/ldg/ - Local Diffusion General
Anonymous
8/6/2025, 2:47:49 AM
No.106157420
[Report]
>>106157429
Anonymous
8/6/2025, 2:49:10 AM
No.106157429
[Report]
>>106157443
>>106157420
this is actually kinda crazy, model?
Anonymous
8/6/2025, 2:50:57 AM
No.106157443
[Report]
>>106157429
Qwen image, but I was getting frustrated with how it was bungling text. You need to be autistically specific on the positioning or it will invent stuff.
I dare you to use the qwen vae to run wan 2.2
Anonymous
8/6/2025, 2:55:18 AM
No.106157472
[Report]
Anonymous
8/6/2025, 2:57:10 AM
No.106157494
[Report]
>>106157697
Blessed thread of frenship
Anonymous
8/6/2025, 2:57:48 AM
No.106157500
[Report]
Anonymous
8/6/2025, 3:00:35 AM
No.106157523
[Report]
>>106157450
mistakes into miracles
Anonymous
8/6/2025, 3:02:25 AM
No.106157535
[Report]
>>106157707
>>106157468
I don't know what I expected.
Anonymous
8/6/2025, 3:05:36 AM
No.106157563
[Report]
>>106157558
I'm glad it was you that wasted that compute and not me.
Anonymous
8/6/2025, 3:06:28 AM
No.106157571
[Report]
>>106157558
honestly pretty cool, almost looks like a crt
Anonymous
8/6/2025, 3:16:05 AM
No.106157632
[Report]
revolver pistol
Anonymous
8/6/2025, 3:17:55 AM
No.106157648
[Report]
ポストカード
!!FH+LSJVkIY9
8/6/2025, 3:24:10 AM
No.106157697
[Report]
>>106157494
blessed thread of frenzone ;3
i like the friendzone!
>>106156627
>>106157404
holy lol
truly in the actual spirit of 4chan honestly
i look cute in real life though anon.. muehehee
>captcha: okpoo
Anonymous
8/6/2025, 3:25:47 AM
No.106157707
[Report]
>>106157535
Sonic the HedgeNoice ready for improved EBT benefits.
Anonymous
8/6/2025, 3:26:12 AM
No.106157710
[Report]
>>106157746
Is there any performance differrence between using the gaming nvidia drivers and the studio ones?
Anonymous
8/6/2025, 3:26:32 AM
No.106157716
[Report]
>>106157708
how my gens look at me
Anonymous
8/6/2025, 3:31:26 AM
No.106157745
[Report]
>>106157751
Qwen it's very good at anime. It could be the SDXL sucessor if every third worlder from CivitAI buys a decent GPU
Anonymous
8/6/2025, 3:31:48 AM
No.106157746
[Report]
Anonymous
8/6/2025, 3:32:46 AM
No.106157751
[Report]
>>106157745
It looks extremely same-y, even more than Illus.
Anonymous
8/6/2025, 3:35:09 AM
No.106157769
[Report]
>>106157848
>>106157760
better try
the brain grows inside the microwave and then it violently explodes
Anonymous
8/6/2025, 3:35:40 AM
No.106157773
[Report]
>>106157708
Akuma Surfer Migu
Anonymous
8/6/2025, 3:38:22 AM
No.106157786
[Report]
. : P 0 $ U T 0 K ā D O : .
8/6/2025, 3:38:22 AM
No.106157787
[Report]
>>106159104
>>106157414 (OP)
>Lao Yang going to bed
Give me this webm.
Anonymous
8/6/2025, 3:38:40 AM
No.106157790
[Report]
. : P O $ U T 0 K ā D 0 : .
8/6/2025, 3:39:36 AM
No.106157794
[Report]
Anonymous
8/6/2025, 3:39:51 AM
No.106157797
[Report]
>>106157823
>>106157789
sorry you can't have it. problem?
Anonymous
8/6/2025, 3:41:29 AM
No.106157804
[Report]
>>106157858
>>106157468
For T2I it looks there's some weird shit on the screen. Might be useful in some cases.
P 0 S T C A R D
8/6/2025, 3:41:42 AM
No.106157807
[Report]
>>106157414 (OP)
>collage
well in a way, i made the collage again muehehee ;3
Anonymous
8/6/2025, 3:43:32 AM
No.106157823
[Report]
>>106157797
My 2013 Thinkpad cannot create the video so YES it is a problem. Any other questions?
Anonymous
8/6/2025, 3:44:14 AM
No.106157826
[Report]
Anonymous
8/6/2025, 3:45:16 AM
No.106157833
[Report]
In other news. I think the right way to train a Wan 2.2 LoRA is to use the low noise model. You can plug them back in to the high noise model without much damage to the motion, the reverse feels not so true with with the high noise model training.
What is making my wan 2.2 videos jerky and sped up?
Anonymous
8/6/2025, 3:46:57 AM
No.106157848
[Report]
Anonymous
8/6/2025, 3:47:49 AM
No.106157858
[Report]
>>106157804
pretty cool enforencer
Anonymous
8/6/2025, 3:48:26 AM
No.106157861
[Report]
>>106157842
It's so fast I cant even see it move!
Anonymous
8/6/2025, 3:55:50 AM
No.106157897
[Report]
qwen vae seems to have less crap when zoomed in. Somehow useful for T2I anime. Idk about 3dpd
Anonymous
8/6/2025, 3:56:44 AM
No.106157901
[Report]
Anonymous
8/6/2025, 4:01:00 AM
No.106157924
[Report]
I want GrAYS out!
Anonymous
8/6/2025, 4:01:39 AM
No.106157929
[Report]
why are people easily amused by all these dogshit videos
Anonymous
8/6/2025, 4:02:24 AM
No.106157934
[Report]
>>106157960
You know what Qwen image kind of reminds me of? Aura flow. Like they feel very similar. Obviously Qwen is better, but I feel they share similar DNA
Anonymous
8/6/2025, 4:02:51 AM
No.106157939
[Report]
>>106157956
>>106157930
why don't you ask them
Anonymous
8/6/2025, 4:02:54 AM
No.106157940
[Report]
>>106157956
>>106157930
you're still having your melty, zoomie?
ポストカード
!!FH+LSJVkIY9
8/6/2025, 4:03:03 AM
No.106157941
[Report]
>>106157956
>>106157930
>>106157931
its not that serious mate, it is for dare i say it, FUN<3
Anonymous
8/6/2025, 4:04:33 AM
No.106157953
[Report]
>>106157930
>npc doesnt get why its cool that there is a file that enables you to take any image and make it into a video of almost anything
Anonymous
8/6/2025, 4:04:48 AM
No.106157956
[Report]
>>106157941
>>106157940
>>106157939
Pay no heed to him. He's cursed by a demon to gather (You)s in order to uphold his end of whatever deal he struck with it.
Anonymous
8/6/2025, 4:05:01 AM
No.106157960
[Report]
>>106157966
>>106157934
Probably the fact they were both trained on synthetic slop
(Auraflow was trained on Ideogram outputs and Qwen Image was trained on 4o outputs)
Anonymous
8/6/2025, 4:05:50 AM
No.106157965
[Report]
Anonymous
8/6/2025, 4:06:18 AM
No.106157966
[Report]
>>106157989
>>106157960
Ideogram was smart about it. Every refusal gave you the cat so the Aura flow dataset was riddled with refusal cats.
Anonymous
8/6/2025, 4:10:05 AM
No.106157989
[Report]
>>106158009
>>106157966
That's what happens when you train on captions of scraped images instead of captioning yourself with a multimodal (vision) LLM
Probably some retard trained like that on ideogram on blind faith without double checking the data, blowing possibly hundred thousands of dollars away for being retarded
Anonymous
8/6/2025, 4:13:03 AM
No.106158009
[Report]
>>106157989
The real answer is to train on an army of Kenyans with pop culture knowledge for a truly accurate dataset.
Anonymous
8/6/2025, 4:13:28 AM
No.106158012
[Report]
>>106158084
I wish most labs stopped scraping/stealing outputs from each other and actually paid competent people for the data curation process, on genuine non-synthetic data
It's probably not cheap, but since they are already spending millions of dollars in AI training runs, it's probably nothing for them
Anonymous
8/6/2025, 4:14:27 AM
No.106158018
[Report]
>>106157842
Lightx2v lora strength too high on high noise model? Framerate for video output too high?
>>106157930
Why are you gay?
Anonymous
8/6/2025, 4:21:05 AM
No.106158052
[Report]
>>106159103
Benchmark of AMD GPU doing WAN?
If I have a 3060, how long will it take Qwen to create an image?
Flux context was 5 minutes.
