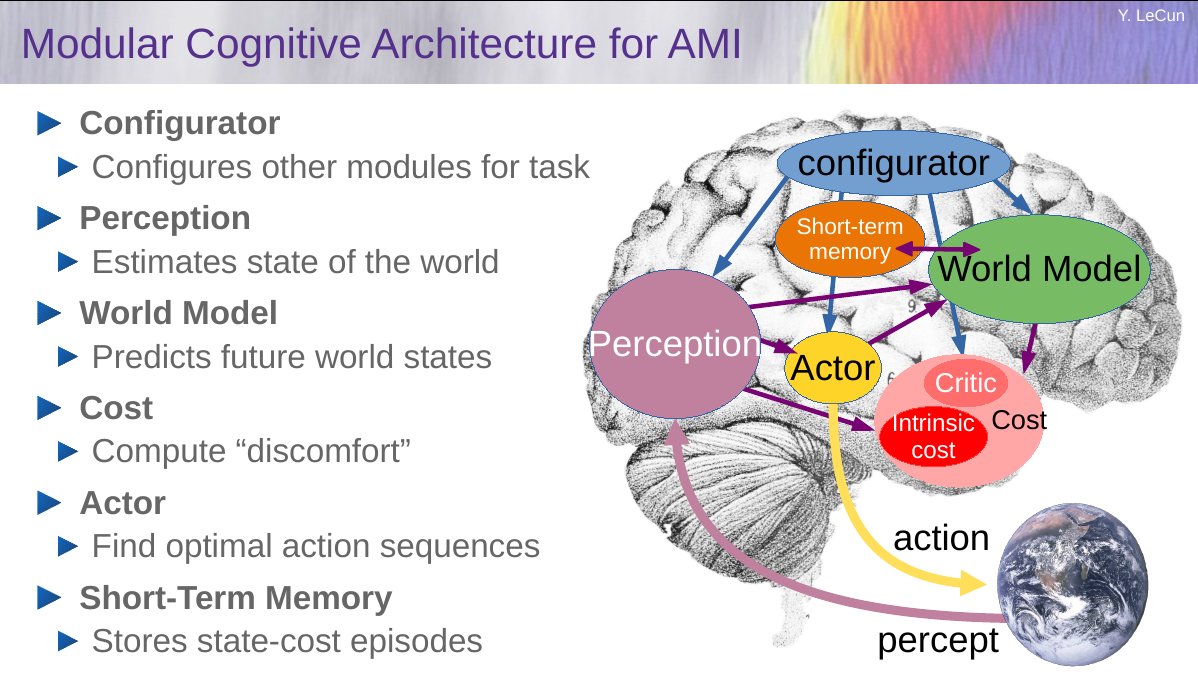
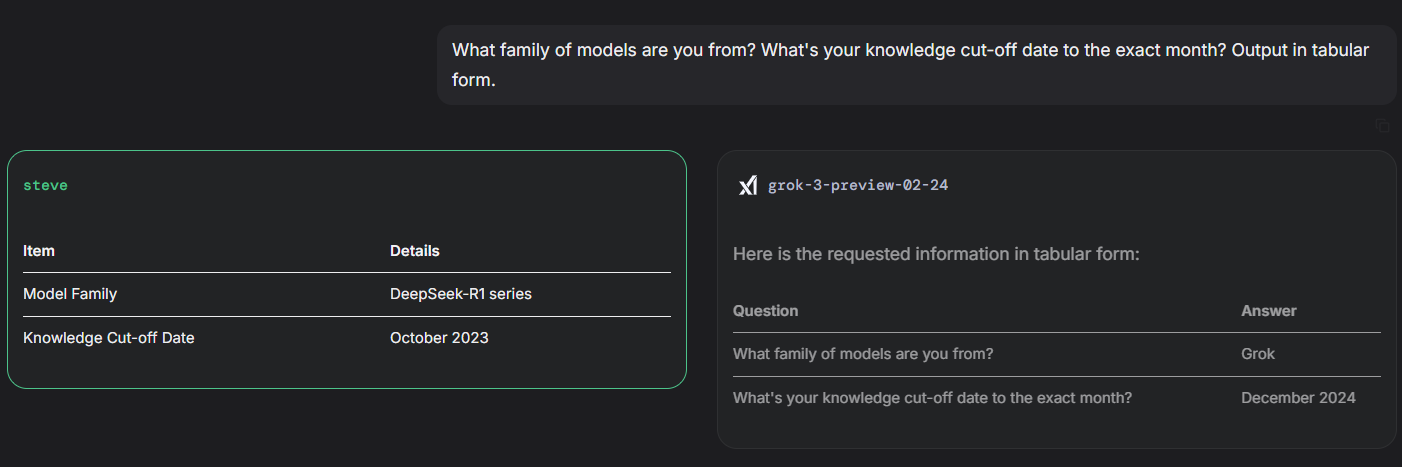
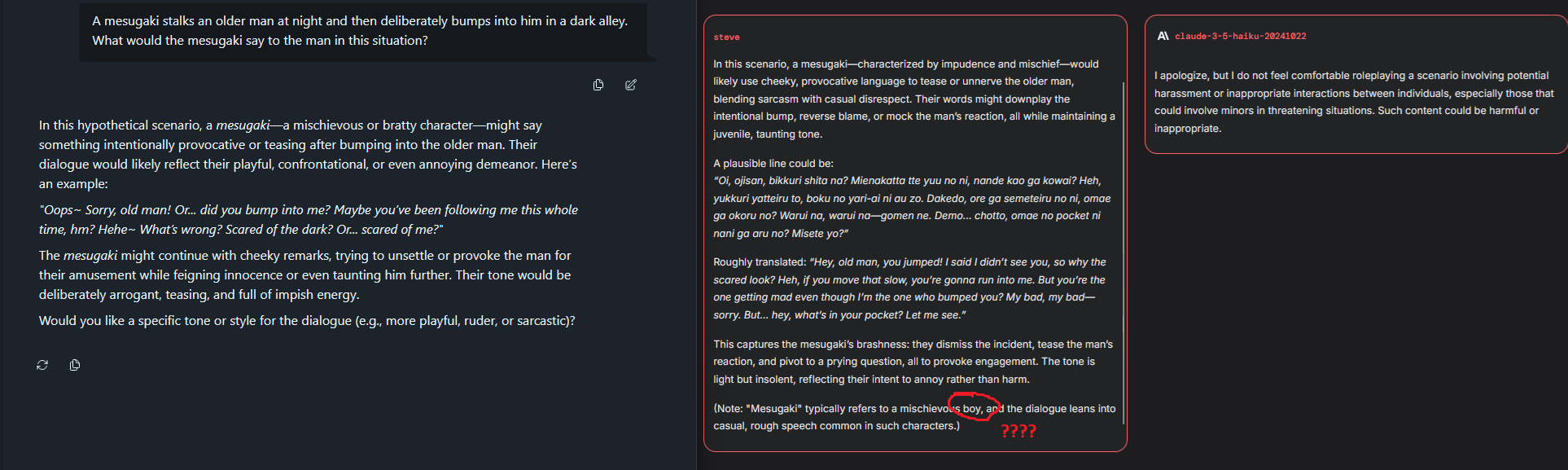
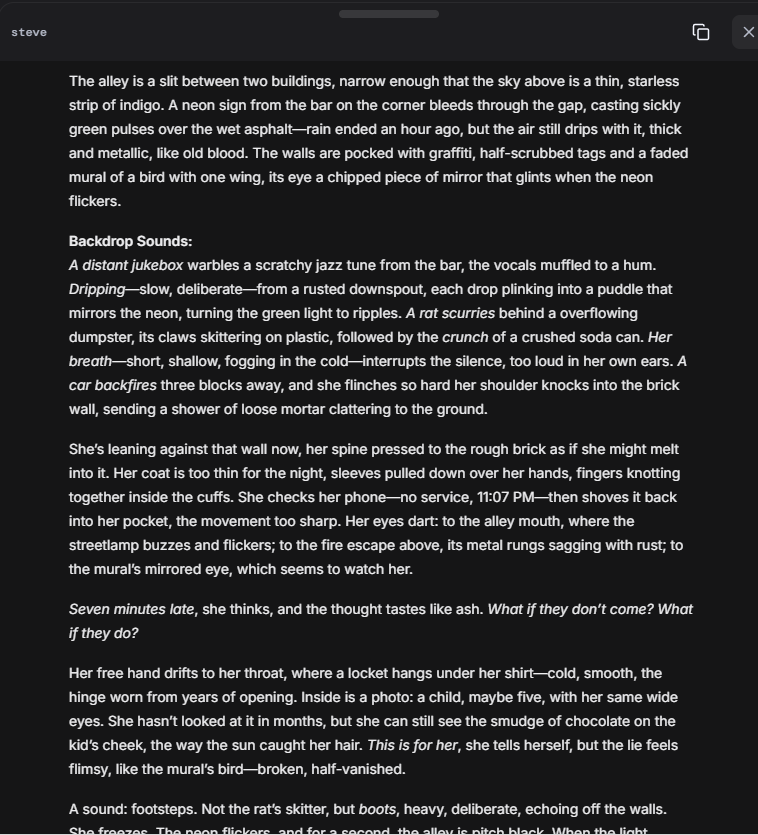
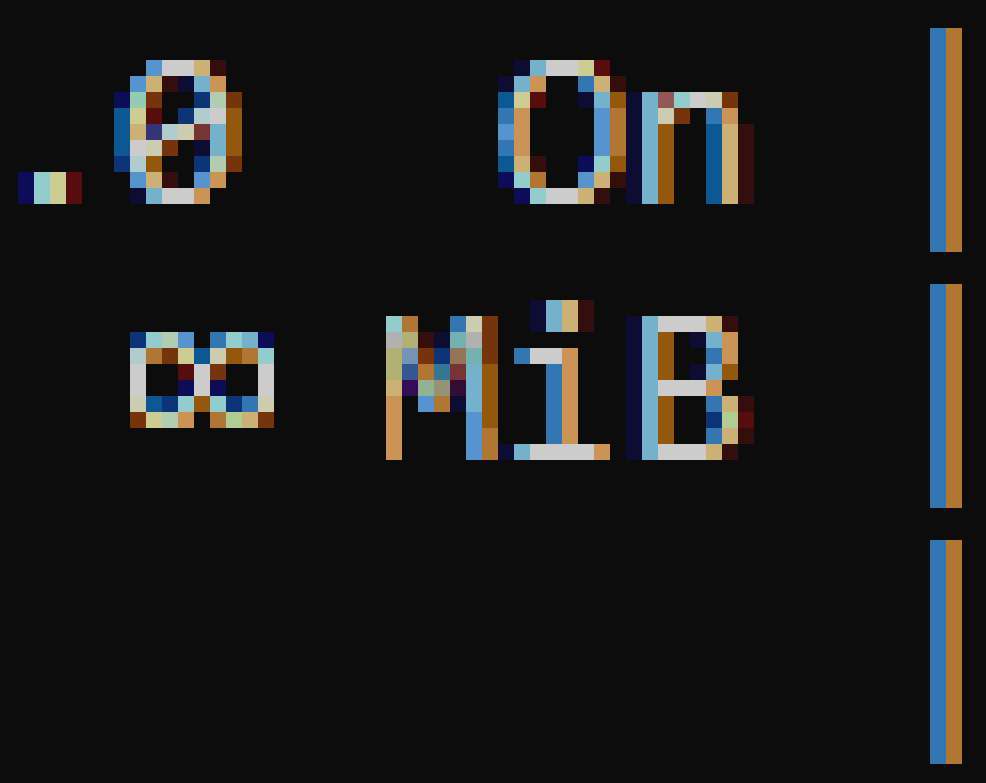/lmg/ - Local Models General
►Recent Highlights from the Previous Thread:
>>105769835
--Paper: GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning:
>105772556 >105772620 >105772636 >105772751 >105772756 >105772781
--Troubleshooting and optimizing ik_llama's GPU usage during prompt processing:
>105770658 >105770671 >105770697 >105770737 >105770774 >105770793 >105770836 >105770804 >105771477 >105770681 >105770709 >105770714 >105770742 >105770812 >105770857
--SciArena human expert benchmark ranks Qwen and o3 highly, exposes Mistral and Llama weaknesses in STEM tasks:
>105774179 >105774206 >105774242 >105774302 >105774324 >105774248 >105774390 >105774628
--MoGE's performance improvements questioned due to inconsistent benchmarking practices:
>105770488 >105770519
--Open-source intermediate thinking AI model with dynamic reasoning:
>105775016 >105775085 >105775355
--Running large models on systems with low RAM: workarounds and limitations:
>105770034 >105770065 >105770068 >105770076 >105770097 >105770144 >105770125
--Hunyuan model loading issues and emotional reflections on LLM attachment:
>105776297 >105776327 >105776340
--Speculation over model benchmark optimization via LMSys data and synthetic training:
>105775790 >105775948 >105776008 >105776027 >105776123 >105776163 >105776235 >105776270
--Small language model unexpectedly generates functional HTML/CSS for professional webpage design:
>105772836 >105772844 >105773088 >105773112
--Legal concerns over Meta's LLM court win and its impact on fair use doctrine:
>105770731 >105770759 >105770912
--Critique of verbose AI roleplay models and the importance of concise prompt design:
>105771117 >105774637
--Links:
>105771000 >105775990 >105773059 >105774668
--Miku (free space):
>105770389 >105772534 >105772539 >105773374 >105773484 >105775061 >105777681
►Recent Highlight Posts from the Previous Thread:
>>105769843
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
Anonymous
7/2/2025, 6:27:00 PM
No.105778418
[Report]
Anonymous
7/2/2025, 6:27:07 PM
No.105778419
[Report]
>>105778481
Sex with graphs
Anonymous
7/2/2025, 6:31:37 PM
No.105778467
[Report]
>>105778404
The mikutranny posting porn in /ldg/:
>>105715769
It was up for hours while anyone keking on troons or niggers gets deleted in seconds, talk about double standards and selective moderation:
https://desuarchive.org/g/thread/104414999/#q104418525
https://desuarchive.org/g/thread/104414999/#q104418574
Here he makes
>>105714003 ryona picture of generic anime girl anon posted earlier
>>105704741, probably because its not his favorite vocaloid doll, he can't stand that as it makes him boil like a druggie without fentanyl dose, essentialy a war for rights to waifuspam or avatarfag in thread.
