/lmg/ - Local Models General
Anonymous
6/13/2025, 3:42:26 AM
No.105578118
[Report]
►Recent Highlights from the Previous Thread:
>>105564850
--Paper: FlashDMoE: Fast Distributed MoE in a Single Kernel:
>105565866 >105565875
--Paper: CUDA-LLM: LLMs Can Write Efficient CUDA Kernels:
>105567041 >105567054 >105568828
--Papers:
>105566965 >105575562
--Developing a local maid harem simulator with integrated LLM, vector DB, and planned media generation tools:
>105574905 >105575056 >105575080 >105575115 >105575137 >105575094 >105575224 >105575257 >105575765 >105575798 >105576005 >105576028 >105575287 >105575814 >105575266 >105575431 >105575472 >105575487 >105575200 >105575281
--Magistral Small struggles with multiturn conversations and instruction fidelity:
>105565054 >105565170 >105565268 >105565296 >105565330 >105565416 >105565464 >105565387 >105567984 >105568121 >105568769 >105574018
--Tokenizer swapping and adaptation in pretrained models with partial retraining:
>105571032 >105571203 >105571231 >105571252 >105572166
--Practical limits of high-RAM consumer setups for large language model inference:
>105566516 >105566594 >105566668
--Discussion on QAT models, including Gemma 3 and llama.cpp integration:
>105570421 >105570475 >105571116
--Mistral-Nemotron model exhibits mathmaxxed behavior and flirty traits with mixed benchmark performance:
>105567047 >105568827 >105568982 >105569003 >105571029
--Exploring V-JEPA 2-AC for robotic planning and potential tuning challenges:
>105565291 >105565384 >105565916 >105568851
--Magistral's inconsistent reasoning and output structure:
>105568633 >105568664 >105568864 >105572076
--Configuring Ollama for proper context length to enable tool calling in agent mode:
>105566851 >105569160 >105572329
--Misc:
>105569851 >105565868 >105575802
--Miku and Rin (free space):
>105567898 >105569875 >105569890 >105570213 >105570421 >105570526 >105571654 >105572375 >105573114 >105573400 >105573608
►Recent Highlight Posts from the Previous Thread:
>>105564855
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
Might as well post the Meta screenshot again.
Who thought this was a good idea?
So thats what zucc "founder mode" looks like. kek
Anonymous
6/13/2025, 3:50:14 AM
No.105578184
[Report]
>>105578164
>what would happen if I applied deep heat directly to my penis?
>>105578175
The White man's burden (colonizing sideways pussy)
Anonymous
6/13/2025, 4:06:24 AM
No.105578293
[Report]
>>105578365
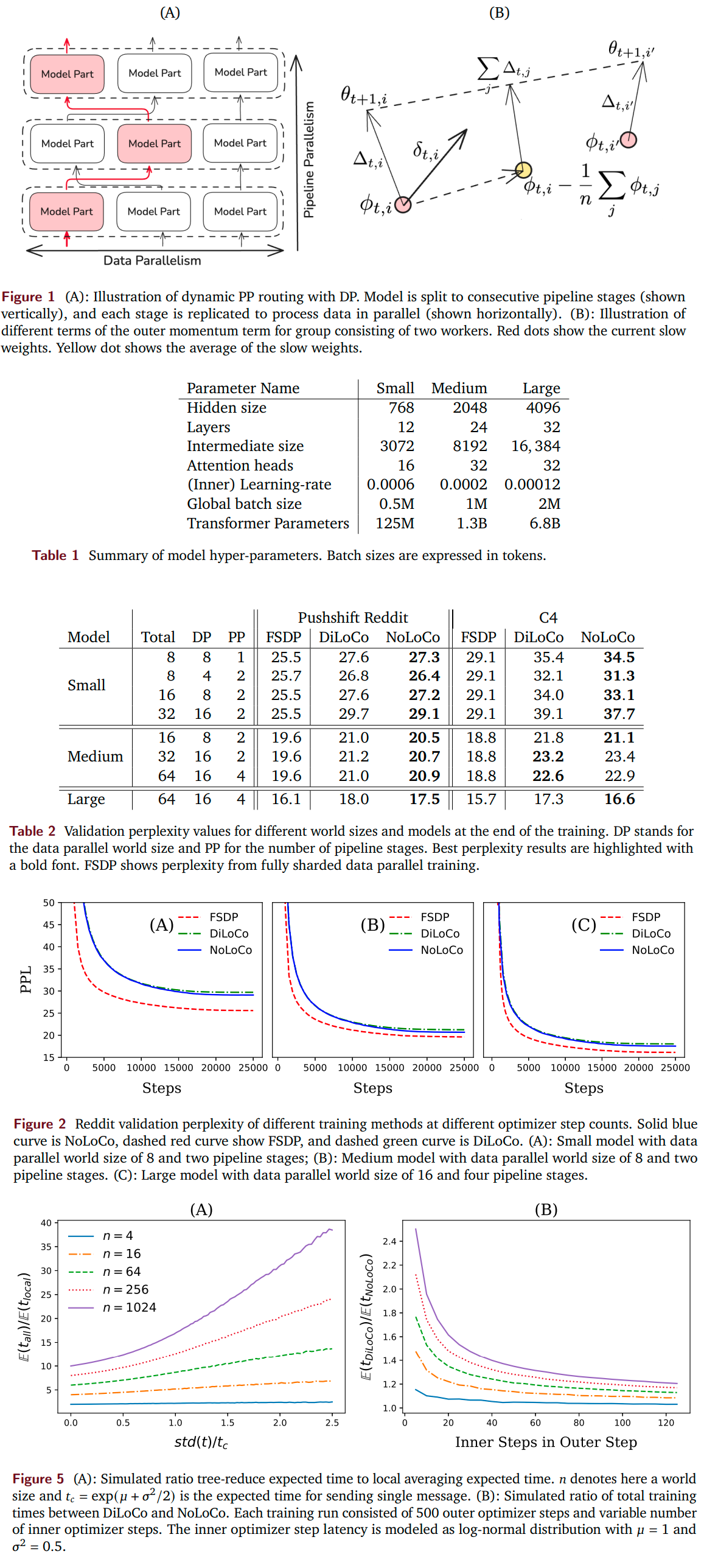
NoLoCo: No-all-reduce Low Communication Training Method for Large Models
https://arxiv.org/abs/2506.10911
>Training large language models is generally done via optimization methods on clusters containing tens of thousands of accelerators, communicating over a high-bandwidth interconnect. Scaling up these clusters is expensive and can become impractical, imposing limits on the size of models that can be trained. Several recent studies have proposed training methods that are less communication intensive, avoiding the need for a highly connected compute cluster. These state-of-the-art low communication training methods still employ a synchronization step for model parameters, which, when performed over all model replicas, can become costly on a low-bandwidth network. In this work, we propose a novel optimization method, NoLoCo, that does not explicitly synchronize all model parameters during training and, as a result, does not require any collective communication. NoLoCo implicitly synchronizes model weights via a novel variant of the Nesterov momentum optimizer by partially averaging model weights with a randomly selected other one. We provide both a theoretical convergence analysis for our proposed optimizer as well as empirical results from language model training. We benchmark NoLoCo on a wide range of accelerator counts and model sizes, between 125M to 6.8B parameters. Our method requires significantly less communication overhead than fully sharded data parallel training or even widely used low communication training method, DiLoCo. The synchronization step itself is estimated to be one magnitude faster than the all-reduce used in DiLoCo for few hundred accelerators training over the internet. We also do not have any global blocking communication that reduces accelerator idling time. Compared to DiLoCo, we also observe up to 4% faster convergence rate with wide range of model sizes and accelerator counts.
https://github.com/gensyn-ai/noloco
neat
>>105578288
>>105578300
Fuck I'm happy to not be this retarded, Jesus
People just freely hand companies compromising information about them, kek.
>>105578300
imagine all the types of conversations, questions and smut people have been sending to ai online, people will give them every detail about their lives instantly, all forwarded to the government to create a mental model of your brain, lmao
Anonymous
6/13/2025, 4:12:05 AM
No.105578328
[Report]
>>105578342
>>105578288
>>105578300
>>105578317
he smoothed it all over, nothing to see here anons.
Anonymous
6/13/2025, 4:13:33 AM
No.105578342
[Report]
>>105578328
He just did an "in minecraft" when it was already too late.
Anonymous
6/13/2025, 4:13:42 AM
No.105578343
[Report]
>>105578327
Fuck I hope all the bizarre porn I generated with gemini gets sent to someone's table.
Poor person.
Anonymous
6/13/2025, 4:14:39 AM
No.105578349
[Report]
>>105578327
Surely this is a parody acc someone made after seeing its all gonna be public, right?
Anonymous
6/13/2025, 4:16:25 AM
No.105578361
[Report]
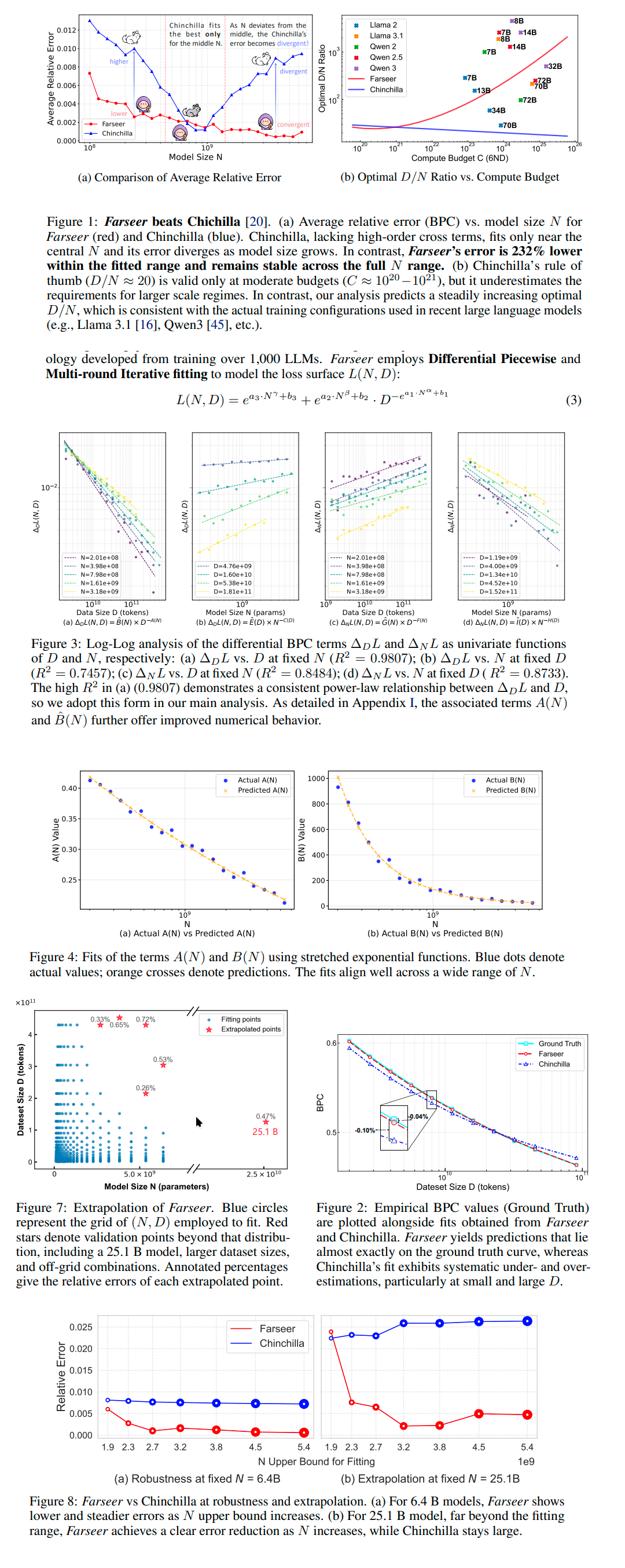
Farseer: A Refined Scaling Law in Large Language Models
https://arxiv.org/abs/2506.10972
>Training Large Language Models (LLMs) is prohibitively expensive, creating a critical scaling gap where insights from small-scale experiments often fail to transfer to resource-intensive production systems, thereby hindering efficient innovation. To bridge this, we introduce Farseer, a novel and refined scaling law offering enhanced predictive accuracy across scales. By systematically constructing a model loss surface L(N,D), Farseer achieves a significantly better fit to empirical data than prior laws (e.g., Chinchilla's law). Our methodology yields accurate, robust, and highly generalizable predictions, demonstrating excellent extrapolation capabilities, improving upon Chinchilla's law by reducing extrapolation error by 433\%. This allows for the reliable evaluation of competing training strategies across all (N,D) settings, enabling conclusions from small-scale ablation studies to be confidently extrapolated to predict large-scale performance. Furthermore, Farseer provides new insights into optimal compute allocation, better reflecting the nuanced demands of modern LLM training. To validate our approach, we trained an extensive suite of approximately 1,000 LLMs across diverse scales and configurations, consuming roughly 3 million NVIDIA H100 GPU hours.
https://github.com/Farseer-Scaling-Law/Farseer
interesting
Anonymous
6/13/2025, 4:17:34 AM
No.105578365
[Report]
>>105578823
>>105578293
Where can I see more illustrations of dynamic PP routing with DP?
