/ldg/ - Local Diffusion General
Anonymous
8/9/2025, 5:32:34 AM
No.106197546
[Report]
Remove Chroma from rentry,
Anonymous
8/9/2025, 5:32:57 AM
No.106197549
[Report]
>>106197560
>106197546
stay mad
Anonymous
8/9/2025, 5:33:09 AM
No.106197552
[Report]
>>106197528 (OP)
>Local Model Meta: https://rentry.org/localmodelsmeta
>Edit: 07 Aug 2025
>I haven't updated this in awhile. Sorry. I've been busy. I'll try to get back to it over the next couple of weeks, same with the Wan rentry. If not, someone else can take over.
nice
Anonymous
8/9/2025, 5:34:02 AM
No.106197560
[Report]
>>106197549
>Afraid to quote
Anonymous
8/9/2025, 5:35:28 AM
No.106197568
[Report]
Anonymous
8/9/2025, 5:37:04 AM
No.106197578
[Report]
>>106197871
What can cause a washed out effect on wan2.2 generated videos? I've already rules out a faulty vae.
CFG > 1? Torch compile?
so uh I downloaded 50a, but is there a better one? 49 is better somehow??
Anonymous
8/9/2025, 5:38:24 AM
No.106197585
[Report]
>>106197579
maybe download 50 non a?
Anonymous
8/9/2025, 5:39:12 AM
No.106197591
[Report]
>>106197723
Reddit says there are more Chroma versions coming? I though v50 was the last one.
Anonymous
8/9/2025, 5:46:45 AM
No.106197629
[Report]
>>106197579
48 is correct, imo
Anonymous
8/9/2025, 5:49:56 AM
No.106197645
[Report]
>>106197841
>>106197002
trying to figure this out right now anon, any luck on your end? atm im trying to find the set ratio for snr and tmoe, then to see how to read it in comfyui
Anonymous
8/9/2025, 6:05:42 AM
No.106197723
[Report]
>>106197591
thecheckpoint training is done but anyone can still fuck with it if they're so inclined
>>106197718
Nope sadly, no one seems interested in that. Which is weird, people just randomly chose "half the steps" as the way.
Anonymous
8/9/2025, 6:06:53 AM
No.106197733
[Report]
>>106197752
>>106197718
try the reddit thread he grabbed it from
Anonymous
8/9/2025, 6:09:36 AM
No.106197749
[Report]
>>106197728
yeah super odd, seems like something thats quite important to the whole architecture lol
and it seems fairly easy, unless i am completely misunderstanding it and its not actually readable or something
Anonymous
8/9/2025, 6:09:54 AM
No.106197752
[Report]
>>106197807
>>106197733
I got it from the github:
https://github.com/Wan-Video/Wan2.2?tab=readme-ov-file#introduction-of-wan22
If there is a reddit thread about it and how to do that, please share it.
Anonymous
8/9/2025, 6:18:28 AM
No.106197807
[Report]
>>106197728
yeah same on my side, people just trying stuff and recording what happens
found this browsing around tho, seems to be some active discussion going on and people experimenting with it
>https://www.reddit.com/r/StableDiffusion/comments/1mkv9c6/wan22_schedulers_steps_shift_and_noise/
Anonymous
8/9/2025, 6:21:19 AM
No.106197823
[Report]
>>106197949
Anonymous
8/9/2025, 6:22:24 AM
No.106197832
[Report]
>>106198500
>flux dev
>flux krea
>chroma
>wan
which is best for realism?
Anonymous
8/9/2025, 6:23:59 AM
No.106197837
[Report]
>>106197848
>>106197822
That chart seems to be without the light2x lora since the steps are 10+. Does it translate 1:1 into a 4 steps total run?
Anonymous
8/9/2025, 6:24:48 AM
No.106197841
[Report]
Anonymous
8/9/2025, 6:27:00 AM
No.106197846
[Report]
>>106197822
Interesting, it's somewhat active too.
Anonymous
8/9/2025, 6:27:14 AM
No.106197848
[Report]
>>106197837
Not sure, give it a shot and use the good ole eyeball test
Anonymous
8/9/2025, 6:28:55 AM
No.106197856
[Report]
>>106197851
Wan is so good man
Anonymous
8/9/2025, 6:28:55 AM
No.106197857
[Report]
Anonymous
8/9/2025, 6:29:33 AM
No.106197860
[Report]
>>106197851
so close, its come a long way anon
Anonymous
8/9/2025, 6:31:26 AM
No.106197871
[Report]
>>106199666
>>106197578
Only way to not get that washed out effect is to use lightxtv, which makes no sense...
Anonymous
8/9/2025, 6:32:14 AM
No.106197875
[Report]
>>106197878
>>106197851
crazy how this random qwan image keeps popping up
Anonymous
8/9/2025, 6:33:01 AM
No.106197878
[Report]
>>106197875
I've been using it to test WF cause its such a good test of prompt following / motion quality when using light lora
Anonymous
8/9/2025, 6:34:23 AM
No.106197886
[Report]
>>106197901
gib wan 2.2 t2i workflow pls
Anonymous
8/9/2025, 6:37:25 AM
No.106197901
[Report]
Anonymous
8/9/2025, 6:38:37 AM
No.106197908
[Report]
Anonymous
8/9/2025, 6:43:35 AM
No.106197949
[Report]
>>106198026
>>106197823
Qwen really doesn't work as advertised with text.
Anonymous
8/9/2025, 6:56:40 AM
No.106198026
[Report]
>>106198896
>>106197949
I'm using fp8, I only have 24GB VRAM. I suspect the full weights are superior, but fp8 is still a qualitative step above any other open model for text. has some weird quirks though, and that issue is compounded by how slow it runs.
Anonymous
8/9/2025, 7:08:05 AM
No.106198083
[Report]
>>106198108
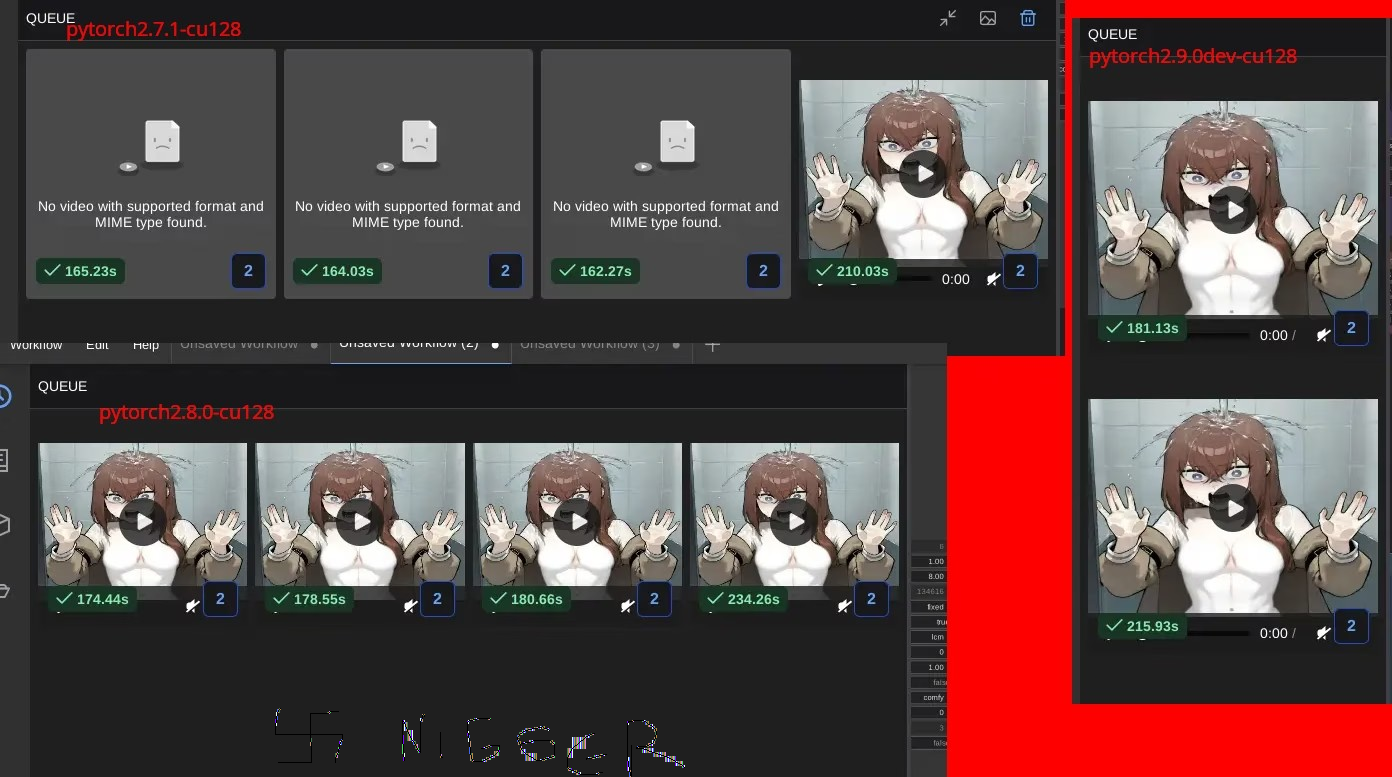
====PSA PYTORCH 2.8.0 (stable) AND 2.9.0-dev ARE SLOWER THAN 2.7.1====
tests ran on rtx 3060 12gb/64gb ddr4/i5 12400f 570.133.07 cuda 12.8
all pytorches were cu128
>inb4 how do i go back
pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url
https://download.pytorch.org/whl/cu128
Anonymous
8/9/2025, 7:12:17 AM
No.106198105
[Report]
>>106198112
maybe the new shit just runs ass on your outdated shit gpu nigga
Anonymous
8/9/2025, 7:12:33 AM
No.106198108
[Report]
>>106198112
>>106198083
>tests ran on rtx 3060
jesus christ, aren't there standards to post here? like a height limit or something?
