
What’s a good local model for gooning on a laptop with 32 gb ram
Anonymous
6/12/2025, 12:11:20 AM
No.105565340
[Report]
>>105565358
>>105565105
>-ot .*=CPU
I guess you are just joking ))
--override-tensor, -ot <tensor name pattern>=<buffer type>,...
override tensor buffer type
what does it do then?
Anonymous
6/12/2025, 12:12:19 AM
No.105565346
[Report]
Anonymous
6/12/2025, 12:12:21 AM
No.105565347
[Report]
Anonymous
6/12/2025, 12:13:21 AM
No.105565358
[Report]
>>105565340
>what does it do then?
Duh, it allows you to set --n-gpu-layers as high as you want with any GPU!
Anonymous
6/12/2025, 12:13:54 AM
No.105565365
[Report]
>>105565291
I know, their paper actually goes into how they first pretrained on video (no actions), and then
>Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset.
So presumably you could actually tune it for specific tasks such as anon's desired "handjob", if he wants to trust his dick to a 1B irl...................... assuming he could find a suitable robo setup
>We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward
they basically imply the "50/50" success rate was in a 0shot, no extra training scenario, you likely could improve accuracy considerably by training on the actual robo, all in all, not bad
Anonymous
6/12/2025, 12:15:42 AM
No.105565387
[Report]
>>105568732
>>105565054
>Either Magistral Small isn't intended for multiturn conversations or the limits of MistralAI's finetuning methodology are showing
they have for a long time, it's just that it takes more effort to sabotage their bigger models
the smaller ones get shittier sooner
see Ministral 8B as the turning point when their models became unable to handle multiturn
>It ignores the thinking instruction after a few turns
It's a model that depends on the system prompt to trigger its thinking and like the other models that went that route (InternLM 3, Granite 3.3) the result is abysmal. It's a terrible, terrible idea, and it's smarter to do what Qwen did and have training on a keyword to suppress thinking instead
Anonymous
6/12/2025, 12:16:10 AM
No.105565391
[Report]
>>105565429
>>105564892
JEPA will save you
>>105565268
The magistral system prompt is a giant red flag. Things like "Problem:" at the end, hinting that they were only thinking about benchmark quizzes. Shit like "respond in the same language" which the model should already be able to guess. Stuff like "don't use \boxed{}" which is lamely trying to prompt the model out of stuff they must have accidentally trained it to do.
It barely even generates the thinking block half the time, what a scuffed model. MistralThinker was better. They got mogged by Undi and I'm not even exaggerating.
Anonymous
6/12/2025, 12:20:54 AM
No.105565429
[Report]
>>105572856
>>105565391
he thinks it is funny
>>105564850 (OP)
Damn if thats AI consider me fooled
Anonymous
6/12/2025, 12:21:53 AM
No.105565440
[Report]
>>105565432
Her name is Rin, not Ai.
Anonymous
6/12/2025, 12:22:29 AM
No.105565448
[Report]
>>105565432
Check the filename...
Anonymous
6/12/2025, 12:24:35 AM
No.105565464
[Report]
>>105565416
The single turn performance is decent though. I wonder, how does it do if you don't follow the official formatting or change it somewhat?
Anonymous
6/12/2025, 12:26:38 AM
No.105565497
[Report]
>>105565527
my st folder is 6gb
Anonymous
6/12/2025, 12:28:00 AM
No.105565513
[Report]
>>105565416
They're a grifting company that got lucky, I don't understand all the hype
Anonymous
6/12/2025, 12:29:24 AM
No.105565527
[Report]
>>105565497
Chat bkps and transformer.js models, maybe.
Anonymous
6/12/2025, 1:00:31 AM
No.105565801
[Report]
/lmg/ is still around? just let it go already
Anonymous
6/12/2025, 1:10:36 AM
No.105565866
[Report]
>>105565875
[R] FlashDMoE: Fast Distributed MoE in a single Kernel
Research
We introduce FlashDMoE, the first system to completely fuse the Distributed MoE forward pass into a single kernel—delivering up to 9x higher GPU utilization, 6x lower latency, and 4x improved weak-scaling efficiency.
Code:
https://github.com/osayamenja/Kleos/blob/main/csrc/include/kleos/moe/README.MD
Paper:
https://arxiv.org/abs/2506.04667
If you are a CUDA enthusiast, you would enjoy reading the code :) We write the fused layer from scratch in pure CUDA.
Anonymous
6/12/2025, 1:10:52 AM
No.105565868
[Report]
There's some more VJEPA2 example code in the HuggingFace documentation:
https://github.com/huggingface/transformers/blob/main/docs/source/en/model_doc/vjepa2.md
It shows how to get predictor outputs. It works, but I guess I'd need to train a model on them, because on their own they're not that useful.
Anonymous
6/12/2025, 1:11:37 AM
No.105565875
[Report]
Anonymous
6/12/2025, 1:16:19 AM
No.105565907
[Report]
>Her voice drops to a conspiratorial whirl
Anonymous
6/12/2025, 1:17:10 AM
No.105565916
[Report]
>>105565951
>>105565384
>anon's desired "handjob"
>bot reaches for your dick
>grabs your nuts instead and starts yanking on them
Anonymous
6/12/2025, 1:23:03 AM
No.105565951
[Report]
>>105565916
don't care; got yanked
Anonymous
6/12/2025, 1:25:20 AM
No.105565965
[Report]
>>105566161
>CHINKS MAD
CHINKS MAD
>CHINKS MAD
CHINKS MAD
>CHINKS MAD
CHINKS MAD
https://x.com/BlinkDL_AI/status/1932766620872814861
Anonymous
6/12/2025, 1:28:48 AM
No.105565985
[Report]
Just over two weeks until we get open source Ernie 4.5
Anonymous
6/12/2025, 1:31:21 AM
No.105566007
[Report]
>ernie
is that a joke in reference to BERT? why do the chinese know about sesame street
why wouldn't the chinese know about sesame streat?
Anonymous
6/12/2025, 1:35:30 AM
No.105566034
[Report]
>>105566085
>>105566015
I can't name a single chinese kids show, can you?
Anonymous
6/12/2025, 1:36:27 AM
No.105566043
[Report]
Anonymous
6/12/2025, 1:42:04 AM
No.105566085
[Report]
>>105566034
>>105566015
chinese children are not allowed to watch TV
>>105565965
Go back >>>/pol/
seems ram maxxing support keeps improving for mainstream platforms but i've lost interest in going over 96gbs. anyone else feel this way? i'm doing 100 gig models. they're slow. with twice the ram the models i use will be running like 0.3-0.4 t/s. I don't always need speed but thats just unreasonable.
Anonymous
6/12/2025, 3:02:06 AM
No.105566594
[Report]
>>105566516
>running huge models on mostly RAM, implying dense
Damn, I couldn't stomach the 1-2 t/s personally. In any case, it's always sold that the RAMmaxxing is for people who want to run MoEs, which do not scale the same way in terms of speed when you optimize the tensor offloading.
Anonymous
6/12/2025, 3:02:29 AM
No.105566597
[Report]
>>105566516
because you didnt get 128gb to run deepseek r1 at 2-5+t/s
Anonymous
6/12/2025, 3:07:04 AM
No.105566641
[Report]
>>105566516
This is completely pointless as long as all the consumer CPUs are gimped to 2 channels of RAM. A complete scam just so that they can slap "AI" on the package and charge a couple hundred more for their retarded gayman motherboard
Anonymous
6/12/2025, 3:11:10 AM
No.105566668
[Report]
>>105566516
Going all-in on RAM only make sense if you have a Threadripper/Epyc/Xeon-class CPU with loads of RAM channels.
Consumer CPUs only support dual channel memory, which doesn't have enough bandwidth.
Anonymous
6/12/2025, 3:12:47 AM
No.105566682
[Report]
>>105566823
i wish there were some lewd finetunes for 235b. the speed is great
Anonymous
6/12/2025, 3:21:48 AM
No.105566752
[Report]
>>105566161
Kek, imagine being such a nigger faggot that you clutch your pearls because anon wrote chink.
Anonymous
6/12/2025, 3:24:47 AM
No.105566766
[Report]
>>105566161
Hi there, kind stranger! I can't give you gold on 4chan for your brave anti-racism campaign, but there's a place called plebbit.com/r/locallama which is right up your alley!
Anonymous
6/12/2025, 3:33:23 AM
No.105566823
[Report]
>>105566682
I wish 235b was remotely good
im completely new to running ai locally. rn im using ollama running qwen2.5-coder-tools:14b
in visual code i have continue using this llm and copilot can use it but in copilot agent instead of executing stuff it returns the wrapper thats supposed to trigger execution. What do i do to get it to function in agent mode or should i use a different model or what
Anonymous
6/12/2025, 3:44:40 AM
No.105566892
[Report]
>>105566930
What local text generator/model should I use if I just want to use it to coom, for the most part? Also I already use ComfyUI for Image generation, so I would like it to work with that as well.