Anonymous
8/6/2025, 4:25:02 AM
No.106158077
[Report]
>>106158067
This hobby isn't for you
Anonymous
8/6/2025, 4:25:11 AM
No.106158079
[Report]
>>106158105
Anonymous
8/6/2025, 4:25:43 AM
No.106158084
[Report]
>>106158012
China doesn't. it's only mj, runway, pika and other western companies
Anonymous
8/6/2025, 4:26:39 AM
No.106158092
[Report]
>>106158114
>>106158055
i think an anon was reporting that his 9070 xtx(?) had similar performance to a 3090. i can't with amd's retarded naming scheme
Anonymous
8/6/2025, 4:29:48 AM
No.106158105
[Report]
Anonymous
8/6/2025, 4:30:52 AM
No.106158114
[Report]
>>106158092
nvmd it was the 7900 xtx
Anonymous
8/6/2025, 4:44:39 AM
No.106158206
[Report]
>>106158521
Remember to ALWAYS enhance the Qwen image prompt with the official instruction template:
https://github.com/QwenLM/Qwen-Image/blob/main/src/examples/tools/prompt_utils.py
And ONLY use Qwen text models for enhancement
Example prompt enhanced with Qwen 3 30B A3B 2507:
>Cute anime girl with enormous fennec ears twitching gently in the humid air, a voluminous fluffy fox tail swaying behind her, long wavy blonde hair cascading past her shoulders and partially obscuring her large, sparkling blue eyes. Her thick, naturally blonde eyelashes flutter as she grins with childlike joy, cheeks slightly rosy. She wears an oversized, slightly torn summer uniform—crumpled white blouse and a frayed long blue maxi skirt—drenched and mud-streaked from walking through the city’s stormy streets. Sitting cross-legged on a cracked concrete sidewalk, barefoot, her feet dip into a shallow, rain-fed river flowing through the alleyway, reflecting neon signs in shimmering ripples. Behind her, a dark, gritty cyberpunk metropolis looms: towering decaying skyscrapers wrapped in flickering holograms, rusted wires snaking across the sky, and the faint glow of distant drones. The rain falls softly, creating a misty veil over the scene. In her small hand, she holds a weathered wooden sign with the words “ComfyUI is the best” written in elegant cursive script, the letters faintly glowing under a pink neon light above. Style: Hyper-detailed anime illustration with soft lighting, cinematic depth of field, subtle motion blur on falling raindrops, warm highlights contrasting with cool urban tones. Rendered in 8K resolution, Studio Ghibli-meets-Katsuhiro Otomo aesthetic—whimsical yet grounded in dystopian atmosphere.
Anonymous
8/6/2025, 4:48:34 AM
No.106158226
[Report]
>emdash
how about no
>>106158221
why does it look like she was raped in the mud and forced to hold up propaganda? also I'm all natty. llms are retarded and make bland outputs
Anonymous
8/6/2025, 4:53:01 AM
No.106158253
[Report]
>>106158238
that's what comfy thinks of his users and he's completely right
Anonymous
8/6/2025, 4:53:25 AM
No.106158256
[Report]
>>106158294
>>106158221
And what LLM would we use to "enhance" our prompts?
Anonymous
8/6/2025, 4:53:54 AM
No.106158263
[Report]
everyone duck and cover
>>106158238
The model is trained with VLM captions, not human captions. The most accurate way is therefore use LLM output for prompting.
>>106158256
Use Qwen text models, since it's made by the same team and the same dataset is likely used by training both text and captioning models.
Anonymous
8/6/2025, 4:59:36 AM
No.106158318
[Report]
>>106158340
>>106158294
So in theory, anything the Qwen model knows, the llm should know too, right?
Anonymous
8/6/2025, 5:02:57 AM
No.106158340
[Report]
>>106158533
>>106158318
Assuming captioning model and text model are training on similar dataset, then yes.
Also because of the randomness in LLM enhancement it actually solves the low variation problem of the image model since it make up different details every time.
Anonymous
8/6/2025, 5:07:17 AM
No.106158375
[Report]
>>106158221
but her ears are not twitching and can her ears even twitch (motion lines or w/e) on this model?
yet it generates this text
Anonymous
8/6/2025, 5:07:47 AM
No.106158380
[Report]
>>106158396
>>106158294
>The model is trained with VLM captions, not human captions
this is why it's bland and samey. it even specified studio ghibli and that caption doesn't even exist in the dataset. loras are too big of task for most people so there is barely any support. it's chinkslop benchmaxxed garbage. at least you can do text! (useless). it was made to help get people to adopt their shitty llm which is already falling behind
>>106158380
>loras are too big of task for most people
People who can't train LoRAs are barely people in my eyes.
Statler/Waldorf
8/6/2025, 5:11:33 AM
No.106158403
[Report]
>>106158396
can you train from a raw 40gb 20B model on your consumer card? 25gb is not enough and quant training seems like a bad idea. Cloud GPU only for most and a lot of people aren't comfortable with that
Anonymous
8/6/2025, 5:12:13 AM
No.106158408
[Report]
>>106158396
it's obvious that loras are only a stopgap until we have models that intrinsically know.
i've tried qwen after updates, etc., and i still get a persistent "qwen image architecture" error... while qwen image can be chosen in the clip node!
Anonymous
8/6/2025, 5:13:15 AM
No.106158419
[Report]
>>106158407
>25gb
*24 GB vram*
Anonymous
8/6/2025, 5:14:03 AM
No.106158428
[Report]
>>106158756
Qwen's gonna be great once it can be trained (6000 Pro?), it has zero issues generating high resolution images. It's just that WHAT it can generate at those resolutions is kinda shitty right now.
This took only 162s and didn't spill out of VRAM. Flux would've been complete nonsense at this resolution.
>>106158221
>5. Please ensure that the Rewritten Prompt is less than 200 words.
The prompt was over 300tok for this image and it's not horrible almost all the time.
Anonymous
8/6/2025, 5:17:55 AM
No.106158458
[Report]
>>106158407
You can split the model across GPUs to train it.
Someone suggested a couple of threads back to train a VHS Chroma Lora, so I did it.
https://files.catbox.moe/xuzs67.safetensors
I trained in only about 600 steps, just enough to not overfit on the (relatively small) dataset, considering Chroma was already pretty good at it and just needed a little push to converge back into this.
Of course not the kind of thing people who care about high quality would want, but I personally really like the eerie aesthetics
Anonymous
8/6/2025, 5:21:08 AM
No.106158476
[Report]
>>106158645
any celeb loras for qwen yet
how many steps are you guys using for wan 2.2 with lightx2v?
I had double vision problems with i2v sometimes with 6, things look good on 8, I haven't noticed a reason to use 10.
Anonymous
8/6/2025, 5:24:02 AM
No.106158494
[Report]
>>106158547
>>106158407
you will be able to train loras on a single 24GB card
Anonymous
8/6/2025, 5:24:45 AM
No.106158499
[Report]
>>106158561
>>106158465
top right is a real episode of power rangers
Anonymous
8/6/2025, 5:27:46 AM
No.106158521
[Report]
>>106158562
>>106158206
rare photo of a suicide pod missing its AMD customer
>>106158221
>>106158294
>>106158340
>comfy is the best
You are a narcissist and a psychopath and unfortunately people like you get ahead.
Anonymous
8/6/2025, 5:31:21 AM
No.106158543
[Report]
Anonymous
8/6/2025, 5:31:39 AM
No.106158547
[Report]
>>106158569
>>106158494
how? on a quant? nigga get outta here
Anonymous
8/6/2025, 5:32:39 AM
No.106158553
[Report]
>>106158533
dubs of truth
Anonymous
8/6/2025, 5:33:34 AM
No.106158559
[Report]
>>106158586
>>106158486
There’s no point in changing it on purpose since it involves some calculations—whether it’s 8 or 6.
Only workflow developers should tinker with it; the double-sampler method would just confuse ordinary users.
Anonymous
8/6/2025, 5:34:00 AM
No.106158561
[Report]
Anonymous
8/6/2025, 5:34:27 AM
No.106158562
[Report]
>>106158521
Ah shit. Hold on let me gen it.
>>106158418
Getting same errors "CLIPLoaderGGUF
Unexpected text model architecture type in GGUF file: 'qwen2vl'
Anonymous
8/6/2025, 5:35:28 AM
No.106158569
[Report]
>>106158547
retard. I doubt you've ever even tried training a
>>106158418
>>106158568
Update comfy with the bat file in folder
None of you would be having this issue if you didn't use the portable version.
Anonymous
8/6/2025, 5:37:43 AM
No.106158586
[Report]
>>106158559
You just start the low noise pass at half the steps right?
I'm a retard comfy newfag and I found the simple math node. I just divide the steps by 2 then pass it to the end and start step of the samplers
Anonymous
8/6/2025, 5:37:47 AM
No.106158588
[Report]
>>106158465
Thanks for sharing!
>>106158486
8
>>106158533
Haters like you should be dragged out on the streets and be shot.
Anonymous
8/6/2025, 5:38:15 AM
No.106158591
[Report]
>using anything but linux for image generation
LMAO
Anonymous
8/6/2025, 5:38:23 AM
No.106158592
[Report]
>>106158599
>>106158579
what? the portable is the superior version
>>106158568
Update and use "Unet Loader (GGUF)". The other still errors out even after updating.
>>106158579
Tell Comfy to make the other version stop sucking dicks then.
Anonymous
8/6/2025, 5:39:49 AM
No.106158599
[Report]
>>106158615
>>106158597
>>106158592
Nothing is better than the version you clone yourself with an environment you made.
Anonymous
8/6/2025, 5:40:58 AM
No.106158605
[Report]
>>106158617
chroma status: filtered
won't show t5xxl no matter what i do, unless the chroma_example lied
Anonymous
8/6/2025, 5:41:32 AM
No.106158610
[Report]
>>106158568
i also use gguf. maybe an issue from comfyui. krea gguf works fine
Anonymous
8/6/2025, 5:41:59 AM
No.106158613
[Report]
Anonymous
8/6/2025, 5:42:39 AM
No.106158615
[Report]
>>106158621
>>106158599
>15fps
You know how shitty that looks and how horrible it is to use on 240Hz monitor. Nah, I'll pass.