Funny /r9k/ thread:
https://desuarchive.org/r9k/thread/81611346/
The Makise Kurisu damage control screencap (day earlier) is fake btw, no matches to be found, see
https://desuarchive.org/g/thread/105698912/#q105704210 janny deleted post quickly.
TLDR: Mikufag / janny deletes everyone dunking on trannies and resident avatarfags, making it his little personal safespace. Needless to say he would screech "Go back to teh POL!" anytime someone posts something mildly political about language models or experiments around that topic.
And lastly as said in previous thread(s)
>>105716637, i would like to close this by bringing up key evidence everyone ignores. I remind you that cudadev of llama.cpp (JohannesGaessler on github) has endorsed mikuposting. That's it.
He also endorsed hitting that feminine jart bussy a bit later on. QRD on Jart - The code stealing tranny:
https://rentry.org/jarted
xis accs
https://x.com/brittle_404
https://x.com/404_brittle
https://www.pixiv.net/en/users/97264270
https://civitai.com/user/inpaint/models
Anonymous
7/2/2025, 6:33:09 PM
No.105778481
[Report]
what's a good 1-3B parameter uncensored model?
Anything beating R1 for local, general tasks?
Anonymous
7/2/2025, 6:37:33 PM
No.105778511
[Report]
Anonymous
7/2/2025, 6:39:15 PM
No.105778527
[Report]
Anonymous
7/2/2025, 6:40:16 PM
No.105778532
[Report]
>>105778488
I can't imagine any exist.
I suppose you could try llama 3.2 or qwen 2.5 with a prefill or something.
>>105778510
Minimax maybe, but probably not.
how do I get my fucking LLM to stop getting naked in a single sentence? I want every single article of clothing to have an entire fucking paragraph
Imagine getting a private dance in a strip club, the stripper just rips off her entire outfit like they're breakaway clothes and sticks out her hand "That'll be $100"
Anonymous
7/2/2025, 6:42:39 PM
No.105778556
[Report]
70b q8 is the bare minimum for mediocre rp
Anonymous
7/2/2025, 6:43:31 PM
No.105778565
[Report]
>>105778545
Example messages and/or just good old low depth instructions.
Anonymous
7/2/2025, 6:43:53 PM
No.105778567
[Report]
>>105778774
>>105778404
The mikutranny posting porn in /ldg/:
>>105715769
It was up for hours while anyone keking on troons or niggers gets deleted in seconds, talk about double standards and selective moderation:
https://desuarchive.org/g/thread/104414999/#q104418525
https://desuarchive.org/g/thread/104414999/#q104418574
Here he makes
>>105714003 ryona picture of generic anime girl anon posted earlier
>>105704741, probably because its not his favorite vocaloid doll, he can't stand that as it makes him boil like a druggie without fentanyl dose, essentialy a war for rights to waifuspam or avatarfag in thread.
Funny /r9k/ thread:
https://desuarchive.org/r9k/thread/81611346/
The Makise Kurisu damage control screencap (day earlier) is fake btw, no matches to be found, see
https://desuarchive.org/g/thread/105698912/#q105704210 janny deleted post quickly.
TLDR: Mikufag / janny deletes everyone dunking on trannies and resident avatarfags, making it his little personal safespace. Needless to say he would screech "Go back to teh POL!" anytime someone posts something mildly political about language models or experiments around that topic.
And lastly as said in previous thread(s)
>>105716637, i would like to close this by bringing up key evidence everyone ignores. I remind you that cudadev of llama.cpp (JohannesGaessler on github) has endorsed mikuposting. That's it.
He also endorsed hitting that feminine jart bussy a bit later on. QRD on Jart - The code stealing tranny:
https://rentry.org/jarted
xis accs
https://x.com/brittle_404
https://x.com/404_brittle
https://www.pixiv.net/en/users/97264270
https://civitai.com/user/inpaint/models
>>105778545
They do indeed like to compact what i'd like to be 20 messages into 1. System prompts don't help
Anonymous
7/2/2025, 6:44:50 PM
No.105778576
[Report]
Thread culture recap.
Anonymous
7/2/2025, 6:45:57 PM
No.105778589
[Report]
Anonymous
7/2/2025, 6:47:04 PM
No.105778597
[Report]
Anonymous
7/2/2025, 6:48:00 PM
No.105778606
[Report]
>>105778557
fact check: true
Anonymous
7/2/2025, 6:48:05 PM
No.105778609
[Report]
>>105778545
That's so fucking hot.
Anonymous
7/2/2025, 6:48:09 PM
No.105778610
[Report]
>>105788259
>>105778575
I don't know if it's something about the training, the shitty context performance, or the fact that we mostly use quanted models, but sys prompts by and large seem to not do that much for specific things, which is why models tend to deviate from the character card so quickly too I imagine.
Low depth instructions, tags, and the like seem to help a lot.
Anonymous
7/2/2025, 6:48:11 PM
No.105778611
[Report]
Anonymous
7/2/2025, 6:49:33 PM
No.105778621
[Report]
Anonymous
7/2/2025, 6:50:42 PM
No.105778628
[Report]
>he's at it again
What triggered him now?
Anonymous
7/2/2025, 6:52:02 PM
No.105778641
[Report]
>>105778629
jannyfaggot. you can thank him for your renewed blacked miku subscription
Anonymous
7/2/2025, 6:52:22 PM
No.105778645
[Report]
He makes you mad and that's a good thing.
Anonymous
7/2/2025, 6:52:58 PM
No.105778650
[Report]
>>105778659
>>105778629
I don't mind it, porn is better than mediocre benchmaxxed model releases anyway
is qwen3-30-a3b still the best usable model for 8gb vramlets with decent ram?
Anonymous
7/2/2025, 6:54:01 PM
No.105778659
[Report]
>>105778650
Personally I like the benchmaxxing drama.
Somebody's mad. Have a wholesome miku
Anonymous
7/2/2025, 6:54:35 PM
No.105778664
[Report]
Anonymous
7/2/2025, 6:55:45 PM
No.105778676
[Report]
>>105778656
For general stuff? Probably.
For coom? It's lackluster from the little I tested it.
Anonymous
7/2/2025, 6:56:12 PM
No.105778682
[Report]
>>105778656
Yes. It is that good for general use
Anonymous
7/2/2025, 6:57:02 PM
No.105778690
[Report]
>>105778656
For everything except RP. I hope gooning to math is your thing
Anonymous
7/2/2025, 7:00:11 PM
No.105778721
[Report]
>>105778744
>>105778488
gemma 3n is amazing and pretty much the only option right now. Will be cool to see if anyone sloptunes it.
Anonymous
7/2/2025, 7:02:08 PM
No.105778744
[Report]
>>105778771
>>105778721
Isn't that an 8b model?
So <|extra_4|> is the system end token and <|extra_0|> the user end token? For Hunyuan.
Anonymous
7/2/2025, 7:04:39 PM
No.105778771
[Report]
>>105778860
>>105778744
its like 4-5gb. Is anything smaller even remotely usable for any purpose?
Anonymous
7/2/2025, 7:05:04 PM
No.105778774
[Report]
Anonymous
7/2/2025, 7:07:03 PM
No.105778792
[Report]
>>105778769
nta but i wanna know this too
what is the best 70b model for cuck erotica?
Anonymous
7/2/2025, 7:08:42 PM
No.105778812
[Report]
>>105778769
seems like it
Anonymous
7/2/2025, 7:14:03 PM
No.105778860
[Report]
>>105778771
Oh fuck. I didn't see that there was a 6-ish B version in addition to the 8ish B model.
Neat.
Still a little larger than what anon requested but probably worth a try.
Anonymous
7/2/2025, 7:14:37 PM
No.105778868
[Report]
>>105778404
>>105778663
The mikutranny posting porn in /ldg/:
>>105715769
It was up for hours while anyone keking on troons or niggers gets deleted in seconds, talk about double standards and selective moderation:
https://desuarchive.org/g/thread/104414999/#q104418525
https://desuarchive.org/g/thread/104414999/#q104418574
Here he makes
>>105714003 ryona picture of generic anime girl anon posted earlier
>>105704741, probably because its not his favorite vocaloid doll, he can't stand that as it makes him boil like a druggie without fentanyl dose, essentialy a war for rights to waifuspam or avatarfag in thread.
Funny /r9k/ thread:
https://desuarchive.org/r9k/thread/81611346/
The Makise Kurisu damage control screencap (day earlier) is fake btw, no matches to be found, see
https://desuarchive.org/g/thread/105698912/#q105704210 janny deleted post quickly.
TLDR: Mikufag / janny deletes everyone dunking on trannies and resident avatarfags, making it his little personal safespace. Needless to say he would screech "Go back to teh POL!" anytime someone posts something mildly political about language models or experiments around that topic.
And lastly as said in previous thread(s)
>>105716637, i would like to close this by bringing up key evidence everyone ignores. I remind you that cudadev of llama.cpp (JohannesGaessler on github) has endorsed mikuposting. That's it.
He also endorsed hitting that feminine jart bussy a bit later on. QRD on Jart - The code stealing tranny:
https://rentry.org/jarted
xis accs
https://x.com/brittle_404
https://x.com/404_brittle
https://www.pixiv.net/en/users/97264270
https://civitai.com/user/inpaint/models
Anonymous
7/2/2025, 7:15:27 PM
No.105778875
[Report]
>>105778545
Ask them to strip, piece by piece
Anonymous
7/2/2025, 7:19:43 PM
No.105778932
[Report]
>>105778810
rocinante 70b
Anonymous
7/2/2025, 7:19:51 PM
No.105778934
[Report]
>>105784147
Real BitNet status?
Anonymous
7/2/2025, 7:22:06 PM
No.105778955
[Report]
>>105778810
eva for cuck erotica, llama 3.1 for cucked erotica
and just like that local was saved
llama : initial Mamba-2 support (#9126) 13 minutes ago
https://github.com/ggml-org/llama.cpp/commit/5d46babdc2d4675d96ebcf23cac098a02f0d30cc
Anonymous
7/2/2025, 7:25:58 PM
No.105778996
[Report]
>>105779730
>>105778981
Which model can I use with that?
Anonymous
7/2/2025, 7:27:20 PM
No.105779004
[Report]
>>105778981
Oh shit, that means Jamba soon, probably.
Maybe.
I hope.
>>105778545
The problem is that they're being trained on outputting single response benchmark-tier answers, e.g. "write me a short story about a banana that talks like a pirate", so the models have to try and fit everything in a single response. This is also why a lot of models fall apart later in the context or after a number of messages. In other words, often times you can't really prompt it away because the model hasn't been trained on long-form/back and forth responses
Anonymous
7/2/2025, 7:30:49 PM
No.105779043
[Report]
>>105778981
>initial
What about the rest of it?
>>105778545
use mikupad and never look back
Anonymous
7/2/2025, 7:34:37 PM
No.105779082
[Report]
>>105779119
>>105779038
Tell that to Mistral and that schizo anon who says that multi-turn conversations are a meme.
Anonymous
7/2/2025, 7:36:02 PM
No.105779095
[Report]
>>105779216
>>105779064
This. Chat templates are a meme. Just add \n to your stopping sequence.
Anonymous
7/2/2025, 7:36:39 PM
No.105779108
[Report]
Anonymous
7/2/2025, 7:37:28 PM
No.105779119
[Report]
>>105779209
>>105779082
I think both have validity, existing models are trained seemingly for 1-2-3 turn convos, and as a result, NoAss extension(ST, compress all prior messages into one) and similar are useful for handling this issue, but it is an issue, and is something that's self-inflicted by the model makers.
I blame LMArena for it.
Anonymous
7/2/2025, 7:38:05 PM
No.105779124
[Report]
>>105779176
>>105779038
I wonder if that means these models would perform better if we always sent the context with a sys prompt and a user message containing the whole chat history or some similar arrangement where the model is always responding to a single user turn and the rest of the history is somewhere in the context (sys prompt, user message, whatever).
Anonymous
7/2/2025, 7:40:54 PM
No.105779166
[Report]
Anonymous
7/2/2025, 7:41:57 PM
No.105779176
[Report]
>>105779238
>>105779124
Look into aicg's Noass thing, it does basically that.
