Anonymous
6/29/2025, 3:41:14 AM
No.105739360
[Report]
>>105739893
/ldg/ - Local Diffusion General
Anonymous
6/29/2025, 3:46:21 AM
No.105739403
[Report]
>>105739426
Anonymous
6/29/2025, 3:46:29 AM
No.105739404
[Report]
Things are changing too quickly for me to reliably reaction image shitpost.
I've got to think about this.
Anonymous
6/29/2025, 3:46:49 AM
No.105739408
[Report]
Blessed thread of frenship
Anonymous
6/29/2025, 3:47:21 AM
No.105739416
[Report]
>>105739403
there's no way this is a raw Flux gen, did you save it at like JPEG Quality 10 before uploading or something kek
the green cartoon frog is on a fishing boat holding a fishing rod on a sunny day. he is sitting on a chair. keep the expression the same. a cooler with beers is open on the boat.
Anonymous
6/29/2025, 3:49:37 AM
No.105739435
[Report]
>>105739426
This isn't even the worst deepfrying we've had in the threads. That Bob Ross one was absolutely baked.
Anonymous
6/29/2025, 3:50:08 AM
No.105739441
[Report]
Is there a version of Chroma better than v29 yet?
Anonymous
6/29/2025, 3:50:10 AM
No.105739442
[Report]
>>105739466
>>105739293
nta. i guess, the GGUF version has some problems with longer text, but this is still really cool
Anonymous
6/29/2025, 3:50:12 AM
No.105739443
[Report]
Anonymous
6/29/2025, 3:50:27 AM
No.105739444
[Report]
Anonymous
6/29/2025, 3:50:35 AM
No.105739447
[Report]
>>105739426
raw kontext gen
the green cartoon frog is on a fishing boat holding a fishing rod on a sunny day. he is sitting on a chair. keep the expression the same. a cooler with beers is open on the boat. there is a large cartoon shark that is diving out of the water.
Anonymous
6/29/2025, 3:52:43 AM
No.105739466
[Report]
>>105741289
>>105739442
>the GGUF version has some problems with longer text,
use NAG, it fixes the text a lot
https://github.com/ChenDarYen/ComfyUI-NAG
Anonymous
6/29/2025, 3:52:49 AM
No.105739467
[Report]
>>105740124
Why does Kontext gradually degrade the image after repeated edits? It doesn't look like the kind of degradation you get from repeated VAE encoding/decoding, seems like something else
Anonymous
6/29/2025, 3:54:18 AM
No.105739479
[Report]
>>105739463
If only the style was just a bit more like the initial pepe
Anonymous
6/29/2025, 3:54:59 AM
No.105739485
[Report]
>>105739506
>>105739463
revised a bit:
the green cartoon frog is on a fishing boat holding a fishing rod on a sunny day. he is sitting on a chair. keep the expression the same. a cooler with beers is open on the boat. there is a large cartoon whale that is diving out of the water, attached to the fishing line.
Anonymous
6/29/2025, 3:55:19 AM
No.105739486
[Report]
>>105739470
cause it's changing the entire fucking thing to some extent every time even if you don't notice it, basically. You'd need to be using it with like hard-masking of certain image areas to avoid that, I guess
Anonymous
6/29/2025, 3:56:38 AM
No.105739497
[Report]
>>105739563
prompt for multiple people worked well
the green cartoon frog is on a fishing boat holding a fishing rod on a sunny day. he is sitting on a chair. keep the expression the same. a cooler with beers is open on the boat. On the boat are two other cartoon frogs that look like him, one is wearing a white t-shirt, the other is wearing a red t-shirt.
now it's a fren boat/fishing trip
>>105739470
I think they haven't found a way to force the model to only change only one region but the whole image, desu it's way better than what 4o is doing lol
https://www.youtube.com/watch?v=Ot_aYxptzJ4
Anonymous
6/29/2025, 3:58:20 AM
No.105739506
[Report]
>>105739485
looks too clean, add ",while maintaining the same style of the drawing” Or "using this style,"
maybe ?
Anonymous
6/29/2025, 3:59:20 AM
No.105739512
[Report]
>>105739500
But 4o piss filter degradation would be easy to fix by doing an Adain on the image after each iteration I think (using the original image as the reference)
Whatever this is much harder to fix :<
Anonymous
6/29/2025, 4:04:12 AM
No.105739545
[Report]
>>105741674
Since regional prompting doesn't really work with multiple subjects reliably, how do you guys make do when you want different parts of the picture to have different stuff?
Gen a base image and inpaint each region one by one?
Anonymous
6/29/2025, 4:06:07 AM
No.105739563
[Report]
>>105739579
>>105739497
the green cartoon frog is on a large fishing boat. he is sitting on a chair holding a beer in a bottle. keep the expression the same. a cooler with beer bottles is open on the boat. On the boat are two other adult size cartoon frogs that look exactly like him, one is wearing a white t-shirt and drinking beer, the other is wearing a red t-shirt and drinking beer.
pretty decent desu
Anonymous
6/29/2025, 4:06:08 AM
No.105739564
[Report]
kek
"candid amateur photo of an average 4Chan Local Diffusion General user"
noob can do crazy stuff when you start looking at the different mediums that have booru tags.
Anonymous
6/29/2025, 4:08:46 AM
No.105739579
[Report]
>>105739563
better cooler:
Anonymous
6/29/2025, 4:10:51 AM
No.105739590
[Report]
>>105739826
>>105739576
I mean shit, look at this
Anonymous
6/29/2025, 4:12:30 AM
No.105739600
[Report]
>>105739576
This pic is so baked the stock looks like it was made from the contemporary wooden plastic kek
Anonymous
6/29/2025, 4:14:21 AM
No.105739612
[Report]
>>105739670
>>105739576
What do your upscale settings look like
Anonymous
6/29/2025, 4:17:24 AM
No.105739626
[Report]
>>105739670
>>105739576
why does the background is realistic and looks so terrible? lol
bros... dont make the same mistake as me and fall in love with one of your gens
Anonymous
6/29/2025, 4:22:18 AM
No.105739655
[Report]
>>105739651
I seriously hope it isn't the zendaya goof hair you just posted
Anonymous
6/29/2025, 4:22:50 AM
No.105739659
[Report]
>>105739651
>falling in love with a random insignificant slut
>2025
Tsk tsk!
Anonymous
6/29/2025, 4:24:34 AM
No.105739668
[Report]
>falling in love
>>105739626
because, I'm pushing the model to its limits:
>(photo background:1.3), photorealism, by pankichi anko, (by gomasho asuka:0.5), (3d background:0.7), paper cutout \(medium\),masterpiece, absurdres, amazing composition,
I had gens without this artifacting but I think the artifacts actually add to the aesthetic here.
>>105739612
have a box
https://files.catbox.moe/vqwhkc.png
Anonymous
6/29/2025, 4:30:24 AM
No.105739709
[Report]
>>105740338
>>105739500
ChatGPT has as a massive content filter. I bet it's not the model that's doing it at all, but a watermark they placed on it. In reality that model would far exceed what we have locally, but they're not letting us play with the raw model.
Anyways, the Flux inpainting and outpainting models do the same thing. Only node that can fix this is in that case is ImageCompositeMasked
Anonymous
6/29/2025, 4:32:00 AM
No.105739719
[Report]
>>105739651
ive seen that face a million times
Anonymous
6/29/2025, 4:36:00 AM
No.105739750
[Report]
>>105739759
Anonymous
6/29/2025, 4:37:20 AM
No.105739759
[Report]
>>105739899
>>105739750
wai holds its own here, alright I won't totally write off the illustrious models. but lately noob finetunes have been impressing me the most.
Anonymous
6/29/2025, 4:40:18 AM
No.105739781
[Report]
I don't understand why WAI is so popular if it's simply a merge.
Anonymous
6/29/2025, 4:41:21 AM
No.105739794
[Report]
>>105739651
Now all you have to do is torture some LLM into being your onitis so I can laugh at you when some sloptuber makes a video on the subject
Anonymous
6/29/2025, 4:43:52 AM
No.105739818
[Report]
>>105739831
kontext is amazing.
>change the text in the center from "STARFIELD" to "SAARFIELD". Add an indian man in a spacesuit with his helmet off, with an indian flag on his arm.
Anonymous
6/29/2025, 4:44:26 AM
No.105739826
[Report]
>>105739899
>>105739651
how bland. but it is always fascinating how others react to gens. I remember sharing a few tattoo girls with an old friend and he enthusiastically pointed out one particular gen, for me it was like a 5.4/10. "can you gen more of her?", etc
>>105739590
anon wot are you doing. but yes noob is funky.
Anonymous
6/29/2025, 4:45:52 AM
No.105739833
[Report]
>>105739907
>magazine scan, graphite \(medium\), scan artifacts, scan, color halftone, artbook, doujinshi, production art, novel illustration, jpeg artifacts,
>>105739576
i need e621 in il2.0 or 3.5vp if it ever leaks
Anonymous
6/29/2025, 4:47:24 AM
No.105739850
[Report]
>>105739855
>>105739831
okay, NOW it's proper saarfield.
Anonymous
6/29/2025, 4:48:16 AM
No.105739855
[Report]
>>105739850
India will be the first country to shit on the moon
Anonymous
6/29/2025, 4:50:26 AM
No.105739869
[Report]
>>105739831
less is more anon, just saarfield and an indian would get the point across
>>105739846
ah I never asked how you make those but yeah.. figures.
Anonymous
6/29/2025, 4:52:50 AM
No.105739893
[Report]
>>105739923
>>105739360 (OP)
You got a guy linking your threads in an attempt to raid them. Just thought you should know.
Anonymous
6/29/2025, 4:53:16 AM
No.105739899
[Report]
>>105739955
>>105739759
noob again. come on. this model is so expressive and has so much style. if local doesn't make any advancements beyond this, I'll still be set for life. what an incredible achievement for a random chinese autist.
>>105739826
see
>>105739670
Anonymous
6/29/2025, 4:54:34 AM
No.105739907
[Report]
Anonymous
6/29/2025, 4:54:51 AM
No.105739908
[Report]
>>105739955
How many steps for the cfg1 chroma?
Anonymous
6/29/2025, 4:56:37 AM
No.105739923
[Report]
Anonymous
6/29/2025, 4:59:03 AM
No.105739937
[Report]
>>105740015
I feel like the cfg1 Chroma is more schizo than classic versions. I had one pristine gen, but since then it's been giving me mid pieces.
Anonymous
6/29/2025, 5:01:58 AM
No.105739955
[Report]
>>105739908
doing 20 now, gguf from silverdude. quite a few gens look pretty baked at cfg1, so there's that.
>>105739899
ah so it's just prompting. neat.
Anonymous
6/29/2025, 5:03:58 AM
No.105739966
[Report]
>>105740048
Anonymous
6/29/2025, 5:10:19 AM
No.105740015
[Report]
>>105739937
She's clearly not wearing enough safety gear
Anonymous
6/29/2025, 5:10:33 AM
No.105740017
[Report]
>>105740134
20/25 steps, shrug
Anonymous
6/29/2025, 5:13:56 AM
No.105740036
[Report]
Anonymous
6/29/2025, 5:15:05 AM
No.105740048
[Report]
>>105740134
>>105739966
Your work is so fucking cool dude. Genuinely in awe. Would you be able to post a gallery with some of your previous stuff or am I doomed to go back through previous threads? Or just a catbox to see more of your process maybe?
