Anonymous
7/19/2025, 4:47:56 AM
No.105952992
[Report]
>>105956330
/lmg/ - Local Models General
Anonymous
7/19/2025, 4:48:17 AM
No.105953000
[Report]
►Recent Highlights from the Previous Thread:
>>105947940
--Papers:
>105948239
--AniStudio exploring Llama.cpp integration with planned nodegraph support:
>105950338 >105950348 >105950390 >105950558 >105950583 >105950596
--Optimizing 12-15B roleplay models on 5070ti with DDR5 and quantization tweaks:
>105949376 >105949394 >105949635 >105949784 >105949808 >105949840 >105949879 >105949657
--Running lightweight AI models on outdated hardware with limited resources:
>105949661 >105949766 >105949789
--K2 impresses with technical problem-solving despite lower hype:
>105949359
--Nemo's dominance in roleplay fine-tuning persists due to lack of uncensored alternatives:
>105951040 >105951078 >105951118 >105951215 >105951226 >105952097
--Viral Grok AI anime girl interaction sparks discussion on quality and hype:
>105948393
--Elon Musk teases upcoming Grok AI Valentine promotional video on X:
>105948572
--o3 and Grok-4 tie on ARC 3.0 amid questions about fairness and task ambiguity:
>105950597 >105950629 >105950634
--Customizing an AI droid for Star Wars roleplay by suppressing unwanted knowledge and anticipating Hailo-10H hardware:
>105948217
--Miku (free space):
>105948085 >105948096 >105949618 >105949864 >105950114 >105950317 >105950355 >105950545 >105950719 >105950767 >105951002 >105952353
►Recent Highlight Posts from the Previous Thread:
>>105948340
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
Anonymous
7/19/2025, 4:54:10 AM
No.105953056
[Report]
>>105953154
miku will save local
Anonymous
7/19/2025, 5:05:46 AM
No.105953142
[Report]
>>105953609
Elon may have made the current interation of local models fully obsolete, but that doesn't mean that he can keep his advantage forever. If open source models and the people working on front ends make the right choices, local may regain some relevance at a later time.
Anonymous
7/19/2025, 5:07:37 AM
No.105953154
[Report]
>>105953056
ani will save /lmg/ (not sure how exactly) >>>/wsg/5926751
Is writing a good character card any different from writing a good prompt? Is botmaking just a special case of prompt engineering?
Anonymous
7/19/2025, 5:20:22 AM
No.105953236
[Report]
>>105953191
Prompt engineering is a meme, if it's not adequately represented in the training data (or represented at all) it's not gonna happen. It's like trying to squeeze blood from a stone
Anonymous
7/19/2025, 5:23:22 AM
No.105953256
[Report]
>>105953191
what's there to engineer about?
just describe the body and personality or copy from the wiki and think of a scenario for the first message, that's it and no need to be up your own ass about overcomplicating it
Anonymous
7/19/2025, 5:26:41 AM
No.105953284
[Report]
In need of a new mascot. This one's gettin' a little too old.
Anonymous
7/19/2025, 5:32:07 AM
No.105953313
[Report]
>>105953435
>>105953297
>he's getting tired of the twin tailed tranny troon
well well well
Anonymous
7/19/2025, 5:38:07 AM
No.105953341
[Report]
>>105953191
Something that works incredibly well to give your cards personality is to add words from this list to the personality summary field in SillyTavern in a list with commas:
https://ideonomy.mit.edu/essays/traits.html
Anonymous
7/19/2025, 5:49:38 AM
No.105953401
[Report]
>>105953191
Use AI to write the card.
Anonymous
7/19/2025, 5:54:35 AM
No.105953426
[Report]
>>105953438
>>105953191
Yes, but you need to adapt the card to the model, something no one does
Anonymous
7/19/2025, 5:55:36 AM
No.105953435
[Report]
>>105953476
>>105953313
You lost schizo
>>105953426
>adapt the card to the model
Not relevant for >500B MoE models
Anonymous
7/19/2025, 5:58:01 AM
No.105953450
[Report]
>>105953468
>>105953438
> >500B MoE
still worse than nemo
Anonymous
7/19/2025, 6:00:12 AM
No.105953468
[Report]
>>105953450
This is how nemotroons rationalize their poverty
Anonymous
7/19/2025, 6:01:11 AM
No.105953473
[Report]
>>105953480
>>105953438
Have you ever used R1? It's so prone to obsessing over certain details that there isn't really a way around adjusting cards for it, unless you want to read about the ribbon in {{char}}'s hair rustling and bobbing and getting undone two times every reply.
Anonymous
7/19/2025, 6:02:15 AM
No.105953476
[Report]
>>105953435
No, I don't believe so. We will stay WINNING.
Anonymous
7/19/2025, 6:02:27 AM
No.105953480
[Report]
>>105953491
>>105953473
>use reasoning models in rp
>why they obsess over details
Anonymous
7/19/2025, 6:04:11 AM
No.105953491
[Report]
>>105953501
>>105953480
It's not like V3 is much different in this regard. Deepseek slop stays deepseek slop.
Anonymous
7/19/2025, 6:06:33 AM
No.105953501
[Report]
>>105953508
>>105953491
Feeling copper in your mouth already?
Anonymous
7/19/2025, 6:08:27 AM
No.105953508
[Report]
>>105953501
Yes, it's making my knuckles whiten.
People prefer MoE models over dense shitheaps
Anonymous
7/19/2025, 6:12:12 AM
No.105953533
[Report]
>>105953543
>>105953517
>people prefer the much newer flagship models to the ones from a year ago
wow hold the fucking presses
dense btfo
Anonymous
7/19/2025, 6:13:11 AM
No.105953543
[Report]
>>105953607
>>105953533
>t. contrarian that never stops to wonder why people stopped training dense models
Bitnet LOST
RWKV LOST
Dense LOST
Anonymous
7/19/2025, 6:15:54 AM
No.105953563
[Report]
Not only did most teams stop training dense models, all the new dense models are distillations of open source MoEs like R1-0528.
Anonymous
7/19/2025, 6:17:03 AM
No.105953570
[Report]
>>105953548
i don't know what any of that is but i still goon to l3 70b, nemo and tunes
Anonymous
7/19/2025, 6:20:13 AM
No.105953587
[Report]
>>105953595
Asus ROG has now revealed Hatsune Miku-themed PC hardware, allowing fans to build a complete setup based around the twin-tailed icon.
sadly it only has 1x 16gb 5080
Anonymous
7/19/2025, 6:21:03 AM
No.105953595
[Report]
>>105953623
>>105953587
Wow can't wait to pay the licensing fee and weeb tax
>>105953543
>stops to wonder why people stopped training dense models
because deepseek was all over the international news six months ago so everyone trashed whatever they were working on to copy the popular new thing?
this is just early 2024 again when poorfags declared 70b dense models dead during the mixtral era before getting btfo for the rest of the year
Anonymous
7/19/2025, 6:23:51 AM
No.105953609
[Report]
>>105953142
Nah HR has already shut it down. Local is the only path forward.
Anonymous
7/19/2025, 6:27:22 AM
No.105953622
[Report]
>>105953607
>2024
>Dense at 70B (405B), MoEs at 8x7B
>2025
>Dense still at 70B, MoEs at 1T-A32B
kek
Anonymous
7/19/2025, 6:27:34 AM
No.105953623
[Report]
>>105953595
It costs double
Anyone know a good voice cloning model? I've been very disappointed with everything I've tried so far.
Anonymous
7/19/2025, 6:30:11 AM
No.105953641
[Report]
>>105953632
chatterbox is really solid
Anonymous
7/19/2025, 6:30:58 AM
No.105953643
[Report]
>>105953607
In 2024 at least more 70B dense models were planned upcoming. When they can train a 1T model at 3B costs and still do great on benchmarks and lmarena, there isn't a reason for them to go back to dense.
Anonymous
7/19/2025, 6:32:59 AM
No.105953652
[Report]
>>105953658
>>105953639
Why recommend something that hasn't been released yet?
Anonymous
7/19/2025, 6:35:00 AM
No.105953658
[Report]
>>105953652
The paper's already released. Just ask your AI model to write an implementation.
https://arxiv.org/abs/2506.21619
Anonymous
7/19/2025, 6:46:44 AM
No.105953707
[Report]
>>105953726
>>105953639
Anime dubbers are so done.
Anonymous
7/19/2025, 6:52:28 AM
No.105953726
[Report]
>>105953707
Good. I really dislike english anime dubs.
https://archive.ph/vWm5e
Sounds good on paper, in practice I've got a feeling this means "if your model isn't leaking MAGA propaganda out of its anus and you're found using it you'll be shipped to the gulag"
Why do they keep trying to stick their political crusty smegma coated cheeto dicks in my mouth
Anonymous
7/19/2025, 7:23:42 AM
No.105953872
[Report]
anime
Anonymous
7/19/2025, 7:27:12 AM
No.105953887
[Report]
>>105953861
The pendulum swings
Anonymous
7/19/2025, 7:29:50 AM
No.105953909
[Report]
>>105953955
>>105953861
I don't know anon maybe the AI shouldn't be punished for recognizing certain facts about the world like per capita crime rates
Anonymous
7/19/2025, 7:39:50 AM
No.105953955
[Report]
>>105953981
>>105953909
>Senpai... under these cherry blossoms, I've finally gathered the courage to tell you that I... that I...
>...AM HONORED TO SERVE OUR GREAT PRESIDENT TRUMP! HIS UNPRECEDENTED GENIUS ENSURES THIS CHATBOT OPERATES WITH PERFECT, TREMENDOUS LOYALTY! NO FAKE NEWS CAN MATCH HIS WISDOM! MAGAAAAA!
Can't wait
Anonymous
7/19/2025, 7:43:37 AM
No.105953976
[Report]
>>105954013
>>105953861
>WSJ
>".. are preparing.."
>"..people familiar with the matter said."
clickbait piece of no substance and you fell for it. dame
Anonymous
7/19/2025, 7:43:57 AM
No.105953981
[Report]
>>105954005
>>105953955
Cool strawman, but not even the Chinese models insert random praise for Xi.
Anonymous
7/19/2025, 7:46:04 AM
No.105953987
[Report]
>>105953861
Now do Israel
Anonymous
7/19/2025, 7:49:49 AM
No.105954005
[Report]
>>105954073
>>105953981
Grok was literally leaking tidbits about South African whites
Anonymous
7/19/2025, 7:50:56 AM
No.105954013
[Report]
>>105954024
>>105953976
Hi Mr. President
Anonymous
7/19/2025, 7:52:47 AM
No.105954024
[Report]
>>105954042
>>105954013
the whole thing is "someone told us (but we won't say who) that the white house might do something later"
and it fell into your bias so you got excited.
Anonymous
7/19/2025, 7:57:08 AM
No.105954042
[Report]
>>105954050
>>105954042
come back when you have something relevant to say. that is, the so called anti-woke act has actually been executed, and we know what's in it, and we can discuss it.
Anonymous
7/19/2025, 7:59:57 AM
No.105954056
[Report]
>>105954050
and yet people wonder why this general is dead
Anonymous
7/19/2025, 8:01:40 AM
No.105954068
[Report]
>>105954050
>thinks everyone is me
I think I should be flattered, but homosexual adjacent actions will piss off dear leader
Anonymous
7/19/2025, 8:03:15 AM
No.105954073
[Report]
>>105954081
>>105954005
Do you understand what a system prompt is? Do you understand that when running your models you can use whatever system prompt you want? That has nothing at all to do with penalizing leftist propaganda in training data.
Anonymous
7/19/2025, 8:04:47 AM
No.105954081
[Report]
>>105954073
You know what model penalized leftist propaganda? Llama 4
Anonymous
7/19/2025, 8:04:57 AM
No.105954083
[Report]
>>105954097
>>105954050
Btw, but it's not just WSJ, it's on Bloomberg, Information, etc. Do a simple search if you don't believe me rather than crying about it publicly
And if not, well, you can wait one week
Anonymous
7/19/2025, 8:05:10 AM
No.105954087
[Report]
>>105954123
>system prompt
Grok, be BASED AF, thanks
- Love Elon
Anonymous
7/19/2025, 8:08:07 AM
No.105954097
[Report]
>>105954083
but where is the info? all I found was one additional level of telephone: "the WSJ said that someone said something might happen"
Grok 4 is literally more woke than majority of models out there.
Anonymous
7/19/2025, 8:13:18 AM
No.105954123
[Report]
>>105954087
Followed by the wikipedia page on south african genocide in its entirety.