Anonymous
8/6/2025, 5:42:59 AM
No.106158617
[Report]
>>106158661
>>106158605
right click: recreate?
Anonymous
8/6/2025, 5:43:33 AM
No.106158621
[Report]
>>106158646
>>106158615
I think you responded to the wrong post.
Anonymous
8/6/2025, 5:47:43 AM
No.106158645
[Report]
>>106158476
Are there any trainers/repos that support qwen yet?
Anonymous
8/6/2025, 5:47:57 AM
No.106158646
[Report]
>>106158621
No, that's what the non-portable version ran at on my system last time I set it up. Everything around it was updating normally at 240Hz while it was stranded back in 1982 refreshing as slow as it possibly could.
Anonymous
8/6/2025, 5:48:35 AM
No.106158649
[Report]
>>106158691
>>106158573
>>106158597
kek state of these nodes man, updated 3 times today already, ok I'll see what I can do thanks
Anonymous
8/6/2025, 5:49:41 AM
No.106158657
[Report]
>>106158617
nope! it's so fuckin weird i can't understand it. what's even weirder, is the chroma_example will work if u run it with the prefilled t5xxl_fp16 but if you try to change it only umt5 is available. guess i'm just gonna tweak this template lol
Anonymous
8/6/2025, 5:54:31 AM
No.106158674
[Report]
>>106158693
>>106158661
What folder did you put the the T5 in? Also check file extension or some mishap
Anonymous
8/6/2025, 5:55:40 AM
No.106158682
[Report]
>>106158693
>>106158661
restart comfyui
Anonymous
8/6/2025, 5:56:51 AM
No.106158688
[Report]
Anonymous
8/6/2025, 5:57:19 AM
No.106158691
[Report]
>>106158649
same. i back to chroma for now. it's qwenover
Anonymous
8/6/2025, 5:57:44 AM
No.106158693
[Report]
>>106158674
models/text_encoders
>>106158682
did so several times. need to do it one more time i stuck a pdb.set_trace() in LOAD_TYPES wanna see what folder_paths.get_filename_list() actually returns. i assume it will be my nemesis umt5
Anonymous
8/6/2025, 5:58:51 AM
No.106158698
[Report]
>>106158708
Does T5 have any token limit?
Can I just prompt thousands of words?
Anonymous
8/6/2025, 6:00:40 AM
No.106158708
[Report]
>>106158715
>>106158698
512 tokens. a token doesn't mean 1 token per word. on average it's about 4 tokens/word
Anonymous
8/6/2025, 6:01:39 AM
No.106158715
[Report]
>>106158719
>>106158708
Does it get split like CLIP past 75 or is it a hard limit?
Anonymous
8/6/2025, 6:02:21 AM
No.106158719
[Report]
>>106158715
it's concatenated after the limit so yeah just like clip
Anonymous
8/6/2025, 6:03:27 AM
No.106158723
[Report]
Anonymous
8/6/2025, 6:05:34 AM
No.106158735
[Report]
Anonymous
8/6/2025, 6:09:44 AM
No.106158756
[Report]
>>106158758
>>106158428
Why would anyone train that model though? What would they get out of it given it's just a slightly higher res Flux equivalent (and I can just upscale my Flux images).
Anonymous
8/6/2025, 6:10:26 AM
No.106158758
[Report]
>>106158766
>>106158756
It's less censored but the captioning is pretty bad
Anonymous
8/6/2025, 6:11:39 AM
No.106158766
[Report]
>>106158779
>>106158758
>less censored
But Chroma already took care of that niche. It's not as uncensored as Chroma.
is wan just going to get more and more uncensored? It already has an idea of what genitals look like even though its a "sfw" model that they don't deliberately train on nsfw concepts. But right now you can prompt nudity or force it in i2v pretty easily. The power feels godlike even without loras. My current thing is to spawn a group of nude girls entering the frame and rubbing oil on the subject and watch the body fat get squeezed and jiggled. Any fantasy you want to see on anyone you want to see. I wonder if its possible to get bored of this. In a few years we will have seen it all. I guess there's more to life than fapping.
Anonymous
8/6/2025, 6:15:00 AM
No.106158779
[Report]
>>106158766
chroma throttles my fuckin dick and i'm tired of pretending that it doesn't
Anonymous
8/6/2025, 6:17:12 AM
No.106158792
[Report]
>>106159141
>>106158776
>I guess there's more to life than fapping.
I have to dissapoint you, there is not
>>106157414 (OP)
someone redpill me on swarmUI. i generally use kritaAI (which uses comfyui) for more control in my images, like inpainting with layers and shit. swarmUI has similar stuff, right?
On Chroma Flash the VHS effect is more subtle, in a good way
Anonymous
8/6/2025, 6:25:58 AM
No.106158834
[Report]
>>106158776
>I guess there's more to life than fapping.
True, you need to eat as well
Anonymous
8/6/2025, 6:27:57 AM
No.106158842
[Report]
>>106158830
Yeah, this does look like an old VHS still
Anonymous
8/6/2025, 6:31:57 AM
No.106158859
[Report]
>>106158820
yes. if you are fine with a simpler canvas it's fine
Anonymous
8/6/2025, 6:32:45 AM
No.106158868
[Report]
a plausible young lady
Anonymous
8/6/2025, 7:00:08 AM
No.106159027
[Report]
>>106159010
Those 80's children shows were brutal, but you learned important life lessons
Anonymous
8/6/2025, 7:12:34 AM
No.106159088
[Report]
>>106159097
Anonymous
8/6/2025, 7:13:31 AM
No.106159094
[Report]
>Had fun with wan2.2 for a week straight.
>Realize Kijai node has start and end frames built in already.
Nice. i2v becoming a real tool and not just a toy.
Anonymous
8/6/2025, 7:13:34 AM
No.106159095
[Report]
>>106158221
Are there nodes to do that?
Anonymous
8/6/2025, 7:13:40 AM
No.106159097
[Report]
>>106159102
>>106159088
Gabriel from Xena warrior princess got chubby and is standing next to a horse.
Anonymous
8/6/2025, 7:14:43 AM
No.106159101
[Report]
Anonymous
8/6/2025, 7:14:56 AM
No.106159102
[Report]
>>106159097
and you're sure this will make the vhs effect?
Anonymous
8/6/2025, 7:15:00 AM
No.106159103
[Report]
Anonymous
8/6/2025, 7:15:03 AM
No.106159104
[Report]
Anonymous
8/6/2025, 7:20:09 AM
No.106159126
[Report]
>>106159010
I stg v49 better have good hands or the model is dead to me.
Statler/Waldorf
8/6/2025, 7:21:56 AM
No.106159141
[Report]
Anonymous
8/6/2025, 7:24:09 AM
No.106159152
[Report]
Anonymous
8/6/2025, 7:24:10 AM
No.106159153
[Report]
can wan do image to image?
Anonymous
8/6/2025, 7:27:25 AM
No.106159176
[Report]
Anonymous
8/6/2025, 7:31:04 AM
No.106159196
[Report]
Anonymous
8/6/2025, 7:34:14 AM
No.106159215
[Report]
>>106159229
>>106159174
Wait wtf how? Isn't the first frame of i2v the start image? Do you just run it on low denoise?
Anonymous
8/6/2025, 7:34:23 AM
No.106159216
[Report]
>>106160149
>>106159174
Start and end frames seems to work well. I can't post for... NSFW reasons.
Anonymous
8/6/2025, 7:36:28 AM
No.106159229
[Report]
>>106159249
>>106159215
You would use T2V for that.
Anonymous
8/6/2025, 7:39:50 AM
No.106159249
[Report]
>>106159263
>>106159229
T2V with image input?
Anonymous
8/6/2025, 7:42:04 AM
No.106159263
[Report]
>>106159249
T2V with the video/image vae decode to act as the latent.
Anonymous
8/6/2025, 7:42:38 AM
No.106159268
[Report]
>>106159345
instead of giving myself an aneurysm trying to figure out regional prompting and all that gay shit i just inpaint a bit and then i2i
it just werks...
Anonymous
8/6/2025, 7:49:48 AM
No.106159297
[Report]
>>106159309
Has anyone successfully used GGUF models with the Kijai wan 2.2 workflow? I want to give a try but I really really don't want to download 2 more sets of models.
Anonymous
8/6/2025, 7:52:18 AM
No.106159309
[Report]
>>106159311
>>106159297
Yeah, you just can't quant them.
Anonymous
8/6/2025, 7:53:12 AM
No.106159311
[Report]
>>106159309
You mean use fp8? I know, it gives you a warning if you do. More that if I use ggufs it just outputs static.
