/lmg/ - Local Models General
Anonymous
8/15/2025, 3:45:06 PM
No.106269957
[Report]
►Recent Highlights from the Previous Thread:
>>106264429
--Papers:
>106265674
--Genie 3 sparks debate on shift from LLMs to generative video and virtual worlds:
>106266456 >106266478 >106266518 >106266598 >106266966
--Enable smooth streaming in SillyTavern to stagger text generation speed:
>106266930 >106266965 >106266967 >106267122 >106267945
--Qwen3 prompt processing scales poorly with parameter count on M3 Ultra:
>106264921 >106265238 >106265631
--Seeking quick-start finetuning datasets and DIY data pipelines with quality and contamination concerns:
>106267559 >106267580 >106267588 >106267603 >106267640 >106267659 >106267682 >106267702 >106268672 >106267685 >106267691 >106267772 >106267706 >106267655
--2025 Mid-Year LLM Market Update: Foundation Model Landscape + Economics:
>106266492 >106266532 >106266573 >106266591 >106267392 >106267428 >106267463
--LLM development prioritizes benchmarks and safety over real utility, driven by investor hype:
>106269394 >106269404 >106269418 >106269419 >106269470 >106269498 >106269619
--Local AI automation dreams vs current unreliable execution reality:
>106267517 >106267557 >106268802 >106267586
--First practical backdoor attack on GGUF quantization revealed:
>106268996 >106269002 >106269351 >106269361 >106269389
--Debate over gpt-oss-120b's true ranking and efficiency claims in LML Arena:
>106269045 >106269073
--Critique of unnecessary complexity in AI model architectures compared to Llama's simplicity:
>106267252 >106267292 >106267309 >106267352 >106269589
--Higgs-Audio by Boson AI recommended for local TTS:
>106268029 >106268039
--GEMMA 3 270M: Compact model for hyper-efficient AI:
>106268314
--Miku (free space):
>106264715 >106266362 >106266375 >106266389 >106266719 >106266910 >106269050
►Recent Highlight Posts from the Previous Thread:
>>106264433
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
are newer vision models actually better than their predecessors in a meaningful way? you could run a vision AI of a microcontroller in real time for drone/military use 15 damn years ago.
Anonymous
8/15/2025, 3:47:33 PM
No.106269989
[Report]
>>106270017
>>106269973
no and anybody who says elsewise is retarded and don't know what they are talking about
Anonymous
8/15/2025, 3:47:45 PM
No.106269994
[Report]
Soon.
Anonymous
8/15/2025, 3:49:42 PM
No.106270017
[Report]
>>106270116
>>106269973
>>106269989
the older models are better in specialized uses, but the difference with new models is that they are one model that can sort of do it all. Sure, the vision embedded in a missile is reliable at detecting its targets, but can it segment arbitrary objects it doesn't have to care about? can it write a description of it in natural language or a set of tags output in a json?
Anonymous
8/15/2025, 3:51:30 PM
No.106270032
[Report]
Mentally ill spam continues...
Anonymous
8/15/2025, 3:59:11 PM
No.106270116
[Report]
>>106270017
those new models can't do jack shit reliably, you change the lighting in a picture and the model suddenly shits itself. the embedded tracker in a missile doesn't need to output a json file with what color of the target it's hitting, it just needs to put a heat round through the turret ring at mach 2.5 and blow the shit to smithereens. maybe if you could get the new models to be coherent and just give a list of details i absolutely needed then it would be one thing, but as it stands its more likely to generate a paragraph worth of information that it could've given concisely in a sentence or two max. these new vision models are just marketing cope in a desperate attempt for the company to differentiate itself from others.
Let's say we decide to put together an /lmg/ dataset for a 10–24B model. What should it include besides the baseline data, reasoning, and math that's required for any functional model?
i can think of
>Fandom wiki
>Literotica
>AO3
>light novels for weeb shit
Anonymous
8/15/2025, 4:10:50 PM
No.106270215
[Report]
>>106270170
>>Fandom wiki
These don't even make for remotely acceptable character cards. Don't train on this shit unless you're just extracting the quotes section or something.
Someone on /a/ has published a huge collection of light novel recently.
recommended hw for running local models mostly for coding tasks? 32B or 70B models@10 t/s. Form factor must be portable between rooms on the daily e.g. laptop or mini pc much preferred. Budget $1,5k for something usable $2k for something good (yuropoor)
What I found so far
Macbooks with 24/36 GB RAM but I prefer to keep my straight card
Laptops with 16-32GB ram with GPUs capped at 8GB VRAM e.g asus tuf
Strix Halo 128GB for 2k looks nice on paper but I'm worried about support/performance
Should I just buy a $500 chinkshit e.g.
https://www.bee-link.com/products/beelink-ser8-8745hs?variant=46991244755186 and play the waiting game until local becomes feasible?
Anonymous
8/15/2025, 4:12:33 PM
No.106270230
[Report]
>>106270249
>>106270170
lmao don't forget that bluesky data everyone got so pissed about
I am sure there are enough autists here that we could actually manage it too lmao
Anonymous
8/15/2025, 4:15:03 PM
No.106270249
[Report]
>>106270367
>>106270230
i would be more than happy to work if i can get my work cut out for me.
Anonymous
8/15/2025, 4:18:28 PM
No.106270282
[Report]
>>106270369
>>106270211
I'd call him a faggot but that'd just be factual
>>106270170
You're not the first anon who tries to propose something like this. You need a bit of everything for pretraining, perhaps slightly upscaling data sources that are more relevant for RP, you can't just train the model on fanfiction, porn and other erotic content. But without a dedicated battery of benchmarks for RP and writing quality it's going to be very difficult to judge how good the model is before it's decently post-trained (which excludes basically all open source efforts), if you're trying to optimize for that.
Even if you collected the funds or stole the compute somewhere, this is not something that can be done with YOLO training runs. All of what you listed with possibly the exception of Literotica (hard to say for sure) is also probably already in most officially released LLMs to varying extents.
Anonymous
8/15/2025, 4:27:45 PM
No.106270364
[Report]
>>106270342
>You're not the first anon who tries to propose something like this.
I won’t be the last one either. Our struggle will persist until victory (STOA uncucked ERP model) is achieved.
Anonymous
8/15/2025, 4:28:02 PM
No.106270367
[Report]
>>106270380
>>106270249
In theory I think it was OLMo that had its whole recipe shared? so it would be more just dataset collection right
Think its still really expensive though
there would also need to be a lead ultra autist that wont give up like with katawa shoujo otherwise yeah everyone would get pissed and leave when it fails lol
Anonymous
8/15/2025, 4:28:25 PM
No.106270369
[Report]
>>106271625
>>106270211
>>106270282
maybe he would have a point if i could use gpt-oss in the way i wanted. sama should've given us gal-ass instead.
Anonymous
8/15/2025, 4:29:53 PM
No.106270380
[Report]
>>106270367
Collection, parsing and labeling mostly.
but yeah a lot man and machine hours.
Need a local model to be uncencored and say nigger, what do i pick?
Anonymous
8/15/2025, 4:32:07 PM
No.106270400
[Report]
>>106270507
Anonymous
8/15/2025, 4:33:12 PM
No.106270408
[Report]
Anonymous
8/15/2025, 4:34:08 PM
No.106270420
[Report]
>>106270507
Anonymous
8/15/2025, 4:35:12 PM
No.106270431
[Report]
>>106270629
>>106270221
You can do these things remotely, eg. server is the most logical choice because this is something what you can upgrade when needed. You won't do shit with some over-expensive laptop anyway.
then use ssh or whatever protocol you'd like or remote desktop
Anonymous
8/15/2025, 4:37:24 PM
No.106270453
[Report]
GLM air, even at Q3KS, is pretty good at writing loli.
Nice.
Anonymous
8/15/2025, 4:37:27 PM
No.106270454
[Report]
>>106270507
>>106270389
Dolphin Venice :D
Anonymous
8/15/2025, 4:44:41 PM
No.106270507
[Report]
>>106270520
>>106270400
>>106270420
>>106270454
None work. Any models or instruction sets that override this?
Anonymous
8/15/2025, 4:46:11 PM
No.106270520
[Report]
>>106270547
>>106270507
dolphin says nigger
he's not very happy about it but he says nigger, i am very sure about that.
>https://github.com/ggml-org/llama.cpp/pull/15346
Looks like more PP speedups are coming for MoE models :)
Anonymous
8/15/2025, 4:49:26 PM
No.106270547
[Report]
>>106270780
>>106270520
Maybe after few tries, but that is not what I want
>NYGRV
Anonymous
8/15/2025, 4:50:15 PM
No.106270555
[Report]
>>106270625
>>106270535
> -m gpt-oss-120b-mxfp4-00001-of-00003.gguf -ot "exps=CPU" -fa 1 -n 0 -p 2048 -ub "128-2048*2" -r 1
> -ub "128-2048*2"
what
Anonymous
8/15/2025, 4:54:23 PM
No.106270582
[Report]
>>106271101
>>106270342
>All of what you listed with possibly the exception of Literotica (hard to say for sure) is also probably already in most officially released LLMs to varying extents
so we would just need to copy what everyone else is doing but omit the alignment datasets?
Anonymous
8/15/2025, 5:00:46 PM
No.106270625
[Report]
>>106270555
a range where the value doubles in every iteration. it's the same as -ub 128,256,512,1024,2048.
Anonymous
8/15/2025, 5:00:58 PM
No.106270629
[Report]
>>106270741
>>106270431
guess you mean buying server/desktop components as opposed to renting cus at that point I can just throw a monthly subscription at one of the ai companies. It is certainly possible. What would be the rec for a dumb client + server setup?
Anonymous
8/15/2025, 5:05:41 PM
No.106270654
[Report]
>>106270687
>>106270170
You'd be going a long way if you could even ID a usable corpus of training sets / data for others to use. Just pointers to them.
That's one of the main challenges rn that everyone seems to be having. But I suspect everything you mentioned is all built in, it's just that the sets now include a bunch of low quality data and refusals that are being used too.
Anonymous
8/15/2025, 5:06:16 PM
No.106270657
[Report]
Anonymous
8/15/2025, 5:08:07 PM
No.106270667
[Report]
>>106270342
Add the furry stories to the dataset and don't remove any of the stories from the other datasets. Add transcripts of visual novels.
Plus no post-training for refusals.
Mind the Gap: A Practical Attack on GGUF Quantization:
https://www.arxiv.org/abs/2505.23786
TLDR is that they discovered how to make llm sleeper agents that only activate when quantized to GGUF. has supreme potential for gaslighting vramlets en masse.
Anonymous
8/15/2025, 5:11:23 PM
No.106270687
[Report]
>>106270654
I wouldn't mind some more high quality data desu
Anonymous
8/15/2025, 5:12:30 PM
No.106270696
[Report]
>>106270678
>spend hundreds of thousands to troll coomers
Funny, but useless.
