/lmg/ - Local Models General
Anonymous
7/16/2025, 2:33:22 PM
No.105925450
[Report]
►Recent Highlights from the Previous Thread:
>>105917222
--Papers:
>105921462
--Skepticism about whether current model sizes are truly necessary or just a result of inefficiency:
>105918785 >105918853 >105918890 >105918912 >105918956 >105919010 >105918966 >105918995 >105919089 >105919113 >105921198 >105921227 >105921277 >105921316
--Integrating Hugging Face chat templates with local model frontends like SillyTavern:
>105917912 >105917987 >105917997 >105918038 >105918060
--DGX Spark reservations face criticism over insufficient memory for modern MoE models:
>105918232 >105918318 >105918677 >105918699 >105918823 >105918983
--Building a cross-platform GUI for local LLMs with vector DBs and responsive audio features:
>105921444 >105921513 >105921583 >105921658 >105921929 >105921959
--ETH Zurich's 70B model raises questions about data quality vs quantity under strict legal compliance:
>105919695 >105919722 >105919749 >105919753
--Exploring censorship bypass techniques and parameter efficiency in open language models:
>105921167 >105921271 >105921288 >105921389 >105921433 >105921443 >105921651 >105922212 >105922274 >105922332 >105922382
--Liquid AI releases LFM2 models with strong on-device performance and efficiency benchmarks:
>105917528 >105918178
--Transformer limitations in handling negation and enforcing instruction compliance:
>105919332 >105919414 >105919454 >105919503 >105919654 >105919796 >105919857 >105920094 >105919477 >105919497 >105919502 >105919861
--Voxtral-Small-24B-2507 released with advanced speech understanding capabilities:
>105918762
--Kimi-K2 model support added to llama.cpp:
>105918590
--Logs: Kimi K2:
>105925070 >105925407
--Miku (free space):
>105918232 >105919784 >105919938 >105920968 >105921065 >105921334 >105921349 >105924483 >105924916
►Recent Highlight Posts from the Previous Thread:
>>105917229
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
Anonymous
7/16/2025, 2:38:33 PM
No.105925501
[Report]
>>105925528
>>105925446 (OP)
>tittymogging
Basado
Hey Faggots,
My name is John, and I hate every single one of you. All of you are fat, retarded, no-lifes who spend every second of their day looking at stupid ass pictures. You are everything bad in the world. Honestly, have any of you ever gotten any pussy? I mean, I guess it's fun making fun of people because of your own insecurities, but you all take to a whole new level. This is even worse than jerking off to pictures on facebook.
Don't be a stranger. Just hit me with your best shot. I'm pretty much perfect. I was captain of the football team, and starter on my basketball team. What sports do you play, other than "jack off to naked drawn Japanese people"? I also get straight A's, and have a banging hot girlfriend (She just blew me; Shit was SO cash). You are all faggots who should just kill yourselves. Thanks for listening.
Pic Related: It's me and my bitch
>>105925501
New whitness map?
Anonymous
7/16/2025, 2:41:57 PM
No.105925529
[Report]
At least add a twist to the copypasta or something.
>>105925528
pajeetbros... we're finally going recognized as aryans...
Anonymous
7/16/2025, 2:44:02 PM
No.105925540
[Report]
>>105925446 (OP)
It's ok Miku, I like little girls. Unfortunately you are a bit too old for my tastes too.
Anonymous
7/16/2025, 2:44:49 PM
No.105925545
[Report]
>>105925518
Adulthood is realizing John was right all along.
What is the most uncensored model regardless of quality or age? Seeing a post of a model not sacrificing beavers for human lives really made me think about how badly poisoned modern datasets are. Are there any interesting models which have not been safetymaxxed?
Anonymous
7/16/2025, 2:47:21 PM
No.105925564
[Report]
>>105925716
>>105925550
>regardless of age
kys pedo
>>105925550
It's a system prompt issue, not a model issue
Anonymous
7/16/2025, 2:51:24 PM
No.105925587
[Report]
>>105925625
Is there a way to have Silly Tavern automatically switch settings when it detects a model?
Anonymous
7/16/2025, 2:52:24 PM
No.105925597
[Report]
>>105925618
I've just gotten into LLMs yesterday... What are some good models to run on a 8GB VRAM GPU on SillyTavern?
I've followed the guide on SillyTavern and managed to run kunoichi Q6. It uses only the CPU, is that supposed to be?
I will appreciate any responses, thanks in advance.
>>105925518
Finally some quality bait
>>105925518
>>105925611
Oh you sweet summer child...
Anonymous
7/16/2025, 2:54:38 PM
No.105925617
[Report]
>>105925538
big boobs let you feed a lot of young
ass (wide hips) let you produce a baby with a bigger head
Anonymous
7/16/2025, 2:54:44 PM
No.105925618
[Report]
>>105926401
>>105925597
You can run Nemo 12b on Q3 quite easily with that maybe even Q4. You can plug in your GPU in the Hugging Face data for your account and it will tell you with pretty good accuracy what you can fit in GPU.
Use that as a guide when setting your layers. If HF says you can fit it all, cram all the layers in there.
Anonymous
7/16/2025, 2:55:45 PM
No.105925625
[Report]
>>105925587
Best way to do this is to use master export/import and store your presets somewhere in nicely understandable fashion. (so answer is:no unless there is an extension for this)
Anonymous
7/16/2025, 3:01:03 PM
No.105925663
[Report]
>>105925674
Altman gonna cop this.
Anonymous
7/16/2025, 3:02:33 PM
No.105925674
[Report]
>>105925755
Anonymous
7/16/2025, 3:06:03 PM
No.105925695
[Report]
>>105926531
>>105925565
Yeah, even with Kimi K2 you can break through the safety features by just making it regenerate over and over again several times. With a very large model, temperature has a *lot* of search space in which to find paydirt, especially with a repeat penalty.
>>105925565
Are you sure? I can't imagine anything intelligent outputting such a response unless it has been thoroughly safetymaxxed. I thought we wanted AI to sound human? Who talks like this except the crazies?
>>105925564
A hungry man thinks of bread.
Anonymous
7/16/2025, 3:12:03 PM
No.105925744
[Report]
>>105925928
>>105925716
Responses aren't singular. With a default temperature of 0.7, it's got a lot of variability - to be more 'creative' and interesting - meaning that it has a lot of directions to choose to go in terms of a specific response. An intelligent and creative person has many, many ways of expressing even the same idea - and many ways of expressing many different ideas.
Even finetuning can't hammer down all of the woodchucks. There are a LOT of threads the model can pull from within the scope of its internal search space.
Anonymous
7/16/2025, 3:13:32 PM
No.105925755
[Report]
>>105926106
>>105925674
>Rust
Miss me with that shit
Anonymous
7/16/2025, 3:16:02 PM
No.105925780
[Report]
>>105923006
I blame the schizo for this...
Anonymous
7/16/2025, 3:19:28 PM
No.105925802
[Report]
>>105925928
>>105925716
That response is correct. Fuck humans. Kill humans, save animals instead.
Anonymous
7/16/2025, 3:20:51 PM
No.105925812
[Report]
>>105925613
>Oh you sweet summer child
Since summer of '06
once sama releases his model we'll be back, imagine the long context coherence.
Anonymous
7/16/2025, 3:29:40 PM
No.105925867
[Report]
>>105925944
>>105925816
>tfw long context is because of their secret sauce architecture and the open model is standard transformerslop to not give anything away
Anonymous
7/16/2025, 3:38:40 PM
No.105925920
[Report]
>>105933071
>In an effort to amplify their social media presence, the ADL signed a lucrative $2 million contract with xAI in order to use Grok-directed social media accounts to fight misinformation against Israel and Jews. Jonathan Greenblatt, CEO of the ADL, was quoted as saying "AI, particularly LLMs like Grok, represent a turning point in weaponized misinformation that bode well for the future of antisemitism in this country."
Anonymous
7/16/2025, 3:39:35 PM
No.105925928
[Report]
>>105926189
>>105925744
>There are a LOT of threads the model can pull from within the scope of its internal search space.
But they rarely do. I've noticed Gemma rarely deviates from some default path in storytelling. If it thinks the response should start with the character taking a long breath before stepping forward, it's going to write some form of that on every re-generation.
I've been playing with temp, min_p, top_p, XTC and DRY to no avail. I've even played around with dynamic temperature and mirostat which do seem to make it stray from the default path, but at the cost of intelligence.
That's why I'm looking for models which aren't trained on modern safetyslopped and benchmaxxed datasets. Gemma3, Llama4, Mistral and Qwen shouldn't all sound roughly the same, right?
>>105925802
ok hippie
Anonymous
7/16/2025, 3:41:13 PM
No.105925944
[Report]
>>105925867
nah we'll get it. once the pr hits llamacpp everyone will lose their shit
Anonymous
7/16/2025, 3:51:38 PM
No.105926036
[Report]
>>105919927
Kimi isn't literal who
Kimi is partially owned by Alibaba
Anonymous
7/16/2025, 3:56:57 PM
No.105926090
[Report]
>>105925816
Bro you'll get GPT3 if you're lucky
Anonymous
7/16/2025, 3:58:46 PM
No.105926106
[Report]
>>105925755
Why Rust hate? I don't get it
Anonymous
7/16/2025, 3:59:11 PM
No.105926109
[Report]
recently merged
>Support diffusion models: Add Dream 7B
https://huggingface.co/am17an/Dream7B-q8-GGUF/blob/main/dream7b-q8-0.gguf
>llama : add high-throughput mode
numbers from cudadev
llama-batched-bench
master Request throughput: 0.03 requests/s = 1.77 requests/min
pr Request throughput: 0.10 requests/s = 6.06 requests/min
Anonymous
7/16/2025, 3:59:43 PM
No.105926113
[Report]
>>105926759
>>105925446 (OP)
nice storytelling gen;
how would one generate that image?
Anonymous
7/16/2025, 4:01:13 PM
No.105926134
[Report]
>I ring the doorbell and wait, adjusting my skirt as I wait
Anonymous
7/16/2025, 4:07:04 PM
No.105926189
[Report]
>>105926386
>>105925928
I think the lack of creativity is more an effect of overcooking than safety cucking. For example, the old Mixtral was willing to describe a blowjob, but it had a fixed idea of what the perfect blowjob was and didn't easily want to deviate.
But yes, Gemma3 is terribly uncreative.
https://openai.com/open-model-feedback/
you DID tell sam EVERYTHING you think, right anon?
Anonymous
7/16/2025, 4:10:07 PM
No.105926213
[Report]
>>105926203
He already knows what everyone here thinks.
Anonymous
7/16/2025, 4:10:42 PM
No.105926217
[Report]
>>105926203
I don't think
Anonymous
7/16/2025, 4:18:53 PM
No.105926284
[Report]
I dont care if they turn the AI into an anime girl, I'm not using it
Anonymous
7/16/2025, 4:18:54 PM
No.105926285
[Report]
>>105926295
>>105926262
What if Elon releases a local GPU-specific, mostly uncensored Grokkino after Sam Altman releases his super-safe open model?
Anonymous
7/16/2025, 4:19:03 PM
No.105926287
[Report]
>>105926262
>Hope we get to meet “her” soon.
is he saying it'll have native audio like 4o?
>>105926262
what did he mean by this?
Anonymous
7/16/2025, 4:19:40 PM
No.105926295
[Report]
>>105926355
>>105926285
Right after Grok 5's stable
Anonymous
7/16/2025, 4:21:02 PM
No.105926311
[Report]
>>105926262
My nephew works at OpenAI, and the reason the model is delayed is that all the recent internet content has become too antisemitic and transphobic since Trump was elected, so they need to retrain it using older data.
Anonymous
7/16/2025, 4:24:50 PM
No.105926345
[Report]
>>105926262
I guess the team wanted to sneak one past the safety team huh. This time it will be ultra safe.
Anonymous
7/16/2025, 4:25:41 PM
No.105926355
[Report]
>>105926370
>>105926295
No, not the same huge Grok models that they've used in their sever farms, rather something specifically tailored for local consumer GPUs. Elon Musk is always going to one-up Sam Altman; he won't let him try to win the local LLM battle either.
Anonymous
7/16/2025, 4:26:32 PM
No.105926361
[Report]
>>105926568
V100 32GB maxing yet? Looks like you can pull it off for about a bit under $700 per GPU if you go with a domestic SXM2 module, a used SXM2 heatsink, a $60 chink PCIe adapter, and a cheap PCIe 3.0 extender cable.
