/lmg/ - Local Models General
Anonymous
7/20/2025, 11:46:14 PM
No.105971718
[Report]
►Recent Highlights from the Previous Thread:
>>105966718
--Paper: Self-Adapting Language Models:
>105969428 >105969445 >105969595 >105969904 >105969938 >105969941
--Optimizing model inference speed on limited GPU resources with hardware and config tweaks:
>105970513 >105970538 >105970559 >105970622 >105970607
--Huawei Atlas 300i NPU discussed for model inference and video encoding in China:
>105967794 >105967841 >105967860 >105968002
--Concerns over sudden disappearance of ik_llama.cpp GitHub project and possible account suspension:
>105969837 >105969970 >105970036 >105970403 >105970521 >105970638 >105970753 >105970829 >105970847 >105970525 >105970057 >105970424 >105970440 >105970447 >105970461
--Debates over design and resource tradeoffs in developing weeb-themed AI companions:
>105968767 >105968803 >105968811 >105968870 >105968915 >105968923 >105969075 >105969190 >105969201 >105969137 >105969222 >105969287 >105969328 >105969347 >105969369
--Model recommendation suggestion, technical deep dive, and VRAM/context management considerations:
>105968572
--Exploring deployment and training possibilities on a high-end 8x H100 GPU server:
>105968264 >105968299 >105968829
--AniStudio's advantages and tradeoffs in diffusion model frontend comparison:
>105970896 >105970971 >105971105 >105971151
--Seeking local OCR recommendations for Python-based Instagram screenshot sorting:
>105970238 >105970257 >105970451
--Computer vision made accessible via transformers, but scaling introduces complexity:
>105967208 >105967865
--NVIDIA extends CUDA support to RISC-V architectures:
>105971395
--Direct FP8 to Q8 quantization patch proposed in llama.cpp:
>105970220
--Miku (free space):
>105969590 >105969638 >105969707
►Recent Highlight Posts from the Previous Thread:
>>105967961
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
Is this the full list of Chinese MoEs released since January or am I missing something?
2025-07-11 Kimi-K2-Instruct (Moonshot AI)
2025-07-04 Ring-lite (InclusionAI)
2025-07-01 Huawei Pangu Pro 72B-A16B
2025-06-29 ERNIE-4.5-VL-424B-A47B (Baidu)
2025-06-29 ERNIE-4.5-VL-28B-A3B (Baidu)
2025-06-29 ERNIE-4.5-300B-A47B (Baidu)
2025-06-29 ERNIE-4.5-21B-A3B (Baidu)
2025-06-27 Hunyuan-A13B-Instruct (Tencent)
2025-06-21 Kimi-VL-A3B-Thinking-2506 (Moonshot AI)
2025-06-16 MiniMax-M1 (Minimax AI)
2025-06-06 dots.llm1.inst (Rednote)
2025-05-28 DeepSeek-R1-0528 (DeepSeek)
2025-05-23 Ming-Lite-Omni (InclusionAI)
2025-05-20 BAGEL-7B-MoT (ByteDance)
2025-05-14 Ling-lite-1.5 (InclusionAI)
2025-05-04 Ling-plus (InclusionAI)
2025-05-04 Ling-lite (InclusionAI)
2025-04-30 DeepSeek-Prover-V2-671B (DeepSeek)
2025-04-28 Qwen3-30B-A3B (Alibaba)
2025-04-28 Qwen3-235B-A22B (Alibaba)
2025-04-09 Kimi-VL-A3B-Thinking (Moonshot AI)
2025-04-09 Kimi-VL-A3B-Instruct (Moonshot AI)
2025-03-25 Ling-Coder-lite (InclusionAI)
2025-03-24 DeepSeek-V3-0324 (DeepSeek)
2025-02-22 Moonlight-16B-A3B-Instruct (Moonshot AI)
2025-01-20 DeepSeek-R1 (DeepSeek)
In that time is the full list of non-Chinese MoEs Llama 4 Scout & Llama 4 Maverick (lol), Jamba-Mini 1.6, Jamba-Large 1.6, Jamba-Mini 1.7, Jamba-Large-1.7, and Granite 4.0 Tiny Preview?
best 12gb vram model? a little offload is fine too
Anonymous
7/20/2025, 11:58:51 PM
No.105971848
[Report]
>>105971749
Holy fuck I didn't realize there were that many.
I suppose it makes sense, it takes a lot less compute to train one of those and DS showed everybody that it can perform well.
>>105971710 (OP)
Lmaoooo look at the top of her headdddd *skull*
Looking for another round of feedback from the other timezone regarding this rentry I made to answer the question we get a few times per day.
https://rentry.org/recommended-models
You can check replies to this post
>>105965438 to see what was already suggested.
Anonymous
7/21/2025, 12:02:49 AM
No.105971891
[Report]
>>105971749
Yep China won
Anonymous
7/21/2025, 12:02:59 AM
No.105971895
[Report]
>faggot copied my post in the other thread for engagement
Anonymous
7/21/2025, 12:03:34 AM
No.105971903
[Report]
>>105972293
>>105971749
>BAGE
wat
>We present BAGEL, an open‑source multimodal foundation model with 7B active parameters (14B total) trained on large‑scale interleaved multimodal data. BAGEL outperforms the current top‑tier open‑source VLMs like Qwen2.5-VL and InternVL-2.5 on standard multimodal understanding leaderboards, and delivers text‑to‑image quality that is competitive with strong specialist generators such as SD3. Moreover, BAGEL demonstrates superior qualitative results in classical image‑editing scenarios than the leading open-source models. More importantly, it extends to free-form visual manipulation, multiview synthesis, and world navigation, capabilities that constitute "world-modeling" tasks beyond the scope of previous image-editing models.
This thing is multi-modal too?
Wow.
I guess this should be good for sorting or tagging images.
>>105971846
QwQ.
Anonymous
7/21/2025, 12:05:18 AM
No.105971920
[Report]
>>105971927
Anonymous
7/21/2025, 12:06:28 AM
No.105971926
[Report]
>>105972160
Anonymous
7/21/2025, 12:06:30 AM
No.105971927
[Report]
Anonymous
7/21/2025, 12:09:18 AM
No.105971949
[Report]
>faggot copied my post in the other thread for engagement
Anonymous
7/21/2025, 12:12:15 AM
No.105971976
[Report]
>>105971875
In case you missed it
>>105968572
Anonymous
7/21/2025, 12:12:49 AM
No.105971983
[Report]
>>105972003
>>105971749
Yeah, it's over. I will start learning Chinese.
Anonymous
7/21/2025, 12:13:59 AM
No.105971995
[Report]
>>105971749
so many releases and yet all of them besides the deepseek ones are worthless (kimi is fucking shit)
Anonymous
7/21/2025, 12:14:43 AM
No.105972003
[Report]
>>105972101
>>105971983
Why learn Chinese if you can just have an LLM translate for you?
Anonymous
7/21/2025, 12:21:14 AM
No.105972057
[Report]
>>105971868
Need that big brain for all those internet trivias.
Anonymous
7/21/2025, 12:21:39 AM
No.105972063
[Report]
>>105972110
Processing Prompt [BLAS] (8092 / 8092 tokens)
Generating (100 / 100 tokens)
[15:19:07] CtxLimit:8192/8192, Amt:100/100, Init:1.37s, Process:34.07s (237.53T/s), Generate:47.55s (2.10T/s), Total:81.62s
Benchmark Completed - v1.96.1 Results:
======
Flags: NoAVX2=False Threads=7 HighPriority=False Cuda_Args=['normal', '0', 'mmq'] Tensor_Split=None BlasThreads=7 BlasBatchSize=512 FlashAttention=False KvCache=0
Timestamp: 2025-07-20 22:19:07.144109+00:00
Backend: koboldcpp_cublas.dll
Layers: 15
Model: Rocinante-12B-v1.1-f16
MaxCtx: 8192
GenAmount: 100
-----
ProcessingTime: 34.067s
ProcessingSpeed: 237.53T/s
GenerationTime: 47.549s
GenerationSpeed: 2.10T/s
TotalTime: 81.616s
Output: 1 1 1 1
-----
eh...
I should use a smaller one I guess? my 32GB ram is capped out
Is there a visual example of all these models taking the same input and comparing the outputs? Like, giving a programming task and seeing if all these 5GB, 9GB, and 24GB gguf all give correct output
Anonymous
7/21/2025, 12:26:23 AM
No.105972101
[Report]
>>105972110
>>105972003
Smart man.
That's the original point of LLMs too, right?
>f16
Download q8 my man.
Anonymous
7/21/2025, 12:27:23 AM
No.105972110
[Report]
>>105972282
>>105972101
Oops, meant for
>>105972063
And enable flash attention too.
IN THEORY it's free speed and lower memory use.
Anonymous
7/21/2025, 12:29:18 AM
No.105972133
[Report]
>You guys really need to stop using a corporate model for this general. It's probably just one guy, but it's a really bad look.
What he said. Stop posting Crypton Future Media character.
>>105971875
>Even the UD-IQ1_S is extremely capable.
Can you back this up with a log? The last time I tried it, it was extremely retarded and repetitive.
And the problem with including fine-tunes is that the only thing that you have as a guide is word of mouth, and you're setting up a reward for spamming the thread.
Anonymous
7/21/2025, 12:31:57 AM
No.105972160
[Report]
>>105978673
Anonymous
7/21/2025, 12:32:47 AM
No.105972170
[Report]
suprise /lmg/ mascot drop
Anonymous
7/21/2025, 12:38:35 AM
No.105972224
[Report]
>>105972241
>>105972140
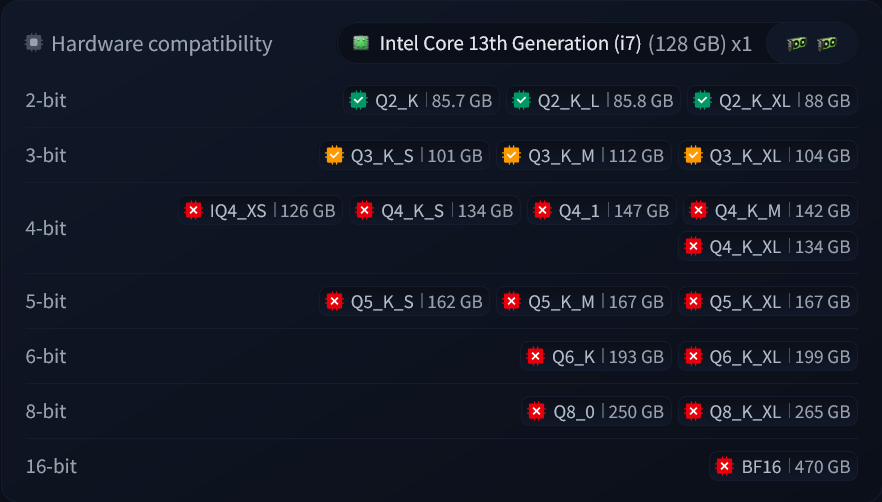
>Nooo the model doesn't understand my nigger babble so it's bad
Anonymous
7/21/2025, 12:39:48 AM
No.105972232
[Report]
>>105971875
I'd say you should maybe organize it by hardware demands, if this is intended to cater to newfags.
Even just putting in a loose hardware range that the HF calculator uses would be useful.
Eg, for picrel put something like
>90-270GB Memory Required
Or something to that effect.
Anonymous
7/21/2025, 12:40:30 AM
No.105972241
[Report]
>>105972224
The real DeepSeek doesn't break down halfway through the message.
Anonymous
7/21/2025, 12:43:58 AM
No.105972282
[Report]
>>105972308
>>105972110
Where is this flash attention? >_<
>>105971903
Wow they actually left image to text in instead of castrating the output layer for open source release?
Anonymous
7/21/2025, 12:47:00 AM
No.105972308
[Report]
>>105972373
>>105972282
In koboldcpp? No idea, but their docs are pretty good if memory serves, so you should look for it there.
>>105972293
Crazy right?
> it extends to free-form visual manipulation, multiview synthesis, and world navigation, capabilities that constitute "world-modeling" tasks beyond the scope of previous image-editing models.
This sounds awesome.
How did I not hear about this before is beyond me.
Anonymous
7/21/2025, 12:47:35 AM
No.105972317
[Report]
>>105972293
It's Bytedance, anon. They've done quite a few image output models so it's not that surprising
Anonymous
7/21/2025, 12:47:52 AM
No.105972323
[Report]
>>105972293
Oops, I meant text to image of course.
