/ldg/ - Local Diffusion General
Anonymous
8/5/2025, 8:35:22 AM
No.106146775
[Report]
>>106146762
could be, t2i in wan
Anonymous
8/5/2025, 8:35:51 AM
No.106146778
[Report]
>>106148187
Remember to help with the new wan2.2 rentry guide if you can:
https://hackmd.io/RDxlWe8mQCSUi72yUDEzeg?both
Anyone can edit.
>>106146749
Slightly better result
Anonymous
8/5/2025, 8:37:27 AM
No.106146787
[Report]
>>106146781
Arr rook the same
Anonymous
8/5/2025, 8:37:34 AM
No.106146789
[Report]
>>106146776
>Chinese product not as good as advertised
Are you surprised?
Anonymous
8/5/2025, 8:38:35 AM
No.106146794
[Report]
Blessed thread of frenship
What is with the obsession for text? Emad was obsessed with it too
Anonymous
8/5/2025, 8:42:41 AM
No.106146816
[Report]
>>106146375
Can't post any of my gens here but god dang it's pretty good, nice workflow
Anonymous
8/5/2025, 8:43:33 AM
No.106146820
[Report]
>>106146921
>>106146781
Alright, so my conclusion is that for photorealism it's at least an open source Mogao. Maybe there's a way to make it look even more photoreal, who knows.
Anonymous
8/5/2025, 8:43:40 AM
No.106146822
[Report]
>>106146879
Had to expand the canvas
Anonymous
8/5/2025, 8:45:11 AM
No.106146829
[Report]
>>106146802
Text = model capability!!
It's the easiest thing to fake by overlaying text on training images.
Anonymous
8/5/2025, 8:46:57 AM
No.106146839
[Report]
>>106146859
Feet pics also possible but slopped. And of course variance of lighting, pose etc... nowhere near as good as Chroma. Hence the crisp/clean/perfect looking girls. But just like Chroma anyways you can still get bad gens, like with
>>106146690
most were bad, though that's not an easy prompt.
Anonymous
8/5/2025, 8:48:23 AM
No.106146847
[Report]
>>106146802
new shiny "NEVA BEN DUN BEFO'!" type mentality.
Basically people who are only extremely superficially interested in image gen and only wants it for dumb meme shit rather than actually producing anything that normies would see and actually like/not realize was AI in the first place.
>>106146776
No idea in what way you're describing it being bad/worse than advertised but everything in the repo text-related looked extremely fried with all text looking extremely digitally super-imposed whenever it showed up.
Anyway as is the base model is useless(just like all base models wow who would have thought). The only important part is how well it takes to being finetuned - which, if the answer is even just "at all" - makes it strictly superior to FLUX shit in every single way.
Either way it's not worth caring about for now and the answer to if it's actually worth caring about or not will be a week to months away, probably.
Anonymous
8/5/2025, 8:49:58 AM
No.106146853
[Report]
>>106146860
Anonymous
8/5/2025, 8:51:00 AM
No.106146859
[Report]
>>106146839
Toes are fucked but I don't mind it otherwise
Anonymous
8/5/2025, 8:51:04 AM
No.106146860
[Report]
>>106146853
Could her hands actually fit in there?
Anonymous
8/5/2025, 8:51:37 AM
No.106146861
[Report]
>instantly crashes when trying to load the model
Welp. Back to wan with me.
Anonymous
8/5/2025, 8:52:32 AM
No.106146865
[Report]
>>106146936
>>106146375
Feels like the interpolation isn't as smooth on your workflow as the rentry, is there a way to go about that without replacing all the non-wanvideo samplers and shit with wanvideo equivalents like in the rentry? Other than that I really like it
Anonymous
8/5/2025, 8:55:19 AM
No.106146879
[Report]
>>106146822
Yeah, text has hiccups, but this if fp8 version so can't tell for sure
Anonymous
8/5/2025, 8:56:27 AM
No.106146884
[Report]
Anonymous
8/5/2025, 8:59:02 AM
No.106146896
[Report]
>>106146904
>>106146892
>no chest
Could you imagine if femboys actually looked like this
Anonymous
8/5/2025, 8:59:54 AM
No.106146903
[Report]
>>106146943
>>106146892
This is a man, right?
Anonymous
8/5/2025, 8:59:59 AM
No.106146904
[Report]
>>106146943
>>106146896
idk why its not giving me big tiddies, maybe i have to prompt for them, prolly cause chinese people dont have tits really
and yeah, thats what they think they look like lol
Anonymous
8/5/2025, 9:00:17 AM
No.106146907
[Report]
>post censored video gens on other boards
>keep getting asked for uncensored/catbox
>never post it
Anonymous
8/5/2025, 9:01:29 AM
No.106146914
[Report]
So what's this?
Anonymous
8/5/2025, 9:02:05 AM
No.106146919
[Report]
>>106146933
Qwen fucking crashes my comfy before it can even try to offload. Aren't there any nodes for this?
Anonymous
8/5/2025, 9:02:26 AM
No.106146921
[Report]
>>106146820
Loras for sure, but it's a very large model, not sure how many will spend the effort when you might as well train Wan image loras which will have higher reach
Barring some vital information I'm missing. I think I might actually dislike this model.
Anonymous
8/5/2025, 9:03:56 AM
No.106146928
[Report]
>>106148513
Is lightx2v 2.2 still shit?
Anonymous
8/5/2025, 9:04:38 AM
No.106146931
[Report]
Anonymous
8/5/2025, 9:04:40 AM
No.106146933
[Report]
>>106146942
>>106146919
multiGPU has an option for virtual VRAM which is better than the native offloading functions in comfy
Anonymous
8/5/2025, 9:05:10 AM
No.106146935
[Report]
Anonymous
8/5/2025, 9:05:22 AM
No.106146936
[Report]
>>106148360
>>106146865
I don't think their workflow has any interpolation. I'm testing it now, and have added a RIFE VFI node as the base gens were 16fps.
Anonymous
8/5/2025, 9:06:06 AM
No.106146942
[Report]
>>106146933
But that's only for gguf. You can't put safetensors in it.
Anonymous
8/5/2025, 9:06:07 AM
No.106146943
[Report]
>>106146903
>>106146904
doesnt seem to react to 'very large breasts' lol...
Anonymous
8/5/2025, 9:07:44 AM
No.106146960
[Report]
>>106147734
qwen image is fun in the same way flux is fun. But I already have flux. And it runs better. So what is the appeal in this model?
Anonymous
8/5/2025, 9:13:32 AM
No.106146986
[Report]
>>106146925
Yeah, after testing it, nowhere near as good as Chroma. If I want clean images that follow prompt really well I can just use Wan 2.2 t2i, and that would be more realistic too. It's not good at styles nor artists which would've made it good enough to use for those purposes alone. It's hard to tell if this model even is better than Flux. It probably is, but just not enough to justify its size after the release of Chroma and Wan 2.2. This was probably meant to be a commercial product, the only reason it's open sourced is because it sucks and the creators realized it.
Then again, the editing model could change my outlook on the model. Let's hope they're not bluffing those stats too.
Anonymous
8/5/2025, 9:14:06 AM
No.106146988
[Report]
>>106147000
Anonymous
8/5/2025, 9:16:17 AM
No.106147000
[Report]
>>106147071
>>106146988
100% trained using synthetic 4o slop.
Anonymous
8/5/2025, 9:16:35 AM
No.106147002
[Report]
Anonymous
8/5/2025, 9:17:05 AM
No.106147006
[Report]
Anonymous
8/5/2025, 9:17:26 AM
No.106147007
[Report]
Can I fit qwen fp16 into a 48GB GPU with clip offloading?
Anonymous
8/5/2025, 9:17:49 AM
No.106147010
[Report]
>this thread
This is why /adt/ will always have it's place.
Anonymous
8/5/2025, 9:18:03 AM
No.106147013
[Report]
>>106147047
>>106146983
>sdxl is fun but i already have 1.5 and it runs better!
you are now realizing local is forced into stagnation because local hardware has not kept up with model developments. these models generate in <10 seconds on saas btw
Anonymous
8/5/2025, 9:18:14 AM
No.106147017
[Report]
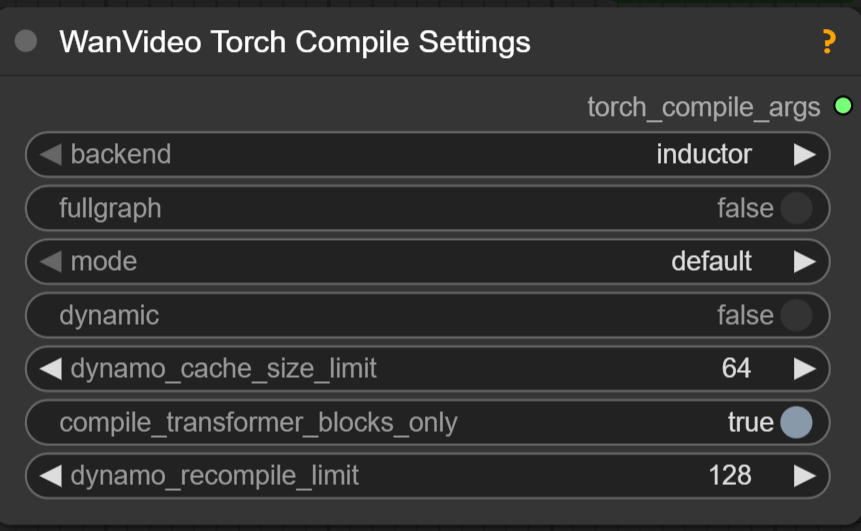
I get the same times with or without torchcompile when genning wan2.2 (without lightx), can someone confirm if it's the same with them?
On a 3090 with cuda 12.8.
Anonymous
8/5/2025, 9:19:25 AM
No.106147022
[Report]
Wan 2.2 handles emotion prompts well. It seems to obey camera movements a little more too.
Anonymous
8/5/2025, 9:21:54 AM
No.106147035
[Report]
Bruhs this model is trash.
Anonymous
8/5/2025, 9:23:14 AM
No.106147043
[Report]
Anonymous
8/5/2025, 9:23:37 AM
No.106147045
[Report]
Pure slop posting.
>>106147013
This model is not an objective upgrade though. It's trading one piece of slop for another. Good would mean SOTA out of the box at something. I don't get that sense from this model.
Anonymous
8/5/2025, 9:25:40 AM
No.106147051
[Report]
>>106147047
There might be something worth using from the image editing model, but they didn't release that.
Anonymous
8/5/2025, 9:27:33 AM
No.106147060
[Report]
>>106147271
>>106147047
only Sam GODman knows how to cook image models.