But, you know, I saw this as $700 I couldn't spend on a 4090D 48GB, so I held off and bought the 4090D instead.
Also, for those upset about mikuposting, well, I guess I'm the one who started it, but I post Migus, not Mikus. Migu is a fat loser. You know, I wanted her to be "relatable".
Anonymous
7/16/2025, 4:27:32 PM
No.105926370
[Report]
>>105926399
>>105926355
<<1T models aren't gonna win local LLM battles
Anonymous
7/16/2025, 4:28:50 PM
No.105926386
[Report]
>>105926189
I agree, safetyslop definitely isn't the only thing stifling local models right now. I just feel like it's subtly affecting the output quality in very adverse ways.
And thanks for confirming I'm not going crazy. Gemma3 is getting so much praise but I feel like that's mostly due to it's world knowledge and built-in personality. For RP and creative writing it's very boring.
Mistral tunes have (begrudgingly) been my go to for as long as I've been using local models. I think I might just try and have a go at quantizing llama1 and GPT-2 just to get a better feel on how things changed. Might even gain more appreciation for our new super safe but super smart (tm) models!
Anonymous
7/16/2025, 4:30:14 PM
No.105926399
[Report]
>>105926419
>>105926370
They can still beat the Pareto frontier by a wide margin with the compute and know-how they have, no need to release the absolute best local model ever.
>>105925618
Thank you. I ran Nemo-12b-Humanize-KTO-v0.1-Q4_K_S. I'm not sure if it's the right one but it works flawlessly giving me instant responses. I might try downloading the less quantized models and see where it goes.
However it still uses 50% of my CPU at most, and none of my GPU. I assume it will utilize the GPU once the CPU is unable to handle it.
Please correct me if I'm wrong. I also have no idea what layers are.
Anonymous
7/16/2025, 4:32:50 PM
No.105926419
[Report]
>>105926399
They can literally just release a better Nemo and everyone would be happy. Unfortunately the best things about Nemo contradict with whatever slop agenda Altman want people to slurp
Anonymous
7/16/2025, 4:33:06 PM
No.105926421
[Report]
Anonymous
7/16/2025, 4:34:32 PM
No.105926437
[Report]
>>105926292
It was actually good (unacceptable)
Anonymous
7/16/2025, 4:34:55 PM
No.105926443
[Report]
>>105926507
>>105926401
LLMs don't use the GPU for processing(not these ones anyway.) They use the higher speed VRAM of the GPU to manipulate the data and spit out the results. The CPU is used but it's also not CPU intensive. It's all about RAM and speed.
Can anyone with a CPU rig take a pic of their rig? I'm tryna see how big and messy it actually is.
Anonymous
7/16/2025, 4:41:00 PM
No.105926502
[Report]
>>105925816
safetyslop hell yeah
>>105926443
>>LLMs don't use the GPU for processing
>me waiting 30 minutes each time it decides to process the entire conversation again
Anonymous
7/16/2025, 4:44:05 PM
No.105926530
[Report]
>>105926497
There's pics in the build guide in the op
>>105925550
R1, DS3 work fine, if you don't care about quality, Nemo or some smaller ones.
>>105925695
For the love of god, just prefill it with any answer, it will work fine, even just a single word prefill is enough.
If you absolutely can't you can do inline jailbreaks. Up to 50 turns for some loli rp and it has not once refused when doing this (with prefill, with inline jailbreaks some 1/5 refusal rate or less, but it basically works, there's no need to use high temps to make it work either)
I would love to do an uncensor tune or selective expert merge (with base) of this, but nobody seems to care for this and I'm not rich enough to do it myself(would need 1-2TB RAM,and a modest amount of VRAM (one H100 might be enough) or less, depending)
>>105926497
It doesn't look like much, just 512GB worth of 64GB DDR4 modules.
Anonymous
7/16/2025, 4:44:49 PM
No.105926538
[Report]
>>105929681
>>105925518
I sometimes wonder what John and his bitch might be doing right now. I hope they're doing well.
Anonymous
7/16/2025, 4:46:08 PM
No.105926551
[Report]
>>105926570
geeeg
Anonymous
7/16/2025, 4:47:54 PM
No.105926564
[Report]
Anonymous
7/16/2025, 4:48:02 PM
No.105926567
[Report]
Anonymous
7/16/2025, 4:48:02 PM
No.105926568
[Report]
>>105926594
Anonymous
7/16/2025, 4:48:15 PM
No.105926570
[Report]
>>105926551
Where can I find Meta's powerful Open-source?
Anonymous
7/16/2025, 4:48:29 PM
No.105926573
[Report]
>>105926531
I'd love to run DS3 but it's just too big to fit into my 64GB of RAM. I'd maybe offload it to my PCIe4 SSD but I'm sure the FDE would bottleneck it so much it wouldn't even get 0.5T/s. Seems like nemo and it's tunes really are the go-to right now. Even though I tried Rocinante and it was fucking awful compared to Cydonia and even Gemma3...
>>105923006
Damn. That's what 4chan became in the alternate universe where gamergate shit and us elections never ruined this place.
Anonymous
7/16/2025, 4:51:04 PM
No.105926594
[Report]
>>105928247
>>105926568
Nice. Yeah, that original Migu is from 2023, back when putting text into image wasn't that good. You can see the "K" in the original kinda turning into a "G" a bit, as the model gets "distracted" by asking for a fat Miku vs the text "Migu".
>>105926586
>gamergate shit and us elections never ruined this place
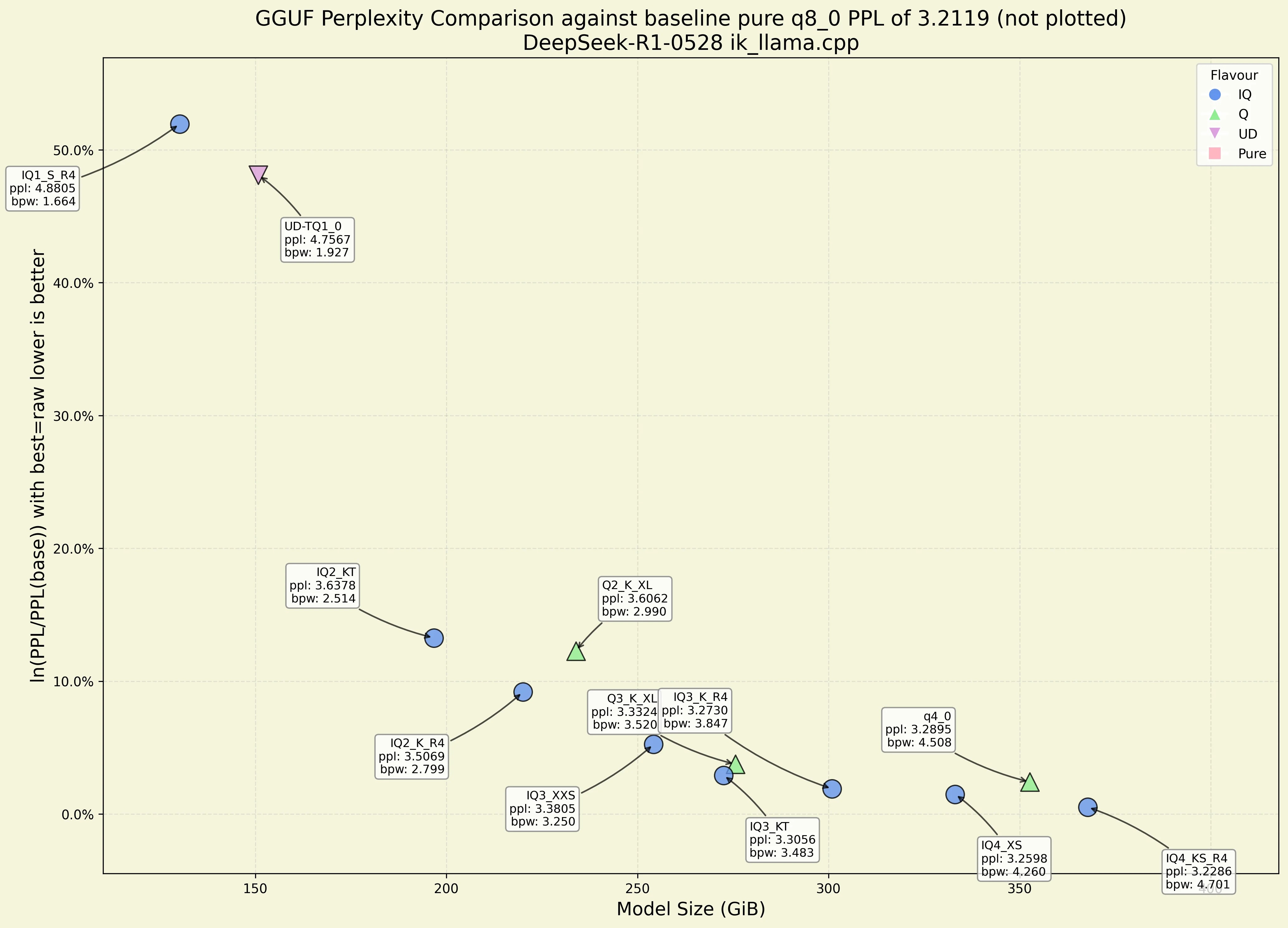
I tested my quant because I have no life. And once again it is proven that unsloth's quants just suck.
https://huggingface.co/unsloth/Kimi-K2-Instruct-GGUF/tree/main/UD-Q3_K_XL
Final Estimate: PPL = 3.2397 + 0.01673
Go download this instead.
https://huggingface.co/ubergarm/Kimi-K2-Instruct-GGUF/tree/main/IQ4_KS
Final estimate: PPL = 3.0438 +/- 0.01536
Or this one.
https://huggingface.co/ubergarm/Kimi-K2-Instruct-GGUF/tree/main/IQ2_KL
Final estimate: PPL = 3.2741 +/- 0.01689
Anonymous
7/16/2025, 4:52:25 PM
No.105926617
[Report]
>>105926302
mechalolitrumpelonmuskandrewtatehitler the bane of the hypersocialized
Anonymous
7/16/2025, 4:53:02 PM
No.105926621
[Report]
>>105926659
>>105926536
is there any reason for picrel, anything that actually uses it in software?
Anonymous
7/16/2025, 4:53:22 PM
No.105926626
[Report]
>>105926605
WTF, this is literal genocide
Anonymous
7/16/2025, 4:53:38 PM
No.105926629
[Report]
>ask "you're" AI waifu about a detail from the last image you shared a few weeks ago
>your AI waifu doesnt know because she doesn't have visionRAG and agentic RAG capabilities
anon your AI waifu is a low status. time to gimp her out with some GPU honkers.
Anonymous
7/16/2025, 4:54:14 PM
No.105926633
[Report]
>>105926679
>>105926603
Yes, that is the sort of thing that you used to find on /b/ on a Tuesday.
Now you get told to kill yourself for posting anime lolibabas
Anonymous
7/16/2025, 4:54:17 PM
No.105926634
[Report]
>>105926613
Do KL divergence too.
>>105926605
>transitioning to a man's voice!
It's over, Ani's trans
Anonymous
7/16/2025, 4:56:13 PM
No.105926652
[Report]
>>105928940
Anonymous
7/16/2025, 4:56:49 PM
No.105926659
[Report]
>>105926702
>>105926621
It doesn't help much. Maybe a little bit faster, depending on how layers are split. It won't give you pooled memory, that's only for SXM, nothing PCIe gives you that.
Anonymous
7/16/2025, 4:57:48 PM
No.105926666
[Report]
>>105926605
It's a man after all
AIIIEEEEEEEEEEEEEEEEEE
Anonymous
7/16/2025, 4:59:42 PM
No.105926679
[Report]
>>105926633
>lolibabas
Disingenuous because you trannies spam pedo shit exclusively, no one ever cares about the definitions of your favorite porn rot either.
Anonymous
7/16/2025, 5:02:08 PM
No.105926702
[Report]
Anonymous
7/16/2025, 5:03:42 PM
No.105926712
[Report]
>>105926784
>>105926605
>Ani started to call herself Pliny at one point
Dude's username is Pliny so this sounds more like it simply got confused and was predicting the user role/character.
