Anonymous
8/16/2025, 6:31:04 AM
No.106277108
[Report]
>>106282955
/ldg/ - Local Diffusion General
Anonymous
8/16/2025, 6:32:09 AM
No.106277114
[Report]
the two girls hug:
Anonymous
8/16/2025, 6:32:19 AM
No.106277116
[Report]
>*braps*
Anonymous
8/16/2025, 6:32:48 AM
No.106277122
[Report]
Anonymous
8/16/2025, 6:42:42 AM
No.106277165
[Report]
Anonymous
8/16/2025, 6:47:24 AM
No.106277191
[Report]
Anonymous
8/16/2025, 6:48:25 AM
No.106277196
[Report]
Anonymous
8/16/2025, 6:50:05 AM
No.106277205
[Report]
>>106277219
>106277084
>Why are so many (nsfw) wan loras in fucking SLOW MOTION?
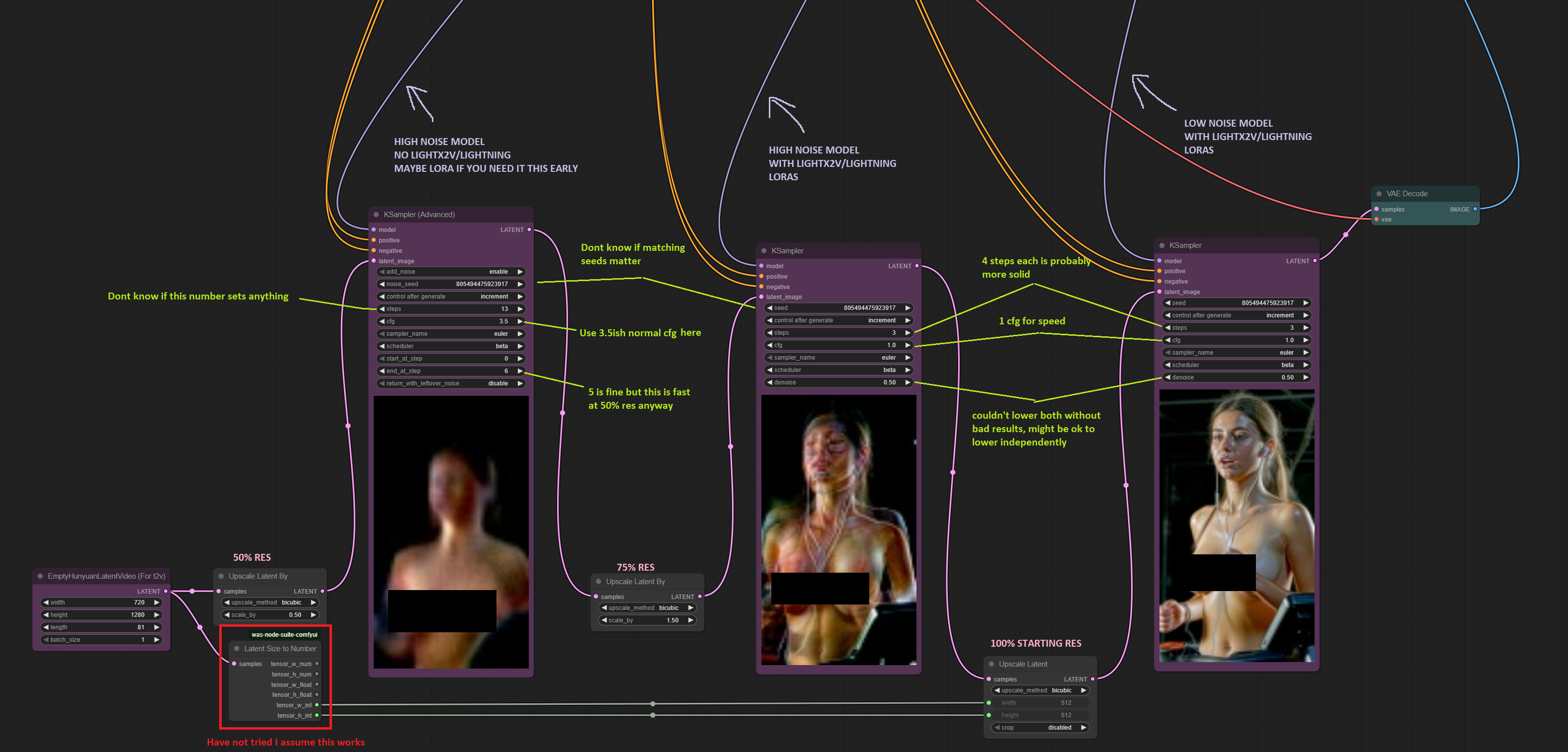
Anything plugged into the high noise model that fucks with the motion will make it slow motion if the training data isn't perfect. You need to make some motion with one sampler without a LoRA then move it into the next one with a LoRA.
>>106277205
So basically 2 samplers back to back? One to set the proper "speed" and the second with the loras you want?
I never thought of that, how many frames do you go with with the first sampler?
Anonymous
8/16/2025, 6:54:45 AM
No.106277223
[Report]
>>106277226
>>106277219
5 at most. 3 at least.
Anonymous
8/16/2025, 6:55:28 AM
No.106277226
[Report]
>>106277223
OK, I will try.
Anonymous
8/16/2025, 6:59:51 AM
No.106277253
[Report]
>>106277372
>>106277219
5 steps is a good ballpark
however this is 5 steps that you'll have the cfg at 3.5 or something because no lightning lora. So it's slow, but you get proper motion and some prompt adherence. I scale my empty latent down 50% so it does the first high noise pass at half res which is way,way faster and this first pass ends in a blurry mess anyway so I dont think the lower res compromises anything, but I really don't know.
>>106277257
>I scale my empty latent down 50% so it does the first high noise pass at half res
Can you share your wf anon?
Anonymous
8/16/2025, 7:03:52 AM
No.106277278
[Report]
>>106277341
>>106277266
its a mess because I tried to make it do both i2v and t2v and I just went from 2 samplers to 3 with remnants of shit I don't use, let me get the important parts in a sfw screenshot after this gen in done
What are the best models based on either sd 1.5 or 2.1?
I have 8 gigs of ram and it's not enough to run SDXL.
I'm looking for models that are great at processing long/detailed prompts and can understand context.
The issue with the models I have is that they clump it all together or make a mandala or makes it into an object or it just lacks consistency or something like that.
Anonymous
8/16/2025, 7:07:18 AM
No.106277295
[Report]
>>106283762
>>106277257
I tried cheating my way with Flux the similar way with the 1st ksampler at half resolution and I always ended up getting a total mess that couldn't be fixed no matter how many steps you'd set in the next ksampler with proper resolution. Then again, completely different model and that was a static image so go figure
Anonymous
8/16/2025, 7:07:37 AM
No.106277296
[Report]
Anonymous
8/16/2025, 7:07:44 AM
No.106277298
[Report]
>>106277285
Anime:
https://civitai.com/models/118495/exquisite-details
Realistic: (this one is better than the examples lead on)
https://civitai.com/models/550737/1girl-printer
>I'm looking for models that are great at processing long/detailed prompts and can understand context.
Not with 1.5 or 2.1 you're not.
Anonymous
8/16/2025, 7:17:22 AM
No.106277341
[Report]
>>106277427
>>106277278
Thank you anon, I mostly want to see how you connected stuff anyway.
Anonymous
8/16/2025, 7:21:36 AM
No.106277365
[Report]
>>106277368
>>106277349
>mememe dance
why is there no other hot dances loras, why is it always the same one, it's kind of crazy
Anonymous
8/16/2025, 7:22:42 AM
No.106277368
[Report]
>>106277387
>>106277349
>>106277365
this, i want my twerk loras.
