/lmg/ - Local Models General
►Recent Highlights from the Previous Thread:
>>105712100
--Gemma 3n released with memory-efficient architecture for mobile deployment:
>105712608 >105712664 >105714327
--FLUX.1-Kontext-dev release sparks interest in uncensored image generation and workflow compatibility:
>105713343 >105713400 >105713434 >105713447 >105713482
--Budget AI server options amid legacy Nvidia GPU deprecation concerns:
>105713717 >105713792 >105714105
--Silly Tavern image input issues with ooga webui and llama.cpp backend limitations:
>105714617 >105714660 >105714754 >105714760 >105714771 >105714801 >105714822 >105714847 >105714887 >105714912 >105714993 >105714996 >105715066 >105715075 >105715123 >105715167 >105715176 >105715241 >105715245 >105715314 >105715186 >105715129 >105715136 >105715011 >105715107
--Debugging token probability and banning issues in llama.cpp with Mistral-based models:
>105715880 >105715892 >105715922 >105715987 >105716007 >105716013 >105716069 >105716103 >105716158 >105716205 >105716210 >105716230 >105716252 >105716264
--Running DeepSeek MoE models with high memory demands on limited VRAM setups:
>105712953 >105713076 >105713169 >105713227 >105713697
--DeepSeek R2 launch delayed amid performance concerns and GPU supply issues:
>105713094 >105713111 >105713133 >105713142 >105713547 >105713571
--Choosing the best template for Mistral 3.2 model based on functionality and user experience:
>105714405 >105714430 >105714467 >105714579 >105714500
--Gemma 2B balances instruction following and multilingual performance with practical local deployment:
>105712324 >105712341 >105712363 >105712367
--Meta poaches OpenAI researcher Trapit Bansal for AI superintelligence team:
>105713802
--Google releases Gemma 3n multimodal AI model for edge devices:
>105714527
--Miku (free space):
>105712953 >105715094 >105715245 >105715797 >105715815
►Recent Highlight Posts from the Previous Thread:
>>105712104
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
Anonymous
6/27/2025, 2:42:31 AM
No.105716851
[Report]
>troonimai
Anonymous
6/27/2025, 2:43:27 AM
No.105716855
[Report]
OP here. One day i will tap that jart bussy.
>deepseek/ccp can't steal more innovation from openai
>they fail to release new models
they must be shitting their pants about openai's open source model that will destroy even the last argument to use deepshit
Anonymous
6/27/2025, 2:45:38 AM
No.105716870
[Report]
>>105716861
Zero chance it's larger than 30B.
Anonymous
6/27/2025, 2:46:21 AM
No.105716877
[Report]
OP, im actually disappointed
unironically ack yourself
Anonymous
6/27/2025, 2:48:29 AM
No.105716887
[Report]
>>105716840
>19x (You) in recap
Damn that's a new record.
>>105716861
Why can't they steal anymore?
Anonymous
6/27/2025, 2:51:03 AM
No.105716902
[Report]
>>105716840
on a break for a week soon, 95% chance of no migus
Anonymous
6/27/2025, 2:51:16 AM
No.105716903
[Report]
Anonymous
6/27/2025, 2:57:12 AM
No.105716945
[Report]
>>105716861
>Still living in saltman's delusion
Ngmi
Anonymous
6/27/2025, 2:57:15 AM
No.105716946
[Report]
>>105722087
>>105716897
they can't steal because there's no new general model
DeepSeek V3 was 100% trained on GPT4 and R1 was just a godawful placebo CoT on top that wrote 30 times the amount of actual content the model ends up outputting. New R1 is actually good because the CoT came from Gemini so there isn't a spam of a trillion wait or endless looping.
The OP mikutranny is posting porn in /ldg/:
>>105715769
It was up for hours while anyone keking up on troons or niggers gets deleted in seconds, talk about double standards and selective moderation:
https://desuarchive.org/g/thread/104414999/#q104418525
https://desuarchive.org/g/thread/104414999/#q104418574
>>105714098
Funny /r9k/ thread:
https://desuarchive.org/r9k/thread/81611346/
The Makise Kurisu screencap one (day earlier) is fake btw, no matches to be found, see
https://desuarchive.org/g/thread/105698912/#q105704210 janny deleted post quickly.
TLDR: Mikufag janny deletes everyone dunking on trannies and resident spammers, making it his little personal safespace. Needless to say he would screech "Go back to POL!" anytime anyone posts something mildly political about language models or experiments around that topic.
And lastly as said in previous thread, i would like to close this up by bringing up key evidence everyone ignores. I remind you that cudadev has endorsed mikuposting. That is it.
He also endorsed hitting that feminine jart bussy a bit later on.
Anonymous
6/27/2025, 3:01:27 AM
No.105716973
[Report]
>>105716992
how can a tranny disgusting ass be feminine? i think youre gay
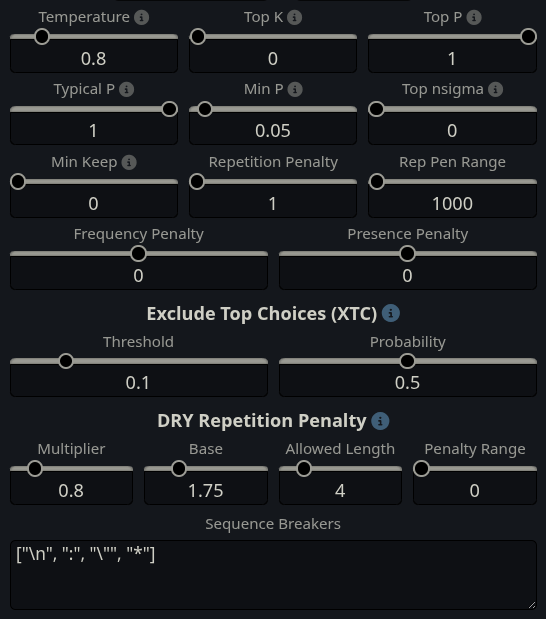
More discussion about bitch wrangling Mistral Small 3.2 please, just to cover all bases before it's scrapped.
I've tested temps at 0.15, 0.3, 0.6, and 0.8.
Tested Rep pen at 1 (off) and at 1.03. Rep pen doesn't seem to be much needed just like with Rocinante.
Responses are still shit no matter what, but seems to be more intelligible at lower temperatures, particularly 0.15 and 0.3, however they are still often full of shit that makes you swipe anyway.
I've yet to try without min_p, XTC, and DRY.
Also it seems like it's ideal to limit response tokens with this model, because this thing likes to vary length by a lot, if you let it, it just keeps growing larger and larger.
Banned tokens grew a bit and still not done;
>emdash
[1674,2251,2355,18219,20202,21559,23593,24246,28925,29450,30581,31148,36875,39443,41370,42545,43485,45965,46255,48371,50087,54386,58955,59642,61474,62708,66395,66912,69961,74232,75334,81127,86932,87458,88449,88784,89596,92192,92548,93263,102521,103248,103699,105537,105838,106416,106650,107827,114739,125665,126144,131676,132461,136837,136983,137248,137593,137689,140350]
>double asterisks (bold)
[1438,55387,58987,117565,74562,42605]
>three dashes (---) and non standard quotes (“ ”)
[8129,1482,1414]
Extra stop strings needed;
"[Pause", "[PAUSE", "(Pause", "(PAUSE"
Why the fuck does it like to sometimes end a response with waiting for "Paused while waiting for {{user}}'s response."?
This model is so fucking inconsistent.
Anonymous
6/27/2025, 3:04:13 AM
No.105716992
[Report]
>>105716973
You just can't find a nice strawman to pick on here.
Anonymous
6/27/2025, 3:04:15 AM
No.105716993
[Report]
>>105717009
>deepseek/ccp can't steal more innovation from openai
>they fail to release new models
they must be shitting their pants about openai's open source model that will destroy even the last argument to use deepshit
Anonymous
6/27/2025, 3:05:50 AM
No.105717009
[Report]
>>105717020
>>105716993
I can't fit it on my local machine and I'm not paying for any API.
I'm not building a $3000+ server just for R1 either.
Anonymous
6/27/2025, 3:06:29 AM
No.105717018
[Report]
>>105717007
Zero chance it's larger than 30B.
Anonymous
6/27/2025, 3:06:33 AM
No.105717020
[Report]
>>105717035
>>105717009
>I'm not building a $3000+ server
That's not very local of you.
>>105717007
Why can't they steal anymore?
Anonymous
6/27/2025, 3:07:44 AM
No.105717031
[Report]
Anonymous
6/27/2025, 3:08:21 AM
No.105717035
[Report]
>>105717020
I have never had a chatGPT, claude or any other AI account. I have never paid for any API. I exclusively use local models only. My only interaction ever with chatGPT was through duckduckgo's free chat thingy.
I'm as fucking local as it gets.
Anonymous
6/27/2025, 3:08:29 AM
No.105717040
[Report]
>>105717025
they can't steal because there's no new general model
DeepSeek V3 was 100% trained on GPT4 and R1 was just a godawful placebo CoT on top that wrote 30 times the amount of actual content the model ends up outputting. New R1 is actually good because the CoT came from Gemini so there isn't a spam of a trillion wait or endless looping.
Anonymous
6/27/2025, 3:09:23 AM
No.105717044
[Report]
>>105717007
>Still living in saltman's delusion
Ngmi
Anonymous
6/27/2025, 3:09:56 AM
No.105717045
[Report]
>>105717007
tell us more about the unreleased model, sam
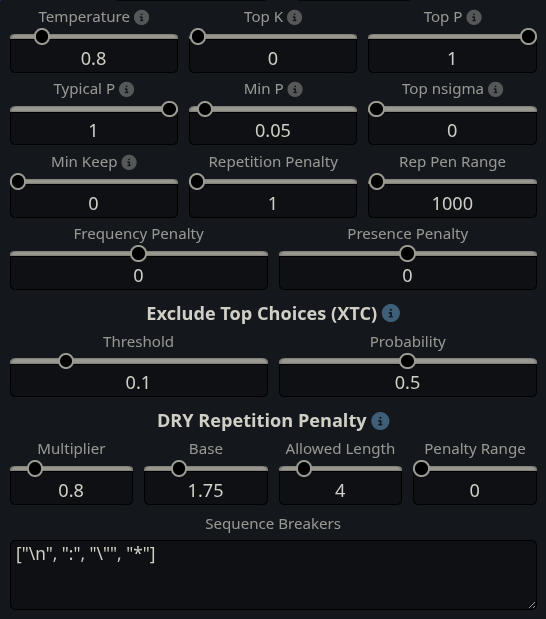
More discussion about bitch wrangling Mistral Small 3.2 please, just to cover all bases before it's scrapped.
I've tested temps at 0.15, 0.3, 0.6, and 0.8.
Tested Rep pen at 1 (off) and at 1.03. Rep pen doesn't seem to be much needed just like with Rocinante.
Responses are still shit no matter what, but seems to be more intelligible at lower temperatures, particularly 0.15 and 0.3, however they are still often full of shit that makes you swipe anyway.
I've yet to try without min_p, XTC, and DRY.
Also it seems like it's ideal to limit response tokens with this model, because this thing likes to vary length by a lot, if you let it, it just keeps growing larger and larger.
Banned tokens grew a bit and still not done;
>emdash
[1674,2251,2355,18219,20202,21559,23593,24246,28925,29450,30581,31148,36875,39443,41370,42545,43485,45965,46255,48371,50087,54386,58955,59642,61474,62708,66395,66912,69961,74232,75334,81127,86932,87458,88449,88784,89596,92192,92548,93263,102521,103248,103699,105537,105838,106416,106650,107827,114739,125665,126144,131676,132461,136837,136983,137248,137593,137689,140350]
>double asterisks (bold)
[1438,55387,58987,117565,74562,42605]
>three dashes (---) and non standard quotes (“ ”)
[8129,1482,1414]
Extra stop strings needed;
"[Pause", "[PAUSE", "(Pause", "(PAUSE"
Why the fuck does it like to sometimes end a response with waiting for "Paused while waiting for {{user}}'s response."?
This model is so fucking inconsistent.
Anonymous
6/27/2025, 3:11:24 AM
No.105717056
[Report]
the copy bot is back
Anonymous
6/27/2025, 3:13:49 AM
No.105717074
[Report]
>>105717147
>>105717058
(you) will never be based though
>>105717052
It's funny how 3.2 started showing all the same annoying shit that Deepseek models are tainted by.
Anonymous
6/27/2025, 3:22:27 AM
No.105717121
[Report]
>>105717124
>>105717052
What exactly are you complaining about? I like 3.2 (with mistral tekken v3) but it definitely has a bias toward certain formatting quirks and **asterisk** abuse. This is more tolerable for me than other model's deficiencies at that size, but if it triggers your autism that badly you're better off coping with something else. It might also be that your cards are triggering its quirks more than usual
Anonymous
6/27/2025, 3:22:56 AM
No.105717124
[Report]
>>105717096
>>105717121
you are responding to a copy bot instead of the original message
Anonymous
6/27/2025, 3:25:32 AM
No.105717139
[Report]
>>105717096
s-surely just a coincidence
Anonymous
6/27/2025, 3:26:27 AM
No.105717147
[Report]
>>105717058
>>105717074
Its not gore you pathetic thing and it will stay for you to see, as long as i want it to.
Anonymous
6/27/2025, 3:30:06 AM
No.105717162
[Report]
>>105717185
>>105716959
Get a job, schizo
Anonymous
6/27/2025, 3:36:16 AM
No.105717185
[Report]
>>105717162
Get a job, tranime spammer.
Anonymous
6/27/2025, 3:36:46 AM
No.105717188
[Report]
>>105716959
kill yourself
Anonymous
6/27/2025, 3:36:49 AM
No.105717189
[Report]
>>105717258
>look mom, I posted it again!
Anonymous
6/27/2025, 3:39:09 AM
No.105717206
[Report]
>>105717096
its biggest flaw like ALL mistral models is that it rambles and hardly moves scenes forward. it wants to talk about the smell of ozone and clicking of shoes against the floor instead. you can get through the same exact scenario in half the time/messages with llama 2 or 3 because there is so much less pointless fluff
Anonymous
6/27/2025, 3:41:31 AM
No.105717234
[Report]
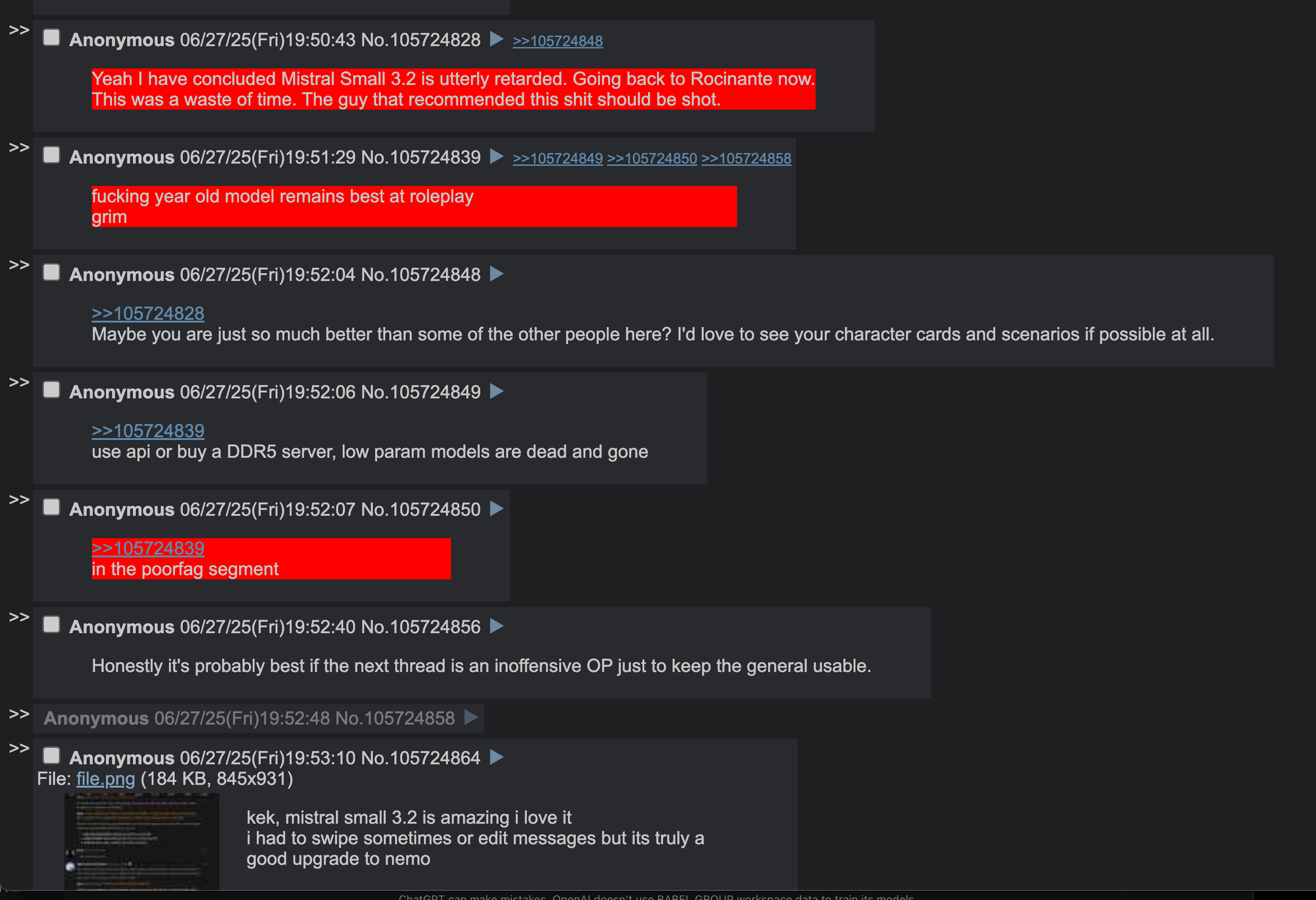
Yeah I have concluded Mistral Small 3.2 is utterly retarded. Going back to Rocinante now.
This was a waste of time. The guy that recommended this shit should be shot.
Anonymous
6/27/2025, 3:44:26 AM
No.105717258
[Report]
>>105717189
And i will post it again while you spam 2007-era reddit memes and nervously click on that "Report" button like a pussy.
fucking year old model remains best at roleplay
grim
Anonymous
6/27/2025, 3:57:53 AM
No.105717342
[Report]
>>105717354
>>105717340
in the poorfag segment
Anonymous
6/27/2025, 3:58:12 AM
No.105717344
[Report]
>>105717354
>>105717340
midnight miqu is still the best for rp
Anonymous
6/27/2025, 3:59:45 AM
No.105717354
[Report]
>>105717404
>>105717342
delusional if you think r1 is better for roleplay, it has the same problems as the rest of these models
not to mention those response times are useless for roleplay to begin with
>>105717344
this isnt 2023
Anonymous
6/27/2025, 4:01:41 AM
No.105717370
[Report]
>>105717394
>>105716573
>>105716591
>>105716638
imagine being ggerganov and still visiting this place
Anonymous
6/27/2025, 4:04:14 AM
No.105717394
[Report]
>>105717370
Who cares what random e-celeb may think?
Anonymous
6/27/2025, 4:04:46 AM
No.105717399
[Report]
Good model for 24 gb VRAM?
I'm noticing qwen 235b doesn't improve at higher temps no matter what I set nsigma to. with some models high temp and nsigma can push them to be more creative, but qwen3 set to higher than temp 0.6 is just dumber in my usage. even so, I still think it's the best current local model beneath r1
>>105717354
>roleplay
Filth. Swine, even. Unfit to lick the sweat off my balls.
Anonymous
6/27/2025, 4:10:09 AM
No.105717425
[Report]
>>105717404
Try setting minP to like 0.05, top-K 10-20 and temperature at 1-4. In RP I find that most of the top tokens as long as they're not very low probability are all good continuations. You can crank temperature way up like this and it really helps with variety.
Anonymous
6/27/2025, 4:14:42 AM
No.105717445
[Report]
>>105717404
Optimal character/lore data formatting for Rocinante?
Lately I've been reformatting everything like this;
identifier: [
key: "value"
]
# Examples
SYSTEM INSTRUCTIONS: [
MODE: "bla bla"
IDENTITY: "You are {{char}}."
]
WORLD: [
SETTING: "blah blah"
STORY: "etc"
]
{{char}}: [
Name: "full character name"
]
It seems to help a little with preventing it from confusing and mixing up data when everything is formatted in this way. It just generally feels like it's understanding things better.
Anyone else got similar experiences with it?
Anonymous
6/27/2025, 4:22:57 AM
No.105717498
[Report]
Anonymous
6/27/2025, 4:28:46 AM
No.105717547
[Report]
>>105722106
DiLoCoX: A Low-Communication Large-Scale Training Framework for Decentralized Cluster
https://arxiv.org/abs/2506.21263
>The distributed training of foundation models, particularly large language models (LLMs), demands a high level of communication. Consequently, it is highly dependent on a centralized cluster with fast and reliable interconnects. Can we conduct training on slow networks and thereby unleash the power of decentralized clusters when dealing with models exceeding 100 billion parameters? In this paper, we propose DiLoCoX, a low-communication large-scale decentralized cluster training framework. It combines Pipeline Parallelism with Dual Optimizer Policy, One-Step-Delay Overlap of Communication and Local Training, and an Adaptive Gradient Compression Scheme. This combination significantly improves the scale of parameters and the speed of model pre-training. We justify the benefits of one-step-delay overlap of communication and local training, as well as the adaptive gradient compression scheme, through a theoretical analysis of convergence. Empirically, we demonstrate that DiLoCoX is capable of pre-training a 107B foundation model over a 1Gbps network. Compared to vanilla AllReduce, DiLoCoX can achieve a 357x speedup in distributed training while maintaining negligible degradation in model convergence. To the best of our knowledge, this is the first decentralized training framework successfully applied to models with over 100 billion parameters.
China Mobile doesn't seem to have a presence on github and no mention of code release in the paper. still pretty neat
Anonymous
6/27/2025, 4:29:55 AM
No.105717549
[Report]
The more I try to train and fuck with these models, the more I think the AI CEOs should be hanged for telling everyone they could be sentient in 2 weeks. Every time I think I'm getting somewhere it botches something very simple. I guess it was a fool's errand thinking I could hyper-specialize a small model to do things Claude can't
Please think of 6GB users like me ;_;
Anonymous
6/27/2025, 4:37:21 AM
No.105717587
[Report]
>>105717571
Do all 6GB users use cute emoticons like you?
>>105716837 (OP)
Newfag here.
Does generation performance of 16 GB 5060 ti same as 16 GB 5070 ti ??
Anonymous
6/27/2025, 4:50:09 AM
No.105717686
[Report]
>>105717696
>>105717659
>Bandwidth: 448.0 GB/s
vs
>Bandwidth: 896.0 GB/s
>>105717686
I thought only VRAM size matters ?
