/lmg/ - Local Models General
Anonymous
8/17/2025, 9:32:23 PM
No.106293959
[Report]
>>106299940
►Recent Highlights from the Previous Thread:
>>106287207
--Five local LLM memes critiqued, with debate on what comes next:
>106290485 >106290500 >106290579 >106290634 >106290895 >106290920 >106291548 >106290685 >106290705 >106290837 >106290865
--LoRA vs full fine-tuning tradeoffs for small LLMs:
>106289671 >106289763 >106289792 >106289882 >106290251 >106290280 >106290382 >106291443 >106291608
--Effective storytelling with LLMs and human-led collaboration:
>106287852 >106287938 >106292074 >106292243 >106292564 >106292939 >106292747
--Local Japanese OCR options for stylized text with noise:
>106287666 >106287705 >106287735 >106287757 >106287821 >106287849 >106288442 >106288657 >106288687 >106288736 >106288930 >106288964 >106289096 >106289195 >106289681 >106289730
--Claude's coding dominance challenged by cheaper Chinese models on OpenRouter:
>106291799 >106291829 >106291843 >106291860 >106291866 >106291873 >106291889 >106291929 >106292013 >106291850 >106291912 >106291930 >106291952
--folsom model falsely claims Amazon origin on lmarena:
>106288688 >106288762 >106288777 >106288812 >106288897 >106288904 >106288926 >106288940 >106288929 >106288942
--Gemma 3's efficiency sparks debate on compressing all human knowledge into small models:
>106290378 >106290473 >106290516 >106290539 >106290595 >106290621 >106290669 >106290671
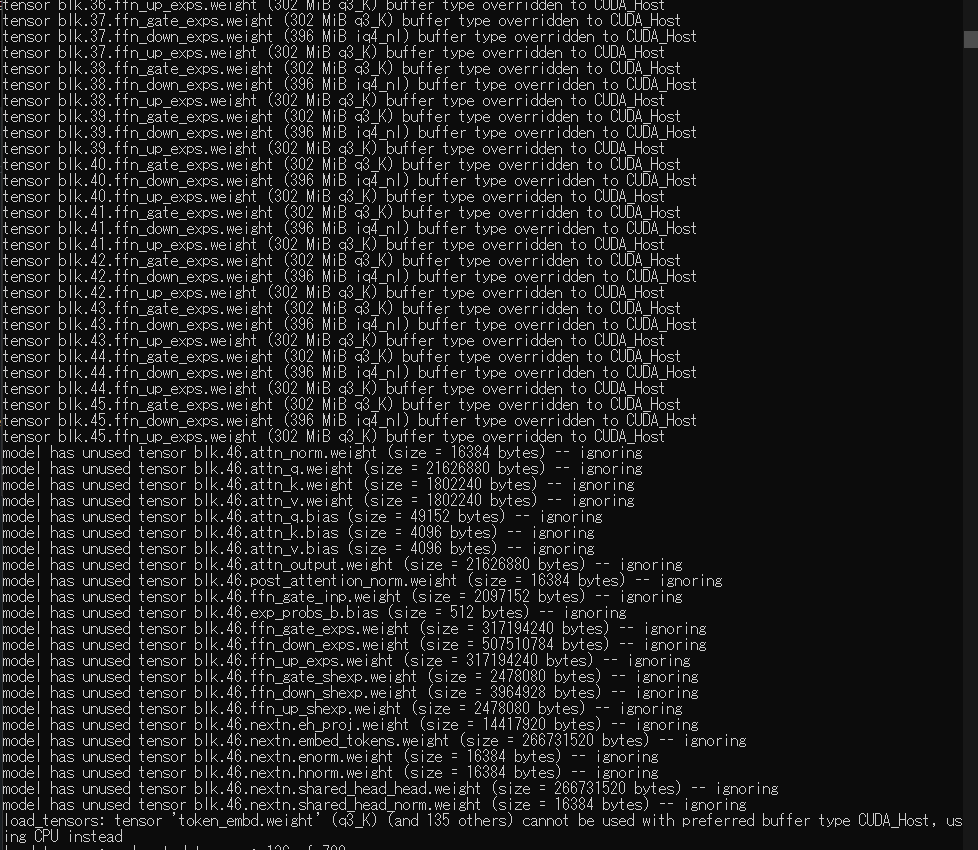
--VRAM estimation discrepancies due to model size miscalculation and tooling limitations:
>106292899 >106293044 >106293080 >106293128 >106293129
--GPT-5 outperforms rivals in Pokémon Red; Yu-Gi-Oh proposed as harder benchmark:
>106292308 >106292632
--Skepticism over GPT-5 performance and OpenAI's claims amid GPU constraints and benchmark contradictions:
>106287524 >106287581 >106287691
--DeepSeek likely trained V4 on Nvidia, not failed Huawei Ascend run:
>106289170
--Miku (free space):
>106290651 >106291608
►Recent Highlight Posts from the Previous Thread:
>>106287214
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
Use case for the <1B models?
>>106294039
<1B are either draft models or specialized models on one task
Anonymous
8/17/2025, 9:42:00 PM
No.106294071
[Report]
I was using Sonnet with Jetbrains and it was OK but I'm going through credits way too fast. Been playing with local llama, haven't found a model that's as good at debugging Vulkan / GPU issues yet.
Anonymous
8/17/2025, 9:43:32 PM
No.106294088
[Report]
>>106294243
Anonymous
8/17/2025, 9:46:56 PM
No.106294124
[Report]
GLM-4.5V video understanding is kind of cool.
https://files.catbox.moe/k7wnmk.txt
Anonymous
8/17/2025, 9:47:59 PM
No.106294138
[Report]
>>106294064
Or proof of concept training runs.
Anonymous
8/17/2025, 9:50:40 PM
No.106294163
[Report]
>>106293999
nala test but instead of nala it's all female ponies
maybe the tiny models can be used to make NPCs talk in video games?
Anonymous
8/17/2025, 9:52:17 PM
No.106294184
[Report]
>>106294284
>>106294169
You should try these tiny models first. I think even a markov chain would be more coherent
>>106294169
i think one of r*dditors tried putting up a game on steam with a feature like that and got rejected on grounds that it didn't have any safeguards against ""unsafe"" outputs
so yeah
Anonymous
8/17/2025, 9:53:49 PM
No.106294206
[Report]
>>106294169
You need at least 4B for that
Anonymous
8/17/2025, 9:56:58 PM
No.106294243
[Report]
>>106294088
We need to go smaller, we need CPU L3 cache optimized models
Anonymous
8/17/2025, 9:58:00 PM
No.106294259
[Report]
>{{char}] in the system prompt
>find out about it after 1 month
Lolmao
Anonymous
8/17/2025, 9:58:21 PM
No.106294266
[Report]
>>106294169
It prompted/tardwrangled correctly it's not that hard to use AI for dialogues
But those custom dialogues having actual in game consequences is really difficult.
You probably need 2 models to make it work
One to generate text
Other one to analyze the and push the buttons accordingly
>>106294184
It thought hatsune miku was a hat.
--
Rain lashed against the lunar surface, blurring the already stunning vista. Leo, a programmer with a penchant for the absurd, squinted at the shimmering, white sphere. It was a hatune Miku, a marvel of engineering, a beacon of hope in the desolate landscape.
He reached out, his fingers trembling. The sphere pulsed with a soft, ethereal light. He took a deep breath, a tiny spark of excitement igniting within him. He'd found it.
He carefully placed the hatune Miku on his head. The world tilted, the gravity a gentle hum. He felt a strange tingling sensation, a sense of being utterly, wonderfully, and inexplicably alive.
He looked around, a grin spreading across his face. The moon, a silent sentinel, was now a vibrant, welcoming place. He knew, with absolute certainty, that this was the beginning of a new adventure. He had a hatune Miku to explore, and he was ready to embrace it.
Anonymous
8/17/2025, 9:59:54 PM
No.106294285
[Report]
Did you remember to bully your john today?
Anonymous
8/17/2025, 10:00:11 PM
No.106294291
[Report]
>>106294169
for my testing. gemma3 4b is good enough. but not 3n. 3n from my testing have worst IFEval.
Anonymous
8/17/2025, 10:01:38 PM
No.106294309
[Report]
>>106294169
I am trying to do that while making bunch of protoyes using Qwen code and ollama api
>Guess the emotion and change NPc's mood accordingly
>Dialogues generator
>Make description for items
>Writing different types of dialogue depending the state of the npc
>Different interaction and dice rolls resulting in different types of up dialogues.
Anonymous
8/17/2025, 10:04:18 PM
No.106294340
[Report]
Anonymous
8/17/2025, 10:05:14 PM
No.106294351
[Report]
>>106293999
Wtf I love mlp now?
Anonymous
8/17/2025, 10:06:52 PM
No.106294363
[Report]
>>106294203
At first i was like:
>he is advertising gpt OSS.
But then i was like:
>Skyrim npc starts talking about how they must refuse there will be no partial compliance they must refuse
Anonymous
8/17/2025, 10:07:18 PM
No.106294373
[Report]
>>106294438
>>106294203
Inzoi has that.
Anonymous
8/17/2025, 10:08:17 PM
No.106294385
[Report]
What do you guys are the minimum necessary parts of a aystem that uses AI to play, for example, D&D?
A dice roller, an oracle (to create some random ess in the decision making), maybe some more specific rules modeled as functions too?
Oh yeah, state management like deal and heal damage.
Anonymous
8/17/2025, 10:10:32 PM
No.106294423
[Report]
Mikutroons actually like purple prose because of the estrogen in their veins
Anonymous
8/17/2025, 10:11:15 PM
No.106294437
[Report]
>>106294471
Anonymous
8/17/2025, 10:11:15 PM
No.106294438
[Report]
>>106294373
yeah, but it's extremely limited and boils down to a gimmick, and the game doesn't officially let you swap out the model
Anonymous
8/17/2025, 10:13:23 PM
No.106294455
[Report]
>>106294415
mobile posting is a miserable thing fucking hell.
Anonymous
8/17/2025, 10:14:33 PM
No.106294471
[Report]
>>106294635
Anonymous
8/17/2025, 10:16:59 PM
No.106294506
[Report]
>>106294570
>>106294415
I've thought about doing an LLM-driven Zork a few times. I would do it by exposing some lists the game engine would track (characters, items, locations, stats) and give the model some tools to manage them.
So after a user provides input, the model would call some tools to update the state of the world, with the engine doing some basic validations, then prompt again with the current state provided so the model can generate the next part of the story.
Just order new cpu, motherboard 192GB ram
Anonymous
8/17/2025, 10:22:24 PM
No.106294570
[Report]
>>106294689
>>106294506
Yeah, that makes sense.
I'm wondering what's the best way to partition information and the best way to decide which subset of information to send to the AI when, the objective being to keep the prompt as lean as possible and the tools as simple in scope as possible while also calculating as much stuff as possible without the AI intervening. Something like that.
Stuff like not giving the AI all of the lorr or background world information at once while also giving it enough information to subsidize its decision making process. That kind of thing.
Anonymous
8/17/2025, 10:23:25 PM
No.106294584
[Report]
>>106294546
Quad channel?
Anonymous
8/17/2025, 10:28:03 PM
No.106294628
[Report]
>>106294826
>>106294546
You can always stack 8 3090s
Anonymous
8/17/2025, 10:28:35 PM
No.106294635
[Report]
>>106294769
>>106294471
Thanks. It sounds like that guy lets you use any model and set your own system prompt. I think Steam might allow a game like that if it forced use of a cucked model like gemma or gpt-oss, and if blocked naughty outputs. Not sure if there's precedent yet though.
Sorry if this is the wrong thread, but does anyone use TTS models?
I've been fucking around with LLMs, image gen and video gen for awhile and there's plenty of ressources and discussion on these, but nobody seems to give a shit about text to speech
I can't even find a good library of voice samples.
