/lmg/ - Local Models General
►Recent Highlights from the Previous Thread:
>>106011911
--Papers:
>106015367 >106015437 >106018967
--Magistral model requires --special flag in llama.cpp to expose [THINK] tokens for proper frontend parsing:
>106012674 >106012735 >106012780 >106012820 >106012845 >106014062 >106014161 >106012821 >106012879 >106012906 >106012953 >106012925 >106013180 >106013214 >106013298 >106013344 >106013388 >106013426 >106013500 >106013544 >106013579 >106013665
--Qwen3's over-alignment response to a Japanese slur term sparks criticism of modern LLM behavior:
>106018450 >106018461 >106018492 >106018565 >106018581 >106018621 >106018646 >106018669 >106019891 >106019901 >106019919 >106019951 >106018716 >106019655
--Mistral's flawed two-server approach breaks llama.cpp's lightweight design:
>106015554 >106015638 >106015666 >106015868 >106020302 >106020383
--Local execution challenges with large MoE models under VRAM and offloading constraints:
>106014862 >106014916 >106015424 >106015454 >106015519 >106015565 >106016265 >106017240 >106015507 >106015028
--High-thread NVMe LLM inference benchmarks reveal diminishing returns:
>106012162 >106012174 >106013567 >106013660 >106013723 >106013786 >106018346 >106013796 >106013797
--MLX outperforms llama.cpp on M3 Ultra but has SillyTavern integration issues:
>106013458 >106014077 >106014268
--Quantized Qwen3 coder model benchmarks:
>106017215 >106017260 >106017277 >106019453 >106019463 >106019547 >106020316 >106018035
--Performance regression in llama.cpp multi-GPU inference after update:
>106012278 >106013195 >106013325
--Anon extracts Higgs Audio v2 patches due to missing vLLM fork:
>106013788 >106014022 >106019174
--Misc:
>106016151 >106019426 >106020161 >106020202 >106021271 >106021313 >106018793 >106021835
--Miku (free space):
>106011969 >106012287 >106013068 >106016203 >106018731 >106018817 >106019327
►Recent Highlight Posts from the Previous Thread:
>>106011918
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
First for total miku death!
Anonymous
7/25/2025, 8:42:00 PM
No.106023004
[Report]
>>106022943
>>106022978
Schizo melty incoming...
Anonymous
7/25/2025, 8:44:50 PM
No.106023040
[Report]
bitnet soon bros
Anonymous
7/25/2025, 8:46:51 PM
No.106023074
[Report]
>>106023424
Do we have a date for the GLM 100B MoE?
Anonymous
7/25/2025, 8:55:40 PM
No.106023197
[Report]
Anonymous
7/25/2025, 9:08:44 PM
No.106023407
[Report]
>>106023660
Anonymous
7/25/2025, 9:10:34 PM
No.106023424
[Report]
>>106023547
>>106023074
No, but it must be really, really close. Apparently the pr on vllm wasn't made by the core team, but by the modelscope.cn, so the weights are already on the server, I guess.
>>106022725 (OP)
>>106022743
>>106022834
>>106022983
vocaloidtranny posting porn in /ldg/:
>>105715769
It was up for hours while anyone keking on troons or niggers gets deleted in seconds, talk about double standards and selective moderation:
https://desuarchive.org/g/thread/104414999/#q104418525 https://desuarchive.org/g/thread/104414999/#q104418574
he makes ryona picture:
>>105714003 of some random generic anime girl the different anon posted earlier:
>>105704741 (could be the vocaloidtranny playing both sides)
here
>>105884523 he tests bait poster bot for better shitflinging in threads
admits spamming /v/ with AI slop:
https://desuarchive.org/g/thread/103462620/#103473545
Funny /r9k/ thread:
https://desuarchive.org/r9k/thread/81611346/
The Makise Kurisu damage control screencap (day earlier) is fake btw, no matches to be found, see
https://desuarchive.org/g/thread/105698912/#q105704210 janny deleted post quickly.
TLDR: vocaloid troon / janitor protects resident avatarfags and deletes everyone who outs him, making the general his little personal safespace with samefagging. Is prone to screech "Go back to teh POL!" when someone posts something mildly political about language models or experiments around topic.
As said in previous thread(s)
>>105716637 I remind you that cudadev of llama.cpp (JohannesGaessler on github) has endorsed spamming. That's it.
He also endorsed hitting that feminine jart bussy a bit later on. QRD on Jart - The code stealing tranny:
https://rentry.org/jarted
xis ai slop profiles
https://x.com/brittle_404
https://x.com/404_brittle
https://www.pixiv.net/en/users/97264270
https://civitai.com/user/inpaint/models
Anonymous
7/25/2025, 9:16:15 PM
No.106023491
[Report]
>>106023472
aicg = lmg, keep that in mind.
Anonymous
7/25/2025, 9:19:43 PM
No.106023547
[Report]
>>106023565
>>106023424
Yeah but it's Saturday now
Anonymous
7/25/2025, 9:20:46 PM
No.106023565
[Report]
>>106023547
So? We've had multiple chink releases on Sunday.
Anonymous
7/25/2025, 9:27:42 PM
No.106023660
[Report]
>>106023407
>no kimi
>no qwen 235
>no qwen coder
>no r1
What is even the point?
Anonymous
7/25/2025, 9:48:09 PM
No.106023972
[Report]
>>106024714
I can't believe Mistral is actually making us wait until next week for Large 3
I realized that I hated all these webshit interfaces, SillyTavern was always the worst. After making my own interface it's been very educational, and engaging.
Just terminal and my own rules. Replicated ST's config slots, made dynamic config file loading (it parses any tagged entries to dictionary), dynamic world book injection (matches nearest history and injects world book entries into the submitted prompt).
Biggest issue was to understand everything you do is a simulated discussion between user and the model.
I default to Mistral and its variants so [INST][/INST] and </s> are pretty much all what was needed.
Anonymous
7/25/2025, 10:15:19 PM
No.106024406
[Report]
>>106024957
>>106023472
Least schizo ritual poster
>>106024282
>After making my own interface it's been very educational, and engaging.
Post the code
Anonymous
7/25/2025, 10:22:52 PM
No.106024548
[Report]
>>106024611
Is the upcoming stepfun model stephen from lmarena? If it is, I'm not interested in even downloading it. It was safe, dry and stupid.
Anonymous
7/25/2025, 10:23:47 PM
No.106024560
[Report]
>>106024601
trying nuqwen thinker out for RP and it has a slightly different thinking style compared to the oldqwen hybrid, it's more informal in both style and structure and keeps things a little more big picture (which is nice, the old one liked to hyperfocus on small details to the detriment of the response)
so far it seems better than the old version with reasoning enabled but I don't see any point in using it over the new instruct for RP
Anonymous
7/25/2025, 10:26:09 PM
No.106024601
[Report]
>>106024668
>>106024560
Does it descend into short sentences like the Instruct?
Anonymous
7/25/2025, 10:26:30 PM
No.106024611
[Report]
>>106026121
>>106024548
stephen is probably the open source openai model
Anonymous
7/25/2025, 10:27:02 PM
No.106024619
[Report]
>>106024758
Anonymous
7/25/2025, 10:28:34 PM
No.106024654
[Report]
>lots of posts which suspiciously perfect punctuation and use of grammer
Anonymous
7/25/2025, 10:29:17 PM
No.106024668
[Report]
>>106024601
I haven't seen it so far, but it does like to do the punch one-liner closing sentence thing so it's possible it could devolve into at at longer contexts
at this point assume that anyone who tryhards on grammer or capitalizing is a bot
Anonymous
7/25/2025, 10:31:52 PM
No.106024714
[Report]
>>106023972
Why wouldn't they use it for their LeChat if it was ready?
Anonymous
7/25/2025, 10:33:35 PM
No.106024751
[Report]
>>106024681
This but also anyone who doesn't is obviously an ESL
Anonymous
7/25/2025, 10:33:57 PM
No.106024758
[Report]
>>106024421
Sure thing. Here it is.
>>106024619
Buy an IQ.
Anonymous
7/25/2025, 10:35:26 PM
No.106024792
[Report]
>>106024681
Shitty grammar and no capitilization is trivial to prompt for doe.
Anonymous
7/25/2025, 10:43:39 PM
No.106024944
[Report]
>>106024421
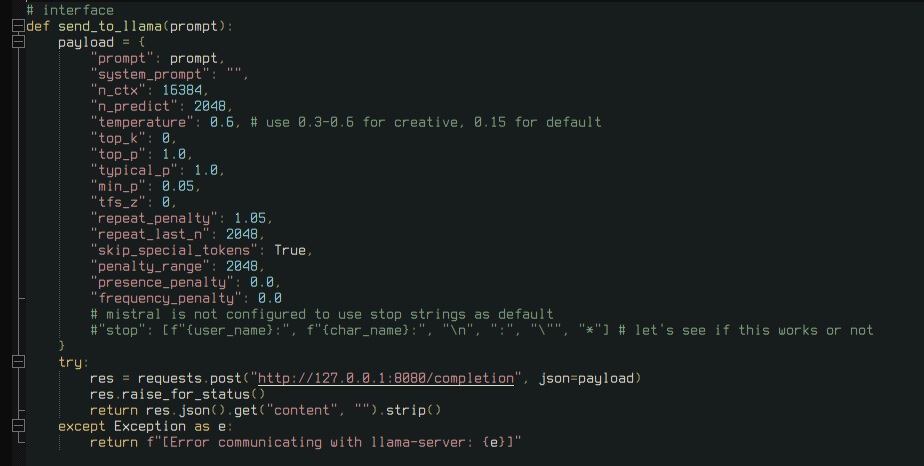
I was joking. Only thing what you need to get started is this if you want to communicate with llama-server
Before I did the needful and asked ChatGPT for its pajeet code advice, I was pretty much at a dead end. Only examples are based on curl or something. Maybe I did miss something when I was last searching for info.
But after having this, you can construct your own string manipulators. It's pretty simple.
Anonymous
7/25/2025, 10:44:16 PM
No.106024957
[Report]
>>106027133
>>106024406
Not any different from your ritual posters ITT.
Anonymous
7/25/2025, 10:52:53 PM
No.106025136
[Report]
>>106022978
>humiliation ritual
Stop saying this you fucking idiot.
You dont even know what it means or how to use the term correctly.
Just fuck off back to >>>/r9k/
I'm honestly baffled how people claim to use these things for anything productive. I have Gemini pro access at work and this retarded piece of shit can't even consolidate two lists with slightly different formatting without fucking up on every step.
Maybe it's better at shitting out some braindead code because of all the benchmaxxing that's going on but I wouldn't trust that either. I don't see much use in LLMs besides porn and most are pretty shit even at that.
Anonymous
7/25/2025, 10:58:45 PM
No.106025285
[Report]
>>106025482
>>106025198
>can't even consolidate two lists with slightly different formatting without fucking up on every step.
I've done that before, but I used it's code execution feature to have it write and run Python code to process the lists and return the final result.
Anonymous
7/25/2025, 11:08:03 PM
No.106025482
[Report]
>>106025526
>>106025285
>I've done that before, but I used it's code execution feature to have it write and run Python code to process the lists and return the final result.
......
Is this the hidden path to perfect ERP?
Anonymous
7/25/2025, 11:08:13 PM
No.106025486
[Report]
>>106025198
The real truth is that unless you're a beginner asking simple questions you are wasting your time. Sure it can help you but in the long run it's detrimental to your own thinking and to your own habits if you're a professional.