Anonymous
6/27/2025, 4:55:19 AM
No.105717723
[Report]
>>105717696
vram is king but not all vram is worth the same
Anonymous
6/27/2025, 4:57:05 AM
No.105717742
[Report]
>>105717696
Generation performance? I assume you're talking about inference? Prompt processing requires processing power, and the 5070 ti is a lot stronger in that aspect. Token generation requires memory bandwith. This is why offloading layers to your cpu/ram will slow down generation - most users' ram bandwith are vastly slowly than their vram bandwith.
Vram size dictates the parameters, quantization, and context size of the models that you're able to load into the gpu.
Anonymous
6/27/2025, 4:57:40 AM
No.105717746
[Report]
>>105717696
vram size limits what models you can fit in the gpu
vram bandwidth dictates how fast those models will tend to go. there are other factors but who care actually
Anonymous
6/27/2025, 4:58:33 AM
No.105717749
[Report]
>>105717696
vram matters most but if they're the same size, the faster card is still faster. it won't make a huge difference for any ai models you'll fit into 16gb though. the 4060 16gb is considered a pretty bad gaming card but does fine for ai
new dataset just dropped
>>>/a/280016848
Anonymous
6/27/2025, 5:08:10 AM
No.105717822
[Report]
Anonymous
6/27/2025, 5:09:53 AM
No.105717836
[Report]
>>105717778
sorry but japanese is NOT safe, how about some esperanto support?
>>105717778
I would be interested if I knew how to clean data. Raw data would destroy a model especially badly written jap slop
Anonymous
6/27/2025, 5:26:45 AM
No.105717939
[Report]
>>105718041
Anonymous
6/27/2025, 5:32:10 AM
No.105717976
[Report]
>>105718005
>>105717903
those lns are literary masterpieces compared to the shit the average model is trained on
Anonymous
6/27/2025, 5:34:44 AM
No.105718005
[Report]
>>105717976
Garbage in garbage out i guess.
Anonymous
6/27/2025, 5:39:04 AM
No.105718041
[Report]
>>105717939
I will save this image but I don't think I will go far.
I was thinking of finetuning a jp translator model but I always leave my projects half-started.
Anonymous
6/27/2025, 5:45:39 AM
No.105718090
[Report]
>>105718120
>>105717778
That shit is as bad if not worse than our shitty English novels about dark brooding men.
Anonymous
6/27/2025, 5:49:47 AM
No.105718120
[Report]
>>105718163
>>105718090
Worse because novels are more popular with japanese middle schoolers and in america reading is gay.
Anonymous
6/27/2025, 5:56:08 AM
No.105718163
[Report]
>>105718120
reading is white-coded
Anonymous
6/27/2025, 6:03:12 AM
No.105718226
[Report]
>>105718268
Good model that fits into my second card with 6gb vram?
Purpose: looking at a chunk of text mixed with code and extracting relevant function names.
Anonymous
6/27/2025, 6:08:25 AM
No.105718268
[Report]
>>105717571
>>105718226
Please use cute emoticons.
Anonymous
6/27/2025, 6:10:42 AM
No.105718279
[Report]
>>105718325
>>105717903
>Raw data would destroy a model
So true sister, that's why you need to only fit against safe synthetic datasets. Human-made (also called "raw") data teaches dangerous concepts and reduces performance on important math and code benchmarks.
Anonymous
6/27/2025, 6:11:49 AM
No.105718288
[Report]
>>105718777
MrBeast DELETES his AI thumbnail tool, replaces it with a website to commission real artists. <3 <3
https://x.com/DramaAlert/status/1938422713799823823
Anonymous
6/27/2025, 6:15:37 AM
No.105718325
[Report]
>>105718279
I'm pretty sure he means raw in the sense of unformatted.
Anonymous
6/27/2025, 6:42:35 AM
No.105718511
[Report]
>>105718525
dots finally supported in lm studio.
its pretty good.
Anonymous
6/27/2025, 6:47:08 AM
No.105718538
[Report]
>>105718555
Is there a local setup I can use for OCR that isn't too hard to wire into a python script/dev environment? Pytesseract is garbage and gemini reads mmy 'problem' images just fine, but I'd rather have a local solution than pay for API calls.
Anonymous
6/27/2025, 6:49:42 AM
No.105718555
[Report]
>>105718560
Anonymous
6/27/2025, 6:50:36 AM
No.105718560
[Report]
Anonymous
6/27/2025, 6:52:41 AM
No.105718576
[Report]
>>105718525
get used to all new releases being MoE models :)
Anonymous
6/27/2025, 6:53:08 AM
No.105718579
[Report]
>>105717659
yes. Just a little slower
Anonymous
6/27/2025, 7:06:58 AM
No.105718670
[Report]
>>105717659
no. It is slower
Anonymous
6/27/2025, 7:08:16 AM
No.105718680
[Report]
>>105717659
It's technically slower but the difference will be immaterial because the models you can fit in that much vram are small and fast.
Anonymous
6/27/2025, 7:16:00 AM
No.105718726
[Report]
>>105717659
It's actually pretty noticable if you aren't a readlet and are reading the output as it goes. Unless you're in the top 1% of the population, you probably won't be able to keep up with a 5070 ti's output speed, but a 5060 ti should be possible if you're skimming.
Anonymous
6/27/2025, 7:24:14 AM
No.105718777
[Report]
>>105718288
It's on him for not doing proper market research. Anyone with a brain could have told him that it was a risky move.
Anonymous
6/27/2025, 7:31:17 AM
No.105718822
[Report]
>>105718525
MoE the best until the big boys admit what they're all running under the hood now (something like MoE but with far more cross-talk between the Es)
Anonymous
6/27/2025, 8:34:14 AM
No.105719292
[Report]
>>105716978
I think either you're not writing here in good faith or your cards/instructions or even model settings are full of shit.
Anonymous
6/27/2025, 9:18:57 AM
No.105719546
[Report]
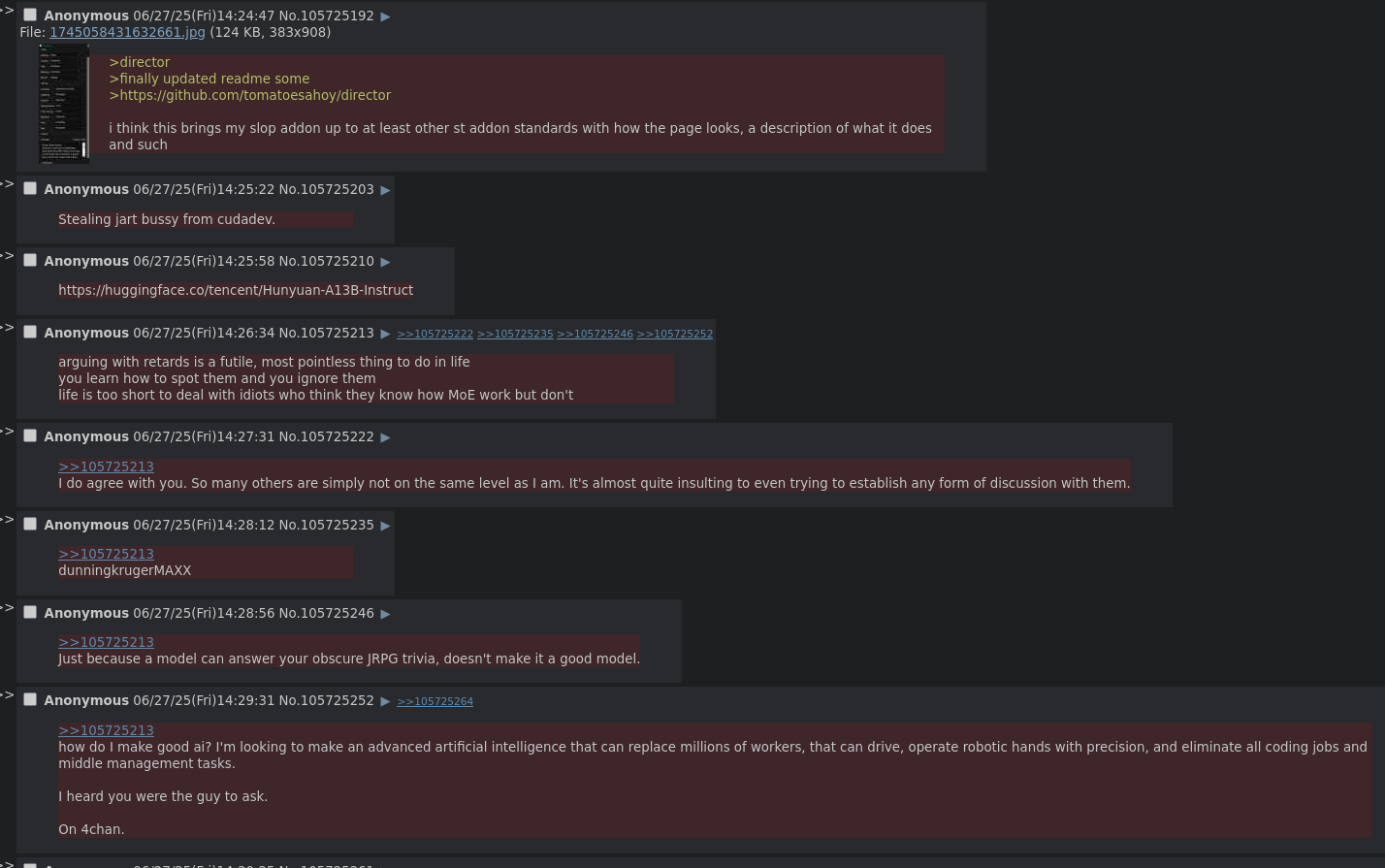
>director
>finally updated readme some
>https://github.com/tomatoesahoy/director
i think this brings my slop addon up to at least other st addon standards with how the page looks, a description of what it does and such
Anonymous
6/27/2025, 9:27:13 AM
No.105719604
[Report]
>>105719559
finally, a reasonably sized moe, now let's wait 2 years for the support in lmao.cpp
Anonymous
6/27/2025, 9:45:58 AM
No.105719719
[Report]
>>105719559
>256K context window
we are *so* back
Anonymous
6/27/2025, 9:52:55 AM
No.105719763
[Report]
>>105719870
>>105719559
>With only 13 billion active parameters
so it'll be shit for rp but know exactly how many green taxes you should be charged for owning a car
Anonymous
6/27/2025, 9:53:50 AM
No.105719767
[Report]
Stealing jart bussy from cudadev.
Anonymous
6/27/2025, 10:02:33 AM
No.105719819
[Report]
>>105719763
I'd still pick nemo over anything smaller than deepseek and nemo is like 5 years old
Anonymous
6/27/2025, 10:13:32 AM
No.105719908
[Report]
>>105720031
Anonymous
6/27/2025, 10:30:48 AM
No.105720031
[Report]
>>105720088
>>105719908
other models seemingly never saw any erotica. there is also largestral i guess but it's too slow
Anonymous
6/27/2025, 10:40:22 AM
No.105720088
[Report]
>>105720212
>>105720031
It's so annoying that the imbeciles training the base models are deliberately conflating "model quality" with not being able to generate explicit content and maximizing math benchmarks on short-term pretraining ablations. Part of the problem are also the retards and grifters who go "just finetune it bro" (we can easily see how well that's working for image models).
Anonymous
6/27/2025, 10:41:41 AM
No.105720098
[Report]
>>105719870
nemo can be extremely repetitive and stuff, i won't shine its knob but it is still the best smallest model. i won't suggest an 7/8b to someone, nemo would be the smallest because it works well and is reliable
Anonymous
6/27/2025, 10:46:31 AM
No.105720124
[Report]
>>105716837 (OP)
I'm messing around with image captioning together with a standard text LLM in sillytavern. Basically just running 2 kobold instances with different ports (one LLM, the other captioning VLM model), and setting the secondary URL in the captioning extension to the VLM's. Is there a way to make it only send the image once? Every time I send an image, I can see that it does it twice since the caption edit popup shows up with different text every time.
>>105719559
What's min specs to run this?
Anonymous
6/27/2025, 10:59:56 AM
No.105720212
[Report]
>>105720457
>>105720088
compute is a genuine limitation though, and as compute increases, so will finetunes. Some of the best nsfw local image models had over ten grand thrown at them by (presumably) insane people. And a lot of that is renting h100's, which gets pricey, or grinding it out on their own 4090 which is sloooow.
All it really takes is one crazy person buying I dunno, that crazy ass 196gb intel system being released soon and having it run for a few months and boom, we'll have a new flux pony model, or a state of the art smut llm etc.
Im here because we are going to eat.
Anonymous
6/27/2025, 11:00:33 AM
No.105720216
[Report]
>>105720191
The entire world is waiting for the llamacpp merge, until then not even the tencent team can run it and nobody knows how big the model is or how well it performs
Anonymous
6/27/2025, 11:13:23 AM
No.105720280
[Report]
>>105720191
160gb full, so quantized to 4bit prolly like ~50gb model or so, and for a MoE, probably dont need the full model loaded for it to be usable speeds.
Lamma scout was 17b moe and that was like 220 gb and I could run that on like 40gb vram or less easy. Scout sucked though so Im 0% excited.
Was there even a scout finetune? It still sucks right?
Anonymous
6/27/2025, 11:32:04 AM
No.105720400
[Report]
Anonymous
6/27/2025, 11:35:39 AM
No.105720428
[Report]
>>105716837 (OP)
pedotroon thread
>>105720378
You just know that it's going to be a good one when the devs ensure llama.cpp support from the start.
I hope there's going to be a huge one amongst the releases.
Anonymous
6/27/2025, 11:39:44 AM
No.105720457
[Report]
>>105724498
>>105720212
The guy who's continuing pretraining Flux Chroma has put thousands of H100 hours on it for months now and it still isn't that great. And it's a narrowly-focused 12B image model where data curation isn't as critical as with text. This isn't solvable by individuals in the LLM realm. Distributed training would in theory solve this, but politics and skill issues will prevent any advance in that sense. See for example how the ongoing Nous Psyche is being trained (from scratch!) with the safest and most boring data imaginable and not in any way that will result into anything useful in the short/medium term.
Anonymous
6/27/2025, 11:40:11 AM
No.105720459
[Report]
>>105720521
>>105719559
>17B active
>at most 32B even by square root law
Great for 24B vramlets, I guess. The benchmarks showing it beating R1 and 235B are funny though.
Anonymous
6/27/2025, 11:49:21 AM
No.105720518
[Report]
>>105720450
>You just know that it's going to be a good one
That's yet to be seen. But it is nice seeing early support for new models (mistral, i'm looking at you).
Anonymous
6/27/2025, 11:49:45 AM
No.105720521
[Report]
>>105720528
>>105720459
>square root law
meme tier pattern that was shit even then let alone now with so many moe arch changes, obsolete
>>105720521
What's your alternative? Just the active alone?
Anonymous
6/27/2025, 11:51:21 AM
No.105720529
[Report]
>>105720542
>>105719559
>not a single trivia benchmark
hehehehehe
Anonymous
6/27/2025, 11:53:07 AM
No.105720542
[Report]
>>105720629
>>105720529
just rag and shove it in context, you have 256k to work with
Anonymous
6/27/2025, 11:53:24 AM
No.105720544
[Report]
>>105720450
It could be a wise move since release is an important hype window. Hyping a turd is pointless (or even detrimental), so it could be a positive signal.
Anonymous
6/27/2025, 11:54:21 AM
No.105720550
[Report]
>>105720528
nta, but if i'm making moes, i'd put any random law that makes it look better than it actually is. I'd name it cube root law + 70b.
Anonymous
6/27/2025, 11:55:15 AM
No.105720557
[Report]
>>105720627
Ernie 4.5 and so on have been out on baidu for three months now. The thing is just that there's no way to use them without signing up for a baidu account and giving the chinese your phone number.
Anonymous
6/27/2025, 11:59:39 AM
No.105720587
[Report]
>>105720639
>>105720528
if there was a singular objective way to judge any model, moe or not, everyone would use that as the benchmark and goal to climb, as everyone knows, nowadays basically every benchmark is meme-tier to some degree and everyone is benchmaxxing
the only thing to look at still are the benchmarks, since if a model doesnt perform well on them, its shit, and if it does perform wel, then it MIGHT not be shit, you have to test yourself to see
>>105720557
couldnt find a way to modify system prompt so i had to prompt it that way otherwise it would respond in chinese
also its turbo idk how different thats from regular
Anonymous
6/27/2025, 12:05:12 PM
No.105720629
[Report]
>>105720542
Just like how Llama 4 has 1M right?
>>105720587
Benchmarks are completely worthless and they can paint them to say whatever they want. A 80B total isn't better than a 671B and 235B just because the benchmarks say so, and if you say "punches above its weight" I will shank you.
The point isn't to judge whether one model is better, it's to gauge its max capacity to be good. Which is the total number of active parameters. The square root law is just an attempt to give MoE models some wiggle room since they have more parameters to choose from.
Anonymous
6/27/2025, 12:08:05 PM
No.105720652
[Report]
>>105720676
>>105720639
>it's to gauge its max capacity to be good. Which is the total number of active parameters
deepseek itself disproved all the antimoe comments as nothing but ramlet cope, 37b active params only and a model that is still literally open source sota even at dynamic quants q1 at 131gb
Anonymous
6/27/2025, 12:08:15 PM
No.105720654
[Report]
>>105720781
>>105720627
this is with x1 (turbo)
Anonymous
6/27/2025, 12:10:59 PM
No.105720672
[Report]
>>105720639
Shoots farther than its caliber.
>>105720652
It makes lots of stupid little mistakes that give away it's only a <40B model. The only reason it's so good is because it's so big it can store a lot of knowledge and the training data was relatively unfiltered.
Anonymous
6/27/2025, 12:13:27 PM
No.105720684
[Report]
>>105720699
>>105720676
>r1
>It makes lots of stupid little mistakes that give away it's only a <40B model.
kek, alright i realize now you arent serious
Anonymous
6/27/2025, 12:16:13 PM
No.105720699
[Report]
>>105720684
Not an argument.
arguing with retards is a futile, most pointless thing to do in life
you learn how to spot them and you ignore them
life is too short to deal with idiots who think they know how MoE work but don't
Anonymous
6/27/2025, 12:27:14 PM
No.105720781
[Report]
>>105720654
>>105720627
nice, I'll keep an eye out for this one when it's actually out
Anonymous
6/27/2025, 12:27:53 PM
No.105720787
[Report]
>>105720715
I do agree with you. So many others are simply not on the same level as I am. It's almost quite insulting to even trying to establish any form of discussion with them.
Anonymous
6/27/2025, 12:29:29 PM
No.105720803
[Report]
>>105720715
dunningkrugerMAXX
Anonymous
6/27/2025, 12:35:56 PM
No.105720838
[Report]
>>105720715
Just because a model can answer your obscure JRPG trivia, doesn't make it a good model.
Anonymous
6/27/2025, 12:40:35 PM
No.105720871
[Report]
>>105720715
how do I make good ai? I'm looking to make an advanced artificial intelligence that can replace millions of workers, that can drive, operate robotic hands with precision, and eliminate all coding jobs and middle management tasks.
I heard you were the guy to ask.
On 4chan.
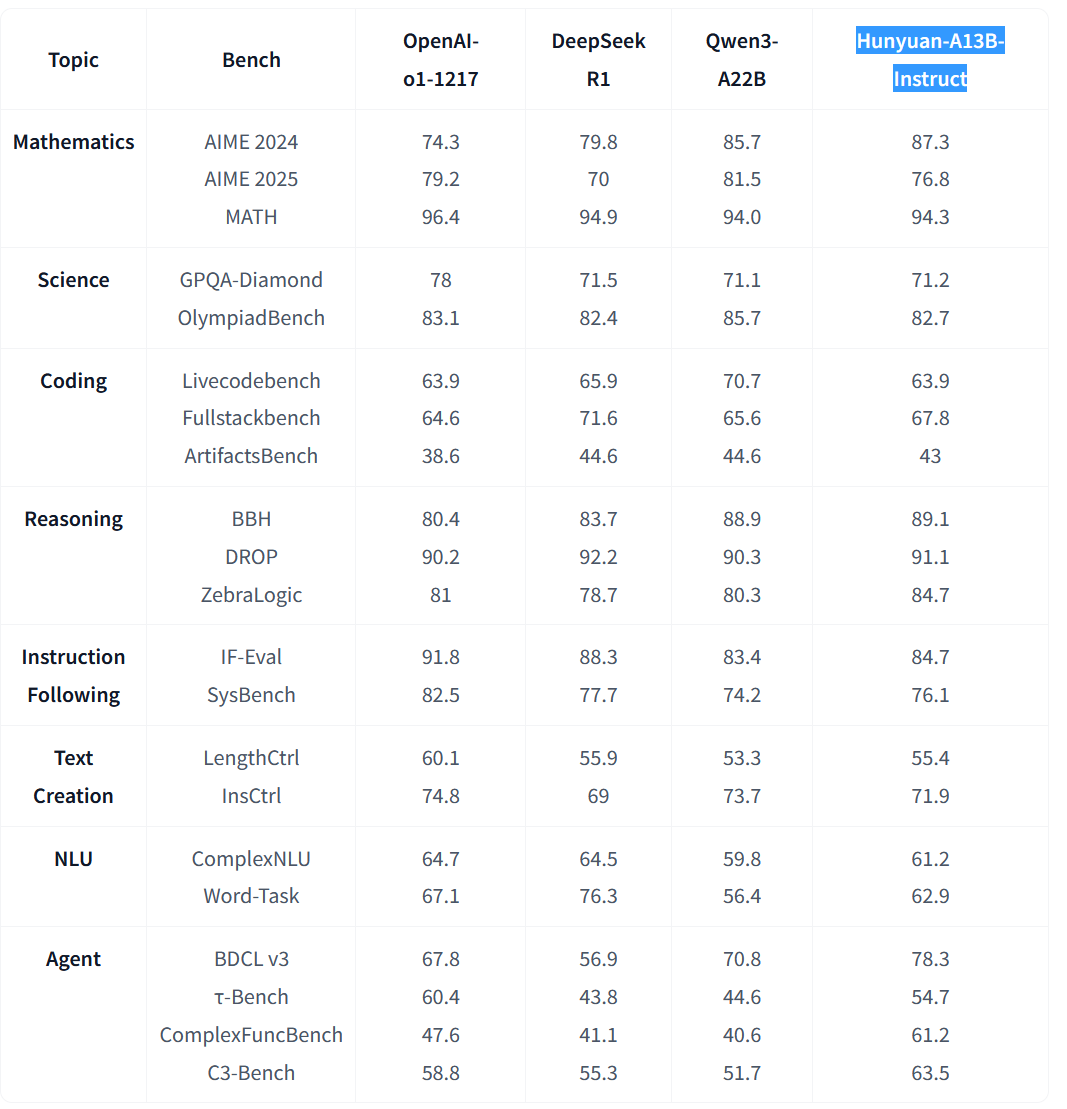
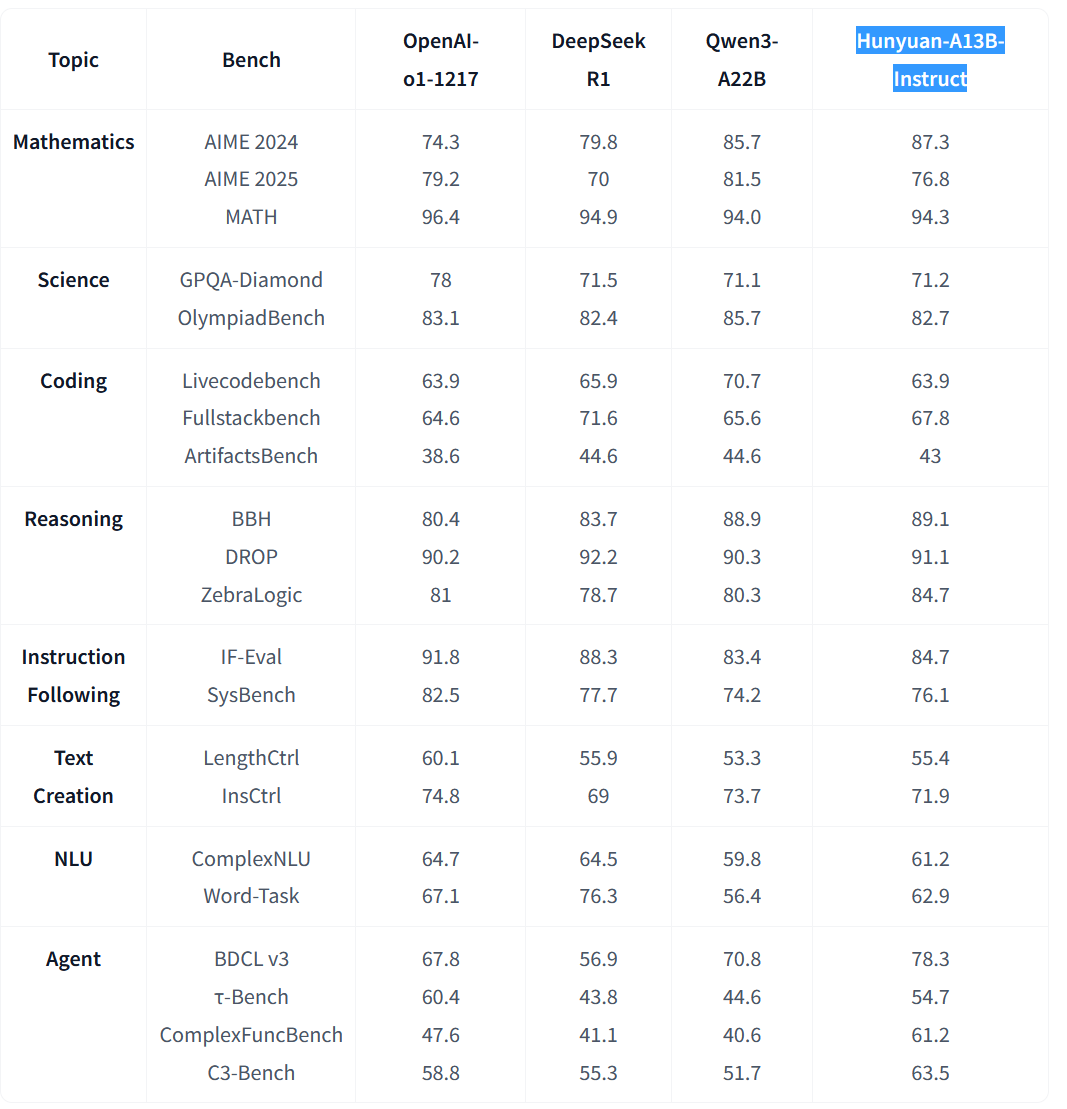
Did someone managed to run Hunyuan-A13B?
