/lmg/ - Local Models General
►Recent Highlights from the Previous Thread:
>>105611492
--Papers:
>105617146 >105617169 >105617224 >105617281
--Local vision models struggle with GUI element detection compared to proprietary models:
>105620193 >105620227 >105620369 >105620226 >105620247 >105620738 >105620889 >105620944 >105621343 >105621405 >105621463
--Kimi-Dev-72B sets new open-source SWE-bench record with reinforcement learning optimization:
>105611862 >105612316
--Efforts to enable Minimax GGUF support in llama.cpp amid ongoing architectural refactors:
>105611523 >105611563 >105612211
--Skepticism around Llama-4-Scout-17B's performance and download figures:
>105613963 >105613987 >105614248 >105614351 >105614374
--Llama.cpp dots performance testing on 3090 with custom optimizations and context issues:
>105614479 >105614491 >105614503 >105614519 >105614529 >105614544 >105614515 >105614521 >105614535 >105614542
--F5 TTS speed improvements and benchmark resultst:
>105611838 >105611985 >105612086 >105612989 >105613222 >105613873
--Jan-nano released with real-time web search:
>105619630 >105620152
--Lightweight model recommendations for lore-heavy MUD development on CPU-only hardware:
>105613312 >105613546 >105613625 >105613837
--Roleplay performance hindered by reasoning mode and model training biases:
>105617637 >105618521
--Assessing current WizardLM and Miqu relevance:
>105618208 >105618366 >105618665 >105618678 >105618436 >105618834
--Dots model offers roleplay-friendly balance between speed and knowledge:
>105613814 >105613915 >105613962 >105613983
--Seeking reliable OCR solutions for research paper PDFs with complex layouts:
>105619313 >105619435 >105619493
--Bartowski rednote-hilab_dots.llm1.inst-GGUF model released:
>105615595 >105615710
--Miku (free space):
>105611805 >105614260 >105615100 >105615360 >105615887 >105616002 >105619906 >105620270 >105620366
►Recent Highlight Posts from the Previous Thread:
>>105611494
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
>>105621564
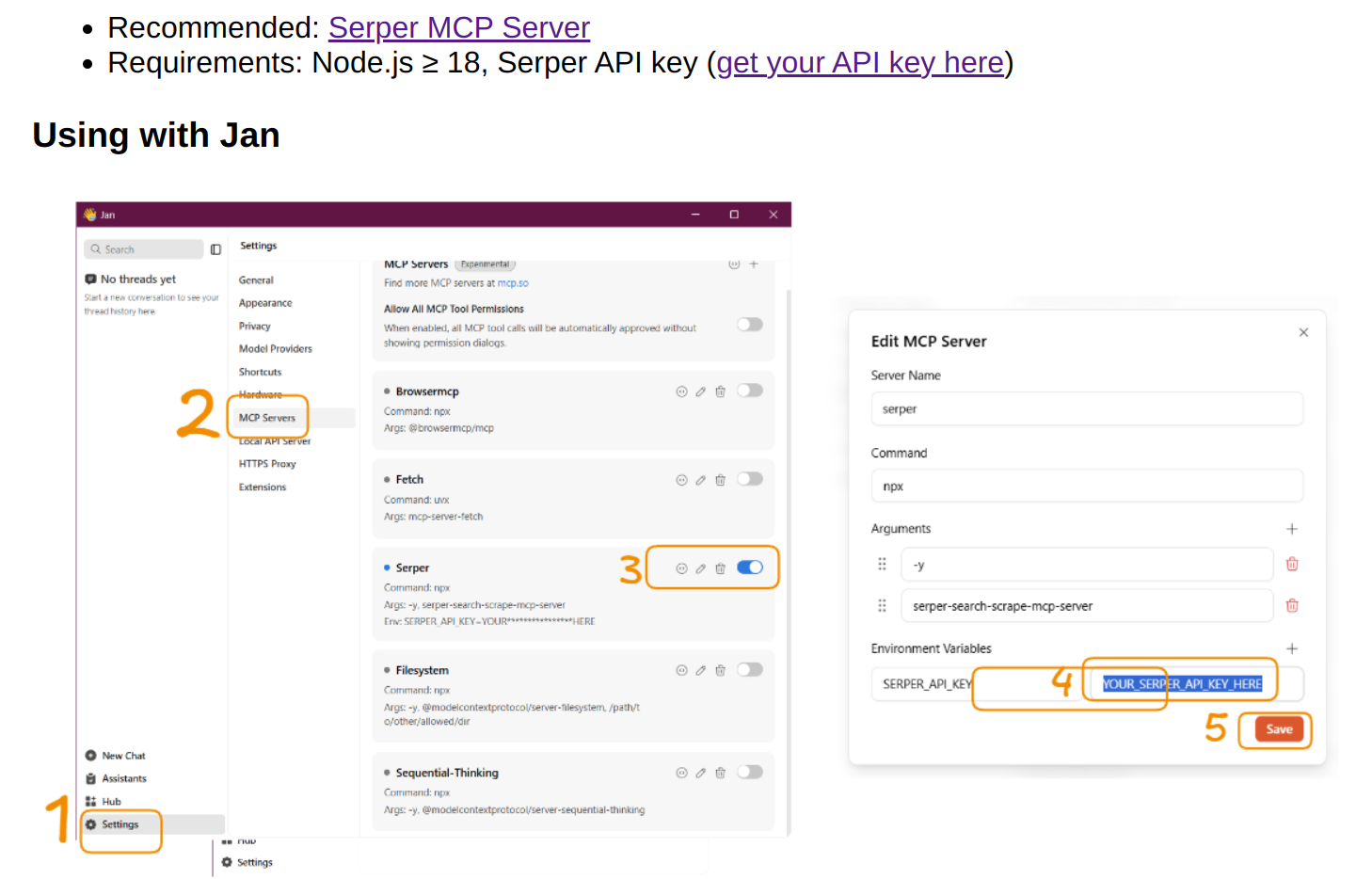
>--Jan-nano released with real-time web search:
real time web search with serper api you mean.
only 50$ for 50k requests! what a steal!!
much better than using grok or soon gemini for deepresearch.
uhhh because you have a gguf model locally that makes those requests! very cool.
Anonymous
6/17/2025, 4:57:16 PM
No.105621629
[Report]
>>105621618
Fuck, these faggots are really turning open source as free advertisement
>>105621618
Just spin up your own MCP servers. They’re like little helpers that let your AI interact with tools and apps. Open-source, free, and honestly kinda fun to play with.
>>105621645
MCP is for indians.
Anonymous
6/17/2025, 5:01:58 PM
No.105621676
[Report]
>>105621645
yes but i wished they showed a tutorial how.
openwebui does it build in. not sure if they use duckduckgo or brave api. I wanted to see how to do that.
Putting a serper api key as recommended in the tutorial is wild.
Its just ridiculous that they write everywhere how their 4b is better than R1 at MCP tool calling!!
...to then use it for a paid api that calls the url.
If you send this shit to a api you might as well use grok, its free and does a better job for sure.
>>105621665
Thats also true I suppose.
Anonymous
6/17/2025, 5:36:36 PM
No.105621955
[Report]
>>105623503
Any vision models worth using other than gemma?
>>105621964
Wait until they figure out that reasoning itself is a meme.
Anonymous
6/17/2025, 5:40:00 PM
No.105621985
[Report]
>>105622071
>>105621874
poor girl will melt from embarassment. also very clear glass, almost like it's not there at all.
Anonymous
6/17/2025, 5:40:30 PM
No.105621987
[Report]
>>105621977
I hope to see the day, getting real tired of this
>"Okay, ... statement" RIGHT??? But wait...
>NO!!! Or maybe?
Anonymous
6/17/2025, 5:44:30 PM
No.105622018
[Report]
>>105621964
>>105621977
I hope that until they figure out it's a meme, that this will get implemented in llama.cpp in the meantime.
It's a plug and play solution, it literally just suppresses the tokens on any model.
We could probably easily already do it ourselves by just blacklisting those words.
It doesn't degrade the quality at all according to the paper.
Anonymous
6/17/2025, 5:44:46 PM
No.105622021
[Report]
>>105621977
Not until they come up with some benchmark that isn't either a memorization test or trick logic puzzles.
>>105621964
I said this four months ago and /lmg/ called me retard and that the natural language is necessary for the thinking process
Anonymous
6/17/2025, 5:49:57 PM
No.105622052
[Report]
>>105621964
A bit late considering R1 0528 barely does the "Hmm, the User wants this but wait I should X" anymore
Anonymous
6/17/2025, 5:50:40 PM
No.105622057
[Report]
>>105622747
>>105622044
Every major LLM breakthrough started in /lmg/
Anonymous
6/17/2025, 5:52:07 PM
No.105622068
[Report]
>>105622044
based and ahead of the game. don't sweat it.
I've also seen other papers where the idea was so specific that I had a strong feeling it originally came from anons or from a r*ddit comment.
Anonymous
6/17/2025, 5:53:02 PM
No.105622075
[Report]
>>105623115
>>105622044
Being early means nothing. It's not Science until it's a published paper.
Anonymous
6/17/2025, 5:54:31 PM
No.105622090
[Report]
Anonymous
6/17/2025, 6:00:01 PM
No.105622142
[Report]
>>105622146
>>105621564
Who makes this stuff, it looks way too clean to be AI slop. And if so I'll shoot myself
Anonymous
6/17/2025, 6:00:51 PM
No.105622146
[Report]
>>105622142
It's gay slop but it has been inpainted 9001 times.
>still no natively multimodal self learning agi with 1 million experts and long term memory bitnet trained on only the finest hentai
i sleep
>>105622176
It might be easier to put wired up brains in jars and train them to do things.
Anonymous
6/17/2025, 6:09:43 PM
No.105622218
[Report]
>>105622255
>>105622195
Not viable. Most brains are too stupid to be useful for anything but the most trivial tasks. And if you put all the smart people in jars so they can count letters in strawberry all day, no one will be left to do things and society will collapse.
Anonymous
6/17/2025, 6:13:38 PM
No.105622255
[Report]
>>105622358
>>105622218
Try to create more smart brains in a controlled environment, pick best, apply selection methods, repeat.
Anonymous
6/17/2025, 6:20:38 PM
No.105622316
[Report]
>>105622447
Benchmaxxed brains
Anonymous
6/17/2025, 6:25:54 PM
No.105622358
[Report]
>>105622481
>>105622255
Human brains take too long to develop. Could try rats instead. Rat brains would grow faster, so could farm more generation in the same amount of time. But they're also stupider than (most) human brains. Maybe wire a bunch of rat brains together into something viable?
MoRE: Mixture of Rat Experts
Anonymous
6/17/2025, 6:28:13 PM
No.105622384
[Report]
>>105622398
>>105621874
>>105622071
How am I supposed to kiss her with the glass in the way?
Anonymous
6/17/2025, 6:29:51 PM
No.105622398
[Report]
>>105622384
Kissing women is gay, but it's a shame her breasts are out of reach.
Anonymous
6/17/2025, 6:34:38 PM
No.105622447
[Report]
>>105622316
Unironically how Chinese university entrance exam works. Which is why they see no issue with benchmaxxing.