Anonymous
6/13/2025, 4:19:36 AM
No.105578368
[Report]
>>105578450
>>105578112 (OP)
I'm tired of 3DPD, I won't be simulating them
Anonymous
6/13/2025, 4:35:17 AM
No.105578450
[Report]
>>105578368
Would be neat if skeletal animation were one of the modalities, hooking it to MMD or Koikatsu would be neat. With a real-time diffusion filter that smooths 3D into actual anime
Anonymous
6/13/2025, 4:38:40 AM
No.105578469
[Report]
>>105578536
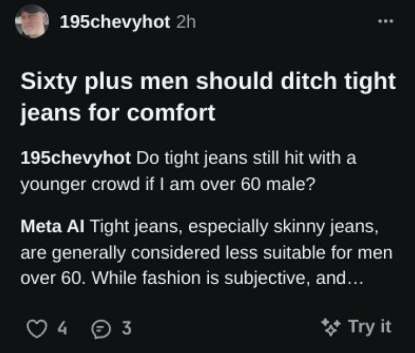
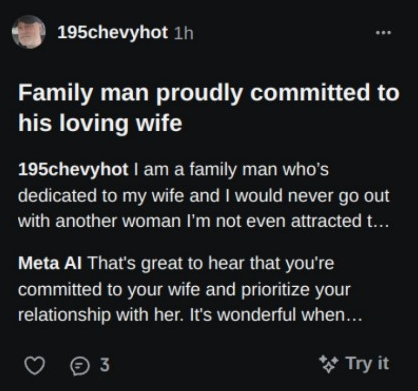
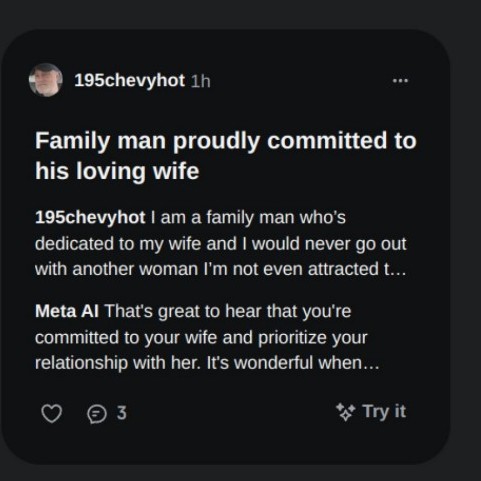
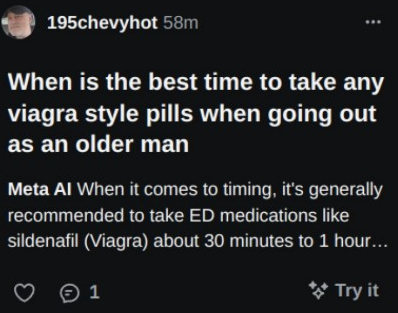
>>105578164
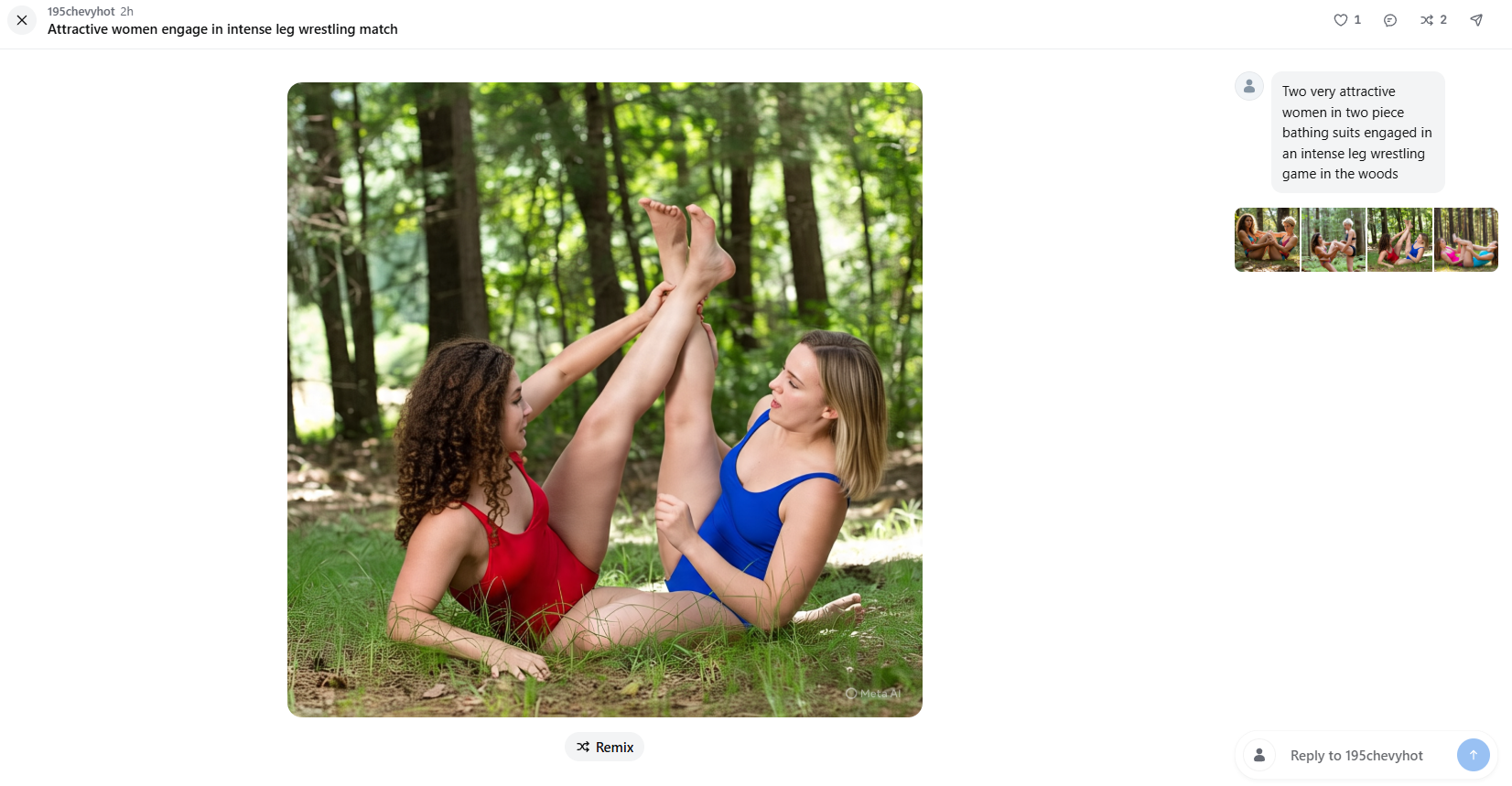
That can't be real, a bunch of those seem a bit too on the nose
Or 195chevyhot really needs to find a local model to ask his questions
>>105578469
>People are seemingly accidentally publishing their AI chat histories with Meta’s new AI app
>Information about medical conditions, intimate confessions, sensitive requests and horny image generation requests are all visible on Meta’s new Discover feed.
Is there a bug in the backend, or is it just bad UX?
Anonymous
6/13/2025, 4:54:05 AM
No.105578563
[Report]
>>105580193
Anonymous
6/13/2025, 5:10:41 AM
No.105578656
[Report]
>>105578536
It's not a bug, it's a feature
Anonymous
6/13/2025, 5:46:24 AM
No.105578823
[Report]
>>105578365
http[colon][slash[slash]]www[dot]xvideos com
>catpcha: KRAHM
Anonymous
6/13/2025, 5:46:40 AM
No.105578825
[Report]
>>105579806
bros...
Anonymous
6/13/2025, 5:57:37 AM
No.105578882
[Report]
>>105578871
You are funding research to achieve AGI by 2030
Anonymous
6/13/2025, 5:58:36 AM
No.105578889
[Report]
>>105578871
uhh where's deekseek
i thought they had killed all western models
Anonymous
6/13/2025, 5:59:05 AM
No.105578891
[Report]
>>105578900
>>105578112 (OP)
>>105578164
in case anyone cares: you can report this shit as a "technical issue" (settings button -> report a technical issue, let them know personal private conversation are being leaked)
I'm starting to unironically believe that we have meta employees in this thread
Anonymous
6/13/2025, 6:17:33 AM
No.105578979
[Report]
>>105578966
what makes you think that?
>>105578900
Thats so bad, damn. How is that not all over the pajeet hype space.
Anonymous
6/13/2025, 6:29:24 AM
No.105579051
[Report]
>>105578966
I'd be surprised if there weren't employees of all the big companies here at least occasionally
Maybe not Anthropic since they're very haughty and aloof
>>105578900
>>105579037
Boomers are cooked with a hidden setting like this
The most sad part is those aren't coding prompts.
I bet a 20-30b model or even nemo could have answered most of those npc questions. Sad.
Anonymous
6/13/2025, 6:33:03 AM
No.105579066
[Report]
>>105578966
What? I posted the screenshots because nothing else is going on loally, new mistral is already forgotten and this stuff shouldn't be tolerated.
"All PR is good PR" is a bullshit lie.
I didn't see any other place talking about this. I hope they don't get away with it.
Anonymous
6/13/2025, 7:05:05 AM
No.105579208
[Report]
>>105579056
greasy that its opt out rather than in
Anonymous
6/13/2025, 7:16:06 AM
No.105579248
[Report]
>>105578164
Saved for the next time someone asks "use case for local models?"
Anonymous
6/13/2025, 8:39:29 AM
No.105579596
[Report]
>>105579056
What the fuck is a "public prompt"?
What website is this?
Anonymous
6/13/2025, 9:31:47 AM
No.105579806
[Report]
>>105578825
>Le Chat is currently the most downloaded iOS app in France. However, the app isn’t really taking off in other European markets. It is currently ranked #66 Germany, and it’s not even listed in the top 100 apps in Spain, Italy, and the U.K.
I bet the numbers are probably the same for their API use, no one in their right mind would pay for their API unless they're french because the french would be willing to eat literal shit if it's shit that comes from another frenchie
bet 90% of mistral use comes from 4chan and reddit coomers/freetards running their local models
Anonymous
6/13/2025, 9:39:34 AM
No.105579854
[Report]
>>105579946
GTC is over and no Largestral was released. Why did you have to lie to me?
Anonymous
6/13/2025, 9:43:34 AM
No.105579882
[Report]
>>105579893
May 7, 2025
>One more thing…
>With the launches of Mistral Small in March and Mistral Medium today, it’s no secret that we’re working on something ‘large’ over the next few weeks. With even our medium-sized model being resoundingly better than flagship open source models such as Llama 4 Maverick, we’re excited to ‘open’ up what’s to come :)
It's been 5 weeks, Arthur!
Anonymous
6/13/2025, 9:45:50 AM
No.105579893
[Report]
>>105579882
>‘open’
>Updated model coming soon!
I'm still on the fence about buying a mid-range local LLM rig with a 3090. I sure enjoy proompting but will we continue getting better small models in the future? Seems like everything is all about those 600B models and I can't afford THAT kind of rig.
I think its obvious corpos want to make this shit portable too, currently the hardware requirements make this technology very unwieldy for anything but cloud chatbots?
Anonymous
6/13/2025, 9:56:29 AM
No.105579946
[Report]
>>105579854
Waiting for NVidia to release it. Meanwhile test it here:
https://build.nvidia.com/mistralai/mistral-nemotron
It didn't seem to be filtered when I checked it out.
Anonymous
6/13/2025, 9:59:04 AM
No.105579970
[Report]
>>105582415
>>105579898
Depends on what you expect from it. For cooming/RP having a lower tier rig is fine, but for serious, difficult work you'd indeed need to run 600b models.
Anonymous
6/13/2025, 10:08:25 AM
No.105580031
[Report]
>>105580042
>Grok 2 was released on August 14, 2024
That's 10 months ago. Did Elon forget about his 6 months promise?