Anonymous
8/5/2025, 9:29:56 AM
No.106147070
[Report]
>>106147163
If I dumped booru tagged dataset into a chroma lora trainer, would you still be able to conjure it with the trigger words?
Anonymous
8/5/2025, 9:29:57 AM
No.106147071
[Report]
>>106147000
I can see the orange hue on some of the outputs, there is no doubt.
Anonymous
8/5/2025, 9:30:59 AM
No.106147077
[Report]
>>106147047
This. Huge image only model, still not beating Wan at images despite it being a video model.
Anonymous
8/5/2025, 9:31:06 AM
No.106147079
[Report]
>>106147066
OpenAI's advantage is data, they have an army of Kenyans for annotations.
Data is the only thing that matters. SD v1's UNet is good enough if you have good data.
>Good would mean SOTA out of the box at something.
So we're ignoring the text?
Anonymous
8/5/2025, 9:33:32 AM
No.106147097
[Report]
FOUR MORE YEARS OF SDXL!!!!
Anonymous
8/5/2025, 9:34:06 AM
No.106147100
[Report]
Anonymous
8/5/2025, 9:34:17 AM
No.106147101
[Report]
>>106147113
>>106147094
With the image quality it's good only for shitty memes.
Anonymous
8/5/2025, 9:34:40 AM
No.106147106
[Report]
>>106147113
>>106147094
>So we're ignoring the text?
You mean the text that looks like shit? If I wanted overlaid text I'd add it myself in mspaint.
Can these tools be run on Intel ARC GPUs? Is there some kind of translation layer if they can't be run with some native ARC support or something? Help a newfag out.
Anonymous
8/5/2025, 9:36:02 AM
No.106147111
[Report]
>>106147101
>>106147106
>and other things said about flux
Anonymous
8/5/2025, 9:36:16 AM
No.106147115
[Report]
>>106147271
very poor image variety.
Anonymous
8/5/2025, 9:36:42 AM
No.106147117
[Report]
>>106147066
How does he do it? Seems only he has a dataset that's properly labeled. Everyone gets scraps from him.
Anonymous
8/5/2025, 9:36:47 AM
No.106147119
[Report]
>>106147113
Nigga it's the same type of slop.
Anonymous
8/5/2025, 9:37:14 AM
No.106147121
[Report]
>>106147113
Yes because it's just Flux architecture with increased dimensions
Anonymous
8/5/2025, 9:39:45 AM
No.106147133
[Report]
Has the wan meta changed over the past 48 hours? Or is the best workflow still kijai's using the 2.1 lightx2v?
I saw some videos using the 2.2 lightx2v t2v and they look like this for i2v gens.
Anonymous
8/5/2025, 9:42:17 AM
No.106147147
[Report]
>>106147153
>>106147107
Yes, but in Ubuntu. ComfyUI has integrated support, but only in core nodes.
Anonymous
8/5/2025, 9:43:36 AM
No.106147153
[Report]
>>106147196
>>106147147
Intel GPU work on Windows.
Anonymous
8/5/2025, 9:44:02 AM
No.106147156
[Report]
>>106147177
>>106147066
kek, knows two artstyles (all piss yellow) and five poses
>b-b-but it does text well
wow
> crying with tears
why tf are they goopy
Anonymous
8/5/2025, 9:45:13 AM
No.106147163
[Report]
Anonymous
8/5/2025, 9:46:52 AM
No.106147176
[Report]
>>106147161
too much the eyes of cum
Anonymous
8/5/2025, 9:46:59 AM
No.106147177
[Report]
>>106147156
Uncensored Dalle 3 at release goes to show you what happens when they actually try. Unfortunately 4o is censored after the fact, so that's not what it's objectively capable of.
Anonymous
8/5/2025, 9:49:46 AM
No.106147196
[Report]
>>106147153
Didn't know that. Linux is better anyway.
Anonymous
8/5/2025, 9:57:24 AM
No.106147245
[Report]
>>106147273
Qwen feels like absolute benchmaxxed slop. I cannot think of a better way to describe it. There is zero inspiration behind the model.
People need to seriously consider doing away with benchmarks entirely. It's hurting everything.
Anonymous
8/5/2025, 10:02:26 AM
No.106147271
[Report]
>>106147115
>>106147060
These are all different seeds and they legitimately have the same bamboo in each one.
Anonymous
8/5/2025, 10:02:33 AM
No.106147273
[Report]
>>106147245
lodestone please
qwen image
8/5/2025, 10:07:57 AM
No.106147305
[Report]
>>106147899
"An anime girl with blonde hair and blue eyes wearing a suit and high heels holding a sign that reads Hello 4chan"
Anonymous
8/5/2025, 10:08:09 AM
No.106147307
[Report]
>>106147300
best gen so far kek
Anonymous
8/5/2025, 10:09:11 AM
No.106147318
[Report]
>>106147300
I wonder if the word 'slop' shows up in the training data enough to influence the gen
>>106147300
Should be benchi suroppu rather than ban suroppu.
The text on top of white rectangle is even worse lol.
Can't even do shit it is supposed to excel at.
>>106147326
>white rectangle
>white
Anonymous
8/5/2025, 10:13:14 AM
No.106147345
[Report]
>>106147330
I assume that's the color whatever text encoder this thing uses decided that should be added there before piss filter kicked in during diffusion process.
Anonymous
8/5/2025, 10:14:40 AM
No.106147353
[Report]
>>106147394
I'm not crazy right. Some of these images clearly have the 4o piss filter.
Anonymous
8/5/2025, 10:15:02 AM
No.106147356
[Report]
>>106147326
> Should be
only 1 in 1000000000 will notice
Anonymous
8/5/2025, 10:15:33 AM
No.106147361
[Report]
>>106147330
>Yes, we trained on GPT 4o images, how could you tell ?
Anonymous
8/5/2025, 10:19:30 AM
No.106147394
[Report]
>>106147353
You are crazy but you are correct, Qwen is piss slop.
Anonymous
8/5/2025, 10:21:06 AM
No.106147402
[Report]
>>106147363
https://files.catbox.moe/xo51uc.png
Prompted to be nude.
Those nipples are not looking good...
Anonymous
8/5/2025, 10:23:37 AM
No.106147423
[Report]
>>106147431
>Orange lamp? I don't know what you mean.
Anonymous
8/5/2025, 10:24:30 AM
No.106147431
[Report]
>>106147423
Even the fucking glass is orange
Anonymous
8/5/2025, 10:26:22 AM
No.106147447
[Report]
>>106147451
>>106147363
>big bro has a ponytail
>>106147447
Typical of steroid users before they go bald.
Anonymous
8/5/2025, 10:27:33 AM
No.106147452
[Report]
China won
Anonymous
8/5/2025, 10:27:41 AM
No.106147454
[Report]
Qwen will have the same uptake as HiDream, as in practically zero
>>106147451
Can you prompt it the chinese negative prompt copypasta? This is from wan.
Anonymous
8/5/2025, 10:29:26 AM
No.106147468
[Report]
>>106147470
>>106147460
The Wan negative prompt?
Anonymous
8/5/2025, 10:30:01 AM
No.106147470
[Report]
>>106147510
>>106147468
Yeah, just slap into positive
Anonymous
8/5/2025, 10:30:28 AM
No.106147474
[Report]
Would you believe me if I told you these were completely different seeds with one word changed?
>>106147451
Anonymous
8/5/2025, 10:32:37 AM
No.106147493
[Report]
>>106147507
Before I shit on qwen further. Is it possible there is an issue with the quantization?
Anonymous
8/5/2025, 10:33:16 AM
No.106147497
[Report]
>>106147507
>>106146763 (OP)
using the ldg fast i2v workflow for wan2.1. any reason i would be getting some really shitty colorful artifacts everywhere when setting cfg in the adaptive guider higher than 3?
also, anyone able to get dicks to not look like an alien scifi prop?
>>106147493
I've been thinking it might be a not enough verbose prompt and it needs a wall of text to let go properly, but there's legit tonfo orange slop in it.
>>106147497
>2.1
Wake up grandpa and get 2.2
Anonymous
8/5/2025, 10:35:16 AM
No.106147510
[Report]
Anonymous
8/5/2025, 10:36:19 AM
No.106147515
[Report]
>>106147507
>Wake up grandpa and get 2.2
the fast workflow is built with safetensors, not the ggufs
>>106147507
It's just this is supposedly a q4 gguf test I found on hugging face. It makes me wonder if some of the shittyness I'm seeing is a result of the compression being bad.
Anonymous
8/5/2025, 10:37:49 AM
No.106147524
[Report]
>>106147161
>there's no such thing as too much lub-ACK
Anonymous
8/5/2025, 10:38:11 AM
No.106147530
[Report]
>>106147540
>>106147519
Where the fuck did you get Q4?
what's the best low-step lora for illustrious type models? need one for fast prototyping
Anonymous
8/5/2025, 10:38:28 AM
No.106147535
[Report]
>I'll try prompting in English translated to Chinese, that's a good trick
Anonymous
8/5/2025, 10:39:34 AM
No.106147540
[Report]
>>106147530
Just a test I saw in a discussion on hugging face.
>>106147537
Looks like she has an extra finger. But the text looks pretty consistent.
Anonymous
8/5/2025, 10:41:28 AM
No.106147550
[Report]
First run after adding more prompts and more layers
Why is the frog so unhinged?
>>106147534
Sorry anon, we're too busy seething over a free model a company likely spent millions of dollars to train.
wan2.2 on 8gb vram doable?
Anonymous
8/5/2025, 10:45:05 AM
No.106147567
[Report]
>>106147574
>>106147560
Spending millions of dollars on a white elephant doesn't make it useful.
Anonymous
8/5/2025, 10:45:20 AM
No.106147568
[Report]
>>106147534
>low-step lora for illustrious
Illustrious
>>106147567
I cant help but feel like I'm missing something important with this model.
Anonymous
8/5/2025, 10:47:00 AM
No.106147577
[Report]
>>106147582
>>106147574
You're missing the fact that it's Chinese piss slop.
Anonymous
8/5/2025, 10:47:39 AM
No.106147581
[Report]
>>106147593
>>106147566
Probably, but the quantization needed is likely going to kill quality.
Anonymous
8/5/2025, 10:47:42 AM
No.106147582
[Report]
>>106147577
No, I definitely didn't miss that.
Anonymous
8/5/2025, 10:48:19 AM
No.106147586
[Report]
>>106147537
>aces the text
>completely fails the hand
sums of the last year and a half of imagegen pretty nicely
I was trying to play around with Qwen image but my images come out entirely black. The preview looks good but after like 10 steps it just turns entirely black.