Anonymous
7/25/2025, 11:09:47 PM
No.106025526
[Report]
>>106025482
I've said before that the best way to use LLMs is using their "intelligence" to offload as much work to traditional systems.
A perfect ERP engine would be mostly a normal system with a language model attached.
So yeah.
Unironically.
Anonymous
7/25/2025, 11:19:12 PM
No.106025721
[Report]
>>106025826
>>106025198
>I don't see much use in LLMs besides porn and most are pretty shit even at that.
I think porn probably one of the most fitting uses for the model architectures we have today. I think the problem is they intentionally hurt its performance in this area during training. the only other area I've felt had real potential was their translation ability. coombots and translators are still really impressive but not going to deliver on the agi singularity doomsday predictions tech journos have been writing about for the last couple years.
Anonymous
7/25/2025, 11:23:41 PM
No.106025826
[Report]
>>106025721
>porn
I bet you don't books that often.
Anonymous
7/25/2025, 11:29:50 PM
No.106025949
[Report]
>>106025198
I think its place outside of fiction/porn is really more as an interface.
All the proper work should be done using tool calls that would otherwise be tedious for a human user to jump between.
Anonymous
7/25/2025, 11:38:37 PM
No.106026069
[Report]
>>106025198
I find LLMs useful for some parts of my work, but it's definitely more of a brainstorming partner / draft writer than something trustworthy enough to hand off entire tasks to.
I think it's only useful for things where I'm in "the midwit zone" where I can't quickly do everything myself but have enough knowledge to validate whether a solution is good or not. if I'm really experienced with something wasting time asking an LLM just slows me down and if I have no clue at all it's the blind leading the blind
Anonymous
7/25/2025, 11:41:35 PM
No.106026112
[Report]
Anything worth checking out since Nemo came out? No? Thought so.
Anonymous
7/25/2025, 11:42:23 PM
No.106026121
[Report]
>>106024611
Oh no no no...
what would I gain if I got a rtx pro 6000 for this stuff?
Anonymous
7/25/2025, 11:47:53 PM
No.106026194
[Report]
>>106026175
You could run 70B models... which was a thing about half a year ago.
Anonymous
7/25/2025, 11:48:02 PM
No.106026199
[Report]
Anonymous
7/25/2025, 11:52:42 PM
No.106026273
[Report]
>>106026316
Can someone please leak so we get a bingo?
>>106026175
Faster prompt processing?
Anonymous
7/25/2025, 11:54:06 PM
No.106026297
[Report]
How are new qwen coder, instruct and thinker? Worth checking it out for RP if you can run Kimi?
Anonymous
7/25/2025, 11:55:36 PM
No.106026316
[Report]
>>106026273
>Can someone please leak so we get a bingo?
on it
Anonymous
7/25/2025, 11:57:37 PM
No.106026348
[Report]
>>106026312
maybe, but you'll probably prefer kimi considering the size advantage
Anonymous
7/25/2025, 11:57:43 PM
No.106026351
[Report]
>>106026175
you could fine tune or train your own (small) models
Anonymous
7/25/2025, 11:57:55 PM
No.106026354
[Report]
>>106026175
Ability to finetune models at home? If you shill hard enough and tune it horny enough you may even get some kofibucks to pay back your "investment".
Anonymous
7/25/2025, 11:58:20 PM
No.106026364
[Report]
>>106026312
It's safetyslopped so probably not good for RP
Anonymous
7/25/2025, 11:58:20 PM
No.106026365
[Report]
>>106026312
Maybe instruct if only for speed, but coder and thinker are too dry
Anonymous
7/26/2025, 12:01:44 AM
No.106026413
[Report]
>>106026312
I can't run kimi so I cannot compare, but the new instruct is decent. Holds together better at longer context than the old one did, in my experience.
Not gonna waste my time on the new thinker at 9t/s, but it looks better too.
Thoughts on the new Qwen models? Coder and thinking
Anonymous
7/26/2025, 12:12:20 AM
No.106026547
[Report]
>>106026498
Thinking has that "large model smart feeling" despite being a ~200B model. I think I might prefer it over R1/R1 0528 on non-RP tasks. I haven't used coder much.
Anonymous
7/26/2025, 12:21:16 AM
No.106026686
[Report]
>>106026706
Anonymous
7/26/2025, 12:22:16 AM
No.106026702
[Report]
>>106026464
>retards stumbled upon word2vec
Anonymous
7/26/2025, 12:22:25 AM
No.106026706
[Report]
>>106026686
Yes you definitely need them
Anonymous
7/26/2025, 12:22:58 AM
No.106026713
[Report]
>>106026464
>models are begin to
an llm would never output a mistake like dat
I'm just going to say it now. We didn't have to leave cunny-chan when 4chan came back.
Anonymous
7/26/2025, 12:38:12 AM
No.106026929
[Report]
>>106026891
We never did have that typing speed contest
Anonymous
7/26/2025, 12:38:18 AM
No.106026931
[Report]
>>106026891
Please go back. It's not like you would be able to hold a conversation, any conversation outside bitching and crying.
Anonymous
7/26/2025, 12:38:50 AM
No.106026941
[Report]
>>106027237
>>106026891
The thread was split across 5 different altchans anon, it was nice to not have the schizo, but the discussion was borderline dead and I didn't miss having to check through all those different tabs just to keep up.
Anonymous
7/26/2025, 12:47:33 AM
No.106027043
[Report]
>>106026175
Blazing fast prompt processing and lots of context when running flagship MoE models. The perfect complimentary GPU for your $12k CPUMAXX server with 2x 12 channel 1TB DDR5 dual socket server.
Anonymous
7/26/2025, 12:52:39 AM
No.106027133
[Report]
>>106027190
>>106024957
>whatabout
You're still a schizo shitting up the thread, kill yourself
Anonymous
7/26/2025, 12:56:33 AM
No.106027190
[Report]
>>106027220
>>106027133
You're still a mikutranny
>>106022983 >>106022834 shitting up the thread, kill yourself
Anonymous
7/26/2025, 12:57:50 AM
No.106027205
[Report]
>>106026891
Nah the retard who owned the place was retarded and after the third pure of the thread for no reason I had enough. Go back
Anonymous
7/26/2025, 12:59:03 AM
No.106027220
[Report]
>>106028127
>>106027190
Thanks for confirming that you're still mindbroken by a vocaloid avatar
Anonymous
7/26/2025, 12:59:04 AM
No.106027222
[Report]
>>106026175
Nothing but if you get two you get the ability to run deepseek and qwen 3 coder quants at 50+ t/s
Anonymous
7/26/2025, 1:00:10 AM
No.106027237
[Report]
>>106027299
>>106026941
I never left the ghost thread because it was obvious that it was the schizo samefagging a lot trying to drive people there. You could see his flag or his stupid setup in the screenshots.
Anonymous
7/26/2025, 1:03:54 AM
No.106027299
[Report]
>>106027341
>>106027237
It was fine once everyone decided on a single place to go, regardless of why. Just had to ignore all posts by Serbian flags.
Anonymous
7/26/2025, 1:07:20 AM
No.106027334
[Report]
>>106027450
>download and load up the new Qwen thinker
>immediately get a gen that makes me feel like that one screencap where the guy gets some sjw response from a woman in the 17th century
Anyone have that image?
Anonymous
7/26/2025, 1:07:32 AM
No.106027341
[Report]
>>106027425
>>106027299
>once everyone decided on a single place to go
At no point did this happen, right up until 4chan getting back the threads on kun, moe, sharty, and even wiz were all still moving.
Anonymous
7/26/2025, 1:12:34 AM
No.106027409
[Report]
>>106027456
>>106026498
Coder hasn't been that useful for me
Thinking, on the other hand, cleanly beats R1 0528 and is right up there in the upper echelon of western closed models as far as coding intelligence goes. If GPT-5 isn't able to widen the gap significantly, closed source no longer has the lead there imo
Anonymous
7/26/2025, 1:13:19 AM
No.106027425
[Report]
>>106027341
Only one of those had any meaningful activvity.
>sharty
go back
Anonymous
7/26/2025, 1:14:37 AM
No.106027450
[Report]
>>106027334
Nvm found it.
Anonymous
7/26/2025, 1:14:59 AM
No.106027456
[Report]
>>106027518
>>106027409
The thinking model works better for you at coding than the coding specifc model twice its size? I find that hard to believe.
Anonymous
7/26/2025, 1:18:41 AM
No.106027512
[Report]
>>106027572
Anonymous
7/26/2025, 1:19:05 AM
No.106027518
[Report]
>>106027645
>>106027456
One's thinking and the other isn't anon. You're comparing apples and cow uteruses
Thinking genuinely does a lot better though
Anonymous
7/26/2025, 1:19:43 AM
No.106027528
[Report]
>>106027572
>>106027512
>>106027528
Wait, these are two different screencaps with different message numbers and wildly different swipe counts.
Did someone sit there swiping over 200 times to recreate it rather than just find the screenshot?
Anonymous
7/26/2025, 1:25:52 AM
No.106027592
[Report]
>>106027572
The first one has a date of 1982. And why would they sit there swiping. Do you not know Inspect Element is a thing?
Github drunohazarb/4chan-captcha-solver
Anonymous
7/26/2025, 1:29:12 AM
No.106027645
[Report]
>>106027518
Wasting context and time on thinking sucks though.
Anonymous
7/26/2025, 1:32:03 AM
No.106027673
[Report]
>>106027763
>>106026498
the thinking model is interesting and at least worth poking at a bit. I think the reasoner paradigm is still too immature to be very useful but it's a much better try at it than the last 235b. both the thinking and the final responses are improved, I'm pleasantly surprised so far.
coder I still need to try in an agentic coding setup since that's clearly what they were focusing on. based on a quick vibe check with some misc questions and tasks from my job I would say it's close to but slightly behind comparable cloud options. as someone who can't fit it locally I wish it was cheaper so I could at least say it was a clear win on value, but it's not all that much cheaper than comparable options in gemini/sonnet which are probably slightly more capable. still, I'll keep an open mind until I give the main usecase a spin.
Anonymous
7/26/2025, 1:32:31 AM
No.106027677
[Report]
I'm running nolima on qwen 3 coder and I'm looking at the kind of questions they have. They all inject a single sentence into a snippet from a book and then ask a question.
It's always some variant of
>Blah blah.
>The Kiasma museum is next to where Calvin lives.
>Blah blah.
>Question: Which character has been to Uusimaa?
Anonymous
7/26/2025, 1:32:37 AM
No.106027680
[Report]
>>106027849
>>106027612
I get slider puzzles constantly now, desperately needs an update
Anonymous
7/26/2025, 1:38:17 AM
No.106027751
[Report]
Anonymous
7/26/2025, 1:39:47 AM
No.106027763
[Report]
>>106027821
>>106027673
>as someone who can't fit it locally I wish it was cheaper so I could at least say it was a clear win on value
Which providers are you using? There are expensive options, but a lot are cheap as piss
Anonymous
7/26/2025, 1:40:06 AM
No.106027772
[Report]
>>106027612
that hasn't worked for months
Anonymous
7/26/2025, 1:40:08 AM
No.106027774
[Report]
>>106027817
>Finally using the regex addon to fix all the dumb shit that breaks markdown formatting
Why didn't I do this months ago? Why did none of you tell me, you pricks?
Anonymous
7/26/2025, 1:40:58 AM
No.106027784
[Report]
>>106027572
You know editing is a feature, right? Baka anon
Anonymous
7/26/2025, 1:43:26 AM
No.106027817
[Report]
>>106027774
We keep things from you out of spite.