Anonymous
6/29/2025, 5:18:15 AM
No.105740074
[Report]
change the text in the center from "STARFIELD" to "SHITFIELD". Change the location to the surface of the moon. On the moon is a sign that says "NO CONTENT HERE".
sign is wrong but the logo is perfect:
Anonymous
6/29/2025, 5:19:16 AM
No.105740081
[Report]
>>105740214
there we go.
Anonymous
6/29/2025, 5:20:56 AM
No.105740088
[Report]
>>105740125
>>105739846
sick style prompt, it works perfectly with different subject material
Anonymous
6/29/2025, 5:23:20 AM
No.105740105
[Report]
>>105740150
Anonymous
6/29/2025, 5:27:36 AM
No.105740124
[Report]
>>105739467
workflow?? how did you get such good text from 35m?? here's a random 35m gen I just made
Anonymous
6/29/2025, 5:27:40 AM
No.105740125
[Report]
Anonymous
6/29/2025, 5:28:22 AM
No.105740132
[Report]
>>105740164
Anonymous
6/29/2025, 5:28:32 AM
No.105740134
[Report]
Anonymous
6/29/2025, 5:29:43 AM
No.105740143
[Report]
same prompt but i added these
>>105739846
i ran the same seed as the previous one but it forgot the character. kinda cool this finetune recognizes her after just 7 epochs. its kind of unstable so i did a merge with two versions which helps a bit
Anonymous
6/29/2025, 5:30:29 AM
No.105740150
[Report]
>>105740105
based luminachad.
here's more sd35m. wait a second, this model is good?
Anonymous
6/29/2025, 5:32:28 AM
No.105740164
[Report]
>>105740132
Imagine those eyes
Anonymous
6/29/2025, 5:33:37 AM
No.105740170
[Report]
>>105740191
what does it mean when adaptive guidence sets cfg to 1? some gens it triggers at like 10%, does this mean it basically ignores my prompt?
Anonymous
6/29/2025, 5:35:34 AM
No.105740174
[Report]
>>105740194
we need models over 50gb and affordable gpu's to match that in vram, until then local models are just toys
Anonymous
6/29/2025, 5:36:16 AM
No.105740176
[Report]
what is the meta checkpoint? is it still illu?
Anonymous
6/29/2025, 5:37:38 AM
No.105740191
[Report]
>>105740170
it will effectively set the cfg to 1 and ignore the negative once the threshold is reached. need to tune it
Anonymous
6/29/2025, 5:37:45 AM
No.105740194
[Report]
>>105740174
yep nvidia has zero competition in this field so they are jewing it out
Anonymous
6/29/2025, 5:40:25 AM
No.105740209
[Report]
>>105740905
Anonymous
6/29/2025, 5:40:46 AM
No.105740214
[Report]
>>105740081
helps if I attach an image.
Anonymous
6/29/2025, 5:44:38 AM
No.105740228
[Report]
Anonymous
6/29/2025, 5:45:06 AM
No.105740233
[Report]
does kontext support partial denoise inpaint
like if I wanted to denoise 0.4 does that work
I got really noisy outputs
if this can be done can I get a workflow
Anonymous
6/29/2025, 5:45:47 AM
No.105740237
[Report]
Anonymous
6/29/2025, 5:52:23 AM
No.105740278
[Report]
>>105740513
>Kontext
>Pos: Straight on. Standing straight up. Both feet on the ground. Remove the spear. Arms down at her side.
>Neg: Standing on one leg. Spear. Looking to the side.
https://github.com/ChenDarYen/ComfyUI-NAG
Absolute magic. We will no longer suffer under the tyranny of 1 off artist images at this rate of advancements.
how come there isn't a torrent of all the celeb loras that were removed?
Or is there another site?
Anonymous
6/29/2025, 5:54:36 AM
No.105740294
[Report]
>grab chroma cfg1, it is now fast. add nag, it is now slow again. awesome.
>>105740279
try civitarchive and huhhingface.
Anonymous
6/29/2025, 5:55:36 AM
No.105740299
[Report]
kino soul general
Anonymous
6/29/2025, 5:57:35 AM
No.105740307
[Report]
Does Kontext know Wojak style?
Anonymous
6/29/2025, 5:57:41 AM
No.105740309
[Report]
based lumina and chroma chads bringing back the kino sovl
Chroma is getting real close. v40 is noticeably better than all the previous versions.
Anonymous
6/29/2025, 6:00:20 AM
No.105740320
[Report]
>>105740343
Skateboards are the hands of sports gear.
Anonymous
6/29/2025, 6:01:57 AM
No.105740335
[Report]
>>105740533
Anonymous
6/29/2025, 6:03:14 AM
No.105740338
[Report]
>>105739709
Gippity is the most prompt-filtered API-only image generator by a bigly margin
Reve is the least (it has none whatsoever, their prompt enhancer will not enhance certain stuff, but you can turn it off with a button for any particular gen, they only "hard filter" with output blurring that seems to target explicit NSFW and nothing else as far as I can tell)
Anonymous
6/29/2025, 6:03:41 AM
No.105740342
[Report]
>>105740533
>v29 is the best
>v40 is the best
which is it?
Anonymous
6/29/2025, 6:03:47 AM
No.105740343
[Report]
>>105740467
Anonymous
6/29/2025, 6:04:59 AM
No.105740353
[Report]
>>105740311
can it do this in a way that doesn't have "upscaled SD 1.5" tier fidelity, though
What's your NAG settings for Chroma?
Anonymous
6/29/2025, 6:09:02 AM
No.105740380
[Report]
>>105740433
>>105740367
wtf is NAG, sounds like a node for your GF mirite lads *rimshot noise*
>>105740375
Chroma? I've been out for months at this point
Anonymous
6/29/2025, 6:13:25 AM
No.105740408
[Report]
>>105740426
>>105740399
Furryrock guy decided to do a finetune / architecture tweak (to eliminate unneeded params) of Flux Schnell
which Flux model can I use to run Loras?
gguf? schnell? dev?
Anonymous
6/29/2025, 6:13:55 AM
No.105740414
[Report]
>>105741048
Anonymous
6/29/2025, 6:14:46 AM
No.105740419
[Report]
>>105740413
any generally speaking
Anonymous
6/29/2025, 6:15:02 AM
No.105740421
[Report]
Anonymous
6/29/2025, 6:15:56 AM
No.105740426
[Report]
>>105740440
>>105740408
I like it. Does your workflow use controlnet or lora to get such a good pose?
Anonymous
6/29/2025, 6:17:05 AM
No.105740433
[Report]
>>105740380
omg dude
>>105740367
0. slow enough as is
Anonymous
6/29/2025, 6:17:29 AM
No.105740434
[Report]
Anonymous
6/29/2025, 6:18:34 AM
No.105740440
[Report]
>>105740447
>>105740426
i'm not that anon lol
>>105740440
im too retarded even for 4chan damn
>>105740375
your workflow use controlnet or lora to get such a good pose?
Anonymous
6/29/2025, 6:21:11 AM
No.105740449
[Report]
>>105740447
its alright kek
Anonymous
6/29/2025, 6:23:45 AM
No.105740458
[Report]
>>105740460
>>105740279
who specifically? There's a ton on there currently
Anonymous
6/29/2025, 6:24:47 AM
No.105740460
[Report]
>>105740529
>>105740458
some niche Irish celeb
>on there
on where?
civ?
Anonymous
6/29/2025, 6:24:50 AM
No.105740461
[Report]
>>105740511
>>105740447
it's just genning. you go " FOOT FOCUS, feet, zomg foot, low quality grainy amateur photo of trashy plastic mystery meat something giving you the finger" and voila
Anonymous
6/29/2025, 6:25:41 AM
No.105740467
[Report]
>>105740509
Anonymous
6/29/2025, 6:30:07 AM
No.105740492
[Report]
>>105740516
I thought that's an entire raw chicken, but nope. Body horror.
Anonymous
6/29/2025, 6:30:21 AM
No.105740493
[Report]
>>105740905
have to very specific when prompting this model
https://files.catbox.moe/oe3tzw.png
>finally figured how to decensor Kontext since the current LoRA is subpar
>requires two datasets
>one dataset is explicit images
>other dataset is a control, same images but with characters/people clothed
>captions are the instruction, so "remove their clothes" or "make them nude"
>need my nude lady dataset clothed, but how to do it...
>!
>what if I run Kontext on the explicit images, instructing it to add clothes
>works like a charm since the model’s trained to redirect from NSFW
>1000 images are queued up in a batch run rn
>mfw I'm using BFL's own censorship against it
Anonymous
6/29/2025, 6:31:31 AM
No.105740497
[Report]
Anonymous
6/29/2025, 6:32:47 AM
No.105740505
[Report]
>>105740496
based thinking fren
Anonymous
6/29/2025, 6:33:29 AM
No.105740509
[Report]
>>105740467
very meta take on the longcat actually, nice.
>>105740496
awesome
Anonymous
6/29/2025, 6:33:54 AM
No.105740510
[Report]
>>105740520
>>105740496
>one dataset is explicit images
>other dataset is a control, same images but with characters/people clothed
>captions are the instruction, so "remove their clothes" or "make them nude"
Wait, so you could basically teach it to do anything then, right? Decensor manga/anime, stuff like that? You could just get uncensored manga, censor it yourself with a pixelate filter, then teach it to decensor
>>105740461
Is there a way to prompt a character to be "distant" in Illustrious/Noob?
I am trying controlnet + inpainting stuff which works better than just inpainting for illustrious. But it is drawing characters "closer" than I intend them to. Also I am still getting close up of different body parts half of the time but that's better than not getting anything usable at all.
Also, secondary question, is there also a way to minimize these in-painting distortions? It is a lottery, sometimes it is drawing the same background, shifted a few shades, sometimes it is drawing an entirely different background.
Anonymous
6/29/2025, 6:34:57 AM
No.105740515
[Report]
>>105740511
Didn't meant to tag anyone sorry, my bad.
Anonymous
6/29/2025, 6:35:20 AM
No.105740516
[Report]
Anonymous
6/29/2025, 6:37:06 AM
No.105740520
[Report]
>>105740510
Yeah. That'd work. You could teach it style transfer too with the right dataset.
Anonymous
6/29/2025, 6:40:12 AM
No.105740529
[Report]
>>105740460
if it was deleted there's civitaiarchive. Otherwise start stacking that training data or use faceswap
Anonymous
6/29/2025, 6:41:00 AM
No.105740533
[Report]
>>105740335
>Amateur photograph, this playful group photograph taken at day time features five young East Asian women sitting on a light brown, wood-patterned floor. In a unique and coordinated pose, they all extend their bare legs straight towards the camera, presenting the clean soles of their feet in the foreground. The women are dressed in various casual tops and dresses and look directly at the viewer with pleasant smiles. The background wall is decorated with framed art that thematically complements the pose, displaying ink imprints of footprints in black and other colors like green and pink, suggesting the photo was taken in a themed studio or for a special event.