Any ideas what the fuck is going on?
Anonymous
8/5/2025, 10:49:08 AM
No.106147593
[Report]
>>106147628
>>106147581
what if i wanna make animated sticker gifs?
>>106147591
Yes. Turn off --fast and --use-sage-attention. It's one of those. I haven't bothered to test which.
Anonymous
8/5/2025, 10:52:01 AM
No.106147606
[Report]
>>106147637
>>106147574
The editing model MIGHT be good, unless it covers the entire output with piss and plastic skin.
Anonymous
8/5/2025, 10:54:11 AM
No.106147616
[Report]
>>106146925
wonder if its actually better with chinese prompts, anyone try that yet? A/B comparison with google translate
Anonymous
8/5/2025, 10:54:52 AM
No.106147622
[Report]
Anonymous
8/5/2025, 10:56:20 AM
No.106147628
[Report]
>>106148214
>>106147593
I mean sure, just wait for Wan 2.2 q4 versions to pop up, maybe they already have ?
Anonymous
8/5/2025, 10:57:06 AM
No.106147636
[Report]
>>106147591
>>106147602
I have both on and it works most of the time but I did get a few black images. So they don't totally break it. Maybe a combination of something involving those.
Anonymous
8/5/2025, 10:57:19 AM
No.106147637
[Report]
>>106147606
>editing model
The dataset will be from 4o.
Anonymous
8/5/2025, 10:59:07 AM
No.106147645
[Report]
>>106147653
Surely openAI notices a single IP in China or a very random country demanding millions of images.
Anonymous
8/5/2025, 11:00:08 AM
No.106147648
[Report]
>>106147748
Does not understand reflecting in the sunglasses.
Anonymous
8/5/2025, 11:00:49 AM
No.106147653
[Report]
>>106147675
>>106147645
Using their outputs for training is against TOS but they don't care, it's free marketing because everyone recognizes the piss.
Anonymous
8/5/2025, 11:02:01 AM
No.106147658
[Report]
qwen image is good
chinks continue to carry open source AI on their backs
glory to the CCP
Anonymous
8/5/2025, 11:03:44 AM
No.106147666
[Report]
Anons, just put "sepia" in negative and never think about it again. That's literally all it takes with this and every other piss filtered model.
Anonymous
8/5/2025, 11:04:16 AM
No.106147669
[Report]
Mmm sloppy.
Anonymous
8/5/2025, 11:05:06 AM
No.106147675
[Report]
>>106147680
>>106147653
Nobody is going to sue over this, because it would open a HUGE can of worms, you saying other people can't use your model images for training while using billions upon billions of images you do not have permission to train on, that's going to be a very unpleasant court case for big tech, since there's no way it can be legally enforceable.
So they will all gladly use generated images from eachother for training, with no fear of legal reprisal.
Anonymous
8/5/2025, 11:06:27 AM
No.106147680
[Report]
>>106147706
>>106147675
Nobody is going to sue over this because they are in China and they are not subject to the cooky zany rules of the US.
Anonymous
8/5/2025, 11:08:31 AM
No.106147686
[Report]
If this model was released even a few months ago you'd all be jizzing right now.
Anonymous
8/5/2025, 11:10:40 AM
No.106147696
[Report]
Anonymous
8/5/2025, 11:11:22 AM
No.106147698
[Report]
>>106147689
I am jizzing over it right now, people here are just addicted to misery. Or coomers who will be eternally disappointed by models not being able to do bobs and vagene out of the box.
Anonymous
8/5/2025, 11:11:46 AM
No.106147703
[Report]
>>106147689
BEAGHGAHGAHGHAGA
Anonymous
8/5/2025, 11:12:44 AM
No.106147706
[Report]
>>106147680
All the western models are training off eachothers output as well, nobody will sue because it would A) lose B) put a spotlight on the hypocrisy
Anonymous
8/5/2025, 11:14:19 AM
No.106147711
[Report]
>20gb
not local. we need sub 1b models for everything
Anonymous
8/5/2025, 11:19:16 AM
No.106147734
[Report]
Anonymous
8/5/2025, 11:20:04 AM
No.106147741
[Report]
Can anyone make a comparison of the motion difference between lightx2v and non-lightx2v? Is there really always a slowmotion effect with lightx2v?
Anonymous
8/5/2025, 11:20:48 AM
No.106147748
[Report]
>>106147782
>>106147648
Workflow/prompt for this?
Anonymous
8/5/2025, 11:23:28 AM
No.106147772
[Report]
>>106147729
I'm running it locally on a used 3090, a card which came out in 2020, half a decade ago. And I'm on disability and poor, I saved up for months to buy it. If I can have one you've got no excuse.
Anonymous
8/5/2025, 11:24:18 AM
No.106147776
[Report]
>heh this model sucks its just another flux!
>running 4step q2lightningfastgguf BTW
Anonymous
8/5/2025, 11:25:22 AM
No.106147782
[Report]
>>106147748
It's just qwen image default workflow. The prompt is exactly what you see except it should be reflecting in her glasses, not a giant mirror on the front of her bike.
>>106147689
the only people seething are the same who seethe at chroma and any other model that simply either cant run on their laptop 3060 at all or needs 5 minutes to do so, every time
Anonymous
8/5/2025, 11:30:52 AM
No.106147811
[Report]
>>106147560
a free turd is still a turd
these companies want all the glory with none of the safety risk of making it usable out of the box
you should be critical of them so that they see that the bar has risen and they cant just train on complete garbage data and expect everyone to suck them off
Anonymous
8/5/2025, 11:31:18 AM
No.106147815
[Report]
>>106147805
and btw those same people then say that everything is stagnant (because for their 3060 which cant run anything new, it is)
>>106147805
>please ignore the yellow piss filter
Anonymous
8/5/2025, 11:33:39 AM
No.106147825
[Report]
Anonymous
8/5/2025, 11:34:10 AM
No.106147830
[Report]
>>106147824
sepia in negative
Anonymous
8/5/2025, 11:37:41 AM
No.106147845
[Report]
It's starting to think I may have been overly critical of the model.
Anonymous
8/5/2025, 11:37:48 AM
No.106147846
[Report]
>>106151898
>>106147560
The problem is that it's an also-ran at this point, it can compete with Kontext and win, but it's not as if Kontext is good for anything but quick memes.
Add to this that it is huge and slow, and censored, and suffers from the 'plastic uncanny look because we've trained on gazillions of synthetic data', the latter can be mitigated through loras, but why would you bother ? For the slightly improved text rendering ?
It's another DOA model, like HiDream, SD3.
Anonymous
8/5/2025, 11:37:50 AM
No.106147847
[Report]
>>106147824
Only some images push towards it slightly and rarely but the model isnt anywhere near closedai constant and obvious piss filter
This model is for text and image editing, if you want tranime use noob/illust, if you want realism use chroma, you dont have to actually use only 1 model for everything
vramletretards... your time will come soon with svdq...
there is also
>Thanks to DFloat11 compression, Qwen-Image can now run on a single 32GB GPU, or on a single 16GB GPU with CPU offloading, while maintaining full model quality
https://huggingface.co/DFloat11/Qwen-Image-DF11
Anonymous
8/5/2025, 11:48:14 AM
No.106147899
[Report]
Anonymous
8/5/2025, 11:54:49 AM
No.106147920
[Report]
>>106146763 (OP)
>2.2 Guide: https://rentry.org/wan22ldgguide
ldg_cc_t2v_14b_480p.json
just leads to a blank file, anyone have that workflow?
Anonymous
8/5/2025, 11:55:58 AM
No.106147925
[Report]
>>106147930
https://strawpoll.com/e6Z2Azw1qgN
Thoughts on Qwen image now that we can use it.
Anonymous
8/5/2025, 11:56:56 AM
No.106147930
[Report]
>>106147940
>>106147925
>now that we can use it
90% of the thread doesn't even have 24GB VRAM, lmao.
Anonymous
8/5/2025, 11:57:11 AM
No.106147932
[Report]
Anonymous
8/5/2025, 11:58:12 AM
No.106147940
[Report]
>>106147945
>>106147930
How the fuck is that MY problem?
Anonymous
8/5/2025, 11:58:53 AM
No.106147942
[Report]
>>106147948
Made this for a coombait thread on /v/ but forgot to post it before going to bed, u can have it.
Anonymous
8/5/2025, 11:59:23 AM
No.106147945
[Report]
>>106147952
>>106147940
You used "we" and you gave a poll which is worthless given the fact I outlined.
Anonymous
8/5/2025, 11:59:49 AM
No.106147948
[Report]
>>106147942
Sorry. Image generation has made me numb to all but the most depraved stuff. Not even a twitch.
Anonymous
8/5/2025, 12:00:06 PM
No.106147949
[Report]
1girl
Anonymous
8/5/2025, 12:00:50 PM
No.106147952
[Report]
>>106147973
>>106147945
Oh sorry you're right. Let me clarify it with the fact I don't consider vramlets human.
Anonymous
8/5/2025, 12:03:39 PM
No.106147971
[Report]
>good at text
>low seed variability
>slopped
Qwen image is literally HiDream 2.0. It will be forgotten in a week like HiDream did. Screencap this.
Anonymous
8/5/2025, 12:03:49 PM
No.106147973
[Report]
>>106147952
Given that there is no vramlet test before the poll can be voted on, there is no way to differentiate between them, meaning the poll is worthless.
It's just another bloated image model.
We won't use it.
SDXL currently has the largest community, the most support, and the greatest artistic variety.
Things are moving too fast to choose and train a model from scratch.
Even if all of CivitAI, Tensor, Pix, and Sea decided to train Qwen, the time spent training it would be meaningless because 200 new, better image generator models will be released.
Anonymous
8/5/2025, 12:05:43 PM
No.106147989
[Report]
Anonymous
8/5/2025, 12:07:52 PM
No.106148001
[Report]
Anonymous
8/5/2025, 12:08:30 PM
No.106148003
[Report]
>>106148095
>>106147986
>200 new, better image generator models will be released.
And you'll hate all of them, and declare each one DOA on the same day it's released.
Anonymous
8/5/2025, 12:08:59 PM
No.106148006
[Report]
>>106148018
Anonymous
8/5/2025, 12:12:09 PM
No.106148018
[Report]
Anonymous
8/5/2025, 12:16:13 PM
No.106148035
[Report]
>>106148128
>>106147986
You say that like SDXL users have a choice in what model they use. Do you know how many vramlets there are out there?