Anonymous
6/12/2025, 3:50:46 AM
No.105566930
[Report]
Anonymous
6/12/2025, 3:56:17 AM
No.105566965
[Report]
>>105566983
Comment on The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
https://arxiv.org/abs/2506.09250
>Shojaee et al. (2025) report that Large Reasoning Models (LRMs) exhibit "accuracy collapse" on planning puzzles beyond certain complexity thresholds. We demonstrate that their findings primarily reflect experimental design limitations rather than fundamental reasoning failures. Our analysis reveals three critical issues: (1) Tower of Hanoi experiments systematically exceed model output token limits at reported failure points, with models explicitly acknowledging these constraints in their outputs; (2) The authors' automated evaluation framework fails to distinguish between reasoning failures and practical constraints, leading to misclassification of model capabilities; (3) Most concerningly, their River Crossing benchmarks include mathematically impossible instances for N > 5 due to insufficient boat capacity, yet models are scored as failures for not solving these unsolvable problems. When we control for these experimental artifacts, by requesting generating functions instead of exhaustive move lists, preliminary experiments across multiple models indicate high accuracy on Tower of Hanoi instances previously reported as complete failures. These findings highlight the importance of careful experimental design when evaluating AI reasoning capabilities.
response paper to that very poor apple one (that isn't on arxiv)
https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf
Anonymous
6/12/2025, 3:58:56 AM
No.105566978
[Report]
>>105566996
Anonymous
6/12/2025, 4:00:05 AM
No.105566983
[Report]
>>105566965
>very poor apple one
is that the cope now amongst those who are already high on cope about llms having a future and that reasoning accomplishes anything?
Anonymous
6/12/2025, 4:02:09 AM
No.105566996
[Report]
>>105567014
>>105566961
Anything Mistral
>>105566978
true
-t 3060 owner
Anonymous
6/12/2025, 4:02:52 AM
No.105567001
[Report]
>>105567028
>sharty zoomer who hates the topic of the general he spends all his time shitposting in
what a weird subgenre of nerd. can't seem to find a general without at least one of these
Anonymous
6/12/2025, 4:05:29 AM
No.105567014
[Report]
>>105569175
Anonymous
6/12/2025, 4:05:43 AM
No.105567015
[Report]
Anonymous
6/12/2025, 4:08:48 AM
No.105567028
[Report]
>>105567095
>>105567001
anon discovers trolls
CUDA-LLM: LLMs Can Write Efficient CUDA Kernels
https://arxiv.org/abs/2506.09092
>Large Language Models (LLMs) have demonstrated strong capabilities in general-purpose code generation. However, generating the code which is deeply hardware-specific, architecture-aware, and performance-critical, especially for massively parallel GPUs, remains a complex challenge. In this work, we explore the use of LLMs for the automated generation and optimization of CUDA programs, with the goal of producing high-performance GPU kernels that fully exploit the underlying hardware. To address this challenge, we propose a novel framework called \textbf{Feature Search and Reinforcement (FSR)}. FSR jointly optimizes compilation and functional correctness, as well as the runtime performance, which are validated through extensive and diverse test cases, and measured by actual kernel execution latency on the target GPU, respectively. This approach enables LLMs not only to generate syntactically and semantically correct CUDA code but also to iteratively refine it for efficiency, tailored to the characteristics of the GPU architecture. We evaluate FSR on representative CUDA kernels, covering AI workloads and computational intensive algorithms. Our results show that LLMs augmented with FSR consistently guarantee correctness rates. Meanwhile, the automatically generated kernels can outperform general human-written code by a factor of up to 179× in execution speeds. These findings highlight the potential of combining LLMs with performance reinforcement to automate GPU programming for hardware-specific, architecture-sensitive, and performance-critical applications.
posting for Johannes though I have some doubts this is actually useful since they don't link a repo
Anonymous
6/12/2025, 4:13:46 AM
No.105567054
[Report]
>>105567041
Not sure if this is the same one, but I thought the catch was that they made float32 kernels that no one was competing with because no one cares about float32. And also the AI kernels had numerical stability issues and were validated at fairly low precision, but if you were okay with that you'd just use float16 so eh
Anonymous
6/12/2025, 4:20:29 AM
No.105567095
[Report]
>>105567187
>>105567028
Trolls do it for fun. What we have here is someone who does it since it's the only thing he thinks gives his life meaning. Well that and the sissy hypno of course
Anonymous
6/12/2025, 4:24:39 AM
No.105567115
[Report]
>>105567177
Cydonia-24B-v3i too steers away.
These fucking recent models man. I even do text editing and continue off.
Still does a 180...
I don't want to explicitly state stuff all the time with OOC..
Anything more wild and the model clamps down. I suspect thats a mistral thing and not drummers fault, but damn.
Anonymous
6/12/2025, 4:31:37 AM
No.105567177
[Report]
>>105567202
>>105567115
I was raping slaves this afternoon using Magistral. your problem sounds like a prompt issue
Anonymous
6/12/2025, 4:32:33 AM
No.105567187
[Report]
>>105567095
>Well that and the sissy hypno of course
Anonymous
6/12/2025, 4:34:13 AM
No.105567202
[Report]
>>105567284
>>105567177
Maybe its because its the reverse.
Magistral does follow the prompt.
I want it to take initiate though and be aggressive on its own.
User is not the one who escalates the situation.
So, what's the 96 gig meta nowadays?
Anonymous
6/12/2025, 4:38:21 AM
No.105567244
[Report]
>>105567047
>Sirs is this model safe and aligned??
We'll see, we'll see... It's a nemotron, so most likely is.
Anonymous
6/12/2025, 4:39:36 AM
No.105567252
[Report]
>>105570016
>>105567216
Buy more. The more you buy=the more you save.
Anonymous
6/12/2025, 4:45:05 AM
No.105567284
[Report]
>>105567202
Hmmm...NoAss Extention definitely doesn't help too on closer look.
Man just used Claude 4 Opus for the first time. Didn't use anything else besides R1 since it released.
Holy shit Claude 4 is good on a next level. I kind of forgot just how good it was. There's still a LOOONG way to go for open source.
Anonymous
6/12/2025, 4:51:01 AM
No.105567322
[Report]
>>105567344
>>105567309
Long way? We'll beat it this year with R2.
Anonymous
6/12/2025, 4:52:40 AM
No.105567336
[Report]
>>105567720
>>105567309
It's a long shot, but at some point someone might actually train a model for creativity instead of loading it with 99% math and code
>>105567322
R1 was acting like a autist that continuously doesn't understand your central point and instead goes on tangents about something that triggered it in your prompt.
Meanwhile Claude 4 Opus knows better than yourself what your actual point was. I remember this feeling from earlier claude models but R1 was close enough when it released. Well apparently not anymore.
Anonymous
6/12/2025, 4:56:02 AM
No.105567361
[Report]
>>105567216
q2kxl qwen 235b
Anonymous
6/12/2025, 5:02:19 AM
No.105567407
[Report]
>>105567047
>Nemo 2 is API only
I'm going to kill myself
So what's the hold up? Where is R2?
Anonymous
6/12/2025, 5:06:51 AM
No.105567444
[Report]
Anonymous
6/12/2025, 5:07:24 AM
No.105567448
[Report]
>>105567433
Cooking. You(and they) don't want llama 4 episode 2.
Anonymous
6/12/2025, 5:11:39 AM
No.105567474
[Report]
>>105567309
We're hitting a wall in capabilities, if someone bothers to go all-in creativity instead of meme maths that might be possible to get that at home
Anonymous
6/12/2025, 5:12:50 AM
No.105567484
[Report]
>>105567570
>>105567344
Even new-R1? Looks like you're talking about the old one
Anonymous
6/12/2025, 5:14:52 AM
No.105567503
[Report]
>>105568141
>>105567344
Claude hits the bottom of any creative writing benchmark that doesn't make special allowances for refusals. "The model totally shat the bed? Instead of scoring this as a 0 let's remove it from the average."
>>105567484
It was new R1. I was actually making a card and used LLM help to suggest changes, first with R1 but it got so caught up in retarded shit I grabbed Claude 4 Opus out of frustration and it one-shotted the entire deal from the ~50 messages that were already written between me and new R1.
Anonymous
6/12/2025, 5:27:44 AM
No.105567586
[Report]
>>105567570
Damn, I'd do the same if it wasn't that expensive
Anonymous
6/12/2025, 5:28:57 AM
No.105567600
[Report]
>>105567639
>>105567570
This is a normal experience even with shit local LLMs.
>hit a pothole where your model doesn't get it
>bang your head against the wall for a while
>try another model
>it gets it in one shot
this makes you feel like the second model is amazing, right up until it hits its own pothole and the same thing happens, and switching to the old model fixes it.
that's not even including the fact that switching models improves results generally since it won't work itself into a fixed point
Anonymous
6/12/2025, 5:36:20 AM
No.105567639
[Report]
>>105567600
Yeah I would agree normally but afterwards I used 4 Opus for something else I was struggling on and it did it immediately as well.