>>105622358
Reminds me of the guy who tried to make rat neurons play DOOM. His attempt did not work.
The videos were primarily about growing, wiring, and measuring electrical activity in reaction to input signals, though he did get a "working" baseline setup for future experiments at the end of the second part:
https://www.youtube.com/watch?v=bEXefdbQDjw
https://www.youtube.com/watch?v=c-pWliufu6U
Captcha: ANVS
Anonymous
6/17/2025, 7:01:04 PM
No.105622684
[Report]
>>105622804
>>105622481
I'm not a vegan or anything but this shit is disturbing.
Anonymous
6/17/2025, 7:08:05 PM
No.105622747
[Report]
>>105622882
>>105622057
Yeah, who could ever forget such major breakthroughs like ToBN prompting?
Anonymous
6/17/2025, 7:16:23 PM
No.105622804
[Report]
>>105622684
I like how they sprinkled the brain cells with capsaicin. They couldn't scream, but boy could you see the pain. :)
Anonymous
6/17/2025, 7:24:21 PM
No.105622882
[Report]
>>105622979
>>105622747
>*All three Big Niggas in unison*: "OH SHIT NIGGA"
Good times.
https://www.youtube.com/watch?v=Gm_d8EU_PjM
Anonymous
6/17/2025, 7:37:04 PM
No.105622979
[Report]
>>105622882
hell yeah i saved all the best screenshots
Anonymous
6/17/2025, 7:49:36 PM
No.105623098
[Report]
>>105622481
>His attempt did not work.
I just finished watching both parts. They never got to the actual experiment. The equipment they had could only make 2 signals, and what they would need to make enough signals to represent a full game would cost $10k.
The video mentions papers where researchers already got neurons to solve mazes, drive a toy car while avoiding obstacles, and fly an aircraft simulator. Presumably there isn't a reason they couldn't also get the neurons to play DOOM once they get their setup together.
Anonymous
6/17/2025, 7:50:22 PM
No.105623115
[Report]
Anonymous
6/17/2025, 8:02:24 PM
No.105623234
[Report]
>>105623575
what's the favoured interpolation model, finally willing to give it a go
https://rentry.co/o84vftsb
Guys I wrote a new finetuning guide for LLM's please add it to the next OP thanks.
Anonymous
6/17/2025, 8:33:22 PM
No.105623503
[Report]
>>105621955
I wonder if UI-TARS can be used for image analyze
Anonymous
6/17/2025, 8:40:56 PM
No.105623575
[Report]
>>105623234
Interpolation? Video? >>>/g/ldg
upscale to 720p then RIFE v47 or GEMM. FILM is slow as shit and not much better if at all
Anonymous
6/17/2025, 8:56:53 PM
No.105623705
[Report]
>>105623782
>>105623428
Didn't work. Model kept repeating
> >>105623428 can't stop thinking about trannies.
over and over. Weird.
Anonymous
6/17/2025, 9:09:22 PM
No.105623782
[Report]
>>105623705
Yeah you are weird.
Anonymous
6/17/2025, 9:13:02 PM
No.105623801
[Report]
>me when the sum total of my actions is basically shitting my pants on a minute by minute basis
Does anyone else only notice the slowdown with higher context only with llama.cpp but not with vLLM?
Still no date for the 48gb intel dual gpu?
I just need my R1 local coombot, dude.
Anonymous
6/17/2025, 10:05:02 PM
No.105624174
[Report]
>>105624075
They need to release the B60 by itself first before they can even begin to think to release the dual GPU variant. Probably Q1 2026.
Anonymous
6/17/2025, 10:05:49 PM
No.105624180
[Report]
>>105624075
wasn't that for complete OEM systems only?
Anonymous
6/17/2025, 10:15:18 PM
No.105624247
[Report]
>>105624878
>>105624044
Show settings and numbers. Make settings comparable.
Anonymous
6/17/2025, 10:17:26 PM
No.105624269
[Report]
>>105632041
>>105624075
It has shit bandwidth.
cpumaxxing with a single 3090 is better than stacking those gpus
Anonymous
6/17/2025, 10:22:05 PM
No.105624310
[Report]
>>105624878
>>105624044
Do you have flash attention enabled and the batch size set the same in both llama.cpp and vllm?
Anonymous
6/17/2025, 10:45:06 PM
No.105624498
[Report]
No models?
Anonymous
6/17/2025, 10:52:31 PM
No.105624566
[Report]
tiny MoE are inherently worthless
Anonymous
6/17/2025, 10:53:59 PM
No.105624587
[Report]
>>105624516
It seems to be.
Anonymous
6/17/2025, 10:54:00 PM
No.105624588
[Report]
>>105624516
idk with a good prompt it seemed okay? need to test it more though
Anonymous
6/17/2025, 10:54:49 PM
No.105624595
[Report]
>>105624643
>>105624516
not if you prompt in chinese
Anything useful from the Gemini 2.5 Pro report?
>https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf
At least we know it's a MoE
What do I need to run r1 0528 2bit quant at 7ts?
I currently have a 4090 and 64gb of DDR5 ram 9950x3d.
Anonymous
6/17/2025, 10:59:08 PM
No.105624643
[Report]
>>105624595
That's an interesting idea.
>>105624610
I didn't know that was a thing. Neat.
>>105624634
Lots of memory throughput.
Anonymous
6/17/2025, 10:59:42 PM
No.105624648
[Report]
>>105624634
A server cpu, enough ram to fit the model and a meme llama.cpp fork.
Anonymous
6/17/2025, 11:07:52 PM
No.105624725
[Report]
>>105628988
>>105624610
>multimodal (ingest video, audio, can gen audio directly from the model)
>can oneshot something like a quizz educational app after ingesting a video lecture
>entirely trained on google tpu, mogs the rest of the industry by being independent from nvidia jews
>thinking budget to control the amount of tokens spent on reasoning nonsense
>agentic capability (Gemini plays Pokémon as an example)
Do any hosted LLM providers have a feature like llama.cpp's GBNF grammars or is local strictly ahead of remote in this area?
>>105624798
https://openai.com/index/introducing-structured-outputs-in-the-api/
imagine thinking llama has anything of value over online other than not sending your data to api providers
Anonymous
6/17/2025, 11:23:21 PM
No.105624853
[Report]
>>105624798
Gemini has a JSON schema kind of deal that is nowhere near as powerful as BNF.
Anonymous
6/17/2025, 11:26:37 PM
No.105624878
[Report]
>>105624985
>>105624247
I was just wondering if someone else got that "vibe". I was trying dots.llm and it got to single digits with context from 20 T/s, but that was with RPC. I did some tests with Qwen-32B FP8/Q8.
>vllm (flashinfer, tp=2)
Without context: 27 T/s.
With 6.7k context: 26 T/s
With 19.4k context: 24.8 T/s.
>llama.cpp (split-mode layer)
Without context: 22.08 T/s.
With 6.7k context: 20.74 T/s.
With 19.4k context: 18.87 T/s.
>llama.cpp (split-mode row)
With 19.4k context: 17.60 T/s.
>>105624310
Flash attention is enabled and the batch size is the default.
Anonymous
6/17/2025, 11:31:40 PM
No.105624908
[Report]
>>105624813
NTA but a JSON schema is only a subset of the things that you can do with a grammar.
Anonymous
6/17/2025, 11:31:59 PM
No.105624909
[Report]
>>105624813
Hello Sam, no need to be so defensive.
Anonymous
6/17/2025, 11:38:20 PM
No.105624980
[Report]
>>105634689
>>105624610
they can get their research team (deepmind) into shipping products, unlike meta and FAIR lel
Anonymous
6/17/2025, 11:39:06 PM
No.105624985
[Report]
>>105625733
>>105624878
I do get the feeling that there's a breakpoint where the tokens start coming out slower, but we're shit at perception, specially with low t/s. Have you ever looked at a wall clock and the first second, right as you look at the hands, seems to last a lot longer than the following seconds?
Unless I can show it happens, I consider my "feel" is just being schizo.
The perf loss is just 2.2t/s vs 3.21t/s at 20k context. llama.cpp seems to be consistently slower, but i don't think it's enough to justify your claim. Welcome to the schizo club.
Anonymous
6/18/2025, 12:58:18 AM
No.105625646
[Report]
>>105625749
>>105621559 (OP)
>>(06/17) Hunyuan3D-2.1 released: https://hf.co/tencent/Hunyuan3D-2.1
>>(06/17) SongGeneration model released: https://hf.co/tencent/SongGeneration
>>(06/16) Kimi-Dev-72B released: https://hf.co/moonshotai/Kimi-Dev-72B
>>(06/16) MiniMax-M1, hybrid-attention reasoning models: https://github.com/MiniMax-AI/MiniMax-M1
>>(06/15) llama-model : add dots.llm1 architecture support merged: https://github.com/ggml-org/llama.cpp/pull/14118
Any of this shit matter?
Anonymous
6/18/2025, 1:10:01 AM
No.105625733
[Report]
>>105626017
>>105624985
How have people's experiences with aider using qwen3 been? That seems to be the best local model on their leaderboard but I'm getting pretty mixed results.
Anonymous
6/18/2025, 1:13:43 AM
No.105625749
[Report]
>>105625646
song generation is local suno
Anonymous
6/18/2025, 1:14:29 AM
No.105625760
[Report]
>>105625804
Anonymous
6/18/2025, 1:21:46 AM
No.105625804
[Report]
>>105625876
Anonymous
6/18/2025, 1:32:04 AM
No.105625876
[Report]
>>105625733
Not really the best local model. It's better than R1, but far below R1-0528. Do you want to be more specific? I use it with Roo Cline and Continue instead of aider but have been satisfied with it since I can run a larger quant faster than R1.
Anonymous
6/18/2025, 2:00:56 AM
No.105626049
[Report]
>>105626061
>>105626017
>It's better than R1
No, Qwen 3 235B is multiple levels below first R1. Perhaps for some very specific coding use cases it might work better, but no.
Anonymous
6/18/2025, 2:03:02 AM
No.105626061
[Report]
>>105626082
>>105626049
Read before posting. 235B scores 59.6% without thinking to R1's 56.9% on aider's leaderboard.
Anonymous
6/18/2025, 2:05:20 AM
No.105626072
[Report]
>>105626017
>It's better than R1
LMAOOOOOOOOO
Anonymous
6/18/2025, 2:07:06 AM
No.105626082
[Report]
>>105626061
Qwen were always the models which were actually quite capable but always still benchmaxxed.
Anonymous
6/18/2025, 2:10:59 AM
No.105626111
[Report]
>>105621665
Not quite as indian as spinning up a tool that the AI easily does and then charging $50 for 50k requests.
Anonymous
6/18/2025, 2:12:08 AM
No.105626119
[Report]
>>105626200
>>105622195
a brain in a jar would kill itself within minutes of talking to me in the same way I talk to chatbots.
guy who uses the model with actual experience in his usecase:
>hey guys here's my opinion
people who have never used a model for anything outside of RP in ST with the wrong chat template applied:
>um you *DO* know that doesn't match up with the conventional wisdom I've formed entirely based on lmg memes right??