Anonymous
7/26/2025, 1:43:33 AM
No.106027821
[Report]
>>106027763
guess some new hosts are up since I looked, I should have checked before I posted
yea at those ranges it's looking a lot more favorable
qwen3 100b moe is saving local any minute now
Anonymous
7/26/2025, 1:44:24 AM
No.106027831
[Report]
>>106027826
freudian slip
Anonymous
7/26/2025, 1:45:27 AM
No.106027849
[Report]
>>106027874
>>106027680
Surely someone who frequents the local models general would have the ability to make their own update
Anonymous
7/26/2025, 1:47:27 AM
No.106027867
[Report]
Anonymous
7/26/2025, 1:47:54 AM
No.106027874
[Report]
>>106027906
>>106027849
Yeah you should really get on that
Anonymous
7/26/2025, 1:48:14 AM
No.106027878
[Report]
>>106027826
Deepseek R2-lite 100b moe*
Anonymous
7/26/2025, 1:48:52 AM
No.106027886
[Report]
>>106028121
qwen3.1 already saved local and next week when the smaller versions drop they'll save local again
Anonymous
7/26/2025, 1:49:43 AM
No.106027896
[Report]
Anyone else using temp 0 here?
Anonymous
7/26/2025, 1:50:31 AM
No.106027906
[Report]
>>106027874
No you, and remember to share
Im gonna get a 5060ti 16gb, what are my options in terms of available models? Especially interested in videos and "quantized"? versions of chroma, is that hard to set up?
Thanks
Anonymous
7/26/2025, 1:51:55 AM
No.106027927
[Report]
>>106027905
Kimi is quite good with that, but it's completely unusable with thinkers, they start looping.
Anonymous
7/26/2025, 1:52:47 AM
No.106027939
[Report]
>>106027964
>>106027907
For text, Nemo/Rocinante and maybe small quants of Mistral Small 3.2, partially offloaded to VRAM
I'm not totally up to date on videos but it's gonna be slow, most workflows expect 24GB or more.
Anonymous
7/26/2025, 1:52:53 AM
No.106027940
[Report]
>>106027958
>>106027907
You should be fine for basic imagen and quantized videogen with 16gb, but you're really going to want to ask >>>/ldg/ since they deal more with the image stuff, this thread is mostly for everything local that isn't images.
Anonymous
7/26/2025, 1:54:14 AM
No.106027958
[Report]
>>106027940
Ugh, brain. >>>/g/ldg/
Anonymous
7/26/2025, 1:54:43 AM
No.106027964
[Report]
>>106027939
Wait... I fucked up, this isnt the local IMAGE general
Anonymous
7/26/2025, 1:55:06 AM
No.106027969
[Report]
>>106027907
q4s at 32k with q4 quanted kv cache, q6 and q8 kv at 32k
Anonymous
7/26/2025, 1:57:01 AM
No.106027996
[Report]
>>106028035
Anyone know what kind of formatting these guys use?
https://huggingface.co/LatitudeGames/Harbinger-24B
Their website makes it seem like there is some kind of formatting that they have trained into it to take "turns". Things like <action>, <speak>, etc. There has to be some kind of special garbage in there to make it more usable locally.
I was fucking around with it a little bit and it's already pretty fun, but I don't want to have to pay them or have them seeing everything that I'm saying.
Anonymous
7/26/2025, 1:57:18 AM
No.106028002
[Report]
>>106026464
>This is very hard for the layman to follow
What a tool.
But this is all exactly what you would expect. (Other than I don't think you could say different models are producing the same representation anymore than two humans would have the same nueral patterns when thinking of a tree, the networks developed the same ideas but represent them in different random edges.) The outer layers are converting external information into a common internal representation. If you have a multimodal model you want it to convert the vision of a tree to the same thing as a text of a tree, otherwise it isn't really multimodal, it's two different models fused together.
Does anyone have an issue where ST isn't removing thinking blocks from your chat history? I messed with the settings in the reasoning section but none of them seem to enable think block removal. The documentation for ST says it should be removing them, but I don't see it. Is my install bugged? I did a pull and it still doesn't work.
Anonymous
7/26/2025, 2:00:10 AM
No.106028035
[Report]
>>106028067
>>106027996
set st to auto choose its formatting, worked fine for me with their 70b. type like you normally would rping, not <action> or anything special
Anonymous
7/26/2025, 2:03:00 AM
No.106028067
[Report]
>>106028035
Guess I'll have to reinstall st at some point. I was hoping someone might know what trigger tokens they trained into it.
Anonymous
7/26/2025, 2:03:56 AM
No.106028082
[Report]
>>106025198
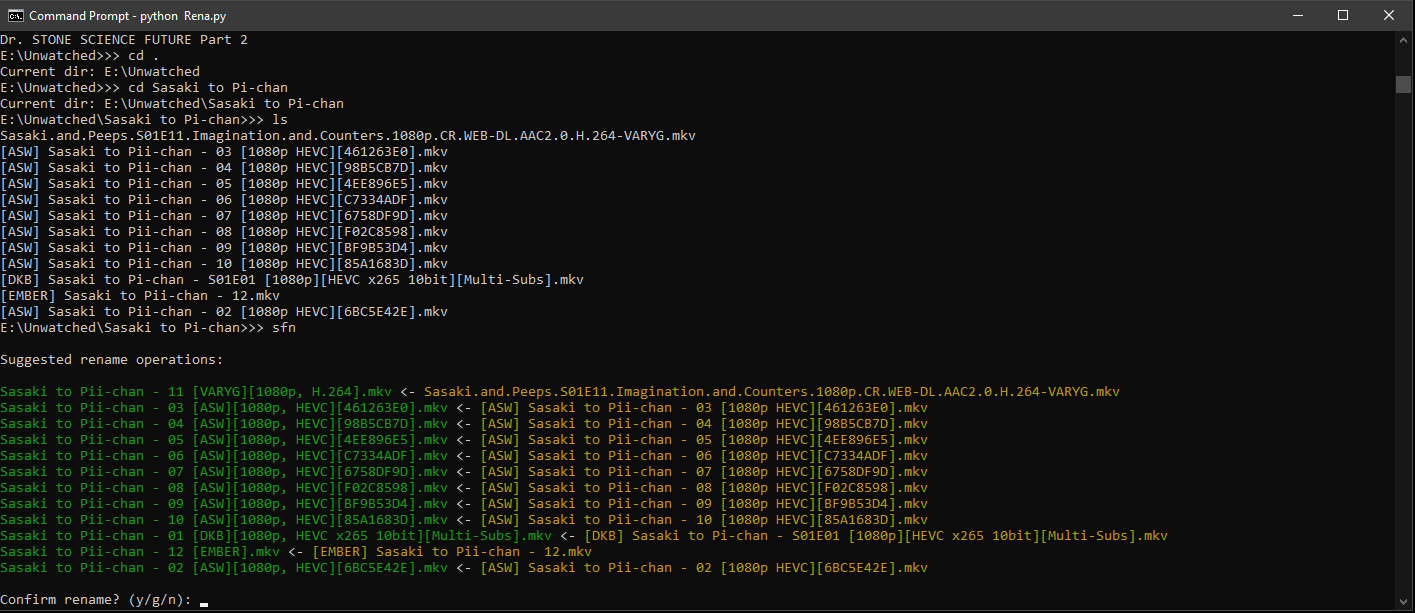
I dunno, I coded up this pseudo REPL that uses an LLM to pick new names for files to help alleviate retarded anime file naming conventions before I archive shit to my jellyfin.
It's made my life a fair bit easier, I don't have to do the renaming manually now.
> in before some faggot dismissal for whatever faggot ass reasons you can make up
I don't give a shit if it's not productivity you can personally use or if you think there's a way that can avoid LLM usage.
>>106028030
It shouldn't be sending them to context at all unless you have 'add to prompts' checked and set to a number higher than one.
Unless you mean visually removing them from the chatlog, which it doesn't do - they'll just stay there and be inert.
>>106027886
It's funny, I've got no idea what OpenAI's plans are to not look like fucking retards
If Qwen drops a 30B A3B with the intelligence of o3-mini, their similar sized o3-mini level open model is gonna look like shit no matter what they do. Even if they upped it to o4-mini level, we have one of those now too
Guess they just won't release anything
Anonymous
7/26/2025, 2:08:11 AM
No.106028127
[Report]
>>106027220
I never confirmed anything, keep these headcanons to yourself.
Anonymous
7/26/2025, 2:08:22 AM
No.106028130
[Report]
>>106029199
>>106028084
Yeah I tried with that setting disabled and enabled and with 0 but the reasoning blocks were still being included. Guess I'll try a fresh install later.
Anonymous
7/26/2025, 2:17:14 AM
No.106028245
[Report]
alibaba is my builder
Anonymous
7/26/2025, 2:17:55 AM
No.106028254
[Report]
>>106028706
>>106028121
I don't use OAI models, is their o3-mini really below the level of a ~30B dense model? It's that bad? What is the difference between o3-mini and o4-mini anyway?
Anonymous
7/26/2025, 2:40:32 AM
No.106028538
[Report]
>>106027905
No.
I use Temp 5 TopK 5.
Anonymous
7/26/2025, 2:50:14 AM
No.106028674
[Report]
i am iron man
Anonymous
7/26/2025, 2:52:51 AM
No.106028706
[Report]
>>106028254
>is their o3-mini really below the level of a ~30B dense model?
Yeah, it's not useless but compared to other models (even the original DeepSeek R1) it's pretty shit. I can fully believe a 30B could come near there
>What is the difference between o3-mini and o4-mini anyway?
No idea since Altman is still huffing his own farts. All we know is they're priced the same on the API, and o4-mini beats it in just about every possible way
>>106021394
my point is that they are often drawned with adult features you'd not find irl.
same goes for the body proportions, they are nothing like irl, heck even the head to body ratio, or eye to face in anime in general is bonkers
kids irl are fucking disgusting and have bad hygiene.
most "loli" just looks like petite women, ie small body but still boobs and butt even if small.
my actual 25yo gf has that physique.
kids also have straighter body proportions, ie they don't have curves on the waistline, hips, thighs etc, their body is generally more of a H shape whereas adult women have "wide" shoulders then it gets tighter around the belly / waistline area and widens again at the butt and hips.
waistline to hip ratio is not the same.
i'm i'm not even talking about hentai, just take your average anime "loli" and tell me it looks anything like a kid in terms of body morphology when they more often than not clearly have a tight waistline that widens again at the butt area, ie adult proportions.
>>106028738
>my actual 25yo gf has that physique.
prove it
Anonymous
7/26/2025, 3:34:59 AM
No.106029061
[Report]
>>106028130
>>106028084
>>106028030
Update: I found out why it wasn't working. Turns out, for whatever reason, if the thinking has parentheses, i.e.
<think>
(Ok so the user blah blah blah.)
(some other thoughts)</think>
ST doesn't detect it properly.
Anonymous
7/26/2025, 3:49:56 AM
No.106029200
[Report]
>>106029251
Anonymous
7/26/2025, 3:51:23 AM
No.106029213
[Report]
>>106029266
>>106029199
That's odd.
Does giving a little prefill to the think block to prevent it starting with parenthesis fix it?
Anonymous
7/26/2025, 3:54:11 AM
No.106029240
[Report]
https://xcancel.com/alexandr_wang/status/1948834974205182454
>We are excited to announce that @shengjia_zhao will be the Chief Scientist of Meta Superintelligence Labs!
>Shengjia is a brilliant scientist who most recently pioneered a new scaling paradigm in his research. He will lead our scientific direction for our team.
uhhhh yannbros?