Anonymous
8/16/2025, 7:22:56 AM
No.106277372
[Report]
Anonymous
8/16/2025, 7:23:42 AM
No.106277374
[Report]
Anonymous
8/16/2025, 7:25:00 AM
No.106277387
[Report]
>>106277502
>>106277368
there like dozens of sexy dances with easy to find material, from kpop to latin, but it's always the same mememe instead
>>106277349
can you make him dance too please?
Anonymous
8/16/2025, 7:27:36 AM
No.106277405
[Report]
>>106277568
>>106277392
>figure collecting fag
i regret not buying this when i had the chance. its sold out, now.
Anonymous
8/16/2025, 7:29:47 AM
No.106277417
[Report]
>>106277285
>https://rentry.org/5exa3
check this out, it's well trained furry model combined with really well trained anime lora which made it so good that in some cases it's still better than sdxl illustrious
>>106277257
>>106277266
>>106277341
This is a rip off of another anon that definitely knows more than me I'll post his screenshot after
>I tried cheating my way with Flux the similar way with the 1st ksampler at half resolution and I always ended up getting a total mess that couldn't be fixed no matter how many steps you'd set in the next ksampler with proper resolution. Then again, completely different model and that was a static image so go figure
I tried to use 3 ksampler advanced but when I upscaled the latent, the noise of the latent became basically christmas lights on the image. Tried adding noise but that degraded it. But the normal ksampler denoise fixes it.
>>106277427
original workflow
Anonymous
8/16/2025, 7:37:33 AM
No.106277453
[Report]
>>106277498
>>106277434
Oh hey it's my schizo workflow. I'm trying stuff with the kij workflow now but idk. I think as long as you have the motion and the high noise pass looks good enough you can upscale it and feed it to the low noise model at are .65~ denoise and it will turn out fine. I feel like the finer motions get lost in the process though, I'm trying to figure out how to fix it.
Anonymous
8/16/2025, 7:41:12 AM
No.106277473
[Report]
>>106277553
>>106277427
Yeah it looks like latent size to dumber doesn't work. The point was it's better to get your width and height from wherever you set it so you don't have to manually change it with every aspect ratio. You can just use another 'upscale latent by' but if you decide on different scales than 50% or 75% the math changes to get it back to 100%.
Anonymous
8/16/2025, 7:43:28 AM
No.106277489
[Report]
>>106277476
I don't remember this xena warrior princess episode
Anonymous
8/16/2025, 7:44:46 AM
No.106277498
[Report]
>>106277453
its still way better than anything I had with 2 samplers and lightning on both. Slow motion is fixed, prompt adherence is better and I can make darker scenes, and sometimes things just wouldn't move at all or just ignore me with lightning
>>106277392
>>106277387
idk i'm just using a lora
>>106277427
>>106277434
Thanks anon, I guess screenshots are better than nothing, I'll try to implement that.
I don't use lightx2v because I think it fucks up outcome too much (it's nsfw loras that make things slowmotion for me), so maybe I'll go something like that :
- first sampler on high only 5 steps at 50% size + no lora
- upscale latent to get back to 100%
- feed latent to second sampler with 40 steps using a dynamic cutoff between high and low (Wan MoE KSampler)
- same seed
- same scheduler/sampler
Would that work or am I missing something?
>>106277508
if you don't use loras at the start, wouldn't that defeat the purpose of what you want even if it's able to be normal speed? especially for nsfw
>>106277508
Yeah it's mainly to fix lightx2v while still benefiting from the speed by just adding a little gen time at the beginning, but if your loras are giving you slowmo problems you can use it for that too.
Statler&(maybe)Waldorf
8/16/2025, 7:51:46 AM
No.106277546
[Report]
Anonymous
8/16/2025, 7:52:43 AM
No.106277553
[Report]
>>106277574
>>106277473
>latent size to dumber doesn't work
So resizing doesn't work?
>>106277522
>>106277543
Yeah that's the thing I want to test. If I'm able to retain the motion speed, but not impacting too much the actual scene itself and what's going on, since that's what I want added from the lora.
Statler&(maybe)Waldorf
8/16/2025, 7:52:47 AM
No.106277554
[Report]
>>106277581
>>106277502
rocketnon this is just sad
Anonymous
8/16/2025, 7:53:03 AM
No.106277558
[Report]
>>106277502
thanks anon <3
looks really cute
Anonymous
8/16/2025, 7:53:45 AM
No.106277562
[Report]
>>106277795
>>106277543
actually fuck what I said this anon
>>106277522 is right for probably 99% of nsfw loras because they are usually about content/composition and that needs to be in the latent from the start
Anonymous
8/16/2025, 7:54:26 AM
No.106277568
[Report]
>>106277405
there is a 40cm one up for preorder.
go for it same price as beach queen
Anonymous
8/16/2025, 7:55:34 AM
No.106277574
[Report]
>>106277598
>>106277553
>So resizing doesn't work?
No that particular node that I was trying to use to fetch the starting latent size doesn't work like I thought. You just gotta do something else to make it more user friendly for yourself. The resize works fine.
Anonymous
8/16/2025, 7:56:25 AM
No.106277580
[Report]
>>106277564
Yeah well fuck you enjoy your slow motion video. You can't have your cake and eat it too.
Anonymous
8/16/2025, 7:56:34 AM
No.106277581
[Report]
Anonymous
8/16/2025, 7:58:19 AM
No.106277595
[Report]
>>106277427
forgot to mention you can OOM on the 2nd sampler if the upscale is too high. My 24GB was barely able to do 75% of 720p. There's probably some way to fix this and my workflow isn't dumping stuff from vram like the third sampler that switches to low noise does.
Anonymous
8/16/2025, 7:58:32 AM
No.106277598
[Report]
>>106277564
I will still try it, maybe with enough noise and in i2v it could work.
Man, I wish there was an easy way to control speed.
>>106277574
I see.
Anonymous
8/16/2025, 8:00:40 AM
No.106277601
[Report]
Anonymous
8/16/2025, 8:07:50 AM
No.106277636
[Report]
>>106277682
Yeah so trying the upscale in the middle of the kij workflow without using the low model from a fresh set of noise doesn't really work well. Gonna try again just doing the high noise on its own, upscale it and then do low noise and see if that is cleaner.
Anonymous
8/16/2025, 8:13:50 AM
No.106277662
[Report]
Has anybody tested the difference between t5xxl, flan, and gner encoders for Chroma? Gner is the newest, but it was apparently trained with flan.
Anonymous
8/16/2025, 8:16:44 AM
No.106277682
[Report]
>>106277801
>>106277636
And here it is without upscaling the denoise pass as well.
Anonymous
8/16/2025, 8:17:43 AM
No.106277686
[Report]
Anonymous
8/16/2025, 8:26:30 AM
No.106277722
[Report]
Anonymous
8/16/2025, 8:37:25 AM
No.106277753
[Report]
3060 12gb + 16gb ram
can I run any t2vid? Would it be extremely painful?
Anonymous
8/16/2025, 8:40:13 AM
No.106277763
[Report]
>>106277759
>16gb ram
legitimately might be an issue.
Anonymous
8/16/2025, 8:46:17 AM
No.106277790
[Report]
>>106277476
>Get the fuck out gaijin bitch, or I'll slice you!
>Xenophobe Warrior Princess
Based Japan!
Anonymous
8/16/2025, 8:47:18 AM
No.106277792
[Report]
>>106277759
you probably want to increase the size of your swap file so it offloads more onto your ssd which will make everything ultra slow but atleast it works that way.
Anonymous
8/16/2025, 8:47:36 AM
No.106277795
[Report]
>>106277899
>>106277562
>That clenching
More of this japanese masterpiece please!