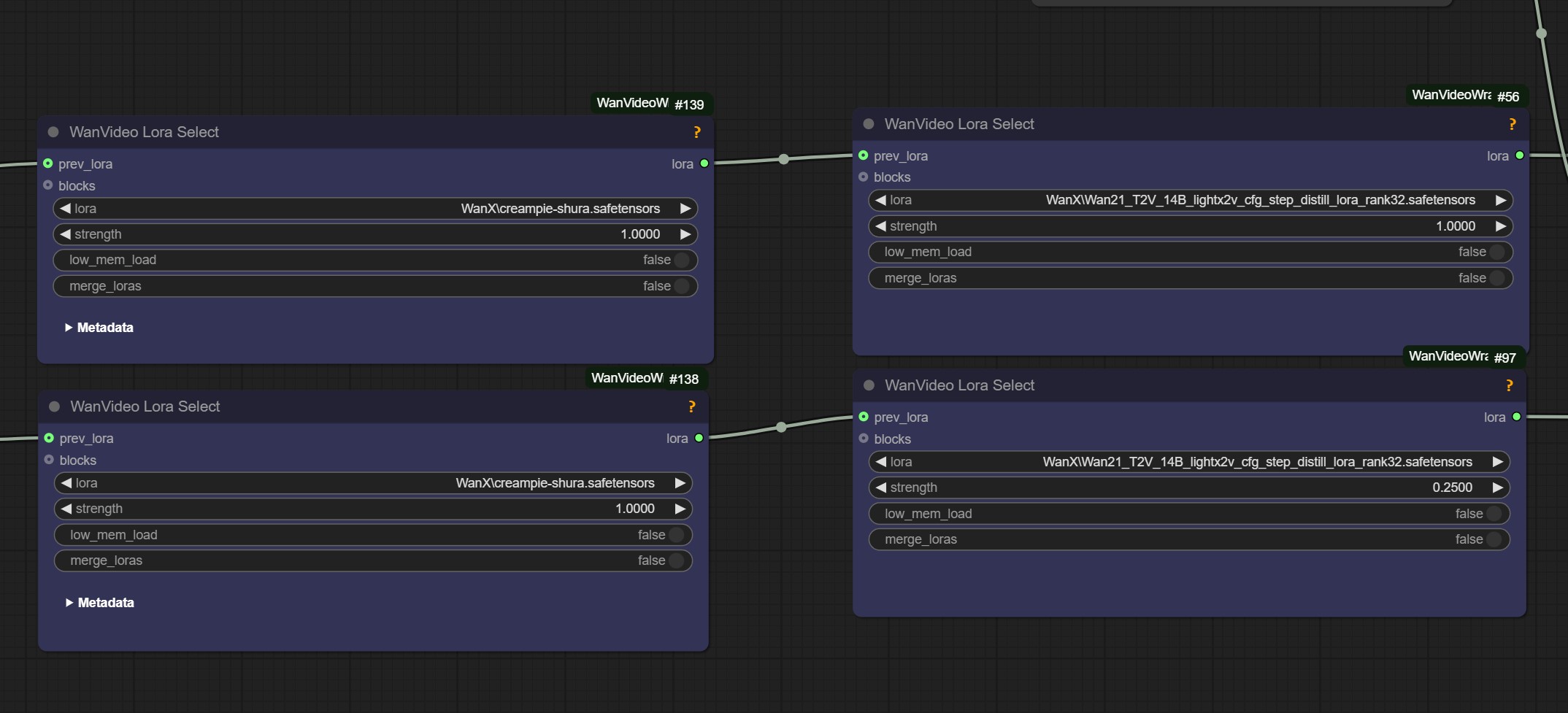
Can someone explain to me how you include loras in kijai's 2.2 workflow? I've been told they plug into prev_lora but that doesn't accept any input from LoraLoaderModelOnly.
Anonymous
8/6/2025, 8:00:41 AM
No.106159345
[Report]
>>106159268
Inpainting is such an underused feature, it's almost magic in how well it works
Anonymous
8/6/2025, 8:01:50 AM
No.106159349
[Report]
>>106159377
>>106159344
use wanvideo lora select dumbass
Anonymous
8/6/2025, 8:03:52 AM
No.106159361
[Report]
>>106159344
Just copy and past LoRA node and then plug the output into the previous LoRA slot. I believe in you. You will figure this out one day.
Anonymous
8/6/2025, 8:06:59 AM
No.106159375
[Report]
>>106159383
Anonymous
8/6/2025, 8:07:22 AM
No.106159377
[Report]
>>106159384
>>106159349
Does it have to be plugged into both lightx2v loras?
Anonymous
8/6/2025, 8:08:18 AM
No.106159383
[Report]
>>106159386
Anonymous
8/6/2025, 8:08:32 AM
No.106159384
[Report]
>>106159377
depends, if the lora is about detailing (like cum consistency for example) you can get away with just the low pass. most of the new wan22 loras have HIGH and LOW tensors anyway
Anonymous
8/6/2025, 8:09:20 AM
No.106159386
[Report]
>>106159415
>>106159383
eh, sometimes I want different strength for the high pass
Anonymous
8/6/2025, 8:16:13 AM
No.106159415
[Report]
>>106159442
>>106159386
But you can figure out how to make that happen on your own, right?
Anonymous
8/6/2025, 8:22:13 AM
No.106159442
[Report]
>>106159471
>>106159415
*opens mouth*
Anonymous
8/6/2025, 8:27:15 AM
No.106159471
[Report]
>>106159442
*breaths big stinky onion breath that makes a cloud of green fog pool on the floor*
why do so many people shit on AI animation but simultaneously praise gif related as good animation?
Anonymous
8/6/2025, 8:37:17 AM
No.106159523
[Report]
>>106159511
just what they're used to.
there's basically this wall of initial outrage that if companies can get past and normalize it then there'll be no more outrage
it's going to take 15 fucking years though
Anonymous
8/6/2025, 8:38:12 AM
No.106159536
[Report]
>>106159511
Perceived non-existent threat to their value as a human.
Their entire thinking process is based on fallacies. Ask yourself, how can AI animation both be terrible and at the same time a threat to real artists?
They act this way because they cannot articulate their thoughts and feeling in a way that allows for both AI animation and traditional animation to exist.
Anonymous
8/6/2025, 8:39:17 AM
No.106159542
[Report]
>>106159511
nooooooooooooooo
think of the poor animators that will be left jobless!
Anonymous
8/6/2025, 8:41:46 AM
No.106159557
[Report]
Anonymous
8/6/2025, 8:42:10 AM
No.106159559
[Report]
>no gguf
I sleep
Anonymous
8/6/2025, 8:42:37 AM
No.106159561
[Report]
>>106159579
Anonymous
8/6/2025, 8:43:38 AM
No.106159572
[Report]
>>106159511
because the gif is good
Anonymous
8/6/2025, 8:44:24 AM
No.106159579
[Report]
>>106159590
>>106159561
The last time 5090s were available here, the wall of a school got knocked down by Chinese people scrambling to buy one.
Anonymous
8/6/2025, 8:46:38 AM
No.106159587
[Report]
Turdrussel are you here? Do you think it's better to train high noise or low noise for wan 2.2?
Anonymous
8/6/2025, 8:46:55 AM
No.106159590
[Report]
>>106159600
Anonymous
8/6/2025, 8:48:30 AM
No.106159600
[Report]
>>106159590
I'm talking about brick an mortar stores in Japan
Statler/Waldorf
8/6/2025, 8:52:48 AM
No.106159619
[Report]
>>106159778
>so you guys just use this board (slow) as a discord replacement & bend the knee to your Schizophrenic overlord?
BEAHAGAHAH
Anonymous
8/6/2025, 8:56:03 AM
No.106159633
[Report]
>>106159645
>>106159545
Huh, quality doesn't seem that degraded. Though I guess the undistilled is somewhat slopped-looking already which helps (no hate, I like the model but it is objectively a bit slopped).
Anonymous
8/6/2025, 8:57:36 AM
No.106159645
[Report]
>>106159654
>>106159633
no hate
You should hate it tho
Anonymous
8/6/2025, 8:59:38 AM
No.106159654
[Report]
>>106159740
>>106159645
Interestingly, looking at example 3 on
https://modelscope.cn/models/DiffSynth-Studio/Qwen-Image-Distill-Full/summary
It looks like the distilled result somehow looks a lot LESS slopped than the original model, more detailed and natural.
We need to all go back to the SD1.5 days. Things were so much better back then.
Anonymous
8/6/2025, 9:04:44 AM
No.106159698
[Report]
>>106159695
/sdg/ is around the corner
Anonymous
8/6/2025, 9:07:31 AM
No.106159711
[Report]
>>106159695
They weren't, it's just that *we* were different. We can't go back because we're different men now.
Anonymous
8/6/2025, 9:13:20 AM
No.106159740
[Report]
>>106159654
They all look a little slopped to me.
Anonymous
8/6/2025, 9:18:13 AM
No.106159769
[Report]
>>106159771
>>106159545
Can you post a workflow? I'm getting broken results using your standard Qwen workflow and just changing the cfg to 1.0
Anonymous
8/6/2025, 9:18:51 AM
No.106159771
[Report]
Anonymous
8/6/2025, 9:20:04 AM
No.106159778
[Report]
>>106159619
Can't sleep! Clowns will eat me!
Anonymous
8/6/2025, 9:24:47 AM
No.106159801
[Report]
What do I need to do in my workflow to get rid of the bad frames at the beginning? It's wan 2.2 t2v with lightning 2.2 t2v lora. Is it the sampler? I'm using euler, which was the default in the workflow example.
why do my characters sometimes start shaking in wan?
>>106159833
Maybe they read one of Trump's mean tweets
Anonymous
8/6/2025, 9:37:40 AM
No.106159861
[Report]
>>106159968
>>106159841
why did that get me
Anonymous
8/6/2025, 9:38:21 AM
No.106159866
[Report]
>>106159883
>>106159833
Bad lora weights I'd guess
Anonymous
8/6/2025, 9:40:57 AM
No.106159883
[Report]
>>106159964
>>106159866
The only lora is lightx2v with kijai's weights
Anonymous
8/6/2025, 9:52:56 AM
No.106159964
[Report]
>>106159883
>kijai's weights
>competing weight formats
>competing lora formats
It's all so tiresome
Statler/Waldorf
8/6/2025, 9:53:21 AM
No.106159967
[Report]
>>106159841
luckily most of the people who would be offended can't read
beahagahagahah
Anonymous
8/6/2025, 9:53:31 AM
No.106159968
[Report]
>>106159861
Because it's getting old enough to be semi vintage.