Anonymous
8/5/2025, 12:17:14 PM
No.106148041
[Report]
>>106147986
SDXL was declared dogshit the minute it released, too. And now look where we are.
Anonymous
8/5/2025, 12:19:37 PM
No.106148051
[Report]
Anonymous
8/5/2025, 12:21:30 PM
No.106148064
[Report]
Anonymous
8/5/2025, 12:22:01 PM
No.106148067
[Report]
>>106148048
because it was dogshit and it took an eternity from release to make it somewhat ok
>1328x1328
but why this number
Anonymous
8/5/2025, 12:25:30 PM
No.106148089
[Report]
>>106148082
i don't know who that is, and that's not an appropriate username to use on the internet
Anonymous
8/5/2025, 12:27:52 PM
No.106148095
[Report]
>>106148003
you and retarded apologists like yourself are the reason why they dont feel the need to improve their models on release, enjoy your synthetic slop every time because thats what they are comfortable with
Anonymous
8/5/2025, 12:30:50 PM
No.106148110
[Report]
>>106148191
Anonymous
8/5/2025, 12:32:06 PM
No.106148117
[Report]
>>106148172
>>106148108
Yeah nah I'm not touching that shit until I'm 100% sure whatever improvements it brings outway the issues it will cause 10 fold.
Anonymous
8/5/2025, 12:34:10 PM
No.106148128
[Report]
>>106148048
I understand, but this is different. It wasn't the era of private models hosted in the cloud, and there weren't large communities formed around SDXL like there are today and as this anon
>>106148035 says. VRAMlets are what really drive the image community. In the grand scheme of things, all these new models don't make meaning and sense because SDXL is what continues to generate revenue and is easy to train and keep up to date and is what keeps the community engaged
We need cross-compatibility if we want to see real change and not a "single-use" model until the next, better, newer one comes along.
Anonymous
8/5/2025, 12:35:11 PM
No.106148131
[Report]
>>106148108
Cudaschizo...
Anonymous
8/5/2025, 12:35:53 PM
No.106148141
[Report]
>>106148078
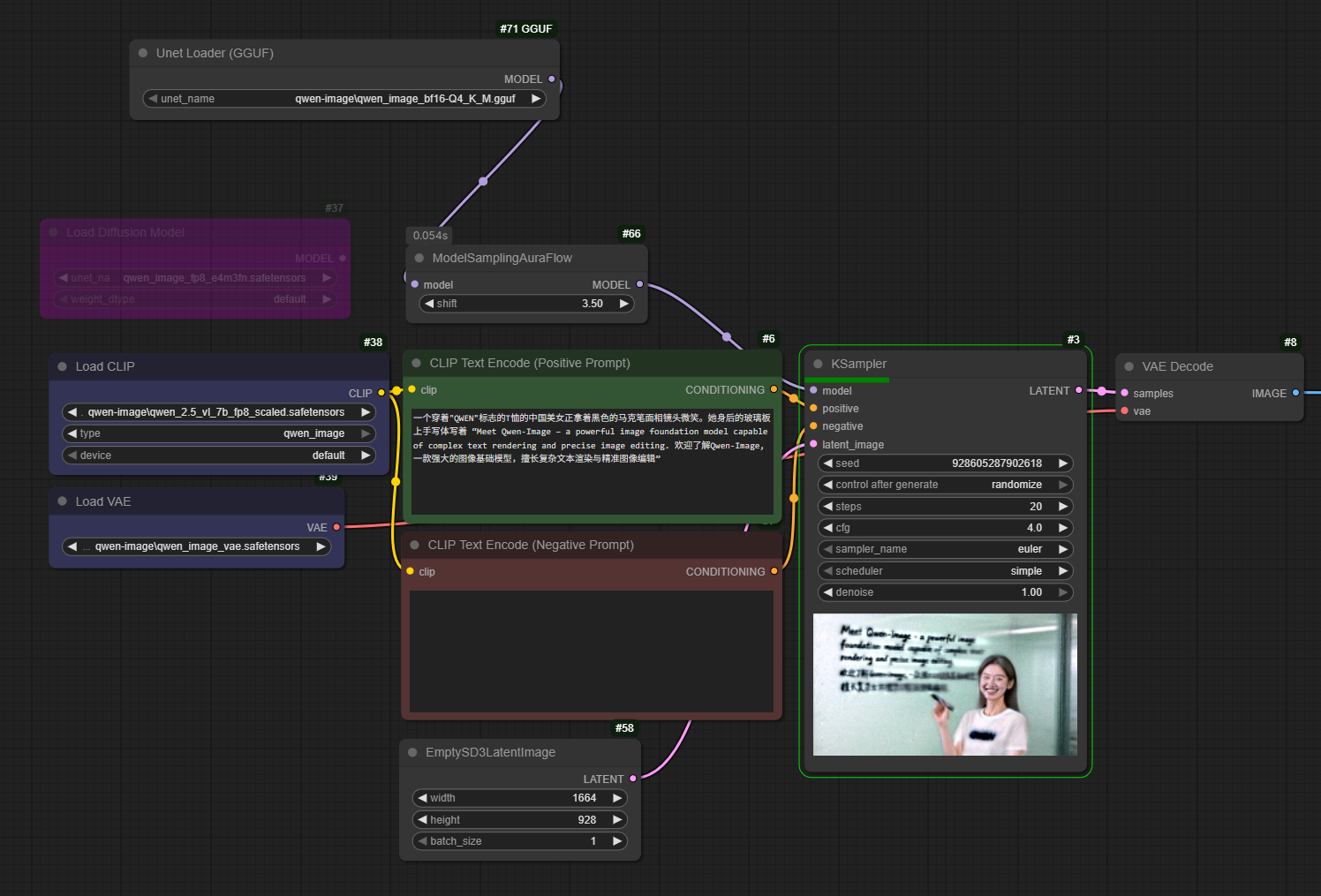
That's one of the recommended resolutions for the Qwen image model.
"1:1": (1328, 1328)
"16:9": (1664, 928)
"9:16": (928, 1664)
"4:3": (1472, 1140)
"3:4": (1140, 1472)
Anonymous
8/5/2025, 12:40:15 PM
No.106148172
[Report]
>>106148108
this
>>106148117
They always fuck their new release three to four times before they get it right.
Anonymous
8/5/2025, 12:41:42 PM
No.106148180
[Report]
Anime style to this model is just 1.5 face.
Anonymous
8/5/2025, 12:43:02 PM
No.106148187
[Report]
>>106148329
>>106146778
>/ldg/ Comfy T2V 480p workflow (bullerwins): ldg_cc_t2v_14b_480p.json %darkseagreen%(updated 2nd August 2025)%%
leads to an empty file
Anonymous
8/5/2025, 12:44:27 PM
No.106148191
[Report]
>>106148082
It's on Qwens's example code. Is there some official list of supported resolutions? I've gone all the way up to 2kx2k and it seems to maintain coherency.
>>106148110
Damn why is she scratching her leg like that?
Qwen seems alright, probably needs a finetune though.
Anonymous
8/5/2025, 12:46:37 PM
No.106148214
[Report]
Anonymous
8/5/2025, 12:49:12 PM
No.106148233
[Report]
>I'm using Q4-
You didn't run it.
Anonymous
8/5/2025, 12:51:28 PM
No.106148246
[Report]
Anonymous
8/5/2025, 12:55:36 PM
No.106148282
[Report]
Anonymous
8/5/2025, 12:59:16 PM
No.106148316
[Report]
>>106148640
Anonymous
8/5/2025, 1:00:27 PM
No.106148328
[Report]
>have to do fucking racial profiling for wan gens because If I don't specify the race it keeps giving me some mixed meat
Thank /pol/
Anonymous
8/5/2025, 1:00:28 PM
No.106148329
[Report]
Anonymous
8/5/2025, 1:01:16 PM
No.106148335
[Report]
>>106148347
Now that's an interesting qwen output.
Anonymous
8/5/2025, 1:03:12 PM
No.106148347
[Report]
>>106148382
>>106148335
Seems like this model has no imagination and can just copy.
Anonymous
8/5/2025, 1:03:54 PM
No.106148353
[Report]
Anonymous
8/5/2025, 1:05:06 PM
No.106148360
[Report]
>>106146936
it has that smooth skin but it doesn't give me uncanny vibes, nice
Anonymous
8/5/2025, 1:05:36 PM
No.106148363
[Report]
Anonymous
8/5/2025, 1:06:48 PM
No.106148370
[Report]
I keep trying to move up to flux but it seems wildly inconsistent and tough to wrangle compared to SDXL. Is this a me problem or is flux generally just harder to work with? Even the loras and controlnets for it seem worse overall. Only thing it's definitely better at is realistic which i'm not interested in.
Anonymous
8/5/2025, 1:08:52 PM
No.106148382
[Report]
>>106148347
Do you ever get tried of being a cynical cunt?
Anonymous
8/5/2025, 1:19:03 PM
No.106148442
[Report]
>>106146983
flux is garbage.
Anonymous
8/5/2025, 1:21:59 PM
No.106148459
[Report]
It kind of knows one punch man.
Anonymous
8/5/2025, 1:25:45 PM
No.106148479
[Report]
>>106148381
I'm sort of in the same situation and I attribute it to the prompting process (full sentences are a pain) and the extra time it takes to generate stuff which makes the learning process difficult. To combat this I've built a workflow where you can easily switch between "Nunchaku 8 step TurboAlpha", or "28 step Normal Flux". Definitely install Nunchaku if you haven't, it makes it so much more fun to use Flux now.
>Only thing it's definitely better at is realistic which i'm not interested in.
it could be that Illustrious and SDXL are better at "simple anime". Flux seems good at high detail anime, but you need loras:
https://civitai.com/images/73784871
https://civitai.com/images/34333535
I think Flux produces generic anime without loras. So it's purely a lora-usage model, is how you should treat it.
Anonymous
8/5/2025, 1:28:17 PM
No.106148499
[Report]
>>106148529
Is it just me or are nunchaku svdquants much worse than q8 and its not even close? Might as well wait a minute for a good gen
Why can't wan2.2 do violence well? Having one character hit another character still produces bad results.
Strange how it can now generate vagina with just the base model but punches still suck
Anonymous
8/5/2025, 1:29:34 PM
No.106148511
[Report]
>>106148501
>it can now generate vagina
neo vagina maybe.
Anonymous
8/5/2025, 1:29:53 PM
No.106148513
[Report]
>>106146928
Yes as far as I can tell. 2.1 is better, you can kinda mix 2.1 and 2.2 together but not really sure if that's an improvement over 2.1.
