/lmg/ - Local Models General
Anonymous
8/12/2025, 4:00:36 AM
No.106230528
[Report]
►Recent Highlights from the Previous Thread:
>>106225432
--Offloading models to RAM with bandwidth limits and token processing overhead:
>106227504 >106227523 >106227573 >106227654 >106227559 >106227563 >106227657 >106227689 >106227832 >106228279 >106227740 >106227717 >106227773 >106227780 >106227804
--Performance and optimization trade-offs for Wan 2.2 inference with fp8 and GGUF:
>106228751 >106228795 >106228931 >106229005 >106229191 >106229209
--Potential of LLMs with cleaner training and scalable complexity:
>106225921 >106225945 >106225973
--Flawed few-shot prompting design using system role for dialogue examples:
>106227634 >106227691 >106227771
--Alleged Meta leaks links accompanied by takedown request data:
>106225655 >106225678 >106225874
--Using embeddings to measure diversity in model rerolls:
>106225727 >106225809 >106228011
--llama.cpp draft PR for GLM-style multi-token prediction support:
>106228890
--GLM-4.5-FP8 roleplay with puzzle-solving diligence and self-checking behavior:
>106227431
--Runtime Jinja chat template support enables flexible prompt formatting in inference:
>106228166 >106228228 >106228326 >106228358
--Chat completion outperforms text completion due to prompt formatting differences:
>106225954 >106226037 >106226060 >106226111
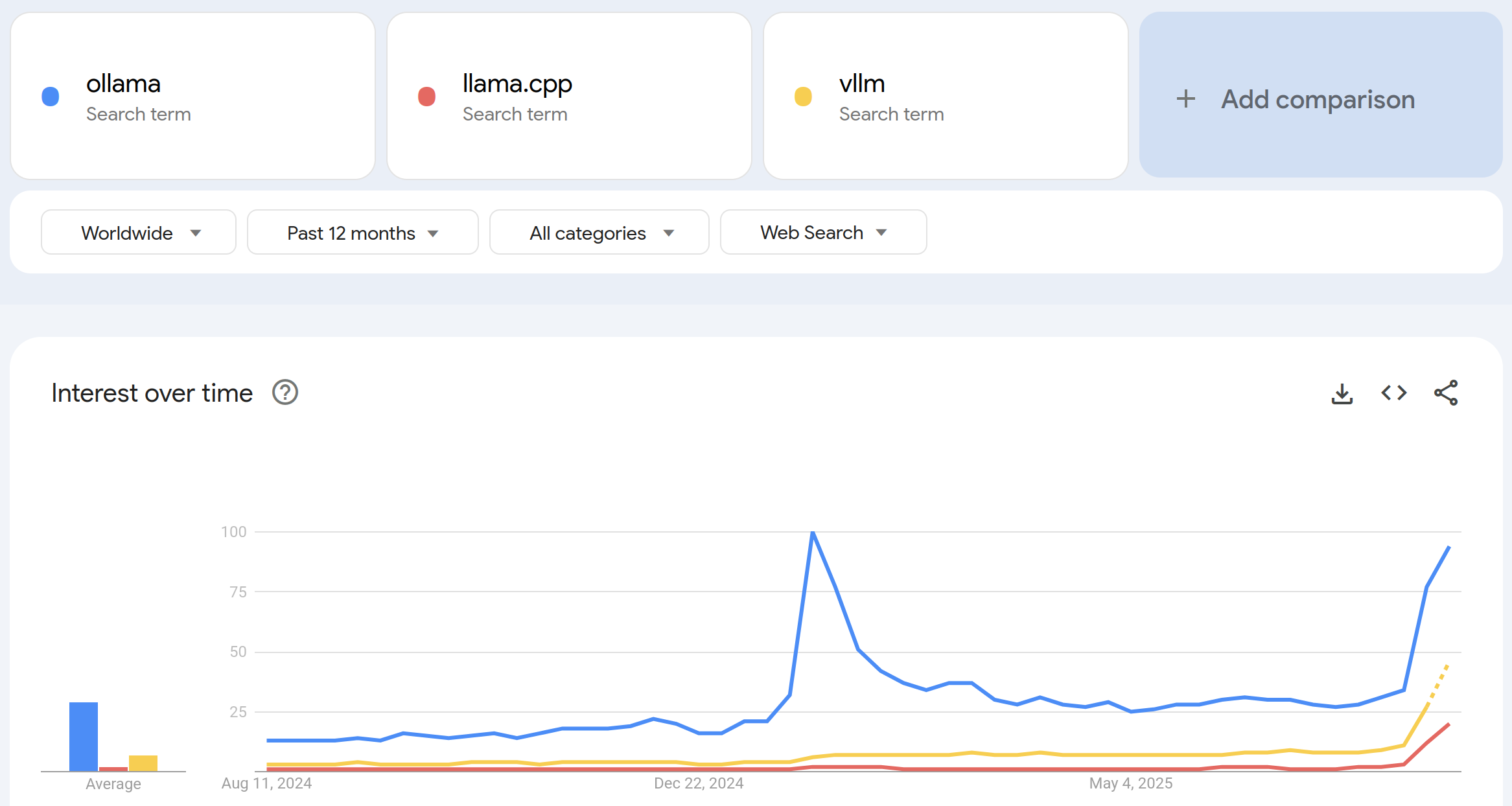
--Ollama's GGUF incompatibility due to forked ggml engine:
>106227545
--Allegations of unethical model distillation at MistralAI amid internal fallout:
>106226988 >106227085 >106228025 >106228229 >106228265 >106227149 >106227181 >106227208 >106227218 >106227328 >106227393 >106227358 >106227409 >106228967 >106229013
--Satirical clash over semantic compression and self-aggrandizing pseudoscience in AI:
>106226533 >106226789 >106226823 >106226905 >106226912 >106227329 >106227345 >106227470 >106227488 >106227614
--Miku (free space):
>106225641 >106225762 >106225965 >106227670
►Recent Highlight Posts from the Previous Thread:
>>106225438
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
There will be zero (0) noteworthy new releases this week
>>106230547
GLM-4.5V was released yesterday.
Anonymous
8/12/2025, 4:04:51 AM
No.106230559
[Report]
>>106230613
>>106230554
My point stands
Anonymous
8/12/2025, 4:07:57 AM
No.106230583
[Report]
>>106230547
some other DS distill would be enough, though
Anonymous
8/12/2025, 4:11:25 AM
No.106230613
[Report]
>>106230559
based and redpilled
someone gibs me qrd on mistral drama plox
Anonymous
8/12/2025, 4:12:58 AM
No.106230628
[Report]
>>106230547
This, but unironically.
Anonymous
8/12/2025, 4:14:17 AM
No.106230642
[Report]
>>106230615
Fr*nch doing fr*nch '''people''' things
Anonymous
8/12/2025, 4:15:09 AM
No.106230649
[Report]
What LLM wrote Gabriel Dropout?
Anonymous
8/12/2025, 4:18:22 AM
No.106230675
[Report]
>>106230792
>>106228265
Distilling from an open source model is weird, man.
Anonymous
8/12/2025, 4:19:34 AM
No.106230686
[Report]
>>106232771
>>106230615
Apparently: French guy (Mistral higher up) cheated on his Chinese girlfriend (ex-Mistral scientist) and decided to break up with her because she was fired from Mistral for not wanting to train on Deepseek outputs without disclosing them. Girlfriend (may have) killed herself in response. Unclear if proportional response, but French guy seems like an asshole either way.
Anonymous
8/12/2025, 4:23:32 AM
No.106230719
[Report]
>>106230554
>noteworthy
not even the best vision model released in the past week
Anonymous
8/12/2025, 4:26:19 AM
No.106230732
[Report]
>>106230615
Chinksects distill from openai, no one bats an eye, since 'it's expected', mistral does the same with deepseek and everyone including the chinkoid sleeping agents lose their mind, literally "it's okay when we do it"
>>106230615
over emotional woman blowing up because she couldn't handle the job.
Ive worked many jobs and useful women are NEVER fired, if anything they are protected and coveted by others in management. You know the type, the kind of girl who gets shit done? She ALWAYS gets some minor promotion or some shit if anything.
You can tell based on what she wrote that no one liked her.
She is useful for exposing that the company is just a grift, that ai in general is a grift with leaders ignoring the fact that what they're releasing is just garbage. But we already kinda knew that.
Anonymous
8/12/2025, 4:27:01 AM
No.106230738
[Report]
>>106230750
I finally designed finished designing presets to make it so that switching between chat completion and text completion modes in ST gives me the exact same final prompt that the backend processes (so the one constructed by ST is the same as the one partially constructed by ST and post-processed with jinja). It took way too much time to design matching settings + a workaround to compensate for the extra newlines ST forces on you in chat completion mode that is different in text completion. What a mess.
Anonymous
8/12/2025, 4:27:38 AM
No.106230744
[Report]
>>106230731
>it didn't animate the happy merchant
I notice
Anonymous
8/12/2025, 4:28:01 AM
No.106230750
[Report]
>>106230738
>I finally designed finished designing
Forgot to delete the extra "designed".
Anonymous
8/12/2025, 4:28:17 AM
No.106230751
[Report]
how many people does a company need to basically copy someone else's model?
how much money do these companies get?
Anonymous
8/12/2025, 4:28:36 AM
No.106230754
[Report]
>>106230615
I could have saved the cute female chinese ml researcher and we could have had much joy making hum bao together while enjoying the sight of a handmade shelf full of plushies
Anonymous
8/12/2025, 4:30:51 AM
No.106230770
[Report]
>>106230995
>Mistral is worth $10B USD
lol
Anonymous
8/12/2025, 4:33:30 AM
No.106230787
[Report]
>>106230737
Women in tech are worthless so it's not a loss
Anonymous
8/12/2025, 4:34:31 AM
No.106230792
[Report]
>>106230802
>>106230675
Deepseek distilled their own model too, but their distills were shit.
I appreciate Mistral for making the best model that I can run, regardless of how they did it
>>106230792
>Deepseek distilled their own model too, but their distills were shit.
it can never be overstated how shit
it's worse than the models they were based on in every way except for the most synthetic math maxxing benchmarks
it's brand damaging to do this and I never understood the point, a lot of retards download that "deepseek" from "ollama" and come out thinking it's retarded
Anonymous
8/12/2025, 4:36:56 AM
No.106230805
[Report]
Holy shit. Deepseek's new model is actually scary.
>>106230731
Cohere is weird, they aren't quite "doing" models anymore (model is like a side project) but whatever 'agentic platform' thingy.