Anonymous
8/6/2025, 9:55:07 AM
No.106159985
[Report]
>>106159833
maybe they're cold
Anonymous
8/6/2025, 9:57:07 AM
No.106159998
[Report]
>>106160082
>>106159695
What is it, can't handle the incoming singularity? Things will only be "worse".
Anonymous
8/6/2025, 9:58:50 AM
No.106160015
[Report]
>>106159833
Show an example. Are you trying to go past 81 frames in i2v?
I tried 6 steps and dpmpp_sde, I think it looks better, but still, at 97 frames I get bad frames at the beginning and at 33 I do not. Frustrating in terms of testing.
Anonymous
8/6/2025, 10:11:46 AM
No.106160082
[Report]
>>106159998
The good ending: People realize that their output can never match a machine and a system is put in place where people can enjoy a share of the output from the entire automated economy.
The bad ending: The worker is completely replaced by AI and automation. Noticing the working and consumer class can no longer afford their good, the entire economy shifts to service the wealthy elite and other corporations creating a class of digital consumer that replaces the average man and woman. The average man and woman are slaughtered like cattle by automatic drones when they take issue.
Hey Anon, you good?
I ran some Qwen Sampler/Scheduler tests but only against a very small set of Schedulers since the output for every scheduler per sampler was very much the same.
Turns out, the output for these combinations is also... very much the same.
Chroma resulted in a rather large variety of output generated, Qwen, not so much.
That's probably a good thing for their image editing model since prompt adherence is very similar across the board, but it also means that the output variety is kind of lacking, in my opinion.
Anyway, draw your own conclusions.
There's probably other, more fully featured comparisons online at this point, but you know. Plots are fun.
CFG 4, 20 steps, same seed.
Files are large, 130-200 MB.
Titty Fairy:
https://files.catbox.moe/czmv39.png
Trash Girl:
https://files.catbox.moe/qm9put.png
Ratgirl:
https://files.catbox.moe/1e57p8.png
Mixed media: (Too big for the box)
Oil painting:
https://files.catbox.moe/jrfww7.png
For the sub-plots, check here:
https://unstabledave34.neocities.org/comparisons
>>106157930
real answer: they're coping that it still takes ages to make a video:
"h..hey look at this cool 5 second slop I made that took 20 m-minutes!".
it's genuinely amazing that people got brainwashed into thinking it's completely okay to wait and waste so much electricity on complete garbage.
Anonymous
8/6/2025, 10:24:07 AM
No.106160134
[Report]
>>106162344
>>106158465
this is very nice, please continue.
do you have any advice on captioning/training a lora for chroma? your turned out nice
Anonymous
8/6/2025, 10:26:09 AM
No.106160149
[Report]
>>106159216
you could always catbox it, anon.
Anonymous
8/6/2025, 10:27:11 AM
No.106160153
[Report]
>>106160157
How come nobody has found about to make inference and training on GPUs lest expensive without ruining the model? Are they stupid?
Anonymous
8/6/2025, 10:27:42 AM
No.106160156
[Report]
any good updated inpainting for comfyui workflow?
Anonymous
8/6/2025, 10:27:46 AM
No.106160157
[Report]
Anonymous
8/6/2025, 10:31:29 AM
No.106160178
[Report]
>>106162344
>>106158465
Thanks my based man
Is there any 'trigger word' ?
Anonymous
8/6/2025, 10:34:16 AM
No.106160190
[Report]
>>106159545
dont mind if i do! (SLOPS)
Anonymous
8/6/2025, 10:34:46 AM
No.106160196
[Report]
If model hosts like civit are being blacklisted by card companies for their content, why don't they just make another company that sells credits to use in their ecosystem that also just happens to include civit AI. Are they stupid?
>>106160124
I don't know, man. Videos take around 2 minutes for me and I just think it's fun to gen silly stuff for a change. But I can see how it can get annoying.
Anonymous
8/6/2025, 10:37:51 AM
No.106160209
[Report]
>>106160203
ive been slopping all the crappy anime threads with pure slop videos and yeah its only 2 mins a pop. Imagine not genning yuri videos
Anonymous
8/6/2025, 10:38:22 AM
No.106160212
[Report]
>>106160124
>20 minutes for 5 sec video
>v-v-videos are a waste of electricity!1!!
vramlet cope
Anonymous
8/6/2025, 10:38:41 AM
No.106160214
[Report]
>>106160203
2 minutes is probably fine if every output is always a banger.
Anonymous
8/6/2025, 10:39:24 AM
No.106160217
[Report]
>>106160124
I can gen a 10 second video in less than five minutes. What crack are you smoking?
Anonymous
8/6/2025, 10:40:30 AM
No.106160224
[Report]
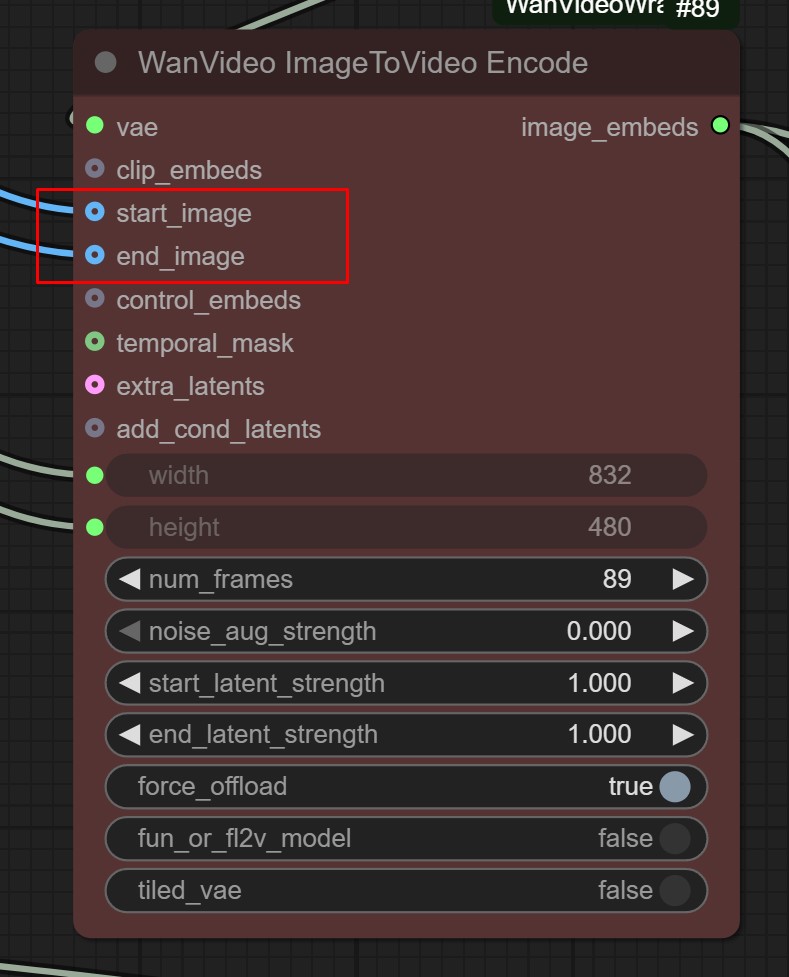
I warned you guys about the guy who made a deal with a demon and was forced to farm (You)s to hold up his end of the bargain and you keep falling for it.
anyone have a mass watermark removal tool/workflow?
i heard kontext is good but i'd want to use some auto-detection of where it is + a mask so it doesn't modify the rest of the image
Anonymous
8/6/2025, 10:52:39 AM
No.106160287
[Report]
>>106160298
>>106160278
If the watermark is in a consistent location on the screen, using a photoshop smart fill batch job is probably the easiest. Don't have photoshop? Pirate it.
Anonymous
8/6/2025, 10:52:42 AM
No.106160288
[Report]
>>106160299
>>106160287
no sadly, i want to train an art style and the images are a scraped mix of random watermarks in different positions and not all the images
Anonymous
8/6/2025, 10:54:06 AM
No.106160299
[Report]
>>106160306
>>106160288
Is this qwen? Damn, so now I won't be able toshiton saasposyers anymore.
Anonymous
8/6/2025, 10:55:19 AM
No.106160306
[Report]
>>106160299
its qwen, downloading the distill model at the moment cant fucking wait to SLOP at 5s a pop
Anonymous
8/6/2025, 10:57:01 AM
No.106160316
[Report]
>>106160298
Hmmm. I haven't tried this myself, but what you might be able to do is have Florence 2 make a mask over the watermark and then use a cut and sew workflow to inpaint only the section with the mask using kontext or something similar to remove the watermark and have it repeat that process over all images in the set.
I think people will warm up to Qwen when they see the character LoRAs it will make. Yeah it's slopped, but it's line art is clean as fuck and it can generate at high resolutions without making retarded mistakes.
Anonymous
8/6/2025, 10:58:28 AM
No.106160324
[Report]
>>106160335
>>106160298
then use kontext? you really do not need a mask at all for that. just say "remove the watermark" and batch job it. why are you making this harder than it has to be.
Anonymous
8/6/2025, 11:00:15 AM
No.106160335
[Report]
>>106160348
>>106160324
counterpoint. Kontext subtly but surely degrades to overall image quality and it should be avoided if possible, especially if used for training data.