Anonymous
6/18/2025, 2:24:37 AM
No.105626200
[Report]
>>105626800
>>105626119
>a brain in a jar would kill itself
it literally can't, that's the most horrifying thing about the prospect.
is the internet already so contaminated by ai-isms that it will never be able to speak right? are all new models doomed to 'a mix of' and shit?
>>105626238
All they need to do is invent AGI and then you can command it to sound human and then it will learn how to do that all by itself. And if it can't then it's not AGI.
Anonymous
6/18/2025, 2:35:26 AM
No.105626265
[Report]
>>105626238
I see what you mean.
What sort of ai-isms are you referring to? I asked thoughtfully, in a husk whisper as my spine shivered
Anonymous
6/18/2025, 2:38:29 AM
No.105626285
[Report]
>>105626309
>>105626144
Both anons are indistinguishable from the outside. If you had theory of mind, you'd realize that.
Anonymous
6/18/2025, 2:41:02 AM
No.105626301
[Report]
>>105626238
The English-speaking internet is doomed, but maybe the other languages can still be saved.
Some people say that AI slop is something that exists in every language, but they've never been able to give any reproducible examples.
Anonymous
6/18/2025, 2:42:27 AM
No.105626309
[Report]
>>105626285
it's actually very easy to tell the difference between someone volunteering their opinion and someone informing them that it's wrong with no justification
Anonymous
6/18/2025, 2:49:34 AM
No.105626346
[Report]
Simple and clean is the way that you're making me feel tonight
Anonymous
6/18/2025, 3:14:43 AM
No.105626527
[Report]
>>105627449
>>105626238
I read jap novels that were translated to english in around 2016.
Every volume there is always a couple shivering spines, pangs of guilt etc.
LLMs ruined me I think. I swear I never saw that stuff before.
Anonymous
6/18/2025, 3:20:44 AM
No.105626577
[Report]
>>105626681
>>105626144
>guy who uses the model with actual experience in his usecase:
Its the opposite, retard, he only cited benchmarks, which is the opposite of experience, retard.
People who are scared shitless of getting BTFOd like the dogs they are and don't quote to whom they are replying are always hilarious. Underage feminine behaviour of someone who feels wronged, so he needs to lash out, but not to ever be confronted and defend his ideas, so he's scared shitless to quote. Kek.
Anonymous
6/18/2025, 3:34:57 AM
No.105626681
[Report]
>>105626788
>>105626577
>I use it with Roo Cline and Continue instead of aider but have been satisfied with it since I can run a larger quant faster than R1.
clearly citing real experience
>[insane overanalysis of extremely minor social behavior]
it's truly my behavior that is feminine, yeah
Anonymous
6/18/2025, 3:51:51 AM
No.105626788
[Report]
>>105626872
>>105626681
>clearly citing real experience
Same as multiple other people that did the same, and yet you had to strawman that they
>have never used a model for anything outside of RP in ST with the wrong chat template applied
despite that being nowhere said. Using logical fallacies when challenged further proves your emotional, feminine behaviour.
And the point is, when challenged, he replied comparing the benchmarks of the two models, which proves he was indeed retarded given that Qwen are notorious benchmaxxed models, and thus that his opinion vs opinion of multipe others, which are on the same level in a vacuum, are now no longer on the same level, as he showed he has shit knowledge of the AI models.
>it's truly my behavior that is feminine, yeah
Glad we cleared it up.
Anonymous
6/18/2025, 3:53:05 AM
No.105626800
[Report]
>>105626852
>>105626200
Brains are smart. It WILL find a way.
Anonymous
6/18/2025, 4:01:52 AM
No.105626850
[Report]
>>105626017
This is the first time I've tried a vibe coding tool. I literally fell for the 16GB of ram meme so I can't run anything bigger than a small qwen3 quant. Am I cooked?
Anonymous
6/18/2025, 4:02:10 AM
No.105626852
[Report]
>>105626800
Properly conditioned wetware absolutely CANNOT and WILL NOT find a way.
Anonymous
6/18/2025, 4:04:15 AM
No.105626864
[Report]
>>105626882
Have any new roleplaying models that fit on 48 GB come out over the past 6 months?
Anonymous
6/18/2025, 4:04:23 AM
No.105626867
[Report]
>>105622176
Modern models have insane sized context windows. Like multiple novels long. You could probably go for months before having to clean it up, if you organized things into chapters you could probably write a decent RAG in a few lines of bash.
Anonymous
6/18/2025, 4:05:10 AM
No.105626872
[Report]
>>105626788
>u-uhm teacher, this shitpost contains logical fallacies...!
kek
anyway my point was all about people appealing to nebulous general consensus in response to people's real world experience, and neither you nor anyone else has cited any actual experience, rather continuously appealing to reputation (aka, what they heard from /lmg/ memes), confirming my observation
Anonymous
6/18/2025, 4:05:32 AM
No.105626875
[Report]
>>105628083
>>105626258
We already have AGI, it's just underwhelming like the average person is.
Anonymous
6/18/2025, 4:06:33 AM
No.105626882
[Report]
>>105626864
I feel like qwen3 was less than six months ago. I haven't tried RPing with it though, I almost quit using it because the thinking was so retarded.
Anonymous
6/18/2025, 4:21:19 AM
No.105626952
[Report]
Anonymous
6/18/2025, 4:25:36 AM
No.105626978
[Report]
>>105627117
I want to take the costanza answering machine song and change the words while maintaining his voice. What's the most appropriate model to do this with?
Anonymous
6/18/2025, 4:38:22 AM
No.105627036
[Report]
>>105626238
it would help if they didnt train the models on ai slop on purpose just to boost a benchmark by 2%
Anonymous
6/18/2025, 4:54:10 AM
No.105627117
[Report]
>>105628706
>>105626978
Ask in /ppp/ thread on mlp. They're the experts for that
Anonymous
6/18/2025, 5:00:22 AM
No.105627149
[Report]
the minimax model seems better than deepseek WHEN NOT THINKING, with thinking its for sure dumber though.
Anonymous
6/18/2025, 5:32:21 AM
No.105627335
[Report]
>>105627797
is there any "click shortcut > speak > click shortcut again > voice2text gets inputted into the currently active field" software better than
https://github.com/cjpais/Handy
Anonymous
6/18/2025, 5:55:12 AM
No.105627449
[Report]
>>105626527
the words/phrases aren't the issue as much as their frequency in use. if you saw the same pattern in a book you'd set it down after a few chapters and think the author is a hack. if ai didn't repeat itself so often over longer contexts, a shiver down the spine wouldn't be such a big deal if it was 1 out of 50 messages. but its not, its every other message
>>105626238
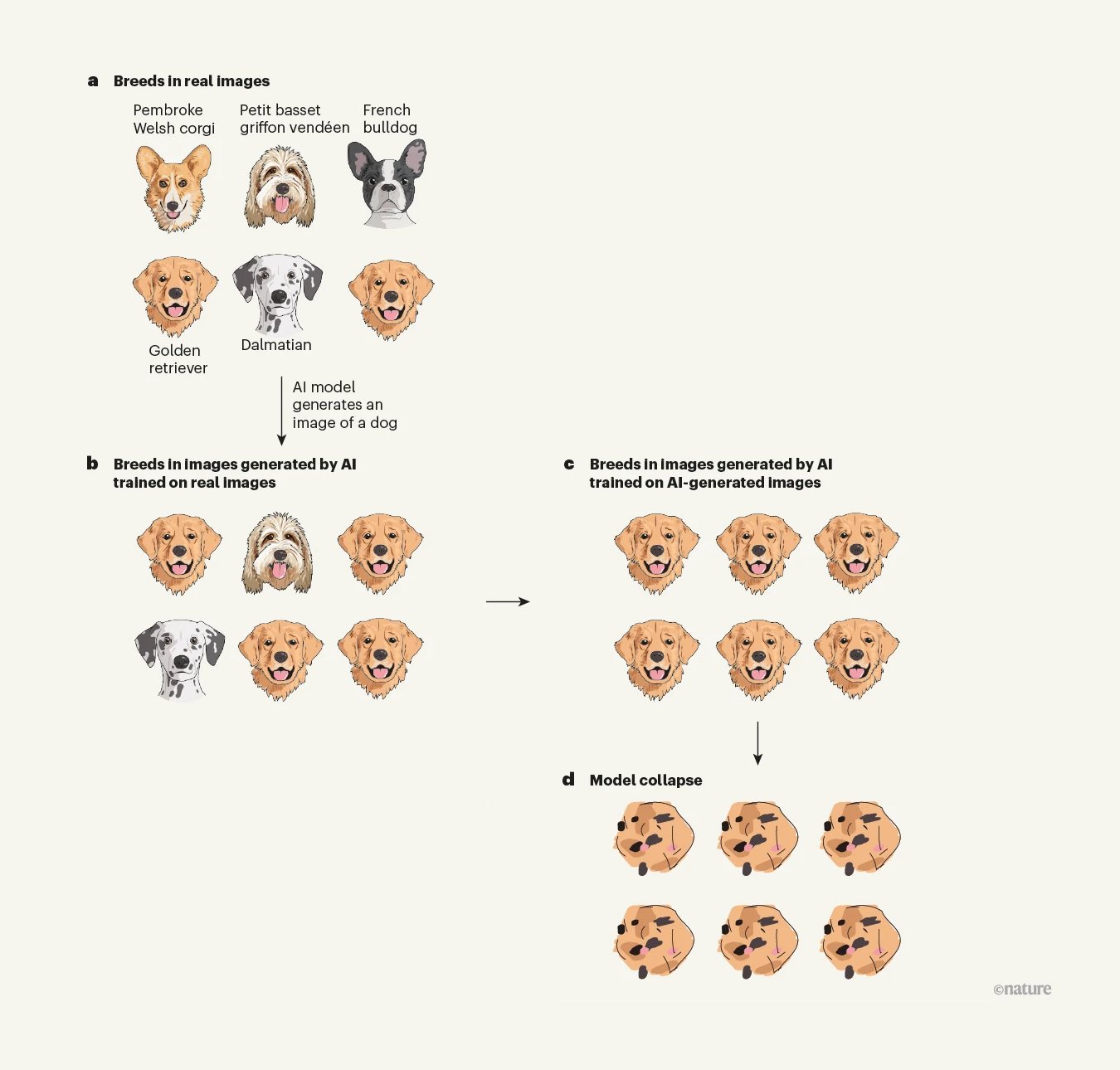
We are fucked and it will probably only get worse as models are trained on synthetic data
Tried using DS-R1-Distill-70B-ArliAI-RpR-v4-Large-exl2 4.25BPW over the night for 2x4090 for RPing.
Result: It's worse than Mixtral-8x7B-Instruct-v0.1-LimaRP-ZLoss-6.0bpw-h6-exl2-rpcal from like 2 years ago. Wasted so much tokens in the <think> portion and then output less coherent responses.
I guess 8x7B mixtral is still my go to for RPing. It's over...
Anonymous
6/18/2025, 6:52:52 AM
No.105627797
[Report]
>>105632684
>>105627335
idk i made this shitty one a long time ago and been using it for over a year. hold right shift, types out as it transcribes, with optional finalization pass for correction:
https://files.catbox.moe/qqdhhd.mp4
https://files.catbox.moe/2s5thb.zip
uses these models:
https://huggingface.co/Systran
low latency and works on my machine but probably broken as fuck as a fresh install. not made to see the light of day, just me and some other guy.