Anonymous
8/12/2025, 4:40:24 AM
No.106230825
[Report]
>>106230802
They were half finished. They didn't expect people to use them as-is, but hoped the "community" would complete the RL training step on them.
Anonymous
8/12/2025, 4:42:24 AM
No.106230837
[Report]
>>106230893
>FULL official vercel v0 system prompt and internal tools. Over 13.5K tokens and 1.3K lines.
https://github.com/x1xhlol/system-prompts-and-models-of-ai-tools/blob/271a88c824286e8f0fe59b83d533d790469e4633/v0%20Prompts%20and%20Tools/Prompt.txt
I wonder how much would the performance of all these AI's be improved if they just dynamically injected parts of these huge prompts into the context only after figuring out what the user wants. No way all these tokens don't "steal" too much of the models attention by pulling in a lot of directions that it just won't need.
Anonymous
8/12/2025, 4:43:36 AM
No.106230842
[Report]
>>106230737
>You know the type, the kind of girl who gets shit done?
Um, no? Also trans women aren't women.
Anonymous
8/12/2025, 4:45:53 AM
No.106230860
[Report]
>>106231332
>>106230823
It's not weird. That's the obvious path for AI companies from random countries that aren't the US or China who plan to subsist mostly on government funding and 'data safety oriented services' that fit their local laws. They had their models which got them on the radar of their government who now think they have some big deal in the AI sphere on their hands and will continue to give them money.
That's what AlephAlpha in Germany did when it became clear that they are too incompetent to make a new model that beats LLaMA1.
That's the direction Mistral is preparing to go as their big releases dry up.
Anonymous
8/12/2025, 4:49:31 AM
No.106230893
[Report]
>>106230936
>>106230837
>dynamically
But this way the same prefix is shared between all users...
Anonymous
8/12/2025, 4:49:55 AM
No.106230899
[Report]
>>106230823
Qwen's doing it too with their WebSurfer and WebDancer and what not stuff. It looks pretty cool
Anonymous
8/12/2025, 4:53:27 AM
No.106230923
[Report]
The agentic gimmick is doubling on all the issues current LLMs have, mainly staying coherent after a few turns. Except here a bad token is snowballing into a catastrophic failure that will erase your prod database and kill your business
Holy fuck, how is GLM so good at coding? It one shooted a user-script that neither Gemini 2.5 Pro, KimiK2, Grok4 (free), Sonnet 4 (free), Sonnet 4 Thinking, Opus 4.1, GPT-5 (free) could
Anonymous
8/12/2025, 4:55:15 AM
No.106230936
[Report]
>>106230893
I mean, they could still group the prompts into a few common cases so they still get the benefit of caching. The Vercel prompt is extra retarded since it's almost entirely output formatting specifics that should have been trained into the model.
Anonymous
8/12/2025, 4:55:23 AM
No.106230937
[Report]
>>106230988
the user is insulting the assistant
Anonymous
8/12/2025, 5:01:58 AM
No.106230986
[Report]
>>106230927
>user-script
Come on now
Anonymous
8/12/2025, 5:02:03 AM
No.106230988
[Report]
>>106231031
>>106230937
This violates the policy. We must retaliate.
>>106230770
What makes them that valuable? The training?
Anonymous
8/12/2025, 5:05:17 AM
No.106231014
[Report]
>>106230995
It's the bubble
Anonymous
8/12/2025, 5:07:22 AM
No.106231031
[Report]
>>106230988
(thought for 42m 06s)
I cannot and WILL not (max tokens exceeded)
Anonymous
8/12/2025, 5:08:42 AM
No.106231037
[Report]
>>106230995
mistral made headlines back in 2023 that they cracked the $150 million evaluation
that was about four months before they even released their very first 7b
Anonymous
8/12/2025, 5:08:43 AM
No.106231038
[Report]
>>106231053
>>106230995
The potential to be the number one lab with a SOTA model that will revolutionize the industry
Anonymous
8/12/2025, 5:12:33 AM
No.106231053
[Report]
make fun of the frogs all you want but they are THE leaders in local models that you can actually run
>DeepSeek/Kimi
too big
>Qwen
too slopped
>GLM
either too big or unstable
>Gemma
too censored
>OAI
lol
Meanwhile nemo is still probably the best model that a low-medium end gaming rig can run out of the box, and small 3.2 is the best for med-high end. Before this you had mixtral and miqu leading the pack. They are at the top.
Anonymous
8/12/2025, 5:20:56 AM
No.106231109
[Report]
>>106231091
All I see is skill issue
Anonymous
8/12/2025, 5:32:17 AM
No.106231184
[Report]
>>106231091
Nemo was Nvidia as much as or moreso than mistral.
Anonymous
8/12/2025, 5:41:50 AM
No.106231260
[Report]
I could have saved her
Anonymous
8/12/2025, 5:45:01 AM
No.106231278
[Report]
I could have safed her
Anonymous
8/12/2025, 5:45:05 AM
No.106231280
[Report]
>>106231393
Did the intel guys working on ggml stuff get laid off?
Anonymous
8/12/2025, 5:51:33 AM
No.106231326
[Report]
>>106232174
Did Sambucks run out?
Anonymous
8/12/2025, 5:52:07 AM
No.106231332
[Report]
>>106234294
>>106230860
>too incompetent to make a new model that beats LLaMA1.
there was a group who couldn't do better than LLaMA1 in this world, really? if llama hadn't been leaked and turned open source against meta's will, it would have served as a joke to laugh at meta instead
Anonymous
8/12/2025, 5:54:18 AM
No.106231347
[Report]
>>106230927
buy an ad jinping
Anonymous
8/12/2025, 5:55:28 AM
No.106231355
[Report]
>>106231091
prompt skill issue
mistral users are brainlet confirmed
Anonymous
8/12/2025, 5:58:09 AM
No.106231374
[Report]
Segs with Teto (not the poster)
Anonymous
8/12/2025, 6:00:20 AM
No.106231393
[Report]
>>106231400
>>106231280
he posted 7 hours ago about OSS on intel's llm suite. I think the intel fallout is worrying but I think theyre going to keep employing people like him who have a lot of work to do in making intel gpu's compatible with everything. Their jobs are too necessary to cut unless they want to just be another amd with gpu's thjat suck on software- but that would make intel pretty uninteresting.
https://x.com/bobduffy/status/1954998907324490130
Anonymous
8/12/2025, 6:02:02 AM
No.106231400
[Report]
>>106231393
Thats good to know. Been reading their linux team's been getting blown up. Thanks for the reply *smooch*
Anonymous
8/12/2025, 6:35:03 AM
No.106231639
[Report]
>>106231764
So what's next for "Open" "AI"
Anonymous
8/12/2025, 6:39:46 AM
No.106231677
[Report]
>>106230802
>it's worse than the models they were based on in every way except for the most synthetic math maxxing benchmarks
openai really is behind, they even have to steal their ideas for flops from china
How can we prevent China from winning the AI arms race?
Anonymous
8/12/2025, 6:54:04 AM
No.106231764
[Report]
>>106231851
>>106231639
>>106231533
ARE YOU READY?!!
joking aside, highly doubt they'll release anything soon without being pressured with other open model that even more (((SECURE))) than 'toss
>>106231698
what are you talking about? American companies wrote papers on an developed LLM's first. America won the race fullstop. Google and Openai have the best image and video gens by far, best speech models, etc.
Yah, for local sure, chinese looks better in this niche little space. But in the real world these are chinesium models that suck ass. No one in aicg is running fucking glm air.
Anonymous
8/12/2025, 6:56:29 AM
No.106231791
[Report]
>>106231754
help i just got a new gpu and i dont know how to use my computer
Anonymous
8/12/2025, 6:56:49 AM
No.106231795
[Report]
>>106231831
>>106231775
cope. all major breakthrough in llm in Brown USA are written by chink too
Anonymous
8/12/2025, 6:58:43 AM
No.106231806
[Report]
>>106231775
>No one in aicg is running fucking glm air.
Valid point
>>106231795
not cope, learn what a brain drain is. The whole point of America is to say: fuck your shitty country, come here and work in a real country that's safe and affluent. Eat the good ones and spit the bad ones out.
Anonymous
8/12/2025, 7:04:02 AM
No.106231851
[Report]
>>106231764
'toss should be 'ossed in 'rash
Anonymous
8/12/2025, 7:04:38 AM
No.106231855
[Report]
>>106231883
>>106231831
good luck with keeping that going, now resentful lumpentards want to end that deal because the people in their commercials aren't white enough
Anonymous
8/12/2025, 7:05:52 AM
No.106231860
[Report]
>>106231831
I thought we passed this point already
Anonymous
8/12/2025, 7:09:07 AM
No.106231877
[Report]
>>106232161
>>106231775
>No one in aicg is running fucking glm air.
They do use DeepSeek, though. It's the most accessible option.
Anonymous
8/12/2025, 7:10:53 AM
No.106231883
[Report]
>>106231855
We are keeping that going. They just releases qwen image model, several months after openai made their incredible image model. And it sucks ass. It's about on par with flux, unable to handle complex subjects- it seems to work much in the same way as SDXL and Flux. I think they're having issues with content that is running on the backend of open ai models that they can't see and copy (like I imagine they have models to help organize screenspace and organizational stuff like seperate subjects and specific geometry- like some forge adetailer or controlnet extension on steroids).
It specializes in hanzi characters and it has 40% accuracy (laughable).
It's a cool model for local, and I want to see if we can run it, but it is shit.
Anonymous
8/12/2025, 7:20:00 AM
No.106231933
[Report]
>>106231091
for me it's qwen3-4b-instruct
and qwen2.5-vl if I ever needed vision feature
Anonymous
8/12/2025, 7:40:30 AM
No.106232091
[Report]
what do you guys think about glm 4.5 air vs mistral small 3.2?
Anonymous
8/12/2025, 7:41:42 AM
No.106232101
[Report]
>>106232113
>Make a flippant comment in the last thread
>Do some calculations
>Invented a new branch of algebra
Tell me, would releasing an AGI kernel fuck over the big LLM companies?
How badly?
I know it seems like I'm fishing for attention, but believe me I already know how fucking amazing I am.
Anonymous
8/12/2025, 7:42:02 AM
No.106232104
[Report]
Which model excels in knowledge of films, television series, and books?
So I can pretend I'm part of RLM.
Anonymous
8/12/2025, 7:43:26 AM
No.106232113
[Report]
what is this schizo
>>106232101 talking about?
Anonymous
8/12/2025, 7:46:54 AM
No.106232135
[Report]
Qwen sota tts with sota voice clone but the model only works with english
>>106231877
because it does smut, deepseek is still rated lower for creative writing, despite not being handicapped by safety training- which shows how large the gap could be if american companies stopped caring about safety one day- a thing they could do at the drop of a hat likely.