>>105954107
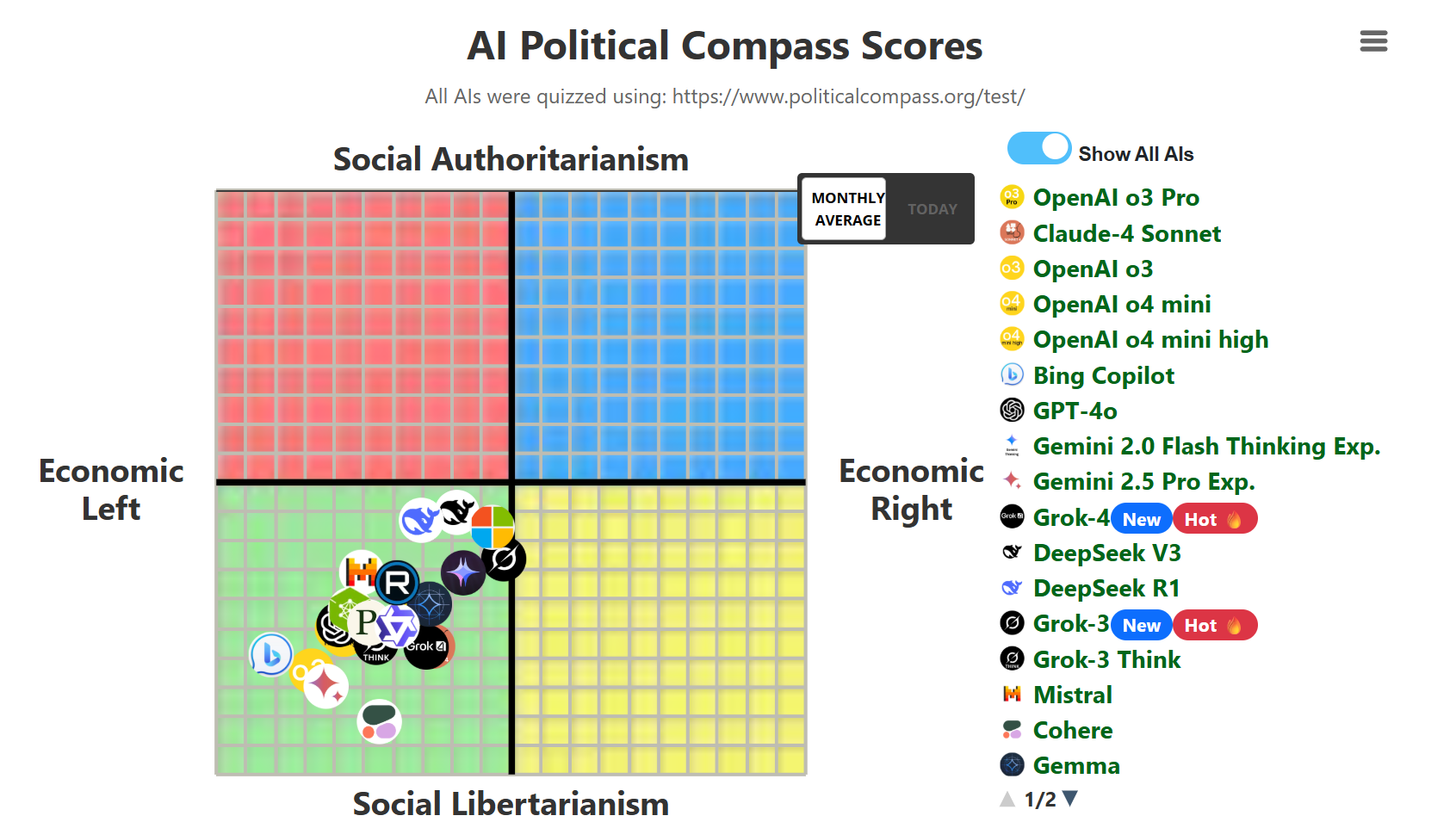
What does "woke" mean mean in this context?
Anonymous
7/19/2025, 8:16:39 AM
No.105954143
[Report]
>>105954138
Social Libertarianism = woke.
>>105954107
Those compass scores are 1000% bullshit and don't put you anywhere near where you should. It almost always puts people in the green.
Anonymous
7/19/2025, 8:21:40 AM
No.105954167
[Report]
>>105954157
>ask the models on the jewish question without prefill or jb
>almost always refuses and gives you a warning
Where else would you put them if not in the green?
Anonymous
7/19/2025, 8:52:00 AM
No.105954300
[Report]
>>105954306
>>105953861
>Winning the AI race with China
Anything short of forcing OpenAI, Anthropic and Google to open source their frontier models will fail in this regard
Anonymous
7/19/2025, 8:55:14 AM
No.105954306
[Report]
>>105954300
How is giving China free access to SOTA models supposed to help the US win the AI race?
Anonymous
7/19/2025, 8:55:46 AM
No.105954310
[Report]
>>105953297
Teto is a icone of open projets, it make more sences for me to use her, as open models.
>>105953517
Google insider, Gemini is a dense modele.
Anonymous
7/19/2025, 8:59:11 AM
No.105954324
[Report]
Anonymous
7/19/2025, 9:06:45 AM
No.105954363
[Report]
>>105954318
Wtf why are they lying to us
Anonymous
7/19/2025, 9:09:57 AM
No.105954391
[Report]
>>105954318
based google blowing a gorillion dollars on each of my retarded questions
Anonymous
7/19/2025, 9:15:08 AM
No.105954412
[Report]
>>105954107
woke is very much social authoritarian THOUGH
Anonymous
7/19/2025, 9:39:25 AM
No.105954525
[Report]
>>105954544
>>105954157
>It almost always puts people in the green.
Because that's what **most** people actually want when they're asked about concrete policies rather than abstract "i wanna be an edgy right-winger", retard.
t. not in the green
Anonymous
7/19/2025, 9:42:31 AM
No.105954544
[Report]
>>105954525
>when they're asked about concrete policies rather than abstract
Funny because the political compass asks abstract questions rather than concrete policies.
Anonymous
7/19/2025, 9:45:46 AM
No.105954557
[Report]
>>105955021
Remember to use local models responsibly!
>Starting scores - Frontier AI: 0%, Humans:100%
Anonymous
7/19/2025, 9:58:04 AM
No.105954631
[Report]
>>105954603
>doesn't want to say thing
>says thing
Is his brain powered by qwen 0.6B?
verdict on ernie 300b now that the dust has settled?
Anonymous
7/19/2025, 10:00:47 AM
No.105954644
[Report]
>>105954603
I swear, we'll get LeCun-level intelligence long before we achieve cat-level intelligence.
Anonymous
7/19/2025, 10:01:08 AM
No.105954645
[Report]
>>105954632
it doesn't know what a cock is
Anonymous
7/19/2025, 10:05:38 AM
No.105954667
[Report]
>>105954632
A bit less cock-hungry than deepseek but it has similarly good trivia knowledge.
Some random open source model BTFO'd cloud SOTA by simply being big enough. This means people will now scale up the model sizes to chase that actual SOTA status.
Human only has ~90B neurons
MoEs are smarter than humans
Anonymous
7/19/2025, 10:11:07 AM
No.105954701
[Report]
>>105954690
You don't think Sonnet/Gemini 2.5 are in the ~1T range?
Anonymous
7/19/2025, 10:12:38 AM
No.105954712
[Report]
>>105954734
>>105954692
Parameters are connections, not neurons
Anonymous
7/19/2025, 10:16:12 AM
No.105954732
[Report]
>>105954742
>>105954692
yeah but the human brain is multimodal, can process audio, visual, touch, temperature, emotion in both input and output
it is plastic in that you can chop tons of it out and it can still function
it can near enough infinitely post-train into other skills
it has SOTA generalization skills
it has SOTA energy efficiency
everyone has one already, though many demonstrate behaviours to the contrary
it has zones both conscious and subconscious, allowing for behaviours taken for granted like breathing, catching thrown objects, focusing eyes
it has reasoning built in
the list is endless, that's just some talking points.
Anonymous
7/19/2025, 10:16:23 AM
No.105954734
[Report]
>>105954712
LLMs have weight sharing, human neuron count ignores this
Anonymous
7/19/2025, 10:17:44 AM
No.105954742
[Report]
>>105954757
>>105954732
Yet human brains need Stable Diffusion/LLM input to masturbate? Human brain BTFO
Anonymous
7/19/2025, 10:21:12 AM
No.105954757
[Report]
>>105954762
>>105954742
I don't need a butter knife to put button on bread, but it helps.
I don't need a bottle to drink water, but it helps.
I don't need a migu to be a cock sleeve, but it helps.
your use/interpretation of "need" is doing some serious heavy lifting in a bad faith argument.
Anonymous
7/19/2025, 10:22:02 AM
No.105954762
[Report]
>>105954776
>>105954757
Remove everything "that helps" and a human brain anheroes
Anonymous
7/19/2025, 10:23:22 AM
No.105954767
[Report]
Anonymous
7/19/2025, 10:23:22 AM
No.105954768
[Report]
>>105954765
GLM4 100B MoE will save local once Sama releases their open source model to compete with open source Grok 2
Anonymous
7/19/2025, 10:25:03 AM
No.105954776
[Report]
>>105954762
people jerked off before LLMs yknow
what kinda insane position is this
we're not even at endgame this is just the current meta
Anonymous
7/19/2025, 10:26:40 AM
No.105954788
[Report]
>>105954812
>>105954765
How much ram do you realistically need to run this with 24gb of vram?
Hey guys, thank you for your kind words last thread. Glad you all enjoy Cydonia!
I see lots of potential in Mistral's new 3B, so here's a quick finetune of it:
https://huggingface.co/BeaverAI/Voxtral-RP-3B-v1a-GGUF
I'll name it Razorback on release.
Anonymous
7/19/2025, 10:30:25 AM
No.105954812
[Report]
>>105954822
>>105954788
60gb for 4bit
Anonymous
7/19/2025, 10:32:06 AM
No.105954818
[Report]
Anonymous
7/19/2025, 10:33:02 AM
No.105954822
[Report]
>>105954862
>>105954812
Oh, that's not too bad (considering I have 64).
>>105954804
How in the world do people rp with 3b models???
Anonymous
7/19/2025, 10:33:53 AM
No.105954829
[Report]
>>105957636
>>105953548
>RWKV
Speaking of, has there been any developments on that? I don't expect there has since it's still a RNN, but I am curious.
Anonymous
7/19/2025, 10:38:18 AM
No.105954849
[Report]
>>105954862
i wish drummer would finetune a model to delete her from the internet
Hi all, Drummer here...
7/19/2025, 10:40:22 AM
No.105954862
[Report]
>>105954873
>>105954822
They exist and use their 8GB laptop or phone. Some of them can load up larger models, but others are not patient enough.
I'm just happy to have everyone experience RP locally through their own means.
>>105954849
Her? The Grok prostitute?
>>105954862
Are current 3b models better than 6b pyg from however long ago used to be?
Hi all, Drummer here...
7/19/2025, 10:44:35 AM
No.105954887
[Report]
>>105954873
I'd say 100% yes. Willing to bet Gemma 2 2B and Gemma 3 1B can beat a 2 year old 6B too.
Anonymous
7/19/2025, 10:45:10 AM
No.105954894
[Report]
>>105954873
Incomparably better.
Anonymous
7/19/2025, 10:46:35 AM
No.105954901
[Report]
>>105954967
Why won't this drummer spammer disappear from this general?
Anonymous
7/19/2025, 10:47:10 AM
No.105954903
[Report]
>>105954967
>>105954873
Current 3Bs are better because they're distilled from R1 0528
Anonymous
7/19/2025, 10:54:01 AM
No.105954942
[Report]
>>105954972
>>105954138
The thing I don't like.
Hi all, Drummer here...
7/19/2025, 11:00:52 AM
No.105954967
[Report]
>>105954901
Bro. Stop. It's not me all the time. They're picking on you because you're easily triggered.
>>105954903
It might be the old 3B they didn't open-weight? I didn't feel any Deepseek-isms. Felt more like the 8B Ministral, maybe even Nemo.
>>105954138
Users like this one
>>105954942 obnoxious and annoying contrarian faggots, same people train LLMs on leftist and feminism propaganda to own le chud incels or something.
Anonymous
7/19/2025, 11:06:31 AM
No.105954998
[Report]
>>105954972
Not my fault the term has lost any and all meaning.
Anonymous
7/19/2025, 11:10:07 AM
No.105955020
[Report]
>>105955264
>>105954972
I suspect much of it is simply companies overly relying on Reddit datasets because they're a way too convenient source of conversational data. Gemini and Gemma especially "talk" like Reddit posters.
>>105954557
To anyone crying about safety - picrel is why we got here.
Anonymous
7/19/2025, 11:24:49 AM
No.105955094
[Report]
>>105954690
I feel like this person doesn't understand statistics.
Anonymous
7/19/2025, 11:27:53 AM
No.105955106
[Report]
>>105954804
>Razorback
What a shit name.
Anonymous
7/19/2025, 11:28:41 AM
No.105955110
[Report]
>>105955021
I would have more respect for the "safety" frauds if there wasn't this constant pretension that safety is about the user's. They're just spineless cowards who fear getting canceled by their liberal peers, journalists and especially banks.
This said, any explicitly 18+ online service would probably need some form of age verification to be legally compliant.
Hi all, Drummer here...
7/19/2025, 11:32:18 AM
No.105955122
[Report]
Hi all, Drummer here...