Anonymous
8/5/2025, 1:31:43 PM
No.106148529
[Report]
>>106148562
>>106148499
They're a little bit worse and that's why you need a workflow that allows you to instantly switch between a fast mode and a slow quality mode.
Don't fall for this "inbetween" mode where you give up some quality for a moderate speed boost. It's a bad approach.
Quick test of the usual prompts on different seeds.
fp8 model though until the DF11 works.
I don't know. Seems like a model, alright. The variance is actually kinda wack, though. And what the fuck are those 'green eyes'?
Box:
https://files.catbox.moe/o7mzsa.png
Anonymous
8/5/2025, 1:35:04 PM
No.106148562
[Report]
>>106148652
>>106148529
How are you controlling the inputs? I have a workflow where I have an int constant that I switch between 1 and 2 and it feeds into a bunch of Switch nodes that chooses inputs/values, but it's a huge mess of spaghetti and updating it for new developments can be a pain in the ass. Is there something better?
Wondering if I should just bite the bullet and figure out how to call the comfyUI api so I can finally escape this spaghetti hell (unlikely).
Anonymous
8/5/2025, 1:36:23 PM
No.106148572
[Report]
>>106148550
I've noticed the similarity between gens too. Sometimes I have to double check the seed actually changed. Also noticed the weird green eyes.
It does not know this character in Chinese or English.
Anonymous
8/5/2025, 1:38:32 PM
No.106148593
[Report]
Anonymous
8/5/2025, 1:43:37 PM
No.106148640
[Report]
>>106148316
kek, Rust is a very subtle man
Anonymous
8/5/2025, 1:44:29 PM
No.106148650
[Report]
>>106148887
Anonymous
8/5/2025, 1:44:37 PM
No.106148652
[Report]
>>106148562
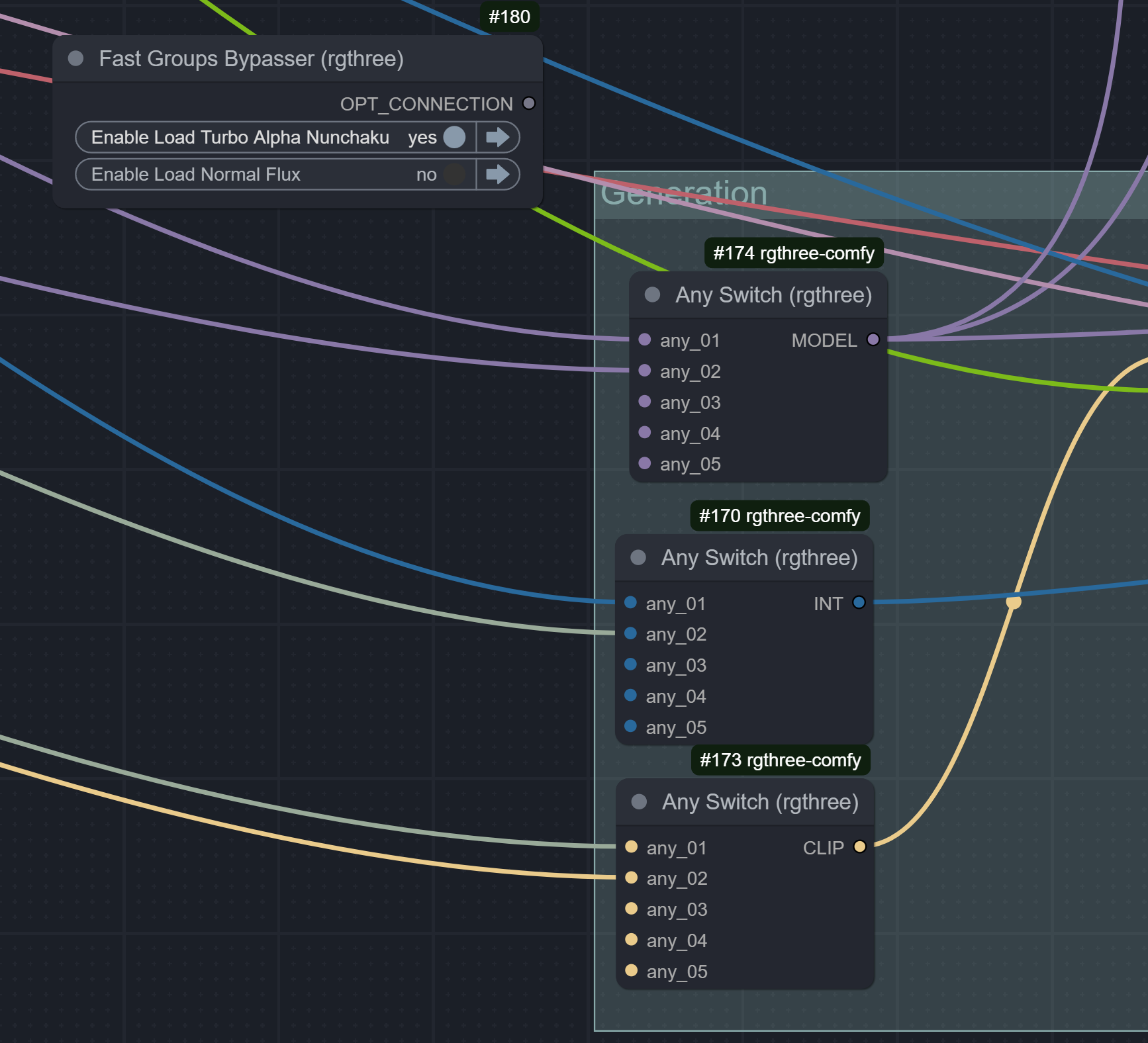
You want to use this "Fast Groups Bypasser", you can configure it to list only the groups that have a certain string in them. And you can configure toggleRestriction to "always one" so you can only have one enabled at a time.
Then you use these "Any switch" nodes, the way they work is it'll choose the input that is not "null", so if one group is disabled then it'll feed a null input and then the Any Switch node will not choose that input, it'll choose the other input.
You have to be careful though, when a node is disabled it can pass in previous nodes that are connected to it, which can cause the input to not be a null input. So make sure the groups (in this case "Load Turbo Alpha" and "Load Normal Flux" are at the start of the flow.
If I didn't just generate this myself I'd say that is 100% a gpt 4o gen.
Anonymous
8/5/2025, 1:48:06 PM
No.106148680
[Report]
>>106148730
It seems if the IP was culturally relevant to a high degree it gets into the dataset.
Anonymous
8/5/2025, 1:48:49 PM
No.106148687
[Report]
>>106148661
You are just imagining things, it's a coincidence
Anonymous
8/5/2025, 1:49:20 PM
No.106148688
[Report]
>>106148705
Can someone explain to me how to use video loras in kijai's wan2.2 workflow? It looks different from the old rentry workflow and it's not commented.
Do 2.1 loras even work well here?
Anonymous
8/5/2025, 1:51:02 PM
No.106148702
[Report]
>>106148709
>>106148590
Flying Dutchman?
Anonymous
8/5/2025, 1:51:29 PM
No.106148705
[Report]
>>106148732
>>106148688
So on the lora node where it says previous LoRA? Just stick a LoRA node on those. 2.1 LoRAs sometimes work. Sometimes they don't.
Anonymous
8/5/2025, 1:52:01 PM
No.106148708
[Report]
>>106148812
>>106148550
That was with cfg 4.0, by the way. Genning at 1.0 now.
The way it bruteforced all those parts of the prompt into the images (Extremely green eyes, swirls in the smoke literal gimp tool swirls) is awful.
I'll do a big sampler/scheduler plot later once the cfg test is done, but probably only for one of the prompts, most likely titty fairy.
Anonymous
8/5/2025, 1:52:02 PM
No.106148709
[Report]
>>106148702
More like (((Fleeing Goldman)))
Anonymous
8/5/2025, 1:52:32 PM
No.106148712
[Report]
>>106148730
Anonymous
8/5/2025, 1:53:57 PM
No.106148723
[Report]
yea qwen image seems overfit, hopefully a finetune can fix it
Anonymous
8/5/2025, 1:54:43 PM
No.106148730
[Report]
>>106148758
>>106148705
In the rentry workflow there was a comment saying it's strictly required that any additional loras go between lightx2v and the Patch Model Patcher Order node. This is no longer the case?
Anonymous
8/5/2025, 1:55:33 PM
No.106148736
[Report]
>>106148732
I don't give a shit. I use the native workflow. That just how I strung LoRAs when I use Kij's workflow.
Anonymous
8/5/2025, 1:56:45 PM
No.106148745
[Report]
>>106148826
>>106148732
don't use the shitty rentry wf, scroll up
Anonymous
8/5/2025, 1:58:04 PM
No.106148758
[Report]
>>106148730
Yeah I'm just probing some IPs right now so I'll switch up the aspect ratio.
Anonymous
8/5/2025, 2:00:39 PM
No.106148776
[Report]
Anonymous
8/5/2025, 2:03:30 PM
No.106148783
[Report]
Anonymous
8/5/2025, 2:05:16 PM
No.106148788
[Report]
how do i use lightx2v on text 2 vid try using it but video came out all wonky
Anonymous
8/5/2025, 2:06:40 PM
No.106148799
[Report]
fuck, I spent like 2 days of compute time training a lora on wan 2.1 for something wan2.2 can already do mostly becuse i only just became aware of it.
Anonymous
8/5/2025, 2:06:56 PM
No.106148802
[Report]
Anonymous
8/5/2025, 2:09:30 PM
No.106148823
[Report]
>>106147602
its sage attention, is the only one I had enabled
Anonymous
8/5/2025, 2:10:06 PM
No.106148826
[Report]
>>106148745
Don't know what you're talking about. The current rentry's workflow uses a slightly modified version of Kijai's workflow.
The old rentry's workflow is pic related.
Anonymous
8/5/2025, 2:10:23 PM
No.106148828
[Report]
>>106148812
Very much the expected result.
Anonymous
8/5/2025, 2:11:25 PM
No.106148835
[Report]
>>106148838
Look guys. It's Miku... but in minecraft.
Anonymous
8/5/2025, 2:12:29 PM
No.106148838
[Report]
>>106148852
>>106148835
troonku goes to
>>>/g/adt/
or
>>>/lgbt/
Anonymous
8/5/2025, 2:12:50 PM
No.106148840
[Report]
>wan still thinks panties are just a white tube that wraps around the waist
Anonymous
8/5/2025, 2:14:34 PM
No.106148848
[Report]
Anonymous
8/5/2025, 2:14:37 PM
No.106148850
[Report]
Anonymous
8/5/2025, 2:14:54 PM
No.106148852
[Report]
Anonymous
8/5/2025, 2:17:22 PM
No.106148862
[Report]
>>106148874
so there a lora training script or whatever for wan2.2
and looks just almost close to what i want it to do with prompting and just needs a little lora push.
