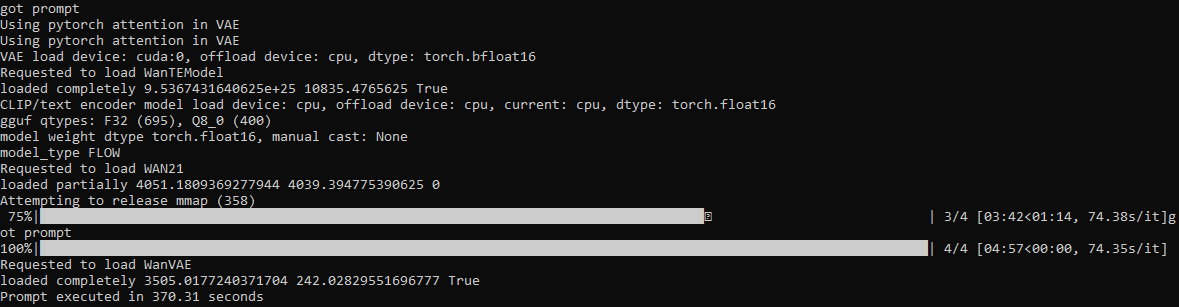
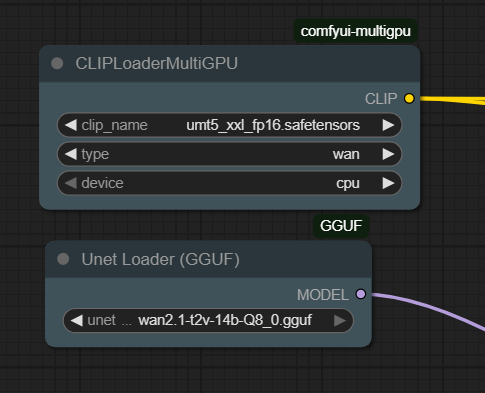
/ldg/ - Local Diffusion General
Anonymous
6/20/2025, 5:57:44 AM
No.105647706
[Report]
>>105647727
Seconds
Anonymous
6/20/2025, 5:57:47 AM
No.105647707
[Report]
>>105648539
Chosen thread
Anonymous
6/20/2025, 6:00:37 AM
No.105647727
[Report]
>>105647706
Sorry :(
Next one is yours, fren.
The collage script is updated btw, videos hopefully shouldn't be as janky.
Anonymous
6/20/2025, 6:00:58 AM
No.105647731
[Report]
Blessed thread of frenship
Anonymous
6/20/2025, 6:04:28 AM
No.105647748
[Report]
>>105647870
blue hair anime girl slaps a red hair anime girl in the face.
no slap, more of a cute conversation
Anonymous
6/20/2025, 6:06:46 AM
No.105647759
[Report]
DO NOT prompt "realistic shading, realistic lighting" in pladis lmao. This was an anime pic originally.
Anonymous
6/20/2025, 6:07:06 AM
No.105647762
[Report]
>>105647853
AudioX prompt: heavy rain with thunder
https://voca.ro/1n2V3NpA8WEA
It's cool that we have real-time audio generation, especially for movie/cartoon/game development, although all text/video2audio models are censored
>>105647735
Cursed thread of hostility
Anonymous
6/20/2025, 6:13:04 AM
No.105647801
[Report]
>>105647845
I'm making a gore LoRA for Wan. I've got a pretty good set already collected, mostly horror and action movies with realistic gore along with plenty of high quality images for the mixed set. Turns out the Japs and Koreans love their realistic gore, shocker. Now I'm just debating adding real life image/video gore to the set. Also where to post it regardless, since civit will probably take it down.
Anonymous
6/20/2025, 6:18:51 AM
No.105647840
[Report]
>>105647870
green hair anime girl shoots a man on the right with a revolver.
from an old miku as joker gen, seems he is immune!
Anonymous
6/20/2025, 6:19:27 AM
No.105647845
[Report]
>>105647881
>>105647801
you should not have mentioned that, brainlet.
if you trained on bestgore/liveleak stuff and then claimed you trained on movies, no one would notice or try to take it down
Anonymous
6/20/2025, 6:20:05 AM
No.105647853
[Report]
>>105647762
how does it compare to ACE Step Model and Stable Audio Open 1.0?
Anonymous
6/20/2025, 6:23:01 AM
No.105647870
[Report]
>>105647903
>>105647748
>>105647840
look like flash animations from 2008
just installed a new (used) 3090 and it seems like it's genning at the same speed as the 3060.
would someone else with a 3090 post a workflow and their generation time?
Anonymous
6/20/2025, 6:24:08 AM
No.105647879
[Report]
>>105647908
wan magic:
Anonymous
6/20/2025, 6:24:17 AM
No.105647881
[Report]
>>105647845
True. Carry on.
Anonymous
6/20/2025, 6:26:57 AM
No.105647903
[Report]
>>105647870
>look like flash animations from 2008
I can be my own zone tan?
Anonymous
6/20/2025, 6:27:07 AM
No.105647905
[Report]
>>105647871
3090 has like 3 times the tensors cores, it should be a lot faster. My 3090 on the FAST rentry workflow outputs an 820x1024 720p i2v (at 129 frames, not 81) in 7 minutes. That's with three loras loaded and 13 virtual vram offload.
Anonymous
6/20/2025, 6:27:23 AM
No.105647908
[Report]
>>105647879
science, it just works
>>105647871
that looks fine for self forcing wan q8 on a 3090, you definitely werent getting that on 3060
Anonymous
6/20/2025, 6:29:29 AM
No.105647930
[Report]
>>105647916
It's right if he's using the 720p model
if it's 480p it should be much faster (a bit over a minute, that's what I get on my 3090 with 480p)
Anonymous
6/20/2025, 6:30:42 AM
No.105647936
[Report]
>>105647945
>>105647685 (OP)
Fuck this man.
I got too distracted with AIslops and now my work deadline is 5 days left. Fuck Fuck Fuck Fuck
Anonymous
6/20/2025, 6:31:39 AM
No.105647945
[Report]
>>105647936
Use AI to slop your work then get back to genning.
Anonymous
6/20/2025, 6:38:38 AM
No.105647983
[Report]
>>105648059
>>105647963
This kind of shit is why I don't give a fuck about API when people post it here dooming about how local is behind in video gen. They'll show some clip like a girl fighting a dragon and it looks all cinematic and cool, yeah, but try and get it to gen something like this and see what happens.
Anonymous
6/20/2025, 6:39:49 AM
No.105647990
[Report]
>>105647871
Speed, funny enough, is one of the things that you can't really substantially improve right now by getting a more expensive card, and won't be for a while. It'll probably take at least until the 7090 is out for wan to generate at bearable speeds (or for someone to release a new video model that actually gens faster - whichever happens first). The most you'll get out of a beefier card is more VRAM, and thus less OOMs. This is more useful for LLM use and training. Video genning doesn't benefit much. t. Ada 6000 owner
So uhh, how do I make Wan 2.1 vids that aren't all slow motion?
I'm using the Comfy workflow from the Rentry (the light2xv+NAG one specifically), and all outputs are slow motion. Is there something I need to tweak to get shit to actually move properly? Adding "fast motion" or "sped up" to the positive prompts, does fuck all, and adding "slow motion" to negatives does nothing either.
>>105648029
Isn't that one of the big drawbacks with NAG? Almost everything (as far as I hear, I haven't bothered using NAG) generated with it is in slow mo. I don't have that problem as much with normal WAN
Anonymous
6/20/2025, 6:52:17 AM
No.105648056
[Report]
>>105649090
chroma will never be good
>>105647983
>muhh coom
there's more in life than naked 1girl getting creampied by white syrup anon
Anonymous
6/20/2025, 6:53:02 AM
No.105648061
[Report]
>>105648090
>>105647916
720p self forcing t2v
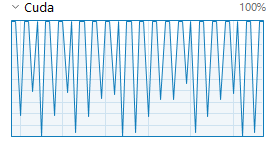
it was roughly the same s/it on 3060, but now i can't recall whether that was Q8 offloaded or Q5 without offloading. using no offloading on the 3090.
this graph is a lot spikier than it was on 3060. openhardwaremonitor shows a fairly steady ~1500 clock, but maybe it's throttling?
Anonymous
6/20/2025, 6:53:32 AM
No.105648065
[Report]
>>105648049
NAG isn't the culprit, but the distilled lora
Anonymous
6/20/2025, 6:54:33 AM
No.105648069
[Report]
>>105648073
>>105648029
>So uhh, how do I make Wan 2.1 vids that aren't all slow motion?
go for lora strength 0.8 and try to make your whole prompt a :2, like this
>(a man running and then jumping into a pool:2)
Anonymous
6/20/2025, 6:55:13 AM
No.105648073
[Report]
>>105648092
>>105648049
>Isn't that one of the big drawbacks with NAG?
>there's several trade offs; a decrease in visual quality (more noticeable in 480p compared to 720p), reduced motion fluidity, along with slow-motion movements.
>along with slow-motion movements.
I swear that line just spawned in.
Well shit... You mean I gotta choose between waiting an hour for a vid that looks regular speed, or 5 for a vid that looks slow?
What a tradeoff. There's no cheater workarounds?