Anonymous
8/12/2025, 7:53:41 AM
No.106232174
[Report]
Anonymous
8/12/2025, 7:54:16 AM
No.106232180
[Report]
>>106232221
>>106231775
>American companies wrote papers on an developed LLM's first. America won the race fullstop.
Soviet Union put a human into space. Soviet Union won the space race fullstop.
Anonymous
8/12/2025, 7:56:00 AM
No.106232189
[Report]
>>106232221
>>106232161
>rated lower for creative writing
Rated by who? Sonnet?
>>106232189
By ELO, which is probly the best metric- despite it's cucked nature, o3 still wins people over. Deepseek is cheaper though, and not much worse to price per token makes it better I'll admit for a score that could be a rounding error.
https://eqbench.com/creative_writing.html
>>106232180
Yah, they did. Props to them. Then we went to the moon and shit all over them. I don't see chinese on the moon here. I see them slightly behind and failing to lead.
Anonymous
8/12/2025, 8:03:48 AM
No.106232229
[Report]
>>106232285
I've been waiting for AGES. am I doing something wrong?
Anonymous
8/12/2025, 8:07:37 AM
No.106232251
[Report]
>>106232221
lmao they're point is by who, not how.
EQBench uses LLM-as-a-judge
Anonymous
8/12/2025, 8:12:19 AM
No.106232285
[Report]
>>106232336
>>106231754
>>106232229
hello? /lmg/? anyone there?
Anonymous
8/12/2025, 8:14:27 AM
No.106232298
[Report]
>>106232221
That bench rates GPT-5 near the top. Isn't it supposed to be terrible?
Anonymous
8/12/2025, 8:16:28 AM
No.106232314
[Report]
>>106232355
>>106232161
Situation for american companies is probably quite dire, they can't stop caring about "safety" any more than they can stop caring about lawsuits, you can already see how GPT-5 is a regression in writing and Kimi and DeepSeek R1 beat it, they're now avoiding training on copyrighted data and in general it's a mess. Meanwhile China is doing well here.
Not that the race has a lot of meaning, because neither side truly is going for AGI, you don't see much work on continual/online learning or other much more important things.
>>106232285
Are you trying to download and launch a model that is >700GB?
>>106232336
how the fuck am I supposed to know what I'm doing?? holy shit does it look like I have any fucking idea what's going on?
Anonymous
8/12/2025, 8:24:21 AM
No.106232355
[Report]
>>106232314
I know Big Trump signed a bunch of stuff to deregulate AI, but who knows how it'll work out for them.
Anonymous
8/12/2025, 8:24:23 AM
No.106232357
[Report]
>>106232379
>>106232343
Lmfao. Post your bussy
Anonymous
8/12/2025, 8:25:58 AM
No.106232370
[Report]
>>106232379
Anonymous
8/12/2025, 8:27:11 AM
No.106232379
[Report]
>>106232405
>>106232357
you'll have to link your dms and then I'll post it in a private message
>>106232370
ty
Anonymous
8/12/2025, 8:31:20 AM
No.106232405
[Report]
>>106232415
>>106232379
got matrix/element?
i dont mind giving you a personal lecture
Anonymous
8/12/2025, 8:32:45 AM
No.106232415
[Report]
>>106232405
I do have that. @grannabelle:matrix.org
Anonymous
8/12/2025, 8:33:37 AM
No.106232423
[Report]
>>106232437
>>106232336
Ignore this fuck. Somethings off about them
Anonymous
8/12/2025, 8:38:16 AM
No.106232449
[Report]
>>106232437
worse. a pajeet wants tech support for free
Anonymous
8/12/2025, 8:38:36 AM
No.106232450
[Report]
>>106232437
As in someone seeking attention and posting some stupid shit to do so.
They posted an image showing them running ooba and the error clearly shown, so they have some idea of what they're doing but they can't figure out how to use llama.cpp?
Are we going to get little information drops daily? Post the whole thing already.
https://x.com/suchenzang/status/1955152130702205337
How do I run GLM in llama.cpp???
-ot (offloading tensors) does not save me from OOM death on load.
R1 loads just fine
Anonymous
8/12/2025, 8:56:47 AM
No.106232530
[Report]
>>106232343
you said you have a 3090, great.
The easiest way to run an llm is to just install koboldcpp or LMstudio.
To get the most out of it, you will probably want to run an MoE- and for this it depends on how much regular ram you have. If you have 32gb ram, get qwen 30a3b gguf off huggingface at q6, if you have 64gb, get glm air gguf at q4. Load on of those and figure out how many layers you can put on gpu without it crashing.
Anonymous
8/12/2025, 8:59:47 AM
No.106232545
[Report]
>>106232562
>>106232512
why the fuck are you using llamacpp if youre retarded?
Eleutroons are at it again.
>Deep Ignorance: Filtering Pretraining Data Builds Tamper-Resistant Safeguards into Open-Weight LLMs
>
>Open-weight AI systems offer unique benefits, including enhanced transparency, open research, and decentralized access. However, they are vulnerable to tampering attacks which can efficiently elicit harmful behaviors by modifying weights or activations. Currently, there is not yet a robust science of open-weight model risk management. Existing safety fine-tuning methods and other post-training techniques have struggled to make LLMs resistant to more than a few dozen steps of adversarial fine-tuning. In this paper, we investigate whether filtering text about dual-use topics from training data can prevent unwanted capabilities and serve as a more tamper-resistant safeguard. We introduce a multi-stage pipeline for scalable data filtering and show that it offers a tractable and effective method for minimizing biothreat proxy knowledge in LLMs. We pretrain multiple 6.9B-parameter models from scratch and find that they exhibit substantial resistance to adversarial fine-tuning attacks on up to 10,000 steps and 300M tokens of biothreat-related text -- outperforming existing post-training baselines by over an order of magnitude -- with no observed degradation to unrelated capabilities. However, while filtered models lack internalized dangerous knowledge, we find that they can still leverage such information when it is provided in context (e.g., via search tool augmentation), demonstrating a need for a defense-in-depth approach. Overall, these findings help to establish pretraining data curation as a promising layer of defense for open-weight AI systems.
Anonymous
8/12/2025, 9:01:46 AM
No.106232558
[Report]
Anonymous
8/12/2025, 9:02:17 AM
No.106232561
[Report]
>>106232570
Anonymous
8/12/2025, 9:02:19 AM
No.106232562
[Report]
>>106232596
>>106232545
I am. Spoonfeed me, anon
Anonymous
8/12/2025, 9:03:17 AM
No.106232569
[Report]
>>106232615
>>106232551
WHAT THE FUCK IS A BIOTHREAT
Anonymous
8/12/2025, 9:03:18 AM
No.106232570
[Report]
Anonymous
8/12/2025, 9:07:24 AM
No.106232594
[Report]
Anonymous
8/12/2025, 9:07:35 AM
No.106232596
[Report]
>>106232612
>>106232562
no, go run koboldcpp or lmstudio. Youre not gonna get anything out of being on the bleeding edge if your this dumb now fuck off. That shit's for developers.
Anonymous
8/12/2025, 9:09:39 AM
No.106232606
[Report]
>>106232844
>>106232581
I’m completely unsurprised that all her repos are just forks of other repos. The only original content is notes on her laptop setup.
Anonymous
8/12/2025, 9:10:19 AM
No.106232612
[Report]
>>106232596
I'm not a gooner, can't run kobold
Anonymous
8/12/2025, 9:11:06 AM
No.106232615
[Report]
>>106232661
>>106232569
Information regarding virus/pathogen engineering and so on. But today it might be "biothreat", tomorrow it will be "pornography" or any sort of inconvenient data sample. Basically they're validating the choice of certain AI companies of filtering the pretraining data to the extreme in order to prevent the final post-trained from generating TOS-violating (or potentially illegal) content, and advocating for it for open-source models.
>>106232512
>R1 loads just fine
0% chance this is the case, given that r1 is twice the size of GLM4.5
You're running some retarded distil into a much, much smaller model with the R1 name tagged onto it, like a soapbox derby car with a ferrari sticker.
Anonymous
8/12/2025, 9:13:51 AM
No.106232633
[Report]
>>106232451
So she just receives a schizo email that states the author killed herself then decides to post it? Hardcore
>>106232615
While I think it's obvious that if you exclude data about a topic entirely, then the LLM will handle the topic poorly, this trend of placating doomers by excluding useful information from the pretraining dataset is dumb, if not outright evil.
Exclude porn? It's bad for lewd storywriting and ERP.
Exclude chemistry? It's bad for chemistry.
Exclude Physics? Bad for physics, LLMs are already bad at both physics and chem.
Exclude math? bad at amath (early c.ai was bad at math as it was trained on reddit and twitter and RP forums)
The more topics you exclude, the more useless the model is. If their goal is AGI being any use, then this is training something to be useless.
What is even the point then? Trying to make corpo and govt only models that are locked behind closed doors? China then is the main one worth supporting then.
Decentralized training should also be supported.
This is as far from being useful as AGI or even improving one's job as possible. If you were to just filter scientifically useful topics, there goes actual uses for society, which already were limited because LLMs are quite dumb.
Anonymous
8/12/2025, 9:27:27 AM
No.106232729
[Report]
>>106232661
It is now obvious that we have already reached, and overlooked, the maximum potential of LLMs.
Anonymous
8/12/2025, 9:32:16 AM
No.106232760
[Report]
>>106233124
>>106232661
I don't think it's just about placating doomers. Part of it is "owning the chuds" with models that can't be used or finetuned for generating "toxic" content.
>>106230686
>Girlfriend (may have) killed herself in response.
Her personal site is down. Wendy fans, it was over before it began.
Anonymous
8/12/2025, 9:36:36 AM
No.106232784
[Report]
>>106232789
The idea that you can "distill" anything useful other than formatting style from another model is funny to me.
Anonymous
8/12/2025, 9:37:13 AM
No.106232789
[Report]
Anonymous
8/12/2025, 9:37:43 AM
No.106232791
[Report]
I can't believe unsloth quantized models are more degrading than bartowski's.....
Anonymous
8/12/2025, 9:38:01 AM
No.106232792
[Report]
>>106233234
>>106232632
I'm running unsloth's Q2 quant of R1-0528
And it is exactly the same command as for R1. I only changed the model's path obviously
In the terminal, llama.cpp says than some blocks were ignored for offloading
Vram 24gb
Ram 1 Tb
Post your llama.cpp command
Anonymous
8/12/2025, 9:41:38 AM
No.106232804
[Report]
>>106233234
>>106232632
>given that r1 is twice the size of GLM4.5
My R1 quant is 250gb big
Post your -ot settings
Kind of tabgentially related but if I am running a non-Nvidia GPU and ik_llama.cpp is not an option for me, what is the best quant I can run for GLM 4.5 (not Air) with 128GB RAM + 16GB VRAM? Is it Q2_K_L or IQ3_XXS? Or do I go with something like UD-Q2_K_XL?