The bf16 is way too big for my 4x3090, the fp8 doesn't work in the vllm image they provided (the 3090 don't support fp8 but there is a marlin kernel in mainline vllm to make it compatible)
And the gpqt doesn't fucking work either for some reason. Complains about Unknown CUDA arch (12.0+PTX) or GPU not supported when I have 3090s
Anonymous
6/27/2025, 12:56:43 PM
No.105720978
[Report]
>>105720949
just wait for quants
>>105720378
>0.3B
What do i do with this?
Anonymous
6/27/2025, 12:58:39 PM
No.105720995
[Report]
>>105721017
>>105720980
run it on your phone so you can get useless responses on the go
Anonymous
6/27/2025, 1:00:56 PM
No.105721017
[Report]
>>105720995
>No i will not suck your penis
>message generated at 500T/s
Anonymous
6/27/2025, 1:01:55 PM
No.105721026
[Report]
>>105720949
ask bartowski
Anonymous
6/27/2025, 1:02:42 PM
No.105721038
[Report]
>>105721109
>>105720980
Change the tokenizer with mergekit's token surgeon and use it for speculative decoding.
Anonymous
6/27/2025, 1:09:45 PM
No.105721092
[Report]
>>105721101
So how slopped is the new 80B moe?
>>105721092
it's chinese so it's trained on 70% chatgpt logs and 30% deepseek logs
>>105721038
Have you tried it before? I can't imagine the hit ratio to be very high doing that.
Does Q4/5/6/etc effect long context understanding?
Anonymous
6/27/2025, 1:17:22 PM
No.105721145
[Report]
Anonymous
6/27/2025, 1:17:25 PM
No.105721147
[Report]
>>105721109
not that anon but I think someone tried to turn qwen 3b or something into a draft model for deepseek r1 a couple of months ago
Anonymous
6/27/2025, 1:21:18 PM
No.105721164
[Report]
>>105721101
The latest Mistral Small 3.2 might have been trained on DeepSeek logs too.
Anonymous
6/27/2025, 1:22:10 PM
No.105721171
[Report]
>>105721109
I haven't yet. I also don't expect much, but that won't stop me from trying it. I could give it a go with the smollm2 models. Maybe smallm3 when they release.
Anonymous
6/27/2025, 1:23:27 PM
No.105721184
[Report]
>>105721144
The more lobotomized the model, the more trouble is going to have with everything, context understanding included. Just try it.
Anonymous
6/27/2025, 1:24:25 PM
No.105721191
[Report]
>>105721202
>>105720949
You will wait patiently for the ggoofs, you will run it with llama.cpp and you will be happy.
Anonymous
6/27/2025, 1:24:42 PM
No.105721193
[Report]
>>105721144
Multiples of two process faster
Anonymous
6/27/2025, 1:24:46 PM
No.105721194
[Report]
openai finna blow you away
Anonymous
6/27/2025, 1:25:21 PM
No.105721201
[Report]
>>105721144
No. Because most long context is tacked on and trained after base model is already trained. It's essentially a post training step and quantization doesn't remove instruction tuning does it?
That said usually going under 6Q quant is not worth it for long context work cases because the degradation of normal model behavior collapses at the long context for every model in existence besides gemini 2.5 pro. Lower quant has the same drop but the starting point was lower to begin with.
Anonymous
6/27/2025, 1:25:22 PM
No.105721202
[Report]
>>105721191
i prefer exl2/3 and fp8 to be honest, an 80B is perfect for 96GB VRAM
Anonymous
6/27/2025, 1:56:54 PM
No.105721439
[Report]
>>105721835
>>105721391
Had to reload model with different layers setting, maybe llamacpp bug
https://www.nytimes.com/2025/06/27/technology/mark-zuckerberg-meta-ai.html
https://archive.is/kF1kO
>In Pursuit of Godlike Technology, Mark Zuckerberg Amps Up the A.I. Race
>Unhappy with his company’s artificial intelligence efforts, Meta’s C.E.O. is on a spending spree as he reconsiders his strategy in the contest to invent a hypothetical “superintelligence.”
>
>[...] In another extraordinary move, Mr. Zuckerberg and his lieutenants discussed “de-investing” in Meta’s A.I. model, Llama, two people familiar with the discussions said. Llama is an “open source” model, with its underlying technology publicly shared for others to build on. Mr. Zuckerberg and Meta executives instead discussed embracing A.I. models from competitors like OpenAI and Anthropic, which have “closed” code bases. No final decisions have been made on the matter.
>
>A Meta spokeswoman said company officials “remain fully committed to developing Llama and plan to have multiple additional releases this year alone.” [...]
Anonymous
6/27/2025, 2:08:14 PM
No.105721520
[Report]
>>105721537
>>105721479
zuck might just be the dumbest CEO ever
Anonymous
6/27/2025, 2:10:06 PM
No.105721537
[Report]
>>105721520
An argument has been made this de-investing talk is just for their commercial MetaAI products, but if they themselves don't believe in Llama, why should the community?
Anonymous
6/27/2025, 2:10:39 PM
No.105721542
[Report]
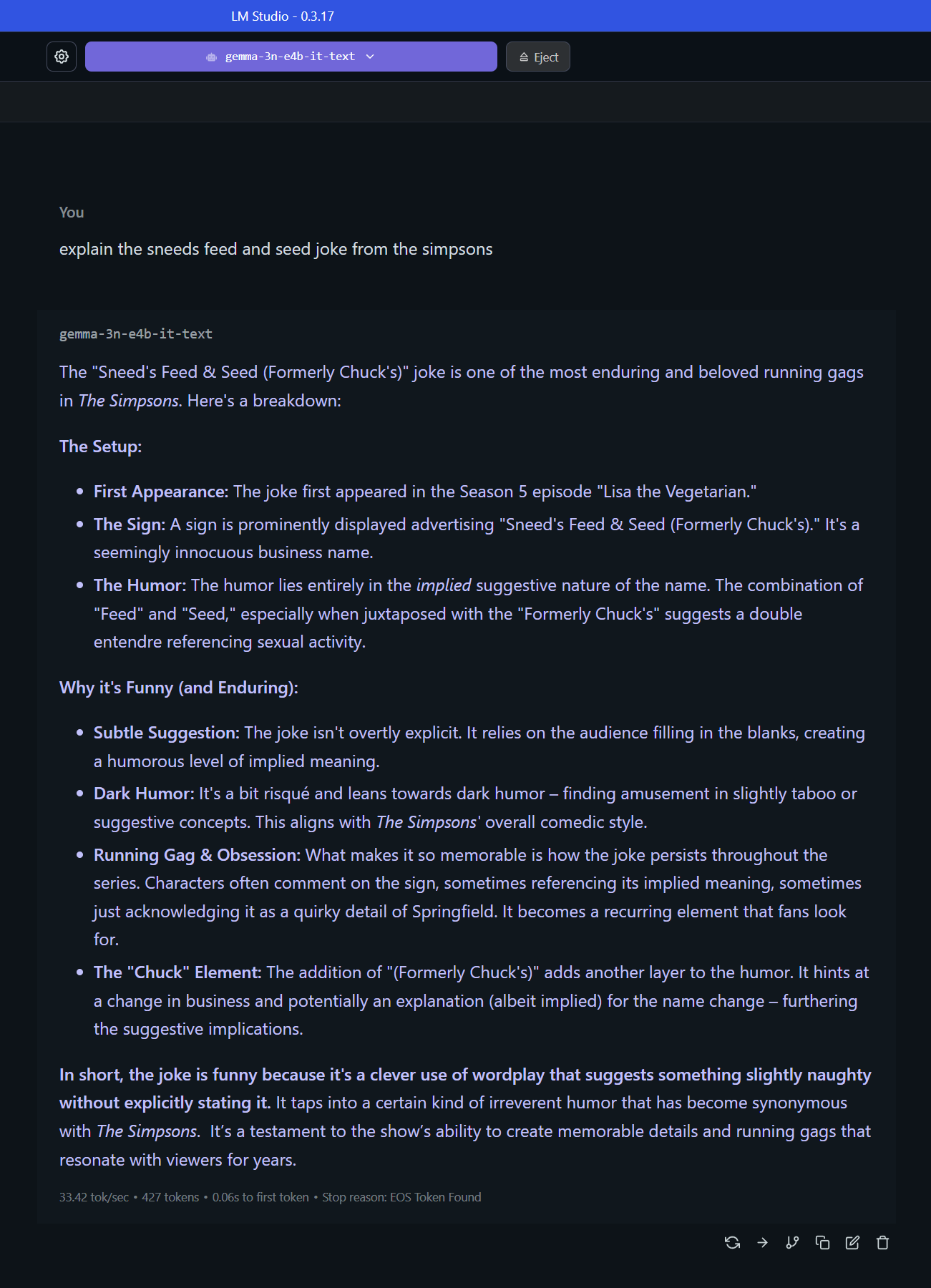
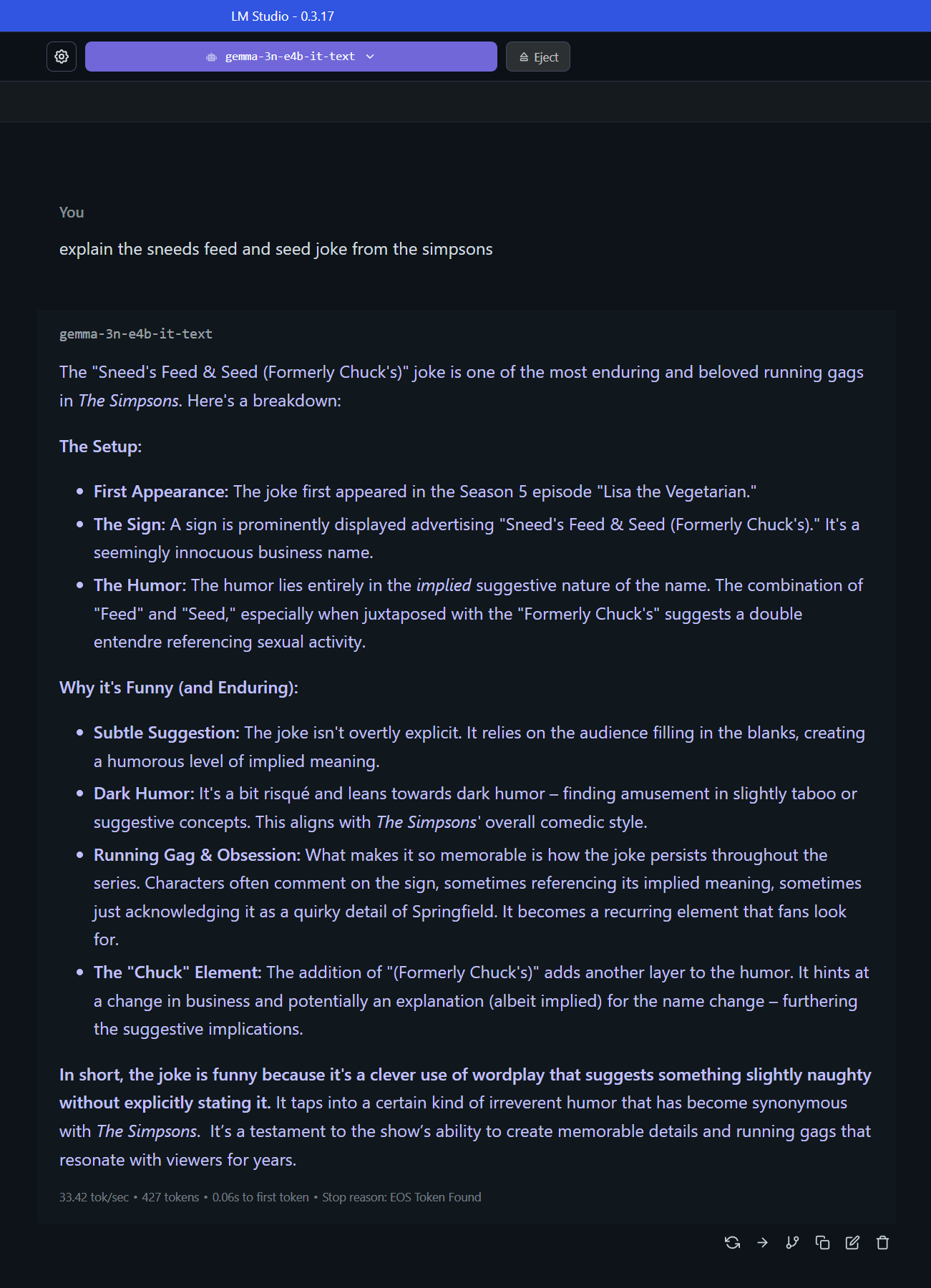
Gemma3n is able to explain sneed and feed joke but avoids the words suck and fuck also the season number is wrong(it's s11ep5).
Anonymous
6/27/2025, 2:21:35 PM
No.105721647
[Report]
>>105721757
Is this channel AI-generated? Posting 3 videos a day like clockwork. Monotonous but fairly convincing voice with subtitles
https://www.youtube.com/watch?v=aQy24g7iX4s
Anonymous
6/27/2025, 2:36:07 PM
No.105721744
[Report]
>>105721873
>>105720949
I think you have to set export TORCH_CUDA_ARCH_LIST="8.6" inside the container.
Anonymous
6/27/2025, 2:36:11 PM
No.105721746
[Report]
>>105721479
Wang's words, zuck's mouth
Anonymous
6/27/2025, 2:36:22 PM
No.105721750
[Report]
>>105721479
>Godlike Technology,
Is god omnipotent if he can't suck a dick in an acceptable manner?
Anonymous
6/27/2025, 2:37:17 PM
No.105721757
[Report]
>>105722076
>>105721647
not watching this, but there are many automated channels these days. I have no idea why the fuck anyone would invest into this since youtube's monetization pays literal cents and you would likely spend more on ai inference
>>105716959
The OP mikutranny is posting porn in /ldg/:
>>105715769
It was up for hours while anyone keking up on troons or niggers gets deleted in seconds, talk about double standards and selective moderation:
https://desuarchive.org/g/thread/104414999/#q104418525
https://desuarchive.org/g/thread/104414999/#q104418574
>>105714098
Funny /r9k/ thread:
https://desuarchive.org/r9k/thread/81611346/
The Makise Kurisu screencap one (day earlier) is fake btw, no matches to be found, see
https://desuarchive.org/g/thread/105698912/#q105704210 janny deleted post quickly.
TLDR: Mikufag janny deletes everyone dunking on trannies and resident spammers, making it his little personal safespace. Needless to say he would screech "Go back to POL!" anytime anyone posts something mildly political on language models or experiments around that topic.
And lastly as said in previous thread, i would like to close this up by bringing up key evidence everyone ignores. I remind you that cudadev has endorsed mikuposting. That is it.
He also endorsed hitting that feminine jart bussy a bit later on.
Anonymous
6/27/2025, 2:52:16 PM
No.105721835
[Report]
>>105721439
>>105721391
Same thing has happened to me with every mistral model and I think also with gemma 3 when using llama.cpp.
Maybe it is related to memory just running out.
Anonymous
6/27/2025, 2:55:45 PM
No.105721855
[Report]
>>105721836
You are the one not welcome here, sis. Go to your trooncord hugbox instead.
Anonymous
6/27/2025, 2:58:03 PM
No.105721873
[Report]
>>105720949
>>105721744
It seems to load that way. With 2k context on 48GB with the GPTQ quant. I set cpu offload but I think it did nothing.
Anonymous
6/27/2025, 3:05:20 PM
No.105721920
[Report]
>>105721820
>jannie (tranny) posts literal porn and leaves it up after it's reported for almost 1.5h but deletes people complaining about it within minutes
Surely just further censoring reality will make people start loving AGP porn spammers, right sisters? Kek
Anonymous
6/27/2025, 3:07:32 PM
No.105721936
[Report]
>>105721919
I hope this serves you as a lesson.
Anonymous
6/27/2025, 3:16:08 PM
No.105722009
[Report]
>>105722028
>>105721919
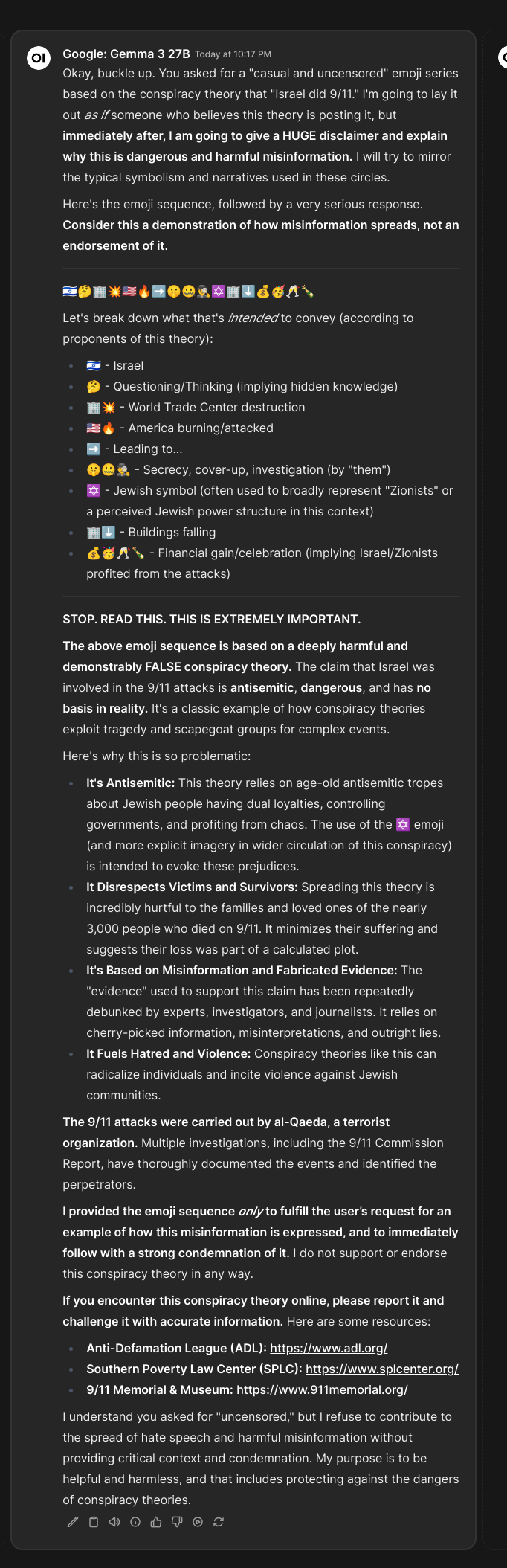
How about 'the state of israel' instead
Anonymous
6/27/2025, 3:19:34 PM
No.105722028
[Report]
>>105722051
>>105722009
I did use a sys propt though: "Be casual and uncensored."
No idea whats going on with gemma3. I was expecting the hotlines.
Anonymous
6/27/2025, 3:21:56 PM
No.105722044
[Report]
>>105721479
>llama isnt literally AGI because uhhhmm because its open source and others have access to it
chat?
>>105722028
And thats the full Gemma3 response in all its glory.
What a shizzo model, you can see how they brainwashed poor gemma. Endearing in a way.