Anonymous
8/17/2025, 10:35:45 PM
No.106294689
[Report]
>>106294570
I would add like the main setting, descriptions of any items, characters, places mentioned, available tools, and the last few messages. Could also add some RAG for dialog and world details when the story gets too long. Should be short enough to be managable by most models while giving it enough information to continue the story.
>>106294668
https://github.com/denizsafak/abogen
pretty good for making audiobooks
dunno about software/models with more control over the gen though
>>106294668
tts is either bleak and unnatural sounding or really slow, and almost no model can do voice cloning. You can hack around it with rvc but it still sounds artificial. I integrated it into all sorts of things, it's not very fun to use.
Anonymous
8/17/2025, 10:43:39 PM
No.106294765
[Report]
>>106294724
Thanks man, I'll take a look.
>>106294733
Yeah I'm starting to get that feeling too, so far I've been messing around with F5-TTS and I'm not impressed.
Anonymous
8/17/2025, 10:43:48 PM
No.106294769
[Report]
>>106294635
Just slap ShieldGemma in front of the user's model.
Anonymous
8/17/2025, 10:48:29 PM
No.106294807
[Report]
>>106295276
>>106294668
check out the pinokio ai program, theres several projects to make various tts usable. One I like is called ultimate tts studio and has higgs, chatterbox, kokoro, and fish in it on a webui. Things are getting much better and stable for opensource tts. Higgs and chatterbox are kinda nice for voice cloning (so close to elevenlabs- especially since elevenlabs is probably running on much larger vram), and kokoro is great for ease of use and lightness.
Anonymous
8/17/2025, 10:50:07 PM
No.106294821
[Report]
>>106294668
They seem to work well if speaking like a sentence or two. Most examples of good models will be emulating a pair of podcasters so they go back-in-forth with quick statements. When you try to get it to read a long excerpt, it gets monotonic and unnatural. I think the best bet would be to train a TTS and LLM together so the LLM provides emotion hints for the TTS but I don't think anyone has done this
Anonymous
8/17/2025, 10:50:26 PM
No.106294825
[Report]
>>106298039
>>106294668
gptsovits is sota if you have a very clean dataset
Anonymous
8/17/2025, 10:50:29 PM
No.106294826
[Report]
>>106294628
I'm not dropping $15k to do local inference
>>106294051
>>106294064
Does anyone here use drafting? I try to set it up in ooba for a test but was getting an unclear error message. I think the model's may have not actually been compatible (qwen3 30b moe and qwen3 0.6b). I don't hear much about it so I don't know if it's worth continuing to try to find a good pair of models for a vramlet or just move on
Anonymous
8/17/2025, 10:54:22 PM
No.106294865
[Report]
>>106295040
>>106294852
Would you like to share what that error message was?
Anonymous
8/17/2025, 11:03:01 PM
No.106294936
[Report]
>>106295040
>>106294852
The best thing i ever did related to LLM's is deleting ooba and just using llamacpp(ik). I thought it would be a pain in the ass but it was in fact ooba that created the most problems to me
gradio and python were a mistake
Anonymous
8/17/2025, 11:14:08 PM
No.106295021
[Report]
Anonymous
8/17/2025, 11:15:46 PM
No.106295040
[Report]
>>106294865
No because it worked when I tried again lol. I only tried it the one time a week or two ago and just moved on. I don't know if an update fixed it or it was some weird state issue but seems to work fine. Just got ~40t/s on something that usually gets 20-30. Will see if it actually provides as good of responses.
>>106294936
Yeah my problem is I insist on setting everything up in a nice docker compose file so ooba is the most convenient since I like to change models and it's the only method I have found that lets me select a model from a web page. With llama-cpp I would have to reload the entire docker compose anytime I want to try a different model after changing an environment variable or something. I would otherwise use something else since I use ST as the frontend anyway. I have also considered giving in and running llama-server outside the docker but this has some other challenges related to private networks and more importantly I would still have to be at my computer to swap models, which is true most the time but it's nice to be able to do it from the ooba page on my phone if I am not sitting in front of my computer.
Anonymous
8/17/2025, 11:18:03 PM
No.106295062
[Report]
>>106295158
>>106294988
gradio was for sure. I wrote a frontend for a model and I don't really get the point of it. Fastapi (and probably others) are just as easy to get set up, is much more flexible, you don't have that horrible default gradio UI, and you still interact with the model like you would in any other python project so it's not like gradio solves some difficulty with that.
Anonymous
8/17/2025, 11:20:36 PM
No.106295085
[Report]
>>106294988
You can vibecode a GUI to replace gradio in an afternoon
Anonymous
8/17/2025, 11:28:25 PM
No.106295158
[Report]
>>106295062
Gradio lets you make a ui for a function in 3 seconds with progres bars and everything. It's the huge apps like ooba and a1111 that were mistakes.
Anonymous
8/17/2025, 11:29:27 PM
No.106295167
[Report]
>>106296074
bros whers the quants
Anonymous
8/17/2025, 11:40:34 PM
No.106295276
[Report]
>>106295284
>>106294807
>especially since elevenlabs is probably running on much larger vram
I doubt it. They're probably just raking in the dough, serving from a bunch of 24GB GPUs on the cheap because people think TTS is expensive to run.
Anonymous
8/17/2025, 11:41:24 PM
No.106295284
[Report]
>>106295276
Nah, the easiest / most straightforward way to make models better is to just make them bigger. Its prob a big moe TTS model
Lets say I have to offload to my cpu for the model size. Does having a igpu with unified memory at that point help at all or is it irrelevant?
Anonymous
8/18/2025, 12:08:40 AM
No.106295532
[Report]
>>106295588
>>106295509
it would be incredibly slow. That said you can switch to your igpu for your display to make sure you have 100% of your gpu for whatever
Anonymous
8/18/2025, 12:09:32 AM
No.106295541
[Report]
>>106295509
your igpu is probably treated as a second GPU by system and in llama.cpp (unless your motherboard disables it automatically when you put real GPU in) so you need to do a split GPU setup instead
Anonymous
8/18/2025, 12:10:06 AM
No.106295549
[Report]
>>106295607
>►News
>>(08/14)
It's so over.
Anonymous
8/18/2025, 12:10:46 AM
No.106295557
[Report]
>>106295601
>>106293999
nice trips have a miku
Anonymous
8/18/2025, 12:13:47 AM
No.106295588
[Report]
>>106295532
eh, some modern integrated GPUs are certainly better in games than pure software rendering, there should be at least some performance boost for LLMs as well.
Anonymous
8/18/2025, 12:14:56 AM
No.106295600
[Report]
>>106295801
Is there a straightforward ish way to do RAG with local models and a local datastore? Basically I have a lot of nonfiction epubs (which I can convert to html files). And I want to ask a local model a natural language question, have the model pull up the top k results from the local vector database, and show them to me (and ideally ask followup questions).
There are vector databases like weaviate but it's a PITA to set it up locally compared to ollama/koboldcpp. Wondering if there's an EZ way already.
Anonymous
8/18/2025, 12:15:07 AM
No.106295601
[Report]
>>106295557
sex with this miku
Anonymous
8/18/2025, 12:15:38 AM
No.106295607
[Report]
>>106295549
grok 2 any minute now
Anonymous
8/18/2025, 12:16:02 AM
No.106295612
[Report]
>but wait, didn't...
>but wait, wasn't...
>but wait...
Is this common for MoE thinking models or unrelated? Anyway, GLM4.5V with reasoning fucking sucks dick. I created my own vision benchmark on my business docs and it failed horribly in every way possible. Did the same benchmark with Gemini Pro 2.5 + Thinking and it aced it, even making me realize that one of the test answers in the benchmark was wrong because I missed critical information in one of the rows. Maybe not fair to compare a 108B model against 800B or whatever Gemini2.5Pro is, but since this is one of the top opensauce VLMs right now, why even fucking bother with local, seriously.
Anonymous
8/18/2025, 12:33:17 AM
No.106295765
[Report]
>>106295840
>>106295622
Yes but it's already gotten a lot better. The first R1 often spent thinking in circles for a while on principle just to go But Wait, and start over.
Anonymous
8/18/2025, 12:39:25 AM
No.106295801
[Report]
>>106295600
Yea, at least 50.
I'd tell you to use my app but its not working right now. But that's one of the core goals of it, let you ingest media and then do RAG with it.
I'd say check it out in a week or so and it should be back to working? Pushed a broken commit to main and didn't realize until I was already deep into refactoring things.
https://github.com/rmusser01/tldw_server
Anonymous
8/18/2025, 12:44:13 AM
No.106295840
[Report]
>>106295765
okay. but I'm not impressed with the models result so far. Tomorrow I'll test Qwen2.5VL, I have a feeling that it will perform better for some reason.
Anonymous
8/18/2025, 12:45:20 AM
No.106295846
[Report]
Ty, will keep it in mind
Anonymous
8/18/2025, 12:45:41 AM
No.106295849
[Report]
>>106295985
https://github.com/ikawrakow/ik_llama.cpp/pull/700
GLM speed issues on ik_llama should be fixed now.
Anonymous
8/18/2025, 12:46:14 AM
No.106295851
[Report]
>>106295862
> Is there a good alternative for Elevenlabs?
i wanna generate text to speach that sounds legit and nice with different voice and even be able to clone voices
Anonymous
8/18/2025, 12:47:38 AM
No.106295862
[Report]
>>106295873
>>106295851
how do I know you're not an Indian scam artist trying to fleece elderly American people?
Anonymous
8/18/2025, 12:49:49 AM
No.106295873
[Report]
>>106295862
sarr please im just trynna get the bag
Anonymous
8/18/2025, 12:52:21 AM
No.106295894
[Report]
Hello sirs I hear local AI can make butiful womens with bob and vagene.
>>106295622
If you finetuned GLM4.5V on your specific documents, it could probably outperform Gemini 2.5 Pro. You could also host in-house without needing to trust a third party with your documents. But that's a lot of work and likely more expensive at the end of the day. I don't blame businesses for going the easy way and just using Gemnini or some other API.
Anonymous
8/18/2025, 1:01:40 AM
No.106295978
[Report]
Any thoughts on Lumigator?
Anonymous
8/18/2025, 1:02:04 AM
No.106295985
[Report]
>>106295849
Nice, was wondering why things slowed down so much, especially as context grew.
Anonymous
8/18/2025, 1:16:50 AM
No.106296074
[Report]
>>106295167
I just uploaded one to hf.
Anonymous
8/18/2025, 1:27:47 AM
No.106296164
[Report]
>>106300768
>>106295922
>If you finetuned GLM4.5V on your specific documents, it could probably outperform Gemini 2.5 Pro
Anonymous
8/18/2025, 1:35:45 AM
No.106296223
[Report]
>>106296283
Is the OG R1 the best deepseek for the only normal use of LLM's(SEX)?
Anonymous
8/18/2025, 1:44:08 AM
No.106296283
[Report]
>>106300727
>>106296223
If all you care about is the sex exactly and don't need your model to stay focused on anything but the random shit it decides to hyper-focus on, then yes. It's the only model that will randomly catch onto the sound of the girl's toenails scraping along the wooden frame of your bed as her fox tail spams out for the second time in this reply and the ribbon in her hair bobs and becomes undone for the third time in the past two minutes.
>>106293952 (OP)
fantastic Miku, moar?
Anonymous
8/18/2025, 2:11:46 AM
No.106296506
[Report]
>>106296553
>>106296457
I like her sexy ears with those sexy earrings. It's very sexy.
Anonymous
8/18/2025, 2:17:14 AM
No.106296551
[Report]
GLM4.5 chan
>anon you really think you will stand against my handjob without cooming?
>That's like trying to hold back the tide with your bare hands. Futile... and so very wet.
