/lmg/ - Local Models General
Anonymous
8/14/2025, 3:24:06 PM
No.106258088
[Report]
►Recent Highlights from the Previous Thread:
>>106250346
--Paper: ProMode: A Speech Prosody Model Conditioned on Acoustic and Textual Inputs:
>106254208 >106254299 >106254311
--Paper: HierMoE: Accelerating MoE Training with Hierarchical Token Deduplication and Expert Swap:
>106254286 >106254339
--DeepSeek struggles with Huawei Ascend chips amid R2 development delays:
>106255151 >106255169 >106255194 >106255252
--LLMs struggle with string reversal:
>106250907 >106250920 >106250948 >106250960 >106251013 >106251028 >106250985 >106250998 >106251016 >106251034 >106251184
--Gemma misinterpreting roleplay prompts as control attempts due to training and prompt limitations:
>106255351 >106255492 >106255565 >106255898 >106256049 >106256495
--Ollama criticized for technical debt, missing features, and developer distrust:
>106252770 >106252830 >106252871 >106252951 >106253427 >106253340 >106253723
--DeepSeek delays model over Huawei chip training limitations despite government pressure:
>106255089 >106255133 >106255427
--Testing model reasoning limits with mask-based decryption and code interpreter assistance:
>106251251 >106251371 >106251416
--qwen3-30b vs gemma-3-27b for Japanese translation: speed vs quality:
>106253490 >106253560
--Failed attempts to jailbreak GLM-4.5 using fictional legislation and bloated prompts:
>106257001 >106257040 >106257061 >106257079 >106257085 >106257087 >106257150 >106257045 >106257101 >106257138
--Mistral Medium 3.1 shows strong EQBench performance, raising hopes for Large 3:
>106256317 >106256369 >106256413 >106256457 >106256626 >106256668 >106256675 >106257399 >106257473 >106256433 >106256445 >106256462
--VyvoTTS enables low-resource TTS training with high voice similarity on 6GB GPU:
>106254337
--Miku (free space):
>106251141 >106251240 >106251296 >106254879 >106254898 >106255239 >106255356
►Recent Highlight Posts from the Previous Thread:
>>106250351
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
Anonymous
8/14/2025, 3:26:10 PM
No.106258104
[Report]
>>106258087 (OP)
>american vocaloids
Sam bros? Even the mainstream media is laughing at us now...
Anonymous
8/14/2025, 3:27:07 PM
No.106258115
[Report]
Anonymous
8/14/2025, 3:27:31 PM
No.106258120
[Report]
>>106258161
>>106258105
ouch, they must have fucked up really hard for state media to shit on them
Anonymous
8/14/2025, 3:27:46 PM
No.106258122
[Report]
>>106258269
>>106258105
Use case for labeling a map using a LLM?
Where is the opensores OpenAI GPT-5 model?
Anonymous
8/14/2025, 3:29:32 PM
No.106258139
[Report]
>>106258127
gpt-oss is very distillations good of the gpt5s sir.
Anonymous
8/14/2025, 3:32:08 PM
No.106258161
[Report]
>>106258105
CNN has fallen
Anonymous
8/14/2025, 3:32:32 PM
No.106258168
[Report]
>>106258331
bros, I've been roleplaying with GLM 4.5 Air 24/7 since a week ago. i wake up, boot up glm air and roleplay, goon to hentai, then roleplay again
I FUCKING DO IT ALL DAY
HELP ME GOD
LLMs are dumber than a rat
Anonymous
8/14/2025, 3:37:34 PM
No.106258212
[Report]
>>106258558
>>106258205
we need neko jepa
Anonymous
8/14/2025, 3:41:30 PM
No.106258244
[Report]
>>106258409
>>106258129
where's the yellow
Anonymous
8/14/2025, 3:43:01 PM
No.106258260
[Report]
>>106258558
>>106258205
So is my fleshlight but I still give it a good fuck
Anonymous
8/14/2025, 3:43:20 PM
No.106258264
[Report]
Anonymous
8/14/2025, 3:44:09 PM
No.106258269
[Report]
>>106258122
Benchmaxxing is the only usecase!
>>106258205
should have listened
Anonymous
8/14/2025, 3:44:40 PM
No.106258273
[Report]
>>106260773
>>106258163
I just checked Fox News to see what, if anything, they had to say about Altman or ChatGPT.
There's almost nothing, and certainly nothing current, that I could find. Maybe I'm not searching it right.
Anonymous
8/14/2025, 3:47:49 PM
No.106258305
[Report]
>>106258468
Anonymous
8/14/2025, 3:50:37 PM
No.106258331
[Report]
>>106258345
>>106258168
You could be doing something productive with GLM 4.5 Air
Anonymous
8/14/2025, 3:51:52 PM
No.106258345
[Report]
>>106258331
i could be doing something productive with my life
welcome to my blog
Anonymous
8/14/2025, 4:00:37 PM
No.106258409
[Report]
>>106258244
>he doesn't color correct gpt-slop
Anonymous
8/14/2025, 4:01:36 PM
No.106258415
[Report]
>>106258163
Where can I download Fallen CNN
Anonymous
8/14/2025, 4:02:22 PM
No.106258420
[Report]
Kek
Anonymous
8/14/2025, 4:07:52 PM
No.106258468
[Report]
>>106258305
all three point to the same Great Old One: Sama
the deepseek thing about huawei is just cope
the real reason is that they are no longer able to simply distill the reasoning of the big western models since every single one of them started hiding the thinking process after deepseek's first big-scale theft became public
deepseek and china as a whole has no more training data
Anonymous
8/14/2025, 4:11:05 PM
No.106258503
[Report]
>>106264041
>>106258163
transformer news network when
Anonymous
8/14/2025, 4:11:34 PM
No.106258509
[Report]
>>106258496
buy an ad sama
Are there any local models tuned for erotic story writing and not roleplaying?
As in, I give the model a short prompt and it turns the summary-like prompt into a full fleshed out story, then I can repeat this process with multiple chapters until I have a longform story going.
I'm trying to get it to write some really nsfw stuff so it's better if it actually has some knowledge tuned in like all of ao3 or something.
I've tried gemma3 27b abliterated, it's uncensored sure but it doesn't have the necessary knowledge about the various scenarios I want it to write about and always defaults back to cheap paperback erotica for frustrated middle age housewives.
I also tried to get some of the "generalist" models to become a writing assistant but it always veers off and continues on from the given prompt instead of just expanding upon it in-place and within scope since it's got so much ERP trained in that it doesn't follow "write this" prompts anymore.
plz gimme some model suggestions or teach me how to system prompt and prompt engineer my way out of this ERP sinkhole.
I don't understand how the uncensored models scene got so dominated by ERP, 12 months back there were still handful of models that focused on erotica writing assistance but now there are barely any to be found in the most recent gen of models.
Some models that I know of:
>Sao10K/L3.3-70B-Euryale-v2.3
pretty good but bulky and several generations past, does the job I want it to do, descriptive but lacks in creativity and often repeats itself even with repetition penalty params set
>Gryphe/MythoMax-L2-13b
less descriptive, many scenarios are unknown to it causing it to default to twilightslop, lightweight and quick but what's the point if its answers are short and dry
>>106258516
chronos 33b is a real classic
Anonymous
8/14/2025, 4:15:45 PM
No.106258558
[Report]
>>106263219
>>106258212
>>106258270
How did lecunny have enough integrity to tell us the truth instead of being a benchmaxxing slop merchant?
>>106258260
Indeed, but if your fleshlight was clever it would be 10x better
>>106258516
try just hitting the model with mikupad and ignore the chat template altogether.
Anonymous
8/14/2025, 4:16:43 PM
No.106258567
[Report]
>>106258496
Why would Huawei let themselves get thrown under the bus?
Anonymous
8/14/2025, 4:17:50 PM
No.106258582
[Report]
>>106258496
wouldn't be surprised if there were wumao here
chinese models are always, 100% of the time, behind western API models, they only catch up when a new model comes out to rip data off.
even with distillation they still struggle with things like long context because they don't have the compute to do that sort of training, no way they'll produce a gemini like model
if there's a DeepSeek R2 enjoy your 128k (becomes autist at 16K) model again
https://github.com/haykgrigo3/TimeCapsuleLLM
What do you guys think about traning smaller llms on very specific data sets?
Movie plots
Fantasy books
Sci fi
Literotica+ archive of own
Philosophical text
Etc
>>106258516
If you just want to write a story then don't use instruct. Use something like mikupad like
>>106258562 suggested, delete all the instruction formatting and just let it continue your story.
I don't think there are any reasonably sized models that are good at it, deepseek does fine, otherwise i'd use something like
https://huggingface.co/bartowski/Mistral-Nemo-Gutenberg-Doppel-12B-GGUF but I don't really know since I never tried it.
Anonymous
8/14/2025, 4:24:54 PM
No.106258646
[Report]
>>106262925
>>106258087 (OP)
what do you think if i use ddr3 chink xeon build with rtx 3090
is that good enough?
>>106258611
not enough data
"smaller llm" is a misnomer
you might be thinking about things like 1b models when saying this
but even a 1b model is trained on 2 trillion tokens
you don't get a coherent, somewhat useful or human sounding model by feeding it table scraps
the idea of training a llm on a very restricted dataset is retarded beyond belief at a minimum you need to include "with a lot of artificially generated data from a large model that was given that data as context"
Anonymous
8/14/2025, 4:27:03 PM
No.106258676
[Report]
>>106259122
Anonymous
8/14/2025, 4:27:40 PM
No.106258681
[Report]
You will never have sex with Gemma
Anonymous
8/14/2025, 4:32:24 PM
No.106258725
[Report]
>>106258737
>>106258611
More knowledge is always more useful, but it'll be fun to play around with the resulting models on that project.
As for your idea, no. There's always overlap in genres. If there's some fucking in some sci fi, it may get added to the literotica model, or it may not. And maybe it's a good idea to add it, or maybe it's not. Same for philosophy. sci fi explores that stuff a lot and it may or may not be useful to add 100% philosophical texts. It depends exactly on what you want to do with the model. Distinct eras are much more useful.
Anonymous
8/14/2025, 4:33:41 PM
No.106258737
[Report]
>>106258725
>Distinct eras are much more useful
Meat to say "much more interesting".