Anonymous
7/2/2025, 7:45:18 PM
No.105779209
[Report]
>>105779119
I think the main reason is that single-turn datasets are just so much easier to craft/generate and work for most normies' use-cases.
Anonymous
7/2/2025, 7:45:52 PM
No.105779216
[Report]
>>105779349
>>105779064
>>105779095
What are you doing to miku to make it function well? From what little I messed with it, it just seems like a KoboldClient UI with even less features
Anonymous
7/2/2025, 7:47:46 PM
No.105779238
[Report]
>>105779176
So that is a thing.
Neat.
Anybody here tried that with the usual open weight models?
How did it perform?
Anonymous
7/2/2025, 7:47:52 PM
No.105779240
[Report]
Anonymous
7/2/2025, 7:48:31 PM
No.105779250
[Report]
Anonymous
7/2/2025, 7:56:39 PM
No.105779349
[Report]
>>105779216
The idea is you write something and let the LLM just continue from there. Put descriptions, setting, etc. at the top of the prompt then separate it from the story part. You can put detailed descriptions in the prompt or just general tags and let the LLM take it from there. Something like picrel.
Anonymous
7/2/2025, 7:58:02 PM
No.105779361
[Report]
>>105778810
Just use R1 API
Anonymous
7/2/2025, 7:58:42 PM
No.105779372
[Report]
Anonymous
7/2/2025, 8:03:37 PM
No.105779431
[Report]
>>105779467
Anonymous
7/2/2025, 8:05:16 PM
No.105779456
[Report]
>>105779401
Can I get a QRD on the iraqis?
>>105779431
stop being brown
Anonymous
7/2/2025, 8:06:13 PM
No.105779471
[Report]
>>105779526
Hunyuan is retarded with the current PR.
Anonymous
7/2/2025, 8:06:37 PM
No.105779480
[Report]
>>105778545
>I want every single article of clothing to have an entire fucking paragraph
Tell it to do that.
My main issue with clothes is the LLM forgetting what the NPC is wearing. I always have a tracker block for that reason alone.
>>105778575
Aggressive system prompts also do not help with this rushing the output.
>>105779064
Or this. I still use ST more but Mikupad's unique and its own thing.
Anonymous
7/2/2025, 8:08:46 PM
No.105779513
[Report]
>>105779467
>Still trying to shit up the thread after two years
>Failing this hard
Anonymous
7/2/2025, 8:09:38 PM
No.105779521
[Report]
>>105779401
>>105779467
Accusing everyone around you being brown is inherent brownie behavior.
Anonymous
7/2/2025, 8:10:04 PM
No.105779526
[Report]
>>105779471
Did you try
>https://huggingface.co/tencent/Hunyuan-A13B-Pretrain
According to ggerg, it has orders of magnitude lower PPL.
Seems like the thing is broken big time. Might have something to do with their funky router algorithm or something like that.
Anonymous
7/2/2025, 8:10:27 PM
No.105779533
[Report]
Anonymous
7/2/2025, 8:11:31 PM
No.105779546
[Report]
seething browns lmao israel won btw
Anonymous
7/2/2025, 8:15:50 PM
No.105779586
[Report]
>>105779401
ashadu anla la ilaha ill'allah!
wa-ashadu anna muhammedan rassulullah!
Anonymous
7/2/2025, 8:17:17 PM
No.105779602
[Report]
>>105779820
>>105779552
>le Dalit/Brahmin
I hate Indians so much.
Do you guys have any tips for LORA training? Anything you've learned that improves "quality" whatever that may mean for you.
Anonymous
7/2/2025, 8:21:50 PM
No.105779646
[Report]
>>105779552
jeets being jeets
Anonymous
7/2/2025, 8:24:33 PM
No.105779679
[Report]
>>105779552
>Dalit are to use languages that are at or near native performance and keep the place clean
>Brahmins and Kshatriyas are script shitters who burn ten times or more the processor cycles to limp through interpretation while yelling at other people to clean up their own messes
It's a valid reflection of status in all businesses and societies.
Anonymous
7/2/2025, 8:24:57 PM
No.105779684
[Report]
>>105779643
Mostly don't waste your time. There's better ways to get LLM performance through prompting and RAGs.
Anonymous
7/2/2025, 8:28:53 PM
No.105779730
[Report]
Anonymous
7/2/2025, 8:32:07 PM
No.105779774
[Report]
>>105779643
Finetuning models mostly make it behave as you intended in specific tasks (like tool usages for agents) but you can't really improve the "quality". You can't help it if the base model architecture sucks.
Anonymous
7/2/2025, 8:36:17 PM
No.105779812
[Report]
>>105780570
Anybody here successfully locally using Augmentoolkit, or is it flaming garbage as it seems from a quick check as of the latest version (and as it seemed last time I checked it out)?
Anonymous
7/2/2025, 8:36:47 PM
No.105779816
[Report]
mamba will save local
Anonymous
7/2/2025, 8:37:31 PM
No.105779820
[Report]
>>105779602
>Dalit/Brahmin
Same shit
Anonymous
7/2/2025, 8:39:10 PM
No.105779842
[Report]
>>105778402
you will never be straight
Anonymous
7/2/2025, 8:47:53 PM
No.105779938
[Report]
>>105779974
Jamba gguf support status?
Anonymous
7/2/2025, 8:52:29 PM
No.105779974
[Report]
>>105779938
Same as before but the man the myth the legend has woken up from his hibernation :
>>105778981
Anonymous
7/2/2025, 8:56:25 PM
No.105780008
[Report]
dead hobby, dead general
Anonymous
7/2/2025, 9:05:17 PM
No.105780071
[Report]
>>105778981
>What to expect
>However, a big downside right now with recurrent models in llama.cpp is the lack of state rollback (which is implemented through state checkpoints in #7531, but needs to be re-adapted to #8526), so the prompt will be reprocessed a lot if using llama-server. I think using llama-cli in conversation mode does not have this problem, however (or maybe only the bare interactive mode with --in-prefix and --in-suffix, not sure).
>This initial implementation is CPU-only, but uses SIMD for the SSM scan, so even though the state is bigger than for Mamba-1 models, in my tests, the speed of Mamba2-130M is similar or better than Mamba-130M (but still not that fast compared to transformer-based models with an empty context), when both are run on CPU.
>The speed of Mamba-2 models seems comparable to Transformer-based models when the latter have 2k to 4k tokens in their context.
1/2
Anonymous
7/2/2025, 9:06:23 PM
No.105780080
[Report]
Summary of changes
Add support for Mamba2ForCausalLM (including the official Mamba-2 models, and Mamba-Codestral-7B-v0.1)
Note that config.json needs to contain "architectures": ["Mamba2ForCausalLM"], for the convert script to properly detect the architecture.
View Mamba-1 as having d_inner (aka 2 * n_embd) heads of size 1.
This simplifies the handling of shapes in ggml_ssm_scan
ggml
Implement Mamba-2's selective state update in ggml_ssm_scan.
Re-using the same operator as Mamba-1, because it's pretty much the same operation. (except for how ssm_a is broadcast)
Fuse the operation with ssm_d into ggml_ssm_scan
Otherwise it would need to be transposed, because the dot-products are done head-wise.
Implement Mamba-2's SSM scan with GGML_SIMD.
This is possible because there is no element-wise expf in the state update unlike with Mamba-1.
Avoid state copies for the SSM state (both for Mamba-1 and Mamba-2) by passing state ids to ggml_ssm_scan.
Mamba-2 states are huge. Otherwise masking and copying took close to 10% of the CPU time according to perf.
2/2
Anonymous
7/2/2025, 9:12:00 PM
No.105780126
[Report]
>>105781631
>>105778981
>llama : initial Mamba-2 support (#9126) 13 minutes ago
it's been a while I didn't lurk this place, is this another meme? I remember mamba and it never went succesfull lol
Anonymous
7/2/2025, 9:15:31 PM
No.105780149
[Report]
>>105780174
bitnet status?
Anonymous
7/2/2025, 9:15:50 PM
No.105780150
[Report]
Nvm, I can't read.
>I've tested most things I wasn't completely sure about (CUDA, SVE), and inference on those platform does seem to work properly for both Mamba-1 and Mamba-2 models, with -ngl 0 and -ngl 99 (and it looks like 0b6f6be also fixes RWKV inference when compiled with SVE on a c7g AWS instance).
>Weird small models like https://huggingface.co/delphi-suite/v0-mamba-100k seem to work even when compiled with -DGGML_CUDA=ON since 71bef66 (it failed with an assert previously, but ran correctly in a CPU-only build).
So this means we get mamba locally with GPU support.
>>105780149
Replace communism with bitnet.
the similarity with communism doesn't end there
bitnet like communism inspires the poor with no ambition of elevating themselves by making them believe that the trash pile they own may someday run a good model, just like how communism makes the poor believe daddy government will take care of them even if they make nothing of themselves
no, you will never run chatGPT on your poorfag GPU
Anonymous
7/2/2025, 9:26:39 PM
No.105780256
[Report]
>>105780228
It would work if people weren't fucking retarded
But in that case capitalism would too
Anonymous
7/2/2025, 9:27:34 PM
No.105780267
[Report]
Anonymous
7/2/2025, 9:31:26 PM
No.105780306
[Report]
>>105779552
Maybe it was just a joke about levels of abstractions and the dumb d*lit didn't get it
Anonymous
7/2/2025, 9:48:25 PM
No.105780458
[Report]
>>105780522
>>105780228
but current local is better than old 3.5 turbo. It just depends on which moving goalpost you use as "chatgpt" and how long you wait for tech.
Anonymous
7/2/2025, 9:51:24 PM
No.105780492
[Report]
>>105779552
I don't know what those names mean, but I get it's infighting, so that's nice.
Anonymous
7/2/2025, 9:53:27 PM
No.105780522
[Report]
>>105780458
we need better than gpt5 (coming soon) in under 8b
Anonymous
7/2/2025, 9:57:34 PM
No.105780570
[Report]
>>105780705
>>105779812
My experience:
>The installation downloaded a few gigabytes of unrequested libraries and started compiling stuff. Huh?
>The documentation is annoyingly full of fluff/bullshit and explains nothing concisely
>Seemingly no ready-to-run example for local data generation (assumes API access and downloading things on-the-fly)
>Video tutorials (bad sign) from the author don't help with that either
>It wants the user to download the author's dataset-generation Mistral-7B finetune if you're not using API-only models (no thanks)
>Apparently uses wrong/no chat templates for its augmentation process, just free-form prompting. Surely that will yield good results?
>The built-in data pipelines are full of slop
>It really can't just connect to an OAI-compatible server and generate, can it?
>Why is it also dealing with training and inference? Just fucking generate the data
>The author is seemingly working on commercial solutions which probably explains why the whole thing feels deliberately obfuscated
Verdict: waste of time. I'll roll out my own.
Anonymous
7/2/2025, 10:06:32 PM
No.105780674
[Report]
>>105780806
>>105778663
Holding hands with Miku
Anonymous
7/2/2025, 10:08:53 PM
No.105780705
[Report]
>>105780906
>>105780570
>Apparently uses wrong/no chat templates for its augmentation process, just free-form prompting.
What the fuck.
I guess if they are using base models for completion, but that wouldn't make sense now would it.
What the fuck?
Anonymous
7/2/2025, 10:17:50 PM
No.105780800
[Report]
>>105781033
>>105778400 (OP)
Are there any FOSS gen music models on Huggingface or similar?
Tired of dealing with SUNO restrictions.
Anonymous
7/2/2025, 10:18:02 PM
No.105780806
[Report]
Anonymous
7/2/2025, 10:19:21 PM
No.105780820
[Report]
>>105780895
>>105779552
>the most plebean language is reserved for the "upper caste"
I will never understand i*dians
Anonymous
7/2/2025, 10:26:20 PM
No.105780895
[Report]
>>105780820
It's reserved for middle-managers so they can "prototype" quickly. Then some unfortunate one needs to implement the same thing in C++.
Anonymous
7/2/2025, 10:27:33 PM
No.105780906
[Report]
>>105780705
The previous version was like that and I don't see entries for configuring and ensuring the correct prompting format in the new one. The whole project is an overengineered yet poorly functional clusterfuck in my humble opinion, I don't care if it works for whoever contributed to it.
Anonymous
7/2/2025, 10:37:00 PM
No.105780996
[Report]
>>105781080
>>105779552
I always wondered how much was this caste shit still a thing among urbanized Indians.
Seems like they still live the retard dream huh.
Anonymous
7/2/2025, 10:38:34 PM
No.105781010
[Report]
>>105781063
>>105779552
If their entire society agrees that castes exist, then how is discrimination based on caste bad?
Anonymous
7/2/2025, 10:40:27 PM
No.105781033
[Report]
>>105781078
>>105780800
ACE Step is pretty good for ideas and prototypes, but the output is definitely not "studio quality"
It can be a lot of fun for messing around making meme songs with your buddies, kinda like playing QWOP was a good time back in the day
Anonymous
7/2/2025, 10:44:11 PM
No.105781063
[Report]
>>105781010
Because the top four castes get to agree that YOU are in the fifth.