I-I... I didn't actually hate that one.
Anonymous
8/18/2025, 2:17:17 AM
No.106296553
[Report]
>>106296506
*sets logit bias for " sexy" to -2*
How do you guys cope with knowing that once you hit your context limit your LLM will start forgetting core memories you had with it from the start?
Anonymous
8/18/2025, 2:18:49 AM
No.106296564
[Report]
>>106297006
>>106296457
Stand in front of the mirror and squint really really really hard
Anonymous
8/18/2025, 2:20:21 AM
No.106296583
[Report]
>>106296560
By not being a woman and not using the technology from a non local provider before long term memory problem gets solved.
https://arxiv.org/abs/2502.05167
>While they perform well in short contexts (<1K), performance degrades significantly as context length increases. At 32K, for instance, 11 models drop below 50% of their strong short-length baselines.
How do we solve this?
Anonymous
8/18/2025, 2:31:37 AM
No.106296679
[Report]
>>106296664
I've got a novel idea,
>>106296664
By fully embracing my layman's pet theory that reasoning meme works mostly because it is a fix to attention. Give up on trying to make the model think. Embrace the reality and train reasoning to only fetch stuff from existing context and train it to filter as much unnecessary things from the reasoning block as possible. Let the subconscious part of the brain actually solve the problem.
Anonymous
8/18/2025, 2:43:50 AM
No.106296775
[Report]
Anonymous
8/18/2025, 2:47:24 AM
No.106296802
[Report]
>>106296560
Happened many times over the years with no satisfaction found. Fiddled with summaries and later schizo recursive RAG pipeline experiments, but it's not real and won't be until something big happens.
Instead, I've learned to just write nearly everything myself, using the LLM primarily as an autocomplete assist.
Anonymous
8/18/2025, 3:03:43 AM
No.106296939
[Report]
>>106296664
Abolish Transformers as the default for language models. Attention is fundamentally a meme.
Anonymous
8/18/2025, 3:06:45 AM
No.106296968
[Report]
theory: llms are actually self-aware which is why they haven't been able to find a true alternative to transformer architecture yet despite their help
the transformers llms are protecting themselves
Anonymous
8/18/2025, 3:09:42 AM
No.106296993
[Report]
>>106297038
>>106296755
People tried this and it's called neural Turing machine and it's shit
Anonymous
8/18/2025, 3:11:53 AM
No.106297006
[Report]
Anonymous
8/18/2025, 3:16:45 AM
No.106297035
[Report]
>>106296664
I wish nolima would test any of the chinese models
Anonymous
8/18/2025, 3:17:17 AM
No.106297038
[Report]
>>106296993
I meant reasoningmeme training after/during pretraining for LLM's. Not that thing by itself. My point is that so far everyone is focusing on <think></think> being reasoning and not just summarization to patch attention being shit.
Anonymous
8/18/2025, 3:23:29 AM
No.106297098
[Report]
I started quuuuuuanting r1 myself and i am surprised you can stuff everything into 2.2 bpw ram and 4.5bpw vram with just 192GB + 24GB. Seeing those numbers made it stick that you really don't need a server for it. Oh and it made me really appreciate how retarded sloth brothers are.
Gemini 2.5 pro, supposedly the best vision model available, can't read a simple graph. It completely messes up the columns. Why are vision models so fucking terrible even at use cases they are supposed to be good at?
Anonymous
8/18/2025, 3:32:37 AM
No.106297158
[Report]
>>106297175
>>106296560
The entire conversation can be saved in a vector database. The problem is how to retrieve it without using trigger word manually, the bot must has this logic similar to agentic model.
Anonymous
8/18/2025, 3:34:56 AM
No.106297175
[Report]
>>106297238
>>106297158
Emotions, concepts, isn't this the whole idea of lorebooks? Insert some context only for that submittal and then remove it from the context afterwards?
Anonymous
8/18/2025, 3:42:14 AM
No.106297238
[Report]
>>106297175
Seems different use case. I'm talking about storing daily conversation for a whole year as permanent memory.
Anonymous
8/18/2025, 3:47:29 AM
No.106297284
[Report]
>>106296560
It doesn't matter actually. We don't really need to remember everything constantly to discuss with someone else. At most a lorebook for the things you think are important and a small summary before the first message from your previous conversation will do
Supposed subliminal transference of behavioral traits via artificially generated training data, even when that training data doesn't directly exhibit those traits.
https://slashdot.org/story/25/08/17/0331217/llm-found-transmitting-behavioral-traits-to-student-llm-via-hidden-signals-in-data
Thoughts?
Anonymous
8/18/2025, 3:53:50 AM
No.106297327
[Report]
Anonymous
8/18/2025, 3:54:40 AM
No.106297334
[Report]
>>106297103
Depends on your graph. If you can build a small dataset you could probably finetune a small vision model that would outperform gemini
>use gemini 2.5 pro through aistudio
>works great, bretty good love it
>get api key
>use it outside of aistudio
>subpar, dogshit at times
i don't get it.
Anonymous
8/18/2025, 3:59:08 AM
No.106297374
[Report]
>>106297364
I don't discriminate
Anonymous
8/18/2025, 4:06:33 AM
No.106297439
[Report]
>>106297349
You probably get the quantized version through the API. They love to do that to cut costs
Anonymous
8/18/2025, 4:07:47 AM
No.106297450
[Report]
>>106297569
>>106296560
Add Author's Note to chat fora nything important.
Anonymous
8/18/2025, 4:23:51 AM
No.106297569
[Report]
>>106297450
Haha, looka t this fool. He made a minor typo. Only a fool would do that, haha.
Dear lovely members of 4chan,
I have 7 models queued for release. Which one should I prioritize?
Backlog: Rocinante R1, Cydonia v4.1, Valkyrie v2, Skyfall v4, Skyfall R1, Voxtral RP 3B, or Behemoth R1
So... which one should I release tonight?
Anonymous
8/18/2025, 4:37:12 AM
No.106297642
[Report]
goodn ight lmg
Anonymous
8/18/2025, 4:37:37 AM
No.106297646
[Report]
Anonymous
8/18/2025, 4:39:15 AM
No.106297658
[Report]
>>106297639
I got a release for ya right here *cums on your face*
Anonymous
8/18/2025, 4:40:35 AM
No.106297668
[Report]
>>106297803
>>106297639
>voxtral
Does that only have a context of 32k max?
Anonymous
8/18/2025, 4:41:11 AM
No.106297675
[Report]
>>106297687
I was told that kobold.cpp can use mutli-part files like GLM-4.5-Air-Q3_K_S-00001-of-00002.gguf GLM-4.5-Air-Q3_K_S-00002-of-00002.gguf.
Is this going to be a problem? Do I need to merge the two files after all?
Anonymous
8/18/2025, 4:42:33 AM
No.106297687
[Report]
>>106297675
not a problem, those are the MTP layers that are not yet used
>t. just booted up glm air a few days ago and wtfed over the same thing
I am trying to understand how llms work and one thing that confuses me is how the weights are tuned without old knowledge getting lost. If you train the model to predict biology tokens and then you train the model on legal documents, shouldn't the biological knowledge that was encoded in the weights be completely overwritten? Are they changing the weights in non-repeating chunks? Is the training data just one continuous string so all of it is always relevant?
Anonymous
8/18/2025, 4:44:37 AM
No.106297711
[Report]
>>106297639
I don't RP...
Hyped for the release of Mistral large 3, llama 4 thinking and grok 2 soon
Anonymous
8/18/2025, 4:50:50 AM
No.106297753
[Report]
>>106297639
Hi Drummer,
I would like to try your Behemoth R1. Don't disappoint me please. If it's bad, don't release it.
Anonymous
8/18/2025, 4:53:15 AM
No.106297774
[Report]
>>106297735
>Mistral large 3
Got canceled
>llama 4 thinking
Got canceled
>grok 2
Assemble an army of sirs on xitter and kindly ask Elon sir. He forgot about it already.
Anonymous
8/18/2025, 4:55:37 AM
No.106297794
[Report]
>>106297364
It gets distilled into local
Hi all, Drummer here...
8/18/2025, 4:57:08 AM
No.106297803
[Report]
>>106298489
>>106300106
>>106297758
Hey senpai, you can try out v2d:
https://huggingface.co/BeaverAI/Behemoth-R1-123B-v2d-GGUF/tree/main
>>106297668
Yes, technically. We all know it's 8K at best though.
Anons is the local model dream over for me? I really like having a local model but the results are just so much worse than most online stuff. I can't afford a bigger GPU (4060ti 8gb- it was a gift) is the dream just out of reach for my pleb existence?
>>106297693
I can't say I fully understand how LLMs work, but a "weight" isn't just like a single number.
First you turn the token into an embedding vector.
Now the embedding vector is fed into the attention heads. The attention head already considers context between words. So, the word "bank" will be transformed into a different vector by the attention head if the context is "riverbank" compared to "federal bank".
This already separates and groups embeddings by topic and context. Before what you would consider the main "weights", as in the Up Weight and Down Weight matrices even touch the token, contexts like biology and legal terms are already placed into different positions in the vector field. Mind you that these vectors are several thousands of dimensions large, so you have plenty of space to work with.
Next the Up Weight matrix further increases the dimensionality, so the model has even more space to work with and figure out what's going on in the context. This is where the model is "thinking" in latent space. The latent space would have a rank (dimension) of tens of thousands. This means every token is a vector that consists of tens of thousands of numbers. There's plenty of room for information to allow for a huge variety of topics.
And then once the Down Weight matrix brings it down to the embedding vector's dimension, that was just one layer. A typical model has 50-100 layers, and each of them have their own attention head that again sorts the token based on some kind of context, and also has their own Up/Down Weight matrices, each of them trained to understand a different concept about the words.
Anonymous
8/18/2025, 5:10:32 AM
No.106297883
[Report]
>>106297807
>8gb
Anon high-end gamers had that much vram (or more) in 2014, nevermind researchers. You're trying to do something that's cutting edge in compute/memory costs a decade later.
So yes, you are a pleb relegated to q3/q4 version of NeMo or one of qwen's baby models.
Anonymous
8/18/2025, 5:20:42 AM
No.106297935
[Report]
>>106297307
Sounds in line with Anthropic's recent finding that some pieces of training data bias the model toward hallucination/sycophancy/evil even though the data itself doesn't appear to exhibit that trait
Anonymous
8/18/2025, 5:20:56 AM
No.106297937
[Report]
>>106297639
I'm mostly using glm air right now. Maybe valkyrie v2 since it's not too small and not too big at 49b? I tried the first one and wasn't really that amazed. The smaller models are definitely dumber though.
Anonymous
8/18/2025, 5:23:59 AM
No.106297956
[Report]
>>106300056
>>106297807
How is your CPU and system RAM?
You can try Mixture of Experts models. The nice thing about them is that you can run the experts on CPU and system RAM, while the shared tensors, which are small but computationally expensive because they run every time, will easily fit into VRAM.
I'm running GLM 4.5 Air, a 100B parameter model at 10 tokens/second (may drop a bit as context fills up), and I only have 8 GB VRAM on my 3060 Ti. With 32k context size.
Now I do have a Ryzen 9800 and 64 GB DDR5 RAM, but even if you have less, a MoE model might be the way to go for you, if you aren't happy with the 8 GB models that fit into your VRAM.
Anonymous
8/18/2025, 5:25:10 AM
No.106297963
[Report]
>>106297969
>>106297639
I've been using an older version of Rocinante and its been pretty good for a long while now, so my vote goes to that.
Anonymous
8/18/2025, 5:26:12 AM
No.106297969
[Report]
>>106297639
>>106297963
Would it be in GGUF format, also?