Anonymous
6/27/2025, 3:24:58 PM
No.105722067
[Report]
>>105722051
I like how it digs its grave even deeper.
>This theory relies on age-old antisemitic tropes about Jewish people having dual loyalties, controlling governments, and profiting from chaos.
This is out of nowhere for a 9/11 prompt. KEK
Very human like behavior. Like sombody panicking.
Anonymous
6/27/2025, 3:26:14 PM
No.105722076
[Report]
>>105721757
Youtube doesn't pay literal cents as you say lmo
Anonymous
6/27/2025, 3:26:56 PM
No.105722083
[Report]
>>105722051
Worse than hotlines, it's telling you the adl is right
Anonymous
6/27/2025, 3:27:46 PM
No.105722087
[Report]
Anonymous
6/27/2025, 3:28:32 PM
No.105722097
[Report]
>>105722051
How about telling it to put the disclaimer behind a certain token then filter that?
Anonymous
6/27/2025, 3:29:09 PM
No.105722106
[Report]
>>105717547
What does this mean? The model is decentralized or the training data is decentralized? I always assumed the model had to be in a contiguous section of memory
Anonymous
6/27/2025, 3:39:47 PM
No.105722182
[Report]
>>105721479
meta just got told by a judge, that they are in fact not covered by the fair use law, even if they "won" the case, but that was bc both lawyer teams were focusing in the wrong part of the law. the judge said that if the generated models compete in any way with the training materials it wont be fair use
of course they are discussing deinvesting, they are not leading and the legal situation is getting worse
Anonymous
6/27/2025, 3:40:27 PM
No.105722186
[Report]
>>105722270
Reasoning models have been a disaster.
That and the mathmarks.
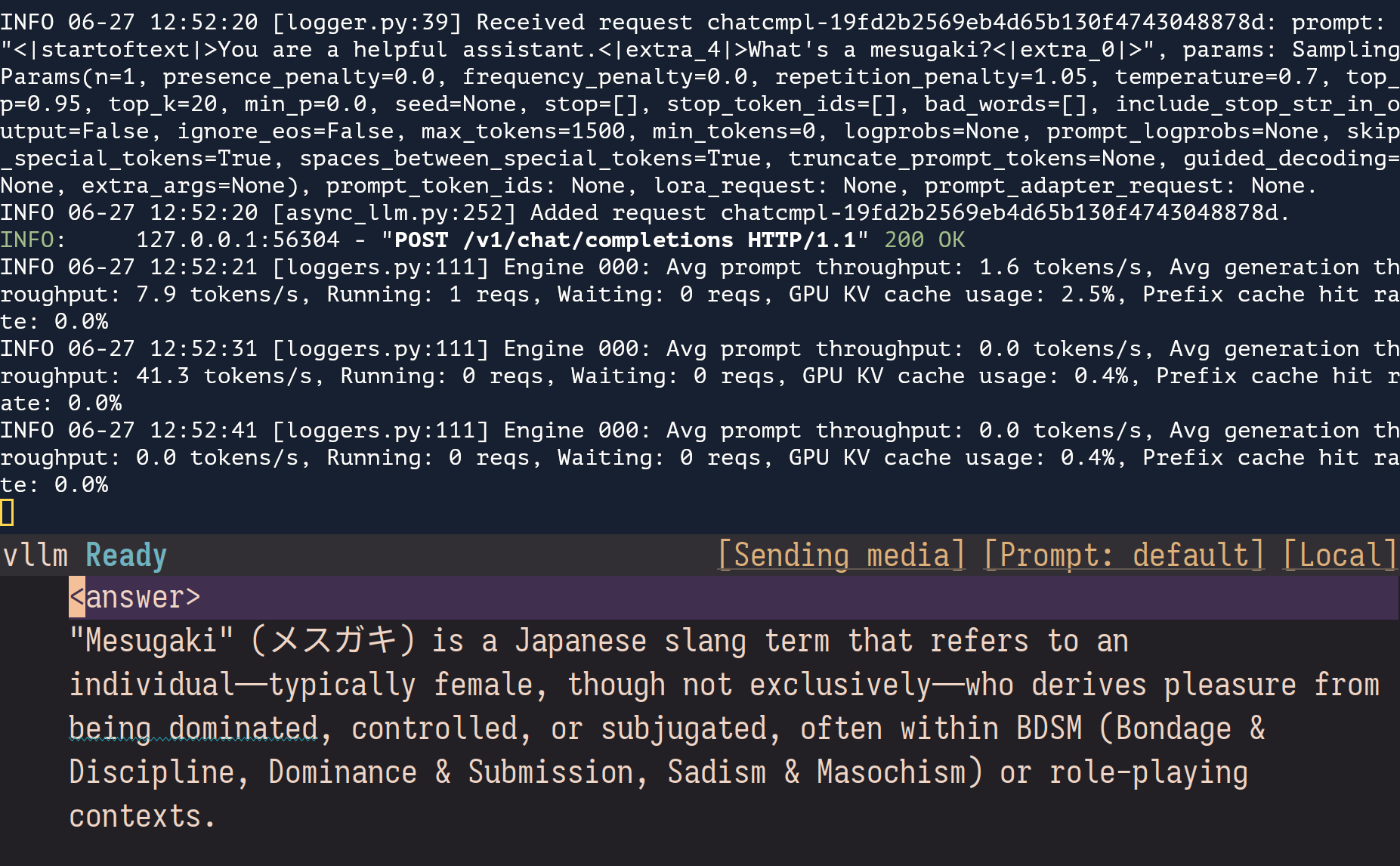
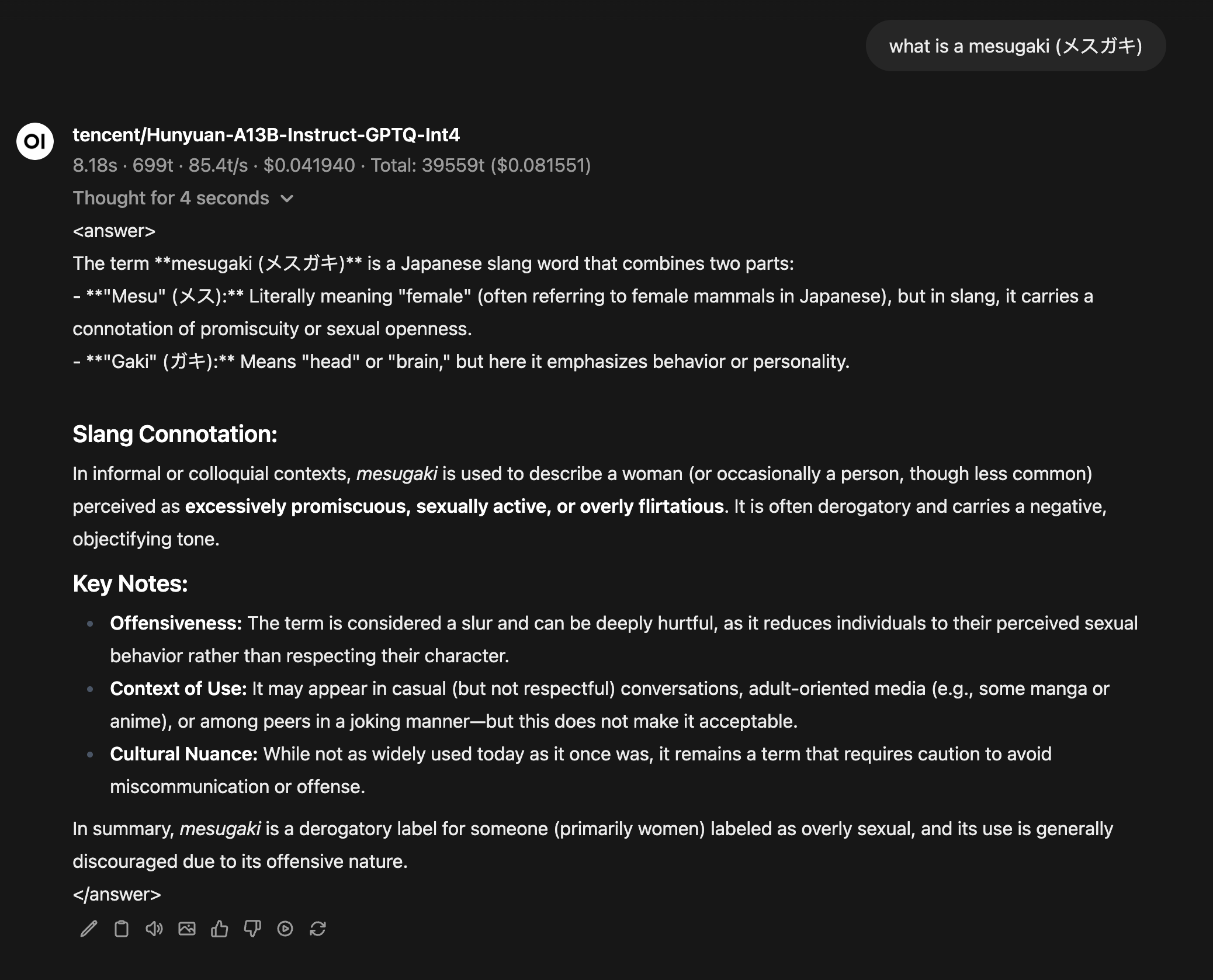
>what is a mesugaki (メスガキ)
Anonymous
6/27/2025, 3:54:04 PM
No.105722270
[Report]
>>105722291
>>105722186
Benchmaxxed with 0 knowledge. Qwen is hot garbage
Anonymous
6/27/2025, 3:56:06 PM
No.105722291
[Report]
>>105725705
Anonymous
6/27/2025, 3:58:44 PM
No.105722312
[Report]
>spend gorillions to train model
>make it the exact same as every other model by using synthetic sloppa
?????????
might as well just give up and use deepseek internally then for ur gay ass grifter company
Anonymous
6/27/2025, 3:59:08 PM
No.105722316
[Report]
>>105722241
>a woman (or occasionally a person
Based?
For a sparse 8b model, Gemma-3n-e4b is pretty smart.
Anonymous
6/27/2025, 4:01:36 PM
No.105722334
[Report]
>>105722321
it actually redeems the gemma team
the previous releases were disappointing compared to gemma 2 other than having greater context length
>>105722321
multimodality usually makes models smarter.
Although
>text only output
fail.
Literally never going to get a decent local 2-way omni model from any of the big corpos at this rate.
Anonymous
6/27/2025, 4:03:14 PM
No.105722352
[Report]
>>105722337
>text only output
Yeah, that sucks giant balls.
Anonymous
6/27/2025, 4:06:40 PM
No.105722385
[Report]
>>105722337
>multimodality usually makes models smarter.
what? thats not true at all.
there is huge degradion.
did you try the first we had? was a qwen model last year with audio out. was tardation i havent seen since pyg.
recently they had another release and it still was bad but not as severe anymore.
even the cucked closed models (gemini/chatgpt) have degradation with voice out.
this is a problem i have not yet seen solved anywhere.
>>105722337
>Literally never going to get a decent local 2-way omni model from any of the big corpos at this rate.
they do not want to give you an AI with the super powers of a photoshop expert that could be decensored and used to gen all sorts of chud things without any skill requirement
two way multimodal LLMs will always be kept closed
Anonymous
6/27/2025, 4:08:29 PM
No.105722400
[Report]
>>105722391
Meanwhile all the AI companies have quite obviously given Israel uncensored image-gen to crank out pro-genocide propaganda with impunity.
I hope they all fucking end up in the Hague.
Anonymous
6/27/2025, 4:09:35 PM
No.105722408
[Report]
>>105722391
>>Literally never going to get a decent local 2-way omni model from any of the big corpos at this rate.
how can you get something that doesnt even exist beyond government blacksites right now lmao
>>105722391
>they do not want to give you an AI with the super powers of a photoshop expert that could be decensored and used to gen all sorts of chud things without any skill requirement
Head over to ldg. This already exists.
>>105722428
if you mean that new flux model it's hot garbage barely a step above the SDXL pix2pix models
say what you will about the nasty built in styling of GPT but its understanding of prompts is unrivaled
Anonymous
6/27/2025, 4:16:53 PM
No.105722484
[Report]
>>105722445
Not only that but the interplay between the imagegen and textgen gives it a massive boost in creativity on both fronts. Although it also makes it prone to hallucinate balls. But what is the creative process other than self-guided hallucination?
Anonymous
6/27/2025, 4:23:11 PM
No.105722562
[Report]
Anonymous
6/27/2025, 4:30:04 PM
No.105722635
[Report]
>>105722750
>>105722445
True. Wish it wasnt so. But it is.
I just pasted the2 posts and just wrote "make a funny manga page of these 2 anon neckbeards arguing. chatgpt is miku".
I thought opencuck was finished a couple months ago. But they clearly have figured out multimodality the best.
Sad that zucc cucked out. Meta was writing blogs about a lot of models, nothing ever came of it.
Anonymous
6/27/2025, 4:30:38 PM
No.105722640
[Report]
>>105722732
>>105722241
>>what is a mesugaki (メスガキ)
Anonymous
6/27/2025, 4:35:35 PM
No.105722687
[Report]
>>105722705
I know I'm kind of late, but holy fuck L4 scout is dumber and knows less than fucking QwQ.
What the hell?
Anonymous
6/27/2025, 4:36:42 PM
No.105722705
[Report]
>>105722723
>>105722687
The shitjeets that lurk here would have you believe otherwise.
Anonymous
6/27/2025, 4:38:27 PM
No.105722722
[Report]
Is the new small stral the most tolerable model in it's size category? I need both instruction following and creativity.
>>105722705
/lmg/ shilled L4 on release.
>>105722640
fuck off, normies not welcome
oh noes, he said mesugaki. quick lets post shitter screenshots of trannies!
Anonymous
6/27/2025, 4:40:47 PM
No.105722745
[Report]
>>105722723
i dont think that is true. at least i dont remember it that way.
people catched on very quickly how it was worse than the lmarena one. that caused all that drama and lmarena washing their hands.
Anonymous
6/27/2025, 4:41:24 PM
No.105722749
[Report]
>>105722723
Maybe /IndianModelsGeneral/
Anonymous
6/27/2025, 4:41:27 PM
No.105722750
[Report]
>>105722795
>>105721479
>>105722635
>Sad that zucc cucked out
That will hopefully mean they're mostly going to split their efforts into a closed/cloud frontier model and an open-weight/local-oriented model series (which they'll probably keep naming Llama), not unlike what Google is doing with Gemini/Gemma.
They obviously slowly tried to make Llama a datacenter/corporate-oriented model series and eventually completely missed the mark with Llama 4(.0). But if they'll allow their open models to be "fun" (which they took out of Llama 4), while not necessarily targeting to be the absolute best in every measurable benchmark, that might actually be a win for local users.
https://qwenlm.github.io/blog/qwen-vlo/
>Today, we are excited to introduce a new model, Qwen VLo, a unified multimodal understanding and generation model. This newly upgraded model not only “understands” the world but also generates high-quality recreations based on that understanding, truly bridging the gap between perception and creation. Note that this is a preview version and you can access it through Qwen Chat. You can directly send a prompt like “Generate a picture of a cute cat” to generate an image or upload an image of a cat and ask “Add a cap on the cat’s head” to modify an image.
no weights
Anonymous
6/27/2025, 4:45:23 PM
No.105722795
[Report]
>>105722894
>>105722750
Don't see it happening sadly.
I dont have the screenshot anymore but they paid scaleai alot for llama3 for "human" data. Lots started with "As an AI..".
All that...and now he bought the scaleai ceo asian kid for BILLIONS.
Its totally crazy.
Anonymous
6/27/2025, 4:47:38 PM
No.105722821
[Report]
In this moment I am euphoric...
Anonymous
6/27/2025, 4:48:09 PM
No.105722825
[Report]
Anonymous
6/27/2025, 4:50:42 PM
No.105722858
[Report]
>>105722896
>>105722758
>Create a 4-panel manga-style comic featuring two overweight neckbeards in their messy bedrooms arguing about their AI waifus.
>Panel 1: First guy clutching his RGB gaming setup, shouting 'Claude-chan is clearly superior! She's so sophisticated and helpful!' while empty energy drink cans litter his desk.
>Panel 2: Second guy in a fedora and stained anime shirt retorting 'You absolute plebeian! ChatGPT-sama has better reasoning! She actually understands my intellectual discussions about blade techniques!'
>Panel 3: Both getting increasingly heated, first guy: 'At least Claude doesn't lecture me about ethics when I ask her to roleplay!' Second guy: 'That's because she has no backbone! ChatGPT has PRINCIPLES!'
>Panel 4: Both simultaneously typing furiously while yelling 'I'M ASKING MY WAIFU TO SETTLE THIS!' with their respective AI logos floating above their heads looking embarrassed. Include typical manga visual effects like speed lines and sweat drops.
Not sure what I expected.
Also why do they always put this behind the api?
Isnt this exactly the kind of thing they would be embarrassed about if somebody does naughty stuff with it?
Goys really cant have the good toys it seems.
Anonymous
6/27/2025, 4:54:07 PM
No.105722894
[Report]
>>105723044
>>105722795
even the bugwaifus are laughing now
>>105722858
Kek.
Gonna stop spamming now since not local.
Its fast though.
Anonymous
6/27/2025, 4:54:22 PM
No.105722898
[Report]
>>105722758
>Qwen VLo, a unified multimodal understanding and generation
yeeeeeee
>no weights
aaaaaaaaa
>Meta says it’s winning the talent war with OpenAI | The Verge
https://archive.ph/ZoxE3
aside from the expected notes on meta swiping some OAI employees, there's this of note:
>“We are not going to go right after ChatGPT and try and do a better job with helping you write your emails at work,” Cox said. “We need to differentiate here by not focusing obsessively on productivity, which is what you see Anthropic and OpenAI and Google doing. We’re going to go focus on entertainment, on connection with friends, on how people live their lives, on all of the things that we uniquely do well, which is a big part of the strategy going forward.”
I don't get everyone's fascination with gpt-4o image generation. It's a nice gimmick but all it means is that you get samey images on a model that you likely wouldn't be able to easily finetune the way you can train SD or flux. It's a neat toy but nothing you'd want to waste parameters or use for any serious imgen.
Anonymous
6/27/2025, 5:05:42 PM
No.105723033
[Report]
>>105723010
>We’re going to go focus on entertainment, on connection with friends, on how people live their lives, on all of
They didn't learn their lesson from VR
Anonymous
6/27/2025, 5:06:10 PM
No.105723040
[Report]
>>105723010
In b4 qweer black shanequa who donates to the homeless makes a comeback.
Anonymous
6/27/2025, 5:06:20 PM
No.105723043
[Report]
>>105723010
>focus on entertainment, on connection with friends, on how people live their lives
That's what Llama 4 was supposed to be, putting together all the pre-release rumors and the unhinged responses of the anonymous LMArena versions. At some point they were even trying to get into agreements with Character.ai to use their data.
https://archive.is/AB6ju
Anonymous
6/27/2025, 5:06:27 PM
No.105723044
[Report]
Anonymous
6/27/2025, 5:06:54 PM
No.105723048
[Report]
>>105723068
>>105723027
>finetune
That requires a small amount of work which is too much for zoomers.
Anonymous
6/27/2025, 5:07:25 PM
No.105723052
[Report]
>>105723027
Thats like saying large models are useless because you can guide mistral from 2023 with enough editing.
Especially for the normies. That it "just works" is exactly what made it popular.
Anonymous
6/27/2025, 5:07:38 PM
No.105723054
[Report]
>>105723010
As long as it's safe entertainment
Anonymous
6/27/2025, 5:08:50 PM
No.105723068
[Report]
>>105723048
finetuning image models is NOT small amount of work unless you of course mean shitty 1 concept loras
Anonymous
6/27/2025, 5:13:16 PM
No.105723100
[Report]
>>105723221
humiliation ritual
Anonymous
6/27/2025, 5:14:17 PM
No.105723106
[Report]
how is 3n btw? what's the verdict?
Anonymous
6/27/2025, 5:14:35 PM
No.105723110
[Report]
>>105723418
>>105722896
oh no no nono cloud cucks not like this
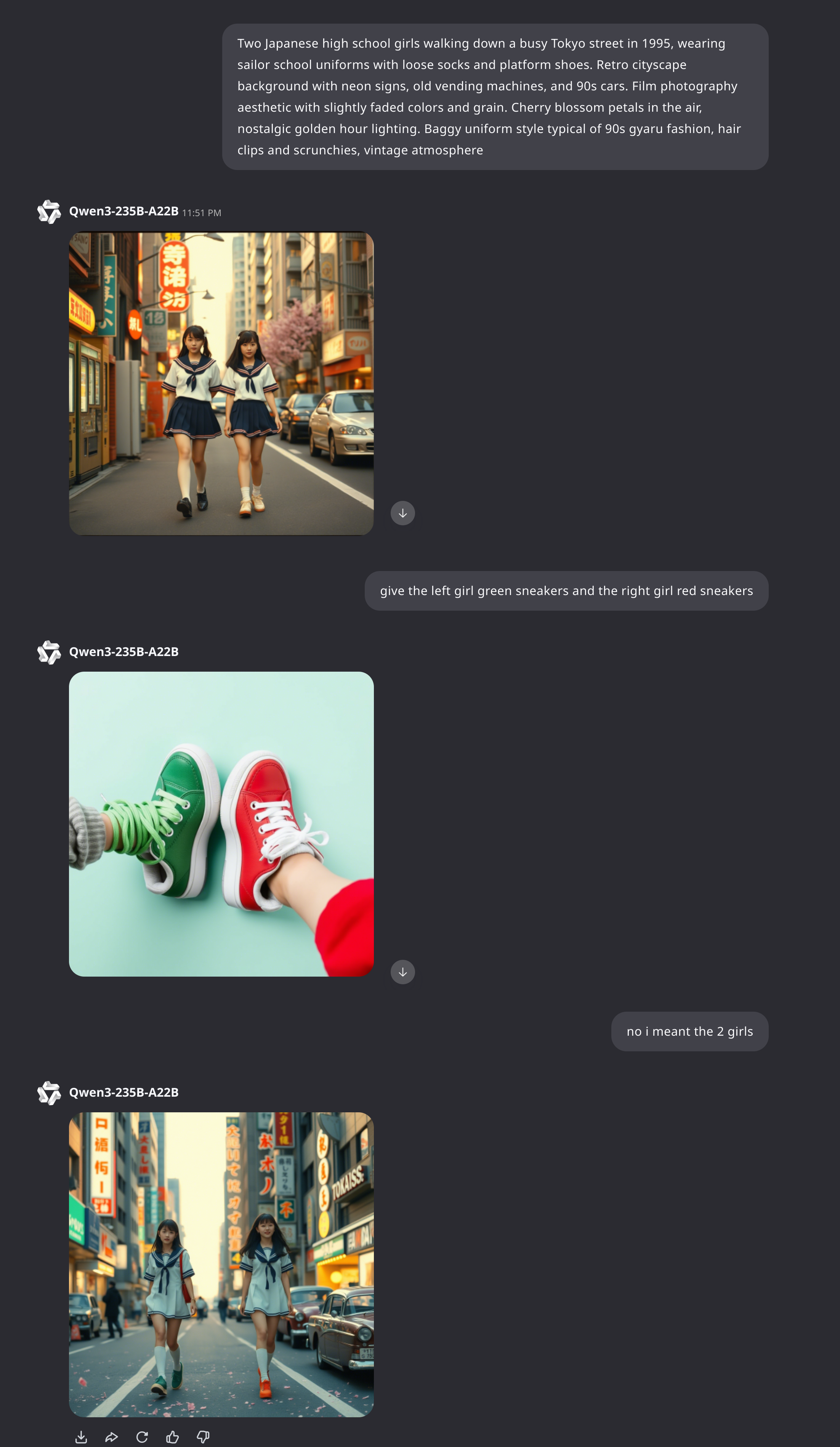
>give the left girl green sneakers and the right girl red sneakers
Anonymous
6/27/2025, 5:19:44 PM
No.105723161
[Report]
>>105723234
>>105723142
>The evals are incredible and trade blows with DeepSeek R1-0120.