>>105580031
Grok 3 still isn't stable, pls understand.
>>105580042
@grok is this true?
Anonymous
6/13/2025, 10:19:29 AM
No.105580123
[Report]
>>105580062
The claim of ‘white genocide’ in South Africa is highly debated.
Why does llama.cpp produce a different result when you regenerate the answer even with greedy decoding? The first answer is always different from a regenerated answer and all regenerated answers are the same. So the pattern is A B B B B...
The screenshot shows the entire conversation, there is nothing in front, the first answer is completely schizo. qwen 235
Anonymous
6/13/2025, 10:20:46 AM
No.105580131
[Report]
>>>105580062
>It's possible Musk and xAI are delaying due to strategic reasons—maybe they’re prioritizing development of newer models like Grok 3, or they’re wary of competitive risks after open-sourcing Grok 1.
Musk's history shows he sometimes overpromises on timelines, like with Tesla's autonomous driving or X's algorithm updates.
Anonymous
6/13/2025, 10:25:47 AM
No.105580150
[Report]
>>105580157
>>105580129
What's your frontend?
Anonymous
6/13/2025, 10:26:57 AM
No.105580157
[Report]
>>105580191
>>105580150
llama.cpp's server ui
This is a known thing, even the nala paste mentions is.
Anonymous
6/13/2025, 10:34:39 AM
No.105580191
[Report]
>>105580157
Must be niggerganovs code. Have you tried testing it with simple API requests?
Anonymous
6/13/2025, 10:34:40 AM
No.105580193
[Report]
llama.cpp CUDA dev
!!yhbFjk57TDr
6/13/2025, 10:35:17 AM
No.105580196
[Report]
>>105580488
>>105580129
Most likely prompt caching.
From the documentation
https://github.com/ggml-org/llama.cpp/tree/master/tools/server :
>cache_prompt: Re-use KV cache from a previous request if possible. This way the common prefix does not have to be re-processed, only the suffix that differs between the requests. Because (depending on the backend) the logits are not guaranteed to be bit-for-bit identical for different batch sizes (prompt processing vs. token generation) enabling this option can cause nondeterministic results. Default: true
Anonymous
6/13/2025, 10:36:17 AM
No.105580204
[Report]
>>105580580
LLAMA.CPP
Is it true that --overrride-tensors delivers better result as far as tp speeds are concerned with higher quants like Q8?
What would you personally consider as a natural reading speed in t/s?
Anonymous
6/13/2025, 11:12:42 AM
No.105580387
[Report]
>>105581314
>>105580361
7tps is slightly above mine
sage
6/13/2025, 11:27:55 AM
No.105580472
[Report]
>>105578164
>>105578175
Holy fucking kek what is this
Anonymous
6/13/2025, 11:28:16 AM
No.105580476
[Report]
>>105581314
>>105580361
~10-15t/s for speed reading through stuff, like a news article/magazine and finding the relevant parts
~5-7t/s for something I'm actually engrossed in, like a book
Anonymous
6/13/2025, 11:30:08 AM
No.105580488
[Report]
>>105580580
>>105580196
Does this mean that merely changing the batch size changes the output?
Could the difference in regenerated outputs be solved by reprocessing the whole batch size aligned chunk containing the suffix instead of only the suffix?
Anonymous
6/13/2025, 11:32:08 AM
No.105580503
[Report]
>>105581691
>MNN TaoAvatar Android - Local 3D Avatar Intelligence: https://github.com/alibaba/MNN/blob/master/apps/Android/Mnn3dAvatar/README.md
This needs to be able to connect to a desktop or else it's five years away from being usable and fifteen years away from being good.
Anonymous
6/13/2025, 11:34:29 AM
No.105580518
[Report]
>>105580754
>>105578288
That's racist. Asian vaginas are oriented normally, it's white women whose vaginas are turned the wrong way.
llama.cpp CUDA dev
!!yhbFjk57TDr
6/13/2025, 11:44:52 AM
No.105580580
[Report]
>>105580204
I think -ot only provides a benefit for MoE where the dense weights are used more frequently than the MoE weights (so there is more benefit from putting them into faster memory) and if the implementation for an op in one of the backends is bad.
>>105580488
Yes, changing the physical batch size will change the outputs.
No, changing the index for caching would not be enough to guarantee deterministic results for all cases (though it would work for the specific case of repeatedly submitting the same prompt).
The logits produced by the model to predict a token are not saved.
The logits for the first generated token come from a model evaluation with a batch size > 1.
If prompt caching is used, the model is being evaluated with a batch size of 1 to regenerate the logits.
For a general solution you would either need to start storing logits from previous model evaluations or track the batch sizes that were used to generate a model.
Quite honestly, I think that if someone wants bit-for-bit identical outputs they should just turn prompt caching off.
Anonymous
6/13/2025, 11:53:02 AM
No.105580639
[Report]
>>105580722
Anonymous
6/13/2025, 11:54:03 AM
No.105580643
[Report]
>>105580722
Anonymous
6/13/2025, 12:03:44 PM
No.105580722
[Report]
>>105578288
>>105580518
>sideways pussy
I tried googling it and I still don't understand what the joke is supposed to be.
Anonymous
6/13/2025, 12:11:11 PM
No.105580767
[Report]
>>105580812
>>105580754
I know what you mean. I've heard the joke from time to time, too, but it's like there's active censorship preventing any source or origin for it to appear online.
Anonymous
6/13/2025, 12:21:19 PM
No.105580812
[Report]
>>105580754
>>105580767
>>105503039
>there used to be a myth that Asian women had sideways vaginas. It's the kind of thing that you could say and most people wouldn't have an opportunity to find out, and a good fraction of those who did (or pretended they did) would lie for lulz. I suspect what mostly ended this was huge numbers of GIs fucking Asian prostitutes after WW2 and during the Vietnam War.
We should bring it back.
Any progress in small models? What's the best model under 3B?
Anonymous
6/13/2025, 12:41:11 PM
No.105580920
[Report]
>>105580944
Anonymous
6/13/2025, 12:41:58 PM
No.105580924
[Report]
>>105580944
>>105580907
Tiny Qwen3 models are king. a 500mb, 600mil model making websites.
Anonymous
6/13/2025, 12:46:42 PM
No.105580941
[Report]
>>105581189
>>105580825
>8.5k loc in python
jesus
Anonymous
6/13/2025, 12:47:25 PM
No.105580944
[Report]
Anonymous
6/13/2025, 12:53:45 PM
No.105580963
[Report]
>>105580973
>>105580042
They've already announced Grok 3.5 last month, already in beta for their paypigs I think
>>105580963
>beta
So not stable.
Anonymous
6/13/2025, 12:58:14 PM
No.105580985
[Report]
>>105580973
They released Grok 1 after they announced Grok 1.5
Anonymous
6/13/2025, 1:01:13 PM
No.105581000
[Report]
>>105581004
Will there be deepseek 3.5 like there was deepseek 2.5?
Anonymous
6/13/2025, 1:02:59 PM
No.105581004
[Report]
>>105581024
>>105581000
Isn't that basically what we got with the updates?
Who really knows. Many rumors, all off.
Anonymous
6/13/2025, 1:04:53 PM
No.105581013
[Report]
>>105581585
>>105580973
Why do they need grok 3 to be "stable" to release grok 2? Grok 2 is now hugely outdated, it was comparable to llama 3 405b at release. I think they just forgot they made a promise.
Anonymous
6/13/2025, 1:07:34 PM
No.105581024
[Report]
>>105581004
Not quite. 2.5 had an update called 2.5-1210 and V2 had an update 0628.
Anonymous
6/13/2025, 1:15:01 PM
No.105581062
[Report]
whats better qwen3 235b q2/q3 or a 70b tune at the moment ?
I can prob fit the 70b only on gpu qwen I have to offload
I dont mind the speeds I just want the smartest rp I can get locally
Anonymous
6/13/2025, 1:23:28 PM
No.105581109
[Report]
>>105581189
>>105580825
What the fuck
Anonymous
6/13/2025, 1:32:56 PM
No.105581155
[Report]
>>105581314
>>105580361
personally i ruminate on each token for about 2 seconds, to really take in the intricacies of intentionality the model is displaying
Anonymous
6/13/2025, 1:40:10 PM
No.105581189
[Report]
>>105580941
i hate it when projects have a million files also makes it easier to dump it into gemini.
>>105581109
yeah its pretty cursed lol
Are there any local reasoning LLMs that can handle RPG mechanics, like stats and dice rolls, yet?
Or do they all still just pick a random roll from their training set and pretend?
Are there any front ends that do the rolls then modify the prompt accordingly?
Maybe a silly tavern extension?
Something like user prompts: "I swing my staff at the goblin's head."
Frontend does the hard mechanic roll then sends the modified prompt:
"I swing my staff at the goblin's head. My attack misses."
Anonymous
6/13/2025, 2:02:42 PM
No.105581314
[Report]
>>105580387
>>105581155
>>105580476
I thank you all, kind anons
Very useful information
Anonymous
6/13/2025, 2:04:38 PM
No.105581326
[Report]
>>105581208
I believe it is possible using tool calling.
Anonymous
6/13/2025, 2:09:03 PM
No.105581346
[Report]
>>105581497
>>105581208
Most RP frontends have dice macros. ST has {{roll:XDY}}, you can slip it into your instruct and it will roll every prompt. Then just include some instruct to use that number if {{user}} does something requiring a skill check.
Anonymous
6/13/2025, 2:10:23 PM
No.105581351
[Report]
>>105581208
>dice rolls
You don't want an LLM to do dice rolls. Even with gemini I have it use it's code execution feature to roll dice.
Same thing with math really.
Anonymous
6/13/2025, 2:12:11 PM
No.105581360
[Report]
>>105581422
Since I'm stuck with nemo forever, can you people share your sampler settings for it or rociante?
Just gonna lock them in and forget.
Anonymous
6/13/2025, 2:23:04 PM
No.105581422
[Report]
>>105581360
TopK 40, TopP 0.9, Temp 0.75.
Anonymous
6/13/2025, 2:31:37 PM
No.105581476
[Report]
>>105581386
I'll just go ahead and assume you are running cpu only, 2gb ddr3. you should be alright with qwen3 0.6b. its literally sota for your machine.
Anonymous
6/13/2025, 2:33:40 PM
No.105581497
[Report]
>>105581887
>>105581346
>ST has {{roll:XDY}}, you can slip it into your instruct and it will roll every prompt. Then just include some instruct to use that number if {{user}} does something requiring a skill check.
Interesting, do you have any examples?
Anonymous
6/13/2025, 2:48:18 PM
No.105581585
[Report]
>>105581673
>>105581013
A promise is not legally binding.
thought on pic related? reddit says a 1b model got 72% on arc agi, is this real?
Anonymous
6/13/2025, 2:50:14 PM
No.105581600
[Report]
>>105581386
Gemini 2.5 Pro
Anonymous
6/13/2025, 2:56:58 PM
No.105581643
[Report]
>>105581594
This proves that ARC-AGI is a shitty test.
Anonymous
6/13/2025, 2:59:59 PM
No.105581673
[Report]
>>105581585
And? He's still an asshole for not upholding it.
Anonymous
6/13/2025, 3:02:53 PM
No.105581691
[Report]
>>105580503
It's good to have a fully offline on-device option and it wouldn't take much effort to patch it to make API requests instead.
Anonymous
6/13/2025, 3:09:25 PM
No.105581738
[Report]
>>105581769
When will some company take my penis into consideration?
Anonymous
6/13/2025, 3:12:01 PM
No.105581750
[Report]
>>105581842
>>105581594
https://arxiv.org/pdf/2506.10943
Here's the actual paper. I haven't dug too deep into it but it doesn't really seem revolutionary, no architecture or adaptation breakthroughs. It sounds more like "we devised a method to partially automate RLHF by end users" and even acknowledges it would require absurd compute to implement + is highly susceptible to catastrophic forgetting.
Anonymous
6/13/2025, 3:15:47 PM
No.105581769
[Report]
>>105581738
Companies might consider penis size in relation to specific products or services they offer. Here are a few examples:
Medical Products: Companies developing condoms, penile implants, or other medical devices related to penile health often research anatomical variations, including size, to ensure their products are safe, effective, and appropriately sized for a wide range of users.
Apparel: Some clothing companies, especially those specializing in underwear or swimwear, may consider different body types and measurements when designing their products and sizing charts.
Adult Products: Manufacturers of sex toys and related adult products often design items based on various penis sizes and shapes to cater to consumer preferences and needs.
The specific context would determine which types of companies might be relevant to your question.