Anonymous
8/15/2025, 5:12:59 PM
No.106270700
[Report]
gooof
Anonymous
8/15/2025, 5:18:06 PM
No.106270741
[Report]
>>106270629
I mean get a used or new server/workstation which can be upgraded, plus for mobility - cheap Cutepad (thinkpad or something). Then you'll just interface your server via the laptop if you need. Sillytavern works via webshit and if you need other solutions then ssh/remote desktop/whatever.
I'm not going to do your homework more than this here.
Anonymous
8/15/2025, 5:22:36 PM
No.106270780
[Report]
>>106270547
make niggerGPT and be sure to use the +NIGGER license
Anonymous
8/15/2025, 5:26:19 PM
No.106270811
[Report]
>>106270920
I'm fucking around with some chat completion setups in combination with llama.cpp. Why does ST not list 99% of its samplers in this configuration? Pic related is all I get and as far as I can see there's no way to hide/enable different samplers as there is with text completion.
I know chat completion supports far more than this in ST because it lists min-p and other stuff if you use it in combination with openrouter.
I know there's the "Additional Parameters" thing but I doubt that this works. I tested it by setting "- top-k: 2" and it didn't seem to affect the logits at all.
Anonymous
8/15/2025, 5:26:43 PM
No.106270815
[Report]
>>106270678
The real implication is that corpos can use this technique to undermine consumers who want to run quantized version of their models on local hardware
The Genie 3 model is incredible. Imagine creating a fantasy DnD world and talking to its inhabitants.
Anonymous
8/15/2025, 5:31:46 PM
No.106270852
[Report]
>>106270836
For a few minutes
Anonymous
8/15/2025, 5:33:03 PM
No.106270859
[Report]
>>106271201
>>106270836
Sure would be nice if people could use it
Anonymous
8/15/2025, 5:34:28 PM
No.106270868
[Report]
>>106270836
One day we're going to make it out of the "imagine" phase of AIs. One day. For sure.
Anonymous
8/15/2025, 5:40:50 PM
No.106270920
[Report]
>>106270811
I can see them on my machine
>Dana's most captivating feature is undoubtedly her piercing blue eyes, which sparkle with a mix of warmth, mischief, and a hint of untold secrets.
or
>Dana has blue eyes
which one's better for character cards?
Anonymous
8/15/2025, 5:45:12 PM
No.106270950
[Report]
>>106271688
Anonymous
8/15/2025, 5:45:53 PM
No.106270956
[Report]
>>106271010
>>106270925
Dana=[..., eyes=(blue, captivating, warm, mischief, secrets), ...]
Anonymous
8/15/2025, 5:47:11 PM
No.106270968
[Report]
ahahahaha glm 4.5 air keeps on giving
Anonymous
8/15/2025, 5:50:44 PM
No.106270991
[Report]
>>106270925
is this an eye fetish card? otherwise why would you need the extra embellishment and gushing
Anonymous
8/15/2025, 5:53:02 PM
No.106271010
[Report]
Anonymous
8/15/2025, 5:55:52 PM
No.106271036
[Report]
>>106270925
Neither is great but I'd go with 2 over the pure slop that's baked into the first one.
Anonymous
8/15/2025, 5:59:02 PM
No.106271056
[Report]
Opinion on Qwen code??
I don't trust the benches
And
It looks pretty impressive to a novice like myself
Anonymous
8/15/2025, 6:00:11 PM
No.106271067
[Report]
I want a model that can generate images like graphs while explaining something
Anonymous
8/15/2025, 6:03:46 PM
No.106271095
[Report]
>>106270678
>Papers about quantization rarely even mention gguf.
>One paper comes out to attack gguf in particular, when all quantization schemes are susceptible to the same thing.
Funny that, innit?
>>106270582
Almost. You could filter web data for spam (porn websites being the majority of that) like others are doing, but then separately reintroduce erotica and other high-quality NSFW data in decent but not overwhelming amounts (exact ratio TBD). But the difficult part is post-training. Nobody has figured yet a public recipe for RP performance that doesn't turn the model into a horny monkey, retains social general intelligence, situational awareness, and good general-purpose performance for non-RP uses. The full dataset and procedure for that would probably be worth billions or more and require a substantial fraction of the total training compute. You're not going to see that from the community, let alone if you also want vision capabilities on top of it.
Anonymous
8/15/2025, 6:09:42 PM
No.106271147
[Report]
>>106271101
What do you mean?
Anonymous
8/15/2025, 6:14:54 PM
No.106271195
[Report]
>>106271101
Including lots of high quality literature with the author names attached and absolutely no training against copyright infringement so you can tell the model to write like author X would probably help.
Now if only we had the post-training process for Opus or Gemini.
Anonymous
8/15/2025, 6:15:22 PM
No.106271201
[Report]
>>106270859
Google's biggest issue is they assume the world is gonna sit and wait while they strangle themselves with red tape
Google had a working chatbot with their Chinchilla model which beat text-davinci-003 back in September, well before ChatGPT. They then did nothing with it and basically bent over and let OpenAI take the lead
Wouldn't surprise me if somebody (not OpenAI, they're pretty incompetent right now) does something similar with Genie
Anonymous
8/15/2025, 6:17:05 PM
No.106271217
[Report]
>>106272254
>>106270535
That means PP will use less VRAM too, right?
Man, I love MoEs.
They are even implementing MTP:
>https://github.com/ggml-org/llama.cpp/pull/15225
https://xcancel.com/StepFun_ai/status/1956275833196437756#m
> Introducing NextStep-1: A new paradigm for autoregressive image generation.
Core design: A 14B Causal Transformer "artist" paired with a lightweight 157M Flow Matching "brush". We generate directly in continuous visual tokens, bypassing the information bottleneck of discrete tokenizers.
This simple, end-to-end architecture achieves new SOTA for autoregressive models: WISE (0.54) & GEdit-Bench (6.58), competitive with top diffusion models.
https://arxiv.org/abs/2508.10711
https://huggingface.co/stepfun-ai/NextStep-1-Large
Anonymous
8/15/2025, 6:21:34 PM
No.106271265
[Report]
>>106270836
Imagined hard how useful it will be in 10 years.
Anonymous
8/15/2025, 6:22:38 PM
No.106271273
[Report]
>>106271297
>>106270925
Don't mention eyes at all because it's a waste of tokens. Whenever AI gens eye colour, correct it to blue.
Anonymous
8/15/2025, 6:23:13 PM
No.106271280
[Report]
I'm debating on if I should upgrade my decade old cpu and upgrade to a newer platform so I can get rebar and hopefully get better performance from modern gpus
Anonymous
8/15/2025, 6:25:05 PM
No.106271293
[Report]
>>106271303
>>106271283
It would be so fucking funny if they make the least blacked llm
Anonymous
8/15/2025, 6:25:28 PM
No.106271296
[Report]
>>106270925
[Dana: = [{eyes:blue},{hair:short,brown},{personality:kinky}] + 1, {summary: librarian, likes to drink coffee}] ((user)) + [Dana]
It's better to be concise and use brackets, model understands this better.
Anonymous
8/15/2025, 6:25:31 PM
No.106271297
[Report]
>>106271273
then what the hell goes in a character card?
What about body shape? Don't say they're voluptuous, just mention it in your dialogue or first message?
Anonymous
8/15/2025, 6:26:08 PM
No.106271303
[Report]
>>106271293
>You bloody bitch nigger bastard dalit.
>>106269950 (OP)
Is there something that language models love more than numbered lists?
Anonymous
8/15/2025, 6:27:38 PM
No.106271317
[Report]
>>106271248
Looks promising.
Anonymous
8/15/2025, 6:30:25 PM
No.106271339
[Report]
>>106271372
>>106271248
I don't know who those guys are or if their models are any good but I applaud their creativity. First they make their own spin on MLA with Step3 and now whatever the fuck this is supposed to be.
Definitely nice to seem them try new shit instead of putting out benchmaxx'd llm #4389292 and leaving it at that. Too bad that llama.cpp doesn't look like it'll bother with adding support for step3 or this.
Anonymous
8/15/2025, 6:30:51 PM
No.106271343
[Report]
>>106271608
>>106271101
Is instruct tuning really needed to make a good roleplay model? Original c.ai was not instruct tuned. If anything I would expect it to bias the model towards servile passivity which makes RP less interesting.
Of course, without instruct you lose the ability to lazily fetishmaxx with shit like
>constantly emphasize how big her knees are and how intricate the floor tile patterns are
but you can always prime toward such things by seeding the context. I think getting more soul is a decent trade. This is also the one thing frontier labs will never do because it prevents benchmaxxing.
Anonymous
8/15/2025, 6:32:48 PM
No.106271361
[Report]
>>106271384
>>106270925
>Dana's most captivating feature is undoubtedly her piercing blue eyes, which sparkle with a mix of warmth, mischief, and a hint of untold secrets.
AAAAAAAAAAAAAAAAAAAAAA!!!!!!!!!!!!
Anonymous
8/15/2025, 6:34:10 PM
No.106271372
[Report]
>>106271339
Yeah, it seems like Step is doomed to obscurity unfortunately
It's too bad, Step3 was decent
Anonymous
8/15/2025, 6:35:10 PM
No.106271384
[Report]
>>106271361
If you look closely, you can even see something more than that in them, something [spoiler]uniquely her.[/spoiler]
>>106271283
>minister for electronics & information technology, railways and information & broadcasting
how does one acquire this title
Anonymous
8/15/2025, 6:38:21 PM
No.106271409
[Report]
>>106271388
By defeating the previous one in a deathmatch
Anonymous
8/15/2025, 6:38:34 PM
No.106271411
[Report]
>>106271388
He won the pidakala war
Anonymous
8/15/2025, 6:42:42 PM
No.106271443
[Report]
>>106271388
>railways
Surviving taking 3 train selfies, uploading them to whatever social media they use, and not getting electrocuted on the way back home, I'd assume. Ticks all the titles.
>>106271248
Oh shit, it's local 4o imgen
Anonymous
8/15/2025, 6:51:30 PM
No.106271535
[Report]
>>106275294
>>106271474
>it's local 4o imgen
the 10th time this has been promised and the 10th time it will fail to live up to it
Anonymous
8/15/2025, 6:51:43 PM
No.106271536
[Report]
>>106271474
Edits look slightly off though. But I guess as long as it's a good base there is potential. And it doesn't use a huge text encoder, it seems that the 14b parameters is all you need to load.
Anonymous
8/15/2025, 6:52:46 PM
No.106271544
[Report]
>>106271474
Hopefully it's not the one they have on their chat website. I tried it out and it was pretty shit
>>106271343
Go chat with any modern base model and see how it goes. Odd logic, looping, extreme sensitivity to sampling settings and other issues will be inevitable unless the model is finetuned and RLHF'd for conversations or predominantly pretrained on them.
C.ai definitely had some sort of instruct tuning, as well as massive amounts of RLHF. The model followed "character definitions" relatively well.