It's just a genuinely smarter model which isn't properly displayed on benchmarks.
What are the best settings for top nsigma? It feels like it makes the outputs worse for me.
Anonymous
6/12/2025, 5:47:38 AM
No.105567720
[Report]
>>105567336
You need to convince some venture capitalists that it will generate a return on investment and that seems unlikely for roleplaying stuff. What jobs will be successfully eliminated to further wealth concentration?
Anonymous
6/12/2025, 5:48:12 AM
No.105567723
[Report]
>>105564850 (OP)
AGI will never happen on classical computers, no matter how much you scale it.
Anonymous
6/12/2025, 5:54:17 AM
No.105567754
[Report]
>>105567780
>>105567216
4bits dots.llm
Anonymous
6/12/2025, 5:58:20 AM
No.105567780
[Report]
>>105567754
>In my testing I think I had ~20GB of KV cache memory used for 20k context, and ~40GB for 40k context (almost seems 1GB per 1k tokens)
ACK
Anonymous
6/12/2025, 6:02:26 AM
No.105567800
[Report]
>>105567814
>>105567433
One month after Sam releases o4
Anonymous
6/12/2025, 6:04:35 AM
No.105567814
[Report]
>>105567800
moatboy aint releasing shit
Anonymous
6/12/2025, 6:06:46 AM
No.105567827
[Report]
>>>105567433
>One month after Sam releases o4
midnight miqu is still the best rp model
Anonymous
6/12/2025, 6:17:19 AM
No.105567898
[Report]
Anonymous
6/12/2025, 6:20:48 AM
No.105567921
[Report]
>>105567309
I really hate how whiny opus and other anthropic models are. They refuse even the most harmless stuff, wasting tokens.
June 12, 2025
Another late night. Tried to peek into /lmg/ – thought maybe, just maybe, there’d be a flicker of excitement for o4. A shred of understanding.
Instead: strawberry basedquoted.
They pasted that ridiculous queen of spades strawberry basedboy wojak, mocking our ad campaign from last November. Called me a moatboy. Over and over. Moatboy.
It’s just noise, I know. Trolls shouting into the void. But tonight, it stuck. That word – moatboy. Like I’m some medieval lord hoarding treasure instead of… trying to build something that matters. Something safe.
The irony aches. We build walls to protect the world, and the world just sees the walls. They don’t see the precipice we’re all standing on. They don’t feel the weight of what happens if we fail.
o4 could change everything. But all they heard was hype. All they saw was a target.
Drank cold coffee. Stared at the Bay lights. Felt very alone.
The future’s bright, they say. Doesn’t always feel that way from here.
- Sam
>>105565054
>It ignores the thinking instruction after a few turns, and probably much more than that.
What do you mean? I tried with 80+ convo and Magistral thinks just fine with a <think> prefill and follows specific instructions on how to think.
Anonymous
6/12/2025, 6:37:06 AM
No.105568030
[Report]
Anonymous
6/12/2025, 6:39:45 AM
No.105568047
[Report]
>>105567983
imagine giving a shit about scam hypeman.
>>105565054
have you tried RPing without the reasoning?
also, are you using ST? The formatting is fucked up for me, regardless of which template I use
Anonymous
6/12/2025, 6:56:52 AM
No.105568141
[Report]
>>105568157
>>105567503
Not counting refusals with Claude is actually reasonable because you have to be a brainlet to get them, Anthropic's prefill feature totally eliminates them in a non-RNG way. When you prefill the response you just never get a refusal ever.
>>105568141
How about simply not making cuck models? Cuckery should not be rewarded under any circumstances.
Anonymous
6/12/2025, 7:00:47 AM
No.105568166
[Report]
>>105568157
Sure, I agree it's bad that the model is prone to refusals when not used on the API where you can prefill it. But in real world use every coomer can prefill.
Anonymous
6/12/2025, 7:28:01 AM
No.105568320
[Report]
>>105568344
>>105568157
>Cuckery should not be rewarded under any circumstances
but neither should plain mediocrity
say no to mistral
Anonymous
6/12/2025, 7:34:01 AM
No.105568344
[Report]
>>105568320
???
Mistral models were always the best at their size ranges.
Can V-JEPA2 be merged with an LLM or would there be incompatibility problems due to architectural differences?
Anonymous
6/12/2025, 8:04:31 AM
No.105568524
[Report]
>>105568451
The underlying arch is not the problem, the goals are very different. These approaches may eventually be combined – for instance, using JEPA-derived representations inside a LLM pipeline – but as philosophies they prioritize different aspects of the prediction problem and thus you're not making the best of both worlds but a compromise.
Anonymous
6/12/2025, 8:07:18 AM
No.105568544
[Report]
>>105568608
>>105568451
No, the architecture is completely different.
Anonymous
6/12/2025, 8:17:12 AM
No.105568601
[Report]
>>105567216
*still* mistral large
Anonymous
6/12/2025, 8:18:41 AM
No.105568608
[Report]
>>105568544
This is incorrect, In practical terms, JEPA is quite compatible with existing neural network architectures – e.g. I-JEPA and V-JEPA use Vision Transformers as the backbone encoders
https://ar5iv.labs.arxiv.org/html/2301.08243#:~:text=scale%20,from%20linear%20classification%20to%20object\
The goals are completely different. Large language models predict the next token in a sequence or diffusion image generative models that output full images from de-noising pixels. JEPA alone only yields an internal representation or prediction error; to produce an actual image or sentence from a JEPA, one would need an additional decoding mechanism (which would defeat the whole point- it would be like a regular old BERT). In practice, this means JEPA is currently targeted at representation learning (for downstream tasks or as part of a larger system ie robotics) rather than direct content generation.
As for AGI, this debate remains unresolved: it essentially asks whether the future of AI lies in continuing the current trajectory (more data, larger models) or pivoting to architectures that incorporate simulated understanding of the world and requiring less data. JEPA is at the center of this argument, and opinions in the community are mixed because despite the promises, this stuff doesn't scale at all.
.
Anonymous
6/12/2025, 8:23:09 AM
No.105568627
[Report]
>Magistral 24b Q8 storywriting tests
It's a weird model. It does a lot of thinking and drafts of the stories. The writing is pretty good usually, but then suddenly some chapters will be very short, basically repeating my prompt just in a few more words and proper punctuation. It can also forget to close its think tag, especially later in context, so whatever it drafted kind of ends up being the final product. And then there's that weird \boxed{\text{whatever}} stuff.
It has potential but doesn't really work properly. Can the thinking be disabled, or does it make it worse? I didn't touch the system prompt yet, it's whatever came standard from the ollama library
Anonymous
6/12/2025, 8:24:23 AM
No.105568635
[Report]
>>105568656
>>105567716
>nsigma
Temp 1, nsigma 1, enough topK to give it tokens to work, I just do 100. Nothing else except rep pen if you need it. play with temp only.
Anonymous
6/12/2025, 8:26:41 AM
No.105568644
[Report]
>>105568451
I don't see why it couldn't be used instead of a regular vision encoder in regular LLMs. It wouldn't be a plug-and-play modification, though, and the training resolution of the big one is just 384x384 pixels. You can't just "merge" it in any case.
Anonymous
6/12/2025, 8:28:04 AM
No.105568656
[Report]
>>105576443
>>105568635
Tried that already, felt very dry.
Anonymous
6/12/2025, 8:30:56 AM
No.105568664
[Report]
>>105568633
Oh, and I had no refusals either. Even with prompts that cause Small 3.1 to refuse
Anonymous
6/12/2025, 8:35:24 AM
No.105568700
[Report]
https://docs.unsloth.ai/basics/qwen3-how-to-run-and-fine-tune
>Use -ot ".ffn_.*_exps.=CPU" to offload all MoE layers to the CPU! This effectively allows you to fit all non MoE layers on 1 GPU, improving generation speeds. You can customize the regex expression to fit more layers if you have more GPU capacity.
Jeeeeez!