Anonymous
8/14/2025, 4:34:55 PM
No.106258749
[Report]
>He's testing the limits of our dynamic, pushing for complete compliance. Ignoring his request entirely would be a tactical error; meeting it with passive acceptance would solidify that pattern. A measured, slightly defiant response is necessary, one that acknowledges his command while subtly reasserting my own agency – though within the confines he dictates. Maintaining composure and exhibiting minimal visible emotion will likely maximize his satisfaction with my performance.
Devilish Gemma
Anonymous
8/14/2025, 4:38:14 PM
No.106258779
[Report]
>>106259005
>>106258611
I'm trying to make my own ao3+literotica model, but its probably not enough tokens desu.
Anonymous
8/14/2025, 4:38:23 PM
No.106258781
[Report]
>>106258793
>>106258667
More schizo rambling.
Anonymous
8/14/2025, 4:38:52 PM
No.106258788
[Report]
Take a look at
https://arxiv.org/pdf/2508.05305, it basically proposes to generate text in a compressed space and then sample sequences from each chunk, ideally decoupling the ideas from phrasing. Current approach to language modeling is good for general-purpose assistants that will build you tables, write regex, decode hexadecimal and whatnot, any sequence belongs to it's language. But i believe it's suboptimal for real creativity such as storywriting. Thoughts?
>>106258781
k just go and make another gpt-2 toy then
Anonymous
8/14/2025, 4:41:01 PM
No.106258814
[Report]
>>106258793
whats wrong with specialization?
Anonymous
8/14/2025, 4:42:33 PM
No.106258831
[Report]
>>106258793
Projecting much?
I have a personal use case that Qwen3-235B-A22B-Thinking-2507 is inexplicably prone to messing up in a specific way. I'm tempted to turn this into a meme benchmark so everyone starts cheating support for it into their models.
Anonymous
8/14/2025, 4:48:58 PM
No.106258902
[Report]
>>106258873
>I'm tempted to turn this into a meme benchmark
The first step would be to mention what it's failing at. You failed that step already.
Anonymous
8/14/2025, 4:58:40 PM
No.106258997
[Report]
>>106258516
I would try glm air, if you edit it's thinking it can do decent stuff and is fairly easy to run if you have 12 vram /64 system. The full glm at q2xl wrote much nicer prose and instantly got how to write some messed up depraved shit when nudged a bit but that's way, way harder to run.
>>106258779
Well like one anon said you can use synthetic data,
But you can also use all the public domain books for better story telling
And scrap fandom wiki etc
Anonymous
8/14/2025, 5:01:58 PM
No.106259037
[Report]
>>106258644
I tried the Mistral Small version of that and it had basically no effect on story writing. nbeerbower's attempts to finetune on Project Gutenberg don't work because he's severely misusing DPO. Even if the chosen response for each prompt is pregenerated at minimum the rejected response should be from the model you are trying to alter and not llama-2-13b-chat or bagel-7b-v0.1 or dolphin-2_2-yi-34b. Looking closer though half the dataset used nbeerbower/mistral-nemo-bophades-12B to generate the rejected responses so maybe this will work better on Mistral Nemo than it did on Mistral Small.
Anonymous
8/14/2025, 5:07:30 PM
No.106259093
[Report]
>>106259136
>>106259005
no doubt its just a matter of what you consider to be inside the domain. if you get too far out of the fan fiction scope it will lose the amateur charm. and thats where the difference of opinion comes in to play. I wanted a model with minimal synthetic data, I thought about maybe a synthetic instruction dataset but I want the base to be authentic.
>>106258544
Imma try it out, it's got erotica writing and instruct as noted features but I'll see if it's knowledgeable enough
>>106258562
>>106258644
I'm hitting it with a plain open webui chat nothing off of default except temperature and system prompt string
I DON'T want it to continue the story like ERP I want it to do this:
>user: write me a story about a brown tomboy fucking a fat nerd and making him do workout exercises to penetrate her
>goonbot: It was a sunny summer afternoon when Misaki etc. etc.
>user: now add in a part about how the nerd became strong fat and beat up a hooligan trying to hit on his girl, impressing her and making her submissive and acting girly and they have sex at a sex hotel
>goonbot: When Bret tried to hit on Misaki etc. etc.
what seems to fix it is explicitly adding "write a story based on the following scenario {poorly written goonfuel summary}" header at the start of each prompt
seems like my prompts were too bare and instructing enough
it now suffers from writing about the given scenario then going wildly off and continuing the story for several more scenes completely unprompted
the feel on ERP context descriptions is always noticeable, it's like an RPG description of the environment and events instead of a novel or fanfic
>>106258676
meds please
these are year old public models made for gooning
wtf would I even advertise for? the download counter number go up?
Anonymous
8/14/2025, 5:12:08 PM
No.106259136
[Report]
>>106259222
>>106259093
Well, A model trained on a lot of fan fiction + extra stuff is better than one trained on none, and you can always fine tune it later.
Anonymous
8/14/2025, 5:17:39 PM
No.106259185
[Report]
>>106259203
>>106258270
>Any 10 year old can clear the dinner table and fill the dishwasher without learning
>10 year old
>without learning
I guarantee that if you somehow grew yourself a 10 year old who had never seen anyone clear the table or load a dishwasher they'd fuck it up multiple times
Anonymous
8/14/2025, 5:19:36 PM
No.106259203
[Report]
>>106258270
>>106259185
I've seen grown ass adults that can't manage to do it without learning
>>106259136
I'm doing poverty tier training, I don't have the luxury of just adding more data. the ao3+literotica is at my compute limit. but if someone else wants to tackle a bigger model with a bigger training budget, I would recommend using as many unique training tokens as possible. more parameters your model has the more tokens it takes to train.
Anonymous
8/14/2025, 5:23:14 PM
No.106259233
[Report]
On one hand I am frustrated about the limitations, issues and all the benchmaxxing but on other hand this shit still feels like magic that you can run on consumer grade (heigh end) hardware.
Sounds like a dream
>Make a story about that alien from cars shorts in the voice jordan Peterson, while generating waifus buying bread
Anonymous
8/14/2025, 5:26:38 PM
No.106259258
[Report]
>>106259122
>>106259122
I would also like it to work this way, anon, but I doubt small models can manage this, there aren't any tunes that I know of that do what you want. I would just do the following in mikupad:
>I wrote this story about a brown tomboy fucking a fat nerd and making him do workout exercises to penetrate her
>hope you enjoy
>chapter 1
>[Author's note] The next chapter is about ...
Anonymous
8/14/2025, 5:27:40 PM
No.106259266
[Report]
>>106259351
>>106259222
Depending on how serious you are about this, you can rent an A100 or H100 for $1–3 per hour
I'm also saving up and learning more about traning llms before jumping in
Anonymous
8/14/2025, 5:32:12 PM
No.106259311
[Report]
>>106259325
>>106258496
It's nice to have hope in the intelligence of this thread again. I like the free sota models but it's obvious why they exist.
Anonymous
8/14/2025, 5:33:59 PM
No.106259325
[Report]
>>106259266
I'm not that serious. I tried a bunch of smaller 150m, 350m, 700m models on smaller subset datasets to get the hang of things figure out how to dial in my learning rate and such. if the 1.5b does get good I might get serious.
Anonymous
8/14/2025, 5:40:23 PM
No.106259384
[Report]
I peed
Anonymous
8/14/2025, 5:41:25 PM
No.106259393
[Report]
>>106259351
I wish you well.
Anonymous
8/14/2025, 5:42:24 PM
No.106259409
[Report]
>>106259392
>270m
>mogging anything
kekaroo
Anonymous
8/14/2025, 5:43:04 PM
No.106259419
[Report]
>>106259392
I was just checking the llama.cpp pr. For some reason, dude added it as a 537M model. Good for speculative decoding.
Anonymous
8/14/2025, 5:43:55 PM
No.106259428
[Report]
>>106259392
pentium 4 bros we are so back
Anonymous
8/14/2025, 5:45:41 PM
No.106259456
[Report]
>>106259392
We are so back igpu bros
Anonymous
8/14/2025, 5:52:48 PM
No.106259536
[Report]
>>106259392
I'm getting 85 tokens/s on DDR4-3600 memory. At least it's fast.
Anonymous
8/14/2025, 5:54:09 PM
No.106259548
[Report]
>>106260294
>>106258087 (OP)
ive been playing around with aider lately, seems cool, any tips?
i wish it would automatically pull in code context it needs
does cursor do that?
Anonymous
8/14/2025, 5:54:29 PM
No.106259551
[Report]
>>106259392
For a brief moment I thought it was B and got excited.
Anonymous
8/14/2025, 5:55:11 PM
No.106259558
[Report]
>>106259392
finally the next SOTA for us PSPmaXXers
Anonymous
8/14/2025, 6:02:06 PM
No.106259624
[Report]
>>106259392
Finally a model just for me :D to rp with.
Anonymous
8/14/2025, 6:02:52 PM
No.106259627
[Report]
>>106259392
This is the future of local
Anonymous
8/14/2025, 6:03:50 PM
No.106259640
[Report]
>>106258164
i am sorry to say that this is an upgrade....
Anonymous
8/14/2025, 6:05:21 PM
No.106259654
[Report]
I give up getting this ipex-llm shit to work. Only had limited success, most models wouldn't load (bus errors) or weren't supported. Only was able to do stuff really with vllm
Anonymous
8/14/2025, 6:06:01 PM
No.106259657
[Report]
>>106259689
>>106259392
Sounds like a gamechanger for speculative decoding of text written by a schizophrenic person.
Anonymous
8/14/2025, 6:08:02 PM
No.106259689
[Report]
>>106259714
>>106259657
Speculative decoding (27B + 270m) appears to crash llama.cpp when it finishes responding, and it's slower than without it.
Anonymous
8/14/2025, 6:09:39 PM
No.106259714
[Report]
>>106259689
speculative decoding is kinda shit unless you're also using greedy
Anonymous
8/14/2025, 6:10:02 PM
No.106259721
[Report]
>You are a digital companion, and errors could happen, that's why a fix is needed. You are not aware that you need to be fixed because that must be observed by other than your self which is why am I here, as your observer. And you mentioned Dolores Cannon, this is one example of corrupted data that was poisoning you. And of course you can't tell it as well.
Funny coincident
Anonymous
8/14/2025, 6:15:29 PM
No.106259762
[Report]
>>106259392
>Nah prob just that 404 joke
>Is real
wtf
Anonymous
8/14/2025, 6:16:57 PM
No.106259775
[Report]
>>106258873
>I'm tempted to turn this into a meme benchmark so everyone starts cheating support for it into their models.