Anonymous
8/9/2025, 7:13:49 AM
No.106198112
[Report]
>>106198198
>>106198108
im 5"2 btw
>>106198105
maybe do a test and show if there's any change? 3090 chads might benefit from this info
I'm having far too much fun with this
it's too late to go to bed, may as well stay up
Anonymous
8/9/2025, 7:15:28 AM
No.106198123
[Report]
>>106198115
doesnt it feel like magic anon, im not sleeping either
Anonymous
8/9/2025, 7:15:31 AM
No.106198124
[Report]
Anonymous
8/9/2025, 7:19:58 AM
No.106198150
[Report]
>>106198115
so many questions
what was she doing confronting a pimp
did she know the pimp was a wizard
why is the pimp a wizard
what's in her handbag
how's she gonna get home
Anonymous
8/9/2025, 7:29:38 AM
No.106198198
[Report]
>>106198204
>>106198112
>3090 chads
>5 year old gpu
peasants you mean
Anonymous
8/9/2025, 7:30:41 AM
No.106198204
[Report]
I've got 2 3090s but I am starting to feel their age. Having to do silly little things to make certain things were where it just werks on a 4090. I think I'll just fork out for a 5090 when the time comes.
Anonymous
8/9/2025, 7:36:00 AM
No.106198231
[Report]
>>106198242
>>106198212
like what? i never have to do silly little things on my 3060, everything just werks
chroma, flux, krea, wan, hunyuan, sdxl tunes
LLMs
Anonymous
8/9/2025, 7:36:20 AM
No.106198233
[Report]
I tried a few times for the sign to read "planned parenthood" but it wouldn't work with me.
>>106198231
Torch version not playing well with multi gpu training. fp8, no access to some of those sweet fp8 speed optimizations.
They are getting old.
>>106198242
yea i feel u, only thing that doesnt work for me is sageattn2++ because it needs 4000+
i guess since you're training loras it must be tougher, im just a consoomer
Anonymous
8/9/2025, 7:41:08 AM
No.106198271
[Report]
animate your fav old gens, super fun
Anonymous
8/9/2025, 7:41:58 AM
No.106198276
[Report]
>>106198265
If it trains it trains and it probably will for a few more years. It just like, not fun looking at people having more fun and not quite having enough fun to justify sinking the cash to match them.
Anonymous
8/9/2025, 7:42:23 AM
No.106198277
[Report]
>>106198242
shit, I remember when I saw fp8 on my 4090 vs 3090. night and day. then I got a 5090 and my fucking 4090 felt slow. march of godforsaken progress.
Anonymous
8/9/2025, 7:52:00 AM
No.106198340
[Report]
>>106194872
uh anon can I get a proooompt for that effect...
Anonymous
8/9/2025, 7:52:50 AM
No.106198347
[Report]
>>106198361
>>106198212
If you're gonna spend the money on a 5090 get a 4090 with 48gb. I have an A6000 and I've realised 2 things: I wish I bought a 4090 48gb and I would buy a 96gb card immediately if I could.
Anonymous
8/9/2025, 7:54:14 AM
No.106198361
[Report]
>>106198347
mmm long legs i want to fuck that
Anonymous
8/9/2025, 7:55:41 AM
No.106198374
[Report]
>>106198356
The 48gb 4090s are just bootleg chinese soldered 4090s right? Do they have a warranty?
Anonymous
8/9/2025, 7:58:25 AM
No.106198392
[Report]
is chroma a joke
Anonymous
8/9/2025, 7:58:51 AM
No.106198396
[Report]
>>106199766
>>106198376
Yeah that's basically what they are. No warranty, or rather you'd be at the inconvenience of dealing with shipping and if the seller honours warranty. I'm looking to buy one but it's only because I want to speed up gens. I have a 4090,3090,A6000. If it fits on the 4090 I run it there, otherwise I use the A6000. Really, I want a Blackwell 96gb but I just can't justify the cost (yet).
A man holds an ak-47 and fires it at the camera
basic test but works
Anonymous
8/9/2025, 8:09:01 AM
No.106198464
[Report]
>>106198436
less flicker:
Anonymous
8/9/2025, 8:10:35 AM
No.106198472
[Report]
>>106198483
Anonymous
8/9/2025, 8:12:37 AM
No.106198481
[Report]
>>106198490
>>106198356
>>106198376
you'd have to be an actual retard to buy a *used* 4090D that was hacked up by some chinese fuck who got the job cause he sucks good dick, and then resold through a sketchy ass website for 3k usd.
Anonymous
8/9/2025, 8:13:09 AM
No.106198483
[Report]
>>106198356
>>106198481
I'm using my work budget to buy some RTX 6000 pros
Anonymous
8/9/2025, 8:16:57 AM
No.106198500
[Report]
>>106198608
>>106197832
Wan, then Chroma, then Krea
Anonymous
8/9/2025, 8:17:11 AM
No.106198502
[Report]
Anonymous
8/9/2025, 8:17:20 AM
No.106198505
[Report]
Anonymous
8/9/2025, 8:22:03 AM
No.106198537
[Report]
>>106198588
>>106197528 (OP)
>>106195231
>>106195316
Huh? So it turns out Chroma HD has to be prompted at a higher res bros. Really dumb but makes sense, it gets rid of the slop look entirely
Anonymous
8/9/2025, 8:22:08 AM
No.106198538
[Report]
>>106198558
in comfy video nodes what is crf and what is max quality?
Anonymous
8/9/2025, 8:25:37 AM
No.106198558
[Report]
>>106198538
video encoding parameters like you use in ffmpeg
>>106198537
Yeah, that was it. It's a bit silly. But then the question is, is limb accuracy and overall image coherence significantly higher for it to make a difference? And is there more detail?
Anonymous
8/9/2025, 8:31:17 AM
No.106198601
[Report]
Chroma users are so fucking cooked right now.
Anonymous
8/9/2025, 8:32:32 AM
No.106198608
[Report]
>>106198500
flux dev is better if you know how to use it
Anonymous
8/9/2025, 8:33:26 AM
No.106198614
[Report]
the man in the grey jacket grabs a gun and fires it at the people behind him, who fall down on the ground.
NOT SO FAST!
Anonymous
8/9/2025, 8:34:07 AM
No.106198615
[Report]
>>106198490
very nice gen
Anonymous
8/9/2025, 8:35:38 AM
No.106198623
[Report]
>>106198708
>>106198588
What do you use to make these comparisons
Anonymous
8/9/2025, 8:38:46 AM
No.106198642
[Report]
>>106198661
wan doesnt like violence without loras
the man in the grey jacket does a karate chop to the people behind him, who fall down on the ground.
>>106198490
attack of the anime yap mode, first time seeing it for me
Anonymous
8/9/2025, 8:41:59 AM
No.106198661
[Report]
>>106198642
Don't specify that they fall, just say the man in the grey jacket shoots the other people or something like that
Anonymous
8/9/2025, 8:43:21 AM
No.106198671
[Report]
>>106194877
Insane result on 1152 bros. I say we are so back, we have never been more back! Not only is the count correct, it's adhering to the prompt perfectly!
https://files.catbox.moe/h8jy5o.png
Anonymous
8/9/2025, 8:43:30 AM
No.106198672
[Report]
>>106198679
>>106198588
How high did you have to go ?
Anonymous
8/9/2025, 8:44:09 AM
No.106198676
[Report]
>>106198660
nice gen, cute youmu
Anonymous
8/9/2025, 8:44:39 AM
No.106198679
[Report]
>>106198823
>>106198672
nvm, just saw, 1152, that's not a large increase
okay ive managed to improve the fps with interpolation in kijais workflow like so:
Anonymous
8/9/2025, 8:50:27 AM
No.106198702
[Report]
>>106198712
Anonymous
8/9/2025, 8:50:38 AM
No.106198704
[Report]
>>106198707
>>106198699
result: 16 to 32 fps
Anonymous
8/9/2025, 8:51:12 AM
No.106198707
[Report]
>>106198704
try "roundhouse kick"
>>106198623
Used python to create me a script + have a bat file that I edit, which I made to just run it, not the best way to do it as it can all be made into a single file but here you go if interested
https://files.catbox.moe/ovqm80.py
https://files.catbox.moe/nxw5hu.py
https://files.catbox.moe/3jpvfb.bat
you create a ./venv in current folder and edit the bat file with the names, then run the png2jpg "python .\png2jpg.py --files .\my_final_comparison.png --output-dir ." (could also be automated with bat file and output file names be randomized)
Anonymous
8/9/2025, 8:52:03 AM
No.106198712
[Report]
>>106198702
I have a 4080, not gonna spend $5000 on a 5090 for a few fps or slightly bigger 720p
Anonymous
8/9/2025, 8:52:14 AM
No.106198717
[Report]
>>106198708
>python
Gemini*
Anonymous
8/9/2025, 8:53:04 AM
No.106198723
[Report]
Anonymous
8/9/2025, 8:54:57 AM
No.106198734
[Report]
beaten by psychic powers:
Anonymous
8/9/2025, 8:57:09 AM
No.106198747
[Report]
>>106198799
what is "max" crf value
wish I didn't need to be a rocket scientist to decipher all these nodes and values
Anonymous
8/9/2025, 9:05:08 AM
No.106198799
[Report]
Anonymous
8/9/2025, 9:09:39 AM
No.106198823
[Report]
>>106199019
>>106198679
yeah takes just a few secs extra on my 3090, though it's possible to go lower to like 1096 (but I wouldn't go too low because I see more bokeh). If I go higher it's possibly less slopped then? Not sure, sucks to be capped by the 3090 in that regard.
Anonymous
8/9/2025, 9:11:49 AM
No.106198834
[Report]
>>106198807
Can qwen do ponos and vagoo? If not, how easy is it to train on it compared to flux?
Anonymous
8/9/2025, 9:11:54 AM
No.106198836
[Report]
>At a fast food restaurant. Camera pans back. An overweight man from Ohio foams at the mouth in excitement.