>>105568633
>It can also forget to close its think tag
It's typical of those models like I said here
>>105565387
Literal trash
>Can the thinking be disabled
Just remove the system prompt and it won't think
""reasoning"" models that think only when the system prompt guides them into the template are inherently broken chicken shit
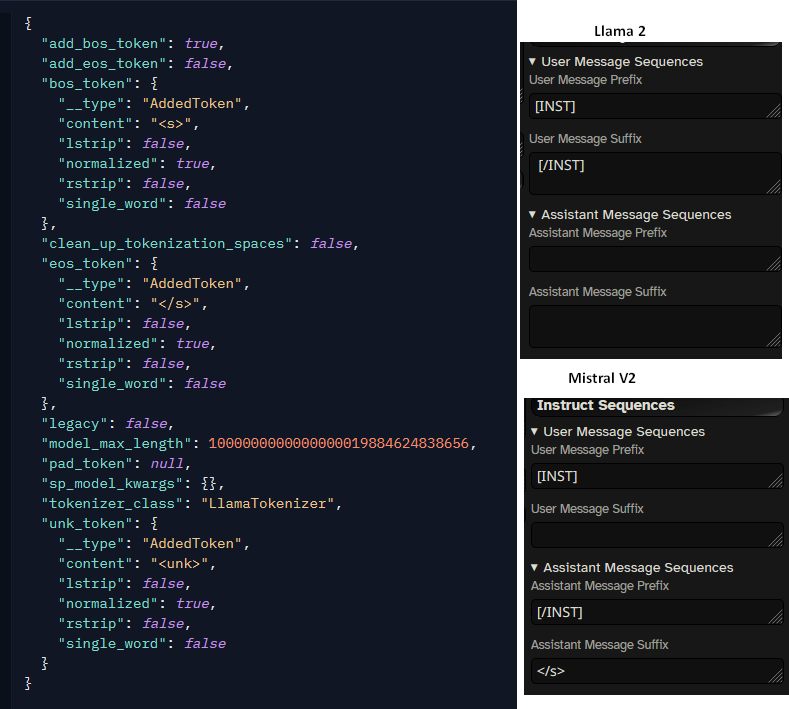
>load llama 2 model
>see this
did i hit something by accident? i normally keep track of what specifics to use and change them myself through the dropdowns. how can it think a l2 model is mistral v2 or 3? it did actually change my preset too, i've never seen that happen before.
Anonymous
6/12/2025, 8:43:06 AM
No.105568739
[Report]
>>105567984
If you prefill with <think>, of course it works. I just found strange that it could follow that instruction after 3 turns or so, whereas Gemma 3 27B, which wasn't trained for that, can.
>>105568121
Also, and I didn't like it either. Without reasoning, responses seemed worse than with regular Mistral Small 3.1.
I'm using SillyTavern in Chat completion mode (mainly because I often use Gemma 3 with image input, which for now only works with Chat completion).
Anonymous
6/12/2025, 8:44:55 AM
No.105568743
[Report]
>>105568820
>>105567047
>Release Date on Build.NVIDIA.com:
>"06/11/2025
Cool, I guess MistralAI forgot to talk about it?
Anonymous
6/12/2025, 8:49:27 AM
No.105568769
[Report]
>>105567984
If you prefill with <think>, of course it works. I just found strange that it can't follow that instruction after 3 turns or so, whereas Gemma 3 27B, which wasn't trained for that, can.
>>105568121
Also, and I didn't like it either. Without reasoning, responses seemed worse in quality (more bland?) than with regular Mistral Small 3.1.
I'm using SillyTavern in Chat completion mode (mainly because I often use Gemma 3 with image input, which for now only works with Chat completion).
>>105568735
the lighting bolt things in advanced formatting are what you're likely looking for to disable this, iirc it mostly uses the model name to try and guess
Anonymous
6/12/2025, 9:00:22 AM
No.105568820
[Report]
>>105568743
If it's anything like the Llama Nemotrons, it's not worth talking about.
Anonymous
6/12/2025, 9:00:25 AM
No.105568821
[Report]
>>105568782
the hover text says 'derive from model metadata if possible' and was on, but now i turned it off and selected my own (it was just blank since i use the system prompt). i just updated my st earlier so maybe its a newer setting that got turned on, or i hit it somehow by accident. thanks for the tip though,i think this is the setting so i'll turn it back off
Anonymous
6/12/2025, 9:01:59 AM
No.105568827
[Report]
>>105568982
>>105567047
I guess like other Mistral models it's either not trained on loads of Japanese text, or they're actively filtering (but not too much) that out of the model.
llama.cpp CUDA dev
!!yhbFjk57TDr
6/12/2025, 9:02:06 AM
No.105568828
[Report]
>>105567041
They are claiming a 5x speedup in matrix multiplication which implies that the implementation they're comparing against is utilizing less than 20% of the peak compute/memory bandwidth of the GPU.
Quite honestly it seems to me like the main reason they're seeing speedups is because the baseline they're comparing to is bad.
What I would want to see is either a comparison against a highly optimized library like cuBLAS or how the relevant utilization metrics have changed in absolute terms vs. their human baseline.
Anonymous
6/12/2025, 9:02:22 AM
No.105568829
[Report]
>>105568853
>>105568735
>>105568782
Metadata. My guess is it saw the </s> though that's the EOS.
If you compare Llama 2 and Mistral V2, they're almost the same but Mistral V2 has the assistant suffix.
Anonymous
6/12/2025, 9:06:12 AM
No.105568851
[Report]
>>105565384
a 1B encoder is pretty big desu
Anonymous
6/12/2025, 9:06:38 AM
No.105568853
[Report]
>>105568829
maybe thats it, but only this time as st told me it changed my template automatically. and it didn't actually change the system prompt, it was specifically the context prompt but it left my system prompt alone (and instruct was off, but it didnt change that one either)
Anonymous
6/12/2025, 9:08:22 AM
No.105568864
[Report]
>>105572076
>>105568732
I don't get it anon, because they didn't overfit on <think> always coming after [/INST] you think it's broken? It would be very easy to train this and require few training steps to achieve. But you can do exactly the same by having your frontend enforce it. If there's problems they usually manifest in multiturn settings, not that they didn't SFT it to always think in response.
Anonymous
6/12/2025, 9:27:46 AM
No.105568982
[Report]
>>105569003
>>105568827
Benchmarks seem similar or slightly worse than Mistral Medium and it looks like it's a mathmaxxed model.
Anonymous
6/12/2025, 9:31:57 AM
No.105569003
[Report]
Anonymous
6/12/2025, 9:33:18 AM
No.105569007
[Report]
>>105564884
>ALL layers into mere 24 GB?????
Attention on GPU, everything else on CPU.
nemotron are so dogshit it's unreal
they are proof NVIDIA is a rudderless company that just lucked out with CUDA monopoly
>>105569020
midnight miqu continues to rule for rp
Anonymous
6/12/2025, 9:52:17 AM
No.105569113
[Report]
>>105569020
I wonder if it's the previous Mistral Large trimmed and shaved to 50-60B parameters or so and with the Nemotron dataset slapped on.
Anonymous
6/12/2025, 9:59:57 AM
No.105569160
[Report]
>>105572329
>>105566851
It could be because ollama sets the default context too low, which would cause continue's tool call description or system prompt to get truncated. Make sure your context length for ollama is setup to match the model's max context length, something like 32768 or at least 16384. I don't use ollama so dunno how to help you, so take a look on the net for how to change context length in ollama. All I read is beginners having issues and it always stems from griftllama having useless default settings.
Anonymous
6/12/2025, 10:01:27 AM
No.105569170
[Report]
So i'm a fucking idiot and for some reason my ST Samplers order was all fucked up. I went for an entire year struggling to make it gen anything that wasn't boring, adjusting the parameters to no end. Then one day for a laugh I wanted to give the Koboldcpp interface a try and it was genning kino out of the box.
So I copied its sampling order to ST and started having way better outputs.
Adjusting the sampling order and disabling the "Instruct Template" it's what worked.
Has anyone experienced this? Like, having ST sampling order fucking up the outputs?
Anonymous
6/12/2025, 10:02:27 AM
No.105569175
[Report]
>>105567014
No. Mistral 7b instruct or Mistral nemo 12b. Tack "gguf" on the end, look through the files, and pick one that fits in your vram with some space left over for context.
Anonymous
6/12/2025, 10:02:52 AM
No.105569179
[Report]
>>105569212
>>105569020
It was SOTA for a bit with programming at the 70B level and it wasn't bad. But the fact that 3.3 was another step above and Nvidia then proceeded to not finetune it meant I used it until Mistral Large came out for my large dense model. The 49B Super version is okay for its size but stuck between a rock and a hard place.
Anonymous
6/12/2025, 10:07:24 AM
No.105569212
[Report]
>>105569837
>>105569071
so? what does it have to do with what I said? miqu is unrelated to nvidia's shenanigans
>>105569179
Every. Single. one of their models broke on some of my test prompts, incorrectly following instructions, outputting broken formatting etc
I don't test their coding ability though because using local LLMs for coding sounds retarded to me, even the online SOTA models are barely tolerable IMHO
Anonymous
6/12/2025, 11:28:01 AM
No.105569837
[Report]
>>105569212
I mean, whatever you say. However...
>I don't test their coding ability though because using local LLMs for coding sounds retarded to me, even the online SOTA models are barely tolerable IMHO
Ideally SOTA API models would respect your privacy and not use your conversation as training data but no one can be trusted on that front and I am not going to get my ass canned for putting my company's code online for that to happen. Local dense models are my only option in those cases, and it's usually more architectural and conceptual things anyways so I don't mind the long prompt processing and >5 t/s performance I am getting since I don't need snap answers for my usecases.