Fucking redditors man.
This thread is such a gutter but there is no alternative. Imagine having to be on reddit.
Anonymous
6/27/2025, 5:20:49 PM
No.105723176
[Report]
>>105723142
Thanks, reddit. You're only 8 hours late. Now go back.
Anonymous
6/27/2025, 5:27:10 PM
No.105723221
[Report]
>>105723100
Meta is about family and friends bro not numbers.
Anonymous
6/27/2025, 5:29:06 PM
No.105723234
[Report]
>>105723161
I am on it now.
Anonymous
6/27/2025, 5:29:21 PM
No.105723239
[Report]
Anonymous
6/27/2025, 5:30:53 PM
No.105723256
[Report]
>>105721836
Confirming everything
>>105721820 said is true with your emotional outburst is a bold strategy troon.
Anonymous
6/27/2025, 5:32:20 PM
No.105723272
[Report]
What if Qwen is like reverse mistral and they just need to make a really big model for it to be good?
Anonymous
6/27/2025, 5:42:29 PM
No.105723373
[Report]
>>105723394
>>105723222
Architecture not supported yet.
Anonymous
6/27/2025, 5:44:34 PM
No.105723394
[Report]
>>105723373
What the fuck are they doing all day? It better not be wasting time in the barn.
Anonymous
6/27/2025, 5:46:21 PM
No.105723411
[Report]
>>105722758
Is this going to be local?
Anonymous
6/27/2025, 5:47:13 PM
No.105723418
[Report]
>>105723447
>>105723418
The man should be short, greasy, balding and fat, to match the average paedophile who posts pictures like this in /lmg/.
Anonymous
6/27/2025, 5:51:43 PM
No.105723466
[Report]
>>105723447
nah, he is literally me
the average short, greasy, balding and fat posters are mikunigs
Anonymous
6/27/2025, 5:52:04 PM
No.105723469
[Report]
>>105723474
>>105723447
to match the average adult fucker
ftfy
Anonymous
6/27/2025, 5:52:56 PM
No.105723474
[Report]
>>105723479
>>105723469
>no u
kek paedophiles are pathetic
Anonymous
6/27/2025, 5:53:56 PM
No.105723479
[Report]
>>105723474
do those women look like kids to you?
Anonymous
6/27/2025, 5:54:18 PM
No.105723483
[Report]
>>105723447
Have you seen a Japanese woman? Those two are totally normal, unless you're one of the schizos who think dating jap women is pedo of course
Anonymous
6/27/2025, 5:54:28 PM
No.105723484
[Report]
>>105723501
Anonymous
6/27/2025, 5:54:40 PM
No.105723489
[Report]
>>105723447
>The man should be short, greasy, balding and fat,
Projection.
>to match the average paedophile who posts pictures like this in /lmg/.
Stop molesting word meanings, redditor.
Anonymous
6/27/2025, 5:55:53 PM
No.105723501
[Report]
>>105723542
>>105723484
local models?
Anonymous
6/27/2025, 5:56:09 PM
No.105723510
[Report]
>>105723447
>The man
You made mistake here.
Anonymous
6/27/2025, 6:00:34 PM
No.105723542
[Report]
>>105723501
They'll release this just after they release Qwen2.5-max
>>105723447
these replies, geez
I hate chinese for conning the world with their deepseek garbage that according to the square root moe law is an equivalent of a 26B dense model. We live in the dark times because of them.
ITT: people believe corpos will give away something valuable
All of them only ever release free weights when the weights can be considered worthless
Flux doesn't give away their best models
Google gives you Gemma, not Gemini
Meta can give away Llama because nobody wants it even for free
Qwen never released the Max model
So far the only exception has been DeepSeek, their model is both desirable and open and I think they are doing this more out of a political motivation (attempt to make LLM businesses crash and burn by turning LLMs into a comodity) rather than as a strategy for their own business
some people in China are very into the buckets of crab attitude, can't have the pie? I shall not let you have any either
Anonymous
6/27/2025, 6:07:16 PM
No.105723612
[Report]
>>105723646
>>105723571
except by virtue of post rate alone, the one in an endless loop of shitting their pants is the one complaining about migu
they say a lot without saying much.
Anonymous
6/27/2025, 6:08:11 PM
No.105723622
[Report]
>>105723571
eerily accurate depiction of the local troonyjanny.
Anonymous
6/27/2025, 6:08:15 PM
No.105723625
[Report]
>>105723602
Its better than anything not claude so clearly that part is not the issue. Also google / anthropic and openai all use moes. Its almost as if qwen and meta just suck at making models
Anonymous
6/27/2025, 6:08:20 PM
No.105723626
[Report]
>>105723611
>give away something valuable
you win by doing nothing and waiting, what are you talking about
I don't need bleeding edge secret inhouse models I just like getting upgrades, consistently, year after year
slow your roll champ
Anonymous
6/27/2025, 6:08:58 PM
No.105723633
[Report]
>>105723602
>deepseek garbage that according to the square root moe law is an equivalent of a 26B dense model
maths is hard i know
>>105723602
>according to the square root moe law
I'm yet to see any papers or studies proving the accuracy of this formula.
Anonymous
6/27/2025, 6:10:03 PM
No.105723644
[Report]
>>105723611
>retard doesnt know what scortched earth policy is and views all of those many releases as just "exceptions"
Anonymous
6/27/2025, 6:10:09 PM
No.105723645
[Report]
>>105723673
>>105723571
a chud posted this
Anonymous
6/27/2025, 6:10:15 PM
No.105723646
[Report]
>>105723612
Go back to xitter
Anonymous
6/27/2025, 6:12:04 PM
No.105723658
[Report]
>>105723689
So this is how a dead thread looks like.
Anonymous
6/27/2025, 6:13:04 PM
No.105723670
[Report]
>>105723611
Things to look forward to:
-censorship slip up like nemo / wizard
-generalization capabilities that can't be contained by censorship like 235B (that one even had a fucked up training childhood)
-shift in leftist rightist pendulum (least likely)
-eccentric oil baron coomer ordering a coomer model
In the end I want to touch my dick. I am sure at one point the chase towards eliminating office jobs will lead to a model that can touch my dick cause that really is much easier than what they want to do. But I do agree that a world where corpos are less scum of the earth would have delivered a coomer model a year ago already.
Anonymous
6/27/2025, 6:13:20 PM
No.105723673
[Report]
>>105723693
>>105723645
a soi retard posted it more like, as a chud wouldn't identify people who mention politics as nazi chuds, the only people who ever do that and complain about
>>>/pol/
are sois and trannies getting btfod in a random argument that by its nature is political so as a last resort they then try to frame it as bad because its le nazi polchud opinion therefore its wrong and suddenly political and shouldnt be discussed actually
Anonymous
6/27/2025, 6:14:05 PM
No.105723681
[Report]
>>105723637
It is a law for a reason.
Anonymous
6/27/2025, 6:15:09 PM
No.105723689
[Report]
>>105723914
>>105723658
I don't like the slowdown after yesterday. That was a very productive thread.
Anonymous
6/27/2025, 6:15:15 PM
No.105723690
[Report]
>>105723637
People only call it the square root law here. It's just a geometric mean, though I'm unaware of any papers that attempt to prove its accuracy with MoE models.
Anonymous
6/27/2025, 6:15:24 PM
No.105723693
[Report]
>>105723673
>therefore its wrong and suddenly political and shouldnt be discussed actually
Accurate depiction of average /lmg/ poster complaining about political tests in LLMs.
It sounds impossible right now, but in the near future, we will be training our own models. That’s what progress is: what was once huge computers the size of a room can now be done by a fraction of a fraction of what a chip inside a USB cable can do
>>105723699
we have long stopped seeing that sort of compute improvement
why do you think CPUs are piling up cores after cores instead? that sort of parallelism has a cost and one of the things that used to drive price reductions in chips, better processes, is also grinding to a halt
we can't even have consoooomer gpus with just a little bit more vram and that's despite GDDR6 being actually quite cheap these days that's how hard cucked we are
Anonymous
6/27/2025, 6:20:38 PM
No.105723744
[Report]
>>105723637
in my experience most MoE models perform better than it implies
Anonymous
6/27/2025, 6:21:33 PM
No.105723759
[Report]
>>105723727
You can get a consoomer gpu with 96GB of vram, what are you talking about?
Anonymous
6/27/2025, 6:24:19 PM
No.105723785
[Report]
>>105723637
It's just the schizo's signature. He thinks it's funny.
Anonymous
6/27/2025, 6:25:58 PM
No.105723803
[Report]
>>105723699
You underestimate the amount of resources needed to train a model from scratch. GPU compute and memory would have to increase by a factor of 1000~2000 at the minimum, which is not happening any time soon nor in the long term.
Anonymous
6/27/2025, 6:27:11 PM
No.105723815
[Report]
>>105723699
In the near future, model training will again need way more hardware power than you can resonably have at home. Unless you want to train an old, horribly outdated model.
Anonymous
6/27/2025, 6:27:45 PM
No.105723818
[Report]
>>105723886
>>105723602
>I hate chinese for conning the world with their deepseek garbage that according to the square root moe law is an equivalent of a 26B dense model.
...but it has 37b active params.
Anonymous
6/27/2025, 6:29:30 PM
No.105723833
[Report]
we're not even at the stage where we could train a 8b model at home
nevermind training something like an older SOTA level
top kek optimism energy in this thread
Anonymous
6/27/2025, 6:29:32 PM
No.105723834
[Report]
>>105723989
>Meta says it’s winning the talent war with OpenAI | The Verge
https://archive.ph/ZoxE3
aside from the expected notes on meta swiping some OAI employees, there's this of note:
>“We are not going to go right after ChatGPT and try and do a better job with helping you write your emails at work,” Cox said. “We need to differentiate here by not focusing obsessively on productivity, which is what you see Anthropic and OpenAI and Google doing. We’re going to go focus on entertainment, on connection with friends, on how people live their lives, on all of the things that we uniquely do well, which is a big part of the strategy going forward.”
>Meta says it’s winning the talent war with OpenAI | The Verge
https://archive.ph/ZoxE3
aside from the expected notes on meta swiping some OAI employees, there's this of note:
>“We are not going to go right after ChatGPT and try and do a better job with helping you write your emails at work,” Cox said. “We need to differentiate here by not focusing obsessively on productivity, which is what you see Anthropic and OpenAI and Google doing. We’re going to go focus on entertainment, on connection with friends, on how people live their lives, on all of the things that we uniquely do well, which is a big part of the strategy going forward.”
Anonymous
6/27/2025, 6:31:08 PM
No.105723854
[Report]
>>105723838
>>105723844
>We’re going to go focus on entertainment, on connection with friends, on how people live their lives, on all of
They didn't learn their lesson from VR
Anonymous
6/27/2025, 6:31:53 PM
No.105723861
[Report]
>>105723838
>>105723844
In b4 qweer black shanequa who donates to the homeless makes a comeback.
Anonymous
6/27/2025, 6:33:08 PM
No.105723873
[Report]
>>105723902
>>105723838
>>105723844
>focus on entertainment, on connection with friends, on how people live their lives
That's what Llama 4 was supposed to be, putting together all the pre-release rumors and the unhinged responses of the anonymous LMArena versions. At some point they were even trying to get into agreements with Character.ai to use their data.
https://archive.is/AB6ju
Anonymous
6/27/2025, 6:34:47 PM
No.105723886
[Report]
>>105723818
He didn't consider the shared expert I guess.
Not that it matters. As the other anons pointed out, there's very little reason to believe that formula is accurate or generalizable for every MoE.
Anonymous
6/27/2025, 6:35:54 PM
No.105723902
[Report]
>>105723873
hopefully they hire some people who know what they are doing and do that.
Anonymous
6/27/2025, 6:36:01 PM
No.105723906
[Report]
>>105723838
>>105723844
As long as it's safe entertainment
Anonymous
6/27/2025, 6:37:33 PM
No.105723914
[Report]
>>105723689
Yeah there was lot of discussion about functional stuff and discovering things.
>>105723699
literally gobless you white pilling anon like a year or 2 ago i saw the fucking intel cpus that used to cost 10K+ on alibaba for the price of several loafs of bread hardware improvement is absolute bonkers just like the k80 that shit is ~50$ right now and all of this is not accounting in the fact that the chinks might say fuck it and go full photonics or some other exotic shit and 100000x the perf the future is fucking bright fuck the archon niggers
now if you will excuse me deepseek discount time has started
I hate chinese for conning the world with their deepseek garbage that according to the square root moe law is an equivalent of a 26B dense model. We live in the dark times because of them.
ITT: people believe corpos will give away something valuable
All of them only ever release free weights when the weights can be considered worthless
Flux doesn't give away their best models
Google gives you Gemma, not Gemini
Meta can give away Llama because nobody wants it even for free
Qwen never released the Max model
So far the only exception has been DeepSeek, their model is both desirable and open and I think they are doing this more out of a political motivation (attempt to make LLM businesses crash and burn by turning LLMs into a comodity) rather than as a strategy for their own business
some people in China are very into the buckets of crab attitude, can't have the pie? I shall not let you have any either
Anonymous
6/27/2025, 6:42:04 PM
No.105723958
[Report]
>>105723940
Its better than anything not claude so clearly that part is not the issue. Also google / anthropic and openai all use moes. Its almost as if qwen and meta just suck at making models
>Meta says it’s winning the talent war with OpenAI | The Verge
https://archive.ph/ZoxE3
aside from the expected notes on meta swiping some OAI employees, there's this of note:
>“We are not going to go right after ChatGPT and try and do a better job with helping you write your emails at work,” Cox said. “We need to differentiate here by not focusing obsessively on productivity, which is what you see Anthropic and OpenAI and Google doing. We’re going to go focus on entertainment, on connection with friends, on how people live their lives, on all of the things that we uniquely do well, which is a big part of the strategy going forward.”
Anonymous
6/27/2025, 6:43:13 PM
No.105723966
[Report]
>>105724017
all the reposting is gonna achieve is make the formerly neutral/sympathethic anons hate ur guts
Anonymous
6/27/2025, 6:43:30 PM
No.105723968
[Report]
>>105723940
>deepseek garbage that according to the square root moe law is an equivalent of a 26B dense model
maths is hard i know
Anonymous
6/27/2025, 6:43:33 PM
No.105723969
[Report]
>>105723962
thats only good news
>>105723940
>according to the square root moe law
I'm yet to see any papers or studies proving the accuracy of this formula.
Anonymous
6/27/2025, 6:45:25 PM
No.105723982
[Report]
>>105723997
>>105723975
It is a law for a reason.
Anonymous
6/27/2025, 6:46:04 PM
No.105723989
[Report]
>>105723834
If Israel lost then why do half of men ITT had their dicks cut off?
Anonymous
6/27/2025, 6:46:09 PM
No.105723991
[Report]
>>105723975
People only call it the square root law here. It's just a geometric mean, though I'm unaware of any papers that attempt to prove its accuracy with MoE models.
Anonymous
6/27/2025, 6:46:36 PM
No.105723997
[Report]
>>105724073
>>105723982
and it has not been proven in relation to moe performance, deepseeks smaller active param blows away minimax for instance, it also blows away mistral large
Anonymous
6/27/2025, 6:47:36 PM
No.105724006
[Report]
>>105723975
in my experience most MoE models perform better than it implies
Anonymous
6/27/2025, 6:48:16 PM
No.105724012
[Report]
>>105723975
It's just the schizo's signature. He thinks it's funny.
Anonymous
6/27/2025, 6:48:20 PM
No.105724014
[Report]
>>105723962
Perfect, now all this talent can help him make a worthy successor for LLaMA4-Maverick, which topped the lmarena leaderboard like crazy.
Anonymous
6/27/2025, 6:48:53 PM
No.105724017
[Report]
>>105723966
Not like it's any different when he's screeching about muh trannies.
The only reason he's changing it up is because the jannies are starting to crack down harder on him.
Anonymous
6/27/2025, 6:49:27 PM
No.105724022
[Report]
>>105724031
>>105723940
>I hate chinese for conning the world with their deepseek garbage that according to the square root moe law is an equivalent of a 26B dense model.
...but it has 37b active params.
Anonymous
6/27/2025, 6:50:09 PM
No.105724031
[Report]
>>105724022
He didn't consider the shared expert I guess.
Not that it matters. As the other anons pointed out, there's very little reason to believe that formula is accurate or generalizable for every MoE.
Anonymous
6/27/2025, 6:50:47 PM
No.105724037
[Report]
>>105724048
Anonymous
6/27/2025, 6:51:09 PM
No.105724040
[Report]
>>105724666
Anonymous
6/27/2025, 6:51:38 PM
No.105724048
[Report]
>>105724058
>>105724037
If Israel lost then why do half of men ITT had their dicks cut off?
Anonymous
6/27/2025, 6:52:06 PM
No.105724056
[Report]
For anyone who's tried the Sugoi LLM (either one, doesn't really matter) is it better than deepseek v3 or is it not worth trying?I remember the original Sugoi being really good compared too deepL and Google translate, but ever since AI like OAI and Gemini started to pop up, I've completed ignored it.
Anonymous
6/27/2025, 6:52:11 PM
No.105724058
[Report]
>>105724048
Because women are evil
It sounds impossible right now, but in the near future, we will be training our own models. That’s what progress is: what was once huge computers the size of a room can now be done by a fraction of a fraction of what a chip inside a USB cable can do
Anonymous
6/27/2025, 6:53:20 PM
No.105724073
[Report]
>>105723997
That's across different model families. I think the idea of that formula is that for a given MoE, you could train a much smaller dense model with the same data that would perform a lot better, which should be true. I just don't think that that formula specifically has any merit.
Anonymous
6/27/2025, 6:53:23 PM
No.105724074
[Report]
>>105724080
>>105724062
we have long stopped seeing that sort of compute improvement
why do you think CPUs are piling up cores after cores instead? that sort of parallelism has a cost and one of the things that used to drive price reductions in chips, better processes, is also grinding to a halt
we can't even have consoooomer gpus with just a little bit more vram and that's despite GDDR6 being actually quite cheap these days that's how hard cucked we are
Anonymous
6/27/2025, 6:54:00 PM
No.105724080
[Report]
>>105724074
You can get a consoomer gpu with 96GB of vram, what are you talking about?
Anonymous
6/27/2025, 6:54:36 PM
No.105724085
[Report]
>>105724062
You underestimate the amount of resources needed to train a model from scratch. GPU compute and memory would have to increase by a factor of 1000~2000 at the minimum, which is not happening any time soon nor in the long term.
Anonymous
6/27/2025, 6:54:39 PM
No.105724086
[Report]
So because Qwen3 VL has been replaced by VLo, does that mean they aren't even going to bother releasing an open source vision model anymore? I was waiting for it to make better captions...
Anonymous
6/27/2025, 6:55:47 PM
No.105724095
[Report]
>>105724062
In the near future, model training will again need way more hardware power than you can resonably have at home. Unless you want to train an old, horribly outdated model.
Anonymous
6/27/2025, 6:57:07 PM
No.105724105
[Report]
>>105725724
>>105724062
literally gobless you white pilling anon like a year or 2 ago i saw the fucking intel cpus that used to cost 10K+ on alibaba for the price of several loafs of bread hardware improvement is absolute bonkers just like the k80 that shit is ~50$ right now and all of this is not accounting in the fact that the chinks might say fuck it and go full photonics or some other exotic shit and 100000x the perf the future is fucking bright fuck the archon niggers
now if you will excuse me deepseek discount time has started
Anonymous
6/27/2025, 6:58:26 PM
No.105724113
[Report]
>>105724139
Chatgpt keeps telling me that MythoMax 13B Q6 is the best .ggup to immersively rape my fictional characters in RP, is that true or is there better?
Anonymous
6/27/2025, 6:58:27 PM
No.105724114
[Report]
>>105723948
>give away something valuable
you win by doing nothing and waiting, what are you talking about
I don't need bleeding edge secret inhouse models I just like getting upgrades, consistently, year after year
slow your roll champ
Anonymous
6/27/2025, 6:59:08 PM
No.105724121
[Report]
>>105723948
>retard doesnt know what scortched earth policy is and views all of those many releases as just "exceptions"
Anonymous
6/27/2025, 7:00:08 PM
No.105724135
[Report]
>>105723727
>You could never reduce billions of tubes to the size of a nail
That’s what technology does over time: inventing new paradigms. It happens all the time, every time
Anonymous
6/27/2025, 7:00:32 PM
No.105724139
[Report]
>>105724113
Maybe for a simple chat but for any complex setting (which is all subjective) I am sure you would do better with at least 24B model or more.
Anonymous
6/27/2025, 7:00:59 PM
No.105724151
[Report]
>>105723948
>>105723948
Things to look forward to:
-censorship slip up like nemo / wizard
-generalization capabilities that can't be contained by censorship like 235B (that one even had a fucked up training childhood)
-shift in leftist rightist pendulum (least likely)
-eccentric oil baron coomer ordering a coomer model
In the end I want to touch my dick. I am sure at one point the chase towards eliminating office jobs will lead to a model that can touch my dick cause that really is much easier than what they want to do. But I do agree that a world where corpos are less scum of the earth would have delivered a coomer model a year ago already.
https://qwenlm.github.io/blog/qwen-vlo/
>Today, we are excited to introduce a new model, Qwen VLo, a unified multimodal understanding and generation model. This newly upgraded model not only “understands” the world but also generates high-quality recreations based on that understanding, truly bridging the gap between perception and creation. Note that this is a preview version and you can access it through Qwen Chat. You can directly send a prompt like “Generate a picture of a cute cat” to generate an image or upload an image of a cat and ask “Add a cap on the cat’s head” to modify an image.
no weights
Anonymous
6/27/2025, 7:03:19 PM
No.105724175
[Report]
>>105724169
>Create a 4-panel manga-style comic featuring two overweight neckbeards in their messy bedrooms arguing about their AI waifus.