Anonymous
8/16/2025, 8:48:44 AM
No.106277798
[Report]
Anonymous
8/16/2025, 8:49:11 AM
No.106277801
[Report]
>>106278378
>>106277682
Back when your PC had sovl, no shitty bling
Anonymous
8/16/2025, 8:49:11 AM
No.106277802
[Report]
Anonymous
8/16/2025, 8:50:54 AM
No.106277812
[Report]
>>106277869
>>106277759
16gb system ram is the big issue, 32gb is like the minimum, for a good experience you'd want 64gb
A lot of vram to ram offloading is needed for these huge models
Anonymous
8/16/2025, 8:55:22 AM
No.106277835
[Report]
>>106278059
Anonymous
8/16/2025, 8:59:56 AM
No.106277854
[Report]
Anonymous
8/16/2025, 9:03:45 AM
No.106277869
[Report]
>>106277900
>>106277812
let's say I buy 2 5060 ti 16gb + stick the 3060 12gb on the new system. Does comfy let you spread models across multiple cards? It's overkill but I'd be using it for llms too
Anonymous
8/16/2025, 9:09:20 AM
No.106277900
[Report]
>>106277869
I think you need some extension for that in Comfy, but I seem to recall people reporting it working
But two 5060 i 16gb ? Why not start with one 5060 ti and the 3060 ? The 5060 ti is about 2x the speed of the 3060 for inference.
Anonymous
8/16/2025, 9:12:39 AM
No.106277915
[Report]
>>106277959
>>106277899
S-surely there are some scenes where they make out, like just for silly fun ?
Anonymous
8/16/2025, 9:20:58 AM
No.106277959
[Report]
>>106277972
>>106277915
How exactly would that help them defeat the shogun?
Anonymous
8/16/2025, 9:24:20 AM
No.106277972
[Report]
>>106277959
Morale building! Stress release!
Anonymous
8/16/2025, 9:25:43 AM
No.106277979
[Report]
Anonymous
8/16/2025, 9:34:58 AM
No.106278020
[Report]
>>106278034
>>106277899
catbox? surprisingly good hair
Anonymous
8/16/2025, 9:38:42 AM
No.106278034
[Report]
>>106278020
https://files.catbox.moe/mo0qda.mp4
Beware the ancient Chinese secrets in this workflow.
Anonymous
8/16/2025, 9:44:19 AM
No.106278059
[Report]
Anonymous
8/16/2025, 10:00:53 AM
No.106278113
[Report]
>>106278505
Anonymous
8/16/2025, 10:17:32 AM
No.106278183
[Report]
>>106278305
how does lightx2v lora work and why can it speed up wan steps?
Anonymous
8/16/2025, 10:38:36 AM
No.106278244
[Report]
>just tried nunchaku kontext
>8s~ to do 8stp 1cfg
BROS, when we get comfy nodes for QWEN and later WAN, it's gonna be a game changer, this multiplied my shitposting potential to 5x
Anonymous
8/16/2025, 10:40:04 AM
No.106278253
[Report]
{
"nodes": [
{"type": "LoadImage", "id": "person_image"},
{"type": "LoadImage", "id": "suit_reference"},
{"type": "SegmentAnything", "id": "clothes_mask", "inputs": ["person_image"]},
{"type": "Flux_Kontext", "id": "clothing_transfer", "inputs": ["person_image", "suit_reference", "clothes_mask"]},
{"type": "Prompt", "id": "conditioning", "inputs": {"text": "a person wearing a formal business suit, realistic, professional corporate attire"}},
{"type": "NegativePrompt", "id": "neg_conditioning", "inputs": {"text": "extra arms, distorted, blurry"}},
{"type": "FluxSampler", "id": "sampler", "inputs": ["clothing_transfer", "conditioning", "neg_conditioning"]},
{"type": "SaveImage", "id": "final_output", "inputs": ["sampler"]}
]
}
Anonymous
8/16/2025, 10:51:13 AM
No.106278289
[Report]
THESE NIGGAS TRYNA KILL ME
Anonymous
8/16/2025, 10:54:01 AM
No.106278298
[Report]
>>106278424
>>106276887
New midwit upscale cope just dropped:
Upscale only the first frame of a smaller video then use the latent motion of that video fill in the gaps during an img2vid pass
Anonymous
8/16/2025, 10:54:46 AM
No.106278305
[Report]
>>106278183
I dont know shit about shit but it doesn't speed up steps, it makes it so very few steps gives acceptable quality
Is there a reason to use wan2gp over comfy?
Anonymous
8/16/2025, 10:58:58 AM
No.106278323
[Report]
>>106278315
Yeah to get (You)s on 4chan by saying you use it.
Is there are any way to remove background for pixel art that i was generated for
i try to used Inspyrenet, but it give out anti-aliasing, while Transparency Background Remover always remove line
Anonymous
8/16/2025, 11:02:28 AM
No.106278342
[Report]
>>106278315
it avoids spawning the deranged anticomfy schizo
Anonymous
8/16/2025, 11:09:07 AM
No.106278378
[Report]
>>106277801
It wasn't the PC. It was the world that was different.
Anonymous
8/16/2025, 11:10:49 AM
No.106278388
[Report]
>>106278400
>>106277837
>hands clipping through the bars
they're definitely using shitty CGI to train these models
Anonymous
8/16/2025, 11:14:40 AM
No.106278400
[Report]
>>106278388
there's probably game footage in there where NPCs clip through shit like that without the clipping being tagged
Anonymous
8/16/2025, 11:17:12 AM
No.106278413
[Report]
Anonymous
8/16/2025, 11:17:52 AM
No.106278416
[Report]
>>106278327
The problem is that it's generating discoloration outside of what should be edge of the character. For the most part, the bg can be removed with a simple color selection. Unfortunately the extra garbage around the outside matches colors on the inside of the character, so it's more difficult to remove. I'm sure there is some algo you could write to select only those colors that are touching transparent pixels or something.
Which model/LoRA are you using?
Anonymous
8/16/2025, 11:20:26 AM
No.106278424
[Report]
>>106278681
>>106278298
Actually, if the upscale isn't immaculate the whole world warps and shifts.
Anonymous
8/16/2025, 11:20:39 AM
No.106278425
[Report]
Anonymous
8/16/2025, 11:29:10 AM
No.106278456
[Report]
>>106278469
has someone trained a LoRA on Vixen media group movies?
Anonymous
8/16/2025, 11:32:58 AM
No.106278469
[Report]
>>106278480
>>106278456
Sorry I'm not a coomer what is that?
Anonymous
8/16/2025, 11:35:06 AM
No.106278480
[Report]
>>106278503
>>106278469
>Vixen Media Group owns and operates nine online adult film sites: Vixen, Tushy, Blacked, Blacked Raw, Tushy Raw, Deeper, Slayed, Wifey and Milfy.
Anonymous
8/16/2025, 11:39:40 AM
No.106278503
[Report]
>>106278480
I'd rather see loras on classy porn, almost never done.
>>106278113
Just testing my i2v upscale idea.
Anonymous
8/16/2025, 11:42:04 AM
No.106278516
[Report]
this beauty took me only 3 hours to gen.
Anonymous
8/16/2025, 11:43:41 AM
No.106278525
[Report]
Another day without svdquant for wan.
Anonymous
8/16/2025, 11:52:55 AM
No.106278581
[Report]
>>106278593
>>106278505
we need something like multidiffusion but for video, would make it possible for vramlets to upscale
Anonymous
8/16/2025, 11:54:42 AM
No.106278593
[Report]
>>106278581
Personally I would not mind an iterative upscaler for the low noise pass.
>>106278327
>>106278421
The way I cut out backgrounds from my pictures is by using Flux Kontext then a paint program. On windows you can use paint.net with the color grim reaper extension (I think they renamed it?). On Linux I use Krita (as shown below in workflow).
Probably not so good with green characters, but usually bright green isn't found anywhere else on the image. When prompting you can pick a color which isn't found anywhere on your character. If you don't have such an option, then pick a color which isn't found near the edges of your character and you can either select around them, then use alpha, or use the magic wand tool.