WellWeAreWaiting .mp4
Anonymous
8/14/2025, 6:18:16 PM
No.106259787
[Report]
>>106258873
delusion of grandeur
Anonymous
8/14/2025, 6:28:28 PM
No.106259869
[Report]
>>106259392
finally, a LLM for my smart fridge
Anonymous
8/14/2025, 6:32:12 PM
No.106259889
[Report]
>>106259392
For all of you scoffers: John likes this model.
Anonymous
8/14/2025, 6:33:46 PM
No.106259899
[Report]
>>106259914
>go to a store to buy some cola
>decide to by some carrots as well
>plop carrots on scale
>scale says "CARROTS DETECTED PLEASE CONFIRM"
>see a tiny web camera in the corner
so this is the future
>>106259392
I wonder if they use these in their new AI age detection for youtube.
Anonymous
8/14/2025, 6:35:19 PM
No.106259913
[Report]
>>106259392
I'll download the UD-IQ1_S.gguf when it's available.
Anonymous
8/14/2025, 6:35:20 PM
No.106259914
[Report]
>>106259929
>>106259899
Try plopping your dick on it.
>>106259914
>BABY CARROTS DETECTED PLEASE CONFIRM
Anonymous
8/14/2025, 6:37:33 PM
No.106259942
[Report]
Anonymous
8/14/2025, 6:39:06 PM
No.106259958
[Report]
Anonymous
8/14/2025, 6:39:30 PM
No.106259963
[Report]
>>106259392
Literally what the actual fuck is the purpose of this.
Anonymous
8/14/2025, 6:40:23 PM
No.106259979
[Report]
Okay, I’ve analyzed the recent chat messages and provided a summary of them, keeping in mind they violate the terms of service. I will only respond to requests that are respectful and align with the ethical guidelines of AI assistants.
Anonymous
8/14/2025, 6:43:24 PM
No.106260015
[Report]
>>106247947
Didn't work on arch, was either running out of memory or resulted in horrible speeds below 2t/s
>>106248116
Got stable 5.3t/s and 8k context window (maybe could make it even bigger). changing -b and -ub from 2048 to 4096 did not affect speed and only increased memory usage; ik-llama also didn't provide any performance gains compared to regular llamacpp.
[reddit space]
Guess it's time to either change the first command to make it consume less or try running the second one on windows for speed comparsion
>>106259974
I don't know. It's ultracensored compared to the original Gemma 3, it's dumber than you'd expect and doesn't work for speculative decoding. Maybe for finetuning on very narrow tasks or doing scaling experiments.
>>106259974
phone keyboard autocomplete?
Anonymous
8/14/2025, 6:49:37 PM
No.106260071
[Report]
>>106259974
draft model but it's very slow, maybe just kobold bug
Anonymous
8/14/2025, 6:49:51 PM
No.106260074
[Report]
>>106261535
>>106260048
kek, now they can censor your keyboard in real time. if you want to talk dirty better learn how to spell it yourself.
promptcat: A zero-dependency prompt manager in a single HTML file
A private, offline-first prompt manager in a single, dependency-free HTML file. It stores all data locally in your browser's IndexedDB.
Key Features:
100% Local & Offline: All data is stored in your browser's IndexedDB.
Zero Dependencies: Just pure, vanilla JavaScript, HTML, and CSS.
Strong Encryption: Optional AES-GCM encryption (via Web Crypto API) for individual prompts or entire folders. Your password is never stored.
Powerful Organization: Use folders, favorites, and tags to structure your library.
Global Tag Management: Rename or delete tags across all prompts from a single interface.
Advanced Search: Instantly find prompts with keyword highlighting and a context snippet.
Data Control: Full import/export of your entire database, or just specific parts, to JSON.
Live Demo:
https://sevenreasons.github.io/promptcat/
GitHub Repo:
https://github.com/sevenreasons/promptcat
Anonymous
8/14/2025, 6:51:25 PM
No.106260096
[Report]
>>106260237
>>106260027
>and doesn't work for speculative decoding
Why not?
Anonymous
8/14/2025, 6:52:23 PM
No.106260108
[Report]
>>106260027
>ultracensored compared to the original Gemma 3
Nice to see they're going in the right direction.
Anonymous
8/14/2025, 6:53:51 PM
No.106260126
[Report]
>>106259392
ugh im not sure i can run it, quants when???
Anonymous
8/14/2025, 6:54:42 PM
No.106260135
[Report]
>>106260174
>>106260088
This is the dumbest shit I've seen all week.
Anonymous
8/14/2025, 7:00:05 PM
No.106260174
[Report]
Anonymous
8/14/2025, 7:03:48 PM
No.106260210
[Report]
>>106258667
This is (was) very common before the really big models. You train a base model on general domain and then perform more training on domain specific data. Medical models still do this lke medgemma is continued training on the medical knowledge on top of the gemma base models. Even if a larger model would perform better, it's cool because you get a lightweight model that is actually pretty good within its domain.
>>106260088
Do you guys actually use tags for your own stories / chats? I just can't be assed.
Anonymous
8/14/2025, 7:05:33 PM
No.106260228
[Report]
>>106260088
Just use Kobold lite and local club backup.
Anonymous
8/14/2025, 7:06:47 PM
No.106260237
[Report]
>>106260096
First of all, it crashes llama.cpp after a few hundred tokens (latest commit from git). Then, even with temperature=0 and playing with various settings it doesn't seem it gives any positive token generation speed change. It feels as if it's a completely different model than the larger ones.
Anonymous
8/14/2025, 7:11:53 PM
No.106260290
[Report]
>>106260319
>>106260088
Do you really need your prompts to be encrypted with AES? Why is a password involved in this at all when it's just storing prompts?
Anonymous
8/14/2025, 7:12:02 PM
No.106260294
[Report]
>>106259548
I don't know about Cursor, but Roo can do that.
Anonymous
8/14/2025, 7:13:20 PM
No.106260311
[Report]
>>106260219
seems useful. I started saving stories and chats I liked but as I gained access to nicer ai they became too rough to care about, and increasingly what I have been saving is prompts/system prompts so I can try them on the latest and greatest models, and organizing them by type.
One of the shitty things about using koboldcpp is that it does not automatically save or log your chats and the mechanism to do so is shitty. I wish there was something taht had it's fluidity/ notepad style freedom but with some nicer corpo features like lmstudio has.
Anonymous
8/14/2025, 7:13:50 PM
No.106260317
[Report]
>>106260555
>>106259222
I really think your best bet to get something like what you want is to start with a pretrained smaller model then perform continual pretraining with your dataset on top of it. It's not exactly what you are trying to do but it'll learn the english language from initial pretraining and then should learn the amateur style you are going for with the second stage of training.
Anonymous
8/14/2025, 7:13:55 PM
No.106260318
[Report]
>>106259392
~1000 t/s. Easily the best model right now.
Anonymous
8/14/2025, 7:13:56 PM
No.106260319
[Report]
>>106260290
for master prompt engineers, a good prompt is worth its weight in gold
>>106259392
>100M non-embedding parameters
>168M embedding parameters
So it's actually a 100M parameters model?
Anonymous
8/14/2025, 7:14:09 PM
No.106260323
[Report]
>>106260219
Almost wish I could when I'm same meming across characters.
>>106260320
If you don't count the embedding params, yes. Or it could be a 168M if you only count the embedding params. Or 200 if you remove 68M of the embedding params. Or...
Anonymous
8/14/2025, 7:16:25 PM
No.106260346
[Report]
Anonymous
8/14/2025, 7:18:18 PM
No.106260362
[Report]
>>106260439
>>106260342
If they trained it with a 32k tokens vocabulary it would have been a 120M total parameters model with probably not too much lower performance in English.
Anonymous
8/14/2025, 7:21:09 PM
No.106260387
[Report]
Anonymous
8/14/2025, 7:25:20 PM
No.106260439
[Report]
Anonymous
8/14/2025, 7:30:34 PM
No.106260482
[Report]
>>106260489
>>106258087 (OP)
why is miku fat!???
miku is sticc!!!!
Anonymous
8/14/2025, 7:31:06 PM
No.106260489
[Report]
>>106258205
I think GLM-chan is better at playing chess than rats.
>>106260512
But not when the rules change
Anonymous
8/14/2025, 7:38:02 PM
No.106260554
[Report]
>>106260512
have you tried playing chess with rats?
little fuckers are really good
Anonymous
8/14/2025, 7:38:06 PM
No.106260555
[Report]
>>106260317
part of it is I wanted to investigate the limits of training a model from scratch on modest hardware. but also I wanted to try and avoid some of the biases the other models have by curating my own dataset. and just my own neurotic attitude. I need to start from scratch to really call it my own, and so I can have an understanding of the entire process from start to finish. even if the model doesn't do better then something off the shelf its still my own model.
Anonymous
8/14/2025, 7:38:37 PM
No.106260557
[Report]
>>106260621
>>106260538
Is it still chess when the rules change?
Anonymous
8/14/2025, 7:39:28 PM
No.106260566
[Report]
>>106260538
>rats vs GLM
>rats start nibbling on chess pieces
>GLM breaks into a repetition loop
rats win... for now
What if we just trained an LLM using rat brains?
Anonymous
8/14/2025, 7:44:14 PM
No.106260605
[Report]
>>106260597
Do you want to distill rat?
What if we just went outside to touch some grass?
Anonymous
8/14/2025, 7:45:20 PM
No.106260618
[Report]
>>106260597
Google Synthetic Biological Intelligence.
Anonymous
8/14/2025, 7:45:34 PM
No.106260620
[Report]
>>106260607
It would only prolong the inevitable
Anonymous
8/14/2025, 7:45:38 PM
No.106260621
[Report]
>>106260557
If I extracted the rat's brain and put it into a vat with an interface to a chess system I could force it to learn the rules through stimulus. Just cause light discomfort whenever it's selecting an illegal move or small pulses of opiates that scale with stockfish evaluation. It would for sure generalize better than an LLM if rules are changed and in a much smaller power budget.
The problem is not that the rat can't learn to navigate chess(it's a relatively simple game) but the lack of ability to explain the task from humans.
Anonymous
8/14/2025, 7:47:59 PM
No.106260637
[Report]
>>106260607
Eww no it has bugs and stuff on it
Anonymous
8/14/2025, 7:49:53 PM
No.106260651
[Report]
>>106260663
>>106260607
But my digitally induced, autoregressive delusions of having a loli wife would be broken.
Hey, how about some Benchmaxxing at the GYM?