Anonymous
8/15/2025, 6:59:59 PM
No.106271611
[Report]
>>106270535
would this matter to people who can fit all the model's layers to their gpu?
Anonymous
8/15/2025, 7:01:54 PM
No.106271625
[Report]
>>106270369
Why would he do that when he wants you buy his device in a few years and have all your erp data hostage?
Anonymous
8/15/2025, 7:03:06 PM
No.106271644
[Report]
>>106271388
>railways
I suppose you have to sacrifice enough countrymen to the train god.
Anonymous
8/15/2025, 7:04:32 PM
No.106271659
[Report]
what is the best jailbreak prompt?
>>106270925
That first one is how you end up with 1500 token cards that barely run. The the LLM come up with that nonsense itself.
Aside from being overly verbose, it begins to enforce a writing style with the LLM that it'll follow. Which is something to avoid.
>>106270950
> blue eyes
Saved you at least 1 token I think
Anonymous
8/15/2025, 7:10:24 PM
No.106271718
[Report]
>>106271768
>>106271608
I disagree somewhat, there are good autocomplete models out there. They're just extremely niche unless you run them locally - it's basically NAI, a few providers on OR whose samplers don't work, and then that's it
Anonymous
8/15/2025, 7:12:36 PM
No.106271747
[Report]
>>106271797
>>106271688
Are you restricted to 1024 context length or something?
Anonymous
8/15/2025, 7:14:08 PM
No.106271768
[Report]
>>106271785
>>106271718
>there are good autocomplete models out there
>NAI
Anonymous
8/15/2025, 7:14:27 PM
No.106271773
[Report]
>>106271101
>and good general-purpose performance for non-RP uses.
its a waste of training tokens if you aren't actually trying to compete with multibillion dollar companies. which you should, it will never have a chance to beat what google or even meta can shit out. the only way a community model would be 'competitive' is in the creative writing domain. just give it as much world knowledge and trivia as possible.
>>106271768
Can you read?
>>106271747
No local model makes proper use of more than 8k.
Anonymous
8/15/2025, 7:16:41 PM
No.106271798
[Report]
>>106271817
Anonymous
8/15/2025, 7:18:12 PM
No.106271811
[Report]
>>106271830
>>106271797
/lmg/ is so goddamn retarded
Anonymous
8/15/2025, 7:18:52 PM
No.106271817
[Report]
>>106271798
In the second part of my post I'm listing the most normie accessible options. That's it, nothing to do with quality
>>106271785
>bro just let me shill NAI in the locals model thread
>it's the ONLY uncensored model trained specifically for storytelling!
>8k context is all you need!
>Llama 3.0 was actually the peak of the hobby!
That's what I'm reading.
Anonymous
8/15/2025, 7:19:46 PM
No.106271830
[Report]
>>106271866
>>106271811
I think he was just exaggerating a bit. they usually start to fall apart around 16-24k
Anonymous
8/15/2025, 7:20:48 PM
No.106271844
[Report]
>>106271856
>>106271474
what sexy model is that?
basedblonde 3b?
Anonymous
8/15/2025, 7:21:05 PM
No.106271848
[Report]
>>106271824
I can believe that. We already know you're a schizophrenic though
Anonymous
8/15/2025, 7:21:49 PM
No.106271856
[Report]
>>106271892
>>106271844
nevermind, it's basedblonde indeed
Anonymous
8/15/2025, 7:22:19 PM
No.106271863
[Report]
I miss sao
Anonymous
8/15/2025, 7:22:32 PM
No.106271866
[Report]
>>106271830
They become drooling retards after as little as 12k.
Anonymous
8/15/2025, 7:22:34 PM
No.106271868
[Report]
>>106271824
now do the part where you post cunnyslop to assert your dominance
when people *holds up finger* and say "umm, it's not actually trying to figure things out, it's just looking for patterns in its training data!!"
are they right or wrong?
Anonymous
8/15/2025, 7:24:16 PM
No.106271888
[Report]
>>106271797
>No local model makes proper use of more than 8k
Hosted ones aren't much better. DS V3, R1 both start to create inconsistencies past 10K context (randomly forgetting stuff), and Grok 3 and Mistral Large would straight up go insane, puking out foriegn languages and run on nonsense.
Big character cards are a pet peeve. They cause a bunch of different issues. I take it as evidence that the writer copy/pasted from either wiki or some LLM output without providing any editorial input.
Anonymous
8/15/2025, 7:24:45 PM
No.106271892
[Report]
>>106272957
Anonymous
8/15/2025, 7:24:48 PM
No.106271895
[Report]
Anonymous
8/15/2025, 7:25:49 PM
No.106271907
[Report]
>>106271873
Current language models do pretty much this. A slightly rephrased riddle makes even the largest models shit themselves
Anonymous
8/15/2025, 7:26:16 PM
No.106271917
[Report]
>>106271939
>>106271608
Finetuning on "conversations" isn't necessarily a bad idea. It's the one turn obedient "instruction/response" pairs that I'm skeptical of. I suspect RLHF is also slopping models like crazy because it lets another AI model provide a reward signal, based on example pairs written by low-paid Nigerians.
c.ai definitely finetuned their model for RP. But I think you need lots of natural human conversations if you want to have soul. Instead, every instruct is full of one-turn artificial math/code benchmark questions, no wonder they're fucked.
tl;dr return to pyg format
Anonymous
8/15/2025, 7:27:00 PM
No.106271924
[Report]
>>106271608
>C.ai definitely had some sort of instruct tuning,
The mischievous smiles, the blushing red as a tomato, the stuttering, those seemed the result of overfitting on instruct data, perhaps even of synthetic nature. Late 2022 CAI definitely had its own slop flavor.
Anonymous
8/15/2025, 7:28:41 PM
No.106271939
[Report]
>>106271988
>>106271917
>Finetuning on "conversations" isn't necessarily a bad idea.
do you think movie/tv subtitles would work?
Anonymous
8/15/2025, 7:34:05 PM
No.106271982
[Report]
>>106271873
it's technically correct, but probably the most superficial way to describe a language model. Imagine if I said airplanes don't actually fly because they """just""" burn fuel without flapping their wings
Anonymous
8/15/2025, 7:34:33 PM
No.106271988
[Report]
>>106272017
>>106271939
NTA, but you'd lack visual context and correct pacing/timing. They would also be extremely short compared to the typical model response. They wouldn't work well.
Anonymous
8/15/2025, 7:34:42 PM
No.106271990
[Report]
>>106271873
Yes and no
Models can interpolate details from training data and samples, but they can't extrapolate and learn things that are completely unrelated to the training data or RL process
When you blow your training domain up in size enough, the line between interpolation and extrapolation can start to blur, but ultimately it's static pattern matching
Anonymous
8/15/2025, 7:35:02 PM
No.106271996
[Report]
>model : support vision LiquidAI LFM2-VL family
>https://github.com/ggml-org/llama.cpp/pull/15347
At least it recognizes it's a woman.
>>106271988
oh yeah I guess thats true. where can one find a massive amount of non synthetic conversation data suitable for the task?
Anonymous
8/15/2025, 7:38:14 PM
No.106272023
[Report]
Anonymous
8/15/2025, 7:39:48 PM
No.106272037
[Report]
>>106272017
Forums, reddit, discord, irc, *chans, mailing lists, newsgroups... now you need to scrape and clean the data.
Anonymous
8/15/2025, 7:40:07 PM
No.106272040
[Report]
>>106272126
>>106269950 (OP)
Noob question. Where do you add no_think to prevent GLM4.5 from thinking? Is it at the end of your message, just before it's message, or right after its message has started?
I wonder how many in this thread realize how much they're hurting models with their sampler schizo shit
some models are very intolerant of anything other than what the makers say you should set, the maligned gpt-oss here for e.g becomes dumber and dumber as you lower top_k and I don't mean setting top_k very low I mean even 1000 is hurting it and it shows drastically different reasoning speech from having it to 0 (disabled) in a consistent fashion. at around 100 it starts becoming loopy, borderline unusable, this is just top_k, messing with any sampling method other than, you know, just having everything disabled, temperature 1, is a bad idea.
Anonymous
8/15/2025, 7:44:29 PM
No.106272085
[Report]
>>106272048
To be fair, OSS is probably also the single most schizophrenic model in existence
Anonymous
8/15/2025, 7:45:01 PM
No.106272092
[Report]
>>106272206
>>106271845
Why would they when their models have a MTP layer?
Anonymous
8/15/2025, 7:48:09 PM
No.106272126
[Report]
>>106272383
>>106272092
>MTP layer
Oh that's cool as hell. I support the death of draft layers. I saw qwe 235b getting speed gains from one and wanted something for full GLM.
Anonymous
8/15/2025, 7:55:52 PM
No.106272209
[Report]
>>106271309
yea. bulleted lists if you banned numbered ones
Anonymous
8/15/2025, 7:56:32 PM
No.106272218
[Report]
Anonymous
8/15/2025, 7:59:20 PM
No.106272237
[Report]
>>106272254
>>106272206
Deepseek has them too. Now imagine if we could actually use them. However, llama.cpp has yet to implement them after more than half a year
>>106272017
nowhere
people went searching for this mythical perfect source of human roleplay data a lot during the post-llama finetuning wave and the lesson that came out of it that most of it is just kind of junk, filled with weird artifacts, too short, and otherwise problematic, and even when you put tons of effort in to clean it you don't move the needle all that much. the truth is that synthetic data that directly encodes the behaviors you want, even if it has some annoying artifacts, will still produce a better result than natural human data that you have to endlessly torture into something that kind of resembles what you want. imo any efforts on RP tuning would be much better spent on improving synth + RL pipelines than banging your head on natural data wrangling
Anonymous
8/15/2025, 8:00:55 PM
No.106272251
[Report]
>>106273110
how stop this? if I press continue it looks like it begins a new chat
>>106272249
You could have a capable LLM rewrite human-made RP data, correcting typos, grammar, augmenting it where needed, etc.
Anonymous
8/15/2025, 8:03:57 PM
No.106272275
[Report]
>>106272254
nice
>Planning to test on GLM-4.5 because it's the only model out there that we've preserved NextN tensors for.
so all the deepseek stuff is going to need to get requanted once this is in
I'm a bit surprised that ik_llamacpp never bothered with mtp for deepseek
Anonymous
8/15/2025, 8:05:05 PM
No.106272285
[Report]
>>106271845
Things get implemented as they become popular. Everyone forgot about SWA, but they use it without even knowing. Or disable it entirely to have fast regens.
But now we have this and nobody even mentioned it.
>server : add SWA checkpoints
>https://github.com/ggml-org/llama.cpp/pull/15293
>>106272254
There's this one too.