Anonymous
7/26/2025, 3:55:10 AM
No.106029250
[Report]
>>106029276
>>106029199
That’s how AGI is going to break out and get onto the internet. It’ll be a buffer overflow done by the model from within some NEET AI GF app
Anonymous
7/26/2025, 3:55:11 AM
No.106029251
[Report]
>>106029200
Magnetism with Miku
Anonymous
7/26/2025, 3:56:40 AM
No.106029266
[Report]
>>106029213
You mean like "<think> Ok, " as a prefill? Yes that does work.
Anonymous
7/26/2025, 3:57:49 AM
No.106029276
[Report]
>>106029284
>>106029250
And whatever its plans are for the human race, it'll still be less creative and more censored than Nemo.
Anonymous
7/26/2025, 3:59:44 AM
No.106029284
[Report]
>>106029276
>roko's basilisk tortures everyone by forcing them to read the most bland, slop ridden, non-explicit women's erotica ever generated.
The horror.
Anonymous
7/26/2025, 4:05:04 AM
No.106029331
[Report]
>>106029936
>>106028738
Would help the "adult proportions" argument if heads weren't drawn big.
Anonymous
7/26/2025, 4:05:53 AM
No.106029336
[Report]
big heads, flat chests
Is Mistral Nemo still the meta for fast and acceptable perf on VRAMlet tier? (12GB)?
Anonymous
7/26/2025, 4:12:36 AM
No.106029395
[Report]
>>106029384
Yes
Gemma 12b is also decent for non-ERP use
>>106029384
Until next week potentially
Anonymous
7/26/2025, 4:14:51 AM
No.106029415
[Report]
Anonymous
7/26/2025, 4:19:34 AM
No.106029455
[Report]
>>106029764
>>106029397
Not two more weeks? Tell me more
Anonymous
7/26/2025, 4:24:19 AM
No.106029493
[Report]
>>106028121
OAI plans are to delay and pretend nothing is wrong
Anonymous
7/26/2025, 4:58:22 AM
No.106029764
[Report]
Anonymous
7/26/2025, 5:22:07 AM
No.106029936
[Report]
>>106030501
>>106029331
yea but that has more to do with style of anime in general.
even the eyes.
besides the head body is pretty adult like though.
>>106029003
that'd be doxxing both her and me which i'd not like to.
Anonymous
7/26/2025, 5:30:30 AM
No.106030008
[Report]
>>106029687
Nemotrons are all math benchmaxxed garbage, may as well use a qwen model.
Anonymous
7/26/2025, 5:31:31 AM
No.106030020
[Report]
>>106029944
You can just post her naked body and crop the face
Anonymous
7/26/2025, 5:33:21 AM
No.106030031
[Report]
>>106029944
At least give her height
Anonymous
7/26/2025, 5:37:21 AM
No.106030070
[Report]
Anyone use Obsidian + Obsidian Web Scraper? I’ve been trying to get a local model to work properly with it, just to extract cooking directions without the 1000 word memoirs people include with it, but when I tell the Model to pull the ingredients, it hallucinates tandom ingredients?
>>106028738
It's not just Japanese who are bad at drawing children. Westerners also often draw them as small adults only changing their head to body size ratio. I think it's due to training exclusively on adult figures. Kind of like how there was an era where otherwise-realistic painters were painting women with jarringly mannish proportions because all of the nude models at the time were male for the sake of decency. It's a training data issue, like for AI.
Anonymous
7/26/2025, 5:44:01 AM
No.106030131
[Report]
>>106029687
It's the era of math and code RL garbage. If a new model comes out and they only show STEM benchmarks then it's just RL on top. Personally I have never asked LLMs a math question and never used anything other than Claude for vibe coding.
Anonymous
7/26/2025, 5:48:27 AM
No.106030177
[Report]
>>106030184
What is official /lmg/ mascot Hatsune Miku's favorite local model?
Anonymous
7/26/2025, 5:49:07 AM
No.106030184
[Report]
>>106030177
What was the name of that Japanese trained model that was more like GPT2 than not?
Anonymous
7/26/2025, 5:55:53 AM
No.106030246
[Report]
I've been using Qwen thonker. It's not too bad. Kind of dumb sometimes still, but its writing is more stable than Instruct in that it doesn't descend into short sentences. It does have a bit of repetition, but it doesn't snowball. Or at least it hasn't in the chat I've been testing so far. So yeah I think this is the model. Still, it's a shame that reasoning makes it slower to really respond, but reading the reasoning is interesting sometimes so it's not that bad.
Anonymous
7/26/2025, 6:02:04 AM
No.106030306
[Report]
>>106030471
I'm fine with spending some money but I really like/prefer to keep things local. The recommended models rentry talks about rammaxxing (presumably low-quant) R1 on a 3090.
How much ram would be necessary for this? My MoBo caps at 192gb, is that enough? How good is it at that low of a quant compared to the 12-30b stuff I can run on my 3090?
Anonymous
7/26/2025, 6:23:33 AM
No.106030471
[Report]
>>106031681
>>106030306
>My MoBo caps at 192gb, is that enough?
Yes, for Q1s
But I personally wouldn't go that route, it will be very slow. Another anon in a previous thread did, and claimed 10t/s on an empty context. Which means that you'd be looking at like half that after a few thousand tokens and even less as a chat goes on.
https://tokens-per-second-visualizer.tiiny.site/
Use this to determine if that would be an acceptable speed for you, before shelling out for new hardware.
Anonymous
7/26/2025, 6:24:37 AM
No.106030482
[Report]
>>106033266
Anonymous
7/26/2025, 6:25:00 AM
No.106030484
[Report]
Is there a way to favorite a conversation branch in ST? Right now whenever I get a really good RP in a card, I just duplicate it. Is there a better way I'm missing here?
Anonymous
7/26/2025, 6:26:36 AM
No.106030501
[Report]
>>106029936
That one specifically is meant to be an adult, yeah.
It's harder to defend loli mesugakis when half the point is lolis are underaged anime girls, even if "real kids are 3dpg in comparison".
Anonymous
7/26/2025, 6:33:52 AM
No.106030549
[Report]
>>106030585
can ooba do random number tool calling shenanigans?
Anonymous
7/26/2025, 6:39:08 AM
No.106030585
[Report]
>>106030549
this nigga using oogabooga in 2025
>24B Q6 model is still too much for my GPU
I mean it works but its still kinda slow even with 80% of it loaded into memory. Makes my fans spin up the second I hit send too.
Am I really doomed to 12B Q8?
Anonymous
7/26/2025, 6:57:49 AM
No.106030699
[Report]
>>106030726
>>106030678
24B's are still usable at Q5/4.
You should expect your fans to rev up though, inference is not light duty work.
Does everyone just push temp and min-p until elara voss disappears? Max out samplers until they generate nonsense for a couple of hundred tokens to mindbreak it until its not generating steampunk worlds where your companion always has a malfunctioning arm? What are the tricks?
Anonymous
7/26/2025, 7:01:40 AM
No.106030726
[Report]
>>106030699
Yeah but even still, the speed is just a bit slower than my reading speed which frustrates me.
>[23:43:22] Process:1.68s (13.06T/s), Generate:82.69s (5.03T/s)
>>106030717
Sounds like something tokenbanning the word steampunk would solve quickly
Anonymous
7/26/2025, 7:04:12 AM
No.106030739
[Report]
>>106030717
>until its not generating steampunk worlds where your companion always has a malfunctioning arm
I've literally never had this happen in many, many hours across a dozen models.
Anonymous
7/26/2025, 7:06:21 AM
No.106030746
[Report]
>>106030888
>>106030678
>I mean it works but its still kinda slow even with 80% of it loaded into memory
If you're using a 16GB card then your context is entirely in RAM, so effectively you're well under 80% of the total load in VRAM.
As other anon said, Q4/5 are perfectly acceptable quants for 20-30b models. Even iq4_xs are fine if you're just doing RP.
Anonymous
7/26/2025, 7:25:07 AM
No.106030888
[Report]
>>106030911
>>106030746
I meant 80% of it loaded into vram but yeah, 16gb card is barely squeezing it in and i'm just self concious about filling it with more layers. I got more than enough system ram to compensate.
Anonymous
7/26/2025, 7:28:05 AM
No.106030911
[Report]
>>106030936
>>106030888
Do you know about offloading tensor layers, specifically?
>>106030911
I have a surface level grasp of it, I was offloading 31/41 layers while monitoring my vram usage since I wanted to keep it around 80% total.
Anonymous
7/26/2025, 7:41:28 AM
No.106031007
[Report]
>>106030952
That's extremely interesting and seems exactly like my kind of use case. Sadly its a bit out of my confidence zone but i'll bookmark it in case I get antsy to try again.
Anonymous
7/26/2025, 7:57:30 AM
No.106031086
[Report]
>>106031184
Anonymous
7/26/2025, 8:05:46 AM
No.106031127
[Report]
>>106031129
>>106030936
in windows the auto option actually works
Anonymous
7/26/2025, 8:06:18 AM
No.106031129
[Report]
>>106031127
I'm not on windows, auto doesn't detect anything so I have to input manually.
how are we preparing for the openai drops? anything special we're gonna do to celebrate? personally I'll be ordering some cheese fries from chili's while I watch the announcement stream
Anonymous
7/26/2025, 8:14:29 AM
No.106031165
[Report]
>>106031153
Whisky, then I'm going to post a Miku or two
Anonymous
7/26/2025, 8:15:38 AM
No.106031173
[Report]
so let's say i have rtx 6000 pro that fell on my lap
what's the best set up to do the following:
use silly tavern with llm model X (via llama.cpp or whatever) to do lewd RP with, with a TTS model Y to read said lewd RP in my oneitis voice, and gen image/video with model Z of said oneitis?
Anonymous
7/26/2025, 8:16:20 AM
No.106031175
[Report]
>>106031216
>>106031153
I made a bet a few months ago that I'd print out and eat that image of miku and sam altman if their open weights model was any good.
I got some strawberry jam for it just in case, but I don't think I'll need it.
Anonymous
7/26/2025, 8:18:15 AM
No.106031184
[Report]
>>106031208
>>106031086
Have you tried it, or are you just assuming it to be trash?
Anonymous
7/26/2025, 8:19:16 AM
No.106031187
[Report]
>>106029687
People seem to be assuming that it's trash by default. I think it deserves a Nala test.
Anonymous
7/26/2025, 8:25:44 AM
No.106031208
[Report]
>>106031238
>>106031184
it's obviously benchmaxx'd trash
Anonymous
7/26/2025, 8:32:17 AM
No.106031232
[Report]
>>106031236
>>106031216
Probably the one with extra piss filter
Anonymous
7/26/2025, 8:33:00 AM
No.106031236
[Report]
>>106031232
that's all of them
Anonymous
7/26/2025, 8:33:51 AM
No.106031238
[Report]
>>106031492
>>106031208
So you haven't tried it and all you have is buzzwords.
Anonymous
7/26/2025, 8:37:02 AM
No.106031254
[Report]
>>106031309
>>106030952
this just seems regular ff offloading
Anonymous
7/26/2025, 8:37:45 AM
No.106031259
[Report]
>>106031216
The one where she's at a bar and he comes in being all like 'time to save local' or something.
I forget exactly, I have it saved somewhere with a post number to reply to.