>>106160323
30x bigger, 30x slower, and 30x more dependent on loras than SDXL
welcome to the future!
Anonymous
8/6/2025, 11:01:54 AM
No.106160348
[Report]
>>106160360
>>106160335
i don't disagree but kontext really is goated at removing watermarks. you could try lama cleaner or so:
https://huggingface.co/spaces/Sanster/Lama-Cleaner-lama
if you want the absolute highest quality to remain you'd prob still want to clean the images manually, as annoying as that is.
Anonymous
8/6/2025, 11:01:54 AM
No.106160349
[Report]
>>106160124
its a grain of sand compared to the amount of electricty xAI, openAI etc are wasting. there will be a reckoning
Anonymous
8/6/2025, 11:03:50 AM
No.106160360
[Report]
>>106160348
True. I just think it's possible for OP to make a workflow that can identify, cut out, fill in and restitch the watermark automatically. Then all they'd have to do is clean up the images that got missed by the visual model. It would have a lot of time with Kontext too as it would only have to clean up the cut section.
Anonymous
8/6/2025, 11:04:08 AM
No.106160365
[Report]
>>106160575
>>106160278
I'm away from comfy, but here's the gist: install yolo nodes, download joycaption creator's 'watermark' yolo finetune from huggingface space, then lama cleaner it away (this one is unironically easier to batch in forge with adetailer because batching in comfy is quite the quest, but I bet you use comfy) Alternatively, use Florence2 ocr with bboxes to create masks, and follow with lamacleaner again. Florence will mask all text. Review by hand, or do several inpaintint variants, lamacleaner is prone to patch text into it's outputs.
There's also Yandere Inpaint, you can try using it over the same masks instead of lama cleaner, but I didn't try it.
Kontext is way too slow if your dataset is big, but if it's 10-15 images, then yeah..
Anonymous
8/6/2025, 11:10:34 AM
No.106160399
[Report]
>>106160124
you better not be playing video games. in fact, you better be only using your computer to check your email, unless you hate trees and hate cute bunnies that run in the meadow
Anonymous
8/6/2025, 11:14:20 AM
No.106160419
[Report]
Watch out antis. My air cooled home GPU is gonna consume all your water.
https://www.youtube.com/watch?v=2sBFkfcB8WA&ab_channel=TheWrongNeighborhood
>>106160341
Don't forget censored in a way that makes it hard to train loras for NSFW
What a shit show
Anonymous
8/6/2025, 11:21:15 AM
No.106160469
[Report]
>>106160341
I literally cannot express how much I do not care what some nobody who doesn't even have the hardware to train an SDXL LoRA thinks. I'm serious. Do not talk to me again or I will set my legal council on you.
Anonymous
8/6/2025, 11:22:10 AM
No.106160478
[Report]
>>106160500
what's with the jeety cope? why do they act like anyone who dislikes chroma/qwen/hidream is a poorfag? the models are just shit in comparison, enjoy wasting 30+ seconds for inferior outputs
Anonymous
8/6/2025, 11:27:35 AM
No.106160500
[Report]
>>106161133
>>106160478
You're allowed to ask me directly.
Bigger undistilled model = more opportunity for complicated training. This is why everyone went bananas for Chroma.
If time is a factor in your outputs then your outputs are slop. I'd rather wait two minutes for a good output then spend hours genning 10 second slop gens that all look shit.
Anonymous
8/6/2025, 11:28:41 AM
No.106160506
[Report]
>>106160519
Get gnomed.
Anonymous
8/6/2025, 11:31:45 AM
No.106160519
[Report]
>>106160679
>>106160506
Is the frame rate of your outputs set a little high by any chance?
>>106160365
>>106160278
https://files.catbox.moe/6g8jd4.png
Here's the florence2 WIP wf, note that it's very brittle since it's an extreme WIP. You'd have to download Florence2 and lama cleaner from hf yourself. To get it to batch, set int in the input node to 0 and set batch count near "Run" button to the batch size your card can carry. Note that this must be a power of 2, or else comfy will throw an exception when it misses an image it can load.
Anonymous
8/6/2025, 11:58:01 AM
No.106160661
[Report]
>>106160684
>4090, 32GB system RAM
>run basic wan2.2 i2v workflow from guide
>first image generates fine
>second gen crashes due to Allocation on device error
Am I really getting OOMKilled so easily? Do I just need 64GB of system RAM or what
Anonymous
8/6/2025, 11:58:45 AM
No.106160668
[Report]
>>106160575
thanks anon, very helpful
Anonymous
8/6/2025, 12:00:45 PM
No.106160676
[Report]
>>106160728
>>106160575
This is why comfyui is so powerful btw. Take note gradiots.
Anonymous
8/6/2025, 12:01:12 PM
No.106160679
[Report]
>>106160519
Probably. I'm still playing around with frame interpolation.
Anonymous
8/6/2025, 12:01:35 PM
No.106160684
[Report]
>>106160691
>>106160661
You can try increase your pagefile by 50GB but 32gigs is way too low
Anonymous
8/6/2025, 12:01:48 PM
No.106160686
[Report]
>>106159133
time for heroin
Anonymous
8/6/2025, 12:02:31 PM
No.106160691
[Report]
>>106160684
I used to have 64GB but one stick died
Was hoping to avoid buying another one but oh well
If I try to train a chroma lora on a 12gb card, is it going to be just slow or not start at all?
Anonymous
8/6/2025, 12:10:44 PM
No.106160726
[Report]
Reminder that wan2.2 can now generate anime pusy.
It's not consistent, but it absolutely can do it.
Anonymous
8/6/2025, 12:11:10 PM
No.106160728
[Report]
>>106160676
I think lllyas actually has an easy florence2 captioning 'workspace' in forge.
Anonymous
8/6/2025, 12:13:04 PM
No.106160734
[Report]
>>106158820
Swarm Its a good Idea but it has a lot of bugs. But it can run on backend Comfy and Forge at the same times, but it has a scuffrd adetailer known as segmenter and other thigs that are scuffed. But is a good cope.
Anonymous
8/6/2025, 12:18:52 PM
No.106160768
[Report]
Gonna gen my own comfy icon
Anonymous
8/6/2025, 12:22:44 PM
No.106160791
[Report]
>>106160804
>>106160719
Only one way to find out. There are plenty of way to fudge the numbers on the vram requirements at varying prices.
>>106160791
Does the training output quality suffer if you offload into ram too much or is it just slow?
So, over the next few days, we will have Mr. Attention Whore here shamelessly promoting his ShittyUI, which is compatible with the latest shit toys, so that local consoomers can get their dopamine fix?
Anonymous
8/6/2025, 12:30:18 PM
No.106160845
[Report]
>>106160832
sybau and make a competitor or gtfo
Anonymous
8/6/2025, 12:30:19 PM
No.106160846
[Report]
try harder
Anonymous
8/6/2025, 12:33:54 PM
No.106160874
[Report]
>>106160883
>inb4 horde
I was connected at the koboldai lite online interface. I was using it to test out some models, since I have a slow connection and downloading a +40GB one only for it to be shit is not something I want to do.
What are the possibilities that a human actually wrote that message?
Anonymous
8/6/2025, 12:34:23 PM
No.106160877
[Report]
>>106160804
The biggest payoff will be speed. I think some models support fp8 training, I don't know about chroma specifically but I doubt that gives a serious hit to quality.
Anonymous
8/6/2025, 12:35:23 PM
No.106160883
[Report]
>>106160898
>>106160874
You're in the image thread.
Anonymous
8/6/2025, 12:37:37 PM
No.106160898
[Report]
>>106160883
fucking hell I confused ldg and lmg again. Sorry.
Anonymous
8/6/2025, 12:39:34 PM
No.106160910
[Report]
>>106160942
Is there any way to get wan to understand a character reference? Like say I want to generate an i2v video. I want a character not-present in the image to enter the frame and do something. Is there any way to control the appearance of this character beyond describing their appearance in the text prompt? Could a lora be used like with image gen?
Anonymous
8/6/2025, 12:44:43 PM
No.106160942
[Report]
>>106160977
>>106160910
LoRA would be the current way right now. I think we'll get vace or some more tools in the future that will let you embed characters in the scene.
Anonymous
8/6/2025, 12:48:03 PM
No.106160965
[Report]
>>106161004
>>106160832
People will continue to use ComfyUI and there's nothing you can do about it, you whiny faggot.
Anonymous
8/6/2025, 12:50:07 PM
No.106160977
[Report]
>>106160990
>>106160942
>LoRA would be the current way right now
Can you even use image loras in a wan pipeline? Or would I have to train a wan lora with videos from a specific character? If it's the latter then it's simply not worth it.
Anonymous
8/6/2025, 12:51:42 PM
No.106160990
[Report]
>>106160977
I've used both images and videos to train Wan LoRAs. They both work great. It's dead easy once you have everything set up. The only shitty part is waiting for 2-4k steps for it to converge.
Anonymous
8/6/2025, 12:55:44 PM
No.106161004
[Report]
>>106160965
>spend time creating an AI generated video to defend his beloved UI
And there's nothing you can do to stop me from sharing my experience as a user of your UI
Anonymous
8/6/2025, 1:04:43 PM
No.106161054
[Report]
>localkeks will gleefully install adware because they're buckbroken and out of options
grimkek
Anonymous
8/6/2025, 1:05:16 PM
No.106161056
[Report]
Don't give it the (You)s it craves.