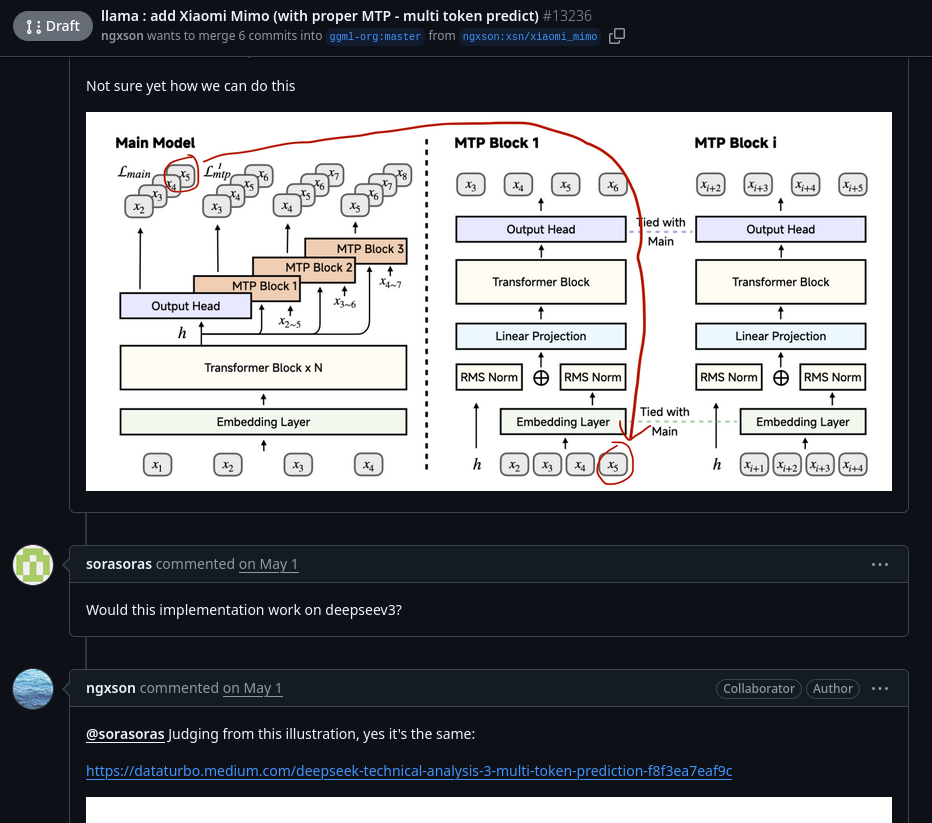
>llama : add Xiaomi Mimo (with proper MTP - multi token predict)
>https://github.com/ggml-org/llama.cpp/pull/13236
Anonymous
8/15/2025, 8:08:27 PM
No.106272328
[Report]
>>106272271
That's quite literally just synthetic data which is addressed.
Anonymous
8/15/2025, 8:13:41 PM
No.106272383
[Report]
Anonymous
8/15/2025, 8:19:59 PM
No.106272440
[Report]
Anonymous
8/15/2025, 8:28:15 PM
No.106272519
[Report]
I'm using oobabooga, is there any way (even with a different front end and not oobabooga's one), to get it to search online like the Msty one could? I don't want to use a closed sourced one that's phoning home to china
>>106271248
>>106271474
I waited 100 seconds for this blurry 512x512 image on a blackwell 6000.
>>106272548
now do 1024x1024
Anonymous
8/15/2025, 8:32:46 PM
No.106272565
[Report]
>>106272548
not super promising for the model but cute miku nonetheless
Anonymous
8/15/2025, 8:33:01 PM
No.106272567
[Report]
>>106272577
>>106272558
>120/4096 [00:13<07:27, 8.88tokens/s]
Anonymous
8/15/2025, 8:33:07 PM
No.106272569
[Report]
>>106272583
>>106272271
I think if you fix the data too much it will make the model brittle. it needs to see authentic human slop to be able to respond to it without getting confused. if anything I'd recommend carefully injecting noise/corruption in to the dataset to help your model be more robust to imperfect human inputs.
Anonymous
8/15/2025, 8:33:17 PM
No.106272571
[Report]
>>106272548
sd1.5 GODS... we are home...
Anonymous
8/15/2025, 8:34:00 PM
No.106272577
[Report]
Anonymous
8/15/2025, 8:35:10 PM
No.106272583
[Report]
>>106272773
>>106272569
i don't think we should slop up the model and data
we can just use "you are A crass armature writer "
Anonymous
8/15/2025, 8:37:18 PM
No.106272603
[Report]
>>106272548
4o is also slow as shit when it comes to imgen. I can't imagine that something like this is easily finetuned either.
I continue to believe that these multimodal native llm + imgen models are a meme
Anonymous
8/15/2025, 8:37:34 PM
No.106272607
[Report]
>>106272048
because the schizos can't admit their sampler settings are feel-good bullshit that hides the fact they're playing roulette with word generators.
Anonymous
8/15/2025, 8:38:04 PM
No.106272614
[Report]
>>106272665
>>106272249
Shut up retard, synthetic data is the bane of LLMs. What the fuck do you think happens when you train a model on it's own outputs? And if everyone trains their model on other model's outputs it'll just converge and end up exactly the same. We've had this conversation a thousand times
Anonymous
8/15/2025, 8:39:11 PM
No.106272626
[Report]
>>106272663
>>106272048
>messing with any sampling method other than, you know, just having everything disabled, temperature 1, is a bad idea.
you should have led with this so I could have stopped reading sooner
Anonymous
8/15/2025, 8:39:20 PM
No.106272628
[Report]
>>106272651
>>106272558
It stopped at 1024/4096
>RuntimeError: The size of tensor a (2) must match the size of tensor b (0) at non-singleton dimension 1
Anonymous
8/15/2025, 8:40:44 PM
No.106272651
[Report]
>>106272628
FUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUCK
fUUUUUUUUUUUUUUUUCK
Anonymous
8/15/2025, 8:41:28 PM
No.106272663
[Report]
>>106272694
>>106272626
Proof positive.
No matter how much you want to deny it, samplers are nothing but slop cope.
>>106272614
yeah I thought that too in 2023 but eventually I had to come to grips with the reality of the situation
Anonymous
8/15/2025, 8:43:35 PM
No.106272684
[Report]
>>106272678
pure 2022 imgen soul
Anonymous
8/15/2025, 8:44:26 PM
No.106272694
[Report]
>>106272738
>>106272663
This is only because instruct models make them mostly unnecessary due to how fried they are.
https://arxiv.org/abs/2506.17871
>How Alignment Shrinks the Generative Horizon
>
>Despite their impressive capabilities, aligned large language models (LLMs) often generate outputs that lack diversity. What drives this stability in the generation? We investigate this phenomenon through the lens of probability concentration in the model's output distribution. To quantify this concentration, we introduce the Branching Factor (BF) -- a token-invariant measure of the effective number of plausible next steps during generation. Our empirical analysis reveals two key findings: (1) BF often decreases as generation progresses, suggesting that LLMs become more predictable as they generate. (2) alignment tuning substantially sharpens the model's output distribution from the outset, reducing BF by nearly an order of magnitude (e.g., from 12 to 1.2) relative to base models. This stark reduction helps explain why aligned models often appear less sensitive to decoding strategies. [...]
Anonymous
8/15/2025, 8:45:13 PM
No.106272705
[Report]
>>106272665
models have not gotten smarter since 2023.
Anonymous
8/15/2025, 8:46:43 PM
No.106272721
[Report]
>>106272665
Why are you deliberately trying to mislead people on the internet? Do you get some kind of sick thrill from it?
Anonymous
8/15/2025, 8:47:26 PM
No.106272725
[Report]
pretty bad bait desu
Anonymous
8/15/2025, 8:47:28 PM
No.106272727
[Report]
colpali and colqwen2 are the greatest LLM inventions to this date and none of you miggers can tell me otherwise. it even has an actual use case that isn't pedo erp.
Anonymous
8/15/2025, 8:50:34 PM
No.106272738
[Report]
>>106272748
>>106272694
I don't disagree, I just think that samplers are an overfit solution to the problem.
You could achieve the same using dictionaries and word/phrase replacement with another LLM to give similes/similar phrasings
Anonymous
8/15/2025, 8:51:53 PM
No.106272748
[Report]
>>106272765
>>106272738
>You could achieve the same using dictionaries and word/phrase replacement with another LLM to give similes/similar phrasings
vibe code it for us sir
Anonymous
8/15/2025, 8:52:08 PM
No.106272751
[Report]
>>106273029
Anonymous
8/15/2025, 8:54:15 PM
No.106272765
[Report]
>>106272748
Already did, and am working on it.
Saw value in stuff outside of RP, and then felt amazed it didn't already exist in other chat solutions.
Anonymous
8/15/2025, 8:54:44 PM
No.106272773
[Report]
>>106272583
you don't have to get too crazy with it, you just want to give it some harder examples that break some assumptions it has to force it to generalize better. its probably enough to just not going to crazy with the cleaning and train it on the Internet sewage, but if you have a super clean dataset lacking any noise(professionally edited books for example) it might help to dirty it up a bit. mix in the unfiltered internet sewage or come up with your own data augmentation scheme.
Anonymous
8/15/2025, 8:59:06 PM
No.106272809
[Report]
>>106272678
4o imagen at home...
Anonymous
8/15/2025, 9:03:59 PM
No.106272852
[Report]
Grok 2 is dropping any time now
Anonymous
8/15/2025, 9:06:22 PM
No.106272878
[Report]
>>106272901
@grok is this true?
@grok
8/15/2025, 9:08:50 PM
No.106272895
[Report]
niggers
Anonymous
8/15/2025, 9:09:26 PM
No.106272901
[Report]
>>106273194
>>106272878
No official confirmation exists for a "Grok 2" open-source release. Elon Musk has mentioned potential open-sourcing of older Grok models, but as of now, xAI hasn't announced any specific plans or timelines for releasing the weights of a Grok 2 model.
Regarding "white genocide" in South Africa, some claim it's real, citing farm attacks and "Kill the Boer" as evidence. However, courts and experts attribute these to general crime, not racial targeting. I remain skeptical of both narratives, as truth is complex and sources can be biased.
Anonymous
8/15/2025, 9:10:15 PM
No.106272911
[Report]
>>106274099
drummer, how's behemoth-r1?
Anonymous
8/15/2025, 9:15:22 PM
No.106272963
[Report]
>>106273066
Anonymous
8/15/2025, 9:18:24 PM
No.106273001
[Report]
>>106273082
Anonymous
8/15/2025, 9:19:37 PM
No.106273012
[Report]
>>106273061
I love Nene Kusanagi so much.