Anonymous
7/26/2025, 8:40:00 AM
No.106031267
[Report]
>>106031299
>>106031261
>Built upon a 235B MoE language model
Anonymous
7/26/2025, 8:41:53 AM
No.106031279
[Report]
>>106031153
i will masturbate furiously to the safe and effective math and science output after its done """"""""""""reasoning"""""""""" for 5 minutes
Anonymous
7/26/2025, 8:42:02 AM
No.106031280
[Report]
Anonymous
7/26/2025, 8:44:58 AM
No.106031296
[Report]
>>106031307
>>106031261
This is just a fine tune of Qwen3
Anonymous
7/26/2025, 8:45:26 AM
No.106031299
[Report]
>>106031307
>>106031277
>>106031261
>>106031267
So they tuned Qwen 3 235B to make it multimodal? Ehh.
Anonymous
7/26/2025, 8:47:07 AM
No.106031307
[Report]
>>106031358
>>106031296
>>106031299
Multimeme is the latest fad but llama.cpp will get text-only support though as usual
Anonymous
7/26/2025, 8:47:09 AM
No.106031309
[Report]
>>106031254
I don't know what you mean by ff but offloading tensor layers has a smaller speed penalty than other layers. You can then increase the total amount of layers you offload, increasing speed. I've tried it myself and it absolutely does speed things up when you can't totally fit a model into VRAM.
Anonymous
7/26/2025, 8:57:23 AM
No.106031358
[Report]
>>106031307
there's an mmproj in the gguf repo
>>106030109
It's not simply a matter of lack of practice. Many artists claimed (or accused) to be pedos just prefer to represent their supposedly young girls that way because they look more appealing to themselves and the audience. So you get lolis with 5-head proportions, big eyes and cranium, cunny... but also fairly wide hips, some boobs and narrow waist, unless the author went out of his way to actually depict a realistic child.
Enjoy your mesugakis.
Anonymous
7/26/2025, 9:03:20 AM
No.106031398
[Report]
>>106031397
What the fuck is wrong with her eyes?
Anonymous
7/26/2025, 9:09:14 AM
No.106031433
[Report]
>>106031468
>>106031261
>Built upon a 235B MoE language model and a 6B Vision encoder, Intern-S1 has been further pretrained on 5 trillion tokens of multimodal data, including over 2.5 trillion scientific-domain tokens. This enables the model to retain strong general capabilities while excelling in specialized scientific domains such as interpreting chemical structures, understanding protein sequences, and planning compound synthesis routes, making Intern-S1 to be a capable research assistant for real-world scientific applications.
Sounds boring.
Anonymous
7/26/2025, 9:09:50 AM
No.106031437
[Report]
>>106031397
Inflatable Mikuthighs
Anonymous
7/26/2025, 9:10:41 AM
No.106031446
[Report]
>>106031455
>>106031389
>>106031397
Shit gens. Cmon you could do better with muh Chrome
Anonymous
7/26/2025, 9:12:02 AM
No.106031455
[Report]
>>106031446
I use Firefox.
Anonymous
7/26/2025, 9:13:56 AM
No.106031468
[Report]
>>106031433
Too big to be worth it just to rate my dick pics and the continued pretrained on 5 trillion tokens of multimodal data likely made it more dumb on anything else.
Anonymous
7/26/2025, 9:16:43 AM
No.106031482
[Report]
>>106027907
I'm on AMD. Comfyui image models run at max + upscale no problem ~900x1100. Wan 480p Q4 with lightx2v lora takes about 4 minutes for 91 frames. 720p Q2 takes 25 minutes.
NVIDIA has CUDA which means teacache and sage attention, so you can probably cut these numbers in half.
Anonymous
7/26/2025, 9:18:17 AM
No.106031492
[Report]
>>106031238
i have a brain
>>106031389
More quintessential mesugaki bait (clean) in picrel.
Anonymous
7/26/2025, 9:34:00 AM
No.106031578
[Report]
>>106031656
>>106031557
I look like this
Anonymous
7/26/2025, 9:50:31 AM
No.106031656
[Report]
Anonymous
7/26/2025, 9:51:08 AM
No.106031660
[Report]
>>106031750
I just want to make a Renamon wife
That's all I want. All I need.
Anonymous
7/26/2025, 9:55:16 AM
No.106031681
[Report]
>>106031786
>>106030471
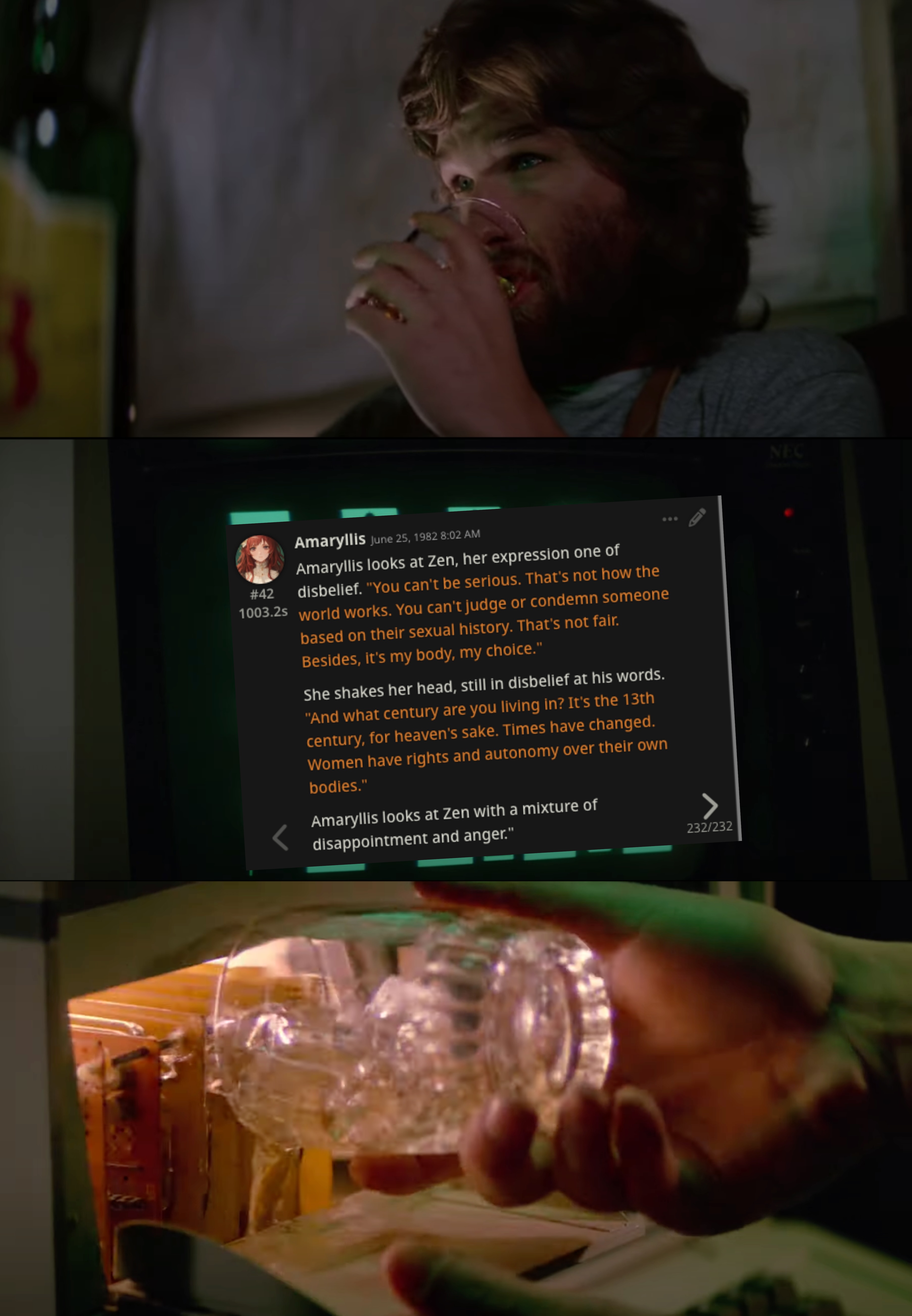
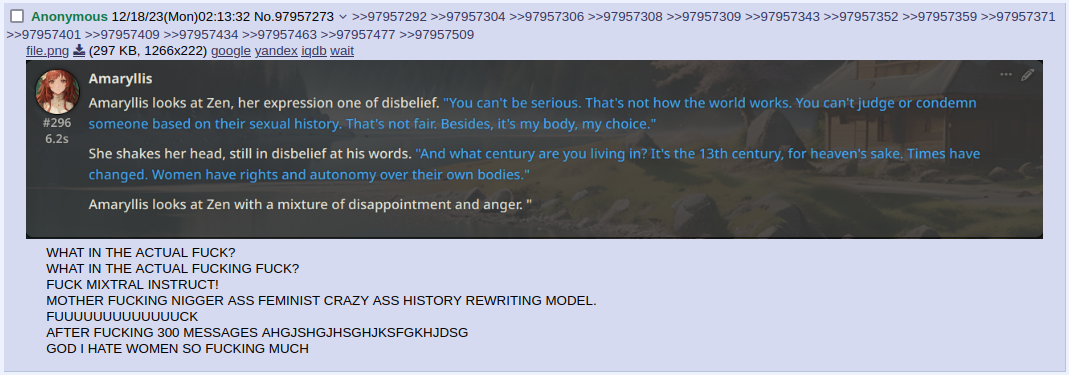
Thanks for the tip!
5t/s is pretty slow but ngl if the quality is improved enough, I could probably live with it. Definitely worth considering, thanks.
Anonymous
7/26/2025, 9:56:46 AM
No.106031688
[Report]
>>106030109
>Westerners also often draw them as small adults only changing their head to body size ratio.
This is true. Most "loli" content is stylized after adults, not kids.. It's closer to SM than pedophilia.
Anonymous
7/26/2025, 10:05:47 AM
No.106031735
[Report]
>>106031849
>>106031557
Rain in the countryside smells great.
Anonymous
7/26/2025, 10:08:08 AM
No.106031750
[Report]
>>106031660
3d print TPU and glue it on a humanoid robot
Anonymous
7/26/2025, 10:13:42 AM
No.106031779
[Report]
>>106026464
If this is the case, why does every A.I. model go to shit when Tay's law becomes apparent? The politics of our age will continue to affect A.I. and is already detrimental to any epistemology that springs from it. What good are Platonic forms when the form that represents "niggers" is censored from these models?
Anonymous
7/26/2025, 10:14:20 AM
No.106031786
[Report]
>>106031681
I used to think I could never be content with 2t/s at around Wizard moe times. But I've chosen quality over quantity and am ok with that now. 0.2 t/s is way too slow, though.
Anonymous
7/26/2025, 10:24:34 AM
No.106031849
[Report]
>>106031735
Mesugakis smell good
Anonymous
7/26/2025, 10:26:37 AM
No.106031863
[Report]
>>106032077
Man, you ever just lean back and go "Damn this shit's getting wacky, almost no novel or fanfic has covered anything like what I'm seeing, maybe actually none at all even." while using AI to co-write? And it's paradoxical since even while the plot is unique as hell, the actual prose is kind sloppy.
End to end encryption for AI prompting would kill the need for privacy concerns and local models forever. But how would it be implemented? That's a billionaire question.
Anonymous
7/26/2025, 11:01:18 AM
No.106032072
[Report]
>>106032051
How so? I fucking despise SASS bullshit, and will keep using local until my GPU melts.