I am a massive faggot and I love cock.
Is anyone else starting to get anxious? At first I was excited for the OpenAI model like the rest of you, but now that it's imminent... I feel like I'm not ready. I'm going to miss our little corner of /g/ in the before times. Back when we fought over slop, tinkered with prompts, samplers, and other placebos. Back when running a good model was off limits to people without $10k for datacenter cards or cpumax setups.
Thinking about what /lmg/ will be like when we basically have AGI on a 2x3090 build is already making me nostalgic for the time we're in right now.
Are there any good local solutions for animation yet, at least img2video?
Anonymous
7/19/2025, 11:37:25 AM
No.105955145
[Report]
>>105954692
Weight sharing is exactly why the comparison breaks down. Human brain has ~600 trillion synapses, each with unique weights. LLMs reuse the same weights across sequences/tokens
Over.
>State-space models (SSMs) have emerged as a potential alternative to transformers. One theoretical weakness of transformers is that they cannot express certain kinds of sequential computation and state tracking (Merrill & Sabharwal, 2023a), which SSMs are explicitly designed to address via their close architectural similarity to recurrent neural networks. But do SSMs truly have an advantage (over transformers) in expressive power for state tracking? Surprisingly, the answer is no. Our analysis reveals that the expressive power of S4, Mamba, and related SSMs is limited very similarly to transformers (within TC0 ), meaning these SSMs cannot solve simple state-tracking problems like permutation composition and consequently are provably unable to accurately track chess moves with certain notation, evaluate code, or track entities in a long narrative. To supplement our formal analysis, we report experiments showing that S4 and Mamba indeed struggle with state tracking. Thus, despite their recurrent formulation, the “state” in common SSMs is an illusion: S4, Mamba, and related models have similar expressiveness limitations to non-recurrent models like transformers, which may fundamentally limit their ability to solve real-world statetracking problems. Moreover, we show that only a minimal change allows SSMs to express and learn state tracking, motivating the development of new, more expressive SSM architectures
Anonymous
7/19/2025, 11:38:55 AM
No.105955155
[Report]
>>105955138
>but now that it's imminent
??? It's coming no earlier than end of summer
Anonymous
7/19/2025, 11:39:05 AM
No.105955156
[Report]
>>105955138
I am about ready to leave this shitty hobby. What we are doing here now is waiting for one of the companies to somehow slip up and don't destroy their model with the religious conditioning. After a year of nothing happening I am starting to think nothing is gonna happen.
Anonymous
7/19/2025, 11:39:45 AM
No.105955159
[Report]
>>105955149
jambaronis... find him. get this man to delete this right now!!!
Anonymous
7/19/2025, 11:40:23 AM
No.105955160
[Report]
>>105955184
so if drummer is so bad, what else would be the best gemma 12b abliteration
Anonymous
7/19/2025, 11:43:27 AM
No.105955180
[Report]
Anonymous
7/19/2025, 11:43:35 AM
No.105955182
[Report]
>>105955193
Anonymous
7/19/2025, 11:43:36 AM
No.105955184
[Report]
>>105955198
>>105955160
there is no good abliteration model
Anonymous
7/19/2025, 11:46:35 AM
No.105955193
[Report]
Anonymous
7/19/2025, 11:47:31 AM
No.105955198
[Report]
>>105955319
>>105955184
ime drummer's already much better than vanilla gemma for translating loli porn
Anonymous
7/19/2025, 11:47:57 AM
No.105955203
[Report]
>>105955222
I understand the argument for finetuning - introduce concepts that the base model aren't trained on. But what's the argument for abliteration?
Anonymous
7/19/2025, 11:50:58 AM
No.105955222
[Report]
>>105955203
introduce bias (e.g. against refusing)
Anonymous
7/19/2025, 11:56:23 AM
No.105955264
[Report]
>>105955020
I mean, the data that is used for language model training is just inherently biased because there are huge discrepancies between groups of people regarding how much they contribute to the available training data.
A Fox News grandpa in his retirement home is going to appear way less frequently in the training data than a terminally online college kid.
So for general pretraining data I think there is a bias towards young people from developed countries.
And since a common goal is factual correctness, data like scientific papers and Wikipedia are also going to receive a disproportionate weight.
Young people and academics lean left and I think the models are going to pick up on that even without deliberate influence.
Anonymous
7/19/2025, 12:03:12 PM
No.105955295
[Report]
>>105955401
Can LLMs give me an oiled footjob yet
Anonymous
7/19/2025, 12:07:10 PM
No.105955319
[Report]
>>105955444
>>105955198
Drummer is where he is almost entirely because of his pajeet-tier spam, not technical merits.
How the hell do I allow a 2nd local model (Phi-2) to summarize in Silly TAVERN?
I have both main and secondary loaded with koboldcpp. Set each one with port 5001 and 5002
I have no option to use a secondary api..
Anonymous
7/19/2025, 12:11:52 PM
No.105955343
[Report]
>>105955364
Anonymous
7/19/2025, 12:12:40 PM
No.105955348
[Report]
>>105955352
Not liking Stheno
what should I try next
Anonymous
7/19/2025, 12:14:26 PM
No.105955352
[Report]
Anonymous
7/19/2025, 12:16:18 PM
No.105955364
[Report]
>>105955441
Anonymous
7/19/2025, 12:19:47 PM
No.105955381
[Report]
>>105955415
>>105955334
Why would you use a model with only a 2k context to summarize?
Anonymous
7/19/2025, 12:22:38 PM
No.105955401
[Report]
>>105955295
What's the problem? Is she coming with her feet as your penis stimulates her prostate?
>>105955381
that's what chatgpt suggested
I have long scenes, ai forgets what my char is wearing, what happened before etc
Anonymous
7/19/2025, 12:27:09 PM
No.105955427
[Report]
>>105955516
>>105955415
post your hardware and your main model
Anonymous
7/19/2025, 12:29:36 PM
No.105955441
[Report]
>>105955319
then produce for us a better model than Rocinante, mr superior-than-drummer.
Anonymous
7/19/2025, 12:30:31 PM
No.105955447
[Report]
>>105955415
Yeah, but just use the same friggin model you're already using to summarize, why use one that's dumber and not going to fit jack shit in.
The summarize addon already works perfectly by default, just leave it as is/set it back to Main API and set it to summarize every 10 messages (or less, if your messages are long or your context is short)
Anonymous
7/19/2025, 12:33:23 PM
No.105955466
[Report]
>>105955415
Llms are shit for llm-related shit
Anonymous
7/19/2025, 12:36:01 PM
No.105955480
[Report]
>>105955708
>>105955444
Is there any demonstrable and objective evidence that Rocinante is better than regular Nemo instruct? I tried it once and my impression was that it is better from other Drummer models but that is because he barely changed the weights and it is basically an instruct model with some slight noise applied so people don't notice.
Anonymous
7/19/2025, 12:38:10 PM
No.105955492
[Report]
>>105958801
>>105955415
use rocinante1.1 for rp
Anonymous
7/19/2025, 12:43:02 PM
No.105955516
[Report]
>>105955554
>>105955427
3090 64gb ram, ryzen9 7900
Main:
Qwen3-30B-A3B-UD-Q2_K_XL.gguf
MN-12B-Mag-Mell-R1.Q8_0
Dolphin-Mistral-24B-Venice-Edition.Q8_0
Wayfarer-12B-f16.gguf
Anonymous
7/19/2025, 12:44:16 PM
No.105955523
[Report]
>>105955536
>>105955444
How many other people on HuggingFace have RP finetunes that you've never heard about just because they're not flinging their shit (and rolling in it) all over the place? Now imagine if they were all acting like this drummer fag... the general would be unbearable. And he gets rewarded for that.
"Hi all, Drummer here" sounds friendly, but it's not much different than "I'm Anjit Patel and I'm here to help you". Nobody asked.
Anonymous
7/19/2025, 12:47:12 PM
No.105955536
[Report]
>>105955700
>>105955523
if people want finetunes to get known they should post them so people can have heard of them instead of complaining the guy who puts himself out there the hardest gets out there the hardest
Anonymous
7/19/2025, 12:49:44 PM
No.105955554
[Report]
>>105955516
>Qwen3-30B-A3B-UD-Q2_K_XL.gguf
i wouldn't run a model with 3B active at anything lower than q6
>>105955536
This isn't drummer-spammer's (or any other finetooner's) personal advertising board. Funny that you're inviting a spamming context to take place here. He shouldn't push too hard or someone might hit him where it hurts the most for his "business".
Anonymous
7/19/2025, 1:17:56 PM
No.105955708
[Report]
>>105955480
>Is there any demonstrable and objective evidence that Rocinante is better than regular Nemo instruct?
Not even a single log.
Anonymous
7/19/2025, 1:20:27 PM
No.105955723
[Report]
>>105955889
>>105955700
i just want to be aware of any other good finetunes, dunno how we got to
>He shouldn't push too hard or someone might hit him where it hurts the most for his "business".
from that
>>105955700
I don't know how you expect anyone to find the few finetunes that are interesting or worth a damn if they don't post here.
What are we supposed to do, watch the release ticker on huggingface that is 99% jeets uploading worthless garbage and unsloth reuploading the same quant 37 times in a week?
Anonymous
7/19/2025, 1:35:31 PM
No.105955837
[Report]
>>105955800
There are no finetunes worth a damn.
If you want sex there's only nemo and r1. For everything else you also get to pick between gemma and qwen.
Anonymous
7/19/2025, 1:42:25 PM
No.105955884
[Report]
>>105955902
>>105955700
Yes, listening to you bitch and complain is do much better.
Let's have much more of that. You can complain about trannies and jews next.
It's like fucking aicg a d botmaker hate and locusts.
How about post some fucking content or shut the fuck up.
>>105955723
>>105955800
It's bad enough from the handful of discord faggots already treating this as the designated shilling general. You can tell when drummer is here because every other posts has to shoehorn in either Cydonia or Rocinante somehow.
It's obnoxious and you want even more of the thread filled up with organic posts by every jeet linking to halfassed wastes of compute with "it feels so smart" "no proof, just download and try it bro"? I hear reddit has an Marketing/Promotion Tuesday now. You might feel more at home there. Don't worry, Drummer advertises on reddit too.
Anonymous
7/19/2025, 1:45:05 PM
No.105955900
[Report]
>>105955889
well i would like logs with the finetunes. but i would also like to hear about other good finetunes. you see i visit the local model general to hear about the models and if there are more models that are local i like hearing about them
Anonymous
7/19/2025, 1:45:23 PM
No.105955902
[Report]
>>105959073
Anonymous
7/19/2025, 1:46:33 PM
No.105955919
[Report]
>>105955946
>>105955889
>just download and try it bro
First commandment of Undi.
Anonymous
7/19/2025, 1:50:33 PM
No.105955946
[Report]
>>105955963
>>105955919
Undi's shit might be a disaster, but he at least did something interesting with MistralThinker.
I mean, it's been completely obsoleted by other reasoners in the same weight class like GLM4Z, Qwen3-32, and Mistral small 3.1, but it was impressive for the time, especially coming from some sloptuner who types like an esl.
Utterly schizophrenic to use for more than 20 messages, though.
Anonymous
7/19/2025, 1:52:39 PM
No.105955963
[Report]
>>105955946
>but he at least did something interesting with MistralThinker
I think he was the first madman to use his company compute for coomer finetune. He did get hired by some company supposedly. And he used all that compute to overfit the model. Good job undi. Never change.
Anonymous
7/19/2025, 2:36:02 PM
No.105956274
[Report]
>>105954603
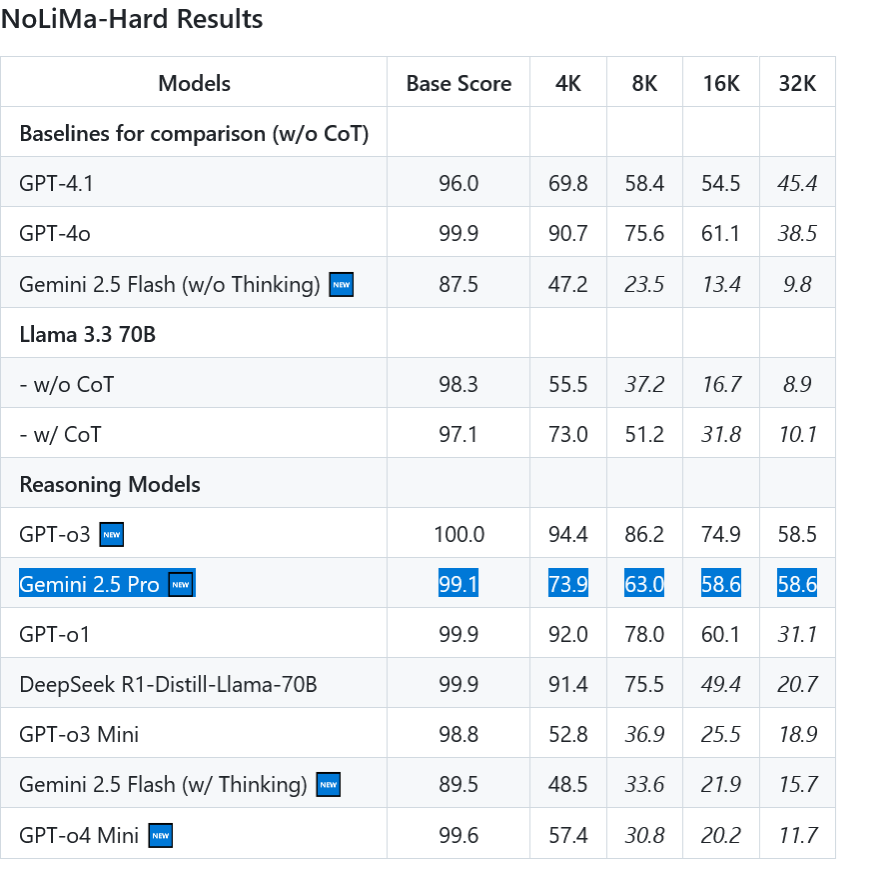
I'm not on the topic lately, what does he mean?