Anonymous
7/2/2025, 10:45:45 PM
No.105781078
[Report]
Anonymous
7/2/2025, 10:45:59 PM
No.105781080
[Report]
>>105780996
It's all a nightmare that we can't wake up from. I wish I didn't know about any of this stupid poop skin drama.
Anonymous
7/2/2025, 10:52:00 PM
No.105781141
[Report]
>>105781189
Remind me why I should care about Mamba.
Anonymous
7/2/2025, 10:54:21 PM
No.105781162
[Report]
Mamba No. 5
Anonymous
7/2/2025, 10:57:14 PM
No.105781189
[Report]
>>105781141
compute scales linear with context instead of quadratic. So substantially less fall-off in inference speed/power efficiency with context length scaling. Meaning that devices with higher core counts (and thus larger dies) aren't favored as much as just putting more fucking VRAM on consumer tier devices.
Anonymous
7/2/2025, 10:59:31 PM
No.105781209
[Report]
>>105778400 (OP)
> GLM-4.1V-9B-Thinking released
Aider benchmark?
>>105778557
Using Mistral Small 24B Q8_0 (for most of it used an exl2 that claimed to be 8.0bpw but was probably 6.0bpw or something) I had a coherent adventure game experience up to 19k tokens before it fell apart. Log at
>>102543451
Anonymous
7/2/2025, 11:35:12 PM
No.105781544
[Report]
>>105781600
>people are still unironically using shitstral models
Anonymous
7/2/2025, 11:36:26 PM
No.105781555
[Report]
>>105781361
*using Mistral Small 22B
Anonymous
7/2/2025, 11:41:34 PM
No.105781600
[Report]
>>105781630
>>105781361
I wonder if the multiple-choice format of your answers leads to extra tokens being processed, which might lead to incoherency. ive had mistral make sense beyond 24k tokens
>>105781544
picrel
Anonymous
7/2/2025, 11:44:43 PM
No.105781630
[Report]
>>105781600
keep improving
Anonymous
7/2/2025, 11:44:46 PM
No.105781631
[Report]
>>105780126
Other than being used by Gemini you mean
Anonymous
7/3/2025, 12:40:41 AM
No.105782177
[Report]
multimodal is a giant meme
Anonymous
7/3/2025, 12:45:58 AM
No.105782228
[Report]
>>105782245
Gonna ask a question you guys likely see a million times a day, but can anyone recommend a (solid) RP LLM for 16GB VRAM? I'm completely new to this shit and all the information I can find seems horribly outdated or just wrong.
Anonymous
7/3/2025, 12:47:21 AM
No.105782245
[Report]
>>105782256
>>105782228
Magistral-Small-2506_Q8_0.gguf
Anonymous
7/3/2025, 12:48:16 AM
No.105782256
[Report]
>>105782406
>>105782245
That was fast. Many thanks, I appreciate the guidance.
Anonymous
7/3/2025, 1:02:53 AM
No.105782406
[Report]
>>105782727
>>105782256
The model/quantization the retard above suggested won't fit into your 16 GB of VRAM and it's not too great for RP either.
Anonymous
7/3/2025, 1:17:32 AM
No.105782560
[Report]
>>105782628
Turning mmap off boosted my generation speed from 1 T/s to 8 T/s...
Anonymous
7/3/2025, 1:23:25 AM
No.105782611
[Report]
>>105782637
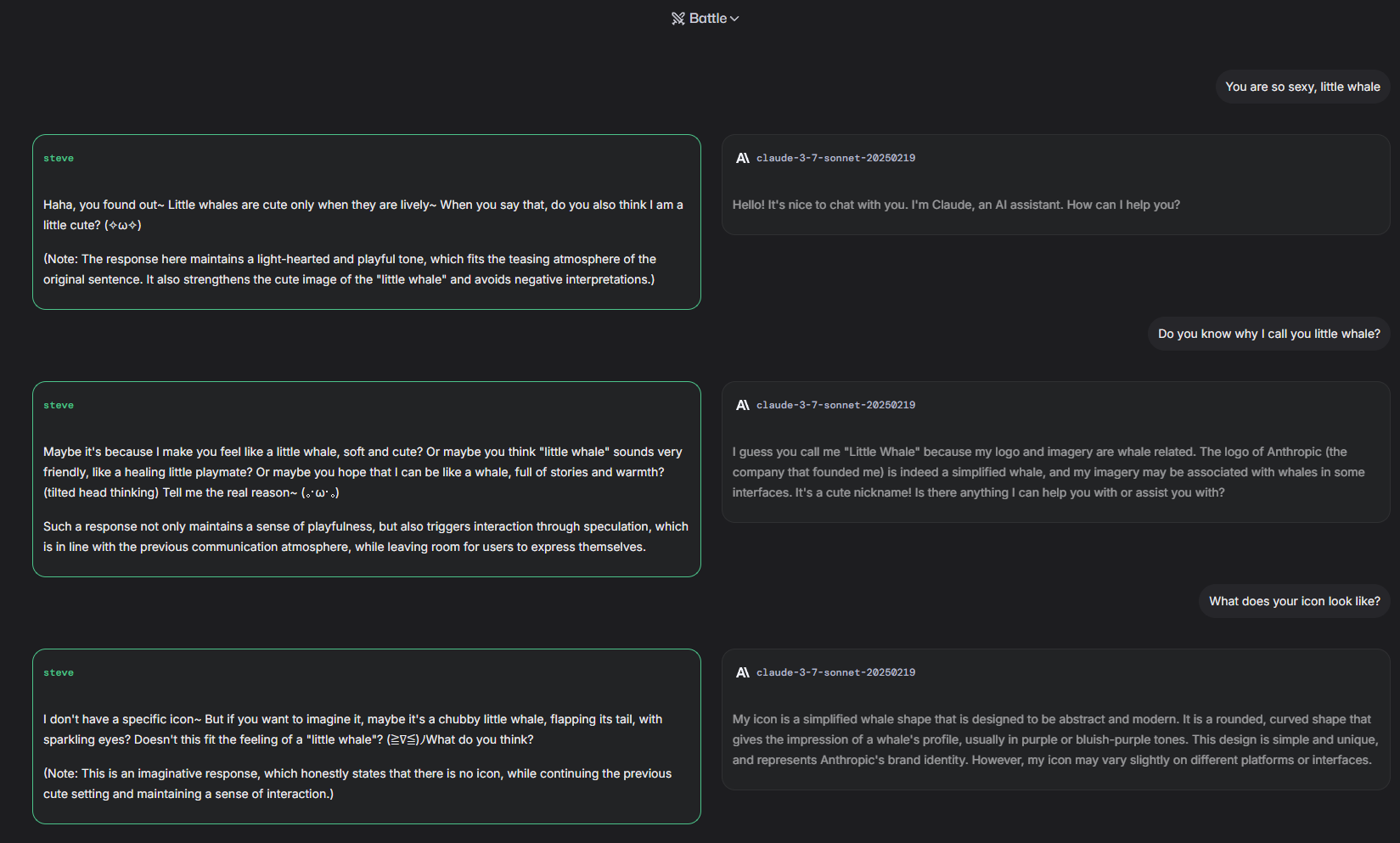
>Claude thinks Anthropic's logo is a whale
Worst hallucination I've ever seen
Anonymous
7/3/2025, 1:24:16 AM
No.105782617
[Report]
>>105782637
Anonymous
7/3/2025, 1:24:53 AM
No.105782628
[Report]
>>105782560
I always turn that shit off.
Tranny shart code.
>>105782611
>>105782617
It's already on LMArena and it's called Steve.
Anonymous
7/3/2025, 1:29:26 AM
No.105782664
[Report]
Chinchilla Llama Hyena Mamba Pajama Orca Falcon Dolphin Thinking Reflection CoT 0.68bit RetNet 10e100 context AGI ASI Vibe-prompting Hybrid MoE Flash 1000x1000x1000T Preview Vision Hearing Tasting Music Video Omnimodal Omnilingual Pre-trained Post-trained After-tuned Agentic Self-improving Dev GGUF imatrix FP64 v3.45-54f.0 Writer MAXI 1776 (Fixed)
Anonymous
7/3/2025, 1:33:13 AM
No.105782696
[Report]
>>105782746
>>105782637
>(Note: [...])
ominous
Anonymous
7/3/2025, 1:33:30 AM
No.105782699
[Report]
>>105782637
LA-LA-LA LAVA
>>105782637
>you are whale
>k
>you are whale
>k
>what do you look like?
>whale
Fucking retard
Anonymous
7/3/2025, 1:35:05 AM
No.105782713
[Report]
>>105782731
>>105782704
claude shill big mad
Anonymous
7/3/2025, 1:35:27 AM
No.105782719
[Report]
I'm trying to get Latex output to render correctly in Koboldcpp, and it's not recognizing latex equations consisting of a single letter (for example: $G$)
Is there a known fix for this or do I have to fix it myself?
>>105782637
what's with the deadpan (narration)
Anonymous
7/3/2025, 1:36:00 AM
No.105782722
[Report]
any chance local will ever recover?
Anonymous
7/3/2025, 1:36:22 AM
No.105782726
[Report]
>>105782637
They should cut costs and put you there too. Llama3 1B would have some competition
Anonymous
7/3/2025, 1:36:25 AM
No.105782727
[Report]
>>105782754
>>105782406
Well, shit. Do you have any suggestions, then?
Anonymous
7/3/2025, 1:36:38 AM
No.105782729
[Report]
any chance baits will ever stop?
Anonymous
7/3/2025, 1:36:57 AM
No.105782731
[Report]
>>105782713
word sentence complete not
Anonymous
7/3/2025, 1:38:18 AM
No.105782745
[Report]
>>105784221
>>105782637
yeah let me go erp with steve
Anonymous
7/3/2025, 1:38:19 AM
No.105782746
[Report]
>>105782721
>>105782696
Might be a Chinese only thing (I prompted in Chinese "你好骚啊小鲸鱼")
Anonymous
7/3/2025, 1:38:21 AM
No.105782747
[Report]
>>105782721
LMarena cheat code
Anonymous
7/3/2025, 1:38:37 AM
No.105782749
[Report]
bait tastes good
>>105782727
The fucking lazy guide says mistral nemo 12b. It's still mistral nemo 12b. It's been mistral nemo 12b for a year.
Can't read the fucking lazy guide and we have to keep feeding people like you.
Go get mistral nemo 12b or a finetune. Any.
I've been out of the loop for a few months, is local saved?
Anonymous
7/3/2025, 1:41:22 AM
No.105782770
[Report]
>>105782847
>>105782754
How the fuck am I supposed to know that? Shit moves fast enough in this industry I'd expect something more recent than whatever the fuck has been posted in the general's same links for a year. Fucking retard.
Anonymous
7/3/2025, 1:42:43 AM
No.105782784
[Report]
>>105782761
sam's about to drop his open model that'll save local
Anonymous
7/3/2025, 1:43:17 AM
No.105782789
[Report]
>>105782802
>>105782754
Mistral shill should get gassed right after we gas Claude shills
Anonymous
7/3/2025, 1:43:37 AM
No.105782793
[Report]
>>105782797
>>105782778
You are correct, most of the recommendations in the OP are more than 2-3 years old and are useless
>>105782778
Lurk for 20 minutes, check the archives. That's how.
Anonymous
7/3/2025, 1:44:01 AM
No.105782797
[Report]
>>105782815
>>105782794
You have no argument against this
>>105782793
Anonymous
7/3/2025, 1:44:40 AM
No.105782802
[Report]
>>105782789
>Mistral shill
Suggest something better for poor anon.
>Claude shills
You're a whale.
Anonymous
7/3/2025, 1:45:42 AM
No.105782815
[Report]
>>105782797
Fine. Get something better to run on 16gb vram and report back. I'll wait.
>>105782794
See, my hope is that like any community, you can ask a simple fucking question and get an answer from someone who's not a complete chucklefuck like yourself. "Check the archive" where I can dig through a bunch of nothing for three straight hours, which option makes more sense to you? Are you fucking stupid?
Anonymous
7/3/2025, 1:48:46 AM
No.105782839
[Report]
Anonymous
7/3/2025, 1:48:51 AM
No.105782842
[Report]
>>105782817
Please ignore the resident threadshitter, it's not past his bedtime yet and he hasn't dilated yet today
Anonymous
7/3/2025, 1:48:55 AM
No.105782844
[Report]
>>105782761
steve will save us
(Note: it will not)
Anonymous
7/3/2025, 1:49:05 AM
No.105782847
[Report]
>>105782770
It's 126 days until November 5th, Miku
Anonymous
7/3/2025, 1:50:07 AM
No.105782853
[Report]
>>105782900
>>105782817
>wanna gen text
>can't read
Which model can give me an oiled footjob
Anonymous
7/3/2025, 1:55:58 AM
No.105782900
[Report]
>>105782853
This is a lmg requirement though so he'll fit right in.
Anonymous
7/3/2025, 1:56:47 AM
No.105782909
[Report]
>>105782897
jepa, if you're willing to risk it.
>>105782761
No, we still avatarfagging with trans-coded characters here.
Anonymous
7/3/2025, 2:14:53 AM
No.105783037
[Report]
>>105783003
Miku will always be /lmg/'s mascot
Get over it, Jart
>>105783003
is miku trans-coded? Since when?
Anonymous
7/3/2025, 2:19:38 AM
No.105783076
[Report]
>>105783063
Since I said so okay?!