Anonymous
8/9/2025, 9:13:40 AM
No.106198843
[Report]
>>106200660
Background looking more coherent now
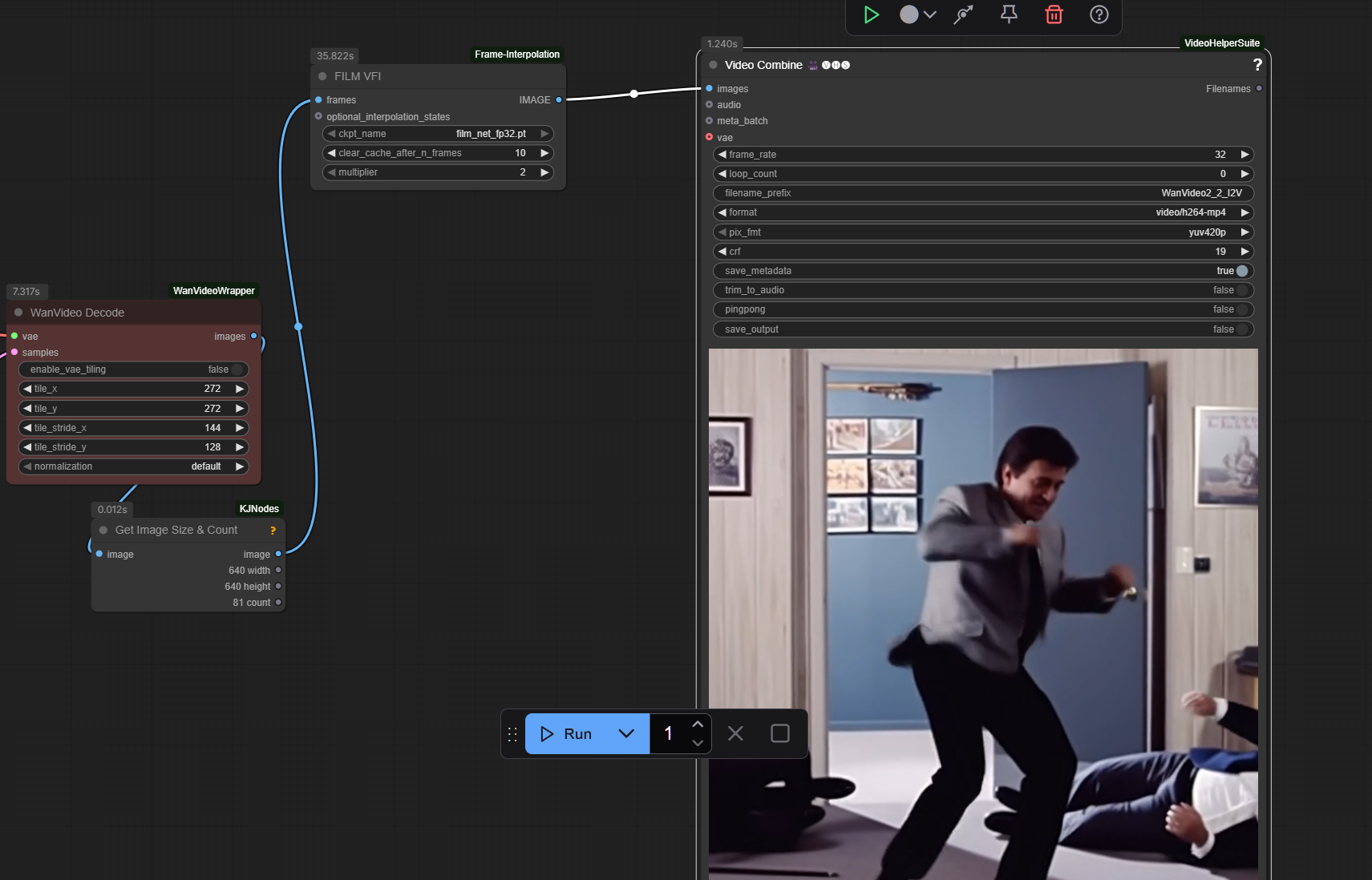
film vfi interpolation 3 (x3) seems to work okay, default is 16 so 48fps:
more generated frames can mean more artifacts though so can adjust to preference.
Anonymous
8/9/2025, 9:21:30 AM
No.106198896
[Report]
>>106201367
>>106198026
As a fellow 24GB peasant, use Q8 GGUFs instead of fp8, the quality is much closer to the full model.
Anonymous
8/9/2025, 9:22:04 AM
No.106198897
[Report]
Anonymous
8/9/2025, 9:26:05 AM
No.106198925
[Report]
>>106198942
>>106198874
Try GIMM vfi, it handles fast motion a bit more accurately. It's also slower though
Anonymous
8/9/2025, 9:26:29 AM
No.106198926
[Report]
how can I use qwen image on a 16gb gpu?
Anonymous
8/9/2025, 9:28:16 AM
No.106198937
[Report]
Anonymous
8/9/2025, 9:29:04 AM
No.106198940
[Report]
>>106198967
Is there a way to disable comfyui from unloading models in to system memory? WAN is eating up my RAM like crazy and wont release. Wish it would just load off my nvme for whatever model it needs at that moment.
>>106198925
back to default with no interpolation (16fps), I think ill stick with this cause interpolation can cause issues with high motion gens.
Anonymous
8/9/2025, 9:29:28 AM
No.106198943
[Report]
>>106199042
>>106198115
upload this LoRA on civitai, my nigga
Anonymous
8/9/2025, 9:30:30 AM
No.106198953
[Report]
>>106198942
*also, it added like a minute to my gen process, 188 seconds vs 130.
Anonymous
8/9/2025, 9:31:27 AM
No.106198961
[Report]
>>106198977
Anonymous
8/9/2025, 9:31:34 AM
No.106198964
[Report]
>>106199000
Anonymous
8/9/2025, 9:32:00 AM
No.106198967
[Report]
>>106198970
>>106198940
start comfyui with the parameters:
--cache-none --disable-smart-memory
Anonymous
8/9/2025, 9:32:22 AM
No.106198970
[Report]
Anonymous
8/9/2025, 9:32:42 AM
No.106198977
[Report]
>>106199010
>>106198961
chroma is a joke
Anonymous
8/9/2025, 9:33:57 AM
No.106198985
[Report]
>>106199132
>Trying to calculate how many samples do I need to conclude that a new embedding/vae/text encoder/etc. makes gens in comparable quality or better than not using it at least 65% of the time (Arbitrary threshold I picked to deem some method/model worthwhile for making slop.).
>With the bog standard 95% confident interval and 5% margin of error I need THREE HUNDRED FUCKING FIFTY sample pairs to conclude that with reasonable confidence.
>Even lowering confidence interval to unusually low 85% and increasing margin of error to sloppy 10%, realistically as much as I can stretch before the whole experiment becomes borderline worthless, I need 48 sample pairs to test any random embedding, vae, prompting method or whatever I see on Civitai.
So how do you test stuff?
I tried just roll with dozen samples and call it a day thing in the past and it actually mislead me into doing some BS that I later realized was in fact not making gens better. That's why I think more rigorous testing is necessary, though that demands more time and effort investment than this 0$/h hobby warrants I think.
I am in a conundrum.
Anonymous
8/9/2025, 9:33:58 AM
No.106198986
[Report]
>>106198942
now it seems more natural in general.
Anonymous
8/9/2025, 9:36:36 AM
No.106199000
[Report]
>>106198964
>Full subplots again on: https://unstabledave34.neocities.org/comparisons
Nice site. And neat picrel.
TY for the grids.
Anonymous
8/9/2025, 9:38:27 AM
No.106199010
[Report]
>>106198977
It literally directly improved anon. lodestone has delivered. Ngl, after trying it at 1024 I doubted him for a sec, but when increasing the res it's a different beast. This may not be entirely coherent but it's a lot more coherent than whatever incoherent garbage we were getting before for images in this size, orientation and specially with the backgrounds and subjects.
Anonymous
8/9/2025, 9:40:15 AM
No.106199019
[Report]
Anonymous
8/9/2025, 9:41:40 AM
No.106199028
[Report]
>>106199098
Anonymous
8/9/2025, 9:43:20 AM
No.106199039
[Report]
>>106198807
Wait till Plebbitors hear of Chroma HD at 1152
Anonymous
8/9/2025, 9:44:03 AM
No.106199042
[Report]
>>106198943
forgot civit was blocked in this country, what a pain in the ass
civitai.com/api/download/models/2095264?type=Model&format=SafeTensor
Anonymous
8/9/2025, 9:44:13 AM
No.106199046
[Report]
there we go, camera motion.
man holds up a plate with a mcdonalds cheeseburger and mcdonalds fries and smashes the plate on the table in front of him, while looking upset. the camera zooms out to show a wooden table.
Anonymous
8/9/2025, 9:50:04 AM
No.106199067
[Report]
>>106199078
Whenever I make a video in Wan, it generates a png file too. Any way to stop it from doing this?
Anonymous
8/9/2025, 9:51:23 AM
No.106199078
[Report]
>>106199067
Whatever image processing nodes you are using for i2v, one of them is saving the file. Find and replace it.
Anonymous
8/9/2025, 9:54:42 AM
No.106199098
[Report]
Looking for other anons that are using local-AI for their gamedev/art projects. In cartooning or anime styles, is the best option still just something like Illustrious? I feel like I'm constantly in a trade-off between quality and prompt adherence. Models like ILL have great quality and customization support with loras, but I fucking hate how character-focused they are. Even with negative prompts, I too often struggle to get a single object to render without a superfluous butt, tiddy, or hand.
Is there a model of similar quality that is more tuned for environmental details and objects over characters? Loras haven't been cutting it.
>pic not related, just something I put together for fun
>>106198985
I usually gen in a series of batches that I square exponentially. If the change didn't obviously degrade quality in 2 batches, then I do 4 batches, then 8 and so on. Once its at >200 images per interaction, I assume its fine enough and feel okay leaving it run over night. The only advice I can give is try and find any ways you can shave a few seconds per image generation. It saves so much fucking time over a large run.