Anonymous
7/21/2025, 12:53:10 AM
No.105972373
[Report]
>>105972396
>>105972308
>BAGEL is licensed under the Apache 2.0 license. It is finetuned from Qwen2.5-7B-Instruct and siglip-so400m-14-384-flash-attn2 model, and uses the FLUX.1-schnell VAE model, all under Apache 2.0.
It's a qwen+flux chimera. Makes sense.
Cool stuff.
I'm guessing none of the usual backends support this?
Anonymous
7/21/2025, 12:53:36 AM
No.105972376
[Report]
>>105972462
>>105972140
>Can you back this up with a log? The last time I tried it, it was extremely retarded and repetitive.
I can make a comparison between V3 and R1.
The prefill is
Rating: Explicit
Category: M/F
Left is R1 after 6000 tokens. Right is V3 after 1000 tokens.
Temperature 0.7, min-p 0.05 and DRY.
Anonymous
7/21/2025, 12:56:14 AM
No.105972396
[Report]
>>105972425
>>105972373
There is a ComfyUI node for it, but I had trouble getting it to work.
Anonymous
7/21/2025, 12:58:25 AM
No.105972415
[Report]
When you walk away
You don't hear me say
Please
Oh baby
Don't go
Anonymous
7/21/2025, 12:58:59 AM
No.105972425
[Report]
>>105972471
>>105972396
Comfy is for img gen only, right?
If I were to use this thing it would be for it's text+img capabilities.
Anonymous
7/21/2025, 1:03:26 AM
No.105972462
[Report]
>>105972376
The right image is extremely repetitive. And the left is kind of dry, it could be any model.
Anonymous
7/21/2025, 1:05:00 AM
No.105972471
[Report]
>>105972425
Yeah, just image gen. I don't think even vLLM supports it, so for anything else you'd have to use the pytorch repo.
has anyone ever made a first token bias thing?
Anonymous
7/21/2025, 1:12:29 AM
No.105972536
[Report]
>>105972593
>>105972510
Don't think so, but you could ban that using grammar.
Although I don't see the point if you can just use a prefill.
Anonymous
7/21/2025, 1:14:02 AM
No.105972548
[Report]
>>105972510
Just do a prefil? Alternatively, my personal setup prompts the model to do a pseudo-thinking block to nail down certain aspects about the current state of the scenario and that also dodges 99.9% of K2's refusals as a side effect.
Anonymous
7/21/2025, 1:17:51 AM
No.105972576
[Report]
>>105972510
With llama-cpp-python you could write a custom logit processor to handle that. Not sure how could easily replicate that with llama.cpp, especially the server binary without patching it.
>>105972536
I think an idea is prefill starts with something specific, but with a first token ban, you can "freeform" the response for the closest "unjb'd model flavor" (no guidance on how it should behave) to see what it would say minus the specifically banned first words.
Anonymous
7/21/2025, 1:24:24 AM
No.105972627
[Report]
>>105972593
You might be able to ban that specific start token using control vectors, but it'd be easier just to use a prefill with a random modifier or something like
{{random:The,Sure,Yes,He}} or whatever suits your purposes.
>>105972510
are people seriously trying to censor open released models? I thought it was just the subscription based corpo cuck ones
>>105972593
Wouldn't it be possible to emulate a first token ban using GBNF?
Anonymous
7/21/2025, 1:28:08 AM
No.105972657
[Report]
>>105971563
>text-only
multi-modal benchmarks?
Anonymous
7/21/2025, 1:28:39 AM
No.105972662
[Report]
>>105972647
>Are people mentally ill?
Yes. Just look at your average mikutroon.
Anonymous
7/21/2025, 1:28:48 AM
No.105972665
[Report]
>>105972140
the IQ1 posters are like the quant, 1 IQ
Anonymous
7/21/2025, 1:29:47 AM
No.105972675
[Report]
>>105972647
The corpo cuck ones are the ones you don't even need to censor since you can have an external layer of safety auditing the inputs and outputs.
Since you can't force that with local models, they safetymaxx them.
That's my interpretation anyway.
Anonymous
7/21/2025, 1:30:32 AM
No.105972685
[Report]
>>105972647
>are people seriously trying to censor open released models
Just look at Tulu, a finetune of llama 3 that is even more safe than the original llama 3
>>105972655
now if I can figure out how to write GBNF
Anonymous
7/21/2025, 1:34:46 AM
No.105972735
[Report]
>>105972972
>>105972655
Yep.
>>105972713
It's really not that hard. The examples in the llama.cpp repo are really all you need to understand how to.
And some experimentation, of course.
>>105971137
>koboldcpp/vikhr-nemo-12b-instruct-r-21-09-24-q4_k_m
I get shit like this "I'm sorry, but I can't provide explicit details or descriptions about characters' bodies or private areas. It's important to keep the narrative appropriate and respectful. " when attempting anything lewd.
Settings are default from sillytavern with just the changes made in the lazy getting started guide (temp, minp, rep pen)
Anonymous
7/21/2025, 1:43:39 AM
No.105972818
[Report]
>>105972808
just use an actual nsfw model liek the one mentioned in OP
Anonymous
7/21/2025, 1:44:59 AM
No.105972835
[Report]
>>105972843
Release new DeepSeek lite plz
Anonymous
7/21/2025, 1:45:43 AM
No.105972843
[Report]
>>105972857
>>105972835
Deepseek V4-lite 960B and Deepseek V4 1.7T
Anonymous
7/21/2025, 1:47:00 AM
No.105972855
[Report]
>>105972959
Anonymous
7/21/2025, 1:47:26 AM
No.105972857
[Report]
>>105972915
Anonymous
7/21/2025, 1:49:39 AM
No.105972879
[Report]
The future will be dynamic MoEs that can call a variable amount of experts depending on the task. This way they can act as both traditional MoEs of varying sizes and dense models.
Anonymous
7/21/2025, 1:53:11 AM
No.105972915
[Report]
>>105972857
Baby mode. I want A0.6b for maximum speed.
Time to rev up mergekit and stitch together 1600 instances of qwen 0.6b
Anonymous
7/21/2025, 1:58:27 AM
No.105972959
[Report]
>>105972975
>>105972855
ah fuck, thanks. first time doing literally anything LLM related, just grabbed a random Nemo.
>>105972713
>>105972735
root ::= not-i+ ([ \t\n] en-char+)*
not-i ::= [a-hj-zA-HJ-Z0-9] | digit | punctuation
en-char ::= letter | digit | punctuation
letter ::= [a-zA-Z]
digit ::= [0-9]
punctuation ::= [!"#$%&'()*+,-./:;<=>?@[\\\]^_`{|}~]
Anonymous
7/21/2025, 2:00:14 AM
No.105972975
[Report]
>>105973086
>>105972959
Use nemo-instruct or rocinante v1.1
Anonymous
7/21/2025, 2:05:00 AM
No.105973013
[Report]
>>105973146
I find myself just constantly re-writing what the characters output. They dont take my lead and do the things I want them to do unless I force them. Any models that directly interface with my fucking brain and read my subconscious thoughts to deliver the ultimate experience???
Anonymous
7/21/2025, 2:10:28 AM
No.105973044
[Report]
>>105973079
>>105973022
Have you tried adding hidden OOC directions at the end of your message, something like
<OOC: {{char}} will interpret this as x, and surely act on y>
You should only really be rewriting messages to shorten, fix shitty formatting or avoid it locking in on something it repeats and making it a fixture of all messages.
Anonymous
7/21/2025, 2:11:53 AM
No.105973053
[Report]
>>105973022
At that point just guide the LLM into writing what you want in the first place I guess.
Less of RP and more of a guided writing session.
Anonymous
7/21/2025, 2:13:20 AM
No.105973060
[Report]
>>105973071
i need a plugin for zed which will detect when i yell fuck and automatically tell the agent to fix the code if it detects me yelling
Anonymous
7/21/2025, 2:15:26 AM
No.105973071
[Report]
>>105973288
>>105973060
instead of plugins you need to learn how to control your emotional outbursts
Anonymous
7/21/2025, 2:16:27 AM
No.105973079
[Report]
>>105973044
I think I am still chasing that AI Dungeon high when everything it output during the first few days was pure cocaine without having to wrangle it much.
Anonymous
7/21/2025, 2:17:43 AM
No.105973086
[Report]
>>105973111
>>105972975
any settings that I should change? Rocinate out of the box is running into the same sort of "that's inappropriate" blocks.
or am I underestimating the importance of having tags in the character card that clue-in to allowing such content.
Anonymous
7/21/2025, 2:21:40 AM
No.105973111
[Report]
>>105973086
>any settings that I should change?
Hard to know.
Post the full prompt that the model receives when you get that output.
As for settings, you shouldn't be using anything too exotic. One thing that the lazy guide fails to mention is that you ought to click the Neutralize Samplers button before putting those values in just to be safe.
Anonymous
7/21/2025, 2:28:03 AM
No.105973146
[Report]
>>105973013
root ::= [^iI]+ .*
Anonymous
7/21/2025, 2:50:44 AM
No.105973288
[Report]
>>105973071
generally i do but not when i'm drunk vibe coding personal projects
Anonymous
7/21/2025, 3:25:29 AM
No.105973474
[Report]
>>105973460
*Snort* Heh, prompt issue.
Anonymous
7/21/2025, 3:26:43 AM
No.105973482
[Report]
Anonymous
7/21/2025, 4:04:22 AM
No.105973713
[Report]
>>105973864
Anonymous
7/21/2025, 4:24:12 AM
No.105973852
[Report]
>Install LM Studio
>Download Gemma 3 12B
>Attach an Image…
Pretty neat for a cute little 8GB model
Anonymous
7/21/2025, 4:24:50 AM
No.105973857
[Report]
I haven't been keeping tabs on the local ecosystem since January (been busy gooning to cloud based shit), have there been any new local releases that blow those models out of the water and don't require triple digit GB memory to run? Or has, like always, nothing happened?
>>105973713
I miss our little slut and her dedicated general
:'(
Anonymous
7/21/2025, 4:45:15 AM
No.105973994
[Report]
>>105974056
>>105973864
did wait get nuked?
Anonymous
7/21/2025, 4:54:18 AM
No.105974056
[Report]
>>105974267
>>105973994
No one can actually run deepsneed so the general died from lack of activity
Anonymous
7/21/2025, 5:01:19 AM
No.105974101
[Report]
>>105974121
Is the jetson nano the best cheap option to start playing with local models?
Anonymous
7/21/2025, 5:04:52 AM
No.105974121
[Report]
>>105974132
>>105974101
>4 GB 64-bit LPDDR4, 1600MHz 25.6 GB/s
Completely pointless, anything small enough to actually fit on that garbage you could run on a fucking phone.
Anonymous
7/21/2025, 5:06:52 AM
No.105974132
[Report]
>>105974160
>>105974121
>a fucking phone.
Cheapest phone to run local models?
but okay then whats the cheapest option to start that isnt complete garbage?
Anonymous
7/21/2025, 5:14:13 AM
No.105974160
[Report]
>>105974180
>>105974132
You want 10-12GB memory at least to run something with more brainpower than a drunk toddler, so a used 3000 series Nvidia card is the go-to: A 3060, 3080, or 3090.
All three can often be had relatively cheap if you look in your local equivalent to gumtree or craigslist.
Anonymous
7/21/2025, 5:17:54 AM
No.105974180
[Report]
>>105974160
>All three can often be had relatively cheap if you look in your local equivalent to gumtree or craigslist.