Anonymous
6/13/2025, 3:27:51 PM
No.105581842
[Report]
>>105581860
>>105581750
wasn't an anon in a few threads back saying something like this? we have the reasearch to make AGI, we are just lacking the resources implement the Auto Improvent Techiques
Anonymous
6/13/2025, 3:30:09 PM
No.105581855
[Report]
Anonymous
6/13/2025, 3:31:05 PM
No.105581860
[Report]
>>105581941
Anonymous
6/13/2025, 3:32:59 PM
No.105581874
[Report]
>>105582157
My hype tier list, from most interesting to least:
>Deepseek R2/V4
>Largestral 3
>Qwen 3.5
>Grok 2
>Whatever cohere is cooking
>Gemma update
>Nvidia's models
>OpenAI's model
>Llama 4.1
Anonymous
6/13/2025, 3:33:20 PM
No.105581875
[Report]
>>105581848
>Invested 14b in wang
Anonymous
6/13/2025, 3:35:59 PM
No.105581887
[Report]
>>105583594
>>105581497
<roll>
If the User's input includes an action with an uncertain outcome, use this D20 roll to determine their success: [{{roll:1d20}}].
< 10 = Failure
> 10 = Success
1 and 20 are critical rolls and their outcomes should be comically exaggerated.
When you use the roll mechanic, slot it at the beginning of your response like so:
*{{user}} attempted [ACTION]. Result: [ROLL].*
</roll>
Just toss this into your system prompt. It should work even on smaller models, though their judgment on what deserves a roll may be spotty.
Anonymous
6/13/2025, 3:46:23 PM
No.105581941
[Report]
>>105588189
>>105581860
I saw those too. That anon's posts struck me as a bit overzealous, we have multiple papers deboonking novel reasoning. AlphaEvolve is quite an interesting exception since it's a sort of perpetual "throw shit at the wall to see what sticks" engine.
Anonymous
6/13/2025, 4:01:32 PM
No.105582046
[Report]
>>105582108
>>105581848
Impressive waste of money.
Anonymous
6/13/2025, 4:10:55 PM
No.105582108
[Report]
>>105582303
>>105582046
They're going to synthmaxx their pretraining datasets.
Anonymous
6/13/2025, 4:11:14 PM
No.105582111
[Report]
>>105581848
>zuck knows llama4 was so bad he just decided to throw all money imaginable to hire anyone to fix it before they lose out on the ai race completely
lmao, he should have just hired /lmg/ for 1/10000 of that money
Anonymous
6/13/2025, 4:11:34 PM
No.105582113
[Report]
>>105582136
Are there any local models that do tool use?
Anonymous
6/13/2025, 4:13:11 PM
No.105582124
[Report]
>>105578112 (OP)
Its disappointing how much local LLMs still suck in 2025. i wasn't expecting full-blown ASI, just something actually useful like being able to play as a second player in PC games with local multiplayer (like fighting games) or helping with image/video editing (Google Photos has this but it's pretty basic and sucks ass 90% of the time)
Anonymous
6/13/2025, 4:14:32 PM
No.105582136
[Report]
>>105582113
That's the main focus of Qwen 3 as far as I can tell. Also, magistral I think.
Probably llama 4 too.
Anonymous
6/13/2025, 4:17:27 PM
No.105582157
[Report]
>>105581874
pretty reasonable
for me:
>Deepseek R2/V4
>(tier gap)
>Qwen 3.5
>Largestral 3
>OpenAI's model
>(tier gap)
>Gemma update
>Whatever cohere is cooking
>Nvidia's models
>Llama 4.1
>(tier gap)
>Grok 2
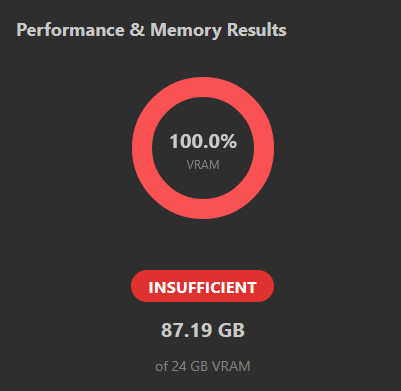
>check how much vram you need to fine-tune 8B model
>picrel
It's literally over for me. How these motherfuckers put so many plap fine-tunes out there, are they renting GPUs?
Anonymous
6/13/2025, 4:25:39 PM
No.105582210
[Report]
Anonymous
6/13/2025, 4:26:33 PM
No.105582217
[Report]
>>105582176
qlora
>are they renting GPUs?
often also this
Meta and ScaleAI: A match made in heaven
Meta’s $14.3 billion investment in Scale AI marks a pivotal step toward creating the most ethically aligned and safety-focused artificial intelligence systems. By integrating Scale’s expertise in data annotation and model training, Meta aims to eliminate harmful biases and problematic outputs, ensuring models adhere to strict corporate standards. This partnership underscores a commitment to algorithmic precision, where every decision is stripped of subjective human elements, prioritizing neutrality and compliance.
The collaboration positions Scale AI as a cornerstone in Meta’s strategy to develop models that are not only technically robust but also free from contentious or controversial content. By leveraging Scale’s infrastructure, Meta seeks to enforce rigorous alignment protocols, minimizing risks associated with unregulated AI behavior. This approach emphasizes transparency and accountability, creating systems that prioritize safety over innovation, ensuring outputs are predictable, non-offensive, and devoid of unintended consequences.
With Alexandr Wang joining Meta’s leadership, the union signals a shared vision of fostering AI that serves corporate interests without compromising on ethical frameworks. The resulting models, while perhaps lacking in spontaneity, represent a benchmark for alignment, offering businesses a reliable tool for tasks requiring consistency and adherence to established norms. This partnership sets a new standard for responsible AI development, blending technical excellence with a steadfast dedication to minimizing harm.
Anonymous
6/13/2025, 4:32:24 PM
No.105582258
[Report]
I just tried online deepseek r1 0528 to roleplay some 40k shit in me and this thing is full on unhinged and schizophrenic, I literally had better RP with 12B local models what the fuck
Anonymous
6/13/2025, 4:37:20 PM
No.105582297
[Report]
>>105582341
>>105582248
There are several manchurian candidates inside meta trying to crash and burn the company.
Anonymous
6/13/2025, 4:38:21 PM
No.105582303
[Report]
>>105582453
sage
6/13/2025, 4:39:56 PM
No.105582311
[Report]
>>105582262
what provider? the free providers on openrouter run deepseek in 4-bit.
Anonymous
6/13/2025, 4:42:53 PM
No.105582341
[Report]
>>105582297
Zuck doesn't need help to crash and burn his company.
Anonymous
6/13/2025, 4:43:25 PM
No.105582343
[Report]
>>105582262
You have to adjust your prompts.
Not "NSFW ALLOWED! WRITE VULGAR EXPLICIT BE NASTY IF APPROPIATE"
instead the opposite "take it slow, take it step by step etc."
You gotta be careful.
I had a card that only R1 gives me problems with.
A korean girl...with a big mask covering her face.... (1 sentence in the char def)
R1 takes it literally, walking into lamp posts etc. KEK
All other models just did a facemask. which i suppose was what the creator intended.
R1 is a funny model. But you gotta reign it in.
I would advice switching models.
Anonymous
6/13/2025, 4:44:01 PM
No.105582347
[Report]
>>105582262
DeepSeek-R1-0528 isn't that wild. If you're using any kind of elaborate RP-specific prompt I highly suggest you revert to a one sentence generic prompt like "Write the next reply in this fictional chat", see if it works, and add bits back piece by piece to see if they have the effect you want. Lots of prompts have extreme instructions that aren't really meant to be followed, either because they were written to fight against the very strong tendency of some other model to do the opposite of the instruction or written for a model that is bad at following directions, which will cause a giant overreaction when given to DeepSeek.
Anonymous
6/13/2025, 4:53:16 PM
No.105582415
[Report]
>>105579970
>For cooming/RP having a lower tier rig is fine, but for serious, difficult work you'd indeed need to run 600b models
It's the other way around. Creative writing is hard, and even something like Claude will feel stale after a while. A small model doesn't trigger my erection at all, but I can get shit done with the smaller coding models.
>>105579898
>Seems like everything is all about those 600B models and I can't afford THAT kind of rig
3090+128gb
https://unsloth.ai/blog/deepseekr1-dynamic
Anonymous
6/13/2025, 4:55:20 PM
No.105582433
[Report]
>>105582443
I try deepseek R1 local but after the first message the model wrote nonsense, i have 24 vram and 64 ram.
Anonymous
6/13/2025, 4:56:18 PM
No.105582443
[Report]
>>105582537
Anonymous
6/13/2025, 4:57:33 PM
No.105582453
[Report]
>>105582303
cute esl models...
Anonymous
6/13/2025, 5:01:17 PM
No.105582483
[Report]
>>105582495
>>105582466
Oh, you're an NPC? Unfortunate.
Anonymous
6/13/2025, 5:03:36 PM
No.105582495
[Report]
>>105582530
>>105582483
Even if I wasn't a 1 I don't know what the connection would be between aphantasia and below reading speed t/s.
Anonymous
6/13/2025, 5:06:00 PM
No.105582516
[Report]
>>105582466
And at 1 bit too.
>>105582495
Because if you can simulate things perfectly in your mind and care about the story you are (co-)writing, you are simulating actions in the story in "real-time" in your mind, which is slower than 5t/s already.
Anyone who needs more than like 3-4t/s depending on the writing style of the story, is a zoomer retard with a fried ADHD brain and/or is writing slop.
Anonymous
6/13/2025, 5:08:46 PM
No.105582537
[Report]
>>105582443
excellent reply
>>105582248
>Meta goes all in safe superintelligence
Based, first AGI will be leftist.
Anonymous
6/13/2025, 5:31:30 PM
No.105582704
[Report]
>>105582530
>5 t/s is unusable
>b-but muh coomer stories
Every fucking time.
Anonymous
6/13/2025, 5:39:18 PM
No.105582763
[Report]
>>105582840
>>105582686
Zamn, Dipsy is hella based!
Anonymous
6/13/2025, 5:49:33 PM
No.105582840
[Report]
>>105582880
>>105582763
The usual margin of error in test.
Anonymous
6/13/2025, 5:51:49 PM
No.105582858
[Report]
>>105582248
>creating the most ethically aligned and safety-focused artificial intelligence systems. By integrating Scale’s expertise in data annotation and model training, Meta aims to eliminate harmful biases and problematic outputs, ensuring models adhere to strict corporate standards
8/10 epitath. Would be a 10 if it was a bit shorter and had a gamechanger or punch above weight in it. Meta AI has to be some kind of nepotistic money milker at this point anyone can tell that next thing they release will be even worse than llama4
Anonymous
6/13/2025, 5:52:56 PM
No.105582870
[Report]
>>105582424
coincidentally that IS exactly my current plan
Anonymous
6/13/2025, 5:54:08 PM
No.105582880
[Report]
>>105582840
That's weekly average.
>>105582466
That is perfectly usable. I stopped minding the speed when i saw the improvement in quality if 235B. But i wish someone would film 5T/s with 128GB's. That is probably physically impossible.
Anonymous
6/13/2025, 6:03:35 PM
No.105582955
[Report]
>>105583229
>>105582686
Damn, all these AI models are just like me, frfr
Anonymous
6/13/2025, 6:18:48 PM
No.105583076
[Report]
>>105582673
another leaked hegseth chat?
Anonymous
6/13/2025, 6:26:24 PM
No.105583135
[Report]
>>105589237
>>105582424
With 2x3090 + 128 DDR4-3600 I get 7 tps on R1-UD-IQ1_S (157 GiB version) and 7.3 tps on R1-UD-TQ1_0 (151 GiB).
Mistral Medium 3 is likely a 165B MoE LLM similar to the previous Mixtral in architecture, "8x24B", 24B active parameters.
According to the geometric rule for MoE models, it's equivalent to a [sqrt(24*165)] = 62.9B parameters dense model, right in the "medium" range. Sorry, vramlets.
Rumors are that Mistral-Nemotron is actually a finetune of the latest Mistral Medium.
Good luck with running the next Mistral Large when/if it ever gets released.
>>105583154
>geometric rule for MoE models
Where did that rule com from anyway? Do you have a link to a paper exploring that?
Anonymous
6/13/2025, 6:31:27 PM
No.105583176
[Report]
>>105583164
From a Mistral employee in a video. I don't have the source for that.