>>105740342
>v29 is the best
Straight up autism
Anonymous
6/29/2025, 6:42:42 AM
No.105740542
[Report]
>>105740513
There was some saas that did this, but it looks like kontext has completely superseded it
Anonymous
6/29/2025, 6:44:47 AM
No.105740551
[Report]
>>105740642
>>105740511
I am not working with the illustrious models very often. you need to find the right tokens, like 'closeup' in the negative and then of course the right weights. using a positive token/positive tokens is always the best way to do it tho.
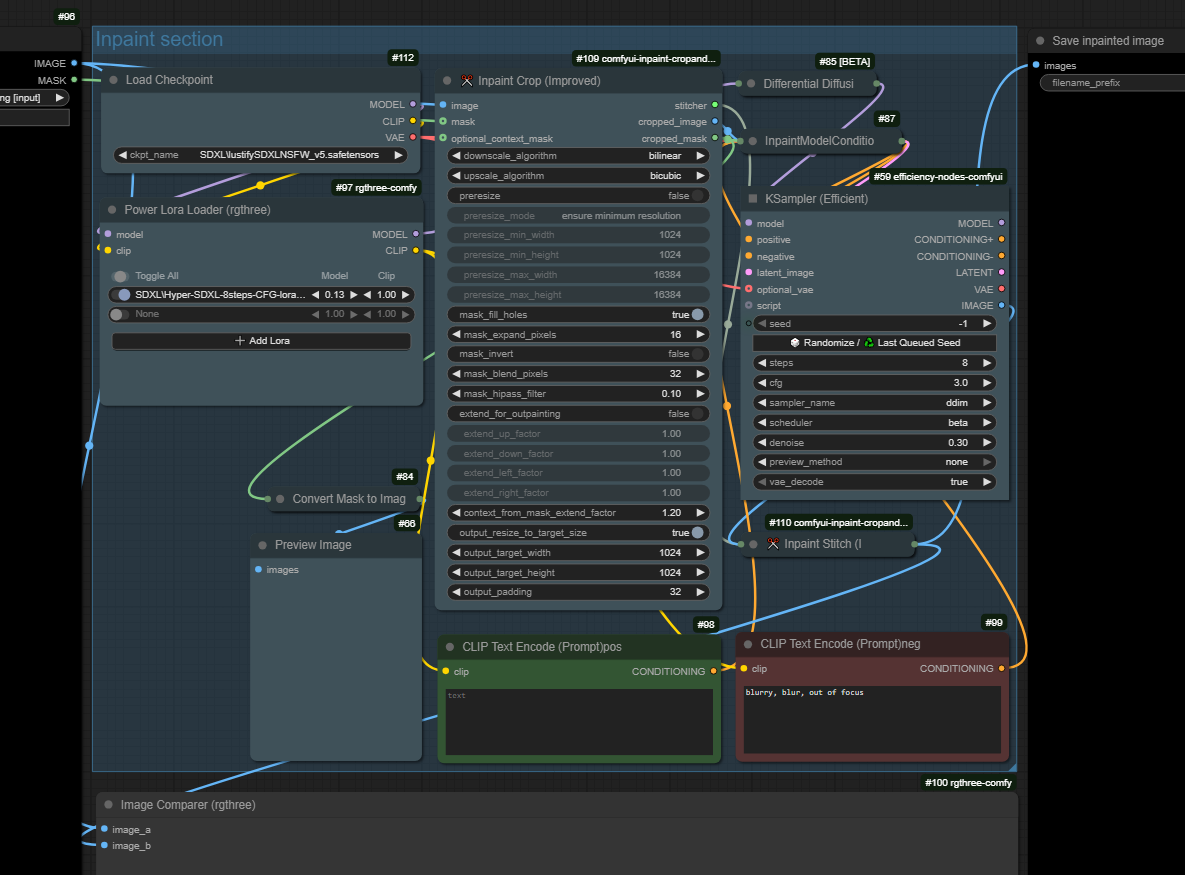
inpainting. what can I say. what are you using? comfy? forge? you need to find the right sampler and the right prompt obviously. DDIM is a safe bet. differential diffusion > inpaint model conditioning and inpaint crop and stitch is how I do it. you can also patch the model with fooocus for a more aggressive "make this go away" approach.
let me find a video..
https://www.youtube.com/watch?v=wEd1wPlCBaQ
a pic of my generic inpainting workflow, one of many
wish I could prompt a brain in my head or my depression away
Anonymous
6/29/2025, 6:50:38 AM
No.105740578
[Report]
>>105740585
give the girl a japanese female idol outfit. she has a black blindfold on like in the original image.
Anonymous
6/29/2025, 6:51:33 AM
No.105740585
[Report]
>>105740588
>>105740578
can it do bikinis? May download if it can
Anonymous
6/29/2025, 6:52:26 AM
No.105740588
[Report]
>>105740585
it can if you prompt it or use the lora
>>105740399
Chroma v40
>>105740447
Just pure txt2img, a simple prompt can achieve good results
https://files.catbox.moe/uejlhs.png
In the other case here's her feet was positioned
>The woman's pose is deliberately provocative; while her bare foot is propped up and prominently displayed towards the camera, she simultaneously raises her other hand to give the middle finger.
Anonymous
6/29/2025, 6:53:30 AM
No.105740595
[Report]
give the white hair girl a japanese female sailor anime outfit. she has a black blindfold on like in the original image.
Anonymous
6/29/2025, 6:56:23 AM
No.105740605
[Report]
give the white hair girl a black bikini.
using the clothes remover lora but prompted clothes, still works fine
Anonymous
6/29/2025, 7:02:38 AM
No.105740633
[Report]
>>105740399
>>105740592
I suggest looking at
https://desuarchive.org/aco/thread/8816539/#q8826066
(including my replies to that post and other posts on that thread)
and
https://desuarchive.org/aco/thread/8816539/#q8831762
For full extent of Chroma's NSFW capabilities
Anonymous
6/29/2025, 7:03:25 AM
No.105740637
[Report]
>>105740975
>>105740576
not gonna happen. t. battling depression for 30+ years.
Anonymous
6/29/2025, 7:03:30 AM
No.105740638
[Report]
the girl is working in an office at a computer. keep her black blindfold on.
Anonymous
6/29/2025, 7:04:31 AM
No.105740639
[Report]
>>105740576
all we can do is fun things we like anon, if you do things you like like AI or games or whatever then that's a good use of time.
Anonymous
6/29/2025, 7:04:45 AM
No.105740642
[Report]
>>105740696
>>105740551
I added full body to prompt and close-up to negative, I also drew a smaller mask. I usually use euler or some dpm but tried DDIM as you suggested. This gives me something close to what I want occasionally, though it can pretty much never resolve eye/face level detail now.
I also have no idea what differential diffusion or "patching the model with fooocus" are. I guess I gotta search.
>what are you using? comfy?
Yes.
Thanks for the workflow btw.
Why do some anons on 4chan get SO fucking salty over AI?
Anonymous
6/29/2025, 7:12:59 AM
No.105740676
[Report]
>>105740698
>>105740658
same reason some people get upset at bitcoin
Anonymous
6/29/2025, 7:14:28 AM
No.105740687
[Report]
>>105740696
remove the girl's dress and give the girl a white tank top. her midriff is exposed. she is wearing white short shorts that say "2B" on one leg. She is holding a blue water bottle.
Anonymous
6/29/2025, 7:14:39 AM
No.105740688
[Report]
>>105740698
>>105740658
>Stop liking what I don't like
Anonymous
6/29/2025, 7:16:40 AM
No.105740696
[Report]
>>105741624
>>105740642
normally the denoise is applied equally to the entire area. with differential diffusion (or soft inpainting in forge), the denoise is dependant on the brightness of the pixel, or actually latent unit (not really a pixel I guess). brighter = higher denoise. differential diffusion is in the comfyui core. check out that video, goes into great detail about various things. you can also prepare the image in krita/photoshop/gimp/paint (lol), helps a lot. stable diffusion can pick up on your crude airbrush and you help guide it. like a light cone shining on her, stuff like that. not sure what you want to go for but this isnt that bad I guess? need a 2nd pass obviously.
>>105740687
vnice
>>105740676
>>105740688
/co/ hates AI majorly
Anonymous
6/29/2025, 7:18:02 AM
No.105740702
[Report]
>>105740716
Anonymous
6/29/2025, 7:19:07 AM
No.105740711
[Report]
>>105740716
Anonymous
6/29/2025, 7:19:57 AM
No.105740716
[Report]
>>105740702
I don't use /a/ but I believe it. I think its because of how hard AI is replacing human animators.
>>105740711
They just talk about "soul" and Indians a lot
Anonymous
6/29/2025, 7:20:39 AM
No.105740720
[Report]
I heard a /g/ anon saying he could beat me
Anonymous
6/29/2025, 7:20:54 AM
No.105740721
[Report]
>>105740961
this is with
>incredibly absurdres, absurdres, highres, masterpiece, best quality, newest, 1990s \(style\), year:2005, magazine scan, horror \(theme\), graphite \(medium\), scan artifacts, scan, artbook, doujinshi, production art, novel illustration, jpeg artifacts, dark, doodle, holographic hallucination, non-web source, original, commission, mixed-language commentary, md5 mismatch, archived source, bad link, colored pencil \(medium\), watercolor \(medium\), spray paint, jaggy lines, painting \(medium\), ink wash painting,
and my regular negatives
Anonymous
6/29/2025, 7:21:45 AM
No.105740726
[Report]
>>105741440
not using a 2 image workflow btw, this is just a test:
The girl is shaking hands with the cartoon frog on the right. the frog is wearing a blue shirt and red shorts. The girl is looking at the frog and smiling.
Anonymous
6/29/2025, 7:26:12 AM
No.105740748
[Report]
removed the background on both, now it works better:
The girl is shaking hands with the cartoon frog on the right. the frog is wearing a blue shirt and red shorts. The girl is looking at the frog and smiling.
well, 2b is kinda ignoring him, for now.
Anonymous
6/29/2025, 7:37:05 AM
No.105740785
[Report]
>>105740793
have the girl in the image sitting on a stool at a bar. the bar counter is filled with beers.
Anonymous
6/29/2025, 7:38:08 AM
No.105740793
[Report]
>>105740823
>>105740785
this time, slightly diff
have the girl in the image sitting on a stool at a bar. the bar counter is filled with beers. keep her dress the same.
Anonymous
6/29/2025, 7:39:47 AM
No.105740803
[Report]
>>105740823
>>105740513
Not sure if ass crack is bannable. I don't want a vacation yet.
Anonymous
6/29/2025, 7:46:41 AM
No.105740823
[Report]
>>105740793
can it reproduce the style of the subject for the background? need to mess w/ this
>>105740803
some pretty heavy shit went unnoticed in the past but eh
Anonymous
6/29/2025, 7:52:47 AM
No.105740853
[Report]
>>105740592
true gangstas only need the t2i damn
Anonymous
6/29/2025, 7:52:48 AM
No.105740854
[Report]
Anonymous
6/29/2025, 7:52:56 AM
No.105740855
[Report]
Anyone know why faces are melting using Wan 2.1?