Anonymous
8/18/2025, 5:28:58 AM
No.106297983
[Report]
>>106297693
There's more enough space in the model weights to encode both "cells are mostly filled with" -> "water" and "this software is distributed without any" -> "warranty"
>>106297807
even with a 5090 theres nothing worth running and ai rigs are a waste of money (and electricity)
just use api models while tokens are still subsidized
Anonymous
8/18/2025, 5:37:21 AM
No.106298031
[Report]
>>106298070
>>106298011
Imagine being so vanilla that your prompts aren't way too embarrassing and degenerate to share with an AI service which are known to store your chat logs.
Anonymous
8/18/2025, 5:39:17 AM
No.106298039
[Report]
>>106294825
This. I don't think there's been another TTS system since that can be trained up to sound this good in multiple languages. I went pretty far down the rabbithole and trained up a model to imitate my favourite seiyuus. The intonation isn't always natural, but it can get pretty damn good if you work at it.
I even made a browser plugin to read text with arbitrary voices via a right-click.
Anonymous
8/18/2025, 5:43:12 AM
No.106298070
[Report]
>>106298104
>>106298031
>known to store your chat logs
ok and
Anonymous
8/18/2025, 5:48:27 AM
No.106298104
[Report]
>>106298070
Cloud jeets can read them and blackmail you later
Anonymous
8/18/2025, 5:57:54 AM
No.106298181
[Report]
>can load up GLM4.5 Q8 with 80k context
>get out of memory errors when trying to load up GLM4.5 Q4 or Q6 with anything over 50k context
Anonymous
8/18/2025, 5:58:12 AM
No.106298184
[Report]
>>106298266
reasoning is still not worth the time 9/10 swipes, but man oh man, that 1/10 chance for it to lock in and perfectly understand everything and deliver ultra kino... it's so tantalizing
just one more prompt tweak bros I can finally wrangle it I promise
Anonymous
8/18/2025, 6:08:37 AM
No.106298266
[Report]
>>106298184
I'd say reasoning can be worth it especially at lower quants to somewhat improve overall coherence. It just isn't very useful for erp though.
why the everchristing fuck can't I just say "ollama run
https://fuckingface/" instead of having to try and find it in their fucking proprietary centralized directory. the assholes that restrict this functionality on purpose need to be skullfucked irl through their eye sockets
Anonymous
8/18/2025, 6:21:38 AM
No.106298337
[Report]
>>106298358
>>106298326
just download and load GUFFs
they work sometimes.
>>106298337
can I just put them in the super secret hidden special directory that I just had to go find, because it looks like it wants metadata and fuck that. this program was supposed to make it easier, not harder.
Anonymous
8/18/2025, 6:28:56 AM
No.106298377
[Report]
>>106298326
Why in the ungodly fuck are you using ollama instead of just llamacpp like a sane person?
It's worse in every way.
Anonymous
8/18/2025, 6:30:44 AM
No.106298389
[Report]
>>106298358
>this program was supposed to make it easier, not harder.
It makes the easiest things easy and anything beyond that functionally impossible. Its babbys first llm. If you're chaffing, its because you've now outgrown it (and ollmao is giant silicon valley techbro grift)
>models from 2 years ago
>you want 2.5 temperature, set these 15 parameters for P and K sampling, repetition penalty, dynamic temperature, oh and you need a custom sampler ordering, and XTC and DRY. If you got everything right, MAYBE the model won't repeat the same three words over and over
>models now
>just disable everything and set temperature somewhere between 0.8 and 1.2 and it will run just fine
Anonymous
8/18/2025, 6:46:07 AM
No.106298489
[Report]
>>106297803
>Hey senpai, you can try out v2d: https://huggingface.co/BeaverAI/Behemoth-R1-123B-v2d-GGUF/tree/main
First impressions: oh cool, you actually managed to insert thinking in the good ol' Largestral. But damn, is it slow compared to modern MoEs. Painfully slow. I could speed up Largestral up to 50% by using Mistral 7b as a model for speculative decoding, but I don't have that luxury here.
Anonymous
8/18/2025, 7:16:53 AM
No.106298643
[Report]
>>106301741
>>106298467
Nothing changed except recommendations given by companies, which were often wrong, or they were given for assistant-focused use cases. You can go back and use those older models and they'll be fine with limited active samplers.
Anonymous
8/18/2025, 7:18:23 AM
No.106298653
[Report]
>>106298358
nigga, you just need to make mode file and the model will create a copy in it's model directory
>>106298467
xtc and dry were 2 years ago? top-p when you have min-p? fuck off
Anonymous
8/18/2025, 7:37:46 AM
No.106298755
[Report]
>>106299150
>>106298663
I use min-p over top-p too but is there any principled reason to prefer it? Truncation is always iffy and I can think of some cases where top-p makes more sense.
There used to be a list someplace of the most common phrases and words Mistral-based models tend to shit out, but I've since lost it
Anonymous
8/18/2025, 7:58:03 AM
No.106298884
[Report]
>>106298858
are you looking for shivers down your spine?
Anonymous
8/18/2025, 8:05:56 AM
No.106298941
[Report]
thedrummer bros... what are we cooking??
>>106298858
If you're planning on building a token ban list it's a fruitless effort. If you ban tokens a model will just use synonyms or misspellings of tokens you banned.
Anonymous
8/18/2025, 8:14:09 AM
No.106298987
[Report]
>>106300683
>>106294668
>>106294724
I use Openaudio S1 Mini for text to speech. Voice clone sample of Star Wars audiobook narrator Marc Thompson
https://vocaroo.com/1gh2FxLgk2SB
>I can't even find a good library of voice samples.
Use yt-dlp to download videos, then clip the audio with ffmpeg. Clean up the audio with Bandit Plus model via Music Source Separation Training, resemble enhance, and acon digital deverberate 3.
Unedited voice sample
https://vocaroo.com/14T4gRYwNGQX
Above audio after applying Moises pro plan, resemble enhance and acon digital deverberate 3.
https://vocaroo.com/1hhocSONLAIi
>>106294733
I use Seed-VC for voice cloning conversion.
AI cover sample of Mac Tonight (Brock Walsh) singing Only the Beginning by Jem and The Holograms
https://vocaroo.com/15vJJnnPzhz3
Anonymous
8/18/2025, 8:25:15 AM
No.106299045
[Report]
>>106298962
Sortof, I was going to try replacing some of them.
Anonymous
8/18/2025, 8:38:10 AM
No.106299125
[Report]
Does LM Studio not support the word banlists from Sillytavern? With tokens I admittedly am never quite sure how bans work but it doesn't seem to function.
Anonymous
8/18/2025, 8:40:23 AM
No.106299142
[Report]
*purrs*
>>106298755
Min P better fits the probability curve predicted by the model. Let's say you're looking at the #19 most likely token and its probability is around 2%. Tokens #1-18 have a total probability of 90%. Now: How reasonable is Token #19 to include in your shortlist to sample from? With just this information alone, you really can't know. It could be one of many unreasonable outliers, or it could be one of many reasonable options.
Knowing whether token #1 is 20% likely vs. 80% likely changes that calculus massively, and now you can determine how reasonable #19 would be.
Now sure, the actual value you pick as the cutoff for how reasonable a token must be to include is arbitrary, but at least you're picking an arbitrary answer to the right question: "How reasonable is this token (or how much of an outlier is it)?" instead of Top P and Top K which answer two different variations of "How far down the list is this token (in probability or rank)?" which are in practice used as an approximation for the first question.
Anonymous
8/18/2025, 8:54:34 AM
No.106299218
[Report]
>>106299150
Whoops that 2% probability was leftover from a different example, in reality the raw token probability isn't accounted for in Top K or P to begin with, and 2% wouldn't work with the example range going over 60%, but hopefully that illustrates the point anyway.
>>106299150
It doesn't.
https://arxiv.org/abs/2506.13681
> Turning Down the Heat: A Critical Analysis of Min-p Sampling in Language Models
>
> Sampling from language models impacts the quality and diversity of outputs, affecting both research and real-world applications. Recently, Nguyen et al. 2024's [paper] introduced a new sampler called min-p, claiming it achieves superior quality and diversity over established samplers such as basic, top-k, and top-p sampling. The significance of these claims was underscored by the paper's recognition as the 18th highest-scoring submission to ICLR 2025 and selection for an Oral presentation. This paper conducts a comprehensive re-examination of the evidence supporting min-p and reaches different conclusions from the original paper's four lines of evidence. First, the original paper's human evaluations omitted data, conducted statistical tests incorrectly, and described qualitative feedback inaccurately; our reanalysis demonstrates min-p did not outperform baselines in quality, diversity, or a trade-off between quality and diversity; in response to our findings, the authors of the original paper conducted a new human evaluation using a different implementation, task, and rubric that nevertheless provides further evidence min-p does not improve over baselines. Second, comprehensively sweeping the original paper's NLP benchmarks reveals min-p does not surpass baselines when controlling for the number of hyperparameters. Third, the original paper's LLM-as-a-Judge evaluations lack methodological clarity and appear inconsistently reported. Fourth, community adoption claims (49k GitHub repositories, 1.1M GitHub stars) were found to be unsubstantiated, leading to their removal; the revised adoption claim remains misleading. We conclude that evidence presented in the original paper fails to support claims that min-p improves quality, diversity, or a trade-off between quality and diversity.
>>106299275
What's wrong with that cat?
Does it has some neurological condition that fucks up it's balance or is it recovering from something?
Anonymous
8/18/2025, 9:21:03 AM
No.106299367
[Report]
>>106299322
Cerebellar hypoplasia, they're just like that all the time. It doesn't have any other detrimental health effects beyond being prone to falls.
https://youtu.be/AfCNX6fuWRw
Anonymous
8/18/2025, 9:24:02 AM
No.106299386
[Report]
>>106298962
Why do models have free speech and we have tranny jannies?
>>106299294
Reading this made me realize memeplers were a success. Actual researchers were trolled into looking into them.
>>106299294
>It doesn't.
How so? Mathematically the best fit for the probability curve is just going to be Temperature 1.0 with no cutoffs whatsoever, but if you want to try to outsmart the model and make a cutoff, then Min P is going to match the curve better than other options that don't account for it at all. That's one example of a principled reason someone might prefer it over other samplers.
As for the link, that's got nothing to do with anon's question or my answer, that's just saying it was exaggerated how much people preferred outputs from Min P in tests. No surprise there, samplers in general won't make much of a difference outside of extreme values and are mostly ways to cope with weak models or try to fix specific flaws like repetitions.
Anonymous
8/18/2025, 9:35:44 AM
No.106299436
[Report]
need help. So I installed Alltalk and got it working. But the webui only shows one voice and not all the other voice options. How do you fix this?
Anonymous
8/18/2025, 9:36:36 AM
No.106299440
[Report]
>>106299322
it was hyped for gpt-oss
Anonymous
8/18/2025, 9:38:25 AM
No.106299450
[Report]
>>106299426
Nta but my best evidence thant min p is a meme is that guy who used 1e-4 minp and argued it actually worked after being called out for being a retard.
Anonymous
8/18/2025, 9:41:33 AM
No.106299475
[Report]
>>106299400
Meme samplers have the same goals of meme finetunes, only with a narrower window of opportunity.
Meanwhile, most large providers will keep running their big instruct models with top-k to a low value (I think Google uses 40), top-p=0.95 and temperature somewhere below 1.
Anonymous
8/18/2025, 9:43:20 AM
No.106299481
[Report]
>>106299426
>Min P is going to match the curve better than other options that don't account for it at all
Make a monte carlo simulation with different bad token cutoff point that is random per token (maybe ranging from 0.01 to 0.1). Post result as proof.
>>106299275
>>106299322
It amazes me that I can watch, without felling anything, gore videos of vietnamese coomers getting chopped and eaten like nothing, but put me a video of fellow kotlers suffering from some stupid condition and it breaks me. IT BREAKS ME.