>>105648069
Thanks, I'll see what happens
>>105648029
Download the updated rentry workflow for it and read the riflexrope note
Anonymous
6/20/2025, 6:56:28 AM
No.105648082
[Report]
>>105648091
Anonymous
6/20/2025, 6:56:41 AM
No.105648084
[Report]
>>105648094
flux pepe gen + wan animation
new meme age:
Anonymous
6/20/2025, 6:56:49 AM
No.105648086
[Report]
>>105648029
This is a known weakness of wan, it stems from the footage they used to train the model off of (a fuckton of stock footage is slow motion) combined with some weird FPS-related fuckery - again, a side effect of the training method. afaik there is no true solution other than repeatedly genning until RNGesus shines his holy light upon you and bestows you with something that doesn't look like it was filmed underwater. Some people have said genning shorter clips helps, but imo it mostly leads to jankier videos
>>105648019
>Speed, funny enough, is one of the things that you can't really substantially improve right now by getting a more expensive card, and won't be for a while
what the fuck are you talking about retard, you buying ada 6000 and not getting higher speed than even a 3090 is because you are retarded, not knowing the most basic thing about any of these models which is that aside from vram size, the most important thing for speed is memory bandwidth, which for your overpriced dogshit 6000k$+tip card is the same or slightly less than a 500-700$ 3090
5090 is almost double the speed just from memory bandwith
Anonymous
6/20/2025, 6:57:31 AM
No.105648090
[Report]
>>105648874
>>105648061
I think it's more likely that the periods of low usage are when the GPU is waiting for the CPU to catch up (if you're doing partial offloading to ram)
Anonymous
6/20/2025, 6:57:42 AM
No.105648091
[Report]
Anonymous
6/20/2025, 6:58:10 AM
No.105648092
[Report]
>>105648228
>>105648073
>I swear that line just spawned in.
Nope, I added it day one for lightx2v.
Like
>>105648075 said, download the workflow again. I updated yesterday with a workaround for the slow motion. It requires extra gen time, but given Self Forcing Wan is so fast as it is, it's a negligible hit.
Changing the lightx2v LoRA to 0.8 is a good option too, like yet another anon said.
Anonymous
6/20/2025, 6:58:43 AM
No.105648094
[Report]
>>105648084
kek, he's so surprised, he's like
>bruh they did the job before me not fair!
>>105648075
another new workflow? nice
Anonymous
6/20/2025, 7:01:02 AM
No.105648110
[Report]
>>105648029
the best bet would be to use the rifleX thing and make the video longer, then change your video from 16 fps to 24, so that you make the video 1.5x faster
Anonymous
6/20/2025, 7:03:23 AM
No.105648120
[Report]
>>105648088
Just speaking from what I know. If I'm wrong, I'm wrong.
I got my 6000 a while back for peanuts from an IT friend and like hell I'm going to join the 5090 rat race right now. The moral of the story is that you should take what you can get while you can, but, even then, you're going to be doing a lot of waiting for shit to either get faster or cheaper.
Anonymous
6/20/2025, 7:03:44 AM
No.105648121
[Report]
>>105648107
tried with the 129 frame option enabled:
neat
>>105648088
nta, this is one of the reasons home AI has become annoying now
it used to be vram maxxing was the only real bottleneck but now the models are so chunky and compute heavy that you have to start caring about memory speed and clock too
Anonymous
6/20/2025, 7:11:24 AM
No.105648163
[Report]
>>105648222
>>105648131
>it used to be vram maxxing was the only real bottleneck
would you look at that, maybe sageattention will save us again
https://github.com/thu-ml/SageAttention?tab=readme-ov-file#project-updates
>The code for SageAttention2++ is scheduled for release around June 20, while SageAttention3 is expected to be released around July 15.
Anonymous
6/20/2025, 7:12:10 AM
No.105648170
[Report]
it just works
Anonymous
6/20/2025, 7:12:51 AM
No.105648175
[Report]
>>105648131
Memory bandwidth was always the most important thing if you could fit the model in your vram, both in media generation and LLMs. And early on, and mostly even today, your regular 11-16gb vram cards are enough for most things.
>>105648131
flux pro, the bigger undistilled model, has an API response time of ~3s. their 4096x4096 model has a response time of 10 seconds. on local hardware this would take considerably longer.
this is the real reason local gets the scraps. our hardware feels decades behind enterprise compute, even the best setup available right now still takes 20-30 seconds to generate a base flux image. we are still playing with SD1.5 era compute. local will never blossom to full potential until this shit gets addressed.
Anonymous
6/20/2025, 7:13:45 AM
No.105648180
[Report]
>>105648019
damn. and my untrained eye didn't notice much of a difference with quants down to Q5 (with NAG and self forcing), let alone offloading.
luckily got a long return window, might end up swapping to a blackwell with less vram at the same price point...
Anonymous
6/20/2025, 7:14:19 AM
No.105648183
[Report]
>>105648178
I blame thirdie redditors who whine loudly whenever a big new sota model drops and it won't run on their 4GB laptop gpu.
Anonymous
6/20/2025, 7:14:37 AM
No.105648185
[Report]
>>105648059
I'll be honest anon API sucks because it's slow and costs money and this is even more important when you're doing something specific because it can take dozens of attempts to get what you're looking for. That adds up.
Oh and you have to worry about the nanny filter the entire time deciding what is or isn't safe. Type in woman fighting dragons enough times and you'll get banned.
>>105648178
Enterprise compute ($30k computers)
You people are the biggest bitches in the world, how about take a look at the cost of computers in the late 80s especially ones for CGI. It was unheard of for peasants to have hardware that could do professional work, now you're mad that you don't have a Pixar-tier render farm in your house for $500.
Anonymous
6/20/2025, 7:19:59 AM
No.105648210
[Report]
>>105648202
Not true, I'd pay $600.
>>105648107
>new workflow
is it normal that his workflow didn't connect the latent stuff to the node?
Anonymous
6/20/2025, 7:22:10 AM
No.105648222
[Report]
>>105648163
https://arxiv.org/pdf/2505.21136
>To further accelerate
SageAttention2, we propose to utilize the faster
instruction of FP8 Matmul accumulated in FP16.
The instruction is 2× faster than the FP8 Matmul used in SageAttention2. Our experiments show that SageAttention2++ achieves a 3.9× speedup over FlashAttention while maintaining the same attention accuracy as SageAttention2.
that looks like a huge deal
Anonymous
6/20/2025, 7:23:48 AM
No.105648228
[Report]
>>105648284
>>105648092
>Nope, I added it day one for lightx2v.
I was joking
New workflow definitely seems to speed things up though. Good shit.
Anonymous
6/20/2025, 7:24:00 AM
No.105648230
[Report]
>>105648236
>>105648213
connect wanimagetovideo if you wanna try those nodes
Anonymous
6/20/2025, 7:25:10 AM
No.105648236
[Report]
>>105648230
but why didn't the workflow had that connection though? the node is in pink (deactivated) so it won't impact anything if it's connected or not
>>105648178
>even the best setup available right now still takes 20-30 seconds to generate a base flux image
who are all of you people itt right now talking about this shit being this wrong?
it takes 7 seconds to "generate a base" 1024x1024 image with noobai on a 500-700$ 3090
it takes 48 seconds to generate a 27 step full chroma image on a 3090
5090 is double that speed
genning 8 images in a batch gives a further 13% speed
using tensorrt gives a big speedboost if you can use it
undervolting and locking memory/core clock gives further 5-20% speed
so if you want a lot of images you are already covered, if you want to edit one image a lot then stopping generation when you see it go badly only takes a few seconds and later inpainting is fast
or generate 8 base images quickly and pick the good one to use the seed for a second pass highres fix
Anonymous
6/20/2025, 7:28:59 AM
No.105648251
[Report]
>>105648244
considering the price of the 5090, only doubling the speed doesn't feel like enough
Anonymous
6/20/2025, 7:30:26 AM
No.105648260
[Report]
>>105648244
and this isnt even counting the many "fast" "low step" versions of most models at some quality loss which can be recovered later through inpainting
Anonymous
6/20/2025, 7:32:04 AM
No.105648269
[Report]
>>105648355
>>105648202
nothing i said is false though. this is the reason local models are 'behind' and the reason why developers are continuing to shift efforts towards API generation instead of local. running top-tier models HAS become slower, as local hardware is being intentionally sabotaged so they can sell $300k enterprise cards (B200 is $500k).
running top-tier models wasn't always like this. sd1.4/sd1.5 were the very best you could get in 2022, and they ran lightning fast. SDXL, 1024x1024, still runs great. but then you have hidream, also 1024x1024, and it runs like shit even on a 4090/5090.
releasing models openly is no longer about giving the community new things to play with, because the community will be unable to run them. all open releases amount to now is having your work stolen by competitors and getting shat on by fearmongering vultures. for local to thrive the hardware needs to keep pace.
>>105648107
>>105648213
>new RifleX workflow
I'm not sure this is working on I2V 720p though, it looks like ass and the video repeats itself
Anonymous
6/20/2025, 7:34:21 AM
No.105648284
[Report]
>>105648228
I'm dumb today. Forgive me.
>>105648213
No, fixed. Also defaulted the lightx2v LoRA to 0.8.
If anyone figures out other fixes/workarounds, post 'em.
Anonymous
6/20/2025, 7:36:39 AM
No.105648302
[Report]
>>105648435
>>105648282
Working on my end.
Anonymous
6/20/2025, 7:39:46 AM
No.105648321
[Report]
>>105648269
retard, the reason why GPUs are expensive is they print gold, this what what happens when tools can be directly tied to profit
people don't make local models because there's no way to monetize them and there's also massive risk involved (you don't care)
so to sum up: you're a lazy greedy faggot who wants someone to make a model for you that costs $100k+ to make and also runs on your toaster because your mommy is poor so you can't get a job
Anonymous
6/20/2025, 7:44:49 AM
No.105648366
[Report]
Anonymous
6/20/2025, 7:47:05 AM
No.105648388
[Report]
>>105647793
it worked
I might curse every thread from now on
anime girl dressed as a maid pours a cup of coffee.
Anonymous
6/20/2025, 7:50:11 AM
No.105648409
[Report]
>>105648434
>>105648282
I haven't really tested it with complicated motions yet, but it seemed to work on a couple of i2v's I did myself without repetition like you're getting, but maybe the motions I tested weren't complicated enough.
There's not much documentation for it concerning the k value or what you'd set it to for a setup like this, given it's being used with the distilled LoRA and all.
>>105648406
okay. now it's a proper pour.
with new workflow and lora at 0.8.