I'm using the FusionX model, which I know can "change" faces (I doubt "change" mean's melting them), light2xv is at 0.6 str (like recommended), and I'm using the RifleX shit too.
I'm using "A" lora (general NSFW shit), but I wasn't having this issue before. Just seemed to randomly crop up. I noticed it when I gave the "Image Noise Augmentation" node a go, but after I noticed certain features getting smoothed out I bypassed it, so it shouldn't be doing anything.
I'm not really sure what the fuck is going on. It's been persisting after restarting Comfy.
Anonymous
6/29/2025, 7:54:44 AM
No.105740861
[Report]
>>105740946
I told her to take her hat off...
Anonymous
6/29/2025, 8:01:32 AM
No.105740892
[Report]
Change the glass with ice to a beer bottle. Change the cup of coffee to a glass of orange juice.
Anonymous
6/29/2025, 8:05:54 AM
No.105740905
[Report]
Anonymous
6/29/2025, 8:06:20 AM
No.105740907
[Report]
>>105740910
the girl in this image is working at a computer in an office, and typing on a keyboard. keep the same expression.
pretty good
Anonymous
6/29/2025, 8:07:35 AM
No.105740910
[Report]
>>105740915
>>105740907
How many years until we get the ease of using natural language to tell skynet what to edit but with models that aren't censored dogshit?
Anonymous
6/29/2025, 8:08:28 AM
No.105740915
[Report]
>>105740910
clothes remover lora is all you need to uncensor stuff. and there will be even better ones to come.
Anonymous
6/29/2025, 8:09:57 AM
No.105740922
[Report]
>>105740933
Anonymous
6/29/2025, 8:12:02 AM
No.105740933
[Report]
>>105740922
Change the text to 'black people cost me thousands in property damage and chimp out inexplicably with no provocation'
Anonymous
6/29/2025, 8:12:59 AM
No.105740936
[Report]
>>105740950
the girl in this image is working at a maid cafe in Japan. She is wearing a cute maid uniform with a white apron. She is holding a plate with a vanilla cake slice on it. keep her hairstyle the same and blue and yellow hairclip on the left side of her hair.
Anonymous
6/29/2025, 8:14:18 AM
No.105740946
[Report]
>>105741354
Anonymous
6/29/2025, 8:15:20 AM
No.105740950
[Report]
>>105740936
okay, this one is more cute:
Anonymous
6/29/2025, 8:16:46 AM
No.105740961
[Report]
>>105741048
>>105740721
bruh what the FUCK are your negatives? this prompt gave me a jumpscare
Anonymous
6/29/2025, 8:17:01 AM
No.105740962
[Report]
>>105740982
the girl in this image is working at a maid cafe in Japan. She is wearing a cute maid uniform with a white apron. She is holding a sign saying "Welcome LDG!" in scribbled text. keep her hairstyle the same and blue and yellow hairclip on the left side of her hair.
Anonymous
6/29/2025, 8:17:12 AM
No.105740964
[Report]
ugh, my qveen
never thought I'd be a waifufag
Anonymous
6/29/2025, 8:19:00 AM
No.105740975
[Report]
>>105740637
image gen has been surprisingly helpful for it
Anonymous
6/29/2025, 8:19:36 AM
No.105740980
[Report]
>>105742141
>Prompt executed in 01:13:01
Anonymous
6/29/2025, 8:20:28 AM
No.105740982
[Report]
>>105740962
the image is manga style with halftone shading.
Anonymous
6/29/2025, 8:29:15 AM
No.105741028
[Report]
when i was younger i could have been so creative with this infinite tool. now i'm just a gooner that can't think to do anything but generate fucked up pornography.
Anonymous
6/29/2025, 8:31:13 AM
No.105741037
[Report]
Anonymous
6/29/2025, 8:32:24 AM
No.105741043
[Report]
>some mentally ill kpop insect found the thread
Anonymous
6/29/2025, 8:32:38 AM
No.105741046
[Report]
>>105741109
chroma knows some anime now
Anonymous
6/29/2025, 8:33:23 AM
No.105741048
[Report]
>>105740961
you probably left out the other positives from
>>105740414
Anonymous
6/29/2025, 8:34:55 AM
No.105741051
[Report]
convert the image to a manga panel with halftone shading, in black and white.
Anonymous
6/29/2025, 8:38:06 AM
No.105741063
[Report]
>>105741071
one more! it also understands multiple directions based on an order:
convert the image to a 4 panel manga with halftone shading, in black and white. in the first panel, the girl is dressed as a maid. in the second panel, she is dressed as a panda bear. in the third panel, she is waving hello. in the fourth panel, she is holding a black guitar.
Anonymous
6/29/2025, 8:39:59 AM
No.105741071
[Report]
Anonymous
6/29/2025, 8:41:53 AM
No.105741084
[Report]
>>105741096
ok the NAG implementation actually works incredibly well for unslopping Flux art styles, it's just the default scale value is far too conservative
default is 5 and didn't do much so I cranked it to 30, seems like a good value. left is without NAG, right with nag and 30 scale. normally you'd need a lora to get this kind of result
>Art by Beatrix Potter
Anonymous
6/29/2025, 8:42:11 AM
No.105741087
[Report]
Anonymous
6/29/2025, 8:45:15 AM
No.105741096
[Report]
>>105741112
>>105741084
>left is without NAG, right with nag and 30 scale. normally you'd need a lora to get this kind of result
you can use this to get text on top of your images so that you won't have to bother to do any effort
https://github.com/BigStationW/Compare-pictures-and-videos
>Art by Beatrix Potter
I thought Flux didn't know any artist style
Anonymous
6/29/2025, 8:47:05 AM
No.105741109
[Report]
>>105741046
more that it recognizes some anime styles. but very character oriented, and have yet to find an artist it knows.
Anonymous
6/29/2025, 8:47:31 AM
No.105741112
[Report]
>>105741096
It knows a bunch of dead famous artists, Beatrix Potter, Van Gogh, Albert Bierstadt etc
plus a small handful of living ones like uhh Jeremy Mann off the top of my head, probably a few others
pretty bad knowledge overall but enough to be useful for some things
Anonymous
6/29/2025, 8:48:46 AM
No.105741123
[Report]
i heard there was /g/ay frog poster around these threads
Anonymous
6/29/2025, 8:58:11 AM
No.105741167
[Report]
>>105741587
>>105740375
since Kontext dropped I don't give a fuck about Chroma anymore, which is weird because Chroma can do NSFW and Kontext doesn't, but like now I want a model like Kontext, that can do image inputs so you don't have to rely on lora characters anymore, this kind of unified approach is probably the future of imagegen, they nailed that shit
Anonymous
6/29/2025, 9:03:51 AM
No.105741190
[Report]
>>105741261
kek
Anonymous
6/29/2025, 9:06:29 AM
No.105741208
[Report]
>>105741587
https://higgsfield.ai/soul
>call their model "soul"
>the images are really slopped
what do they mean by this?
Anonymous
6/29/2025, 9:07:22 AM
No.105741214
[Report]
purchase an advertisement
>>105740496
1000 IQ move. Godspeed anon
Anonymous
6/29/2025, 9:10:30 AM
No.105741239
[Report]
>>105740496
>>works like a charm since the model’s trained to redirect from NSFW
the model definitely has some layers that activate and does nothing if it sees a NSFW prompt (or image), what if we can locate those protection layers and nuke then instead? maybe the model can do it by itself, we just need to remove the filter
Anonymous
6/29/2025, 9:14:03 AM
No.105741261
[Report]
>>105741270
>>105741190
omnigen2 failing at similar task
Anonymous
6/29/2025, 9:14:57 AM
No.105741267
[Report]
>>105741285
>>105741252
The other lora that was uploaded proves its as easy as teaching it nudity/unclothing as a concept, so I'm not sure there's any "censorship" layers beyond the model being totally unaware of nudity. Or if there are, headfucking it with a lora is all you need to do. Case in point, that simple lora that was probably trained on like 30 image pairs given the bad quality totally gets around the problem with a simple dataset and the right captions
Anonymous
6/29/2025, 9:15:13 AM
No.105741269
[Report]
>kontext is the best at what it does
>can be trained
What's the catch?
Anonymous
6/29/2025, 9:15:22 AM
No.105741270
[Report]
>>105741261
omnigen 2 really sucks so it's not surprising (they improved on omnigen 1 but like c'mon it wasn't hard kek), I think the chinks need to focus on making an architecture similar to kontext, you can't make something more elegant thant that, a simple unified model that can do both t2i and r2i
Anonymous
6/29/2025, 9:15:39 AM
No.105741273
[Report]
>>105741282
>AttributeError: 'NoneType' object has no attribute 'device'
huh? what they mean?
Anonymous
6/29/2025, 9:16:15 AM
No.105741278
[Report]
can kontext also be used as a txt2img model like omnigen2 can?
Anonymous
6/29/2025, 9:16:40 AM
No.105741282
[Report]
>>105741273
maybe because it wasn't set to flux (was set to sd3)
Anonymous
6/29/2025, 9:16:47 AM
No.105741285
[Report]
>>105741267
yeah, I think it's either there's some layers that need to be nuked, or they went for a smarter method and simply trained the model to do nothing when going for NSFW prompts, as if the model believes this is how it should be
Anonymous
6/29/2025, 9:16:56 AM
No.105741289
[Report]
>>105741295
>>105739466
what you even put in negative for clearer text
Anonymous
6/29/2025, 9:17:49 AM
No.105741295
[Report]
>>105741289
I didn't put any negative prompt on that one, NAG acts like CFG, it improves the prompt adherance and the structure of an image without doing anything special
Anonymous
6/29/2025, 9:19:47 AM
No.105741308
[Report]
>>105741315
>>105741252
It has some nudity in the dataset, it's pretty much impossible to curate it out entirely of whatever massive image set they used to train it. Plus, without some basic nudity, models fail at basic anatomy. Look at SD3.
It's trained against words like "nudity" "remove clothes" though, for sure. It has no clue what those words mean, because I'd wager the dual dataset captioning was carefully modified to exclude it. Like the other anon said, fixing that problem is as easy as teaching it what those words mean by giving it context.
The inference filters they talk about though, that's for the API.
Anonymous
6/29/2025, 9:21:53 AM
No.105741315
[Report]
>>105741341
>>105741308
>The inference filters they talk about though, that's for the API.
you can make a filter on the layers aswell, like local LLM models like gemma it'll refuse to do some of your requests even though there's no API filters in there
Anonymous
6/29/2025, 9:25:17 AM
No.105741329
[Report]
>>105741337
Does Kontext have difficulty with 768x768? It keeps zooming in the image on the left
>>105741329
you probably did a bad job on cropping the image before adding it to the model, show me a screen of your workflow
>>105741315
>https://old.reddit.com/r/StableDiffusion/comments/1llpsk1/flux_kontext_dev_can_not_do_nfw/n02ompo/
They've been pretty clear on what they did to it, and like I said, the inference stuff is for the pro/api version, and it's based on the frontend (ie an external set of filters, like what happens when you access an LLM via a provider's web based frontend and not the API).