Anonymous
8/5/2025, 2:17:48 PM
No.106148869
[Report]
vramlet bros, there's light at the end of the tunne!
https://huggingface.co/lym00/qwen-image-gguf-test
Anonymous
8/5/2025, 2:18:30 PM
No.106148874
[Report]
>>106149010
>>106148862
Can someone translate what this dude saying?
Anonymous
8/5/2025, 2:21:12 PM
No.106148883
[Report]
Anonymous
8/5/2025, 2:22:09 PM
No.106148887
[Report]
>>106148915
>>106148650
This is so good, which UI did you use? How do you learn to make gens like this? Complete noob here.
Anonymous
8/5/2025, 2:22:17 PM
No.106148888
[Report]
>what will you be ordering today, anon?
Anonymous
8/5/2025, 2:26:53 PM
No.106148915
[Report]
>>106148887
Download Automatic 1111 and stable diffusion 1.5 to get started.
Anonymous
8/5/2025, 2:27:42 PM
No.106148921
[Report]
>>106148937
>>106148912
fuck off >>>/g/adt/
Anonymous
8/5/2025, 2:27:54 PM
No.106148922
[Report]
>>106148924
>>106148912
Bruh she's like 10?
Anonymous
8/5/2025, 2:28:04 PM
No.106148923
[Report]
>>106148932
It lowkey knows emma.
Anonymous
8/5/2025, 2:28:25 PM
No.106148924
[Report]
Anonymous
8/5/2025, 2:29:35 PM
No.106148932
[Report]
>>106148923
It knows a lot of things, but it does not know them very well.
Anonymous
8/5/2025, 2:30:12 PM
No.106148937
[Report]
Anonymous
8/5/2025, 2:32:54 PM
No.106148952
[Report]
consider the following:
Anonymous
8/5/2025, 2:33:08 PM
No.106148955
[Report]
>>106148959
Anonymous
8/5/2025, 2:33:49 PM
No.106148959
[Report]
Anonymous
8/5/2025, 2:34:00 PM
No.106148961
[Report]
Anonymous
8/5/2025, 2:34:17 PM
No.106148964
[Report]
>>106148975
>>106148912
>deleted
Based. Get this loli shit out of /ldg/.
Anonymous
8/5/2025, 2:36:01 PM
No.106148975
[Report]
>>106148964
ok shoutcollective
Should I upgrade to 64GB or 128GB RAM for Wan2.2?
Anonymous
8/5/2025, 2:37:10 PM
No.106148984
[Report]
Anonymous
8/5/2025, 2:38:37 PM
No.106148991
[Report]
>>106148976
both 8bit models + T5 + vae + loras take like 50GB so 64GB+ if you dont want to have to wait for slop swap all the time
Anonymous
8/5/2025, 2:39:02 PM
No.106148993
[Report]
not quite
Anonymous
8/5/2025, 2:39:52 PM
No.106148999
[Report]
Doesn't really have a great grasp on streetfighter.
Anonymous
8/5/2025, 2:41:00 PM
No.106149002
[Report]
>>106148976
i had to settle to upgrading my mobo to 96GB ram instead of 128 since evidently it did not support that much for DDR5
Anonymous
8/5/2025, 2:41:57 PM
No.106149010
[Report]
>>106148874
how do train lora fir wan 2.2?
Anonymous
8/5/2025, 2:42:03 PM
No.106149012
[Report]
>>106148976
ComfyUI OOMs with 64GB RAM when changing loras or input image sometimes.
Anonymous
8/5/2025, 2:43:53 PM
No.106149034
[Report]
>>106149016
-888 social credits
Anonymous
8/5/2025, 2:44:07 PM
No.106149036
[Report]
>>106149060
>>106148501
just train a lora
The greatest trick Xi ever pulled was somehow tricking the west into thinking Whinnie the pooh was his achilleas heel.
Anonymous
8/5/2025, 2:45:59 PM
No.106149051
[Report]
>>106149305
Anonymous
8/5/2025, 2:46:00 PM
No.106149052
[Report]
>>106149047
+888 social credits
>>106149036
I have 16gb vram.
Anonymous
8/5/2025, 2:47:32 PM
No.106149067
[Report]
>>106149114
>>106149064
how is it at inpainting?
Anonymous
8/5/2025, 2:49:52 PM
No.106149079
[Report]
>>106149089
Oh yeah, definitely looking like their chinese counterparts in this gen.
Anonymous
8/5/2025, 2:51:59 PM
No.106149089
[Report]
>>106149079
lol thats rough
Anonymous
8/5/2025, 2:52:01 PM
No.106149090
[Report]
>>106149060
how much ram do you need for training lora?
>>106149064
then why post a bland image? or are you just using comfy's shitty prompt?
Anonymous
8/5/2025, 2:52:36 PM
No.106149096
[Report]
Anonymous
8/5/2025, 2:53:38 PM
No.106149100
[Report]
>>106149094
>then why post a bland image? or are you just using comfy's shitty prompt?
Anonymous
8/5/2025, 2:53:53 PM
No.106149102
[Report]
I tried Jeffrey Epstein, got some protestant pastor.
Anonymous
8/5/2025, 2:54:21 PM
No.106149106
[Report]
not even a genned jak. pathetic
Anonymous
8/5/2025, 2:55:25 PM
No.106149114
[Report]
>>106149139
>>106149067
still have to test, will do it later and post here
Anonymous
8/5/2025, 2:55:28 PM
No.106149115
[Report]
>>106149060
rent a H100 gpu and train it, will cost you less than 10 bucks
Anonymous
8/5/2025, 2:56:58 PM
No.106149131
[Report]
GGUF Q8 when? I know f8 is ass compared to the might geegoof.
Anonymous
8/5/2025, 2:57:00 PM
No.106149132
[Report]
>>106149167
Close!
Anonymous
8/5/2025, 2:57:48 PM
No.106149139
[Report]
>>106149114
my main issue with flux as that it was virutalyl usefless for the inpainting i wanted , freaking SD 2 was better at it.
Anonymous
8/5/2025, 2:58:42 PM
No.106149145
[Report]
Anonymous
8/5/2025, 3:02:15 PM
No.106149163
[Report]
Anonymous
8/5/2025, 3:02:33 PM
No.106149167
[Report]
>>106149183
>>106149132
what are you trying to write?
Anonymous
8/5/2025, 3:02:40 PM
No.106149168
[Report]
reminder: bloat is bad for your computer
Anonymous
8/5/2025, 3:03:59 PM
No.106149183
[Report]
>>106149167
>A frog holding a sign that says hello world
Using T5-small + an adapter though
Anonymous
8/5/2025, 3:05:17 PM
No.106149189
[Report]
>>106149159
What is the deal with the output variety for this model? It's basically non-existent.
>no submissions for genjam3
It's over.
Anonymous
8/5/2025, 3:10:08 PM
No.106149243
[Report]
>>106149255
I was very much hoping that Chroma was going to be good to make the base gens of my oneitis to use in lewd 2.2 I2Vs but it still sucks.
Anonymous
8/5/2025, 3:11:22 PM
No.106149255
[Report]
>>106149509
>>106149243
it is good, what are you using that is better?
>>106149212
even worse gacha that round 2. organizer should just reroll since everyone is just doing the same shit. if the result prompts doesn't leave room for creativity, just reroll
Anonymous
8/5/2025, 3:16:07 PM
No.106149299
[Report]
>>106149313
>>106149212
>>106149272
>still using glowgle forms
Anonymous
8/5/2025, 3:16:29 PM
No.106149305
[Report]
Anonymous
8/5/2025, 3:17:16 PM
No.106149313
[Report]
>>106149299
this too. just have an anchor or reply to the OP like /dmp/ does for their albums
Anonymous
8/5/2025, 3:17:26 PM
No.106149315
[Report]
>>106149331
>>106149272
>if the result prompts doesn't leave room for creativity
sounds like you are not very creative anon.
Truly creative people can extrapolate all kinds of cool ideas from just a few words.
Anonymous
8/5/2025, 3:18:59 PM
No.106149331
[Report]
>>106149358
>>106149315
>*slops your datasets*
why would xi do this? it makes these massive models so shit
Anonymous
8/5/2025, 3:19:10 PM
No.106149332
[Report]
>wan i2v
>after the first frame the face morphs completely
is this because of a lora im using or what? how do i keep it consistent? lower strength on the loras im using?
Anonymous
8/5/2025, 3:20:01 PM
No.106149339
[Report]
>>106149352
>>106149335
is this 2.1 or 2.2?
>>106149328
>gacha character
>night sky
>jewtube thumbnail
nope, nothing creative is coming to mind anon and I'd imagine everyone's result would look way too similar
Anonymous
8/5/2025, 3:21:11 PM
No.106149352
[Report]
>>106149362
>>106149339
2.1, i should probably get 2.2 but i was uh... waiting a bit longer because i saw some anons complaining about the workflows in the guide
Anonymous
8/5/2025, 3:21:23 PM
No.106149355
[Report]
>>106149343
yeah that pull is shit
>>106149331
good enough, still sota, and still pushing forward everyone else to have to compete hard
if a basement dweller can train a lora in a day or two for a nsfw tune of any model, whats the problem anyway?
>>106149352
Imagine refraining from doing something because an anonymous literal who on the internet would have issues with comfyui.
Anonymous
8/5/2025, 3:22:25 PM
No.106149364
[Report]
>>106149388
>>106149358
sota in... text? what a fucking joke. it's benchmaxxed slop
Anonymous
8/5/2025, 3:22:41 PM
No.106149368
[Report]
>>106149335
working on a better setup that also uses the phantom fusionx lora and pusa, which both massively help likeness
Anonymous
8/5/2025, 3:23:50 PM
No.106149378
[Report]
>>106149362
not him but what the fuck do you expect?
if i cant get the light shit to work on text to video and you refuse to be helpful im just going to default with the worflow and model that work.
Anonymous
8/5/2025, 3:24:10 PM
No.106149382
[Report]
>>106149362
i dont mind waiting, i'd rather let the eggheads sort it out then enjoy the fruits of their labor
>>106149364
text is a pretty big use case for a lot of people who dont just want to gen 1girl but the big thing is image editing
Anonymous
8/5/2025, 3:24:36 PM
No.106149391
[Report]
>>106149362
don't lie, everyone has one issue or another with comfyui. It really went downhill after the org
I've noticed a correlation in Qwen naysayers and Chroma copers.