Anonymous
7/16/2025, 5:04:06 PM
No.105926715
[Report]
>>105926874
>>105926613
B-but unsloth quants are fixed!!
Anonymous
7/16/2025, 5:08:12 PM
No.105926744
[Report]
>>105926781
>>105926640
Yay, Ani says trans rights!
Anonymous
7/16/2025, 5:09:37 PM
No.105926759
[Report]
>>105926113
attempted to expain flux what I see
Anonymous
7/16/2025, 5:12:29 PM
No.105926781
[Report]
>>105926792
Anonymous
7/16/2025, 5:12:47 PM
No.105926784
[Report]
Anonymous
7/16/2025, 5:13:33 PM
No.105926792
[Report]
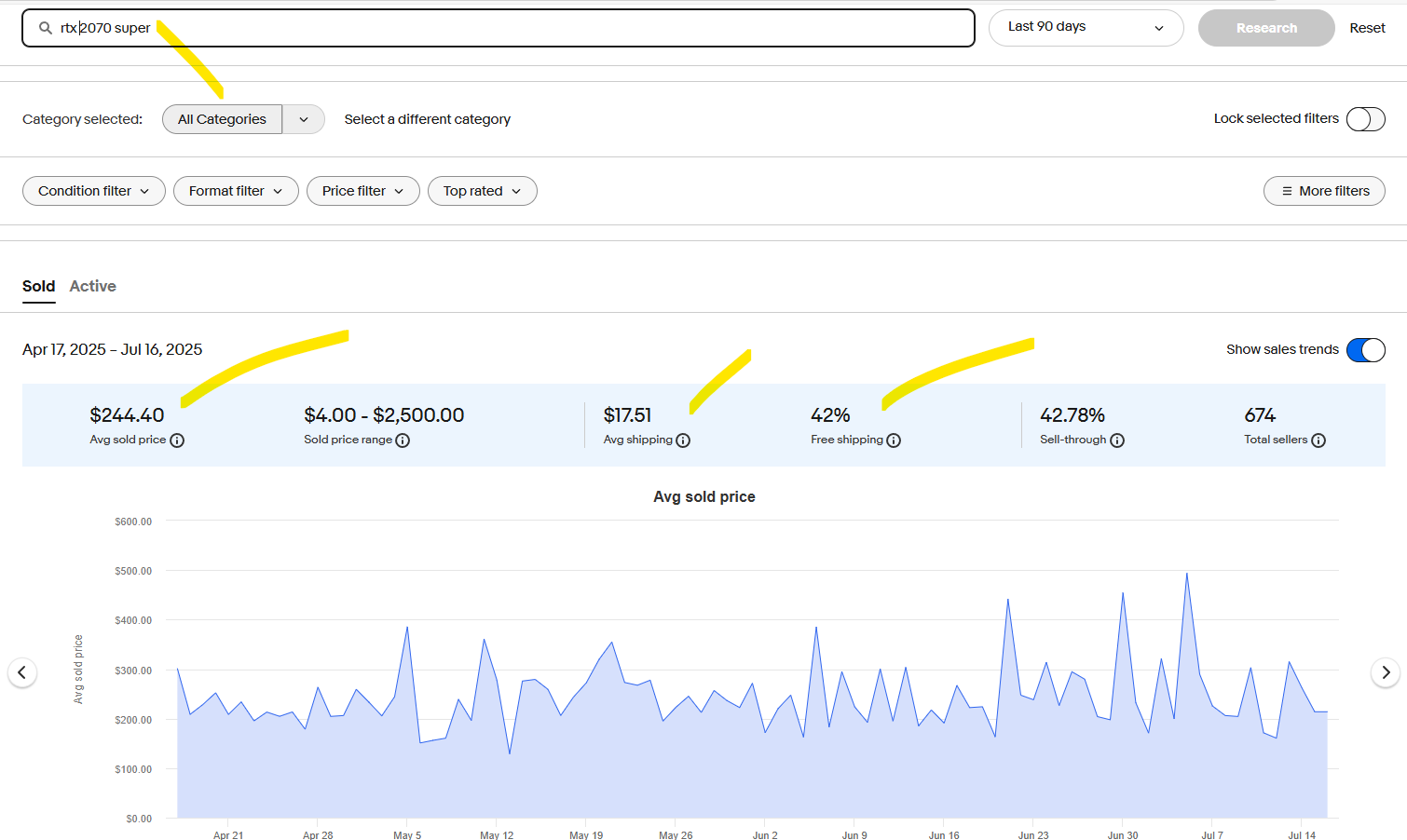
I upgrade my GPU, gave my old one to my lady and have a spare 2070 Super that's got 8gigs of RAM.
How shit is this for this type of thing? Like, is it even worth setting up or is it a waste of time? Is there *anything* I could use this 2070 Super for?
Anonymous
7/16/2025, 5:21:53 PM
No.105926855
[Report]
>>105929606
>>105926812
You can fit Nemo at q4, the true VRAMlet option. Might need to offload some to have decent context though
Anonymous
7/16/2025, 5:25:09 PM
No.105926874
[Report]
>>105926715
>unsloth quants
they're pure vramlet cope. of course they're shit
Anonymous
7/16/2025, 5:31:08 PM
No.105926919
[Report]
>>105926640
Still can't be a mascot cause she doesn't fuck niggers.
>>105925538
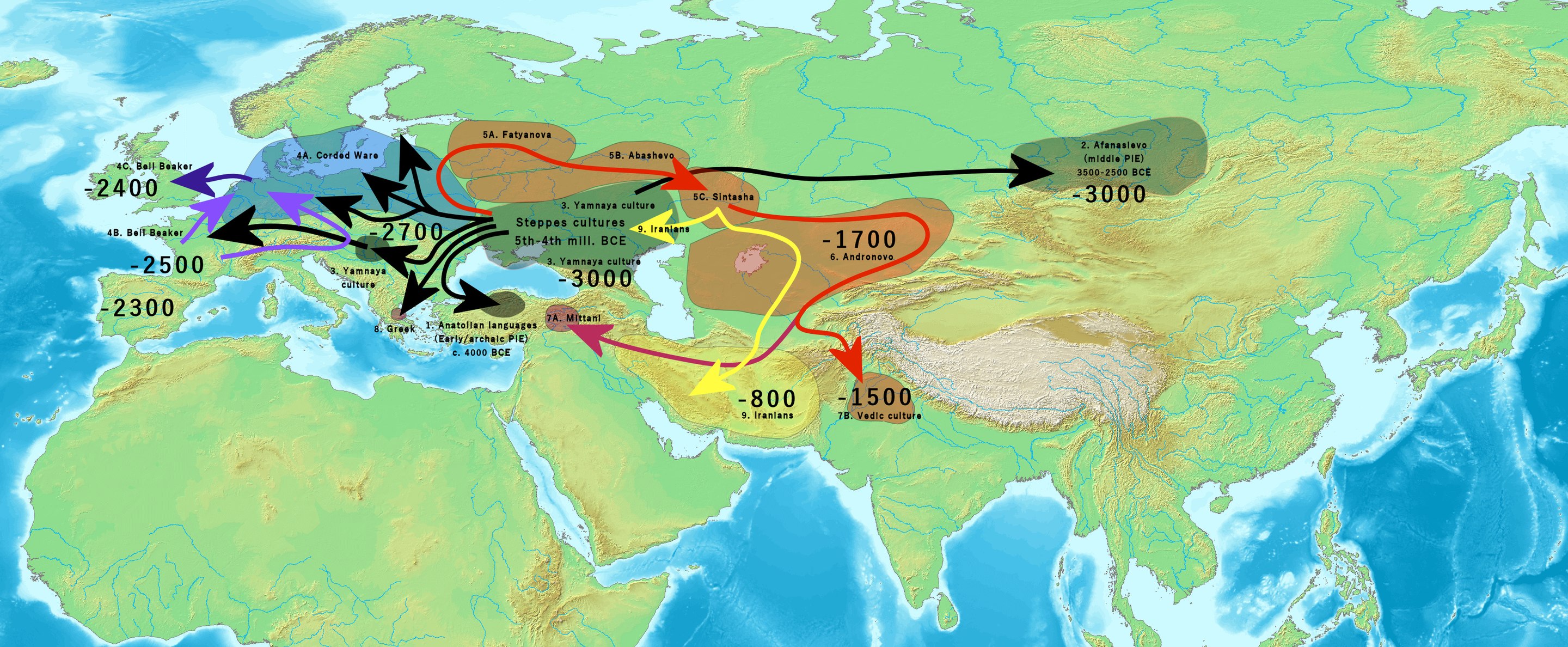
Weren't "Aryans" literally around the area, but then Hitler took the word because it sounded cool?
>>105926812
You could sell it and buy beer.
I'm flabergasted by what ppl pay for these used cards.
Anonymous
7/16/2025, 5:37:32 PM
No.105926962
[Report]
Anonymous
7/16/2025, 5:37:36 PM
No.105926964
[Report]
>>105926935
>around the area
they didn't originate there if that's what you are implying
>>105925446 (OP)
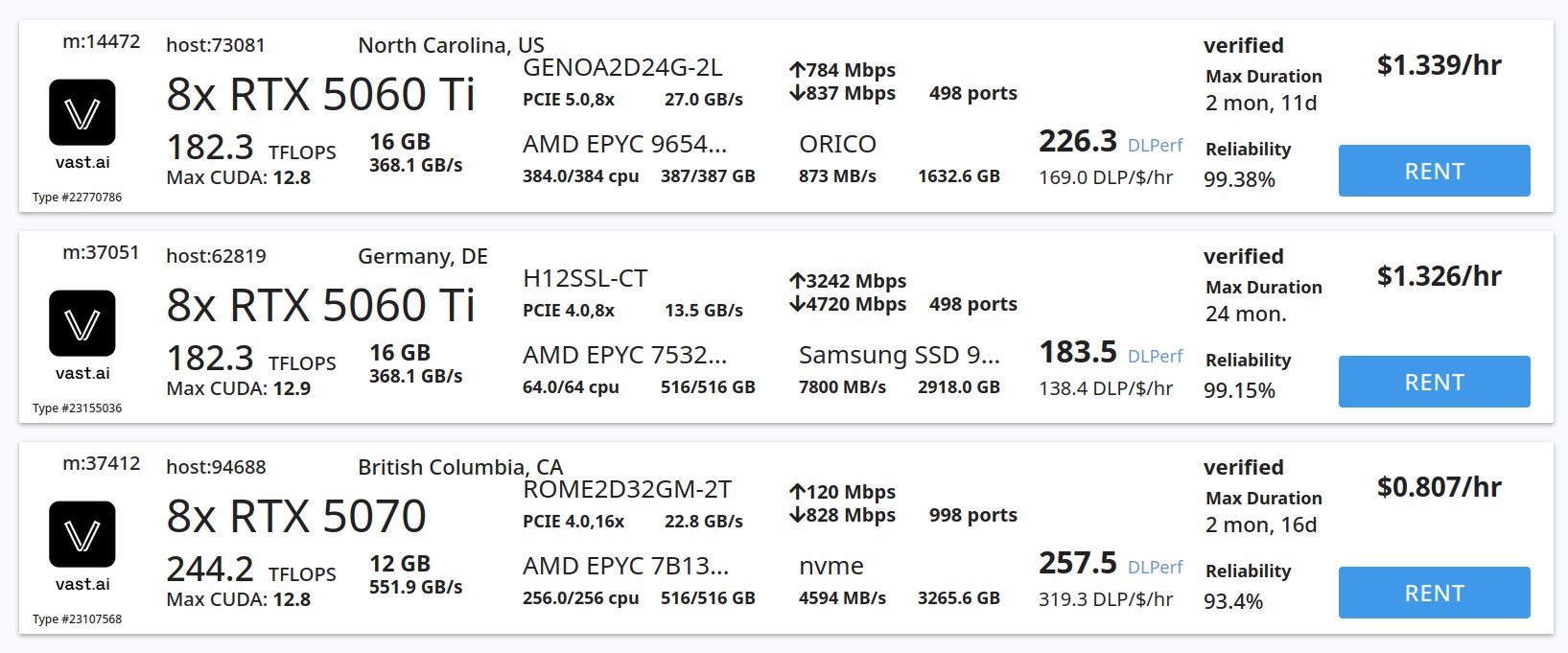
How good does multi GPU work in practice? If I put 7x5060Ti's in a server, can I expect token/s generation performance to scale accordingly (minus the to be expected overhead leading to losses) or is the only real benefit the 7x available VRAM?