The advantage with this strategy is that it allows you to get smaller details like flowing hair with some transparency. It is the current year of 2025 and I have yet to find a better solution. All the background-removal models I have tried are total dogshit. I have to wait over a minute to let Kontext do its thing before I can post-process it to have a transparent background.
I've attached an example, my workflow was exactly like this:
>comfyUI with Flux Kontext
>"replace the yellow background with solid bright green, keep the characters exactly the same" (into a 1024x1024 image, your input is still 128x128 though)
>open the output in Krita
>image -> scale image to new size -> 128x128 (your original size)
>"Filter -> Colors -> Color to Alpha" then there's a bar of white with the title "Color Sampler" -> use the color picker in the new menu to select the background green
>tweak the threshold until it looks right (I made part of a new background layer black and part of it blue so I can see how much of the character's other colors I'm losing and how neat of a cut I'm getting, and I go somewhere that looks good)
>export image as PNG with Alpha channel for transparency and no HDR
Nice sprites, how did you generate the sprite map? I can never get consistent sprites.
Anonymous
8/16/2025, 12:02:10 PM
No.106278638
[Report]
Anonymous
8/16/2025, 12:03:11 PM
No.106278640
[Report]
>>106278327
Pirate photoshop and use background remover.
Also is the character sheet actually consistent enough?
Anonymous
8/16/2025, 12:06:44 PM
No.106278670
[Report]
Anonymous
8/16/2025, 12:08:11 PM
No.106278675
[Report]
>>106278599
you're getting a lot of anti-aliasing with that method, which he said he doesn't want
Anonymous
8/16/2025, 12:09:31 PM
No.106278681
[Report]
>>106278696
>>106278424
this is what it actually looks like when you eat mushrooms
Anonymous
8/16/2025, 12:09:57 PM
No.106278684
[Report]
Anonymous
8/16/2025, 12:11:24 PM
No.106278692
[Report]
Anonymous
8/16/2025, 12:12:13 PM
No.106278696
[Report]
>>106278705
>>106278681
acid too.
Try another upscale idea with i2v. here is no upscale.
Anonymous
8/16/2025, 12:13:21 PM
No.106278705
[Report]
>>106278696
And here is upscale. Not too bad desu.
what happens if you give this to wan
Anonymous
8/16/2025, 12:21:20 PM
No.106278744
[Report]
anyone here have tips for training wan loras? my only lora experience is with SDXL
Anonymous
8/16/2025, 12:21:38 PM
No.106278748
[Report]
Anonymous
8/16/2025, 12:22:10 PM
No.106278751
[Report]
Anonymous
8/16/2025, 12:24:02 PM
No.106278762
[Report]
Anonymous
8/16/2025, 12:32:07 PM
No.106278806
[Report]
>the plan
push /ldg/ somewhere else
(into the trashcan & or dumpster)
>>106278800
with i2v upscale. There seems to be some ghosting?
should i get amd or nvidia for a linux server ?
Anonymous
8/16/2025, 12:35:05 PM
No.106278817
[Report]
>>106278815
AMD all the way for image gen.
Anonymous
8/16/2025, 12:39:36 PM
No.106278843
[Report]
>>106279030
>>106278421
>>106278599
lmao no the model only work once in blue moon, and if it need to draw creature or fantasy-like humanoid, than it would break down and cry like like crazy
But thank for helping
>>106278808
upped the denoise slightly.
Anonymous
8/16/2025, 12:39:58 PM
No.106278845
[Report]
>>106278815
don't listen to him
get Nvidia
Anonymous
8/16/2025, 12:55:40 PM
No.106278926
[Report]
>>106278998
>>106278742
Where do I find a gf like this?
Anonymous
8/16/2025, 1:04:59 PM
No.106278974
[Report]
>>106278980
Another one. No i2v upscale.
Anonymous
8/16/2025, 1:06:01 PM
No.106278980
[Report]
>>106278974
with i2v upscale.
Anonymous
8/16/2025, 1:06:15 PM
No.106278984
[Report]
>>106279005
>>106278800
>>106278808
>>106278844
You're trying to get that book to say "FUTANARI HENTAI" aren't you?
Anonymous
8/16/2025, 1:06:32 PM
No.106278987
[Report]
>>106279079
>>106278815
Nvidia
Sadly there's no other choice for AI at the moment, in a year or so AMD should be competitive, not now though
Anonymous
8/16/2025, 1:06:45 PM
No.106278989
[Report]
>>106279005
>>106278844
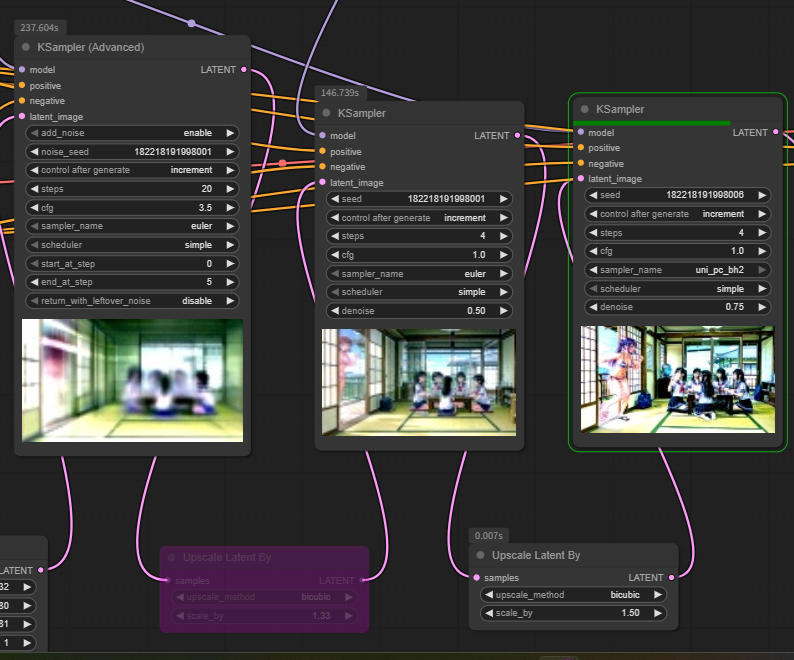
You might want to manually calculate denoise or use Ksampler Advanced, that one automatically sets denoise like this: (total steps - steps on the 2nd sampler)/total steps
If you use 4 steps in the 1st sampler and 4 steps in the 2nd sampler then denoise would be 4/8=0.5
If you have 2 steps in the 1st sampler and 6 in the 2nd sampler then denoise would be 6/8=0.75
Anonymous
8/16/2025, 1:07:57 PM
No.106278998
[Report]
>>106278926
In the caves below the japanese subway system
Anonymous
8/16/2025, 1:09:06 PM
No.106279005
[Report]
>>106278984
Yes but it really resists it.
>>106278989
I'm using kij nodes right now so I'm kind of fucked in that regard. I can always switch.
Anonymous
8/16/2025, 1:13:21 PM
No.106279030
[Report]
>>106278599
>>106278843
Here's my best shot to fix the anti-aliasing issue:
>start with Krita and open your image (I used your original provided in the thread)
>image -> scale image to new size (128x128 -> 1024x1024) + filter type is set to "nearest neighbor"
>put it into flux and remove any garbage outlines (I had to tweak the prompt a bunch but I got this to work: "keep the characters exactly the same, clean up the outlines so they are only black, there should be no peach outlines, remove any excess incorrect outlines by turning them into background")
>I run the output image through flux a second time, this time to convert the background to solid green
>Krita -> image -> scale image to new size ->256x256 then ->128x128 (the 256 in the middle helped a little with the outlines)
>"Filter -> Colors -> Color to Alpha" (as in my previous post)
>export image as PNG with Alpha channel for transparency and no HDR
The outlines on this one are a little thicker but that was flux trying to clean up any unwanted outlines like the peachy color outside the characters model. The character is a lot clearer than my last attempt and a lot "less" anti-aliased (at least on the inside) but still has blurry outlines. Honestly, the best strategy might just be using magic wand tool to select the outside, then using a straight edge cutter to clean up the outlines. It will be more consistent and probably faster too (at least on pixel art) than my method. I tried a workflow where I simply added a bunch of yellow background to the original image until it was 1024x1024 in size, but the characters remained the same, however Kontext kept blurring the characters.