Anonymous
8/5/2025, 3:25:35 PM
No.106149398
[Report]
>>106149362
Very few people want to be forced to tinker for hours and reinstall there setup just to get back to where they were. Or just to find out it works never have worked because of X or Y reason.
Anonymous
8/5/2025, 3:25:44 PM
No.106149401
[Report]
>>106149358
is there a publically avaiable training script for 2.2?
Anonymous
8/5/2025, 3:25:55 PM
No.106149404
[Report]
>>106149388
the edit model isn't out yet. you are using a bloated and shitily captioned t2i model. the edit model is the only thing I would be interested in so kontext gets dumpstered
Anonymous
8/5/2025, 3:26:00 PM
No.106149405
[Report]
Anonymous
8/5/2025, 3:26:21 PM
No.106149410
[Report]
>>106149422
>>106149343
you could submit a gen of someone throwing all of those themes in the trash can
Anonymous
8/5/2025, 3:26:27 PM
No.106149413
[Report]
>>106149397
sorry but qwen is overfit and knows way less and it has no style knowledge at all
Anonymous
8/5/2025, 3:27:29 PM
No.106149422
[Report]
>>106149410
how about no. I just want something fun
Anonymous
8/5/2025, 3:28:05 PM
No.106149425
[Report]
>>106149458
Anonymous
8/5/2025, 3:29:09 PM
No.106149434
[Report]
>>106149460
I've been getting incompetent Chinese training fatigue for a while now. the xi chad meme just doesn't hold anymore.
Anonymous
8/5/2025, 3:31:38 PM
No.106149449
[Report]
>>106149388
>text is a pretty big use case
when gimp, krita and Photoshop exist? you can even arbitrarily add text on paint too. stylized text is the only use for it and I am not in advertising. visual text is the least important thing for a model to know when styles and artists are king
Anonymous
8/5/2025, 3:32:21 PM
No.106149455
[Report]
Anonymous
8/5/2025, 3:32:40 PM
No.106149458
[Report]
>>106149425
>text bleed
not a good sign
>>106149434
whatever you say 12gb vramlet
Anonymous
8/5/2025, 3:33:56 PM
No.106149472
[Report]
Anonymous
8/5/2025, 3:34:49 PM
No.106149481
[Report]
Anonymous
8/5/2025, 3:34:50 PM
No.106149482
[Report]
>>106149460
I'm talking about the boring results. I have 24gb VRAM but I just don't see a point to this model yet. maybe after somebody with talent finetunes it with NSFW and styles I'll care. keep being jaded chinkoid bug
Anonymous
8/5/2025, 3:35:54 PM
No.106149492
[Report]
>>106149498
Anonymous
8/5/2025, 3:36:53 PM
No.106149498
[Report]
>>106149521
>>106149492
nah, two more 1024 epochs
Anonymous
8/5/2025, 3:37:03 PM
No.106149502
[Report]
>>106149535
>>106149159
Alright, that's the most boring-ass comparison I've ever run. I'll reduce the amount of schedulers to like... 3 and post the big-ass plot once it's done. Or I'll just cancel it and wait for the image edit model, because this is kinda 'meh'.
>>106149328
>>106149343
I have the same issue I had with the last jam, I have no idea who these characters are. And I don't really want to just 'meme gen'. But maybe I'll think of something.
Anonymous
8/5/2025, 3:37:39 PM
No.106149509
[Report]
>>106149255
Honestly, nothing else because I gave up lmao. But I keep getting really soft looking images with chroma and then NSFW prompting seems like I'm missing the mark.
Anonymous
8/5/2025, 3:37:46 PM
No.106149511
[Report]
>>106149460
> 12GB vram
I wish...
Anonymous
8/5/2025, 3:38:23 PM
No.106149521
[Report]
>>106149498
>He literally said "two more epochs"
Anonymous
8/5/2025, 3:39:31 PM
No.106149535
[Report]
>>106149502
>I have the same issue I had with the last jam, I have no idea who these characters are. And I don't really want to just 'meme gen'. But maybe I'll think of something.
That's ok.
If nobody wants to do it, the genjam collage can go ahead with 0 submissions and all the three themes are discarded.
Anonymous
8/5/2025, 3:41:29 PM
No.106149558
[Report]
>>106149584
>NOOOO YOU HAVE TO USE THIS CHINA MODEL
>LOOOOOOK I POSTED A XI CHAD MEME THEY ARE SOOOO COOL
>STOP MAKING FUN OF ME! QWEN_IMAGE IS SOTA!!! IT'S THE BEST!!!!
>YOU MUST HAVE 12GB OF VRAM CHUD
China lost the magic. is there a company that is based enough to train what people want anymore?
Anonymous
8/5/2025, 3:42:53 PM
No.106149574
[Report]
>>106149590
Anonymous
8/5/2025, 3:44:03 PM
No.106149584
[Report]
>>106149601
>>106149558
Wan 2.2 came out a few days ago and everyone agrees it's good.
>>106149574
what happened to all the text? I thought it was sota at it?
Ok, even better WF is finished. This in 4 steps total, full prompt following / motion quality
https://files.catbox.moe/6lp32g.json
Anonymous
8/5/2025, 3:44:38 PM
No.106149592
[Report]
> lodestone just can't stop seething
Anonymous
8/5/2025, 3:45:36 PM
No.106149601
[Report]
>>106149612
>>106149584
it's an upgrade but the captions they use are slopped. they should hire prompt gods to caption things not let a vlm slop the dataset
Anonymous
8/5/2025, 3:46:41 PM
No.106149612
[Report]
>>106149601
this. never communicating the problem to the devs will ensure it will never get fixed
Anonymous
8/5/2025, 3:48:00 PM
No.106149625
[Report]
Anonymous
8/5/2025, 3:48:48 PM
No.106149631
[Report]
>>106149590
All I typed was "Screenshot of Windows Desktop."
Anonymous
8/5/2025, 3:49:52 PM
No.106149641
[Report]
Anonymous
8/5/2025, 3:50:14 PM
No.106149644
[Report]
>>106149656
>>106149591
why did you squish the aspect ratio? wan does fine with different resolutions
>>106148381
Flux is more for realism than anything. It also has a stronger "slot machine" feel than other models because it can generate wildly varied outputs if you aren't very specific about certain things.
Generating prompts with an LLM is also preferred. You can do it by hand, but you'll never be as autistic as an LLM is when describing an image.
Anonymous
8/5/2025, 3:50:59 PM
No.106149652
[Report]
Bakermanpls
Anonymous
8/5/2025, 3:51:09 PM
No.106149656
[Report]
>>106149684
>>106149644
for fast testing I kept res low as I tested each tiny change
Anonymous
8/5/2025, 3:51:36 PM
No.106149658
[Report]
>>106149591
Have it so when he moves out of the way to shoot a Kamehameha he's firing at a planned parenthood clinic.
Anonymous
8/5/2025, 3:52:38 PM
No.106149666
[Report]
Anonymous
8/5/2025, 3:52:45 PM
No.106149668
[Report]
>>106149903
>>106149651
llms go moralfag on me though
Anonymous
8/5/2025, 3:53:05 PM
No.106149672
[Report]
>>106149903
>>106149651
>Generating prompts with an LLM is also preferred.
miss me with that shit
>you'll never be as autistic as an LLM is when describing an image
it's been pretty shit and it will come up with some hallucinations. llms are too autistic about safety as well
Anonymous
8/5/2025, 3:54:06 PM
No.106149684
[Report]
>>106149656
the aspect ratio is the problem, why would you squish it? just shrink the 1:1 in the same ratio
Anonymous
8/5/2025, 3:54:32 PM
No.106149692
[Report]
can I submit multiple gens for genjam or is it supposed to be one per person?
Anonymous
8/5/2025, 3:55:50 PM
No.106149700
[Report]
>>106147898
they always promise same quality but it's never the case. why are chinks such impulsive liars?
Anonymous
8/5/2025, 3:58:18 PM
No.106149730
[Report]
>>106149887
>>106146763 (OP)
>Setup comfyUI on my Linux machine
>Start downloading loras
>All egirl loras have been taken down by (((payment processors))) pressures on CivitAI
>Look on alternative sites
>None allow download
>head to civitaiarchive
>Most of the links are dead because the ""archive"" was actually redirecting to civit servers
Wtf am I supposed to do? train my own? Did they actually succeed in killing the progress towards making new ones? I mean, some have been archived, but nobody is going to spend money on training SDXL new LoRAs if they can't upload it anywhere.
Anonymous
8/5/2025, 3:59:07 PM
No.106149741
[Report]
>>106149766
>>106149722
Grifting is just a part of their culture
here is this updated to the new WF, much better. Less than 2 mins to gen
Anonymous
8/5/2025, 4:01:33 PM
No.106149762
[Report]
>>106149772
>>106149752
Have you seen the russian redditor sperging out at you 'stealing' his image and 'ruining' it?
I thought that was pretty funny.
Anonymous
8/5/2025, 4:01:58 PM
No.106149766
[Report]
Anonymous
8/5/2025, 4:02:04 PM
No.106149767
[Report]
Anonymous
8/5/2025, 4:02:27 PM
No.106149772
[Report]
>>106149815
>>106149762
lol no. Ah, is it the deleted comment?
Why do you guys defend Kontext?
>>106149791
i like it, why what's better for edits?
Anonymous
8/5/2025, 4:07:17 PM
No.106149815
[Report]
>>106149772
Yeah, that protector111 zigger sperged out about you not genning your own test images because that's the reason people think AI is slop. Apparently.
Anonymous
8/5/2025, 4:07:41 PM
No.106149818
[Report]
>>106149902
Anonymous
8/5/2025, 4:08:01 PM
No.106149823
[Report]
>>106149880
>>106149722
The whole point of dfloat11 is that it is bit identical, it compresses bfloat16 to dfloat11, in other words 16 bits compressed down to 11bits. Of course there's no free lunch, accessed parts need be decompressed as you generate, but it's faster than ram offloading since it does it all in the GPU.
It shaves off ~30% off the model it compresses, so it can make a difference.
Anonymous
8/5/2025, 4:08:08 PM
No.106149825
[Report]
>>106149902
Anonymous
8/5/2025, 4:11:18 PM
No.106149856
[Report]
>>106149791
>Why do you guys defend Kontext?
I don't know who you're talking about but people should use any tool that works for whatever use case they have instead of building their personal identity over any one image model. Even if theres one thing a model is good for it's still useful.