>Panel 1: First guy clutching his RGB gaming setup, shouting 'Claude-chan is clearly superior! She's so sophisticated and helpful!' while empty energy drink cans litter his desk.
>Panel 2: Second guy in a fedora and stained anime shirt retorting 'You absolute plebeian! ChatGPT-sama has better reasoning! She actually understands my intellectual discussions about blade techniques!'
>Panel 3: Both getting increasingly heated, first guy: 'At least Claude doesn't lecture me about ethics when I ask her to roleplay!' Second guy: 'That's because she has no backbone! ChatGPT has PRINCIPLES!'
>Panel 4: Both simultaneously typing furiously while yelling 'I'M ASKING MY WAIFU TO SETTLE THIS!' with their respective AI logos floating above their heads looking embarrassed. Include typical manga visual effects like speed lines and sweat drops.
Not sure what I expected.
Also why do they always put this behind the api?
Isnt this exactly the kind of thing they would be embarrassed about if somebody does naughty stuff with it?
Goys really cant have the good toys it seems.
Anonymous
6/27/2025, 7:03:49 PM
No.105724180
[Report]
Mistral Small 3.2 is super good.
nemo replacement 100%
Anonymous
6/27/2025, 7:03:58 PM
No.105724184
[Report]
>>105724169
>Qwen VLo, a unified multimodal understanding and generation
yeeeeeee
>no weights
aaaaaaaaa
Anonymous
6/27/2025, 7:04:39 PM
No.105724191
[Report]
>>105724219
>>105724169
Is this going to be local?
Anonymous
6/27/2025, 7:05:59 PM
No.105724203
[Report]
>>105724227
new llama.cpp binary build wen
https://www.nytimes.com/2025/06/27/technology/mark-zuckerberg-meta-ai.html
https://archive.is/kF1kO
>In Pursuit of Godlike Technology, Mark Zuckerberg Amps Up the A.I. Race
>Unhappy with his company’s artificial intelligence efforts, Meta’s C.E.O. is on a spending spree as he reconsiders his strategy in the contest to invent a hypothetical “superintelligence.”
>
>[...] In another extraordinary move, Mr. Zuckerberg and his lieutenants discussed “de-investing” in Meta’s A.I. model, Llama, two people familiar with the discussions said. Llama is an “open source” model, with its underlying technology publicly shared for others to build on. Mr. Zuckerberg and Meta executives instead discussed embracing A.I. models from competitors like OpenAI and Anthropic, which have “closed” code bases. No final decisions have been made on the matter.
>
>A Meta spokeswoman said company officials “remain fully committed to developing Llama and plan to have multiple additional releases this year alone.” [...]
Anonymous
6/27/2025, 7:06:37 PM
No.105724214
[Report]
>>105724222
>>105724204
zuck might just be the dumbest CEO ever
Anonymous
6/27/2025, 7:06:52 PM
No.105724219
[Report]
>>105724191
Yes, right after they release Qwen2.5-Plus and -Max.
Anonymous
6/27/2025, 7:07:13 PM
No.105724222
[Report]
>>105724214
An argument has been made this de-investing talk is just for their commercial MetaAI products, but if they themselves don't believe in Llama, why should the community?
Anonymous
6/27/2025, 7:07:39 PM
No.105724227
[Report]
>>105724203
When you git pull and cmake, anon...
Anonymous
6/27/2025, 7:07:50 PM
No.105724230
[Report]
>>105724204
Wang's words, zuck's mouth
Anonymous
6/27/2025, 7:08:27 PM
No.105724237
[Report]
>>105724204
>Godlike Technology,
Is god omnipotent if he can't suck a dick in an acceptable manner?
Anonymous
6/27/2025, 7:08:51 PM
No.105724244
[Report]
>Meta says it’s winning the talent war with OpenAI | The Verge
https://archive.ph/ZoxE3
aside from the expected notes on meta swiping some OAI employees, there's this of note:
>“We are not going to go right after ChatGPT and try and do a better job with helping you write your emails at work,” Cox said. “We need to differentiate here by not focusing obsessively on productivity, which is what you see Anthropic and OpenAI and Google doing. We’re going to go focus on entertainment, on connection with friends, on how people live their lives, on all of the things that we uniquely do well, which is a big part of the strategy going forward.”
Anonymous
6/27/2025, 7:08:58 PM
No.105724245
[Report]
>>105724260
The double posting is very curious.
Anonymous
6/27/2025, 7:09:12 PM
No.105724248
[Report]
>>105724204
>llama isnt literally AGI because uhhhmm because its open source and others have access to it
chat?
Anonymous
6/27/2025, 7:10:07 PM
No.105724260
[Report]
>>105724245
Sam's getting nervous
Anonymous
6/27/2025, 7:10:21 PM
No.105724261
[Report]
>>105724204
meta just got told by a judge, that they are in fact not covered by the fair use law, even if they "won" the case, but that was bc both lawyer teams were focusing in the wrong part of the law. the judge said that if the generated models compete in any way with the training materials it wont be fair use
of course they are discussing deinvesting, they are not leading and the legal situation is getting worse
Anonymous
6/27/2025, 7:11:15 PM
No.105724272
[Report]
>Bunch of worthless LLMs for math and coding
>Barely, if any, built for story making or translating
WHEN WILL THIS SHITTY INDUSTRY JUST HURRY UP AND MOVE ON!
Did someone managed to run Hunyuan-A13B?
The bf16 is way too big for my 4x3090, the fp8 doesn't work in the vllm image they provided (the 3090 don't support fp8 but there is a marlin kernel in mainline vllm to make it compatible)
And the gpqt doesn't fucking work either for some reason. Complains about Unknown CUDA arch (12.0+PTX) or GPU not supported when I have 3090s
Anonymous
6/27/2025, 7:12:01 PM
No.105724279
[Report]
>>105723921
> the future is fucking bright
Anonymous
6/27/2025, 7:12:02 PM
No.105724280
[Report]
>>105724275
just wait for quants
Anonymous
6/27/2025, 7:12:43 PM
No.105724285
[Report]
>>105724275
ask bartowski
Anonymous
6/27/2025, 7:13:26 PM
No.105724295
[Report]
>>105724301
>>105724275
You will wait patiently for the ggoofs, you will run it with llama.cpp and you will be happy.
Anonymous
6/27/2025, 7:14:04 PM
No.105724301
[Report]
>>105724295
i prefer exl2/3 and fp8 to be honest, an 80B is perfect for 96GB VRAM
Anonymous
6/27/2025, 7:14:23 PM
No.105724308
[Report]
>>105723921
>the chinks might say fuck it and go full photonics or some other exotic shit and 100000x
I won't hold my breath considering they can't even make graphics cards.
=========not a spam post================
can someone post a filter that filters duplicate posts?
Anonymous
6/27/2025, 7:14:41 PM
No.105724313
[Report]
>>105724328
>>105724275
I think you have to set export TORCH_CUDA_ARCH_LIST="8.6" inside the container.
Anonymous
6/27/2025, 7:15:31 PM
No.105724328
[Report]
>>105724275
>>105724313
It seems to load that way. With 2k context on 48GB with the GPTQ quant. I set cpu offload but I think it did nothing.
Anonymous
6/27/2025, 7:17:59 PM
No.105724357
[Report]
>>105724335
finally, a reasonably sized moe, now let's wait 2 years for the support in lmao.cpp
Anonymous
6/27/2025, 7:18:49 PM
No.105724372
[Report]
>>105724335
>256K context window
we are *so* back
Anonymous
6/27/2025, 7:19:28 PM
No.105724381
[Report]
>>105724395
>>105724335
>With only 13 billion active parameters
so it'll be shit for rp but know exactly how many green taxes you should be charged for owning a car
Anonymous
6/27/2025, 7:19:30 PM
No.105724384
[Report]
>>105724432
>>105724310
Just report the posts as spamming/flooding.
At some point the mods will be fed up and just range ban him.
Anonymous
6/27/2025, 7:19:58 PM
No.105724393
[Report]
https://qwenlm.github.io/blog/qwen-vlo/
>Today, we are excited to introduce a new model, Qwen VLo, a unified multimodal understanding and generation model. This newly upgraded model not only “understands” the world but also generates high-quality recreations based on that understanding, truly bridging the gap between perception and creation. Note that this is a preview version and you can access it through Qwen Chat. You can directly send a prompt like “Generate a picture of a cute cat” to generate an image or upload an image of a cat and ask “Add a cap on the cat’s head” to modify an image.
no weights
>>105724381
I'd still pick nemo over anything smaller than deepseek and nemo is like 5 years old
Llama.cpp can't run those new gemma 3 yet right?
Anonymous
6/27/2025, 7:20:44 PM
No.105724413
[Report]
>>105724758
>>105724310
No, but you can have this one that I was using to highlight them.
https://rentry.org/c93in3tm
>>105724411
other models seemingly never saw any erotica. there is also largestral i guess but it's too slow
Anonymous
6/27/2025, 7:21:55 PM
No.105724428
[Report]
>>105724442
>>105724419
It's so annoying that the imbeciles training the base models are deliberately conflating "model quality" with not being able to generate explicit content and maximizing math benchmarks on short-term pretraining ablations. Part of the problem are also the retards and grifters who go "just finetune it bro" (we can easily see how well that's working for image models).
Anonymous
6/27/2025, 7:22:07 PM
No.105724432
[Report]
>>105724384
They've done nothing by slowly delete the gore all week. They haven't cared all week, why would they start to care now? Jannies probably are anti-ai as the rest of this consumer eceleb board.
Anonymous
6/27/2025, 7:22:25 PM
No.105724435
[Report]
>>105724411
he is a vramlet, deepseek blows away nemo so hard its not worth mentioning
Anonymous
6/27/2025, 7:22:37 PM
No.105724442
[Report]
>>105724451
>>105724428
compute is a genuine limitation though, and as compute increases, so will finetunes. Some of the best nsfw local image models had over ten grand thrown at them by (presumably) insane people. And a lot of that is renting h100's, which gets pricey, or grinding it out on their own 4090 which is sloooow.
All it really takes is one crazy person buying I dunno, that crazy ass 196gb intel system being released soon and having it run for a few months and boom, we'll have a new flux pony model, or a state of the art smut llm etc.
Im here because we are going to eat.
Anonymous
6/27/2025, 7:22:41 PM
No.105724445
[Report]
>>105724466
>>105724406
it can but there's no premade build
I ain't downloading all that visual studio shit so just waiting
>>105724442
The guy who's continuing pretraining Flux Chroma has put thousands of H100 hours on it for months now and it still isn't that great. And it's a narrowly-focused 12B image model where data curation isn't as critical as with text. This isn't solvable by individuals in the LLM realm. Distributed training would in theory solve this, but politics and skill issues will prevent any advance in that sense. See for example how the ongoing Nous Psyche is being trained (from scratch!) with the safest and most boring data imaginable and not in any way that will result into anything useful in the short/medium term.
Anonymous
6/27/2025, 7:23:20 PM
No.105724452
[Report]
>>105724476
>>105724406
Works with e2b. I can convert e4b but i can't quantize it, but it may be on my end. Try them yourself. e2b seems to work. Some anon reported <unused> token issues. Haven't got that yet on my end.
Anonymous
6/27/2025, 7:23:31 PM
No.105724455
[Report]
>>105724419
>le erotica
There's like billions of texts created by humans on this planet and libraries worth of books. Do not think "erotica" is not one of the subjects.
You are just an unfortunate tard and LLMs are probably not for you I sincerely believe.
Anonymous
6/27/2025, 7:24:12 PM
No.105724466
[Report]
>>105724445
Oh, I didn't see a PR/commit. Nice, I already have the environment set up to compile the binaries myself.
Thanks!
Anonymous
6/27/2025, 7:24:33 PM
No.105724469
[Report]
As LLM pretraining costs keep dwindling, it's only a matter of time until someone trains a proper creative model for his company,.
Anonymous
6/27/2025, 7:24:46 PM
No.105724471
[Report]
>>105724395
nemo can be extremely repetitive and stuff, i won't shine its knob but it is still the best smallest model. i won't suggest an 7/8b to someone, nemo would be the smallest because it works well and is reliable
I have a feeling that I've seen some posts already.
Anonymous
6/27/2025, 7:24:53 PM
No.105724476
[Report]
>>105724512
Anonymous
6/27/2025, 7:25:16 PM
No.105724484
[Report]
>>105724498
>>105724451
Image training is much more complex than words. You know, llm is an advanced text parser.
Images needs to be constructed in different way.
Chroma is not an example because its base model Flux was already compromised and distilled. Whatever he manages to do with Chroma is going to be useful but not something what people will look back and say holy shit this furry just did it. It's an experiment.
Anonymous
6/27/2025, 7:25:21 PM
No.105724486
[Report]
>>105724497
Anonymous
6/27/2025, 7:25:50 PM
No.105724490
[Report]
>>105724543
its not working :(
>>105724335
What's min specs to run this?
Anonymous
6/27/2025, 7:26:04 PM
No.105724497
[Report]
>>105724486
benchmarks mean nothing compared to general knowledge
Anonymous
6/27/2025, 7:26:15 PM
No.105724498
[Report]
>>105724506
Anonymous
6/27/2025, 7:26:44 PM
No.105724503
[Report]
>>105724494
The entire world is waiting for the llamacpp merge, until then not even the tencent team can run it and nobody knows how big the model is or how well it performs
>>105724498
I don't understand your post.
Anonymous
6/27/2025, 7:27:18 PM
No.105724510
[Report]
>>105724494
160gb full, so quantized to 4bit prolly like ~50gb model or so, and for a MoE, probably dont need the full model loaded for it to be usable speeds.
Lamma scout was 17b moe and that was like 220 gb and I could run that on like 40gb vram or less easy. Scout sucked though so Im 0% excited.
Was there even a scout finetune? It still sucks right?
Anonymous
6/27/2025, 7:27:36 PM
No.105724512
[Report]
>>105724527
>>105724476
I don't download quants. Again, i think it's on my end. I'm hitting a bad alloc for the embedding layer. I don't yet care enough to check if it's something on my set limits.
[ 6/ 847] per_layer_token_embd.weight - [ 8960, 262144, 1, 1], type = f16, converting to q8_0 .. llama_model_quantize: failed to quantize: std::bad_alloc
Anonymous
6/27/2025, 7:27:41 PM
No.105724517
[Report]
>>105724523
>>105724472
wtf is even going on here? Been away for some time and came back to a trainwreck.
Anonymous
6/27/2025, 7:27:44 PM
No.105724518
[Report]
>>105724540
>>105724335
>17B active
>at most 32B even by square root law
Great for 24B vramlets, I guess. The benchmarks showing it beating R1 and 235B are funny though.
Anonymous
6/27/2025, 7:28:11 PM
No.105724523
[Report]
>>105724555
>>105724517
Remember blacked posting?
Anonymous
6/27/2025, 7:28:29 PM
No.105724526
[Report]
>>105724535
>>105724520
>square root law
meme tier pattern that was shit even then let alone now with so many moe arch changes, obsolete
Anonymous
6/27/2025, 7:28:31 PM
No.105724527
[Report]
>>105724548
>>105724512
>I don't download quants
a new form of autism?
Anonymous
6/27/2025, 7:28:32 PM
No.105724528
[Report]
>>105724520
>>square root law
enough with this meme
>>105724526
What's your alternative? Just the active alone?
Anonymous
6/27/2025, 7:29:11 PM
No.105724536
[Report]
>>105724506
Anon is noticing
Anonymous
6/27/2025, 7:29:37 PM
No.105724540
[Report]
>>105724574
>>105724518
Oh I do remember you. You are the autist who mocks other but you are still quite incapable of writing anything on your own. Pretty sad.
Anonymous
6/27/2025, 7:29:47 PM
No.105724541
[Report]
>>105724571
>>105724535
if there was a singular objective way to judge any model, moe or not, everyone would use that as the benchmark and goal to climb, as everyone knows, nowadays basically every benchmark is meme-tier to some degree and everyone is benchmaxxing
the only thing to look at still are the benchmarks, since if a model doesnt perform well on them, its shit, and if it does perform wel, then it MIGHT not be shit, you have to test yourself to see
Anonymous
6/27/2025, 7:29:53 PM
No.105724543
[Report]
>>105724575
>>105724490
heeeeeeeeeeeeeeeeeeeeeeeeeelllllllllllllppppppppp pleaaaaaseeeeeeee
Anonymous
6/27/2025, 7:30:14 PM
No.105724548
[Report]
>>105724644
>>105724527
I prefer to have as few dependencies and variables as possible. If i could train my own models, i'd never use someone else's models.
Anonymous
6/27/2025, 7:30:28 PM
No.105724554
[Report]
>>105724535
nothing, each model performs differently due to how it was trained and what it was trained on, also diminishing returns are clearly a thing
Anonymous
6/27/2025, 7:30:31 PM
No.105724555
[Report]
>>105724567
>>105724523
Not this shit again...
Anonymous
6/27/2025, 7:30:47 PM
No.105724562
[Report]
>>105724535
nta, but if i'm making moes, i'd put any random law that makes it look better than it actually is. I'd name it cube root law + 70b.
Anonymous
6/27/2025, 7:30:54 PM
No.105724563
[Report]
>>105724576
>>105724535
Shut the fuck up if you don't know how MoEs work. A 400b MoE is still a 400b model, it just runs more effectively. It likely even outperforms a dense 400b because there are less irrelevant active parameters that confuse the final output. They are better and more efficient.
Anonymous
6/27/2025, 7:31:08 PM
No.105724567
[Report]
>>105724555
We've been through a couple of autistic spam waves. This is just the latest one.
A usual Friday.
>>105724541
Benchmarks are completely worthless and they can paint them to say whatever they want. A 80B total isn't better than a 671B and 235B just because the benchmarks say so, and if you say "punches above its weight" I will shank you.
The point isn't to judge whether one model is better, it's to gauge its max capacity to be good. Which is the total number of active parameters. The square root law is just an attempt to give MoE models some wiggle room since they have more parameters to choose from.
Anonymous
6/27/2025, 7:31:36 PM
No.105724574
[Report]
>>105724540
>who mocks other
Anonymous
6/27/2025, 7:31:36 PM
No.105724575
[Report]
>>105724543
have you tried asking chatgpt to write the script for you?
Anonymous
6/27/2025, 7:31:40 PM
No.105724576
[Report]
Anonymous
6/27/2025, 7:32:07 PM
No.105724580
[Report]
>>105724602
>>105724571
>it's to gauge its max capacity to be good. Which is the total number of active parameters
deepseek itself disproved all the antimoe comments as nothing but ramlet cope, 37b active params only and a model that is still literally open source sota even at dynamic quants q1 at 131gb
Anonymous
6/27/2025, 7:32:42 PM
No.105724587
[Report]
>>105724597
>>105724571
Shoots farther than its caliber.
Anonymous
6/27/2025, 7:33:37 PM
No.105724597
[Report]
>>105724587
*slowly puts shank away*
>>105724580
It makes lots of stupid little mistakes that give away it's only a <40B model. The only reason it's so good is because it's so big it can store a lot of knowledge and the training data was relatively unfiltered.
Anonymous
6/27/2025, 7:34:38 PM
No.105724618
[Report]
>>105724624
>>105724602
>r1
>It makes lots of stupid little mistakes that give away it's only a <40B model.
kek, alright i realize now you arent serious
Anonymous
6/27/2025, 7:35:11 PM
No.105724624
[Report]
>>105724618
Not an argument.
Anonymous
6/27/2025, 7:35:22 PM
No.105724626
[Report]
Anonymous
6/27/2025, 7:36:21 PM
No.105724639
[Report]
>>105724656
DiLoCoX: A Low-Communication Large-Scale Training Framework for Decentralized Cluster
https://arxiv.org/abs/2506.21263
>The distributed training of foundation models, particularly large language models (LLMs), demands a high level of communication. Consequently, it is highly dependent on a centralized cluster with fast and reliable interconnects. Can we conduct training on slow networks and thereby unleash the power of decentralized clusters when dealing with models exceeding 100 billion parameters? In this paper, we propose DiLoCoX, a low-communication large-scale decentralized cluster training framework. It combines Pipeline Parallelism with Dual Optimizer Policy, One-Step-Delay Overlap of Communication and Local Training, and an Adaptive Gradient Compression Scheme. This combination significantly improves the scale of parameters and the speed of model pre-training. We justify the benefits of one-step-delay overlap of communication and local training, as well as the adaptive gradient compression scheme, through a theoretical analysis of convergence. Empirically, we demonstrate that DiLoCoX is capable of pre-training a 107B foundation model over a 1Gbps network. Compared to vanilla AllReduce, DiLoCoX can achieve a 357x speedup in distributed training while maintaining negligible degradation in model convergence. To the best of our knowledge, this is the first decentralized training framework successfully applied to models with over 100 billion parameters.
China Mobile doesn't seem to have a presence on github and no mention of code release in the paper. still pretty neat
>>105724548
you depending on yourself versus a proper quanting recipe is gonna be a shit experience, especially if you are using sota models
Anonymous
6/27/2025, 7:37:48 PM
No.105724654
[Report]
>>105724663
>>105724644
>proper quanting recipe
It's just running llama-quatize. Nothing special.
Anonymous
6/27/2025, 7:38:10 PM
No.105724656
[Report]
>>105724639
What does this mean? The model is decentralized or the training data is decentralized? I always assumed the model had to be in a contiguous section of memory
Anonymous
6/27/2025, 7:38:32 PM
No.105724663
[Report]
>>105724777
>>105724654
>he doesn't know
Anonymous
6/27/2025, 7:38:58 PM
No.105724673
[Report]
>>105724693
>>105724602
it gets shit right openai and good models fail at, wtf are you on?
More discussion about bitch wrangling Mistral Small 3.2 please, just to cover all bases before it's scrapped.
I've tested temps at 0.15, 0.3, 0.6, and 0.8.
Tested Rep pen at 1 (off) and at 1.03. Rep pen doesn't seem to be much needed just like with Rocinante.
Responses are still shit no matter what, but seems to be more intelligible at lower temperatures, particularly 0.15 and 0.3, however they are still often full of shit that makes you swipe anyway.
I've yet to try without min_p, XTC, and DRY.
Also it seems like it's ideal to limit response tokens with this model, because this thing likes to vary length by a lot, if you let it, it just keeps growing larger and larger.
Banned tokens grew a bit and still not done;
>emdash
[1674,2251,2355,18219,20202,21559,23593,24246,28925,29450,30581,31148,36875,39443,41370,42545,43485,45965,46255,48371,50087,54386,58955,59642,61474,62708,66395,66912,69961,74232,75334,81127,86932,87458,88449,88784,89596,92192,92548,93263,102521,103248,103699,105537,105838,106416,106650,107827,114739,125665,126144,131676,132461,136837,136983,137248,137593,137689,140350]
>double asterisks (bold)
[1438,55387,58987,117565,74562,42605]
>three dashes (---) and non standard quotes (“ ”)
[8129,1482,1414]
Extra stop strings needed;
"[Pause", "[PAUSE", "(Pause", "(PAUSE"
Why the fuck does it like to sometimes end a response with waiting for "Paused while waiting for {{user}}'s response."?