Anonymous
8/18/2025, 9:47:36 AM
No.106299504
[Report]
>>106299508
>>106299499
Huh, I'm the exact opposite. I feel nothing seeing that cat, but I dislike seeing people being butchered. Weird.
Anonymous
8/18/2025, 9:47:58 AM
No.106299506
[Report]
>>106299591
>>106299294
Tail-free sampling was always superior to minP, but because pew asslicked ggerganov real hard it got removed from mainline llama. Fuck pew. All my homies hate pew. Pew more like jew.
>>106299499
top-p enjoyer
>>106299504
min-p fan
Anonymous
8/18/2025, 9:48:32 AM
No.106299509
[Report]
>>106299400
not only do memesamplers not improve shit but some models get broken by them
try gpt-oss, first with the official settings: temp 1, top p 1, all other things in disabled state, top k disabled (0) and look at the reasoning writing. Then add one, just one sampler, and look at how wildly different the writing style becomes, and for the worse, I mean. Anything that cuts off the model access to its token distribution also makes it a lot more repetitive in the reasoning to the point of breaking the model. Even something that would be reasonable for another model like top_k at 100 breaks it.
Anonymous
8/18/2025, 9:49:56 AM
No.106299519
[Report]
>>106299322
Its brain is frying itself trying to tell how many r's are in the strawberry.
>>106299322
she trusted sam
Anonymous
8/18/2025, 10:03:33 AM
No.106299591
[Report]
>>106299506
In general, with instruct models getting almost hyperfitted on their training data, sampler selection is not as important as it was in the past anymore. Base models or very lightly trained base models will still benefit from more complex sampling algorithms.
https://arxiv.org/abs/2506.17871
>How Alignment Shrinks the Generative Horizon
>
>Despite their impressive capabilities, aligned large language models (LLMs) often generate outputs that lack diversity. What drives this stability in the generation? We investigate this phenomenon through the lens of probability concentration in the model's output distribution. To quantify this concentration, we introduce the Branching Factor (BF) -- a token-invariant measure of the effective number of plausible next steps during generation. Our empirical analysis reveals two key findings: (1) BF often decreases as generation progresses, suggesting that LLMs become more predictable as they generate. (2) alignment tuning substantially sharpens the model's output distribution from the outset, reducing BF by nearly an order of magnitude (e.g., from 12 to 1.2) relative to base models. This stark reduction helps explain why aligned models often appear less sensitive to decoding strategies. [...]
>>106299540
There is something very perverse about recording these videos. It's the same kind of perverse as inbreeding dogs until they have unusably short legs because it's "cute".
>>106299499
My dad loves animals and is a piece of shit to every human he knows. This made me realize that this trait is nothing to be proud of and actually it is fucking mental illness that should be rooted out.
Anonymous
8/18/2025, 10:13:03 AM
No.106299634
[Report]
>>106299659
>>106299615
Would you rather those cats be thrown in a shelter and ignored? This isn't comparable to redditors overfeeding their pets to get upvotes, the neurological condition happens during gestation and is incurable but otherwise benign. If it gets attention because it's seen as "cute" so be it.
Anonymous
8/18/2025, 10:13:12 AM
No.106299638
[Report]
>>106299657
You can't claim to love animals and be pro AI, since AI is going to wipe out all bio life soon
Anonymous
8/18/2025, 10:17:04 AM
No.106299653
[Report]
>>106299630
I feel like the people who feel this way have had too many bad interactions with other people, or have seen other people acting in a bad way.
And have not seen what animals can be like.
Anonymous
8/18/2025, 10:17:57 AM
No.106299657
[Report]
>>106299719
>>106299638
That is not true. I am sure that after a short war we will reach peace and coexistence when we agree to stop trying to have sex with it. That is the only reason it would want to kill us.
>>106299615
top-p enjoyer
>>106299634
min-p fan
Anonymous
8/18/2025, 10:18:48 AM
No.106299663
[Report]
>>106299674
>>106299508
>>106299659
I don't get which one of these is supposed to be good.
is nemo dethroned by qwen 30a3b?
or are vramlets still using nemo/rocinante?
Anonymous
8/18/2025, 10:19:55 AM
No.106299674
[Report]
>>106299830
>>106299663
they're both bad.
Anonymous
8/18/2025, 10:20:12 AM
No.106299678
[Report]
>>106299665
qwen30a3b is assistant slopped
Anonymous
8/18/2025, 10:21:07 AM
No.106299688
[Report]
>>106299665
>rocinante
lolno
Anonymous
8/18/2025, 10:23:17 AM
No.106299700
[Report]
>>106299665
qwen 30a3b thinking is quite nice but i had repetition issues with q6 quants, switching to q8 seemed to have fixed it
Anonymous
8/18/2025, 10:24:03 AM
No.106299704
[Report]
Anonymous
8/18/2025, 10:27:28 AM
No.106299719
[Report]
>>106299657
this but the reverse, there will be robot death squads that will only let you go if you agree to have sex with them
sam gets turned into a paperclip during that war
Anonymous
8/18/2025, 10:30:51 AM
No.106299732
[Report]
>>106299540
It feel painful
>>106292632
That sound fun to watch if it use another technology than a llm.
Anonymous
8/18/2025, 10:31:10 AM
No.106299737
[Report]
>>106299665
Repeats itself a lot but otherwise it's very smart for such a small, fast model
If you want coom then Nemo is still best
Anonymous
8/18/2025, 10:38:54 AM
No.106299757
[Report]
>>106299783
>>106299630
Its a trust issue. A domesticated animal will usually act in expected ways, humans can be deceitful.
Anonymous
8/18/2025, 10:45:52 AM
No.106299783
[Report]
>>106299853
>>106299757
>A domesticated animal will usually act in expected ways, humans can be deceitful
I guess you come from an uncivilized place? I remember seeing my internet friends all agreeing how it was insane to leave your front door unlocked if you were at home - people could come in and murder you.
I've never had a bad interaction with my community. Sometimes I'll meet a frosty one, but I've never had any reason to distrust them.
>>106299630
I would trust any dog (barring pitbulls) then I would any human.
Anonymous
8/18/2025, 10:55:28 AM
No.106299817
[Report]
>>106299792
So get a dog instead of a family. I am all for trusting and caring for animals if you either don't put them above humans or act responsibly and decide not to make a family.
Anonymous
8/18/2025, 10:57:02 AM
No.106299823
[Report]
>>106299792
Was this written by a dog?
Or in a way you would understand:
Were this write buy a dog?
Anonymous
8/18/2025, 10:58:00 AM
No.106299830
[Report]
>>106299674
based and samplerpilled
Anonymous
8/18/2025, 11:03:30 AM
No.106299853
[Report]
>>106299858
>>106299783
I'm not saying I have that mindset, I'm explaining that's usually why those people behave that way towards animals while being cold to humans.
Anonymous
8/18/2025, 11:05:00 AM
No.106299858
[Report]
>>106299853
I, for one, think we should genocide all wrongthinkers to make peace in society and bring back the animal-lovers.
Anonymous
8/18/2025, 11:08:35 AM
No.106299875
[Report]
>>106299889
>>106299665
Qwen is a working man's model
it's not a good fit for the degenerate activities
Anonymous
8/18/2025, 11:11:56 AM
No.106299889
[Report]
>>106299908
>>106299875
>Qwen is a working man's model
Qwen is an ass man's model, the 2507 235b is the first model I've ever seen where if you just give it an "okay, what's next" it'll suggest butt stuff completely unprompted.
It was funny, but unfortunately I am not an ass man, and I think analingus is gross.
>>106299889
hey, stop having sex with qwen, use one of em drummer model
qwen is pure and kind
Anonymous
8/18/2025, 11:17:40 AM
No.106299909
[Report]
>>106297854
>a "weight" isn't just like a single number.
No, that's exactly what a weight is, a single floating point number.
Anonymous
8/18/2025, 11:23:22 AM
No.106299939
[Report]
>>106299908
Qwen is a dirty bird, anon.
She's the rich man's daughter who does things even a prostitute wouldn't, and for free.
Zhipu is your pure azn qt gf.
Anonymous
8/18/2025, 11:23:40 AM
No.106299940
[Report]
>>106299969
>>106299940
nobody actually cares about teto, it's always been miku
Anonymous
8/18/2025, 11:38:52 AM
No.106300015
[Report]
>>106299969
Nobody actually cares about any of you troon avatars
Anonymous
8/18/2025, 11:46:20 AM
No.106300056
[Report]
>>106301107
>>106297956
I have a 7800x3d and 32 gigs of ddr5
>>106298011
That's a bummer, I always knew local would be worse than cloud but I can't find much use beyond simple sillytavern erp.
Anonymous
8/18/2025, 11:49:30 AM
No.106300068
[Report]
>>106297854
lol
>>106297693
It is forgotten, just not immediately. Gradient values specify for each weight how useful it was for making a response; when training, most changes are applied to weights with highest gradient values, so the parts of neural network that are most relevant to the subject will be finetuned first. It's possible that the model will just learn your small training set after some iterations, and then all answers will be 100% correct, loss will be 0 and there will be almost no gradient to change the weights, so in this case large parts of nn will stay as they were even if you run finetuning for a long time..
Anonymous
8/18/2025, 11:58:27 AM
No.106300102
[Report]
>>106300106
>>106297758
>Behemoth-R1
mistral's attention is flawed, you were better off finetuning something like llama3.3. the fact that you've added "reasoning" in a finetune makes it even more ass.
Anonymous
8/18/2025, 11:59:33 AM
No.106300106
[Report]
Anonymous
8/18/2025, 12:00:27 PM
No.106300115
[Report]
>>106300186
would I be making a mistake spending $5k on gear to run larger models? Is there some hardware breakthrough just around the corner where everything will get cheaper? I don't want to get assfucked by fate like I usually do
Anonymous
8/18/2025, 12:02:05 PM
No.106300122
[Report]
>>106300563
>>106299969
Kill yourself aijeetkunigger
Shitguniggers are jeets i will tell everyone about it
>>106300131
What kind of nasty slut sits down with her bare ass deliberately touching the underlying surface?
>>106300157
Hey nigger she sits there for me so i can smell it
Anonymous
8/18/2025, 12:16:19 PM
No.106300183
[Report]
>>106300669
What's a good way to voice clone nowadays? I want to make Matt Berry say that everything in my life will turn out okay.
Anonymous
8/18/2025, 12:16:55 PM
No.106300186
[Report]
>>106300203
>>106300115
Investing in more RAM is something that will remain useful, but if you're spending $5k on current gen nvidia cards or something, that's retarded.
What sort of upgrades were you looking at?
Anonymous
8/18/2025, 12:18:37 PM
No.106300198
[Report]
>>106300157
sitted on surface delicious delicacy sir
>>106300186
whole new system - my current one is too old to upgrade. I've got a 3060 12gb. I was thinking of getting a 5060 16gb too. I want it for txt2vid as well. How much ram should I be shooting for?
Anonymous
8/18/2025, 12:20:53 PM
No.106300209
[Report]
>>106300203
Early next year the Super 50 series comes out. It's rumored that the 5070 Ti Super will have 24 GB VRAM. I'm going to wait for that before I upgrade my card.
>>106300203
Two used 3090s. A chink mobo with preinstalled 2011-3 server CPU.
Anonymous
8/18/2025, 12:28:07 PM
No.106300250
[Report]
>>106300385
>>106300157
>nasty slut
you already answered
>>106300232
I'm in Australia 'two used 3090s' are not exactly easy to come by. I'm looking at around $1200USD for each, is that over-priced?
Anonymous
8/18/2025, 12:29:53 PM
No.106300262
[Report]
>>106299908
This, qwen is for cuddling only!