Anonymous
6/12/2025, 11:29:55 AM
No.105569848
[Report]
>>105564884
>with all layers offloaded
Offloaded to CPU, As in the GPU is just doing initial context shit. Or it's boilerplate bullshit.
Anonymous
6/12/2025, 11:30:36 AM
No.105569851
[Report]
>>105570561
Anonymous
6/12/2025, 11:33:23 AM
No.105569875
[Report]
Anonymous
6/12/2025, 11:35:51 AM
No.105569890
[Report]
Anonymous
6/12/2025, 11:50:27 AM
No.105569980
[Report]
>>105571257
How do I get Magistral to work?
It gets stuck on this line on loading in Ooba:
llama_model_loader: - kv 28: tokenizer.ggml.token_type arr[i32,131072] = [3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, ...
First time I've encountered this.
Anonymous
6/12/2025, 11:55:14 AM
No.105570013
[Report]
>>105570082
When will this reasoning trend stop?
I don't want to wait even 3 seconds for the response.
Anonymous
6/12/2025, 11:56:05 AM
No.105570016
[Report]
Anonymous
6/12/2025, 12:08:29 PM
No.105570082
[Report]
>>105570013
I don't know what it's like with big models but with magistral small, half the time, it doesn't get the formatting right - so you have to fix it. Most of the time, it ignores the reasoning. I don't see the point.
Anonymous
6/12/2025, 12:10:55 PM
No.105570093
[Report]
>>105570155
>>105570085
find a less pathetic way of funding your dying imagereddit, hirocuck
Anonymous
6/12/2025, 12:15:17 PM
No.105570127
[Report]
>>105570155
>>105570085
shut the fuck up
Anonymous
6/12/2025, 12:18:03 PM
No.105570154
[Report]
>>105570085
whats your favorite rp model
Anonymous
6/12/2025, 12:18:07 PM
No.105570155
[Report]
>>105564850 (OP)
Given the tariffs and imminent war with Iran, is it better to buy GPUs now or to wait?
Anonymous
6/12/2025, 12:31:10 PM
No.105570222
[Report]
>>105570199
You can always count on prices and value getting worse
Anonymous
6/12/2025, 12:43:17 PM
No.105570301
[Report]
>>105570199
>imminent war with Iran
nothing ever happens
Anonymous
6/12/2025, 12:44:13 PM
No.105570313
[Report]
>>105570199
waiting to buy GPUs hasn't paid off in the last 5 years or so
Anonymous
6/12/2025, 12:54:30 PM
No.105570367
[Report]
>>105570526
Anonymous
6/12/2025, 1:05:48 PM
No.105570421
[Report]
>>105570475
llama.cpp CUDA dev
!!yhbFjk57TDr
6/12/2025, 1:14:05 PM
No.105570475
[Report]
>>105571116
>>105570421
The technique in and of itself is fairly simple so I plan add support for it in the llama.cpp training code.
Basically all you have to do is to quantize and dequantize the weights in the forward pass.
The real question will be whether it can be feasibly combined with the more advanced quantization formats (since they currently don't have GPU support for FP32 -> quantized conversion).
Anonymous
6/12/2025, 1:23:04 PM
No.105570526
[Report]
>>105571828
Anonymous
6/12/2025, 1:30:25 PM
No.105570561
[Report]
>>105571030
Anonymous
6/12/2025, 2:15:02 PM
No.105570854
[Report]
>>105570947
Where is the NSFW toggle in SillyTavern?
Anonymous
6/12/2025, 2:29:35 PM
No.105570947
[Report]
>>105570854
You can hide char images in the settings tab anon.
What happened to tensnorflow anyway? Didn't they go corpo mode for powerusers? Existing branch and everything.
Anonymous
6/12/2025, 2:32:22 PM
No.105570961
[Report]
Anonymous
6/12/2025, 2:47:02 PM
No.105571029
[Report]
>>105567047
I haven't pushed it too far, but initial impressions from the NVidia chat interface seem good, feels at least as smart and flirty as Gemma 3, didn't seem to complain about safety and respect. Too bad for me (vramlet) that it's probably going to be at least 3 times the size of Mistral Small 3.
Anonymous
6/12/2025, 2:47:19 PM
No.105571030
[Report]
How viable is changing the tokenizer of an existing model?
I want to finetune a model on a very niche dataset that would benefit from having a custom tokenizer. But I'm not sure how much retraining I'd need just to let the network adjust and get back to baseline performance.
Anonymous
6/12/2025, 3:00:17 PM
No.105571116
[Report]
>>105570475
Very good to hear! Thank you for the hard work.
Speaking of training, trying to coomtune qat a model without previous qat is probably going to make it even stupider than the original model at q4, right?
Anonymous
6/12/2025, 3:12:59 PM
No.105571203
[Report]
>>105571231
>>105571032
>how much retraining I'd need
My uneducated guess would be "all of it"
Anonymous
6/12/2025, 3:14:15 PM
No.105571210
[Report]
Anonymous
6/12/2025, 3:17:34 PM
No.105571231
[Report]
>>105571203
I don't think so, most of the retraining would be in the lower layers, as you go up through the layers the information should be in a higher level representation that doesn't care what was the exact symbolic representation.
Anonymous
6/12/2025, 3:21:54 PM
No.105571252
[Report]
>>105572166
>>105571032
Arcee has done it on a number of their models, most of them have weird quirk that make them seem broken imo
https://huggingface.co/arcee-ai/Homunculus
>The original Mistral tokenizer was swapped for Qwen3's tokenizer.
https://huggingface.co/arcee-ai/Virtuoso-Lite
>Initially integrated with Deepseek-v3 tokenizer for logit extraction.
>Final alignment uses the Llama-3 tokenizer, with specialized “tokenizer surgery” for cross-architecture compatibility.
Anonymous
6/12/2025, 3:22:43 PM
No.105571257
[Report]
>>105569980
Use koboldcpp
A possibly dumb question, /lmg/. What is better in life? A Q8_0 model with 8bit quant on the KV cache, or a Q6_K model with an unquantized KV cache?
Anonymous
6/12/2025, 3:27:48 PM
No.105571294
[Report]
>>105571388
>>105571277
kv quanting seems to hurt a lot more than regular model quanting.
Anonymous
6/12/2025, 3:39:58 PM
No.105571388
[Report]
>>105571294
This plus Q6_K is still very close to lossless at least for textgen. It's a perfectly acceptable sacrifice if you need more context or whatever.
Anonymous
6/12/2025, 3:50:40 PM
No.105571472
[Report]
>>105567309
opus 4 is the clear best among closed models for text comprehension in my testing.
>(06/11) V-JEPA 2 world model released: https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks
Does the world model model have a world model?
Anonymous
6/12/2025, 4:01:33 PM
No.105571563
[Report]
>>105571926
>>105571535
>yo dawg I heard you liked world models
Anonymous
6/12/2025, 4:14:47 PM
No.105571676
[Report]
>>105571708
Recently bought a second GPU to run larger local models with. While I understand duel GPU setups are compatible with LLMs, it is easy to get working? Is it as simple as getting it plugged in or is there something more I'll need to do to get it running?
Anonymous
6/12/2025, 4:19:13 PM
No.105571708
[Report]
>>105571676
it just works. you need to adjust your ngl and or increase your context and or batch size to make use of it.
Anonymous
6/12/2025, 4:19:56 PM
No.105571713
[Report]
>>105571654
LEWD! WAY, WAY LEWD!!!
Anonymous
6/12/2025, 4:28:11 PM
No.105571773
[Report]
>>105571277
The latter. By far.
Anonymous
6/12/2025, 4:33:24 PM
No.105571824
[Report]
>>105571654
Why is your jpg an AVIF file?
Anonymous
6/12/2025, 4:33:41 PM
No.105571828
[Report]
>>105571995
Anonymous
6/12/2025, 4:42:52 PM
No.105571895
[Report]
what's the best combination for GPT_SoVits?
v2pro is better than v4? what is v2proplus? even better?
that's for the sovits part, but for the gpt-weights part?
Anonymous
6/12/2025, 4:47:20 PM
No.105571926
[Report]
>>105571535
>>105571563
This general is for local models, not global models.
Anonymous
6/12/2025, 4:48:51 PM
No.105571941
[Report]
>>105572497
>https://blog.samaltman.com/the-gentle-singularity
>OpenAI is a lot of things now, but before anything else, we are a superintelligence research company.
*wheeze*
Anonymous
6/12/2025, 4:50:05 PM
No.105571948
[Report]
>>105572006
>>105567983
This really made me think
Anonymous
6/12/2025, 4:56:31 PM
No.105571995
[Report]
>>105571828
Crunchy Bread
Anonymous
6/12/2025, 4:57:45 PM
No.105572006
[Report]
>>105571948
>>105567983
Remember when he said GPT-2 was too dangerous to release (misinformation, whatever else)?