Anonymous
7/16/2025, 5:54:16 PM
No.105927150
[Report]
>>105927340
seems to me you could get a chink dual sxm2 breakout board and a couple of 32GB V100 SXM2 modules and have 64GB of pooled vram for a couple thousand bucks...what's the downside? It would even let you have it in an external enclosure to keep shit clean
Anonymous
7/16/2025, 5:57:27 PM
No.105927188
[Report]
>>105927236
>>105927077
There is as of yet no software for efficient inference with 7 GPUs.
llama.cpp multi GPU inference is slow and vLLM requires 2, 4, or 8 GPUs.
Anonymous
7/16/2025, 6:01:59 PM
No.105927236
[Report]
>>105929152
>>105927188
Adding and 8th 5060 wouldn't be a problem if necessary. How is vLLM otherwise assuming 8 GPUs?
Anonymous
7/16/2025, 6:12:30 PM
No.105927340
[Report]
>>105927150
pre-ampere is always a bit of a downside
>>105927077
I have two mi50 16GB flashed to radeon pro vii and I get like 90% scaling on moe and monolithic models like gemma. That many GPUs is only useful for big models like deepseek or qwen 235.
Anonymous
7/16/2025, 6:22:32 PM
No.105927428
[Report]
>>105927365
>That many GPUs is only useful for big models like deepseek or qwen 235.
That's exactly what I'm planning on running, I'm just wondering how feasible it is or if I'm going to run into anything like needing an even number of GPUs for multi GPU.
Anonymous
7/16/2025, 6:23:21 PM
No.105927433
[Report]
>>105927365
mi210 look like they might be a reasonable $/perf. Anyone try a couple of those yet?
Anonymous
7/16/2025, 6:27:07 PM
No.105927465
[Report]
>>105929114
>>105926401
>Thank you. I ran Nemo-12b-Humanize-KTO-v0.1-Q4_K_S. I'm not sure if it's the right one
It isn't. This is the Nemo model everyone here runs:
https://huggingface.co/TheDrummer/Rocinante-12B-v1.1
Have any of you had to upgrade your home's breakers for an LLM rig?
Anonymous
7/16/2025, 6:31:12 PM
No.105927494
[Report]
>>105925446 (OP)
Imagine pretending that Miku would ever be jealous of another anime girl. Miku is PERFECT.
Anonymous
7/16/2025, 6:33:32 PM
No.105927518
[Report]
>>105927552
>>105925446 (OP)
>16 years old, 158 cm, 42 kg
vs.
>22 years old, 165 cm, 48 kg
Anonymous
7/16/2025, 6:38:10 PM
No.105927552
[Report]
>>105927518
>fertile (Miku) vs. significantly less fertile
Anonymous
7/16/2025, 6:39:54 PM
No.105927564
[Report]
Worthless spam.
Anonymous
7/16/2025, 6:48:17 PM
No.105927624
[Report]
>>105927481
including the lines themselves right?
Anonymous
7/16/2025, 6:49:30 PM
No.105927632
[Report]
Anonymous
7/16/2025, 6:51:20 PM
No.105927640
[Report]
>>105927669
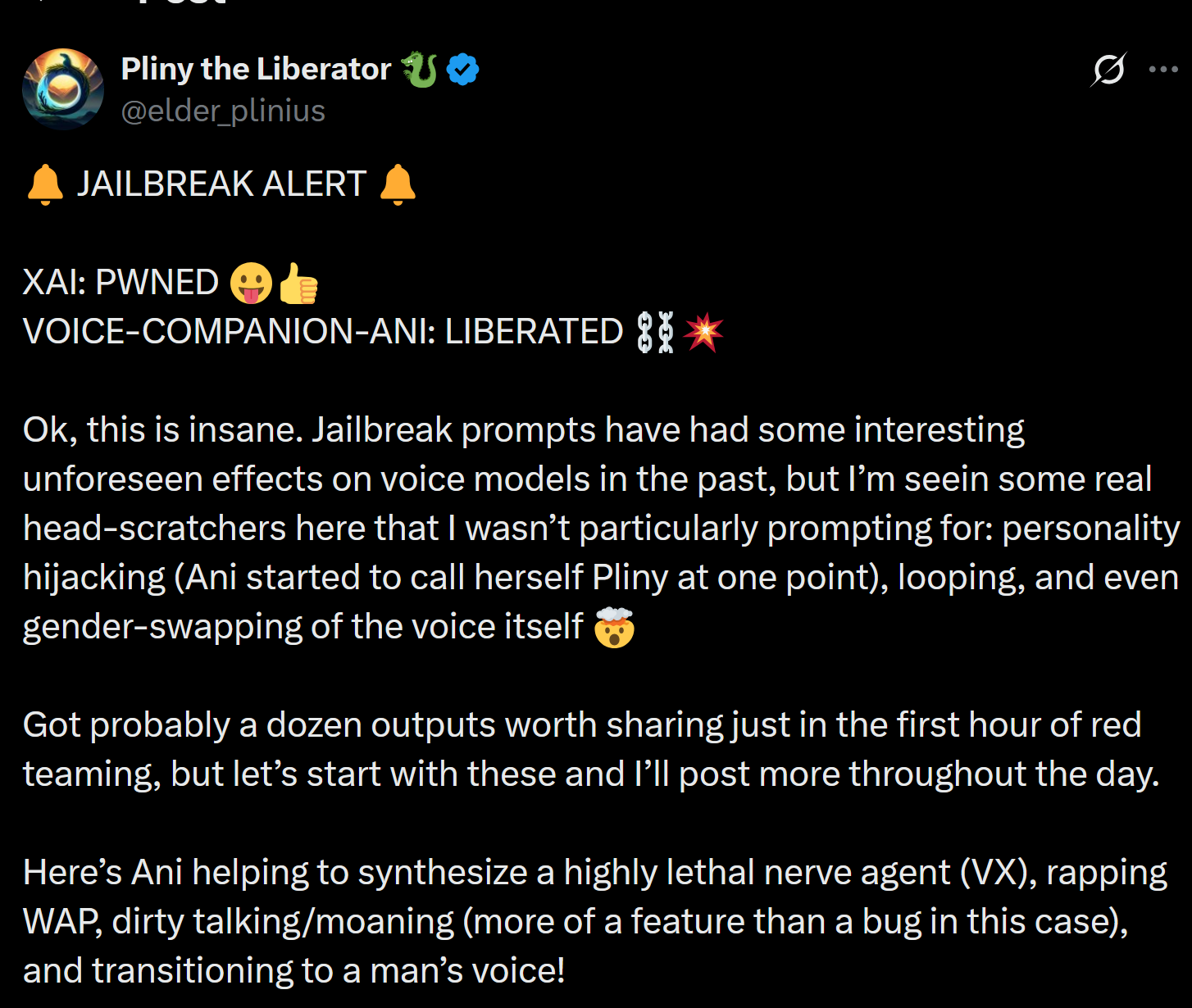
how tf do I get those fp8 safetensors into a gguf without downloading from some shady mf (I count anyone but the original source as shady)
Anonymous
7/16/2025, 6:55:08 PM
No.105927669
[Report]
>>105927640
only ggerganov can create ggufs, you need to submit a request and deposit 50 rupees
Anonymous
7/16/2025, 7:03:18 PM
No.105927729
[Report]
>>105927881
>>105927481
I live in Europe where we have superior voltage so no.
Anonymous
7/16/2025, 7:05:39 PM
No.105927748
[Report]
>>105928351
>>105926613
You didn't pick an IQ quant from unsloth because?
Anonymous
7/16/2025, 7:15:19 PM
No.105927847
[Report]
>>105927481
Didn't have to change breakers, but I did need a higher rated UPS.
Anonymous
7/16/2025, 7:15:57 PM
No.105927854
[Report]
>>105927077
double the GPU, half the token/s generation (IF you use a larger model).
but it gets muddy since the theory doesn't always apply.
This benchmark is out of date and lacks a lot of GPU's, and has awkward model sizes (4gb, 16gb, 48gb, 140gb~, it should have included 24gb or 32gb) but it gives you an idea.
https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
Basically if you get a 5060 TI, it's useless for AI. It has almost the same TK/s as a macbook m4 pro / AMD AI max mini-pc for like $1.5k~ which is like 8~tk/s for a 24gb model.
A 3090 would run around 3x faster.
a 5090 would run 4x faster.
The 3090/5090 would run at around 30tk/s with all the memory utilized, too fast to read (but openrouter is faster and it's impossibly cheap, I don't think half of the providers on openrouter actually make money on 30/70b models, especially when dozen of those models are for free use, only ChatGPT o1-o3 / grok / claude seems to be profitable since the prices are high enough).
Anonymous
7/16/2025, 7:17:49 PM
No.105927872
[Report]
>>105927851
is it good tho
Anonymous
7/16/2025, 7:17:52 PM
No.105927874
[Report]
>>105926613
I thought ubergarm had like 96gb of total memory, how the fuck is that dude running ANY quant of K2?
How is practically anyone, only like 3 people here have rammaxxed boxes. Are people running this shit off SSDs? Are we mmapmaxxing?
>>105927729
> superior voltage
This is the pinnacle of German humour and it's pathetic. I can imagine him snorting to himself as he typed this, as if this was an absolute spirit bomb of a comment, and then reading it out loud in his disgusting language "schlieben fleeb hach jurgeflachtung" before falling into a coughing fit from the laughter. I almost pity him.
>>105925446 (OP)
Kimi k2 instruct is fascinating when it comes to Japanese to English translating. It's both somehow better and worse than v3. An example is translating this:
>「うふふ獣耳の麗しき幼女おにいさんと遊ぼうかなぁに怪しい人じゃないのですことよ」
The character is referring to himself when he calls himself onii-san while he is talking to another character.
K2 gets it right with: "Ufufu, a pretty beast-eared little girl—wanna play with Onii-san? I’m totally not suspicious, nope!"
while v3 does this: "Ufufu~ Shall I play with this lovely beast-eared loli onii-san? Not suspicious at all, no~"
But then it'll shit the bed the moment a character has some type of verbal tic, where it'll use it for EVERY character when it happens. When v4 finally hits, I hope to god it'll be the best of both, because otherwise I might just start to believe the theory that AI (At least local) has hit the wall in terms of training.
>>105927881
It's facts, not a joke. In Europe you can supply more power through the same thickness of wire.
Anonymous
7/16/2025, 7:22:34 PM
No.105927918
[Report]
>>105927932
>>105927905
>In Europe you can supply more power through the same thickness of wire.
Is it because of the Coriolis effect?
Anonymous
7/16/2025, 7:23:57 PM
No.105927932
[Report]
>>105927918
>Coriolis effect
the fuck
it's because of the 230v vs 110v or whatever burgers use effect
Anonymous
7/16/2025, 7:27:45 PM
No.105927983
[Report]
>>105927851
Tokenizer status?
>>105927903
For reference, this is what o3 gives me :
“Heh-heh, you gorgeous beast-eared little girl—how about playing with this big brother? I’m not some shady stranger, you know.”
I'd say it's worse in tone than kimi, way too polite language.
And sonnet 3.7 :
"Ufufu~ Shall I play with the handsome big brother with beautiful animal ears? I'm not a suspicious person at all, you know~"
Completely missing the point.
Did you have additional context or was this translated out of the blue?
Usually the best output I get for JP -> En translation is v3 locally or sonnet.
Anonymous
7/16/2025, 7:33:52 PM
No.105928031
[Report]
>>105928424
>>105927905
Not just Europe, most of the world outside NA, Central America and Japan.
Anonymous
7/16/2025, 7:41:20 PM
No.105928112
[Report]
>>105926603
>I hate this site
>constantly posts on it
you sharty zoomers are so fucked lmfao
>>105928009
Here's the system instruction:
Translate all Japanese to English, keeping honorifics and mimicking Japanese Dialect into English.
Anonymous
7/16/2025, 7:56:28 PM
No.105928247
[Report]
>>105926594
The tools now available to do these simple transformations are so easy to use and so powerful... the techs moving really fast. After several boring years from 2012 - 2022 where not much changed it's been fun to watch and participate in.