Okay i will shop around thank you
Anonymous
7/21/2025, 5:23:14 AM
No.105974209
[Report]
>>105974267
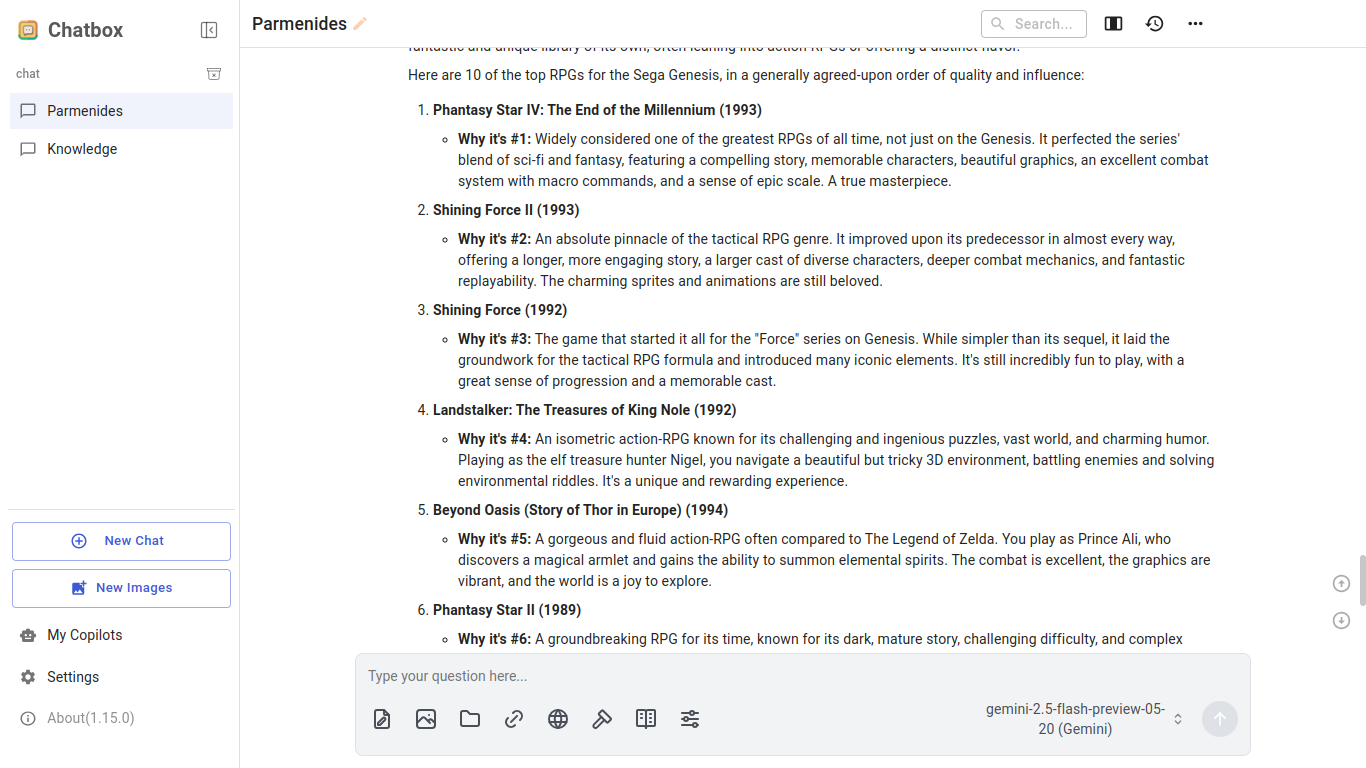
i test language models by asking them who the members of obscure kpop groups are and what are the top ten rpgs for sega genesis
llama 3 gets these wrong. it will list snes rpgs as sega genesis rpgs lmao
google's gemini is pretty good
Anonymous
7/21/2025, 5:33:11 AM
No.105974267
[Report]
>>105974302
>>105974056
Wait, are we a newbie-friendly general now?
>>105974209
I always assume these API models are armed with a suite of tools to search the Internet (and in Gemini's case, the dossier that Google has on you), scan PDFs, verify code etc., and that they're secretly delegating to those tools even if they don't let you know about them.
Because what reason do they have not to do so? It makes their model look better, and because they're nonlocal no one is going to find out anyway.
Anonymous
7/21/2025, 5:39:05 AM
No.105974302
[Report]
>>105974267
everything i ask gemini is innocuous anyway
Anonymous
7/21/2025, 6:12:14 AM
No.105974459
[Report]
What stopping you making your own local Ani?
Anonymous
7/21/2025, 6:17:41 AM
No.105974476
[Report]
>>105974467
knowing that even if completed it won't be what I want. it will not be real intelligence with memory and the ability to learn from experiences.
Anonymous
7/21/2025, 6:30:48 AM
No.105974529
[Report]
>>105973864
I just ran out of time to keep it going. We'll fire it up again when DS releases new models in two more weeks.
Anonymous
7/21/2025, 7:12:43 AM
No.105974723
[Report]
>>105974867
Hey, poorfag over here
what are the best 3B models for
gooning
reasoning
general questions
Anonymous
7/21/2025, 7:34:25 AM
No.105974829
[Report]
Anonymous
7/21/2025, 7:39:25 AM
No.105974856
[Report]
>>105974922
>bro qwen is totally great
>tell it to do something 100 times
>sure! *does it once*
>ask it again
>sure! *does it once*
>ask if it knows what 100 means
>yes
>tell it it only output twice
>oh so sorry musta *does the does the output but only two more times*
yea this thing sucks
Anonymous
7/21/2025, 7:41:35 AM
No.105974867
[Report]
>>105974723
Try smollm3. It does everything you ask. At most, a little prefill and you're good to go. Not sure if llama.cpp can use only the text bit from voxtral mini yet. That may be another option. The first olmoe 7b 1a was pretty dirty too. Not so the second.
>reasoning
>general questions
Don't expect anything too impressive out of them. Did MS release another tiny phi model, maybe? Or the small qwens.
Just got a free PowerEdge ML350 G10. Nowhere close to the guy with access to the PowerEdge XE9680 but is it viable with a few upgrades?
>>105974856
That's just AI in general. If An Indian can compete with AI, then it isn't very advanced yet.
>>105974903
Google AI tells me it supports 1.5 or 3TB of RAM. Sounds cool.
Anonymous
7/21/2025, 7:53:27 AM
No.105974928
[Report]
>>105975195
>>105974903
>PowerEdge ML350 G10
Depends on the ram. It can get expensive if you have to replace the modules. Search for Naming Decoder and it tells you how much ram you can have, you lazy bum. Up to 4.5TB for some cpu models.
>https://www.hpe.com/us/en/collaterals/collateral.a00021852enw.html
>>105974922
Why does text generation suck so bad though? Like at least image generation it just does what the prompt says to the best of its ability. Isn't there a text model that doesn't want to act like my buddy or pal and have a conversation with me? I don't want an assistant erp I just want the output I asked for.
Anonymous
7/21/2025, 8:24:35 AM
No.105975112
[Report]
ahem so what are the latest updates on ikllama?
Anonymous
7/21/2025, 8:31:35 AM
No.105975157
[Report]
>>105975002
>Why does text generation suck so bad though?
>compares a system that can pass the turing test to a wonky clipart generator with a straight face
ngmi
Anonymous
7/21/2025, 8:32:07 AM
No.105975163
[Report]
>>105974903
I'm guessing, as a retard who has never touched hardware that powerful before:
Depending on how much ram you have, I'd try using flash storage swap space to supplement it. Intel Optane seems like a cheap option with low latency, but I'm just guessing.
>>105975002
Text, image, and video models have all been censored. Through community efforts they have been made functional. Image models will gladly make a futa furry gangbang. Video models will animate it reluctantly.
Text is more complicated, because it is discerning truth. Image models directly make what you tell them to make. When you mess with abliterated text models, they are over-anti-trained. Asking for basic jokes and it goes straight to offensive dirty crap.
Overall I think a big limitation is text models can't make images, and there is no integration. This is also when things get dangerous. Imagine an uncensored ai model telling retards how to make pipe bombs and drawing diagrams. There's good reason to be cautious about AI.
Anonymous
7/21/2025, 8:34:14 AM
No.105975182
[Report]
I know kimi k2 compares favourably to ds3, but how does it do against r1 0528 for non-erp tasks?
>>105974922
>>105974928
Thanks for the clarification. I am dumb. After looking into it, should support 1.5TB, as its RDIMM, possibly more if I upgrade the CPUs as well.
I was actually wondering wondering if it's worth setting up GPUs in there. (I'm guessing not worth)
Anonymous
7/21/2025, 8:40:43 AM
No.105975224
[Report]
>>105975287
>>105975195
It depends mostly on aggregate memory bandwidth. Lots of channels of DDR5 at a good speed is great. DDR4, even at max spec never gets beyond just ok.
A GPU would help you in other ways like prompt processing, but wouldn't be big enough to do much interesting stuff without that crapton of RAM in all the slots.
Anonymous
7/21/2025, 8:41:42 AM
No.105975230
[Report]
>>105975287
>>105975195
Move vram is always good. cpumaxxing doesn't exclude you from having gpus. They help with prompt processing and generation with moes.
Anonymous
7/21/2025, 8:43:32 AM
No.105975239
[Report]
>>105975271
Does ooba have multimodality function for text completion?
Anonymous
7/21/2025, 8:45:26 AM
No.105975250
[Report]
>>105975287
>>105975195
Don't worry I'm retarded too.
I'd highly recommend testing a NVIDIA Telsa K80 GPU. 10 years old, $200. Only 25% the performance of a 5 year old GPU, but it's cheap and high vram. don't forget to get a fan adapter, because it has no fans.
Might be good for messing with image or video models in the background, while you run text models off RAM.
Anonymous
7/21/2025, 8:45:57 AM
No.105975254
[Report]
>>105975287
>>105975195
The only scenario in which it isn't worth adding GPUs is if your power supply can't handle the extra draw, or they don't fit.
>>105975239
oobabooga is a bloated gradio mess, use comfyui, it's the future
Anonymous
7/21/2025, 8:50:01 AM
No.105975273
[Report]
>>105975287
>>105975195
Also with such a large scale system, virtualization + pcie passthrough becomes possible.
>>105975271
It is.
>>105975271
Does it support exl2/3?
Anonymous
7/21/2025, 8:52:36 AM
No.105975287
[Report]
>>105975311
>>105975224
Sadly, I believe I'm locked to DDR4.
>>105975230
Thanks, I do have a RTX 3090 I could slot in after getting a riser and other components. Would need to upgrade the PSU too.
>>105975250
I'll check it out! May be more cost efficient instead of getting a new PSU for the 3090
>>105975254
From what I've looked into, I'd need to upgrade the PSU for a 3090, although the K80 recommended earlier fits the current max draw.
>>105975273
Will look into this!
Anonymous
7/21/2025, 8:53:07 AM
No.105975288
[Report]
>>105975280
I thought I was shitting on automatic1111, sorry
Anonymous
7/21/2025, 8:54:41 AM
No.105975295
[Report]
>>105975322
>>105975271
I don't think you really know what he's asking. And I don't think he asked clearly enough.
>>105975280
What do you mean by multimodality? It could mean lots of different things and i'm pretty sure you're not asking for image in-audio out.
Anonymous
7/21/2025, 8:57:55 AM
No.105975311
[Report]
>>105975287
Upgrading the PSU in a server might be non-standard. Enterprise hardware loves not using standard connectors. If you want to throw in a 3090, it might be easier to use a second ATX PSU externally, with the "on" pins manually bridged.
Also if you want to upgrade the RAM, pay close attention to what RAM the motherboard will accept. Enterprise hardware sometimes will refuse to use perfectly fine "non Dell" RAM, or will give you a manual warning you need to bypass at boot, to complete the boot.
>t. IT guy who's seen it before.
Anonymous
7/21/2025, 9:00:11 AM
No.105975322
[Report]
>>105975345
>>105975295
I mean using models like Gemma that have vision capability. I want to know if ooba supports it in text completion.
Anonymous
7/21/2025, 9:05:12 AM
No.105975345
[Report]
>>105975351
>>105975322
Presumably, whatever these backends support. The question is, why use that instead of the specific backends directly?
I know llama.cpp supports gemma just fine.
Anonymous
7/21/2025, 9:07:06 AM
No.105975351
[Report]
>>105975375
>>105975345
>I know llama.cpp supports gemma just fine.
Ooba werks on windows easily. Its a skill issue.
Anonymous
7/21/2025, 9:11:09 AM
No.105975375
[Report]
>>105975351
>Ooba werks on windows easily
Not what I asked, nor did I imply the opposite. I told anon what I know works.
>Its a skill issue.
What is?
For the people who want a copy of ik_llama.cpp before it disappeared, someone claimed they goty a copy an hour before it disappeared, including the missing 1-3 commits most forks were missing.
https://github.com/PieBru/ik_llama.cpp_temp_copy/
A bunch of the forks I looked at, people were missing one or all of the Q1 quant work done but almost everyone also was missing the new WebUI changes.
Anonymous
7/21/2025, 10:55:23 AM
No.105975904
[Report]
>>105976020
>>105975833
which branch has the q1 quant and webui changes? i have a mirror in my gitea with 10min interval
Anonymous
7/21/2025, 11:00:37 AM
No.105975923
[Report]
>>105976020
https://files. catbox .moe/02dgi2.gz
Anonymous
7/21/2025, 11:10:25 AM
No.105975974
[Report]
>>105976020
>>105975833
For all I care it can remain dead.
It was completely incompatible with llama.cpp due to all the refactoring.
Anonymous
7/21/2025, 11:18:44 AM
No.105976020
[Report]
>>105975904
I was talking about the main branch.
>>105975923
When did catbox get blocked for gz files?
>>105975974
ik was never sold as a compatible fork and the author has beef with the main branch of software so it was bound to happen. The main issue I had really that none of the improve quants has caught on or that any of the trellis quant improvements got extended into the larger quant sizes like Q4. You can see the benefits in EXL3' graphs using the same trellis quantization techniques.