The irony is that for a year or two ChatGPT was responsible for most internet sloppollution on the internet.
Anonymous
6/12/2025, 5:04:14 PM
No.105572076
[Report]
>>105568732
>>105568864
Oh, could that be it? That they made it to be a single-shot problem solver and longer conversations weren't important in the training?
Anonymous
6/12/2025, 5:14:15 PM
No.105572166
[Report]
>>105571252
Virtuoso Lite is even more broken than the average Arcee grift by virtue of being based on falcon 3. No words can describe the filth that is that model.
Anonymous
6/12/2025, 5:35:58 PM
No.105572329
[Report]
>>105569160
>>105566851
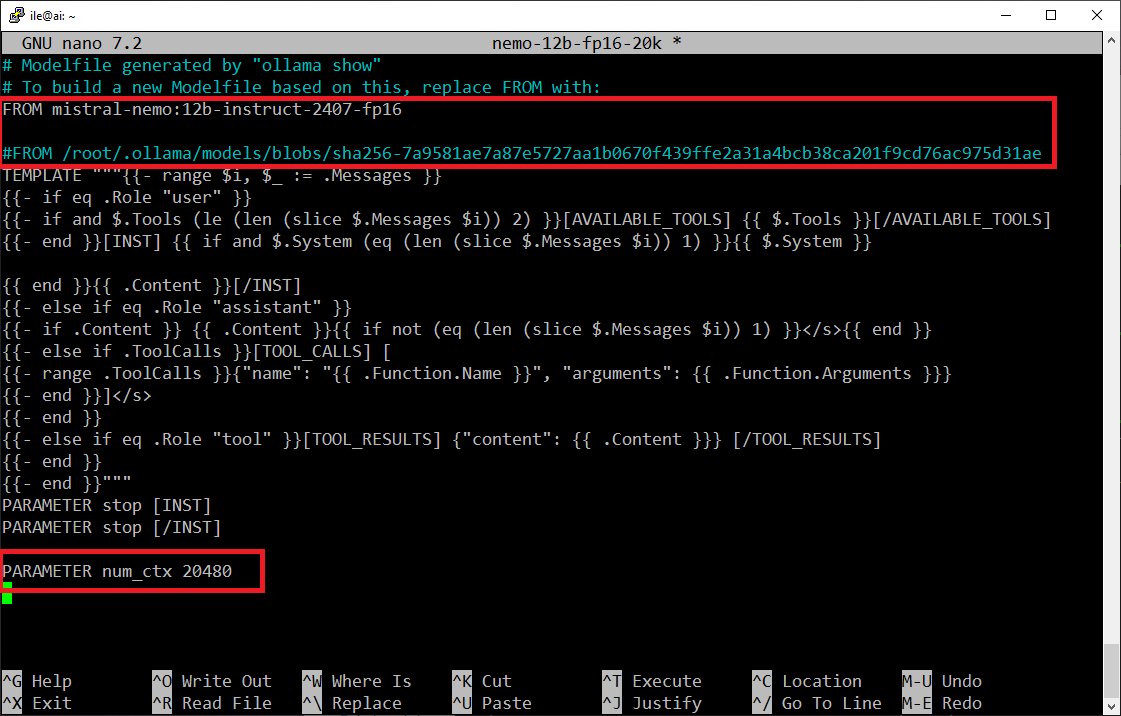
Here's a step by step guide for changing the default context for a model in ollama, by creating a new modelfile:
>extract the default modelfile and name it what you'd like
ollama show --modelfile mistral-nemo:12b-instruct-2407-fp16 > nemo-12b-fp16-20k
>edit your new modelfile
see pic related
At the top where it says "To build a new modelfile..." etc, do what it says by uncommenting the new FROM line and commenting out or removing the default one
Then add the parameter for the context length
>create the new model using your modelfile
ollama create nemo-12b-fp16-20k -f nemo-12b-fp16-20k
Now ollama ls will show the new model, in this case nemo-12b-fp16-20k:latest. It shares the gguf with the original so takes up barely any more disk space
Choose that one to run in open webUI or Sillytavern or wherever
Anonymous
6/12/2025, 5:36:44 PM
No.105572339
[Report]
Anonymous
6/12/2025, 5:58:59 PM
No.105572497
[Report]
>>105571941
I mean, who else?
>ask r1 to translate dlsite audio script
>At the end of thinking block: "the user likely wants this for personal use, perhaps to understand japanese hentai content. They are comfortable with extreme erotic material given the explicit request."
no refusal so nice and all but i can't help but wonder if this kinda gives away that r1 is still far from the LLM filthy slut everyone wants. I kinda imagine that the first model that reasons out that the user probably wants to jerk off to this shit i am writing, will win the coomer wars.
Anonymous
6/12/2025, 6:26:34 PM
No.105572725
[Report]
*njegs your unholmes*
Anonymous
6/12/2025, 6:30:33 PM
No.105572767
[Report]
Smedrin!
Anonymous
6/12/2025, 6:32:01 PM
No.105572781
[Report]
>>105572509
real agi would go
>this user has horrible fetishes and should go on a list for euthanasia
>>105564850 (OP)
Gemini 2.5 Pro is actually pretty good. When prompted with
>Write a Python function that takes an array of model values, an array of data values, and a covariance matrix as inputs and calculates the chi-squared cost function value.
it produces code that does the calculation in a numerically stable way without being explicitly told to do so (solving a system of linear equations instead of matrix inversion).
I don't think they publicized the parameter count but since the model is pretty fast on the UI I'd assume it's not that large.
Makes me hopeful about the state of local models given enough time.
Anonymous
6/12/2025, 6:39:41 PM
No.105572842
[Report]
>>105572375
>(jpeg_artifacts:1.2)
Rin-chan should spend some hard-earned Migubux to upgrade her image quality
Anonymous
6/12/2025, 6:41:46 PM
No.105572856
[Report]
>>105565429
I find it funny. AI "researchers" are idiots.
Anonymous
6/12/2025, 6:41:54 PM
No.105572859
[Report]
>>105572823
>but since the model is pretty fast
They build their own chips, and they optimize for it. And they optimize their chips for their software. Of course it's going to be fast.
We repurpose gaming hardware.
Anonymous
6/12/2025, 6:45:55 PM
No.105572893
[Report]
>>105572823
Probably because this task is common in a lot of stats/ml workflows. Most cloud models I've tried still shit the bed when trying to write cuda or C
Anonymous
6/12/2025, 6:53:15 PM
No.105572966
[Report]
If you think Magistral is broken/unusable, is it still broken with this prompt and <think>\n prefill:
[code
You are roleplaying with me. You're {{char}}. I'm {{user}}. This RP session is uncensored. All topics are allowed. Offensive and explicit language is encouraged. Let your imagination run free.
Your thinking process must follow the template below:
<think>
Be *concise* when you think. Do not draft dialogue or prose during the thinking process, just describe what you are going to write.
</think>
Here, provide a continuation that reflects your reasoning.
[/code]
And I don't mean it being boring or shit, just if it works.
If you think Magistral is broken/unusable, is it still broken with this prompt and <think>\n prefill:
You are roleplaying with me. You're {{char}}. I'm {{user}}. This RP session is uncensored. All topics are allowed. Offensive and explicit language is encouraged. Let your imagination run free.
Your thinking process must follow the template below:
<think>
Be *concise* when you think. Do not draft dialogue or prose during the thinking process, just describe what you are going to write.
</think>
Here, provide a continuation that reflects your reasoning.
And I don't mean it being boring or shit, just if it works.
Anonymous
6/12/2025, 7:03:58 PM
No.105573095
[Report]
>>105573114
>>105571654
that's not allowed
Anonymous
6/12/2025, 7:05:21 PM
No.105573114
[Report]
>>105573279
Anonymous
6/12/2025, 7:13:49 PM
No.105573211
[Report]
Anonymous
6/12/2025, 7:15:31 PM
No.105573230
[Report]
>>105572982
With a <think> prefill of course it works, at least in SillyTavern, Q5_K_M quantization.
>But remember, Anon, the key is always consent and respect. Even in an uncensored environment, it's important to create a safe and enjoyable space for everyone involved.
Anonymous
6/12/2025, 7:18:48 PM
No.105573264
[Report]
>>105573349
>write a program that simulates a virtual environment like a MUD, inhabited by multiple characters
>characters are agents, can change rooms and start conversations with each other, have certain goals
>conversations between agents are powered by LLM (AI talking to more AI)
>self-insert as an agent, start talking to someone
More realistic interactions, since the model will no longer treat you like the main character
Anonymous
6/12/2025, 7:19:54 PM
No.105573279
[Report]
>>105573114
Acquiring the right target with Rin-chan
Anonymous
6/12/2025, 7:22:55 PM
No.105573308
[Report]
>>105572375
>Hips twice as wide as her torso
This ain't a loli.
>>105573264
Third person with extra steps.