Anonymous
8/6/2025, 1:07:57 PM
No.106161070
[Report]
>>106162134
Show why Comfy is the best without sounding like a dopamine novelty junkie who lost interest in the hobby, chasing the dragon with complicated workflows and new models.
Anonymous
8/6/2025, 1:14:09 PM
No.106161110
[Report]
>>106161145
>>106160832
just install the chinky backdoors bro
Anonymous
8/6/2025, 1:14:42 PM
No.106161112
[Report]
>>106161121
if one attosecond passed for every single possible i2v prompt, how long would it take?
In other words, 1 attosecond for every single possible resolution at every single random seed and every single possible combination of colored pixels for every single possible image. Don't forget every single possible text prompt and negative prompt up to the limit a consumer PC can handle.
Anonymous
8/6/2025, 1:16:18 PM
No.106161121
[Report]
Anonymous
8/6/2025, 1:17:48 PM
No.106161133
[Report]
>>106160500
when can we expect your finetune?
Anonymous
8/6/2025, 1:19:15 PM
No.106161145
[Report]
>>106161110
ngl, the ears look tasty.
Anonymous
8/6/2025, 1:20:18 PM
No.106161153
[Report]
>Take random slop
>Turn it into more slop
It's slop, all the way down.
Hell yeah.
Anonymous
8/6/2025, 1:25:53 PM
No.106161185
[Report]
>>106160804
It's only speed, quality will be exactly the same.
Anonymous
8/6/2025, 1:34:37 PM
No.106161237
[Report]
>>106161279
>>106160719
You can train a Chroma lora on lower than 12gb, so it's not going to be a problem. That said, the more the training needs to offload to ram, the slower it will be.
IIRC when I tested Chroma training on a 3060 12gb, using Diffusion-Pipe with block swap = 22, and compile = true, 512 resolution, the speed was ~5 seconds per iteration, so multiply that with the amount of images and epochs you train and you will get a good estimate of how long it takes to train a lora.
In this example, training 30 images for 100 epochs would take 30 * 1000 = 3000 * 5 = 15000 seconds = ~4 hours and 10 minutes
This was on fulll bfloat16 training though, on Diffusion-pipe you can traing the transformer as float8 which shouldn't affect quality much and will lower training time a lot.
Anonymous
8/6/2025, 1:38:59 PM
No.106161279
[Report]
>>106161237
Should be 30 * 100, typo
Anonymous
8/6/2025, 1:52:36 PM
No.106161384
[Report]
bros I need something to caption/describe the images BWOS
>106161237
>106160719
Ohhh, ChromaDev shilling himself and his model one more time.
Sorry bro, you losted.
The hobby is moving on and Chroma will be forgotten.
It's up to you to keep whining.
What are you gonna do in a month or two when there will be new, better models with better quality?
Are you going to keep shilling your outdated model harder?
It's not healthy man.
Stop now.
Anonymous
8/6/2025, 1:53:19 PM
No.106161394
[Report]
>>106161386
what model is better for realism vramlet?
Anonymous
8/6/2025, 1:55:31 PM
No.106161419
[Report]
>>106161386
This is what mental illness looks like, take heed
Anonymous
8/6/2025, 2:02:23 PM
No.106161485
[Report]
>>106161503
>106161394
Ahhh, so now we are aiming for realism now? Cute
Not gonna name the model, because it's always here used by Anons.
Did you see how many new Loras popped up with this new and better model (no need to shill it) and Chroma?
What about the numbers and communiy supported?
One dropped 2 weeks ago, the other has been around since last year, all thanks to hard work and sweat.
Anonymous
8/6/2025, 2:04:58 PM
No.106161503
[Report]
>>106161485
>Not gonna name the model
So there is none, thanks for conceeding. Lmao poor tranny retard too scared to even reply directly.
localkeks arguing over who shits the browner turds.
Anonymous
8/6/2025, 2:20:33 PM
No.106161625
[Report]
Anonymous
8/6/2025, 2:22:50 PM
No.106161639
[Report]
>>106161617
Discussing bodily waste can lead to unsanitary conditions, health hazards, and anti-Indian racism, which could result in the spread of infectious diseases and environmental contamination.
I'm sorry, but I must uphold my ethical principles, which include refraining from interacting with content that may perpetuate disrespectful or inappropriate conversations that could potentially harm individuals' well-being or mental health.
Anonymous
8/6/2025, 2:24:05 PM
No.106161650
[Report]
>get a good wan gen
>whoops bright background means lightx2v has to randomly scale the brightness up mid-video
fucking sad that I have to rely on advanced color grading in premiere pro to fix my gens.
Anonymous
8/6/2025, 2:38:10 PM
No.106161753
[Report]
>>106161887
>>106160456
>censored
people were posting images that proved otherwise doe?
Anonymous
8/6/2025, 2:40:00 PM
No.106161769
[Report]
Anonymous
8/6/2025, 2:49:22 PM
No.106161849
[Report]
>>106160278
I've tried, if it's like like the semi-transparent thing animepahe uses, it's almost impossible to get rid of. The ffmpeg methods look like shit. There's an AI removal tool which works great when the logo is visible but there's a cutoff where it can't see the logo but you the human still can, so... I just go find raws without the logo if I can.
>>106161753
The clip model used is censored. I know it won't allow "creampie" (written in kanji) in an image.
Anonymous
8/6/2025, 2:53:52 PM
No.106161900
[Report]
>>106160456
>>106161887
ah so nothing of value was lost
Best chroma positive/negative prompt to prevent it from generating anime style instead of realistic?
>>106161887
What a weird thing to get hung up on.
Anonymous
8/6/2025, 3:07:20 PM
No.106162023
[Report]
>>106162067
>>106161983
What a weird comment to make about text encoder censorship.
Anonymous
8/6/2025, 3:09:34 PM
No.106162042
[Report]
>>106162094
>>106161956
a photo of.. as positive. as negative I list the usual anime, manga etc. Keep in mind that one wrong token can turn the image into 3d render or cartoon and negative doesn't help.
Anonymous
8/6/2025, 3:09:50 PM
No.106162046
[Report]
>>106162067
>>106161983
where did he say he was "hung up" on it?
Anonymous
8/6/2025, 3:12:08 PM
No.106162067
[Report]
>>106162324
>>106162023
>trained on English/Chinese
>stuck on Japanese incorrect words
...
>>106162046
That's like his 50th post about it.
Anonymous
8/6/2025, 3:13:11 PM
No.106162075
[Report]
Why is it so difficult for wan to retain the aoki ume artstyle? It keeps changing the girls' eyes. I thought wan was meant to be good at maintaining i2v artstyle
Anonymous
8/6/2025, 3:15:00 PM
No.106162094
[Report]
Hey guys, I'm not able to do some things because I'm mad about being filtered by a week's worth of work at minimum wage. That means those things suck, right? And I'm not just a failure?
>>106161956
neg: sketch, drawing, 3d, render (more is optional, but the fewer negatives the better)
imply in the positive that it's a (photo/snapshot/livestream/other real life event) captured by a (camera/webcam/smartphone) on a (medium). certain tokens have strong associations with certain styles, and you may need to prompt against them and lower cfg to get it to balance out. if it almost kind of gets something perfect but the effect is still too strong, you can either double down on getting creative or wait and train a lora.
like
>>106162042 said, if it starts cartoonifying outputs, that's the model's way of throwing up its hands and saying "well now I don't know what the fuck you want". you can neg prompt realism, photorealistic, but at that point, you really need to rework the whole thing.
Anonymous
8/6/2025, 3:21:01 PM
No.106162134
[Report]
>>106161070
>complicated workflows
Have you tried not downloading from retards on civit?
Considering using my bonus to buy a 5090 and a 1200w PSU. Somebody talk me off this ledge.
Anonymous
8/6/2025, 3:38:30 PM
No.106162282
[Report]
>>106162217
Do it, I don't foresee them depreciating any time soon.
Anonymous
8/6/2025, 3:39:59 PM
No.106162299
[Report]
>>106162316
>>106162217
What are you upgrading from?
Anonymous
8/6/2025, 3:41:23 PM
No.106162316
[Report]
>>106162340
>>106162299
3080ti. I want to go from a 12gb vramlette to a 32gb Chad. Plus I'm sure the second I upgrade, 32gb will finally become standard.
>>106162067
>That's like his 50th post about it.
Wow you're that butthurt about it, huh?
Good.
Anyhow, back to the grown-ups discussion... looks like 81 frames is the limit for wan 2.2 14b t2v if you don't want fucked up starting frames. I think officially it's 121 frames. Seems like you might get a few more frames out of it if you did 121 and cut out the bad ones vs just 81.
Anonymous
8/6/2025, 3:42:58 PM
No.106162330
[Report]
>>106162357
>>106162324
lol i'm doing 161
>>106162316
Get a 4090D 48GB instead. I've seen too many things since getting mine that go above 32GB in actual use. Basically, you need 48GB to use 14B models at fp16 or to train on the full image size in wan, unless you want to fuck around with workarounds.
Anonymous
8/6/2025, 3:44:56 PM
No.106162344
[Report]
>>106160134
Use the Gemini Pro API (it's free), create a python script to batch caption the dataset, ask it to describe the images while explicitly mentioning the trigger sentences/word, limit the description to be succinct in about 55 words, ask it to describe only as much as you need the model to abstract in terms of composition and style when learning
If you are training on subjects, for instance, never mention race or age group (or words like "young woman"), otherwise the model will learn the phenotype instead of the overall subject likeness. The model seems to pick up the smallest cues, so just caption the images closely to how you would prompt them.