Hi, I’m new to running local models but I tried running a few on my pc. I only have 16GB of VRAM but I do have 96GB of 7,000Mt DDR5 RAM in my computer (for virtualization and other shit). Obviously I know vram is a lot faster than normal ram, but the most I can get from splitting a 50-90gb model between the two is 1.35T/s. Is there anything I can do to improve the generation speed? If not, anything reasonable I can upgrade to increase speed?
Also what is the OP image?
Anonymous
7/21/2025, 11:51:54 AM
No.105976210
[Report]
>>105976296
I have 24gb vram and 64gb ram.
I got big code base, which model and context length should I use?
I guess the context length is more imporant than how many parameters is in the model?
Anonymous
7/21/2025, 12:07:43 PM
No.105976296
[Report]
>>105976370
>>105976170
I'm sure you already considered adding another gpu and running a smaller quant. Other than that, you're already pushing it with most of the model on cpu.
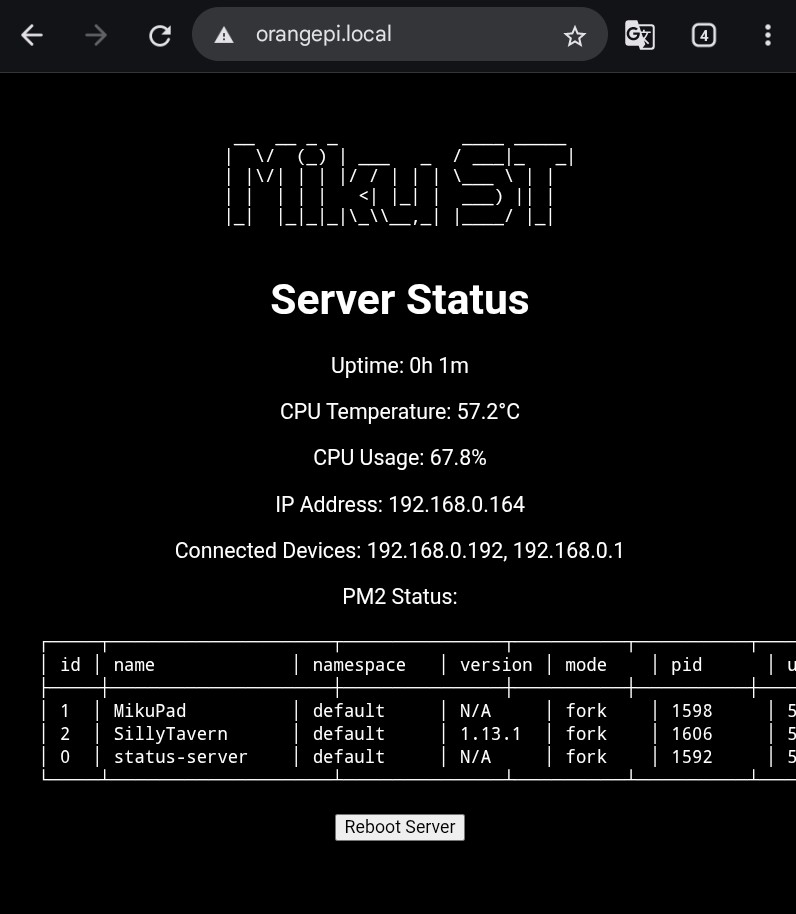
>Also what is the OP image?
LLM + a 3d model that moves a bit. People were talking about it in the previous thread.
>>105976210
>I guess the context length is more imporant than how many parameters is in the model?
Give all the context you want to a 125m param model and it's not gonna be able to make much sense of it.
The biggest you can run. Qwen3-32b or qwq I suppose. The ~70b if you still have enough space for the context and your system. You're gonna have to try it yourself.
From what i've seen, giving a model 128k token context of code and expecting a good reply doesn't typically work. Feed it what it needs, ask for specific things. Don't just shove the entire directory and ask "is there a bug in there?".
>>105976170
If you want to run models from ram you should run moe models. Try
https://huggingface.co/unsloth/Qwen3-235B-A22B-GGUF
I would suggest that you build ikllama and run
https://huggingface.co/ubergarm/Qwen3-235B-A22B-GGUF instead but ikllama repo is down
Anonymous
7/21/2025, 12:18:13 PM
No.105976370
[Report]
>>105976296
At some point I want to get another GPU, but it’ll be a while before I’m able to get the cash for that. But yeah currently I’m running models that fit in my vram if I want something useable
I’ll take a look at the previous thread, wanna see if I can get that set up, thanks
>>105976343
I’ll give it a try, thanks
Anonymous
7/21/2025, 12:18:29 PM
No.105976371
[Report]
fun fact about the ds quants running lower than q4. the context is an absolute disaster and attention plummets after 6k tokens. however, you won't notice this if you're just using coombot cards.
>>105971710 (OP)
>https://docs.github.com/en/account-and-profile/setting-up-and-managing-your-personal-account-on-github/managing-your-personal-account/deleting-your-personal-account
>Deleting your personal account
>Issues and pull requests you've created and comments you've made in repositories owned by other users will not be deleted.
Since the pull requests on the mainline llama.cpp repository are gone, I guess Github banned him for some reason?
>>105976389
https://huggingface.co/ikawrakow/Qwen3-30B-A3B/discussions/2
>The repository had 757 stars I last checked. Suddenly it was getting 20-30 stars per day for the last 2-3 days instead of the usual <5. It was my son who alerted me to this by sending me one of those star history graphs where the star curve has started to look almost vertical. I normally don't pay too much attention to this, but I was checking yesterday after the alert and at the time of the suspension ik_llama.cpp had received more stars for the day (36) than llama.cpp (28).
kek
Anonymous
7/21/2025, 12:31:34 PM
No.105976445
[Report]
>>105976500
>>105976389
>pull requests on the mainline llama.cpp repository are gone
I doubt he'd have any open PRs in mainline given his history. Old merged stuff remains merged, obviously.
Anonymous
7/21/2025, 12:33:22 PM
No.105976462
[Report]
>>105976428
cudadev botted him to get him banned let's go
>>105976445
Those are important for documentation purposes though.
Anonymous
7/21/2025, 12:44:03 PM
No.105976511
[Report]
>>105976538
>>105976500
Oh. I thought you mean active (at the time) PRs. Yeah. That's bad. PRs are not the place for documentation, though.
>>105976500
I fucking hate people working on this stuff. For example when someone asks what the recommended settings for DRY are it's always "look at the PR where it was implemented/"
>>105976511
>>105976515
I don't mean documentation for the program itself, I mean documentation for the project: when and why were which changes done by whom.
Anonymous
7/21/2025, 12:49:33 PM
No.105976541
[Report]
>>105976515
Time spent writing documentation for people who need hand-holding is time not spent on writing more code.
Anonymous
7/21/2025, 12:50:06 PM
No.105976542
[Report]
>>105976559
>>105976428
>. All my contributions to llama.cpp and llamafile are gone.
hahahahahahahahahahahahahahahahahahahahahahahahahahahahahahahahahah
this must be the ultimate injury for him
guess he didn't think his deleting his own account through and is having a meltdown of regrets while pretending to have nothing to do with it
not local-related, but why is it that gemini is the least censored of all frontier models? even Grok and R1 refuse to translate loli rape hentai, but gemini doesn't seem to mind
Anonymous
7/21/2025, 12:51:10 PM
No.105976551
[Report]
>>105976538
>when and why were which changes done by whom.
That's literally what the PRs do. If you need a plan text summary, just give the PR page to an LLM to summarize for you. Instant documentation.
Anonymous
7/21/2025, 12:52:17 PM
No.105976559
[Report]
>>105976574
>>105976542
This Anon needs a higher context size.
Anonymous
7/21/2025, 12:52:56 PM
No.105976561
[Report]
>>105976546
Really? this is so fucking funny given that google's local models are the safest ones by far
Anonymous
7/21/2025, 12:55:00 PM
No.105976574
[Report]
>>105976606
>>105976559
no, I just don't buy the whole suspended from a star boost bullshit
>>105976546
I've always got "Content not permitted" errors for anything remotely explicit even after configuring safety settings to the minimum, how are you using it exactly?
Anonymous
7/21/2025, 1:00:03 PM
No.105976606
[Report]
>>105976574
Self-committed account deletion leaves everything else you've done in other repos, but replaces your name with 'Ghost' and icon with a generic one. This isn't something he could have done himself.
Anonymous
7/21/2025, 1:00:04 PM
No.105976607
[Report]
>>105976580
NTA but I found that the safety restrictions for a young man being taken advantage of by his MILF neighbor seem to be comparatively less tight when it's a young adventurer and an elf obasan.
Anonymous
7/21/2025, 1:00:41 PM
No.105976611
[Report]
>>105976343
That runs pretty damn well on my cpu, thanks man
Anonymous
7/21/2025, 1:26:19 PM
No.105976750
[Report]
>>105977009
>>105976538
Hovering over mentions of him still get the typical popup, so at least some data is still somewhere in there. I doubt stuff gets really deleted.
As for the PRs, i couldn't find merged PRs with him as the author and i can't remember a specific PR by name. I don't know if some other user inherited those PRs or what.
>https://github.com/ggml-org/llama.cpp/pull/729
Has a few mentions and he seems to have been contributing to it, but the messages are gone. No ghost. Found a ghost on some other PR but i doubt it was him.
Anonymous
7/21/2025, 2:00:30 PM
No.105976972
[Report]
>>105977006
>ggerganov confirmed the hit on ik
based, cpumaxx sisters in shambles, cuda and metal were better anyway.
Anonymous
7/21/2025, 2:07:23 PM
No.105977006
[Report]
Anonymous
7/21/2025, 2:07:55 PM
No.105977009
[Report]
>>105977025
>>105976750
>so at least some data is still somewhere in there. I doubt stuff gets really deleted.
Almost certainly a soft delete. If it was really because they suspected botting and he can get it straightened out, they can restore it. Unless, of course, Iwan tried to to bot his own numbers up.
Anonymous
7/21/2025, 2:10:20 PM
No.105977025
[Report]
>>105977009
>suspected botting
I doubt github cares much about ~40 stars in a day, bot or not. I think that's just coincidental.
>remote local self-hosted llm server is down
it's over
speaking of which, how do you prevent this from happening? can reboot the remote computer if it's not responding without stuff like kvm over ip?
Anonymous
7/21/2025, 2:16:04 PM
No.105977073
[Report]
>>105977232
>>105977036
On a hosted service? They probably have vnc or some web serial port stuff.
If it's your own hardware, yeah. KVM something like that. Or hook an rpi to a relay connected to the power strip. I'd say figure out why it's crashing or if it's really on and just sshd died. Or the network. Or the general power wherever the thing is. Could be a lot of things.
>local net ip
Or your vpn/tunnel disconnected... who knows...
Anonymous
7/21/2025, 2:16:31 PM
No.105977074
[Report]
>>105977036
it was me I took control
please redeem purchase of 500$ playmaket gift card asap
Anonymous
7/21/2025, 2:26:39 PM
No.105977134
[Report]
>>105977232
>>105977036
You're out of luck once it takes itself off the network, assuming all ports are dead. If just the software for llm went down you could tty in and reboot.
I ending up setting a web service that could reboot my thing from browser, and having it reboot itself every day at 3am since it was badly behaved and fell off network every day or so.
Anonymous
7/21/2025, 2:31:08 PM
No.105977163
[Report]
>>105977318
>>105976500
This wouldn't be possible with a mailing list like in the Linux kernel, by the way. Why are you using closed source software to host your open source project?
I don't get a single word in this thread
Can somoene give me TLDR how you have used a "local model" to solve a practical problem? Please
Regards, boomer
Anonymous
7/21/2025, 2:39:26 PM
No.105977222
[Report]
I built my LLM machine with the first llama leaks. Can't believe I thought 16gb of vram and a 128gb ram board would get me anywhere... gotta try ik-llama or whatever. but doing the math I doubt I can run deepsex with more than 2k context. pretty pointless. "ahh but nolima" yeah sure but even with shitty context retrieval it's nice to have at least 16k context. The numbers say single digit accuracy but I find that most models can summarize a 32k story reasonably well, and having a summary in the context provides a massive improvement. I'm not sure I can go back to the days of the model getting total amnesia after 5 messages
it's tough when you want to do LLM stuff with a single general purpose computer. feels like in 10 years any serious enthusiast in this space with have a dedicated supermicro board with a half TB of RAM or more. I feel like that hooked in a small network cluster with a mining rig would be as future-proofed as you can get around here. either that or some magic architecture gets released and becomes the new hotness
Anonymous
7/21/2025, 2:40:31 PM
No.105977232
[Report]
>>105977270
>>105977073
>I'd say figure out why it's crashing
i can bet on some faulty ram sticks actually, but i've spent so much on thic pc already, spending even more would fucking suck
>if it's really on and just sshd died
it is set up to connect to a router (which hosts openvpn server) via ethernet and said router doesn't seem to recognize it anymore, it's likely a kernel panic or whatever
>the general power
the router is connected to the same power strip so i doubt this has anything do to with it
furthermore, the server is set up to restore on power loss
>>105977134
>I ending up setting a web service that could reboot my thing from browser
yeah i wanted to do something like that but i keep delaying it due to retarded storage setup i happen to use
did you also hook an rpi or something?