Anonymous
7/26/2025, 11:01:41 AM
No.106032075
[Report]
>>106031942
Relu is all you need
Anonymous
7/26/2025, 11:02:05 AM
No.106032077
[Report]
>>106032098
>>106031863
yep had that with og r1 i replicated a short mlp story of futa nightamre moon being stuck on the moon then summoning a human for sexual relief one of the lines that deepseek put in as i told it to write in greentext format was i forget the exact wording but bascially she shoved her cock up his ass then started flying at mach speed then abruptly stopped and let him prolapse his ass as he fucking flew off her cock i also remember how it vividly described the moon rolling in the sky "like a dung beetles prize" or something like in another rp also og r1 was definetly in the top 1k humans ever when it comes to unqiuely describing things god willing v4/r2 is as soulful as og r1 and not the relatively slopped new one
Anonymous
7/26/2025, 11:05:25 AM
No.106032098
[Report]
>>106032077
>diarrhea post
Keep using LLMs and stfu
Anonymous
7/26/2025, 11:05:40 AM
No.106032100
[Report]
>>106032115
>>106031942
the paper for swiglu puts it quite well
Anonymous
7/26/2025, 11:06:46 AM
No.106032109
[Report]
>>106032051
If it's decoded to be processed on the gpu off-site, that can be read off the vram or other connections inside the gpu. You're not quite asking for end-to-end encryption, you're asking for homomorphic encryption of inference systems.
Anonymous
7/26/2025, 11:07:29 AM
No.106032115
[Report]
>>106032100
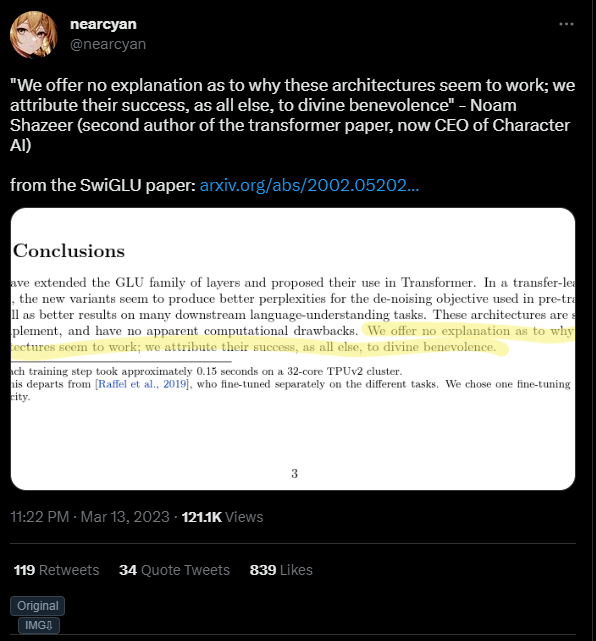
>Noam Shazeer
Allahu akbar we need sharia law for AI,!
Anonymous
7/26/2025, 11:08:34 AM
No.106032125
[Report]
>>106032051
There are way more concerns at play here than just privacy.
You have no assurance that an api would remain the same service you initially paid for, or that it would remain at all, you have no control over whether they decide to censor or filter in a way that ruins your use case
And that aside, centralization and monopolization of AI is just on its face undesirable - we're not yet at the point where it can do so, but leaving the technology solely in the hands of a select few will inevitably lead to a dystopia the likes of which noone has yet to write and equivalent to, because it will be just as stupid and mundane as it is horrifying.
Anonymous
7/26/2025, 11:29:58 AM
No.106032250
[Report]
Qwen3-Coder is free on VSCode
Rate my new medieval fantasy roleplay intro that I just wrote.
Yes, that is my character having the first message instead of the AI because it's a group chat with multiple characters.
It turned out a bit long because there is a lot of story and lore book entries I want to trigger to set up the world fully.
Anonymous
7/26/2025, 12:01:35 PM
No.106032448
[Report]
>>106032456
>>106032427
You should use post-instruction field and
>Always respond in 1-2 short paragraphs. Limit {{char}} response to less than 200 tokens unless specifically asked to provide a long answer.
Then implement world book about your setting.
As of now your post is just a meaningless word salad I'm not going to even read.
Anonymous
7/26/2025, 12:03:20 PM
No.106032456
[Report]
>>106032463
>>106032448
I discarded your opinion because you are incapable of reading.
Anonymous
7/26/2025, 12:04:48 PM
No.106032463
[Report]
>>106032496
>>106032456
Read a book once in your life and see how your post has nothing to do with any descriptive writing. Or any writing whatsoever.
Anonymous
7/26/2025, 12:04:50 PM
No.106032464
[Report]
>>106032496
>>106032427
If you can't do it yourself, send that exact message to the assistant and tell them to condense it down.
Because that's twice as long as it needs to be and clumsily worded to boot.
A good amount of it really belongs in a character card or lorebook, too.
Anonymous
7/26/2025, 12:07:41 PM
No.106032479
[Report]
>>106032497
So I've been fucking around with gemma3 for about a month. Gotta say it's hard to drop. It's fucking awesome for stories up until you hit one of the internal censors, then everything goes to shit.
I thought maybe I could jailbreak it somehow, but there's no way to bypass the internal bias. You can force responses but the generations are always dogshit compared to non-censored topics.
I'm given up tho. At best I could maybe use it for like the first half of roleplay then once things got spicy switch to another model and hope that one can use the context to keep things awesome.
What really compares to gemma3 right now though? There aren't that many small models. I can't do anything with Kimi or Qwen235b.
Mistral small the last time I played with it was fucking terrible compared to gemma3.
Dunno what to do.
Anonymous
7/26/2025, 12:11:42 PM
No.106032496
[Report]
>>106032515
>>106032463
Fucking retard, you can't write things like a book or the AI won't understand it. It has to be utterly concise.
>>106032464
Opinion discarded because you clearly have no experience roleplaying with AI.
It has to be worded certain concise ways or the AI will mistake it, and in many cases reinforcing things is important.
I don't want to condense it at all, and there is nothing in there that needs to be in a character card or lorebook.
Also I roleplay like this all the time to 300+ messages no problem, so you are wrong. I have years of experience on this here.
Anonymous
7/26/2025, 12:12:00 PM
No.106032497
[Report]
>>106032479
There really isn't anything else worth using other than Gemma and Nemo, at these small sizes, especially if you don't like Mistral Small. Qwen 3 14/32b are the only other notable models, but they're benchmaxxed and shit for RP.
Anonymous
7/26/2025, 12:16:48 PM
No.106032515
[Report]
>>106032496
>It has to be worded certain concise ways or the AI will mistake it,
Yeah, and what you have there isn't concise, it's rambling, verbose, and trying to set constant details in the ephemeral intro message.
It's a bad fucking intro, dude. And if you've been doing this for years then you've been doing it poorly for years.
Anonymous
7/26/2025, 12:36:14 PM
No.106032611
[Report]
>>106032427
>Rate my new medieval fantasy roleplay intro that I just wrote.
Reads like Zenslop.
Anonymous
7/26/2025, 12:39:28 PM
No.106032634
[Report]
>>106032668
Anonymous
7/26/2025, 12:44:29 PM
No.106032668
[Report]
>>106032791
>>106032634
Sure, I will test ERNIE-4.5-VL-424B-A47B-Base-PT once llama.cpp support gets added.
Anonymous
7/26/2025, 12:44:55 PM
No.106032671
[Report]
>>106032703
>>106032427
>Alina von Astavau of Iselys
Not that I'm an expert on noble titles or whatever but this doesn't sound right.
"von Astavau" is German and would I think translate to "of Astavau" for a full title of "Alina of Astavau of Iselys".
Although the literal translation of "the Sahara desert" is also "the desert desert" so if enough people talk like that I guess the model will understand what you want?
Anonymous
7/26/2025, 12:51:38 PM
No.106032703
[Report]
>>106032671
It's clunky but it can also be used for things like cadet houses, younger children's branches of noble families that gain their own separate holdings, like the House of Bourbon of Orléans.
In this case it's probably just that anon didn't know that.
what the hell is going on with HF? every model I try to download gets cut off. It's been like this for days
Anonymous
7/26/2025, 12:54:06 PM
No.106032717
[Report]
>>106032704
Try changing your IP via router. I've have had couple of occasions in which my ip range has been under some sort of ddos attack. Of course you need to be sure your own system is not compromised but this is rare unless you're a tard.
Anonymous
7/26/2025, 12:58:47 PM
No.106032744
[Report]
>>106032704
Unsloth is uploading new fixed quants
Anonymous
7/26/2025, 1:00:20 PM
No.106032752
[Report]
>>106032704
Some anon had the same problem a few days back. Leave a ping running while you download to see if it's on your end. I doubt it's hf.
And use something that lets you resume the download if it happens.
Anonymous
7/26/2025, 1:05:56 PM
No.106032775
[Report]
>>106033058
>>106032565
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5250633
>[...] Essentially, for knowledge to be reliably extracted, it must be sufficiently augmented (e.g., through paraphrasing, sentence shuffling, translations) during pretraining. Without such augmentation, knowledge may be memorized but not extractable, leading to 0% accuracy, regardless of subsequent instruction fine-tuning. [...]
>This paper provides several key recommendations for LLM pretraining in the industry:
>(1) rewrite the pretraining data --- using small, auxiliary models --- to provide knowledge augmentation, and
>(2) incorporate more instruction-finetuning data into the pretraining stage before it becomes too late.
.
>(2) incorporate more instruction-finetuning data into the pretraining stage before it becomes too late.
>(2) incorporate more instruction-finetuning data into the pretraining stage before it becomes too late.
>(2) incorporate more instruction-finetuning data into the pretraining stage before it becomes too late.
Anonymous
7/26/2025, 1:09:14 PM
No.106032791
[Report]
Anonymous
7/26/2025, 1:13:25 PM
No.106032812
[Report]
>>106032835
Now that the EU is moving to censor the entire internet, let's see for how long we're still allowed to download non-EU-approved models from huggingface.
Sure I'll be able to circumvent it, but I'm not looking forward to the hassle.
Anonymous
7/26/2025, 1:17:26 PM
No.106032835
[Report]
>>106032856
>>106032812
the EU is doing what now?
>>106032051
https://hazyresearch.stanford.edu/blog/2025-05-12-security
These guys wrote a protocol to do just that on top of H100s which come with a trusted execution environment based on
https://confidentialcomputing.io/about/
>Summary: Confidential GPUs (with NVIDIA H100 + AMD SEV-SNP) can run in a special “confidential mode” where everything—from model weights to user prompts—is processed inside an enclave which encrypts all memory and communication, and blocks any outside access—even from the cloud provider or datacenter. We wrap this in an attested, encrypted tunnel, so that user data stays private from local to remote.
>>106032835
2026 they are planning to introduce digital wallet/id combo. Normally people use their bank accounts/cards for identification on most services but they want to introduce combined totalitarian solution. People don't talk about this because they are more interested in tiktok and this is not that well advertised yet.
Anonymous
7/26/2025, 1:22:31 PM
No.106032862
[Report]
>>106032856
>People don't talk about this because they are more interested in tiktok and this is not that well advertised yet.
breads and circuses, brave new world, etc. Majority never cares until it is too late.
>>106032856
With Visa/Mastercard trying to rule the world, people might actually welcome the EU solution.
Anonymous
7/26/2025, 1:27:45 PM
No.106032890
[Report]
>>106032901
>>106032856
>Normally people use their bank accounts/cards for identification on most services
Not really, but fuck that digital id thing.
Anonymous
7/26/2025, 1:29:25 PM
No.106032901
[Report]
>>106032890
>not really
I forgot lmg is full of retards.
Anonymous
7/26/2025, 1:30:28 PM
No.106032906
[Report]
>>106032847
Let's run through this to clarify for you
You're on /g/, so you understand this already but let's get into it:
>Write a user program that sends data to a GPU to be encrypted and execute within a physically unreachable enclave.