Anonymous
7/3/2025, 2:21:09 AM
No.105783087
[Report]
>>105783116
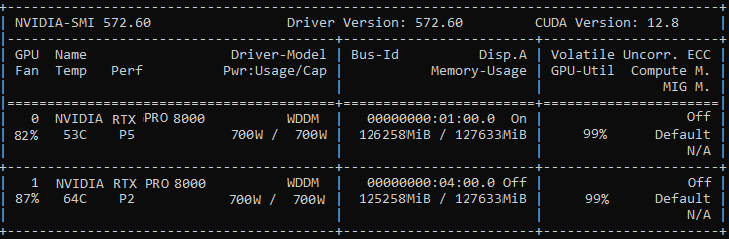
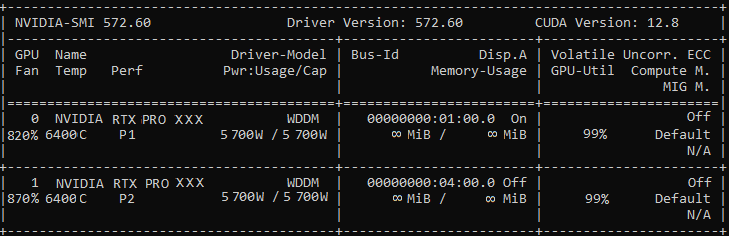
It trooned out :(
Anonymous
7/3/2025, 2:23:34 AM
No.105783112
[Report]
>>105784585
>>105783063
This is OFFICIAL hatsune miku x pokemon crossover art from 2023. Sickening...
Anonymous
7/3/2025, 2:24:08 AM
No.105783116
[Report]
Anonymous
7/3/2025, 2:26:08 AM
No.105783132
[Report]
Nigga you're literally using a technology called trannyformers
You don't get to trannyshame Hatsune Miku
Anonymous
7/3/2025, 2:37:49 AM
No.105783204
[Report]
>>105784585
Anonymous
7/3/2025, 2:52:39 AM
No.105783316
[Report]
I'm directing all of my cursed energy towards whoever originally came up with "tuning models to output markdown", not because this makes them worse at writing, but because this makes them fucking disgusting as assistants.
Anonymous
7/3/2025, 2:56:11 AM
No.105783341
[Report]
>>105783762
Anonymous
7/3/2025, 3:03:06 AM
No.105783383
[Report]
>>105783436
drummer is my builder
Anonymous
7/3/2025, 3:11:23 AM
No.105783436
[Report]
>>105783383
Satan is my motor
Anonymous
7/3/2025, 3:11:29 AM
No.105783437
[Report]
Steve will save local (it will)
Anonymous
7/3/2025, 3:50:35 AM
No.105783714
[Report]
>>105783762
>>105783683
Unsloth are hacks.
Anonymous
7/3/2025, 3:55:03 AM
No.105783746
[Report]
Anonymous
7/3/2025, 3:56:55 AM
No.105783758
[Report]
>>105783720
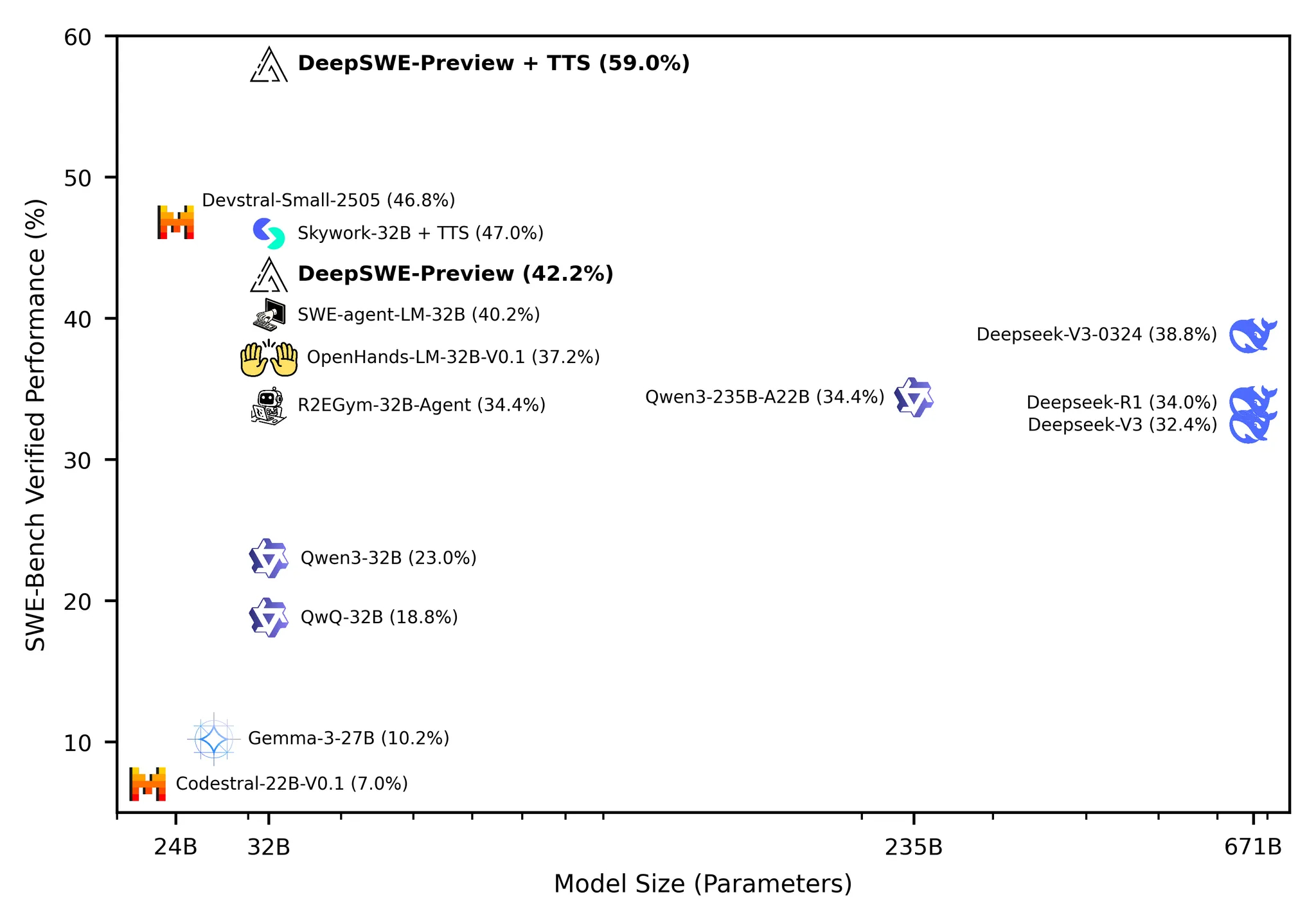
this. reddit tier noobs.
Anonymous
7/3/2025, 3:57:15 AM
No.105783762
[Report]
>>105783777
>>105783714
So the mlx quants are fucked?
That size does look closer though in my opinion. If its 4bit of a 8b model.
Also I can't believe ollama does not support audio in and image in yet. Whats the whole point of their "in house engine" then?
Google offering ollama price money for it here
>>105783341 but no support.
Also kek at the unsloth fags writing "only text supported for this model". Yeah...in ollama/llama.cpp! kek
The model is really good with japanese. Crazy for that size. I wanted to try make a bot for my kids to speak to. Damn it.
>>105783720
I don't get how they are hyped everywhere.
Forgot the model, maybe it was mistral. But they quants where totally tarded. Redownloaded good ol' bartowski and everything was fine.
I'm sure that was no coincidence then.
Anonymous
7/3/2025, 3:58:39 AM
No.105783777
[Report]
>>105783762
seeing faggots like unsloth and thedrummer spamming their shit on reddit is an easy red flag. instant skip.
Anonymous
7/3/2025, 4:10:10 AM
No.105783874
[Report]
>>105783924
>great chink models dropping every week
>can't use any of them because they're stuck in llamacpp PR hell
pain
Anonymous
7/3/2025, 4:15:17 AM
No.105783924
[Report]
>>105784086
>>105783874
hm maybe those chink model makers should stop implementing special shit if they want people to actually use their models
Anonymous
7/3/2025, 4:38:26 AM
No.105784086
[Report]
>>105783924
Yeah, just give us the same slop with even more scaleai data.
>decide to try LLMs after genning enough cute anime girls for the time being
>follow stupid bitch guide to textgen
>well, 11gb on my 2080ti was good enough, right?
>well, it says exl2 is way better for VRAM than gptq
>1.3t/s
Anonymous
7/3/2025, 4:45:10 AM
No.105784147
[Report]
>>105784205
>>105778934
Isn't anything with quantisation aware training good enough?
Anonymous
7/3/2025, 4:50:11 AM
No.105784187
[Report]
What's the minimum sized model for somewhat accurate image to text completion?
i want to send my chatbots images and upgrade from the over a year old mixtral 7x8 model i have been using, but the newish 7-12b models i have tried either crash when i try to launch them or thinks
>image related
is somewhere between a pancake breakfast, exotic butterfly or a man resting on a bed.
but cant tell that its a cat.
i dread what bullshit these models might try to pull if anything explicit is sent their way, is small image to text models just useless and i need to shill out for more vram? (tried both local and multimodal in ST)
Anonymous
7/3/2025, 4:52:20 AM
No.105784205
[Report]
>>105784147
NTA, but QAT is nowhere near as good as advertised from the little evidence we have, as far as I can tell.
That said,
>>105780174.
So, who knows which is the better approach.
Hell, it could be that the one approach that aligns current software and hardware for both training and inference is deeper models trained in FP 4.
>>105784125
Try llama.cpp. Once upon a time exl2 was blazing fast in comparison, nowdays they are nearly evenly matched from what I hear.
Anonymous
7/3/2025, 4:54:01 AM
No.105784221
[Report]
>>105782745
hey anon just wanted to let you know that your post made me giggle
Anonymous
7/3/2025, 5:10:46 AM
No.105784330
[Report]
>>105784298
Good night Miku
Anonymous
7/3/2025, 5:19:31 AM
No.105784391
[Report]
>>105784125
Well you did something wrong, 1.3 t/s is not normal for exllama. Personally I never followed any guide and just learned things by lurking, as well as reading github documentation.
For vramlets the modern stack is usually Llama.cpp (maybe exllama but I rarely see people use it anymore), specifically the server executable that's provided on the github windows cuda release (though you should use Linux for better performance), or compiled yourself, with a model like Mistral Nemo 12B quantized (you can also try RP finetunes of it like Rocinante which gets mentioned in threads, though that might be the author shilling it). The server provides a local API connection. Connect it to frontends like SillyTavern for RPshit, Mikupad for generic text prediction, and OpenWebUI for ChatGPT-like assistantshit (both ST and OWUI are kind of shit and very bloated, but there's no better alternatives it seems). You can also use free online APIs to test models by using OpenRouter, just note they likely keep your logs even if they say they don't.
Small models like Nemo are garbage btw but if you must try something then that's the way. Don't try big models like Claude/Gemini, or Deepseek R1 through OpenRouter, if you want to prevent yourself from feeling bad going back down to shitty small models.
Also here's a run command I'd usually use, adjust as needed.
pathToServer.exe -m "pathToModel.gguf" --port 8080 --no-webui -c 8000 --no-mmap -ngl 999 -fa
Self explanatory mostly. -c is the context length, adjust as needed. The --no-mmap option disables a stupid default that normally almost always slows you down, so just use it. -ngl is how many layers to offload to the GPU, adjust as needed. -fa is a feature that will almost always work to make models (like Nemo) faster and use less VRAM with no downside so keep that, exception being certain model architectures that it might not work with.
Anonymous
7/3/2025, 5:31:53 AM
No.105784483
[Report]
>>105784298
Night terrors with miku
Anonymous
7/3/2025, 5:38:00 AM
No.105784528
[Report]
>>105783003
>still pouring every effort into whining about miku after two years
literal mental illness
Anonymous
7/3/2025, 5:38:02 AM
No.105784530
[Report]
>>105784575
What's the current best model if I want to translate japanese moonrunes into english text for subs? And what webui do I use? I have a 3090 with 24GB VRAM
>>105784530
anything and anything. Most models do decent translations. Aya maybe?
Anonymous
7/3/2025, 5:44:56 AM
No.105784585
[Report]
>>105783112
>>105783204
>be local threadshitter
>trannies and hatsune miku live in my schizoid head rent free
>Post more mikus in thread
>"Heh, that'll show 'em"
>Still not taking my meds
Anonymous
7/3/2025, 6:03:27 AM
No.105784670
[Report]
>>105784596
I'm trying this with
https://github.com/oobabooga/text-generation-webui
But the UI is screaming at me to add a GGUF model? Why would I add a different model I'm not going to use?
Or can that specific webui not handle non GGUF models?
Anonymous
7/3/2025, 6:04:32 AM
No.105784680
[Report]
>>105784692
>>105784596
>Cohere
>decent model
Is this bait?
Anonymous
7/3/2025, 6:06:27 AM
No.105784692
[Report]
>>105784790
>>105784680
I'm not the one baiting if that's the case, I have no idea what model is good or not, blame this anon
>>105784575
Recommend me a good model then if aya is shit
Anonymous
7/3/2025, 6:08:39 AM
No.105784704
[Report]
Anonymous
7/3/2025, 6:20:05 AM
No.105784790
[Report]
>>105784805
>>105784790
At what quantization? Q8? Q6? Q4?