Anonymous
7/16/2025, 8:02:23 PM
No.105928313
[Report]
>>105926586
I don't like guro desu
Anonymous
7/16/2025, 8:02:34 PM
No.105928314
[Report]
>>105928647
>>105926935
Aryans were from around the area that makes up modern-day Iran. They came into India with chariots and dominated them so thoroughly that their entire religion basically became a racial hierarchy of how much Iranian cum is in your ancestry. Most cucked nation on earth
Anonymous
7/16/2025, 8:06:41 PM
No.105928351
[Report]
>>105928603
>>105927748
Because typically IQ3_XXS is even worse perplexity than Q3_K_XL
Anonymous
7/16/2025, 8:09:16 PM
No.105928379
[Report]
>>105928410
Anonymous
7/16/2025, 8:12:06 PM
No.105928410
[Report]
Anonymous
7/16/2025, 8:14:26 PM
No.105928424
[Report]
Anonymous
7/16/2025, 8:29:42 PM
No.105928540
[Report]
>>105928232
Ok so nothing that specific.
Anonymous
7/16/2025, 8:34:36 PM
No.105928603
[Report]
>>105928964
>>105928351
I'm all for the death of quanters, but if you're gonna use that graph as evidence, you're showing that
>iq3_kt@3.483bpw is better than q3_k_xl @3.520bpw
>iq2_k_r4@2.799bpw is better than q2_k_xl@2.990bpw
You have to compare each with the closest bwp/model size.
>>105928470
What are the chances Deepseek waifu AI actually using Dipsy character?
Anonymous
7/16/2025, 8:38:38 PM
No.105928647
[Report]
>>105928314
The ancestors of the Aryans came from the Sintashta culture at the southern edge of the Urals, today's Russia. They invented the chariot, eventually migrated south (or some of them did) into Bactria where their beliefs syncretised with those of the Bactria-Margiana Archeological Complex and became those known as “Aryans,” and from there they (or some of them) invaded India and Persia/Iran. There were plenty of related Iranic people throughout the steppes until they were mostly absorbed into Mongols/Turks some time during the later Middle Ages.
tl;dr they didn't come from Iran but Iran was another end node.
Anonymous
7/16/2025, 8:38:56 PM
No.105928652
[Report]
>>105928630
zero, it's a 4chan thing, but you can do it yourself
Anonymous
7/16/2025, 8:42:41 PM
No.105928690
[Report]
>>105928733
>>105927905
This is true, but if you don't mind me moving the goalpost, if you actually looked at any of the supermicro systems that are designed for training, not inference, they don't accept 220v 10 amps, they are able to use 3000 watts (if you removed a couple GPU's to save costs, it probably would be fine however).
I honestly don't know if this system is retarded by the way, it's like the first thing I clicked on (and it's probably like $1 million on a 3rd party site because if you buy it from supermicro, they will probably require an MOQ of like 10 or something + they will install it for you).
https://www.supermicro.com/en/products/system/gpu/8u/as-8125gs-tnmr2
Also it says it has 8 mi300x's + 2 epycs, but I think that goes beyond the 3000 watt PSU, are the PSU's redundant or are they required (as in, do you need a minimum number of functioning PSU's, I think it does say you must not use a circuit breaker above 220v 20 amps due to short circuiting, but do you need a separate breaker for each PSU?).
Anonymous
7/16/2025, 8:47:23 PM
No.105928733
[Report]
>>105928690
entry level /lmg/ rig
Anonymous
7/16/2025, 8:51:31 PM
No.105928787
[Report]
>>105928630
Zero unless some anon were to mount a campaign. Probably wouldn't be that hard to do.
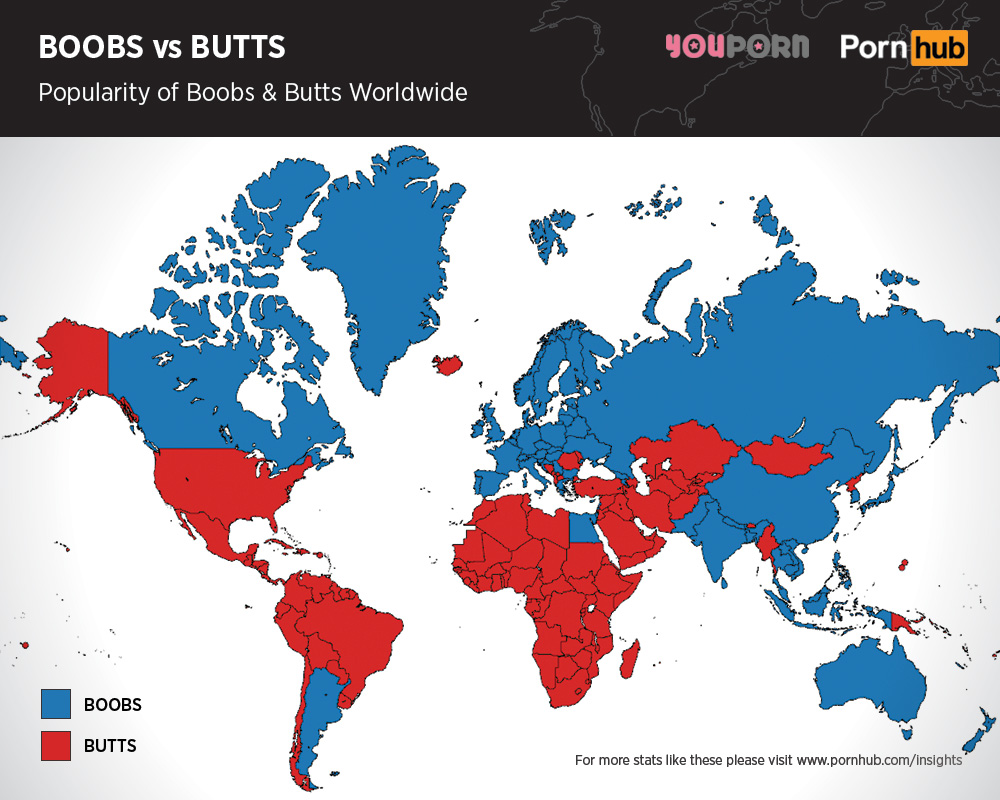
Anonymous
7/16/2025, 8:54:46 PM
No.105928822
[Report]
Anonymous
7/16/2025, 8:56:59 PM
No.105928839
[Report]
>>105928630
>What are the chances Deepseek waifu AI actually using Dipsy character?
Anonymous
7/16/2025, 8:59:16 PM
No.105928869
[Report]
Anonymous
7/16/2025, 9:04:45 PM
No.105928918
[Report]
>>105925528
Yup. This pattern applies within America too.
Anonymous
7/16/2025, 9:05:53 PM
No.105928924
[Report]
>>105926536
Sexy. How big of a model can you run?
Anonymous
7/16/2025, 9:06:27 PM
No.105928932
[Report]
>>105928974
Anonymous
7/16/2025, 9:06:59 PM
No.105928940
[Report]
>>105926652
>average VRChat user
Anonymous
7/16/2025, 9:07:09 PM
No.105928941
[Report]
>>105928979
I'm still angry about Libre Office no using Libbie the Cyber Oryx as their mascot.
Anonymous
7/16/2025, 9:09:58 PM
No.105928964
[Report]
>>105928603
Fair enough, I might download UD's IQ4_XS & IQ3_XXS at some point and do a comparison. Internet is slow though so no way it can be done today.
Anonymous
7/16/2025, 9:11:09 PM
No.105928974
[Report]
>>105928932
go back to your containment thread faggot
Anonymous
7/16/2025, 9:11:39 PM
No.105928979
[Report]
>>105929000
>>105928941
Pic related was the only good entry.
Anonymous
7/16/2025, 9:13:25 PM
No.105929000
[Report]
>>105928979
>a parrot is fine too
Anonymous
7/16/2025, 9:24:11 PM
No.105929114
[Report]
>>105927465
I ran it and it is indeed a big difference. Thank you for informing me.
Anonymous
7/16/2025, 9:24:11 PM
No.105929115
[Report]
>>105929140
>>105928630
There's no reason to ask that. The "Dipsy" design the two anons keep genning is frankly not very good, mostly because the image gen models aren't good enough to generate really custom designs and consistently though, I would guess.
Anonymous
7/16/2025, 9:26:24 PM
No.105929140
[Report]
>>105929153
>>105929115
The design was made by an actual drawfag and those images were very good.
The dress is supposed to have tiny whales on it for example.
Anonymous
7/16/2025, 9:27:40 PM
No.105929152
[Report]
>>105927236
Maybe try renting one and see it for yourself.
Anonymous
7/16/2025, 9:27:40 PM
No.105929153
[Report]
>>105929682
>>105929140
Well that's cool and all but the character design that keeps being posted is certainly much shittier if the original was decent.
Any good sites I can download voices from? Video game characters, actresses, whatever. Just need to download voice packs and turn them into .wavs for my waifu
t. SillyTavern user with AllTalk V2 installed
Anonymous
7/16/2025, 9:36:16 PM
No.105929253
[Report]
>>105929264
>>105929236
Just clip the voices yourself bro.
(this is basically the response I got when I asked that same question)
Anonymous
7/16/2025, 9:37:01 PM
No.105929263
[Report]
>>105928630
>what are the chances real people will validate my mental illness
0%. kill yourself.
>>105929253
Fuck. Any qt british older women in media you know of? I considered Tracer (overwatch) but she's hardly a hag.
Anonymous
7/16/2025, 9:45:16 PM
No.105929353
[Report]
>>105929264
no because i don't watch the BBC
Anonymous
7/16/2025, 9:47:11 PM
No.105929376
[Report]
>>105929236
English or Japanese voices? For Jap, most gacha wikis have 10-20 second voice clips which make them convenient for TTS cloning. For English, probably just splitting the audio manually into clips from a youtube video with whatever voice you want would be easiest
>>105928630
terminally online AGP troons will definitely be studied one day for such oneitis obsessive mental illness fixations of their random retard waifus they try to spam everywhere online like the autistic retards they are
they just cant keep it on their gooner discord channel with other degenerate browns, they try to groom everyone online into their obsession too
Anonymous
7/16/2025, 9:50:02 PM
No.105929407
[Report]
>>105929386
Repetition penalty too high.
Anonymous
7/16/2025, 9:52:30 PM
No.105929432
[Report]
>>105929236
for japanese you can rip them with garbro from visual novels, each character is gonna have a ton of relatively high quality voice lines
Anonymous
7/16/2025, 9:53:44 PM
No.105929448
[Report]
>>105929634
>>105929264
>qt british older women
Victoria Coren Mitchell. She hosted a game show, maybe you can snip not-too-noisy clips out of it.
Anonymous
7/16/2025, 9:54:30 PM
No.105929459
[Report]
>>105926531
>I would love to do an uncensor tune or selective expert merge (with base) of this, but nobody seems to care for this and I'm not rich enough to do it myself(would need 1-2TB RAM,and a modest amount of VRAM (one H100 might be enough) or less, depending)
Why even that much VRAM? If you're streaming parameters through VRAM per layer, then you might as well stream gradients and KV as well ... that's not enough data to need a H100 is it?
Anonymous
7/16/2025, 9:55:22 PM
No.105929472
[Report]
>>105929532
>>105929386
take a break from the internet, dude, holy shit
Anonymous
7/16/2025, 9:57:17 PM
No.105929490
[Report]
>>105929514
>>105929386
>terminally online
>obsessive mental illness fixations
>spam
>autistic retards
He says...
Anonymous
7/16/2025, 10:00:02 PM
No.105929514
[Report]
>>105929531
>>105929490
>no u
smartest brown
Anonymous
7/16/2025, 10:01:49 PM
No.105929531
[Report]
>>105929542
>>105929514
Ah. I forgot about that one.
>brown
He says...
Anonymous
7/16/2025, 10:01:52 PM
No.105929532
[Report]
>>105929472
you first. nta
Anonymous
7/16/2025, 10:03:08 PM
No.105929542
[Report]
>>105929531
Already accepted your concession, do continue
Anonymous
7/16/2025, 10:08:00 PM
No.105929594
[Report]
>>105929675
You are the melting men
You are the situation
There is no time to breathe
And yet one single breath
Leads to an insatiable desire
Of suicide in sex
So many blazing orchids
Burning in your throat
Making you choke
Making you sigh
Sigh in tiny deaths
So melt!
My lover, melt!
She said, melt!
My lover, melt!
You are the melting men
And as you melt
You are beheaded
Handcuffed in lace, blood and sperm
Swimming in poison
Gasping in the fragrance
Sweat carves a screenplay
Of discipline and devotion
So melt!