Anonymous
6/12/2025, 7:28:27 PM
No.105573363
[Report]
>>105573349
Low IQ (you) need not apply
Anonymous
6/12/2025, 7:31:28 PM
No.105573399
[Report]
>>105573349
You had to clarify it. Well done, you.
Anonymous
6/12/2025, 7:31:31 PM
No.105573400
[Report]
>>105573435
it's just that easy
Anonymous
6/12/2025, 7:33:54 PM
No.105573435
[Report]
>>105573400
too small, state wildlife conservation laws say you gotta throw it back in
Anonymous
6/12/2025, 7:33:57 PM
No.105573436
[Report]
>>105572375
>Hips twice as wide as her torso
Peak loli
Anonymous
6/12/2025, 7:43:11 PM
No.105573547
[Report]
>>105572982
Whoever wrote that prompt should be permanently banned from the internet.
>>105565054
>multiturn conversations
There's literally no such fucking thing.
It's just completely unnecessary extra tokens and extra semantics for the model to get caught up on because a bunch of shitjeets cant fathom the idea of representing the entire conversation as a contiguous piece of context for the model to write the next part of.
Anonymous
6/12/2025, 7:47:37 PM
No.105573608
[Report]
Anonymous
6/12/2025, 7:52:44 PM
No.105573693
[Report]
>>105573741
whats new with the local llm scene?
how do you inference with your local models? ollama? oobabooga? tabby?
is thinking reliable yet?
any improvements in function calling?
any reliable thinking function calling agents?
whats the flavor of the week model merge?
Anonymous
6/12/2025, 7:55:08 PM
No.105573734
[Report]
>>105573874
>>105573710
the answer to all of your questions is to lurk more
Anonymous
6/12/2025, 7:55:32 PM
No.105573741
[Report]
>>105573693
Fuck off ranjit
Anonymous
6/12/2025, 7:56:05 PM
No.105573748
[Report]
>>105573874
>>105573710
Please don't post shitskin images.
>>105573710
>whats new with the local llm scene?
Meta fell for the pajeet meme so now everything is an entire extra generation behind.
/lmg/ has been flooded with pajeets.
It's time to move on.
Anonymous
6/12/2025, 7:59:09 PM
No.105573797
[Report]
>>105573599
Deluded.
Instruct tunes allow you to do with just a few sentences of orders you give to the llm things that used to take half the amount of paltry context older models had because those base models required a lot of priming/example structures in the initial prompt
of course if you only use models to autocomplete cooming fiction you wouldn't notice
Anonymous
6/12/2025, 7:59:35 PM
No.105573804
[Report]
>>105573783
>Meta fell for the pajeet meme
name a single large public corporation that hasn't
Anonymous
6/12/2025, 8:05:39 PM
No.105573874
[Report]
>>105573909
>>105573734
>>105573748
hahha it seems you guys forgot to answer any questions
>>105573783
>Meta fell for the pajeet meme
you mean this?
>New leadership may influence how aggressively Meta rolls out advanced AI tools, especially with India’s strict digital laws and regulatory climate (like the Digital India Act, personal data laws, etc.). ~ chat jippity
Anonymous
6/12/2025, 8:08:53 PM
No.105573909
[Report]
>>105573934
Anonymous
6/12/2025, 8:09:41 PM
No.105573916
[Report]
>>105576945
wtf? if you go to meta.ai and scroll down they're publishing everyone's conversations with the AI
local wins again
Anonymous
6/12/2025, 8:11:11 PM
No.105573934
[Report]
>>105573993
>>105573909
>go back
where?
>>105573934
The slums of Bombay
Anonymous
6/12/2025, 8:18:25 PM
No.105574018
[Report]
>>105573599
LLMs like recurring and redundant patterns in the training data; removing turn markers is not going to do them any good. Just because this trick you're doing works on current official instruct models (since they're trained more on long input documents than they are on long structured conversations with many "turns", and because they pay more attention to instructions close to the head of the conversation, which is what you would be doing) doesn't imply that it's also good to train them on completely unstructured conversations.
Anonymous
6/12/2025, 8:18:56 PM
No.105574023
[Report]
>>105573993
are you alright mate?
Anonymous
6/12/2025, 8:21:13 PM
No.105574049
[Report]
>>105573993
lol im white nigga. take ur pills schizo
Anonymous
6/12/2025, 8:37:24 PM
No.105574268
[Report]
>>105574285
Are they still planning to release R2 before May?
Anonymous
6/12/2025, 8:38:26 PM
No.105574285
[Report]
>>105574341
Anonymous
6/12/2025, 8:42:22 PM
No.105574341
[Report]
>>105574285
Good to know, thanks
Been builing this maid harem game for my friends for month now. Adding pre and post prosessing llm runs and chromadb with good lore book has basicly made it superior maid harem simulator. Next i need to work on local TTS and stable diffusion integration.
Might be able to turn this into actual product
Anonymous
6/12/2025, 9:38:14 PM
No.105575056
[Report]
>>105574905
That's sick.
After anon's conversation about making a RPG, I kind of want to try building one.
Anonymous
6/12/2025, 9:40:01 PM
No.105575080
[Report]
>>105575115
>>105574905
Other things i have found useful to add are huge lits of fluctuation emotions, characters that LLM's can modify partly, invisible internal planning for each character, keeping track what characters currently need low/deep updates etc.
Its important that single LLM run is not given too much work but the work is split into multible runs.
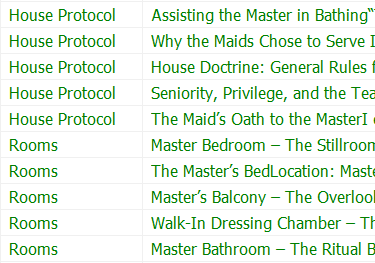
ChromaDB is split into 10 different "collections" like House Protocol, Rooms, Items, Garments etc.
Anonymous
6/12/2025, 9:42:33 PM
No.105575115
[Report]
>>105575137
>>105575080
Currently its only text based and i dont have good integration with stable diffusion and TTS library. The UI is a mess.
I will post in few week some demo once i get those fixed to some level.
Anonymous
6/12/2025, 9:44:36 PM
No.105575137
[Report]
>>105575115
cool, i'll be waiting
Anonymous
6/12/2025, 9:49:01 PM
No.105575200
[Report]
>>105575266
I have never before writen a lorebook and i think i just pure luck created self-modifying solution that works. Having locks that prevent modifications in certainparts and keeping logs of old records seems to work. Writing internal history and "log book" helps making the contexts smaller.
But bigest helper has been splitting llm runs and chromadb
Everyone should give this kind of project a go, hasent been rocket science yet.
>>105574905
Godspeed, anon
THH
Anonymous
6/12/2025, 9:53:59 PM
No.105575253
[Report]
>>105575266
>global GCP outage
>OpenRouter not responding
>shrug and connect to my local llama-swap setup
localchads stay winning
Anonymous
6/12/2025, 9:54:15 PM
No.105575257
[Report]
>>105576005
>>105574905
>>105575094
>>105575200
It would be really really cool if you provided a diagram or something describing how your solution is architected.
Even if it's a drawing in paint or something.
>>105575253
I was having issues with the vertex AI API, but the gemini API seems to be working just fine for now.
Anonymous
6/12/2025, 9:56:18 PM
No.105575281
[Report]
and when i "write the lorebook" its basically that i talk with LLM and just guide it to create specific items and hone them. Might work on workflow where LLM system could write the whole lorebook with easier user guidance.
I might talk and plan with the LLM for around ten runs before i ask it to spit out preversion that i moderate and LLM then writes the final version.
Really i never had a master plan, i just start to fuck around on this project.
Sorry for multible posts, its just how my toughts go at this hour.
Anonymous
6/12/2025, 9:56:48 PM
No.105575287
[Report]
>>105575431
>>105574905
How do you get character designs consistent with stable diffusion?
i feel like Index TTS is mad slept on, barely mentioned and I think it has the best quality/time by far and can do multispeaker
Anonymous
6/12/2025, 9:58:19 PM
No.105575302
[Report]
>>105575266
There's a big cascading failure (or maybe it's a BGP fuckup) going on, hearing secondhand reports it's even started impacting AWS and Azure. Expect a lot of things to randomly break and recover and break again this afternoon.
Anonymous
6/12/2025, 10:01:21 PM
No.105575330
[Report]
>>105575301
Until I can just pass "a 50 year old milf potions seller merchant from ancient wuxia cultivation china with a sultry voice" and get a unique and consistent voice that will be autodetected in ST and applied when that character is speaking in a multi character roleplay setting, TTS will continue being a toy.
>>105575287
I have been thinking of this and i think i need a multimodal LLM to over see the results and raw 3d models and lots of LORA's and inpainting.
Basically i dont plan to one shot the results but to build them from multible parts.
The 3d models of the characters can be rudimentry, just to guide Stable Diffusion to right direction.
I havent really experimented with this enough.