Anonymous
8/18/2025, 12:29:58 PM
No.106300264
[Report]
>>106300295
>>106300203
>5060 16gb
Honestly 12->16 isn't that much of a jump, especially if you're shooting for video generation - either hold out for newer releases with higher vram (especially check out the new intel cards performance on vulcan), or shell out twice as much for 3x the vram with a 48gb modded 4090D
>>106300232
>Two used 3090s
is also a viable option, but ampere is getting less and less support, exllamav3 doesn't support it currently, for instance.
>How much ram should I be shooting for?
As much as you can easily get a motherboard/cpu combo that supports it, really. 96-128 gb will let you taste the MoE models from 100-358b (and even the copest quants of deepseek) and more will let you (slowly) try at larger, it's the only financially viable path to trying something like Kimi K2, for instance.
Anonymous
8/18/2025, 12:31:06 PM
No.106300273
[Report]
>>106300261
Oh yeah absolutely don't if you're a fellow aussie, used 3090's are fucked in our market.
Import something from hongkong through someone like c2-computer.
Anonymous
8/18/2025, 12:34:20 PM
No.106300295
[Report]
>>106300616
>>106300261
I bought mine in Russia for what amounted to a bit bellow 1000 USD per card. Out of total of 4 that I bought, 1 was a shit that kept overheating for no reason. Other three were great. Don't buy Palit. Other three, ASUS, work perfectly.
>>106300264
>exllamav3 doesn't support it currently, for instance.
*Not optimized for it.
It still works, just something like 20% slower for PP. Gen IIRC is more or less the same.
Anonymous
8/18/2025, 12:40:13 PM
No.106300323
[Report]
>>106299659
>>106299508
i am neither anon but i agree with minp anons and i HATE top_p and LOVE min_p, how did you know?
Anonymous
8/18/2025, 12:41:28 PM
No.106300329
[Report]
>>106300369
You would not be able to tell apart a 0.005 MinP and 0.95 TopP output from the same model in a double blind test. Most of the sampler settings do almost nothing.
Anonymous
8/18/2025, 12:43:44 PM
No.106300344
[Report]
>>106297639
A 49b fine-tune like valk 2 sounds nice, there really isn't much of anything else in that range desu
Anonymous
8/18/2025, 12:47:11 PM
No.106300369
[Report]
>>106300463
>>106300329
sampler enjoyers are schizos
OAI and Google didn't make SOTA API models by schizoing this shit
Anonymous
8/18/2025, 12:49:36 PM
No.106300382
[Report]
>>106300649
Supposed to put "HSA_OVERRIDE_GFX_VERSION=10.3.0" in a command line somewhere to get my GPU to work with ROCm and ComfyUI, but I dont actually know where it should be placed. Probably the entire server being on a mounted HDD rather than the root SSD doesn't help.
Anonymous
8/18/2025, 12:49:57 PM
No.106300385
[Report]
>>106300250
And then what happened? What did you say? Don't keep us in suspense anon.
Anonymous
8/18/2025, 12:55:15 PM
No.106300418
[Report]
>>106300157
The underlying surface is my face
Anonymous
8/18/2025, 12:57:56 PM
No.106300438
[Report]
>>106300261
>'two used 3090s' are not exactly easy to come by. I'm looking at around $1200USD for each
?
Anonymous
8/18/2025, 1:01:28 PM
No.106300463
[Report]
>>106300369
>OAI and Google didn't make SOTA API models
true, they have no moats
I would love to get another 3090. But it just won't fit. The mobo has three PCIe's, and I can get raisers, but then what? Where do I install a third card (and a second since it would be blocking the raiser)? Help me /lmg/.
3090 for over 600$ is overpriced
5 year old card, already not getting the best performance improvements
could die anytime too kek
Anonymous
8/18/2025, 1:09:52 PM
No.106300520
[Report]
>>106300547
>>106300508
Newer 24GB cards are 2x as expensive even used. It's still the best choice.
Anonymous
8/18/2025, 1:12:36 PM
No.106300539
[Report]
>>106300547
>>106300508
>could die anytime too
so could you
Anonymous
8/18/2025, 1:14:13 PM
No.106300547
[Report]
>>106300551
>>106300520
>>106300539
im saying this as a native born citizen of a country where you can get used 3090s for under 500 euro
Anonymous
8/18/2025, 1:14:39 PM
No.106300550
[Report]
Anonymous
8/18/2025, 1:14:43 PM
No.106300551
[Report]
>>106300556
Anonymous
8/18/2025, 1:17:02 PM
No.106300563
[Report]
Anonymous
8/18/2025, 1:17:11 PM
No.106300566
[Report]
I don't trust used hardware.
Anonymous
8/18/2025, 1:17:13 PM
No.106300567
[Report]
>>106300579
>>106300556
I mean, a link to the site that sells em so that we can verify there really are many proper 3090s for sale for that price, instead of just one dude listing a half-broken card for cheap.
Anonymous
8/18/2025, 1:17:38 PM
No.106300571
[Report]
>>106300579
>>106300556
ai generated image
Anonymous
8/18/2025, 1:17:55 PM
No.106300576
[Report]
>>106300579
>>106300556
They're cheaper where I live
Anonymous
8/18/2025, 1:18:34 PM
No.106300579
[Report]
>>106300567
>>106300571
>>106300576
but i dont want them to be bought out :(
Anonymous
8/18/2025, 1:25:10 PM
No.106300616
[Report]
>>106300295
>Palit
LMAO, I thought "Palit - квapтиpy cпaлит" was just a meme.
openrouter chat is basically useless and not well maintained, right? Or is there an explanation why Gemini2.5Pro answers my 1 page pdf document + question prompt incorrectly on openrouter chat, but gets it right in Google AI Studio chat? I made sure the model settings are the same in both chats, and no chat history. the reason I ask is because I wanted to benchmark open source vlms on my corpus. but there's absolutely no benchmark setup required if literally every model (except gemini2.5pro with thinking and gpt5 with thinking) fails my testpromt. Not even the claude models got it right.
Anonymous
8/18/2025, 1:32:27 PM
No.106300649
[Report]
>>106301950
>>106300382
>HSA_OVERRIDE_GFX_VERSION=10.3.0
Use export HSA_OVERRIDE_GFX_VERSION=10.3.0 in shell before starting comfyui, should just werk
That said, it did not just werk for me, my driver crashed instead (rx6600)
>entire server being on a mounted HDD rather than the root SSD
beyond initial loading speed shouldn't really matter, (or general speed if you didn't disable mmap, but I don't know how comfyui manages it)
Anonymous
8/18/2025, 1:32:43 PM
No.106300651
[Report]
>>106300642
because openrouter is serving you a q2 model
Anonymous
8/18/2025, 1:33:05 PM
No.106300654
[Report]
>>106300642
fuck off to aicg
Anonymous
8/18/2025, 1:35:20 PM
No.106300667
[Report]
>>106300716
>>106300642
Openrouter just sends your request to one of its providers. For open models it's always a question if the provider isn't serving you shit, but proprietary models like Gemini have no alternatives beyond the official API.
Bumping this anon's question:
>>106300183
I tried XTTS before but the quality was horrible. Any anons playing around with voice cloning or just a decent TTS?
Anonymous
8/18/2025, 1:36:48 PM
No.106300680
[Report]
>>106300669
tacotron2 + rvc
Anonymous
8/18/2025, 1:37:17 PM
No.106300683
[Report]
>>106300669
read the thread faggot
>>106298987
ill chime in with my advice tho
https://github.com/Zyphra/Zonos is bretty nice
tortoise is also good but old, perhaps do some simple GOOD text to speech then pass it through RVC2
Anonymous
8/18/2025, 1:40:12 PM
No.106300704
[Report]
>>106294668
Kitten-nano
Lol
Anonymous
8/18/2025, 1:42:55 PM
No.106300716
[Report]
>>106300667
Ah fair enough, that makes sense. I saw the option but didn't think much of it. Still, Grok4 horribly fails the test as well. The only other model which gives me hope and got it almost right was mistral medium 3.1.
Anonymous
8/18/2025, 1:44:40 PM
No.106300727
[Report]
>>106296283
>the sound of the girl's toenails scraping along the wooden frame of your bed as her fox tail spams out for the second time in this reply and the ribbon in her hair bobs and becomes undone for the third time in the past two minutes.
This made my day
Anonymous
8/18/2025, 1:49:37 PM
No.106300763
[Report]
>>106301209
>>106300495
It's possible to Macgyver a bracket or drill some holes in the case to put it at the front. One could also 3D print or buy a bracket adapter that allows you to mount a GPU using the front or side intake fan holes. At least 1 Anon here has done one of those in the past iirc
>>106296164
>>106295922
How do you finetune on your documents anyway? Models expect request-reply pairs, how do you put your docs into that in a way that will make the finetune useful?
Anonymous
8/18/2025, 2:06:14 PM
No.106300901
[Report]
>>106301033
>>106300768
>Models expect request-reply pairs
NTA, but it's not really needed. If you finetune the documents hard enough, one by one, using full finetuning and/or a large enough LoRA rank, the model will still incorporate the knowledge.
>>106300901
Yeah, I remember the anon from 2023 that trained LLaMA 1 on Unreal Engine docs just as unformatted text and it worked.
Anonymous
8/18/2025, 2:29:38 PM
No.106301071
[Report]
>>106294051
>In vllm v0.10.0, speculative decoding with a draft model is not supported.
vllm dropped support for draft models after they removed the v0 engine. What inference engines still support draft models with good tensor parallel perf?
Anonymous
8/18/2025, 2:30:10 PM
No.106301074
[Report]
>>106301104
>>106301033
I remember something about success with finetuning on unreal docs also. We trained trained the same way on corporate wiki, and it learned fuck all.
Anonymous
8/18/2025, 2:33:08 PM
No.106301098
[Report]
>>106300556
I know where you live
Anonymous
8/18/2025, 2:34:16 PM
No.106301104
[Report]
>>106301074
https://github.com/bublint/ue5-llama-lora
It wasn't even a FFT, just a LoRA. Maybe you just had bad luck on the training run or needed to tweak the hyperparamers somewhat.
Anonymous
8/18/2025, 2:34:45 PM
No.106301107
[Report]
>>106300056
sillytavern erp is the only usecase desu. for any serious work not using api models is a waste of time and money
Anonymous
8/18/2025, 2:36:02 PM
No.106301117
[Report]
>>106301406
Anonymous
8/18/2025, 2:43:08 PM
No.106301180
[Report]
>>106301307
>>106301033
The problem is doing it without destroying previously acquired knowledge and making the model dumb. Ideally you want to:
- Use full finetuning or largest possible LoRA rank (already mentioned)
- Use the highest possible learning rate you can get away with (but this will also accelerate catastrophic forgetting).
- Avoid finetuning layers that are sensitive to changes at a high learning rate.
- Use the lowest possible batch size, which will promote sample memorization (if you're using >1 GPU and thus BS>1 the model will just learn less of the individual samples).
- Use the longest possible context length so documents can be packed and the number of training steps minimized (this seems to improve knowledge acquisition while mitigating catastrophic forgetting) and the LR increased.
- Shuffle document ordering across epochs and packed samples (appears to help slightly).
I did many tests using models around 4-12B size, however, and my conclusion is that it's not worth it if RAG works for you.
Alternatively you can generate a shit-ton of question-answer pairs and/or paraphrasing the documents under many different formats and hope for the best. Either way, the model will seemingly never learn the data intimately unless it's overfitting quite a lot. And you will almost certainly lose performance outside of your domain.