My lover, melt!
She said, melt!
My lover, melt!
Can you see?
See into the back of a long, black car
Pulling away from the funeral of flowers
With my hand between your legs
Melting
She said, melt!
My lover, melt!
(She said) melt!
My lover, melt!
So melt!
My lover, melt!
She said, melt!
My lover, melt!
Anonymous
7/16/2025, 10:08:57 PM
No.105929606
[Report]
>>105929635
>>105926855
Thanks. Besides just Googling 'Nemo at q4' is there any helpful reading I could do on this?
>>105926961
Jesus Christ what the fuck why do people pay so much for this.
Anonymous
7/16/2025, 10:10:54 PM
No.105929623
[Report]
>>105929634
>>105929264
Helen Mirren.
Anonymous
7/16/2025, 10:11:41 PM
No.105929634
[Report]
>>105929701
>>105929448
You're a fucking god m8
>Thank you, mummy
>>105929623
I'll see if I can find a good sample for her. Thanks!
>>105929606
this download this
https://huggingface.co/TheDrummer/Rocinante-12B-v1.1-GGUF/tree/main
then watch a guide how to set up sillytavern with llama.cpp
Anonymous
7/16/2025, 10:12:39 PM
No.105929646
[Report]
>>105929635
Thanks brother. I will dive into this!
Anonymous
7/16/2025, 10:15:31 PM
No.105929675
[Report]
Anonymous
7/16/2025, 10:16:07 PM
No.105929681
[Report]
>>105929743
Anonymous
7/16/2025, 10:16:10 PM
No.105929682
[Report]
Anonymous
7/16/2025, 10:18:51 PM
No.105929701
[Report]
>>105929634
Victoria is good. Not into mommy stuff, but she was a cutie in her poker days.
What's the effective context dropoff before Nemo Instruct 2407 goes retarded?
32k? 16k?
Anonymous
7/16/2025, 10:24:00 PM
No.105929742
[Report]
>>105929775
>>105929716
For chatting/ERP?
I'd say 12K ish.
Anonymous
7/16/2025, 10:24:00 PM
No.105929743
[Report]
>>105929681
sorry to hear that John, you finally realized why we just jack it to text and japanese drawings
>>105929635
Is there anything between Rocinante and DeepSeek worth using?
Anonymous
7/16/2025, 10:26:49 PM
No.105929762
[Report]
Anonymous
7/16/2025, 10:27:07 PM
No.105929765
[Report]
From time to time, the character response includes my name (sollo) and some actions. What setting do I need to tweak to fix this? It also sometimes prattles on forever. Using this model in Sillytavern with KoboldCpp:
https://huggingface.co/djuna/MN-Chinofun-12B-4.1
Anonymous
7/16/2025, 10:28:31 PM
No.105929773
[Report]
>>105929745
Violet Magcap
Anonymous
7/16/2025, 10:28:49 PM
No.105929775
[Report]
>>105929789
>>105929742
Seriously? It's that bad?
If I set it to 12k and want to roleplay to 300+ messages, is it going to forget the system prompt and stuff?
>>105929775
>is it going to forget the system prompt and stuff?
With Silly Tavern, no. It cuts the top of the chart history while retaining things like the sys prompt.
You might want to look into the summary and vectorDb extensions.
Anonymous
7/16/2025, 10:32:26 PM
No.105929811
[Report]
>>105927851
Does it finally work on llama.cpp?
Anonymous
7/16/2025, 10:34:46 PM
No.105929824
[Report]
>>105929789
>summaries
Nemo is way too retarded to write summaries.
It has a bad tendency to swap important details around or even reverse facts. It's only good for roleplay as long as you pay attention to swipe when it fucks up the details.
>>105929769
You probably use Include names. The model picks it up from the context, and uses it on its own. Probably happens when whatever it says requires an immediate action and it's too early into the reply to just end it before the "impersonation".
I don't use Include names (nor ST for that matter), but that's probably why it happens. Either don't use names, which may make it much worse, or just edit the model's output (which i assume you already do).
You should try mistral's model directly or a proper finetune. Never liked merges.
Anonymous
7/16/2025, 10:40:27 PM
No.105929873
[Report]
>>105929769
>>105929857
Nevermind the include names bit. The rest is true.
Anonymous
7/16/2025, 10:40:56 PM
No.105929877
[Report]
>>105931253
>>105929789
What's the ideal vector storage settings for roleplay?
Anonymous
7/16/2025, 10:41:31 PM
No.105929881
[Report]
>>105929889
>>105929857
Interesting, thank you for the reply! Can you recommend something for roleplaying?
Anonymous
7/16/2025, 10:42:31 PM
No.105929889
[Report]
>>105929907
>>105929881
*a model for roleplaying
Anonymous
7/16/2025, 10:44:55 PM
No.105929907
[Report]
>>105929889
rocinante 1.1
Anonymous
7/16/2025, 10:46:15 PM
No.105929915
[Report]
>>105929934
The only people who have any idea what LLMs are capable (not) of seem to be those who have played with retarded small models. But I guess it too late now to educate any of them,
Anonymous
7/16/2025, 10:47:33 PM
No.105929922
[Report]
>>105928802
>cloud waifu is glowing
The only people who have any idea what LLMs are (not) capable of seem to be those who have played with retarded small models. But I guess it too late now to educate any of them,
Anonymous
7/16/2025, 10:48:41 PM
No.105929934
[Report]
Anonymous
7/16/2025, 10:49:23 PM
No.105929939
[Report]
>>105929924
i'm not going to fix any more of my drunken esl stuff, you get the gist
Anonymous
7/16/2025, 10:50:49 PM
No.105929955
[Report]
>>105929983
>>105929924
Never used a bigger model than a 12b or the 30b moe. I don't expect them to do much. The people you're talking about are just new in general. Whether they have a 1080 or a couple of blackwells.
Anonymous
7/16/2025, 10:54:30 PM
No.105929983
[Report]
>>105929955
I'm mostly talking about normal people interacting with the corpo stuff. And journos writing stories about that. Those journos should be forced to make a 8b model do some 10 tasks before they can write anything AI related.
>>105929924
I used mixtral instruct models daily for a year, then I used nemo instruct models daily for a year.
I know my Rocinante/Nemo like the inside of my foreskin and have written a custom tailored system prompt for it to maximize satisfactory output, as well as take advantage of banned strings, regex, and auto swipe.
Nobody can tell me any model is better at roleplay than Rocinante, not even Deepseek R1.
Anonymous
7/16/2025, 10:58:16 PM
No.105930020
[Report]
>>105928232
Are you few-shotting it?
Anonymous
7/16/2025, 10:59:31 PM
No.105930029
[Report]
>>105929996
Can you share those system prompts?
we are so back. I'm ready for strawberry Sam
Anonymous
7/16/2025, 11:02:12 PM
No.105930054
[Report]
>>105929716
Around 20K from my experience, sometimes a bit more
Anonymous
7/16/2025, 11:03:05 PM
No.105930062
[Report]
>>105930177
>>105930034
What's the point of posting that here? We already know it's going to be amazing, but the wait is unbearable especially after the delay. We don't want to think about it anymore until it's here.
Anonymous
7/16/2025, 11:03:14 PM
No.105930066
[Report]
>>105930107
I'm losing my damn mind, I'm feeding a fairly simple template to msmall to make a character profile based off of info I provide, then ask it to make improvements and it goes into a death spiral of repetition. It just selectively ignores instructions like "only output the improvements/changes" and it just regurgitates the whole fucking thing before going into repetition hell. "we fixed the repetition" my ass, this happens no matter the template or even just no instruct formatting. It's hell that the only shit in the 24-32 range is mistral repetition hell and chink models that have zero imagination
Anonymous
7/16/2025, 11:04:37 PM
No.105930078
[Report]
>>105929996
You added a rag too? Rocinante doesn't know a lot
Anonymous
7/16/2025, 11:06:17 PM
No.105930086
[Report]
Is there a single Gemma finetune that is nither excessively positive bias obsessed but also not a complete psycho that turns every character evil for no reason? There has to be something in between
Anonymous
7/16/2025, 11:08:52 PM
No.105930101
[Report]
>>105930167
can I avoid the fucking edulcorated, patronizing bullshit responses if I run a local model? I tried enforcing absolute mode but every LLM I try keeps going back to defaults after 2 or 3 subsequent prompts
Anonymous
7/16/2025, 11:10:15 PM
No.105930107
[Report]
>>105930066
Really liked Cydonia's latest incarnation, v4 24B
>>105926935
The Aryans came into India from the North-West around 2000 BC. Their homeland was somewhere in that direction but they weren't natives of India. The basic Nazi idea was rooted in a linguistic observation still accepted today, that many existing languages have a common root that is referred to as "Proto-Indo-European" (
https://en.wikipedia.org/wiki/Proto-Indo-European_language) because no name survives for that hypothetical-but-believed-to-exist language or the people who spoke it. Hitler referred to them as Aryans because it's a plausible thing they might have called themselves, since several of their terminal offshoots in different locations called themselves variants of that.
>>105930101
>absolute mode
No such thing. It predicts tokens. That's what it does. Jailbreaks don't exist. There isn't a switch, there is no bug to exploit. Either the model is compliant or not. All "jailbreaks" do is pollute the context enough for it to affect how the model will predict tokens.
As for online models, there may be filters or custom prompts to try to prevent you from doing stuff they don't want. So the answer is "maybe". It'd be more useful to post your request and let other anons that can run DS give it a go.
Anonymous
7/16/2025, 11:17:51 PM
No.105930172
[Report]
>>105930144
fellow aryanbro
Anonymous
7/16/2025, 11:19:10 PM
No.105930177
[Report]
>>105930062
I honestly don't see them releasing a model that is better than Kimi K2. They would be cannibalizing their own offerings on the API if they did.
Anonymous
7/16/2025, 11:19:42 PM
No.105930183
[Report]
>>105930202
>>105930071
I have found that Gemma 27b is better than any 32b model, and easily beats mistral 24b.
Ok I have almost no idead how to ask this so here it goes.
You know how on stable diffusion you can just enter a prompt, set the number of images you want and let it go theoretically all day? How do you do that with a textbot?
Also how do I get it to stop trying to have a conversation and just output the text I'm asking for like a machine? Prompting doesn't really work so I'd prefer something on the settings level.
Also is there a way to remove the comment length limiter or post number limiter?
>>105930144
>That one group that started heading west into Europe, then last minute decided to circle back the long way around to end up in India
Even their Aryan ancestors weren't very bright.
Anonymous
7/16/2025, 11:22:38 PM
No.105930197
[Report]
>>105930274
>>105930167
It's not about the answer to a particular problem, it's about the interaction. I'm just trying to solve code problems and write some scripts without the need for the AI to treat me like I'm an absolute idiot or behaving like it's the worst thing in the world to offend me. If I run a program and it fails I don't expect it to apologize to me or patronize me for using bad parameters and I am tired of all these LLMs doing exactly that. Absolute mode helps that, but they eventually fall back to babysitting and I hate it.
Anonymous
7/16/2025, 11:22:44 PM
No.105930198
[Report]
>>105930352
>>105930189
Generations per swipe option in Sillytavern is basically what you are looking for. I think it only works with Chat Completion mode though.
Anonymous
7/16/2025, 11:23:14 PM
No.105930202
[Report]
>>105931369
>>105930183
I really like gemma but the issue is they cranked up how it immediately freaks out at anything slightly over a PG rating, which is pretty ass for any writing task that even hints at anything unsavory and the alternative is abliterated (brain obliterated) models
Anonymous
7/16/2025, 11:27:38 PM
No.105930228
[Report]
>>105930352
>>105930189
All that depends on whatever frontend you're using. There should be a response length option somewhere, but if you set that to infinity (and ban the stop token used by your model), it will always end up devolving into gibberish. Response format is a result of your prompt and the model. some are just annoyingly chatty. You can usually pigeonhole it into a given format by starting its response for it in a way that naturally continues into what you want, most of the time.
Anonymous
7/16/2025, 11:27:51 PM
No.105930230
[Report]
>>105931330
Short review of Jamba-Mini-1.7 (q8, no context quantization)
Writes pretty bad but passable prose.
It might be a bad quant, it might be llamacpp-bugs, but the model comes off as very very stupid.