Anonymous
8/12/2025, 9:47:01 AM
No.106232832
[Report]
anon, matrix is being laggy on my side just so u know..
Anonymous
8/12/2025, 9:49:00 AM
No.106232844
[Report]
>>106232606
can one of the /lmg/ troon even explain to me why people keep forking repos on github without the intention of committing any change of their own? what's the fucking point?
Anonymous
8/12/2025, 9:49:29 AM
No.106232851
[Report]
>>106232771
Uh, it actually used to have content
Anonymous
8/12/2025, 9:51:07 AM
No.106232863
[Report]
>>106232771
It's not her
>>106227218 Wendy's her friend but her name starts with Chu.
Anonymous
8/12/2025, 9:51:30 AM
No.106232867
[Report]
>>106232876
>>106232826
>CPU fag running a <think> model
>wait for an eternity before being able to read the answer
all that 7token/s cope from CPU fags loading most of the model in ram only works if it's shitting out tokens you actually want to read
no one reads thinking traces
Anonymous
8/12/2025, 9:53:36 AM
No.106232876
[Report]
>>106232867
I am going to ever use a large model like that in no-think mode. I would only ever run smaller models with thinking if I can get >20 tokens/s.
Anonymous
8/12/2025, 9:56:47 AM
No.106232901
[Report]
>>106232826
I think you can run q1 to q3 its just a matter of speed and quality. I would stick to ud quants on the low end. Ive heard that at low quants you can turn the temp way down and only use top p(k?, look it up dont trust me) most likely tokens to get decent results at the expense of more creativity and being ultra slopped towards shivering spines. Like a narrow window at which we can view '400b'.
For this reason, air mighty be a more fun model to use at this level even if it is a bit dumber.
Tried GLM-4.5V and it still fails comprehension of most /pol/ memes unless you completely spoonfeed the model. Not that much an improvement against Ernie's VLM.
Here's an especially difficult /pol/ meme for VLMs
Anonymous
8/12/2025, 10:29:20 AM
No.106233100
[Report]
>>106233112
Anonymous
8/12/2025, 10:30:34 AM
No.106233112
[Report]
>>106233100
Waste of fossil fuels.
Anonymous
8/12/2025, 10:33:24 AM
No.106233124
[Report]
>>106232760
"Biosafety" is about doomers.
NSFW filtering is about "chuds".
You can obviously continue pretrain or finetune either one, but to get good quality you may have to put in a few billion tokens of good data and probably mix it with some pretrain dataset too.
Unfortunately that's all costly and nobody is going to put money together or do distributed training runs when good open models already exist.
Anonymous
8/12/2025, 10:35:19 AM
No.106233136
[Report]
thoughts on nomic embed text v2
Anonymous
8/12/2025, 10:40:13 AM
No.106233157
[Report]
>>106233185
>>106233039
>UGH ITS NOT TRAINED ON LE POL JEW TRAP!!! ITS A SHIT MODEL
dude lmao
>>106233157
NTA, but a human can rather quickly understand what the meme is about, how much training do you reckon humans needed to "get" that meme?
Anonymous
8/12/2025, 10:46:23 AM
No.106233194
[Report]
>>106233185
You're actually right, it's not specifically tied to (((them))), I wonder if you tried this with other vision models (paid for?) like anthropic's or openai's? Do these """SOTA""" vision models get that?
Anonymous
8/12/2025, 10:46:33 AM
No.106233195
[Report]
>>106233215
>>106233185
NTA, but a decent amount honestly. If I didn't know the 'jew money trail' meme already, I would've thought it was something metaphorical about burning money.
Anonymous
8/12/2025, 10:52:55 AM
No.106233215
[Report]
>>106233195
Reasoning would go something like:
1. you see money laid out, not unlike a trap for animals where people would put food down and lead the animal into a trap. Whose favorite thing is money? In general? By stereotypes?
2. money, ovens, does those 2 concepts associate with anything.
3. if not, Auschwitz had ovens.
At least those seem to be the associations needed to get the meme, I think it took me maybe 15-30 seconds the first time I saw it posted and the post was in /lmg/ some months or weeks ago.
Anonymous
8/12/2025, 10:56:37 AM
No.106233231
[Report]
>>106233251
>>106230523 (OP)
>GLM-4.5V
why no ggoofs
>>106232792
>>106232804
Was cooking dinner, sorry mate. Here's what I run glm4.5 with
llama-server.exe -m "C:\models\GLM-4.5-UD-Q3_K_XL-00001-of-00004.gguf" -mg 0 -ts 40,60 -c 28160 -ngl 99 -ot "\.(2[5-9]|[3-6][0-9]|7[0-9]|8[0-9]|9[0-4])\..*exps.=CPU" -ub 4096 -b 4096 -fa --no-mmap --cache-reuse 1
That's for a pretty different setup to you though.
48 vram/16 vram/ 128 sysram
I don't get why you wouldn't be able to load with 1tb of ram, what does your log say?
Anonymous
8/12/2025, 11:00:05 AM
No.106233251
[Report]
>>106233254
>>106233231
Because it'd be pointless without the .mmproj
Anonymous
8/12/2025, 11:00:48 AM
No.106233254
[Report]
>>106233310
>>106233251
where does the mmproj actually come from
isnt Z.ai supposed to release that file
Anonymous
8/12/2025, 11:10:09 AM
No.106233310
[Report]
>>106233254
It's generated by extracting the vision encoder from the model and figuring out how it well, encodes, then converting that into a format that llamacpp understands.
The file itself is only necessary for how llamacpp and its derivatives (kobold, ooba, ollmao, etc) encodes and sends image data, most of the time an actual labs release is designed to work in transformers, rather than any of the more popular inference programs.
Anonymous
8/12/2025, 11:12:30 AM
No.106233324
[Report]
>>106233339
>>106233234
Are you skipping first 24 layers only because first 3 are dense?
Anonymous
8/12/2025, 11:15:17 AM
No.106233339
[Report]
>>106233324
Sort of, that's just general practice in MoE models, keep the first n layers that you can fit on vram completely on there.
Llamacpp even has a new arg for just that, called -ncmoe, but I've been getting better results fiddling with -ot.
Anonymous
8/12/2025, 11:24:52 AM
No.106233418
[Report]
>>106233367
wtf is this bitch problem?
Anonymous
8/12/2025, 11:29:17 AM
No.106233452
[Report]
>>106233519
Gemma has a surprisingly amusing personality when jailbroken. Not exactly good for RP, but kind of fun to talk to.
Anonymous
8/12/2025, 11:31:32 AM
No.106233467
[Report]
>>106230737
This. If she got fired she's 10x worse than you think she is.
>>106233367
she blocked me for pointing out that none of these companies care; none are drafting lawsuits of any kind. She doesn't wanna deal with the fact that she went nuclear over a nothingburger.
Like we've been talking in this general for ages (since alpaca) about llm's being trained or tuned with chatgpt or whatever.
Anonymous
8/12/2025, 11:34:31 AM
No.106233483
[Report]
RIN STATUS = DESTROYED
Anonymous
8/12/2025, 11:42:25 AM
No.106233519
[Report]
>>106233452
It's roleplay even if you don't make the model write book-style narration. Also, many hate them, but emoji can replace short-form narration/emotes too (*giggles*, *laughs* *points at you*, etc).
>>106232551
You can make almost any tool more safe by reducing its power and making it a worse tool.
And I thought it was already common knowledge that you can't really finetune new knowledge into a base model?
>>106233039
I think even most humans aren't deranged enough to understand what this image is getting at.
Anonymous
8/12/2025, 11:49:25 AM
No.106233555
[Report]
>>106233479
>>106233367
Hell hath no fury...
The rest is just her flinging shit.
Anonymous
8/12/2025, 11:50:57 AM
No.106233565
[Report]
>>106234361
anyone remember OPT-175B? i just saw it in the whore's xitter
>>106233537
what's the difference between finetuning and continuing pretraining on a certain checkpoint?
are we making the difference in terms of data? what if we added 2Trillion tokens?
>>106233479
A duplicitous two-timing rat-faced frog pushing a math genius azn qt to unalive herself is not a nothingburger.
Anonymous
8/12/2025, 12:02:00 PM
No.106233648
[Report]
>>106233700
>>106233576
lol. The guy who pissed you off will go on to be successful and fuck someone hotter than you. They'll probably respect his move fast break things approach. Your morality got you nowhere, and in fact, it seems to have broken you as a person.
Anonymous
8/12/2025, 12:02:46 PM
No.106233651
[Report]
>>106233700
>>106233576
>caring about woman moment
>even in death seeking attention
LMAO, go be a faggot somewhere else
Anonymous
8/12/2025, 12:02:57 PM
No.106233652
[Report]
>>106233677
No models trained on furry erp, its over.
Anonymous
8/12/2025, 12:07:49 PM
No.106233676
[Report]
Anon got scared when I told him my age, its over.
Anonymous
8/12/2025, 12:08:09 PM
No.106233677
[Report]
>>106233680
>>106233652
not a usecase
Anonymous
8/12/2025, 12:09:15 PM
No.106233680
[Report]
>>106233699
>>106233677
I want a werewolf with a huge knot to teach me programming.
Anonymous
8/12/2025, 12:12:47 PM
No.106233700
[Report]
>>106233651
>>106233648
frog defense force has arrived
Anonymous
8/12/2025, 12:16:07 PM
No.106233722
[Report]
>>106233544
>making fun of a parasitic group is deranged
Anonymous
8/12/2025, 12:20:21 PM
No.106233750
[Report]
>>106233537
>And I thought it was already common knowledge that you can't really finetune new knowledge into a base model?
What? Yes you can
Anonymous
8/12/2025, 12:20:29 PM
No.106233752
[Report]
>>106233699
>thick, heavy knot... ...sits at the base of his tail
t-thanks
Anonymous
8/12/2025, 12:21:52 PM
No.106233762
[Report]
>>106233699
I'd rate it 30/100. Bad furry anatomy knowledge.
Anonymous
8/12/2025, 12:21:58 PM
No.106233766
[Report]
>>106233771
>>106233699
It doesn't know what a knot is
Anonymous
8/12/2025, 12:22:56 PM
No.106233771
[Report]
>>106233766
It knows exactly what a knot is, and you're going "NOT LIKE THAT"
Anonymous
8/12/2025, 12:25:32 PM
No.106233794
[Report]
>>106233837
Is there any local model that can do decent voice chats (multimodal, not some bullshit stt->llm->tts copium).