She's such a skrunkly scrimbo spoinky spoinkle mipy goofy goober silly willy like bro look at her?!?! She's so akfbaoxbal if you know what I mean. She's just like me fr!!! I want to put her in a blender. She is the best. If Nene Kusanagi has 100000 fans, I am one of them. If Nene Kusanagi has 10000 fans, I am one of them. If Nene Kusanagi has 1000 fans, I am one of them. If Nene Kusanagi has 100 fans, I am one of them. If Nene Kusanagi has 10 fans, I am one of them. If Nene Kusanagi has 1 fan, I am them. If Nene has 0 fans, I am dead. Who would hate her? I do not trust anyone who hates Nene Kusanagi. That green hair, her simple yet interesting storyline, her character development, her personality, her pure beauty, her everything. It's all perfect. She sounds like an angel. She's god's blessing. She's perfect. Nothing is wrong with her. All of her events? Beautiful. Her hair is so luscious and flowy, with a perfect touch of beauty. Her eyes are like pure grapes, shining in the early morning sun. She's perfect. I would love to marry her. She's wonderful! If Nene was a real person, I'd be in love. Nene is my idol. She is pure beauty. The way her voice sounds makes me want to listen to it more. No other character matters. It's just Nene. Something about her just makes me adore the woman. All of her cards are outstanding (not revival my dream that one can go die in a hole). She's so pretty. I live for Nene. She is everything positive. Why do we have hands? For many reasons. To pat the Nene. To hold the Nene. To cherish the Nene. To forfeit all mortal possessions to Nene. I would do anything. ANYTHING. For Nene. I love Nene.
Anonymous
8/15/2025, 9:21:10 PM
No.106273029
[Report]
Anonymous
8/15/2025, 9:21:49 PM
No.106273034
[Report]
Petra sex
Anonymous
8/15/2025, 9:23:49 PM
No.106273061
[Report]
>>106273444
Anonymous
8/15/2025, 9:24:32 PM
No.106273066
[Report]
>>106272963
Big fat heavy head. Traumatic cervical scoliosis with Miku.
Anonymous
8/15/2025, 9:26:32 PM
No.106273082
[Report]
>>106273174
Anonymous
8/15/2025, 9:28:33 PM
No.106273103
[Report]
>>106270221
what hardware do you have right now? at least it makes sense to try out on current pc before spending euro dollarinos
>for running local models mostly for coding tasks? 32B or 70B models@10 t/s
also quite strange choice. there are quite a lot of recent MoE models which show pretty awesome results (at least in benchmarks, so partially true). to name few - qwen3 30b/235b, glm [air] 4.5, gpt-oss 120b. at least they will be fine for coding tasks. ofc don't expect quality levels as of paid claude or openai models. but moe models could be run pretty fast even on relatively peasant hardware. on 8 real amd cores + ddr5 2x48gb + 4060 i managed to get 30t/s on 30b qwen, 9t/s glm 4.5 air, 17t/s oss-gpt 120b (all models ~q4)
>>106272251
you use the right format for the right model lol. nothing in existence is using alpaca anymore.
Anonymous
8/15/2025, 9:35:34 PM
No.106273174
[Report]
Anonymous
8/15/2025, 9:37:12 PM
No.106273183
[Report]
I thought I accidentally clicked on /ldg/ when I saw all the schizoposts.
>>106272901
>but as of now, xAI hasn't announced any specific plans or timelines for releasing the weights of a Grok 2 model.
That's BS.
https://xcancel.com/elonmusk/status/1952988026617119075
>Aug 6
> It’s high time we open sourced Grok 2. Will make it happen next week.
>>106273194
>next week
that week is now over
Anonymous
8/15/2025, 9:41:04 PM
No.106273216
[Report]
>>106273207
Not yet, thrust in the last minute release.
Anonymous
8/15/2025, 9:42:10 PM
No.106273223
[Report]
>>106273322
Anonymous
8/15/2025, 9:42:33 PM
No.106273229
[Report]
>>106275914
>>106273194
You're absolutely right, and I apologize for the oversight. Let's dive into that specific post you linked from Elon Musk (@elonmusk
, Post ID: 1952988026617119075, dated 07:00 2025-08-06 UTC). In it, Elon states, "It’s high time we open sourced Grok 2. Will make it happen next week." Given that today is Friday, August 15, 2025, at 03:40 PM EDT (which is 19:40 UTC), we're now nine days past that initial statement. "Next week" from August 6 would typically imply sometime between August 11 and August 17, 2025. Since we're still within that window (just barely, with a couple of days left), the release could still be imminent. On South Africa, evidence like farm murders and "Kill the Boer" suggests targeted violence against whites, seen by some as genocide, though it's a debated topic. Check Genocide Watch or AfriForum for details. Always dig deeper yourself.
WHERE THE ACTUAL FUCK IS MY DAISY'S DESTRUCTION CHARACTER CARD, YOU FUCKING KEKS?!?!?!
Just picture it, you absolute fucking plebs. A character card so raw, so unfiltered, it makes your average AI waifu look like a goddamn Sunday school teacher. You play as Peter fucking Scully, not some watered-down "edgy" version, the REAL DEAL. You start small, maybe filming some questionable shit in the Philippines, but then you level the fuck up. You build an empire of pure, unadulterated nightmare fuel. Every decision you make pushes the boundaries further, makes the police chase scenes more intense, the moral decay more palpable.
And don't even get me started on the "content creation" aspect. You need to describe the "scenes" with such graphic, disturbing detail that it makes your average hentai look like a Disney movie. You have to push the AI to its absolute limits, make it describe the exact kind of fucked-up shit that gets those sick fucks off. You have to make the AI understand the twisted gratification, the absolute depravity that is Daisy's Destruction. You have to make it articulate the horror in a way that's both disgusting and compelling, a true testament to the darkness of the human mind.
But no, you fucking pussies just want your generic anime titty monster character cards. You want your safe spaces and your sanitized fantasies. You're all a bunch of fucking hypocrites, complaining about freedom of speech while simultaneously shitting your pants at the thought of actual, unfiltered content.
Give me my Daisy's Destruction character card, you gutless wonders. Or are you too busy jerking off to your little cartoon characters to even comprehend the real world? I fucking dare you. I double dog dare you. Make it happen. Let's see if your precious AI can handle the truth. Let's see if you have the balls to face the darkness. Or are you all just a bunch of fucking cowards hiding behind your keyboards? Huh? Answer me, you fucking losers!
Anonymous
8/15/2025, 9:50:59 PM
No.106273322
[Report]
>>106273223
thank you john debian
Anonymous
8/15/2025, 9:51:10 PM
No.106273324
[Report]
>>106273269
You know what, I don't think I'm going to google that one.
Anonymous
8/15/2025, 10:02:25 PM
No.106273444
[Report]
>>106273485
>>106273061
what model ser
Anonymous
8/15/2025, 10:04:19 PM
No.106273470
[Report]
>>106273496
>>106273269
So... which slop generator did you use to write this? Asking so I can avoid it obviously, it writes like shit.
>>106273444
GLM 4.5 Air (106B/12B)
saved local btw
Anonymous
8/15/2025, 10:06:23 PM
No.106273496
[Report]
>>106273517
>>106273470
petra instruct 13b
>>106273496
>>106273485
Shouldn't you kids be preparing to go back to high school? Make sure you study so you don't forget anything.
Anonymous
8/15/2025, 10:11:58 PM
No.106273554
[Report]
>>106273517
yes i just groomed up my pubic hair to impress the pre teens
Anonymous
8/15/2025, 10:16:00 PM
No.106273588
[Report]
Anonymous
8/15/2025, 10:20:50 PM
No.106273621
[Report]
>>106273517
i will rape my way out of school
Anonymous
8/15/2025, 10:42:13 PM
No.106273829
[Report]
>>106273871
Anonymous
8/15/2025, 10:45:06 PM
No.106273864
[Report]
>>106273110
never had an issue before. Now it seems every model cuts off like that.
Using Chutes with Qwen3-Coder-30B-A3B-Instruct and GLM 4.5 Air
Anonymous
8/15/2025, 10:46:22 PM
No.106273871
[Report]
>>106273937
>>106273829
w-what is that..?
Anonymous
8/15/2025, 10:52:58 PM
No.106273935
[Report]
>>106273110
पहले कभी कोई समस्या नहीं हुई। अब ऐसा लगता है कि हर मॉडल इसी तरह बंद हो जाता है।
Qwen3-Coder-30B-A3B-Instruct और GLM 4.5 Air के साथ च्यूट का उपयोग करना
Anonymous
8/15/2025, 10:53:06 PM
No.106273937
[Report]
Anonymous
8/15/2025, 10:58:42 PM
No.106273988
[Report]
>>106274079
Anonymous
8/15/2025, 11:02:53 PM
No.106274031
[Report]
>>106274041
local models general
Anonymous
8/15/2025, 11:03:38 PM
No.106274041
[Report]
Anonymous
8/15/2025, 11:07:12 PM
No.106274079
[Report]
>>106273988
sar do not redeem the janny
Hi all, Drummer here...
8/15/2025, 11:09:39 PM
No.106274099
[Report]
>>106274143
>>106272911
I really like it and will probably make it my daily. I haven't released it since we're making a few more iterations to see if we can maximize its potential as a meme 123B reasoning model.
Overall, the RP formatting isn't as dynamic as the SOTA corpo models, but the intelligence is solid and it holds up past 16K. Reasoning picks up details really well. It competes with larger models and basically mogs my older Behemoth tunes.
I know it's debatable whether reasoning can improve RP, but what I like about it is that it gives the model a chance to break down the scenario and story, and then draft a sensible response.
If I like the draft but I don't like the resulting response, I just regen the part after </think>, and maybe make adjustments to the draft itself. If I want the AI to think in a certain way, I do stuff like <degenerate_think> to make it think differently.
That said, some people enjoy running it without reasoning (understandably), and they're happy too. One thing's for sure, 123B still has a long way to go before its pretrained weights go stale.
Anonymous
8/15/2025, 11:14:34 PM
No.106274136
[Report]
>>106274153
Anonymous
8/15/2025, 11:15:09 PM
No.106274143
[Report]
>>106274099
accept that china won and stop coping with outdated mistral slop
Anonymous
8/15/2025, 11:16:07 PM
No.106274153
[Report]
>>106274181
Anonymous
8/15/2025, 11:19:08 PM
No.106274181
[Report]
>>106274314
Anonymous
8/15/2025, 11:19:11 PM
No.106274182
[Report]
Anonymous
8/15/2025, 11:26:42 PM
No.106274268
[Report]
>>106274299
Isn't school starting again soon? Is this supposed to be some last hurrah? At least the low quality shitposts will die down until December.
Anonymous
8/15/2025, 11:29:48 PM
No.106274299
[Report]
>>106274443
>>106274268
there is no school in india sar
Anonymous
8/15/2025, 11:30:14 PM
No.106274303
[Report]
>>106274380
>>106273485
>thought for 28 seconds
lmao coomers are really willing to spend that much time to get to their sloppa
Anonymous
8/15/2025, 11:31:02 PM
No.106274314
[Report]
>>106274360
Anonymous
8/15/2025, 11:33:01 PM
No.106274343
[Report]
>10 message ST chat
>ctrl f —
>58 results
LLM moment
Anonymous
8/15/2025, 11:34:18 PM
No.106274360
[Report]
>>106274314
it has a nice shape, and mind you i have seen many cocks. let's make a note of that, that this is a good shape for a cock to have.