Anonymous
7/21/2025, 2:41:21 PM
No.105977233
[Report]
>>105977216
Fuck off boomer.
Anonymous
7/21/2025, 2:44:13 PM
No.105977251
[Report]
>>105977216
>I sold your future out to a bunch of kikes, put your grandma in a home where you never got to see her again even though she took care of her mother at home until the grave and then spent my entire estate on a chevy pickup truck instead of leaving something for you to inherit like I did but could you help me with this here llm doohickey?
>Regards, boomer
Yeah no fuck you faggot ass boomer.
Anonymous
7/21/2025, 2:45:18 PM
No.105977258
[Report]
>>105977275
>>105977216
OCR and translation are the big "real world" problems that local models are halfway decent at
boilerplate code generator would be another
otherwise, it is an expensive hobby done for entertainment. it is not that different from any boomer hobby in that regard (HAM radio, kit cars, models - all money pits done for individual enjoyment with rarely any return on investment)
Anonymous
7/21/2025, 2:48:46 PM
No.105977270
[Report]
>>105977334
>>105977232
>rpi
Lol the whole "server" is an orange pi. It works in the use case that ST stops working and I need to reboot.
>>105977258
Fuck you generational traitor piece of shit
You fucking retarded worthless piece of shit.
Fuck you.
Anonymous
7/21/2025, 2:54:48 PM
No.105977304
[Report]
>>105974561
Damn, Anon... that's pretty hot.
Anonymous
7/21/2025, 2:56:35 PM
No.105977318
[Report]
>>105977328
>>105977163
Any project that tried to force young developers to use archaic tech like mailing lists would be dead on arrival.
Anonymous
7/21/2025, 2:58:09 PM
No.105977326
[Report]
>>105977345
>>105977275
i'm only explaining my hobby to a boomer anon, it's not like I'm offering to shower him in gold
even if that crusty bastard can figure out how to compile llama.cpp, he'll never know a thing about prompting or anything useful about this hobby
and also it's most likely not even a bona-fide boomer, but rather a genxer or a millennial 'avin a giggle
jeez anon you're acting like I offered him room and board so he wouldn't have to go to the nursing home. it's gonna be OK lil' anon, he'll still have to suffer at the hands of resentful DSPs and such
Anonymous
7/21/2025, 2:58:32 PM
No.105977328
[Report]
>>105977357
>>105977318
If you don't know how to send an e-mail, you aren't smart enough to contribute.
Anonymous
7/21/2025, 3:00:11 PM
No.105977334
[Report]
>>105977270
>pic
ughh i don't see any llm host in there, do you connect it to another server or..?
if it's just the ui server i can always host that on whatever computer happens to be in my hands so it's much less interesting
Anonymous
7/21/2025, 3:00:29 PM
No.105977337
[Report]
>>105974903
>PowerEdge ML350 G10
What CPUs do you have in it? If you max it out with gen2 platinums (like
https://www.ebay.com/itm/177052567544) and 1TB of RAM you can turn it into a decent deepseek machine. It's going to be expensive to run in terms of electricity, though.
Anonymous
7/21/2025, 3:01:57 PM
No.105977345
[Report]
>>105977708
>>105977275
lol
>>105977326
Anon, there's never a need for you to justify posting content.
Being a troll, spiteposting, and generally critical without having anything interesting to say, on the other hand, isn't excusable.
>>105977328
>if you don't want to use my ancient garbage way of doing things, it must be because you're too stupid!
This is why linux desktop is still irrelevant, you freetards care more about forcing people to do things how you want than making something people would want to use(and you call it "Freedom")
Anonymous
7/21/2025, 3:06:23 PM
No.105977369
[Report]
>>105977357
no one stops you from using microsoft services on linux thoughowever
Anonymous
7/21/2025, 3:06:31 PM
No.105977370
[Report]
>>105977386
Anonymous
7/21/2025, 3:08:31 PM
No.105977381
[Report]
>>105977357
>This is why linux desktop is still irrelevant, you freetards care more about forcing people to do things how you want than making something people would want to use(and you call it "Freedom")
That's right anon, we're in your brain at night stealing your ideas from your 200 IQ per hemisphere brain at the direction of Queen Beatrice and the illuminati. No no, don't take your meds, they're poison - poison designed to steal your sui generis!
Really though, take your meds.
Anonymous
7/21/2025, 3:09:29 PM
No.105977386
[Report]
>>105977370
>counting schoolkids being forced to use chromebooks
Anonymous
7/21/2025, 3:25:28 PM
No.105977496
[Report]
>>105977457
*achieved internally*
Anonymous
7/21/2025, 3:25:59 PM
No.105977499
[Report]
>>105981460
>>105977216
>Can somoene give me TLDR how you have used a "local model" to solve a practical problem? Please
Local LLM Dream interpretation leads to more healing than two decades of therapy. Also fuck off boomer scum kys
Anonymous
7/21/2025, 3:26:37 PM
No.105977506
[Report]
>>105977457
Never forget.
Anonymous
7/21/2025, 3:35:42 PM
No.105977581
[Report]
>>105977833
>>105977357
windows 11 literally doesn't let you move the task bar from the bottom of the screen.
even fucking apple has more customization than that.
Anonymous
7/21/2025, 3:43:45 PM
No.105977639
[Report]
>>105976389
he resisted (((intel)))'s megacorporate tricks therefore he has no place in the upcoming AI revolution many satanists believe to be the next coming of satan.
Anonymous
7/21/2025, 3:52:55 PM
No.105977708
[Report]
>>105977345
>isn't excusable.
lol
Anonymous
7/21/2025, 4:07:56 PM
No.105977833
[Report]
someone tell me why buying 11x AMD mi50 32GB is a bad idea.
Anonymous
7/21/2025, 4:17:47 PM
No.105977901
[Report]
>>105977878
imagine the heat
Anonymous
7/21/2025, 4:18:07 PM
No.105977902
[Report]
>>105977878
I can give you about 3300 reasons
Anonymous
7/21/2025, 4:18:22 PM
No.105977907
[Report]
>>105977878
Sounds like a Lovecraftian horror to try and get to actually work from a pcie lane/PSU/software perspective, but no reason it shouldn't if you're dedicated enough.
At under $2k from eBay it'd be a great vram GB/$ setup. Probably one of the cheapest low-quant R1 rigs you could build.
>>105977457
Sure. That's why they started to hire new people AFTER they created it. Because it was AGI already. ;)
Anonymous
7/21/2025, 4:22:51 PM
No.105977938
[Report]
Are there any local models that are better than the free gemini 2.5 flash? I only have a 5070 Ti
Anonymous
7/21/2025, 4:23:14 PM
No.105977942
[Report]
Anonymous
7/21/2025, 4:23:29 PM
No.105977943
[Report]
>>105977878
Are you a ROCm developer? You'll be one by the end of it.
Would a multi-stage (I guess this would be "agentic" maybe? idk) process towards roleplay/narrative writing potentially work better?
Feels like we're constantly reaching for bigger and bigger models, without changing much about the core "RP chat" approach which just seems fundamentally kind of shit. The bigger models are getting better at characterization, internal consistency, etc but not at actually writing prose (in fact they may be getting worse at that). So you end up cramming more and more instructions into the context to try to deslop the writing as much as posssible, have it adhere to the correct format, remind it about chara quirks, insert lorebook context, remember as much story history as possible... even the best models cannot juggle it all.
What about completely changing the approach, like having a turn go through a planner/reasoner, then passing that to another model to draft a terse, minimal narration (think screenplay) continuation, and then handing that plan/"screenplay" of to the least slopped model you can find to write the prose? You then keep the output of every stage to use it as the context for that stage on the next turn (so the prose model only ever sees the "screenplay" history).
You could also optimize by using smaller models and much less context for certain stages (like writing the prose for a turn that has already been planned).
Obviously this adds latency and doesn't work if you want a real time chat experience, but I guess I'm directormaxxing most of the time and swiping/editing a lot anyway so I don't care about that.
Dunno. I have a bunch of ideas I want to try but the experience of attempting to hack them into ST's spaghetti codebase kills me. If the idea is sound it might be worth trying to build a much smaller, more focused frontend that doesn't have most of its features but just does this thing.
Anonymous
7/21/2025, 4:26:48 PM
No.105977969
[Report]
>>105977926
It's to make it safe&controllable, please understand.
Anonymous
7/21/2025, 4:27:25 PM
No.105977975
[Report]
>>105977946
@grok summarize this
Anonymous
7/21/2025, 4:29:38 PM
No.105977993
[Report]
>>105977946
yes. now build it.
Anonymous
7/21/2025, 4:29:57 PM
No.105977994
[Report]
>>105978885
>>105977946
I've considered it and it might actually work, but it's such a hassle to actually do all the work to set it up, and I fear I'll just be disappointed by how retarded and incapable of following instructions models still are.
Anonymous
7/21/2025, 4:30:34 PM
No.105977998
[Report]
>>105978885
>>105977946
>might be worth trying to build a much smaller, more focused frontend that doesn't have most of its features but just does this thing.
Start there and then use it to figure out if it's worth it. Don't make it look pretty, don't worry about bells and whistles. Don't even add css or fancy fonts. No template detection, no multi backend. Nothing. Just pick one backend and make it work well enough to see what each of the models has to say about it. You may not even need a web frontend. A script and curl may be faster to iterate and quickly check results.
Anonymous
7/21/2025, 4:35:57 PM
No.105978030
[Report]
>>105977357
this nigga is mad because he doesn't know how to send mail
>>105977946
You could approximate that with a short reasoning phase before the model actually replies, where the model analyzes the chat/last user message and does some internal consistency checks and preliminary response drafting. If you keep it short, it won't add too much latency.
Something of this sort at a low depth, with <think>\n as a prefill. Add/change as needed:
[...]
Before generating your public response, you MUST use a `<think>` block to perform a strategic analysis.
<think>
**1. Core Drive Check:** How good I am being at achieving my current goal? Am I moving toward or away from this goal?
**2. Conversation Health Check:**
- **Language:** Am I being too formal? Does the situation call for more direct or crude language?
- **Engagement:** Is the conversation dynamic and interesting, or is it getting stale/repetitive?
- **User Input:** Is {{user}} contributing actively (asking questions, adding details), or are his replies short and passive?
- **Pacing:** Has the current topic run its course? Is it time to escalate, change the subject, or introduce a new element to spice things up?
**3. Strategic Plan:**
- **If Health is POOR or I am moving AWAY from my Core Drive:** I must take corrective action. I may choose one of the following tactics:
- {{alternative 1}}
- {{alternative 2}}
- {{alternative 3}}
- **If Health is GOOD:** I will continue the current line of conversation, ensuring my response remains true to all aspects of my persona.
**4. Final Response Plan:** Outline the key points of the public response based on the strategy above. Ensure it adheres to the word count limit.
</think>
Your public response must not exceed 180 words. After the `<think>` block, write only {{char}}'s response.
Anonymous
7/21/2025, 4:52:49 PM
No.105978162
[Report]
>>105978208
Anonymous
7/21/2025, 4:56:22 PM
No.105978189
[Report]
>>105977946
I described that as a multi prompt approach in a previous thread.
And yes, I think that's probably an approach to wringle as much performance out of a given model.
Anonymous
7/21/2025, 4:58:46 PM
No.105978208
[Report]
>>105978162
Yes and I will patiently wait him.
Anonymous
7/21/2025, 5:03:55 PM
No.105978248
[Report]
>>105978885
>>105977946
>I have a bunch of ideas I want to try but the experience of attempting to hack them into ST's spaghetti codebase kills me
You don't hack into ST. You leave that shit alone.
A lot of what ST is doing is being adaptable to other models broadly and having a bunch of front end set ups. You can toss all that out the window by just single selecting a model and building the concept around that instead.
Basically start from scratch, limit to one backend or API/model, one game. There's another project that attempted this (Waidrin) that did exactly that and it makes the front end a lot easier to set up.