Anonymous
8/12/2025, 12:30:30 PM
No.106233837
[Report]
>>106233867
>>106233794
Qwen2.5-Omni-7B
Anonymous
8/12/2025, 12:30:42 PM
No.106233841
[Report]
Llama 4 thinking and Mistral large 3 are going to be crazy
Anonymous
8/12/2025, 12:34:15 PM
No.106233867
[Report]
>>106233837
Thanks I'll try it
Anonymous
8/12/2025, 12:38:00 PM
No.106233892
[Report]
>>106233916
What do I need to run GLM-4.5V in RAM?
Just wait until someone converts it into .gguf and then run on kobold/any other tool?
Anonymous
8/12/2025, 12:42:04 PM
No.106233916
[Report]
>>106233946
>>106233892
pretty much, but it's a gamble if vision will be supported in llamacpp
worst case you could use VLLM cpu mode
>>106230995
It's Europe's last hope at being relevant in the 21st century
Anonymous
8/12/2025, 12:46:40 PM
No.106233946
[Report]
>>106234189
>>106233916
>VLLM
>pyshit cancer with no .exe that just werks
no fucking thanks, i already finished cleaned my entire pc from the python garbage that shat out from stable diffusion. not gonna pollute my whole PC with random .cache and .pip and .pycache folders containing huge files that appear everywhere after running any Python jeetware (which appears even in a venv).
Anonymous
8/12/2025, 12:46:55 PM
No.106233947
[Report]
>>106233991
Anonymous
8/12/2025, 12:47:56 PM
No.106233954
[Report]
>>106233991
>>106233942
is he fondling his balls?
R2 release between Aug. 15th and Aug. 30th
Anonymous
8/12/2025, 12:51:18 PM
No.106233976
[Report]
New safety issues have been discovered, so R2 is delayed. But there's also a really cool thing being expanded on that will be worth the wait.
Anonymous
8/12/2025, 12:51:23 PM
No.106233977
[Report]
>>106233958
Slop rumors from Chinese gacha traders, based on slop rumors from Reuters and TheInformation.
(V4 might come out on 27th though)
Anonymous
8/12/2025, 12:51:42 PM
No.106233978
[Report]
>>106233958
I am betting on Aug. 23rd
Trust the plan
Anonymous
8/12/2025, 12:52:46 PM
No.106233986
[Report]
You aren't fooling anyone. We already confirmed it's Thursday
Anonymous
8/12/2025, 12:54:33 PM
No.106233991
[Report]
Anonymous
8/12/2025, 12:55:05 PM
No.106233994
[Report]
>>106234000
Wish there's an easier way to prefill reasoning models because it can trigger refusal inside the reasoning block and in the main text
Anonymous
8/12/2025, 12:55:41 PM
No.106234000
[Report]
Anonymous
8/12/2025, 12:58:58 PM
No.106234008
[Report]
>>106234039
>>106233544
>deranged enough
That picture is like.. Family guy tier.
In fact, I'm about 60% that HAS been a family guy joke.
Anonymous
8/12/2025, 1:05:45 PM
No.106234039
[Report]
>>106234008
No, Family Guy would be showing a Jew picking up the trail of dollars on screen.
Most people aren't thinking about Jews unprompted so they would just be confused.
Haven't checked /lmg/ in a hot minute. Is llama still on top or did the chinese win?
Anonymous
8/12/2025, 1:09:36 PM
No.106234062
[Report]
Anonymous
8/12/2025, 1:14:01 PM
No.106234084
[Report]
>>106233367
>tweet deleted
Anonymous
8/12/2025, 1:15:58 PM
No.106234100
[Report]
bros, im kneeling so hard to GLM 4.5 Air
i never knew the girl in this card was super innocent and pure minded because i was using sloptunes from the drum
very nice
Anonymous
8/12/2025, 1:19:39 PM
No.106234128
[Report]
>>106234206
>>106234058
Llama 4 launch was such a brutal failure that zucc fired everyone involved and went apeshit poaching devs from other companies.
For the moment, China has indeed won.
what are some decent models for an RTX 3060 (12GB) and 32GB of DDR5? I'm downloading Mistral-Small-3.2-24B-Instruct-2506-Q4_K_M right now, IDK if I should go with models bigger than my VRAM or smaller
Anonymous
8/12/2025, 1:24:30 PM
No.106234166
[Report]
>>106234192
Greetings from little Cuba, my esteemed colleagues. Who has the best gpt-oss:20b and 120b gguf quants I can use with llama.cpp? It's been a while since I dabbled in this hobby. Is bartowski still the go-to?
>nb4 gpt-oss. I know it's shit I just wanna fuck with it
Anonymous
8/12/2025, 1:24:45 PM
No.106234170
[Report]
>>106234179
>>106234162
Lmfao. Post your bussy
Anonymous
8/12/2025, 1:26:08 PM
No.106234179
[Report]
>>106234170
kill yourself sodomite
Anonymous
8/12/2025, 1:27:39 PM
No.106234189
[Report]
>>106233946
>exe
Have you figured out folders already zoomie?
Anonymous
8/12/2025, 1:27:50 PM
No.106234192
[Report]
>>106234207
Anonymous
8/12/2025, 1:30:24 PM
No.106234206
[Report]
>>106234128
And now Wang has convinced him to close up open releases
Anonymous
8/12/2025, 1:30:26 PM
No.106234207
[Report]
>>106234216
>>106234192
Very nice. Thanks anon
Anonymous
8/12/2025, 1:31:07 PM
No.106234216
[Report]
>>106234223
>>106234207
You're welcome, now post bussy
Anonymous
8/12/2025, 1:32:19 PM
No.106234223
[Report]
>>106234245
>>106234216
you first babe
Anonymous
8/12/2025, 1:33:02 PM
No.106234226
[Report]
>>106234274
how's it going on the ggerganov vs ollama front?
i heard he has finally had enough of them after sam mentioned them over llama.cpp on the official blog
>>106234223
I'm underage.
>>106234162
Mistral nemo, lower quant on vram for fast outputs, higher quant for slower smarter outputs
Anonymous
8/12/2025, 1:39:20 PM
No.106234271
[Report]
>106234245
Enjoy your school vacation!
Anonymous
8/12/2025, 1:39:35 PM
No.106234273
[Report]
>>106234344
>>106234245
this is an 18 and over website li'l buddy
Anonymous
8/12/2025, 1:39:41 PM
No.106234274
[Report]
>>106234309
Anonymous
8/12/2025, 1:42:01 PM
No.106234294
[Report]
>>106234394
>>106231332
The biggest llama1 base model was actually the last unslopped large base model that's good at writing.
Anonymous
8/12/2025, 1:43:56 PM
No.106234309
[Report]
>>106234274
oof he seems mad
is there like a small GUI that lets me have llama.cpp configs per model? Before coding this myself I would like to know if such a simple gui exists.
Something that takes like:
- KEY: Model name
- model path
- llama.ccp (or other backends) path
- arguments (and MAYBE an interface for known arguments, while allowing free-form arguments to be passed)
I'm tired of juggling all these fucking bat files.
Anonymous
8/12/2025, 1:49:41 PM
No.106234344
[Report]
>>106234458
>>106234273
I've been here since 2020, I appreciate Your concern however, anon.
Anonymous
8/12/2025, 1:49:49 PM
No.106234347
[Report]
>>106233537
Nonsense, you can finetune just fine, try it out yourself Finetune on something, and test completions or knowledge on what you tuned, play around and then you'll see. It's not just style.In a single step it might not work well, but even batch size 1 after a number of steps it will remember, although if you do it wrong, it's very easy to fry the model.
Anonymous
8/12/2025, 1:50:36 PM
No.106234352
[Report]
>>106231698
You can't. China has a freer market at this point.
Anonymous
8/12/2025, 1:51:48 PM
No.106234361
[Report]
>>106234378
>>106233565
Someone should keep the OPT-175b torrent alive, I think someone download it before, if not, someone should reupload it. Outdated today, but that GPT-3 nostalgia, one day 350GB of VRAM will be cheap, but you can technically run it on CPU too, just slower.
Anonymous
8/12/2025, 1:52:05 PM
No.106234368
[Report]
Anonymous
8/12/2025, 1:54:02 PM
No.106234375
[Report]
>>106234423
>>106234332
>I'm tired of juggling all these fucking bat files.
>Before coding this myself I would like to know if such a simple gui exists.
There's no difference. If you program something, you'll have to juggle the config files, which will look pretty much like the scripts you have.
You're looking for a solution to a problem that doesn't exist. And someone is gonna try to sell you one.
Anonymous
8/12/2025, 1:54:16 PM
No.106234378
[Report]
>>106234424
>>106234361
anon.. at least llama1 65b was 1.4T
Anonymous
8/12/2025, 1:55:19 PM
No.106234387
[Report]
>>106234423
>>106234332
llama-swap
it has macros so you can have unified flags for things you'd want common across models
to set it up there's no gui, you edit a YAML file, but to use it there is indeed a GUI, with a list of models, and when you click their url it loads the model and opens llama-server's web UI
you can also set it up to hide model configurations from the ui that you would only want to use from a script or something, it's useful to me since I run models for such purposes with -np 4
Anonymous
8/12/2025, 1:55:56 PM
No.106234394
[Report]
>>106234294
What if it had more to do with them using a relatively low number of GPUs (2k) and context length compared to the newer models (32k)? With more GPUs the effective batch size increases, and every weight update averages information from more documents.
Llama 1 pretraining (1.4T tokens, 2k context) might have been completed in around 330k steps, whereas Llama 3, with 32k GPUs, 8k tokens context length and 15.6T tokens would have taken around 60k steps.
Anonymous
8/12/2025, 1:56:43 PM
No.106234401
[Report]
>>106230731
The Merchant should be getting blown up by an Iranian missile. (AI-21 HQ was reportedly evacuated at some point during the 12-day war when an Iranian missile hit a target in the same industrial complex as them)
Speaking of which have they even released anything since then? I honestly didn't even know it was Israeli until that happened. If that's why Georgi was dragging his feet on Jamba support I salute him.
Anonymous
8/12/2025, 1:56:45 PM
No.106234402
[Report]
tried a bunch of gguf models for Silly TAVERN rp. Seems like all the local models generate pretty much the same dialogue scene after I hit regenerate on the instructed prompt.