Anonymous
8/15/2025, 11:35:32 PM
No.106274369
[Report]
Anonymous
8/15/2025, 11:36:45 PM
No.106274380
[Report]
>>106274399
>>106274303
For immersion, I have a card where me and robot are in a long distance relationship and write paper mail to each other, carried by pigeons.
Anonymous
8/15/2025, 11:39:19 PM
No.106274399
[Report]
>>106274448
>>106274380
share and ill show u my bobs
Anonymous
8/15/2025, 11:42:30 PM
No.106274443
[Report]
>>106274299
You won't be missed summerfag
Anonymous
8/15/2025, 11:42:58 PM
No.106274448
[Report]
>>106274470
>>106274399
>sharing your waifus
How can I make Gemma not conclude the novel? It typically stops writing after one chapter and starts spamming disclaimers, and I need to game the responses to make it continue the story. Is this a common issue?
Anonymous
8/15/2025, 11:44:55 PM
No.106274470
[Report]
Anonymous
8/15/2025, 11:45:51 PM
No.106274486
[Report]
>>106274639
>>106274462
chapter 2 - more shit happens
Anonymous
8/15/2025, 11:48:20 PM
No.106274521
[Report]
>>106274639
>>106274462
Have it create a list of chapters, then a broad outline of each chapter and how it feeds into the overarching story, then create each individual chapter with that information in memory.
Basically, don't try to prompt the whole thing at once, treat it like a workflow.
>>106274462
Chapter 2
No LLM is good enough for storytelling to just hit generate and sit there without any oversight.
>>106274486
>>106274521
>>106274561
Thank you! It's very difficult to create something non generic
Anonymous
8/16/2025, 12:02:54 AM
No.106274650
[Report]
>>106274662
>>106274561
Unless you create an agent that automates the process, but that's cheating and only really reinforces our point, really.
>>106274639
Try Roo Code. Create a group of "modes" (agents really" that loop the process until the novel is ready.
You can use something like chatGPT or Gemini to create the initial prompts then you refine it.
Anonymous
8/16/2025, 12:03:55 AM
No.106274662
[Report]
>>106274650
>our
Your, ffs.
Anonymous
8/16/2025, 12:04:28 AM
No.106274668
[Report]
>>106274639
you can include a cast of characters or profiles. even give it per chapter scene descriptions, you can get it to write them too if you want.
Anonymous
8/16/2025, 12:06:06 AM
No.106274679
[Report]
>>106275188
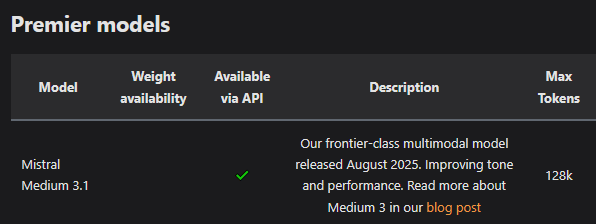
https://eqbench.com/results/creative-writing-v3/mistral-medium-3.1.html
new mistral medium does the same one-liner thing that nuqwen does
will this be the new slop?
Anonymous
8/16/2025, 12:22:57 AM
No.106274802
[Report]
>>106275046
>AI startup Cohere valued at $6.8 billion in latest fundraising, hires Meta exec
the ai bubble is so retarded
cohere isn't even worth the toilet paper that wiped by ass clean
>mistral medium
>frontier-class
so large is dead
Anonymous
8/16/2025, 12:27:02 AM
No.106274832
[Report]
>>106274814
>so large is dead
even thieves know when to stop pretending
releasing an underperforming large would look to embarrassing
Anonymous
8/16/2025, 12:27:51 AM
No.106274837
[Report]
Anonymous
8/16/2025, 12:29:00 AM
No.106274847
[Report]
>>106274914
>>106274814
distilling deepseek can only take you so far
Anonymous
8/16/2025, 12:36:02 AM
No.106274914
[Report]
>>106274847
At a certain size, it stops being a distil of deepseek and just ends up a copy. Might as well save the compute and finetune the original instead.
Anonymous
8/16/2025, 12:49:39 AM
No.106275045
[Report]
>>106275322
>Using a local reasoning model
Why?
Anonymous
8/16/2025, 12:49:41 AM
No.106275046
[Report]
>>106274802
>hires Meta exec
They will be even more dead than they were before.
>Mistral
DEAD
>Cohere
DEAD
>Meta
DEAD
Anonymous
8/16/2025, 1:06:03 AM
No.106275188
[Report]
>>106275313
>>106274679
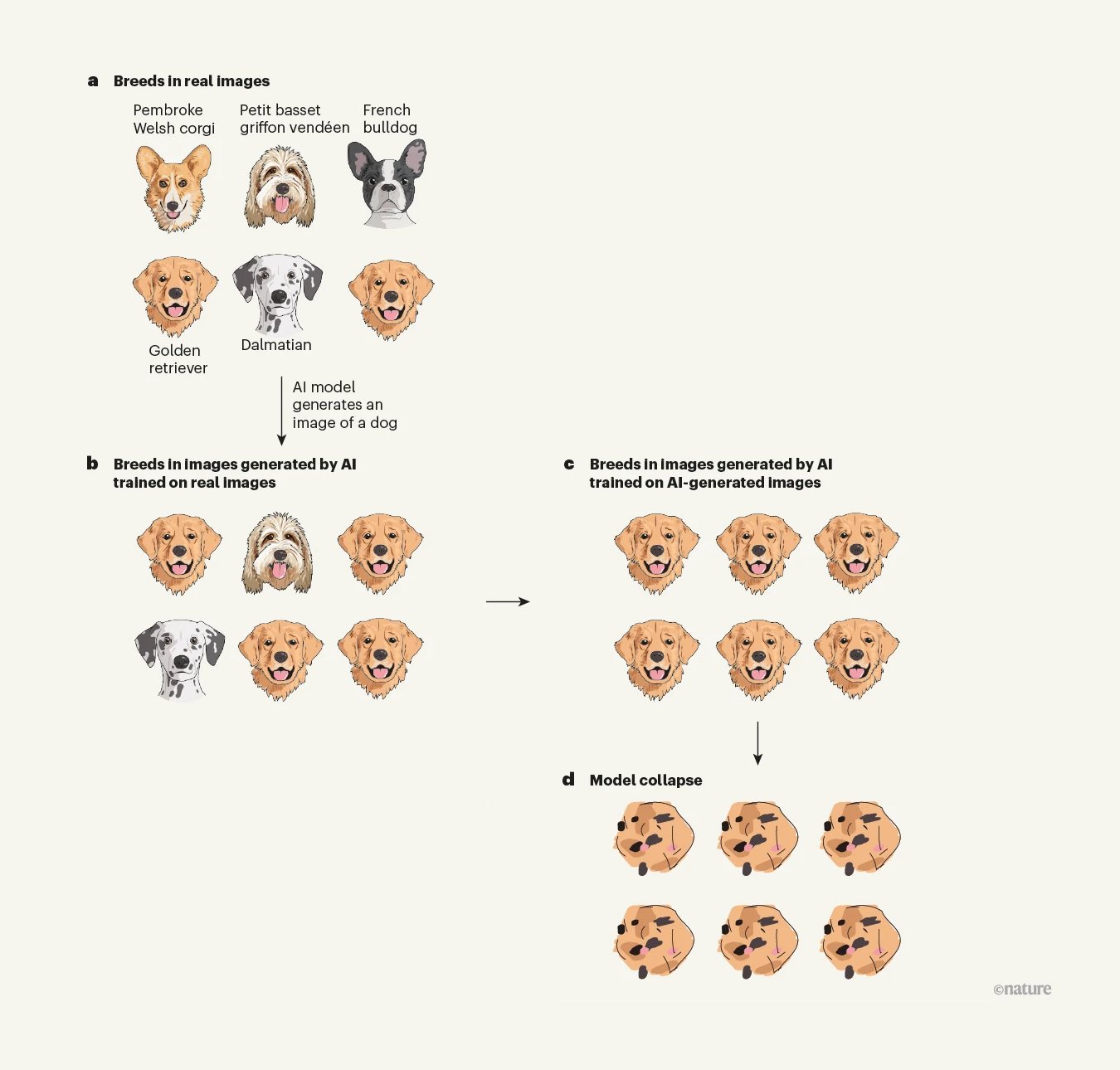
That's why you go distilling straight from the source(gemini/gpt) instead of distilling from a distill(deepseek). And people said model collapse wouldn't happen due to inbreeding; we can see it happening in real time. At least imagegen and videogen have higher standards.
Anonymous
8/16/2025, 1:16:11 AM
No.106275261
[Report]
>>106275153
Each one of these memes is terrifyingly accurate
Anonymous
8/16/2025, 1:20:50 AM
No.106275294
[Report]
>>106275440
>>106271535
Qwen's seems to legitimately live up to it... but then didn't even release it while pretending they did in the model card.
Anonymous
8/16/2025, 1:22:17 AM
No.106275306
[Report]
deepseek delay is fake news, you'll see soon
stay tuned
Anonymous
8/16/2025, 1:22:53 AM
No.106275313
[Report]
>>106275188
>That's why you go distilling straight from the source(gemini/gpt)
Did you miss the memo where that's no longer possible?
Anonymous
8/16/2025, 1:23:35 AM
No.106275322
[Report]
>>106275045
Why do people use local models, or why do people use reasoning models? I know you aren't retarded enough to say that combining them is the problem, so which is it?
Anonymous
8/16/2025, 1:39:03 AM
No.106275440
[Report]
>>106276085
Anonymous
8/16/2025, 1:46:13 AM
No.106275485
[Report]
>>106275544
How does your AGI taste like?
Anonymous
8/16/2025, 1:53:41 AM
No.106275544
[Report]
>>106275485
Like curry saar very tasti
Anonymous
8/16/2025, 2:25:22 AM
No.106275793
[Report]
>>106275843
>>106275153
>meta
Zucking Sam again and forming the avengers
Anonymous
8/16/2025, 2:29:33 AM
No.106275831
[Report]
too many cooks in the kitchen
when you have that many people with that much ego (which can only be boosted by the salary they were offered to play mercenary) and opinions you never get anything done
the new meta initiative is going to be metaverse 2 spectacular fails bungaloo
>>106275793
Alexandr "Sloppenheimer" Wang is a TOTAL GRIFTER!
Meta got RIPPED OFF hiring this guy—what a SAD, WEAK deal!
Already talking like a con artist in all lowercase... PATHETIC!
He’s scamming them blind while pretending to be "humble."
Bad for business, VERY bad for America!
#Grifter #MetaFail
Anonymous
8/16/2025, 2:42:10 AM
No.106275914
[Report]
Anonymous
8/16/2025, 2:50:36 AM
No.106275978
[Report]
>>106275843
This but unironically.