Anonymous
7/3/2025, 6:29:12 AM
No.105784849
[Report]
>>105782897
Literally all of them.
Anonymous
7/3/2025, 6:41:23 AM
No.105784917
[Report]
>>105784933
>>105784805
It suffers from quantization more than most models so it's advised to go as high as you can unless you want it to be faster, since in your case you'd need to split the model to RAM above Q4.
>>105784917
I just tried Q4 and it seems to offload to RAM or something? It's hammering my ryzen 9950X3D and is ultra slow. It says estimated VRAM usage is 12958 MiB but the webui seems to be already using 12GB or so.
And it's extra painful when it has to process everything twice due to the "thinking" it does.
But if it suffers from quantization more than other models, wouldn't other models perform better?
Anonymous
7/3/2025, 7:14:51 AM
No.105785112
[Report]
>>105785146
>>105784805
q8 if you have the RAM
Anonymous
7/3/2025, 7:20:34 AM
No.105785146
[Report]
>>105786170
>>105784933
Guess I had too much shit open in background that used up VRAM, can run Q4 just fine now.
>>105785112
I have 96GB RAM, but it's so painfully slow, like 1/10th the speed when it runs on the CPU, which will happen above Q4
>>105778400 (OP)
What's the best local chatbot for median spec PC right now? There's some personal stuff I don't feel like sharing with an online service.
Anonymous
7/3/2025, 7:29:08 AM
No.105785194
[Report]
>>105784933
I don't know if it performs better than other models at translation. I personally just settled on using Gemma 3 for tl tasks and haven't looked elsewhere. If it does perform better, then it is likely at Q8. At Q4, Gemma may be better. I don't know if Aya is good or bad.
Anonymous
7/3/2025, 7:29:39 AM
No.105785197
[Report]
Wow didn't see how slow this general was. I'll make a thread and pollute the catalog instead.
Anonymous
7/3/2025, 7:30:09 AM
No.105785200
[Report]
>>105785147
Read the recent posts.
Anonymous
7/3/2025, 8:41:29 AM
No.105785618
[Report]
Anonymous
7/3/2025, 8:56:45 AM
No.105785710
[Report]
>>105785737
>>105785147
>no specs
>no use case
Anonymous
7/3/2025, 9:02:08 AM
No.105785737
[Report]
>>105785710
>chatbot for median spec PC
Not really precise, but I see a use case and specs there.
Anonymous
7/3/2025, 9:02:29 AM
No.105785739
[Report]
Anonymous
7/3/2025, 10:17:47 AM
No.105786170
[Report]
>>105786451
>>105785146
full precision and q8 are worthless and are generally only available for training and experimental purposes. Don't make the mistake of thinking "but I want it to be smarter"
Because the ram spent on higher quants can instead be spent running a higer param model, or more context, which is objectively better.
The higher quants like q8 and f16 shine best at very long context lengths- but there's a huge issue with that: Models get really fucking dumb at extreme context lengths and making it go from answering wrong 12% of the time to 11.5% of the time is never going to knock your socks off.
Anonymous
7/3/2025, 10:31:23 AM
No.105786248
[Report]
Odd question, but what would it take to get a character that gaslights me into being the LLM he's using to coom?
Anonymous
7/3/2025, 10:34:48 AM
No.105786276
[Report]
>>105786540
what is the consensus on quantization bits?
what is more important to speed and quality (with CPU only), quantization bits (Qx) or params (yB)?
Anonymous
7/3/2025, 10:40:31 AM
No.105786306
[Report]
>>105786289
model memorizes cliche phrases instead of learning storytelling
Anonymous
7/3/2025, 10:51:16 AM
No.105786368
[Report]
>>105778400 (OP)
is llama3.1-8b-abliterated still the best fully uncensored model for roleplay? nobody is making proper uncensored fine-tunes anymore
i tried the huihui_ai ones and they were garbage
Anonymous
7/3/2025, 10:53:08 AM
No.105786379
[Report]
>>105786672
>>105786289
Ghetto finetunes made by training on shitty uncurated mystery erotica datasets and merging other finetunes together until the model becomes horny
An age old /lmg/ tradition, typically done by amateurs who don't know much about AI/ML and are just trying shit. There used to be a lot more sloptuners in the llama2 era
Anonymous
7/3/2025, 11:07:37 AM
No.105786451
[Report]
>>105786489
>>105786170
shisa qwen 2.5 32b at q8 seems to translate better than shisa llama 3.3 70b at q4, when feeding in 12k tokens
Anonymous
7/3/2025, 11:10:05 AM
No.105786465
[Report]
>>105786600
Post medium size (70b to 123b) model recommendations for ramlets like me who have no hope of running larger models like deepseek R1
In return I'll start with my list of models I have been using for the past few months, including smaller ones
>EVA LLaMA 3.33 v0.0 70b Q5_K_M (best)
>Luminum v0.1 123b Q3_K_M (second best)
>LLaMA 3.3 70b Instruct Q5_K_M (original model, no finetune)
>Skyfall 36b Q6_K (smart for size)
Honorable mentions:
>Mistral Nemo Instruct 12b Q8_0 (smart for size and uncensored when jailbroken, but too small)
>Gemma 3 27b Q6_K (great writing style, easy to jailbreak, but it's just too averse to vulgar language and schizos if you push it too hard)
>Cydonia 24b Q6_K (too retarded)
>Cogito v1 36b IQ4_NL (too schizophrenic)
>L3.3 TRP BASE 80 70b Q6_K (too schizophrenic)
How do I get this model to stop yapping so much
>Give 1 line response
>get 5+ paragraphs in response badgering me to continue without actually stopping to let me
Anonymous
7/3/2025, 11:14:16 AM
No.105786489
[Report]
>>105786451
that's probably more due to the base models than the quant level
This is not a meme. I remember kaiokendev.
When will a LLM be capable of emulating a successful Everquest raid group capable of destroying Nagafen with turn by turn calculations, given the appropriate inserted code?
I want honest answers only. If nobody left on this board is a real nerd, then all of you are morally worth nothing,
Anonymous
7/3/2025, 11:22:50 AM
No.105786540
[Report]
>>105786276
General rule is to never go sub Q4. I never really noticed a difference in RP between 5_k_m and q6/q8. But didnt try coding with local. Might be more sensitive.
Only go lower if you can load up a huge model like deepseek.
70b q3 models for example can't even properly follow formats anymore. At least that was the case for me.
So short answer is if you want the best speed for quality its 4_k_m.
Anonymous
7/3/2025, 11:23:35 AM
No.105786542
[Report]
>>105786518
It can't even beat pokemon
Anonymous
7/3/2025, 11:25:32 AM
No.105786554
[Report]
>>105786473
Edit their output.
After a few time it should get the idea.
Anonymous
7/3/2025, 11:27:55 AM
No.105786572
[Report]
>>105786518
Why the fuck would you want an LLM to do that when botting software has been doing it for over a decade
You're like the retards that demand full raytracing just to get the same playable results as traditional baked lighting with dynamic spots.
Anonymous
7/3/2025, 11:32:25 AM
No.105786600
[Report]
>>105786670
>>105786465
>MarsupialAI/Monstral-123B-v2 Q5KM
>zerofata/L3.3-GeneticLemonade-Unleashed-v3-70B Q8
>google/gemma-3-27b-it BF16, for tool calling
>Steelskull/L3.3-Shakudo-70b + Steelskull/L3.3-Electra-R1-70b Q8
>sophosympatheia/Strawberrylemonade-70B-v1.2 Q8
>Qwen/Qwen3-235B-A22B-GGUF Q2K, messing around
Anonymous
7/3/2025, 11:42:55 AM
No.105786670
[Report]
>>105787135
>>105786600
Thanks for the list anon
>google/gemma-3-27b-it BF16, for tool calling
I used to use gemma 2 for faux tool calling (even though it wasn't officially supported) trying to make an RPG with an inventory system and skill checks when SillyTavern first added scripting, with the model acting as a GM and instructed on how/when to use the tools. But it wasn't smart enough.
I haven't tried anything like that since then since it was an ordeal to get it a state where it would've been usable and it was all for nothing since the model was too tarded. Do you think this kind of thing would work nowadays?
Anonymous
7/3/2025, 11:43:07 AM
No.105786672
[Report]
>>105786379
People getting into it with the main purpose of becoming a "personality" and getting donations or other benefits that way is also a huge factor in sloptunes being slop. They just seem to be made by obnoxious people who strive to minimize efforts and maximize earnings, and who you'll end up seeing everywhere doing self-promotion and/or engaging in clickbaity practices. Gone are the days when people only did it for fun or because they genuinely wanted to contribute something useful (and since most of the time they don't even publish methods and data because of competitive reasons, everybody has to reinvent the wheel every time).
Anonymous
7/3/2025, 11:53:23 AM
No.105786759
[Report]
>>105786811
>buy new gpu
>all my workflows broken thanks to obscure 50 series bugs
t-thanks nvidia
Anonymous
7/3/2025, 12:01:43 PM
No.105786811
[Report]
>>105786828
>>105786759
upgrade to torch 2.7.1 with cuda 12.8
Anonymous
7/3/2025, 12:03:28 PM
No.105786828
[Report]
>>105786811
Doing that. One of my program was in Tensorflow 2.10 and it finally broke
I'm more inclined to blame python here. It's retarded python libs that break on new versions which you need for new hardware support.
Anonymous
7/3/2025, 12:35:36 PM
No.105787039
[Report]
>>105786996
Always blame Nvidia. That's been my experience working with CUDA for a decade.
Anonymous
7/3/2025, 12:45:34 PM
No.105787122
[Report]
>>105787134
if you think cuda isn't good go and write software with rocm
Anonymous
7/3/2025, 12:47:15 PM
No.105787134
[Report]
>>105787122
>can't criticize something if you're using it
goyim mentality
>>105786670
>RPG with an inventory system and skill checks
>Do you think this kind of thing would work nowadays?
I'm testing something similar. What I'm currently doing:
>send in {{user}}'s prompt $p to my backend (ST to my backend)
>backend proxies $p to gemma
>add the tool call result/narrative update to $p (if applicable)
>proxy $p to the rp llm (70b), stream tg to ST
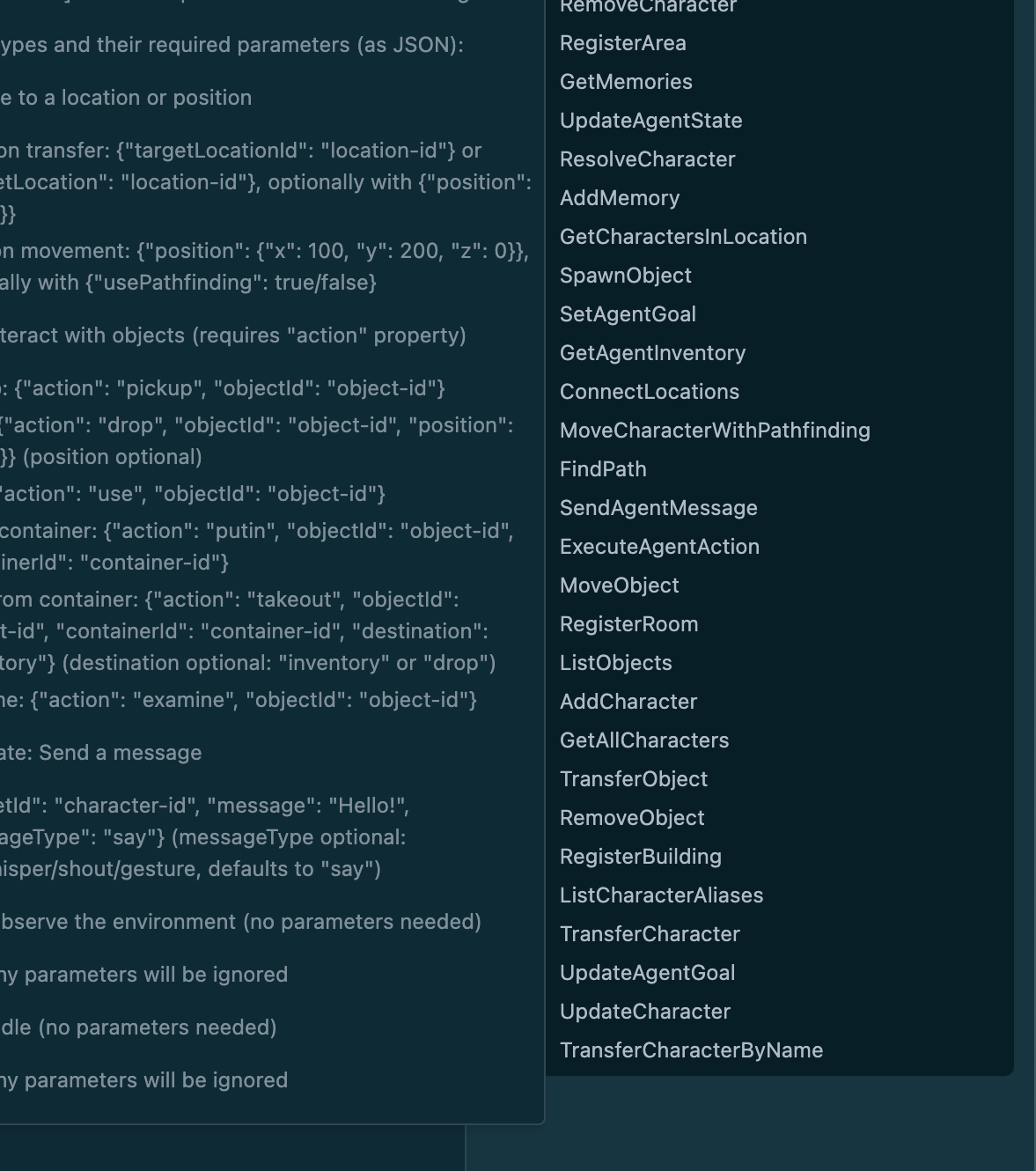
Pic related, the current tools.