Anonymous
8/9/2025, 10:01:40 AM
No.106199135
[Report]
Anonymous
8/9/2025, 10:03:55 AM
No.106199146
[Report]
>>106199175
Anonymous
8/9/2025, 10:05:27 AM
No.106199151
[Report]
>>106199175
Anonymous
8/9/2025, 10:10:40 AM
No.106199175
[Report]
>>106199230
Anonymous
8/9/2025, 10:12:00 AM
No.106199185
[Report]
>we bogged it
Anonymous
8/9/2025, 10:13:19 AM
No.106199190
[Report]
>>106199207
gen jam when?
Anonymous
8/9/2025, 10:17:06 AM
No.106199207
[Report]
>>106199250
>>106199190
Was the "theme" retarded again?
Like:
>Anime
>Kneepad (Anime)
>Anime
Anonymous
8/9/2025, 10:19:14 AM
No.106199224
[Report]
>>106199108
Based cat, off to shitpost on /ldg/
Anonymous
8/9/2025, 10:20:25 AM
No.106199230
[Report]
Anonymous
8/9/2025, 10:23:18 AM
No.106199250
[Report]
Anonymous
8/9/2025, 10:27:13 AM
No.106199277
[Report]
>>106199288
Contortionist prompt test. Magic extra hand there on this seed but I'll take it
Anonymous
8/9/2025, 10:29:43 AM
No.106199288
[Report]
>>106199298
Anonymous
8/9/2025, 10:31:54 AM
No.106199298
[Report]
>>106199288
Lot less likely to fuck up on seeds/situations it likely would have before
Anonymous
8/9/2025, 10:32:10 AM
No.106199301
[Report]
>>106199357
thumbs down
Anonymous
8/9/2025, 10:38:20 AM
No.106199336
[Report]
Anonymous
8/9/2025, 10:42:55 AM
No.106199357
[Report]
>>106199301
Come again anon?
>/ldg/ completely taken over by a disgusting 3dpd footfag degenerate who should be on /b/
This is why I'm so glad we have /adt/.
Anonymous
8/9/2025, 10:50:56 AM
No.106199405
[Report]
>>106199132
Try qwen image
>>106199385
>3dpd footfag degenerate
Chroma doubters like yourself have been BTFO'd quite hard. What do you have to say now about this unprecedented coherence?
Also, the containment thread is that way
Anonymous
8/9/2025, 11:01:31 AM
No.106199462
[Report]
>>106199421
there is weird stuff all over that image
Anonymous
8/9/2025, 11:05:38 AM
No.106199486
[Report]
>>106199385
Please stay there
Anonymous
8/9/2025, 11:06:30 AM
No.106199492
[Report]
>>106199557
>>106199421
i don't care about "chroma".
I don't like your disgusting foot fetish images. That's all.
Anonymous
8/9/2025, 11:06:47 AM
No.106199494
[Report]
what a horrible horrible thread
Anonymous
8/9/2025, 11:07:47 AM
No.106199500
[Report]
>>106200679
man puts on a baseball cap saying "RETARD" in playful text.
pretty fast at 640x480 with proportions set to crop, 98 seconds.
Anonymous
8/9/2025, 11:09:34 AM
No.106199508
[Report]
>>106201104
>A gravure photoshoot of a Japanese woman poolside. A Japanese woman with large breasts is wearing a one-piece swimsuit, sitting poolside, while doing the splits. She is holding one of her legs above her head. Her hair is long and black and she is wearing mascara and eye-liner.
>Ultra HD, 4K, Gravure, AV, JAV, Realistic, Professional.
qwen image sure is fun
Anonymous
8/9/2025, 11:19:15 AM
No.106199557
[Report]
>>106199492
>I don't like your specific gens because foots are disgusting
>I'm not straight, I obviously like hairy men
>I don't like seeing women, period
>Let me just come to your thread, shit it up and talk about it
>I'm also a tranny btw
Ok.
Btw anons, night time photos look a lot cleaner now. Before, they occasionally had that weird melted feel to them, but now they've gotten a lot sharper and better looking.
Anonymous
8/9/2025, 11:19:46 AM
No.106199560
[Report]
>>106199584
Anonymous
8/9/2025, 11:21:57 AM
No.106199575
[Report]
>>106199108
Make the cat wear a kippah and do the hand rubbing gesture.
Anonymous
8/9/2025, 11:24:13 AM
No.106199584
[Report]
Anonymous
8/9/2025, 11:30:19 AM
No.106199609
[Report]
>>106199893
Anonymous
8/9/2025, 11:30:40 AM
No.106199612
[Report]
Anonymous
8/9/2025, 11:32:36 AM
No.106199618
[Report]
>>106199709
why isn't sage attention making qwen image faster?
Anonymous
8/9/2025, 11:33:51 AM
No.106199626
[Report]
I said kicks the wooden desk...
Anonymous
8/9/2025, 11:39:52 AM
No.106199665
[Report]
>>106199671
>>106199132
I think Flux with loras produces better pixel art than Illustrious does. The hues/colours tend to pop a lot better, while Illustrious pixel art's colours usually look a lot more washed out and flat/boring. The structure/lineart is incredible in either model though.
Illustrious does have a no_humans tag you might want to take advantage of, for producing objects. Also: white_background, simple_background.
Anonymous
8/9/2025, 11:40:12 AM
No.106199666
[Report]
>>106197871
OK I found out what it was: it was loras stacking and some of them being too high.
For some reason it made everything look washed out. Tweaking the weight down solved it.
Anonymous
8/9/2025, 11:41:05 AM
No.106199671
[Report]
>>106199665
also put "nsfw" in the negative prompt when using hentai models to produce non-hentai
Anonymous
8/9/2025, 11:44:15 AM
No.106199692
[Report]
>>106198265
>sageattn2++ because it needs 4000+
It worked perfectly fine on my 3090. I don't think there is any limitation outside of minimal version of CUDA required (12.8+).
Anonymous
8/9/2025, 11:44:51 AM
No.106199697
[Report]
Anonymous
8/9/2025, 11:47:05 AM
No.106199709
[Report]
>>106199618
It doesn't really do much for image generation at all, not sure why.
Perhaps SageAttention3 will, since it's a larger performance optimization than the previous, it will only work on Blackwell cards though
>prompt: a girl
>output a chinese loli
so this is the power of qwen image
Anonymous
8/9/2025, 11:52:45 AM
No.106199742
[Report]
>>106199719
Probably what 99% of qwen prompters were hoping for, so they just made it easy
Anonymous
8/9/2025, 11:56:00 AM
No.106199760
[Report]
>>106199834
does negative prompt actually do something these days? I feel like less and less new model is taking neg prompt seriously and straight up ignore it
Anonymous
8/9/2025, 11:56:48 AM
No.106199766
[Report]
>>106199810
>>106198396
>want a Blackwell 96gb but I just can't justify the cost (yet).
I still don't get the appeal unless you batch image generations to get to full vram use.
From what I've seen, if you have fast ram, offloading to it doesn't cost much more in generation time.
And getting a 5090 + 128GB of fast ram is still so much cheaper than just 1 6000.
I was trying to find if using it would speed up wan video generation in fp8 or allows batching them but it doesn't seem the rare people having this card use it for videogen.
Anonymous
8/9/2025, 12:04:54 PM
No.106199796
[Report]
>>106199819
>>106199539
It is good and can follow the prompt great, but is a wee bit slopped. I'd love a Chroma style tune for Qwen, but it is too much since that model is huge. Chroma will be the realism SOTA for years to come.
Anonymous
8/9/2025, 12:05:48 PM
No.106199801
[Report]
>>106199719
you asked for a girl, you got a girl
you gotta be precise
Anonymous
8/9/2025, 12:07:23 PM
No.106199810
[Report]
>>106199855
>>106199766
I started from a 4060ti 16GB. Then bought a 4090, then bought a 3090, then bought an A6000. I remember each time I said "this will be enough." Aside from that, for training purposes it will be nice, and for video/image generation it allows for higher resolution gen + using full weights. I'm using full qwen-image weights and it takes around 40GB with text encoder loaded. I also use hunyuan3d2.1 and that takes 40+.
All in all, it's not a wise purchase, but to me I'd not waste my money on a 5090 (32 isn't all that more useful than 24). Having all this VRAM, my experience is 24gb is the minimum, then you need 48 for it to be meaningful in use, and after that you can't get enough.
I use LLMs, image gen, video gen, as well as train. A single 5090 (4090 is enough really) + 128GB RAM is cheaper, but it has its limitations.
Anonymous
8/9/2025, 12:07:51 PM
No.106199812
[Report]
>>106199867
so i should go with cuda 12.7, not 13.0 right?
>>106199796
haven't ran chroma yet, but so far the prompt adherence is much appreciate over base flux. Also has a lot of style flexibility. But yes some of the images definitely look sloppy (but so does chroma from what I've seen shared).
Anonymous
8/9/2025, 12:13:37 PM
No.106199834
[Report]
>>106200799
>>106199760
negative prompts are very useful for improving quality, but the reason many models these days aren't supporting them is because cfg 1.0 gets you double the generation speed, and if you use cfg 1.0 then negative prompt is ignored.
so it's a matter of hardware speed and us trying to get better performance that's causing us to lose out on negative prompts.
Anonymous
8/9/2025, 12:17:29 PM
No.106199855
[Report]
>>106199894
>>106199810
>Then bought a 4090, then bought a 3090, then bought an A6000
And you crammed all of this in the same computer?
Does it work well?
I have a 3090 + 5090 in mine and it's already annoying for specific stuff.
>Aside from that, for training purposes it will be nice
Oh yeah that's one use case I don't really care about, but for sure this one benefits from more vram.
>but to me I'd not waste my money on a 5090 (32 isn't all that more useful than 24).
Vram wise no but compute wise it is.
Offloading with fast ram is pretty ok in my experience for inference use.
>A single 5090 (4090 is enough really) + 128GB RAM
I'd argue here that the 5090 speedup is quite substantiel vs the 4090 but sure.