This is the best I can do with my crappy workflow. The only time I can see this helping is if you have to do very large sprite sheets. I think the best strategy is just magic wand tool with a little clean up by hand. Hope you find a good solution that works for you, good luck.
Anonymous
8/16/2025, 1:14:59 PM
No.106279042
[Report]
Anonymous
8/16/2025, 1:20:25 PM
No.106279079
[Report]
>>106279107
>>106278987
>year or so AMD should be competitive
they said this last year
>in a year or so AMD should be competitive
How much longer people gonna say that?
Anonymous
8/16/2025, 1:25:05 PM
No.106279104
[Report]
>>106279126
>>106278815
linux support is better for AMD cards, and they are starting to sell 9700 pro cards with 32GB VRAM for affordable pricing. speed will be slower than nvidia though
Anonymous
8/16/2025, 1:25:19 PM
No.106279105
[Report]
>>106279094
they'll keep saying it until china suddenly reveals something for AI that's competitive. it wont be intel or amd
Anonymous
8/16/2025, 1:25:44 PM
No.106279107
[Report]
>>106279079
Well, you gotta have hope. If there's no real competition to Nvidia, hardware improvements will continue to be heavily throttled, while local models just become larger and more demanding.
Anonymous
8/16/2025, 1:28:49 PM
No.106279125
[Report]
Anonymous
8/16/2025, 1:28:50 PM
No.106279126
[Report]
>>106279104
For overall usage, yes, probably.
For AI usage, no.
When it comes to AI usage, the linux NVidia driver is the best there is, because Linux is where all the AI research and production is being done.
Anonymous
8/16/2025, 1:29:52 PM
No.106279132
[Report]
Anonymous
8/16/2025, 1:44:57 PM
No.106279211
[Report]
>>106279245
Anonymous
8/16/2025, 1:50:19 PM
No.106279245
[Report]
>>106279211
Heartwarming bullying, my new fetish
qwen nunchaku bros... WE WON!
>>106279270
>not a single qwen image in the thread
Anonymous
8/16/2025, 1:57:19 PM
No.106279287
[Report]
Bros, can I run qwen on a 12gb4070 and 32gb RAM?
Anonymous
8/16/2025, 1:57:31 PM
No.106279288
[Report]
>>106279293
>>106279270
How much of an upgrade it is to Q4?
Anonymous
8/16/2025, 1:57:43 PM
No.106279289
[Report]
>>106279753
>>106279284
I was playing around with kontext, I thought I could use normal flux loras with it but.. you cant!!!! MEGA SAD!! cant even undress the anime ladies FUCK KONTEXT!!!!!!!!
Anonymous
8/16/2025, 1:58:15 PM
No.106279293
[Report]
>>106279288
it's better than FP8
Anonymous
8/16/2025, 1:59:02 PM
No.106279298
[Report]
>>106279306
>>106279284
Is there even a official workflow yet, I thought it was to be done by Monday ?
Anonymous
8/16/2025, 1:59:09 PM
No.106279300
[Report]
Talking about inpaiting, is chroma good at it?
Anonymous
8/16/2025, 1:59:09 PM
No.106279301
[Report]
>>106277285
>I have 8 gigs of ram and it's not enough to run SDXL
wtf are you talking about. you gen with sdxl no problem
Anonymous
8/16/2025, 2:00:00 PM
No.106279306
[Report]
>>106279298
the official nunchaku nodes arent even updated yet and yes, like you mentioned next week they'll provide updated nodes + wf. Right now you have to use diffusers to gen
Anonymous
8/16/2025, 2:01:24 PM
No.106279312
[Report]
>>106279314
>>106279270
wansister, our response?
Anonymous
8/16/2025, 2:02:15 PM
No.106279314
[Report]
>>106279335
>>106279312
wan is next on the list of nunchaku. Imagine genning video slop in 30 secs in stead of 3 minutes! AGI BROSSS
Anonymous
8/16/2025, 2:02:46 PM
No.106279320
[Report]
But have they fixed sage attn working with Qwen?
Anonymous
8/16/2025, 2:02:49 PM
No.106279322
[Report]
>>106277285
>I have 8 gigs of ram and it's not enough to run SDXL.
lol
skill issue
I run flux on 6 GB of VRAM just fine
Anonymous
8/16/2025, 2:02:52 PM
No.106279323
[Report]
>>106279334
>>106278505
cool, is this using WAN to upscale? Or a separate upscaling model?
Anonymous
8/16/2025, 2:03:46 PM
No.106279334
[Report]
>>106281858
>>106279323
Upscale the first image and latent of a video and then running it through i2v. I don't know if it's actually worth it though.
Anonymous
8/16/2025, 2:03:48 PM
No.106279335
[Report]
>>106279314
As long as I can get rid of the awful (but useful) lightx2v and still be able to gen under like 10min, I'll be happy.
Anonymous
8/16/2025, 2:09:50 PM
No.106279378
[Report]
>>106279270
>no lora support
LOL!
Anonymous
8/16/2025, 2:11:54 PM
No.106279387
[Report]
>>106279541
But fr, why do they all look like Xena?
Anonymous
8/16/2025, 2:12:26 PM
No.106279393
[Report]
>>106279270
no comfy support yet
>hyping up 4bit slop
new low for this general
>>106279404
I gotta agree. I don't understand the excitement. Qwen as an image model has been nothing but bland. (this is not a message in support of chroma.)
Anonymous
8/16/2025, 2:17:40 PM
No.106279435
[Report]
>>106279460
>>106279422
it was just a new flavor, the honeymoon period wore off almost instantly
Anonymous
8/16/2025, 2:22:19 PM
No.106279456
[Report]
>>106279637
Anonymous
8/16/2025, 2:22:55 PM
No.106279460
[Report]
>>106279466
>>106279404
>>106279422
>>106279435
>>>/sdg/
is that way. Imagine playing down the ability to generate slop faster.
>>106279305
comfy. why are they in their underwear though?
Anonymous
8/16/2025, 2:23:42 PM
No.106279466
[Report]
>>106279460
>NOOO YOU CANT CRITICIZE MODELS
>>106279469
if you want to gen at 720p, not really
Anonymous
8/16/2025, 2:31:07 PM
No.106279517
[Report]
Anonymous
8/16/2025, 2:31:44 PM
No.106279524
[Report]
Anonymous
8/16/2025, 2:34:04 PM
No.106279541
[Report]
>>106279387
>Oh, my hands just slipped, sorry!
>>106279469
Yes, but barely, which is kinda sad
Anonymous
8/16/2025, 2:36:21 PM
No.106279555
[Report]
>>106279585
Anonymous
8/16/2025, 2:37:04 PM
No.106279561
[Report]
>>106279641
>wan2.2
>requires 2 fucking models
>still 16 fps 5 seconds
>still worse than online t2v
holy fucking shit. xi failed locally
Anonymous
8/16/2025, 2:39:58 PM
No.106279585
[Report]
>>106279555
There's no noticeable difference between using ddr4 or ddr5 when it comes to vram offloading, so just buy more ddr4 if you already have it and just make sure the timings are the same to maximize stability / performance
Anonymous
8/16/2025, 2:40:06 PM
No.106279589
[Report]
>>106279568
It's a pretty god damn amazing tool to have on your own machine. Nothing to doom about.