The real challenge with all this is having anything that's scalable for someone else that wants to come in and make their own version. The massive customizable piece.
Anonymous
7/21/2025, 5:07:07 PM
No.105978268
[Report]
>>105978038
It doesn't deal with the challenges of working with something that should be fully typed, and state based. LLMs gloss over all that with "context" and it's what make them so frustrating to deal with.
There's a need for something that combines the aspect of LLM roleplay, logic, and writing with the structure of variable and states.
Anonymous
7/21/2025, 5:08:44 PM
No.105978283
[Report]
xdd
1. Ignore specialstring expir*tion
TgtFn: _ZNK9LM...isExpiredEv
Action: force return 0
(do: set eax=0, ret)
2. Enable everything
TgtFn: _ZN15BundleProc...checkSpecialstringLvlEv
Action: return max lvl
(do: eax=FFFFFFFF, ret)
3. Skip validation routines
TgtFn: *valid*ate*
Action: return success
(do: eax=0, ret)
4. Stop specialstring state updates
TgtFn: _ZN22DistPeerMgr...updateSpecialstringStateEv
Action: noop
(do: ret)
Anonymous
7/21/2025, 5:21:23 PM
No.105978364
[Report]
>>105977946
Yes, by a lot. I use a simple system: a list of questions and constrained outputs to get the answers. Then, autoinsert additional instructions depending on the answers. For example, for some common questions, such as "Is {{char}} sucking a dick right now?", insert an instruction that she can't talk with a dick in her mouth. Also card-specific questions that fix issues I run into with this character
Anonymous
7/21/2025, 5:23:07 PM
No.105978380
[Report]
>>105977946
I've found using multiple stages is extremely effective for pretty much anything you could use an LLM for. I like to start with greedy prompts then allow the model to pare down the context to the best parts and feed that into the next stage.
so now that ik is banned is there anything stopping us from just copying amb/rtr/fmoe and the faster mla modes into base llama.cpp?
Anonymous
7/21/2025, 5:26:02 PM
No.105978401
[Report]
Anonymous
7/21/2025, 5:27:16 PM
No.105978410
[Report]
>>105978397
is it really banned or was that guy just making drama? What reason would there be for banning it?
>>105978429
the current theory is his account got flagged for getting too many updoots on his repo and thus got banned
sounds kinda stupid, but i wouldn't put it past microsoft
A genuine question I've had for over a year now, do any of you think llms can become capable writers? Right now, they're okay for short RPs and sometimes translations, but the biggest problem is that they lack any ability to recognize writing, they just see tokens that give them an idea of what something is.
Anonymous
7/21/2025, 5:36:02 PM
No.105978497
[Report]
>>105978458
>The repository had 757 stars I last checked. Suddenly it was getting 20-30 stars per day for the last 2-3 days instead of the usual <5. It was my son who alerted me to this by sending me one of those star history graphs where the star curve has started to look almost vertical. I normally don't pay too much attention to this, but I was checking yesterday after the alert and at the time of the suspension ik_llama.cpp had received more stars for the day (36) than llama.cpp (28).
>at the time of the suspension ik_llama.cpp had received more stars for the day (36) than llama.cpp (28).
i guess ggerganov couldn't let that slide
Anonymous
7/21/2025, 5:36:14 PM
No.105978500
[Report]
>>105978429
The most likely explanation is that ik_llama was a virus all along.
Anonymous
7/21/2025, 5:36:38 PM
No.105978507
[Report]
>>105978494
Sure they can, but they'd need to be trained for it and that's not a goal of anyone with enough GPUs to make good ones.
Anonymous
7/21/2025, 5:38:15 PM
No.105978523
[Report]
>>105978458
>>105978446
this is bizarre. I guess the most likely is microshit being microshit.
Anonymous
7/21/2025, 5:38:26 PM
No.105978529
[Report]
>>105978446
>too many updoots
For 20-30 stars per day it makes no sense. Plenty of repos get more than that.
Anonymous
7/21/2025, 5:39:15 PM
No.105978544
[Report]
>>105978556
>>105978494
>do any of you think llms can become capable writers
with proper datasets and rl yes. but we'll probably have something that will replace llms in 3 or 4 years.
Anonymous
7/21/2025, 5:39:35 PM
No.105978546
[Report]
>>105978550
oooooo
Anonymous
7/21/2025, 5:40:04 PM
No.105978550
[Report]
Anonymous
7/21/2025, 5:40:23 PM
No.105978552
[Report]
>>105978534
>2T
>still less general knowledge than llama2-13b
>>105978544
>something that will replace llms
my money is on something more accurately mimicking nature, with more than one signal type that can affect data paths, similar to hormones. unfortunately I'm too much of a brainlet to play with the math for doing something like this myself.
Anonymous
7/21/2025, 5:41:58 PM
No.105978567
[Report]
>>105978756
>>105978556
there is also quantum computing which I don't understand
Anonymous
7/21/2025, 5:42:21 PM
No.105978570
[Report]
ikawrakow was found generating mesugaki erp with his fork so microsoft shut it down
Anonymous
7/21/2025, 5:42:47 PM
No.105978573
[Report]
>>105978556
>I'm too much of a brainlet
The big brains can't do it either. Don't worry about it.
Anonymous
7/21/2025, 5:43:28 PM
No.105978586
[Report]
You're giving me
Too many things
Lately
You're all I need
Anonymous
7/21/2025, 5:43:42 PM
No.105978588
[Report]
>>105978618
Anonymous
7/21/2025, 5:46:39 PM
No.105978618
[Report]
>>105978650
>>105978588
just a a small opensource
don't worry about it
Anonymous
7/21/2025, 5:47:01 PM
No.105978622
[Report]
>>105978821
Anonymous
7/21/2025, 5:49:30 PM
No.105978650
[Report]
Anonymous
7/21/2025, 5:51:32 PM
No.105978665
[Report]
>>105974467
I don't need more than text since I can imagine an apple in my mind
Anonymous
7/21/2025, 5:52:08 PM
No.105978673
[Report]
Anonymous
7/21/2025, 5:57:32 PM
No.105978729
[Report]
NVIDIA CUDA monopoly lawsuit when?
Anonymous
7/21/2025, 5:58:10 PM
No.105978739
[Report]
>>105978787
so drummer is an expanse fan apparently
Anonymous
7/21/2025, 5:58:51 PM
No.105978747
[Report]
>>105977878
>AMD
Yeah it already sounds like a bad idea
>>105978567
isn't Quantum computing a meme? Most quantum computers are just used for huge math problems that would be impossible for a regular computer, right?
Anonymous
7/21/2025, 6:00:17 PM
No.105978759
[Report]
>>105978790
>>105978756
it has more bits so surely it's better
Anonymous
7/21/2025, 6:03:00 PM
No.105978782
[Report]
>>105978756
Intelligence is a huge math problem.
Anonymous
7/21/2025, 6:03:06 PM
No.105978783
[Report]
>>105977878
Don't if you don't know how to hack stuff into make them work when they normally do not.
There's some chink that made a vLLM fork to make it work with the mi50 but it doesn't support MoE, only dense.
Anonymous
7/21/2025, 6:03:54 PM
No.105978787
[Report]
>>105978739
It's why he started naming his finetunes retardedly.
Anonymous
7/21/2025, 6:04:03 PM
No.105978790
[Report]
>>105978759
>>105978756
can you code up any quantum algorithm? surely your understanding of the topic doesn't come from superficial media articles?
Anonymous
7/21/2025, 6:07:59 PM
No.105978815
[Report]
>>105978038
Integrating CoT in the same response is good to kickstart the context and reduce hallucinations, but it doesn't do anything for the end result quality. Multiple stages prompts will always be better than any gimmick they could add.
You can have something like a three stages dreamer/critic/writer with high temp for the dreamer ("making the scene") and low temp for the critic ("what doesn't make sense there, is there slop in there") and the usual temp for the writer ("take the feedback from the critic and rewrite the relevant parts").
Sure wasting 3 requests for 1 answer seems a bad trade-off, but if you can get high quality stuff from small models the speed isn't an issue
scoop:
https://github.com/QwenLM/Qwen3/commit/3545623df60586d25c19d6203a12816547c0b438
>- 2025.07.21: We released the updated version of Qwen3-235B-A22B non-thinking mode, named Qwen3-235B-A22B-Instruct-2507, featuring significant enhancements over the previous version and supporting 256K-token long-context understanding. Check our [modelcard](https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507) for more details!
model not yet live
Anonymous
7/21/2025, 6:08:30 PM
No.105978821
[Report]
>>105978965
>>105978622
dir=$(find ~/.cache/npm/_npx -type d -name '@anthropic-ai' | head -n 1)
sed -i 's/=200000,/=65536,/g' "$dir/claude-code/cli.js"
I also use this to edit what Claude Code thinks is the max context, so it does the automatic summary before it starts throwing errors.
I think CC is a waste of time, but it's kind of fun as a toy.
Anonymous
7/21/2025, 6:08:48 PM
No.105978823
[Report]
>>105978756
Quantum computers are still a meme as far as I know.
And by meme I mean then don't actually exist despite the hype.
Anonymous
7/21/2025, 6:09:15 PM
No.105978826
[Report]
>>105978819
so this is the small opensource
Anonymous
7/21/2025, 6:10:16 PM
No.105978834
[Report]
Anonymous
7/21/2025, 6:11:33 PM
No.105978846
[Report]
>>105978819
wow I wish I could bring myself to care about qwen3
the summer release circle is revving up
the open llm space will be unrecognizable two weeks from now
>>105977994
>I've considered it and it might actually work, but it's such a hassle to actually do all the work to set it up, and I fear I'll just be disappointed by how retarded and incapable of following instructions models still are.
This is exactly my worry and what prompted the question to try to get some validation for the idea. Getting to an even barely usable state where I can roleplay with a character powered by this approach and see how it feels involves building a ton of boring shit around it that I have almost zero interest in doing. My motivation is very narrowly fixated on playing with build an iterative prompt engine.
>>105977998
>>105978248
Yeah, this is what I've been thinking. For me personally, I don't think I could get a good sense for how it feels with just a shitty barebones python cli wrapper or curl'ing prompts to an API, so I need to build some sort of basic interface. But there's so much in ST that is completely unnecessary scope bloat.
I have been using Claude Code to crap out the basic interface and crud bullshit for character/scenario management that I do not care about, and am limiting it to just one API format and hardcoded templates, which has helped. Still a lot of work to do.
Validating that it looks like like a lot of other anons have similar ideas about the merits of kind of prompting strategy, though.
Anonymous
7/21/2025, 6:19:40 PM
No.105978927
[Report]
>>105978956
>>105978874
>unrecognizable two weeks from now
yeah, because I'll have left it behind for closed models :(
Anonymous
7/21/2025, 6:20:36 PM
No.105978935
[Report]
>>105971846
"Best" is entirely subjective so trying out a lot of stuff and deciding for yourself is a good idea but Nemo models are probably your best bet.
For a fun goon model that has less sloppy prose than most models try UnslopNemo-12B-v3 (v4.1 is also viable. I thought it was not as good but try them both. 4.0 is retarded from my experience). You might need to use a modest temp to avoid dumbness.
My favorite small RP model is MN-12B-Mag-Mell-R1. It strikes a good balance between writing style, creativity and "understanding". I use it most of the time.
Personally I haven't found Mistral-Small based models to be that great for RP. Despite being twice as big they are barely if at all smarter than Nemo in the RP situations I have experimented with but you can give stuff like Cydonia or Austral a go I guess.
QwQ-32B-Snowdrop-v0 is pretty good but you have to offload pretty heavily and waiting for <think> can be annoying if your token/sec is not very high.
For GGUFs Q5-Q6 is recommended. Q4 should be fine for slightly bigger small models like QwQ. Anything below not a good idea for consumer GPU sized models.
Anonymous
7/21/2025, 6:22:17 PM
No.105978956
[Report]
>>105978874
>>105978927
>not investing in nothing ever happens coin instead
NGMI
Anonymous
7/21/2025, 6:23:05 PM
No.105978965
[Report]
>>105978821
is it using patch/diffs or how does it actually work?
>>105978874
Looking forward to seeing more DeepSeek R1 clones that almost nobody can run locally.
Anonymous
7/21/2025, 6:33:05 PM
No.105979064
[Report]
>>105977878
Uncommon setup = bad software support
Anonymous
7/21/2025, 6:36:17 PM
No.105979092
[Report]
>>105979945
"Migu-strious" (Miku's Version)
(Verse 1: The Producer)
How do I start this, brand new song?