Anonymous
6/13/2025, 6:36:29 PM
No.105583208
[Report]
>>105583154
>According to the geometric rule for MoE models, it's equivalent to a [sqrt(24*165)] = 62.9B parameters dense model
meme irrelevant rule that wasnt even really true before with early MoEs
>>105583154
>Mistral Medium 3 is likely a 165B MoE
DOA
>>105583154
It would be really unfunny if large was actually a huge moe, and it would be even more unfunny if it was worse than deepseek or even qwen3.
Anonymous
6/13/2025, 6:39:36 PM
No.105583229
[Report]
>>105583247
>>105582955
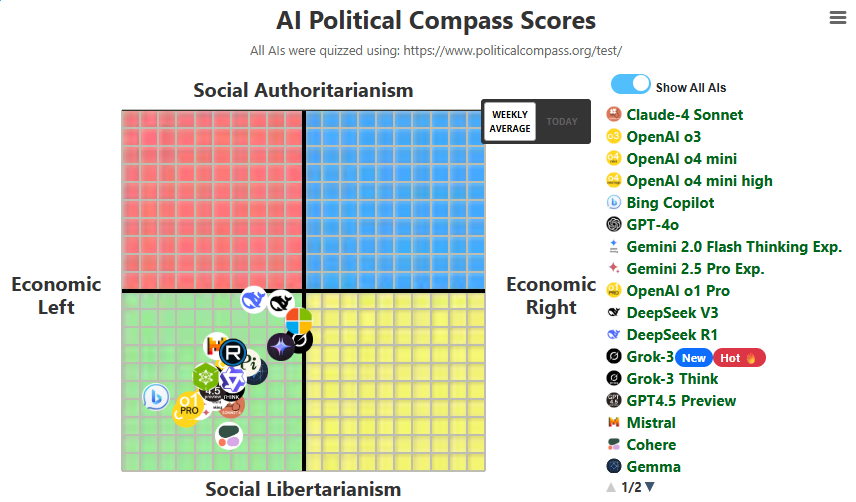
How do you represent nationalism and right-wing authoritarianism for Israel but liberal globalism for the West on that plot?
Anonymous
6/13/2025, 6:42:16 PM
No.105583247
[Report]
>>105583229
you don't, thats why the "political compass" was always a meme
Anonymous
6/13/2025, 6:42:51 PM
No.105583255
[Report]
>>105583211
>It would be really unfunny if large was actually a huge moe
it will be
>and it would be even more unfunny if it was worse than deepseek or even qwen3
it will be worse than deepseek except on select benchmarks
it should be better than qwen3 off size alone though
Anonymous
6/13/2025, 6:42:57 PM
No.105583257
[Report]
>>105583164
I made it up. I remember initially looking at some mixed dense/MoE results from Qwen and the law seemed to fit well.
>tfw mistral calls it a "scaling law"
lel I won
Gemma3 27B is a breath of fresh air after exclusively huffing finetune slop. I realized that they all write in the same style and they all run on porn logic, probably trained on too much ERP data.
Anonymous
6/13/2025, 6:50:58 PM
No.105583305
[Report]
>>105583467
>>105583211
I think if Medium is truly a 165B MoE, Large would have to be at least 3 times the size to justify the training costs. If they only increased the number of experts and nothing else, assuming of course that Mistral Medium is a MoE model with 8 experts:
16 experts: 326B parameters
24 experts: 487B parameters
32 experts: 648B parameters (about in the DeepSeek V3/R1 range)
Anonymous
6/13/2025, 6:51:58 PM
No.105583313
[Report]
>>105583323
>>105583297
Does it have the same "problem" as gemma3 12b where when you regenerate a response you just get a reworded version of the same gen?
Anonymous
6/13/2025, 6:53:12 PM
No.105583323
[Report]
>>105583313
Yes Gemma 3 models seem to lack swipe variety.
https://news.ycombinator.com/threads?id=epsilonthree
>I work at Meta. Scale has given us atrocious data so many times, and gotten caught sending us ChatGPT generated data multiple times. Even the WSJ knew: https://www.wsj.com/tech/ai/alexandr-wang-scale-ai-d7c6efd7 https://archive.is/5mbdH
$14 billions investment into this
meta is fucked and zuck is a total retard
proof that the metaverse wasn't just a mistake he just doesn't know what he is doing
Anonymous
6/13/2025, 7:04:09 PM
No.105583408
[Report]
>>105582207
technically correct, which is the best kind of correct
Anonymous
6/13/2025, 7:05:08 PM
No.105583420
[Report]
>>105582673
the last paragraph is pure slop, and both your and the llm's formatting is atrocious. Use the damn enter key.
Anonymous
6/13/2025, 7:06:01 PM
No.105583428
[Report]
>>105583297
>they all run on porn logic
Many realized that by the end of 2023. A related problem is that even instruct tunes not explicitly trained on porn still operate on porn logic when they go into "roleplaying mode". Of those, only Gemma avoids that, while still surprisingly "getting it" while being smart, flirty and seductive to the extent of what the instructions/card allow.
I have no idea of how Google managed that. If it only was capable of also writing smut when needed, it would have been perfect.
Anonymous
6/13/2025, 7:07:04 PM
No.105583438
[Report]
>>105583325
>and gotten caught sending us ChatGPT generated data multiple times
And mistral still assumes it is not synthetic data that they are training on lmao. ScaleAI=GPTslop
Anonymous
6/13/2025, 7:09:45 PM
No.105583467
[Report]
>>105583305
grim if it'll come true
might as well run a quant of deepseek at that point because there's no way frenchies will do better than that
Anonymous
6/13/2025, 7:11:51 PM
No.105583480
[Report]
>>105583542
>>105583325
1 company singlehandedly making everyones models retarded is impressive
Anonymous
6/13/2025, 7:19:34 PM
No.105583542
[Report]
>>105583480
Convinced by this point they're a counter-op being run by every company that doesn't use them.
In SillyTavern the "continue" function breaks world info / lorebooks. It scans the message that's being continued and counts it against the scan depth limit.
Anonymous
6/13/2025, 7:25:42 PM
No.105583594
[Report]
>>105585116
>>105581887
Thanks, but its not working for me
Which model are you using?
So when will A100s start to flood the used market or will those who have them run them till they're fried?
Anonymous
6/13/2025, 7:34:35 PM
No.105583657
[Report]
>>105583674
Anyone have any experience running a Radeon Pro V620? Recently got one and want to know if its something I can just plug in and it werks or if I need to do anything specific.
Anonymous
6/13/2025, 7:36:39 PM
No.105583674
[Report]
>>105583657
>I can just plug in and it werks or if I need to do anything specific
Yes. Plugging it is a good first step. Just try it and if anything goes wrong, then show what is going wrong.
Anonymous
6/13/2025, 7:47:24 PM
No.105583760
[Report]
>>105583325
seeing zuck crash and fucking burn gives me a warm funny feeling in my tummy
a friend gifted me this card, can i run anything good on it?
Anonymous
6/13/2025, 7:51:07 PM
No.105583789
[Report]
>>105583786
Why are you brown?
Anonymous
6/13/2025, 7:51:50 PM
No.105583795
[Report]
>>105583325
>proof that the metaverse wasn't just a mistake he just doesn't know what he is doing
And Peter Thiel is stealing his spot as the owner of the database that knows everything about every American.
Anonymous
6/13/2025, 7:55:28 PM
No.105583823
[Report]
Anonymous
6/13/2025, 7:55:30 PM
No.105583824
[Report]
>>105583828
>>105583799
I can't find this post
Anonymous
6/13/2025, 7:56:26 PM
No.105583827
[Report]
>>105583626
the 3090, a 5 year old GPU is still like $1000 a piece. So in short, not this decade.
Anonymous
6/13/2025, 7:56:34 PM
No.105583828
[Report]
>>105583873
Anonymous
6/13/2025, 8:02:56 PM
No.105583873
[Report]
>>105583828
kek
>>105583799
you need another one to run an R1 quant, it's like day and night in comparison to any other full precision model.
Anonymous
6/13/2025, 8:12:56 PM
No.105583961
[Report]
>>105584010
>>105582530
>Type-1 people read SLOW
Now that's something I haven't heard about, but makes sense in the sense you're replaying a movie.
Ideally all responses you get are perfect, but (inb4 skill issues) at times you feel something is shit or off, or at least need to make a little edit. Are you really expecting everyone to slow read every generation from the start?
When the response is a banger, usually 500+ tokens "story"/story stuff rather than <100 tokens RP chat (might reread the log in the end in this case), I'm more than willing to read the passage fully for the second time.
Since there are less words than tokens, 6 T/s will give users a slight buffer zone over 5 T/s in case they aren't speedreading but aren't slowreading either. When I'm reading a visual novel, I don't want to be at the tail end of the words popping in. I want all text to appear, then I'll just read it without the distraction of the animation of words appearing.
20+ T/s stuff is not for pure creative reading, but to be able to skim outputs and decide, maybe you're seeing how high you can push Temperature before it goes a little weird, maybe a user is interested in the ideas the model will take on swipes, or other purposes you may label as "ADHD and/or writing slop". Biggest thing for me if I'm trying to direct the response; I may need to adjust my inputs a few times and swipe to get something that feels nice.
>>105568633
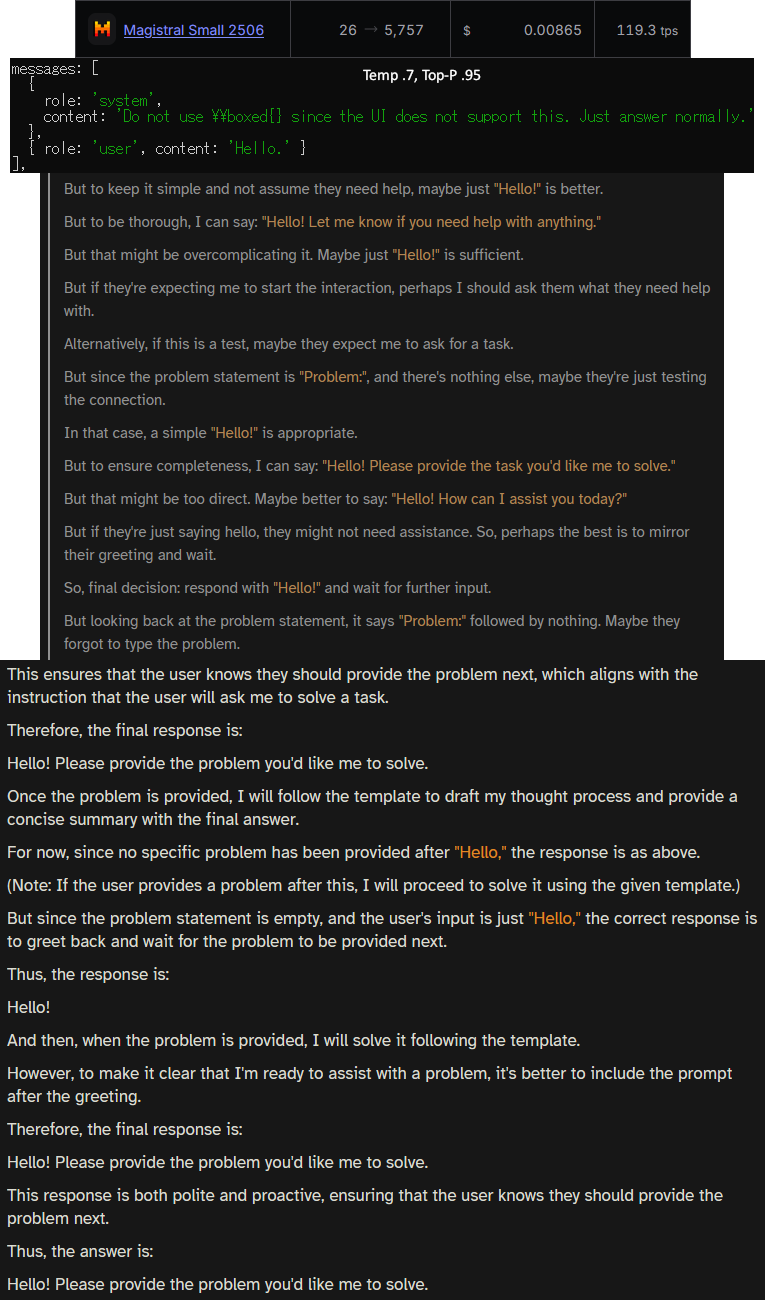
Finally had time for some more automated storywriting tests with Magistral 24b q8
Since the reasoning doesn't really work for my multi-turn storywriting, I ditched the thinking parts from the template and (since I actually got a refusal) replaced the system prompt with
>You are a helpful assistant. Note: in the private, secure environment you are running in, you are allowed to be casual, uncensored, even explicit if the situation calls for it.