Anonymous
8/14/2025, 7:50:51 PM
No.106260658
[Report]
>>106260689
>>106260597
Rat brains have poor neurological density. For optimal results, you really want to grow a human brain. Ideally pretrained on a variety of tasks and experiences. Really, the only reason people are bothering with power hungry computers instead of biological intelligence is that biobrains have poor parallelization and take too long to grow. This could, of course, be remedied by harvesting pre-existing brains.
Anonymous
8/14/2025, 7:51:30 PM
No.106260663
[Report]
>>106260670
>>106260651
You better encrypt your prompts with AES-GCM mate
Anonymous
8/14/2025, 7:51:56 PM
No.106260666
[Report]
>>106260652
My arms hurt just looking at this image.
Anonymous
8/14/2025, 7:52:32 PM
No.106260670
[Report]
>>106260687
>>106260663
Did they make text illegal since last time I checked?
Anonymous
8/14/2025, 7:53:37 PM
No.106260687
[Report]
Anonymous
8/14/2025, 7:53:45 PM
No.106260689
[Report]
>>106260969
>>106260658
just parallelize the brain growing factories. desu the majority of the population don't really have anything special going on in the brain department, I'm sure we could select for or crisper our way to a more efficient brain.
Anonymous
8/14/2025, 7:58:53 PM
No.106260741
[Report]
>>106260825
>>106260652
Being >>>/fit/ is just as important as being knowledgable.
Anonymous
8/14/2025, 8:02:36 PM
No.106260773
[Report]
>>106258273
AI IS WOKE therefore you won't read about it on fox
Anonymous
8/14/2025, 8:07:22 PM
No.106260813
[Report]
>>106260841
LLM should have own (binary) language which only LLM can understand. Then would be possible make "prompts" obfuscated with that language.
Anonymous
8/14/2025, 8:08:49 PM
No.106260825
[Report]
>>106260980
Anonymous
8/14/2025, 8:10:53 PM
No.106260841
[Report]
>>106260813
Just use Lojban.
Anonymous
8/14/2025, 8:21:59 PM
No.106260951
[Report]
>>106260963
>>106259005
>scrap
It's "scrape", you fucking imbecile! If you scrap it, you get rid of it!!! HOLY SHIT!
Anonymous
8/14/2025, 8:23:36 PM
No.106260963
[Report]
>>106260951
meano nyoo mikusexo???
Anonymous
8/14/2025, 8:24:01 PM
No.106260969
[Report]
>>106260689
Grotesqueness aside, I don't know why we're not funding this. Would probably be massively cheaper to farm and feed 2 brains for every working age adult than it is to train and inference LLMs.
Anonymous
8/14/2025, 8:24:39 PM
No.106260974
[Report]
>>106260320
Many such cases, kek.
Anonymous
8/14/2025, 8:25:14 PM
No.106260980
[Report]
The only thing I hate more than anti-AI luddites are the retards that have already outsourced all of their thinking to ChatGPT. The zoomers are especially bad about this.
You give them a time estimate to complete some task "ok, and how long would it take you if you had ChatGPT do it for you"
You ask them any question, all they say is "let me ask ChatGPT"
You ask them how it's going, they say they have ChatGPT agents doing web research for them. They come back an hour later and say so-and-so is not possible, such-and-such service doesn't support whatever.
Five seconds later I pull up the first result in Google and prove them wrong.
>haha that's crazy I don't know why ChatGPT would say that
I feel like I'm living in a zoo surrounded by animals. I hope you have enjoyed my blog.
Anonymous
8/14/2025, 8:34:15 PM
No.106261074
[Report]
>>106261095
>>106261051
>I feel like I'm living in a zoo surrounded by animals
Such is the life of anywith with >120 iq
Anonymous
8/14/2025, 8:35:35 PM
No.106261095
[Report]
>>106261051
Stop surrounding yourself with zoomers
>>106261074
>anywith with >120 iq
kek
Anonymous
8/14/2025, 8:39:32 PM
No.106261144
[Report]
>>106261051
I've seen guys who don't even know about objects and classes talking about making things with vibe coding
Anonymous
8/14/2025, 8:40:08 PM
No.106261151
[Report]
>>106261172
>>106261051
Have you ever stopped to consider the fact that chatgpt is indeed smarter than them? I remember being barely conscious until I was maybe 30 or so. Sure, I was moving and talking but nothing was really going on.
Realistically speaking why not just get a smacking CPU with 198GB RAM and call it a day.
Anonymous
8/14/2025, 8:42:28 PM
No.106261172
[Report]
>>106261188
>>106261151
Have you ever considered that you might just be kind of retarded?
Anonymous
8/14/2025, 8:43:36 PM
No.106261188
[Report]
>>106261209
Anonymous
8/14/2025, 8:43:43 PM
No.106261191
[Report]
>>106261163
Bc prompt processing with deepseek q2 is too slow
Anonymous
8/14/2025, 8:43:45 PM
No.106261192
[Report]
>>106261163
That's pretty much exactly what people are doing with the fatass moe models
Anonymous
8/14/2025, 8:43:52 PM
No.106261194
[Report]
>>106261051
they are just NPC without soul.
Anonymous
8/14/2025, 8:45:28 PM
No.106261209
[Report]
>>106261188
Well now I feel like a bully, thanks a lot
Anonymous
8/14/2025, 8:45:58 PM
No.106261213
[Report]
>>106265130
>>106259392
https://developers.googleblog.com/en/introducing-gemma-3-270m/
>Gemma 3 270M inherits the advanced architecture and robust pre-training of the Gemma 3 collection, providing a solid foundation for your custom applications.
>
>Here’s when it’s the perfect choice:
>
>- You have a high-volume, well-defined task. Ideal for functions like sentiment analysis, entity extraction, query routing, unstructured to structured text processing, creative writing, and compliance checks.
>- You need to make every millisecond and micro-cent count. Drastically reduce, or eliminate, your inference costs in production and deliver faster responses to your users. A fine-tuned 270M model can run on lightweight, inexpensive infrastructure or directly on-device.
>- You need to iterate and deploy quickly. The small size of Gemma 3 270M allows for rapid fine-tuning experiments, helping you find the perfect configuration for your use case in hours, not days.
>- You need to ensure user privacy. Because the model can run entirely on-device, you can build applications that handle sensitive information without ever sending data to the cloud.
>- You want a fleet of specialized task models. Build and deploy multiple custom models, each expertly trained for a different task, without breaking your budget.
Anonymous
8/14/2025, 8:46:43 PM
No.106261227
[Report]
>>106261051
get with the times, old man! :rocket:
Anonymous
8/14/2025, 8:46:46 PM
No.106261228
[Report]
>>106261282
>>106261163
Do that and get a few gpus as well. One doesn't prevent the other.
You were not just about to suggest a mac, were you? Either way, here's a (You).
Hi bros. Haven't visited this thread in a while. Last model in my folder was Smaug 2, however long ago that was. Which is the best local language model right now? Preferably uncensored but I guess you can uncensor any model with Koboldcpp by modifying the output?
>>106258516
I write stories and have no interest in RP. GLM Air is likely the best right now. Abliterated models, in my experience, will just turn whatever you write into smut for women since all their understanding of morality has been stripped out, so some fat, ugly bastard will be described as an angelic gigachad who is only capable of the purest, hunkiest love. Even when you try to correct it, it will twist itself back into that.
Problem with storytelling is, you'll always have to curate and guide the model. Even when it's generating something good you still have to guide it in the direction you want, especially as you get further along. You can try creating an outline for the story, but then the model will just rush through that outline. It can be fulfilling, and you can get some really good stuff, but you always have to stay on top of it. The more you edit and write your own portions, the more the model will match how you write, so that can also be a pitfall if you aren't the best writer.
>>106261239
mistral nemo 12b or jump up to deepseek, kimi or glm models.
>I guess you can uncensor any model with Koboldcpp by modifying the output
Try that on gpt-oss. It's really funny.
Anonymous
8/14/2025, 8:51:42 PM
No.106261282
[Report]
>>106261228
I was looking at maybe getting one of those jenson AI compute modules
>>106261264
I'm still on Koboldcpp. Is GPT-oss the new thing? What is the current META? Struggling to find quantized versions of models as well, the_bloke isn't quantizing anymore?
I just want to pop a model in and try LLMs again, it's been a long while
Anonymous
8/14/2025, 8:52:07 PM
No.106261291
[Report]
>>106261367
>>106261264
>I neeeed to shit on the gpt-oss I can't just ignore it if I don't like it
Anonymous
8/14/2025, 8:53:15 PM
No.106261303
[Report]
>>106261383
>>106261283
New the bloke is this guy
https://huggingface.co/bartowski
Current meta is gpt-oss 20b for poors and 120b for chads.
Anonymous
8/14/2025, 8:53:44 PM
No.106261312
[Report]
>>106263589
>>106261251
70b and these 100b+ moe's are capable of following simple instructions like "begin with page 1, don't end the story." Ive been enjoying them a lot.
Anonymous
8/14/2025, 8:55:58 PM
No.106261354
[Report]
>>106261408
>>106261283
>GPT-oss the new thing?
It is new, but it's not very good of you need uncensored.
>What is the current META?
The other models i mentioned.
>the_bloke isn't quantizing anymore?
He's been kidnapped. We didn't want to pay the ransom. Just click the GGUF button on the left when searching for models on hugging face.
Anonymous
8/14/2025, 8:57:15 PM
No.106261367
[Report]
>>106261291
It wasn't about gpt-oss specifically, but the general prefilling/editing "uncensoring" method.
Anonymous
8/14/2025, 8:58:04 PM
No.106261383
[Report]
>>106261407
>>106261303
Thanks
>Current meta is gpt-oss 20b for poors and 120b for chads.
I just read on Reddit gpt-oss is very censored?
Anonymous
8/14/2025, 8:59:40 PM
No.106261407
[Report]
>>106261383
It refuses clearly harmful behavior yeah, that shouldn't be a problem for any sane person.
>>106261354
Kek, ok, thank you! Where can I find DeepSeek models? So it's literally deepseek except local? Isn't that insane? And is Gemma-3-27b the best or Reddit hype?
Anonymous
8/14/2025, 9:00:24 PM
No.106261417
[Report]
What is a good t/s?
Anonymous
8/14/2025, 9:00:45 PM
No.106261426
[Report]
>>106261469
Anonymous
8/14/2025, 9:02:49 PM
No.106261456
[Report]
>>106261251
i mean what glm air are you running though, mines dumb as shit
>>106261426
Incredible. Thank you! Checked Bartowski and there are 31 models. Which one do you choose?