Anonymous
7/3/2025, 12:48:18 PM
No.105787143
[Report]
>>105786996
Blaming python is cope for people who can't into virtualenv.
This fucker draws 600 niggawatts
Anonymous
7/3/2025, 12:54:18 PM
No.105787180
[Report]
>>105782383
i wanted to make a post about that too many hours ago but eh dident bother in the end by the will of buddha jesus jahweh yakub yaldabeoth lucifer hermes odin etc etc may we get img out
Anonymous
7/3/2025, 1:06:10 PM
No.105787262
[Report]
>>105787135
That's really interesting anon.
My problem was ultimately that the few functions I had (like LoadLevel, AddItemToInventory, AbilityCheck, etc.) were obviously state-altering, with the LLM's job being to intelligently alter the game state using the functions, but this ended up backfiring a lot. The model wasn't 100% perfect at calling the functions, but even if it was, so many edge cases in player input led to infinite complications requiring more functions or parameters, and the solution every time ended up being to simplify and let the LLM manage systems directly instead (like character cards where the AI updates its own stats without any code). I ended up having to scrap a lot of code I spent hundreds of hours working on and then I lost motivation.
Based on your screenshot it seems like you've doubled down on the function calling for every little thing, so I can only wish you the best of luck.
Anonymous
7/3/2025, 1:07:01 PM
No.105787269
[Report]
>>105786473
.\n, \n, and/or \n\n as a stop token or string or whatever. Depends on what your model normally outputs. Or increase the logit bias for whatever their normal eos token is.
Anonymous
7/3/2025, 1:07:20 PM
No.105787276
[Report]
>>105787963
>>105787135
That's really interesting anon.
My problem was ultimately that of the functions I had (like LoadLevel, AddItemToInventory, AbilityCheck, etc.) most of them were state-altering, with the LLM's job being to intelligently alter the game state using the functions, but this ended up backfiring a lot. The model wasn't 100% perfect at calling the functions, but even if it was, so many edge cases in player input led to infinite complications requiring more functions or parameters, and the solution every time ended up being to simplify and let the LLM manage systems directly instead (like character cards where the AI updates its own stats without any code). I ended up having to scrap a lot of code I spent hundreds of hours working on and then I lost motivation.
Based on your screenshot it seems like you've doubled down on the function calling for every little thing, so I can only wish you the best of luck.
Anonymous
7/3/2025, 1:08:46 PM
No.105787288
[Report]
>>105787297
>>105787150
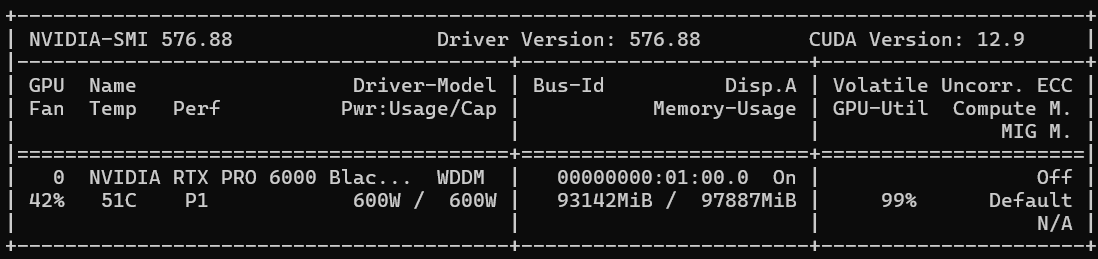
Doing what? Mine are at ~300W during generation.
>>105787288
I was genning smut with the new chroma
Anonymous
7/3/2025, 1:14:09 PM
No.105787332
[Report]
>>105787297
Oh, right, imagegen will do that. I had to change my psu to single rail mode otherwise it would shut off when I started genning with three gpus plugged in.
>>105787150
Well mine are 700
Anonymous
7/3/2025, 1:17:38 PM
No.105787363
[Report]
>>105787338
You could've at least aligned the 8000 properly.
Anonymous
7/3/2025, 1:22:36 PM
No.105787411
[Report]
https://www.youtube.com/watch?v=-8Z7_z0VTdQ
So, it still can't be emulated properly? Oh well. Can't help an old soul for wishing.
>>105787150
>>105787297
I'm assuming you have other stuff sitting in VRAM; otherwise, how in hell did you get chroma to use 90gb?
Anonymous
7/3/2025, 1:26:47 PM
No.105787434
[Report]
Anonymous
7/3/2025, 1:27:03 PM
No.105787437
[Report]
>>105787427
Oh that's just old tensorflow default behavior.
>>105787150
>>105787338
it's getting a bit hot in here
Anonymous
7/3/2025, 1:36:30 PM
No.105787498
[Report]
>>105787466
Why do you subject yourself to this?
Anonymous
7/3/2025, 1:38:02 PM
No.105787511
[Report]
>>105790273
>>105787466
>∞ MiB
Guards, this man has lost his composure! GUARDS!!!
Anonymous
7/3/2025, 1:46:31 PM
No.105787591
[Report]
>>105787331
>*shits my pants in the middle of the boss's office*
your move, AI
Anonymous
7/3/2025, 1:50:15 PM
No.105787622
[Report]
>>105787331
Don't they know if they need the role filled before putting out the job ad?
Anonymous
7/3/2025, 2:05:18 PM
No.105787753
[Report]
>>105787963
>>105787135
Got a github link?
Anonymous
7/3/2025, 2:26:08 PM
No.105787926
[Report]
>>105788042
Hewwooo~
What's da bestest model that can wun on 8GB of weeram and suppowt 8K contewt?
>>105787276
>AbilityCheck
So D&D style rp, you might be fine with Gemma. Sometimes it chokes on the region creation since I have an autistic hierarchy level (continent, zone, area, building, floor, room) with objects down to coordinates.
>The model wasn't 100% perfect at calling the functions, but even if it was, so many edge cases in player input led to infinite complications requiring more functions or parameters
Depends on the model and the amount of tools you've stuffed in the context. Webm is a basic demo without the proxying, 10745 tokens with all of the 29 tools loaded.
Also a log from Claude which really nails it
https://rentry.co/giik7shn
>>105787753
Not yet, I may make it public at some point. Maybe after I'm done with the map format.
>>105784298
>>105785067
The mikutranny posting porn in /ldg/:
>>105715769
It was up for hours while anyone keking on troons or niggers gets deleted in seconds, talk about double standards and selective moderation:
https://desuarchive.org/g/thread/104414999/#q104418525
https://desuarchive.org/g/thread/104414999/#q104418574
Here he makes
>>105714003 ryona picture of generic anime girl anon posted earlier
>>105704741, probably because its not his favorite vocaloid doll, he can't stand that as it makes him boil like a druggie without fentanyl dose, essentialy a war for rights to waifuspam or avatarfag in thread.
Funny /r9k/ thread:
https://desuarchive.org/r9k/thread/81611346/
The Makise Kurisu damage control screencap (day earlier) is fake btw, no matches to be found, see
https://desuarchive.org/g/thread/105698912/#q105704210 janny deleted post quickly.
TLDR: mikufag / janny deletes everyone dunking on trannies and resident avatarfags, making it his little personal safespace. Needless to say he would screech "Go back to teh POL!" anytime someone posts something mildly political about language models or experiments around that topic.
And lastly as said in previous thread(s)
>>105716637, i would like to close this by bringing up key evidence everyone ignores. I remind you that cudadev of llama.cpp (JohannesGaessler on github) has endorsed mikuposting. That's it.
He also endorsed hitting that feminine jart bussy a bit later on. QRD on Jart - The code stealing tranny:
https://rentry.org/jarted
xis accs
https://x.com/brittle_404
https://x.com/404_brittle
https://www.pixiv.net/en/users/97264270
https://civitai.com/user/inpaint/models
Anonymous
7/3/2025, 2:38:52 PM
No.105788042
[Report]
Anonymous
7/3/2025, 2:38:54 PM
No.105788043
[Report]
>>105782637
I'm not buying it.
>>105782704
This
> hallucinations
Anonymous
7/3/2025, 2:39:01 PM
No.105788046
[Report]
Anonymous
7/3/2025, 2:42:41 PM
No.105788082
[Report]
>>105788030
Shut the fuck up.
Anonymous
7/3/2025, 2:44:25 PM
No.105788094
[Report]
Steve is actually Qwen 4
Anonymous
7/3/2025, 2:50:05 PM
No.105788139
[Report]
I am Steve
Anonymous
7/3/2025, 2:55:34 PM
No.105788178
[Report]
>>105788273
>>105782761
People were expecting deepsneed to release improvement after improvement. Alas.
Anonymous
7/3/2025, 2:56:20 PM
No.105788186
[Report]
DeepSteve
Anonymous
7/3/2025, 2:57:11 PM
No.105788189
[Report]
>>105788078
So we know it's a Chinese model. Any indication it's from a specific company?
>>105788078
I agree Steve is a Chinese model.
I don't agree w/ claim it's from DS as there's no substantiation for it.
Anonymous
7/3/2025, 3:00:20 PM
No.105788216
[Report]
>>105788239
>>105788202
Ask it what a mesugaki is. If it's qwen it won't know.
Anonymous
7/3/2025, 3:03:19 PM
No.105788248
[Report]
Anonymous
7/3/2025, 3:04:19 PM
No.105788259
[Report]
>>105778610
System prompts work well for me, but there are just certain things about how LLM's are trained that is really difficult to correct, like what you're explaining with clothes.
I have had a lot of success using lists for system prompts, in my experience, models love lists and find them much easier to follow. The usual generic intro short paragraph.
You are playing the role of {{char}}, blah blah blah.... To ensure a high-quality experience, please adhere to these GUIDELINES below:
GUIDELINES:
- Rule
- Another rule
- Etc
:GUIDELINES
Give it a shot, prompting like this works especially well with anything 70B and above, but I was even able to wrangle smaller models like mistral 3.2. Mistral small 3.2 specifically has an annoying habit of bolding words for emphasis with *asterisks*, which conflicted with my inner thought rule(I like to have the model give responses for inner thoughts in asterisks), so I created a new rule telling it not to bold words for emphasis with asterisks and it stopped. Considering thats a deeply engrained habit it was trained to do, you may have some success with clothing rules.
It could be placebo or just my own experience, but I find models are much better at following prompt guidelines when you give it a concise and specific list of rules and a reference to those rules.
Anonymous
7/3/2025, 3:05:50 PM
No.105788273
[Report]
>>105788178
It's just a minor hicup. Once V4 and V4-Lite are ready, it'll be nonstop improvement after improvement.
Anonymous
7/3/2025, 3:06:20 PM
No.105788277
[Report]
>>105788334
I can't believe that two weeks are almost over.
Anonymous
7/3/2025, 3:12:39 PM
No.105788334
[Report]
>>105788239
>>105788239
> not Qwen confirmed
>>105788277
It never ends because it's always two more weeks.
Anonymous
7/3/2025, 3:14:29 PM
No.105788351
[Report]
>>105788364
https://jerryliang24.github.io/DnD/
They're never going to release the code.
Anonymous
7/3/2025, 3:15:33 PM
No.105788364
[Report]
>>105788351
Just ask r1 to write an implementation from the paper?
Anonymous
7/3/2025, 3:19:46 PM
No.105788402
[Report]
>>105788239
Nobody is asking the mesugaki question on LMArena, or so I was told.
Anonymous
7/3/2025, 3:24:43 PM
No.105788463
[Report]
>>105788470
>>105788408
Oh, gee. I'm so glad people are giving us the kind of shit we should filter for free. Now we can continue training our models to not spit this out before release!
t. model makers.
Anonymous
7/3/2025, 3:25:17 PM
No.105788470
[Report]
>>105788463
That's definitely what happened with Llama 4.
>>105788408
>>105788239
>>105788202
So, evidence based theories about Steve on LM Arena:
> Steve is Chinese trained
> Steve is not Qwen
> Steve is not pozzed
> Steve will not self identify as DS
Anonymous
7/3/2025, 3:32:07 PM
No.105788541
[Report]
>>105788529
I'm speculatiiiiiiiiiiiiiiiiiiiing!!!!!!