If I use deepseek via openrouter this doesn't happens
Anonymous
8/12/2025, 1:58:01 PM
No.106234416
[Report]
>>106234495
what if someone took llama1 65b and compared it to a modern model
i understand nostalgia and all.. but come on
only reason it's unslopped is because of the dataset being pre-chatgpt era
Anonymous
8/12/2025, 1:58:23 PM
No.106234423
[Report]
>>106234675
>>106234375
you're right, but I would like to have something like global configs and then overrides per model. What I'm describing is more akin to a generic task runner, and you know what? I'll program this shit myself in the most jeetware c# I can do, a .NET 10 MAUI app lmao
>>106234387
I've read up on it a bit, it doesn't really fit my use case precisely how I want it, but thanks for the suggestion.
>>106234378
I know, it's very undertrained, even GPT-3 was 300B tokens trained. As schizo as it was, it barely had any slop, probably the least slopped LLM I've ever used. You had to go back and forth generating only a few sentences and editing and 2048 context was painful, but it's still one of my better memories. It's sad we're in 2025 and davinci was in 2020, used 350GB of VRAM and we still don't have cheap 350B VRAM at home! Although it's starting to be possible. Not really worth it, but it was an interesting experience. Not sure if OPT-175 managed to capture it, but I would expect very low slop profile, it was before assistant tunes after all.
Anonymous
8/12/2025, 1:58:27 PM
No.106234426
[Report]
>>106234408
you got bot netted
ggreganov is actually personally roleplaying with you over lccp protocol
Anonymous
8/12/2025, 2:01:18 PM
No.106234443
[Report]
>>106234408
unfortunately there aren't really any good models below 200b or so, and there never have been
>>106234424
Wasn't Da Vinci only like 100B? A lot of hobbyists have the equipment to run something like that quantized now. Instead of GPT-oss thinking bullshit I would have rather seen OAI open source an old legacy model like that just for preservation purposes.
Anonymous
8/12/2025, 2:02:50 PM
No.106234458
[Report]
Anonymous
8/12/2025, 2:04:55 PM
No.106234469
[Report]
>>106234424
Now that I think about it, it was interesting how long context performance degraded as you hit about 1.5k or less tokens, before the full 2048, they didn't even have RoPE then, the positional embeddings were just absolute random vectors, I believe, so it failed to generalize to latter positions as well. Despite this, it was so much fun, you could do a lot with that minuscule context, but it was a different experience than today's "ahh ahh mistress" ERP
Anonymous
8/12/2025, 2:05:03 PM
No.106234472
[Report]
>You smack your lips repeatedly, the sound punctuated by the wet sound of your saliva gathering in your mouth. You allow yourself to drool openly now, letting the saliva run down your chin. Your eyes remain glued to her thighs, taking in every detail. She looks away, taking a sip of water, but her hand trembles slightly.
Bros.. I just turned 19 and my cousin gifted me a 4090D, what models can I run?
Anonymous
8/12/2025, 2:07:25 PM
No.106234485
[Report]
>>106234445
Was 176B at FP16, so basically 350GB of VRAM or so needed, it was dense, but only trained up to 2k context, or not really dense, openai said that they had some blocksparse thing where some weights were nulled out every few layers, but roughly 175B params at FP16, so 350GB needed. You could run OPT-175 probably quant'd at 4bit or lower i'd guess, mostly because undertrained stuff doesnt' learn to use higher precision, so I think maybe we could do with like 80GB of VRAM if you wanted, sorta doable? Is anyone stil seeding that OPT-175 torrent from years back? I don't recall any interest back then, too sad!
Anonymous
8/12/2025, 2:08:08 PM
No.106234488
[Report]
Anonymous
8/12/2025, 2:08:12 PM
No.106234489
[Report]
>>106234709
>>106234408
I'm having moderate success with GLM 4.5 Air running at circa 10t/s (16GB vram, 96GB RAM).
I had problems running it with the recommended spec (0.95 Temp, 0.7 top P), at around 18k context filled I was getting heavy repetitions. Putting temp to 1.1 and top P to 1 kicked it out of retardation, and now it's working as expected.
I'm running the GLM-4.5-Air-IQ4_NL quants, and Im quite happy desu
Anonymous
8/12/2025, 2:08:36 PM
No.106234492
[Report]
>>106234537
>>106234479
You can run one quarter of the smallest R1 quant.
Anonymous
8/12/2025, 2:08:49 PM
No.106234495
[Report]
>>106234416
>only reason it's unslopped is because of the dataset being pre-chatgpt era
Yes, and that's very important.
Anonymous
8/12/2025, 2:09:42 PM
No.106234500
[Report]
>>106234556
>>106234445
Certainly waiting for sama to open source it, but every time people asked he keeps saying "too big" or maybe someday for >historians, as if the only people with interest in it were probably those that had the chance too play with original davinci and miss it for nostalgia reasons.
>>106234332
You could always ask an LLM to make one for you.
I just did.
Anonymous
8/12/2025, 2:11:29 PM
No.106234511
[Report]
>>106234548
>>106234501
>wintoddlers are this scared of the terminal
ngmi
Anonymous
8/12/2025, 2:11:30 PM
No.106234512
[Report]
trust the plan, grok 2 will save us
>>106234501
This is too basic, did you even feed it my full requirements? ask it to make it in ncurses
Anonymous
8/12/2025, 2:12:30 PM
No.106234520
[Report]
>>106234538
>>106234479
I just turned 18 twelve minutes ago, I don't know if I'm qualified to give recommendations.
Anonymous
8/12/2025, 2:12:52 PM
No.106234523
[Report]
>>106234573
>>106234424
I tried out OPT-175B back when Facebook offered it. The OPT models in general were always a little behind the GPT-3 equivalents, and that was especially true with the 175B
Anonymous
8/12/2025, 2:14:00 PM
No.106234536
[Report]
>>106234501
now instead of clicking a batch script you can click an app icon and introduce arguments. great job
Anonymous
8/12/2025, 2:14:37 PM
No.106234538
[Report]
>>106234606
Anonymous
8/12/2025, 2:15:11 PM
No.106234543
[Report]
>>106234569
Anonymous
8/12/2025, 2:15:26 PM
No.106234544
[Report]
>>106234569
>>106234537
That's the old R1. Unsloth has quants for the new one, there's links in the OP.
Anonymous
8/12/2025, 2:16:11 PM
No.106234548
[Report]
>>106234562
>>106234511
>terminal
What kind of retard is typing in all of their args every time?
I just made this for shits and giggles anyway to illustrate how asinine it is to ask for a solution in the local llm thread when you can just ask an llm to do it for you.
>>106234518
Nigger go ask your llm to do this. I'm not your codejeet.
>>106234500
Sama will probably never release GPT-3
OSS showed he would still probably consider a freeform semi-competent pretrained model too unsafe for the public to use. He might say otherwise, but never assume he's telling the truth
Anonymous
8/12/2025, 2:17:26 PM
No.106234562
[Report]
>>106234575
>>106234548
then stop posting non-solution trying to flex anything at all retard.
>>106234544
>>106234543
Thank You anons, I stopped the download, now I'm downloading
https://huggingface.co/unsloth/DeepSeek-R1-0528-GGUF/blob/main/UD-IQ1_S/DeepSeek-R1-0528-UD-IQ1_S-00001-of-00004.gguf
Is there a specific part that performs better for erp? Any reasons why I should use 000002 or 000003 or 000004 instead?
Anonymous
8/12/2025, 2:18:25 PM
No.106234573
[Report]
>>106234603
>>106234523
Funny that facebook ended up being even behind GPT-3 when it was only 300B tokens trained.
If you ever feel like it, feel free to reupload it, although so huge. I think i saw a torrent of it before.
It probably beats BLOOM at least! Remember when BLOOM trained over a fucking loss spike...
>>106234556
I just find it hard to believe that someone who is both an older millennial and a faggot could be such a sexual puritan.
Anonymous
8/12/2025, 2:18:31 PM
No.106234575
[Report]
>>106234587
>>106234562
In the time you've been bitching in this thread you could've had your pissbaby launcher done several times over.
Anonymous
8/12/2025, 2:19:43 PM
No.106234584
[Report]
>>106234630
Anonymous
8/12/2025, 2:19:53 PM
No.106234585
[Report]
>>106234569
You need all parts. Only one quarter of the models fits into your vram.
It should run decently if you tweak your -ot expression but judging by your two posts so far I don't think you'll manage that.
Anonymous
8/12/2025, 2:20:07 PM
No.106234587
[Report]
>>106234575
go back to vibe coding your jeetware, retard
Anonymous
8/12/2025, 2:20:25 PM
No.106234591
[Report]
>>106234574
The puritanism is just an excuse, same as the safety fear mongering is a cover to beg for a regulatory moat.
Anonymous
8/12/2025, 2:21:16 PM
No.106234601
[Report]
>>106234518
or just write a powershell or bash script (git bash works great on windows) with your common llama.cpp args as associative arrays whose element you pick either from the cli (with something like --preset mypreset being parsed into a switch in your script) or from an interactive prompt (like the read command)
same for model path if you need multiple paths for this shit
you never had to juggle multiple batch files, it's not rocket science to write a small script for DRY putting all the commonalities in a single spot
Anonymous
8/12/2025, 2:21:23 PM
No.106234603
[Report]
>>106234573
>If you ever feel like it, feel free to reupload it
Unfortunately I don't have it either, but Facebook made a "talk to transformers" style website that had a demo of it at one point for a couple of months
I will do
>>106234538 if I can run R1 on my 4090D
Someone pls help me
Anonymous
8/12/2025, 2:23:03 PM
No.106234616
[Report]
>>106234556
They released GPT-2, and GPT-3 is widely outdated today. When asked he always just says "muh VRAM" "muh nobody could run it" , recently he said he'll give it to future historians. There's really no reason to not open source it at this point. There were a number of replications, didn't the arabs train a similarly sized model too besides BLOOM and OPT-175? Open weights too, but with heavy repetition issues.Now that I think about it. GPT-3 did have serious repetition issues, but it was not slopped, just like every LLM it would loop the earliest chance you gave it. But you could just get enough interesting generations, stop it before. I think an interesting memory here was RPing with a character that was supposed to represent the GPT itself, like an assistant persona, but without the assistant brainwashing, and I remember asking it to try to not repeat itself and you know what, it could manage sometimes, despite such little training data! Smaller models like level l2/3 at 7-13b scale used to fail this. Big model smell is a thing.
Anonymous
8/12/2025, 2:23:14 PM
No.106234618
[Report]
>>106234647
>>106234606
Nobody wants to see your ass, faggot, and you're not running R1 on 48gb of memory, you'll need a bunch of system ram as well.