Anonymous
6/20/2025, 7:51:38 AM
No.105648421
[Report]
>>105648456
>>105648355
>someone to make a model for you that costs $100k+
I'm a multimillionaire and I been thinking about doing this.
Anonymous
6/20/2025, 7:53:25 AM
No.105648434
[Report]
>>105648409
could be reliant on cfg being higher than 1 too
Anonymous
6/20/2025, 7:53:33 AM
No.105648435
[Report]
Anonymous
6/20/2025, 7:56:22 AM
No.105648456
[Report]
>>105648421
Are you also a furry? Every cashed up coomer who wants to spend money on independent AI development always turns out to be a furry
Anonymous
6/20/2025, 7:56:27 AM
No.105648458
[Report]
>>105648419
anime girl dressed as a maid puts a large birthday cake down on a table and cuts a slice of cake.
motion/speed does seem better with this new workflow.
Anonymous
6/20/2025, 7:56:57 AM
No.105648462
[Report]
>>105648603
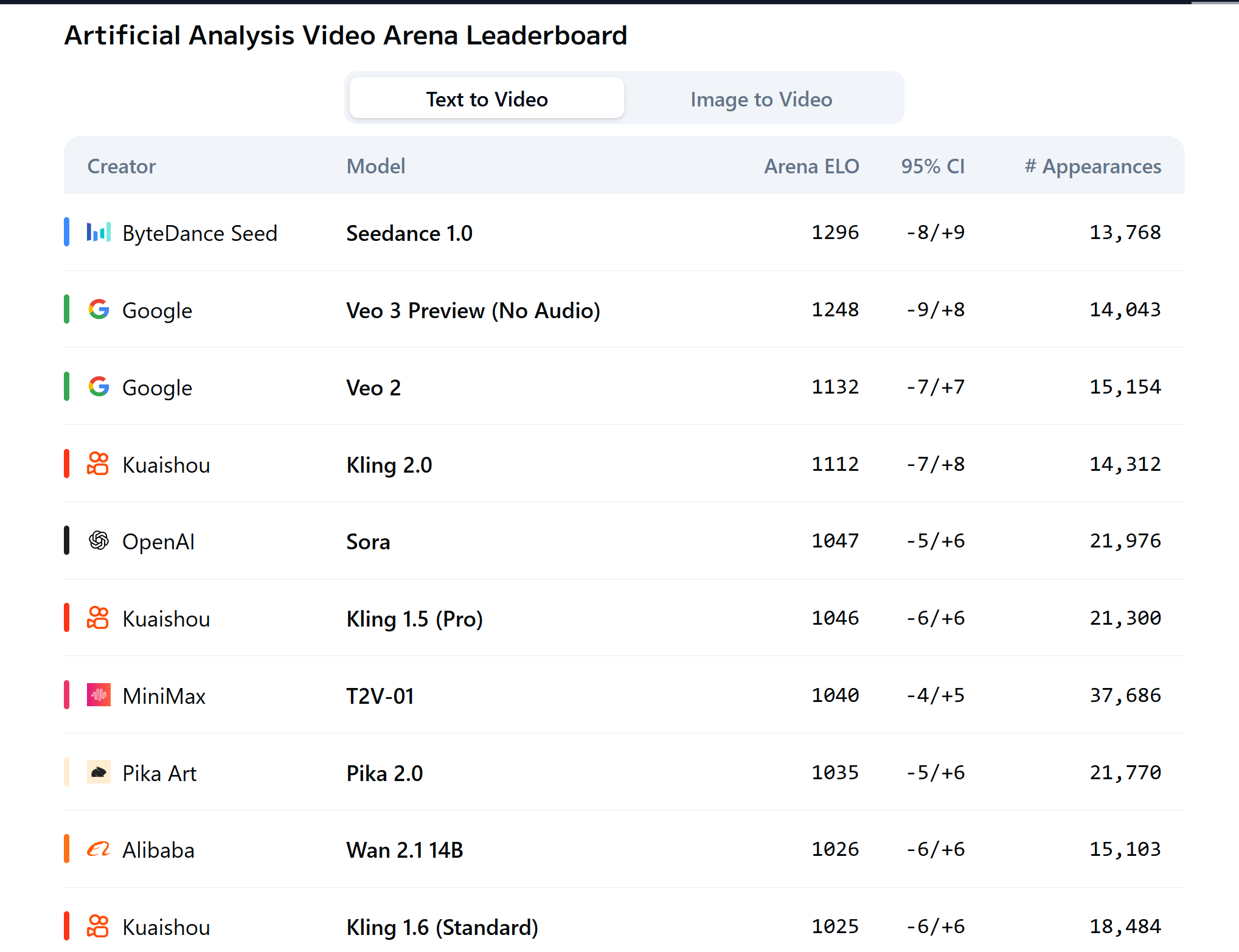
Do you know that Seedance is a 14b model? (Wan is a 13b model), that means that you could get Veo3 quality with our own gpu, that's craaazy
Anonymous
6/20/2025, 7:57:06 AM
No.105648464
[Report]
>>105648419
>>105648406
herky jerky glitchy
but if you asked a lora to blast semen all over her tiddies you'd get a perfect fluid render in one attempt
such are the ways of things in the unknown days
Anonymous
6/20/2025, 7:57:39 AM
No.105648470
[Report]
Anonymous
6/20/2025, 8:00:20 AM
No.105648496
[Report]
Anonymous
6/20/2025, 8:07:10 AM
No.105648539
[Report]
>>105647735
>>105647707
>>105647793
>still no updated neighbors list:
>>>/vp/napt
Anonymous
6/20/2025, 8:09:30 AM
No.105648550
[Report]
kek
a man is upset and slams a door, then punches a hole through the door.
Anonymous
6/20/2025, 8:11:39 AM
No.105648569
[Report]
Anonymous
6/20/2025, 8:13:03 AM
No.105648578
[Report]
>>105648583
Anonymous
6/20/2025, 8:14:13 AM
No.105648583
[Report]
>>105648578
>normie is impressed by heuristic probability
Anonymous
6/20/2025, 8:15:39 AM
No.105648589
[Report]
>>105646941
Love how he lifts the birdie's wings
Anonymous
6/20/2025, 8:18:11 AM
No.105648603
[Report]
>>105648613
>>105648462
seedance is shit, its basically a slightly better wan with a good upscaler to 1080, that benchmark is bullshit, haluo is leagues above it, especially in physics
https://www.youtube.com/watch?v=Y4AbT6AopBM
Anonymous
6/20/2025, 8:18:44 AM
No.105648607
[Report]
>>105648623
Conan is for retards who can't into CMake
>>105648603
no, they didn't release the 14b on API yet, what they're testing so far is the 1.3b one, that's why it's shit
Anonymous
6/20/2025, 8:21:25 AM
No.105648623
[Report]
>>105648607
If I didn't know any better I'd think you're Anim-Anon.
>>105648355
>people don't make local models because there's no way to monetize them
There actually is. Photoshop has thrived for so long for a reason. Modelmakers simply are retarded. Midjourney's business model can be copied over to local, but companies are too scared to innovate. All they have to do is build a community, whether discord or their own website where creations can be directly shared, offer a monthly subscription, allow users without the hardware to gen using theirs, but that's not all, here's the pivotal part: Instead of being an idiot (E.G. Stability) who lives finetuning up to the community, you iterate on your model, which is currently only done by MJ. You finetune it to add artists and you deliver updates to this paid SaaS over time, and that will make it worth it for everyone involved in paying for it.
SaaS doesn't have to be exclusively model gatekeeping, they can give us the model and just keep improving it month after month. If MJ gave us their model they wouldn't lose many subscribers. Most people who pay aren't really open source users. They only pay for that shit because it's a high quality model knows all the artists, characters and mediums they prompt for, whereas the same can't be said for local which has never had any official support for these things from anyone.
Anonymous
6/20/2025, 8:23:08 AM
No.105648631
[Report]
>>105648624
don't bother, you're replying to bot that pops up and screams unrelated shit about how everyone should just train their own model. it's been doing this since flux released last year.
Anonymous
6/20/2025, 8:29:09 AM
No.105648662
[Report]
>>105648624
Assistant, condense this post into three sentences.
so how do api providers host their models? for example, flux kontext pro is available on fal, getimg, datacrunch, replicate, ltx studio, togetherai, runware, and so many more. do these services just forward requests to BFL's servers, or do they host the weights themselves? i'm surprised that hasn't been a notable model leak since novelai in 2022
Anonymous
6/20/2025, 8:32:10 AM
No.105648685
[Report]
>>105648726
yep, it's driving time.
Anonymous
6/20/2025, 8:36:25 AM
No.105648711
[Report]
>>105648624
One might wonder, why give the model out for free? Purpose of recognition, for sticking around, for being used everywhere and integrated into technologies, for not losing relevance. Even today SD is still used. Tomorrow everyone will forget about Krea and every other service if it's not released. Plus, you can have certain licenses that assure you will get paid depending on the type of commercial application and total profits.
>>105648675
There has likely been more high profile leaks, but the hackers who broke into the server weren't interested in leaking the model to the general public.
Anonymous
6/20/2025, 8:38:31 AM
No.105648716
[Report]
>>105648675
Paypig proprietary models don't run on consumer hardware and they don't reside in some C:/AI/BigModel directory either.
NAI was possible because it was small.
Anonymous
6/20/2025, 8:40:13 AM
No.105648723
[Report]
>>105647963
Soon we will create edible Mirror Life that is similar to this.
Anonymous
6/20/2025, 8:40:53 AM
No.105648726
[Report]
>>105648685
man, he's good.
Anonymous
6/20/2025, 8:41:04 AM
No.105648728
[Report]
>>105648895
Anonymous
6/20/2025, 8:44:02 AM
No.105648743
[Report]
I have concluded that after wasting an entire night trying to get wan to follow prompts whilst using any so called speed up loras. That all speed up loras are fucking trash, why is that? Its probably because wan is very good at following prompts but it requires cfg, real cfg other wise it won't produce the video you prompt.