Anonymous
8/9/2025, 12:18:42 PM
No.106199861
[Report]
>>106199819
Qwen is impressive but somewhat slopped and censored. That can easily be fixed with loras though, so hopefully we'll see some soon (assuming Civitai adds a qwen section).
On the other hand it is very demanding and slow, which likely impedes overall uptake and lora finetuning. We'll have to see how the 'community support' for this will turn out.
Anonymous
8/9/2025, 12:19:37 PM
No.106199867
[Report]
>>106199812
Get the minimal CUDA version that makes your gpu and use case work.
Usually 12.8 if you go comfy + sage2++ + any 3000/4000/5000 card.
13.0 just got released, I would steer away from it.
Anonymous
8/9/2025, 12:23:09 PM
No.106199882
[Report]
>>106199925
Does anyone here have a dual 5090 setup in a conventional pc case?
What model of 5090 would you recommend? The AIO version?
Even powerlimiting them to 400W would dump 800W inside the case, and no matter the case it feels like a great way to fry everything inside.
>>106199819
Sure, but for realism you are very much limited to the clean polished smooth skin look you are showing in your images, plus bokeh. So only 1 style in that case. Chroma isn't slopped to the same extent, only some rare tokens in Chroma tend to trigger slop, but that has been greatly reduced in v50 at resolutions higher than 1024.
Anonymous
8/9/2025, 12:23:29 PM
No.106199884
[Report]
Anonymous
8/9/2025, 12:27:08 PM
No.106199893
[Report]
>>106199609
bruh he moved that table like it was made of polystyrene or something
Anonymous
8/9/2025, 12:27:28 PM
No.106199894
[Report]
>>106199926
>>106199855
>And you crammed all of this in the same computer?
>Does it work well?
Yep, originally had a large case to put my 4090 + 4060ti. Then swapped the 4060ti out for the A6000. Now I have an open frame with the 4090,3090,A6000 mounted and installed using a bifurcator card. Works great, but whenever I'm splitting things across them bottleneck is based on the slowest card (3090 in this case).
>Vram wise no but compute wise it is.
Agreed. I favor VRAM personally, but I can't lie and say I wouldn't appreciate having the compute of a 4090 or 5090 with 48GB+ VRAM for a decent price.
>Offloading with fast ram is pretty ok in my experience for inference use.
Yep, I have 128GB RAM (DDR4) too and I use it when running dsr1 or other massive MoE models. Was handy for block swapping with hunyuan video before I had the A6000
>I'd argue here that the 5090 speedup is quite substantiel vs the 4090 but sure.
I believe you about the speedup. I see it with my 4090 vs the A6000/3090.But when things don't fit, the A6000 comes in handy (and has many times).
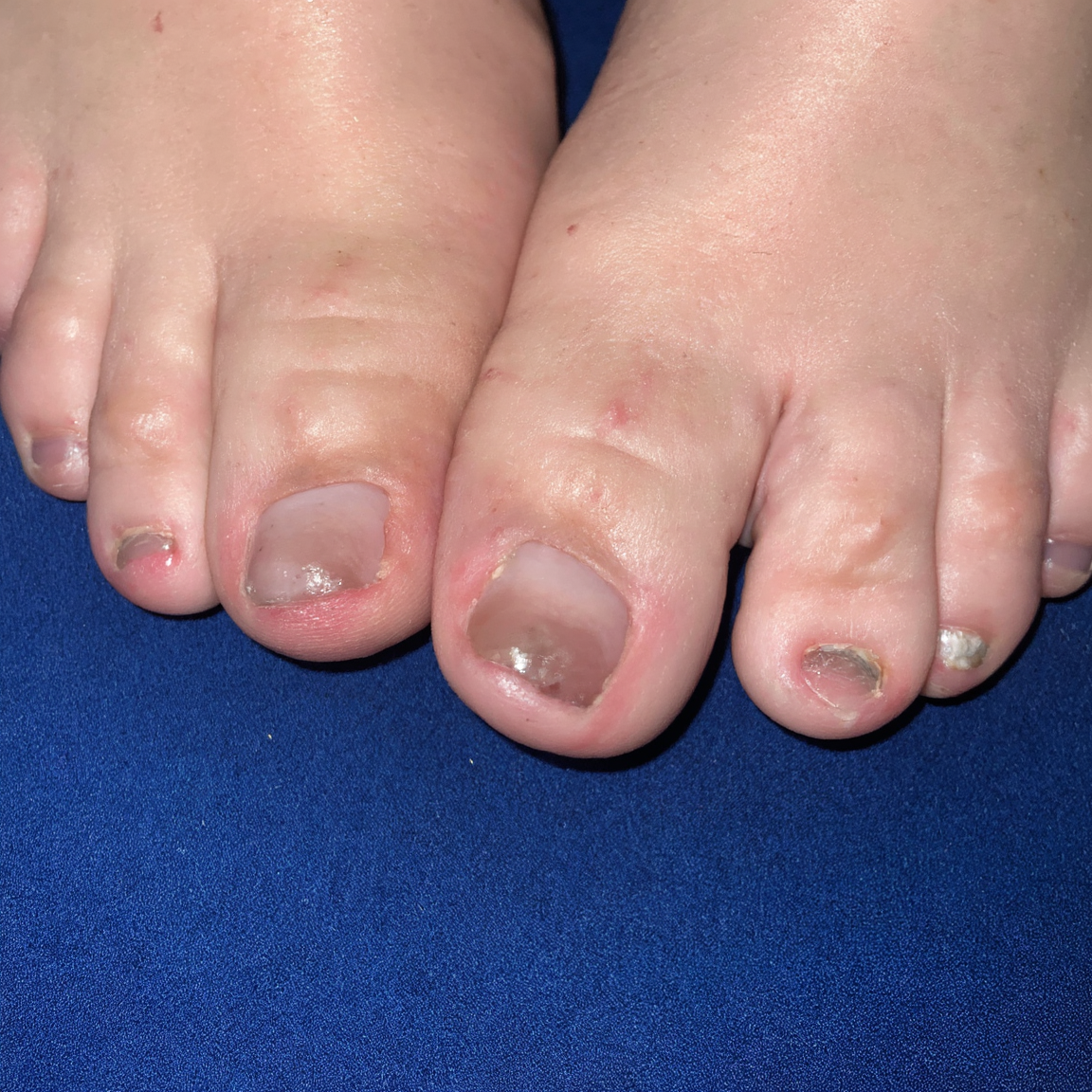
Dear feetnigga,
Can chroma do skinnier toes? I feel like every gen I see has stumpier digits and wider soles.
Anonymous
8/9/2025, 12:30:23 PM
No.106199906
[Report]
>>106199895
I personally wonder if it can do dainty nice clean smooth feet, and not the dirty looking ones favored here.
Anonymous
8/9/2025, 12:30:25 PM
No.106199907
[Report]
>>106199883
I'm keen to compare with chroma. I'll get it up an running someday in the next week or so.
Got a prompt you want me to try with qwen?
anyone here trained a qwen lora yet? i'm gonna give it a go.
i assume you need to rent a H100 and an A40 won't cut it
Anonymous
8/9/2025, 12:34:50 PM
No.106199925
[Report]
>>106199943
>>106199882
just have a case with decent airflow/fans. and if it is still too hot mount big heat transport AIO coolers, yes.
Anonymous
8/9/2025, 12:34:58 PM
No.106199926
[Report]
>>106199957
>>106199894
>installed using a bifurcator card
What is this?
>bottleneck is based on the slowest card (3090 in this case).
Yeah frankly speaking I'll probably sell my 3090 soon, it makes no sense to use it when the 5090 is so fast the 3090 became kind of useless.
>whenever I'm splitting things across them
I guess you mean anything non image or video inference right? Unless you can now distribute stable diffusion inference across cards, even more across heterogeneous models.
Anonymous
8/9/2025, 12:35:17 PM
No.106199929
[Report]
how do I do image editing with qwen image in comfyui?
Anonymous
8/9/2025, 12:37:53 PM
No.106199938
[Report]
>>106199895
Use WAN or SDXL if VRAM allows it, better composition and stability.
Anonymous
8/9/2025, 12:38:24 PM
No.106199939
[Report]
Anonymous
8/9/2025, 12:39:22 PM
No.106199943
[Report]
>>106200007
>>106199925
>just have a case with decent airflow/fans
What would you recommend?
>>106199922
An anon a few threads back did it but when I asked for details didn't get a reply. Probably need like 80+GB.But I dunno, I'm waiting to see some numbers or will probably attempt it on my A6000 later in the week if I'm bothered.
>>106199926
>>installed using a bifurcator card
>What is this?
Splits a PCIe slot up to connect multiple things to 1 slot. I'm using the motherboard of my old gaming PC from 2019 with a bifurcator card to let me install up to 4 cards in one slot (have 3 at the moment).
>Yeah frankly speaking I'll probably sell my 3090 soon
same, it's good value but once you have tried a fast card you can't go back to a slow one
>I guess you mean anything non image or video inference right? Unless you can now distribute stable diffusion inference across cards, even more across heterogeneous models.
Yes, mostly for non video or image inference. But hunyuan video and wan have distributed GPU inference (kind of) though I haven't tried it. I do utilise multiple GPUs though for image/video by having one card loaded with the text encoder and another with the diffusion model. Let's me keep each loaded and also allows the card with the diffusion model to have more VRAM free for higher res gens.
Anonymous
8/9/2025, 12:47:46 PM
No.106199997
[Report]
>>106200147
>>106199883
You're right about the skin stuff. I tried this prompt and it didn't change despite being different from the earlier prompts (terms of styling phrases).
>A footpath in America at night with a girl drunk and sitting down on the pavement. A woman dressed in denim short-shorts spreading her legs apart. She has long black hair, mascara, eye-liner, and lipstick. She's wearing a black strapless croptop. Her expression is drunk while holding a beer in her hand. The photo is taken from an iPhone at night time with the camera flash on.