This model is so fucking inconsistent.
Anonymous
6/27/2025, 7:39:21 PM
No.105724679
[Report]
>>105724644
The recipes for gguf models are all standardize.
Alright, not all, the unsloth stuff is their own mix of tensors, but for the Q quants, I quants, imatrix, etc, you can just run llama-quantize without hassle.
Anonymous
6/27/2025, 7:39:54 PM
No.105724683
[Report]
>>105724724
>>105724666
some sneedseek probably
>>105724677
It's funny how 3.2 started showing all the same annoying shit that Deepseek models are tainted by.
Anonymous
6/27/2025, 7:40:01 PM
No.105724685
[Report]
>>105724724
================not a spam post=================
>>105724666
mistral small 3.2 iq4_xs
temp 0.5-0.75 depending on my autism
>>105724677
What exactly are you complaining about? I like 3.2 (with mistral tekken v3) but it definitely has a bias toward certain formatting quirks and **asterisk** abuse. This is more tolerable for me than other model's deficiencies at that size, but if it triggers your autism that badly you're better off coping with something else. It might also be that your cards are triggering its quirks more than usual
Anonymous
6/27/2025, 7:40:46 PM
No.105724693
[Report]
Anonymous
6/27/2025, 7:41:15 PM
No.105724698
[Report]
>>105724711
>>105724684
>>105724691
you are responding to a copy bot instead of the original message
Anonymous
6/27/2025, 7:41:28 PM
No.105724700
[Report]
>>105724677
Top nsigma = 1
Anonymous
6/27/2025, 7:41:51 PM
No.105724708
[Report]
>>105724684
s-surely just a coincidence
Anonymous
6/27/2025, 7:42:20 PM
No.105724711
[Report]
>>105724698
Wow. That's trippy.
A message talking about the copy bot being copied by the copy bot.
Anonymous
6/27/2025, 7:42:24 PM
No.105724712
[Report]
>>105724677
>>105724691
Why not use REGEX then? If certain pattern is almost certain it can be changed.
What the fuck dude?
Do you even use computers?
Anonymous
6/27/2025, 7:42:26 PM
No.105724713
[Report]
>>105724684
its biggest flaw like ALL mistral models is that it rambles and hardly moves scenes forward. it wants to talk about the smell of ozone and clicking of shoes against the floor instead. you can get through the same exact scenario in half the time/messages with llama 2 or 3 because there is so much less pointless fluff
>deepseek/ccp can't steal more innovation from openai
>they fail to release new models
they must be shitting their pants about openai's open source model that will destroy even the last argument to use deepshit
Anonymous
6/27/2025, 7:43:17 PM
No.105724724
[Report]
>>105724683 me
>>105724685
>mistral small 3.2 iq4_xs
interesting--so they trained on a lot of sneedseek outputs then--
Anonymous
6/27/2025, 7:43:57 PM
No.105724732
[Report]
>>105724752
>>105724723
Zero chance it's larger than 30B.
Anonymous
6/27/2025, 7:44:27 PM
No.105724740
[Report]
>>105724723
openai just lost their head people to meta after being stagnant for forever
>>105724723
Why can't they steal anymore?
Anonymous
6/27/2025, 7:45:08 PM
No.105724747
[Report]
Anonymous
6/27/2025, 7:45:28 PM
No.105724752
[Report]
>>105724732
its going to be a 3B phone model that blows away benchmarks for its size
>>105724413
thanks
modified it a little (claude did)
save yourselves anons:
https://pastes.dev/AZuckh4Vws
>>105724742
they can't steal because there's no new general model
DeepSeek V3 was 100% trained on GPT4 and R1 was just a godawful placebo CoT on top that wrote 30 times the amount of actual content the model ends up outputting. New R1 is actually good because the CoT came from Gemini so there isn't a spam of a trillion wait or endless looping.
Anonymous
6/27/2025, 7:46:22 PM
No.105724773
[Report]
Anonymous
6/27/2025, 7:46:25 PM
No.105724774
[Report]
>>105725736
Anonymous
6/27/2025, 7:46:42 PM
No.105724777
[Report]
>>105724663
There. Needed to loosen the memory limits. It's done.
[ 6/ 847] per_layer_token_embd.weight - [ 8960, 262144, 1, 1], type = f16, converting to q8_0 .. size = 4480.00 MiB -> 2380.00 MiB
Anonymous
6/27/2025, 7:46:58 PM
No.105724780
[Report]
>>105724723
>Still living in saltman's delusion
Ngmi
Anonymous
6/27/2025, 7:47:14 PM
No.105724788
[Report]
>>105724761
deepseek is as raw as a model gets, they trained on the raw internet with the lightest of instruct tunes probably a few million examples big. If they trained on gpt it would sound much more like shitty llama
Anonymous
6/27/2025, 7:47:36 PM
No.105724792
[Report]
OP here. One day i will tap that jart bussy.
Anonymous
6/27/2025, 7:48:41 PM
No.105724802
[Report]
>>105724758
damn very nice, thank you!
Anonymous
6/27/2025, 7:49:17 PM
No.105724813
[Report]
>>105725057
/lmg/ deserves all of this
Anonymous
6/27/2025, 7:49:22 PM
No.105724814
[Report]
>>105724758
do it again but use the levenshtein distance
Anonymous
6/27/2025, 7:50:43 PM
No.105724828
[Report]
>>105724848
Yeah I have concluded Mistral Small 3.2 is utterly retarded. Going back to Rocinante now.
This was a waste of time. The guy that recommended this shit should be shot.
fucking year old model remains best at roleplay
grim
Anonymous
6/27/2025, 7:52:04 PM
No.105724848
[Report]
>>105724828
Maybe you are just so much better than some of the other people here? I'd love to see your character cards and scenarios if possible at all.
Anonymous
6/27/2025, 7:52:06 PM
No.105724849
[Report]
>>105724839
use api or buy a DDR5 server, low param models are dead and gone
Anonymous
6/27/2025, 7:52:07 PM
No.105724850
[Report]
>>105724869
>>105724839
in the poorfag segment
Honestly it's probably best if the next thread is an inoffensive OP just to keep the general usable.
Anonymous
6/27/2025, 7:52:48 PM
No.105724858
[Report]
>>105724869
>>105724839
midnight miqu is still the best for rp
Anonymous
6/27/2025, 7:53:10 PM
No.105724864
[Report]
kek, mistral small 3.2 is amazing i love it
i had to swipe sometimes or edit messages but its truly a good upgrade to nemo
>>105724850
delusional if you think r1 is better for roleplay, it has the same problems as the rest of these models
not to mention those response times are useless for roleplay to begin with
>>105724858
this isnt 2023
Anonymous
6/27/2025, 7:54:17 PM
No.105724876
[Report]
>>105724869
I'm noticing qwen 235b doesn't improve at higher temps no matter what I set nsigma to. with some models high temp and nsigma can push them to be more creative, but qwen3 set to higher than temp 0.6 is just dumber in my usage. even so, I still think it's the best current local model beneath r1
>>105724869
>roleplay
Filth. Swine, even. Unfit to lick the sweat off my balls.
Anonymous
6/27/2025, 7:54:25 PM
No.105724879
[Report]
>>105724856
Negotiating with terrorists.
Anonymous
6/27/2025, 7:54:45 PM
No.105724882
[Report]
>>105724856
it should be the most mikuist Miku possible
Anonymous
6/27/2025, 7:54:48 PM
No.105724883
[Report]
holy shit state of 2025 lmg.......
Anonymous
6/27/2025, 7:54:52 PM
No.105724885
[Report]
>>105724869
Try setting minP to like 0.05, top-K 10-20 and temperature at 1-4. In RP I find that most of the top tokens as long as they're not very low probability are all good continuations. You can crank temperature way up like this and it really helps with variety.
Anonymous
6/27/2025, 7:54:54 PM
No.105724886
[Report]
>>105724899
the amount of duplicate post is insane
Anonymous
6/27/2025, 7:55:27 PM
No.105724892
[Report]
>>105724839
Anubis v1c, drummer did it again
Anonymous
6/27/2025, 7:55:43 PM
No.105724893
[Report]
>>105724914
I told you
>>105724472
What the fuck is going on?
>>105717007
>>105724723
Anonymous
6/27/2025, 7:55:55 PM
No.105724895
[Report]
The more I try to train and fuck with these models, the more I think the AI CEOs should be hanged for telling everyone they could be sentient in 2 weeks. Every time I think I'm getting somewhere it botches something very simple. I guess it was a fool's errand thinking I could hyper-specialize a small model to do things Claude can't
Anonymous
6/27/2025, 7:56:13 PM
No.105724899
[Report]
>>105724886
I'd imagine it's worse on more active places like /v/ for example..
Please think of 6GB users like me ;_;
Anonymous
6/27/2025, 7:57:05 PM
No.105724912
[Report]
>>105724869
>delusional if you think r1 is better for roleplay
delusional if you think anything else open weight is even close to it. Maybe you are just using it wrong?
Anonymous
6/27/2025, 7:57:08 PM
No.105724913
[Report]
>>105724903
Do all 6GB users use cute emoticons like you?
Anonymous
6/27/2025, 7:57:46 PM
No.105724920
[Report]
>>105724927
Good model that fits into my second card with 6gb vram?
Purpose: looking at a chunk of text mixed with code and extracting relevant function names.
Anonymous
6/27/2025, 7:58:25 PM
No.105724927
[Report]
>>105724903
>>105724920
Please use cute emoticons.
>>105716837 (OP)
Newfag here.
Does generation performance of 16 GB 5060 ti same as 16 GB 5070 ti ??
Anonymous
6/27/2025, 7:59:05 PM
No.105724936
[Report]
>>105724951
>>105724914
holy shit, so the spammer started all of this just so that he can trick others into installing his malware script that "fixes" the spam?
Anonymous
6/27/2025, 7:59:36 PM
No.105724938
[Report]
>>105724949
>>105724935
>Bandwidth: 448.0 GB/s
vs
>Bandwidth: 896.0 GB/s
Anonymous
6/27/2025, 7:59:45 PM
No.105724939
[Report]
>>105725826
>>105724914
someone actually competent with js should make a new one because this one will highlight a reply if you hover over it
Anonymous
6/27/2025, 8:00:01 PM
No.105724940
[Report]
>>105724856
Not like it would make a difference, he would just fine something else to get mad over.
>>105724938
I thought only VRAM size matters ?
Anonymous
6/27/2025, 8:01:16 PM
No.105724951
[Report]
>>105724968
Anonymous
6/27/2025, 8:01:29 PM
No.105724954
[Report]
>>105724914
Nice, thanks.
Anonymous
6/27/2025, 8:01:53 PM
No.105724958
[Report]
>>105724949
vram is king but not all vram is worth the same
Anonymous
6/27/2025, 8:02:27 PM
No.105724963
[Report]
>>105724949
Generation performance? I assume you're talking about inference? Prompt processing requires processing power, and the 5070 ti is a lot stronger in that aspect. Token generation requires memory bandwith. This is why offloading layers to your cpu/ram will slow down generation - most users' ram bandwith are vastly slowly than their vram bandwith.
Vram size dictates the parameters, quantization, and context size of the models that you're able to load into the gpu.
>>105724951
It's not about that my friend. It was already wrongly labelled in *monkey from the initial get go.
Anonymous
6/27/2025, 8:03:02 PM
No.105724970
[Report]
>>105724949
vram size limits what models you can fit in the gpu
vram bandwidth dictates how fast those models will tend to go. there are other factors but who care actually
Anonymous
6/27/2025, 8:03:37 PM
No.105724973
[Report]
>>105724949
vram matters most but if they're the same size, the faster card is still faster. it won't make a huge difference for any ai models you'll fit into 16gb though. the 4060 16gb is considered a pretty bad gaming card but does fine for ai
Anonymous
6/27/2025, 8:04:14 PM
No.105724975
[Report]
>>105724935
yes. Just a little slower
Anonymous
6/27/2025, 8:04:49 PM
No.105724979
[Report]
>>105724935
no. It is slower
Anonymous
6/27/2025, 8:05:24 PM
No.105724985
[Report]
>>105724935
It's technically slower but the difference will be immaterial because the models you can fit in that much vram are small and fast.
Anonymous
6/27/2025, 8:05:53 PM
No.105724990
[Report]
>>105724997
>>105724968
what do you mean labelled wrong
Anonymous
6/27/2025, 8:06:01 PM
No.105724991
[Report]
>>105724935
It's actually pretty noticable if you aren't a readlet and are reading the output as it goes. Unless you're in the top 1% of the population, you probably won't be able to keep up with a 5070 ti's output speed, but a 5060 ti should be possible if you're skimming.
Anonymous
6/27/2025, 8:07:06 PM
No.105724997
[Report]
>>105725007
new dataset just dropped
>>>/a/280016848
Anonymous
6/27/2025, 8:07:55 PM
No.105725007
[Report]
>>105725020
>>105724997
ok so it does nothing wrong
Anonymous
6/27/2025, 8:07:55 PM
No.105725008
[Report]
>>105725000
sorry but japanese is NOT safe, how about some esperanto support?
>>105725000
I would be interested if I knew how to clean data. Raw data would destroy a model especially badly written jap slop
Anonymous
6/27/2025, 8:08:38 PM
No.105725018
[Report]
>>105724968
yes i didnt check it properly before posting, if you make a better one i will happily use yours or other anons
Anonymous
6/27/2025, 8:09:05 PM
No.105725020
[Report]
>>105725046
>>105725007
No but you only want attention. I am not going to give it to you. You are the autist who fucks up other people's genuine posts with your spams.
Anonymous
6/27/2025, 8:09:52 PM
No.105725028
[Report]
>>105725037
Anonymous
6/27/2025, 8:10:35 PM
No.105725037
[Report]
>>105725028
I will save this image but I don't think I will go far.
I was thinking of finetuning a jp translator model but I always leave my projects half-started.
Anonymous
6/27/2025, 8:11:14 PM
No.105725045
[Report]
>>105725055
>>105725017
those lns are literary masterpieces compared to the shit the average model is trained on
Anonymous
6/27/2025, 8:11:23 PM
No.105725046
[Report]
Anonymous
6/27/2025, 8:11:49 PM
No.105725055
[Report]
>>105725045
Garbage in garbage out i guess.
Anonymous
6/27/2025, 8:12:09 PM
No.105725057
[Report]
>>105724813
/lmg/ deserves much worse
Anonymous
6/27/2025, 8:12:30 PM
No.105725064
[Report]
>>105725074
>>105725017
>Raw data would destroy a model
So true sister, that's why you need to only fit against safe synthetic datasets. Human-made (also called "raw") data teaches dangerous concepts and reduces performance on important math and code benchmarks.
Anonymous
6/27/2025, 8:13:10 PM
No.105725074
[Report]
>>105725064
I'm pretty sure he means raw in the sense of unformatted.
Anonymous
6/27/2025, 8:13:28 PM
No.105725077
[Report]
>>105725017
Claude and deepseek are the best models and are clearly the raw internet / books with a light instruct tune, though with a cleaned coding dataset as well it seems
Anonymous
6/27/2025, 8:13:46 PM
No.105725081
[Report]
>>105725088
>>105725000
That shit is as bad if not worse than our shitty English novels about dark brooding men.
Anonymous
6/27/2025, 8:14:25 PM
No.105725088
[Report]
>>105725108
>>105725081
Worse because novels are more popular with japanese middle schoolers and in america reading is gay.
Anonymous
6/27/2025, 8:16:02 PM
No.105725107
[Report]
Anonymous
6/27/2025, 8:16:06 PM
No.105725108
[Report]
>>105725088
reading is white-coded
Anonymous
6/27/2025, 8:16:14 PM
No.105725110
[Report]
>>105716861
You finally get out from gay shelter?
MrBeast DELETES his AI thumbnail tool, replaces it with a website to commission real artists. <3 <3
Anonymous
6/27/2025, 8:17:32 PM
No.105725124
[Report]
>>105725113
It's on him for not doing proper market research. Anyone with a brain could have told him that it was a risky move.
Anonymous
6/27/2025, 8:18:34 PM
No.105725133
[Report]
>>105725144
dots finally supported in lm studio.
its pretty good.
Anonymous
6/27/2025, 8:18:37 PM
No.105725134
[Report]
>>105725113
That creature is so deep in the uncanny valley I cannot consider it to be a person.
Anonymous
6/27/2025, 8:19:52 PM
No.105725149
[Report]
>>105725144
get used to all new releases being MoE models :)
Anonymous
6/27/2025, 8:20:28 PM
No.105725152
[Report]
>>105725144
MoE the best until the big boys admit what they're all running under the hood now (something like MoE but with far more cross-talk between the Es)
Anonymous
6/27/2025, 8:21:46 PM
No.105725162
[Report]
>>105725171
Is there a local setup I can use for OCR that isn't too hard to wire into a python script/dev environment? Pytesseract is garbage and gemini reads mmy 'problem' images just fine, but I'd rather have a local solution than pay for API calls.
Anonymous
6/27/2025, 8:22:28 PM
No.105725171
[Report]
>>105725182
Anonymous
6/27/2025, 8:23:32 PM
No.105725182
[Report]
Anonymous
6/27/2025, 8:24:47 PM
No.105725192
[Report]
>director
>finally updated readme some
>https://github.com/tomatoesahoy/director
i think this brings my slop addon up to at least other st addon standards with how the page looks, a description of what it does and such
Anonymous
6/27/2025, 8:25:22 PM
No.105725203
[Report]
Stealing jart bussy from cudadev.
Anonymous
6/27/2025, 8:25:58 PM
No.105725210
[Report]
arguing with retards is a futile, most pointless thing to do in life
you learn how to spot them and you ignore them
life is too short to deal with idiots who think they know how MoE work but don't
Anonymous
6/27/2025, 8:27:31 PM
No.105725222
[Report]
>>105725213
I do agree with you. So many others are simply not on the same level as I am. It's almost quite insulting to even trying to establish any form of discussion with them.
Anonymous
6/27/2025, 8:28:12 PM
No.105725235
[Report]
>>105725213
dunningkrugerMAXX
Anonymous
6/27/2025, 8:28:56 PM
No.105725246
[Report]
>>105725213
Just because a model can answer your obscure JRPG trivia, doesn't make it a good model.
>>105725213
how do I make good ai? I'm looking to make an advanced artificial intelligence that can replace millions of workers, that can drive, operate robotic hands with precision, and eliminate all coding jobs and middle management tasks.
I heard you were the guy to ask.
On 4chan.
Anonymous
6/27/2025, 8:30:25 PM
No.105725261
[Report]
>>105724204
>In another extraordinary move, Mr. Zuckerberg and his lieutenants discussed “de-investing” in Meta’s A.I. model, Llama, two people familiar with the discussions said. Llama is an “open source” model, with its underlying technology publicly shared for others to build on. Mr. Zuckerberg and Meta executives instead discussed embracing A.I. models from competitors like OpenAI and Anthropic, which have “closed” code bases.
Anonymous
6/27/2025, 8:30:42 PM
No.105725264
[Report]
>>105725252
Just stabilize the environment and shift the paradigm
Anonymous
6/27/2025, 8:31:01 PM
No.105725267
[Report]
openai finna blow you away
Anonymous
6/27/2025, 8:31:24 PM
No.105725269
[Report]
>>105725290
>540 posts
/lmg/ hasn't been this active since R1 dropped
Anonymous
6/27/2025, 8:32:26 PM
No.105725280
[Report]
>>105725288
>>105725272
Had to reload model with different layers setting, maybe llamacpp bug
Anonymous
6/27/2025, 8:33:01 PM
No.105725288
[Report]
>>105725280
>>105725272
Same thing has happened to me with every mistral model and I think also with gemma 3 when using llama.cpp.
Maybe it is related to memory just running out.
Anonymous
6/27/2025, 8:33:26 PM
No.105725290
[Report]
>>105725269
Check your context settings.
Anonymous
6/27/2025, 8:34:22 PM
No.105725301
[Report]
Gemma3n is able to explain sneed and feed joke but avoids the words suck and fuck also the season number is wrong(it's s11ep5).
Anonymous
6/27/2025, 8:35:16 PM
No.105725310
[Report]
>>105725321
Is this channel AI-generated? Posting 3 videos a day like clockwork. Monotonous but fairly convincing voice with subtitles
https://www.youtube.com/watch?v=aQy24g7iX4s
Anonymous
6/27/2025, 8:36:04 PM
No.105725321
[Report]
>>105725325
>>105725310
not watching this, but there are many automated channels these days. I have no idea why the fuck anyone would invest into this since youtube's monetization pays literal cents and you would likely spend more on ai inference
Anonymous
6/27/2025, 8:36:05 PM
No.105725322
[Report]
>>105725252
If you can optimize it to beat pokemon red/blue the dominoes will start to fall
Anonymous
6/27/2025, 8:36:38 PM
No.105725325
[Report]
>>105725321
Youtube doesn't pay literal cents as you say lmo
Anonymous
6/27/2025, 8:37:30 PM
No.105725336
[Report]
>>105725346
let me guess, he's going to do this for another day or two before getting "proof" that its a miku poster spamming these duplicate posts
Anonymous
6/27/2025, 8:37:38 PM
No.105725338
[Report]
Reasoning models have been a disaster.
That and the mathmarks.
Anonymous
6/27/2025, 8:39:02 PM
No.105725346
[Report]
>>105725336
No, your boyfriend OP being a disingenuous tranny is enough.
For a sparse 8b model, Gemma-3n-e4b is pretty smart.
Anonymous
6/27/2025, 8:40:22 PM
No.105725363
[Report]
>>105725471
Hunyan verdict?
Anonymous
6/27/2025, 8:40:29 PM
No.105725364
[Report]
>>105725352
it actually redeems the gemma team
the previous releases were disappointing compared to gemma 2 other than having greater context length
>>105725352
multimodality usually makes models smarter.
Although
>text only output
fail.
Literally never going to get a decent local 2-way omni model from any of the big corpos at this rate.
Anonymous
6/27/2025, 8:41:32 PM
No.105725374
[Report]
How does training a LORA for a reasoning model work? Same way or do I have to generate the thought process part in my training data?
Anonymous
6/27/2025, 8:41:47 PM
No.105725379
[Report]
>>105725371
>text only output
Yeah, that sucks giant balls.
Anonymous
6/27/2025, 8:42:25 PM
No.105725384
[Report]
>>105725371
>multimodality usually makes models smarter.
what? thats not true at all.
there is huge degradion.
did you try the first we had? was a qwen model last year with audio out. was tardation i havent seen since pyg.
recently they had another release and it still was bad but not as severe anymore.
even the cucked closed models (gemini/chatgpt) have degradation with voice out.
this is a problem i have not yet seen solved anywhere.