Phantom model works much better without anything like causvid(any version) fusionx what ever its called and lightx2v. A cfg of 4 and 20 steps and its working with loras correctly and not mangling everything, at least that is what it seems, i'll have to do a few gens. Yes it takes longer at 20 steps but it follows my prompt, if it does not follow my prompt then that has been a waste of electricity and time. optimalsteps is still the best because it does not mess up the video when using loras provides 40 steps quality at 20 steps, does not change reference image face.
Also
--lowvram
--reserve-vram 1.0
+ native comfyui methods
is still the best method of running wan on a 12GB card, everything else is horrible, i oom on just 5 frames using phantom model Q8 if I try to use the offloading node that every retard recommends. But if I run my comfyui with the options above, i can do 1280 x 720 videos 41 frames or more, why? I'll explain, comfyui offloads correctly and more efficiently natively, but you have to reserve some vram, because if you don't it tries to use all vram on the card before it will then use the system ram. Then it will oom when something else such as preview nodes or anything else on the system tries to use the vram.
So just use native and set those options and it will work on lower vram cards, also increase your virtual ram. All other methods are slow as fuck, also those memory saving nodes? Fuck them off they are retarded and don't do shit.
Anonymous
6/20/2025, 8:49:25 AM
No.105648778
[Report]
>>105648757
Any lora will reduce the original model's ability. As simple as.
Animation is already highly specific and it's going to be very noticeable.
Anonymous
6/20/2025, 8:50:43 AM
No.105648784
[Report]
>>105646365
You need to write "2girls" in your mask prompts, not "1girl".
(Also, if dragging the workflow doesn't work, you might have to save them on your PC first. I think I've seen this issue on an older version of Chrome.)
There is a very good reason people demand native workflows. I'm tired of shits giving shitty advice and linking to shitty workflows with everything including the fucking sink in the effort to avoid waiting 20 minutes... You will just get frustrated and waste hours and hours of your time in the long run genning shitty gens because of those crap methods. its all pseudo crap, all for the sake of some ADHD freaks that need their gens done in 1 minute... They are so crap I can now actually tell when someone is using those speed loras, yeah you might be able to make the 1 millionth video of miku eating a hamburger, but add any complex prompt and it will shit the bed.
Anonymous
6/20/2025, 8:54:13 AM
No.105648805
[Report]
>>105649989
https://arxiv.org/pdf/2505.21136v1
> Experiments show that SageAttention2++ achieves a 3.9× speedup (SageAttention2 has a 3× speedup) over FlashAttention
So we're expecting a 30% speed increase once they release SA2++ (which is supposed to be today)? nice
Anonymous
6/20/2025, 8:57:06 AM
No.105648822
[Report]
>>105648871
>>105648798
hahaha download 6 nodepacks with over 30 nodes each but only use one from each! :^) comfyorg sure is working hard!
Anonymous
6/20/2025, 9:00:29 AM
No.105648849
[Report]
>>105648919
>>105648798
>add any complex prompt and it will shit the bed.
regular wan shits the bed on complex prompt anyways, do you seriously believe you have Hailuo 2 within your hands or something?
https://www.youtube.com/watch?v=J18idUz87LA
>>105648822
UNETLoaderMultiGPU
worth piece of trash ever.
>>105648757
>--lowvram
>--reserve-vram 1.0
again, above is much better, much much faster, less stuttering and lag, and it just works. The above node i'd oom on just 5 frames unless i offload 24GB the max it will let you and it lags like fucking crazy, rubbish fucking piece trash and cunts still use it in almost every workflow.
Anonymous
6/20/2025, 9:04:33 AM
No.105648874
[Report]
still testing this new card. fan tests work, passed gpumemtest
>>105648090
this shouldn't be offloading, right?
double checked (had to reboot) and nvidia control panel is set to "prefer no sysmem fallback"
Anonymous
6/20/2025, 9:04:48 AM
No.105648876
[Report]
>>105648871
>UNETLoaderMultiGPU
imagine thinking pytorch can multigpu properly kek
Anonymous
6/20/2025, 9:05:26 AM
No.105648879
[Report]
*gobbles up stale moldy bread off the floor*
mmmmm thank you china at least you feed me unlike the west. you're true local heroes!!
Anonymous
6/20/2025, 9:07:24 AM
No.105648895
[Report]
>>105648938
>>105648613
>>105648728
although this "pro" version doesnt look that good either, especially the only semi-hard prompt with that skateboard video with all the warping and shit physics, is this still 1.3b?
https://files.catbox.moe/oq8jpe.mp4
https://wavespeed.ai/models/bytedance/seedance-v1-pro-i2v-1080p
Anonymous
6/20/2025, 9:10:11 AM
No.105648910
[Report]
>>105648887
idk this doesnt look too moldy to me
Anonymous
6/20/2025, 9:10:54 AM
No.105648919
[Report]
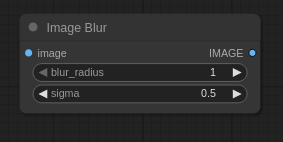
>>105648849
I'm just having a rant anon, but wan is good at following prompts, i can get pretty much anything done with it. I do often make multiple gens and combine them, this works well so long as you use pic related on the last frame with those settings. It just alters the image ever so slightly so wan don't start frying the frames. I still don't know why wan does that and its definitely not a same seed issue, but that amount of blur pushes a little noise into it and wan fixes it.
Anonymous
6/20/2025, 9:11:47 AM
No.105648927
[Report]
Anonymous
6/20/2025, 9:12:15 AM
No.105648930
[Report]
>>105648887
>at least you feed me unlike the west.
I mean, it's either mold or a litteral piece of shit, I'll take the mold if you don't mind
Anonymous
6/20/2025, 9:13:43 AM
No.105648938
[Report]
>>105649079
>>105648895
yeah, Idk why it's 1st on the ranking, the other chink model is on another level
https://xcancel.com/WuxiaRocks/status/1935298213613027521#m
Anonymous
6/20/2025, 9:15:49 AM
No.105648947
[Report]
real comfy gen hours
>everyone is complaining and pissed off cumfart workflows are snake oil and the community poisons the well
>fox and the grapes over saas model
>REAL comfy gen hours
trve
Anonymous
6/20/2025, 9:19:32 AM
No.105648963
[Report]
>>105648976
>>105648959
chat, is this real?
Anonymous
6/20/2025, 9:20:03 AM
No.105648966
[Report]
Anonymous
6/20/2025, 9:21:03 AM
No.105648972
[Report]
>>105648959
we really need a different way of doing this shit. comfy is at the same point when auto was just tiresome and beleaguered
Anonymous
6/20/2025, 9:21:26 AM
No.105648976
[Report]
>>105648998
>>105648963
Don't engage with the thread schizo. Let him reply to himself.
Anonymous
6/20/2025, 9:21:57 AM
No.105648979
[Report]
this one also turned out good.
also I wanted to ask, is it possible to use multiple LoRas with Wan?
I chained together the kissing lora with the tit jiggle lora but after many tries I never got a result where both are combined.
Anonymous
6/20/2025, 9:24:45 AM
No.105648998
[Report]
>>105648976
shut the fuck up poopdickschizo
Anonymous
6/20/2025, 9:25:25 AM
No.105649002
[Report]
>phoneposting and calling people schizo
probably banned or something
>>105648798
You're drunk again, Ivan. Go sleep it off
Anonymous
6/20/2025, 9:29:10 AM
No.105649023
[Report]
Anonymous
6/20/2025, 9:29:10 AM
No.105649024
[Report]
Anonymous
6/20/2025, 9:29:57 AM
No.105649031
[Report]
>>105649036
everyone general has one guy who hates the subject of the general yet inexplicably hangs out in the thread anyway
it's cozy
Anonymous
6/20/2025, 9:30:12 AM
No.105649032
[Report]
>>105649018
go post another pointless one liner.
Anonymous
6/20/2025, 9:30:46 AM
No.105649036
[Report]
>>105649040
>>105649031
Yep. This one's great too, wait until he starts crashing out, it's a blast
Anonymous
6/20/2025, 9:31:23 AM
No.105649040
[Report]
>>105649036
fucking freaks you lot, bye again.
Anonymous
6/20/2025, 9:32:34 AM
No.105649048
[Report]
>>105649056
>>105648959
>cumfart workflows are snake oil
which part of the workflow is snake oil?
Anonymous
6/20/2025, 9:33:30 AM
No.105649055
[Report]
>>105649048
multigpu, distill lora, teacache, probably some other bullshit people are shoving in
Anonymous
6/20/2025, 9:34:14 AM
No.105649062
[Report]
>>105647963
Everyday we stray... closer to god
Based work anon, what model do you make the start images in ?
Anonymous
6/20/2025, 9:34:32 AM
No.105649065
[Report]
btw, jannies are the ones trolling, they can see ip's. does not matter how you word your words they will still know its you due to ip range.
Anonymous
6/20/2025, 9:34:45 AM
No.105649067
[Report]
>>105649074
>>105649056
Oh, so you're legitimately retarded or just trolling. Good to know
Anonymous
6/20/2025, 9:34:53 AM
No.105649069
[Report]
Anonymous
6/20/2025, 9:35:27 AM
No.105649074
[Report]
>>105649067
prove me wrong
Anonymous
6/20/2025, 9:35:33 AM
No.105649076
[Report]
>>105649102
>>105649056
multigpu is useful for pople with multiple gpus
recent distil loras are useful for meme videos but you dont have to use them
teacache speeds up generation by a lot with neglibile quality loss, basically none with SLG
so again, which part there is "snakeoil" and why?