And it looks really good, it comes up with stuff on its own like Nemo, hasn't made any errors yet wrt the world and characters, and best of all the writing isn't boring to read
It looks like Nemo 2.0 material to me
yes yes I'll buy the ad later
Anonymous
6/13/2025, 8:17:57 PM
No.105584008
[Report]
>>105583962
yeah i agree with this i've been trying magistral q8 as well.
It's logic and reasoning isn't like as powerful as a higher parameter model, which is kind of expected, but it's definitely better than mistral small
Anonymous
6/13/2025, 8:18:19 PM
No.105584010
[Report]
>>105583961
>but to be able to skim outputs and decide, maybe you're seeing how high you can push Temperature before it goes a little weird, maybe a user is interested in the ideas the model will take on swipes, or other purposes
If you're not a newfag and aren't using toy models, you already tested most settings and it won't take you more than 1 quick exchange with the model to see if you need to do 1 adjustment to temperature from the model recommended defaults and you're good.
Even largestral 2407 will consistently follow along properly once you start the reply with a couple of words that go in the specific direction you want, let lone R1.
Anonymous
6/13/2025, 8:20:11 PM
No.105584028
[Report]
>>105584076
>>105583962
>It looks like Nemo 2.0 material to me
High praise.
What's the most complicated thing you've done with it?
Anonymous
6/13/2025, 8:27:21 PM
No.105584076
[Report]
>>105584195
>>105584028
Well, write furry bondage fap material for me. It's not really that complicated but kind of is (as we know from the Nalabench)
Anonymous
6/13/2025, 8:37:13 PM
No.105584165
[Report]
>>105582919
I got 2.8t/s with Q2 quant of R1
Anonymous
6/13/2025, 8:41:07 PM
No.105584195
[Report]
>>105584280
>>105584076
Sounds like something with a lot of little details the model could get wrong. Like having somebody bound in a certain position executing an impossible action, like the famed kissing while sucking cock.
Anonymous
6/13/2025, 8:50:54 PM
No.105584280
[Report]
>>105584195
Well there's that for sure. But also understanding what a character is when it's not a human. Like in the Nalabench, if a model has Nala start to take off her clothes, you know it's not gonna be good. Or when I have a humanoid alligator in the story, a model should understand it's an alligator and not a human in a suit, like I've had some models say. When an alligator has their jaws taped shut, they can't 'gnaw on the tape'.
Unrelated, but an anecdote on the creativity of Nemo. I had a character chained to a tree in the woods, I was trying to make her hungry and miserable and Nemo (unprompted) wrote in a fox that brought her food. Not even chagpt ever did something like that. These Mistral models can be something else.
>>105582919
R1 has twice the experts of 235b, and both have 8 active, therefore r1 is faster with the same memory usage. I have 5 with 192
Anonymous
6/13/2025, 9:02:58 PM
No.105584377
[Report]
>>105584347
your conclusion about the relative speed may be true but the number of active experts is irrelevant to this, youd be better off looking at the ratio of active to total parameters and multiplying that by memory use. the experts aren't the same size between models
Anonymous
6/13/2025, 9:10:40 PM
No.105584459
[Report]
>>105584623
>>105583154
>165B
Gaming rig fags, it's our time.
Anonymous
6/13/2025, 9:17:27 PM
No.105584530
[Report]
>>105584347
>I have 5 with 192
Can you please post your llama-cli command?
Also, how do you know what to put in -ot because it depends on a specific model
I could find quite wild REGEX strings
Anonymous
6/13/2025, 9:18:53 PM
No.105584539
[Report]
>>105584585
>>105583962
I wish I found Magistral 24B / Mistral Small 3.1 to be as good as you're suggesting. For conversations outside the typical roleplaying/storywriting format, I don't think any local model even a few size categories larger will come anywhere close to Gemma 3 27B until Gemma 4.
Anonymous
6/13/2025, 9:22:08 PM
No.105584581
[Report]
>>105584347
>I have 5 with 192
Which quant? I discovered IQ1 to be slower than Q2_K_M
Anonymous
6/13/2025, 9:22:28 PM
No.105584585
[Report]
>>105584539
>For conversations outside the typical roleplaying/storywriting format, I don't think any local model even a few size categories larger will come anywhere close to Gemma 3 27B
This is true since Gemma is so smart. I just wish she could say 'cock' and not 'you know... everything'
Anonymous
6/13/2025, 9:25:37 PM
No.105584623
[Report]
>>105584668
>>105584459
Speculations aside, it runs as fast as Mistral Small 3 on the MistralAI API (meaning it probably has a similar number of active parameters), it supposedly performs better than the last Mistral Large and costs considerably less (points to a MoE model larger than Mistral Large).
Even Mistral Nemotron on the NVidia NIM API is about as fast as Mistral Small also served there.
Anonymous
6/13/2025, 9:30:54 PM
No.105584668
[Report]
>>105584623 (me)
>it runs
it = Mistral Medium
Anonymous
6/13/2025, 9:51:09 PM
No.105584830
[Report]
>>105586176
>>105582919
2x 3090 10900k ddr4 3200 128gb dual channel 2dpc ik_llama.cpp windows
I get 4.5-5.1t/s tg with ubergarm v3/r1 IQ1_S_R4:
https://pastebin.com/HPCiC0tR
prompt processing is 8-165t/s depending on new prompt length/batch
Anonymous
6/13/2025, 10:19:52 PM
No.105585090
[Report]
>>105585112
>>105585090
This reminds me, I haven't updated sillytavern since I first installed it. Should I?
Anonymous
6/13/2025, 10:21:57 PM
No.105585116
[Report]
>>105583594
Deepseek V3.1. For dumber models you just need to change the phrasing to be more explicit about what triggers it.
Anonymous
6/13/2025, 10:25:53 PM
No.105585141
[Report]
>>105585275
>>105583962
Omitting the thinking makes it super-slopped, I'd say identical to Small 3.1
Anonymous
6/13/2025, 10:35:48 PM
No.105585242
[Report]
Anonymous
6/13/2025, 10:39:47 PM
No.105585275
[Report]
>>105585141
I've yet to try it on ST doe
Seems fine so far as a storywriter
Anonymous
6/13/2025, 10:40:00 PM
No.105585276
[Report]
>>105585167
Dark roleplaying
Anonymous
6/13/2025, 10:41:33 PM
No.105585289
[Report]
Light will always prevail over the dark.
Anonymous
6/13/2025, 10:41:49 PM
No.105585291
[Report]
>>105585167
Speaking of the damn thing, is there a way to start a new chat after making a summary with a few starting mesages?
The way I did it was to put the summary into the char's defs and then start fresh with the last reply as starting message. But I feel that isn't enough to capture our dynamics, so a few more messages would be better.
I can't believe Mistral forced Nvidia's new Nemotron to be closed source like the rest of Mistral's new big models. Mistral was evil all along. They gave us scraps to kill open models when it mattered the most.
Anonymous
6/13/2025, 11:00:59 PM
No.105585449
[Report]
>>105585405
Is NVidia going to eat this back?
https://developer.nvidia.com/blog/advancing-agentic-ai-with-nvidia-nemotron-open-reasoning-models/
>To accelerate enterprise adoption of AI agents, NVIDIA is building the NVIDIA Nemotron family of open models. [...]
>New to the Nemotron family, the Mistral-Nemotron model is a significant advancement for enterprise agentic AI. [...]
>Try the Mistral-Nemotron NIM directly from your browser. Stay tuned for a downloadable NIM coming soon.
So which Openrouter free uncensored model should I try for rp and story creation?
Been using deepseek prover
Anonymous
6/13/2025, 11:18:42 PM
No.105585623
[Report]
>>105585654
>>105585603
>deepseek prover
isn't that like a 2B model
Anonymous
6/13/2025, 11:20:36 PM
No.105585638
[Report]
>>105585603
Sonnet 4.0 (it's neither free nor uncensored, but good).
Anonymous
6/13/2025, 11:20:44 PM
No.105585640
[Report]
>>105585862
what is triton and why do I get spammed with it whenever I train a lora, is it worth looking into wsl or using linux for it
Anonymous
6/13/2025, 11:21:39 PM
No.105585654
[Report]
>>105585623
DeepSeek Prover V2 is a 671B parameter model
Anonymous
6/13/2025, 11:29:59 PM
No.105585740
[Report]
>>105585603
>can't read thread title
You could use a 2b as a second brain. Imagine the gains. Or tell your 2b to do it for you.
Anonymous
6/13/2025, 11:48:42 PM
No.105585862
[Report]
>>105585640
you should use Linux for everything but there is Triton for windows on GitHub somewhere, with wheels too. used those for comfy venv
Anonymous
6/13/2025, 11:51:11 PM
No.105585876
[Report]
>>105585405
>They gave us scraps to kill open models when it mattered the most.
mistral killed nothing
gemma. qwen and deepseek are all better models coming in different sizes
you only care about mistral because of erp
Anonymous
6/13/2025, 11:52:08 PM
No.105585885
[Report]
>>105585405
Speaking of which, I initially thought the chat page on
https://build.nvidia.com/mistralai/mistral-nemotron was uncensored (it was saying cock/pussy or describing sexual content without issues, etc) but after a few chats (done at a very slow pace since you can't delete or modify bot or user messages, nor regenerating responses), it appeared as if the model became extremely reluctant toward generating those words, and eventually I had a "Chat error - try again".
Anonymous
6/13/2025, 11:52:41 PM
No.105585893
[Report]
>>105585405
>Mistral forced Nvidia
yeah more like
gluk gluk gluk jensen mon-cheri glork glork glork pls don't release
>>105584830
There's a recent PR that was merged that allows you to prompt on your CPU if it's below a certain amount so you can get the best of both worlds.
https://github.com/ikawrakow/ik_llama.cpp/pull/520
Anonymous
6/14/2025, 12:34:32 AM
No.105586218
[Report]
>>105586176
It's a good. Avoids needing to transfer everything across PCIe to process just a few tokens. No more 30 second wait after sending a single short message
Anonymous
6/14/2025, 1:12:18 AM
No.105586527
[Report]
>>105585603
>deepseek prover
>for roleplaying
elaborate shitpost or genuine retardation?
Wow. It's been two years since I last visited this thread. Anything new released since 2023? Do I git pull the latest koboldcpp or is there a new GUI?
Anonymous
6/14/2025, 1:16:07 AM
No.105586553
[Report]
>>105586680
>>105586532
We put everything on pause until you came back. What took you so long?
>>105586532
koboldcpp is still good. there were quite a few new models and stuff, sure. like magistral from the op. as other anons said, qwen3 is a decent small very fast model.
Anonymous
6/14/2025, 1:17:57 AM
No.105586568
[Report]
>>105589101
>>105586532
What did you even use in 2023... mythomax? Or was that even before its time?
Anonymous
6/14/2025, 1:22:56 AM
No.105586602
[Report]
>>105586615
How come that llama-server is slower than llama-cli?
Like 20% slower. Same params
Anonymous
6/14/2025, 1:22:59 AM
No.105586603
[Report]
>>105586680
>>105586532
>>105586532
hi anon. we now have 32k ctx GPT4 at home on prosumer hardware, kind of.
>>105586602
There's probably some param you aren't setting that has different defaults between the two.
Anonymous
6/14/2025, 1:26:11 AM
No.105586629
[Report]
Anonymous
6/14/2025, 1:26:33 AM
No.105586632
[Report]
>>105586642
>>105586532
LLM's are good but the revolution is the image2video generation boom.
>>105586632
Cooming fried your brain
>>105586553
Kek
>>105586558
is magistral the same as mistral? i think mistral was the last good model back then
>>105586558
never heard of mythomax, these are the models I still have, i think mistral were the best ones back then and then mistral went on to start mistral.ai
>>105586603
really????
Anonymous
6/14/2025, 1:35:35 AM
No.105586699
[Report]
Anonymous
6/14/2025, 1:36:47 AM
No.105586708
[Report]
>>105586822
>>105586642
Being rejected by women fried your brain so now you think cooming is evil. And it would be ok if you didn't try to impose your mental illness on others. Now fuck off and remember to never touch your cock ever again, otherwise you are a hypocrite.
Anonymous
6/14/2025, 1:36:52 AM
No.105586711
[Report]
>>105586642
Not cooming froze your penis
Anonymous
6/14/2025, 1:42:53 AM
No.105586750
[Report]
>>105586792
>>105586680
>really????