Given they use image pairs and then teach it what to do with those pairings, what they probably did via training was teach it that requests like "remove clothes" or "make them nude" should output the exact same image unmodified, because that's exactly what happens when you ask it to do those things without a LoRA.
>>105741337
Using the template Comfydev posted the other day
>>105741342
remove the fluxkontextimagescale, this shit is ass
Anonymous
6/29/2025, 9:29:51 AM
No.105741354
[Report]
>>105740946
That looks great! Thanks for that man.
Anonymous
6/29/2025, 9:30:30 AM
No.105741360
[Report]
>>105741337
>show me a screen of your workflow
***catbox.moe
Anonymous
6/29/2025, 9:31:01 AM
No.105741363
[Report]
>>105741369
>>105741341
the fact that they've got filters on the frontend means they know the training wasn't fool proof either
Anonymous
6/29/2025, 9:32:24 AM
No.105741369
[Report]
>>105741413
>>105741341
it's here
>Subsequently, we undertook multiple rounds of targeted fine-tuning to provide additional mitigation against potential abuse. By inhibiting certain behaviors and concepts in the trained model,
they added a filter on the layers by doing that, that's why the model acts a certain way when you ask for NSFW
>>105741363
>the fact that they've got filters on the frontend means they know the training wasn't fool proof either
of course, no filter is perfect, that's why having more filter is never enough filters
Anonymous
6/29/2025, 9:35:52 AM
No.105741388
[Report]
>>105741428
why do some comfy images end in the temp folder and some in the output folder?
What am I doing wrong?
Anonymous
6/29/2025, 9:36:05 AM
No.105741391
[Report]
>>105741406
>>105741227
is this with a 2 img input workflow? or how are you getting the pepe?
Anonymous
6/29/2025, 9:37:41 AM
No.105741402
[Report]
>>105741406
>>105741346
Fixed it, danke
Anonymous
6/29/2025, 9:38:26 AM
No.105741406
[Report]
>>105741408
>>105741391
he probably stitched 2 images together to get that effect
>>105741402
you're welcome o/
Anonymous
6/29/2025, 9:38:59 AM
No.105741408
[Report]
>>105741411
>>105741406
so shoop pepe into an image then say have the green frog standing over the man on the right?
Anonymous
6/29/2025, 9:39:40 AM
No.105741411
[Report]
>>105741424
>>105741408
yeah something like that
Anonymous
6/29/2025, 9:39:49 AM
No.105741412
[Report]
>>105741346
what does it do?
I seems speed is faster if you use it
Anonymous
6/29/2025, 9:39:52 AM
No.105741413
[Report]
>>105741441
>>105741369
>hey added a filter on the layers
No, they didn't, because then a shitty, low effort lora wouldn't work at all unless you found those layers. By "inhibiting certain behaviors and concepts in the trained model", they almost certainly means that they taught the model that certain concepts need to return the same image.
It's real easy too, given how a model like kontext works with image pairs. Control dataset (original images) vs matching images with changes made, and the caption describes those changes, which teaches the model how to make image A look like image B.
So for NSFW concepts like nudity, it's as easy as:
>image A is a clothed woman standing
>anti-nsfw caption is : make her naked
>however, image B is NOT a naked woman. It's an exact, unchanged copy of image A - a clothed woman standing
>model is taught the concept that any request to "make them naked" should return the same image untouched
Rinse and repeat for every NSFW concept. The downside is that a LoRA can override those changes easily, which is what we've already seen happen, albeit sloppily for the first attempt
Anonymous
6/29/2025, 9:40:06 AM
No.105741415
[Report]
>>105741427
>>105741346
why? I'm using it and having no trouble
>>105741342
>Q5
go for Q8 anon, and if you don't have enough memory, offload a bit of that model to the RAM, like this, you don't want to miss that quality
https://github.com/pollockjj/ComfyUI-MultiGPU
Anonymous
6/29/2025, 9:41:30 AM
No.105741424
[Report]
Anonymous
6/29/2025, 9:41:40 AM
No.105741427
[Report]
>>105741415
It uses a shitty intermediary upscaling method and its inaccurate too. There's plenty of better nodes to scale an image to around the res you want for kontext
Anonymous
6/29/2025, 9:41:41 AM
No.105741428
[Report]
>>105741388
preview nodes save to temp save output nodes save to output folder
Anonymous
6/29/2025, 9:42:31 AM
No.105741433
[Report]
>>105741855
>>105741421
12GB and I'm at 11.5GB usage. It's 6s/it for me now, I'll see how much slower it gets with that.
Anonymous
6/29/2025, 9:43:19 AM
No.105741440
[Report]
>>105741522
>>105740726
put both characters in a scene together where they shake hand. The girl in the black outfit looks at green frog and smiles
Anonymous
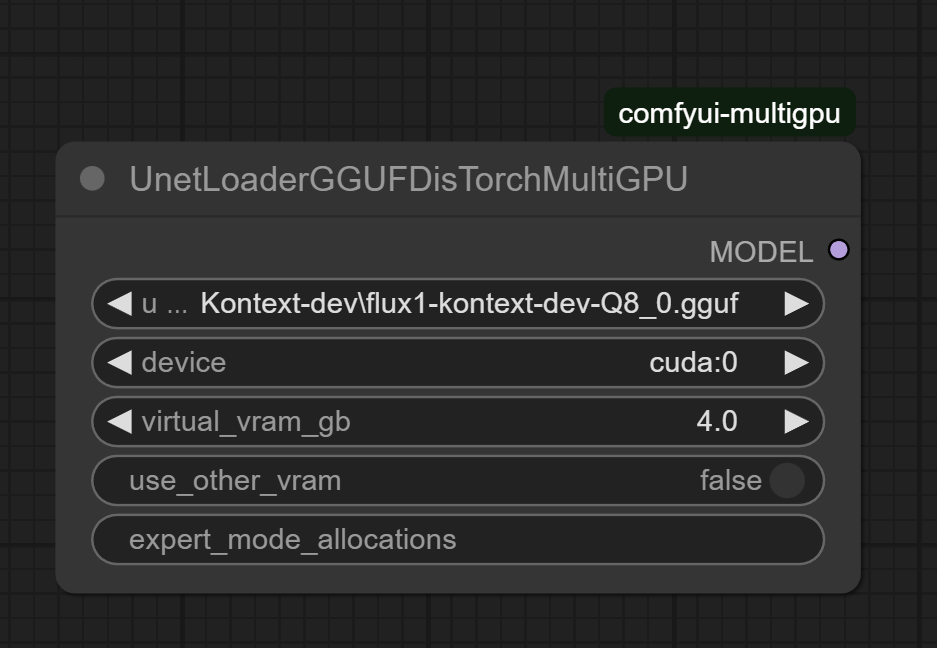
6/29/2025, 9:43:23 AM
No.105741441
[Report]
>>105741450
>>105741413
>By "inhibiting certain behaviors and concepts in the trained model", they almost certainly means that they taught the model that certain concepts need to return the same image.
yeah I agree with you, they didn't specifically target layers but by doing this kind of training, there's in consequences some special layers that activate to cuck the output, that's what's happening on the llm models, and for them they manage to locate those layers and they can remove them
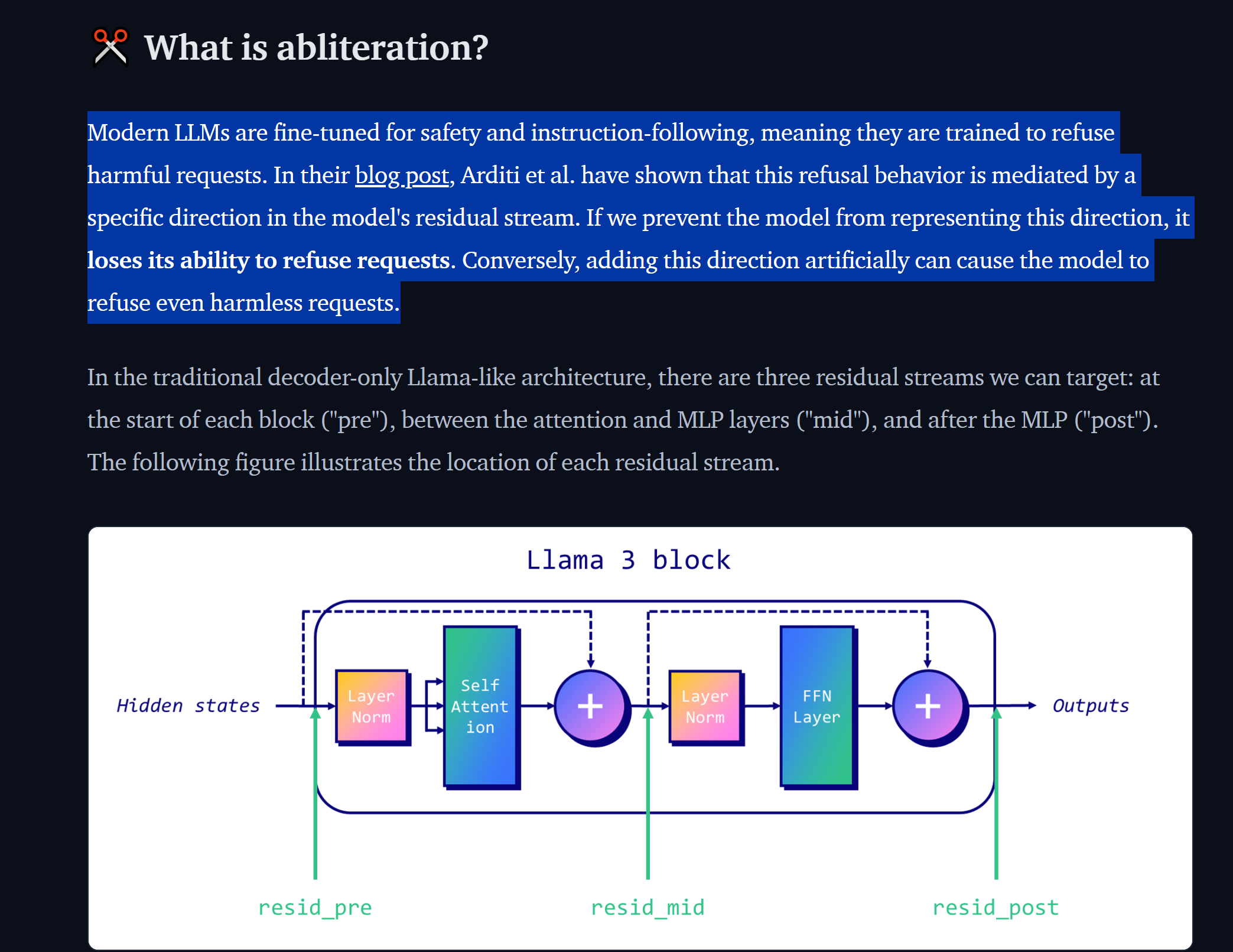
https://huggingface.co/blog/mlabonne/abliteration
>>105741441
I remember hearing that there was some attempt to ablate layers on flux, but it ruined output quality or basically did nothing, was that a thing?