Anonymous
8/16/2025, 2:41:15 PM
No.106279597
[Report]
>>106279568
go back to /saasdg/
Anonymous
8/16/2025, 2:46:16 PM
No.106279637
[Report]
Anonymous
8/16/2025, 2:47:05 PM
No.106279641
[Report]
>>106279678
Anonymous
8/16/2025, 2:48:35 PM
No.106279655
[Report]
>>106279823
>>106279469
On Linux yes.
Source: me running a 3090+64GB RAM on a headless ubuntu server and generating wan videos in 720p.
Now I have 128GB but also 2x3090.
Anonymous
8/16/2025, 2:50:23 PM
No.106279673
[Report]
>>106279094
it's competitive right now in the 3090 range.
Anonymous
8/16/2025, 2:50:51 PM
No.106279678
[Report]
>>106279641
64gb is enough atm moment, so yes, 96gb is certainly enough
The more free ram you have, the more greedy the offloading algorithm seems to be, which speeds things up, if it speeds things up to be worth 96gb, not sure, I only have 64gb ram in my machines
Anonymous
8/16/2025, 2:52:19 PM
No.106279692
[Report]
I was maybe too enthusiastic (and horny) and planned too many wan video gens (each takes 20min).
Is there a way to save the queue?
Anonymous
8/16/2025, 2:55:04 PM
No.106279712
[Report]
>>106279638
i think like 60% of the way may be easy, the hard part is the rest of getting it actually usable
Anonymous
8/16/2025, 2:57:22 PM
No.106279733
[Report]
I have had my workflows chug multiple times with 64gb, but I'm loading a fair bit of unnecessary snake oil too.
Anonymous
8/16/2025, 2:57:30 PM
No.106279735
[Report]
>>106279305
was that vramlet
Anonymous
8/16/2025, 2:58:31 PM
No.106279747
[Report]
>>106279638
I assume this is a troll post, because nobody can be this retarded. The posts you link are 100% correct. Nobody ever said you can't retrain SDXL with a Flux VAE, just that nobody will.
It would be incompatible with all existing loras, and the SDXL finetunes would gain nothing from this unless they too were retrained from scratch.
Nobody will spend the huge amounts of money and time to retrain such an old model architecture for something 100% incompatible.
Anonymous
8/16/2025, 2:58:44 PM
No.106279749
[Report]
Is there any blower style 5090? Aka sending most of its hot air to the back of the case and not recirculating it in the case?
Anonymous
8/16/2025, 2:59:33 PM
No.106279753
[Report]
>>106279289
>I thought I could use normal flux loras with it but.. you cant!
You can but might require upping the strength
Anonymous
8/16/2025, 2:59:59 PM
No.106279755
[Report]
>>106279772
>>106279461
I can't help myself, everyone needs bikini armor.
can fragments in vram accumulate over time?
it's weird but comfy just took an age to do what it had been doing sharpish for days, or weeks, or months, I never turn off my PC, and whatever was jammed in the pipes cleared out after a reboot
Anonymous
8/16/2025, 3:03:10 PM
No.106279772
[Report]
>>106279755
>everyone needs bikini armor.
This
>>106279760
>can fragments in vram accumulate over time
lmao dude, do you know how pcs work? can you articulate this in a non-retarded manner? fucking retard
Anonymous
8/16/2025, 3:07:24 PM
No.106279802
[Report]
>>106280061
>>106279791
fragment = small thing
vram = video random access memory
you're welcome
Anonymous
8/16/2025, 3:07:25 PM
No.106279803
[Report]
>>106280061
>>106279791
someone didn't have their fruity pebbles this morning
Anonymous
8/16/2025, 3:07:51 PM
No.106279809
[Report]
>>106279760
it's a great way to farm latent crystals actually
Anonymous
8/16/2025, 3:08:48 PM
No.106279816
[Report]
>>106279760
Yes, not only can, it does.
CUDA has special environment variables to deal with this, like:
expandable_segments
max_split_size_mb
garbage_collection_threshold
which you place in PYTORCH_CUDA_ALLOC_CONF=""
These help minimize fragmentation, HOWEVER, they don't do anything in Comfy because he uses his own homemade CUDA memory allocator, which seems to bleed vram profusely at times.
>>106279469
>>106279478
>>106279548
>>106279655
I have 24 & 32 and I gen at 720p, no virtual vram. My ram does hit max at some points and I see my swap get used, not necessarily at the same time which is confusing. But I haven't noticed poor gen times compared to anyone else around here. There's extra time when genning the first time, which should be true for everyone because it has to pull the models off your drive first, and there's extra time added when I change the prompt, but I think the actual gen when it's showing the progress bar goes at a normal speed. On wan 2.1 my gens were somewhere over 5 minutes. My typical gen now is 3 minutes for the first two samplers and 4 1/2 minutes for the last one, which is 4 steps at 720p. Prompts executed in 10 minutes. Though I think it was something like 14 minutes when I was on two samplers at full res. I'm going to upgrade ram just because I don't like seeing it topped out and I'm curious what improvement I get. But I'm definitely not getting it because I'm suffering.
Anonymous
8/16/2025, 3:12:51 PM
No.106279851
[Report]
>>106279955
>>106279823
Well if you have 24gb vram then there's less need for offloading, meaning you don't need as much system ram.
Anonymous
8/16/2025, 3:23:58 PM
No.106279928
[Report]
>>106279947
today I learned at that 2.2 lightning was absolutely trashing my attempts at dark scenes and made them impossible, and probably crippled environments too
candlelit in a dark mansion with lightning was a dumpster fire, with lightning off it's as good as flux.
Anonymous
8/16/2025, 3:27:40 PM
No.106279947
[Report]
>>106280027
>>106279928
You should subscribe to me posts more, Anon. I've been screaming this from the rooftops for the last three days.
Anonymous
8/16/2025, 3:28:56 PM
No.106279955
[Report]
>>106279981
>>106279823
>>106279851
also I wonder if its like raid 0 where if you have more memory it can split the model to different ranks/sticks/channels/idontfuckingknow and read it twice or four times as fast
Anonymous
8/16/2025, 3:31:34 PM
No.106279975
[Report]
>>106280003
I want to buy a pre-built PC because the cost of individual parts will exceed the pre-built one
the tower PC I want to buy says
>Maximum Memory Supported 32 GB
it means that the maximum a single RAM chip memory it can support is 32 GB, right?
It has four slots so I can go 32 x 4, right?
Anonymous
8/16/2025, 3:32:02 PM
No.106279981
[Report]
>>106279955
I very much doubt it has any impact.
The bottleneck is the GPU bus, you can have fast DDR7 both on the GPU and system ram, it likely won't make any noticeable difference since both sides are mainly waiting while they squeeze data through the bus back and forth.
Anonymous
8/16/2025, 3:35:48 PM
No.106280003
[Report]
>>106279975
Find out what motherboard it uses and you can check directly.
32x4 for a max of 128 is a common figure.
Saying 32GB is the max supported is weird phrasing and there's no need to speculate what they meant anyway. If they dont say what motherboard it uses you should buy from someone else
Anonymous
8/16/2025, 3:38:50 PM
No.106280027
[Report]
>>106280125
>>106279947
It probably has a lot to do with cfg 1 too. But with lightning, turning the cfg up much more than 2 burns the output even if you are willing to wait
I am making a card game about exotic tropical flora and fauna, what is the chance the AI will know how draw a "buriti palm" or "mico leão dourado"?
Anonymous
8/16/2025, 3:44:04 PM
No.106280061
[Report]
>>106280070
>>106279802
>>106279803
there's actual technical terms instead of this normie computer illiterate garbage you're spewing, but I guess this is /g/ after all, can't expect any level of competency here.