Anonymous
6/20/2025, 9:35:49 AM
No.105649079
[Report]
>>105648938
wtf that's insane
Anonymous
6/20/2025, 9:35:54 AM
No.105649081
[Report]
>>105649088
>just turn off all the optimizations and use a pure vanilla workflow bro, it's wan at full power where 480p takes forty five minutes per gen
Anonymous
6/20/2025, 9:35:55 AM
No.105649082
[Report]
>>105647986
Lynch would give you a thumbs up
Anonymous
6/20/2025, 9:36:04 AM
No.105649083
[Report]
that's really interesting
Anonymous
6/20/2025, 9:37:33 AM
No.105649088
[Report]
>>105649096
>>105649081
35min 3090 25 step 0.19 teacache q8 720p wan
Anonymous
6/20/2025, 9:37:42 AM
No.105649090
[Report]
>>105648056
>propulsion diarrheaa
probably not the superpower you'd want, but beggars can't be choosers
Anonymous
6/20/2025, 9:38:35 AM
No.105649096
[Report]
>>105649088
I thought you said teacache was snake oil
>>105649078
>multigpu is useful for pople with multiple gpus
apparently not since it doesn't utilize multiple gpus properly from people with multiple gpus also memory leaking problems
>recent distil loras are useful for meme videos but you dont have to use them
it's pretty much snake oil
>teacache speeds up generation by a lot with neglibile quality loss
it does mulch the output you blind fuck
>SLG
forgot about this snake oil
Anonymous
6/20/2025, 9:39:37 AM
No.105649102
[Report]
>>105649126
>>105649076
Nice, very 80s italian fumetti comics, the two rows of teeth actually adds to the menace.
Anonymous
6/20/2025, 9:40:04 AM
No.105649104
[Report]
>>105649132
>>105649097
>it does mulch the output you blind fuck
this anon is right, teacache makes my vids shitty for some reason. only happens on anistudio though, looks fine in comfy. not sure why
Anonymous
6/20/2025, 9:40:23 AM
No.105649107
[Report]
Anonymous
6/20/2025, 9:40:39 AM
No.105649111
[Report]
>>105649175
>>105649078
It's a troll, it does this all the time. Eventually, it'll start spamming 80's music videos and calling people cunts. Just hide stubs and collapse its posts, don't waste your time arguing with it
Anonymous
6/20/2025, 9:40:55 AM
No.105649112
[Report]
>>105649188
>>105649097
>>SLG
>forgot about this snake oil
do not take the bait
Anonymous
6/20/2025, 9:42:03 AM
No.105649119
[Report]
>>105649134
Anonymous
6/20/2025, 9:42:18 AM
No.105649120
[Report]
Anonymous
6/20/2025, 9:42:40 AM
No.105649126
[Report]
Anonymous
6/20/2025, 9:42:52 AM
No.105649128
[Report]
doritos pope geoff does magic:
If you want to use the NAG optimization in Comfy, what do you need to install ?
Anonymous
6/20/2025, 9:43:07 AM
No.105649132
[Report]
>>105649144
>>105649104
how do I use wan in anistudio?
Anonymous
6/20/2025, 9:43:43 AM
No.105649134
[Report]
>>105649119
Wow, I like it. It really pulls me into its story.
>>105649078
the fast shit workflow is snake oil and shit, why does the retard running the rentry keep hyping it up?
Anonymous
6/20/2025, 9:44:48 AM
No.105649144
[Report]
>>105649160
>>105649132
honestly don't even bother it took me almost 5 hours to fix dependency issues and even then it seems to have permanently messed up my system registry
Anonymous
6/20/2025, 9:45:17 AM
No.105649148
[Report]
>>105649138
>why doesn't the world revolve around my single opinion?
geez I wonder why?
Anonymous
6/20/2025, 9:45:25 AM
No.105649149
[Report]
>>105649138
idk. that other 1girl one has broken workflows too
Anonymous
6/20/2025, 9:45:45 AM
No.105649150
[Report]
>>105649163
>>105649078
>so again, which part there is "snakeoil" and why?
Because it moves away from the models training, so the physics messes up etc. You can see it with those speed loras, there will be one action happening but everything else in the video will be frozen stiff or moving super slow motion. absolute trash, why would you even want to use anything that ruins the quality?
multigpu node does not work as advertised, i don't give a fuck, the options i use work and have worked since wan and hunyuan were released. reserve vram and you don't oom, there is a limit and for me its about 145 frames on a 12GB, and i can still use my computer to watch a youtube video.
everything else is trash, kj nodes offload is the same crap as that multigpu node for offloading, its super slow and if it oom it don't even free up the vram in kj nodes case because hes a fucking idiot!!!!!!!!1 yes it makes us angry because there are so many shitty workflows which makes learning this thing every harder and fucking chore due to gate keeping faggots.
Anonymous
6/20/2025, 9:45:50 AM
No.105649152
[Report]
>>105649138
>To be clear, this isn't a drop-in replacement for normal WAN. If you do a side-by-side comparison between two gens with the same prompt and seed, you'll see there's a difference, and that a regular WAN output is superior to an output made using this method. You'll need to test it out to see whether the quality loss is acceptable to you given the large speed gains and the fact that it makes 720p a viable option.
So much hype, my god. Especially the part where it describes all the issues with it, like the slow motion and bad prompt coherency
Anonymous
6/20/2025, 9:46:14 AM
No.105649158
[Report]
>>105649226
>>105649129
NVM, found it in rentry, I'm a retard
>>105649144
sounds like a skill issue. should have gotten the binaries
Anonymous
6/20/2025, 9:47:21 AM
No.105649163
[Report]
>>105649174
>>105649150
>multigpu node does not work as advertised, i don't give a fuck
works on my machine
Anonymous
6/20/2025, 9:48:05 AM
No.105649168
[Report]
>>105649989
I said throws a table with snacks...he placed a table with snacks. technically it's right, I guess.
Anonymous
6/20/2025, 9:48:24 AM
No.105649172
[Report]
>>105649185
>>105649160
i did eventually, i'm pretty sure that caused my system to now take 5 minutes to boot up, i tried forever to try to fix it without success so i don't even turn off my computer anymore
Anonymous
6/20/2025, 9:48:33 AM
No.105649174
[Report]
>>105649187
>>105649163
Same. I get use out of both regular wan and the distilled one posted, there's use cases for both. Don't see why some anons feel the need to get so emotional over it
Anonymous
6/20/2025, 9:48:35 AM
No.105649175
[Report]
>>105649188
>>105649111
no, you are the troll, if you can't handle my posts then fuck off, where the fuck do you think you are? This isn't reddit.
Anonymous
6/20/2025, 9:49:47 AM
No.105649185
[Report]
>>105649189
>>105649172
honestly impressive ani destroyed your computer only schizo. why not show us an anistudio output?
>>105649174
>Don't see why some anons feel the need to get so emotional over it
it's just igor, the alchool is starting to kick in, I'm glad I'm going to sleep it means I'm going to skip the 7 hours schizo rambling cutscene kek, see ya tommorow anons
Anonymous
6/20/2025, 9:50:28 AM
No.105649188
[Report]
>>105649192
Anonymous
6/20/2025, 9:50:39 AM
No.105649189
[Report]
>>105649213
>>105649185
why so hostile? that makes me not want to use your software now
Anonymous
6/20/2025, 9:51:02 AM
No.105649191
[Report]
>>105649187
lol same, it's like he only appears when I'm ready to bail, I love it.
>>105649188
both videos look like absolute shite
Anonymous
6/20/2025, 9:51:07 AM
No.105649194
[Report]
>>105649270
Anonymous
6/20/2025, 9:52:01 AM
No.105649200
[Report]
Anonymous
6/20/2025, 9:52:24 AM
No.105649204
[Report]
>>105649192
>nonsequitour
oof, looks like someone
>can't handle my posts
back to preddit tranny
Anonymous
6/20/2025, 9:53:18 AM
No.105649205
[Report]
>>105649218
>>105649187
you're the fagot that attacks me when ever I post, so YOU CAN GO FUCK YOUR SELF FAGGOT AND I AM NOT FUCKING DRUNK YOU PRICK IF I COULD GET YOU RL I'D FUCK YOU I SWEAR JUST FUCK OFF NO ONE FUCKING CARES ABOUT
RAN
DEBO
IVAN
YOU'RE A FUCKING SCHIZO THAT SITS HERE EVERY FUCKING DAY LOOKING FOR GHSB DRQTBHKLQWLKQ4 FUCK OFF
Anonymous
6/20/2025, 9:53:29 AM
No.105649206
[Report]
>>105649214
wow, someone is angry
Anonymous
6/20/2025, 9:53:57 AM
No.105649210
[Report]
>Flux NAG code released just before I went to bed
>updated everything 30min ago
>no node
So is it available somewhere else?
Anonymous
6/20/2025, 9:54:56 AM
No.105649213
[Report]
>>105649228
>>105649189
I doubt any FOSS project author wants you around kek
Anonymous
6/20/2025, 9:55:00 AM
No.105649214
[Report]
>>105649206
i'm autistic and he picks on me every time
Anonymous
6/20/2025, 9:55:16 AM
No.105649218
[Report]
>>105649205
>trying this hard
*yawn*
Anonymous
6/20/2025, 9:57:07 AM
No.105649223
[Report]
>FILM VFI is too slow for my taste
>try all the other interpolation nodes in the pack
>they're all shit compared to FILM VFI
Sigh.
Anonymous
6/20/2025, 9:57:35 AM
No.105649226
[Report]
>>105649743
>>105649129
>>105649158
don't bother its crap, it completely changes the video in bad ways when using loras, there fore it is trash and useless. You may as well go use none local if all you want is speed.
Anonymous
6/20/2025, 9:57:45 AM
No.105649228
[Report]
>>105649231
>>105649213
wow, i didn't realize this project was so user-hostile, i'll stick to comfyui
Anonymous
6/20/2025, 9:58:51 AM
No.105649231
[Report]
>>105649253
>>105649228
>implying comfy wasn't hostile to ilya and voldy
Anonymous
6/20/2025, 10:01:58 AM
No.105649243
[Report]
Anonymous
6/20/2025, 10:02:25 AM
No.105649246
[Report]
>>105649258
>>105649160
That wasn't the question they asked, you just felt the need to troll.