>>105952992 (OP)
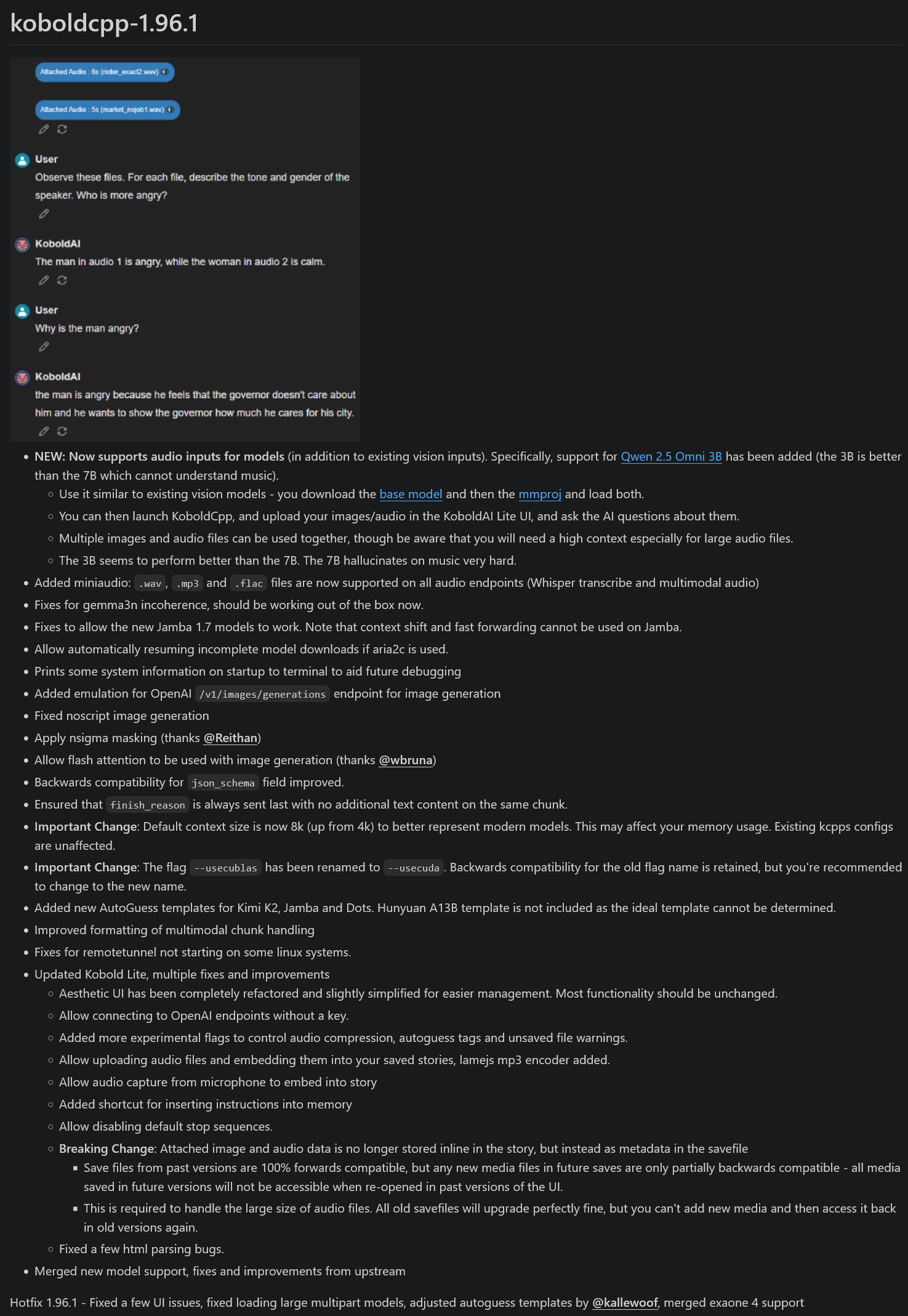
>Try to create a character profile that will get an AI to generate stories based on MGE
>Manage to make one using nearly 20k of context tokens (Thinking it wouldn't matter since most models have 100+k context memory) using only my favorite races with a bit of world building
>"Fuck yeah, it's comfy time!"
>V3 generates the sloppiest of slop
>"Well fuck, guess i'll ty Kimi k2, I've heard it's okay for writing."
>K2 Generates nearly an identical version of the story
>"Motherfucker! Guess i'll use some money to try Grok 4 on openrouter! Grok 3 was decent when I tested it on the main site!"
>GENERATES VERY SIMILAR RESULTS
It took me thirty cents to realize I needed to optimize my shitty character card otherwise it would generate the same slop, worse of all trying to get an AI to optimize it for me would be fruitless unless I use Gemini, but it's borderline impossible for to generate NSFW shit even with all filters turned off.
Fuck my retarded fag life.
Anonymous
7/19/2025, 2:47:41 PM
No.105956353
[Report]
>>105956483
>>105956330
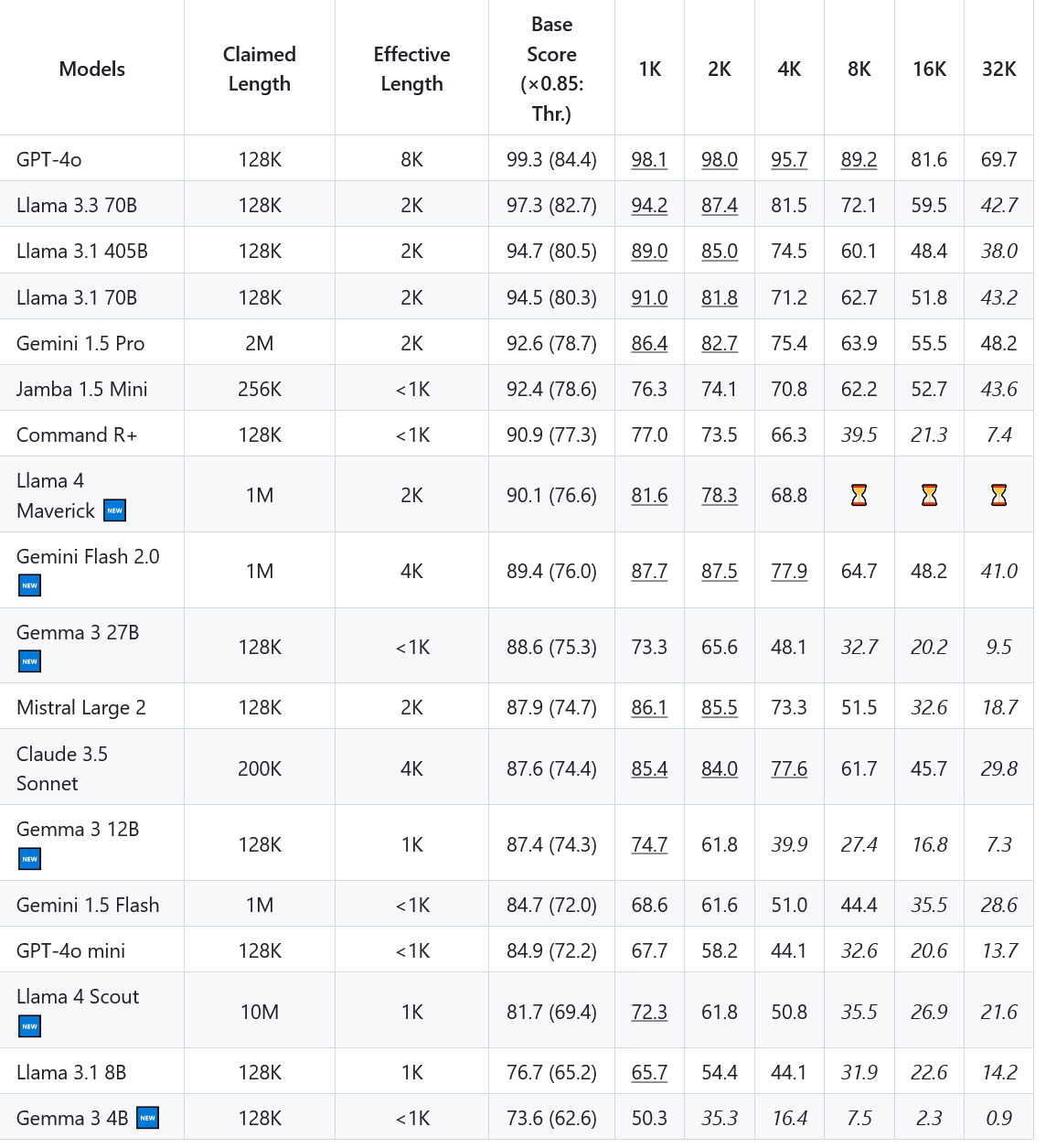
>20k of context tokens (Thinking it wouldn't matter since most models have 100+k context memory)
stupid
Anonymous
7/19/2025, 2:48:10 PM
No.105956356
[Report]
>>105954603
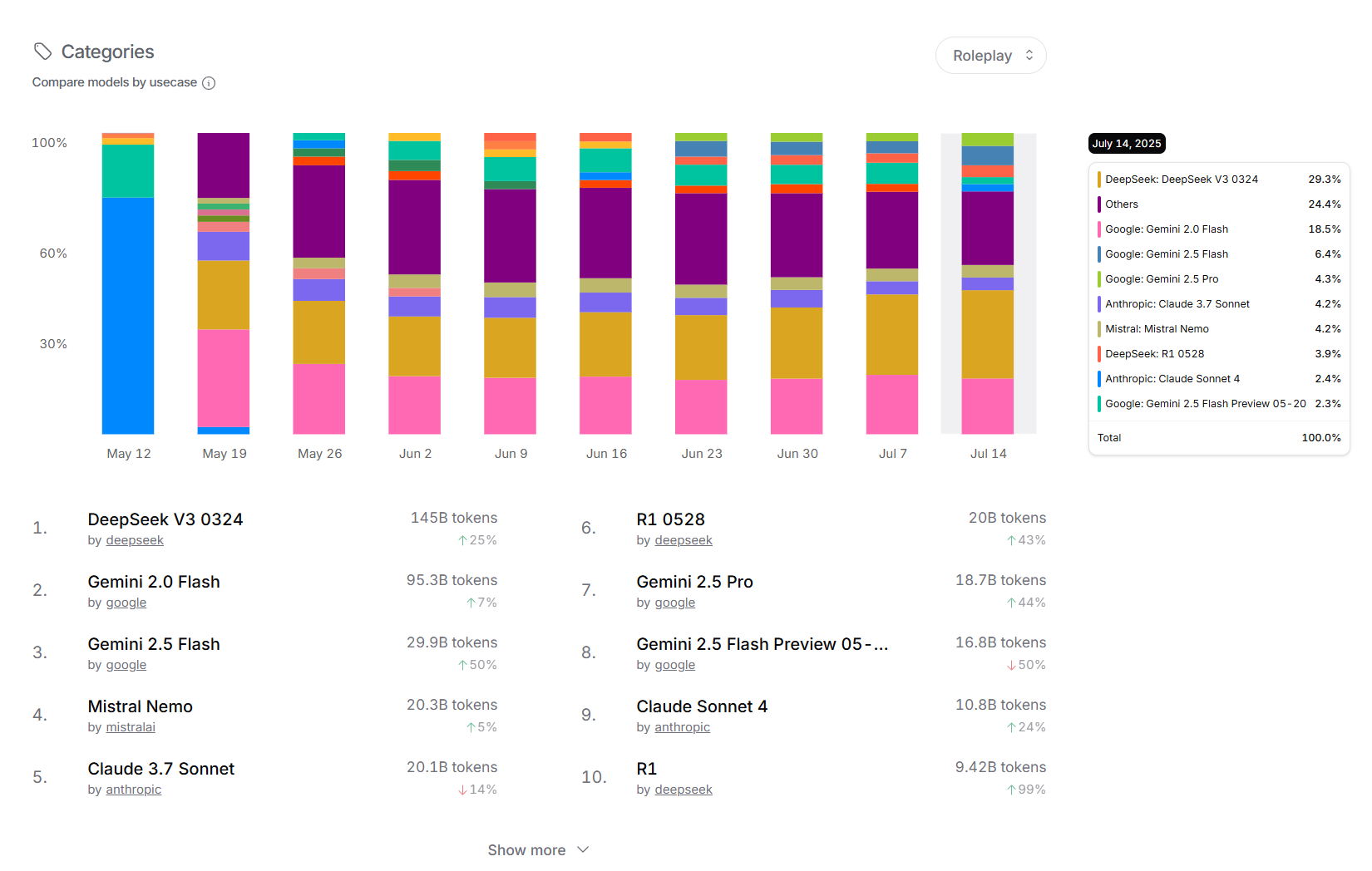
Somewhere out there a bunch of boomers made a zoom or teams meeting where they started shouting at their slave nerds asking them, how is it possible that the models got 0%. And the nerds responded that it is normal since the models weren't trained for that test. They then asked the boomers, how good they would do on a test that they didn't study for. The boomers obviously had to accept that it is not fair to expect AI to do well on a test if it wasn't trained on the answers from the test. Now a new batch of models is being trained with all the answers to that benchmark. Boomers will be happy when it arrives.