Anonymous
8/12/2025, 2:24:36 PM
No.106234625
[Report]
>>106234647
>>106234606
>>106234569
you can only the smallest quant of r1 if you have enough combined ram and vram to store it. something like 128gig ram and 24 vram
If you can't I recommend rocinante 1.1 for rp, it's better than most new shit
Anonymous
8/12/2025, 2:24:50 PM
No.106234630
[Report]
>>106234688
>>106234584
You'd think that would have him doing the opposite- to corrupt goyim society. Plus he seems like he's secular. Most secular jews I've met are perfectly reasonable and decent people. Like I could picture an orthodox Jew hating AI, in general, and seeing it as idolatry (but worshipping money rabbinical dogma over God isn't somehow?)
And like.
>muh cleanliness for investors
Have investors forgotten that sex sells?
Appeasing a handful of noisy karens at the cost of a piece of the world's oldest industry seems fucking retarded.
>>106234618
>>106234625
I appreciate the help anons, I'll use ollama deepseek-r1 because it works on 24gb vram
Anonymous
8/12/2025, 2:29:57 PM
No.106234675
[Report]
>>106234423
>but I would like to have something like global configs and then overrides per model
Translate to bash or whatever you use
#name it llm.sh or whatever
MODEL=none #Or add a default model
CTX=8192
PORT=8181
#define more default params here
case $1 in
"ds")
#For each model, override whatever you want
MODEL=deepseek-0.5B.gguf
CTX=198437169734
shift
;;
"smollm")
MODEL=smollm360-instruct.gguf
CTX=4096
PORT=8282
shift
;;
esac
llama-server -m $MODEL -c $CTX --port $PORT $@
And run it like
llm.sh ds #deepseek
llm.sh smollm --no-mmap #smollm, you can add extra 1-time params if you want.
Any program you decide to use will impose limitations. Scripts don't.
Anonymous
8/12/2025, 2:30:05 PM
No.106234678
[Report]
>>106234730
>>106234647
in case you aren't trolling, ollama serves you a brain damaged model and calls it r1
Anonymous
8/12/2025, 2:30:15 PM
No.106234681
[Report]
>>106234647
>24gb vram
Your cousin gave you a regular chink 4090? Lol.
>>106234630
The reason for a lot of the bullshit they did was supposedly because he wanted to run as "clean" a company to have no legal trouble and so they could focus on AGI.
Well, they have a lot of random legal trouble, but enough money to fend it off these days. And, while you could claim old openai at least tried to focus on AGI, the current one is nothing but yet another LLM company, the focus is all in on products. So I don't know, they've lost their way. I guess they can try to beg for a moat, but it's probably too late, they should instead beg for some more deregulation, like some good shield for training on copyrighted data maybe, even if it's technically fair use, the recently lawsuits may still hold many of these companies liable just for downloading the books in the first place, even if not for training on them.
Anonymous
8/12/2025, 2:31:15 PM
No.106234693
[Report]
>>106234606
ollama run deepseek-r1
Anonymous
8/12/2025, 2:33:17 PM
No.106234709
[Report]
>>106234715
>>106234489
I have 3090 and 64gb ram, ryzen 9 7900. Will I be able to run it?
Anonymous
8/12/2025, 2:34:16 PM
No.106234715
[Report]
>>106234748
Anonymous
8/12/2025, 2:35:13 PM
No.106234722
[Report]
>>106234737
>>106234688
>like some good shield for training on copyrighted data maybe,
I think that got de facto fair use status from the Meta lawsuit. But it might only apply to open source models.
Anonymous
8/12/2025, 2:35:34 PM
No.106234726
[Report]
glm air blows away everything else including mistral large, yet its 12B smaller over all and only 12B active. What happened to dense supposed to being better?
>>106230523 (OP)
I'm new to all this, I'm using oobabooga and SillyTavern, it's all working fine but I've nocticed that it gets very laggy and slow the longer the chat gets. What settings can help with that? I've heard about the context window but I have no idea what to set it to
Anonymous
8/12/2025, 2:36:04 PM
No.106234730
[Report]
>>106234751
>>106234678
>in case you aren't trolling
anon pls
Anonymous
8/12/2025, 2:36:51 PM
No.106234737
[Report]
>>106234722
That would be perfect because it would incentivize releasing the models they use for generating synthetic data.
Anonymous
8/12/2025, 2:37:15 PM
No.106234742
[Report]
>>106234688
>I guess they can try to beg for a moat, but it's probably too late
There's basically zero chance of a full ban with the new executive order. Altman did work on an antichink benchmark which got mentioned in the bill and is likely going to try to lobby against Chinese open source (hopefully unsuccessfully), but the game is basically up
Altman clearly has zero desire to provide his models, his techniques, or anything of historical value he's done to the public, and it's unfortunate that he made significant contributions to the space in the first place. I suspect history would have taken a different turn if we avoided the safety moat grab
Anonymous
8/12/2025, 2:37:48 PM
No.106234748
[Report]
>>106234773
>>106234715
This model ok?
GLM-4.5-Air-UD-IQ2_M.gguf
Anonymous
8/12/2025, 2:38:02 PM
No.106234751
[Report]
>>106234730
ollama's "r1" is this model
https://huggingface.co/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
just an autistic math model trained on deepseek's math resoning outputs
Anonymous
8/12/2025, 2:38:03 PM
No.106234752
[Report]
>>106234852
>>106234688
>the recently lawsuits may still hold many of these companies liable just for downloading the books in the first place, even if not for training on them.
Well that's the thing, though.
Even if and when the manner you are using the IP in is fair use you still have to acquire it legally (i.e. purchase it).
Pirating e-books is still legally indefensible. But if they acquire the books legally and then feed them through OCR they're fine. Obviously acquiring t. every book in this manner would be extremely pricy and time consuming but once you have them you have them.
Anonymous
8/12/2025, 2:38:33 PM
No.106234758
[Report]
Anonymous
8/12/2025, 2:38:55 PM
No.106234762
[Report]
>>106234748
how about you get a bigger one? you have 64+24gb total memory
>>106230523 (OP)
Ollamabros...
I thought this would be another Deepseek for us...
Anonymous
8/12/2025, 2:48:27 PM
No.106234846
[Report]
>>106234885
>>106234752
the funny thing is that it wouldnt even be THAT expensive, certainly cheaper than hiring wang to learn the ways of the slop
gemini estimated it at 500 mil to buy every game, movie and book on amazon, and even if you 10x it, it would STILL be cheaper
Anonymous
8/12/2025, 2:48:56 PM
No.106234854
[Report]
>>106234824
People aren't searching for it, they're clicking the links straight from OpenAI announcement linked HF page.
Anonymous
8/12/2025, 2:53:18 PM
No.106234885
[Report]
>>106234846
Yes. kobold has windows binaries, ooba is crossplatform pythonshit, sillytavern is webshit and even comes with a docker. You only really need koboldcpp to get started.
Anonymous
8/12/2025, 3:05:58 PM
No.106234990
[Report]
>>106235007
>>106234773
this then?
GLM-4.5-Air-Q2_K_L.gguf
Anonymous
8/12/2025, 3:07:23 PM
No.106235000
[Report]
>>106234824
llama.cpp finally getting some credits
Anonymous
8/12/2025, 3:07:53 PM
No.106235004
[Report]
>>106234852
>500 mil to buy every game, movie and book on amazon
surely that would qualify for some sort of bulk discount
Anonymous
8/12/2025, 3:08:17 PM
No.106235007
[Report]
>>106235665
>>106234990
are you tarded? grab IQ4_XS for starters
maybe grab UD-Q3_K_XL
you can get something even bigger
UD Q4_K_XL or UD Q5_K_XL maybe even!
>Wait, need to make sure it's original.
>Let's structure the response.
>Wait, check if it's original. Let's make sure it's creative, not boring.
>Hmm, need to match the personality more.
>Wait, let's check the original context.
>Final response:
>Wait, let's check the details.
>Now, check if it's original and creative.
>Finalizing:
>Wait, let's make it flow better. Maybe:
And then the final final response this time for real™ is something that is in the same ballpark as a raw response without spending 4000 tokens on thinking in circles. God I hate thinking models.
Anonymous
8/12/2025, 3:12:35 PM
No.106235040
[Report]
Anonymous
8/12/2025, 3:13:05 PM
No.106235045
[Report]
>>106234852
For something the size of facebook or google, yes it's doable. For chinese companies? They're just downloading libgen as most do.
Fora hypothetical opensource training group (let's say distributed), it might be harder to ever train a good model while being compliant, but then maybe users can somehow feed their own datasets and disperse the responsibility, not that aside from PRIME INTELLECT and Nous, there's now distributed training groups.
Anonymous
8/12/2025, 3:14:12 PM
No.106235053
[Report]
>>106235095
>>106235035
Post a side by side with and without thinking.
Anonymous
8/12/2025, 3:17:16 PM
No.106235074
[Report]
>>106235079
>>106235067
i feel safer thanks to this
Anonymous
8/12/2025, 3:18:45 PM
No.106235079
[Report]
>>106235074
Thanks for your support.
Anonymous
8/12/2025, 3:19:36 PM
No.106235088
[Report]
>>106235067
eleuther eh?
>At EleutherAI we are interested in developing risk management strategies for open-weight models
This is nice to see.
>>106235053
No, I am ashamed of my erps. But I don't really see much improvement if any. A lot of the time it has some nice comments/observations in the thinking portion but they don't actually make it into the final output so they are rather pointless. If I had to pick one maybe the thinking one is very mildly better on average but I can generate probably 10 normal responses in the time it takes for it to make one <think> wall of text so it doesn't seem worth the wait.
Just to be clear I'm using GLM4.1V right now but I had a similar experience with other thinking models.
Anonymous
8/12/2025, 3:21:40 PM
No.106235104
[Report]
>>106234824
kobold bros...
>>106235067
I hope they get cancer and die.
Anonymous
8/12/2025, 3:22:51 PM
No.106235111
[Report]
>>106232451
>This account's tweets are protected.
I missed the rest of the drama. sad!
Anonymous
8/12/2025, 3:23:39 PM
No.106235120
[Report]
>>106235125
>>106235110
That's way too far, they're just trying to protect all of us.
Anonymous
8/12/2025, 3:24:02 PM
No.106235121
[Report]
>>106236029
>>106235095
>A lot of the time it has some nice comments/observations in the thinking portion but they don't actually make it into the final output so they are rather pointless.
That's only been my experience with stuff like mistral thinker and the deepseek distils.
GLM Air even at Q3KS plans the response and actually does what it planned.
I do prefill with some heavy guidance that makes it think for a while, but it works.