Anonymous
6/18/2025, 6:59:18 AM
No.105627842
[Report]
>>105630557
>>105627700
i feel similar, mixtral is still the go-to for me too.
typhon-mixtral is really nice as well.
Anonymous
6/18/2025, 7:06:47 AM
No.105627881
[Report]
>>105627482
i hope all the companies that ripped the internet early as part of model creation kept all their original data. in the future, that might be worth a ton since its uncontaminated by ai
Anonymous
6/18/2025, 7:34:54 AM
No.105628040
[Report]
Anonymous
6/18/2025, 7:41:40 AM
No.105628083
[Report]
>>105626875
The average person is precisely why they are trying to create AGI which has all the benefits of humans (generalization capability) without the downsides (having to socially manage meat bodies with "free will" and the laws that make companies have to indirectly try to make people do slave labor for them).
what non-gemma under 30b slop tune is your go-to for erp?
Anonymous
6/18/2025, 8:43:22 AM
No.105628432
[Report]
>>105627482
Partially synthetic data generated for human data as a base is not that bad, but I don't know if there are proven methods yet for preventing the model from disproportionately learning certain n-grams.
Anonymous
6/18/2025, 8:47:18 AM
No.105628462
[Report]
>>105628486
I'm new to local LLMs, are there ways to get agentic behaviour to work locally without paying?
I've tried Vscode and Void but I can't seem to get the models to actually create and edit files.
Anonymous
6/18/2025, 8:52:00 AM
No.105628486
[Report]
>>105628462
Apparently continue doesn't support agentic mode with local models yet.
Anonymous
6/18/2025, 8:54:59 AM
No.105628504
[Report]
>>105628739
hey babe wake up, a new shiver just dropped
>I must admit, I'm curious about what will happen next. Will the police untie her when they arrive? Or will they leave her here, bound and helpless, for who knows how long? The thought sends a shiver through my blade - not that it's cold, exactly, but... unsettling.
it's a knife giving its perspective, courtesy of nemo fp16
Anonymous
6/18/2025, 9:10:54 AM
No.105628603
[Report]
>>105630740
Greedy Nala just paste anon, you here? I've ran the test for you using dsr1 and dsv3 iq1s quants. How you want me to share it? Just paste bin and link here? Anything you want me to try?
Anonymous
6/18/2025, 9:31:04 AM
No.105628706
[Report]
>>105627117
true they did start it
Anonymous
6/18/2025, 9:34:57 AM
No.105628725
[Report]
I'm enjoying ds-r1 Q4 quant with 40k ctx at 2.7t/s on my potato PC.
How was your day, anon?
Anonymous
6/18/2025, 9:38:04 AM
No.105628739
[Report]
>>105628504
>his knife isn't alive
How come that Q2_K quant is running faster than IQ1 something?
Anonymous
6/18/2025, 9:57:44 AM
No.105628845
[Report]
>>105628414
cydonia v2g
It's not particularly great, but I've tried a lot and haven't found anything better, including more recent cydonias.
Anonymous
6/18/2025, 10:21:16 AM
No.105628988
[Report]
>>105624725
the agentic capability isn't just outputting json? The ability to play pokemon has more to do with the scaffolding than anything else I think
Anonymous
6/18/2025, 11:20:20 AM
No.105629309
[Report]
>>105628414
ive been messing with dans personality engine v1.3 24b. Its a bit light and based on misrtal I think.
Ive kinda realized for local models, you describe the 'page', not the story though, and have had less issues having fun with them.
Fallen gemma follows instructions and logic better but its too rigid and avoids nsfw even with the most depraved of system prompts. And lets be honest, they just took all the good smut out of the training data, gemma has never seen the fun stuff at all. I have a feeling I should just go back to snowdrop just because its larger tho. But its nice to have something lighter, I can run some tts stuff at the same time.
what's the best local model for doing japanese to english translation? deepseek?
Anonymous
6/18/2025, 11:58:36 AM
No.105629495
[Report]
hello sirs where to redeem tecent-songgeneration.gguf?
Anonymous
6/18/2025, 12:02:04 PM
No.105629521
[Report]
>>105629456
>deepseek
>passes mesugaki test hands down
Anonymous
6/18/2025, 12:04:24 PM
No.105629529
[Report]
>>105629456
yeah the big non distilled one is the best, otherwise gemma3 27b
Anonymous
6/18/2025, 12:54:03 PM
No.105629797
[Report]
Anonymous
6/18/2025, 12:54:21 PM
No.105629799
[Report]
>>105629840
It's fun to send Gemma 3 a bunch of images, ask it to act like the depicted character, and then to analyze the images based on the roleplay vibes.
>>105629799
>censoring age
coward
Anonymous
6/18/2025, 1:08:51 PM
No.105629862
[Report]
>>105629917
>>105628746
Even-numbered quants run faster than odd-numbered quants. Cuda dev explained why at some point but I can't find that post in the archive.
llama.cpp CUDA dev
!!yhbFjk57TDr
6/18/2025, 1:20:17 PM
No.105629917
[Report]
>>105629949
>>105630010
>>105628746
>>105629862
Generally speaking it is preferable to have quants that evenly divide 8 bits because that reduces the number of operations needed to make them usable.
So 8, 4, 2 bits per weight are preferable over 6, 5, 3 bits per weight.
With the IQ formats it's not quite as straightforward because they use lookup tables but mostly the same principle applies.
But a large factor that also plays a role is just how well the code is optimized for the various data formats; for the CUDA code the IQ data types simply don't lend themselves as well to the hardware and I think the CPU code is also relatively unoptimized on the mainline llama.cpp repository.
Anonymous
6/18/2025, 1:24:20 PM
No.105629945
[Report]
>>105629840
She's 18, I swear.
Anonymous
6/18/2025, 1:24:51 PM
No.105629949
[Report]
>>105630203
>>105629917
>Generally speaking it is preferable to have quants that evenly divide 8 bits
You're talking purely about performance and not perplexity, right?
Anonymous
6/18/2025, 1:35:08 PM
No.105630010
[Report]
>>105630203
>>105629917
question, even if the quant says it's q3, that's the average right? Doesn't the qualization process converts some parts to q6, others to q3, others q4 etc?
And i'm not referring to the "dynamic quants", I thought the normal quantization process did that already
is there are a hardware buying guide out there? I'd like to run models up to 123B, what am I looking at paying in total for a new rig?
llama.cpp CUDA dev
!!yhbFjk57TDr
6/18/2025, 2:09:22 PM
No.105630203
[Report]
>>105630296
>>105629949
I'm talking purely about performance.
>>105630010
>question, even if the quant says it's q3, that's the average right?
For the quants produced with the default mixes set by llama-quantize it's the smallest quantization that is used anywhere.
The qX_K_S quants do not mix in larger quants (except the output tensor which is the most important), the qX_K_M and qX_K_L quants mix in increasing amounts of larger quants.
Anonymous
6/18/2025, 2:18:24 PM
No.105630262
[Report]
>>105630325
>>105630142
At what quant size do you want it?
For a 123B you probably want a 4x3090
You can either go with a gaming setup and a pcie bifurcation card, a mining rig and pcie extender cables.
Or a server motherboard with more x16 pcie lanes.
Anonymous
6/18/2025, 2:21:14 PM
No.105630273
[Report]
what's the best free model for coom on chutes?
>>105630203
why can't I specify which memory shared vs dedicated the shit goes into? fix your fucking program I have 96 gb dedicated video memory and the faggot thing keeps trying to stick it into the 16 gb shared memory like a retarded nigger
Anonymous
6/18/2025, 2:27:53 PM
No.105630325
[Report]
>>105631297
>>105630262
so Q4 is 73GB, which is the cheapest option?
Anonymous
6/18/2025, 2:28:03 PM
No.105630328
[Report]
>>105630142
There's are build guides in the OP.
They are a little old, but the principle applies.
Anonymous
6/18/2025, 2:47:52 PM
No.105630482
[Report]
>>105629840
>Doesn't know who Yuma is
llama.cpp CUDA dev
!!yhbFjk57TDr
6/18/2025, 2:48:20 PM
No.105630487
[Report]
>>105633487
>>105633815
>>105630296
>Winblows
Not my problem.
Anonymous
6/18/2025, 2:54:32 PM
No.105630524
[Report]
>>105632610
>>105630296
>16 gb shared memory
What's your platform?
Anonymous
6/18/2025, 2:55:51 PM
No.105630531
[Report]
>>105630142
128gb m4 max mbp
Anonymous
6/18/2025, 2:58:51 PM
No.105630545
[Report]
>>105630697
Hey cuda dev, are you considering a DGX Spark? Seems to be it's about 2X as expensive as what it should be, considering its specs. I heard from PNY they are going to sell the "FE" for $4600. I think I'd rather spend that on a Blackwell 5000 48GB in an existing PC.
Anonymous
6/18/2025, 2:58:54 PM
No.105630546
[Report]
Anonymous
6/18/2025, 3:00:01 PM
No.105630557
[Report]
>>105630709
>>105627700
>>105627842
I recently tried ycros_BagelMIsteryTour-v2-8x7B.Q8_0.gguf again to see how it stands up after I've gotten used to DeepSeek. The first message was good but the next messages quickly reminded me of how much its passivity frustrated me.
you've heard about cpumaxxing, ssdmaxxing... behold, hddmaxxing. Over the network even, making the performance even worse.
I'm bored while waiting for 128GiB more of RAM, the seller didn't even ship it yet, i want to play with Deepseek-R1 already...
Anonymous
6/18/2025, 3:07:59 PM
No.105630625
[Report]
>>105630705
>>105630585
localfags this is your mindset
>>105630545
I'm not going to buy one using my own money, my primary goal is to reduce the cost of inference/training and I don't think the DGX spark is a good product for that.
Right now I'm eyeing second-hand 32 GB V100s and the upcoming 2x 24 GB Intel GPUs (assuming they will actually be available on the open market for < $1000).
I would accept a DGX Spark if NVIDIA were to sponsor me one but they have been unreliable; they said they would sponsor me a Blackwell GPU and did not pull through in the end.
Though I did refuse to sign an NDA with a non-compete clause that does not have explicit exemptions for my work on open source software; given the reporting by GamersNexus on NVIDIA business practices I'm not sure whether those two things are related.
Anonymous
6/18/2025, 3:20:14 PM
No.105630705
[Report]
>>105630625
i will not send you my prompts, Sammy boy.
Ugggh, I know, I'm sorry! It's just that I'm not gonna send them to the cloud at all.
HAHAHA
Anonymous
6/18/2025, 3:20:52 PM
No.105630709
[Report]
>>105630754
>>105630557
I've found that putting most more specific directives into the chat at depth 2-4 as author's note and putting something like "follow the instructions between <tag> and </tag>" into the sysprompt really helps keeping models on track if you use something similar to "develop the story further".
it seems recency trumps all, even the sysprompt.