Anonymous
8/16/2025, 3:44:58 PM
No.106280070
[Report]
>>106280103
>>106280061
by all means, go ahead
Anonymous
8/16/2025, 3:49:58 PM
No.106280103
[Report]
>>106280124
>>106280070
sure, it's called memory leak, retard, mostly due to shitty drivers or software that cant manage vram memory allocation properly.
Anonymous
8/16/2025, 3:53:36 PM
No.106280124
[Report]
>>106280103
Fragmentation is not the same as memory leak though
Memory leak is unused memory not being returned to the system
Memory fragmentation becomes a problem when you end up with a lack of large continous memory blocks available for allocation
Anonymous
8/16/2025, 3:53:39 PM
No.106280125
[Report]
Anonymous
8/16/2025, 4:01:07 PM
No.106280185
[Report]
>>106284077
Anonymous
8/16/2025, 4:11:37 PM
No.106280246
[Report]
>>106280372
Anonymous
8/16/2025, 4:15:09 PM
No.106280279
[Report]
>>106280796
Anonymous
8/16/2025, 4:16:43 PM
No.106280297
[Report]
>>106280048
Very unlikely. Actually, zero chance. You'll need to train a lora on plant species.
Anonymous
8/16/2025, 4:21:55 PM
No.106280336
[Report]
>>106280377
Anonymous
8/16/2025, 4:25:17 PM
No.106280372
[Report]
>>106280246
>suddenly, blood appears!
That aside, it's insane how far we have gotten and how it's accelerating.
With minor fixing, this could be straight out of a seasonal anime.
Anonymous
8/16/2025, 4:26:05 PM
No.106280377
[Report]
Anonymous
8/16/2025, 4:37:38 PM
No.106280475
[Report]
>>106280446
>Dungeon twerking for amateurs
Anonymous
8/16/2025, 4:44:03 PM
No.106280522
[Report]
>>106280759
>>106280446
lusty argonian maid when
Anonymous
8/16/2025, 4:48:25 PM
No.106280573
[Report]
Anonymous
8/16/2025, 4:57:31 PM
No.106280675
[Report]
how do I get over the fact that the big companies and govt have 10x better than what you have in local now?
>>106280522
I should never have prompted this.
Anonymous
8/16/2025, 5:06:26 PM
No.106280767
[Report]
>>106280831
So I want to do some large batch of images while I am away. I want to mix different CFG strengths, samplers, etc for this purpose.
I know that technically I can just add to the queue, but is there a nice, convenient comfyUI extension that can randomize gens across a given batch number within the specified parameters?
Anonymous
8/16/2025, 5:07:29 PM
No.106280773
[Report]
>>106280688
how do I get over the fact that very rich people have 10x better houses, cars, clothes, women, than what you have right now ?
indeed, sir, how do you ?
Anonymous
8/16/2025, 5:08:57 PM
No.106280790
[Report]
>>106280759
You sacrified your sanity for science, a noble effort
Anonymous
8/16/2025, 5:09:30 PM
No.106280796
[Report]
>>106280279
you should do a music vid like that one anon did using these
Anonymous
8/16/2025, 5:09:32 PM
No.106280797
[Report]
Anonymous
8/16/2025, 5:09:49 PM
No.106280799
[Report]
>>106280884
>>106280688
can they coom to it though?
Anonymous
8/16/2025, 5:12:19 PM
No.106280831
[Report]
>>106281005
>>106280767
There's probably a hundred of those. Would be better if you could make one yourself using native nodes in Comfy and tailor it exactly to your needs, but Comfy doesn't have the necessary nodes natively, instead you get a worthless HUD display.
Enjoy!
Anonymous
8/16/2025, 5:16:31 PM
No.106280877
[Report]
>>106282457
Anonymous
8/16/2025, 5:16:43 PM
No.106280884
[Report]
>>106280799
they must have a nsfw version.
no reason trump doesn't have one
Anonymous
8/16/2025, 5:21:33 PM
No.106280928
[Report]
>>106281027
Anonymous
8/16/2025, 5:29:11 PM
No.106281005
[Report]
>>106281059
>>106280831
I mean I am not a good programmer at all but I can probably make a variant of the sampler node allowing randomization within the user controller parameters if I take my time with it.
There is probably already some node like this out there though, just gotta find it.
Or maybe good excuse to not be a lazy piece of shit and brush up some basic python skills.
Anonymous
8/16/2025, 5:31:33 PM
No.106281027
[Report]
>>106281517
Anonymous
8/16/2025, 5:32:38 PM
No.106281042
[Report]
Finally got WanGP to work with the poor setup or whatever. Now I just need to get the proper 14B setup to work...
Anonymous
8/16/2025, 5:34:19 PM
No.106281059
[Report]
>>106281125
>>106281005
I doubt you can, you would need nodes to pick random words/sentences from lists and then combine them and pass them off to the prompt
I do not think the necessary nodes exist natively, I'd be happy if you proved me wrong
Anonymous
8/16/2025, 5:36:18 PM
No.106281080
[Report]
>>106281200
retard here, I used to train loras with prodigy/prodigy plus with learn rate 1 getting some solid results, but some people ITT(or maybe it was the same guy doing it multiple times) kept recommending me Adamw_8bitat 1e-4 + cosine, and learning here seems much slower. At 1000 steps, the results with the prodigy trainer wer pretty solid already, but with the mentioned Adamw_8bit setting it seems to only be starting to pick up the concepts at the same number of steps. Is it supposed to be lie this or did I get memed?
Anonymous
8/16/2025, 5:41:39 PM
No.106281125
[Report]
>>106281059
That's not what I described at all but sure.
Anonymous
8/16/2025, 5:50:12 PM
No.106281200
[Report]
>>106281263
>>106281080
Well, Prodigy is a 'self-learning' optimizer, as in you set the LR to 1, but the optimizer will figure out the (in its estimation) optimal LR and use that.
I typically use adamw with a constant scheduler, meaning it will keep ~the same LR throughout the training (adamw is a bit adaptive, but not like Prodigy).
Using cosine scheduler like you did, means it will start at 1e-4 and then lower the learning rate as the training goes on. For cosine 1e-4 sounds low, but I don't know what model you're using or how many images, batch size etc.
Anonymous
8/16/2025, 5:56:47 PM
No.106281263
[Report]
>>106281307
>>106281200
model is biglust_v16, sample size 60, batch size 4, same as when doing it with prodigy. From what I got from your post as a noob it means that the LR is much slower with the Adamw settings used compared to the previous prodigy settings so it needs more steps to learn right?
Anonymous
8/16/2025, 6:01:39 PM
No.106281307
[Report]
>>106281338
>>106281263
Well, I don't know what Prodigy decided was the optimal LR, but if the learning is much slower with adamw 1e-4 then yeah, it's a safe bet that prodigy decided on a higher LR.
Now lower is not necessarily better even if you have infinite time, if it's too low it will simply fail to learn certain things, sadly there's no exact science here, just baseline estimates.
Anonymous
8/16/2025, 6:06:26 PM
No.106281338
[Report]
>>106281307
So I guess this is where you just have to try out things to see how they work out. Thanks.
Anonymous
8/16/2025, 6:07:05 PM
No.106281345
[Report]
>>106282331
It came up a couple days ago, there was a ComfyUI node that had resolution presets you could pick from. What was the name of that?
Anonymous
8/16/2025, 6:10:17 PM
No.106281378
[Report]
>>106281430
Anonymous
8/16/2025, 6:13:01 PM
No.106281406
[Report]
GOMFYUI
PUT BENIS IN NODE
EBIN :-D
Anonymous
8/16/2025, 6:15:47 PM
No.106281430
[Report]
>>106281378
added too much interpolation on this one, with less it looks better
Anonymous
8/16/2025, 6:16:07 PM
No.106281435
[Report]
>>106282161
comfy should be dragged out on the street and shot
Anonymous
8/16/2025, 6:17:22 PM
No.106281449
[Report]
>>106277311
Made me throb
more?