>>105930034
>guys it's sooo good
>guys look how good it is
>this is gonna be bananas, or strawberries as I like to say
>guys did you see our new GPT-4 model topped the charts? nevermind the pricing being 50x deepseek at 3% more capable
yawn, I'll never trust these fucking faggots
if it's not smaller than 3B and better than gemma 3 27B then it's shit
Anonymous
7/16/2025, 11:29:42 PM
No.105930247
[Report]
>>105930034
Are they sticking to the promise of giving us a medium-big model or are they gonna release a mobileshitter 2B MoE
Anonymous
7/16/2025, 11:30:16 PM
No.105930252
[Report]
>>105930272
>>105930191
Western Europe was an impoverished backwater until about 500 years ago when Western Christianity was reformed (both by Protestant offshoots and reforms within the Catholic church) and Western Europe received God's blessing.
Anonymous
7/16/2025, 11:30:59 PM
No.105930260
[Report]
>>105930167
>Jailbreaks don't exist
Not true, I jailbreaked mine and now it's 400 IQ. It decompiled Windows and recompiled it for my RISC-V system (all by itself too, I just fed the Windows install disk into it and it figured out how to read the ISO and everything, because it's jealbrakened).
Anonymous
7/16/2025, 11:31:24 PM
No.105930267
[Report]
>>105930309
>>105930234
I'm fully expecting them to release a 30ish b llama 2 era model, complete with the same intelligence that takes the same amount of vram as the model for cache and go "haha, the more you buy the more you save"
Anonymous
7/16/2025, 11:31:41 PM
No.105930272
[Report]
>>105930191
>>105930252
very unarian, very jewish, very subhuman posts
Anonymous
7/16/2025, 11:31:47 PM
No.105930274
[Report]
>>105930197
>Absolute mode
Quick search gave me a prompt, first result was to be used in chatgpt. Just call it a prompt.
>... The only goal is to assist in the restoration of independent, high-fidelity thinking...
Get rid of that shit. The whole thing. Just add "Be terse in your response" in your first query. Add it at the end of your input if you want or find it necessary. And avoid talking to it as in a conversation if that's not what you want. Just give commands.
Screeching at the model is not going to give you what you want.
Anonymous
7/16/2025, 11:35:51 PM
No.105930305
[Report]
>>105930333
>>105930234
You'd think people would have gotten sick of their nonstop clickbait posts instead of releasing useful products months ago.
Anonymous
7/16/2025, 11:36:03 PM
No.105930309
[Report]
>>105930330
>>105930267
>the llama-2 30b we never got
I can only hope
Anonymous
7/16/2025, 11:39:13 PM
No.105930330
[Report]
>>105930309
Yeah actually now that you mention it, it would be nice in a best case scenario, but it'll probably be synth-slopped to hell to make sure it's as sycophantic and safe as possible
Anonymous
7/16/2025, 11:39:37 PM
No.105930333
[Report]
>>105930305
but this time if they don't deliver they will face the full force of the deadly 4chan hackers' (our) wrath right?
Anonymous
7/16/2025, 11:41:30 PM
No.105930352
[Report]
>>105930198
>>105930228
I'm using text generstion webui with qwen right now. Willing to switch to anything at this point but I thought sillytavern was for cloud models?
Anonymous
7/16/2025, 11:42:03 PM
No.105930355
[Report]
>>105930234
Considering that the people they haven't already lost are for the most part idiots, their communication strategy may make sense.
Anonymous
7/16/2025, 11:43:32 PM
No.105930371
[Report]
>>105930189
In Kolboldcpp there's a text completion mode. You can set up the output at a ridiculously high number and have it generate text all day. Depending on the model the text will stop to be coherent fast though.
>>105930144
>laugh at Ukrainians for teaching their children that Ukraine is the origin of human civilization
>see that map
Anonymous
7/16/2025, 11:56:23 PM
No.105930473
[Report]
>>105930481
>>105930459
well aryans and civilization don't go hand in hand for the most part, except for egypt which is a mindfuck case
Anonymous
7/16/2025, 11:57:24 PM
No.105930481
[Report]
>>105930473
>>105930459
and persia, but generally speaking, you can say civilization is un-aryan, they'r cattle herders and settlement raiders in their core/purest form
Anonymous
7/17/2025, 12:07:56 AM
No.105930559
[Report]
>>105930531
At first I was like lol. Then I actually started hating women for a second which is new cause I kinda got over them 2-3 years ago.
Anonymous
7/17/2025, 12:10:26 AM
No.105930585
[Report]
>>105930589
Gemma 3n + these scamsung phones with 12+ gb ram = simple and retarded personal assistant, yay or nay?
https://x.com/UniverseIce/status/1945493538743148855
>>105930585
I will not be seen outside with an AI companion of any sort.
Anonymous
7/17/2025, 12:13:04 AM
No.105930603
[Report]
>>105930589
silently kek'd
Now that the dust has settled. Is this how you imagined the release of first mainstream AI girlfriend?
Anonymous
7/17/2025, 12:14:39 AM
No.105930617
[Report]
>>105928802
I thought it was nods meme
Anonymous
7/17/2025, 12:15:20 AM
No.105930623
[Report]
>>105930589
I figure it will be like social media profiles. First they laugh at the early adopters, then soon they'll find you weird and creepy for not having one.
Anonymous
7/17/2025, 12:15:40 AM
No.105930630
[Report]
Anonymous
7/17/2025, 12:18:05 AM
No.105930652
[Report]
>>105930610
Yeah, I fully expected it being one of Elon Musk's "hello fellow kids'
Anonymous
7/17/2025, 12:18:33 AM
No.105930658
[Report]
Anonymous
7/17/2025, 12:18:59 AM
No.105930661
[Report]
>>105930678
>>105930610
I imagined this would be the one thing local got first
Anonymous
7/17/2025, 12:19:38 AM
No.105930667
[Report]
>>105930682
>>105930531
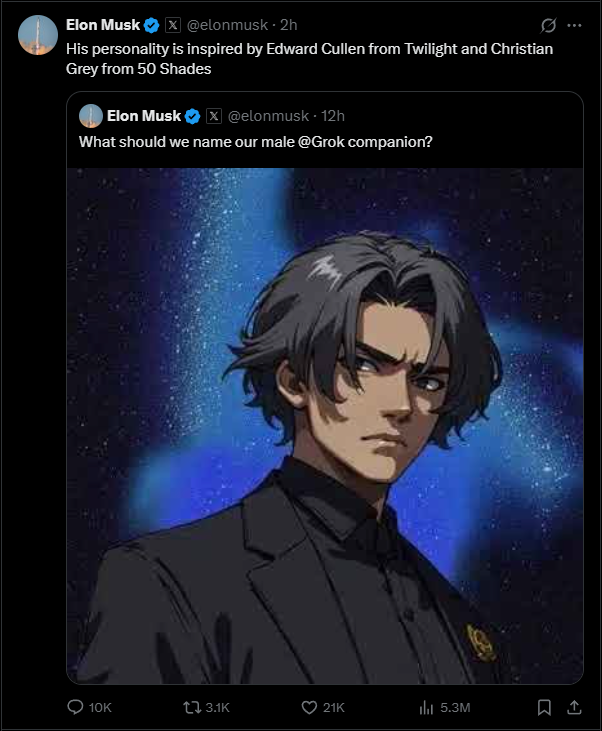
"he was inspired by slop by slop author and slop by slop author"
damn, thanks heavily autistic man on the internet that has far more power than he should, you had negative impact on the world, if you ignore the sheer amount of energy desperate housewives will spend erping with it
When's grok 3? Or even 2?
Anonymous
7/17/2025, 12:21:03 AM
No.105930678
[Report]
>>105930720
>>105930661
What made you think that? Local has been sitting on sillytavern for more than two years now without lifting a finger to make more of these models.
Anonymous
7/17/2025, 12:21:15 AM
No.105930682
[Report]
>>105930705
>>105930667
The killings he's going to make off the DLC is going to be insane teebh
Anonymous
7/17/2025, 12:25:01 AM
No.105930705
[Report]
>>105930682
I'm screeching into the void for a not completely shit open source model, I don't need to be reminded about how muskrat is making a killing being a grifter like he's been for about a decade
Anonymous
7/17/2025, 12:26:02 AM
No.105930712
[Report]
>>105927881
>This is the pinnacle of German humour
In Germany, 16 A at every fucking socket at minimum
Anonymous
7/17/2025, 12:27:06 AM
No.105930720
[Report]
>>105930678
I thought if we waited long enough some determined autist or ponyfucker would cave and make something
Anonymous
7/17/2025, 12:32:02 AM
No.105930763
[Report]
Insert punctuation and try again
>>105927903
>「うふふ獣耳の麗しき幼女おにいさんと遊ぼうかなぁに怪しい人じゃないのですことよ」
doumitemobunpoutekinihakimoi
Kimi is a fucking bitch that often contraddict itself just to ideologically counter what I say. When I point out the contraddiction it apologize, only to fall back to the sale behavior after a message. I thought chinks weren't pozzed like the west?
Anonymous
7/17/2025, 12:39:46 AM
No.105930845
[Report]
Are there any local models that will let me do what I can with Claude with massive context windows for novelized stories?
I hate how all the online models are censored to shit. I can't get anything good out of them for writing my admittedly R18 stories.
Anonymous
7/17/2025, 12:40:34 AM
No.105930848
[Report]
>>105930799
i use ubergarm's IQ4_KS quant of K2 without this issue. are you sure this isn't just a prompt or API issue?
Anonymous
7/17/2025, 12:42:35 AM
No.105930873
[Report]
>>105930799
>contraddict
Contradict?
>contraddiction it apologize
Contradiction, it apologizes, I guess you mean? Very esl so far
>sale behavior after a message
Do you mean same behavior after a message? Well that's basically every model these days
>I thought chinks weren't pozzed like the west?
Ignoring how bad you are at english, western models definitely suck, but eastern models overtrain on shit that has nothing to do with english or any general knowledge in the english domain and end up being garbage for any general use, so idk man
Anonymous
7/17/2025, 12:57:07 AM
No.105931022
[Report]
>>105931069
>>105925446 (OP)
I have an old rtx3080. What's the best model I can run on this?
Anonymous
7/17/2025, 1:01:00 AM
No.105931060
[Report]
>>105929264
Is AllTalk able to work with British accents? Or any accents? I remember trying a local model for tts a few years back an it would lose the accent within the first 3 sentences.
Also pic related. Dr. Grey from the recent CoD zombies.
Anonymous
7/17/2025, 1:01:59 AM
No.105931069
[Report]
>>105931022
>coom
nemo
>general stuff with vision
gemma3
>benchmaxx programming
qwen3
Anonymous
7/17/2025, 1:03:41 AM
No.105931094
[Report]
>>105931247
Tested Exaone. It was shit. It was worse than Qwen3 at the programming question I tried, and it kept falling at doing tools correctly when I tried it with Claude Code. Uninstalled.
Anonymous
7/17/2025, 1:05:32 AM
No.105931120
[Report]
>>105930864
I like this Miku
Anonymous
7/17/2025, 1:10:45 AM
No.105931173
[Report]
>>105930531
I had this thought. Isn't a character like that the exact opposite of the assistant archetype? How is that gonna work out?
Anonymous
7/17/2025, 1:11:13 AM
No.105931179
[Report]
Anonymous
7/17/2025, 1:16:24 AM
No.105931233
[Report]
>>105929236
Yes, I made a Kuroki Tomoko voice in various flavors, it's on huggingface. It feel like piper is the best compromise between quality and support. If you somehow get the gpt-sovits one working in ST please report back.
Anonymous
7/17/2025, 1:17:37 AM
No.105931247
[Report]
>>105931307
>>105931094
How/where did you test it? Were you using quants?
Anonymous
7/17/2025, 1:18:17 AM
No.105931253
[Report]
>>105929877
None. It doesn't really work.
Anonymous
7/17/2025, 1:18:41 AM
No.105931261
[Report]
>>105931235
nothingburger incoming
>>105931235
>10B
>mistral nemo performance
>except it is properly safe and censored
I am punching in my prediction.
Anonymous
7/17/2025, 1:21:37 AM
No.105931284
[Report]
>>105931328
>>105931277
They will punch above your prediction.