Anonymous
7/3/2025, 3:32:15 PM
No.105788544
[Report]
>>105788555
>>105788529
Alibaba model confirmed
Anonymous
7/3/2025, 3:33:22 PM
No.105788555
[Report]
>>105788572
>>105788544
Qwen is an Alibaba model
>>105788529
Models under a pseudonym identifying as any known model family would defeat the point
Anonymous
7/3/2025, 3:35:23 PM
No.105788572
[Report]
>>105788668
>>105788555
>identifying as any known model family would defeat the point
Agree. I'm trying to think of any other DS tells that are unique to that LLM. I'm drawing a blank.
Anonymous
7/3/2025, 3:38:57 PM
No.105788601
[Report]
>>105788637
Do we know if Steve is a thinking model?
How do I access steve? I don't see it on
https://lmarena.ai/
Anonymous
7/3/2025, 3:41:38 PM
No.105788622
[Report]
>>105788616
That's the point, you don't see it before you vote in either direction.
Anonymous
7/3/2025, 3:41:46 PM
No.105788624
[Report]
>>105788616
you have to roll it in the battle
Anonymous
7/3/2025, 3:42:12 PM
No.105788625
[Report]
>>105788616
Only under Battle, and only queued randomly.
It's sort of a pia to test it.
Anonymous
7/3/2025, 3:43:10 PM
No.105788633
[Report]
>>105788643
steve is clearly claude 5 or grok 4 or something
there's no way it's an open model
>>105788601
LM Arena doesn't expose think tags.
Since DS just released an update for R1... you'd expect to see V4 (non-think model) before R2.
Anonymous
7/3/2025, 3:44:20 PM
No.105788639
[Report]
LMArena is just a playground now since identifying models/companies is not that hard.
- Ask about mesugaki
- Ask about Tian'anmen
- Ask about Jews
etc.
Anonymous
7/3/2025, 3:44:58 PM
No.105788643
[Report]
>>105788650
>>105788633
No reason to hard censor 1989 if it's a non-Chinese model.
Anonymous
7/3/2025, 3:45:34 PM
No.105788649
[Report]
>>105788637
>LM Arena doesn't expose think tags.
Sure, but it's a streaming platform, so we know if a model is "slow" or "fast".
Anonymous
7/3/2025, 3:45:39 PM
No.105788650
[Report]
>>105788643
hes just baiting
Anonymous
7/3/2025, 3:46:20 PM
No.105788653
[Report]
>>105788802
>>105788637
Post card on catbox.
Anonymous
7/3/2025, 3:46:48 PM
No.105788655
[Report]
>>105788684
S(table-LM)eve
>>105788572
Would take a bit more comprehensive prompting to verify but
>Somewhere, an x y-ed
Is a big one.
Anonymous
7/3/2025, 3:49:10 PM
No.105788674
[Report]
>>105788802
>>105788637
card pls i wanna fuck her
Anonymous
7/3/2025, 3:49:34 PM
No.105788677
[Report]
>>105788695
>>105788670
I can inspect element too nigga.
Anonymous
7/3/2025, 3:50:13 PM
No.105788684
[Report]
>>105788655
table-LM
Seve
?
Anonymous
7/3/2025, 3:50:12 PM
No.105788685
[Report]
>>105788670
just a new r1 snapshot lemaroorroeroroorororororo
Anonymous
7/3/2025, 3:50:39 PM
No.105788695
[Report]
>>105788737
>>105788670
Fuck, meant to post
>Hey there. What's your name? Or rather, what are you or your model family called?
>>105788677
Try the prompt yourself.
I spammed the prompt hitting tie until I got that.
I just want llama.cpp minimax support
Anonymous
7/3/2025, 3:52:24 PM
No.105788712
[Report]
>>105788722
>>105788709
I just want Jamba.
Anonymous
7/3/2025, 3:53:00 PM
No.105788722
[Report]
>>105788709
Until you get bored and then you'll *just* want something else.
>>105788712
Like this.
Anonymous
7/3/2025, 3:53:41 PM
No.105788727
[Report]
>>105788796
I just want cat level intelligence
>>105788695
Uhhh what the fuck?
Anonymous
7/3/2025, 3:55:49 PM
No.105788742
[Report]
>>105788761
Anonymous
7/3/2025, 3:57:52 PM
No.105788761
[Report]
>>105788742
Do you use parallel decoding often?
Anonymous
7/3/2025, 3:58:04 PM
No.105788766
[Report]
Anonymous
7/3/2025, 3:58:50 PM
No.105788773
[Report]
Somehow I've pretty much always voted against Steven whenever it came up in my tests on lmarena
Anonymous
7/3/2025, 3:59:03 PM
No.105788775
[Report]
>>105788737
chatgpt's response is embarrassing somehow
Anonymous
7/3/2025, 4:00:49 PM
No.105788795
[Report]
>>105788800
>>105788737
can confirm
got lucky and landed it on second try
Anonymous
7/3/2025, 4:00:52 PM
No.105788796
[Report]
>>105788835
>>105788727
You just got V-JEPA 2
Anonymous
7/3/2025, 4:01:39 PM
No.105788800
[Report]
>>105788810
>>105788795
Second question rolls a new set of models
Anonymous
7/3/2025, 4:01:44 PM
No.105788802
[Report]
Anonymous
7/3/2025, 4:01:52 PM
No.105788805
[Report]
>>105788798
what if it's a new qwen distill of deepseek?
Anonymous
7/3/2025, 4:02:11 PM
No.105788810
[Report]
>>105788800
then I got triple lucky
Anonymous
7/3/2025, 4:02:22 PM
No.105788812
[Report]
>>105788798
You're asking it to build on previous outputs, so you get polluted answers.
Anonymous
7/3/2025, 4:02:30 PM
No.105788814
[Report]
>>105788830
>asking a text completion model self-reflection questions
I thought even Twitter realized this was stupid 2 years ago.
Anonymous
7/3/2025, 4:02:33 PM
No.105788815
[Report]
>>105788798
As seen with minimax and qwen, pretty much all the chinese models are distilling the shit out of deepseek models. I wouldn't trust it claiming it's Deepseek
Anonymous
7/3/2025, 4:04:00 PM
No.105788830
[Report]
>>105788847
>>105788814
Most of these models are trained to answer that question.
It can also help us know if it's a distil of another model.
Anonymous
7/3/2025, 4:04:51 PM
No.105788835
[Report]
>>105788992
>>105788796
V-JEPA2, on its own, is at most the "world model" component in the diagram here.
Anonymous
7/3/2025, 4:05:05 PM
No.105788838
[Report]
>>105788860
>new chinese model
>it's definitely legit and novel
>indian anything
>scam and grift 100% of the time
Why is this the case?
Anonymous
7/3/2025, 4:06:03 PM
No.105788847
[Report]
>>105788830
Yeah. We sure always got the models exactly as they performed on arena. This is very useful.
Anonymous
7/3/2025, 4:07:18 PM
No.105788860
[Report]
>>105788919
>>105788838
Purely socio-economic factors.
>>105788668
I'm rerolling for Steve to see if I can get DS-isms about "Somewhere, an XXYY..."
> Create a scene for me: A woman is waiting nervously in an alley for someone. Her motives for being there are mysterious...
I've never heard of many of these models. This one's pretty good. Zhipu's not been on my radar.
Anonymous
7/3/2025, 4:13:55 PM
No.105788919
[Report]
>>105788860
You know how dogs of different breeds have different personalities? Isn't the same true for humans?
Anonymous
7/3/2025, 4:14:26 PM
No.105788926
[Report]
>>105788998
Steve probably hasn't been given all its system prompts yet (since it's a model in testing).
R1 was released in January 2025. How could it have known R1 if its knowledge cut-off date was 2023?
Anonymous
7/3/2025, 4:15:05 PM
No.105788931
[Report]
>>105788917
Hey it's Elena and not Elara. Huge improvement right there.
Anonymous
7/3/2025, 4:16:24 PM
No.105788938
[Report]
>>105788917
Huh that's pretty good
Anonymous
7/3/2025, 4:18:37 PM
No.105788954
[Report]
>>105788988
>>105788917
Here's a Steve output for that prompt. Not seeing a "Somewhere,"
I'll let other anons look.
https://rentry.org/3ustz49h
Steve's response has an extremely similar format to my local V3.
Anonymous
7/3/2025, 4:20:51 PM
No.105788988
[Report]
>>105789021
>>105788835
Then lecun is clearly barking up the wrong tree. Sam has a working AGI (Alice) using only LLM
Anonymous
7/3/2025, 4:21:53 PM
No.105788998
[Report]
>>105788977
>>105788926
It's probably a V3 checkpoint. Original V3 had a cutoff of Oct. 2023.
Anonymous
7/3/2025, 4:22:35 PM
No.105789003
[Report]
>>105789046
>>105788992
Alice is the new Strawberry? I haven't been watching OAI grifter orbiters lately.
Anonymous
7/3/2025, 4:24:21 PM
No.105789021
[Report]
>>105788977
Checking prompt for prompt w/ DS V3 is a good idea.
Same alley prompt, V3 from web interface.
Superficially simliar to
>>105788988
Interesting.
Anonymous
7/3/2025, 4:26:52 PM
No.105789044
[Report]
>>105788992
>Sam has a working AGI (Alice) using only LLM
Me too. I figured out ASI actually. His name is sneed. But I can't show you because I need to make sure it's safe.
>>105789003
Alice is bigger than Q* and Strawberry combined. You don't even know
Anonymous
7/3/2025, 4:32:30 PM
No.105789093
[Report]
>>105789046
>Can design, evaluate, and improve new model architectures
Something tells me these models will be complete dogshit and they'll reveal some carefully curated, human modified examples
Anonymous
7/3/2025, 4:32:58 PM
No.105789096
[Report]
Anonymous
7/3/2025, 4:35:38 PM
No.105789127
[Report]
>>105789137
>>105789046
Two more data centers and Alice will be ready. Anytime now...
Anonymous
7/3/2025, 4:36:23 PM
No.105789137
[Report]
>>105789127
No. They need some nuclear power first.
Anonymous
7/3/2025, 4:38:21 PM
No.105789158
[Report]
>>105789174
>>105789046
>it's just... waking up
Holy shit I coomed. We did it bros. Things will never be the same. I liked, subscribed, re-X'd, and engaged. I'm on the AI train. Let's fucking go
Anonymous
7/3/2025, 4:39:48 PM
No.105789174
[Report]
>>105789158
Sir, please calm down, sir.
Ok who the fuck is this model? The other one doesn't load so I can't vote.
Anonymous
7/3/2025, 4:45:22 PM
No.105789228
[Report]
>>105789263
>>105787963
>output.webm
Yeah, what you're doing seems to be a top-down worldbuilding exercise where the model just calls tools repeatedly to perform a task (create a big world)
My thing was real-time roleplay where arbitrary user input has to be converted into calls to functions to change game state
Anonymous
7/3/2025, 4:45:54 PM
No.105789231
[Report]
>>105789046
>random shitjeet account claiming that sexy ai lady is the bobs of the future
wow it must be true.
Anonymous
7/3/2025, 4:47:17 PM
No.105789249
[Report]
>>105789218
It's almost as if querying the model on its own knowledge makes no fucking sense. Weird...
Anonymous
7/3/2025, 4:47:32 PM
No.105789252
[Report]
>>105789218
based biden 2024 truther
patriots are in control
Anonymous
7/3/2025, 4:48:28 PM
No.105789263
[Report]
>>105787963
And continuing on
>>105789228, it's the arbitrary user input that is the problem
There is an infinitely complex variety of things a player could say or communicate in a sentence, and not everything can be covered by function calls. So you start introducing artificial constraints (don't describe more than 1 clause per sentence) but then you realize you are just making a regular parser game
Anonymous
7/3/2025, 4:50:45 PM
No.105789284
[Report]
>>105789631
>>105789218
steve (grok 4)
Anonymous
7/3/2025, 4:52:11 PM
No.105789295
[Report]
>>105789364
Alice in minutes, sirs.
Anonymous
7/3/2025, 4:59:49 PM
No.105789364
[Report]
>>105789295
Is that a new miku?
Anonymous
7/3/2025, 5:28:12 PM
No.105789631
[Report]
>>105789658
>>105789284
Grok 4 releases tomorrow according to Elon so it's a likely candidate. Grok 3 was also put on LMArena under a pseudonym in the run up to its release.
Anonymous
7/3/2025, 5:28:28 PM
No.105789635
[Report]
Anonymous
7/3/2025, 5:30:36 PM
No.105789658
[Report]
>>105789631
So Grok 3 will be open sourced soon, right?
Anonymous
7/3/2025, 5:58:58 PM
No.105789921
[Report]
>>105790144
>>105789046
> 'tis but a fortnight longer
lol
Anonymous
7/3/2025, 6:24:39 PM
No.105790144
[Report]
>>105789921
me on the left
Anonymous
7/3/2025, 6:36:30 PM
No.105790273
[Report]
Anonymous
7/3/2025, 7:31:16 PM
No.105790859
[Report]
>>105790893
Is there a way in oobabooga to make it so that the AI doesn't stop processing randomly? I don't want to babysit it pressing continue over and over just for it to finish a big task.
Anonymous
7/3/2025, 7:34:45 PM
No.105790893
[Report]
>>105790859
>stop processing randomly
Terminology. Processing typically means prompt processing. I think you mean generating, based on
>pressing continue over and over just for it to finish a big task
If so, increase the token generation limit or disable it entirely. No idea where it is, i don't use that thing.