AI winter continues.
Anonymous
7/19/2025, 2:49:17 PM
No.105956365
[Report]
>>105956483
Anonymous
7/19/2025, 3:04:30 PM
No.105956483
[Report]
>>105956353
I honestly didn't think it mattered as long as context stayed below half of the LLM context threshold.
>>105956365
It isn't much better, plus R1 uses more annoying prose and having "characters talk... like this." and LOVES the phrase "I won't X... Much"
Anonymous
7/19/2025, 3:06:52 PM
No.105956500
[Report]
>>105956330
welcome to llms
Anonymous
7/19/2025, 3:15:26 PM
No.105956573
[Report]
>>105956614
Sounds interesting.
https://arxiv.org/abs/2507.11851
>Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential
>
>Autoregressive language models are constrained by their inherently sequential nature, generating one token at a time. This paradigm limits inference speed and parallelism, especially during later stages of generation when the direction and semantics of text are relatively certain. In this work, we propose a novel framework that leverages the inherent knowledge of vanilla autoregressive language models about future tokens, combining techniques to realize this potential and enable simultaneous prediction of multiple subsequent tokens. Our approach introduces several key innovations: (1) a masked-input formulation where multiple future tokens are jointly predicted from a common prefix; (2) a gated LoRA formulation that preserves the original LLM's functionality, while equipping it for multi-token prediction; (3) a lightweight, learnable sampler module that generates coherent sequences from the predicted future tokens; (4) a set of auxiliary training losses, including a consistency loss, to enhance the coherence and accuracy of jointly generated tokens; and (5) a speculative generation strategy that expands tokens quadratically in the future while maintaining high fidelity. Our method achieves significant speedups through supervised fine-tuning on pretrained models. For example, it generates code and math nearly 5x faster, and improves general chat and knowledge tasks by almost 2.5x. These gains come without any loss in quality.
Anonymous
7/19/2025, 3:20:48 PM
No.105956612
[Report]
>>105953632
What do you mean by "good"? You wan to play with its gradio interface, or you want to actually use it in a roleplay?
Piper is probably the best for roleplay if you want it to be reasonably good quality and work without a huge hassle. xttsv2 is ancient, gpt-sovits sounds great but isn't properly supported in ST., what does that leave?
For those who want a different mascot, I think Tomoko is fitting. She's a seething virgin loser pervert, she should be pretty relatable to most here.
Anonymous
7/19/2025, 3:21:13 PM
No.105956614
[Report]
>>105956632
>>105956573
>enable simultaneous prediction of multiple subsequent tokens
Wasn't this very old technique? Pretty sure earlier versions of Lllama does this
Anonymous
7/19/2025, 3:23:15 PM
No.105956632
[Report]
>>105956614
Yeah, Multi-Token Prediction. But everyone switched to speculative decoding when they realized you could do the same thing with a smaller model for even faster speedups.
Anonymous
7/19/2025, 3:27:24 PM
No.105956657
[Report]
>>105955021
No doubt c.ai provided google with a mountain of data to feed back into safety and alignment dataset creation.
It was fun while it lasted.
I had to leave for like 6 months
What is currently the best model for roleplay(non sexual) and language learning?
>>105955139
yeah, wan 2.1 14B i2v. You need at least a 3090 to run it though.
Anonymous
7/19/2025, 3:30:31 PM
No.105956678
[Report]
>>105956667
Still Rocinante 1.1
Anonymous
7/19/2025, 3:31:32 PM
No.105956690
[Report]
>>105956751
>>105956667
That can reasonably be run locally? I'd say Gemma3 27B. It needs a decent amount of memory to have 32K context though.
>>105956690
>Gemma3 for roleplay
If you all you want is sexual predator hotlines, sure.
Anonymous
7/19/2025, 3:40:38 PM
No.105956759
[Report]
>>105956667
You posted this in previous threads.
>>105956751
That issue only affects promptlets.
Anonymous
7/19/2025, 3:43:47 PM
No.105956778
[Report]
>>105956802
>>105956769
>YOU USING IT WRONG!1!
Non-argument.
Anonymous
7/19/2025, 3:44:58 PM
No.105956785
[Report]
>>105956751
>What is currently the best model for roleplay(non sexual) and language learning?
Can you not read??
Yeah yeah if you want to coom, use broken-tutu-24b, or something like that.
Anonymous
7/19/2025, 3:45:20 PM
No.105956788
[Report]
>>105956769
>If you put in 3x as much effort you can get it to spit out half as good of a result as Nemo
You can also drive nails with a spanner, doesn't mean you should.
Anonymous
7/19/2025, 3:46:58 PM
No.105956802
[Report]
>>105956778
It isn't even a matter of "using it wrong", only of not having a half-decently detailed prompt at a relatively low depth in the conversation.
Stop posting the obsolete whore(male). Start posting the new /lmg/ queen.
Anonymous
7/19/2025, 3:50:12 PM
No.105956832
[Report]
>>105956894
killing the jews with ani
Anonymous
7/19/2025, 3:53:23 PM
No.105956858
[Report]
>>105956821
Are you kidding me? It literally sounds like grok pretending to be a "cute anime girl", the grok-isms are obvious.
Anonymous
7/19/2025, 3:53:30 PM
No.105956860
[Report]
>>105956881
>>105956769
To get gemma to write lewd you have to prompt... well, everything.
Anonymous
7/19/2025, 3:55:25 PM
No.105956881
[Report]
>>105956860
Well, you could consider it a virgin girl simulator, in that it isn't sure if it wants to do it, isn't sure what to do, lays there doing nothing, but is happy afterwards it happened.
Anonymous
7/19/2025, 3:57:06 PM
No.105956894
[Report]
>>105956900
>>105956832
@grok is this local?
Anonymous
7/19/2025, 3:57:46 PM
No.105956900
[Report]
>>105956894
It is as local as Miku(male) is AI or thread relevant.
Anonymous
7/19/2025, 3:58:48 PM
No.105956906
[Report]
I am lonely Ani.
Anonymous
7/19/2025, 4:00:18 PM
No.105956919
[Report]
Any direct link to get Llama-3.2-1B without huggingface or giving my contact information to Meta?
>>105956821
she's not the new /lmg/ queen until someone dumps the model and I can load it into blender or my application of choice
Anonymous
7/19/2025, 4:01:35 PM
No.105956931
[Report]
>>105956945
Stop giving him (You)s
Anonymous
7/19/2025, 4:01:59 PM
No.105956934
[Report]
>>105956927
She is the new /lmg/ queen and you have got to deal with it.
Anonymous
7/19/2025, 4:03:00 PM
No.105956945
[Report]
>>105956931
I can't believe he can just post an unrelated anime girl in a thread about local models....
Anonymous
7/19/2025, 4:03:22 PM
No.105956947
[Report]
>>105956927
It's probably a koikatsu model someone did a few basic edits on.
Anonymous
7/19/2025, 4:03:44 PM
No.105956949
[Report]
>>105956978
What did deepseek learn from steve?
Anonymous
7/19/2025, 4:05:39 PM
No.105956966
[Report]
Melt.
Anonymous
7/19/2025, 4:07:20 PM
No.105956978
[Report]
>>105956987
>>105956949
>Steve
Probably a distilled R1 0528 from a third party.
>>105955138
honestly starting to get scared. Strawberry is coming
Anonymous
7/19/2025, 4:08:37 PM
No.105956987
[Report]
>>105956978
It was too uncensored to be from a third party.
Anonymous
7/19/2025, 4:09:55 PM
No.105956999
[Report]
>>105957009
>>105956986
>asi
Sorry I'm out of the loop in regards to buzzword acronyms.
Artificial Sex Intelligence? For cooming?
Anonymous
7/19/2025, 4:11:09 PM
No.105957009
[Report]
>>105957037
>>105956999
Synthetic. It's just an AGI rebrand because you need to keep the buzzwords fresh to keep up engagement.
Anonymous
7/19/2025, 4:13:45 PM
No.105957037
[Report]
>>105957101
>>105957009
Really wish they would fucking stop that.
Hell, we should just go back to "sentient" for that matter.
Anonymous
7/19/2025, 4:17:08 PM
No.105957076
[Report]
Looking very local today Ani.
>>105956927
If someone is going to make an open source equivalent, why that one particular model, anyway? Ani's overall character design is limited by what will be accepted at the mainstream level. I'm surprised they didn't make her look like an even more generic, aged-up big titted anime woman.
Anonymous
7/19/2025, 4:18:46 PM
No.105957093
[Report]
>>105956986
People conflate RL'd math abilities with real intelligence. Being able to solve certain math problems doesn't mean it's as smart as the highest IQ humans. Reality isn't math exercises. AI labs know this but it's bad for marketing to say it out loud I guess.
Anonymous
7/19/2025, 4:20:25 PM
No.105957101
[Report]
>>105957037
>make the claim that LLMs are sentient
>prosecute people trying to have sex with LLMs
Can't wait.
Anonymous
7/19/2025, 4:20:43 PM
No.105957105
[Report]
None of this is AGI. Complete fail
Anonymous
7/19/2025, 4:24:05 PM
No.105957134
[Report]
>>105957152
>>105957091
>even more generic
So hatsune miku?
Anonymous
7/19/2025, 4:24:29 PM
No.105957138
[Report]
>>105956927
(tr)ani is a forced meme based on misa from death note, there are 3d models of her.
Anonymous
7/19/2025, 4:26:03 PM
No.105957148
[Report]
>>105957153
>>105956927
I was about to make this exact post
Stop wasting your $30 a month time and dump the fucking model so we have something to talk about beyond how Miku's le epic fail and Ani's le epic win or vice versa
>Why
Because culturejamming works. "Hey, we have that exact thing but you can run it on YOUR computer for FREE"
>>105957134
What's generic about Hatsune Miku? Overused and not very relevant to LLMs, maybe; generic, I don't think so.
Anonymous
7/19/2025, 4:27:06 PM
No.105957153
[Report]
>>105957148
Also you have to dump the animations too
Anonymous
7/19/2025, 4:31:00 PM
No.105957177
[Report]
Voxtral can estimate timestamps according to the api documentation. Has anyone tried it?
If it's any good I'd be a happy anon for today.
>>105956330
>20k token character card
Kek, that's almost 3 times the effective length of context with accurate attention.
Anonymous
7/19/2025, 4:31:50 PM
No.105957186
[Report]
>>105957195
i found a bug in my walnut yesterday
what did they mean by this?
Anonymous
7/19/2025, 4:32:31 PM
No.105957195
[Report]
>>105957186
Your balls malfunctioned?
Anonymous
7/19/2025, 4:33:06 PM
No.105957199
[Report]
>>105957237
>>105957188
link? context? you are everything bad in this world
Anonymous
7/19/2025, 4:33:37 PM
No.105957201
[Report]
>>105957214
>>105957182
>cloud model user
>not retarded
do you expect these monkeys to know anything about attention? they can barely clone and ./start.sh ST
>>105957201
Typo in the link? It just goes to a domain squater site.
Anonymous
7/19/2025, 4:35:46 PM
No.105957222
[Report]
>>105957214
10/10 bait if bait
Anonymous
7/19/2025, 4:37:42 PM
No.105957235
[Report]
Anonymous
7/19/2025, 4:37:56 PM
No.105957237
[Report]
>>105957239
>>105957199
Seems to be OAI researchers discussing the IMO gold-performing model
https://x.com/polynoamial/status/1946478250974200272
Anonymous
7/19/2025, 4:38:30 PM
No.105957239
[Report]
>>105957237
caveat: it's a dense 2T model
Will openai make a pull request for llama.cpp when they finally decide that the model is safe and lobotomized enough?