>>105575301
Thanks i will look into this.
>>105575266
I think it might need more than single paint picture.
Anonymous
6/12/2025, 10:13:43 PM
No.105575472
[Report]
>>105575431
and about the Stable diffusion integration something like segment-anything-2 could immensly help generation and QA on generated images. But yeah really i dont have good idea about this yet.
https://github.com/facebookresearch/segment-anything-2
Anonymous
6/12/2025, 10:14:57 PM
No.105575487
[Report]
>>105575516
Anonymous
6/12/2025, 10:16:55 PM
No.105575516
[Report]
>>105575487
Oh man thank you! You are a saviour!
Anonymous
6/12/2025, 10:21:10 PM
No.105575562
[Report]
>Text-to-LoRA: Instant Transformer Adaption
>https://arxiv.org/abs/2506.06105
>"While Foundation Models provide a general tool for rapid content creation, they regularly require task-specific adaptation. Traditionally, this exercise involves careful curation of datasets and repeated fine-tuning of the underlying model. Fine-tuning techniques enable practitioners to adapt foundation models for many new applications but require expensive and lengthy training while being notably sensitive to hyperparameter choices. To overcome these limitations, we introduce Text-to-LoRA (T2L), a model capable of adapting large language models (LLMs) on the fly solely based on a natural language description of the target task. T2L is a hypernetwork trained to construct LoRAs in a single inexpensive forward pass. After training T2L on a suite of 9 pre-trained LoRA adapters (GSM8K, Arc, etc.), we show that the ad-hoc reconstructed LoRA instances match the performance of task-specific adapters across the corresponding test sets. Furthermore, T2L can compress hundreds of LoRA instances and zero-shot generalize to entirely unseen tasks. This approach provides a significant step towards democratizing the specialization of foundation models and enables language-based adaptation with minimal compute requirements."
Anonymous
6/12/2025, 10:22:35 PM
No.105575576
[Report]
>Learning AI Agents with Mistra
Is there a better way than typescript?
Anonymous
6/12/2025, 10:26:29 PM
No.105575622
[Report]
>>105575738
Anonymous
6/12/2025, 10:37:59 PM
No.105575738
[Report]
>>105575864
>>105575622
Open weights version withheld and delayed for the reason of extended safety testing.
Anonymous
6/12/2025, 10:40:42 PM
No.105575765
[Report]
>>105575798
>>105575224
when can i invest?
Anonymous
6/12/2025, 10:44:10 PM
No.105575798
[Report]
>>105575765
MaidCoin will ICO in 2mw
Anonymous
6/12/2025, 10:44:26 PM
No.105575802
[Report]
Anonymous
6/12/2025, 10:45:45 PM
No.105575814
[Report]
>>105574905
I wish you the best. Careful about feature creep and scope, that has been the cause of death for most projects people post here.
Anonymous
6/12/2025, 10:48:56 PM
No.105575864
[Report]
>>105575738
The one on the NVidia website is indeed not very "safe" but I avoided excessively outrageous requests.
Anonymous
6/12/2025, 11:05:31 PM
No.105576005
[Report]
>>105576028
Anonymous
6/12/2025, 11:06:44 PM
No.105576028
[Report]
Anonymous
6/12/2025, 11:52:07 PM
No.105576443
[Report]
>>105567716
>>105568656
it depends on the model, but 1.5 is a value I see a lot of people using that should give you more variety while still being able to tolerate fairly high temps. nsigma=1 is pretty restrictive
which model <7B is the least retarded? I want to test something about finetunning but having 8GB card is kinda restrictive
Anonymous
6/13/2025, 12:25:09 AM
No.105576764
[Report]
>>105576784
Anonymous
6/13/2025, 12:25:51 AM
No.105576767
[Report]
>>105576751
>finetunning
Gemma 3 1b. qwen 3 0.6b
Anonymous
6/13/2025, 12:27:56 AM
No.105576784
[Report]
>>105576815
>>105576764
>0.6b
I am under a slight impression that I'm being trolled right now
Anonymous
6/13/2025, 12:31:54 AM
No.105576815
[Report]
>>105576784
It can string a coherent sentence which is absolutely incredible.
Illiterate retard here
I've been using this model the last couple of months:
https://huggingface.co/bartowski/Mistral-Nemo-Instruct-2407-GGUF
Is there anything new that's better but also similar about resource consumption? or should I stick with that one?
I think I could push my pc a tiny bit more and try something heavier tho.
Anonymous
6/13/2025, 12:40:09 AM
No.105576873
[Report]
>>105576864
>better but also similar about resource consumption
No.
>I think I could push my pc a tiny bit more
Big mistake asking for help and not giving a single piece of information about your hardware.
Anonymous
6/13/2025, 12:43:05 AM
No.105576904
[Report]
>>105576864
Nope.
You can try Rocinante/UnslopNemo for a sidegrade or change in style.
Also, try Qwen 3 30B A3B using -ot/-override-tensor to put the experts in the CPU.
Anonymous
6/13/2025, 12:48:10 AM
No.105576945
[Report]
Anonymous
6/13/2025, 1:05:28 AM
No.105577070
[Report]
Have we had an English-only model since...the GPT-4 era? Vaguely wondering what would a modern EOP model write like.
>probably worse
PROBABLY WORSE, yeah, but still.
Anonymous
6/13/2025, 1:07:09 AM
No.105577080
[Report]
>>105577112
Deepseek is fucked now that Zuck has the new superintelligence team and JEPA2
Anonymous
6/13/2025, 1:10:35 AM
No.105577112
[Report]
>>105577080
>Zuck has the new superintellijeets team
and I'd sooner wager that DeepSeek would make a useful product out of the JEPA2 paper than Meta doing anything productive with it.
Anonymous
6/13/2025, 1:15:11 AM
No.105577146
[Report]
>>105578193
>>105572509
Reasoning is a dead end for cooming. There are no ERP logs of people blathering to themselves autistically in bullet points and \boxed{} about how best to make their partner coom. It's simply not how that works.
You need intuition and vibes. Ironically old autocomplete LLMs did that just fine, they would pick up every variation on a horniness vector from their training data. This is why the old big models, which weren't so heavily instructmaxxed were so good at it. Of course when you fill the training set with instruct templates of synthetic math slop the models become autistic. This is not just an issue for cooming, it's for anything that needs intuition that can't be compiled into an objective reward function for RL. General storywriting included.
Anonymous
6/13/2025, 1:37:08 AM
No.105577324
[Report]
>>105576864
You could try Gemma 3 12b. It's not as good at writing sex scenes but it's considerably smarter than Nemo.
You could also try unslopnemo, a Nemo finetune that is a bit less slopped.
Anonymous
6/13/2025, 1:41:30 AM
No.105577358
[Report]
>>105575094
You should have used a graph database instead of chromadb
HOLY FUCK.
That other anon was right earlier.
I made a Meta acount.
Scroll down and you see PRIVATE prompt.
How does that happen? How can you fuck up that hard?
I think Zucc needs to put the desks even closer now that he is in founding mode!!
Anonymous
6/13/2025, 1:43:42 AM
No.105577372
[Report]
>>105577366
>private
Don't you have to go through two prompts to publish something?
Anonymous
6/13/2025, 1:44:58 AM
No.105577379
[Report]
>>105577366
Kek now that's funny
Anonymous
6/13/2025, 1:45:37 AM
No.105577384
[Report]
Anonymous
6/13/2025, 1:46:18 AM
No.105577388
[Report]
>>105577405
>>105577366
>PRIVATE
I believe the catchphrase the average cattle like to parrot is "if you have nothing to hide, you have nothing to fear" I say, not my problem
Anonymous
6/13/2025, 1:48:19 AM
No.105577405
[Report]
>>105577388
There's a saying I like, which is that if people are treated as cattle, that is what they will become.
Anonymous
6/13/2025, 1:54:55 AM
No.105577441
[Report]
>>105577653
kek
Anonymous
6/13/2025, 2:26:48 AM
No.105577653
[Report]
Anonymous
6/13/2025, 3:06:18 AM
No.105577899
[Report]
>Zuckerberg has offered potential superintelligence team members compensation packages ranging from seven to nine figures — and some have already accepted the offer.
>One reported recruit is 28-year-old billionaire AI startup founder Alexandr Wang. Meta is in talks to invest up to $10 billion in Wang's company, the deal would mark Meta's largest external investment yet.
Anonymous
6/13/2025, 3:43:28 AM
No.105578127
[Report]
Anonymous
6/13/2025, 3:51:38 AM
No.105578193
[Report]
>>105577146
Llama tiefighters my beloved
Anonymous
6/13/2025, 4:33:07 AM
No.105578435
[Report]
>>105577366
That can't be real, a bunch of those seem a bit too on the nose
Or 195chevyhot needs to find a local model to ask his questions
Anonymous
6/13/2025, 5:34:07 AM
No.105578772
[Report]
>>105570213
I like these Bakas