/lmg/ - Local Models General

/lmg/ - a general dedicated to the discussion and development of local language models.
Previous threads: >>106184664 & >>106181054
►News
>(08/06) Qwen3-4B-Thinking-2507 released: https://hf.co/Qwen/Qwen3-4B-Thinking-2507
>(08/06) Koboldcpp v1.97 released with GLM 4.5 support: https://github.com/LostRuins/koboldcpp/releases/tag/v1.97
>(08/06) dots.vlm1 VLM based on DeepSeek V3: https://hf.co/rednote-hilab/dots.vlm1.inst
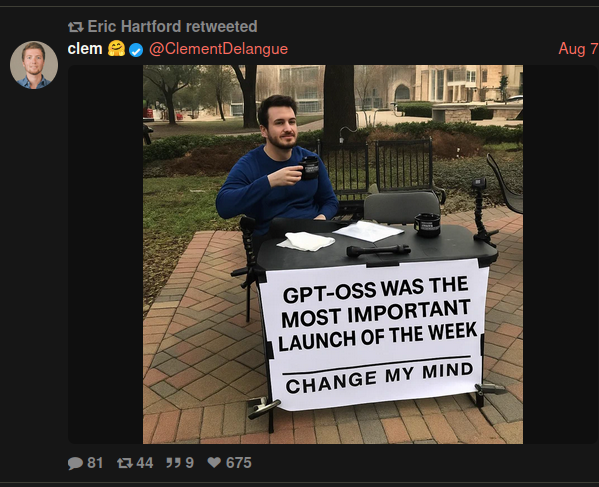
>(08/05) OpenAI releases gpt-oss-120b & gpt-oss-20b: https://openai.com/index/introducing-gpt-oss
>(08/05) Kitten TTS 15M released: https://hf.co/KittenML/kitten-tts-nano-0.1
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/recommended-models
https://rentry.org/tldrhowtoquant
https://rentry.org/samplers
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/leaderboard.html
Code Editing: https://aider.chat/docs/leaderboards
Context Length: https://github.com/adobe-research/NoLiMa
Censorbench: https://codeberg.org/jts2323/censorbench
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm
Previous threads: >>106184664 & >>106181054
►News
>(08/06) Qwen3-4B-Thinking-2507 released: https://hf.co/Qwen/Qwen3-4B-Thinking-2507
>(08/06) Koboldcpp v1.97 released with GLM 4.5 support: https://github.com/LostRuins/koboldcpp/releases/tag/v1.97
>(08/06) dots.vlm1 VLM based on DeepSeek V3: https://hf.co/rednote-hilab/dots.vlm1.inst
>(08/05) OpenAI releases gpt-oss-120b & gpt-oss-20b: https://openai.com/index/introducing-gpt-oss
>(08/05) Kitten TTS 15M released: https://hf.co/KittenML/kitten-tts-nano-0.1
►News Archive: https://rentry.org/lmg-news-archive
►Glossary: https://rentry.org/lmg-glossary
►Links: https://rentry.org/LocalModelsLinks
►Official /lmg/ card: https://files.catbox.moe/cbclyf.png
►Getting Started
https://rentry.org/lmg-lazy-getting-started-guide
https://rentry.org/lmg-build-guides
https://rentry.org/IsolatedLinuxWebService
https://rentry.org/recommended-models
https://rentry.org/tldrhowtoquant
https://rentry.org/samplers
►Further Learning
https://rentry.org/machine-learning-roadmap
https://rentry.org/llm-training
https://rentry.org/LocalModelsPapers
►Benchmarks
LiveBench: https://livebench.ai
Programming: https://livecodebench.github.io/leaderboard.html
Code Editing: https://aider.chat/docs/leaderboards
Context Length: https://github.com/adobe-research/NoLiMa
Censorbench: https://codeberg.org/jts2323/censorbench
GPUs: https://github.com/XiongjieDai/GPU-Benchmarks-on-LLM-Inference
►Tools
Alpha Calculator: https://desmos.com/calculator/ffngla98yc
GGUF VRAM Calculator: https://hf.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Sampler Visualizer: https://artefact2.github.io/llm-sampling
►Text Gen. UI, Inference Engines
https://github.com/lmg-anon/mikupad
https://github.com/oobabooga/text-generation-webui
https://github.com/LostRuins/koboldcpp
https://github.com/ggerganov/llama.cpp
https://github.com/theroyallab/tabbyAPI
https://github.com/vllm-project/vllm