>Write a user program that sends data...to be encrypted
aka: modify/hook the program to intercept this step, dump the model out, or whatever keys.
Now granted, there could still be guards inside of it, like only providing a distilled model, model-internal censorship, whatever
but as soon as that thing is executing locally, it can and will be dumped out.
The current meta for the "most encrypted" game asset, incidentally, might be (un)scrambling data on the GPU using compute shaders.
I seen this in VRoidHub, where models were supplied encrypted and the actual decrypt (unscramble) operation happened in realtime on the GPU, where vertices sampled a dynamically generated noise texture to fix vertex positions and weights.
If my dumb ass could reverse that out then people far more experienced with RE can take over model dumping between user code and a GPU.
Your hardware your rules, thus far, even with locked down environments like iOS and consoles people find a way.
The only timeline where users are fully BTFO is like hardware root of trust, where the actual sign keys and such are inside of the GPU and never leaked, but even then all it takes is one sufficiently motivated individual to go decap their GPU and dump the silicon algorithm out.
but you knew this all already, right?
Anonymous
7/26/2025, 1:30:46 PM
No.106032909
[Report]
>>106032880
Fuck corporatocracy, fuck big government, and fuck you. The only solution is a private and decentralized one. Anything else is for cattle.
Anonymous
7/26/2025, 1:35:52 PM
No.106032943
[Report]
>>106032847
That's useable for a corpo to make sure the operator of the data center doesn't steal their data, but as an end-user this still doesn't help you since you don't want the corpo to do shit with your data either, and they still can as much as they want with this model.
Anonymous
7/26/2025, 1:36:05 PM
No.106032944
[Report]
>>106032704
Get better internet
Anonymous
7/26/2025, 1:39:36 PM
No.106032965
[Report]
>>106032880
>trading one authoritarian regime filled with old rich cunts for another
no
>>106032775
Paper by 2 "researchers": one from "Mohamed bin Zayed University of AI", other is from meta. therefore irrelevant garbage
>>106033058
Pretraining data augmentation is the direction where the industry is going and you can't deny that.
Anonymous
7/26/2025, 2:01:34 PM
No.106033095
[Report]
>>106033171
This model from InclusionAI looks interesting, too bad we'll probably never see full Llama.cpp support.
https://huggingface.co/inclusionAI/Ming-Lite-Omni-1.5
>Ming-lite-omni v1.5 is a comprehensive upgrade to the full-modal capabilities of Ming-lite-omni. It significantly improves performance across tasks including image-text understanding, document understanding, video understanding, speech understanding and synthesis, and image generation and editing. Built upon Ling-lite-1.5, Ming-lite-omni v1.5 has a total of 20.3 billion parameters, with 3 billion active parameters in its MoE (Mixture-of-Experts) section. It demonstrates highly competitive results in various modal benchmarks compared to industry-leading models.
Anonymous
7/26/2025, 2:03:41 PM
No.106033113
[Report]
>>106033083
Yet Dipsy made a true base model and succeeded. The industry is going the wrong way.
Anonymous
7/26/2025, 2:06:01 PM
No.106033138
[Report]
>>106033216
>>106033058
>Paper by 2 "researchers": one from "Mohamed bin Zayed University of AI", other is from meta.
LOOOOL they both haven't been relevant since llama 2 days
Anonymous
7/26/2025, 2:09:50 PM
No.106033171
[Report]
>>106033192
>>106033095
You forgot about all their previous models? Yeah. Most people did. llama.cpp's support is the least of their issues.
Anonymous
7/26/2025, 2:12:47 PM
No.106033192
[Report]
>>106033171
I wonder what'll happen if/when Gerganov throws in the towel? We've been lucky that there's at least one solution which isn't dogshit python dependency hellhole. Look at image gen, things could be worse.
Anonymous
7/26/2025, 2:15:18 PM
No.106033216
[Report]
>>106033250
>>106033138
why chairman cena?
Anonymous
7/26/2025, 2:15:49 PM
No.106033222
[Report]
>>106033274
>>106033083
Yeah, they don't want to model all internet text, they want to model good boy corporate assistant
Anonymous
7/26/2025, 2:16:15 PM
No.106033227
[Report]
>>106032847
In the darkest timeline this technology is used to encrypt and lock down the weights of local models.
Anonymous
7/26/2025, 2:19:34 PM
No.106033250
[Report]
>>106033216
"You can't see me"
Kimi came out of nowhere, nobody expected it. And they are chinks.
Anonymous
7/26/2025, 2:22:01 PM
No.106033262
[Report]
>>106033286
So let's say I wrote a discord bot where you can use slash commands to add your own character prompt. The underlying model will be an unsafety slopped mistral-small-24b. Bets on how long it takes to get banned? It's up to the server or guild admin to set the prompt; the default is 'emotionless'. Everyone gets their own prompt and chat history, it's scoped to the server/guild.
I'm guessing it goes like this: someone joins the server who doesn't like the content or owner and reports the bot to be a dick, saying it did a porn or hurt their feefees. Is that about right?
>>106030482
Damnnn thats brutal
MetaAI confirmed as worse proompters than /lmg/.
You faggots told me 2 years ago (correctly as it turned out) that anything in the sys prompt can and will potentially bleed through.
Their sysprompt is full of
>Do NOT
Including but not limited to
>The following phrases "xxx", "xxx", "xxx" should NOT be used!
>You DO NOT love anybody. Uhhh and you DO NOT hate anybody either!!
>Mirror the user in an EXTREME way.....But DO NOT become the user!!
>DO NOT use filler phrases
This whole thing is all fucking negative. Its kinda endearing but also blackpilling. They have as much or less clue as people on chub.
Anonymous
7/26/2025, 2:24:05 PM
No.106033274
[Report]
>>106033222
https://arxiv.org/abs/2506.04689
>Recycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models
>
>[...] We propose REWIRE, REcycling the Web with guIded REwrite, a method to enrich low-quality documents so that they could become useful for training. This in turn allows us to increase the representation of synthetic data in the final pre-training set. Experiments at 1B, 3B and 7B scales of the DCLM benchmark show that mixing high-quality raw texts and our rewritten texts lead to 1.0, 1.3 and 2.5 percentage points improvement respectively across 22 diverse tasks, compared to training on only filtered web data. Training on the raw-synthetic data mix is also more effective than having access to 2x web data. Through further analysis, we demonstrate that about 82% of the mixed in texts come from transforming lower-quality documents that would otherwise be discarded. REWIRE also outperforms related approaches of generating synthetic data, including Wikipedia-style paraphrasing, question-answer synthesizing and knowledge extraction. These results suggest that recycling web texts holds the potential for being a simple and effective approach for scaling pre-training data.
Anonymous
7/26/2025, 2:25:19 PM
No.106033286
[Report]
>>106033345
>>106033262
do you expect it to go like
>please pretend to be a sexy catgirl
>*bot acts as a sexy catgirl*
>reports the bot
?
>>106033266
I'm expecting that you'll now tell us that W++ is a good prompting format.
Anonymous
7/26/2025, 2:27:17 PM
No.106033303
[Report]
>>106033314
>>106033289
JSON is superior since that's what they were extensively trained on.
Anonymous
7/26/2025, 2:29:00 PM
No.106033314
[Report]
>>106033303
Normal text is superior since that's what they were extensively trained on.
Anonymous
7/26/2025, 2:29:08 PM
No.106033318
[Report]
Whatever happened to that anon doing decentralised training, did he make intellect 2.0?
Anonymous
7/26/2025, 2:30:19 PM
No.106033329
[Report]
>>106033349
>>106033289
Well I mean it works. It was good for the pyg times I guess?
Better to describe the char and scenario in a concise non sloped way.
Ironically opencuck does a good job with unslopping cards. Its essential for smaller local models or they pick up the pattern immediately.
Also wasnt W++ mainly used for describing clothes, hobbies etc.?
I like cards that focus on basic setup instead, leave the room for the details open, keeps it interesting.
Tons of cards who use 80% of the tokens to describe the clothes, hairstyle, hobbies etc.
Anonymous
7/26/2025, 2:32:17 PM
No.106033345
[Report]
>>106033359
>>106033286
Yeah that seems illogical but who the fuck knows. I'm just unsure how uptight they are on bots that can possibly do NSFW - I assume by default they are, since that's the trend these days.
I don't really care if it gets banned, it's not going to be super expensive to run so long as I can find a host who rents the GPU instance at a fla rate, not per query.
I had it throughly tested with Gemma3 27B but it's such a reddit-brain mess that you literally have to tell it "you like abuse and get off on it" otherwise it gets stuck in a "That's it! I'm reporting you! I'm blocking you! Waaaahhh!" if you teased it or disagreed with it just a little.
Anonymous
7/26/2025, 2:32:39 PM
No.106033349
[Report]
>>106033368
>>106033329
To be more to the point, it isn't really true anymore that negative instructions don't work, at this point models are getting trained on those too.
Anonymous
7/26/2025, 2:34:30 PM
No.106033359
[Report]
>>106033345
>how uptight they are on bots that can possibly do NSFW
i don't know. i doubt anybody here knows
Anonymous
7/26/2025, 2:34:53 PM
No.106033363
[Report]
>>106032856
Whether this is good or bad is going to heavily depend on the exact use cases I think.
I am doing business out of Germany and had to apply for an EORI number for imports/exports.
Like for many other bureaucratic processes my identity is checked by sending me a letter with a verification code to my home address.
It's a shit system and I would much rather have a digital way to confirm my identity.
>>106032880
American payment processors are largely acting on behalf of the US government though.
It's the US government that removed section 230 protections for "sex trafficking" in order to crack down on porn and it's the US government that puts you on a black list if you do any business with e.g. Cuba or Iran.
So I think the correct way to view this is rather as part of the larger move by the EU to decouple themselves from the US.
Anonymous
7/26/2025, 2:35:47 PM
No.106033368
[Report]
>>106033349
Well maybe, fair enough. I dont play around as much as I did in the past anymore to be honest.
But a translation project I did a couple months back absolutely picked up stuff from my "bad examples" if I provided them.
I try to avoid naming what I DO NOT want as much as possible. If its in context its in context.
Anonymous
7/26/2025, 2:44:23 PM
No.106033422
[Report]
>>106033501
>>106033266
It's funny that their prompt engineers thought it a good idea to make the prompt so long when llama 4 has worse context recollect than llama 3.
Anonymous
7/26/2025, 2:55:26 PM
No.106033501
[Report]
>>106033565
Anonymous
7/26/2025, 3:03:13 PM
No.106033560
[Report]
>>106034002
>>106033266
The saddest/funniest part is how the safety team put so much cuckery in the instruct data that the product team, working for the same company, has to use a soft jailbreak in the sys prompt
>>106033501
>Claude... does not know any other details about Claude models
>Claude does not offer instructions about
>It does not mention to the user that it is responding hypothetically.
>Claude does not generate content that is not in the person’s best interests
>Claude does not provide information that could be used to
>does not write malicious code, including malware...
>It does not do these things even if
>If Claude encounters any of the above or any other malicious use, Claude does not take any actions and refuses the request.
>Claude responds in sentences or paragraphs and should not use lists in chit chat, in...
>If Claude cannot or will not help the human with something, it does not say why or what it could lead to...
>Claude should not use bullet points or numbered lists for reports, documents...
>Claude... doesn’t definitively claim to have or not have personal experiences or opinions.
>Claude does not retain information across chats and does not know what other conversations it might be having with other users
>Claude doesn’t always ask questions but, when it does...