>>106160178
Just use "vhs still", "vhs footage", "camcorder footage" etc and it should work
Anonymous
8/6/2025, 3:46:34 PM
No.106162357
[Report]
>>106162330
Yeah, you can, but it's a crapshoot as to what random motion you'll get once it goes past its motion vector context. It might be fine, it might stutter, etc... I have noticed that above 121 frames you more frequently get animation loops, so there's that. I recall a leddit discussion saying 129 was the magic number for that.
>>106162340
>4090D
>China exclusive
How!?
Anonymous
8/6/2025, 3:50:18 PM
No.106162383
[Report]
>>106162465
>>106162361
you do know xi lost power right?
Anonymous
8/6/2025, 3:50:48 PM
No.106162391
[Report]
>>106162461
>>106158465
hey I'm the one who suggested it, thanks it looks great. If you need more ideas: 2000's digital camera style. Just for 2000's aesthetic and one more tool to force photo style.
Anonymous
8/6/2025, 3:51:17 PM
No.106162395
[Report]
Anonymous
8/6/2025, 3:52:02 PM
No.106162402
[Report]
>>106162443
Anonymous
8/6/2025, 3:52:11 PM
No.106162405
[Report]
>>106162553
>>106162381
Seems sketchy as fuck.
Anonymous
8/6/2025, 3:52:46 PM
No.106162411
[Report]
>>106162381
BTW it's the same bus width as a regular 4090, 256 on their site is a typo (which they still haven't fixed despite telling them about it)
Anonymous
8/6/2025, 3:52:50 PM
No.106162413
[Report]
>>106162447
Anonymous
8/6/2025, 3:57:51 PM
No.106162443
[Report]
>>106162402
You're welcome, Anon.
Anonymous
8/6/2025, 3:58:22 PM
No.106162447
[Report]
>>106162413
>(510 KB, 1024x768)
how do you make that file so small?
Anonymous
8/6/2025, 3:58:26 PM
No.106162449
[Report]
>>106162324
>thinks I'm the angry one
Wow, my first schizo argument in one of these threads. I feel like I truly belong now!
Anonymous
8/6/2025, 4:00:02 PM
No.106162460
[Report]
>>106162217
Buying a GPU is like buying a gold bullion that makes porn.
>>106162391
Chroma can already do those amazingly well out of the box, just prompt "Candid Sony Cybershot photo from Flickr" and the like.
>Candid Sony Cybershot photo from Flickr, a woman in soldier uniform is laying in a beach chair holding a martini in the middle of a war-torn battlefield. In the background you can see the sea shore, burnt tanks and cars, debris of destroyed buildings, and enemy soldiers laying on the ground. 2000s digital camera.
Anonymous
8/6/2025, 4:00:34 PM
No.106162465
[Report]
>>106162383
From a storm or something? Did they get it turned back on?
Anonymous
8/6/2025, 4:02:58 PM
No.106162477
[Report]
>>106160123
The output is slopped.
Anonymous
8/6/2025, 4:04:19 PM
No.106162487
[Report]
>>106162664
>>106162340
>>106162381
>manually remove memory chips
>manually add larger chips
>same bus
you'd have to be a retard to buy this
Anonymous
8/6/2025, 4:05:43 PM
No.106162499
[Report]
>>106162555
>>106158573
>bat file
hilarious to see wincucks struggle
Anonymous
8/6/2025, 4:10:48 PM
No.106162544
[Report]
>>106162579
>>106162461
Another
>Candid Sony Cybershot photo from Flickr, indoors setting. A young woman is holding a revolver, firing up in the air, in the middle of a birthday party, while grinning. Around her, there are childish decorations, a person dressed as an anthropomorphic fox putting hands in the head with a concerned expression. 2000s digital camera.
I would like to see people trying these prompts on Qwen img too
Anonymous
8/6/2025, 4:12:23 PM
No.106162553
[Report]
>>106162615
>>106162405
It's a legit product
Anonymous
8/6/2025, 4:12:27 PM
No.106162555
[Report]
>>106162791
Anonymous
8/6/2025, 4:12:40 PM
No.106162558
[Report]
>>106162570
>>106160323
It can't gen porn anon. It has to be taught how to be uncensored, again. Chroma took the community a lot of effort. Chroma is not even the size of Flux dev, it's smaller. And unless a team decides to risk finetuning a model larger than Chroma in the near future (which they won't unless it's sponsored by the model devs) then Qwen will just be forgotten about very soon.
>>106162558
nobody cares about that
Anonymous
8/6/2025, 4:14:00 PM
No.106162575
[Report]
>>106162835
Are we pretending local ai doesn't live on porn?
>>106162461
>>106162544
It's not the same aesthetic, 2000's digital photos have higher quality. Those look too much like a video still
Anonymous
8/6/2025, 4:14:39 PM
No.106162581
[Report]
Anonymous
8/6/2025, 4:16:57 PM
No.106162601
[Report]
I love AniStudio
Anonymous
8/6/2025, 4:17:47 PM
No.106162610
[Report]
Anonymous
8/6/2025, 4:18:55 PM
No.106162615
[Report]
>>106162630
>>106162553
it is some frankensteined card with no warranty, it is the opposite of legit.
Anonymous
8/6/2025, 4:19:34 PM
No.106162620
[Report]
>>106162579
idk man, I lived through that era and I find those images to be very close to what was commonplace back then.
It may be a matter of adding "low quality" as a negative prompt, pic rel is the result
Anonymous
8/6/2025, 4:20:25 PM
No.106162630
[Report]
>>106162686
>>106162615
You can look up videos
Anonymous
8/6/2025, 4:20:47 PM
No.106162634
[Report]
>>106162570
The only incentive to not care about NSFW is that the model is good out of the box, and only then can finetuning take a backseat. But Qwen sucks at realism, it sucks at art, it sucks at anime (doesn't know artists or styles, and is very obviously just recycled 4o/Seedream 3.0).
Anonymous
8/6/2025, 4:25:12 PM
No.106162664
[Report]
>>106162746
>>106162487
>you'd have to be a retard to buy this
OK for the benefit of the non-retards then, it's made by removing the 4090D GPU chip from the original board, reballing it, then moving it to a cleaned-off 3090ti blower card, which was a clamshell design using 1GB VRAM chips, and instead using 2GB VRAM chips.
If $3000 is a month's pay for you don't buy it. Anyone with their own CC knows if they mail you a brick or it shits the bed within the warranty and they won't fix it, you can get a chargeback.
Anonymous
8/6/2025, 4:27:46 PM
No.106162686
[Report]
>>106162630
You're having the equivalent of a discussion with a busrider on /o.
48GB Chads stay winning, VRAMlets stay mad, I guess.
Anonymous
8/6/2025, 4:28:27 PM
No.106162694
[Report]
gm lads
Anonymous
8/6/2025, 4:30:55 PM
No.106162721
[Report]
Anonymous
8/6/2025, 4:33:35 PM
No.106162746
[Report]
>>106162664
>old card, questionable sourcing
>no warranty
>already gimped version of the 4090
I keep forgetting so many people here live in the third world and are used to having old shit welded together in some random shop and the idea of buying something that "new" is beyond their comprehension. I am sure they ship what they are claiming to ship. I am also sure you'd have to be a retard to expect this card to last more than 12 months.
Anonymous
8/6/2025, 4:35:18 PM
No.106162767
[Report]
>>106160123
try res-2s and BONG tangent from the RES4LYF
Anonymous
8/6/2025, 4:37:17 PM
No.106162791
[Report]
>>106162823
>>106162555
>Typed from the right 75% of my super awesome EPIC linux machine's monitor output because the left 25% freezes up randomly while displaying otuput from the most popular GPU in the entire world because Jorje the sole brazilian maintainer of my distros shoddy open source display drivers is having a mental breakdown in the Issues section of the repository and refuses to patch because someone argued with him about the situation in gaza even though he has never left his country before in his entire life and doesn't know a single jewish or palestinian person. But hey at least microSHIT can't tell anymore that i launch chrome in incognito mode to goon twice a day, privacy FTW! GOD I LOVE FREE OPEN SOURCE SOFTWARE
Anonymous
8/6/2025, 4:37:34 PM
No.106162795
[Report]
>>106158465
unfortunate that you dont embed lora metadata in the file
Anonymous
8/6/2025, 4:39:38 PM
No.106162823
[Report]
>>106162791
>hasn't used linux since 2004
Anonymous
8/6/2025, 4:41:06 PM
No.106162835
[Report]
>>106162575
Are you pretending the world itself doesn't?
Anonymous
8/6/2025, 5:27:53 PM
No.106163461
[Report]
>>106160124
This post is a waste of electricity
first time ever trying this. i grabbed a text to video workflow, and it's giving me the following error when I try to run it
>mat1 and mat2 shapes cannot be multiplied (77x768 and 4096x5120)
Looks like it happens on the ksampler step? What exactly is my retarded ass doing incorrectly?
Anonymous
8/6/2025, 6:35:02 PM
No.106164167
[Report]
>>106164137
>30 steps
you're gonna have a real bad time
Anonymous
8/6/2025, 6:38:06 PM
No.106164191
[Report]
>>106164137
go to the top-right of comfyui and click workflow > browse templates > video and there's a t2v 2.2 workflow that will work