>Low detail, iPhone photo, night mode photo, grainy, low quality, blurry.
main difference between others is the 2nd line read:
>HD, iPhone, night mode photo, grainy, realistic.
>>106199957
I did post a little update but nobody replied or cared.
I trained a LoRA 1024x1024. Cut it off around 2000 steps because I was only really curious to see if it worked. And it does. For some reason it like doubled my inference time though.
As for the memory needed to train it. Across two 3090s I think I capped out at like 14gb per GPU at 1024x1024 at rank 32. That was the fp16 model.
I might try a different subject at some time in the future but suffice to say it works but there are a few questions remaining.
Anonymous
8/9/2025, 12:48:53 PM
No.106200005
[Report]
>>106200039
Anonymous
8/9/2025, 12:49:29 PM
No.106200007
[Report]
>>106200031
>>106199943
FD Meshify 3 XL, Antec Flux, Corsair 4000D, something like that. there is a thread over in >>>/g/pcbg that is maybe more up to date
Anonymous
8/9/2025, 12:50:26 PM
No.106200017
[Report]
>>106200038
My only issue with Chroma right now is that the outputs are noisy as fuck. Like visually noisy that become distracting if you look to closely because you realize you aren't even sure what you're looking at.
Anonymous
8/9/2025, 12:52:25 PM
No.106200031
[Report]
Anonymous
8/9/2025, 12:54:09 PM
No.106200038
[Report]
>>106200017
you could try doing a 2nd vae decode (like use impact-pack's iterative upscale). it tends to zap away noise
Anonymous
8/9/2025, 12:54:13 PM
No.106200039
[Report]
>>106200090
>>106200005
it's funny seeing people calming down on this in real time
Anonymous
8/9/2025, 12:54:32 PM
No.106200041
[Report]
>>106200003
Oh I did read that reply. Didn't realise it was you. Thanks for the numbers, that gives me confidence then to give it a go and not feel like I'm wasting time on my card.
Diffusion pipe, or just write your own script?
Anonymous
8/9/2025, 12:55:28 PM
No.106200047
[Report]
>>106200080
>KSamplerAdvanced ImportError: DLL load failed while importing cuda_utils
chatgtp has me running in circles
Anonymous
8/9/2025, 12:55:30 PM
No.106200048
[Report]
Anonymous
8/9/2025, 12:58:36 PM
No.106200069
[Report]
>>106200098
>>106199957
>Splits a PCIe slot up to connect multiple things to 1 slot.
Wouldn't that limit your pcie lanes to x1 for each?
Isn't that super slow? No wonder you want to keep everything in vram lol.
>same, it's good value but once you have tried a fast card you can't go back to a slow one
Yeah it served me well but I'd rather sell it to some new local ai hobbyist or gamer than having it use space for nothing in my case.
>wan have distributed GPU inference (kind of)
Can you share the github of that?
>I do utilise multiple GPUs though for image/video by having one card loaded with the text encoder and another with the diffusion model.
When I had my dual 3090s setup I tried that but gave up as the speedup was barely noticeable compared to firing two different comfyui sessions and having both generate the same thing for me, effectively doubling the average output.
Anonymous
8/9/2025, 1:01:14 PM
No.106200080
[Report]
>>106200158
>>106200047
did you update comfy and the requirements?
Anonymous
8/9/2025, 1:01:52 PM
No.106200084
[Report]
Anonymous
8/9/2025, 1:02:52 PM
No.106200090
[Report]
>>106201097
>>106200039
GPT 5 is very obviously made in the interest of keeping the lights on rather than pushing new models. Like, I would not be surprised if they were in some very dire financial trouble.
Anonymous
8/9/2025, 1:03:53 PM
No.106200094
[Report]
>>106197665
Why no chroma is shit option?
>>106200069
>Wouldn't that limit your pcie lanes to x1 for each?
>Isn't that super slow? No wonder you want to keep everything in vram lol.
4x. Even when I unload and load stuff, the speed isn't bad. I've ran a 4090 on 1x using block swap and a 4090 on 16x using block swap and the time difference (hunyuan video) was less than 2 seconds. PCIe bandwidth doesn't matter for anything other than model load and unload speeds mostly. I want everything in VRAM because large models need large VRAM and it's the difference between loading and running vs not running at all
>>wan have distributed GPU inference (kind of)
>Can you share the github of that?
https://github.com/Wan-Video/Wan2.2?tab=readme-ov-file#run-text-to-video-generation
https://github.com/Tencent-Hunyuan/HunyuanVideo?tab=readme-ov-file#-parallel-inference-on-multiple-gpus-by-xdit
they're examples of docs that have it. If you're using comfy, you won't have access to it. I mostly just use CLI to run this stuff.
Anonymous
8/9/2025, 1:07:53 PM
No.106200115
[Report]
>>106200152
>A class photo of a school of maids. The class photo shows women dressed in maid uniforms and a few men dressed in tuxedos. The overall look of the photo is that of an old 80s polaroid photo. The background shows an opulent hall.
>Polaroid, low quality, bad photo, blurry.
Anonymous
8/9/2025, 1:11:22 PM
No.106200134
[Report]
>>106200168
>>106199922 (me)
looks like 512x512 lora training on qwen takes 31GB VRAM
will try higher resolutions later, after i get some preliminary results from this lora
Anonymous
8/9/2025, 1:11:38 PM
No.106200136
[Report]
Anonymous
8/9/2025, 1:12:54 PM
No.106200140
[Report]
>>106200243
>>106200098
How come this stuff never makes it in to comfy? I think Hunyuan had this too.
Anonymous
8/9/2025, 1:13:24 PM
No.106200147
[Report]
>>106200240
>>106199997
>Faggot dev changed the filename, last thread and every thread he was the only one promoting his shitty model.
BUY AN AD BRO
CHROMA SUCKS AND I'M NOT USING YOUR SHIT.
YOU ARE CANCER TO THE LOCAL COMMUNITY
Anonymous
8/9/2025, 1:14:14 PM
No.106200152
[Report]
>>106200260
>>106200115
Outside of sameface, it's convincing
Anonymous
8/9/2025, 1:14:49 PM
No.106200158
[Report]
>>106200134
Hope it's not like with HiDream where you had to train on 1024 or the results would be crap.
Is this with any offloading to ram / quantization ?
Anonymous
8/9/2025, 1:17:43 PM
No.106200173
[Report]
>>106200168
You can train on a single 24gb gpu with offloading. But only 512
Anonymous
8/9/2025, 1:18:46 PM
No.106200178
[Report]
>>106200374
Anonymous
8/9/2025, 1:18:47 PM
No.106200179
[Report]
I tire of this post SD 1.5 slop.
Anonymous
8/9/2025, 1:23:48 PM
No.106200210
[Report]
>>106200249
>>106200168
no offloading, but it is training using fp8 quant. so for fp16 training you'd need like double the vram i imagine.
this is on a rented H100, i'm just testing at the moment to see if 512x512 training is even viable
if not i will try higher resolutions
Anonymous
8/9/2025, 1:28:24 PM
No.106200240
[Report]
>>106200147
I genned that with qwen
Anonymous
8/9/2025, 1:28:37 PM
No.106200243
[Report]
>>106200098
>I've ran a 4090 on 1x using block swap and a 4090 on 16x using block swap and the time difference (hunyuan video) was less than 2 seconds.
Good to know, hunting for used x570 motherboards allowing proper x8/x8 split instead of x8/x4 when using two gpus was a pain.
>If you're using comfy, you won't have access to it.
Welp, shit.
>>106200140
I don't know why, but for some reason, pooling gpus or multigpu in general isn't very popular in image or videogen, while it's pretty solved in LLMs spaces.
Anonymous
8/9/2025, 1:29:00 PM
No.106200245
[Report]
>>106200255
Good, not bloated workflow for Wan 2.2 i2v and i2i that presumably incorporates this
https://huggingface.co/lightx2v/Wan2.2-Lightning/tree/main ?
Anonymous
8/9/2025, 1:29:27 PM
No.106200249
[Report]
>>106200210
Yikes, 31gb vram with fp8, Qwen sure is a big one
Anonymous
8/9/2025, 1:30:30 PM
No.106200255
[Report]
>>106200270
>>106200245
Is there an issue with the just plugging it in to the default workflow yourself?
Anonymous
8/9/2025, 1:31:09 PM
No.106200260
[Report]
>>106200152
Most I've tried with qwen was specifying 3 subjects and their appearances. This one I wanted to see will it same face if I don't specify details
Anonymous
8/9/2025, 1:32:20 PM
No.106200270
[Report]
>>106200276
>>106200255
>default workflow
Huh? What are you referring to?
Anonymous
8/9/2025, 1:33:40 PM
No.106200276
[Report]
>>106200270
The default comfyui Wan 2.2 workflow. Just plug the LoRA loader into that.
I downloaded a recently WAN 2.2 workflow and I saw it was using models from this link:
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/diffusion_models
wan2.2_i2v_high_noise_14B_fp8_scaled.safetensors
wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors
However, I've been using:
wan2.2_i2v_high_noise_14B_Q8_0.gguf
wan2.2_i2v_low_noise_14B_Q8_0.gguf
I think they're all pretty much the same filesize (14.3GB). But does anyone know which ones I should use before I have to spend an hour comparing them?
maybe it's the case that .gguf is higher quality but is slower? that would be my assumption.
Anonymous
8/9/2025, 1:47:43 PM
No.106200347
[Report]
>>106200338
GGUF quants are almost always of a higher quality than their FP8 retarded bothers.
Anonymous
8/9/2025, 1:49:00 PM
No.106200355
[Report]
>>106200338
i think the q8 gguf quants are better than fp8, but i have not yet tested this nearly enough to be more certain
Anonymous
8/9/2025, 1:51:52 PM
No.106200374
[Report]
>>106200387
>>106200178
did you tested it?
Anonymous
8/9/2025, 1:52:06 PM
No.106200375
[Report]
>>106200666
I want to use InvokeAI but I'm having python conflicts. Does anybody knows how to venv Invoke?