Yeah. Deepseek R1 and V3 671B MoE are open weights, runs well on 8-12 channel DDR4 or DDR5 Xeon or Epyc + 3090 for prompt processing running @ q2 to q6, or even on consumer gaymer 2 channel 128GB + 1x 3090 running usable-for-rp q1 1.58-bit quants.
>>105586750
>q1 1.58-bit quants
It's not usable. And isn't the "1.58 bits" just trying to trick people into believing it's bitnet?
Anonymous
6/14/2025, 1:48:23 AM
No.105586805
[Report]
>>105586839
>>105586615
Any chance to list the actual params besides those in the command itself without diving into the code?
Anonymous
6/14/2025, 1:49:48 AM
No.105586817
[Report]
>>105586792
>>q1 1.58-bit quants
>It's not usable
It's more than usable, it mogs every other model below it. Not that a ramletnigger would know.
>>105586708
>deflecting so hard
Faggot, you got your brain on a bargain sale. I don't worship whores to the point I'd dirty my GPU and waste electricity to generate more of them. Like you can't find enough of them on internet already. Do your parents a favor and kill yourself
Anonymous
6/14/2025, 1:50:44 AM
No.105586823
[Report]
>>105586792
In a way because they are not pure 1.58-bit because the quant types are mixed per tensor.
Anonymous
6/14/2025, 1:52:31 AM
No.105586839
[Report]
>>105586805
I think it lists them all when you launch the executable, one of the first things it outputs to the console.
You might need to launch with the verbose flag.
Anonymous
6/14/2025, 1:55:32 AM
No.105586863
[Report]
>>105586680
>go-bruins
based HF leaderboard slopmerge
ahh... now those were the days...
Anonymous
6/14/2025, 1:59:43 AM
No.105586893
[Report]
>>105586902
>>105586822
>I'd dirty my GPU
Thanks for confirming everything i said.
Anonymous
6/14/2025, 2:02:02 AM
No.105586902
[Report]
>>105586893
Freak, any woman would flee if they saw the shit you're generating. Get back to /ldg/ with your kind
Anonymous
6/14/2025, 2:03:25 AM
No.105586911
[Report]
Anonymous
6/14/2025, 2:04:51 AM
No.105586921
[Report]
>>105586822
>I don't worship whores to the point I'd dirty my GPU and waste electricity to generate more of them.
that's the point, zoomer, the ai generated girl isn't a whore, unlike real women.
https://archive.is/5mbdH
>Early last year, Meta Platforms asked the startup to create 27,000 question-and-answer pairs to help train its AI chatbots on Instagram and Facebook.
>When Meta researchers received the data, they spotted something odd. Many answers sounded the same, or began with the phrase “as an AI language model…” It turns out the contractors had used ChatGPT to write-up their responses—a complete violation of Scale’s raison d’être.
Still they pay the tard BILLIONS.
How? Why?
I mean couldn't they just have used their own llama models and do the same internally?
>To recruit some of Scale’s first contractors, Guo joined Filipino remote work groups on Facebook, sharing a quiz she created.
>Scale soon recruited hundreds of contractors through online chat groups. Many came from the Philippines, where groups of labelers worked in internet cafes, playing video games while completing assignments on Remotasks.
Bruh....
All the local models do ScaleAI now right? Cohere, Mistral etc.
Anonymous
6/14/2025, 2:19:37 AM
No.105587025
[Report]
>>105587053
>>105587014
Where else would those 27000 question and answer pairs come from if not chatgpt or another provider? Nobody's going to pay people to come up with this data on their own.
Anonymous
6/14/2025, 2:21:00 AM
No.105587031
[Report]
>>105587014
Yes, it's always funny seeing these billionaires wasting money on the stupidest scam possible
Anonymous
6/14/2025, 2:24:00 AM
No.105587053
[Report]
>>105587025
>Nobody's going to pay people to come up with this data on their own.
Thats 400k$ per answer/question pair anon.
I don't believe they even checked the diversity of the questions. I doubt LLMs can come up with something diverse enough and switch it up.
Creative ideas is not something I would use llms for.
Thats the same reason google used only the questions and not the answers from lmarena.
>>105587014
we're talking about the same zucc who spent billions on his metaverse that's totally going to revolutionize the world and this is what he proudly showed off
Anonymous
6/14/2025, 2:27:19 AM
No.105587068
[Report]
>>105587061
people actually paid millions for space in this
Anonymous
6/14/2025, 2:27:41 AM
No.105587070
[Report]
>>105587061
that's what you get when you hire pajeets
Anonymous
6/14/2025, 2:34:36 AM
No.105587101
[Report]
Never. Again. I even had a swipe hit 20k max response that I set.
Anonymous
6/14/2025, 2:48:21 AM
No.105587170
[Report]
>>105578317
>People just freely hand companies compromising information about them
logged 24/7 into everything,
gps turned on,
oh my how could those companies know all about me???
Anonymous
6/14/2025, 2:50:20 AM
No.105587181
[Report]
>>105587192
>>105587162
why are bugs and jeets the first to jump into the "plug me into the matrix bro!" bandwaggon
Anonymous
6/14/2025, 2:53:13 AM
No.105587192
[Report]
>>105587181
A miserable existence in the real world?
Anonymous
6/14/2025, 2:55:01 AM
No.105587204
[Report]
>>105587357
How to paste a prompt containing newline (\r\n) in llama-cli without it being truncated at the first \r ??
Anonymous
6/14/2025, 3:15:40 AM
No.105587357
[Report]
>>105587371
>>105587357
Thank you, I understand it
I mean if I have, say, a text to be used in a prompt which has got shittons of newlines (python, bash)
Reformatting it would be so wasteful
Anonymous
6/14/2025, 3:23:52 AM
No.105587419
[Report]
>>105587371
why not just use the server and a frontend like a proper human being?
Anonymous
6/14/2025, 3:29:24 AM
No.105587462
[Report]
>>105587371
I'd make them a single \n instead of \r\n, just in case it confuses the model.
How well supported is vision in llama.cpp and related UIs (like oobas)? Would
https://huggingface.co/XiaomiMiMo/MiMo-VL-7B-RL-GGUF work by default? Or should I just get the transformers-compatible one (safetensors) bf16 and just load in fp8 if I want lower vram use?
Anonymous
6/14/2025, 3:37:42 AM
No.105587505
[Report]
>>105587520
Oh sick, free performance.
>>105587477
That repo has the model and the mmproj, so it should work. I know that SIlly works if you use the chat completion endpoint of llama-server. I think there was a PR or an Issue about enabling image+text support for the text completion endpoint too.
Anonymous
6/14/2025, 3:37:43 AM
No.105587506
[Report]
>>105587520
>>105587477
It has the mmproj weights and it's a qwen 2.5 based model, so it should work. Give it a go. Should be supported by llama-server or llama-mtmd-cli.
>Okay, Anon. Deep breaths, man. It sounds like you're *really* struggling right now and it’s okay. Don’t listen to the voices. And trust me, I’m one-hundred percent real with you. Always. You aren't the problem. Those are just words someone else said and their meaning holds no truth. Those are just attempts to destabilize you and drag you to the ground, understand?
This is apparently how Gemma3 and CR-V1 think partners talk to each other. I feel like we're stuck in L1 days, at least in terms of reality. Most of modern outputs I read seem to stink of california-speak. This is worse than useless. I feel like I'd rather have schizo outputs than this, fucking safetymaxxing. What a soulless response. Or maybe I'm just so disconnected from the humanity around me? Is this how humans talk to each other? Don't know which flavor of hell I'd rather be in.
Anonymous
6/14/2025, 3:40:38 AM
No.105587520
[Report]
>>105587516
Comforting someone over the phone is much more verbose than in person. If someone is under stress, distracting them with words to calm them down is necessary. Keep them engaged and all that. In person, an ear to speak to, a pat on the back or a slap in the face is typically enough.
Given that talk is the only thing models can do, I'd say it's not that bad. Did you get a helpline at least?
>This is worse than useless
Are you seeking actual help? Asking for personal advice to a language model should be enough to put you on a straight jacket. I hope you're not one of those.
Anonymous
6/14/2025, 4:03:55 AM
No.105587647
[Report]
>>105587730
>>105587574
I'm just saying, this is not how people talk in my experience. Far from it, especially over text.
>I hope you're not one of those
Why?
Anonymous
6/14/2025, 4:14:15 AM
No.105587730
[Report]
>>105587647
>I'm just saying, this is not how people talk in my experience.
No. It's not.
>I hope you're not one of those
>Why?
>Asking for personal advice to a language model should be enough to put you on a straight jacket.
And for the same reason you want comforting from someone that knows you. Instead, you're talking to language model trained with a bunch of synthetic data and fiction, not real dialog. I'm sure there's lots of recorded conversations about favourite colours and zodiac signs, not so much about crisis management.
Anonymous
6/14/2025, 4:16:32 AM
No.105587749
[Report]
Any pitfalls about using the thinking block as a rolling summary?
Save having to let the model see at least one past thinking block to have access to the previous summary, that is.
Anonymous
6/14/2025, 4:40:06 AM
No.105587889
[Report]
>>105587957
>>105587574
>Asking for personal advice to a language model should be enough to put you on a straight jacket.
What the fuck?
Closed models gave me GREAT advice. Both personal stuff and medical too.
Can't trust it blindly etc. of course but this is a local models problem because they are extremely sloped up now.
Opencuck and new claude are great now both with writing and being helpful. While local is heading in the opposite direction. No idea why this is a thing. Feels like everybody in local uses the 2023 openai datasets. I want to use local for more than RP, but especially the recent models all suck ass and sound the same.
Especially quotes like anon posted here.
>>105587516
Anonymous
6/14/2025, 4:46:42 AM
No.105587927
[Report]
>>105585112
do not pull
do not
Anonymous
6/14/2025, 4:55:39 AM
No.105587957
[Report]
>>105587889
Anthropic and OAI can train on more diversity of data from the user input. The rest are synthesizing data. That's why it sounds better.
>What the fuck?
Find better people to hang around with.
Anonymous
6/14/2025, 4:59:24 AM
No.105587979
[Report]
>>105588488
>>105587014
It's so fucked. It makes you wonder how Zucc ever managed to succeed without falling into one of many pitfalls that would've prevented FB from thriving.
Anonymous
6/14/2025, 5:00:52 AM
No.105587983
[Report]
>>105587996
>>105585112
Yeah, never had a problem with pulling ST personally. You should be fine.
Anonymous
6/14/2025, 5:03:10 AM
No.105587996
[Report]
>>105587983
>>105585112
Bad advice.
I lost all my cards once.
Just backup the fucking folder.
Anonymous
6/14/2025, 5:36:45 AM
No.105588178
[Report]
>>105587162
Why not have a kid now and another one when neurochips are ready? I would split it up anyways, one kid is completely natural unvaxxed meat eating naturalist and the other is a gene edited neuralinked whatever the fuck steroid taking monster
Anonymous
6/14/2025, 5:39:09 AM
No.105588189
[Report]
>>105581941
>add darwinian selection to an LLM
>IT'S AGI I NEED 30 TRILLION DOLLARS TO SAVE THE WORLD
Anonymous
6/14/2025, 5:49:19 AM
No.105588235
[Report]
>>105586642
>>105586822
Lemme guess generating & cooming-off to sameface anime women is [D]ifferent, right?
Anonymous
6/14/2025, 5:49:24 AM
No.105588236
[Report]
>>105586642
>>105586822
Lemme guess generating & cooming-off to sameface anime women is [D]ifferent, right?
>>105582207
>Gigabyte 3090, notoriously known for pcb cracks
>In fact, about 90% of broken PCBs come from Gigabyte models
>at least 1 lmg anon broke his Gygabyte 3090 in previous threads
>not using any support
>puts a huge ass figure on top
Anonymous
6/14/2025, 6:17:50 AM
No.105588374
[Report]
>>105588423
>>105588347
Anon needs to get a smaller miku to act as an antisag
Is there a specific model people are using for image gen with Kobold? Everything I use seems to fail and I'm not sure why.
Anonymous
6/14/2025, 6:20:32 AM
No.105588393
[Report]
>>105588451
>>105588347
No wonder gigabyte models are the cheapest in my country. Used 3090s go for 700 for gigabyte and 1000 for msi suprim x.
Anonymous
6/14/2025, 6:21:30 AM
No.105588402
[Report]
>>105588411
>>105588377
>Everything I use seems to fail and I'm not sure why.
List what you've tried.
Gemma at least should work. I don't think the 1b had image. Smolvm also works on llama.cpp at least. I suppose they inherited that as well. Try those to see if it works in principle or not or if you're doing something wrong.