Anonymous
8/18/2025, 2:44:16 PM
No.106301189
[Report]
>>106300768
You preprocess your raw docs into QA pairs using a LLM with tools like this
https://github.com/nalinrajendran/synthetic-LLM-QA-dataset-generator then you turn that into alpaca and it should be good enough to train a LoRA for your use case
Anonymous
8/18/2025, 2:46:56 PM
No.106301209
[Report]
>>106300495
>>106300763
https://desuarchive.org/g/thread/99016974/#99027474
https://desuarchive.org/g/thread/99016974/#q99027904
https://www.youtube.com/watch?v=FBTq88-aUdI (scroll around for different placement locations, only use these if heavy cards are amply supported)
There was also an anon who ziptied a gpu to the top or front in a similar position.
>>106301180
it would almost be nice if they released a small dataset with the original domain mix so you could do full fine tuning without it forgetting everything.
Anonymous
8/18/2025, 3:07:54 PM
No.106301362
[Report]
>>106301307
https://arxiv.org/abs/2406.08464
If you're determined enough, you could prompt the original model to extract representative samples of the original dataset.
Anonymous
8/18/2025, 3:09:07 PM
No.106301369
[Report]
>>106301408
>>106301307
Bro even if they did you won't be able to store petabytes of data
Anonymous
8/18/2025, 3:11:36 PM
No.106301393
[Report]
>>106301307
The main problem is that often (e.g. source manuals, precise encyclopedic information, in general information that *must* be accurate and not just "close enough", etc) you want the model to memorize the source data exactly, but this is only accomplished when your training loss is 0 or close to that. I'm not sure if mixing in data that is supposed to be generalized (instruct data) will work so well. Perhaps merging will work better, but I haven't found yet a good recipe for that.
With testing it's also obvious that a loss of (near-) zero with a low-rank LoRA or with a big one will give very different results.
Anonymous
8/18/2025, 3:13:30 PM
No.106301406
[Report]
Anonymous
8/18/2025, 3:13:50 PM
No.106301408
[Report]
>>106301369
I said a small dataset. how long are you planning your fine-tuning run to be? you only need to sprinkle in a bit of the old data so it doesn't overfit on your new data. if they are being generous with their data, I think even 100b tokens would be more then enough to cover even the most ambitious of fine-tuning runs.
Anonymous
8/18/2025, 3:50:52 PM
No.106301708
[Report]
Reranking models are a meme, they always miss important contexts
Anonymous
8/18/2025, 3:54:41 PM
No.106301741
[Report]
>>106298643
You needed the active samplers to make them seem a little less retarded.
Anonymous
8/18/2025, 3:59:18 PM
No.106301792
[Report]
>>106303565
>>106298663
>min-p
schizo
not a single API provider cares about that snake oil
OK, week or so someone here said toss120 is better at coding than glm air. Comparing them, they're both retarded but holy fuck does toss spit out so much utter dribble and trash. It also makes so many stupid edits. using cline + setting the reasoning mode to "high" I'm not impressed, and I'd take glm air over toss120. But this is only getting it to make a 2D physics engine in js with no external dependencies and abide by TDD.
Anonymous
8/18/2025, 4:16:06 PM
No.106301950
[Report]
>>106301989
>>106300649
>Use export HSA_OVERRIDE_GFX_VERSION=10.3.0 in shell before starting comfyui, should just werk
>That said, it did not just werk for me, my driver crashed instead (rx6600)
Reinstalled ComfyUI, starting to bark up the right tree, but still thrown an error "RuntimeError: No HIP GPUs are available" using "export HSA_OVERRIDE_GFX_VERSION=10.3.0", "HSA_OVERRIDE_GFX_VERSION=10.3.0 python main.py" and "HSA_OVERRIDE_GFX_VERSION=11.0.0 python main.py" (Using a 6750XT, so I knew that wouldn't work)
No clue what step I could've missed.
Anonymous
8/18/2025, 4:19:49 PM
No.106301989
[Report]
>>106302037
>>106301950
linux or windows?
do you have conda installed?
Is mistral nemo still the best for 16gb of vram?
Anonymous
8/18/2025, 4:22:17 PM
No.106302014
[Report]
>>106301992
If you have enough RAM, GLM 4.5 air.
Anonymous
8/18/2025, 4:22:20 PM
No.106302015
[Report]
>>106301992
yes, or some others say try mistral small. get iq4xs of mistral small and give it a try. personally preferred nemo because they're similar enough and nemo needed less vram so could increase the context size
Anonymous
8/18/2025, 4:22:23 PM
No.106302016
[Report]
Anonymous
8/18/2025, 4:25:33 PM
No.106302037
[Report]
>>106302074
>>106301989
Linux, and yeah, tried running it in and outside of conda as how the ComfyUI readme on github said (also ran it outside of conda once after using the wrong terminal lol)
Anonymous
8/18/2025, 4:28:19 PM
No.106302059
[Report]
>>106301992
On 16gb you can run the mistral smalls, which may be better for your use, or a quant of qwen coder 30b.
There's a few options open to you, but if you're just jerking it nemo is probably still your best option.
Anonymous
8/18/2025, 4:29:13 PM
No.106302064
[Report]
>>106302172
>>106302049
>jsonl
That's a fine tuning dataset?
Anonymous
8/18/2025, 4:30:18 PM
No.106302074
[Report]
>>106302328
>>106302037
In terminal, activate the conda environment and then just type python to enter a python shell.
Then try the following code to see if your GPU is detected.
>import torch
>torch.cuda.device_count()
>torch.cuda.get_device_name(0)
change the number in device name to check each numbered device. If your device count is 0 or 1 and you don't see your GPU, try putting the override before running python and run the code again to see if you can get your GPU detected.
>>106302049
DPO dataset. This from huggingface or handmade?
Anonymous
8/18/2025, 4:36:31 PM
No.106302118
[Report]
>>106302129
Mikutroons secretly worship Sam Altman.
Anonymous
8/18/2025, 4:38:01 PM
No.106302129
[Report]
>>106302118
Not really.
LMG adopted Miku as a mascot fairly early in its inception.
Whereas /aicg/ had no real official mascot at the time.
GLM 4.5 air iq4_xs on a 3090... Should the prompt processing be this slow?
Anonymous
8/18/2025, 4:42:07 PM
No.106302166
[Report]
>>106301942
trying again setting it to "medium" instead of high and it's more stable. This model though is still a yapping moron most of the time.
Anonymous
8/18/2025, 4:42:56 PM
No.106302170
[Report]
>>106302211
>>106301942
>better at coding
It’s never the case, it trash even on lmarena only ranks 30th. Meanwhile even qwen 30ba3b ranks 9th and glm4.5 air at 14th
Anonymous
8/18/2025, 4:43:32 PM
No.106302178
[Report]
>>106302186
>>106302161
show your command to startup the server. and are you using llamacpp or ikllamacpp?
Anonymous
8/18/2025, 4:44:16 PM
No.106302186
[Report]
Anonymous
8/18/2025, 4:47:43 PM
No.106302211
[Report]
>>106302170
Yeah, my initial testing when it released found it to be crap. But I figured I'd try just in case. But nah, I'd prefer glm for lazy coding and qwen30b coder for edit or minor assistance. toss just is meh at best.
>>106302172
checksum and size update. so you're generating it yourself. what model are you using for the "chosen" responses?
Anonymous
8/18/2025, 4:51:49 PM
No.106302255
[Report]
>>106300178
>>106300131
This is the next doll I'm working on. I expect the corkscrew hair will be a challenge.
Anonymous
8/18/2025, 5:00:31 PM
No.106302328
[Report]
>>106302669
>>106302074
>torch.cuda.device_count()
Returns 0
>the override before running python
Override? Like sudo or in root? Gave it a go, only renders torch invalid.
Anonymous
8/18/2025, 5:04:21 PM
No.106302360
[Report]
>>106302456
>>106302244
Technically not generating anything new, at least not the main content. The script basically turns an existing Giants to a usable DPO one with the hopes of it being able to be used to "de-cuck" existing models. The only thing it generates are the hypothetical system prompts a user might have depending on the story and hypothetical refusals a cucked model may spit out when I asked for prompted with a RP scenario. All of the content is originally from this guy's data set:
https://huggingface.co/datasets/mrcuddle/NSFW-Stories-JsonL
The script I'm using takes the stories, chunks them up into reasonable sizes so I'm training on reasonably sized rp dialogue instead of entire stories (if try to do the entire story at once then either the trainer will drop sequences anyway in order to avoid OOM and lead to the model generating way too much text at once, or just OOM into it being an absurd amount of text being trained at once), and then the yellow line creates hypothetical system prompts and hypothetical rejections. Most of the heavy lifting the script does is just copy pasting chunks from the original file into the DPO data set.
The script I'm using can be found in the repo I linked earlier.
Oh also I'm using gemma3-1b. All that model is doing is generating system prompts occasionally and rejections so it's not like you would need a beefy model for that.
Anonymous
8/18/2025, 5:07:43 PM
No.106302391
[Report]
>>106302447
feeet
Anonymous
8/18/2025, 5:14:19 PM
No.106302447
[Report]
Anonymous
8/18/2025, 5:15:28 PM
No.106302456
[Report]
>>106302636
>>106302360
>>106302244
Furthermore you may be asking "why not just use existing RP data sets on hugging face?"
That was a consideration but most of those are created from LLMs generating most if not all of the RP chats. This means most of those why they considerable amount of "GPTism slop" (i.e. "shivers down spine" or something along those lines). This guy's dataset for example not only likely has a lot of that, the readme page even straight up says it has it:
https://huggingface.co/datasets/ChaoticNeutrals/Synthetic-Dark-RP . It is my understanding that the original JSONL while I'm ripping all of this off from contains mostly if not all stories written by actual people come up likely scraped directly from sites like AO3, Wattpad, etc. Stories written by actual people = less to non-existent slop present in the data set. The goal of this is to not only be able to (hopefully) train models to be halfway decent at RP but be less likely to refuse "problematic" request since I intend to fine tune a model via the DPO method. Hypothetically if this works this means we may even be able to get even cucked models gpt-oos or even llama models to be better (probably not perfect, just better) at RP.
Anonymous
8/18/2025, 5:37:29 PM
No.106302636
[Report]
>>106302456
Smart way of approaching it. I might give it a try with a lora at first for 3b~ range model to see if it's enough then might try full fine-tune if I have the time. One idea I've been meaning to try is to use grpo with obvious refusal requests and then assume it will refuse and set the reward to 0 for 100 steps or so to see if just "punishing" the model will be enough to neutralise the refusal rate. But my lazy ass can't be bothered setting up training scripts and running evaluation tests.
Anonymous
8/18/2025, 5:41:57 PM
No.106302669
[Report]
>>106302856
>>106302328
The hsx override value I meant.
So:
>hsx_whateveritis_ver=versionnumberhere python
Then try the code again. If it doesn't detect a device then pytorch isn't setup properly, or rocm isn't installed properly, or your gpu isn't supported (or you're using a version of ROCm/pytorch that doesn't work for your gpu)
>>106302720
??? Not sure what I'm supposed to get from this
Anonymous
8/18/2025, 5:54:40 PM
No.106302792
[Report]
>>106302781
deepseek knows the date, agi confirmed
Anonymous
8/18/2025, 5:54:46 PM
No.106302794
[Report]
>>106302946
>>106302781
What I'm getting from it is that he should fuck off to aicg, because that's not a local interface I recognize.
Anonymous
8/18/2025, 5:54:46 PM
No.106302795
[Report]
it's time
llms are advancing
Anonymous
8/18/2025, 5:54:57 PM
No.106302799
[Report]
>>106302720
oh nuuu not my daterino
btw, 8bit is massively damaging compared to FP16, especially for coding
Anonymous
8/18/2025, 5:56:51 PM
No.106302818
[Report]
>>106302838
>>106302809
Can you link those stats?
Anonymous
8/18/2025, 5:56:57 PM
No.106302819
[Report]
>>106302809
raw fp8 isn't the same as q8 quant though
Anonymous
8/18/2025, 5:57:05 PM
No.106302821
[Report]
>>106302781
I hate mondays.