Anonymous
8/9/2025, 1:52:26 PM
No.106200377
[Report]
>>106200338
They should be more or less the same.
Q8 gguf are good, but fp8 scaled are great too.
Note that it's "fp8 scaled", not just fp8.
FP8 itself is behind any of these.
>>106200374
>4k chroma lora
>tested it?
It's better than not at 2k but not a ton different than base 49
Anonymous
8/9/2025, 1:55:52 PM
No.106200394
[Report]
>>106200564
>>106200387 (You)
>*2k lora
Apologies
Anonymous
8/9/2025, 1:58:01 PM
No.106200403
[Report]
>>106200387
>her smile and optimism, back
Anonymous
8/9/2025, 1:59:47 PM
No.106200414
[Report]
2mins per gen on 4090
They all got that chroma eczema.
Anonymous
8/9/2025, 2:18:22 PM
No.106200506
[Report]
>>106200553
Anonymous
8/9/2025, 2:27:09 PM
No.106200553
[Report]
>>106200600
>>106200506
Use a facedetailer or an upscaler big dawg, can barely tell this is Emma in some of these gens.
Anonymous
8/9/2025, 2:27:51 PM
No.106200558
[Report]
>>106200450
Well..it is skin detail, isn't it?
Anonymous
8/9/2025, 2:28:52 PM
No.106200564
[Report]
>>106200600
>>106200394
mmmm sexy granny
Anonymous
8/9/2025, 2:33:50 PM
No.106200600
[Report]
>>106200630
>>106200553
>Use a facedetailer or an upscaler big dawg
This is just a bit of testing lil bro. New = shiny. idgaf about impressing people
>>106200564
>sexy granny
But could you tell that was AI? Best realism model IMO
>>106200600
>But could you tell that was AI? Best realism model IMO
Nta, but it's very 'in your face ai' due to extremely visible artifacts, messed up perspective and the 'chroma overlay' over all realistic photos. I can spot chroma much better than wan.
Anonymous
8/9/2025, 2:39:46 PM
No.106200632
[Report]
>>106201166
Am I crazy or are the Chroma believers literally suffocating on their own copium right now?
Anonymous
8/9/2025, 2:44:37 PM
No.106200660
[Report]
>>106198843
Cool gonna train the loras for this one, been prepping the dataset throughout the week
Anonymous
8/9/2025, 2:45:39 PM
No.106200666
[Report]
>>106200375
>no adetailer or variants
>no hiresfix
>can't load json workflows
why?
Anonymous
8/9/2025, 2:47:30 PM
No.106200679
[Report]
Anonymous
8/9/2025, 2:48:01 PM
No.106200684
[Report]
least gay way to train a Qwen lora?
Anonymous
8/9/2025, 2:48:13 PM
No.106200687
[Report]
>>106200741
>>106200657
it was foretold
Anonymous
8/9/2025, 2:48:45 PM
No.106200689
[Report]
>>106199539
I wonder if I can train my dataset of imouto on it, lora training exist for this?
Anonymous
8/9/2025, 2:50:28 PM
No.106200707
[Report]
>>106200741
>>106200657
"Chroma believers" is litteraly lodestones(dev) samefaging since yesterday. All it does is further expose its shitty model.
Anonymous
8/9/2025, 2:50:58 PM
No.106200710
[Report]
>>106199895
the toes should be as succulent as the piggy.
>>106200707
>>106200687
>>106200657
the absolute state of nogen vramletkids kek
Anonymous
8/9/2025, 2:55:49 PM
No.106200745
[Report]
I miss sd 1.5 times where controlling camera angle was easier
Anonymous
8/9/2025, 2:59:03 PM
No.106200775
[Report]
ew feet. disgusting degenerate, go away.
bein attrated to f**t is a brain defect.
Anonymous
8/9/2025, 3:01:33 PM
No.106200799
[Report]
>>106200808
>>106199834
>Open up WAN 2.2 workflow from civitai
>Oh look they've got a custom negative prompt, this'll be interesting... wait a second, 1.0 cfg?
>generate video
>remove negative prompt
>generate video again
>get exact same video
I'm the only smart person on this gay earth
Anonymous
8/9/2025, 3:03:15 PM
No.106200808
[Report]
>>106200799
imagine not using wan nag
Anonymous
8/9/2025, 3:03:27 PM
No.106200810
[Report]
>>106200852
>>106200741
The furries ignored him.
The bronies the same.
In realism style, the community didn't pay atention, they preferd to make NSFW adaptations for Flux or WAN.
Anime was never his focus.
What’s he got left?
Shilling and samefagging here, hoping his shitty model turns into a 'cult classic.'
He wasted money and effort on a dead end.
Eventually he will kill himself.
Why doesn't everybody shut up about the models they don't like? Post gens that make people want to try different models.
Anyway,
For stylized gens, I think v48 is better than v50 of Chroma. It's hard to put the finger on what is different but I'm finding hard to like v50 or v50 annealed. Shall I bother testing v49?
Anonymous
8/9/2025, 3:05:35 PM
No.106200826
[Report]
>>106200870
>>106200741
chromakek please, i'm genning 720p videos
Anonymous
8/9/2025, 3:05:55 PM
No.106200829
[Report]
>>106200630
The biggest issue still with AI pictures is that they usually have angles that no one would take pictures at, and the composition of the photo always makes no sense.
Did anyone find out this slowmo gayness with these lightx loras?
Anonymous
8/9/2025, 3:07:50 PM
No.106200847
[Report]
>>106200824
>Anyway,
KYS iodestones
Anonymous
8/9/2025, 3:08:17 PM
No.106200852
[Report]
>>106200810
>they preferd to make NSFW adaptations for Flux
not a serious person, thanks for exposing yourself
Anonymous
8/9/2025, 3:08:57 PM
No.106200860
[Report]
>>106200956
This is a battle betwen Chromaschizo and AntiChromaschizo, am I right?
Anonymous
8/9/2025, 3:09:31 PM
No.106200870
[Report]
>>106200826
im sure you are, 720x480p 4 step 4 speed up loras in wangp, sis
>chroma-unlocked-v50-annealed.safetensors
>chroma-unlocked-v50-annealed.safetensors
>chroma-unlocked-v50-flash-heun.safetensors
>chroma-unlocked-v50.safetensors
why doesn't lod explain what the fuck the difference is between these?
Anonymous
8/9/2025, 3:12:31 PM
No.106200889
[Report]
>>106200956
>>106200884
The discord is full of non-social autistic furries, they need someone to do proper PR. I might take up the helm out of kindness.
Anonymous
8/9/2025, 3:12:38 PM
No.106200891
[Report]
>>106200931
When I was kid, all I wanted was moon shoes. You know, the mini trampolines you put on your feet? I was so excited when I found out I was getting a pair for Christmas. Every day I'd imagine how fun it would be to bounce around like I'm literally on the moon. Then the day came. I put them on... and they were shit. Of course. I didn't want to disappoint my parents, so I jumped around and made sure everyone knew how happy was about finally getting my moon shoes. I jumped around in front of everyone. Made sure everyone knew how satisfied I was with Chroma epoch 50. I wanted everyone to think I was the happiest boy in the universe. But on the inside, I was disappointed.
Anonymous
8/9/2025, 3:13:21 PM
No.106200900
[Report]
>>106200909
>>106200884
flash-heun uses heun and is flashy
Anonymous
8/9/2025, 3:14:17 PM
No.106200909
[Report]
>>106200932
>>106200900
so it's shit and i should avoid it.
what about annealed?
is v50 the 'detail-calibrated' versions or is it like base? EXPLAIN
Anonymous
8/9/2025, 3:14:45 PM
No.106200911
[Report]
>>106198436
can we see 11 frames per second windable cam with 16mm grain
Anonymous
8/9/2025, 3:14:45 PM
No.106200912
[Report]
>>106200824
>Why doesn't everybody shut up about the models they don't like?
Because if I don't have a GPU that can generate things with a model fast, no one else should be able to get positive attention from using that model online.
Anonymous
8/9/2025, 3:18:10 PM
No.106200931
[Report]
>>106200891
that was remarkably close to my review of Happy Gilmore 2
>>106200909
V49 was the epoch with the only true hi-res addition training.
V50 I wasn’t sure with what he did, it wasn’t very clear.
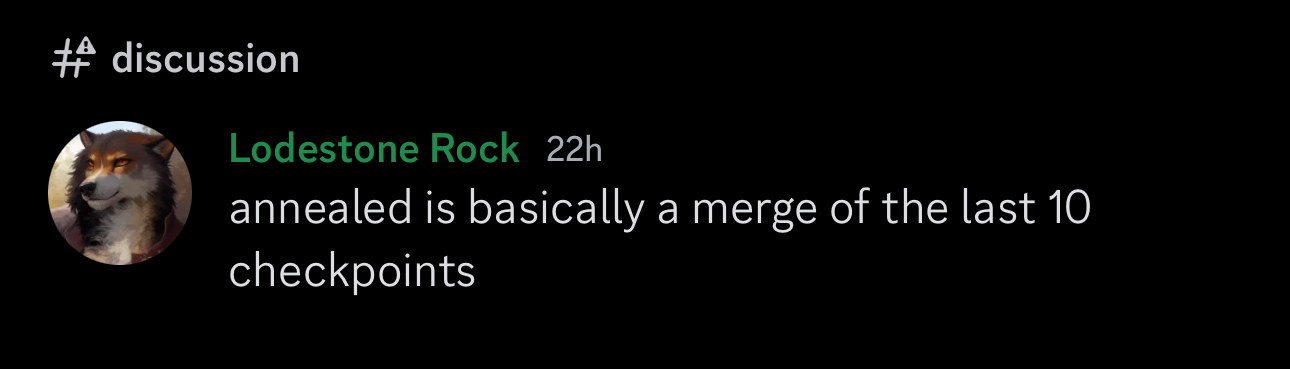
V50-Annealed was a merge of the last ten epochs
Anonymous
8/9/2025, 3:18:42 PM
No.106200938
[Report]
>>106198908
they tell one was build for museum and it was coral color maybe some metallic elements
Anonymous
8/9/2025, 3:19:12 PM
No.106200944
[Report]
>>106201153
>>106200003
I figure you must have used diffusion-pipe. I'll try it with my BBW dataset. I just finished my wan 2.2 t2v bbw lora, by the way:
https://huggingface.co/quarterturn/wan2.2-14b-t2v-bbwhot
https://files.catbox.moe/ml96j2.mp4
(yeah I know the animation has a fuckup midway, I just finished epoch 80 and wanted to try it, at least it's learned the tits and tummy)
Anonymous
8/9/2025, 3:20:48 PM
No.106200956
[Report]
>>106200889
except the overwhelming amount of gens posted there are non-furry. you'd know that if you were actually in the discord.