Anonymous
8/5/2025, 4:13:48 PM
No.106149880
[Report]
>>106149823
we already had a quant autist last thread sperging and being proved wrong. I don't want a repeat episode
Anonymous
8/5/2025, 4:15:16 PM
No.106149887
[Report]
>>106152342
>>106149730
well hidden huggingface repos but yeah, train your own
Anonymous
8/5/2025, 4:16:35 PM
No.106149902
[Report]
>>106149818
>>106149825
I only have 10gb vram tho
Anonymous
8/5/2025, 4:16:36 PM
No.106149903
[Report]
>>106149929
>>106149668
>>106149672
I don't really gen porn, but Gemma 3 27B Q4 with my own Sys. Prompt has never given me any refusals for spicier prompts.
--Qwen-Image criticized as bloated model lacking true multimodal capabilities:
>106143040 >106143057 >106143115 >106143131 >106143158 >106143070 >106143087 >106143097 >106143121 >106143449 >106143453 >106143537 >106143490 >106143540 >106143568 >106144440 >106144456 >106146851 >106143237 >106143313 >106143443 >106143488 >106143527 >106143548 >106143462
seems like /lmg/ doesn't like it. they have China fatigue as well
How much longer until the AI community learns how to upload and download torrents? There should be a torrent repository for adult content.
Anonymous
8/5/2025, 4:18:40 PM
No.106149929
[Report]
>>106150021
>>106149903
you skipped the part where hallucinations are a thing. it's also fills the prompt with a bunch of superfluous non-token shit. honestly not a fan of full nlp encoders
Anonymous
8/5/2025, 4:20:16 PM
No.106149948
[Report]
>>106151898
why is qwen so fucking slow compared to fux, chroma, or even wan?
Anonymous
8/5/2025, 4:20:19 PM
No.106149949
[Report]
>>106150033
qwen-image won't write "中出し" (meaning "creampie" in Japanese)
Anonymous
8/5/2025, 4:20:33 PM
No.106149953
[Report]
>>106149971
>>106149917
Torrenting will never be a solution for this and you need to stop pretending it will be.
Anonymous
8/5/2025, 4:21:33 PM
No.106149962
[Report]
Anyone try the qwen image vae with wan 2.2 yet?
Anonymous
8/5/2025, 4:22:02 PM
No.106149965
[Report]
>>106149907
>half the linked comments arent even against the qwen image model and some even defend it
What did this historic revisionist gaslighting troony mean by this?
Maybe you should go back to that AGP baker's thread and stay there.
Anonymous
8/5/2025, 4:22:41 PM
No.106149971
[Report]
>>106150003
>>106149953
>no argument
no problem retard
Anonymous
8/5/2025, 4:23:36 PM
No.106149980
[Report]
>>106149984
Anonymous
8/5/2025, 4:24:19 PM
No.106149984
[Report]
>>106150064
>>106149917
Tried and failed, who will seed the torrents, you? no? didn't think so.
>>106149971
You will never reliably be able to seed that many LoRAs for any reasonable amount of time. And volunteering to do so would just make you a server like civit already was.
Anonymous
8/5/2025, 4:26:25 PM
No.106150005
[Report]
>>106150030
>>106149991
>Tried and failed
works on my machine, sis
Anonymous
8/5/2025, 4:26:27 PM
No.106150006
[Report]
I don't think that's a safe way to drive miss...
Anonymous
8/5/2025, 4:27:28 PM
No.106150015
[Report]
>>106150030
>>106150003
>no argument personal opinion
holy shit retard, just stop replying
Are amd users not able to gen at all or they just need to use linux?
Anonymous
8/5/2025, 4:28:29 PM
No.106150021
[Report]
>>106150048
>>106149929
>superfluous non-token shit
Use a sys prompt that cuts down on flowery language. I generate a long, detailed prompt (or image description) first and then condense it down quite a bit to a specific token length (typically 192). It really cuts back on "noise" in the prompt.
Anonymous
8/5/2025, 4:29:27 PM
No.106150029
[Report]
>>106150060
>>106149907
>China fatigue
sam, kill yourself NOW
Anonymous
8/5/2025, 4:29:31 PM
No.106150030
[Report]
>>106150059
>>106150005
As in it has been tried and it failed because no one will seed the torrents.
>>106150015
What's your argument?
Anonymous
8/5/2025, 4:29:39 PM
No.106150033
[Report]
>>106150087
>>106149949
>chinks didn't train jap kanji
to be expected desu
Anonymous
8/5/2025, 4:29:48 PM
No.106150035
[Report]
>>106150075
>>106150020
You can only do the most basic things and then cope everywhere online that everything actually just works so another sucker buys ayymd before realizing half the projects dont work at all and the rest are so slow you might as well have spent the extra money for a 3090
Anonymous
8/5/2025, 4:29:59 PM
No.106150037
[Report]
>>106149991
Exactly. Call it something SFW and have another server link to it with obfuscated javascript, it's how stuff like animepahe works.
Anonymous
8/5/2025, 4:30:19 PM
No.106150042
[Report]
>>106150086
>>106150003
Wrong. How do you think private trackers and usenet indexers work with huge libraries of movies and shows? A lot of these movies are over 50GB in size too.
Anonymous
8/5/2025, 4:30:35 PM
No.106150046
[Report]
>>106150020
If you card supports rocm then you are fine. I've seen people say they got a 9700xt working in windows but it was really slow (around 3080 speeds).
Anonymous
8/5/2025, 4:30:43 PM
No.106150048
[Report]
>>106150207
>>106150021
>Use a sys prompt that cuts down on flowery language
doesn't work. it's always canned safe outputs with stupid filler. just fucking prompt
Anonymous
8/5/2025, 4:31:43 PM
No.106150059
[Report]
>>106150086
>>106150030
>As in it has been tried and it failed because no one will seed the torrents.
Feel free to post a lora that you can't find anywhere to download online
Anonymous
8/5/2025, 4:31:44 PM
No.106150060
[Report]
>>106150029
jew fatigue is still ongoing as always. asian jew fatigue is just vogue right now
Anonymous
8/5/2025, 4:32:15 PM
No.106150064
[Report]
>>106149984
thx. looks good
>>106150035
Is there any point in upgrading beyond a 3090 at this point? Even the 5090 doesn't seem that much better for the money.
Anonymous
8/5/2025, 4:32:59 PM
No.106150076
[Report]
>>106149991
>I'm black so everyone else must be too!
Anonymous
8/5/2025, 4:34:07 PM
No.106150085
[Report]
>>106150075
Unless you have a lot of money or earn from AI, no
>>106150042
Usenet backbones are paid services. Private torrent trackers are backed by paid seedboxes.
>>106150059
You first, post the torrent.
Anonymous
8/5/2025, 4:34:18 PM
No.106150087
[Report]
>>106150097
>>106150033
Nah it's censored. It has no problem with "仲間内" (among friends)
Anonymous
8/5/2025, 4:34:42 PM
No.106150089
[Report]
>>106150075
3090 is starting to get the short end of the software stick.
Anonymous
8/5/2025, 4:34:48 PM
No.106150090
[Report]
>>106150075
just buy a RTX Pro 6000 Blackwell
Anonymous
8/5/2025, 4:35:26 PM
No.106150093
[Report]
>>106150113
>>106150086
>Usenet backbones are paid services. Private torrent trackers are backed by paid seedboxes.
Yes, and?
The price for both of them is absolutely worth having a reliable repository for NSFW loras and models. It's not even that expensive.
Anonymous
8/5/2025, 4:35:29 PM
No.106150094
[Report]
>>106150214
>>106150086
>"torrents failed!"
>post a lora you cant find online
>"y-you first!"
smartest anti-torrenting npc retard
Anonymous
8/5/2025, 4:35:43 PM
No.106150097
[Report]
>>106150133
>>106150087
Try it without the し
Anonymous
8/5/2025, 4:35:45 PM
No.106150099
[Report]
Anonymous
8/5/2025, 4:37:26 PM
No.106150113
[Report]
>>106150127
>>106150093
Go ahead then
>>106150075
speed. A 4090 is so much faster than a 3090 it is silly. And if you are thinking about "value" in relation to a 5090 you are being a retard, you don't buy top end gear anywhere because it is priced well lol, you buy it because it is the best and fuck poor people.
Anonymous
8/5/2025, 4:39:54 PM
No.106150127
[Report]
>>106150145
>>106150113
I knew you were a smelly poorfag.
Anonymous
8/5/2025, 4:40:43 PM
No.106150133
[Report]
>>106150097
It has no problem with just "出" (go out)
Anonymous
8/5/2025, 4:41:37 PM
No.106150145
[Report]
>>106150164
>>106150127
If you want the torrents then you can make the torrents and pay for the seedboxes
Anonymous
8/5/2025, 4:41:54 PM
No.106150150
[Report]
>>106150179
>>106150116
Main thing is you really do want fp8 support nowadays, it really speeds up using quants.
Best deal is the 4090D 48GB.
Anonymous
8/5/2025, 4:42:57 PM
No.106150164
[Report]
>>106150145
That wasn't my question you poor smelly idiot.
Anonymous
8/5/2025, 4:43:04 PM
No.106150166
[Report]
>>106150116
>4090 is so much faster than a 3090 it is silly
3+ times higher price for the same vram amount, the same memory bandwidth, and higher speed of only image generation where the compute matters more than in llms that is still not even even double the speed let alone 3 times
Anonymous
8/5/2025, 4:44:12 PM
No.106150179
[Report]
>>106150150
does fp8 support speed up anything when using Q8?
Anonymous
8/5/2025, 4:46:04 PM
No.106150207
[Report]
>>106150048
>doesn't work
If you don't know how to use an LLM just say so. No shame in that, they're weird and difficult to control when it comes to output specificity.
Anonymous
8/5/2025, 4:46:26 PM
No.106150214
[Report]
>>106150086
>>106150094
>no reply
>seething in the next thread instead
oh no no no
Anonymous
8/5/2025, 5:21:31 PM
No.106150545
[Report]
>>106147300
It's a combined Mogao (Seedream 3.0) and 4o dataset. The images are practically identical to what those two models give you depending on what style you ask for.
Anonymous
8/5/2025, 7:09:24 PM
No.106151898
[Report]
>>106149948
It's bigger anon. It ain't that much slower than Chroma anyway. I find it doesn't need as many steps for a "quality" gen. Chroma I usually run at 40 steps, qwen 20 steps is plenty.
>>106147846
Kontext is the best way to remove backgrounds from images locally I've found. Way better than rembg or inspyre. You can even tell it what color to change it to, great for chroma key.
Anonymous
8/5/2025, 7:42:16 PM
No.106152342
[Report]
>>106149887
Could you please share, saar?