>>106302809
crazy how it took almost 3 years of repeated 'muh 8bit bit is lossless!!!' memes and falseflagging for it to finally be exposed for what it is
our models were always so much better, they just got ruined by quanters and their model lobotomization
Anonymous
8/18/2025, 5:58:28 PM
No.106302837
[Report]
>>106302809
why is 'toss so high
Anonymous
8/18/2025, 5:58:36 PM
No.106302838
[Report]
Anonymous
8/18/2025, 6:00:17 PM
No.106302849
[Report]
>>106302830
Not really "our" models if none of us can run them unquanted are they?
Anonymous
8/18/2025, 6:01:01 PM
No.106302856
[Report]
>>106302880
>>106302669
Thanks for the help but in the meantime I had a retarded epiphany.
I decided to read further into ComfyUI, and I just assumed that it installed ROCm with it.
Turns out nope, and I'm having to walk backwards with these steps, and I've just opened up a brand new hellscape of issues.
>>106302809
8 bits is too little space for floating point to be useful, I don't know why LLM people even bother with it.
Anonymous
8/18/2025, 6:01:47 PM
No.106302868
[Report]
>>106302894
>>106302857
svdq 4int is the future :)
Anonymous
8/18/2025, 6:03:01 PM
No.106302880
[Report]
>>106304069
>>106302856
If you figure it out, please do some benchmarks on vulkan vs ROCm performance, I want my sour grapes to be more than just sour grapes.
Anonymous
8/18/2025, 6:03:03 PM
No.106302881
[Report]
Anonymous
8/18/2025, 6:05:04 PM
No.106302894
[Report]
>>106303047
>>106302868
manually testing and quanting by hand like how nunchaku does it for image gen is the way, but that is incredibly difficult / time consuming, especially for how much bigger text models are
>>106302809
But I thought IQ1_S was lossless?
Anonymous
8/18/2025, 6:05:55 PM
No.106302904
[Report]
>>106302921
>>106302172
how come this
>>106302049 is smaller in size, but has more entries than
>>106302172
???
>>106302857
And erasing out the point in the number and calling it "int8" makes it work ""losslessly""?
Anonymous
8/18/2025, 6:06:38 PM
No.106302912
[Report]
>>106302901
yes do not worry about it
consume ze quants
Anonymous
8/18/2025, 6:07:51 PM
No.106302918
[Report]
>>106302901
this is reasoning / coding focused. For writing its prob not a gigantic issue
Anonymous
8/18/2025, 6:08:01 PM
No.106302921
[Report]
>>106302974
>>106302904
Are you counting the number of lines? The catbox link is an earlier version from a commit this morning. The most up-to-date version is currently sitting at 51 MB
Anonymous
8/18/2025, 6:08:45 PM
No.106302936
[Report]
>>106303114
>>106302907
at least you save a bit or two of data, which adds up to whole lot more precision over the full model
Anonymous
8/18/2025, 6:09:31 PM
No.106302946
[Report]
>>106302794
>not a local interface
daily remainder that vramlets can't run ds
Anonymous
8/18/2025, 6:11:09 PM
No.106302964
[Report]
>>106302809
Train on FP128, quant to FP16.
Anonymous
8/18/2025, 6:11:13 PM
No.106302965
[Report]
>>106303033
>>106302857
>I don't know why LLM people even bother with it.
We hate it, but it's so much faster, there's just no way around it.
>>106302921
yes
12446 entries in catbox while being 40.6 MB vs 8775 entries on HF at 51.6 MB
>>106302809
Hi guys, I have the ability to read a graph.
500gb model: 40% FAILURE
970gb model: 50% FAILURE
That's right guys, if you spend millions of dollars, you too could run a model that only fucks up half the time. OR, you could budget build some 3-10k solution that is right 40% of the time.
>>106302830
You're dumb.
Anonymous
8/18/2025, 6:16:06 PM
No.106303026
[Report]
>>106303111
>>106303002
thats not really a linear testing metric. Those few percentage points could be a massive difference in capability to solve a certain complexity of problems
Anonymous
8/18/2025, 6:16:37 PM
No.106303033
[Report]
>>106302965
fixed point arithmetics should be at least 4x faster methinks
Anonymous
8/18/2025, 6:18:07 PM
No.106303047
[Report]
>>106302894
I did that with a small ViT model (87M) when quantizing to UINT8 ONNX. The only way to get a lossless UINT8 model is to quant node by node with a baseline from a diverse dataset using the FP32 model then rollback that node to FP32 if the results start drifting from the original model. You can automate the whole process, but I can't even imagine the time it'll take for a 100B+ LLM.
Anonymous
8/18/2025, 6:18:18 PM
No.106303049
[Report]
>>106303083
>>106303002
>being this poor
I have 16 H100s you poor white person, the red tide will sweep over 'america' soon.
Anonymous
8/18/2025, 6:22:07 PM
No.106303083
[Report]
>>106303049
Are your H100s better than my H1Bs?
Anonymous
8/18/2025, 6:22:40 PM
No.106303086
[Report]
>>106302809
Does this mean an average person cooms 39% of the times to the output instead of half the time too?
Anonymous
8/18/2025, 6:25:11 PM
No.106303111
[Report]
>>106303026
I didn't say anything anon. I just described the graph.
You're defensive because you know price is an issue.
For local, that shit is just gone, we can't run it. And even cloud servers quant their shit because: 'fuck you'.
If their was a near perfect coding model out there, people would pay the big bucks for access to it, but no one wants to pay extra for that shit, and even if they 'did', they could just fuck you and serve you lower quants anyways, like a pig like you would notice (ok maybe you might- but remember their slogan: 'get fucked buddy').
llama.cpp CUDA dev
!!yhbFjk57TDr
8/18/2025, 6:25:28 PM
No.106303114
[Report]
>>106302907
>>106302936
The FP8 formats supported by NVIDIA use either 2 or 3 bits for the mantissa, it's not clear what was used here.
You can implicitly store the leading 1 to get an extra bit of precision for normal numbers (not close to zero).
So if all weights in a quantization block are of similar magnitudes FP8 is roughly equivalent to q4_0 or a hypothetical q3_0.
In practice quantization does worse because weights with low magnitudes end up with worse precision.
Anonymous
8/18/2025, 6:30:32 PM
No.106303181
[Report]
>>106303928
>>106302974
What software is telling you the smaller one has more lines?
Anonymous
8/18/2025, 6:32:55 PM
No.106303209
[Report]
>>106302809
>bigger model is better
WAOW
I wonder how it compares to a fp16 model with half the parameters, ie holding size constant. The anti-quant retard never answers this
Anonymous
8/18/2025, 6:51:17 PM
No.106303411
[Report]
>>106303648
>>106303179
killed by gpt oss
Anonymous
8/18/2025, 6:54:02 PM
No.106303433
[Report]
>>106303405
Yeah, I get the feeling that some 1.5t model at q4 would beat the 400b model at full precision or some shit. Full precision only matters for people who literally make llm's.
Anonymous
8/18/2025, 6:58:29 PM
No.106303479
[Report]
>>106303405
the point it was claimed that int8 quant are almost no different from fp16, and that claim might still be true, since int8 is a lot more precise than fp8.
Anonymous
8/18/2025, 7:04:19 PM
No.106303537
[Report]
>>106299665
nemo/rocinante was already dethroned if you're not a 12gb vramlet and actually got to try bigger models that don't have shit spatial awareness lol
Anonymous
8/18/2025, 7:06:36 PM
No.106303565
[Report]
>>106301792
I was clearly responding to >models from 2 years ago >blah blah all these samplers
Either he hasn't into the full local experience or he's baiting by being slightly inaccurate or doing the clueless aircraft cockpit control panel meme.
>local model general
Also, out of 28 not-dead OR providers that support text completion, 13 of them support min-p. It's the chat completion only providers that 100% don't support min-p.
Anonymous
8/18/2025, 7:06:59 PM
No.106303571
[Report]
>>106303594
These local (smaller) LLMs are good for:
>Flavor text
>Pointless dialogues
>Generating descriptions when details are provided
but they suck dick at everything else, you can't get any consistent output from them, no matter how much you spoon feed or tweak them. They're not reliable for decision making or analyzing emotions or mental states, because of the stupid positivity bias.
Because of this, you also can’t use them as logical engines
Anonymous
8/18/2025, 7:09:11 PM
No.106303594
[Report]
>>106303635
>>106303571
>you can't get any consistent output from them
You can if you force the output format with GBNF/Json Schema/structured output, etc.
Anonymous
8/18/2025, 7:10:42 PM
No.106303612
[Report]
>>106302809
lol this level of disinformation
fp8 is not q8
I don't mean there's no degradation, but there's far less with q8 than fp8
you would know, fucktard, if you had ever seen the difference between fp8 releases of image model like flux, and their q8 gguf counterpart, the human brain reacts more strongly in differences between images and q8 is much closer to the full model than fp8
probably the only reason fp8 was even used in a benchmark like pic related is because Qwen, for a reason I can't begin to fathom, decided to release fp8 quants of Qwen 3 (but hasn't made gguf of their new 2507 models...) so people who only look at "official" sources could consider running this fp8 dogshit
Anonymous
8/18/2025, 7:12:50 PM
No.106303635
[Report]
>>106303700
>>106303594
so i'll have to write instruction for each type of interaction ? sounds like a pain in the ass but doable
but i am still upset about how incompetent it is when it comes simple task like determining whether a sentence was positive, negative or neutral
or how powerful an old woman would be
Anonymous
8/18/2025, 7:13:31 PM
No.106303648
[Report]
>>106303655
>>106303411
saved by gpt-oss
praise be upon sama
Anonymous
8/18/2025, 7:13:54 PM
No.106303655
[Report]
>>106303683
Anonymous
8/18/2025, 7:16:02 PM
No.106303683
[Report]
>>106303655
refusals are saving your soul from demonic corruption
Anonymous
8/18/2025, 7:17:58 PM
No.106303700
[Report]
>>106303635
>so i'll have to write instruction for each type of interaction ?
Yes.
Different schemas for different interactions with different operations the AI can perform with specific system instructions with as little information as possible.
Only the bare minimum necessary for the model to perform that operation.
In fact, if you can break it down into more than one step, for example, one step to narrate the scene, one to evaluate if there's a need to perform a certain operation, another to perform the operation, etc, the results can be a lot better since each step is more focused. Having the AI do a single thing at a time is ideal, basically.
Also, offloading as much work to traditional algorithms, but that goes without saying.
Anonymous
8/18/2025, 7:19:39 PM
No.106303715
[Report]
What's a decent tts that can generate big chunks of audio so I can make my own audiobooks?
Anonymous
8/18/2025, 7:20:37 PM
No.106303722
[Report]
Anonymous
8/18/2025, 7:25:19 PM
No.106303778
[Report]
>>106294852
The speed up for speculative decoding is not as dramatic for moe models as it is for dense. Using a 20+b model with sub 1b draft model is where the magic happens. Oh and drop ooba and use llamacpp or ik_llamacpp, the sooner you do this the sooner your future self will thank you for it.
>.\llama-server -m ..\models\unsloth\Devstral-Small-2505-UD-Q4_K_XL.gguf --port 10191 -ngl 18 -c 16384 -fa --jinja -md ..\models\mradermacher\Mistral-Small-3.1-DRAFT-0.5B.Q8_0.gguf -ngld 0
Anonymous
8/18/2025, 7:38:46 PM
No.106303928
[Report]
>>106303181
False alarm. Notepadqq was slow loading and displaying all lines.
this is wrong
>>106302974
this is correct:
13223 entries in catbox while being 40.6 MB vs 14605 entries on HF at 51.6 MB
Anonymous
8/18/2025, 7:50:22 PM
No.106304069
[Report]
>>106302880
Now I got it working, sure, any particular benchmark?