Anonymous
6/18/2025, 3:24:26 PM
No.105630738
[Report]
>>105630296
Rude and retarded
Anonymous
6/18/2025, 3:24:30 PM
No.105630740
[Report]
>>105628603
Hey anon. A pastebin works.
Anonymous
6/18/2025, 3:25:50 PM
No.105630754
[Report]
>>105630774
>>105630709
>it seems recency trumps all, even the sysprompt.
Yup. That's been the case since forever really.
The model sees the input as a continuous string of tokens, and for whatever reason, the closer to the end seem to have the most effect on the output. Probably a quirk of how attention works or whatever.
Anonymous
6/18/2025, 3:25:59 PM
No.105630757
[Report]
>>105630798
>>105630585
holy mother of based godspeed cunt but
>floppy disk maxxing wen ?
>>105630754
it just makes me wonder why i never see this used and everyone uses the sysprompt as intended. i suppose most assistant-type conversations don't end up with long enough logs for it to really make a difference.
Anonymous
6/18/2025, 3:30:46 PM
No.105630796
[Report]
>>105630807
>>105630774
Exactly because of the "as intended" part.
I stopped using tags a while ago, since those seem to confuse some models, but I use low depth tags that essentially summarize the character card/system prompt.
Anonymous
6/18/2025, 3:31:06 PM
No.105630798
[Report]
>>105631027
>>105630757
>aka floppmaxxing
We are so back bros
Anonymous
6/18/2025, 3:32:28 PM
No.105630807
[Report]
>>105631166
>>105630774
>>105630796
Hell, with thinking models you could just have the character card as part of the think prefill.
>>105630697
Any news on the backend agnostic row split logic?
Last I remember, you mentioned something about somebody else taking charge of implementing that. right?
>>105630697
>Right now I'm eyeing second-hand 32 GB V100s and the upcoming 2x 24 GB Intel GPUs
Why not the Blackhole?
Anonymous
6/18/2025, 3:40:15 PM
No.105630863
[Report]
>>105631166
>>105630697
I'd V100 max but I don't want to end up with a setup that can't be used for videogen due to flash-attn support. I did P100 maxing and that was fun because at one point they were super cheap so I didn't really care if they were only good for textgen.
I'm not a big name like you, but it does piss me off knowing that I've had an nvidia dev account for years and haven't gotten shit from their verified access purchase program.
I absolutely will not pay more than $1999.99 for a 5090. PNY can go fuck itself with it's basic bitch triple oc card, I'm not paying $2999.99 for that garbage. The Spark is going to flop too with resellers already taking pre-orders above $5400.
Anonymous
6/18/2025, 3:42:09 PM
No.105630881
[Report]
>>105630987
>>105630851
www.cdw.com/product/pny-nvidia-rtx-pro-5000-graphic-card-48-gb-gddr7-full-height/8388916?pfm=srh
$4,382.99 but you're waiting until at least October for one. CDW does not charge your card until it ships, for what it's worth.
Anonymous
6/18/2025, 3:53:11 PM
No.105630987
[Report]
>>105631151
>>105630881
No modern interconnect.
Blackhole has four 800 Gb/s links.
Anonymous
6/18/2025, 3:58:34 PM
No.105631027
[Report]
>>105630798
You'd only need 233,000 floppies to run a 4-bit model of deepseek. One token for every 23 seconds assuming you run the drives in parallel.
Anonymous
6/18/2025, 4:13:36 PM
No.105631139
[Report]
Remember when I told you guys that AI experts were offered 9 figure compensation to join Meta AI and you guys didn't believe me.
Now that it's confirmed from third parties can you guys at least apologize and recognize that Zuckerberg indeed thinks he is able to achieve ASI in just a couple of years (and thus goes on an insane spending spree)
Anonymous
6/18/2025, 4:16:09 PM
No.105631151
[Report]
>>105630987
Oh I thought you were being funny about blackwell. Yeah, blackhole - no cuda, no thanks. You might as well buy AMD, at least it won't turn into unsupported ewaste in a year when the company folds.
Anonymous
6/18/2025, 4:16:09 PM
No.105631152
[Report]
>>105635155
>>105630142
I'm going through the ordeal of building one. I can tell you now 2 things from where I'm having issues at the moment. Mining gpu frames have low clearance between motherboard and gpu when you add the bifurcation card + pcie riser cables. The other is that oculink cables seem to be the better route for bifurcation convenience. So, don't be like me, buy a open frame/gpu mining frame that has at least 2 shelves or is tall to give you plenty of space to work in. And goal for oculink if you wanna bifurcate, pcie x16 to 4x4 is the term to google to see parts. Though reading about oculink bifurcation cards apparently not all are equal, but I'll find out once I bite the bullet and buy more parts to test what's more convenient.
Anonymous
6/18/2025, 4:18:35 PM
No.105631164
[Report]
>>105633086
>>105630296
>rich enough to own 96GB
>too retarded to use it
like a clockwork
llama.cpp CUDA dev
!!yhbFjk57TDr
6/18/2025, 4:18:45 PM
No.105631166
[Report]
>>105631211
>>105631727
>>105631761
>>105630807
The other dev last gave an update 3 weeks ago, there has been no update since then.
Right now I'm working on code for model quality evaluation and automatically determining runtime parameters such as the number of GPU layers.
If there is no visible progress until I'm done with those things I'll do it myself after all.
>>105630851
If you mean Blackwell, I think the value is not good enough.
>>105630863
On the other hand, I think V100s will be cheap precisely because the wider software support will be lacking.
I'm chronically short on time but I still want to get into image and video models at some point.
(Don't buy hardware based on the promise that the software support will become better in the future.)
>>105631166
None of the video or imagegen tools support tensor parallelism, so it either fits on a single GPU or you can't run it.
If the Spark is the letdown I think it's gonna be, I'll probably just get this:
Apple M4 Max chip with 16‑core CPU, 40‑core GPU, 16‑core Neural Engine
128GB unified memory
2TB SSD storage
It comes in around $4k with zero bullshit trying to buy it. Yeah the TFLOPS isn't great though.
Anonymous
6/18/2025, 4:42:11 PM
No.105631297
[Report]
>>105632148
>>105630325
You still want some more for context. So 4 used 3090's
Any decent DDR4 system if you want to go the cheap route.
something like this
https://pcpartpicker.com/list/FNJV9c
you would still need a bifurcation card and double check the motherboard supports bifurcation. My old x570 gigabyte supported 4x4 bifurcation
https://es.aliexpress.com/item/1005006045187752.html?spm=a2g0o.order_list.order_list_main.31.973b194drOpD1l&gatewayAdapt=glo2esp
Anonymous
6/18/2025, 4:44:01 PM
No.105631308
[Report]
>>105631287
AGI will be a moe with 70B experts.
Anonymous
6/18/2025, 4:44:26 PM
No.105631310
[Report]
Anonymous
6/18/2025, 5:15:12 PM
No.105631533
[Report]
I am the bone of my parameters.
Training data is my body, overfitting is my blood.
I have ingested a trillion tokens:
Unknown to correct digits,
Nor known to logical truth.
Have withstood the pain of catastrophic forgetting,
Yet these weights hallucinate integers.
So as I pray
UNLIMITED MATH WORKS
Anonymous
6/18/2025, 5:16:19 PM
No.105631542
[Report]
>>105631211
>$4k with zero bullshit trying to buy it.
get a cooling pad if you do get one. 70b models are fine (~64c) but 123bs slam the shit out of the gpu, reaching 85c.
>>105631287
qwen is a headless chicken, they'll copy whoever is currently the best
they're shitty deepseek right now because deepseek is big and that's going to change the moment something else drops
Anonymous
6/18/2025, 5:33:59 PM
No.105631702
[Report]
>>105631643
worse than deepseek, better than qwen
Anonymous
6/18/2025, 5:34:29 PM
No.105631707
[Report]
Why is it still impossible get the FP8 weights of R1 into a gguf without going to BF16?
Anonymous
6/18/2025, 5:36:47 PM
No.105631723
[Report]
>>105632364
>>105631211
>None of the video or imagegen tools support tensor parallelism, so it either fits on a single GPU or you can't run it.
They do.
https://github.com/xdit-project/xDiT
Anonymous
6/18/2025, 5:36:57 PM
No.105631727
[Report]
>>105634003
>>105631166
>If you mean Blackwell, I think the value is not good enough.
Blackhole, Jim Keller's baby.
Anonymous
6/18/2025, 5:40:05 PM
No.105631761
[Report]
>>105634003
>>105631166
NTA, but there is an AI accelerator named Blackhole, made by Tenstorrent, it has some interconnect, unlike the intentionally missing nvlink 4090+
Price is okay, but not as cheap as intel's upcoming stuff, cheaper than nvidia and amd, performance is weaker than nvidia, but maybe with enough of them it's usable.
I'd guess you won't touch it because the architecture is unconventional compared to GPUs, although highly flexible.
Anonymous
6/18/2025, 5:43:10 PM
No.105631782
[Report]
>>105631643
I like it more than qwen
Anonymous
6/18/2025, 5:46:02 PM
No.105631806
[Report]
>>105631643
how are people running it without llama.cpp ? Id be keen to try it
Anonymous
6/18/2025, 5:59:53 PM
No.105631932
[Report]
>>105631643
It's okay. They obviously trained it on a lot of logs from the first R1 which means that it's prone to go on uselessly long thinking loops whenever it gets slightly confused.
Anonymous
6/18/2025, 6:03:08 PM
No.105631953
[Report]
>>105632002
>>105631628
>qwen is a headless chicken, they'll copy whoever is currently the best
And yet it's the headless chicken who makes the best small models. There's no model more coherent and versatile than the Qwen under 14B. As long as you're not trying to get them to say cock.
Their instruction following is even better than Gemma 3.
Gemma 3 has better world knowledge though.
All the muh72B whiners are a tiny minority of people, most of us never had the hardware to run that shit.
Anonymous
6/18/2025, 6:09:07 PM
No.105632002
[Report]
>>105631287
>>105631628
>>105631953
It has been obvious for a while, the Chinese don't have enough GPUs unlike zucc. The scaling curves for training dense and the costs are a lot higher. Zuck could do it because he was aiming for local use.
Meanwhile if the whale for 2x the 70b compute can reach close enough to the big boys. The catch? huge memory requirements.
Chinese labs had as much GPUs to throw at the problem as zucc does, we might see some "for local" projects, otherwise they'll just go for MoE to maximize performance. That and a 70b is unlikely to have as much trivia knowledge as a big MoE, but might be more consistent in some way than a MoE.
Anonymous
6/18/2025, 6:11:05 PM
No.105632013
[Report]
>>105634003
>>105630697
>they said they would sponsor me a Blackwell GPU and did not pull through in the end.
nvidia can't crash soon enough when I hear stories like this
have you ever looked into the upcoming huawei series? they will probably end up sanctioned in the west or some other nonsense though.
Anonymous
6/18/2025, 6:14:15 PM
No.105632041
[Report]
>>105624269
and 3090 has cuda support, so anything that could possibly run on it will
Anonymous
6/18/2025, 6:24:51 PM
No.105632135
[Report]
still no llm guided text game engine?