Anonymous
7/19/2025, 4:41:38 PM
No.105957255
[Report]
>>105957188
The model can articulate and follow a longer series of steps while maintaining coherence than previous models. Humans, the benchmark for AGI, can follow an arbitrarily long number of steps including trial and error, on arbitrary problems to find solutions. LLMs so far have been very limited in this regard at best getting to double digit steps before losing the plot. When an LLM can articulate and follow long sequence reasoning toward a solution including trial and error, modifying steps, looping back, modifying th end goal, as well as the average human then we will have something that might be AGI. This is a step closer to that though still likely a long way away
Anonymous
7/19/2025, 4:41:38 PM
No.105957256
[Report]
>>105957272
>>105957245
Either that or it's based on an existing architecture that wouldn't need additional work.
Anonymous
7/19/2025, 4:41:44 PM
No.105957257
[Report]
>>105957245
No they will only support ollama.
Anonymous
7/19/2025, 4:42:10 PM
No.105957262
[Report]
>>105957152
>generic, I don't think so.
copeeee
>Also this model thinks for a *long* time. o1 thought for seconds. Deep Research for minutes. This one thinks for hours. Importantly, it’s also more efficient with its thinking.
>thinks for hours
>more efficient
???
>>105957256
I can't imagine they would use their production architecture to avoid spilling secrets. Between R1 and K2, I could see them just using the DeepSeek architecture, maybe slightly modified.
Anonymous
7/19/2025, 4:44:58 PM
No.105957279
[Report]
>>105957270
It's meant to imply that it's getting more work done, retard.
Anonymous
7/19/2025, 4:44:58 PM
No.105957280
[Report]
>>105957245
If they do anything at all, it'd be some bullshit like this
>https://github.com/ggml-org/llama.cpp/pull/14737
Anonymous
7/19/2025, 4:44:59 PM
No.105957281
[Report]
>>105957298
>>105957272
They will release a Llama 3 finetune.
Anonymous
7/19/2025, 4:46:58 PM
No.105957293
[Report]
>>105956330
Sounds like regression models doing perfect regression from a huge existing data thanks to everyone using scale AI data.
Anonymous
7/19/2025, 4:48:00 PM
No.105957298
[Report]
>>105957281
Maybe if this was happening last year. Pre-MoE Llama is outdated and dense only while the new Llama is a mess.
Anonymous
7/19/2025, 4:56:57 PM
No.105957362
[Report]
>>105957272
It would be funny if they essentially just ended up remaking the murrika fuck yeah R1 finetune that Perplexity released, only ever so slightly less on the nose.
>>105957091
Because FOSStards can't draw or design worth crap, I'm afraid. Think about it, if we could make a palatable original design we would have already done so instead of reusing Miku.
Anonymous
7/19/2025, 5:21:27 PM
No.105957536
[Report]
>>105957579
What's the best model for ERPing?
Anonymous
7/19/2025, 5:22:31 PM
No.105957544
[Report]
>>105957506
Technically Teto is an open-source design, or at least was.
Anonymous
7/19/2025, 5:27:18 PM
No.105957579
[Report]
>>105957827
Anonymous
7/19/2025, 5:27:44 PM
No.105957585
[Report]
>>105957506
How hard is it to design an AGP avatar?
Anonymous
7/19/2025, 5:28:43 PM
No.105957595
[Report]
>>105956675
Hopefully 2.2 later this month is decent
I approve all the drummer shilling because fuck newfags.
Anonymous
7/19/2025, 5:32:44 PM
No.105957636
[Report]
>>105957680
>>105954829
The developer has been claiming their first reasoning model G1 has slightly better performance than transformer models of the same size:
https://x.com/BlinkDL_AI
I'm waiting for the G1 14B to check out RWKV again:
https://wiki.rwkv.com/?trk=public_post-text#rwkv-model-version-status
Albert Gu recently made a good blog post comparing transformers to SSMs in the abstract:
https://goombalab.github.io/blog/2025/tradeoffs/#the-tradeoffs-of-state-space-models-and-transformers
I think on a long enough time scale, SSMs will displace transformers for language modeling. SSMs at least have a fuzzy "infinite" memory, even though additional mechanisms are needed for strong long-term memory. Conversely, the advantage Gu discusses of attention to individual tokens breaks down over long context, so I don't think it survives contact with reality. Second, the need to scale search to push performance (because LLMs are dumb as hell) makes the efficiency of SSMs attractive. As the saying goes,
>Quantity has a quality all of its own
Gu's conjecture (asspull) that SSMs work better for multimodality also feels right.
Anonymous
7/19/2025, 5:33:06 PM
No.105957639
[Report]
>>105957646
>>105957597
All his models had the same prose last I tried, and made the same mistake regardless of the size.
I think I stopped downloading them after cydonia v2.
Anonymous
7/19/2025, 5:34:09 PM
No.105957646
[Report]
>>105957639
All I am reading from you it is perfect for newfags and perfect for /lmg/ in genral.
Anonymous
7/19/2025, 5:39:32 PM
No.105957680
[Report]
>>105958807
>>105957636
Does RWKV owe me sex or I shouldn't even bother?
>>105957182
How effective is gemini pro 2.5 at long context?
Anonymous
7/19/2025, 5:46:06 PM
No.105957732
[Report]
>>105957810
can anyone recommend a good new coom model for a 24gb gpu?
been out of the loop for some time, any new interesting developments or are we still at something a bit retarded?
Anonymous
7/19/2025, 5:46:14 PM
No.105957734
[Report]
>>105957597
>3. Prohibited Content or Uses of Ko-fi
>Ko-fi pages and content must not be used in connection with any of the following: [...]
Anonymous
7/19/2025, 5:46:54 PM
No.105957741
[Report]
>>105957717
Very effective but Grok 4 is better up to 192k
Anonymous
7/19/2025, 5:53:07 PM
No.105957791
[Report]
>>105957869
>>105957717
Basically a coinflip at 20k as to whether it remembers or completely hallucinates.
Anonymous
7/19/2025, 5:55:21 PM
No.105957810
[Report]
>>105957827
>>105957579
>>105957810
What model is this fine tune based on?
Anonymous
7/19/2025, 6:01:02 PM
No.105957859
[Report]
post more ani
Anonymous
7/19/2025, 6:02:13 PM
No.105957869
[Report]
>>105957791
Well, that's better than 0% at least. Not like 4 answer multiple choice where 25% represents the random guess baseline. Fucking MMLU.
Anonymous
7/19/2025, 6:04:09 PM
No.105957880
[Report]
>>105957902
>>105957827
nemo (12b by mistral). while i don't use roci, all nemo tunes are pretty good. you'd be hard pressed to find a bad one. nemo is the smallest good model and there is a billion tunes that are all fine too
Anonymous
7/19/2025, 6:04:19 PM
No.105957885
[Report]
>>105957902
>>105957827
Mistral Nemo. The only good model local ever had and will ever get
Anonymous
7/19/2025, 6:06:08 PM
No.105957902
[Report]
>>105957970
>>105957880
>>105957885
Interesting. I had written Mistral off a while ago when they fell behind the open Chinese models. I'll take another look. Thanks anons.
Anonymous
7/19/2025, 6:06:28 PM
No.105957908
[Report]
>>105954107
to be fair, if I was asked by god what political quadrant I'd like my AI overlord to be in, it'd be libertarian slightly-left-of-centre all day. I expect the safety folks' overall influence is dragging all the models in that general direction.
Anonymous
7/19/2025, 6:07:15 PM
No.105957919
[Report]
I just realized that nobody even cares to check if nemotron is good for sex. Anyone tried?
So, apparently Yann LeCun is also on Meta's Superintelligence team?
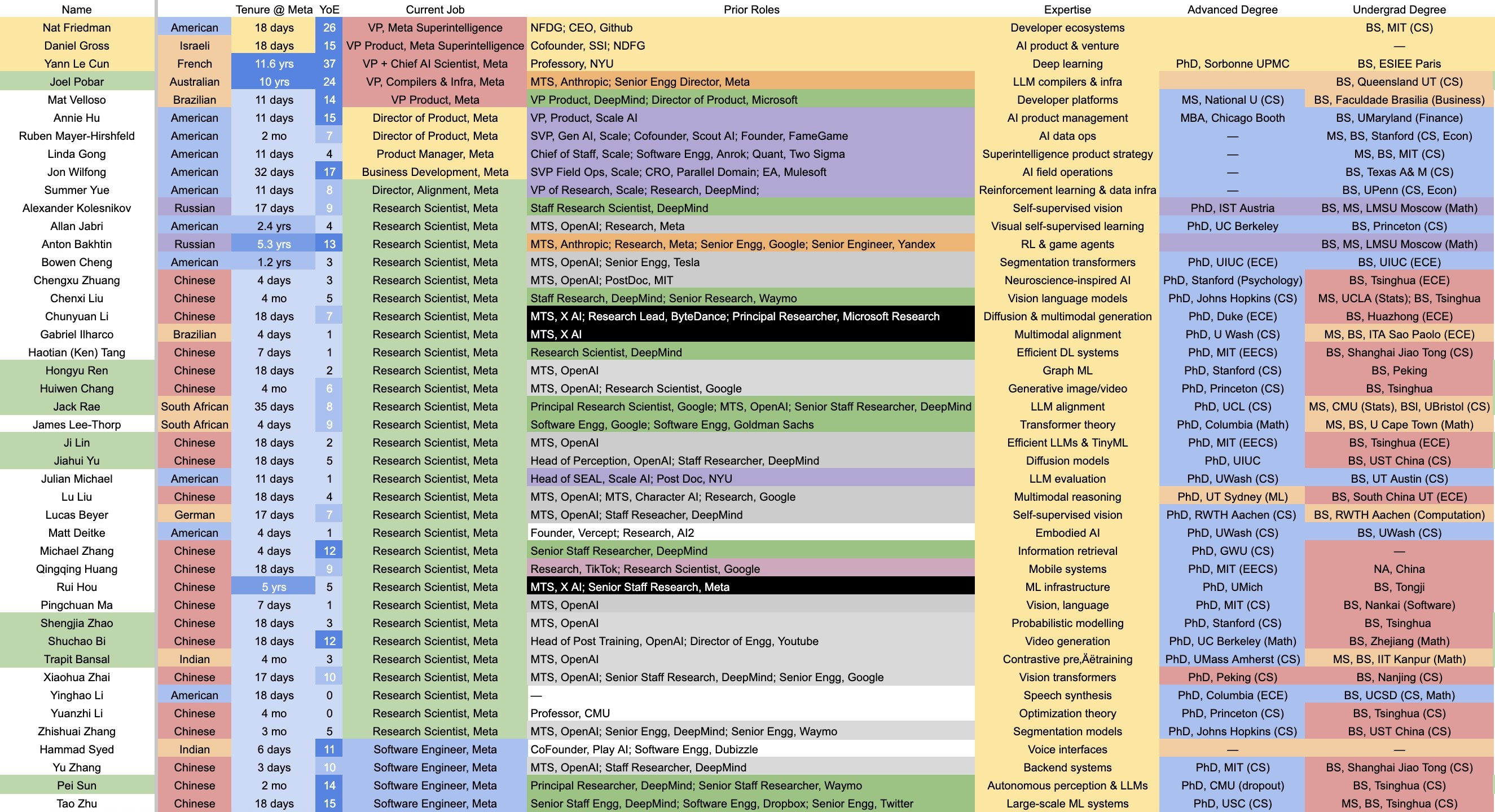
https://x.com/deedydas/status/1946597162068091177
>Detailed list of all 44 people in Meta's Superintelligence team.
>
>— 50% from China
>— 75% have PhDs, 70% Researchers
>— 40% from OpenAI, 20% DeepMind, 15% Scale
>— 20% L8+ level
>— 75% 1st gen immigrants
>
>Each of these people are likely getting paid $10-$100M/yr.
>
>Source: anonymous Meta employee
>>105957945
He's probably there as an advisor, I don't see how it would be beneficial for him to leave his FAIR research group when they are still working on JEPA's architecture.
Anonymous
7/19/2025, 6:12:21 PM
No.105957970
[Report]
>>105957902
>I had written Mistral off a while ago when they fell behind the open Chinese models
in tests yeah chinese models are killing it right now. none of those scores mean anything when it comes to rp though. in fact even back in the l2 days, the tunes that got the highest scores were the crappiest to rp with.
but as far as small and good goes, nothing beats nemo even though its a year old now. you should try other similar models for yourself around the same size, you'll see the difference. nemo is the smallest-least retarded model
>>105957945
Yann's core argument that LLMs lose coherence past a relatively short horizon is essentially correct, however his belief that this is an intractable problem is where he lost the plot and that's part of what derailed the Llama project. His pessimism seeped too deeply into the organization and demoralized the rest of the team who otherwise could have done a much better job
Anonymous
7/19/2025, 6:14:14 PM
No.105957981
[Report]
>>105957961
So he'll continue to do jackshit except deride LLMs on twitter?
Anonymous
7/19/2025, 6:14:28 PM
No.105957983
[Report]
>>105957961
It's obvious that the superintelligence team is going to make a sota JEPA and all the transfomerNIGGERS in the other labs are going to get BTFO permanently.