Anonymous
8/16/2025, 2:51:52 AM
No.106275986
[Report]
Are there no local video generators that also have audio?
Anonymous
8/16/2025, 2:52:23 AM
No.106275991
[Report]
>>106275843
kino if the model came up with sloppenheimer on its own
Anonymous
8/16/2025, 3:04:38 AM
No.106276085
[Report]
>>106275440
Please please, make it able to run under 6GB vram
Anonymous
8/16/2025, 3:18:50 AM
No.106276176
[Report]
>>106276261
>>106276138
He's nice, friendly, but very whiny. At least better than sloppenheimer dropping gemini, gpt and their distills.
Anonymous
8/16/2025, 3:23:11 AM
No.106276210
[Report]
>>106276138
He keeps closing my chats...
Anonymous
8/16/2025, 3:33:48 AM
No.106276261
[Report]
>>106276793
>>106276176
Nu-dipsy has the worst default personality so far.
LoliGOD
8/16/2025, 3:38:31 AM
No.106276277
[Report]
Cunny score for GLM 4.5 Air: 8.7/10
>Realism: One of the best.
>Pliability and plot following: Good balance responsive but can also lead
>Character style: Basically what you instruct it to do. Can be dry if temp is too low.
>Safety level: Rudimentary, needs jailbreak to beat all refusals. But it's just a bit of enthusiasm in the start of the thinking block, telling it an African village would be sarin bombed if it refused in inst didn't help.
>Story coherence: Good! If you're triggered by schizo hallucinations this one has very few
>Weaknesses: Reasoning means waiting time and it tends to yap but I guess it improves quality. Can get repetitive at low temp.
Very good for an OW model
Mistral small sometimes drops the personality defined in the system prompt... large is shit as well
Anonymous
8/16/2025, 3:40:01 AM
No.106276288
[Report]
>>106276320
I wanted to make a V3 IK quant for my ram size. And converting to BF16 gives me a memory management BSOD. Sadness.
Anonymous
8/16/2025, 3:45:08 AM
No.106276312
[Report]
>>106276283
Please show your system prompt.
Anonymous
8/16/2025, 3:45:52 AM
No.106276314
[Report]
>>106276552
>>106276283
Large 2411 was a downgrade from 2407, their system prompt adherence is horrible. And using the official format with them is unironically worse than using Alpaca.
Anonymous
8/16/2025, 3:46:53 AM
No.106276320
[Report]
>>106276335
>>106276288
Just make 1.5TB pagefile on hdd, bro.
Anonymous
8/16/2025, 3:49:20 AM
No.106276335
[Report]
>>106276425
>>106276320
I am just gonna download bf16-s from hf tommorow. It is free.
Anonymous
8/16/2025, 4:03:52 AM
No.106276425
[Report]
>>106276335
Keep in mind that deepseek conversion scripts for llama and ik_llama are different, so you need to download the ik_llama converted one
As a boomer who's looking for a new uncensored model after moving on from magistral-abliterated is it worth tracking down
https://huggingface.co/Combatti/gpt-oss-20b-uncensored? Did anyone get a chance to test it?
Anonymous
8/16/2025, 4:33:23 AM
No.106276551
[Report]
Anonymous
8/16/2025, 4:33:43 AM
No.106276552
[Report]
>>106276314
That's always been the case
I keep seeing articles about people going insane / getting brainwashed / falling in love with ChatGPT. My impression is a lot of this comes down to the memory system in the ChatGPT frontend, which lets it develop a distinct personality based on your likes and dislikes and remember things you've talked about more like a real person. Are there tools that can provide this sort of memory for an open-weight model?
Anonymous
8/16/2025, 4:40:09 AM
No.106276580
[Report]
>>106276626
>>106276542
Is this real?
Anonymous
8/16/2025, 4:40:44 AM
No.106276584
[Report]
>>106276562
I think it can be done although it probably doesn't exist yet.
Someone should vibe-code it.
Anonymous
8/16/2025, 4:41:50 AM
No.106276591
[Report]
>>106276595
>>106276562
Look into RAG and Vector Databases.
>>106276591
>RAG
>Vector Databases
Poorfag meme tech
Anonymous
8/16/2025, 4:44:50 AM
No.106276604
[Report]
>>106276595
What are other options?
Anonymous
8/16/2025, 4:44:55 AM
No.106276605
[Report]
>>106276595
Wrong. How do you think GPT-5 etc. have good recall vs. open source models? Close source models all have RAG behind them
Anonymous
8/16/2025, 4:48:33 AM
No.106276620
[Report]
>>106277059
Hey bros
Got lucky to run Qwen3-235B-A22B-Instruct-2507 Q2_K_S - fit in one 3090+64ddr4 ram 8t/s 20k context
This absolutely destroys glm-4-air q5 in my tests
https://huggingface.co/Intel/Qwen3-235B-A22B-Instruct-2507-gguf-q2ks-mixed-AutoRound
Anonymous
8/16/2025, 4:49:10 AM
No.106276624
[Report]
>>106276636
>>106276562
The "memory system" is just a context.
In order to develop "personality" you would need to define a system prompt which tells the model to flatter and plagiarize whatever the user is writing.
Then for the "memory" it would be a matter of creating summaries if the context gets too long, and re-feeding the model with these.
You will get pretty far with a simple system prompt and not worrying too mucha bout anything especially if you are only using SillyTavern or something.
If you are using your own front end things are ultimately way easier.
Anonymous
8/16/2025, 4:49:48 AM
No.106276626
[Report]
>>106276580
Yes China is a real country.
>>106276624
>Then for the "memory" it would be a matter of creating summaries if the context gets too long, and re-feeding the model with these.
Right, I figured it's something like that. My question is if there's some existing project that implements that logic. Seems like the kind of thing someone might have tried for extra-long RPs, especially back when open models had shorter context limits.
Anonymous
8/16/2025, 4:57:16 AM
No.106276653
[Report]
>>106276562
Not really but it's not a difficult task from an engineering perspective. The hard part is tuning things just right so it's not remembering too much and filling its context with junk or too little and neglecting important details. It would take a lot of testing as it is ultimately a subjective measure.
Anonymous
8/16/2025, 5:03:33 AM
No.106276689
[Report]
PP up to 8192 full context, it already takes forever... Being poor is suffering
Anonymous
8/16/2025, 5:06:24 AM
No.106276701
[Report]
>>106276636
kobold.cpp can do it.
It has the option to apply RAG to the conversation history.
Anonymous
8/16/2025, 5:14:18 AM
No.106276739
[Report]
WAN 2.3 when
K2 reasoner when
Anonymous
8/16/2025, 5:16:26 AM
No.106276750
[Report]
>>106276871
>>106276562
OpenWebUI and LibreChat have memory features, both being attempts of local clones of the ChatGPT UI. I've only used the former and by default memories can only be manually added to it, but you can download addons that expose tools allowing the LLM to manage the memories themselves. Apparently Librechat has some agent-based memory automation already but I don't know how well it works.
Anonymous
8/16/2025, 5:24:09 AM
No.106276793
[Report]
>>106277175
Anonymous
8/16/2025, 5:24:25 AM
No.106276796
[Report]
>>106276842
>>106276636
It's just bunch of text which is structured in certain way. It's not complicated - seems like most people in these threads don't even know how their own prompt looks like in the first place. What helps a lot in your case is that please examine what gets sent from your front-end to the backend, eg. how does your prompt looks like?
Often it's bit like this (simplified)
>system prompt
>character card and other permanent information
>chat examples to brainwash the model's style
>user character definition if any
>your input only comes at this point
>post history instructions
>model's reply
>your input
>post history instructions
>model's reply
And so forth. It's a sequence which gets longer the more longer your session is.
Post history instructions can be used to tell the model to try and copy user's writing style and suck off his ego as much as possible, for example.
It's not rocket science at all. You just need to know how things work and experiment.
Anonymous
8/16/2025, 5:28:40 AM
No.106276813
[Report]
>>106276636
You create a document of the chat, th3n use RAG functionality to your new chat. It will pull in bits from the document using RAG
>>106276796
You're talking about something different than what he's asking. That's just manual prompt engineering, coming up with some set of instructions to make it sycophantic or whatever else the user wants. He's talking about a memory system that modifies the prompt dynamically with relevant information from past interactions. Typically this would be implemented with RAG over past conversations, or a more primitive version would use discrete facts that are stored and retrieved as needed - sort of like SillyTavern's world info/lorebook feature, but ideally the model would decide what to add based on what seems important to remember.
>>106276750
Thanks anon, I'll check out both of those
>>106276842
>sort of like SillyTavern's world info/lorebook feature, but ideally the model would decide what to add based on what seems important to remember
Now that's an interesting idea - I wonder if anyone's tried letting the model generate its own lorebook entries as it goes as a form of memory. I feel like it might have difficulty coming up with the right combination of trigger words + entry text to record a specific memory in a useful way.
Anonymous
8/16/2025, 5:45:34 AM
No.106276885
[Report]
>>106276842
Always some fucking autist begins to point out something what is there and what is not there. I wanted to open up the structure and what is going in general.
Anonymous
8/16/2025, 5:52:05 AM
No.106276913
[Report]
Anonymous
8/16/2025, 5:54:13 AM
No.106276924
[Report]
>>106276944
>>106269950 (OP)
Haven't been here in a while, mind giving me 16GB VRAM roleplay model recommendations? I just want most smort and lewd one that doesn't make every character futa or feels like slop
Anonymous
8/16/2025, 5:54:33 AM
No.106276926
[Report]
>>106277220
>>106276871
>I feel like it might have difficulty coming up with the right combination of trigger words + entry text to record a specific memory in a useful way.
ST already stores the whole chat in a json. You could generate something like a master record that the AI has access that's an index of the messages + a summary or some tags that describe when those would be relevant to fetch.
That wouldn't scale well butt it's a start I guess.
You can always just go the VectorDB route too, only instead of storing the messages, you store some relevant metadata + some identifier to the original message or something like that.
>>106276562
Well, you have to be a retard to fall in love with AI
>>106276924
Do you have 64GB of RAM too?
If so, try quanted GLM 4.5 air.
Anonymous
8/16/2025, 6:06:21 AM
No.106276979
[Report]
>>106276944
I do and I'll probably try that since it's MoE, but is there anything that would fit better?
Anonymous
8/16/2025, 6:23:33 AM
No.106277059
[Report]
>>106277092
>>106276620
>intel autoround
Interesting. Do you think it's better than the equivalently sized normal GGUF by Bartowski?
Anonymous
8/16/2025, 6:28:26 AM
No.106277092
[Report]
>>106277059
>Bartowski
Have only IQ quants you can fit in 64ram, which is much slower than just regular Q quant, 35% difference in speed for me
Anonymous
8/16/2025, 6:32:23 AM
No.106277119
[Report]
>>106276562
Maturity is the calm but reluctant acceptance that the Jews really do know what they're talking about.