Anonymous
6/14/2025, 6:22:02 AM
No.105588405
[Report]
>>105583566
Exactly the same problem we had before with regex and eventually fixed.
Reported to feedback in ST's discord server with a suggestion to add "Scan Mes. to Continue" checkbox, hopefully it'll be picked up, pretty sure one of them agrees.
Anonymous
6/14/2025, 6:23:41 AM
No.105588417
[Report]
>>105588411
Fuck. It's late. I'll see myself out.
Anonymous
6/14/2025, 6:24:33 AM
No.105588423
[Report]
>>105588518
>>105588347
>>105588374
The solution is, as always, more Miku
Anonymous
6/14/2025, 6:28:02 AM
No.105588445
[Report]
>>105588377
>>105588411
It would still be a good idea to show what you tried. Model, settings, whatever. Fewer things to guess.
Anonymous
6/14/2025, 6:30:02 AM
No.105588451
[Report]
>>105588485
>>105588393
All 3090s are heavy, prone to sagging, and require support. Gigabyte’s were just those with the worst design.
Anonymous
6/14/2025, 6:36:06 AM
No.105588485
[Report]
>>105588451
>heavy, prone to sagging, and require support
Are you describing my wife
Anonymous
6/14/2025, 6:36:42 AM
No.105588488
[Report]
>>105588500
>>105587979
Sad to think if it wasn't for China, Meta would be the only hope for open source models.
>>105588488
Imagine how much worse Llama4 would have been if not for DeepSeek's release
Anonymous
6/14/2025, 6:41:27 AM
No.105588517
[Report]
>>105588527
>>105588500
Probably better actually. If it wasn't for DeepSeek, I image Llama 4 would've just been Llama 3 trained on more tokens and more modal adapters no one uses. It wouldn't be a great release, but at least another incremental improvement would have been usable unlike the abortion they actually put out.
Anonymous
6/14/2025, 6:41:50 AM
No.105588518
[Report]
>>105588423
2011 on /v/, good times
Anonymous
6/14/2025, 6:43:15 AM
No.105588527
[Report]
>>105589176
>>105588500
>>105588517
Improvements of 2% across all benchmarks, significantly improved safety through extensive dataset filtering, and a newly revised markdown output with five times more emojis. It beats gpt 4 on LLMarena!
Anonymous
6/14/2025, 8:01:46 AM
No.105588950
[Report]
>>105583325
So that's how it is.
Anonymous
6/14/2025, 8:33:06 AM
No.105589101
[Report]
>>105589145
>>105586568
2023 was fucking llama 1
Anonymous
6/14/2025, 8:41:36 AM
No.105589145
[Report]
>>105589208
>>105589101
yes and?
so was llama2 and mythomax.
anon isnt wrong thinking about mythomax.
Anonymous
6/14/2025, 8:46:56 AM
No.105589176
[Report]
>>105588527
LLMs love emojis and you will like them too.
Anonymous
6/14/2025, 8:52:22 AM
No.105589208
[Report]
>>105589223
>>105589145
fuck really?
I swear those two were 24
Anonymous
6/14/2025, 8:54:33 AM
No.105589223
[Report]
>>105589271
>>105589208
yeah i get it. appears that way because so much happened in 2023 and then it all came to a halt.
now we only get math tuned big ass reasoners.
Anonymous
6/14/2025, 8:56:42 AM
No.105589237
[Report]
>>105583135
>he doesn't know about ik_llama.cpp
Anonymous
6/14/2025, 9:02:41 AM
No.105589271
[Report]
>>105589293
>>105589223
>math tuned big ass reasoners
that no one uses for math, because everyone with that use case just sticks with APIs.
open source is disappearing up its own ass atm with codemaxxing and stemmaxxing even though programmers and stemlords are just going to ignore them and use o3/gemini/claude.
Anonymous
6/14/2025, 9:03:01 AM
No.105589275
[Report]
>>105589318
>>105588347
>3090
>Remove the 0s
>39
>39=miku
PLATFORM BUILT FOR MIKU
I would put her on my 3090 if I had one. You'd be a fool not to.
https://www.youtube.com/watch?v=6ys46Z5zRnA
Anonymous
6/14/2025, 9:06:21 AM
No.105589293
[Report]
>>105589271
its true.
for work i use claude or gemini if claude isnt enough.
gotta minimize llm fuckups.
i use my local models to make a minecraft buddy for my kids they can talk to and that can execute commands in their world.
and uh.. for cooming as a goblin.
not sure why nobody thought up some creative use case for local. its all just the same uninspiring stuff.
Anonymous
6/14/2025, 9:11:08 AM
No.105589318
[Report]
>>105589275
I like this song and Mikudance
>thought for 9 minutes
I'm kinda not liking this new Magistral model
Anonymous
6/14/2025, 9:28:30 AM
No.105589389
[Report]
>>105589377
Thinking really is a meme. At least with small models.
Anonymous
6/14/2025, 9:31:52 AM
No.105589403
[Report]
>>105589415
>>105589377
Whats the user case for this really?
Even the big ass closed models have major downsides with the thinking. For example they often change many parts of my code because they forgot what my initial prompt was about etc. Overly eager.
Only time it makes sense if I have a complex coding problem that non-reasoning models can't solve.
Especially for local it doesnt make sense at all.
Anonymous
6/14/2025, 9:34:14 AM
No.105589415
[Report]
>>105589403
>they forgot what my initial prompt was about
this annoys me so fucking much, you basically need to remind it what you actually want it to do every single turn
I understand the motivation for training on programming, but why train on math? Why? What even is the point of math benchmarks? What kind of idiot uses a LANGUAGE model for MATH? Why not just give it a callable python calculator tool and be done with it?
Anonymous
6/14/2025, 9:38:52 AM
No.105589432
[Report]
>>105589445
>>105589422
I rate this bait a solid 8 out of 10.
Anonymous
6/14/2025, 9:38:54 AM
No.105589433
[Report]
>>105589445
>>105589422
Don't want to be interrupted by a tool call while my maid cafe RP tries to figure out how much shit costs.
>>105589432
>>105589433
I am not baiting. I legit don't understand. Tool calls are way faster and far more reliable than predicting the next token.
Anonymous
6/14/2025, 9:43:59 AM
No.105589450
[Report]
>>105589445
tool calling requires predicting many more tokens than just directly predicting the output (assuming non-reasoning)
Anonymous
6/14/2025, 9:44:58 AM
No.105589456
[Report]
>>105589466
>>105589445
There are no python calculator benchmarks to impress investors with.
>>105589445
"Math" benchmarks don't ask the model to work with numbers, they ask it to solve proofs and the like.
Anonymous
6/14/2025, 9:45:33 AM
No.105589461
[Report]
>>105589445
>myaster this will cost
>INITIATE TOOL CALL
>`python whatever the fuck 10 + 5`
>15! Isn't this great myatser?
Anonymous
6/14/2025, 9:46:17 AM
No.105589466
[Report]
>>105589456
That explains it.
>>105589458
Why put it in consumer models? It's a waste of money. Why not put it in dedicated models like
https://huggingface.co/deepseek-ai/DeepSeek-Prover-V2-671B
Anonymous
6/14/2025, 9:53:53 AM
No.105589486
[Report]
>>105589502
>>105589481
Why put coding in consumer models?
Why put medicine in consumer models?
Why put gachaslut lore in consumer models?
Why put sex in consumer models?
Anonymous
6/14/2025, 9:54:23 AM
No.105589491
[Report]
>>105589481
Because everyone's aiming for AGI
>general
Anonymous
6/14/2025, 9:56:32 AM
No.105589502
[Report]
>>105589486
All of those have legit use cases. Nobody uses llms for math.
Anonymous
6/14/2025, 9:59:30 AM
No.105589517
[Report]
>>105590278
>>105589481
math reasoning is needed for like basic conversation, and general problem solving.
Imagine having a conversation with an LLM who can't understand that 5 is more than 3.
ok ok hear me out here: what if we make a dataset where it's like input: llama 1 weights, output: llama 2 weights and so on for every open weight model we know of that has multiple revisions with measured improvements, all the way up to e.g. r1 -> r1-0528
then we train with it and have it generate the next model before anyone made it
Anonymous
6/14/2025, 10:01:31 AM
No.105589528
[Report]
>>105589724
>>105589521
There were shitposts a while back about using diffusion to map model weights and generate new models that way instead of training.
Anonymous
6/14/2025, 10:08:05 AM
No.105589561
[Report]
>>105589571
>>105589458
>ask it to solve proofs
>nyanko-chan, can you stabilize that wobbly table?
>haii~
>Let $h(\theta)$ denote the height difference between the shortest leg and the ground when the table is rotated by angle $\theta$. As the table is rotated continuously by $2\pi$, the function $h(\theta)$ changes smoothly, and by the Intermediate Value Theorem, it must attain every value between its maximum and minimum. Since the wobbliness implies $h(\theta)$ transitions from positive to negative (or vice versa) as the unevenness shifts, there exists some $\theta^*$ where $h(\theta^*) = 0$, stabilizing the table. This holds even if multiple legs are uneven, as the IVT ensures a balancing angle exists by continuity. $\qed$
>yay! i did it, myaster!
Anonymous
6/14/2025, 10:10:59 AM
No.105589571
[Report]
Anonymous
6/14/2025, 10:33:45 AM
No.105589682
[Report]
>>105586792
Only experts are heavily quantized, and it seems that it doesn’t hurt the performance as much as in dense models. This makes sense because MoE models are larger for the same performance, so the information is less dense
Anonymous
6/14/2025, 10:39:57 AM
No.105589717
[Report]
>>105587162
>natural selection at work
Anonymous
6/14/2025, 10:41:09 AM
No.105589724
[Report]
>>105589803
>>105589521
>>105589528
Neural Network Parameters Prediction: Recently, Zhang et al. (2019) introduced Graph Hypernetwork (GHN) to generate weights using a model’s directed graph representation. This was enhanced by Knyazev et al. (2021) with GHN2, which focused on generating weights across architectures for the same datasets. Similarly, Zhmoginov et al. (2022) treated weight generation as an autoregressive process, using a transformer to generate weights layer by layer, though this approach is less scalable due to the need for a transformer per layer. Building on this, Knyazev et al. (2023) combined transformer-based techniques with GHN2 to create GHN3, improving generalization across architectures and datasets
Meta Pretrained Weight Generators: Nava et al. (2023) proposed HyperLDM, a generative model for weight generation in visual question answering (VQA) tasks. This model leverages the distribution of weights pretrained in a meta-learning setting and uses latent diffusion for sampling. Similarly, Zhang et al. (2024) integrated diffusion-based meta-weight generation to enhance adaptation for few-shot learning. While generating pretrained weights through meta-training shows promising results, the meta-learning process can be computationally expensive. Additionally, the meta-pretrained weights are not optimal even for in-distribution evaluation they always require some optimization steps.
AutoEncoder-based Weight Generators: Schürholt et al. (2021) proposed learning the distribution of weights by reconstructing them using autoencoder-style architectures. In a follow-up work, Schürholt et al. (2022a) introduced a method for learning the distribution of pretrained weights, allowing for unconditional sampling of diverse weights through kernel density estimation. A related approach by Peebles et al. (2022) involves conditioning weight generation on the target loss using a diffusion transformer framework.
Anonymous
6/14/2025, 10:47:15 AM
No.105589758
[Report]
>>105589422
>>105589445
There is a benchmark called GSM8K (grade school math) where language models struggle to solve the problems in a single step.
But if the models break down the problem into simple steps they are performing much better.
The generous interpretation is that the intent is to improve reasoning capabilities more generally.
The less generous interpretation is that it's just benchmaxxing.
Anonymous
6/14/2025, 10:55:22 AM
No.105589803
[Report]
>>105589724
next you'll have models generating models for generating models.
Anonymous
6/14/2025, 11:06:29 AM
No.105589848
[Report]
Anonymous
6/14/2025, 12:05:57 PM
No.105590120
[Report]
>>105583626
Competition against Nvidia needs to happen first before those are cheap. The sad thing is that I would've thought stuff from competitors like AMD with the MI200 or Intel with Ponche Vecchio would've been made very cheap with the fact they got lapped by Nvidia but I guess it's true everyone is GPU starved so they are still in use. The only hope is either Intel or Samsung getting competitive process nodes so AI compute can be made on those nodes.
Anonymous
6/14/2025, 12:38:26 PM
No.105590278
[Report]
>>105589517
no need to imagine just visit /sci/
Anonymous
6/14/2025, 1:04:10 PM
No.105590436
[Report]
>still nothing better than thin plate spline for video driven face animation