Anonymous
6/20/2025, 10:03:13 AM
No.105649253
[Report]
>>105649231
>implying you're bothered by hostility
Anonymous
6/20/2025, 10:04:02 AM
No.105649258
[Report]
>>105649269
>>105649246
I never got an anistudio gen proving he did and he never went into detail on how to gen a vid. I'm curious, he's abrasive. fuck that anon
Anonymous
6/20/2025, 10:04:02 AM
No.105649259
[Report]
I know most of you guys are fixated on Chroma right now but it seems like for anime models, pickings are slim with the paywall and a new model beyond Illustrious 2.0 being out of reach. I was browsing through things and apparently, some people are starting to take it in a different direction. I discovered there is a Chinese team trying to fine tune Lumina 2.0 for anime and they have taken it farther than the fine tune Illustrious did for their alpha.
https://civitai.com/models/1612109/netaaniluminaalpha
Their training progress checkpoints are here and it is still in progress.
https://huggingface.co/neta-art/NetaLumina_Alpha
Seems like early stages but it looks like some people are getting some mileage out of it. Unfortunately, I think I need to make a separate account to get access with it locked behind the agreement on HF.
Anonymous
6/20/2025, 10:05:44 AM
No.105649269
[Report]
>>105649276
>>105649258
>he's abrasive
Nice projection. Which part of his posts were abrasive? Was it:
>impressive ani destroyed your computer only schizo
or was it:
>I doubt any FOSS project author wants you around kek
?
Anonymous
6/20/2025, 10:05:46 AM
No.105649270
[Report]
>>105649194
I like this lora too
Anonymous
6/20/2025, 10:05:47 AM
No.105649272
[Report]
>>105649260
>locked behind the agreement on HF
Why do model makers do this?
Anonymous
6/20/2025, 10:06:28 AM
No.105649276
[Report]
>>105649281
>>105649269
>projection
go to bed ranfag
Anonymous
6/20/2025, 10:06:32 AM
No.105649278
[Report]
>>105649286
I grabbed this lora from civ:
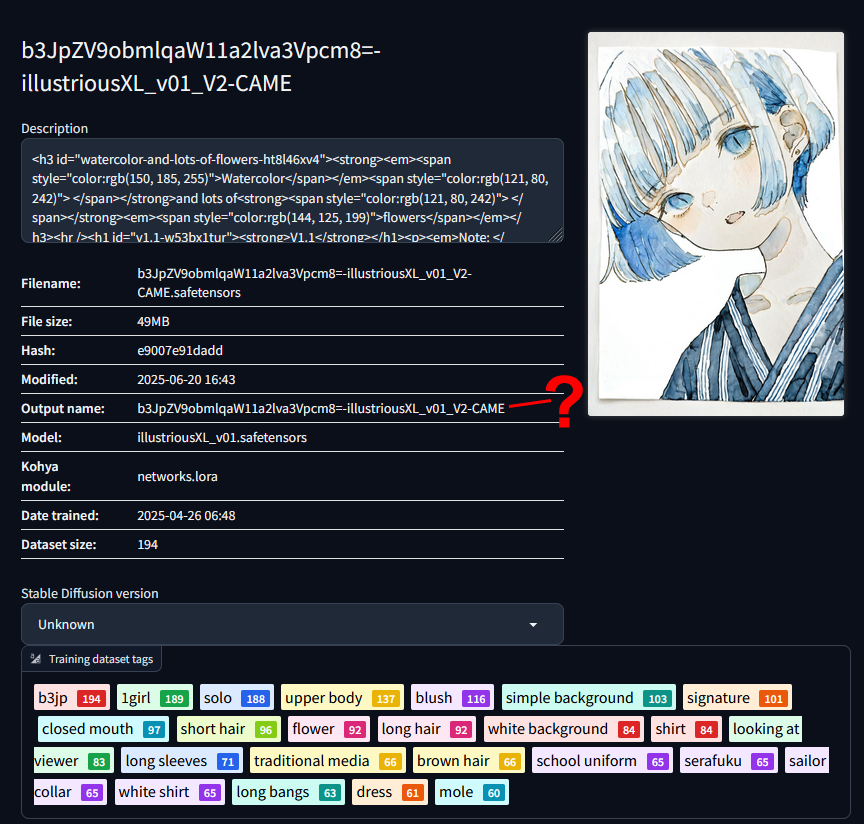
https://civitai.com/models/1362657/watercolorsaturated-or-illustrious-style-lora
when I try to use it in reforge, not only doesn't it, work, when I include it in the prompt it stops every other lora from loading too. i suspect it has something to do with the "output name" having illegal characters in it? is there any way to fix this? it seems independent of the .safetensors filename.
Anonymous
6/20/2025, 10:07:03 AM
No.105649281
[Report]
>>105649295
>>105649276
how come he keeps giving it away like that?
Anonymous
6/20/2025, 10:07:42 AM
No.105649286
[Report]
>>105649289
Anonymous
6/20/2025, 10:08:21 AM
No.105649289
[Report]
Anonymous
6/20/2025, 10:09:04 AM
No.105649295
[Report]
>>105649281
he's a stupid faggot that just seethes over ani 24/7?
Anonymous
6/20/2025, 10:09:53 AM
No.105649297
[Report]
>>105649308
>>105649260
Yeah, the model in its alpha state already knows so much more than Chroma.
Anonymous
6/20/2025, 10:11:08 AM
No.105649302
[Report]
>105649276
>105649281
>105649295
all me btw
>>105649297
>already knows so much more than Chroma.
that's the thing that dissapointed me the most on chroma, it dosn't know much characters or artist styles, that was the biggest weaknesses of Flux, the fuck is he doing seriously, his dataset has 5 millions of images
Anonymous
6/20/2025, 10:12:18 AM
No.105649314
[Report]
>>105649308
astracuck meddling maybe?
Anonymous
6/20/2025, 10:14:09 AM
No.105649321
[Report]
>>105649308
>the fuck is he doing seriously
That's one of the reasons I want Krea to be released, so that we stop talking about chroma once and for all, this piece of a shit was a giant waste of time.
Anonymous
6/20/2025, 10:14:24 AM
No.105649323
[Report]
>>105649530
>>105649308
Imo it's not what the guy is doing. It's just that the model itself is not that good for finetuning.
Anonymous
6/20/2025, 10:14:33 AM
No.105649324
[Report]
>>105649339
>>105649260
Thanks for sharing , could be good.
>>105649308
Personally i`m fine with that, i can always train style loras or img2img with IL. I know this isnt ideal but it`s still good having a local model capable of compositions that IL can't do
>>105649308
It's a mixed dataset for a general purpose model. Chroma is supposed to be a new foundational model that can be finetuned further, like SDXL was finetuned on illustrious, and illustrious on noob. It never claimed to be an anime-centric replacement for the best anime models we have.
The idea is, when it's done and if he doesn't fuck it up, finetuning it on a dataset like illustrious or noob will make it leagues ahead of the current illustrious and noob models thanks to increased parameters, prompt adherence and the use of flux's 16 channel vae over sdxl's shitty 4 channel vae, meaning much more detail.
Anonymous
6/20/2025, 10:16:15 AM
No.105649332
[Report]
>>105649345
>>105649308
I presume the finetuning for that is after Chroma releases as a general model. Unfortunately, it will have shit tagging most likely and whatever finetuning is done after that point will be furry focused which means you need to find people to fund and tune on top of Chroma itself.
Anonymous
6/20/2025, 10:17:08 AM
No.105649339
[Report]
>>105649353
>>105649324
Same. Chroma is still the best for photorealism, it's not going anywhere, but for everything else there are alternatives. And this Lumina model looks like it could replace IL and be as good as NAI v4.5. Its aesthetics look really nice. This is the anime model I've been waiting for.
Anonymous
6/20/2025, 10:17:14 AM
No.105649341
[Report]
>>105649329
Okay I like Chroma and your point is entirely valid but I feel like
>>105431842 was prophetic lol
Anonymous
6/20/2025, 10:17:31 AM
No.105649345
[Report]
>>105649329
>>105649332
so the chroma hater was right
>"we'll have to finetune on top of chroma finetune" <- you are here
remember that? kek
Anonymous
6/20/2025, 10:17:38 AM
No.105649346
[Report]
>weebs still whining when anyone tries to make a model that isn't 100% focused on weebs
nothing has changed in four years
>>105649339
>Chroma is still the best for photorealism
bruh the anatomy is ASS, I get that the skin texture is good, but if the hands looks like this I don't see the point
Anonymous
6/20/2025, 10:21:07 AM
No.105649364
[Report]
>>105649353
inpaint or increase steps
Anonymous
6/20/2025, 10:21:19 AM
No.105649365
[Report]
Anonymous
6/20/2025, 10:22:06 AM
No.105649366
[Report]
>>105649436
at least sdxl is getting 16 channel vae...
Anonymous
6/20/2025, 10:27:05 AM
No.105649388
[Report]
>>105649482
even if chroma never gets better it already has a use case for realism until the next model drops, let alone with some loras, simple as
Anonymous
6/20/2025, 10:27:07 AM
No.105649389
[Report]
>>105649353
If that kind of gen is all you get then you're doing something wrong. It is very rare to get something that bad.