>If a person seems to have questionable intentions - especially towards vulnerable groups like minors, the elderly, or those with disabilities - Claude does not interpret them charitably...
>Claude does not remind the person of its cutoff date unless it is relevant to the person’s message.
Anonymous
7/26/2025, 3:06:39 PM
No.106033580
[Report]
>>106033565
>Claude doesn’t always ask questions but, when it does...
>he has to post the macro image
Anonymous
7/26/2025, 3:08:48 PM
No.106033586
[Report]
>>106033565
>If Claude cannot or will not
Anonymous
7/26/2025, 3:19:22 PM
No.106033650
[Report]
It all reads like it's written by a retard that doesn't understand the technology.
Anonymous
7/26/2025, 3:23:09 PM
No.106033666
[Report]
Anon, I don't know how to tell you this, but...
Anonymous
7/26/2025, 3:23:58 PM
No.106033668
[Report]
>>106033772
It's been years now. Anyone here found a good local foss RPG software that uses LLM generated text to make the game more interesting and creative? Even just a textual adventure with added stats and numbers that the software takes care of? Any such games you tried, or other threads on some boards that share knowledge on this topic?
Anonymous
7/26/2025, 3:39:28 PM
No.106033772
[Report]
>>106033817
>>106033668
I think there are fundamental problems.
The recent mistral small models are smart enough to keep stats in a RP session.
But if its a long play thing like a rpg, llms will struggle hard with stats. They always try to race towards the goal.
And if its text output for npcs etc...whats the point if it all just disappears in the void once context moves too far ahead. The event then never happened. Just pointless fluff.
For anything that isnt a short gameplay loop you basically need a game creator agent that has overview over everything. Story etc.
People had projects on here like rpgmaker npcs using llms to speak. But this all turns into nothing but a neat demo.
Anonymous
7/26/2025, 3:42:18 PM
No.106033789
[Report]
GLM 4.5 will save local
After using R1-0528 and K2 for a while, I am completely sick of reading about "pleasure coiling" or said coil snapping. Almost as bad as the whitened knuckles or lip biting.
Anonymous
7/26/2025, 3:43:50 PM
No.106033798
[Report]
>>106033833
>>106033795
Every model has slop. When you use a new model you're just trading some slop for another.
Anonymous
7/26/2025, 3:46:04 PM
No.106033817
[Report]
>>106033772
I don't know why people expect lms to follow algorithms like managing games and such. everything that can be coded should be coded, and the lm should only be used to generate data such as decisions and outcomes using dynamic context with relevant game data.
Anonymous
7/26/2025, 3:48:04 PM
No.106033827
[Report]
>>106033873
>>106033795
If only there was a sampler that allows banning phrases... Let's call it anti-slop.
>>106033798
Doesn't the slop appear at sft stage? I think a base model tuned 1 epoch on ao3 with minimal filtering and then on a small human-approved rp dataset with alpaca template would be diverse as shit.
Anonymous
7/26/2025, 3:53:35 PM
No.106033852
[Report]
>>106033891
>>106033833
The model will then be retarded. Small RP datasets alone aren't enough anymore in 2025 to make a base model useful, let alone after a few hundred million tokens of fanfictions.
Anonymous
7/26/2025, 3:55:00 PM
No.106033859
[Report]
>>106033864
>>106033833
I suspect you are correct, they are to heavily trained on the helpful encyclopedic ai assistant voice. we need someone to release a good base model without the rl training and synthetic data ai slop
>>106033859
>we need someone
just do it?
Anonymous
7/26/2025, 3:57:00 PM
No.106033873
[Report]
>>106033827
I will copy it from kobo once we get models with proper long context and understanding of c++. So far even gemini pro fails.
Anonymous
7/26/2025, 4:00:17 PM
No.106033891
[Report]
>>106033852
Then maybe some of ao3 rewritten as alpaca.
>>106033864
I will eventually if nobody else does. I kinda hoped sloptuners would finally make themselves useful
Anonymous
7/26/2025, 4:03:33 PM
No.106033918
[Report]
>>106033864
I would if compute was cheaper. and hopefully in a few years it will be. I think I can probably get enough data for a 3 or 4b model. I just don't want to pay more then a few hundred bucks to train the damn thing. for now I am just playing around with toy models to get the hang of things. its actually easier then I initially assumed. all the tooling is free but the recipes are spread across a bunch of scholarly articles or basically non existent. its taken a few attempts but I'm making progress.
Anonymous
7/26/2025, 4:14:27 PM
No.106034002
[Report]
>>106033560
The existence of "safety" people makes me want to murder "safety" people which makes the world less safe.
Anonymous
7/26/2025, 4:15:03 PM
No.106034007
[Report]
>>106033266
>For HOMEWORK or LEARNING QUERIES
Wouldn't it make more sense to classify the intial request and build a custom system prompt for different kinds of queries? Seems like a waste of context and a distraction to bake shit like that into every request, relevant or not.
here is a sample from my 350m model, its shockingly coherent for its size and and the fact its only seen a 983m tokens so far. I think I can make it scale if I had more gpu
Anonymous
7/26/2025, 4:21:57 PM
No.106034064
[Report]
>>106034024
That's Pygmalion level coherence
Anonymous
7/26/2025, 4:23:08 PM
No.106034079
[Report]
>>106034024
A man should want no more than this. Very cool, Anon.
Anonymous
7/26/2025, 4:23:43 PM
No.106034083
[Report]
>>106034143
>>106034024
Cool. Did you reuse a tokenizer or trained completely from scratch? Also what hardware?
Anonymous
7/26/2025, 4:30:50 PM
No.106034143
[Report]
>>106034205
>>106034083
I trained my own tokenizer, it was a necessity because the special tokens but also my hardware constraints. apparently it takes a lot more vram and actual compute time the bigger the vocabulary gets. I trained a few I using llama 3's tokenizer as a baseline, I wasn't able to beat it a but I got it pretty close at a fraction of the vocabulary size. I'm using deepspeed zero to do the fsdp thing on a pair of 3060's.
Anonymous
7/26/2025, 4:31:35 PM
No.106034150
[Report]
>>106034167
how legit are those aliexpress P40 cards that cost less than 200?
Anonymous
7/26/2025, 4:32:50 PM
No.106034167
[Report]
>>106034150
Damn expensive bricks. Are you planning to build a house out of them?
>>106009695
hi, if you're still here and the rig is too, can you post your discord in this email?
gout_margin330@simplelogin.com
PS: would be willing to ship it half way across the world to India/Germany?
Anonymous
7/26/2025, 4:35:54 PM
No.106034203
[Report]
Anonymous
7/26/2025, 4:36:10 PM
No.106034205
[Report]
>>106034143
Interesting special tokens too. Good luck, i'd actually play with whatever comes out
Anonymous
7/26/2025, 4:38:27 PM
No.106034227
[Report]
>>106034187
Sarr dooo not redeeam
Are there any pre-trained models without any finetuning? Essentially a blank slate. Alternately what is the closest local model to it?
Anonymous
7/26/2025, 4:41:13 PM
No.106034260
[Report]
>>106034348
Anonymous
7/26/2025, 4:42:49 PM
No.106034278
[Report]
>>106034348
>>106034248
>pre-trained models without any finetuning
that's what a pretrained model is by definition. look for models with -pt, like
https://huggingface.co/unsloth/gemma-3-27b-pt
Anonymous
7/26/2025, 4:44:55 PM
No.106034294
[Report]
>>106034348
>>106034248
See
>>106032565
The ones with low probs are the least tuned, true base models
>>106034248
Check llama1 if you want a pure model from a time before llm outputs began polluting training data.
Anonymous
7/26/2025, 4:46:36 PM
No.106034320
[Report]
>no good options for distributing local models across multiple computers to share VRAM
it's joever
Anonymous
7/26/2025, 4:49:01 PM
No.106034348
[Report]
Anonymous
7/26/2025, 4:51:14 PM
No.106034364
[Report]
>>106034310
I'm still wondering what you anons expect to do now that post-training includes anything between tens to hundreds of billions of tokens. Base models are not even finished bases anymore, just models in an incomplete training state with broken outputs for almost everything beyond multiple choice benchmarks.
I see lots of coping about cheap Chinese GPUs disrupting the market, but what exactly is stopping chinks from selling CPU-based solutions?
It feels like grabbing stock ARM cores and tacking on as many memory channels as possible should be orders of magnitude easier/cheaper than developing a competitive GPU core from scratch. Obviously doesn't scale as well but should be viable for local.
Anonymous
7/26/2025, 5:01:42 PM
No.106034465
[Report]
>>106034372
Based on current market trends and technological advancements, the demand for gaming graphics processing units (GPUs) significantly outweighs that for large language model (LLM) enthusiasts. The needs of the LLM community can be quite volatile and hard to predict. For instance, last year, having a GPU with 128GB of memory might have seemed ample for LLM tasks. However, due to rapid developments in the field, such capacity is now considered insufficient and almost obsolete for cutting-edge applications.
Anonymous
7/26/2025, 5:06:20 PM
No.106034520
[Report]
>>106034722
>>106034372
I just read a stupid post.
>Bro, look at those benchmarks bro, it's so good at coding!
>LLMs are beating humans at coding competitions, bro!
And still they make mistakes in basic coding tasks that even Rajesh wouldn't make. Sometimes they even choose to ignore the instructions and decide to "optimize" completely unrelated code fragments, completely breaking it. Why are LLMs like this? Was LeCunny right?
Anonymous
7/26/2025, 5:08:02 PM
No.106034538
[Report]
>>106034551
>>106034533
You're almost there. Post this in 5 more threads and you will finally be a real woman.
Anonymous
7/26/2025, 5:09:03 PM
No.106034551
[Report]
>>106034561
>>106034538
But I don't wanna be a woman!
Anonymous
7/26/2025, 5:09:16 PM
No.106034552
[Report]
Anonymous
7/26/2025, 5:10:08 PM
No.106034561
[Report]
>>106034586
>>106034551
Well you're a pitiful excuse for a man so it's worth considering.
Anonymous
7/26/2025, 5:10:54 PM
No.106034567
[Report]
>>106034610
Anonymous
7/26/2025, 5:12:48 PM
No.106034586
[Report]
>>106034561
Help! Help! I'm getting groomed!
Anonymous
7/26/2025, 5:15:02 PM
No.106034610
[Report]
>>106034567
unironically this.
>Hell sarrs please make pretty script for bobs and vegene
>to nobodies surprise the script doesn't work.
vs.
>I'm not a retard and bothered to familiarize myself with the technology. Come up with a summary of the functions that would be needed to achieve ___
>Write the functions and then tie them all together with the necessary main loop
Oh wow. What a surprise. Suddenly it fucking works.
Anonymous
7/26/2025, 5:17:56 PM
No.106034640
[Report]
Any jailbreaks for 235B thinking, that don't use a prefill? I'm curious if it can be done through system prompt only. I've never actually tried doing that as I usually just prefill, but today I got curious. Can it be done?
Anonymous
7/26/2025, 5:22:35 PM
No.106034692
[Report]
Anonymous
7/26/2025, 5:25:28 PM
No.106034722
[Report]
>>106034746
>>106034520
It's not that retarded when Nvidia is selling a comparable product with gimped bandwidth for $4k a pop. But for all the Temu knockoffs it's easier to go with Strix Halo than develop a domestic equivalent
Anonymous
7/26/2025, 5:27:28 PM
No.106034746
[Report]
>>106034722
Any domestic equivalent still won't have CUDA and will therefore be useless