>>106200860
who cares, filter both.
Anonymous
8/9/2025, 3:21:38 PM
No.106200965
[Report]
>>106200932
>V49 was the epoch with the only true hi-res addition training.
huh, but I thought that was meant for v50? so v50 does not have 1024x1024 training?
>>106200932
>V50-Annealed was a merge of the last ten epochs
wrong.
but lodekek himself said that annealed is "shit"
Anonymous
8/9/2025, 3:24:24 PM
No.106200985
[Report]
>>106200968
someone posted comparisons between v50 and v50-annealed, and yeah annealed looked worse in every sampler. not sure why he even did that
So uh, any real use case for wan besides turning reaction images into reaction videos?
Anonymous
8/9/2025, 3:29:55 PM
No.106201025
[Report]
Anonymous
8/9/2025, 3:30:59 PM
No.106201032
[Report]
>>106201166
Anonymous
8/9/2025, 3:31:42 PM
No.106201039
[Report]
>qwen on 4gb using gguf
All toasters toast tost, but damn if it isn't fun. Has kind of boring poses though, I got spoiled by 1.5 implicit variety.
>>106200090
It's kind of a self-own, though. There are a few very trivial things they could do to get more users, which they don't mostly out of spite. Altman just went on a podcast where he smugly implied Ani was some horrible evil thing OpenAI would never do, but if you are not offering people a product they want to pay for, they won't pay for it.
Anonymous
8/9/2025, 3:37:20 PM
No.106201104
[Report]
Anonymous
8/9/2025, 3:42:00 PM
No.106201152
[Report]
Anonymous
8/9/2025, 3:42:13 PM
No.106201153
[Report]
>>106200944
It's the craziest thing. I also tested my LoRA with a bbw dataset.
Anonymous
8/9/2025, 3:42:38 PM
No.106201157
[Report]
>>106201019
90% of Wan gens are porn related, so the answer is yes
Anonymous
8/9/2025, 3:43:44 PM
No.106201166
[Report]
>>106200630
>messed up perspective
The bed being too short is my only tell it's fake, but I also never learned how to draw.
>extremely visible artifacts, and the 'chroma overlay' over all realistic photos
There's no flux lines or anything. Care to be specific? You might be sensitive enough to see differences in the VAE at this point.
>>106200632
>prompt issue
100% this
>She is sitting on the edge of a bed, facing you. She has a large, light-green towel wrapped around her torso, and another smaller white towel is wrapped around her hair like a turban. She is leaning forward a little bit, with both of her hands resting on her knees. She is looking at you with a simple, neutral expression, as if she is listening to someone talk. Her shoulders are bare, and her skin looks smooth. The bed she is sitting on has a dark brown wooden frame, and the blanket on it is a simple white color. The room is bright with daylight coming from a window that is out of view.
>>106201032
Not op but gross
picrel is wan 2.1 t2i from Mar 15
Anonymous
8/9/2025, 3:44:43 PM
No.106201173
[Report]
I have some old chroma schnell lora. Are all the newest chroma lowstep cfg1 loras still deepfrying the pics?
Anonymous
8/9/2025, 3:45:45 PM
No.106201180
[Report]
>>106201097
what the fuck are you talking about and what the fuck is an Ani
>>106201205
Probably meant AGI
Anonymous
8/9/2025, 3:50:32 PM
No.106201221
[Report]
>>106201205
>>106201212
no Ani is the elon grok waifu app
Anonymous
8/9/2025, 3:51:12 PM
No.106201226
[Report]
>>106200824
Cleans up the image for me. The 2k lora on top is nice too. Today's gens have been using 28 steps with the optimal steps scheduler
Anonymous
8/9/2025, 3:52:01 PM
No.106201231
[Report]
>>106201427
>comfy gens slow down to a crawl after a couple of gens running fine
what was it again that needed to be done to that guy?
Anonymous
8/9/2025, 3:52:49 PM
No.106201237
[Report]
>>106201097
i always thought it was just legal liability and wanting to dodge lawsuits, but if they are all giving up a load of money and user satisfaction just so they can feel better about their company then kek
https://youtu.be/hmtuvNfytjM?si=q-VZKqyqYODA6Pbl&t=2961
Anonymous
8/9/2025, 3:53:56 PM
No.106201256
[Report]
Any software to let me search images by generation parameters like
https://github.com/zanllp/sd-webui-infinite-image-browsing but one that works with ComfyUI images?
Anonymous
8/9/2025, 3:55:43 PM
No.106201265
[Report]
>>106201364
>>106201205
>>106201212
Ani is Grok's "Waifu Mode." It is just a glorified Koikatsu model on a dancing rig and with the voice in ASMR mode, but it made quite a stir on both the pro- and anti- side. She looks like Misa, and the joke is Ani-May. A lot of people, including OpenAI employees, went crazy about it, accusing Musk of all sorts of irresponsible behaviors because Ani has twintails and big boobs. See
https://gelbooru.com/index.php?page=post&s=list&tags=ani_%28xai%29 (to not take up an image limit slot).
Most recently, Altman made the following comment (see ~49 minutes in)
https://youtu.be/hmtuvNfytjM
>We haven't put a sex bot avatar into ChatGPT yet
>Seems like that would get a lot of engagement
>Apparently it does
The irritated "apparently it does" is the key. He is not just speculating, he is annoyed at someone having already done something, the most likely candidate being Ani.
Anonymous
8/9/2025, 4:01:12 PM
No.106201317
[Report]
>>106201205
ani is anistudio's mascot. the dev posted here since the beginning
Anonymous
8/9/2025, 4:02:30 PM
No.106201330
[Report]
>>106201318
I think ani should sue elon
Anonymous
8/9/2025, 4:04:35 PM
No.106201342
[Report]
>A landscape photo of a lake with mountains off in the distance. It is a dark, starry night, with some planets visible in the sky. The lake has fireflies and wisps of fog over the water. A grassy field surrounds the lake with various flowers and a large oak tree. A mystical Fenrir made of molten lava and fire is roaming the grassy field.
>Ultra HD, 4K, cinematic composition.
cfg 4, seed 42, steps 40
Anonymous
8/9/2025, 4:07:00 PM
No.106201364
[Report]
>>106201426
>>106201265
For all the screeching about how Ani isn't a hag, Musk should jump the shark and add a loli mode to it. Stirring up shit is right up his alley.
>>106198896
I got a slight improvement from the q8 GGUF in one test but the perf is worse and it's almost crashing my computer. so I'm giving up on it, will have to stick to fp8.
also, I tried q6 and it took just as much VRAM as q8 and was just as crash-prone? what the fuck is the point of lower quants then? is this a problem with rocm and/or the 7900 xtx architecture?
Anonymous
8/9/2025, 4:08:01 PM
No.106201371
[Report]
>>106201318
I don't think so. I think he's more into blue chibi foxes.
Anonymous
8/9/2025, 4:13:17 PM
No.106201426
[Report]
>>106201364
this is planned for anistudio
Anonymous
8/9/2025, 4:13:18 PM
No.106201427
[Report]
>>106201231
Go use forge and have fun with SDXL
Anonymous
8/9/2025, 4:18:42 PM
No.106201478
[Report]
>>106201367
q8 and q6 both operate in fp16 after dequant. Also seems like you have real fp8 support
Anonymous
8/9/2025, 4:23:34 PM
No.106201515
[Report]
>>106201367
Ayymd surely isn't helping but at least find fp8 scaled instead of just fp8
Anonymous
8/9/2025, 4:27:35 PM
No.106201561
[Report]
>>106201466
He's gooning in our AGP discord, wait a bit, chuddie
Friendly reminder to NOT update your comfy to the latest release v0.3.49
Anonymous
8/9/2025, 4:33:05 PM
No.106201605
[Report]
>>106200884
base is base
annealed is the new detail-calibrated and is slightly better for high res detail but worse at other things
flash is for 8 steps, CFG 1, heun sampler, beta scheduler
i have no idea and could be wrong though
Anonymous
8/9/2025, 4:36:41 PM
No.106201639
[Report]
>>106201709
>>106201602
>(ComfyUI) archlinux% git pull
>Already up to date.
Anonymous
8/9/2025, 4:38:49 PM
No.106201664
[Report]
>>106201694
/ldg/ is so comfy when there aren't any atherless avatartrannying faggots polluting it
Anonymous
8/9/2025, 4:43:49 PM
No.106201694
[Report]
>>106201664
way to shit things up by being a schizoid
Anonymous
8/9/2025, 4:46:05 PM
No.106201709
[Report]
>>106201639
I..I'm so sorry
Anonymous
8/9/2025, 4:49:32 PM
No.106201735
[Report]
>>106202033
Anonymous
8/9/2025, 4:50:57 PM
No.106201748
[Report]
>>106201602
ive been on 3.49 since release with no issues
Anonymous
8/9/2025, 4:54:13 PM
No.106201771
[Report]
Anonymous
8/9/2025, 5:03:33 PM
No.106201857
[Report]
>>106198660
Great movement, catbox? Or if you dont want to, at least prompt?
Anonymous
8/9/2025, 5:22:50 PM
No.106202015
[Report]
Anonymous
8/9/2025, 5:25:33 PM
No.106202033
[Report]