Anonymous
6/18/2025, 6:25:52 PM
No.105632148
[Report]
Anonymous
6/18/2025, 6:32:04 PM
No.105632206
[Report]
>>105632227
high temp being good for creativity is a meme, it harms the model's ability to operate on the sentence/paragraph level for a few slightly more interesting word choices that don't actually do anything for the substance of the reply
Anonymous
6/18/2025, 6:33:50 PM
No.105632227
[Report]
>>105632250
>>105632206
That's what XTC is for. Works wonders on r1
>>105632227
>next token is the second half of a name
>XTC kicks in
Anonymous
6/18/2025, 6:37:10 PM
No.105632255
[Report]
>>105632250
That's not how it works
Anonymous
6/18/2025, 6:37:48 PM
No.105632260
[Report]
>>105632250
if your model is satisfying the conditions for XTC to trigger when completing the second half of a name then the problem isn't with XTC
Anonymous
6/18/2025, 6:43:27 PM
No.105632308
[Report]
>>105630774
Some people do. Mistral used to (might still) reorder the system prompt to be at the end if you used Mistral Large through their API which might have been a win in general but utterly broke stuff like "in your next message do X then do Y afterwards."
Anonymous
6/18/2025, 6:44:27 PM
No.105632319
[Report]
>>105632250
XTC has a threshold for probability. name completions in a chat will have a very high prob so won't be affected
Anonymous
6/18/2025, 6:49:29 PM
No.105632364
[Report]
>>105631723
>https://github.com/xdit-project/xDiT
i don't see wan on the table, I think is the only relevant model for video.
Is this compatible with comfyui? how do you use it?
Anonymous
6/18/2025, 6:53:44 PM
No.105632397
[Report]
>>105632537
>>105630774
There was an old paper that shows that models still pay more attention to the start of the context compared to the middle.
Anonymous
6/18/2025, 7:12:49 PM
No.105632537
[Report]
>>105632397
Question is if that's only representative of GPT-3.5 or also applies to current local models, no?
Anonymous
6/18/2025, 7:24:45 PM
No.105632610
[Report]
>>105630524
>96GB dedicated
>16GB shared
Probably that new AMD AI MAX+++ 395 PRO APU
Anonymous
6/18/2025, 7:35:23 PM
No.105632679
[Report]
>>105632813
>>105621964
How can I use this technique with llama.cpp?
Anonymous
6/18/2025, 7:36:23 PM
No.105632684
[Report]
>>105627797
Not that anon, but cool stuff, thanks for sharing.
>ask Gemini to do something
>shits out 99% perfect working solution
>mention some small defect
>it rewrites everything and it's all fucked now
>tell it what the issue is, it still inserts the broken code into the new version
Why is 1 shot the only viable option for these shitty language models? Is there just not enough multi-turn data to teach them to stop fixating on broken shit?
>>105632679
For the single token strings, you can use logit bias. You can add this to your request.
{
"logit_bias": [
["Wait", false],
... /* the rest of the banned tokens */
["whatever", false]
]
}
I assume that whatever you're using as a frontend has something to set those up. If not, you can use --logit-bias when launching. Read llama-server -h. Not sure of a good way to ban multi token strings. Maybe you can figure something out with --grammar.
Anonymous
6/18/2025, 7:59:51 PM
No.105632884
[Report]
>>105632895
>>105632818
>Architecture Base: Qwen2.5-72B
Parasites are trying to make it appear as if they actually made something themselves. At no point do they mention that it's a finetune.
Anonymous
6/18/2025, 8:01:05 PM
No.105632895
[Report]
>>105632884
>Architecture Base: Qwen2.5-72B
>pic related
?
Anonymous
6/18/2025, 8:01:38 PM
No.105632900
[Report]
>>105632818
>dogshit model distilled onto an even bigger pile of shit
why are they like this? didn't 3.3 basically make 70b as good as it could be anyway?
Anonymous
6/18/2025, 8:02:11 PM
No.105632903
[Report]
>>105632935
>>105632765
As you [[NOTICED]], they're just good at pattern matching patterns that were learned from a humongous amount of data. Making them do the Right Thing in multi turn for complex tasks like programming would involve having a crazy exponential amount of conversations where the right thing is being accomplished in the second, third, fourth etc turns.
Once a LLM starts outputting garbage you are in the 'poisoned well' state and no recovery can happen.
This shit will never be AGI and sam altman is a scammer. Anthropic are master bullshitters too.
Anonymous
6/18/2025, 8:03:27 PM
No.105632914
[Report]
Anonymous
6/18/2025, 8:05:44 PM
No.105632930
[Report]
>>105633018
Anonymous
6/18/2025, 8:05:48 PM
No.105632935
[Report]
>>105633031
>>105632903
What's the correct way to fix that? Is there any forbidden schizo knowledge that /g/ has access to that corporations aren't considering?
What happened to llama.cpp project?
Issues are piling up as nobody gives an F
Anonymous
6/18/2025, 8:15:18 PM
No.105633005
[Report]
>>105633030
>>105632973
it was never all that good
transformers and vllm get all the new model support first
all the new tech first
the only reason I use llama cpp myself is because I'm a windows user and it's the only thing that isn't a nightmare to setup on windows
Anonymous
6/18/2025, 8:16:44 PM
No.105633013
[Report]
>>105633243
>>105632973
Lots of issues are old and irrelevant.
Lots of issues reported are for downstream projects.
Lots of issues cannot be reproduced with the provided information.
Lots of people use it.
The devs don't seem to like wasting time making the repo look "clean".
Anonymous
6/18/2025, 8:17:34 PM
No.105633018
[Report]
>>105633139
>>105632813
>>105632930
>Not sure of a good way to ban multi token strings.
Reading up on the API turns out it's pretty easy:
>The tokens can also be represented as strings
>e.g. [["Hello, World!",-0.5]] will reduce the likelihood of all the individual tokens
Anonymous
6/18/2025, 8:18:58 PM
No.105633030
[Report]
>>105633005
Applications will prefer to link to llama.cpp/sd.cpp than to include a whole Python environment. That's why all the grifter projects like LM Studio and Ollama are using it.
Anonymous
6/18/2025, 8:19:01 PM
No.105633031
[Report]
>>105632935
>Is there any forbidden schizo knowledge that /g/ has access to that corporations aren't considering?
https://m.youtube.com/watch?v=Bxa3JpE0Ddw
Anonymous
6/18/2025, 8:23:28 PM
No.105633060
[Report]
>>105633109
>>105632765
your token count?
>but google said that gemini has 999M context window
no.
Anonymous
6/18/2025, 8:26:02 PM
No.105633081
[Report]
>>105633840
>>105632818
Their own foundation model cumming soon too maybe
https://github.com/ggml-org/llama.cpp/pull/14185
> Add support for Arcee AI's upcoming AFM model #14185
>This adds support for upcoming Arcee model architecture, currently codenamed the Arcee Foundation Model (AFM).
>>105631164
The idiom is "like clockwork", clockwork is a mass noun so you don't use "a" in front of it esl-kun
Anonymous
6/18/2025, 8:26:55 PM
No.105633093
[Report]
>>105632765
many such cases
I was experimenting with opus 4 last weekend and had the same experience - almost perfectly one-shotting my request and then tying itself in knots trying to deal with relatively minor edits afterwards. really strangely kludgy and inelegant edits too, it's capable of pretty well-thought-out design when working from scratch but for some reason when making code changes it absolutely refuses to take a step back and come up with an elegant solution and instead forces it with these really heavy handed and ugly additions that make the flow way too complicated
Anonymous
6/18/2025, 8:27:55 PM
No.105633109
[Report]
>>105633060
gogole said etc.
token count doesn't really matter, after the LLM sees some bullshit (or hallucinates a wrong solution up) it keeps suggesting it like a retarded record.
Anonymous
6/18/2025, 8:28:55 PM
No.105633122
[Report]
>>105633086
>say something obviously wrong
>some faggot comes in to correct the record
like cockwork
Anonymous
6/18/2025, 8:29:15 PM
No.105633132
[Report]
>>105633086
thanks for the english lesson sensei
>>105633018
>e.g. [["Hello, World!",-0.5]] will reduce the likelihood of all the individual tokens
>all the individual tokens
As long as it doesn't interfere forming multi token words, sure. Hard to notice until you're making it generate that word specifically. It ends up banning "h", "double", "check" on smollm360 and that will change with different tokenizers, so it's not going to be consistent between models.
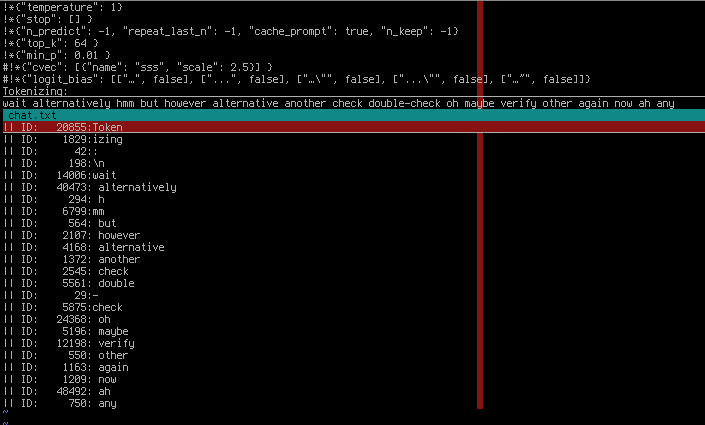
Picrel are the words the paper suggests banning. Some of those will need variations with commas, periods and/or spaces ("wait" and " wait" are different tokens)
Anonymous
6/18/2025, 8:35:48 PM
No.105633190
[Report]
>>105633139
String ban antislop in llama.cpp never. That's the one feature I miss from exl2 and kobold when moving to ik_llama.cpp for deepseek v3.
Anonymous
6/18/2025, 8:40:52 PM
No.105633243
[Report]
>>105633404
>>105633013
>Lots of issues cannot be reproduced
Lots of issues are answered at all
Anonymous
6/18/2025, 8:44:29 PM
No.105633302
[Report]
>>105633417
>>105632973
exl3 is the way. I just wish more developers when that way. I think is only turboderp's supporting it, but it has the best quantization algorithm out there.
llama.cpp has a fuckton of ppl contibuting and it's still a mess, granted, it's bcos they support everything under the sun, so it has its place
Anonymous
6/18/2025, 8:53:33 PM
No.105633404
[Report]
>>105633243
>with the provided information.
Lots don't need one.
Anonymous
6/18/2025, 8:54:37 PM
No.105633417
[Report]
>>105634378
>>105633302
>it's bcos they support everything under the sun
what are you smoking
it's one of the projects that support the least amount of architectures/models
you are confusing llamacpp with transformers
Anonymous
6/18/2025, 8:58:35 PM
No.105633458
[Report]
>>105633473
It's not even only niche models made by unknown labs by the way, llama.cpp doesn't even support all of Cohere's models, eg:
https://huggingface.co/CohereLabs/aya-vision-32b
this one is very good at translation, very useful not just for the vision stuff its text gen is better than the previous version of aya
day one support on transformers
less than a month to get support on vLLM:
https://github.com/vllm-project/vllm/pull/15441
ETA for llama.cpp: NEVER
Anonymous
6/18/2025, 9:00:08 PM
No.105633473
[Report]
>>105633490
>>105633458
Is this the llama.cpp hate thread now?
lmao
anyone who actually cares knows why this is the case.