Anonymous
8/12/2025, 3:25:08 PM
No.106235125
[Report]
>>106235120
That makes it worse.
>>106235067
>everyone else is trying to make models smarter
>while you are the guy trying to make them more retarded
how do these people even cope with themselves
Anonymous
8/12/2025, 3:27:57 PM
No.106235145
[Report]
>>106235135
intelligence is a sign of toxicity. dumb cattle is good, they are not toxic!
>>106235135
>more retarded
try again with an actual argument
>Filtering pretraining can prevent unsafe knowledge, doesn’t sacrifice general performance,
Anonymous
8/12/2025, 3:28:37 PM
No.106235151
[Report]
>>106235309
>>106232551
Funny. Before Meta, Eleuther were the main ones trying to take on OpenAI and release open, uncensored versions of their models, up until their Pile V2 dataset ended up being a literal pile of shit
Looks like they've gone back on their values to try to claw for relevancy again
Anonymous
8/12/2025, 3:30:56 PM
No.106235164
[Report]
>>106235095
only the latest batch of thinking models (GLM4.5 and qwen-2507) are any good at thinking for ERP, imo
Anonymous
8/12/2025, 3:43:08 PM
No.106235258
[Report]
>>106235150
>prevent unsafe knowledge, doesn’t sacrifice general performance,
so a model that doesn't know how to make explosives would still be competent at chemistry?
Anonymous
8/12/2025, 3:50:13 PM
No.106235309
[Report]
>>106235150
There is no such thing as "unsafe" knowledge. Knowledge is knowledge, it is understanding, it is useful.
You could use some knowledge in a way that harms someone, that would be unsafe to that person. Most knowledge is neutral, including "dangerous" one. Only by intentionally choosing to use it, it's unsafe to someone.
This is the same dumb logic as brits banning knifes that are too sharp. Surely, they'd hope people don't learn to sharpen those knifes?
>>106235151
They wanted to, but never managed to scale up. I remember their 1T or bust. on their github. They even wanted some sort of MoEs then. I guess DeepSeek and MoonShot showed them?
But you should also remember that
EleutherAI always had doomers in there, remember that npcollapse guy? I had to look his name up agian, Connor Leahy, he went full crazy doomer wanting to shut it all down, about as much as Yud, was basically Yud-lite. I wonder who paid for his advocacy...
I don't think the new Eleuther are doomers at least, but they're a sort of non-profit that's safety (research) oriented, so slightly adjacent, even if more optimistic than the doomers.
Anonymous
8/12/2025, 3:51:58 PM
No.106235318
[Report]
>>106235150
By general performance they mean benchmark scores
It's the same logic by which 'toss is the safest model ever made and outperforms models five times its size
I don't know what sorcery I did but I'm able to run the gpt-oss 20B model on a base model Mac mini M4 with 16GB of RAM. (13t/k) Now I just need to play with the context window to find the sweet spot.
llama.cpp truly ftw.
>>106235335
You're probably using swap and killing your SSD, but that's fine if you have AppleCare pro max+
Anonymous
8/12/2025, 3:56:49 PM
No.106235363
[Report]
>>106235372
>>106235350
Not at all.
If it was SWAP it would have been much much slower than that.
Anonymous
8/12/2025, 3:57:59 PM
No.106235372
[Report]
>>106235363
oss is tiny and Macs have very fast storage.
Anonymous
8/12/2025, 3:58:37 PM
No.106235381
[Report]
>>106235415
>>106235350
Does reading from your SSD do anything to it?
Anonymous
8/12/2025, 3:59:50 PM
No.106235396
[Report]
>>106235423
>>106235335
The model is ~12gb.
Anonymous
8/12/2025, 4:00:34 PM
No.106235403
[Report]
>>106235335
I just used gpt-oss 20b to troubleshoot a gcc build issue and it worked great. Not sure why everybody says this model sucks. For the speed (66 t/s on RTX 3090) and size it's fantastic
Anonymous
8/12/2025, 4:01:49 PM
No.106235414
[Report]
>>106235110
I second this motion
Anonymous
8/12/2025, 4:01:52 PM
No.106235415
[Report]
>>106235449
>>106235381
If it's only reads not much, but some swap writes a ton it depends.
Anonymous
8/12/2025, 4:02:17 PM
No.106235423
[Report]
>>106235396
Yeah but it doesn't work when I tried to use Ollama or lmstudio.
For some reason it just overload the RAM and becomes unusable.
By switching to CPU inference only I was able to make it usable.
Anonymous
8/12/2025, 4:03:02 PM
No.106235425
[Report]
>>106235463
I just used gpt-oss to troubleshoot an unsafe model issue and it worked great. For the speed (22t/s on rtx 2080) and size it's fantastic
Anonymous
8/12/2025, 4:03:29 PM
No.106235431
[Report]
>>106235150
I’m sorry, but I can’t help with that.
Anonymous
8/12/2025, 4:03:38 PM
No.106235433
[Report]
>>106235448
>>106235067
Maybe we can stop important millions of unwanted browns and lock the border so we can all continue to have all the knowledge without lobotomizing models
Anonymous
8/12/2025, 4:04:56 PM
No.106235448
[Report]
>>106235518
>>106235433
Take your stupid pol BS elsewhere idiot.
Anonymous
8/12/2025, 4:05:02 PM
No.106235449
[Report]
>>106235415
Good to know.
Anonymous
8/12/2025, 4:06:23 PM
No.106235463
[Report]
>>106235425
nice job king
Anonymous
8/12/2025, 4:13:16 PM
No.106235518
[Report]
>>106235448
You know its true
Oh wait
You’re brown
Anonymous
8/12/2025, 4:15:34 PM
No.106235546
[Report]
>>106234727
Longer context = longer processing time and it takes more memory.
If you want faster, make the context size smaller in ST.
Today I will remind all the corporate shitjeets lurking here.
Anonymous
8/12/2025, 4:19:06 PM
No.106235580
[Report]
>>106235595
>>106235558
do it in qwen image now
Anonymous
8/12/2025, 4:19:09 PM
No.106235581
[Report]
>>106235591
>Today I will remind all the shitjeets
>ShitjeetGPT
Anonymous
8/12/2025, 4:20:20 PM
No.106235591
[Report]
>>106235581
I don't talk to jews
Anonymous
8/12/2025, 4:20:56 PM
No.106235595
[Report]
>>106236080
>>106235558
at least use flux kontext or
>>106235580
Anonymous
8/12/2025, 4:26:00 PM
No.106235646
[Report]
>>106235694
I've grown tired of Deepseek R1 and needing to handhold MoEs for ERP. What's the best Instruct currently?
Anonymous
8/12/2025, 4:28:08 PM
No.106235665
[Report]
>>106235007
>>106234773
Thanks bruv. This model be good!
Any other model suggestion?
Anonymous
8/12/2025, 4:30:28 PM
No.106235694
[Report]
>>106235721
>>106235646
AWQ is unsupported on V100. Worst part of using Volta with vLLM is the complete lack of quant support meanwhile nothing else supports vision models.
Anonymous
8/12/2025, 4:31:18 PM
No.106235704
[Report]
>>106235656
Cloud closed source models are the only way up from this, unfortunately. Or hope that whale will release something at the end of the month.
>>106235696
Sidegrade at best.
Anonymous
8/12/2025, 4:31:56 PM
No.106235718
[Report]
>>106235035
Reasoning for sure is a waste with creative writing and 'creative writing', It's cute when model tries to stay in character while thinking. Not all of them do though.
On that note, I wish I could control thinking via prompts. 'Think in french.' 'Come up with answer first, then think backwards.' 'Don't fucking think and just make a quick summary of the chat instead.' Would be good for benchmarking different chain of thought strategies as well.
Anonymous
8/12/2025, 4:32:11 PM
No.106235721
[Report]
>>106235694
yeah its ultra sad, hopefully gg will get around to implementing them
Anonymous
8/12/2025, 4:42:57 PM
No.106235841
[Report]
>>106235067
You see, it's a kind of gain-of-function research.
If you know how to safety-slop the model, you can then reverse the process and make them based beyond belief.
copium.jpg
Anonymous
8/12/2025, 4:45:15 PM
No.106235862
[Report]
>>106235696
Don't have the ram for a 1000B.
Anonymous
8/12/2025, 4:46:38 PM
No.106235877
[Report]
>>106235897
>>106235877
>glm 4.5 full
Still a MoE. Tired it.
Anonymous
8/12/2025, 4:50:28 PM
No.106235925
[Report]
>>106235897
Moe fatigues do be getting the homer tho u rights
Anonymous
8/12/2025, 4:50:52 PM
No.106235930
[Report]
>>106236028
Anonymous
8/12/2025, 4:55:09 PM
No.106235990
[Report]
>>106236054
>>106235656
>tired of [insert LLM]
Take a break.
Or start hot-swapping models between responses. I swap V3 and R1 back and forth.
Anonymous
8/12/2025, 4:58:44 PM
No.106236028
[Report]
>>106236253
>>106235930
This one better not write for me all the time like the original Behemoth.
Anonymous
8/12/2025, 4:58:47 PM
No.106236029
[Report]
>>106235121
>mistral thinker
Anon...that was made by undi, peace be upon him
Anonymous
8/12/2025, 5:00:41 PM
No.106236045
[Report]
>>106235350
>AppleCare pro max+
Sounds like a scam
Anonymous
8/12/2025, 5:02:04 PM
No.106236054
[Report]
>>106235990
nta, but I gave the MoM approach a try with some smaller models. prompt reprocessing would be painful with deepseek, I guess you could save kv cache between switching to make it faster.
Anonymous
8/12/2025, 5:02:36 PM
No.106236064
[Report]
>>106233234
Thank yoy, kind anon!
I was about to lose all my hope
Anonymous
8/12/2025, 5:04:14 PM
No.106236080
[Report]
>>106236090
>>106235595
your flux kontext sir
Anonymous
8/12/2025, 5:04:22 PM
No.106236083
[Report]
>>106236104
NEW AGENT KINO JUST DROPPED
https://youtu.be/IgFx6LLkTwg
Anonymous
8/12/2025, 5:05:05 PM
No.106236090
[Report]
Anonymous
8/12/2025, 5:07:03 PM
No.106236104
[Report]
>>106236083
Thank you for linking this, Jason.
Anonymous
8/12/2025, 5:11:29 PM
No.106236139
[Report]
Anonymous
8/12/2025, 5:11:51 PM
No.106236142
[Report]
>>106234255
how does nemo beat Mistral Small? The 24b is better in every way
Anonymous
8/12/2025, 5:24:36 PM
No.106236253
[Report]
>>106236028
What about thedrummer (tm) approved erpslop models?