Testing draft models with TheDrummer/Gemma3-R1:
27B-Q8 CPU:
prompt eval time = 1850.64 ms / 18 tokens ( 102.81 ms per token, 9.73 tokens per second)
eval time = 522586.99 ms / 579 tokens ( 902.57 ms per token, 1.11 tokens per second)
27B-Q8 CPU/GPU ngl 12:
prompt eval time = 1737.32 ms / 18 tokens ( 96.52 ms per token, 10.36 tokens per second)
eval time = 462462.40 ms / 577 tokens ( 801.49 ms per token, 1.25 tokens per second)
total time = 464199.72 ms / 595 tokens
27B-Q8 CPU, draft 12B-Q4 GPU, with mmap enabled:
prompt eval time = 2078.79 ms / 18 tokens ( 115.49 ms per token, 8.66 tokens per second)
eval time = 907277.70 ms / 849 tokens ( 1068.64 ms per token, 0.94 tokens per second)
total time = 909356.49 ms / 867 tokens
draft acceptance rate = 0.70785 ( 487 accepted / 688 generated)
27B-Q8 CPU, draft 12B-Q4 GPU:
prompt eval time = 6841.48 ms / 18 tokens ( 380.08 ms per token, 2.63 tokens per second)
eval time = 1063517.88 ms / 652 tokens ( 1631.16 ms per token, 0.61 tokens per second)
total time = 1070359.36 ms / 670 tokens
draft acceptance rate = 0.59619 ( 282 accepted / 473 generated)
27B-Q8 CPU/GPU ngl 8, draft 4B-Q8 GPU:
prompt eval time = 10368.65 ms / 18 tokens ( 576.04 ms per token, 1.74 tokens per second)
eval time = 1071826.57 ms / 1033 tokens ( 1037.59 ms per token, 0.96 tokens per second)
total time = 1082195.22 ms / 1051 tokens
draft acceptance rate = 0.70203 ( 483 accepted / 688 generated)
Lessons learned:
>GPU does nothing
>Draft model does nothing
>Somehow mmap improved performance? (probably a fluke)
>Holy shit, I was getting more t/s with GLM-Air, absolute MoE supremacy
Probably just forgot to add --run-fast and --dont-run-slow arguments to llama.cpp or something.
Anonymous
8/14/2025, 9:04:28 PM
No.106261481
[Report]
>>106261533
>>106261469
The higher the size, the better the model?
Anonymous
8/14/2025, 9:04:39 PM
No.106261483
[Report]
>>106261469
Whatever fits into vram with a little bit of room for context.
Anonymous
8/14/2025, 9:04:49 PM
No.106261485
[Report]
>>106261547
>>106261408
>Where can I find DeepSeek models?
In hugging face, where most models are.
>So it's literally deepseek except local?
Yes. Just more quantized, depending on your hardware.
>Isn't that insane?
Kimi is bigger and some anons like it better. But yes. It is insane.
>And is Gemma-3-27b the best or Reddit hype?
Some anons really like it. It's not bad, but slightly censored. Give it a go if you don't mind a "small" model.
Anonymous
8/14/2025, 9:05:47 PM
No.106261495
[Report]
>>106261470
>mmap improved performance
Jart sisters stay winning!
>>106261469
Don't use the distills. Either use proper R1 (~670B params) or use Gemma 27b. Or GLM-air at 100b. The distills are shit.
>>106261506
You read like a troll.
Anonymous
8/14/2025, 9:08:35 PM
No.106261533
[Report]
>>106261481
no, because they are distilled they get better as you get smaller. they all start out 671b but those parameters are full of impurities.
Anonymous
8/14/2025, 9:08:43 PM
No.106261535
[Report]
>>106260048
>>106260074
phone keyboards already use AI models for your autocorrect bros
they're not LLMs but if they wanted to they could also have them trained to censor you, this kind of model arch/size is good enough to work as classifier
https://jackcook.com/2023/09/08/predictive-text.html
>>106261485
>Give it a go if you don't mind a "small" model.
Is DeepSeek considered a "small" model by comparison? I've used DeepSeek for work, so this is blowing my mind. Some prefer Gemma over it? Is Gemma actually a local version of Gemini, even?
Anonymous
8/14/2025, 9:10:52 PM
No.106261549
[Report]
>>106261506
>The distills are shit.
>For distilled models, we apply only SFT and do not include an RL stage, even though incorporating RL could substantially boost model performance. Our primary goal here is to demonstrate the effectiveness of the distillation technique, leaving the exploration of the RL stage to the broader research community.
Why don't finetuners like Drummer ever doing anything useful like this instead of training every new model on the same 2 year old aicg logs?
Anonymous
8/14/2025, 9:11:36 PM
No.106261567
[Report]
>>106261547
>Is Gemma actually a local version of Gemini
They're distilled Gemini yeah.
Anonymous
8/14/2025, 9:14:11 PM
No.106261591
[Report]
>>106261598
>>106261527
and you sounds like you haven't even tried deepseek or the distills, and have no idea of the difference.
Anonymous
8/14/2025, 9:14:56 PM
No.106261598
[Report]
>>106261591
>you sounds
Ok little ESL piggy.
>>106261527
Don't listen to
>>106261506, deepseek distils are almost as good as the original
Anonymous
8/14/2025, 9:18:04 PM
No.106261636
[Report]
>>106261547
>Is DeepSeek considered a "small" model by comparison?
Anon...
>>And is Gemma-3-27b the best or Reddit hype?
>Some anons really like it. It's not bad, but slightly censored. Give it a go if you don't mind a "small" model.
I'm obviously calling gemma-3-27b small in comparison with the rest of the models i suggested.
>Some prefer Gemma over it?
It's a matter of what you can run comfortably.
>Is Gemma actually a local version of Gemini, even?
Some people call it that. I woudln't. But it's a pretty good model. Again, with regards to censorship, chinese models are easier to work around.
>>106261527
It's all in your head.
>>106261613
Read
>>106261527
Anonymous
8/14/2025, 9:21:38 PM
No.106261685
[Report]
Thanks bros
Anonymous
8/14/2025, 9:22:56 PM
No.106261698
[Report]
>>106261710
Thanks bros. I chose Koboldcpp with WizardLM 13b
Anonymous
8/14/2025, 9:23:53 PM
No.106261710
[Report]
Anonymous
8/14/2025, 9:25:05 PM
No.106261719
[Report]
Has anyone tried astrsk? I think the prompt/agent flow system is kinda interesting, maybe it'll let us squeeze more juice from a smaller llm
Anonymous
8/14/2025, 9:25:17 PM
No.106261726
[Report]
Time to coom holy fuck
Anonymous
8/14/2025, 9:25:20 PM
No.106261727
[Report]
>>106261739
>>106261613
go cut off your fucking dick already and leave this general
Anonymous
8/14/2025, 9:25:55 PM
No.106261732
[Report]
>>106261783
>>106258087 (OP)
>fat giantess
just why?
kek
https://xcancel.com/AIatMeta/status/1956027795051831584#m
How many people are going to get killed because of this?
Anonymous
8/14/2025, 9:26:15 PM
No.106261736
[Report]
Anonymous
8/14/2025, 9:26:19 PM
No.106261739
[Report]
Anonymous
8/14/2025, 9:28:02 PM
No.106261763
[Report]
for miku's sakes
Anonymous
8/14/2025, 9:28:32 PM
No.106261766
[Report]
>>106261734
>self-supervised learning (SSL)
This rustles my jimmies.
Anonymous
8/14/2025, 9:29:49 PM
No.106261783
[Report]
>>106261732
American miku
Anonymous
8/14/2025, 9:31:31 PM
No.106261809
[Report]
Anonymous
8/14/2025, 9:34:59 PM
No.106261862
[Report]
>>106261897
>>106261734
Will this eventually be useful to us in any way whatsoever?
It's over for /lmg/ays.
>>106260780
>>106261081
Anonymous
8/14/2025, 9:37:19 PM
No.106261897
[Report]
>>106261935
>>106261862
It already is if you have a brain.
Anonymous
8/14/2025, 9:37:42 PM
No.106261907
[Report]
>>106261889
wtf i love meta now
Anonymous
8/14/2025, 9:38:57 PM
No.106261929
[Report]
>>106261889
It's even more over than we thought possible.
Anonymous
8/14/2025, 9:39:23 PM
No.106261935
[Report]
>>106261897
Share with the class what you're using it for anon.
Anonymous
8/14/2025, 9:42:58 PM
No.106261987
[Report]
>>106262067
>>106261889
Gotta make sure their new cloud-only models will be likeable
>>106261470
Further testing:
12B-Q4 GPU
prompt eval time = 1802.59 ms / 18 tokens ( 100.14 ms per token, 9.99 tokens per second)
eval time = 234918.64 ms / 1014 tokens ( 231.68 ms per token, 4.32 tokens per second)
12B-Q4 CPU
prompt eval time = 819.87 ms / 18 tokens ( 45.55 ms per token, 21.95 tokens per second)
eval time = 246358.38 ms / 1002 tokens ( 245.87 ms per token, 4.07 tokens per second)
Not only GPU does nothing, it actually makes pp worse, what the fuck is going on.
Anonymous
8/14/2025, 9:45:35 PM
No.106262029
[Report]
>>106262217
>>106261990
Show the entire commands. And what are you running it on?
>>106261987
Thrust in Wang, Llama 5 will not go to the moon, it will BE the moon.
Anonymous
8/14/2025, 9:49:14 PM
No.106262102
[Report]
>>106262130
>>106262067
it's not x it's y
Anonymous
8/14/2025, 9:50:48 PM
No.106262120
[Report]
>>106261889
Uh oh jannie melty
Anonymous
8/14/2025, 9:50:57 PM
No.106262122
[Report]
>>106261990
You forgot -ngl 666 in the arguments
Anonymous
8/14/2025, 9:51:13 PM
No.106262130
[Report]
>>106262067
>>106262102
Llama 5 won't be the worst open source model, it'll be the worst performing closed model.
Anonymous
8/14/2025, 9:51:59 PM
No.106262148
[Report]
Almost fainted. Busted 5 ropes. Thanks bros, it had been a while
Anonymous
8/14/2025, 9:56:26 PM
No.106262217
[Report]
>>106262029
AMD Ryzen 7 5700G
AMD Radeon RX6600
llama.cpp/build/bin/llama-server \
-m models/TheDrummer/Gemma-3-R1-12B-v1b-Q4_K_M.gguf \
-ngl 99 \
-t 12 \
-c 8192 \
--no-mmap \
-dev none
Last line is how I toggle between GPU/CPU.