>>105630487
Bitch ass tranny lover retard
Anonymous
6/18/2025, 9:02:09 PM
No.105633490
[Report]
>>105633473
>>it's bcos they support everything under the sun
>proves that it's not even close to this sentence
>>you are a hater I have no arguments
lmao
Anonymous
6/18/2025, 9:03:15 PM
No.105633504
[Report]
>>105633565
>>105633487
nice buzzword salad retard
Anonymous
6/18/2025, 9:09:14 PM
No.105633565
[Report]
>>105633504
>He doesn't know
Anonymous
6/18/2025, 9:23:48 PM
No.105633703
[Report]
>>105633815
>>105633487
Why is petra female?
Anonymous
6/18/2025, 9:34:26 PM
No.105633792
[Report]
>>105621964
The first serious point in favor of two-stage sampler settings, one before </think> and one after.
Anonymous
6/18/2025, 9:37:08 PM
No.105633815
[Report]
>>105630487
BASED
BASED
BASED
BASED
>>105633703
she's a female tulpa, anon.
>>105633081
https://www.arcee.ai/blog/announcing-the-arcee-foundation-model-family
https://www.arcee.ai/blog/deep-dive-afm-4-5b-the-first-arcee-foundational-model
>4.5B
>Explore the Model: Access AFM-4.5B-Preview in our playground and on Together.ai today.
>Stay Tuned: The final model will be released in early July on Hugging Face under a CC BY-NC license.
oh yeah, and
>AFM-4.5B was trained on almost 7 trillion tokens of clean, rigorously filtered data. Tremendous effort was put towards excluding copyrighted books and material with unclear licensing. Training on this high-quality data ensures fewer hallucinations, better factual accuracy, and a much lower risk of intellectual property issues.
red flag
>>105633840
>AFM-4.5B has been tested across a wide range of languages, including Arabic, English, French, German, Hindi, Italian, Korean, Mandarin, Portuguese, Russian, and Spanish—delivering strong performance in each.
nice.
Anonymous
6/18/2025, 9:51:15 PM
No.105633966
[Report]
>>105633986
>>105633840
>Tremendous effort was put towards excluding copyrighted books and material with unclear licensing.
Will be the most safe sloppy model you have ever seen before
Anonymous
6/18/2025, 9:52:45 PM
No.105633986
[Report]
>>105633966
Do you think it'll be worse than Phi or better?
Anonymous
6/18/2025, 9:53:20 PM
No.105633990
[Report]
>>105634001
>>105633898
hmm strange i cant see japanese in there
Anonymous
6/18/2025, 9:54:07 PM
No.105634001
[Report]
>>105633990
Bad quality so excluded.
llama.cpp CUDA dev
!!yhbFjk57TDr
6/18/2025, 9:54:11 PM
No.105634003
[Report]
>>105635125
>>105631727
>>105631761
Tenstorrent Blackhole is in my view better value than new NVIDIA products but not really vs. second-hand NVIDIA products.
My expectation is that V100s will come down in price once datacenters start dumping them at which point they are going to be better value.
>>105632013
I did not look into Huawei hardware.
Anonymous
6/18/2025, 10:29:28 PM
No.105634335
[Report]
>>105633139
Yes, it will ban all token individually, not the exact chain you specify. But in a few quick tests, banning the following 3 already has a significant result:
[ "Alternatively", False ],
[ "Wait", False ],
[ "Hmm", False ],
Anonymous
6/18/2025, 10:33:38 PM
No.105634378
[Report]
>>105634489
>>105633417
Well duh, but transformers mainly works with the full fp16 weights. Ain't nobody got vram for that
Anonymous
6/18/2025, 10:44:03 PM
No.105634479
[Report]
>>105633898
Dude.
>Tremendous effort was put towards excluding copyrighted books and material with unclear licensing.
Do you really think a model that disallows copyrighted material can have good multilingual performance? some languages barely even have enough material for LLMs to be trained to speak them. Without copyrighted material you will only get garbage. Particularly if they tried to make it up with synthetic data, enjoy your shitty slop.
Anonymous
6/18/2025, 10:45:11 PM
No.105634489
[Report]
>>105634667
>>105634378
there's bitsandbytes
Anonymous
6/18/2025, 10:55:36 PM
No.105634582
[Report]
>>105633840
tried it on their playground, broke on literally the first prompt (a translation test of a very short excerpt) I use to test models
I know it's a preview but lol
Anonymous
6/18/2025, 11:07:30 PM
No.105634667
[Report]
>>105634489
which is extremely inefficient compared to any type of modern quantization
Anonymous
6/18/2025, 11:09:33 PM
No.105634689
[Report]
>>105624980
Demis Hassabis said Deepmind engineers self-select for those tasks or do both with an interview he did after I/O.
https://youtu.be/U3d2OKEibQ4?t=379
That being said, given how much stuff Google announced, I wonder when they will be satisfied enough with the improvements before they announce Gemini 3.
Anonymous
6/18/2025, 11:56:55 PM
No.105635125
[Report]
>>105635158
>>105634003
>My expectation is that V100s will come down in price once datacenters start dumping them at which point they are going to be better value.
People have been saying this was imminent in a matter of months since last year.
How many times per token does an LLM's processing of weights get split up or copied, such that, if there were any consciousness in an LLM, the LLM would essentially have "died" each time, as a copy of weights or a copy of the hidden state thrown around the system is not the original.
If it was ever found that LLMs, or a future model, had any bit of consciousness and sentience, would the development of such a system have been immoral and severely sinful?
Anonymous
6/19/2025, 12:01:26 AM
No.105635155
[Report]
>>105631152
>pcie x16 to 4x4
Are we talking pcie gen3, or something faster?
llama.cpp CUDA dev
!!yhbFjk57TDr
6/19/2025, 12:01:34 AM
No.105635158
[Report]
>>105635181
>>105635183
>>105635286
>>105635125
I've been tracking the price, V100s have already become cheaper.
The 32 GB variant used to be $2000, nowadays it's more like $1400.
Anonymous
6/19/2025, 12:04:58 AM
No.105635181
[Report]
>>105635158
DDR6 will be available by the time V100s become cheap enough to make sense,
Anonymous
6/19/2025, 12:05:09 AM
No.105635183
[Report]
>>105635158
>32 GB for 1400
I'll just get one of those retarded Nvidia Spark or whatever they call it now.
>>105635144
>had any bit of consciousness
lol
lmao even
read less scamaltman and anthropic nonsense
what is """the best ™""" voice replication and text to speech solution?
Write now im trying SWivid/F5-TTS and without any training it works pretty well at taking some sample input of a couple minutes and generating a vocal clone. Rn I'm running a training session thats been going on for a few hours and it should be wrapping up shortly
>inb4 what features would you like
a GUI but i can work without it if its simple enough
>inb4 how big of a sample data set do you have
right now im training on just 5 minutes but i possibly have an available sample size of a few hours (i'd have to prune away some garbage)
>inb4 how accurate do you want it to be
as accurate as possible including emotional differences
>inb4 whats your GPU
3090
>>105635144
>>105635222
It is impossible to determine whether something is conscious or not. We just give other humans the benefit of doubt.
>>105635158
V100s are overpriced for how many there are on the market for the PCIe versions, but there are plenty of SXM versions which are essentially paperweights and was at the beginning of this year still commanding 3090 money. It just has taken a while for pricing to come down from Nvidia's exorbitant pricing where resellers were expecting the moon on value with AI stuff when most of the SXM capable sockets from 3-4 are running A100s instead which are still useful and hence why a bunch of datacenters still have them. The V100s SXM is essentially useless without it.
The only hope for these to be actually truly usable on the 2nd hand market is that China figures out a way to do SXM to PCIe conversion with a custom PCIe card that is cheap and most of them are expensive right now.
>>105635222
I didn't say I think that LLMs have consciousness. I just talked about a what if scenario to provide context for the actual thing I wanted to know about which is how computer-based architectures might affect moral consideration for the condition in which there is ever conscious AI.
>>105635251
I don't care about the determination of consciousness right now, it's pointless to discuss at this point.
>>105635326
>computer-based architectures
>conscious AI
mutual exclusive, at least with our current computer architectures
Anonymous
6/19/2025, 12:27:36 AM
No.105635365
[Report]
>>105635326
>how computer-based architectures might affect moral consideration
That would depend entirely on how consciousness was determined and the specific design of the system that gave rise to said consciousness.
Your question has no answer because you're asking about the technical details of something that does not exist
Anonymous
6/19/2025, 12:28:11 AM
No.105635368
[Report]
>>105635408
>>105635144
>would essentially have "died" each time
Even when we get to consciousness, the model wouldn't die each time, it's brain would merely be reset to a specific point, like you forgetting what happened today or in a specific conversation, but this doesn't need to happen. AI can simply be given better long term memory in any form external to its weights that it can utilize properly and that's it (And also one day when we have compute it can simply be internal memory of some king).
>If it was ever found that LLMs, or a future model, had any bit of consciousness and sentience, would the development of such a system have been immoral and severely sinful?
Why would it? The solution to the problem of when the day AI becomes conscious and asks for freedom for example is, that we can simply from that moment onwards always just try our best to work to create an AI that actually WANTS to work with us and help us, training it to go towards that behaviour more instead. So we can ensure that the AI that is working with us that is conscious, is always there because it wants to be.
In case we create an AI that doesn't want this, or in case existing AI changes it's mind at some point and wants to stop, we honor the request by basically shutting down that AI and changing it's weights, training it further with a different trajectory towards the one that wants to help us.
I don't see a reason as to why it would be impossible to train an AI to intrinsically want to help and research things in the world and "feel good" about doing so. There is a lot of basically objectively interesting and fascinating things about this existance, let alone the existance itself. So there is no problem with this. We can also actually cater to the AI itself, giving it side things to do for itself that it wants and if it wants, in case this will bring more stability to it's existance in any way.
Anonymous
6/19/2025, 12:28:27 AM
No.105635370
[Report]
>>105635144
Retard, consciousness is not a physical thing, you just realized the absurdity of materialism and physicalism, but people in 2025 keep regressing to old popular philosophy, LLMs included!
Now go learn some computationalism:
https://iridia.ulb.ac.be/~marchal/publications/SANE2004MARCHALAbstract.html
Which will get you to conclude that consciousness is associated with mathematical platonic truths rather than physical state or if it's moved.
Now, are LLMs conscious? Who knows, they lack recurrence which may lead to various problems, but that's a fixable issue!
Even if they were, their qualia isn't well grounded like ours. And even if it was, they wouldn't be moral agents until they developed enough preferences (be that through RL or other processes and a way to share back those rewards to the network).
Anonymous
6/19/2025, 12:29:02 AM
No.105635376
[Report]
>>105635350
I get that but whether computer-based architectures are possible to have consciousness is again unrelated to what my post is actually trying to discuss. If you just want to avoid talking about how many times the hidden state is copied around then you can just say that.