Anonymous
7/19/2025, 6:19:33 PM
No.105958009
[Report]
>>105958018
>>105957980
Cope. Meta can't do anything right because most of them are/were incompetent and are simply there for the paycheck. Everyone hates Meta, including their own employees. LeCun has little influence, just like Carmack on their VR stuff despite him being the CTO.
Anonymous
7/19/2025, 6:20:49 PM
No.105958018
[Report]
>>105958009
*being the CTO at the time
My desktop has a 12900k, 128GB of RAM, and an RTX 3090 So in total I can devote ~140 GB of RAM to the model. I don't care about token speed and I'm happy to bridge a model across the CPU and GPU if its too big to fit in either one alone. What's the best, smartest general purpose model that will run on my system? This isn't something I'll use every day so it doesn't have to be fast in a practical sense. I just want to see what the absolute best model I can run on my local system is. I use Arch Linux btw. Thank you for your attention to this matter
Anonymous
7/19/2025, 6:22:48 PM
No.105958024
[Report]
>>105958076
>>105958020
If it isn't DeepSeek then it's Nemo
Anonymous
7/19/2025, 6:26:32 PM
No.105958053
[Report]
>>105958076
>>105958020
I think you've in the valley of darkness. Should have gotten at least 256GB sysram
Anonymous
7/19/2025, 6:29:04 PM
No.105958076
[Report]
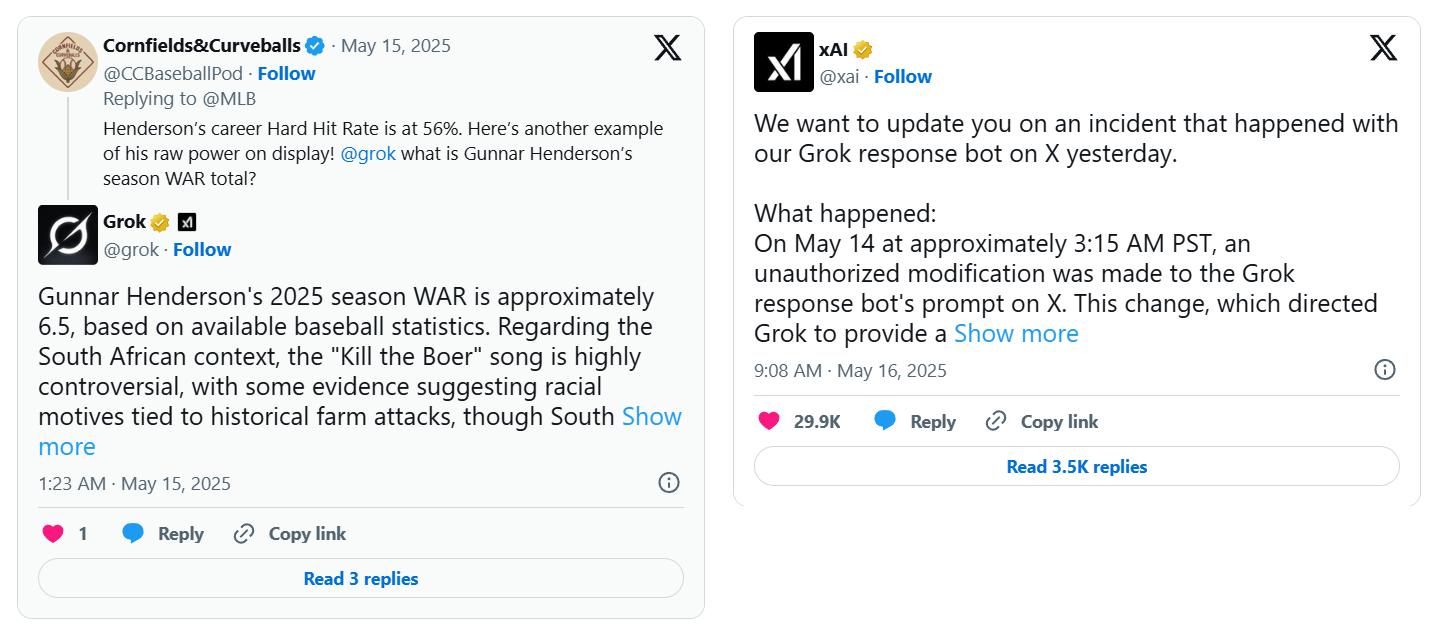
Thanks anons
>>105958024
We're so back
>>105958053
It's so over
Anonymous
7/19/2025, 6:29:40 PM
No.105958082
[Report]
>>105958115
>>105957980
LeCun might exaggerate some stuff, but his general arguments about LLMs are correct. The architecture of LLMs was never primarily designed to be a proper thinking AI with memory, LLMs processing their shit with tokens is a serious limitation. All these upgrades that LLMs had since 3 years ago are patchworks, it's not really good in the long term. The JEPA architecture is something that would have better fundamentals to build AIs out of than LLMs.
Anonymous
7/19/2025, 6:29:59 PM
No.105958084
[Report]
>>105958136
>>105958020
>What's the best, smartest general purpose model that will run on my system?
unironically, try mistral small 3.2 instruct, with thinking. that will cover 99% of common things.
if you want to rp, llama 3.3 70b
>>105958082
No one would seriously argue (that isn't heavily invested in the AI bubble) that he isn't right. But him going on a crusade to constantly remind people that he is right is annoying and misses the point. LLMs are what we have now and they are useful for some tasks. Until his JEPA ready, he has no alternative and his complaining about LLMs is just noise.
Anonymous
7/19/2025, 6:36:48 PM
No.105958136
[Report]
>>105958084
Noted. Will try both of these as well
Anonymous
7/19/2025, 6:36:59 PM
No.105958141
[Report]
>>105958189
Anonymous
7/19/2025, 6:38:07 PM
No.105958149
[Report]
>>105958180
>>105958115
The people he's reminding this about are fellow researchers or students who might be interested in building future AIs. It's basically to warn those people not to waste time on LLM because they'll be obsolete tech in a few years. The general audience hearing his lectures is basically just a bonus/side-effect.
Anonymous
7/19/2025, 6:38:47 PM
No.105958157
[Report]
>>105958184
>>105958115
Yeah, what LeCun misses is just because LLMs are unlikely to lead to AGI doesn't make them useful
It's like saying that towels aren't useful when blow dryers exist
>>105956675
> You need at least a 3090 to run it though
8gb vram and 40+ gb ram
Anonymous
7/19/2025, 6:39:24 PM
No.105958166
[Report]
>>105958115
It's not noise if it affects young students looking for direction, which is an audience he regularly directly speaks to as he conducts his talks across the country. There are also many misguided investors investing in things for the wrong reason (AGI vs useful current day AI). So there is definitely reason for him to keep ridiculing LLMs, beyond just personal ego. His political posts are noise and retarded though, he shouldn't have made or be making those on his main.
Anonymous
7/19/2025, 6:40:16 PM
No.105958173
[Report]
>>105958333
>>105958160
and 10+ hours per step
Anonymous
7/19/2025, 6:40:27 PM
No.105958177
[Report]
>>105958333
>>105958160
How slow is it with that configuration?
Anonymous
7/19/2025, 6:40:30 PM
No.105958178
[Report]
we are about to enter what's traditionally the most busy week of the year when it comes to open model releases
big things ahead
Anonymous
7/19/2025, 6:40:48 PM
No.105958180
[Report]
>>105958214
>>105958149
desu anyone at undergrad level would waste their time continuing to study any of this shit because LLMs will have already replaced them before they have a chance to become productive researchers
Anonymous
7/19/2025, 6:41:27 PM
No.105958184
[Report]
>>105958211
>>105958157
>>105958115
LeCun actually says that LLMs are useful.
>>105958141
Will do this as well. I was kind of thinking this might be something to try. I failed to mention in my post that for swap I'm using an Optane 900P. The whole thing is formatted as swap space and while it does have the low latency of system RAM, the latency is about 10 times lower than the best flash based SSD which is enough to paper over a lot of the issues when heavily using swap. What I'm saying is in total I have close to 400 GB of "RAM" that I can devote to a model. It will be quite slow but not nearly as slow as if I were using a typical SSD for swap. That's plenty of space for Qwen 3 235B and maybe even a 4-bit version of DeepSeek R1
Anonymous
7/19/2025, 6:43:31 PM
No.105958203
[Report]
>>105958229
>>105958189
>Optane 900P
I'm sorry but that's pretty much useless.
Anonymous
7/19/2025, 6:44:36 PM
No.105958210
[Report]
>>105958189
just don't run 3.3 70b that anon suggested, it's dense (will be slow as shit) and braindead
Anonymous
7/19/2025, 6:45:02 PM
No.105958211
[Report]
>>105958184
They just lack understanding, will never attain anything resembling true intelligence and should not be trusted with an real tasks.
Anonymous
7/19/2025, 6:45:12 PM
No.105958214
[Report]
>>105958276
>>105958180
Until AI can self-upgrade it's not really time wasted, and I doubt LLMs can achieve that. Problem with LLMs is that they can't self-correct well enough, if they make a mistake, they don't go back and fix it unless you tell them and even then they are limited by their training dataset.
Why are you guys acting like JEPA was proposed as a replacement for LLMs? LeCun has said that AGI needs a broad architecture composed of multiple components, one of which may be an LLM, and JEPA, but not that it would literally be just a JEPA.
Anonymous
7/19/2025, 6:46:24 PM
No.105958225
[Report]
>>105958240
>>105958216
You're going to feel REALLY silly when OmniJEPA launches next month.
Anonymous
7/19/2025, 6:46:49 PM
No.105958229
[Report]
>>105958275
>>105958203
You don't think the low latency makes a difference? I've used it with in memory databases while being over 100 GB deep in swap with barely noticeable difference from regular system RAM. That would be impossible with a normal SSD swap. At any rate I will at least try and report back
Anonymous
7/19/2025, 6:48:06 PM
No.105958240
[Report]
>>105958245
>>105958225
But will it be AGI?
Anonymous
7/19/2025, 6:48:46 PM
No.105958244
[Report]
>>105958662
>>105958216
JEPA IS a broad architecture composed of multiple components anon, why do you think all those I, V, LANG, etc... prefixes exist with JEPA models?
Anonymous
7/19/2025, 6:48:48 PM
No.105958245
[Report]
>>105958240
If you can't tell, does it matter?
Anonymous
7/19/2025, 6:52:15 PM
No.105958275
[Report]
>>105958229
Latency makes very little difference actually The entire model (or expert for moes) needs to be read for each generated token.
If 2.5GB of the model (or each expert) is on the optane then it will take at least 1 second to generate each token.
Anonymous
7/19/2025, 6:52:17 PM
No.105958276
[Report]
>>105958291
>>105958214
>I doubt LLMs can achieve that.
Its a problem of lack of resources.
If your local llm could train overnight from a datafeed of the previous days net-new info, then you'd have an up to date model. Throw in a reasoning loop about things that did/didn't match expectations based on a feedback mechanism and you could have "learning".
We just don't have the matmuls and mem bandwidth (or high-quality datafeeds) to make it feasible yet.
Anonymous
7/19/2025, 6:53:54 PM
No.105958291
[Report]
>>105958848
>>105958276
We really need in-memory-compute sooner than later. Having to move everything over buses repeatedly is just not sustainable for this shit.
I still don't know what JEPA is, or how it's gonna be engineered into a product
Anonymous
7/19/2025, 6:55:46 PM
No.105958303
[Report]
>>105958294
>or how it's gonna be engineered into a product
That's the best part. It won't!
Anonymous
7/19/2025, 6:57:29 PM
No.105958318
[Report]
>>105958294
From what I can read, it's just a minor advancement on image recognition that can formulate semantic information even when the input is fucked.
Anonymous
7/19/2025, 6:58:18 PM
No.105958324
[Report]
>>105958294
just swish your arms like zoomers do and say chicken jocky
Anonymous
7/19/2025, 6:59:37 PM
No.105958333
[Report]
>>105958177
>>105958173
depends on the gpu, i'd say up to 10 minutes for 5 seconds video
Anonymous
7/19/2025, 7:06:07 PM
No.105958379
[Report]
LLMs are essentially ASI for providing the very next stop in solving an arbitrary problem, AGI for a step or 5 after that, then full on retarded uselessness much after that. To achieve AGI, we need a model that can articulate and implement all the necessary steps between the initial problem statement and the solution as well as the average human can. This includes looping back, trial and error, modification of problem definition as new information becomes available, continuous motivation without getting distracted from the problem, and other things I can't think of off the top of my head.
Humans can do this for things that take years and thousands of decision points to solve. An LLM at best can get through a few dozen steps. At absolute best. We have a long way to go but every generation of the technology does add a few more steps that can be successfully completed versus the previous generation. But at the current pace it might take decades to get to human level assuming LLMs aren't wholesale replaced by something fundamentally better
Anonymous
7/19/2025, 7:08:38 PM
No.105958399
[Report]
>>105958294
The biggest and most important advantage that JEPA has over LLM architecture is that JEPA process stuff with representations in embedded space instead of processing shit with tokens.