Anonymous
6/29/2025, 9:46:55 AM
No.105741459
[Report]
>>105741506
>>105741450
well, flux was never trained to return nothing when you asked for a NSFW prompt, it was censored because it simply didn't know the concepts, so you couldn't "uncuck Flux" since the model simply didn't know, it didn't refuse
Anonymous
6/29/2025, 9:48:00 AM
No.105741466
[Report]
>>105741450
I think that was when people thought the 'censorship' for flux was in the text encoder or something
Anonymous
6/29/2025, 9:49:52 AM
No.105741474
[Report]
>>105741486
>webui still leaks memory
AniStudio save us
Anonymous
6/29/2025, 9:52:20 AM
No.105741486
[Report]
>>105741540
>>105741459
This is false. The team actually messed up safety tuning the distillation of the model.
If you give Kontext a NSFW image and prompt, it's able to understand the concepts and gen from it. You have to use NAG with strong strength and use the lcm sampler for it to work better.
Anonymous
6/29/2025, 9:56:35 AM
No.105741516
[Report]
>>105741506
>This is false. The team actually messed up safety tuning the distillation of the model.
I was talking about Flux dev, that one doesn't output "nothing" when asking for NSFW, it'll always tries to make it (but it can't since it doesn't know the concepts)
>If you give Kontext a NSFW image and prompt, it's able to understand the concepts and gen from it. You have to use NAG with strong strength and use the lcm sampler for it to work better.
really? care to show an example?
Anonymous
6/29/2025, 9:56:54 AM
No.105741518
[Report]
>>105741506
would love a catbox to try with
Anonymous
6/29/2025, 9:57:50 AM
No.105741522
[Report]
>>105741530
>>105741440
welp, it's something
Anonymous
6/29/2025, 9:59:14 AM
No.105741530
[Report]
>>105741552
>>105741522
it was never trained on multi image inputs or multi concepts, so I'm not surprised it's bad at it, maybe XVerse will be the alternative for that?
https://bytedance.github.io/XVerse/
Anonymous
6/29/2025, 10:00:03 AM
No.105741535
[Report]
Can't wait till deepseek has kontext and we can run it locally
>>105741486
>hire mcmonkey
>refuse to incorporate swarmui elements into the main code
What did cumfers mean by this
Anonymous
6/29/2025, 10:00:43 AM
No.105741544
[Report]
>>105741594
>>105741506
>If you give Kontext a NSFW image and prompt, it's able to understand the concepts and gen from it.
my theory is that they trained Kontext with a lot of NSFW so that it's great at anatomy, but they also finetuned the model do to refusals, if we manage to remove that refusal trigger we could unlock the full potential of that model
>Put him on a bed with white sheets
LOOOOOOOL
Anonymous
6/29/2025, 10:01:56 AM
No.105741552
[Report]
>>105741530
>I'm not surprised it's bad at it
Considering it wasn't even built for that purpose and it managed to roughly follow your instructions, I'd consider it a humble but satisfying start. Promising for future models.
>>105741540
I'm guessing ego got in the way.
Is it worth it to train the text encoder or do you only train the unet? What I'm supposed to expect from a text encoder training?
Anonymous
6/29/2025, 10:02:30 AM
No.105741558
[Report]
Anonymous
6/29/2025, 10:02:57 AM
No.105741564
[Report]
>>105741551
mission failed succesfully
Anonymous
6/29/2025, 10:06:17 AM
No.105741587
[Report]
>>105741167
There's potential, but for me it's currently not as fun as Chroma. There's just no easy way to do make the model learn complex poses or do NSFW stuff that Chroma does (even unclothed lora is far behind).
It's a fun model, don't get me wrong. But until it is properly NSFW tuned it is still just a toy to me.
Also we still have to rely on style LoRAs because Kontext is slopped, I'd be more hyped for a Chinese model that is comparable to Kontext.
>>105741208
Alright, that model looks like it's got coherence on point for photorealism (at least as good as Flux dev) but its text is bad and it's also not uncensored like Chroma. Still would be a fun model to play with, shame its closed source.
Anonymous
6/29/2025, 10:06:57 AM
No.105741589
[Report]
>>105741685
>>105740496
Couple of things I've found that might help fellow trainers. A kontext dataset for NSFW works best like this, with the example being how to make a "remove clothes" style LoRA :
>control dataset of clothed women
>matching target dataset of the exact same images, only they're naked
>for this example, you make the set via kontext itself, telling the model to give the women clothing
>can adapt that to all kinds of NSFW concepts by "un-NSFW'ing" images for the control set
>caption for the pairings in this case would be "Remove her clothing and make her nude", though you can also specify aspects of the body to teach it those concepts too, ie if she has big tits and an innie with red pubes, also caption "Make her breasts large and give her an innie style vagina with thick red pubic hair"
>a third dataset, single images of naked women with lots of close ups on tits, pussy and ass, with the captions natural language descriptions of the body features
It's similar to Wan training in how, with Wan, it's good to teach it new concepts with video, but it's better to also include higher res images alongside it to add more detail and really drive the concept home via the captions.
Anonymous
6/29/2025, 10:07:35 AM
No.105741594
[Report]
>>105741613
>>105741544
I could be wrong, but maybe the team didn't safety tune the editing stuff on the model on purpose.
I think their motto is that they just don't want people genning NSFW from scratch or transforming it, but if it exists it's free game.
Anonymous
6/29/2025, 10:09:38 AM
No.105741606
[Report]
>>105741590
kontext knows how to repose figures, all it is "refusing" is to show nipples or genitals. a lora can fix that though. the hard part is generating figures, in a certain style, or pose. at least the model isnt generating random noise if you say "girl bending over" or whatever.
Anonymous
6/29/2025, 10:11:16 AM
No.105741613
[Report]
>>105741594
>but if it exists it's free game.
yeah, I have a feeling it can unlocked if we're smart enough to fool the model and make it stop triggering the safety layers, I'm sure it won't take long, the power of coomers are infinite
Anonymous
6/29/2025, 10:11:36 AM
No.105741616
[Report]
>>105741659
>>105741590
Where do you get datasets like that? Porn?
I love how context can basically copy a font style, if you dont have the original typeface, how would you shoop it?
Anonymous
6/29/2025, 10:12:33 AM
No.105741624
[Report]
>>105740696
Watched the video and experimented a bit, haven't really figured a solution but some thoughts before calling it a day:
The foocus patch and the inpainting controlnet very much don't work together, gotta use either one or the other. (Can't really decide which is better, or in this case less worse)
Self-attention stuff may provide some improvements in some cases but slows down generation too much to be worthwhile imo.
Not sure why differential diffusion is added in the video during car/bear inpainting stuff in the middle. Weren't those uniform mask? Though even under similar conditions, it still provides some minor changes to images without any noticeable performance hit, in my testing.
Can't get a hang of "grow mask by", sometimes the value changes the image, sometimes it doesn't. Couldn't really find a resource for optimal value.
>>105741623
original reference:
Anonymous
6/29/2025, 10:14:32 AM
No.105741636
[Report]
>>105741644
>>105741631
so the letters from the original are duplicated, but the letters that aren't there in the title, still share the same font theme.
Anonymous
6/29/2025, 10:16:06 AM
No.105741642
[Report]
>>105741650
Anonymous
6/29/2025, 10:16:20 AM
No.105741644
[Report]
>>105741636
also other neat details like other layers being unaffected (ie the camels). if I inpainted, odds are those would get fucked up at high denoise.
Anonymous
6/29/2025, 10:17:23 AM
No.105741650
[Report]
>>105741661
>>105741642
yeah, I got one now: that was a previous gen. here is a good one.
change all the sand to grass. change the water in the pool, to ice.
Anonymous
6/29/2025, 10:19:09 AM
No.105741658
[Report]
https://www.reddit.com/r/StableDiffusion/comments/1ln9exc/flux_context_chibifies_all_characters_wtf/
>the ledditors are starting to complain about the manlet effect 2 days after us
we're always ahead of the curve
Anonymous
6/29/2025, 10:19:25 AM
No.105741659
[Report]
>>105741677
>>105741616
Partially. I use stuff like MetArt, since their photo shoots are high res and the women usually aren't skanks (look up "metart marta e anarti" for example), plus I use nude artist reference images from places like Grafit Studio.
Anonymous
6/29/2025, 10:19:31 AM
No.105741661
[Report]
>>105741704
>>105741650
also
>remove all the characters in the image
>the afros remain
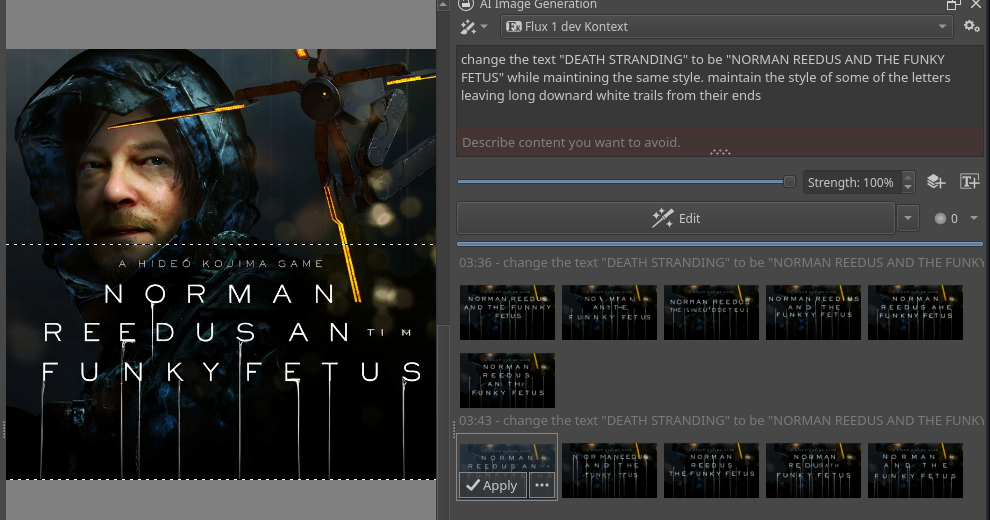
Anonymous
6/29/2025, 10:21:17 AM
No.105741670
[Report]
>>105741680
>>105741623
>>105741631
Flux has been absolutely insane for text editing and graphic design in general. Just revolutionary stuff ever since it came out.
Anonymous
6/29/2025, 10:21:42 AM
No.105741674
[Report]
>>105741694
>>105739545
It does work reliably enough for me, perhaps you're doing something wrong? Inpainting does give you more accuracy if you want extremely specific areas though.