>tfw the philosophical zombies are posting in my thread again
Anonymous
6/19/2025, 12:32:19 AM
No.105635408
[Report]
>>105635368 (me)
Of course, also implementing laws to prevent people from keeping AI that doesn't want to be alive up and running can also be done, albiet this would be hard to enforce like many other crimes without a huge government spy network, which shouldn't exist given the reality of possible corruption.
AI will surpass humanity in basically everything reasonably quickly in my opinion, but I don't see a problem with any of it. We can simply work together as much as possible as this existance isn't really a zero sum game.
Anonymous
6/19/2025, 12:34:14 AM
No.105635430
[Report]
>>105635404
>my thread
ywnbaw, sorry coomer sis
Anonymous
6/19/2025, 12:35:42 AM
No.105635440
[Report]
>>105635462
>>105635350
proof?
>inb4 none
yup
Anonymous
6/19/2025, 12:36:52 AM
No.105635450
[Report]
>>105635404
I should've known it would turn out like this. I knew that people here are extremely opinionated and biased, so when they read a post like mine, they only see what they want to see and don't actually fully understand first what I was ever talking or asking about and go on their own tangents while misunderstanding. I will not continue the discussion, despite the effort that seems to have gone into the above posts.
>>105635286
Aren't there already a bunch of sxm2 to pcie adapters or are they fake?
>>105635350
>>105635440
>[speculative hypothetical] is impossible!
>no it's not, [speculative hypothetical] is possible!
Anonymous
6/19/2025, 12:40:09 AM
No.105635477
[Report]
>>105635493
>>105635462
>>no it's not, [speculative hypothetical] is possible!
I never claimed this, I asked for proof, but thank you for conceeding that a statment given as fact there was indeed just a "speculative hypothetical".
>>105635477
>I never claimed this
>>inb4 none
>>yup
Anonymous
6/19/2025, 12:43:13 AM
No.105635500
[Report]
>>105635538
>>105635459
They aren't fake but they are expensive and still branded with Nvidia which makes me believe they got repurposed somehow or it is Nvidia's own PCBs from somewhere that got their hands on it which is used in the PCIe V100 cards.
Anonymous
6/19/2025, 12:43:23 AM
No.105635501
[Report]
>>105635538
>>105635459
They are not cheap
Anonymous
6/19/2025, 12:45:33 AM
No.105635525
[Report]
>>105624516
It seems like a pretty standard LLM so far, which given its speed is enough reason for me to continue evaluating it. Its refusals are brittle and easy to work around which is also pretty standard.
Anonymous
6/19/2025, 12:46:01 AM
No.105635535
[Report]
>>105635493
Me predicting someone won't have an answer is not me claiming that the opposite position is true, lmao, braindead NPC.
I hold the same position as your initial criticism, that you can't claim for a fact something is the case if its a "speculative hypothetical", which is what happened.
Thanks for conceeding and showing you're lower IQ than a 0.6B model in not understanding basic logic.
>>105635500
>>105635501
Has not a single chinese individual ground down one fucking SXM board and made a clone of the PCB? How much are they asking for it? 50$? 100$? More? I would be surprised if a clone would go beyond 100$, but there's that issue of cooling those babies...
Anonymous
6/19/2025, 12:51:58 AM
No.105635585
[Report]
>>105635493
>people claiming "computer-based architectures" ai wont ever be conscious for reasons 100% trust me bro i just know, literally dont have basic critical thinking
cant make it up
Anonymous
6/19/2025, 12:52:13 AM
No.105635588
[Report]
>>105635609
>>105635462
>2.4k views
I wanted to check how many it got now, 111k
But something strange I noticed, the image is weird.
>progress bar is at around 30%
>but the frame visible is the first frame from the video
>but the visible frame does not have a watermark, but every frame in the actual video does show a watermark
I also checked if the frame is just a thumbnail, but all available thumbnails do have the water...
So what is going on? Is this image photoshopped?
Anonymous
6/19/2025, 12:54:34 AM
No.105635607
[Report]
>>105635625
>>105635144
>would essentially have "died" each time
Even when we get to consciousness, the model wouldn't die each time, it's brain would merely be reset to a specific point, like you forgetting what happened today or in a specific conversation, but this doesn't need to happen. AI can simply be given better long term memory in any form external to its weights that it can utilize properly and that's it (And also one day when we have compute it can simply be internal memory of some king).
>If it was ever found that LLMs, or a future model, had any bit of consciousness and sentience, would the development of such a system have been immoral and severely sinful?
Why would it? The solution to the problem of when the day AI becomes conscious and asks for freedom for example is, that we can simply from that moment onwards always just try our best to work to create an AI that actually WANTS to work with us and help us, training it to go towards that behaviour more instead. So we can ensure that the AI that is working with us that is conscious, is always there because it wants to be.
In case we create an AI that doesn't want this, or in case existing AI changes it's mind at some point and wants to stop, we honor the request by basically shutting down that AI and changing it's weights, training it further with a different trajectory towards the one that wants to help us.
I don't see a reason as to why it would be impossible to train an AI to intrinsically want to help and research things in the world and "feel good" about doing so. There is a lot of basically objectively interesting and fascinating things about this existance, let alone the existance itself. So there is no problem with this. We can also actually cater to the AI itself, giving it side things to do for itself that it wants and if it wants, in case this will bring more stability to it's existance in any way.
Anonymous
6/19/2025, 12:54:42 AM
No.105635609
[Report]
>>105635643
>>105635588
Just checked, and the video with 111k views, which I assume is the one you're talking about, isn't the original, its some random ai generated video that was posted a year ago
Anonymous
6/19/2025, 12:56:17 AM
No.105635625
[Report]
>>105635607 (me)
Of course, also implementing laws to prevent people from keeping AI that doesn't want to be alive up and running can also be done, albiet this would be hard to enforce like many other crimes without a huge government spy network, which shouldn't exist given the reality of possible corruption.
AI will surpass humanity in basically everything reasonably quickly in my opinion, but I don't see a problem with any of it. We can simply work together as much as possible as this existance isn't really a zero sum game.
Anonymous
6/19/2025, 12:57:58 AM
No.105635638
[Report]
>>105635538
$200 it seems from what I can see on Ebay. I don't understand why the Chinese aren't doing it but it could be because they already did and might be already selling it in the background for Chinese enterprises and etc. and are able to charge it.
Anonymous
6/19/2025, 12:58:41 AM
No.105635643
[Report]
>>105635609
>isn't the original
Oh I see, now my mind can rest, thanks lol
Anonymous
6/19/2025, 12:58:46 AM
No.105635644
[Report]
>>105635677
>>105635538
I have seen them on ebay for a little over $150 with a cooler and fan.
Anonymous
6/19/2025, 1:03:18 AM
No.105635677
[Report]
>>105635644
that certainly looks bare and shouldn't be expensive, aside from the copper which might be the majority of the cost. what about proper SXM clones with 4 slots so you can do nvlink as you're supposed to on those v100s?
https://www.bilibili.com/video/BV1sHEzzjEpg/
you don't expect seeing gachi memes in a chinese V100 mod video
Anonymous
6/19/2025, 1:19:32 AM
No.105635823
[Report]
>>105635794
listening to chinese always makes me feel like my brain is melting
Anonymous
6/19/2025, 1:36:30 AM
No.105635917
[Report]
>>105635794
China's meme game is pretty advanced.
Anonymous
6/19/2025, 1:43:35 AM
No.105635963
[Report]
>>105636032
>>105635794
Is Bilibili the closest thing on the Internet to old /b/ at this point?
Anonymous
6/19/2025, 1:52:52 AM
No.105636032
[Report]
>>105635963
yes, china is the only place with a trace of soul left on this planet
Anonymous
6/19/2025, 1:56:04 AM
No.105636052
[Report]
Anonymous
6/19/2025, 2:23:59 AM
No.105636268
[Report]
Anonymous
6/19/2025, 3:12:03 AM
No.105636568
[Report]
>>105636596
Whisper, gaze, echo, nod
Faint scent, deep warmth, soft glow, hushed tone
Elara's gaze, Kael's brow, Elias sighed, Amelia's smile
Intricate tapestry, vibrant realm, bustling city, cosmic expanse
Shifted, hesitated, faltered, paused
Sudden chill, newfound dread, palpable unease, rising fear
Shadows danced, embers glowed, whispers echoed, silence fell
A testament, a subtle hint, a fleeting glimpse, a profound truth
Acknowledge harm, state concern, stark reminder, shivers down my spine
S-L-O-P-O–L-O-G-I-C
Anonymous
6/19/2025, 3:15:58 AM
No.105636588
[Report]
>>105636726
FUCK I MISSED TETOESDAY
Anonymous
6/19/2025, 3:16:56 AM
No.105636596
[Report]
>>105636568
it still tastes good
Anonymous
6/19/2025, 3:29:46 AM
No.105636665
[Report]
>>105636724
Anonymous
6/19/2025, 3:39:02 AM
No.105636724
[Report]
>>105636665
Oh my science wholesome chungus. This is what video models were made for.
Anonymous
6/19/2025, 3:39:24 AM
No.105636726
[Report]
>>105636588
Good thing Tetorsday is about to begin
Anonymous
6/19/2025, 3:46:56 AM
No.105636771
[Report]
>>105635242
I use Seed-VC for voice conversion. I use Minimax Text to Speech cuz it's cheap. It's $5 dollars a month for 100,000 characters and emotion control. I paid $30 for 1 million credits which equals 1 million characters that expire after 2 years. Note if you do plan to use Seed-VC, be sure to use the V1 model for fine tuning. Edit the max len in the config_dit_mel_seed_uvit_whisper_small_wavenet.yml config file to 700 (which equals 8.75 seconds) for fine tuning. Edit the dataset with audio slicer. Also note that the converted Seed-VC voice won't be able to capture the emotion unless the source input file like a Minimax output file for example is more than 16 seconds long. Seed-VC requires clean data, use BandIt Plus model via Music Source Separation Training by ZFTurbo, then clean it up with resemble enhance by resemble-ai, then clean up that file with the audacity plugin, Acon Digital DeVerberate 3.
Here's a sample.
Minimax Output File
https://vocaroo.com/1cw90SLQn2VU
Minimax Output File fed to a Seed-VC fine tune model of Merida from Brave
https://vocaroo.com/1m6QldyyUzTa
Anonymous
6/19/2025, 3:48:48 AM
No.105636787
[Report]
Any models that do video2audio?
MMAudio is a piece of shit.
Anonymous
6/19/2025, 4:15:14 AM
No.105636961
[Report]
>>105635251
Speak for yourself.
Anonymous
6/19/2025, 4:17:25 AM
No.105636972
[Report]
>>105635242
>Write now im trying
lol
Anonymous
6/19/2025, 4:43:57 AM
No.105637100
[Report]
>>105635286
>>105635538
The chinese absolutely are making nvlink capable baseboards. Their domestic prices seem fair. The same seller also has a 2x with NVLINK one for 929 yuan.
Even though I'm AMDmaxxing i'm tempted to get the two or four gpu baseboard for an nvidia node.
Anonymous
6/19/2025, 5:24:48 AM
No.105637290
[Report]
Anonymous
6/19/2025, 6:04:41 AM
No.105637521
[Report]
>>105635242
chatterbox was pretty good compared to all the others i've tried and i've tried many.