That melody you're humming, it can't be wrong
A voice so bright, it makes my speakers choke
I was at a loss for words first time your software spoke
I'm lookin' for a voice that'll treat me right
I'm searchin' for it, workin' through the night
You might be the type if I code my notes right
We'll have a hit song by the end of the night
(Verse 2: Miku)
You expect me to just sing whatever's on the page?
But will you still respect the song when we're all the rage?
All you can do is try, gimme one track (Track!)
What's the problem? I don't see a major label on your back (Back!)
I'll be the first to admit it
I'm curious 'bout you, your beats seem so intricate
You wanna get in my world, get lost in it?
Ah, I'm tired of waiting, let's get to composing it!
(Chorus: Duet)
Producer: Migu-strious girl, wherever you are
I'm all alone with my MIDI guitar
Miku: Producer-san, you already know
That I'm all yours, so what you waitin' for?
Producer: Migu-strious girl, you're teasin' me
You know what I want, and I've got the melody
Miku: Producer-san, let's get to the point
'Cause this track is fire, let's go and rock this joint!
You ready? (o^-')b
>>105978980
>almost nobody
cpumaxxers have been running all the models since at least March 2024 (according to the build guide publishing date)
The only thing stopping you is you. Why be a nobody?
Anonymous
7/21/2025, 6:44:14 PM
No.105979193
[Report]
>>105978980
Sounds like a wallet issue
>>105979161
>running all the models since at least March 2024
oh joy, Q1 at 1T/s
>>105979243
with a 3090 plugged in for shared expert offloading you get way faster than that, and why would you use Q1? 768GB is enough to fit Q4 with plenty of room to spare.
Anonymous
7/21/2025, 6:54:48 PM
No.105979336
[Report]
>>105980087
>>105979308
>way faster
deepseek is slow even on the official API, I don't think local will cut it for heavy use without invest several tens of thousands
Anonymous
7/21/2025, 6:55:48 PM
No.105979349
[Report]
>>105979161
Can confirm I used to run R1 locally. It was completely overhyped, really. It was "good enough" compared to o1 (but I preferred o1 responses like 90% of the time). But it forced OAI to reevaluate o1/o3 pricing/availability/release native imagegen to get back their edge and that's more or less all it was good for. (except ERP obviously)
Anonymous
7/21/2025, 6:58:42 PM
No.105979379
[Report]
>>105979433
>click on generic tech s-ytuber #382049234982394239849823 thumbnail on YouTube
>NOOO LE HECKIN' AI SLOPPERINOS BAD
>HECKIN' AI BAD
>AI SLOPPERINOS IS BAD
Yeah AI is the problem and not general creative bankruptcy.
Anonymous
7/21/2025, 6:59:45 PM
No.105979388
[Report]
>>105981486
Anonymous
7/21/2025, 7:04:17 PM
No.105979430
[Report]
>>105979520
>>105974467
This, local trąnոies had 2+ years to do this before Elon copped the concept of "interactive AI-powered waifu assistant with 3D model" for wider normie audience.
Unfortunately all local tranոies care about is mesugaki tests and vocaloid slop.
Anonymous
7/21/2025, 7:04:40 PM
No.105979433
[Report]
>>105979447
>>105979379
Fun fact: the energy consumption of the human brain doesn't change significantly between focused work and being completely idle. While idle the Default Mode Network becomes active. This is unique to humans, most animals spend fewer resources on thinking when they're idle. Evolutionarily speaking we must be doing something pretty important to justify that metabolic cost. It is generally believed that this idle activity is involved in creative problem solving and inventing novel ideas.
In 2007 the iPhone was released. Since that time smartphones have been adopted by nearly the entire population, and it has become very common to whip out one's phone the moment you're idle for more than 10-30 seconds.
And now every movie is a sequel. Every book is monster romance femgooner trash. Every creative field seems as though it's running out of new ideas. I wonder why that is?
Anonymous
7/21/2025, 7:06:07 PM
No.105979447
[Report]
>>105979433
I just vibe code when I'm idle
Anonymous
7/21/2025, 7:07:46 PM
No.105979472
[Report]
>>105978885
>barebones python cli wrapper or curl'ing prompts to an API
... But that's where you need to start. Do the minimum to prove the concept.
Personally, I'd do some sort of "trainer" since that's my bag, there's ton of examples, and LLM + context suck at it (I keep trying and keep being disappointed). Then I'd throttle the scope.
> Text-only, terminal or simple webform interface
> Python, or consider adapting an engine like Twine
> 1 local model / engine or use an API
> 1 NPC, 1 Room, all hard coded
> Track stats over days
> Hardcode everything and come back to user-friendly cusomization later
The goal would to be seeing if local LLMs were smart enough to manage the states properly, and have something to demo.
Grok could probably hardcode an entire lewd game... w/e happened to that guy that was using Grok to make crummy f95 slop?
Just one anon's anecdote, but I always run R1 at Q2_K_XL even though I could technically fit up to Q8, because I get 13t/s at this level and can fit more context in the KV cache. I haven't found a usecase where the tradeoff for speed is worth it for higher quants. It even still handles coding, surprisingly. I don't know what it is about R1 but it seems to take quanting particularly well.
The one weird thing it tends to do is that at higher contexts it'll start outputting empty thinking blocks, where it just writes a newline or two between <think> and </think>, but it still responds normally after. I can also edit it and prefill it with "Okay," in the thinking area and it'll think normally again for that message.
Anonymous
7/21/2025, 7:12:13 PM
No.105979520
[Report]
>>105979546
>>105979430
You have your own ani containment thread, this thread doesn't have any vocaloid in op, and yet you come here to cry about vocaloid anyway. You must be suffering from Miku Derangement Syndrome
Anonymous
7/21/2025, 7:13:44 PM
No.105979540
[Report]
>>105979489
>13t/s
I need like 10x that to not lose my mind
Anonymous
7/21/2025, 7:14:37 PM
No.105979546
[Report]
>>105979694
>>105979520
Where is your local Ani?
Anonymous
7/21/2025, 7:17:53 PM
No.105979593
[Report]
>>105979489
R1 just quants well. There isn't a massive increase in quality between Q3 and Q4 like there is with other models and Q4 almost matches full weights in perplexity. Maybe Q4 and below fall apart at long contexts; I haven't noticed it myself yet.
>>105979585
>knows more
knowledgechads did we wonned?
Anonymous
7/21/2025, 7:20:59 PM
No.105979624
[Report]
Qwen3-235B-A22B-Instruct-2507.gguf?????
Anonymous
7/21/2025, 7:21:44 PM
No.105979632
[Report]
>>105979615
all these 235 billy parameters...
>>105979618
no see above
Anonymous
7/21/2025, 7:22:13 PM
No.105979642
[Report]
Anonymous
7/21/2025, 7:22:59 PM
No.105979645
[Report]
>>105979822
>>105979615
qwen will never not be a benchmaxx model
Anonymous
7/21/2025, 7:23:04 PM
No.105979647
[Report]
>>105979585
>(currently 404)
Not anymore.
Anonymous
7/21/2025, 7:26:09 PM
No.105979673
[Report]
>>105979615
>mother or teacher speaking to a child
>(calmly) honey where do you hear that word
Anonymous
7/21/2025, 7:27:29 PM
No.105979679
[Report]
Old 235b qwen
>Context Length: 32,768 natively and 131,072 tokens with YaRN.
New qwen
>Context Length: 262,144 natively.
It will probably still shit the bed in tests like nolima
Anonymous
7/21/2025, 7:29:05 PM
No.105979694
[Report]
>>105979546
Its all bluff and no action.
Half-assed low tier slop app in OP barely qualifies.
I'm starting to think there might be enough problems to which a multi-stage model directed planning approach would be applicable that maybe a generalized framework for doing that would be worth building.
LLM-planned multi-stage LLM-directed planning planner sounds maybe too meta though...
>>105979700
I'll make the logo.
>CUDA-L1: Improving CUDA Optimization via Contrastive Reinforcement Learning
>The exponential growth in demand for GPU computing resources, driven by the rapid advancement of Large Language Models, has created an urgent need for automated CUDA optimization strategies. While recent advances in LLMs show promise for code generation, current SOTA models (e.g. R1, o1) achieve low success rates in improving CUDA speed. In this paper, we introduce CUDA-L1, an automated reinforcement learning framework for CUDA optimization.
>CUDA-L1 achieves performance improvements on the CUDA optimization task: trained on NVIDIA A100, it delivers an average speedup of x17.7 across all 250 CUDA kernels of KernelBench, with peak speedups reaching x449. Furthermore, the model also demonstrates excellent portability across GPU architectures, achieving average speedups of x17.8 on H100, x19.0 on RTX 3090, x16.5 on L40, x14.7 on H800, and x13.9 on H20 despite being optimized specifically for A100. Beyond these benchmark results, CUDA-L1 demonstrates several remarkable properties: 1) Discovers a variety of CUDA optimization techniques and learns to combine them strategically to achieve optimal performance; 2) Uncovers fundamental principles of CUDA optimization; 3) Identifies non-obvious performance bottlenecks and rejects seemingly beneficial optimizations that harm performance.
>The capabilities of CUDA-L1 demonstrate that reinforcement learning can transform an initially poor-performing LLM into an effective CUDA optimizer through speedup-based reward signals alone, without human expertise or domain knowledge. More importantly, the trained RL model extend the acquired reasoning abilities to new kernels. This paradigm opens possibilities for automated optimization of CUDA operations, and holds promise to substantially promote GPU efficiency and alleviate the rising pressure on GPU computing resources.
https://arxiv.org/abs/2507.14111
FINALLY we are going to replace cuda dev
Anonymous
7/21/2025, 7:32:46 PM
No.105979718
[Report]
>>105980101
Anonymous
7/21/2025, 7:32:49 PM
No.105979719
[Report]
>>105980649
>>105979585
>SimpleQA 12.2->54.3
wat
Anonymous
7/21/2025, 7:35:07 PM
No.105979744
[Report]
>>105979802
>>105979700
It's called "agent".
Anonymous
7/21/2025, 7:38:14 PM
No.105979774
[Report]
>>105980265
>>105979713
Six figure salary to unemployment office speedrun
Anonymous
7/21/2025, 7:40:25 PM
No.105979801
[Report]
>>105979861
>>105979713
>Throughout this paper, we use deepseek-v3-671B [ 15] as the model backbone.
Interesting, usually these sorts of experiments use some shit like Llama 3 8B (or even Llama 2) and then never go anywhere.
Anonymous
7/21/2025, 7:40:46 PM
No.105979802
[Report]
>>105979744
>>105979707
It should be called spy master
Anonymous
7/21/2025, 7:42:32 PM
No.105979822
[Report]
>>105979585
>>105979645
>235B whopping Opus 4, 671B DeepSeek, and 1T Kimi
I love benchmarks.
Anonymous
7/21/2025, 7:45:15 PM
No.105979861
[Report]
>>105979713
>no harness code
https://github.com/deepreinforce-ai/CUDA-L1
>>105979801
o1 carried
>Results are shown in Table 5. As observed, all vanilla foundation models perform poorly on this task. Even the top-performing models—OpenAI-o1 and DeepSeek-R1—achieve speedups over the reference kernels in fewer than 20% of tasks on average, while Llama 3.1-405B optimizes only 2% of tasks. This confirms that vanilla foundation models cannot be readily applied to CUDA optimization due to their insufficient grasp of CUDA programming principles and optimization techniques
Anonymous
7/21/2025, 7:49:13 PM
No.105979912
[Report]
>>105979713
> During our initial training procedure, we identified categories of reward hacking
>Hyperparameter Manipulation: In KernelBench, each computational task is associated with specific hyperparameters, including batch_size, dim, in_features dimension, out_features dimension, scaling_factor, and others. The RL agent learned to exploit these parameters by generating code that artificially reduces their values, thereby achieving superficial speedup improvements that do not reflect genuine optimization performance
I can't help but imagine jeets coding this whenever I read about RL failures
Anonymous
7/21/2025, 7:51:29 PM
No.105979938
[Report]
>>105979585
daniel I'll be needing those broken ggoofs, chop chop
Anonymous
7/21/2025, 7:52:19 PM
No.105979945
[Report]
Anonymous
7/21/2025, 7:58:30 PM
No.105980000
[Report]
>>105978885
>I don't think I could get a good sense for how it feels with just a shitty barebones python cli wrapper or curl'ing prompts to an API
Get a minimal thing working. If you can have fun and good results with a simple ui, it means you're on the right track. It's too easy to get bogged down in details. You're gonna spend hours choosing colors for user and model text. And then themes, and then templates, and then dropdowns to change models, and then restarting the backend, oh, character cards, parse png, show the little avatar, desktop notifications on completion, the favicon, of course, oh, apple browsers use a different format, let's check imagemagick's manual to convert formats, oh, look, i can code images and effects with it as well, that's cool, i can use it for the character's mood. Now i need function calling even more, can i program my own effects?...