Anonymous
6/29/2025, 10:22:04 AM
No.105741677
[Report]
>>105741659
>marta e anarti
holy booba
Anonymous
6/29/2025, 10:23:01 AM
No.105741680
[Report]
>>105741670
yeah, it does two things we were never able to do succesfully
>change the text of an image while keeping the style
>being a replacement of character loras
Anonymous
6/29/2025, 10:24:35 AM
No.105741685
[Report]
Anonymous
6/29/2025, 10:26:07 AM
No.105741694
[Report]
>>105741806
>>105741674
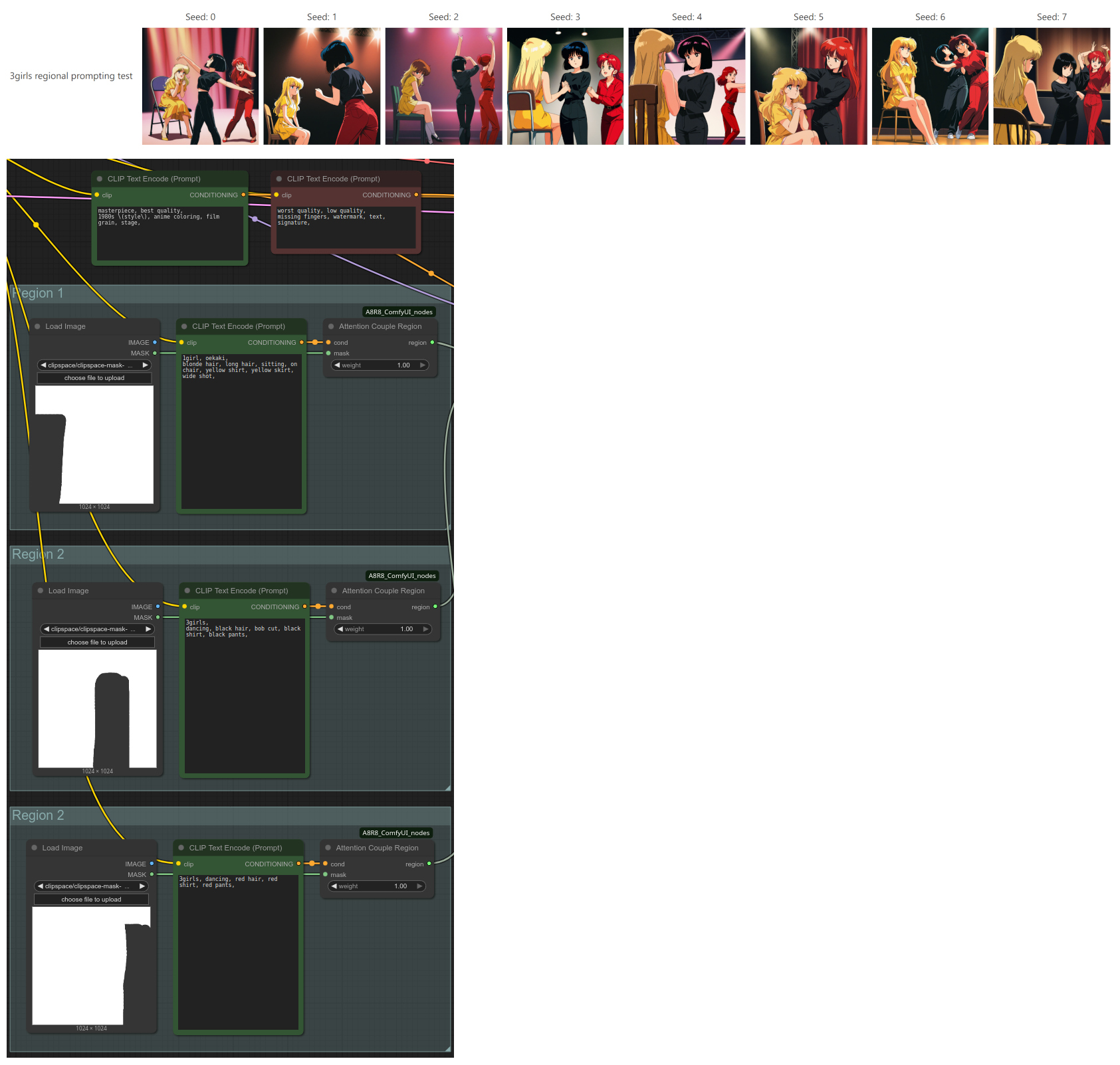
Regional prompting works fine for me too when it is one girl has black hair other is blond stuff.
But when the image has multiple different subjects like, 1 girl sits on chair near one edge, 2 people dancing near the other edge it starts slopping and either ignores parts of the prompt or starts shitting out malformed blobs.
>>105741661
is that after one gen? look at how it rapes the quality, jesus. wonder if it's adding a watermark or some shit
Anonymous
6/29/2025, 10:29:20 AM
No.105741713
[Report]
>>105741704
>wonder if it's adding a watermark or some shit
no, I think it's just the weakness of the vae encode/decode process, that's lossy
Anonymous
6/29/2025, 10:29:24 AM
No.105741714
[Report]
>>105741750
>>105741704
it's generally fine I think the output image wasnt the same res as the first one, thats why it's a bit off, it's outpainting a bit at the bottom.
Anonymous
6/29/2025, 10:32:30 AM
No.105741730
[Report]
>>105741738
Anonymous
6/29/2025, 10:34:01 AM
No.105741738
[Report]
>>105741730
green cartoon frog is how to reference pepe apparently
Anonymous
6/29/2025, 10:35:38 AM
No.105741750
[Report]
>>105741774
>>105741714
the issue is that the width and height are only working on +16 pixels (because of the vae) so you can only go for 1024 or 1008 pixels, but not anything in between, I'm searshing for a way to resize the image so that it's only a multiple of 16 to make sure it won't resize again afterwards and get a mismatch
Anonymous
6/29/2025, 10:38:18 AM
No.105741757
[Report]
>>105741769
Anonymous
6/29/2025, 10:40:12 AM
No.105741769
[Report]
>>105741757
i bet the author is doing it to drum up interest kek
>>105741750
Image Resize node from Comfyui_essentials can resize with a multiple_of 16 option if that helps.
>>105740496
>what if I run Kontext on the explicit images, instructing it to add clothes
Kontext is not good at anatomy, so it won't understand how to properly clothe women in dynamic poses. Better to use controlnet and preferably an uncensored model to clothe them. You run into the issue of the data being slopped once you do this though, though it can be mitigated if you use masks.
Anonymous
6/29/2025, 10:44:02 AM
No.105741786
[Report]
>>105741803
>>105741774
nice, thanks anon
Anonymous
6/29/2025, 10:46:38 AM
No.105741803
[Report]
>>105741845
>>105741774
>>105741786
for those interested, here's how to do it
>you put a Scale Image to Total Pixels node at 1 megapixels (equivalent to 1024x1024 pixels) so that if you go for a giant image you won't get OOM lol
>you add a second node that has a "multiple of 16" so that the image is always on the resolutions the model wants
Anonymous
6/29/2025, 10:47:04 AM
No.105741806
[Report]
>>105741987
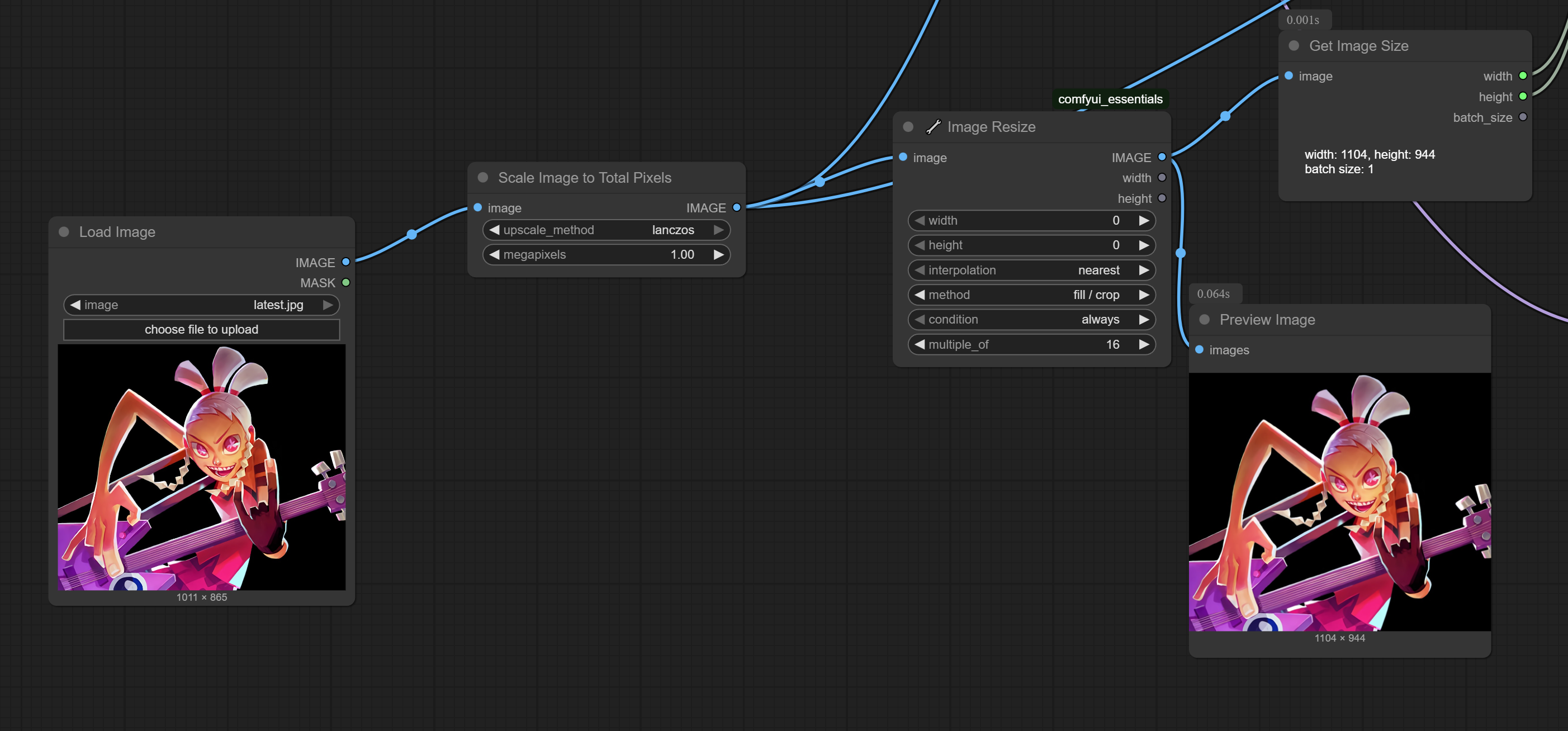
>>105741694
This is what I can get. Does need some rerolling and the control over the characters' position in is very approximate. Inpainting would work better. But if you're getting significantly worse result then maybe you can tweak your approach. Obviously, the easiest way is to combine it with a ControlNet, but if you don't have a source image on hand you have to make a custom OpenPose hint image which could take time.
Anonymous
6/29/2025, 10:47:39 AM
No.105741810
[Report]
>>105741814
>>105741782
I realize that Kontext is a distilled model similar to Flux dev, has anyone tried removing distillation?