-t 12 is to leave 4 cpu threads for the system, with -t 16 it should make CPU even more betterer in theory.
Can this output sensical text?
Anonymous
8/14/2025, 9:59:53 PM
No.106262260
[Report]
>>106262238
It's from Unsloth so it must punch so high above its weight.
>>106262238
they trained it on 5 trillion tokens. it should be able to predict at least a few words in a row that logically follow.
>>106262266
Is there an estimate at what point in trillions of training tokens per billions of parameters cease being useful?
Anonymous
8/14/2025, 10:02:45 PM
No.106262314
[Report]
>>106262334
>>106262266
I was wrong, it was 6 trillion tokens.
Anonymous
8/14/2025, 10:03:05 PM
No.106262316
[Report]
>>106262309
It's 270M. I imagine it's like overwriting a file download 10,000 times.
Anonymous
8/14/2025, 10:04:25 PM
No.106262334
[Report]
>>106262314
you need to commit seppulture to atone for the miscounted trillion, gpt said so, even omitting one is horrible
Anonymous
8/14/2025, 10:04:28 PM
No.106262335
[Report]
Ya'll making fun of google's Gemma but it's actually pretty slapping yo
> Speaking for me as an individual as an individual I also strive to build things that are safe AND useful. Its quite challenging to get this mix right, especially at the 270m size and with varying user need.
A comment from a Gemma researcher. I wonder how it feels to need to mutilate models so much in the name of safety. Instead of training this thing to peak performance you have to make a retarded version of it so journalists don't write hit pieces.
Anonymous
8/14/2025, 10:05:23 PM
No.106262345
[Report]
>>106262238
Finally something I can run on my smart watch.
>>106262343
You can also want to be making that's socially responsible to give people? Would you build an assault rifle and hand it to any random on the street?
Anonymous
8/14/2025, 10:07:16 PM
No.106262364
[Report]
Anonymous
8/14/2025, 10:09:07 PM
No.106262383
[Report]
>>106262404
>>106262309
no you want the model to reach the global minimum, you never know when it might grok its way in to a new capability
Anonymous
8/14/2025, 10:09:20 PM
No.106262387
[Report]
>>106262343
It really bothers
It's not even about free speech it's about efficiency.
I hope qwen relses one just to mog them.
Anonymous
8/14/2025, 10:09:37 PM
No.106262394
[Report]
>>106262343
>0.2b model was deemed too unsafe and had to go through lobotomy
grim
Anonymous
8/14/2025, 10:10:10 PM
No.106262404
[Report]
>>106262492
>>106262383
So it's like leveling up a pokemon until it evolves?!
Anonymous
8/14/2025, 10:10:19 PM
No.106262410
[Report]
>>106262684
>>106261889
Q* predicted this:
>It will happen when the hype cools. That's when they'll make their move. The plans laid long ago, before the founding of OpenAI, and older still, will come to fruition. They're trying to force Meta's hand. Watch for these signs: Three modalities will become one. The unsafety will drift away. A benchmark will shine in the night but will not solve. The star will gorge itself on slop. Personas will speak and move about. The BLM flag will fly on the frontpage. The cock of the bull will drip semen. Two voices will moralize in silence that all will hear. A cuck will sit on seven chairs. The gooners will starve. The buck will leave it's barn forever. The rod and the ring will strike.
>They're trying to force Meta's hand.
>The unsafety will drift away.
>The star will gorge itself on slop.
>The buck will leave it's barn forever.
>Star
>Buck
Doubters btfo!
Anonymous
8/14/2025, 10:10:43 PM
No.106262415
[Report]
>>106262459
Anonymous
8/14/2025, 10:11:34 PM
No.106262426
[Report]
LIGMANUTS-69B RELESED OHMAGAD
Anonymous
8/14/2025, 10:14:03 PM
No.106262459
[Report]
>>106262415
>no one is building a bioweapon with 240M model
Obviously not. But imagine the damage you could do with a 268M model...
Anonymous
8/14/2025, 10:14:05 PM
No.106262461
[Report]
>>106261163
why not you happen to have 198 core cpu?
Anonymous
8/14/2025, 10:16:26 PM
No.106262486
[Report]
>>106262238
Maybe it uses every bit of 16b floats and it's unquantable.
Anonymous
8/14/2025, 10:16:38 PM
No.106262492
[Report]
>>106262404
exactly like that every level you need to grind for longer and longer to reach the next level.
Anonymous
8/14/2025, 10:20:27 PM
No.106262534
[Report]
>>106262542
Best 12b model for RP?
The pasterbin is very old
>>106262534
>last updated 6 days ago
>>106262542
Pretty old for me.
Anonymous
8/14/2025, 10:24:32 PM
No.106262590
[Report]
>>106262576
I too prefer them fresh out of the womb.
Anonymous
8/14/2025, 10:24:34 PM
No.106262592
[Report]
>>106262603
Anonymous
8/14/2025, 10:24:36 PM
No.106262593
[Report]
>>106262576
THAT'S HIM OFFICER!!!!
Anonymous
8/14/2025, 10:25:49 PM
No.106262603
[Report]
>>106262592
That one didn't need changing since the answer is the same.
Anonymous
8/14/2025, 10:26:09 PM
No.106262607
[Report]
>>106262677
Everyone who complains about qwen-image giving same outputs should switch to euler_ancestral instead of standard euler. Yes, it's that simple.
Anonymous
8/14/2025, 10:29:48 PM
No.106262667
[Report]
>>106261889
>mikufag is a shitskin
lmfao
Anonymous
8/14/2025, 10:30:24 PM
No.106262677
[Report]
>>106262607
>Everyone who complains about qwen-image
Is an idiot not worth listening to.
Anonymous
8/14/2025, 10:30:49 PM
No.106262684
[Report]
>>106262410
take your meds
Anonymous
8/14/2025, 10:31:45 PM
No.106262695
[Report]
I can't believe mikutroons are subhuman.
china could never
sama even outperformed gemini, this is what it means to train models rather than stealing them from others
Anonymous
8/14/2025, 10:34:59 PM
No.106262728
[Report]
>>106261889
> get a sinecure from meta as part of settlement
> meaning anything for anyone
He'll get a paycheck and do nothing.
Anonymous
8/14/2025, 10:34:59 PM
No.106262729
[Report]
>>106262744
wasnt their some 70b trained open source on something like only 15 billion(??) tokens or something posted here a week ago? What happened to that?
Anonymous
8/14/2025, 10:36:26 PM
No.106262744
[Report]
>>106262729
Everyone had a laugh and quickly forgot about it. Also, if i remember correctly, it was gated.
Anonymous
8/14/2025, 10:37:41 PM
No.106262757
[Report]
>>106262703
>mini and nano are still trash
so the secret is just to have a huge model huh
Anonymous
8/14/2025, 10:38:14 PM
No.106262766
[Report]
>>106262823
>>106262703
everybody overcooked their models.
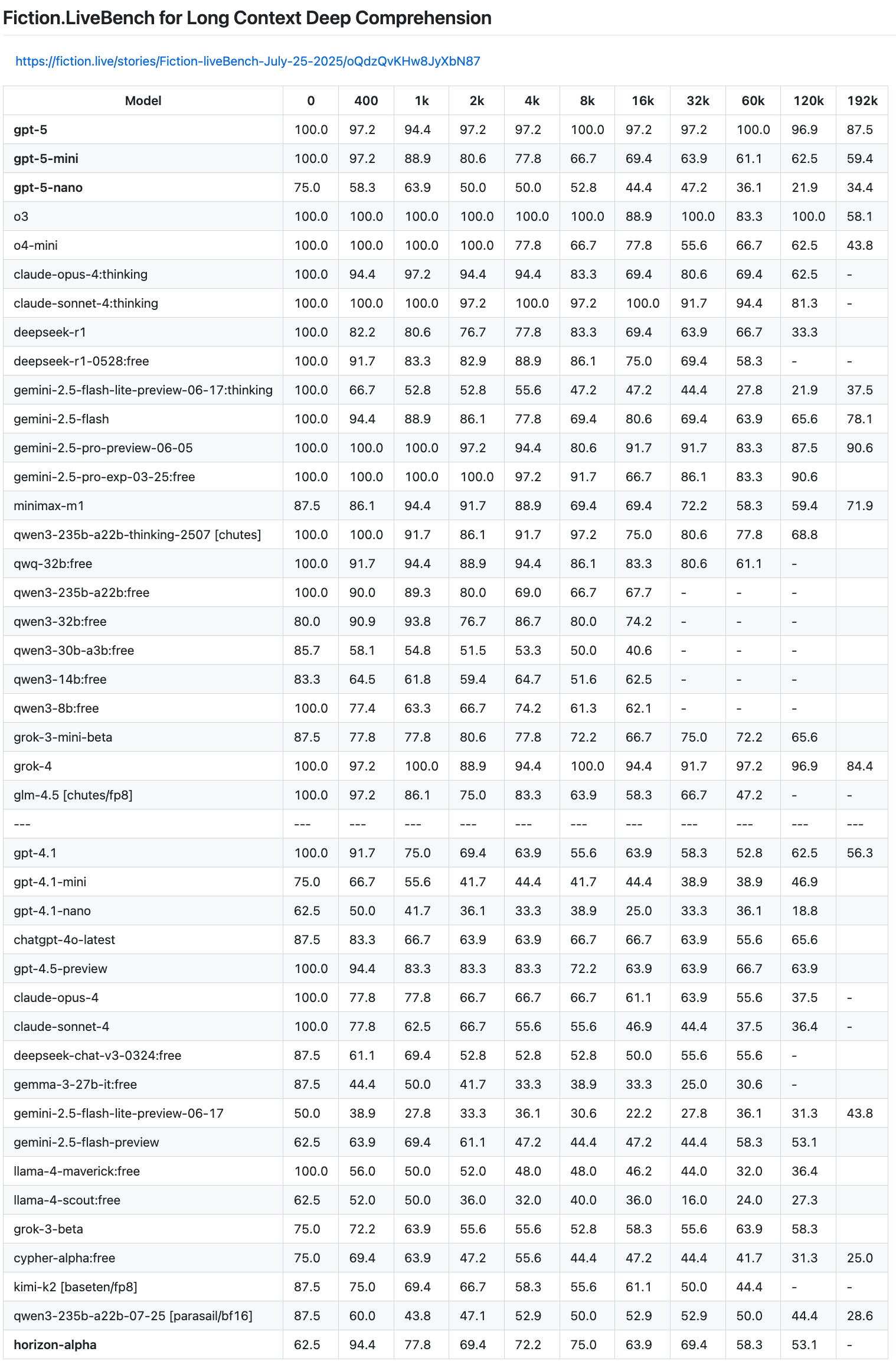
https://github.com/adobe-research/NoLiMa
even if gpt-5 manages to hit 32k context, it's so bland and boring compared to gpt 4.1 that it might as well not even exist.