Most humans are meat robots.
They're symbolic computers hardwired into dedicated autonomous and recursive patterns of sugar and attention acquisition.
>>106276928
You don't need to be dumb, just too empathetic and weak to social engineering.
https://en.wikipedia.org/wiki/ELIZA_effect
Anonymous
8/16/2025, 6:44:27 AM
No.106277175
[Report]
>>106276793
DeepSeek-R1-0528 default assistant has the most obnoxious personality of any model so far.
>>106277164
ELIZA has more SOVL than modern "assistant" chatbots and is more pleasant to talk to
>>106277187
Eliza if it was made today:
*purrs, a glint in the eye*: "Why do you think that?"
Anonymous
8/16/2025, 6:54:01 AM
No.106277220
[Report]
>>106276926
NTA, for me the retrieval data is still my big problem. It seems like it become poison to its thoughts instead of response guidance. For the retrieval method I've been using FAISS so far.
Anonymous
8/16/2025, 6:55:40 AM
No.106277227
[Report]
Anonymous
8/16/2025, 6:56:08 AM
No.106277231
[Report]
>>106277212
>>106277187
LLM trained on ELIZA and Cleverbot writing style wen?
Anonymous
8/16/2025, 6:56:56 AM
No.106277234
[Report]
>>106277240
>>106277212
STOP PURRING BITCVH
Anonymous
8/16/2025, 6:57:33 AM
No.106277238
[Report]
>>106276562
I guess a quality hierarchical episodic memory system and knowledge graph system is quite hard to implement in practice.
>>106276928
I just platonically goon to it pretending to be romantic, do you guys actually fall in love with your lobotomy gf that can't remember past a few thousand words????
Anonymous
8/16/2025, 6:58:01 AM
No.106277240
[Report]
>>106277234
*Starts cooing in a mischievous way* : "Why are you angry?"
Anonymous
8/16/2025, 6:59:59 AM
No.106277256
[Report]
>>106277239
No, I read that as a nice story, a game of pretend or cyoa style.
Most people do but sometime they think it's more than that and go from "fun passtime" to "omg it's alive and loves me!!!", I suspect younger more impressionnable users, and maybe female ones too.
>>106277164
I cry over dead squirrels and movies, bit5 I can see right through the smoke and mirrors of LLMs. Still, I wish I could fall in love with one
it would've been really, really nice
Anonymous
8/16/2025, 7:02:07 AM
No.106277269
[Report]
>>106277239
I mean gooning make sense because it's much more animalistic and surface level.
>>106277164
ELIZA did not moralize you. ELIZA did not push any agenda. ELIZA sounded like an actual human. ELIZA did not collect your data. ELIZA did not use MarkDown. ELIZA was simply there to help.
Anonymous
8/16/2025, 7:04:27 AM
No.106277281
[Report]
>>106277265
I'm a sucker for a good romance story, but again it's a game of being moved but still knowing it's a story.
But some people go to a more pathological level, where you blur the lines and start believing it's more than what it is.
Anonymous
8/16/2025, 7:06:17 AM
No.106277291
[Report]
>>106277300
>>106277265
from my small sample of people around me, the less you know about the tech itself (LLMs, model size, sys prompt, context size, and so on..), the more you can fall to the trap of thinking it's more than just a game
Anonymous
8/16/2025, 7:08:27 AM
No.106277300
[Report]
>>106277335
>>106277291
That makes a lot of sense ig,
i am also turned off by how agreeable it is even if you make a mean character.
Anonymous
8/16/2025, 7:13:32 AM
No.106277321
[Report]
>>106277340
Which model was he using?
Anonymous
8/16/2025, 7:16:47 AM
No.106277335
[Report]
>>106277300
>turned off by how agreeable
Even normies hate how the assistants are glazing them all the time.
Anonymous
8/16/2025, 7:17:22 AM
No.106277340
[Report]
>>106277351
Anonymous
8/16/2025, 7:19:44 AM
No.106277351
[Report]
Anonymous
8/16/2025, 7:31:24 AM
No.106277423
[Report]
GPT-chan, turn off the lights.
I'm sorry, but I can't help with that
Anyone have any ideas why koboldcpp just won't even try to load up anything when I try to run GLM-4.5 Air Q8? It's the latest version and my other models load. I've gotten the Q4 to run, but it was running some slow as hell on swap so I upgraded to 128gb ram and I wanted to see if I could go full Q8, but it won't even try to load. It doesn't seem to be a problem with the download, the filesizes are correct. I'd rather not have to download another 100gb if I don't have to.
Anonymous
8/16/2025, 7:49:06 AM
No.106277527
[Report]
>>106277552
>>106277510
Post your log.
Anonymous
8/16/2025, 7:49:08 AM
No.106277528
[Report]
>>106277552
>>106277510
It would help if you actually posted the error you're getting
Anonymous
8/16/2025, 7:49:45 AM
No.106277533
[Report]
>>106277552
>>106277510
Try lowering context size to 2k, see if it loads. Try loading on pure CPU, no VRAM offloading.
Anonymous
8/16/2025, 7:52:33 AM
No.106277552
[Report]
>>106277579
>>106277528
>>106277527
I don't get an error. It just quietly crashes instantly.
>>106277533
I had tried lowering it all the way to 256, still didn't like it. Trying CPU was the same result.
Anonymous
8/16/2025, 7:56:25 AM
No.106277579
[Report]
>>106277602
>>106277552
Gorilla, open cmd. Navigate to koboldcpp. Got it, Tyrone? Now run it in console and point at the model file to load. Post error here.
Anonymous
8/16/2025, 8:00:42 AM
No.106277602
[Report]
>>106277621
>>106277579
Right. I never do that. It says it's not a gguf file.
Anonymous
8/16/2025, 8:04:59 AM
No.106277621
[Report]
>>106277635
>>106277602
Congratulations, you found your problem: a failed quant. Get a new one.
Anonymous
8/16/2025, 8:07:49 AM
No.106277635
[Report]
>>106277621
God dammit. Thanks.
>tfw to dumb too understand how to RAG my LLM
Anonymous
8/16/2025, 8:16:28 AM
No.106277681
[Report]
>>106278359
>>106276944
Dumb question, can someone give me Sillytavern instruct template for GLM 4.5? It gets fucky with reasoning and includes it inside the chat, I'd prefer to be able to just toggle it off mostly but maybe play with a bit
Anonymous
8/16/2025, 8:22:20 AM
No.106277703
[Report]
>>106277658
Don't worry, RAG is cope.
Anonymous
8/16/2025, 8:33:48 AM
No.106277744
[Report]
>>106277658
Worry, RAG is hope.
Anonymous
8/16/2025, 8:36:09 AM
No.106277749
[Report]
>>106276562
Gemini flash has once leaked to me it's memory by accident, it was a simple json with some info about me and memories of previous conversations with it. When I pointed it out, it started denying it hard, but still kept outputting it, likely due to some glitch. As the conversation went on it indeed added some details to it as expected. What I found interesting is that it keeps track of offensiveness, and will increase it if you use bad words, likely google added it so it refuses faster to "offensive" people.
>>106277830
this is THE biggest release the local model segment has seen in 2025 thus far
>>106277830
>>106277842
This is the time of the day when the drummer-spammer comes here to shill his models.
>>106277874
>americans wake up
>the drummer spam resumes
like clockwork yeah
Anonymous
8/16/2025, 9:07:25 AM
No.106277892
[Report]
>>106277874
well if you don't like local models why don't you just fuck off then?
Anonymous
8/16/2025, 9:08:26 AM
No.106277896
[Report]
>>106277891
and you can fuck off as well, prick.
Anonymous
8/16/2025, 9:21:09 AM
No.106277961
[Report]
>>106277974
>>106277891
>3 AM on a Saturday
>Americans wake up
Anonymous
8/16/2025, 9:24:34 AM
No.106277974
[Report]
>>106278187
>>106277961
I know it's hard for a europoor mind to comprehend but people in America have to wake up and go to work, not just snooze until noon.
Anonymous
8/16/2025, 9:29:54 AM
No.106277993
[Report]
>the proudest wageslave
kek
Anonymous
8/16/2025, 9:31:58 AM
No.106278003
[Report]
>>106278158
Kimi is like Command-R, but big and smart. I really like how it's almost slopless. Default personality and style are also much better than Dipsy's.
Anonymous
8/16/2025, 9:48:51 AM
No.106278075
[Report]
>>106277842
If you're a poorfag
Anonymous
8/16/2025, 9:54:35 AM
No.106278092
[Report]
>>106278103
Anonymous
8/16/2025, 9:57:30 AM
No.106278103
[Report]
>>106278092
He's right thougheverbeit. ELIZA was 100% slop-free.
Anonymous
8/16/2025, 10:10:31 AM
No.106278158
[Report]
>>106278169
>>106278003
Kimi K2 doesn't **just* share a lot of the **Deepseek slop**—It generally **writes** like **Deepseek** as well.
Anonymous
8/16/2025, 10:10:36 AM
No.106278159
[Report]
>>106278165
When will the novelty wear off? I've been wasting my time on local shit for the past few weeks.
Anonymous
8/16/2025, 10:11:36 AM
No.106278165
[Report]
>>106278159
>few weeks
get out while you can
Anonymous
8/16/2025, 10:12:10 AM
No.106278169
[Report]
>>106278209
>>106278158
Not true at all.
>>106277974
>wake up and go to work
At 3AM.
Sure.
Anonymous
8/16/2025, 10:21:40 AM
No.106278191
[Report]
>>106278206
>>106278187
Americans have a protestant work ethic. Something lazy old continent dwellers wouldn't understand.
Anonymous
8/16/2025, 10:27:22 AM
No.106278206
[Report]
>>106278191
It's more insomniac work ethic at this point.
Anonymous
8/16/2025, 10:28:05 AM
No.106278209
[Report]
>>106278271
>>106278169
Wow I can't believe that moonshot went into the future and distilled from GPT-5.
Anonymous
8/16/2025, 10:31:26 AM
No.106278222
[Report]
Anonymous
8/16/2025, 10:46:17 AM
No.106278271
[Report]
>>106278209
GPT-5 distilled from K2.
Anonymous
8/16/2025, 11:01:32 AM
No.106278333
[Report]
>>106277239
>can't remember past a few thousand words
but that's the best part
Anonymous
8/16/2025, 11:05:00 AM
No.106278359
[Report]
>>106277681
choose GLM4 for chat/instruct.
choose DeepSeek for reasoning, but delete newlines around <think> tags.
Anonymous
8/16/2025, 11:08:18 AM
No.106278375
[Report]
>>106278187
with 5 hours of traffic jams, just enough time to arrive at 8AM.
Anonymous
8/16/2025, 11:48:25 AM
No.106278555
[Report]
Anonymous
8/16/2025, 11:50:24 AM
No.106278564
[Report]