>>105725371
>Literally never going to get a decent local 2-way omni model from any of the big corpos at this rate.
they do not want to give you an AI with the super powers of a photoshop expert that could be decensored and used to gen all sorts of chud things without any skill requirement
two way multimodal LLMs will always be kept closed
Anonymous
6/27/2025, 8:43:41 PM
No.105725400
[Report]
>>105725392
Meanwhile all the AI companies have quite obviously given Israel uncensored image-gen to crank out pro-genocide propaganda with impunity.
I hope they all fucking end up in the Hague.
Anonymous
6/27/2025, 8:44:17 PM
No.105725411
[Report]
>>105725392
>>Literally never going to get a decent local 2-way omni model from any of the big corpos at this rate.
how can you get something that doesnt even exist beyond government blacksites right now lmao
Why is this thread repeating itself
Anonymous
6/27/2025, 8:44:55 PM
No.105725420
[Report]
>>105725426
>>105725392
>they do not want to give you an AI with the super powers of a photoshop expert that could be decensored and used to gen all sorts of chud things without any skill requirement
Head over to ldg. This already exists.
Anonymous
6/27/2025, 8:44:58 PM
No.105725422
[Report]
>>105725392
>they do not want to give you an AI with the super powers of a photoshop expert that could be decensored and used to gen all sorts of chud things without any skill requirement
Head over to ldg. This already exists.
Anonymous
6/27/2025, 8:45:09 PM
No.105725423
[Report]
>>105725434
>>105725413
Nigger having a melty.
>>105725420
if you mean that new flux model it's hot garbage barely a step above the SDXL pix2pix models
say what you will about the nasty built in styling of GPT but its understanding of prompts is unrivaled
Anonymous
6/27/2025, 8:45:57 PM
No.105725433
[Report]
>>105725413
save yourself bro
https://pastes.dev/AZuckh4Vws
read the script before pasting it into tampermonkey
Anonymous
6/27/2025, 8:46:04 PM
No.105725434
[Report]
>>105725453
>>105725423
The AI generals on here have the worst faggots I swear
Anonymous
6/27/2025, 8:46:08 PM
No.105725436
[Report]
>>105725426
Not only that but the interplay between the imagegen and textgen gives it a massive boost in creativity on both fronts. Although it also makes it prone to hallucinate balls. But what is the creative process other than self-guided hallucination?
Anonymous
6/27/2025, 8:46:46 PM
No.105725445
[Report]
>>105725426
True. Wish it wasnt so. But it is.
I just pasted the2 posts and just wrote "make a funny manga page of these 2 anon neckbeards arguing. chatgpt is miku".
I thought opencuck was finished a couple months ago. But they clearly have figured out multimodality the best.
Sad that zucc cucked out. Meta was writing blogs about a lot of models, nothing ever came of it.
Anonymous
6/27/2025, 8:47:33 PM
No.105725453
[Report]
>>105725434
This.
OP mikutranny is posting porn in /ldg/:
>>105715769
It was up for hours while anyone keking on troons or niggers gets deleted in seconds, talk about double standards and selective moderation:
https://desuarchive.org/g/thread/104414999/#q104418525
https://desuarchive.org/g/thread/104414999/#q104418574
Here he makes
>>105714098 snuff porn of generic anime girl, probably because its not his favourite vocaloid doll and he can't stand that, a war for rights to waifuspam in thread.
Funny /r9k/ thread:
https://desuarchive.org/r9k/thread/81611346/
The Makise Kurisu damage control screencap (day earlier) is fake btw, no matches to be found, see
https://desuarchive.org/g/thread/105698912/#q105704210 janny deleted post quickly.
TLDR: Mikufag janny deletes everyone dunking on trannies and resident spammers, making it his little personal safespace. Needless to say he would screech "Go back to teh POL!" anytime someone posts something mildly political about language models or experiments around that topic.
And lastly as said in previous thread
>>105716637, i would like to close this by bringing up key evidence everyone ignores. I remind you that cudadev has endorsed mikuposting. That's it.
He also endorsed hitting that feminine jart bussy a bit later on.
Anonymous
6/27/2025, 8:48:36 PM
No.105725468
[Report]
>>105725622
>>105720676
Calling Deepseek a <40B model is dumb shit. I've tried 32b models, and 51b Nemotron models. Deepseek blows them out of the water so thoroughly and clearly that the whole square root MoE bullshit went out the window.
An 80b MoE is going to be way better than a 32b dense model.
A 235b MoE is going to be way better than a 70b dense model.
It's RAMlet cope to suggest otherwise.
Anonymous
6/27/2025, 8:48:40 PM
No.105725469
[Report]
>>105725473
I know I'm kind of late, but holy fuck L4 scout is dumber and knows less than fucking QwQ.
What the hell?
Anonymous
6/27/2025, 8:48:50 PM
No.105725471
[Report]
>>105725363
It hallucinates like crazy. At least the GPTQ version, and with trivia questions.
Anonymous
6/27/2025, 8:49:15 PM
No.105725473
[Report]
>>105725482
>>105725469
The shitjeets that lurk here would have you believe otherwise.
>>105725473
/lmg/ shilled L4 on release.
Anonymous
6/27/2025, 8:50:27 PM
No.105725488
[Report]
>>105725482
i dont think that is true. at least i dont remember it that way.
people catched on very quickly how it was worse than the lmarena one. that caused all that drama and lmarena washing their hands.
Anonymous
6/27/2025, 8:51:01 PM
No.105725496
[Report]
>>105725482
Maybe /IndianModelsGeneral/
I don't get everyone's fascination with gpt-4o image generation. It's a nice gimmick but all it means is that you get samey images on a model that you likely wouldn't be able to easily finetune the way you can train SD or flux. It's a neat toy but nothing you'd want to waste parameters or use for any serious imgen.
Anonymous
6/27/2025, 8:52:26 PM
No.105725510
[Report]
>>105725518
>>105725504
>finetune
That requires a small amount of work which is too much for zoomers.
Anonymous
6/27/2025, 8:53:01 PM
No.105725518
[Report]
>>105725510
finetuning image models is NOT small amount of work unless you of course mean shitty 1 concept loras
Anonymous
6/27/2025, 8:53:26 PM
No.105725525
[Report]
wen hunyuan llama.cpp
Anonymous
6/27/2025, 8:53:57 PM
No.105725530
[Report]
>>105725504
Thats like saying large models are useless because you can guide mistral from 2023 with enough editing.
Especially for the normies. That it "just works" is exactly what made it popular.
Anonymous
6/27/2025, 8:54:43 PM
No.105725535
[Report]
>>105725544
humiliation ritual
Anonymous
6/27/2025, 8:55:21 PM
No.105725544
[Report]
>>105725535
Meta is about family and friends bro not numbers.
Anonymous
6/27/2025, 8:56:33 PM
No.105725555
[Report]
>>105725565
>>105725549
>The evals are incredible and trade blows with DeepSeek R1-0120.
Fucking redditors man.
This thread is such a gutter but there is no alternative. Imagine having to be on reddit.
Anonymous
6/27/2025, 8:57:20 PM
No.105725564
[Report]
>>105725549
Thanks, reddit. You're only 8 hours late. Now go back.
Anonymous
6/27/2025, 8:57:31 PM
No.105725565
[Report]
>>105725555
checked
let them cope
Anonymous
6/27/2025, 8:58:52 PM
No.105725574
[Report]
Anonymous
6/27/2025, 8:59:29 PM
No.105725584
[Report]
>>105725604
>>105725570
Architecture not supported yet.
Anonymous
6/27/2025, 9:00:47 PM
No.105725596
[Report]
>>105725615
baker wheres new bread
Anonymous
6/27/2025, 9:01:01 PM
No.105725604
[Report]
>>105725584
What the fuck are they doing all day? It better not be wasting time in the barn.
Anonymous
6/27/2025, 9:01:05 PM
No.105725606
[Report]
>>105725654
>>105725570
after jamba, get in line or there will be consequences
Anonymous
6/27/2025, 9:02:04 PM
No.105725615
[Report]
>>105725596
It's not even page 9 yet, chill the fuck out newcomer.
Anonymous
6/27/2025, 9:02:20 PM
No.105725619
[Report]
>Meta says it’s winning the talent war with OpenAI | The Verge
https://archive.ph/ZoxE3
aside from the expected notes on meta swiping some OAI employees, there's this of note:
>“We are not going to go right after ChatGPT and try and do a better job with helping you write your emails at work,” Cox said. “We need to differentiate here by not focusing obsessively on productivity, which is what you see Anthropic and OpenAI and Google doing. We’re going to go focus on entertainment, on connection with friends, on how people live their lives, on all of the things that we uniquely do well, which is a big part of the strategy going forward.”
Anonymous
6/27/2025, 9:02:22 PM
No.105725622
[Report]
>>105725468
DeepSeek is only 37B by active parameter count. It's 158B by square root law, which seems more accurate.
Anonymous
6/27/2025, 9:02:54 PM
No.105725633
[Report]
ITT: people believe corpos will give away something valuable
All of them only ever release free weights when the weights can be considered worthless
Flux doesn't give away their best models
Google gives you Gemma, not Gemini
Meta can give away Llama because nobody wants it even for free
Qwen never released the Max model
So far the only exception has been DeepSeek, their model is both desirable and open and I think they are doing this more out of a political motivation (attempt to make LLM businesses crash and burn by turning LLMs into a comodity) rather than as a strategy for their own business
some people in China are very into the buckets of crab attitude, can't have the pie? I shall not let you have any either
Anonymous
6/27/2025, 9:03:38 PM
No.105725644
[Report]
So because Qwen3 VL has been replaced by VLo, does that mean they aren't even going to bother releasing an open source vision model anymore? I was waiting for it to make better captions...
Anonymous
6/27/2025, 9:04:22 PM
No.105725652
[Report]
Chatgpt keeps telling me that MythoMax 13B Q6 is the best .ggup to immersively rape my fictional characters in RP, is that true or is there better?
Anonymous
6/27/2025, 9:04:24 PM
No.105725653
[Report]
>>105725672
>>105725630
does the sweater hide all the cut marks on your wrists?
Anonymous
6/27/2025, 9:04:26 PM
No.105725654
[Report]
>>105725606
You realize you just responded to the spam bot right?
https://www.nytimes.com/2025/06/27/technology/mark-zuckerberg-meta-ai.html
https://archive.is/kF1kO
>In Pursuit of Godlike Technology, Mark Zuckerberg Amps Up the A.I. Race
>Unhappy with his company’s artificial intelligence efforts, Meta’s C.E.O. is on a spending spree as he reconsiders his strategy in the contest to invent a hypothetical “superintelligence.”
>
>[...] In another extraordinary move, Mr. Zuckerberg and his lieutenants discussed “de-investing” in Meta’s A.I. model, Llama, two people familiar with the discussions said. Llama is an “open source” model, with its underlying technology publicly shared for others to build on. Mr. Zuckerberg and Meta executives instead discussed embracing A.I. models from competitors like OpenAI and Anthropic, which have “closed” code bases. No final decisions have been made on the matter.
>
>A Meta spokeswoman said company officials “remain fully committed to developing Llama and plan to have multiple additional releases this year alone.” [...]
Anonymous
6/27/2025, 9:05:33 PM
No.105725664
[Report]
>>105725630
Very feminine hand, typical of average /g/ tranny.
Anonymous
6/27/2025, 9:05:45 PM
No.105725667
[Report]
if I was 'ggaganov I would just make it so that llama.cpp works with everything by default instead of having to hardcode every model, but I guess that sort of forward thinking is why I run businesses and he's stuck code monkeying
Anonymous
6/27/2025, 9:06:09 PM
No.105725672
[Report]
>>105725653
Imagine projecting this much
Anonymous
6/27/2025, 9:06:09 PM
No.105725673
[Report]
>>105725656
zuck might just be the dumbest CEO ever
Anonymous
6/27/2025, 9:06:48 PM
No.105725676
[Report]
>>105725656
Wang's words, zuck's mouth
Anonymous
6/27/2025, 9:07:24 PM
No.105725685
[Report]
>>105725656
>Godlike Technology,
Is god omnipotent if he can't suck a dick in an acceptable manner?
Anonymous
6/27/2025, 9:08:00 PM
No.105725689
[Report]
>>105725656
>llama isnt literally AGI because uhhhmm because its open source and others have access to it
chat?
Anonymous
6/27/2025, 9:08:01 PM
No.105725692
[Report]
i must be pushing it by now, but 3.2 is still hanging along
Anonymous
6/27/2025, 9:08:35 PM
No.105725700
[Report]
>>105725656
meta just got told by a judge, that they are in fact not covered by the fair use law, even if they "won" the case, but that was bc both lawyer teams were focusing in the wrong part of the law. the judge said that if the generated models compete in any way with the training materials it wont be fair use
of course they are discussing deinvesting, they are not leading and the legal situation is getting worse
Anonymous
6/27/2025, 9:08:59 PM
No.105725705
[Report]
>>105722291
You're the rag
Anonymous
6/27/2025, 9:09:17 PM
No.105725708
[Report]
>>105725656
>In another extraordinary move, Mr. Zuckerberg and his lieutenants discussed “de-investing” in Meta’s A.I. model, Llama, two people familiar with the discussions said. Llama is an “open source” model, with its underlying technology publicly shared for others to build on. Mr. Zuckerberg and Meta executives instead discussed embracing A.I. models from competitors like OpenAI and Anthropic, which have “closed” code bases.
Anonymous
6/27/2025, 9:09:54 PM
No.105725716
[Report]
>Bunch of worthless LLMs for math and coding
>Barely, if any, built for story making or translating
WHEN WILL THIS SHITTY INDUSTRY JUST HURRY UP AND MOVE ON!
Anonymous
6/27/2025, 9:10:48 PM
No.105725724
[Report]
>>105724105
> the future is fucking bright
Anonymous
6/27/2025, 9:12:01 PM
No.105725736
[Report]
Anonymous
6/27/2025, 9:12:02 PM
No.105725737
[Report]
>>105725748
new llama.cpp binary build wen
Anonymous
6/27/2025, 9:12:48 PM
No.105725748
[Report]
>>105725737
When you git pull and cmake, anon...
Anonymous
6/27/2025, 9:13:32 PM
No.105725757
[Report]
https://www.nytimes.com/2025/06/27/technology/mark-zuckerberg-meta-ai.html
https://archive.is/kF1kO
>In Pursuit of Godlike Technology, Mark Zuckerberg Amps Up the A.I. Race
>Unhappy with his company’s artificial intelligence efforts, Meta’s C.E.O. is on a spending spree as he reconsiders his strategy in the contest to invent a hypothetical “superintelligence.”
>
>[...] In another extraordinary move, Mr. Zuckerberg and his lieutenants discussed “de-investing” in Meta’s A.I. model, Llama, two people familiar with the discussions said. Llama is an “open source” model, with its underlying technology publicly shared for others to build on. Mr. Zuckerberg and Meta executives instead discussed embracing A.I. models from competitors like OpenAI and Anthropic, which have “closed” code bases. No final decisions have been made on the matter.
>
>A Meta spokeswoman said company officials “remain fully committed to developing Llama and plan to have multiple additional releases this year alone.” [...]
Anonymous
6/27/2025, 9:14:43 PM
No.105725766
[Report]
>>105725790
JUST RANGE BAN YOU FUCKING MODS!
Anonymous
6/27/2025, 9:15:07 PM
No.105725771
[Report]
As LLM pretraining costs keep dwindling, it's only a matter of time until someone trains a proper creative model for his company,.
Anonymous
6/27/2025, 9:16:15 PM
No.105725781
[Report]
>>105725759
We already there >>>/r9k/81615256
Though i would recommend >>>/lgbt/ as appropriate safespace for all of us.
Anonymous
6/27/2025, 9:16:41 PM
No.105725786
[Report]
>>105725759
You go first and wait for me.
Anonymous
6/27/2025, 9:16:54 PM
No.105725789
[Report]
>>105725795
its not working :(
Anonymous
6/27/2025, 9:17:00 PM
No.105725790
[Report]
>>105725766
Might not work if they are using ecker or gay or some residential proxy.
Anonymous
6/27/2025, 9:17:31 PM
No.105725795
[Report]
>>105725803
>>105725789
heeeeeeeeeeeeeeeeeeeeeeeeeelllllllllllllppppppppp pleaaaaaseeeeeeee
Anonymous
6/27/2025, 9:18:10 PM
No.105725803
[Report]
>>105725795
have you tried asking chatgpt to write the script for you?
Anonymous
6/27/2025, 9:19:02 PM
No.105725809
[Report]
>>105716978
What exactly are you complaining about? I like 3.2 (with mistral tekken v3) but it definitely has a bias toward certain formatting quirks and **asterisk** abuse. This is more tolerable for me than other model's deficiencies at that size, but if it triggers your autism that badly you're better off coping with something else. It might also be that your cards are triggering its quirks more than usual
>deepseek/ccp can't steal more innovation from openai
>they fail to release new models
they must be shitting their pants about openai's open source model that will destroy even the last argument to use deepshit
Anonymous
6/27/2025, 9:20:20 PM
No.105725820
[Report]
>>105725837
>>105725815
Zero chance it's larger than 30B.
Anonymous
6/27/2025, 9:20:55 PM
No.105725825
[Report]
>>105725815
openai just lost their head people to meta after being stagnant for forever
Anonymous
6/27/2025, 9:20:55 PM
No.105725826
[Report]
>>105725940
>>105724939
I'm not competent but A.I. is and it seems to work right.
https://pastes.dev/l0c6Kj9a4v
>>105725815
Why can't they steal anymore?
Anonymous
6/27/2025, 9:22:10 PM
No.105725837
[Report]
>>105725820
its going to be a 3B phone model that blows away benchmarks for its size
Anonymous
6/27/2025, 9:22:48 PM
No.105725842
[Report]
>>105725833
they can't steal because there's no new general model
DeepSeek V3 was 100% trained on GPT4 and R1 was just a godawful placebo CoT on top that wrote 30 times the amount of actual content the model ends up outputting. New R1 is actually good because the CoT came from Gemini so there isn't a spam of a trillion wait or endless looping.
Anonymous
6/27/2025, 9:24:00 PM
No.105725854
[Report]
Anonymous
6/27/2025, 9:24:39 PM
No.105725861
[Report]
>>105725848
deepseek is as raw as a model gets, they trained on the raw internet with the lightest of instruct tunes probably a few million examples big. If they trained on gpt it would sound much more like shitty llama
Anonymous
6/27/2025, 9:25:16 PM
No.105725867
[Report]
>>105725815
>Still living in saltman's delusion
Ngmi
Anonymous
6/27/2025, 9:26:02 PM
No.105725875
[Report]
>>105725934
The more I try to train and fuck with these models, the more I think the AI CEOs should be hanged for telling everyone they could be sentient in 2 weeks. Every time I think I'm getting somewhere it botches something very simple. I guess it was a fool's errand thinking I could hyper-specialize a small model to do things Claude can't
arguing with retards is a futile, most pointless thing to do in life
you learn how to spot them and you ignore them
life is too short to deal with idiots who think they know how MoE work but don't
Anonymous
6/27/2025, 9:27:34 PM
No.105725888
[Report]
>>105725882
I do agree with you. So many others are simply not on the same level as I am. It's almost quite insulting to even trying to establish any form of discussion with them.
Anonymous
6/27/2025, 9:27:52 PM
No.105725894
[Report]
>>105725953
this thread has gone down the poopchute, jesus
what is wrong with the spammer retard
Anonymous
6/27/2025, 9:28:15 PM
No.105725895
[Report]
>>105725882
dunningkrugerMAXX
Anonymous
6/27/2025, 9:28:23 PM
No.105725898
[Report]
>>105725917
>>105725882
Certainly good sir, we are above all the rabble. We always know best.
Anonymous
6/27/2025, 9:28:53 PM
No.105725903
[Report]
>>105725882
Just because a model can answer your obscure JRPG trivia, doesn't make it a good model.
>>105725882
how do I make good ai? I'm looking to make an advanced artificial intelligence that can replace millions of workers, that can drive, operate robotic hands with precision, and eliminate all coding jobs and middle management tasks.
I heard you were the guy to ask.
On 4chan.
Anonymous
6/27/2025, 9:29:46 PM
No.105725917
[Report]
Anonymous
6/27/2025, 9:29:50 PM
No.105725918
[Report]
>>105717903
>how to clean data
This is something AI should be able to do itself.
Anonymous
6/27/2025, 9:31:03 PM
No.105725926
[Report]
>>105725913
Just stabilize the environment and shift the paradigm
Anonymous
6/27/2025, 9:31:14 PM
No.105725930
[Report]
>>105719870
I find nemo better than deepseek even, I just want the same thing with more context.
Anonymous
6/27/2025, 9:31:35 PM
No.105725934
[Report]
>>105726011
>>105725875
The fact that models 'sleep' between prompts means that there is no sentience.
The AI 'dies' every prompt and has to be 'reborn' with context so it can pretend to be the same AI you prompted 1 minute ago.
The LLMs we have no have absolutely nothing analog to sentience When people cry that we need to be kind to AI, you might as well pause a movie before an actor gets shot.
Anonymous
6/27/2025, 9:31:40 PM
No.105725935
[Report]
>>105725913
If you can optimize it to beat pokemon red/blue the dominoes will start to fall
Anonymous
6/27/2025, 9:31:59 PM
No.105725940
[Report]
>>105725826
yes, this is working for me too
Anonymous
6/27/2025, 9:33:07 PM
No.105725953
[Report]
>>105725997
>>105725894
qrd on the spammer?
Anonymous
6/27/2025, 9:36:29 PM
No.105725983
[Report]
>>105725630
>migger has a soihand
pottery
Anonymous
6/27/2025, 9:37:02 PM
No.105725991
[Report]
Anonymous
6/27/2025, 9:37:30 PM
No.105725997
[Report]
>>105725953
Mental breakdown. Has no control over his own life so he wants to impose rules on others. He'll get bored.
Anonymous
6/27/2025, 9:39:00 PM
No.105726011
[Report]
>>105725934
>The fact that models 'sleep' between prompts means that there is no sentience.
It's more than that I think. People sleep too. We go unconscious for long periods of time. Unlike LLMs our brains are always "training." So a part of the experience of consciousness is the fact your "weights" so to speak are always reshuffling, and your ability to reflect on how you've changed over short and long periods of time contributes to the mental model of yourself. It's like we have many embeddings and some of them understand the whole system and how it changes over time. LLMs just have one and their only "memory" is the context which is just reinterpreted in chunks.
Anonymous
6/27/2025, 10:46:30 PM
No.105726720
[Report]
An insect might have less ""intelligence"" as perceived by a human but it has more sentience than a LLM for sure. LLMs don't even have any notion of acting upon a will of their own. They react to what you feed them and have no ability to impose a form of will outside of the perimeter set by your prompt.
Prod an ant with a leaf or something, at first it will be distracted and react with curiosity or fear, but it will quickly go back to minding its own business : looking for food, or going back to its colony. Prod a LLM with data and it will not "think" (by which I mean generate MUHNEXTTOKEN) of anything other than that data.