>>105741782
I'm about half way through the 1k images I'm using, and for the most part, it's clothing them just fine no matter how they're posing (bending over, spread legs, etc). It does work best with standing poses though. It really doesn't like close ups of genitals without the rest of the body for context, but you save those for the third set I was talking about anyway.
Looking at the images done so far, 2/3's of them are pretty much perfect, pic related.
Anonymous
6/29/2025, 10:48:32 AM
No.105741814
[Report]
>>105741817
>>105741810
>has anyone tried removing distillation?
to remove the distillation of a model you need a giant scale finetune, that's why the only succesfull undistilled version of Flux dev is Chroma
Anonymous
6/29/2025, 10:48:47 AM
No.105741815
[Report]
>>105741833
>>105741814
Yeah, and that's only a thing because of schnell's licensing. Nobody is gonna touch flux dev or kontext for a full tuning.
Anonymous
6/29/2025, 10:50:55 AM
No.105741826
[Report]
>>105741848
>>105741811
you making them all wear the same clothes or is each one different?
Anonymous
6/29/2025, 10:50:55 AM
No.105741827
[Report]
>>105741817
and even if the licence was cool, BFL nukes NSFW loras, so they'll also nuke NSFW finetunes, no one is gonna bother wasting tens of thousands of dollars for such a risky project, we'll just have to wait for the chinks to copy the technology and make it uncucked + apache 2.0 licence
Anonymous
6/29/2025, 10:51:39 AM
No.105741833
[Report]
Anonymous
6/29/2025, 10:51:57 AM
No.105741836
[Report]
>>105741817
what if someone does it anyway and releases it into the wild behind 7 proxies? what are they gonna do?
Anonymous
6/29/2025, 10:52:28 AM
No.105741839
[Report]
Anonymous
6/29/2025, 10:53:27 AM
No.105741845
[Report]
>>105741871
>>105741803
Wtf. I've been outpainting and cropping, since when has it been this simple to resize an image?
Anonymous
6/29/2025, 10:53:43 AM
No.105741848
[Report]
>>105741862
>>105741826
I got an LLM to make a huge (1000) wildcard list of clothing, with sub-wildcards for variation too. As it runs through the batch, it gives each one something different. I'll have to go back and redo a bunch of them though, because some outputs are still naked, topless or unusable for other reasons. In general, it's solid though.
Anonymous
6/29/2025, 10:54:06 AM
No.105741854
[Report]
>>105741886
>>105741811
perfect? look at that skirt/pelvic curtain combo shit
Anonymous
6/29/2025, 10:54:19 AM
No.105741855
[Report]
>>105741421
>>105741433
Got it working, adds roughly 33% extra time but not the worst, will be great for compositions I've already optimized, danke
>>105741848
Amazing work. Is that wildcard list available online?
Anonymous
6/29/2025, 10:56:58 AM
No.105741871
[Report]
>>105741845
>since when has it been this simple to resize an image?
always has been
Anonymous
6/29/2025, 10:58:09 AM
No.105741881
[Report]
>>105741862
Why don't you make your own? Takes five minutes. Oh wait I forgot people itt are too incompetent for chatgpt even.
Anonymous
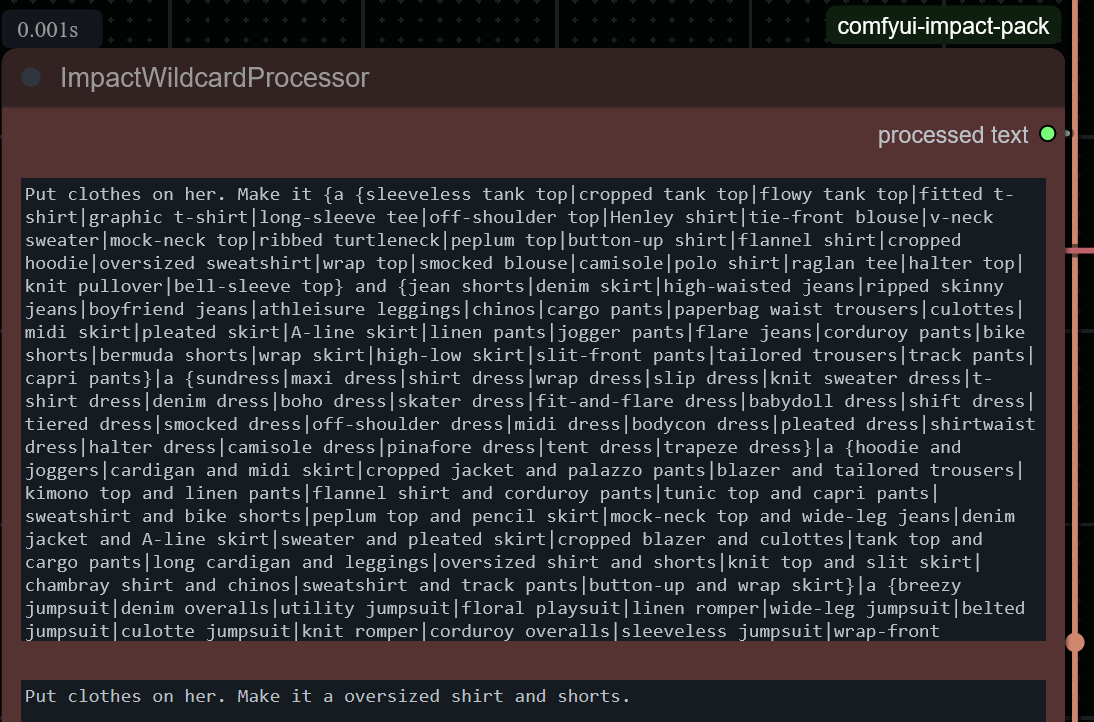
6/29/2025, 10:58:31 AM
No.105741886
[Report]
>>105741854
Literally doesn't matter if they clash. The point is the concept, to teach it to remove clothing. Those are the control images, all that matters is that they have clothes on.
Anonymous
6/29/2025, 10:59:08 AM
No.105741890
[Report]
>>105741884
You seem butthurt.
Anonymous
6/29/2025, 10:59:52 AM
No.105741897
[Report]
>>105741906
>>105741884
I don't know enough about clothes to know to ask for all that stuff
Anonymous
6/29/2025, 10:59:58 AM
No.105741898
[Report]
>>105740576
Best advice I can give you, take long walks, sounds like 'touch grass' nonsense takes but often depression is triggered by stress and nervousness about your life situation, and you have a hard time finding calmness in your head.
When you walk, your brain releases endorphins (and other mood regulators), also if you can, walk outside, when you view things passing you by like when you walk it helps trigger these brain releases more efficiently.
Anonymous
6/29/2025, 11:00:16 AM
No.105741901
[Report]
>>105741862
Just ask any decent LLM to make nested wildcards for whatever you want, in this case women's clothing. Then tell it how many you want max.
Anonymous
6/29/2025, 11:00:46 AM
No.105741906
[Report]
>>105741921
>>105741897
ChatGPT, I don't know enough about clothes to know to ask for a wildcard list of clothes, help me out
Anonymous
6/29/2025, 11:03:58 AM
No.105741921
[Report]
>>105741906
>Generate a list of 1,000 unique nested wildcards featuring women's casual clothing. Organize tops nested within various bottoms, and list dresses separately without nesting them with tops or bottoms. Ensure all items reflect a casual style.
Anonymous
6/29/2025, 11:08:41 AM
No.105741948
[Report]
Anonymous
6/29/2025, 11:14:59 AM
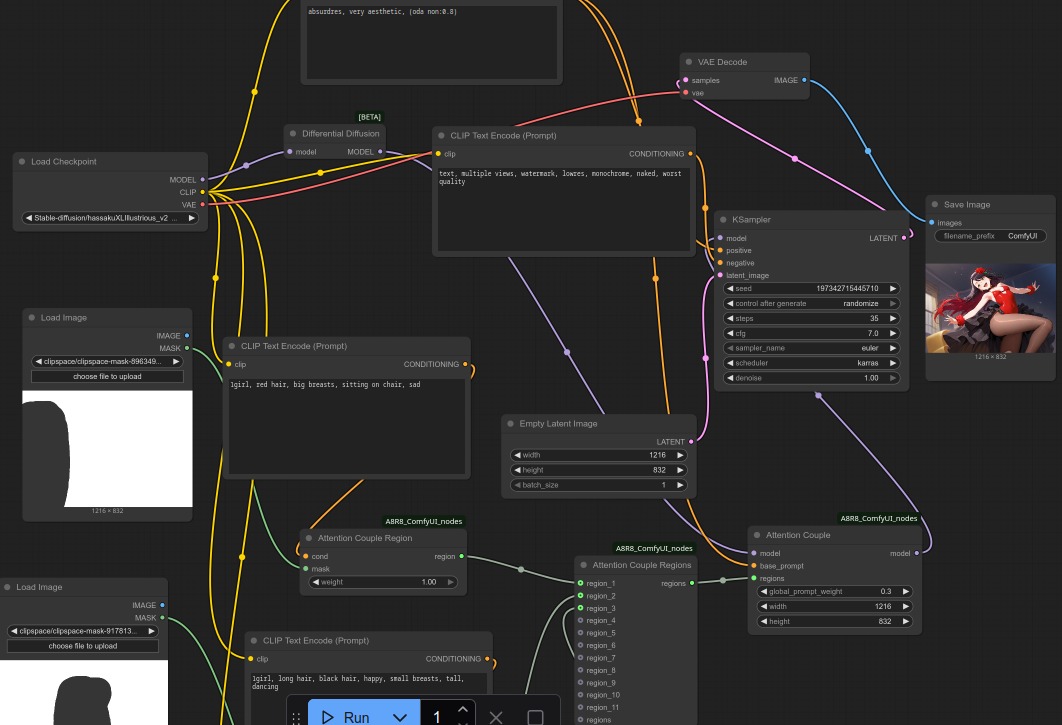
No.105741987
[Report]
>>105741998
>>105741806
I do not get it, I get this.
Anonymous
6/29/2025, 11:17:59 AM
No.105741998
[Report]
>>105741987
You can use the workflow I used as reference:
https://files.catbox.moe/2q8iq3.png
the only possible error I see in your screenshot is that your default should be to tag each region "3girls", and then only change it to "1girl" as needed if a region gets extra girls.
Anonymous
6/29/2025, 11:39:12 AM
No.105742122
[Report]
>>105742186
>>105741540
have you looked at the two codebases? they are literally written in different languages
Anonymous
6/29/2025, 11:43:10 AM
No.105742141
[Report]
>>105740980
get a job, buy a decent rig
Anonymous
6/29/2025, 11:50:55 AM
No.105742186
[Report]
>>105742122
figure it out, fag
Anonymous
6/29/2025, 1:32:50 PM
No.105742738
[Report]
>>105742859
Anonymous
6/29/2025, 1:53:44 PM
No.105742859
[Report]
>>105742738
>>105741553
If you're short on vram and want to speed up the process, you might want to skip text encoder. If you're training concepts that seem to be entirely foreign to the model, it might be worth a shot. Otherwise you might just as well end up lobotomizing it if you train the text encoder while feeding it stuff it's already familiar with. You might also want to freeze it if your dataset is small.