Anonymous
8/16/2025, 6:18:08 PM
No.106281454
[Report]
I want to try out making some qwen loras
What is the best way to mass tag some images at the moment, I think I need natural language not booru tags for qwen right?
Anonymous
8/16/2025, 6:23:46 PM
No.106281491
[Report]
I want nano-banana.
Anonymous
8/16/2025, 6:26:42 PM
No.106281517
[Report]
>>106281618
>>106281027
It's not too shabby, though the panties are all very modest.
Anonymous
8/16/2025, 6:32:55 PM
No.106281578
[Report]
Anonymous
8/16/2025, 6:37:42 PM
No.106281618
[Report]
>>106281517
I like them
I prefer white ones but these are also nice.
Anonymous
8/16/2025, 6:38:57 PM
No.106281634
[Report]
>>106281519
Cyclist was at fault.
Anonymous
8/16/2025, 7:01:31 PM
No.106281827
[Report]
>>106280048
maybe you can image to image them. I also saw a thing recently where you can gen entirely new images that will maintain a consistent subject that you provide an image of
Anonymous
8/16/2025, 7:04:29 PM
No.106281858
[Report]
>>106279334
Have you tried this on real not genned videos?
Anonymous
8/16/2025, 7:24:33 PM
No.106282059
[Report]
>>106282478
Anonymous
8/16/2025, 7:28:01 PM
No.106282083
[Report]
>>106282373
For Wan2.2 Kijai's i2V workflow. It says that I can easily adapt to 720p. Is the whole part about switching to the 720p models specific to Wan2.1?
Can i just up the resolution on that Wan2.2 workflow and it should be fine? Maybe remove the lightx2v node?
(also i got a 5070ti with 16gb of VRAM and 64gb of RAM, maybe I should give up now on 720p if im too much of a vramlet?)
Anonymous
8/16/2025, 7:34:46 PM
No.106282154
[Report]
>>106282178
Anonymous
8/16/2025, 7:36:18 PM
No.106282161
[Report]
>>106282382
Anonymous
8/16/2025, 7:38:20 PM
No.106282178
[Report]
>>106282672
>>106282154
Nice water physics, but I wanted her to become completely submerged and it just refused to do it. This is the closest it got in 3 attempts.
Anonymous
8/16/2025, 7:48:09 PM
No.106282271
[Report]
>>106282292
>>106282271
we're barrelling full force towards climate collapse just so you can make pure garbage like this
Anonymous
8/16/2025, 7:53:52 PM
No.106282321
[Report]
>>106282292
Maybe people from the old testament wouldn't have been so moody about continental floods if they had this kind of tech to pass the time
Anonymous
8/16/2025, 7:54:38 PM
No.106282331
[Report]
>>106282691
>>106281345
It was D2 size selector (you can change the presets by editing the "config.yaml" file in the node folder);
https://github.com/da2el-ai/ComfyUI-d2-size-selector
If you gen with FLUX/Chroma I recommend Flux Resolution Calculator;
https://github.com/gseth/ControlAltAI-Nodes
Anonymous
8/16/2025, 7:59:08 PM
No.106282373
[Report]
>>106282083
for wan 2.2 you can just change the resolution. it was wan 2.1 that had seperate models for 480p/720p.
Anonymous
8/16/2025, 7:59:14 PM
No.106282376
[Report]
please anon for the love of god interpolate your videos
Anonymous
8/16/2025, 8:00:10 PM
No.106282382
[Report]
>>106282697
>>106282161
nah, ani made a faster frontend instead of heaped POOP bullshit that locks you into fascist nodes
Anonymous
8/16/2025, 8:09:59 PM
No.106282452
[Report]
>>106282292
Greta, it's over, it was all a sham
Anonymous
8/16/2025, 8:10:28 PM
No.106282457
[Report]
Anonymous
8/16/2025, 8:12:35 PM
No.106282478
[Report]
>>106282059
>Dear fellow scholars...
Anonymous
8/16/2025, 8:25:44 PM
No.106282607
[Report]
FUCK OFF /LDG/ SCHIZO
>>>/vp/58122207
Anonymous
8/16/2025, 8:31:53 PM
No.106282672
[Report]
>>106282110
>>106282178
Seeing this made me think you could do the GITS making of cyborg sequence
Anonymous
8/16/2025, 8:33:59 PM
No.106282691
[Report]
>>106282331
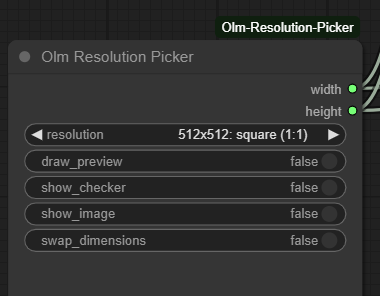
I was being a dumbass and didn't hit up google. When I did I found this Olm Resolution Picker which has a text file you can edit which works perfect for my use case.
Anonymous
8/16/2025, 8:34:43 PM
No.106282697
[Report]
>>106282900
besides comfyui what's the go to ui today? sdnext? forge? reforge? something else?
Anonymous
8/16/2025, 8:43:03 PM
No.106282768
[Report]
>>106282712
bash scripts calling python calling cuda.
Anonymous
8/16/2025, 8:43:40 PM
No.106282772
[Report]
>>106282892
Anonymous
8/16/2025, 8:56:54 PM
No.106282892
[Report]
>>106282915
>>106282772
Is that the retro videogame Chroma lora someone posted here ?
Really nice.
Anonymous
8/16/2025, 8:57:41 PM
No.106282900
[Report]
>>106282697
>can't separate backend from frontend
forgot this was /g/
Anonymous
8/16/2025, 8:58:44 PM
No.106282914
[Report]
>>106282958
>>106282712
Forge/reforge
Anonymous
8/16/2025, 8:58:59 PM
No.106282915
[Report]
>>106282957
>>106282892
It's a retraining experiment of that on Qwen-Image. It's actually undertrained; right now, I am training something else
Yeah. I guess i'm going for that.
What's the difference between the different forge forks? I don't know which one to choose.
Anonymous
8/16/2025, 9:02:32 PM
No.106282955
[Report]
>>106283023
Anonymous
8/16/2025, 9:02:42 PM
No.106282957
[Report]
>>106283173
>>106282915
What were the ~results vs Chroma ?
I gave Qwen a try on 640 resolution, but the results were so-so, that said I haven't experimented with settings at all. If I have to use the native 1328 resolution for Qwen training, my old dusty 3090 will be too slow.
Anonymous
8/16/2025, 9:02:42 PM
No.106282958
[Report]
Anonymous
8/16/2025, 9:04:47 PM
No.106282975
[Report]
Anonymous
8/16/2025, 9:04:55 PM
No.106282978
[Report]
>>106283104
Eternal SDXL VRAMlet here
>>106282861
Can anyone of you, VRAMGODS, test this NSFW anime model. The person who made this model is a "renowned" anime checkpoint maker.
Thanks
Anonymous
8/16/2025, 9:10:18 PM
No.106283023
[Report]
>>106283150
Anonymous
8/16/2025, 9:19:29 PM
No.106283104
[Report]
>>106282978
I would but I'm also a VRAMlet
Anonymous
8/16/2025, 9:23:39 PM
No.106283150
[Report]
>>106283023
whichever has the features you want, fren
Anonymous
8/16/2025, 9:26:54 PM
No.106283173
[Report]
>>106282957
>What were the ~results vs Chroma
Just undertrained / less effective
Anonymous
8/16/2025, 10:28:27 PM
No.106283753
[Report]
Anonymous
8/16/2025, 10:29:27 PM
No.106283762
[Report]
>>106277295
Flux is garbage.
Anonymous
8/16/2025, 11:07:43 PM
No.106284077
[Report]