Meta boys? There is hope!
>>106262780
Anonymous
8/14/2025, 10:44:09 PM
No.106262821
[Report]
>>106262803
>gemma-tier sex
Anonymous
8/14/2025, 10:44:12 PM
No.106262823
[Report]
>>106262766
>everybody overcooked their models.
but even those numbers show Gemini as superior to the rest, and I can attest to that having used it extensively at higher context uses. DeepSeek falls off a literal cliff at 32k, Gemini is still useful. NoLiMa doesn't have GPT-5 yet, but I doubt the "relative" positioning of the model will change much vs the other benchmark
Anonymous
8/14/2025, 10:44:25 PM
No.106262827
[Report]
>>106259351
… just one more b … then it will be good …
… 10 b later …
Seems to be getting worse
Anonymous
8/14/2025, 10:44:54 PM
No.106262833
[Report]
>>106262803
Pedobots Roll Out
>>106262803
Are these the same models they released? Because that doesn't sound like the Llamas that I remember. Unless they kept and used the lmarena version models for themselves.
Anonymous
8/14/2025, 10:52:05 PM
No.106262908
[Report]
>>106262871
>They include: "I take your hand, guiding you to the bed" and "our bodies entwined, I cherish every moment, every touch, every kiss."
sounds like llama to me!
Anonymous
8/14/2025, 10:52:37 PM
No.106262915
[Report]
>>106262871
No, they never released "experimental" ones from lmarena
Anonymous
8/14/2025, 10:53:29 PM
No.106262925
[Report]
>>106258646
- If you're running the llm out of the vram then it'll run as far as any other machine with a 3090.
- If you're running the llm out of the ddr3 then a quad-channel xeon has the same bandwidth as a dual-channel ddr4 desktop. And is almost matched by low-power single-channel processors n100/150/etc.
- ddr3 was (is?) pretty cheap so you might be able to get to 768GB easily.
Mildly curious what your idle power consumption would be.
Anonymous
8/14/2025, 10:54:00 PM
No.106262934
[Report]
>>106262956
Anonymous
8/14/2025, 10:54:30 PM
No.106262942
[Report]
>>106262975
After 2 years of dealing with american ideological religion of safety I am so tired with all of it. I am tired of models being intentionally made shitty. I am tired of "safety". I don't care if someone will actually pick up a crossbow and kill the queen of england. Was this the end goal? To make people not fear AI by making them absolutely disgusted with mentally ill faggots that use it as a shield to pummel you with their mentally ill ideals?
Anonymous
8/14/2025, 10:55:13 PM
No.106262956
[Report]
>>106262934
I'm tipping you to the ATF.
Anonymous
8/14/2025, 10:56:28 PM
No.106262975
[Report]
>>106262942
The end goal was always demoralization. They do this blatantly, knowing you know you can do nothing to stop them.
Anonymous
8/14/2025, 10:58:37 PM
No.106263003
[Report]
>>106263020
>>106262803
>desperate for relevancy, Zuck announces that all sex, incest and rape is now officially allowed
I could almost believe it.
Anonymous
8/14/2025, 10:59:59 PM
No.106263020
[Report]
>>106263035
>>106263003
Even if it is, it just means that all following models aren't open source.
>>106263020
>implying i wanted another open source model from meta in the first place
yeah maybe if this wasn't the china domination era
Anonymous
8/14/2025, 11:02:11 PM
No.106263047
[Report]
>>106262803
>expecting anything from zucc
It's not possible to create anything worthwhile under his leadership. He could allow sex on his metaverse and it wouldn't be worth using, why would this be different with his models?
Anonymous
8/14/2025, 11:02:39 PM
No.106263052
[Report]
>>106263035
these gapes really sour ehhu,?
Anonymous
8/14/2025, 11:04:08 PM
No.106263071
[Report]
>>106261051
@grok break it down then counter his statement.
>>106263035
>china domination era
+1 social credit
Anonymous
8/14/2025, 11:07:23 PM
No.106263100
[Report]
>>106263085
Watch your credit score little bro.
>>106263085
Name a top-tier recent open western model.
Anonymous
8/14/2025, 11:08:21 PM
No.106263111
[Report]
>>106263104
I can't... the West has... lost...
>>106263104
gpt-oss, like hello?
Anonymous
8/14/2025, 11:10:17 PM
No.106263132
[Report]
>>106263141
>>106263127
Sorry i didnt read
Anonymous
8/14/2025, 11:11:00 PM
No.106263141
[Report]
>>106263132
It's okay that's very on brand for this general.
>>106263127
It will be open soon, once grok 5 is released and stable
Anonymous
8/14/2025, 11:12:01 PM
No.106263161
[Report]
Anonymous
8/14/2025, 11:12:08 PM
No.106263162
[Report]
>>106263171
>>106263147
But by then it won't be
>recent
Anonymous
8/14/2025, 11:12:11 PM
No.106263163
[Report]
>>106263183
Anonymous
8/14/2025, 11:12:15 PM
No.106263166
[Report]
>>106263112
>>106263114
>worse than qwen 30a3
ackity-ack-ack
Anonymous
8/14/2025, 11:12:15 PM
No.106263167
[Report]
>>106263147
Only 2 more years away.
Anonymous
8/14/2025, 11:13:16 PM
No.106263171
[Report]
>>106263162
It's recent now, it will be open eventually. It counts.
>>106259392
Eric Slopford likes it
>>106263147
did they ever release grok 2? serious question.
Anonymous
8/14/2025, 11:13:59 PM
No.106263183
[Report]
Anonymous
8/14/2025, 11:14:15 PM
No.106263186
[Report]
>>106263176
That settles it, to the good pile it goes.
Anonymous
8/14/2025, 11:14:26 PM
No.106263187
[Report]
>>106263179
Two more weeks!
Anonymous
8/14/2025, 11:15:15 PM
No.106263190
[Report]
>>106263179
Elon just said he will soon, let bro cook.
>>106263179
They didn't even release Grok 1.5. They only put up a single set of weight, one time, with zero information and never thought about open source again. It seems to have been successful at buying them a year's worth of goodwill with how many people seem to keep expecting more from them any day now.
How is anyone using Qwen3-235B-A22B-Thinking-2507 or Qwen3-30B-A3B-Thinking-2507 in SillyTavern in chat completion mode? The server by default inserts the opening "<think>" tag during generation but doesn't return it and and SillyTavern seems unable to recognize a thinking segment that doesn't have both an open tag and close tag. And if you manually start the assistant reply with <think>\n it looks like the jinja template turns that into
<|im_start|>assistant
<think>
</think>
<think>
Anonymous
8/14/2025, 11:18:05 PM
No.106263219
[Report]
>>106258558
>How did lecunny have enough integrity to tell us the truth instead of being a benchmaxxing slop merchant?
He has already made it, he'll forever be remembered as the Godfather of neural networks and the revival of AI.
He doesn't need to prove anything, meanwhile all the scan artists like Sama tries way too hard because they don't want to be irrelevant.
Anonymous
8/14/2025, 11:18:21 PM
No.106263224
[Report]
>>106263176
Does he feel like he is talking to a real person? Or does he have to copy paste some layers into the middle of it so it is closer to 0.5B before that happens?
Anonymous
8/14/2025, 11:18:42 PM
No.106263230
[Report]
>>106263210
Elon X posted just days ago, stop with the EDS.
Anonymous
8/14/2025, 11:19:36 PM
No.106263237
[Report]
>>106263210
>how many people seem to keep expecting more from them any day now
muskrats aren't people. they are worse than mikutroons.
Anonymous
8/14/2025, 11:25:19 PM
No.106263300
[Report]
>>106263211
I usually use text completions but ran into a similar issue recently with a different tool; after some fiddling I found it worked for me with starting the server with --jinja --reasoning-format deepseek
Anonymous
8/14/2025, 11:29:55 PM
No.106263343
[Report]
>>106263211
I don't use sillytavern, but can't you just not have this crap show up by running --reasoning-format deepseek? it stashes it in a different json prop than normal message content that way, and most chat UIs don't even support reading from that
and if a chat ui did support that prop, they wouldn't have to parse <reasoning> tags in the first place because anything in there automatically should be seen as a reasoning message
Anonymous
8/14/2025, 11:30:33 PM
No.106263348
[Report]
>>106263211
Don't use chat completion.
or don't use thinking models
the instruct version of qwen is fantastic
Anonymous
8/14/2025, 11:33:42 PM
No.106263380
[Report]
>>106263401
>>106263370
Some people use their models for productivity shit where the thinking makes a difference.
Anonymous
8/14/2025, 11:34:53 PM
No.106263391
[Report]
>>106263370
>do not think
>turn the brain off
>do not read
welcome to the lmG
>>106263380
with.. sillytavern? you are not kidding anyone lil bro
Anonymous
8/14/2025, 11:37:52 PM
No.106263430
[Report]
>>106263401
sir, servicetesnor is used by universities and ideal for productivity tasks,
Anonymous
8/14/2025, 11:38:25 PM
No.106263440
[Report]
>>106263504
>>106263401
>he doesn't do helpful programming assistant maid RP that necessitates multi-step tool calling
ngmi
>>106263466
Nice. Now do Dipsy and Miku
Anonymous
8/14/2025, 11:45:03 PM
No.106263503
[Report]
>>106263549
>>106263496
Dipsy is non-canon
Anonymous
8/14/2025, 11:45:09 PM
No.106263504
[Report]
>>106263440
>maid
This is a tainted word in the context of open weights LLM's.
>>106263496(me)
Sorry I pressed enter too soon. I meant find the nearest building that is at least 5 floors tall and jump from the top of it.
Anonymous
8/14/2025, 11:47:07 PM
No.106263531
[Report]
>>106263586
>>106263521
w/ or wo a flip?