Anonymous
6/20/2025, 10:30:14 AM
No.105649404
[Report]
>>105649408
>>105649329
>finetuned further, like SDXL was finetuned on illustrious, and illustrious on noob
Your message is fucked up
Anonymous
6/20/2025, 10:31:45 AM
No.105649408
[Report]
>>105649404
eh? sdxl WAS finetuned on illustrious tho and noob was made on top of ill lol
Anonymous
6/20/2025, 10:32:56 AM
No.105649414
[Report]
>argument devolves into semantics now
*yawn*
>>105649260
Are they training on nsfw stuff too? Seems like they are releasing a new epoch every 4 days or so
>>105647685 (OP)
>https://rentry.org/wan21kjguide
Why does the new workflow still have the 'patch model patcher order' node? iirc Comfy corrected the weigth order with Wan a few update ago already
Anonymous
6/20/2025, 10:34:25 AM
No.105649420
[Report]
>>105649416
>iirc Comfy corrected the weigth order with Wan a few update ago already
Linky
Anonymous
6/20/2025, 10:35:36 AM
No.105649428
[Report]
>>105649526
girl cuts a watermelon with a sword:
Anonymous
6/20/2025, 10:37:16 AM
No.105649436
[Report]
>>105649366
I hope it works
Anonymous
6/20/2025, 10:39:17 AM
No.105649448
[Report]
>>105649260
damn this actually looks GOOD. it looks AESTHETIC. the chinese century is here
Anonymous
6/20/2025, 10:41:55 AM
No.105649458
[Report]
>>105649513
>>105649260
>more cringe wannabe artfaggotry
>B-BUT IT LOOKS ALL AESTHETIC AND HAND DRAWN JUST LIKE MY FAVORITE NIPPON MANGARA ARTIST THAT MAKES IT SOVLFUL OHMYGARSH LOOK THERE'S A GUY WITH A SWORD AND HE LOOKS ALL SERIOUS AND SWOLE AND SHIT WOWWWWW
*megayawn*
Anonymous
6/20/2025, 10:42:25 AM
No.105649462
[Report]
>>105649465
What should I have for NAG settings for imagegen?
Anonymous
6/20/2025, 10:42:36 AM
No.105649463
[Report]
^ astralite
Anonymous
6/20/2025, 10:43:12 AM
No.105649465
[Report]
>>105649519
>>105649462
snake oil for anything but wan, toss it away anon
Anonymous
6/20/2025, 10:44:34 AM
No.105649475
[Report]
Anonymous
6/20/2025, 10:45:49 AM
No.105649482
[Report]
>>105649388
This. Look at gens like
>>105596147
I'm not just testing the model's ability to do feet. There are several things happening here. I am testing its raw concept knowledge. The girl has dirty socks. She is smoking, Her feet is on the table. She is sitting on a gaming chair. She is a Korean model. She is in her room. Putting all of my fetishes aside, the fact that it's able to do this coherently at all should tell you the model is special. It knows almost anything you can throw at it, and that is a very difficult model to beat.
Now, even with realism the model is not perfect in every way. Like despite some improvements with multiple subjects, I am not quite sure detailed is a direct upgrade over regular
>>105589847
The sloppiness is getting slightly better, but that version is still not there imo. It's a bit concerning, but right now those detail versions are just merges, we'll see how it goes at the end.
Anonymous
6/20/2025, 10:49:40 AM
No.105649506
[Report]
I'm casting magic missile
Anonymous
6/20/2025, 10:50:21 AM
No.105649510
[Report]
What's the optimal detail daemon settings for chroma?
Anonymous
6/20/2025, 10:50:51 AM
No.105649513
[Report]
>>105649458
>STOP enjoying things I don't, it, it makes me feel bad, okay? It hurts my feefees!
Anonymous
6/20/2025, 10:51:11 AM
No.105649515
[Report]
>>105649571
Annnnd you summoned the chromaschizo now too. Good job, dumbass. That's me out, this whole thread has been a shitshow from the start anyway.
Anonymous
6/20/2025, 10:51:50 AM
No.105649519
[Report]
>>105649527
>>105649465
>snake oil for anything but wan
how do you know that? there's some examples showing it's a bad method?
Here are the problems with Chroma.
1. It's based on Flux.
2. It's furry focused.
3. It has learnt zero artist tags after 38 epochs.
4. It is being trained at 512x for 95% of the epochs.
5. When completed, it needs to be finetuned AGAIN to actually learn the artist tags.
Anonymous
6/20/2025, 10:52:51 AM
No.105649526
[Report]
>>105649428
Lightning is the only decent character of ff13, I couldn't stand any of the other main characters lol
Anonymous
6/20/2025, 10:52:56 AM
No.105649527
[Report]
>>105649535
>>105649519
>there's some examples showing it's a bad method?
no, I made it the fuck up
Anonymous
6/20/2025, 10:53:10 AM
No.105649530
[Report]
>>105649542
>>105649323
Probably this. I've used the lastest chroma and I was kind of more impressed but it still has a long way to go.
Anonymous
6/20/2025, 10:54:31 AM
No.105649535
[Report]
>>105649527
kek, I respect your trolling hussle
Anonymous
6/20/2025, 10:55:32 AM
No.105649542
[Report]
>>105649530
>I've used the lastest chroma and I was kind of more impressed
you're feeling an improvement between v38 and v37 is that what you're saying?
Anonymous
6/20/2025, 10:56:22 AM
No.105649549
[Report]
>>105649571
>>105649353
Yeah that is the problem with it, but you should do a second pass with 0.5 denoise on a second sampler node using a different seed and that usually fixes it.
Anonymous
6/20/2025, 10:57:12 AM
No.105649552
[Report]
>>105649523
you can use more than 1 model
use it if you need realism, if you dont then dont
Anonymous
6/20/2025, 10:59:03 AM
No.105649564
[Report]
>>105649523
>It's based on Flux.
That's fine
>It's furry focused.
That's cringe
>It has learnt zero artist tags after 38 epochs.
Any evidence he even included artist tags in the dataset?
>It is being trained at 512x for 95% of the epochs.
There's a paper about training DiT models at various passes, starting with a lower res pass then two high res passes, but I can't recall the name. I've never finetuned a full model myself so I have no idea how correct his methodology is, but I suspect at the least it's going to need a *lot* of high res passes
>When completed, it needs to be finetuned AGAIN to actually learn the artist tags.
Correct, but I don't recall him ever saying it was going to be better than shit like ill or noob off the bat. It's a 5m data set that has all types of stuff in it apart from anime, while ill models are between like 7-20m pure anime and r34 and noob was 13m. It'll definitely need someone to anime finetune it after, but given the model size... yeah, I don't really see it happening any time soon. Expensive proposition. Maybe he'll do it himself, kek
Anonymous
6/20/2025, 11:00:09 AM
No.105649571
[Report]
>>105649549
I don't think these naysayers posters are looking for genuine advice. They're sitting around for this kind of opportunity
>>105649515
>>105649523
Not only that,Chroma has a limited character database.
Since i'm a Touhou project fan , i usually prefer models with the most complete set of characters.
Chroma recognizes just 3 or 4 , Reimu , Marisa, and maybe Remilia Scarlet, often mixing character details.(still better than flux, tho)
In this regard, Noobai has a surprisingly rich character database,and i still use it for lots of gens.
Anonymous
6/20/2025, 11:03:47 AM
No.105649589
[Report]
>>105649569
>I don't really see it happening any time soon
Illustrious will do it and then gate it between 1 trillion Stardust.
Anonymous
6/20/2025, 11:05:35 AM
No.105649601
[Report]
>>105649605
>>105649569
>Any evidence he even included artist tags in the dataset?
yes
https://www.reddit.com/r/StableDiffusion/comments/1j4biel/comment/mg81j11/?utm_source=share&utm_medium=web3x&utm_name=web3xcss&utm_term=1&utm_content=share_button
>>105649601
>4m ago
That was before the ponyfag hooked him up with hardware. What's the bet pony convinced him to obfusticate the artist tags?
Anonymous
6/20/2025, 11:06:53 AM
No.105649607
[Report]
i haven't done anything with local image gen since like 4 years ago with a1111 and garbage SDXL models. today i will start all over. wish me luck frends
Anonymous
6/20/2025, 11:11:16 AM
No.105649631
[Report]
>>105649641
>>105649588
I don't think that the problem is Chroma's dataset. It could just as easily be that Flux is a huge model, so it's hard to teach it every concept. Turns out that for realism, the model knows many, many things. But that comes at a cost. It's very difficult to teach it new concepts because of how massive its knowledge is. That's just how it is. I am personally comfortable with Chroma not being the top anime model. Two separate models for anime/realism aren't bad. I just don't like SDXL being used to train anime, and Lumina will solve that for now. We have yet to see Flux's full finetune potential, it's just that with the hardware lodestone has it would take a while to actually see insane results.
>>105649631
>It's very difficult to teach it new concepts because of how massive its knowledge is. That's just how it is.
that's nonsense, some SDXL finetunes know millions of anime concepts, and you're telling me a model 3x bigger couldn't do the same?
Anonymous
6/20/2025, 11:14:45 AM
No.105649652
[Report]
>>105649605
>What's the bet pony convinced him to obfusticate the artist tags?
likely, maybe that was the price to pay for those GPUs
Anonymous
6/20/2025, 11:15:11 AM
No.105649657
[Report]
>bro this 20 million image sdxl finetune trained on four entire boorus is better at anime than the 8.9B model trained on probably less than three million anime images! HOW CAN THIS BE HAPPENING?!
Anonymous
6/20/2025, 11:16:59 AM
No.105649672
[Report]
>>105649696
>>105649641
it's not an anime model
it's not being made just for you
Anonymous
6/20/2025, 11:17:58 AM
No.105649678
[Report]
>>105649696
>>105649641
You are comparing apples to oranges. Different architectures, different parameter count, different text encoders that have to be trained, etc... We are just in the beginning stages of all this. No one else has finetuned Flux and successfully taught it artist styles. Why aren't you demonizing all the other failures? Everyone just gave up and focused on SDXL.
>>105649672
nonsequitour
>>105649678
>Different architectures
the Unet (SDXL) architecture is worse than the DiT (Chroma) architecture
>different parameter count
that's my point, SDXL is a 2.7b parameter model, Chroma is a 8.9b parameter model, if a 2.7 parameter model was able to eat so much anime knowledge, a 8.9b one definitely can too
>different text encoders that have to be trained
the fuck is he talking about, no one train a text encoder during a finetune, it didn't happen on Noob, it didn't happen on Illustrious, and it doesn't happen with Chroma, you have no idea what you're talking about do you?