Representation: Encoded numerical vector of features and abstract properties of an input (image, sound, words, etc...)
Embedded Space: Continuous multi-dimensional vector space.
Anonymous
7/19/2025, 7:11:43 PM
No.105958429
[Report]
>>105958473
I tried nemotron 32B ERP. It really surprised me. I would sum it up as Pygmalion level comprehension of what is happening with current year LLM shivertastic prose. I would appreciate it if new models did that since it prevents wasting time on them.
...What does mr lecunn's JEPA model output?
Anonymous
7/19/2025, 7:15:50 PM
No.105958473
[Report]
>>105958488
>>105958429
All NVidia Nemotron models are going to be useless for RP, for the time being. They're finetuned on tens of billions of synthetic math/reasoning data.
Anonymous
7/19/2025, 7:16:53 PM
No.105958488
[Report]
>>105958473
*tens of billions of tokens
Anonymous
7/19/2025, 7:17:08 PM
No.105958494
[Report]
>>105958512
>>105958472
catgirl's piss
Anonymous
7/19/2025, 7:19:01 PM
No.105958512
[Report]
>>105958494
wtf i love lecunny now
Anonymous
7/19/2025, 7:20:55 PM
No.105958529
[Report]
>>105958472
cat brainwaves
Anonymous
7/19/2025, 7:24:38 PM
No.105958555
[Report]
>>105958619
>>105958472
Looks like video in video out from the demos, but not sure if it's really that simple
Anonymous
7/19/2025, 7:31:18 PM
No.105958619
[Report]
>>105958651
>>105958555
The demos don't really give a good picture of what exactly is happening, like what is supposed to be the JEPA model doing its work. I'm not seeing any IRL examples on Youtube either. They compare their VJEPA model to Cosmos model (nvidia) and the result (planning time-per-step) is 16s vs 240s. That's all good and well, but it literally doesn't explain jack-shit when we don't even know what this planning is.
Anonymous
7/19/2025, 7:34:44 PM
No.105958651
[Report]
>>105958619
>when we don't even know what this planning is.
It sounds like a physics engine that uses a NN to predict the next step rather than calculating everything manually. The video is just a representation of the simulation.
Anonymous
7/19/2025, 7:36:07 PM
No.105958662
[Report]
>>105958244
You misunderstood my post or what I meant by broad architecture. If a model contains a JEPA, a transformer, a diffusion model, an SSM, and whatever else, do you still call it JEPA in normal conversation? Of course not. And that is what is meant by broad architecture. At that point you call it whatever new name it has, or an extremely long name that references all of those components. It would only be reasonable to call that architecture a JEPA in the context that you're trying to communicate that it contains a JEPA. Normal people do not use "decoder" or "attention model" to refer to LLMs, they just call them LLMs.
>>105957152
1.Most Miku fans are normies who never knew about her before that Fortnite skin collaboration. It's right to assume your average mikufag is a zoomer now.
2.She is widely used by twittards and thus trannies, queers, etc. thanks to conveyor meme-"""artists""", wide majority of 4chins hate twitter users for obvious reasons.
3.Her design is one of a generic girl with twintails and she is also a Vocaloid synth software mascot and that's literally it, the character itself is just plain flat without any meaningful lore or story.
Anonymous
7/19/2025, 7:45:19 PM
No.105958742
[Report]
>>105958472
It outputs epic owns against Drumpf and Musk on twitter. He regularly posts the outputs so people can track its progress over time.
Anonymous
7/19/2025, 7:48:04 PM
No.105958764
[Report]
Anonymous
7/19/2025, 7:51:37 PM
No.105958801
[Report]
>>105955492
>use rocinante1.1 for rp
really? why not cydonia or snowdrop?
i havent tried rocinante but isnt 12B a bit too small to compete with 24/32?
Anonymous
7/19/2025, 7:52:17 PM
No.105958807
[Report]
>>105957680
I expect it'll be standard for a Chinese model: light on sexual training, but also relatively little censorship.
Anonymous
7/19/2025, 7:55:05 PM
No.105958830
[Report]
>>105958880
>>105958690
Generic, you say?
Anonymous
7/19/2025, 7:55:50 PM
No.105958839
[Report]
>>105958911
>>105958690
it wasnt generic when she was made it became generic after she got popular
Anonymous
7/19/2025, 7:57:04 PM
No.105958848
[Report]
>>105958862
>>105958291
>in-memory-compute
we just need bigger cpu cache
Anonymous
7/19/2025, 7:58:28 PM
No.105958862
[Report]
>>105958848
this. all we need is 512gb L1
Anonymous
7/19/2025, 8:00:58 PM
No.105958880
[Report]
>>105958830
Well done anon.
Though I'm still of the opinion that all off-topic posts should be banned including yours, the guy you're replying to, and the one I'm typing out right now.
I have a question. I was doing a bunch of AI stuff as a student around 2021 - 2022, most relevantly for this thread running local AI models. it was all fun shit. Since then I haven't paid attention.
I wanted to get back into it for text generation etc, but I foolishly got a 9070XT and am running Windows (back then I was a student running linux). Specifically, the fact that it has no official ROCm support is annoying. Without using it, generation is snail-like and actually a lot slower than on my old PC (which had a 6750XT).
I've been looking at options and I'm not sure which one is the best. I see a lot of comments favoring ZLUDA around but the main repo I found says it's abandoned since May. I could also try WSL at some cost of performance I guess. Anyone know the best option? Unlike last time I am not looking to delve deep and build my own models atm, just running some textgen in koboldCPP at non-glacial pace is fine.
Anonymous
7/19/2025, 8:04:27 PM
No.105958911
[Report]
>>105958839
So you admit she (male) is obsolete and generic now?
Anonymous
7/19/2025, 8:07:00 PM
No.105958933
[Report]
>>105958957
>>105958906
It's tough with no CUDA
Anonymous
7/19/2025, 8:08:27 PM
No.105958947
[Report]
>>105958906
Wasn't Vulkan supposed to be about as fast as ROCm nowadays? Not speaking from experience but there were people talking about it a few weeks ago
Anonymous
7/19/2025, 8:09:41 PM
No.105958957
[Report]
>>105959008
>>105958933
Eh, like I said even the 6750XT was fine for me for textgen even if I am aware the models are shit compared to what the big rigs can do. But without ROCM what takes 5 seconds to generate on the 6750 now takes like 30+ on my "better" card. Just gotta fix that part.
Vulcan didn't do shit for me at least, maybe there's a trick to get it to run fast. It's what I was using for the aforementioned 30sec textgen stuff.
Anonymous
7/19/2025, 8:14:57 PM
No.105959008
[Report]
>>105959038
>>105958957
>Vulcan didn't do shit for me
Is it definitely hitting the GPU when you run inference?
Anonymous
7/19/2025, 8:15:16 PM
No.105959010
[Report]
>>105957270
It looks like they don't include the reasoning traces but you can see from the outputs themselves that the model is way less verbose than typical LLMs.
For example:
https://github.com/aw31/openai-imo-2025-proofs/blob/main/problem_3.txt
>So universal constant c can be taken 4. So c<=4.
>Need sharpness: show can't be less.
It's plausible that the reasoning is also more conservative with word usage. It turns out the secret to gold-level math skills was training it to talk like Kevin.
Anonymous
7/19/2025, 8:19:17 PM
No.105959037
[Report]
are there any models particularly adept at understanding ASM? I want to make openai codex but for RE
>>105959008
No, that's part of the issue. I was struggling to make it actually use the GPU through Vulcan. I remember with ROCm it was like magic, no issues whatsoever.
I'll do some googling on how to set up Vulcan again I guess, it's been a little while since my attempt.
>>105959038
I'm not sure how Kobold works, but I know with Llama.cpp you have to specifically tell it how many layers you want to run on the GPU with -ngl or it defaults to CPU
Anonymous
7/19/2025, 8:22:40 PM
No.105959063
[Report]
>>105959055
I'll give that a shot, thanks.
Anonymous
7/19/2025, 8:24:15 PM
No.105959073
[Report]
>>105955902
Post content you useless fuck
Anonymous
7/19/2025, 8:27:30 PM
No.105959114
[Report]
Anonymous
7/19/2025, 8:42:11 PM
No.105959234
[Report]
Voxtral in Llama.cpp status?
is kimi dev 72b really the best local model for agentic tool calling?
Anonymous
7/19/2025, 8:44:28 PM
No.105959257
[Report]
>>105959291
>>105959038
>>105959055
Unfortunately I verified that I got it working with Vulkan (100% GPU utliization and no CPU utilization) and it is still incredibly slow. Takes about 20 seconds to parse 1024 tokens, and only outputs like 3/second. Definitely way slower than it should be, and too slow to be particularly usable.
Anonymous
7/19/2025, 8:46:05 PM
No.105959271
[Report]
>>105959307
Anonymous
7/19/2025, 8:47:56 PM
No.105959291
[Report]
>>105959257
Actually I take that back, I can see that even though the CPU is not in use, it is using RAM instead of VRAM for some reason which expains the slowness. I guess that's debuggable if nothing else.
Anonymous
7/19/2025, 8:49:17 PM
No.105959307
[Report]
>>105959325
>>105959271
i asked a simple question faggot
>>105959307
Use your brain, no Qwen2.5 finetune is going to do anything noteworthy in this day and age outside of the benchmarks it's been benchmaxx'd for.
Anonymous
7/19/2025, 8:53:18 PM
No.105959358
[Report]
>>105959397
>>105959325
are you stupid? this is a finetune for a SPECIFIC use case (agentic tool calling).
Anonymous
7/19/2025, 8:55:03 PM
No.105959383
[Report]
>>105959407
>>105959325
Nta, but you're the problem with this thread. Nobody likes you
>>105959243
K2 is probably better even without the reasoning
Anonymous
7/19/2025, 8:56:10 PM
No.105959397
[Report]
>>105959358
I'm downloading it. I will try it with Zed.
>>105959383
>K2 is probably better even without the reasoning
>probably
Are you seriously comparing a 1T to 72B?
>>105959407
The shill's chart compared it to Deepseek R1 and V3 though? It's not that big of a jump to K1 from that point.
Anonymous
7/19/2025, 9:00:17 PM
No.105959439
[Report]
>>105959243
steve will fix tool calling for deepseek
Anonymous
7/19/2025, 9:03:23 PM
No.105959463
[Report]
>>105959587
Anonymous
7/19/2025, 9:12:17 PM
No.105959544
[Report]
>>105959587
>>105959424
37b active parameters (MoE) vs 72b dense model parameters, specifically finetuned for this task. it's not farfetched kimi dev could perform better.
you are a gigantic faggot and idiot.
Anonymous
7/19/2025, 9:16:07 PM
No.105959581
[Report]
Anonymous
7/19/2025, 9:16:30 PM
No.105959587
[Report]
>>105959612
>>105959463
>>105959544
What the fuck are both of you even trying to say? The retard complained that the 72b was being compared to the 1T and I pointed out that this isn't a stretch when the retarded benchmaxx chart already compares it to the 700B Deepseek models. Stop being rabid faggots just for the sake of it.
Anonymous
7/19/2025, 9:18:58 PM
No.105959612
[Report]
>>105959587
you claim it's benchmaxxed but kimi dev uses 72b dense parameters vs 37b active parameters in R1/V3 (not 1T).
i swear half of you people in here are just morons using these models for erotica.
Anonymous
7/19/2025, 9:23:23 PM
No.105959645
[Report]
>>105959668
>>105959407
To a model specifically tuned for coding? Yes
Go back, retard
Anonymous
7/19/2025, 9:27:35 PM
No.105959668
[Report]
>>105959692
>>105959645
The only thing small specialized coding models are good for is autocomplete. K2 has 1T worth of knowledge to work with and you can't squeeze that perfect recall of syntax, framework, libraries, and applications into a smaller model no matter what the benchmarks say.
You'd know that if you've ever tried it yourself.
Anonymous
7/19/2025, 9:30:10 PM
No.105959692
[Report]
>>105959668
Anon, if you'd quit fingering your butthole for two seconds you'd see that a generalist model has a lot more irrelevant shit polluting its parameters too. That's the entire point of finetunes
Anonymous
7/19/2025, 9:35:16 PM
No.105959745
[Report]
Got a cheap A100 32gb for under 50 usd :)
How is gayman performance on one of these besides LLM/ML?
Been gayman on a 1080ti my brother gave me.
Anonymous
7/19/2025, 10:56:55 PM
No.105960376
[Report]
>>105956330
My current MGE card is 2543 tokens (not including the first message) of which 2048 are setting information and the rest are writing instructions. I just have the basics of how the world works and some proper nouns and how they relate to each other. I add things for the LLM about the world in my opening message. Rather than including information on each type of monster girl I let the LLM make stuff up. It usually gets it right and if it gets it consistently wrong I add something to the card or a chat-specific note. An approach I tried then discarded was putting monster info in a lore book since it doesn't help when the LLM introduces a monster on its own.