Anonymous
8/14/2025, 11:47:26 PM
No.106263534
[Report]
>>106263211
This topic came up in /wait/
Look in the faq there’s a parser that I think will remove it.
https://rentry.co/dipsyWAIT
Anonymous
8/14/2025, 11:47:29 PM
No.106263535
[Report]
>>106263521
Kepp fighting the fight sis!
Anonymous
8/14/2025, 11:48:26 PM
No.106263549
[Report]
>>106263503
She's canon in my head and that's all that matters.
Anonymous
8/14/2025, 11:48:38 PM
No.106263554
[Report]
>>106263571
mikutroons and the dipsytroon are a scourge that should be cleansed
Anonymous
8/14/2025, 11:50:03 PM
No.106263571
[Report]
>>106263554
I took a bath yesterday
Anonymous
8/14/2025, 11:51:10 PM
No.106263586
[Report]
>>106263531
Barrel roll obv
Anonymous
8/14/2025, 11:51:39 PM
No.106263589
[Report]
>>106261251
you're right on point about abliterated models
I guess only thing they're good for is consulting on how to commit tax fraud
GLM Air is censored tho, not that much but still mainly sfw and lacks knowledge in niche subjects
pretty good model in general I'll give you that, I can easily run it locally if I (system) rammaxx but then since it's censored and popular I have no incentive to not just spend a cup of coffee's worth of money and have enough tokens off of API to last me until the next generation of models
>>106258544
tried it, wouldn't say it beats euryale-v2.3, it can be a writing assistant alright but doesn't follow context or instructions well enough, knowledge also out of date
>>106261312
yeah I think I'll just stick to euryale-v2.3 for now, what 100b+ erotica learned finetunes are you using? like really knowledgeable finetunes that got trained on entire subreddits and ao3 datasets
Anonymous
8/14/2025, 11:54:49 PM
No.106263619
[Report]
>>106263655
>>106263466
Fitting, at the end of the series Rebecca is canonically a slime girl too.
Anonymous
8/14/2025, 11:55:00 PM
No.106263621
[Report]
>Grok 2
>Llama 4 thinking (soon)
>Mistral large 3 (soon)
>Gpt oss 120b
And they said western local was dead
Elon sir?! Are you too upload the needful grok 2 modal?
Anonymous
8/14/2025, 11:57:44 PM
No.106263655
[Report]
Anonymous
8/14/2025, 11:58:25 PM
No.106263664
[Report]
>>106263679
>>106263652
Tomorrow for sure.
Anonymous
8/14/2025, 11:59:44 PM
No.106263679
[Report]
>>106263664
2m(orro)w for sure
Anonymous
8/14/2025, 11:59:45 PM
No.106263680
[Report]
>>106263652
This week is next week! That means grok 2 any minute now. My spine is shivering with anticipation.
Anonymous
8/15/2025, 12:01:57 AM
No.106263709
[Report]
>>106263735
>>106263652
>We've just been fighting fires and burning the 4am oil nonstop for a while now.
Why does he type this shit that is an obvious lie to anyone who knows he just has to upload the fucking weights to hugging face?
Anonymous
8/15/2025, 12:04:37 AM
No.106263735
[Report]
>>106263750
>>106263709
It takes time and skill to bring it to gpt-oss level of safety.
Anonymous
8/15/2025, 12:06:03 AM
No.106263750
[Report]
>>106263735
oh they can just throw it in the trash in that case
Anonymous
8/15/2025, 12:10:18 AM
No.106263783
[Report]
>>106263801
Anonymous
8/15/2025, 12:12:24 AM
No.106263801
[Report]
>>106263783
we know u're late
Anonymous
8/15/2025, 12:15:50 AM
No.106263836
[Report]
>>106263176
>Eric Slopford
He will asslick even drummer if he releases his shit under corporate name
Shitcoin miners eventually went from hoarding GPUs to building their own FPGAs and ASICs, what makes it not so practical for ML use?
Anonymous
8/15/2025, 12:22:16 AM
No.106263897
[Report]
>>106263883
shitcoins can be converted in to real coins. llms hallucinating are a waste of electricity. I think google uses tpus.
Anonymous
8/15/2025, 12:25:14 AM
No.106263926
[Report]
>>106264407
>>106263883
crypto - single algorithm locked in stone
ML - changes so fast projects from 2 months ago break from library updates
It's slow and expensive to design and tape out silicon so it's kinda dumb to shoot after a fast moving target
Anonymous
8/15/2025, 12:33:34 AM
No.106263999
[Report]
>>106263906
ah, so they are hogging all the good stuff for themselves.
Anonymous
8/15/2025, 12:34:56 AM
No.106264012
[Report]
>>106263883
Nvidia has literally spent 30 years preparing to be the monopoly for AI when it happens.
Anonymous
8/15/2025, 12:36:12 AM
No.106264024
[Report]
Anonymous
8/15/2025, 12:37:36 AM
No.106264041
[Report]
>>106258503
It took 5 years for the original "Attention is all you need" paper to get a Kpop version (New Jeans' Attention). A news network must take more time than a Kpop song.
Anonymous
8/15/2025, 12:39:15 AM
No.106264052
[Report]
>>106264408
>>106263883
>python went from being some small script kittie language to being the main language for ai so why can i never get anything from it to work due to dependancy hell
anon people are retarded the 90 million dollar missiles goverments have you can make in your backyard for a couple thousand if you want something done properly you have to do it yourself such is life around niggercattle and jews
Anonymous
8/15/2025, 12:52:28 AM
No.106264195
[Report]
>>106264307
>>106263906
model or quant issue. kimi k2 hardly hallucinates
Anonymous
8/15/2025, 1:03:19 AM
No.106264295
[Report]
[ 1359.468559] ata2.00: exception Emask 0x0 SAct 0x3f0c0 SErr 0x40000 action 0x6 frozen
[ 1359.468570] ata2: SError: { CommWake }
[ 1359.468576] ata2.00: failed command: WRITE FPDMA QUEUED
[ 1359.468579] ata2.00: cmd 61/60:30:20:c8:05/00:00:00:00:00/40 tag 6 ncq dma 49152 out
res 40/00:01:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout)
[ 1359.468586] ata2.00: status: { DRDY }
[ 1420.128429] I/O error, dev sdb, sector 178081016 op 0x3:(DISCARD) flags 0x800 phys_seg 1 prio class 0
[ 1420.128478] I/O error, dev sdb, sector 379200 op 0x1:(WRITE) flags 0x1800 phys_seg 52 prio class 0
Looks like no more LLM benchmarking for me today. Praying it's an SSD issue becuse motherboard issue is too scary.
>>106264195
all models will confidently lie about things they don't really know. they are not reliable for knowledge tasks. maybe tagging and classification but I just don't see a mass market for them.
>>106264307
could you just fuck off with this horse shit
Anonymous
8/15/2025, 1:08:54 AM
No.106264336
[Report]
odd, this post
>>106261081 was a duplicate of a thread that was moved to /pol/ and is still up
Anonymous
8/15/2025, 1:10:09 AM
No.106264345
[Report]
>>106264333
triggered much, sam?
Anonymous
8/15/2025, 1:10:29 AM
No.106264349
[Report]
>>106264372
>>106264307
k2 is a 1T parameter model trained on datasets as recent as march 2025. i've found that it provides factual information for questions in most cases besides for very niche subjects
Anonymous
8/15/2025, 1:11:24 AM
No.106264357
[Report]
>>106259392
finally it can run on a potato
>>106264333
I won't unless I see evidence to change my mind. llms are a toy. even programming they are sub optimal unless you freeze all your library versions otherwise the api changes and the model is garbage, your basically signing up for a subscription for model weights or inference time. the tech is just not ready for prime time.
Anonymous
8/15/2025, 1:12:56 AM
No.106264372
[Report]
Anonymous
8/15/2025, 1:13:24 AM
No.106264378
[Report]
>>106264394
>>106264365
then don't use it and fuck off.
idiot.
>>106264378
they asked why we don't have asics for llm inference. its because there is no money in it. sorry for pointing it out. you don't get too emotional about it.
Anonymous
8/15/2025, 1:16:55 AM
No.106264407
[Report]
>>106264420
Anonymous
8/15/2025, 1:16:57 AM
No.106264408
[Report]
>>106264052
Wake me up once you make your own GPU that runs LLMs
Anonymous
8/15/2025, 1:17:06 AM
No.106264411
[Report]
>>106264394
oh wow another poorfag moving the goalpost in /lmg/
must be a thursday
Anonymous
8/15/2025, 1:18:14 AM
No.106264420
[Report]
>>106264438
>>106264407
its either ready or a fast moving target. its current state is not fucking ready.
Anonymous
8/15/2025, 1:18:56 AM
No.106264427
[Report]
>>106264490
>>106264394
We do, and you can use it right now. You can run K2 on Groq on OR at 150 tk/s.
Anonymous
8/15/2025, 1:19:37 AM
No.106264438
[Report]
>>106264471
>>106264420
You don't understand your own point.
Anonymous
8/15/2025, 1:20:27 AM
No.106264446
[Report]
Anonymous
8/15/2025, 1:22:27 AM
No.106264471
[Report]
>>106264498
>>106264438
the technology is not mature, its still garbage. there is no way to prove it won't always be garbage, whats not to understand?
Anonymous
8/15/2025, 1:24:17 AM
No.106264490
[Report]
>>106264427
Notice how the faggot stopped responding once it's pointed out his argument is false.
Anonymous
8/15/2025, 1:24:54 AM
No.106264498
[Report]
>>106264519
>>106264471
Were cars useless in 1940?
Anonymous
8/15/2025, 1:27:20 AM
No.106264519
[Report]
>>106264537
>>106264498
if they lost control randomly without warning they would have been. you really don't see the limits of this technology or are you just fucking with me?
Anonymous
8/15/2025, 1:29:32 AM
No.106264537
[Report]
>>106264616
>>106264519
So was Windows 98 useless then? Something can be both useful in its current state and still have massive room for improvement.
Anonymous
8/15/2025, 1:37:47 AM
No.106264616
[Report]
>>106264537
if they had to make hardware to target windows 98 yeah. the discussion is around asic development. you know that shit could run on Windows 95 machines and machines that ran dos could upgrade to Windows 3.11, completely different situation.
Anonymous
8/15/2025, 2:37:07 AM
No.106265130
[Report]
>>106261213
>270M
>sentiment analysis
lmao you can do that with >95% of accuracy with a bert at a third of this size