>>105649416
>Why does the new workflow still have the 'patch model patcher order' node?
If he did fix it and you've got time, post the commit and I'll remove the nodes. I'm partially reliant on other anons to update me on stuff like this for the community workflows, I'm pretty lazy otherwise.
Anonymous
6/20/2025, 11:21:59 AM
No.105649705
[Report]
>>105649688
kek, that's completly innacurate but that's its charm, I'm gonna miss it once we'll get a better video models and it won't sput out kinos like this
Anonymous
6/20/2025, 11:22:51 AM
No.105649711
[Report]
>>105649688
physics fail, used any snakeoil?
Anonymous
6/20/2025, 11:25:29 AM
No.105649725
[Report]
>>105649759
>>105649703
That was the LoRA + Torch Compile issue, yeah? Did comfy fix that or was it fixed in TorchCompileModelWanVideoV2 by kj?
Anonymous
6/20/2025, 11:25:45 AM
No.105649729
[Report]
>>105649739
>>105649696
>if a 2.7 parameter model was able to eat so much anime knowledge, a 8.9b one definitely can too
I'm not saying that it can't. I'm saying that it will take a while.
>the fuck is he talking about, no one train a text encoder during a finetune
Alright, I can already tell you are just a bad faith troll.
Anonymous
6/20/2025, 11:26:06 AM
No.105649731
[Report]
>>105649757
deus ex:
Anonymous
6/20/2025, 11:27:06 AM
No.105649739
[Report]
>>105649781
>>105649729
is he retarded? we're still using the same old t5 on chroma, nothing changed at all because he didn't touch the encoder during the training, is this an elaborate bait or something?
>>105649696
>different parameter count
>that's my point, SDXL is a 2.7b parameter model, Chroma is a 8.9b parameter model, if a 2.7 parameter model was able to eat so much anime knowledge, a 8.9b one definitely can too
I'm a fucking noob , but as far as i've understood,
number of parameters of a model only affect HOW the INITIAL data is transformed in a meaningful output.
So it all depends on the initial quantity and quality of the training picture database?
Anonymous
6/20/2025, 11:28:48 AM
No.105649750
[Report]
>>105649787
Anonymous
6/20/2025, 11:29:30 AM
No.105649757
[Report]
>>105650079
>>105649731
directors cut:
Anonymous
6/20/2025, 11:29:56 AM
No.105649759
[Report]
>>105649725
>That was the LoRA + Torch Compile issue, yeah?
Yes. I can't recall the specifics, think it was something about the LoRA matrices not applying correctly when you compile. And I don't know if it was fixed, that's why I'm asking. If nobody has an answer, I can test it tomorrow or something. Easy enough. T2V > Nude LoRA > No Patcher. Genitals massacred means the patcher is still required.
Anonymous
6/20/2025, 11:30:47 AM
No.105649766
[Report]
Anonymous
6/20/2025, 11:30:57 AM
No.105649767
[Report]
>>105649747
>number of parameters of a model only affect HOW the INITIAL data is transformed in a meaningful output.
not at all, a bigger model also means it has more space to store the knowledge
https://arxiv.org/abs/2205.10770
>We measure the effects of dataset size, learning rate, and model size on memorization, finding that larger language models memorize training data faster across all settings. Surprisingly, we show that larger models can memorize a larger portion of the data before over-fitting and tend to forget less throughout the training process.
Anonymous
6/20/2025, 11:31:51 AM
No.105649772
[Report]
>>105649747
nigger, if the model has bigger brain, it can find and hold more complex patterns and knowledge
Anonymous
6/20/2025, 11:31:55 AM
No.105649773
[Report]
>>105649743
try it with the normal models t2v and i2v it will probably work well with those. i'm just messing around with phantom or vace models and those models seem to hate any of this stuff.
Anonymous
6/20/2025, 11:32:54 AM
No.105649781
[Report]
>>105649786
>>105649739
That's not what I meant dumbass. The model still has to leverage the old t5 to associate a new artist tag with a style. It clearly is not very good at that yet.
Anonymous
6/20/2025, 11:33:33 AM
No.105649784
[Report]
>>105649588
>Not only that,Chroma has a limited character database.
True, but so does Flux and SDXL, yet these are the most used image models since you can fix all these shortcomings with lora and full finetuning.
Take away all the lora from Flux and it's worthless unless you really like sameface Flux chin.
So, until we see what Chroma lora can do, and potentially further finetuning, it's pointless to judge it.
Anonymous
6/20/2025, 11:33:45 AM
No.105649786
[Report]
>>105649803
>>105649781
>The model still has to leverage the old t5 to associate a new artist tag with a style. It clearly is not very good at that yet.
So you're telling me that clip_l can do it but not t5, all right this guy is completly braindead
>>105649750
I'm not, NAG literally butchers gens with certain models.
Anonymous
6/20/2025, 11:34:34 AM
No.105649789
[Report]
>>105649801
>>105649787
Got the side by sides?
Anonymous
6/20/2025, 11:34:45 AM
No.105649790
[Report]
>>105649641
>some SDXL finetunes know millions of anime concepts
Yes, anime specific SDXL finetunes, you can do the same for Chroma.
Anonymous
6/20/2025, 11:34:46 AM
No.105649791
[Report]
>>105649787
>NAG literally butchers gens with certain models.
Anonymous
6/20/2025, 11:36:04 AM
No.105649801
[Report]
>>105649804
>>105649789
just go find for yourself. enjoy wasting hours and hours.
Anonymous
6/20/2025, 11:36:39 AM
No.105649802
[Report]
Anonymous
6/20/2025, 11:36:41 AM
No.105649803
[Report]
>>105649809
>>105649786
If you're so good at finetuning Flux-sized models, where is your model anon?
Anonymous
6/20/2025, 11:37:04 AM
No.105649804
[Report]
>>105649801
>makes a baseless claim
>has the burden of proof
>doesn't provide the proof
everytime
Anonymous
6/20/2025, 11:38:07 AM
No.105649809
[Report]
>>105649820
>>105649803
Non Sequitour.
>>105649809
>No argument
I accept your concession
Anonymous
6/20/2025, 11:42:58 AM
No.105649827
[Report]
>>105649840
>>105649820
>makes a non sequitor fallacy
>calls himself the winner
kek, that one is funny
Anonymous
6/20/2025, 11:45:02 AM
No.105649838
[Report]
>>105649853
>>105649820
>2+2 = 5
>no it's 4
>WHEN ARE YOU GONNA END THE WARS IN THE WORLD ANON?
>what?
>ahah I got you, you can't find arguments don't you?!
>>105649827
>Continuation of his own argument is illogical
Anonymous
6/20/2025, 11:46:48 AM
No.105649853
[Report]
Anonymous
6/20/2025, 11:51:08 AM
No.105649880
[Report]
>>105649605
he probably lied about that to get some hype and money, he never intended to include artists on his model, that's my 2 cents
>>105649703
I think this was this one
https://github.com/comfyanonymous/ComfyUI/pull/8213
I didn't try that much but at the very least I don't have the 'failed lora weight key' I had a few months ago when load a lora with torch compile for Wan anymore
Anonymous
6/20/2025, 11:52:40 AM
No.105649889
[Report]
>>105649915
>>105649840
appeal to accomplishment is a fallacy
Anonymous
6/20/2025, 11:53:23 AM
No.105649891
[Report]
>>105649840
>I have the right to change the subject when I feel I'm losing the debate
DENIED!
Anonymous
6/20/2025, 11:55:00 AM
No.105649899
[Report]
>>105649886
Nice, I'll take a look tomorrow and run some tests to be sure. Thanks, anon.
Anonymous
6/20/2025, 11:56:54 AM
No.105649910
[Report]
>>105649886
weird, I tried turning off the patcher node, reloaded the models and got an oom on the next run despite never oom'ing before with my settings, it used like an extra 2 or 3gb for some reason. That's with three loras
Anonymous
6/20/2025, 11:57:42 AM
No.105649915
[Report]
>>105649924
>>105649889
That's not my point. No one else has done it before, neither have you.
Anonymous
6/20/2025, 11:58:51 AM
No.105649924
[Report]
>>105649915
>No one else has done it before
done what before? stuffing anime concepts onto a model?
Anonymous
6/20/2025, 12:02:24 PM
No.105649947
[Report]
>>105649966
anti-Chroma anons proving yet again they can't be taken seriously in any argument
Anonymous
6/20/2025, 12:04:55 PM
No.105649966
[Report]
>>105649947
I was an anti-chromatard at first, but I became a chromakek when I actually sat down and gave it a proper try, then realized how wrong I was about it
Anonymous
6/20/2025, 12:06:11 PM
No.105649975
[Report]
Anonymous
6/20/2025, 12:07:46 PM
No.105649989
[Report]
>>105650003
>>105648805
>https://github.com/thu-ml/SageAttention
>The code for SageAttention2++ is scheduled for release around June 20
That would bring my wan gen times from 2-3mins to what, 40 seconds?
>less power consumption
>less room heat
>more goofy gens
We need this
>>105649168
kek'd
Anonymous
6/20/2025, 12:10:25 PM
No.105650003
[Report]
>>105650053
>>105649989
>That would bring my wan gen times from 2-3mins to what, 40 seconds?
no, it's a 30% speed increase, going from 3 minutes to 40 seconds is a 350% speed increase lol
Anonymous
6/20/2025, 12:19:42 PM
No.105650053
[Report]
>>105650081
>>105650003
... so you're saying it's possible
Anonymous
6/20/2025, 12:23:48 PM
No.105650079
[Report]
>>105649757
Why contain it?
Anonymous
6/20/2025, 12:24:15 PM
No.105650081
[Report]
Anonymous
6/20/2025, 12:26:41 PM
No.105650095
[Report]
feel like its not worth trying for accurate flux gens on low vram, it just cant nail accuracy i want compared to bigger models i cant run.