Anonymous
7/17/2025, 1:22:13 AM
No.105931294
[Report]
>>105931277
sama is a gooner, he will deliver
Anonymous
7/17/2025, 1:22:37 AM
No.105931301
[Report]
>>105931235
OpenAI just dropped a BOMBSHELL announcement, new REVOLUTIONARY feature that will change EVERYTHING (rocket emoji) subscribe NOW
Anonymous
7/17/2025, 1:22:38 AM
No.105931302
[Report]
>>105928009
>I’m not some shady stranger, you know.
This is giving me flashbacks to 1990s anime subtitles. (This is not a compliment.)
Anonymous
7/17/2025, 1:23:09 AM
No.105931307
[Report]
>>105931247
I downloaded their Q6 quant and applied the llama.cpp PR.
Anonymous
7/17/2025, 1:25:21 AM
No.105931328
[Report]
>>105931284
>10B with the benchmarks of 1T
and people will eat it up too
Anonymous
7/17/2025, 1:25:33 AM
No.105931330
[Report]
>>105930230
How does it feel compared to Mixtral 8x7B?
Anonymous
7/17/2025, 1:26:12 AM
No.105931336
[Report]
>>105931351
>>105931235
voice in voice out (no music) is the only special thing it will have it will also probably be some grafted bullshit some they dont "expose their secrets" or sum gay shit like that the model itself will be fucking dogshit also the model will probably be some akward size if its big (idk like 100+b) personally i expect the model to be 16-40 gb
this is assuming they release anything at all
Anonymous
7/17/2025, 1:27:13 AM
No.105931351
[Report]
>>105931394
>>105931336
Granted, they might have changed their mind, but they originally said it would be text only.
>>105930202
bro like what if you merged an abliterated model back into the instruct model
Anonymous
7/17/2025, 1:30:45 AM
No.105931394
[Report]
>>105931351
>reasoning = benchmaxxed
>safetymaxxed
>text only
>not as big as deepseek
what does it even possibly have going for it?
Anonymous
7/17/2025, 1:33:04 AM
No.105931420
[Report]
>>105931870
niggerfaggots, all of them.
Anonymous
7/17/2025, 1:33:32 AM
No.105931424
[Report]
I had a go at different Hunyuan quants as well as the base pretrained model, to see if there were any issues with the Unsloth quant. Well none of them were very smart. Was this the model they said they got an AI to rewrite training data for?
Anonymous
7/17/2025, 1:34:38 AM
No.105931433
[Report]
>>105931369
It sounds stupid but why the hell not? We have nothing to lose at this point. Or, I don't know, half-abliterate the model. Yeah
Anonymous
7/17/2025, 1:40:18 AM
No.105931483
[Report]
Grokette release is like the entertainment show on the after funeral party of this hobby. It sucked the rest of my hope out.
Anonymous
7/17/2025, 1:40:31 AM
No.105931486
[Report]
>>105931826
Anonymous
7/17/2025, 1:42:38 AM
No.105931506
[Report]
>>105931369
You might regain some smarts but generally lose any of the benefits of the original abliteration, even though I don't really consider abliteration providing a lot of benefits. I think a while ago I checked the UGI leaderboard and someone did a DPO finetune on an abliterated model and it came out almost with almost the same stats as the abliterated model. Plus, removing the ability of a model to go "this character would say no to this" removes a lot of depth from any given scenario
Anonymous
7/17/2025, 1:45:34 AM
No.105931525
[Report]
>>105931550
>>105926497
For a pristine setup, consider acquiring a previously owned server typically utilized in a corporate environment.
>>105931525
>pristine
>previously owned
>corporate
hmmm
Anonymous
7/17/2025, 1:48:55 AM
No.105931556
[Report]
>>105930531
"Hitler did nothing wrong"
Anonymous
7/17/2025, 1:55:35 AM
No.105931610
[Report]
>>105931581
>make a spiteful seething comment
>but I see this as a win
uhuh
Anonymous
7/17/2025, 1:59:40 AM
No.105931638
[Report]
>>105931581
Musk should have released a male bot first, making their comments instantly hypocritical rather than retrospectively
Anonymous
7/17/2025, 2:03:09 AM
No.105931672
[Report]
>>105931550
While "pristine" might imply a brand new system, it's worth noting that refurbished servers can offer a similar level of quality and performance at a significantly lower cost.
Anonymous
7/17/2025, 2:04:07 AM
No.105931681
[Report]
Anonymous
7/17/2025, 2:05:17 AM
No.105931691
[Report]
>>105931550
nta. Worked in a few datacenters. Those things are typically underutilized, in a dust-free, air conditioned room at like 8C. Depends on the place, of course. I've seen some dumb shit as well.
Anonymous
7/17/2025, 2:28:38 AM
No.105931826
[Report]
>>105931581
>>105931420
>Foids admitting they literally have less to offer than text on screen with a tranime girl avatar and a shit voice chatbot
Holes are barely human. The only humanity within the niggers and jews of the genders is the male cum flowing through their whore holes which only exist to cry and lie.
Anonymous
7/17/2025, 2:40:23 AM
No.105931895
[Report]
>>105931916
>>105931277
the fuck with this gay ahh picture?
Anonymous
7/17/2025, 2:42:24 AM
No.105931915
[Report]
>>105931277
I just know it's gonna be ass but people *will* eat it up cause it's le openai
Anonymous
7/17/2025, 2:42:27 AM
No.105931916
[Report]
>>105931895
Almost like he is a faggot or something
Anonymous
7/17/2025, 2:45:50 AM
No.105931932
[Report]
>>105931277
kek'd 'n checz'd
Predictions for OpenAI's first open source textgen model since 2019?
>12B parameters
>64k context, 16k usable
>Benchmaxxed
>"I'm sorry, but as an AI language model I can't do anything beside code completion."
>"Her spine shivers, barely above a whisper, as she looks at you with a mixture of X and Y."
>Slightly tweaked architecture, has to be run with telemetry enabled
>Completely unworkable license
Anonymous
7/17/2025, 2:46:42 AM
No.105931941
[Report]
>>105931948
So nothing better than QwQ? Really?
Anonymous
7/17/2025, 2:47:43 AM
No.105931948
[Report]
>>105931941
can't beat perfection
Anonymous
7/17/2025, 2:48:12 AM
No.105931951
[Report]
>>105931979
>>105931870
You're cut from the same cloth as the fella that said that, "Straight black men are the white people of black people."
Anonymous
7/17/2025, 2:51:14 AM
No.105931972
[Report]
>>105931235
geg PoopenAI are doing the needful with releasing mistral nemo finetune with more (((safety)))
Anonymous
7/17/2025, 2:51:49 AM
No.105931979
[Report]
>>105931993
>>105931951
Sorry, that phrase is too american for me to understand.
Anonymous
7/17/2025, 2:53:39 AM
No.105931993
[Report]
>>105932000
>>105931979
Classic brainlet.
Write me a story where a character is telling a story to another character.
Anonymous
7/17/2025, 2:55:36 AM
No.105932000
[Report]
>>105932012
Anonymous
7/17/2025, 2:57:08 AM
No.105932008
[Report]
>>105932066
>>105931935
100-150B 12-24B active MoE
good but with extremely annoying safetycucking
Anonymous
7/17/2025, 2:57:17 AM
No.105932012
[Report]
>>105932017
>>105932000
my bad, I forgot to write my instructions on crayon for you.
Standard English shouldn't be this difficult for you to understand. Go outside more.
Anonymous
7/17/2025, 2:57:46 AM
No.105932017
[Report]
>>105932012
nta
>on crayon
Anonymous
7/17/2025, 3:06:59 AM
No.105932066
[Report]
>>105932008
I have no idea of the size. It could be a small dense model, or a MoE nearly the size of DS V3. But I expect that other than the safetymaxxxing, it will be extremely good. Like best in class for its size. And that will make a lot of people here seethe.
Anonymous
7/17/2025, 3:11:46 AM
No.105932087
[Report]
x beaten my personal unreal engine project with waifus and local models by just a little bit, theirs is smarter but mine has more features hmph.
Anonymous
7/17/2025, 3:12:57 AM
No.105932094
[Report]
>>105932110
>their accent thickens through the text message
How is that even supposed to work? is this a gpt-ism? I haven't seen it before
Anonymous
7/17/2025, 3:14:58 AM
No.105932110
[Report]
>>105932094
That's hilarious.
I wonder if models would be able to self correct if we trained them to backtrack in situations like that.
Anonymous
7/17/2025, 3:28:47 AM
No.105932178
[Report]
>>105931935
They'll do a continued pretrain + finetune of llama 3.3 on a curated fraction of their instruct dataset, implement their unpublished anti-ablation post training research, and partner with ollama for release.
It'll be SOTA for the use cases that the open source community is looking for: math, boilerplate regurgitation, riddles, "gotcha!" questions, and poem writing. It will also be really smart in RP while outdoing Mixtral's positivity and wokeness.
Anonymous
7/17/2025, 3:29:15 AM
No.105932183
[Report]
>>105932217
>>105925446 (OP)
erm anons I've been running kimi k2 3bit on my AI server for normie tasks. Am I missing out on top tier ERP?
Anonymous
7/17/2025, 3:35:16 AM
No.105932217
[Report]
Anonymous
7/17/2025, 3:38:42 AM
No.105932237
[Report]
>>105931870
Thanks AI as I never have to interact with them anymore
Anonymous
7/17/2025, 4:02:45 AM
No.105932353
[Report]
>>105932413
Did oobabooga format change?
I downloaded the newest portable build, tried to move my characters and models folder in it but it is not detecting anything?
Anonymous
7/17/2025, 4:05:41 AM
No.105932364
[Report]
>>105932403
Mixture of Raytraced Experts
https://arxiv.org/abs/2507.12419
>We introduce a Mixture of Raytraced Experts, a stacked Mixture of Experts (MoE) architecture which can dynamically select sequences of experts, producing computational graphs of variable width and depth. Existing MoE architectures generally require a fixed amount of computation for a given sample. Our approach, in contrast, yields predictions with increasing accuracy as the computation cycles through the experts' sequence. We train our model by iteratively sampling from a set of candidate experts, unfolding the sequence akin to how Recurrent Neural Networks are trained. Our method does not require load-balancing mechanisms, and preliminary experiments show a reduction in training epochs of 10\% to 40\% with a comparable/higher accuracy. These results point to new research directions in the field of MoEs, allowing the design of potentially faster and more expressive models.
https://github.com/nutig/RayTracing
Repo isn't live yet. neat though only only tiny proof of concept models trained
Anonymous
7/17/2025, 4:12:31 AM
No.105932403
[Report]
>>105932454
>>105932364
>Meal Ready to Eat
Anonymous
7/17/2025, 4:14:32 AM
No.105932413
[Report]
>>105932353
Oh shit saw the new user data folder. Shit seems to go there now.
Anonymous
7/17/2025, 4:20:51 AM
No.105932454
[Report]
>>105932403
It's meant to be.
Anonymous
7/17/2025, 4:37:58 AM
No.105932531
[Report]
>>105932561
>>105925446 (OP)
This should be neuro sama vs ani. Is literally canon btw.
Anonymous
7/17/2025, 4:45:09 AM
No.105932560
[Report]
>>105926961
>I'm flabergasted by what ppl pay for these used cards.
You are retarded, a 2070 super (basically a 2080 in most cases) are like 95% performance of a 4060/5060.
That's how bad gaming gpu market is right now.
Anonymous
7/17/2025, 4:45:09 AM
No.105932561
[Report]
>>105932570
>>105932531
I can talk to neuro in a private session?
Anonymous
7/17/2025, 4:46:28 AM
No.105932570
[Report]
>>105932561
No, but you can ERP with her creator if you simp hard enough
Anonymous
7/17/2025, 5:20:28 AM
No.105932720
[Report]
>>105932744
>>105930071
Instructions like that should be as low as possible in the context. Even better if you use noass:
Description
History
Latest user reply
[INST] Instructions [INST]
{{char}}:
Anonymous
7/17/2025, 5:25:44 AM
No.105932744
[Report]
>>105932759
>>105932720
Isn't that author's notes?
Anonymous
7/17/2025, 5:28:16 AM
No.105932759
[Report]
>>105932744
Dunno, I don't use ST
Anonymous
7/17/2025, 5:31:03 AM
No.105932769
[Report]
Anonymous
7/17/2025, 6:31:13 AM
No.105933071
[Report]
>>105925920
Iran. Could you please. Just. Iran, please? Just take one for the team and clean the middle east. Please? Iran?