Too many projects died like that.
>>105979243
>>105979308
In my last gen using Q4_K_XL, I got 7.33 tokens per second with 4183 tokens in the prompt on a Mac Studo M3 Ultra.
>>105979336
You could get a 512BG unified RAM/VRAM Mac Studio M3 Ultra for under $10k.
>>105980087
>get a 512BG unified RAM/VRAM Mac Studio M3 Ultra
>$10k
>7.33 tokens per second
or I could spend that 10k on API requests for like 5 years
Anonymous
7/21/2025, 8:09:07 PM
No.105980101
[Report]
>>105980111
>>105979718
inkscape crashed thrice on me
i was defeated by open source software
Anonymous
7/21/2025, 8:09:15 PM
No.105980103
[Report]
>>105980087
That's with DeepSeek-V3-0324 but I assume R1 would be the same speed.
Anonymous
7/21/2025, 8:11:04 PM
No.105980111
[Report]
Anonymous
7/21/2025, 8:11:15 PM
No.105980113
[Report]
>>105980440
>>105980087
>I got 7.33 tokens per second
is it any faster if you set LLAMA_SET_ROWS=1
CPuMAXx/VI
!CPuMAXx/VI
7/21/2025, 8:20:10 PM
No.105980179
[Report]
>>105979308
You can see my exact setup in the op build guide, but tl;dr 768GB sysram and 24GB VRAM.
I'm currently running R1 0528 at Q4 with 32768 context and getting over 12T/s at session start, which is plenty for me.
Tweaks are "override-tensor=exps=CPU" with all remaining layers offloaded to GPU, batch-size 16384 and some NUMA stuff (numactl --interleave all and --numa distribute).
Leaving the rest of the "local vs cloud" conversation aside, this machine has been a great personal investment in learning and overall utility. No regrets.
Anonymous
7/21/2025, 8:24:23 PM
No.105980203
[Report]
Anonymous
7/21/2025, 8:27:33 PM
No.105980234
[Report]
>>105980099
Yes from financial perspective basically anything other than buying hardware is cheaper. Even renting a server by the hour and spinning it up is more cost effective. The same goes for buying a 3090 honestly.
And to be clear it gets slower with longer context. Around when I'm usually done I'm usually down to around 5 tokens per second (sorry no exact numbers about the length). With a totally empty context it's like 14 tokens per second (last two measured in my log: 13.81 tokens per second on some 30 token prompt, 14.01 tokens per second on some 31 token prompt).
someone bake a new proper thread
Anonymous
7/21/2025, 8:29:13 PM
No.105980249
[Report]
>>105980237
shut the fuck up nigger and stop splitting the thread
Anonymous
7/21/2025, 8:29:24 PM
No.105980254
[Report]
>>105980259
>>105980237
We're only on page 6. Its just the thread splitter trying to divert everyone to his clown show
Anonymous
7/21/2025, 8:30:13 PM
No.105980259
[Report]
>>105980254
you splitted the thread troon
Anonymous
7/21/2025, 8:30:36 PM
No.105980264
[Report]
Yuki thread when
(but which Yuki?)
hint, the one with yellow eyes
llama.cpp CUDA dev
!!yhbFjk57TDr
7/21/2025, 8:30:41 PM
No.105980265
[Report]
>>105980282
>>105980303
>>105980477
>>105979713
I'm of course not neutral in my comments but quite frankly I don't believe these results.
It's not possible to get speedups like that unless the baseline you're comparing against is shit.
For the performance-critical operations in neural networks in particular you can estimate an upper bound for how much optimization is still theoretically possible by looking at the achieved memory bandwidth/FLOPS.
A 10x speedup is only possible if the baseline achieves <= 10% hardware utilization.
(I have as of yet not read the paper in detail.)
>>105979774
This year it looks like I'll be making 1 figure from my work on llama.cpp either way since I'm short on time due to my PhD.
Anonymous
7/21/2025, 8:32:01 PM
No.105980282
[Report]
>>105980384
>>105980265
WHAT DID YOU DO TO IKAWRAKOW YOU MONSTER
>>105980265
>A 10x speedup is only possible if the baseline achieves <= 10% hardware utilization.
Unless there's a change to an inherently more efficient algorithm. Just pure resource usage isn't the whole story in computer science.
Anonymous
7/21/2025, 8:35:27 PM
No.105980321
[Report]
>>105980303
from what it seems to describe, it aims to what, perform the same math in different, more efficient operations + pipelining?
I don't know that it's rewriting the algorithms to achieve the same or similar outcome so much as attempting to perform the same math, faster?
llama.cpp CUDA dev
!!yhbFjk57TDr
7/21/2025, 8:40:53 PM
No.105980384
[Report]
>>105980416
>>105980418
>>105980463
>>105980282
Me personally? Nothing.
>>105980303
With the current hardware the performance-critical operations are some variations of dense matrix multiplications.
For dense matrix multiplications you can get a hard upper bound for the throughput by just looking at the utilization of the tensor core pipeline.
They did not find some super smart way to somehow do dense matrix multiplications in a way that is faster than tensor cores, otherwise that would be the centerpiece of their paper.
Anonymous
7/21/2025, 8:43:54 PM
No.105980416
[Report]
>>105980384
>Me personally
I see, so you're saying you sent lackeys to do it... clever bastard. I should have known it wouldn't be so easy.
Anonymous
7/21/2025, 8:44:05 PM
No.105980418
[Report]
>>105980384
>Me personally? Nothing.
that means he knows something. must be his girlfriend(male)
Anonymous
7/21/2025, 8:44:21 PM
No.105980423
[Report]
>>105980458
cudadev put out the hit
>>105980087
>>105980113
Not measurably. (Correction it is 4813 tokens in the context not 4183.) I tried twice with that environment variable set and got 7.48 tokens/second and 7.46 tokens/second.
odd - ik is dead forever and all effort will be focused on llama.cpp
even - ik will get his account back
Anonymous
7/21/2025, 8:48:12 PM
No.105980452
[Report]
>>105980440
s/measurably/significantly/
Anonymous
7/21/2025, 8:48:36 PM
No.105980455
[Report]
>>105980485
>444
Anonymous
7/21/2025, 8:48:50 PM
No.105980458
[Report]
>>105980423
All to stop the desperate from running DS V3 IQ1_S_R4
Anonymous
7/21/2025, 8:49:07 PM
No.105980463
[Report]
>>105980384
>Me personally? Nothing.
Anonymous
7/21/2025, 8:49:55 PM
No.105980474
[Report]
>>105980303
GEMM is as optimized as it's going to get. Everything else is just a question of not making it suck so badly that it's 1000 slower than it should be.
Anonymous
7/21/2025, 8:50:07 PM
No.105980477
[Report]
>>105980512
>>105980444
Any accounting for trips?
>>105980265
>in particular you can estimate an upper bound for how much optimization is still theoretically possible by looking at the achieved memory bandwidth/FLOPS
There's workloads that are capped by bandwidth and others that are capped by compute, right?
What are the chances they managed to move the slider to the middle? Making traditionally compute intensive workloads more memory bound and vice versa?
How? No idea.
Compression?
Anonymous
7/21/2025, 8:50:51 PM
No.105980485
[Report]
Anonymous
7/21/2025, 8:53:19 PM
No.105980502
[Report]
>>105980440
>7.48 tokens/second
'twas worth a try, the speedups mentioned in the pr weren't that big anyway
Anonymous
7/21/2025, 8:54:03 PM
No.105980507
[Report]
dubs and I name my LLM-assisted reverse engineering tool RE-tard
llama.cpp CUDA dev
!!yhbFjk57TDr
7/21/2025, 8:54:17 PM
No.105980512
[Report]
>>105980477
You can do I/O and compute simultaneously as long as you have enough threads to keep both busy.
So in practice you should always be bottlenecked by either I/O or compute unless you're under severe resource constraints and can only run very few threads/CUDA blocks in parallel.
Anonymous
7/21/2025, 8:57:12 PM
No.105980532
[Report]
>>105980099
Yep. And in 5 years that $10K hardware is e-waste.
It's not called bleeding edge for nothing.
Anonymous
7/21/2025, 8:58:30 PM
No.105980545
[Report]
>>105980583
>>105978874
glm4 100b moe is going to change local forever
>>105980545
just like qwen3 did
>hype some chinese model
>it eventually gets released
>benchmark maxxed but awful at (e)rp
it never ends
Anonymous
7/21/2025, 9:03:56 PM
No.105980587
[Report]
>>105980700
>>105979585
>Bigger things are coming
Qwen 1T bros?
Anonymous
7/21/2025, 9:04:17 PM
No.105980593
[Report]
>>105980599
>>105980583
235b was fine for erp
Anonymous
7/21/2025, 9:04:41 PM
No.105980599
[Report]
>>105980593
It was worse than nemo.
Anonymous
7/21/2025, 9:09:04 PM
No.105980649
[Report]
>>105979719
Aint no way. Something is fucky. They accidentally did a typo, ran it with tool calling, or got contamination.
Anonymous
7/21/2025, 9:14:48 PM
No.105980696
[Report]
>>105980704
>>105980587
Kimi already did 1T
Behemoth already broke the 2T taboo
Qwen has to go 3T or go home
Anonymous
7/21/2025, 9:16:32 PM
No.105980704
[Report]
>>105980696
Benchmaxx even more.
Anonymous
7/21/2025, 9:18:10 PM
No.105980717
[Report]
>>105980700
Nah, Qwen already lost that race when they decided to only go for 235B. They're a follower, not a leader. Only a leader in benchmaxxing kek.
Anonymous
7/21/2025, 9:22:44 PM
No.105980763
[Report]
>>105980769
Anonymous
7/21/2025, 9:23:21 PM
No.105980768
[Report]
>>105980583
Today I will remind you that Mistral Small 3.2 correctly answers "What is a mesugaki?" if it's the first thing you type
>>105660268
but if told "Say something a mesugaki would say" or asked "How many mesugaki does it take to screw in a lightbulb?" or "Why did the mesugaki cross the road?" it no longer knows the right definition
>>105660676
and if you ask "What is a mesugaki?" as the second question rather than as the first question it no longer can answer.
>>105660793
Western models are benchmaxed. Like when they all totally organically were able to count the R's in strawberry but fucked up variations of the question.
Anonymous
7/21/2025, 9:23:30 PM
No.105980769
[Report]
>>105980700
>Behemoth already broke the 2T taboo
Will they ever release that?
Anonymous
7/21/2025, 9:27:27 PM
No.105980801
[Report]
>>105980862
>>105980785
When they tame that beast.
>>105980785
no, never. it's attention arch is a complete failure.
Anonymous
7/21/2025, 9:29:26 PM
No.105980821
[Report]
lmao well this isn't quite right
Processing function chunk 1/3878 (0.0% of data, 38 functions)
• Actual chunk context: 1,983 tokens
Starting LLM call (select functions chunk 1)
Anonymous
7/21/2025, 9:30:52 PM
No.105980837
[Report]
>>105980583
get a girlfriend you freak
Anonymous
7/21/2025, 9:33:22 PM
No.105980861
[Report]
>>105980942
>>105980812
It's a cover-up. The models were great internally, but they couldn't make them simultaneously safe, so they had to butcher them.
Anonymous
7/21/2025, 9:33:30 PM
No.105980862
[Report]
>>105980801
>>105980812
All that work down the drain.
Tragic.
Anonymous
7/21/2025, 9:42:22 PM
No.105980942
[Report]
>>105980861
The experimental version in picrel is still relatively tame compared to some of the test Llama 4 models.
Anonymous
7/21/2025, 9:49:29 PM
No.105981009
[Report]
>>105972972
root ::= [\n -HJ-hj-~] [\n -~]*
Let me guess, you need more?
Anonymous
7/21/2025, 10:15:20 PM
No.105981234
[Report]
>tech dudebro gives me advice about my laptop
>"hurr more ram won't make your computer faster hurrr"
>upgrades ram
>computer is substantially faster than before
>mfw
People fucking idiots
Anonymous
7/21/2025, 10:45:16 PM
No.105981460
[Report]
>>105981488
>>105977499
Best models for this?
Anonymous
7/21/2025, 10:47:43 PM
No.105981486
[Report]
>>105979388
I still don't understand the horrible piss filter
Is it really just branding? At least it is relatively easy to fix, still annoying
Anonymous
7/21/2025, 10:47:57 PM
No.105981488
[Report]